Lecture 8: Clustering & Mixture Models
|
|
|
- Kelly Holt
- 5 years ago
- Views:
Transcription
1 Lecture 8: Clustering & Mixture Models C4B Machine Learning Hilary 2011 A. Zisserman K-means algorithm GMM and the EM algorithm plsa clustering
2 K-means algorithm K-means algorithm Partition data into K sets Initialize: choose K centres (at random) Repeat: 1. Assign points to the nearest centre 2. New centre = mean of points assigned to it Until no change
3 Example Cost function K-means minimizes a measure of distortion for a set of vectors {x i },,...,N NX D = kx k i c kk 2 where x k i is the subset assigned to the cluster k. The objective is to find the set of centres {c k },k =1,...,K that minimize the distortion: min c k X N kx k i c kk 2 Introducing binary assignment variables r ik, the distortion can be written as NX KX D = r ik kx i c k k 2 k=1 where if x i isassignedtoclusterk then ( 1 j = k r ij = 0 j 6= k
4 Minimizing the Cost function We want to determine min D = c k,r ik NX KX k=1 Step 1: minimize over assignments r ik r ik kx i c k k 2 Each term in x i can be minimized independently by assigning x i to the closest centre c k Step 2: minimize over centres c k Hence d NX KX r dc ik kx i c k k 2 NX =2 r ik (x i c k )=0 k k=1 P N r c k = ik x i P N r ik i.e. c k is the mean (centroid) of the vectors assigned to it. Note, since both steps decrease the cost D, the algorithm will converge but it can converge to a local rather than global minimum. Decrease in distortion cost with iterations D
5 Sensitive to initialization D F t Sensitive to initialization D F t
6 Practicalities always run algorithm several times with different initializations and keep the run with lowest cost choice of K suppose we have data for which a distance is defined, but it is non-vectorial (so can t be added). Which step needs to change? many other clustering methods: hierarchical K-means, K-medoids, agglomerative clustering

7 Example application 1: vector quantization all vectors in a cluster are considered equivalent they can be represented by a single vector the cluster centre applications in compression, segmentation, noise reduction Example: image segmentation K-means cluster all pixels using their colour vectors (3D) assign pixels to their clusters colour pixels by their cluster assignment

8 Example application 2: face clustering Determine the principal cast of a feature film Approach: view this as a clustering problem on faces Algorithm outline 1. Detect faces for every fifth frame in the movie 2. Describe the face by a vector of intensities 3. Cluster using a K-means algorithm Example Ground Hog Day 2000 frames


9 Subset of detected faces in temporal order Clusters for K = 4 Gaussian Mixture Models
 Combine simple models into a complex model: Component Mixing")
10 Hard vs soft assignments In K-means, there is a hard assignment of vectors to a cluster However, for vectors near the boundary this may be a poor representation Instead, can consider a soft-assignment, where the strength of the assignment depends on distance Gaussian Mixture Model (GMM) Combine simple models into a complex model: Component Mixing coefficient K=3
= NY KX k=1 and the (negative) log-likelihood is L(θ) = NX ln KX k=1 π k N (x i μ k, Σ k ) π k N (x i μ k, Σ k ) where θ are the parameters we wish to estimate (i.e. μ k and Σ k in this case).")
11 Single Gaussian Mixture of two Gaussians Cost function for fitting a GMM For a point x i p(x i )= KX k=1 π k N (x i μ k, Σ k ) The likelihood of the GMM for N points (assuming independence) is NY p(x i )= NY KX k=1 and the (negative) log-likelihood is L(θ) = NX ln KX k=1 π k N (x i μ k, Σ k ) π k N (x i μ k, Σ k ) where θ are the parameters we wish to estimate (i.e. μ k and Σ k in this case).
