Another Walkthrough of Variational Bayes. Bevan Jones Machine Learning Reading Group Macquarie University
|
|
|
- Silvester Houston
- 5 years ago
- Views:
Transcription
1 Another Walkthrough of Variational Bayes Bevan Jones Machine Learning Reading Group Macquarie University
2 2 Variational Bayes? Bayes Bayes Theorem But the integral is intractable! Sampling Gibbs, Metropolis Hastings, Slice Sampling, Particle Filters Variational Bayes Change the equations, replacing intractable integrals This involves searching for a good approximation Variational Calculus of Variations A way of searching through a space of functions for the best one
3 Useful Concepts Probability/Information Theory Bayes Theorem Expectations Jensen s Inequality KL Divergence Calculus Functionals & Functional Derivatives Lagrange Multipliers Logarithms 3
4 Outline The true likelihood Approximating the posterior The lower bound and a definition for best Finding the optimal approximation Functionals & functional derivatives Connection to KL divergence The Mean-field approximation An inference procedure Dirichlet-multinomial example 4


5 The (Log) Likelihood We have some observed data: We have a model relating latent variable z to the data: To guess z The problem is one of computing Or just as good 5
 We ll focus on approximating only part of")
6 Approximating p(z x) The integral in the expression for p(x) may not be easily computed But we might be able to get by with an approximation for p(x, z) We ll focus on approximating only part of it 6
7 Choosing q How to choose q? Ideally, we want the q that is closest to p Define a lower bound on p Make this a function of q Maximize the lower bound to make it as tight as possible Choose q accordingly 7
8 Bounding the Log Likelihood w/ Jensen s Inequality Jensen s Inequality where f is concave 8
9 Bounding the Log Likelihood w/ Jensen s Inequality Jensen s Inequality where f is concave 9

10 Bounding the Log Likelihood w/ Jensen s Inequality Jensen s Inequality where f is concave 10

11 Bounding the Log Likelihood w/ Jensen s Inequality Jensen s Inequality where f is concave 11

12 The Lower Bound We can t calculate the log likelihood, but we can compute the lower bound Maximizing F tightens the lower bound on the likelihood What q maximizes F? If q were a variable we could do this by taking derivatives and solving for q 12
13 Functionals: the Variational in VB Functional: a kind of meta-function that takes a function as input We can view F[q] as a functional of q Calculus of functionals parallels that of functions Then, we can take the derivative of F[q] with respect to q, set it to 0, and solve for q 13
14 Derivatives 14


15 Functional Derivatives The change in functional as we change its function argument 15
16 Useful Derivatives 16
17 Useful Derivatives 17