12 To minimize L(θ), differentiate first wrt μ k dl(θ) dμ k = NX π k N (x i μ k, Σ k ) P Kj=1 π j N (x i μ j, Σ j ) Σ 1 k (x i μ k ) Rearranging γ ik and hence where NX γ ik μ k = μ k = 1 N k NX N X γ ik = π kn (x i μ k, Σ k ) P Kj=1 π j N (x i μ j, Σ j ) γ ik x i γ ik x i N k = weighted mean NX γ ik and γ ik are the responsibilities of mixture component k for vector x i. N k is the effective number of vectors assigned to component k. γ ik play a similar role to the assignment variables r ik in K-means, but γ ik is not binary, 0 γ ik 1 Differentiating wrt Σ k gives Σ k = 1 N k N X γ ik (x i μ k )(x i μ k ) > and wrt π k (enforcing the constraint that P k π k =1withaLagrange multiplier) gives π k = N k N which is the average responsibility for the component weighted covariance Now, an algorithm for minimizing the cost function
13 Expectation Maximization (EM) Algorithm Step 1 Expectation: Compute responsibilities using current parameters μ k, Σ k (assignment) γ ik = π kn (x i μ k, Σ k ) P Kj=1 π j N (x i μ j, Σ j ) Step 2 Maximization: Re-estimate parameters using computed responsibilities μ k = 1 N k N X Σ k = 1 N k N X γ ik x i π k = N k N where N k = γ ik (x i μ k )(x i μ k ) > NX γ ik Repeat until convergence Example in 1D Data: OBJECTIVE: Fit mixture of Gaussian model with K=2 components Model: where Parameters: P(x θ) keep fixed i.e. only estimate x



14 Intuition of EM E-step: Compute soft assignment of the points, using current parameters M-step: Update parameters using current responsibilities E M E M E Likelihood function Likelihood is a function of parameters, θ Probability is a function of r.v. x

15 E-step: What do we actually compute? Point 1 Point 2 Point 6 ncomponents x npoints matrix (columns sum to 1): Component 1 Component 2

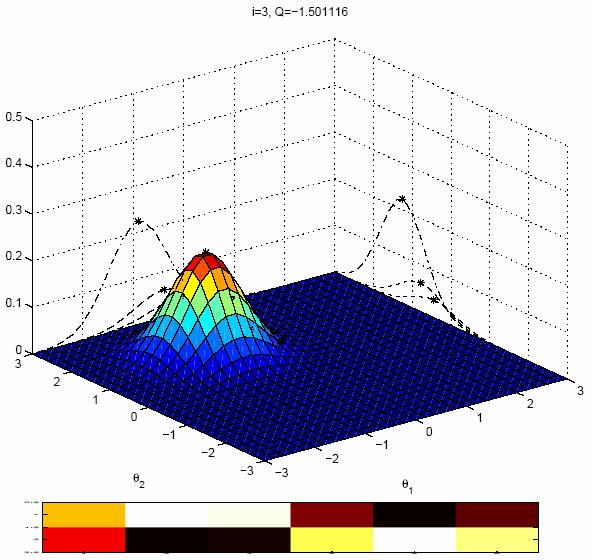
16
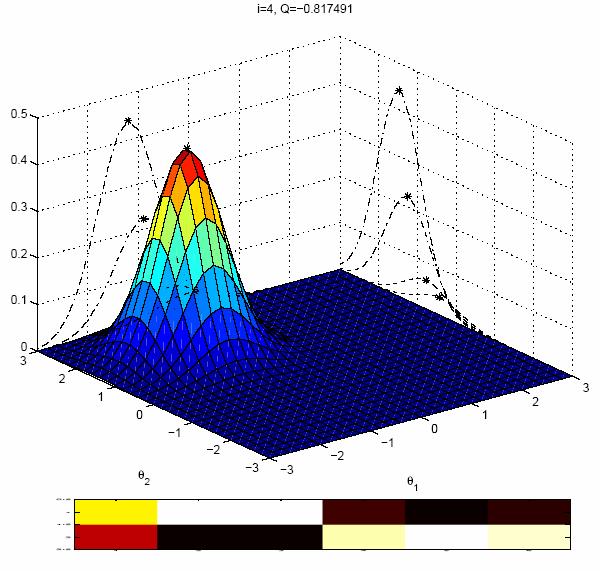

17
18 2D example: fitting means and covariances Practicalities Usually initialize EM algorithm using K-means Choice of K Can converge to a local rather than global minimum
19 Probabilistic Latent Semantic Analysis (plsa) non-examinable Unsupervised learning of topics Given a large collections of text documents (e.g. a website, or news archive) Discover the principal semantic topics in the collection Hence can retrieve/organize documents according to topic Method involves fitting a mixture model to a representation of the collection
20 Document-Term Matrix - bag of words model D = Document collection W = Lexicon/Vocabulary intelligence w j Texas Instruments said it has developed the first 32-bit computer chip designed specifically for artificial intelligence applications [...] d i t d i = artifact artificial intelligence 0interest Document-Term Matrix D d 1... d i... W w 1... w j... w J d I [Hofmann 99] d documents w words z topics Model fitting: find topic vectors P(w z) common to all documents, and mixture coefficients P(z d) specific to each document.
21 [Hofmann 99] d documents w words z topics P(w z) are the latent aspects Non-negative matrix factorization each document histogram explained as a sum over topics Fitting plsa parameters Observed counts of word i in document j Maximize likelihood of data using EM M number of words N number of documents
22 Expectation Maximization Algorithm for plsa E step: posterior probability of latent variables ( topics ) Probability that the occurence of term w in document d can be explained by topic z M step: parameter estimation based on completed statistics how often is term w associated with topic z? how often is document d associated with topic z? Example (1) Topics (3 of 100) extracted from Associated Press news Topic 1 securities firm drexel investment bonds sec bond junk milken firms investors lynch insider shearson boesky lambert merrill brokerage corporate burnham Topic 2 ship coast guard sea boat fishing vessel tanker spill exxon boats waters valdez alaska ships port hazelwood vessels ferry fishermen Topic 3 india singh militants gandhi sikh indian peru hindu lima kashmir tamilnadu killed india's punjab delhi temple shining menem hindus violence
23 Example (2) Topics (10 of 128) extracted from Science Magazine articles (12K) P(w z) P(w z) Background reading Bishop, chapter Other topics you should know about: random forest classifiers and regressors semi-supervised learning collaborative filtering More on web page:
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Computer Vision Group Prof. Daniel Cremers. 6. Mixture Models and Expectation-Maximization
 Prof. Daniel Cremers 6. Mixture Models and Expectation-Maximization Motivation Often the introduction of latent (unobserved) random variables into a model can help to express complex (marginal) distributions
Prof. Daniel Cremers 6. Mixture Models and Expectation-Maximization Motivation Often the introduction of latent (unobserved) random variables into a model can help to express complex (marginal) distributions
Latent Variable Models and Expectation Maximization
 Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Latent Variable Models and Expectation Maximization
 Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Clustering and Gaussian Mixture Models
 Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Clustering. CSL465/603 - Fall 2016 Narayanan C Krishnan
 Clustering CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Supervised vs Unsupervised Learning Supervised learning Given x ", y " "%& ', learn a function f: X Y Categorical output classification
Clustering CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Supervised vs Unsupervised Learning Supervised learning Given x ", y " "%& ', learn a function f: X Y Categorical output classification
COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017
 COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University SOFT CLUSTERING VS HARD CLUSTERING
COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University SOFT CLUSTERING VS HARD CLUSTERING
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
Machine Learning for Data Science (CS4786) Lecture 12
 Lecture 12") Machine Learning for Data Science (CS4786) Lecture 12 Gaussian Mixture Models Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016fa/ Back to K-means Single link is sensitive to outliners We
Machine Learning for Data Science (CS4786) Lecture 12 Gaussian Mixture Models Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016fa/ Back to K-means Single link is sensitive to outliners We
Clustering and Gaussian Mixtures
 Clustering and Gaussian Mixtures Oliver Schulte - CMPT 883 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15 2 25 5 1 15 2 25 detected tures detected
Clustering and Gaussian Mixtures Oliver Schulte - CMPT 883 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15 2 25 5 1 15 2 25 detected tures detected
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Expectation Maximization
 Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Probabilistic clustering
 Aprendizagem Automática Probabilistic clustering Ludwig Krippahl Probabilistic clustering Summary Fuzzy sets and clustering Fuzzy c-means Probabilistic Clustering: mixture models Expectation-Maximization,
Aprendizagem Automática Probabilistic clustering Ludwig Krippahl Probabilistic clustering Summary Fuzzy sets and clustering Fuzzy c-means Probabilistic Clustering: mixture models Expectation-Maximization,
Unsupervised Learning
 2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
1 EM algorithm: updating the mixing proportions {π k } ik are the posterior probabilities at the qth iteration of EM.
 Université du Sud Toulon - Var Master Informatique Probabilistic Learning and Data Analysis TD: Model-based clustering by Faicel CHAMROUKHI Solution The aim of this practical wor is to show how the Classification
Université du Sud Toulon - Var Master Informatique Probabilistic Learning and Data Analysis TD: Model-based clustering by Faicel CHAMROUKHI Solution The aim of this practical wor is to show how the Classification
Clustering, K-Means, EM Tutorial
 Clustering, K-Means, EM Tutorial Kamyar Ghasemipour Parts taken from Shikhar Sharma, Wenjie Luo, and Boris Ivanovic s tutorial slides, as well as lecture notes Organization: Clustering Motivation K-Means
Clustering, K-Means, EM Tutorial Kamyar Ghasemipour Parts taken from Shikhar Sharma, Wenjie Luo, and Boris Ivanovic s tutorial slides, as well as lecture notes Organization: Clustering Motivation K-Means
Latent Variable Models and EM Algorithm
 SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Clustering K-means. Machine Learning CSE546. Sham Kakade University of Washington. November 15, Review: PCA Start: unsupervised learning
 Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Mixture Models and EM
 Mixture Models and EM Yoan Miche CIS, HUT March 17, 27 Yoan Miche (CIS, HUT) Mixture Models and EM March 17, 27 1 / 23 Mise en Bouche Yoan Miche (CIS, HUT) Mixture Models and EM March 17, 27 2 / 23 Mise
Mixture Models and EM Yoan Miche CIS, HUT March 17, 27 Yoan Miche (CIS, HUT) Mixture Models and EM March 17, 27 1 / 23 Mise en Bouche Yoan Miche (CIS, HUT) Mixture Models and EM March 17, 27 2 / 23 Mise
Clustering with k-means and Gaussian mixture distributions
 Clustering with k-means and Gaussian mixture distributions Machine Learning and Object Recognition 2017-2018 Jakob Verbeek Clustering Finding a group structure in the data Data in one cluster similar to
Clustering with k-means and Gaussian mixture distributions Machine Learning and Object Recognition 2017-2018 Jakob Verbeek Clustering Finding a group structure in the data Data in one cluster similar to
Pattern Recognition and Machine Learning. Bishop Chapter 9: Mixture Models and EM
 Pattern Recognition and Machine Learning Chapter 9: Mixture Models and EM Thomas Mensink Jakob Verbeek October 11, 27 Le Menu 9.1 K-means clustering Getting the idea with a simple example 9.2 Mixtures
Pattern Recognition and Machine Learning Chapter 9: Mixture Models and EM Thomas Mensink Jakob Verbeek October 11, 27 Le Menu 9.1 K-means clustering Getting the idea with a simple example 9.2 Mixtures
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Mixtures of Gaussians. Sargur Srihari
 Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
EM Algorithm LECTURE OUTLINE
 EM Algorithm Lukáš Cerman, Václav Hlaváč Czech Technical University, Faculty of Electrical Engineering Department of Cybernetics, Center for Machine Perception 121 35 Praha 2, Karlovo nám. 13, Czech Republic
EM Algorithm Lukáš Cerman, Václav Hlaváč Czech Technical University, Faculty of Electrical Engineering Department of Cybernetics, Center for Machine Perception 121 35 Praha 2, Karlovo nám. 13, Czech Republic
Linear Dynamical Systems
 Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Lecture 11: Unsupervised Machine Learning
 CSE517A Machine Learning Spring 2018 Lecture 11: Unsupervised Machine Learning Instructor: Marion Neumann Scribe: Jingyu Xin Reading: fcml Ch6 (Intro), 6.2 (k-means), 6.3 (Mixture Models); [optional]:
CSE517A Machine Learning Spring 2018 Lecture 11: Unsupervised Machine Learning Instructor: Marion Neumann Scribe: Jingyu Xin Reading: fcml Ch6 (Intro), 6.2 (k-means), 6.3 (Mixture Models); [optional]:
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 203 http://ce.sharif.edu/courses/9-92/2/ce725-/ Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 203 http://ce.sharif.edu/courses/9-92/2/ce725-/ Agenda Expectation-maximization
Clustering with k-means and Gaussian mixture distributions
 Clustering with k-means and Gaussian mixture distributions Machine Learning and Category Representation 2014-2015 Jakob Verbeek, ovember 21, 2014 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.14.15
Clustering with k-means and Gaussian mixture distributions Machine Learning and Category Representation 2014-2015 Jakob Verbeek, ovember 21, 2014 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.14.15
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 2 - Spring 2017 Lecture 6 Jan-Willem van de Meent (credit: Yijun Zhao, Chris Bishop, Andrew Moore, Hastie et al.) Project Project Deadlines 3 Feb: Form teams of
Data Mining Techniques CS 6220 - Section 2 - Spring 2017 Lecture 6 Jan-Willem van de Meent (credit: Yijun Zhao, Chris Bishop, Andrew Moore, Hastie et al.) Project Project Deadlines 3 Feb: Form teams of
Topic Models and Applications to Short Documents
 Topic Models and Applications to Short Documents Dieu-Thu Le Email: dieuthu.le@unitn.it Trento University April 6, 2011 1 / 43 Outline Introduction Latent Dirichlet Allocation Gibbs Sampling Short Text
Topic Models and Applications to Short Documents Dieu-Thu Le Email: dieuthu.le@unitn.it Trento University April 6, 2011 1 / 43 Outline Introduction Latent Dirichlet Allocation Gibbs Sampling Short Text
Statistical learning. Chapter 20, Sections 1 4 1
 Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Lecture 7: Con3nuous Latent Variable Models
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Yuriy Sverchkov Intelligent Systems Program University of Pittsburgh October 6, 2011 Outline Latent Semantic Analysis (LSA) A quick review Probabilistic LSA (plsa)
Probabilistic Latent Semantic Analysis Yuriy Sverchkov Intelligent Systems Program University of Pittsburgh October 6, 2011 Outline Latent Semantic Analysis (LSA) A quick review Probabilistic LSA (plsa)
Matrix Factorization & Latent Semantic Analysis Review. Yize Li, Lanbo Zhang
 Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Clustering. Léon Bottou COS 424 3/4/2010. NEC Labs America
 Clustering Léon Bottou NEC Labs America COS 424 3/4/2010 Agenda Goals Representation Capacity Control Operational Considerations Computational Considerations Classification, clustering, regression, other.
Clustering Léon Bottou NEC Labs America COS 424 3/4/2010 Agenda Goals Representation Capacity Control Operational Considerations Computational Considerations Classification, clustering, regression, other.
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Gaussian Mixture Models, Expectation Maximization
 Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Learning with Noisy Labels. Kate Niehaus Reading group 11-Feb-2014
 Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Advanced Introduction to Machine Learning
 10-715 Advanced Introduction to Machine Learning Homework Due Oct 15, 10.30 am Rules Please follow these guidelines. Failure to do so, will result in loss of credit. 1. Homework is due on the due date
10-715 Advanced Introduction to Machine Learning Homework Due Oct 15, 10.30 am Rules Please follow these guidelines. Failure to do so, will result in loss of credit. 1. Homework is due on the due date
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
Clustering using Mixture Models
 Clustering using Mixture Models The full posterior of the Gaussian Mixture Model is p(x, Z, µ,, ) =p(x Z, µ, )p(z )p( )p(µ, ) data likelihood (Gaussian) correspondence prob. (Multinomial) mixture prior
Clustering using Mixture Models The full posterior of the Gaussian Mixture Model is p(x, Z, µ,, ) =p(x Z, µ, )p(z )p( )p(µ, ) data likelihood (Gaussian) correspondence prob. (Multinomial) mixture prior
K-Means, Expectation Maximization and Segmentation. D.A. Forsyth, CS543
 K-Means, Expectation Maximization and Segmentation D.A. Forsyth, CS543 K-Means Choose a fixed number of clusters Choose cluster centers and point-cluster allocations to minimize error can t do this by
K-Means, Expectation Maximization and Segmentation D.A. Forsyth, CS543 K-Means Choose a fixed number of clusters Choose cluster centers and point-cluster allocations to minimize error can t do this by
Dimension Reduction (PCA, ICA, CCA, FLD,
 Dimension Reduction (PCA, ICA, CCA, FLD, Topic Models) Yi Zhang 10-701, Machine Learning, Spring 2011 April 6 th, 2011 Parts of the PCA slides are from previous 10-701 lectures 1 Outline Dimension reduction
Dimension Reduction (PCA, ICA, CCA, FLD, Topic Models) Yi Zhang 10-701, Machine Learning, Spring 2011 April 6 th, 2011 Parts of the PCA slides are from previous 10-701 lectures 1 Outline Dimension reduction
Latent Variable Models and EM algorithm
 Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Lecture 6: Gaussian Mixture Models (GMM)
") Helsinki Institute for Information Technology Lecture 6: Gaussian Mixture Models (GMM) Pedram Daee 3.11.2015 Outline Gaussian Mixture Models (GMM) Models Model families and parameters Parameter learning
Helsinki Institute for Information Technology Lecture 6: Gaussian Mixture Models (GMM) Pedram Daee 3.11.2015 Outline Gaussian Mixture Models (GMM) Models Model families and parameters Parameter learning
Linear Dynamical Systems (Kalman filter)
") Linear Dynamical Systems (Kalman filter) (a) Overview of HMMs (b) From HMMs to Linear Dynamical Systems (LDS) 1 Markov Chains with Discrete Random Variables x 1 x 2 x 3 x T Let s assume we have discrete
Linear Dynamical Systems (Kalman filter) (a) Overview of HMMs (b) From HMMs to Linear Dynamical Systems (LDS) 1 Markov Chains with Discrete Random Variables x 1 x 2 x 3 x T Let s assume we have discrete
STATS 306B: Unsupervised Learning Spring Lecture 2 April 2
 STATS 306B: Unsupervised Learning Spring 2014 Lecture 2 April 2 Lecturer: Lester Mackey Scribe: Junyang Qian, Minzhe Wang 2.1 Recap In the last lecture, we formulated our working definition of unsupervised
STATS 306B: Unsupervised Learning Spring 2014 Lecture 2 April 2 Lecturer: Lester Mackey Scribe: Junyang Qian, Minzhe Wang 2.1 Recap In the last lecture, we formulated our working definition of unsupervised
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu November 3, 2015 Methods to Learn Matrix Data Text Data Set Data Sequence Data Time Series Graph
CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu November 3, 2015 Methods to Learn Matrix Data Text Data Set Data Sequence Data Time Series Graph
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
Computer Vision Group Prof. Daniel Cremers. 10a. Markov Chain Monte Carlo
 Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Group Prof. Daniel Cremers 10a. Markov Chain Monte Carlo Markov Chain Monte Carlo In high-dimensional spaces, rejection sampling and importance sampling are very inefficient An alternative is Markov Chain
Clustering with k-means and Gaussian mixture distributions
 Clustering with k-means and Gaussian mixture distributions Machine Learning and Category Representation 2012-2013 Jakob Verbeek, ovember 23, 2012 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.12.13
Clustering with k-means and Gaussian mixture distributions Machine Learning and Category Representation 2012-2013 Jakob Verbeek, ovember 23, 2012 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.12.13
Gaussian Mixture Models
 Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Non-negative Matrix Factorization: Algorithms, Extensions and Applications
 Non-negative Matrix Factorization: Algorithms, Extensions and Applications Emmanouil Benetos www.soi.city.ac.uk/ sbbj660/ March 2013 Emmanouil Benetos Non-negative Matrix Factorization March 2013 1 / 25
Non-negative Matrix Factorization: Algorithms, Extensions and Applications Emmanouil Benetos www.soi.city.ac.uk/ sbbj660/ March 2013 Emmanouil Benetos Non-negative Matrix Factorization March 2013 1 / 25
Sequence labeling. Taking collective a set of interrelated instances x 1,, x T and jointly labeling them
 HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
Clustering VS Classification
 MCQ Clustering VS Classification 1. What is the relation between the distance between clusters and the corresponding class discriminability? a. proportional b. inversely-proportional c. no-relation Ans:
MCQ Clustering VS Classification 1. What is the relation between the distance between clusters and the corresponding class discriminability? a. proportional b. inversely-proportional c. no-relation Ans:
Advanced Introduction to Machine Learning
 10-715 Advanced Introduction to Machine Learning Homework 3 Due Nov 12, 10.30 am Rules 1. Homework is due on the due date at 10.30 am. Please hand over your homework at the beginning of class. Please see
10-715 Advanced Introduction to Machine Learning Homework 3 Due Nov 12, 10.30 am Rules 1. Homework is due on the due date at 10.30 am. Please hand over your homework at the beginning of class. Please see
Notes on Latent Semantic Analysis
 Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
Expectation maximization
 Expectation maximization Subhransu Maji CMSCI 689: Machine Learning 14 April 2015 Motivation Suppose you are building a naive Bayes spam classifier. After your are done your boss tells you that there is
Expectation maximization Subhransu Maji CMSCI 689: Machine Learning 14 April 2015 Motivation Suppose you are building a naive Bayes spam classifier. After your are done your boss tells you that there is
Latent Variable View of EM. Sargur Srihari
 Latent Variable View of EM Sargur srihari@cedar.buffalo.edu 1 Examples of latent variables 1. Mixture Model Joint distribution is p(x,z) We don t have values for z 2. Hidden Markov Model A single time
Latent Variable View of EM Sargur srihari@cedar.buffalo.edu 1 Examples of latent variables 1. Mixture Model Joint distribution is p(x,z) We don t have values for z 2. Hidden Markov Model A single time
Statistical Learning. Dong Liu. Dept. EEIS, USTC
 Statistical Learning Dong Liu Dept. EEIS, USTC Chapter 6. Unsupervised and Semi-Supervised Learning 1. Unsupervised learning 2. k-means 3. Gaussian mixture model 4. Other approaches to clustering 5. Principle
Statistical Learning Dong Liu Dept. EEIS, USTC Chapter 6. Unsupervised and Semi-Supervised Learning 1. Unsupervised learning 2. k-means 3. Gaussian mixture model 4. Other approaches to clustering 5. Principle
Kernel Density Topic Models: Visual Topics Without Visual Words
 Kernel Density Topic Models: Visual Topics Without Visual Words Konstantinos Rematas K.U. Leuven ESAT-iMinds krematas@esat.kuleuven.be Mario Fritz Max Planck Institute for Informatics mfrtiz@mpi-inf.mpg.de
Kernel Density Topic Models: Visual Topics Without Visual Words Konstantinos Rematas K.U. Leuven ESAT-iMinds krematas@esat.kuleuven.be Mario Fritz Max Planck Institute for Informatics mfrtiz@mpi-inf.mpg.de
The Expectation-Maximization Algorithm
 The Expectation-Maximization Algorithm Francisco S. Melo In these notes, we provide a brief overview of the formal aspects concerning -means, EM and their relation. We closely follow the presentation in
The Expectation-Maximization Algorithm Francisco S. Melo In these notes, we provide a brief overview of the formal aspects concerning -means, EM and their relation. We closely follow the presentation in
COM336: Neural Computing
 COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
Click Prediction and Preference Ranking of RSS Feeds
 Click Prediction and Preference Ranking of RSS Feeds 1 Introduction December 11, 2009 Steven Wu RSS (Really Simple Syndication) is a family of data formats used to publish frequently updated works. RSS
Click Prediction and Preference Ranking of RSS Feeds 1 Introduction December 11, 2009 Steven Wu RSS (Really Simple Syndication) is a family of data formats used to publish frequently updated works. RSS
Hidden Markov Models and Gaussian Mixture Models
 Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 23&27 January 2014 ASR Lectures 4&5 Hidden Markov Models and Gaussian
Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 23&27 January 2014 ASR Lectures 4&5 Hidden Markov Models and Gaussian
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
STATS 306B: Unsupervised Learning Spring Lecture 3 April 7th
 STATS 306B: Unsupervised Learning Spring 2014 Lecture 3 April 7th Lecturer: Lester Mackey Scribe: Jordan Bryan, Dangna Li 3.1 Recap: Gaussian Mixture Modeling In the last lecture, we discussed the Gaussian
STATS 306B: Unsupervised Learning Spring 2014 Lecture 3 April 7th Lecturer: Lester Mackey Scribe: Jordan Bryan, Dangna Li 3.1 Recap: Gaussian Mixture Modeling In the last lecture, we discussed the Gaussian
Latent Dirichlet Allocation
 Outlines Advanced Artificial Intelligence October 1, 2009 Outlines Part I: Theoretical Background Part II: Application and Results 1 Motive Previous Research Exchangeability 2 Notation and Terminology
Outlines Advanced Artificial Intelligence October 1, 2009 Outlines Part I: Theoretical Background Part II: Application and Results 1 Motive Previous Research Exchangeability 2 Notation and Terminology
Review and Motivation
 Review and Motivation We can model and visualize multimodal datasets by using multiple unimodal (Gaussian-like) clusters. K-means gives us a way of partitioning points into N clusters. Once we know which
Review and Motivation We can model and visualize multimodal datasets by using multiple unimodal (Gaussian-like) clusters. K-means gives us a way of partitioning points into N clusters. Once we know which
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu October 19, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu October 19, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
Expectation Maximization
 Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Machine Learning Techniques for Computer Vision
 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Lecture 16 Deep Neural Generative Models
 Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Lecture 4: Probabilistic Learning. Estimation Theory. Classification with Probability Distributions
 DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
Another Walkthrough of Variational Bayes. Bevan Jones Machine Learning Reading Group Macquarie University
 Another Walkthrough of Variational Bayes Bevan Jones Machine Learning Reading Group Macquarie University 2 Variational Bayes? Bayes Bayes Theorem But the integral is intractable! Sampling Gibbs, Metropolis
Another Walkthrough of Variational Bayes Bevan Jones Machine Learning Reading Group Macquarie University 2 Variational Bayes? Bayes Bayes Theorem But the integral is intractable! Sampling Gibbs, Metropolis
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
K-Means and Gaussian Mixture Models
 K-Means and Gaussian Mixture Models David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 42 K-Means Clustering K-Means Clustering David
K-Means and Gaussian Mixture Models David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 42 K-Means Clustering K-Means Clustering David
MIXTURE MODELS AND EM
 Last updated: November 6, 212 MIXTURE MODELS AND EM Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis,
Last updated: November 6, 212 MIXTURE MODELS AND EM Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis,
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 9: Expectation Maximiation (EM) Algorithm, Learning in Undirected Graphical Models Some figures courtesy
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 9: Expectation Maximiation (EM) Algorithm, Learning in Undirected Graphical Models Some figures courtesy
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017
 COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
CS181 Midterm 2 Practice Solutions
 CS181 Midterm 2 Practice Solutions 1. Convergence of -Means Consider Lloyd s algorithm for finding a -Means clustering of N data, i.e., minimizing the distortion measure objective function J({r n } N n=1,
CS181 Midterm 2 Practice Solutions 1. Convergence of -Means Consider Lloyd s algorithm for finding a -Means clustering of N data, i.e., minimizing the distortion measure objective function J({r n } N n=1,
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we