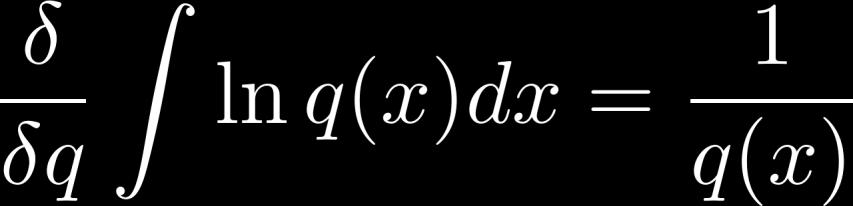
18 Useful Derivatives 18
19 Useful Derivatives 19
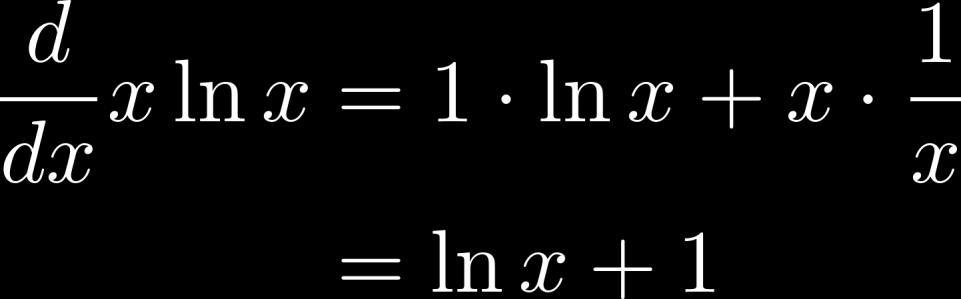
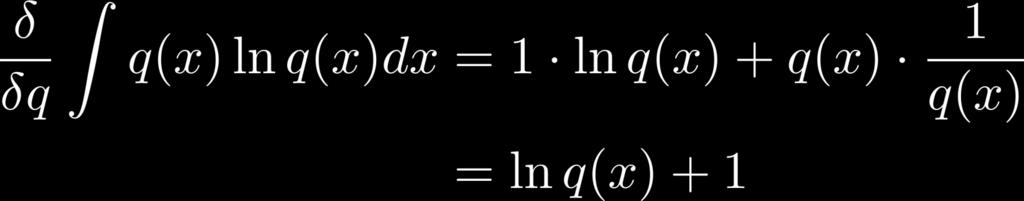
20 Useful Derivatives 20
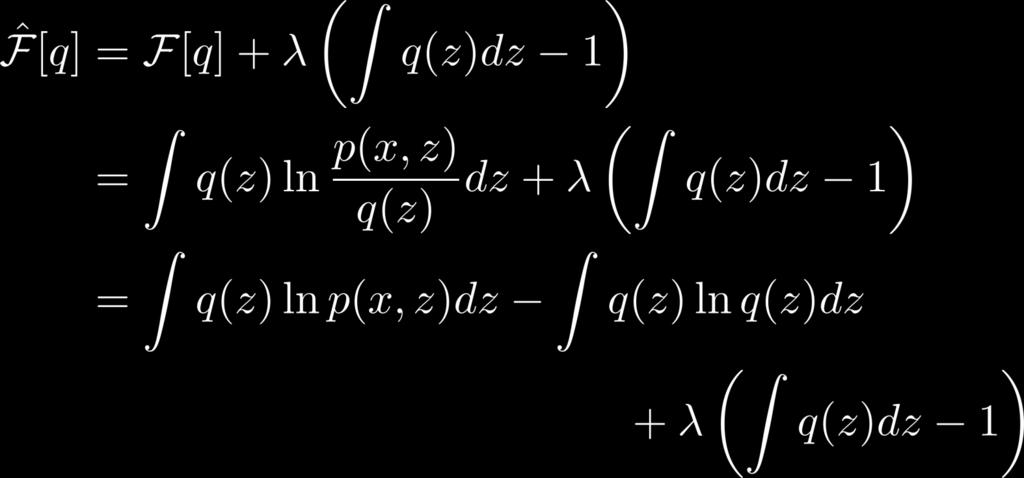
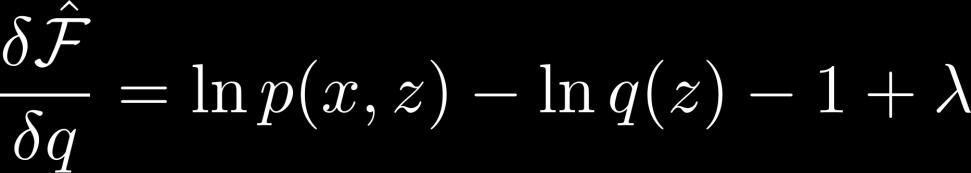
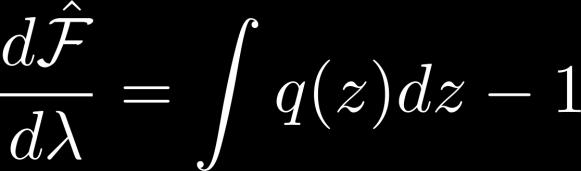
21 Calculating q Use Lagrange multipliers constraint 21
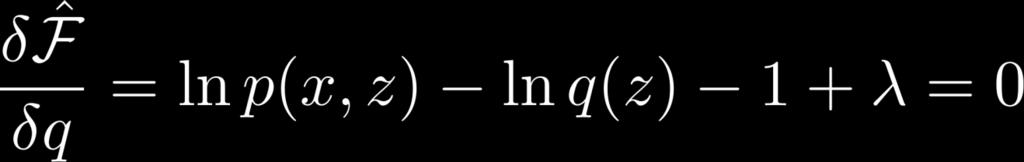
22 Calculating q 22
23 Calculating q 23
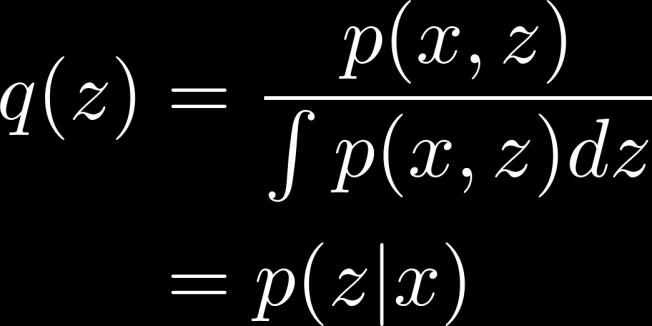
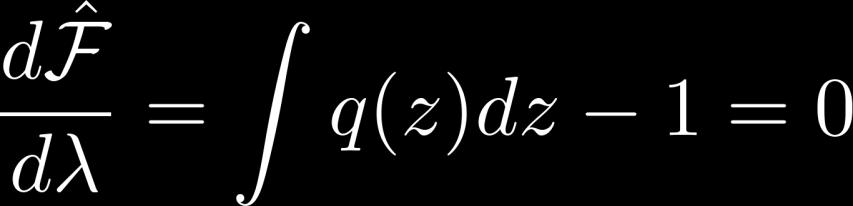
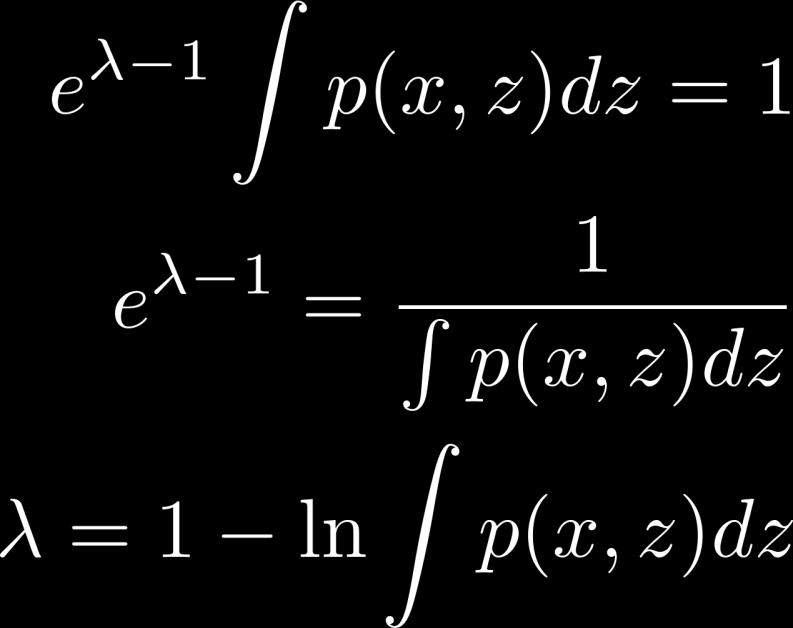
24 Calculating q 24

25 KL Divergence: An Alternative View Maximizing F is minimizing the KL divergence And 25
 is p(z")
26 Optimal q The best q(z) is p(z x) 26
27 Where are we? We ve bounded the likelihood (Jensen s Ineq.) Made this bound tight (Lagrange Multipliers) But the best approximation is no approximation at all! We need to constrain q so that it s tractable 27
28 Optimal q in an Imperfect World We can t compute q(z)=p(z x) directly Instead, constrain the domain of F[q] to some set of more tractable functions This is usually done by making independence assumptions The mean field assumption: cut all dependencies 28

29 Example 2: Mean Field Assumption We have some observed data: We have a model relating latent variables z and θ to the data: To guess z and θ we need But the integral is hard! Apply the mean field assumption 29

30 The New Lower Bound 30

31 The New Lower Bound 31
32 The New Lower Bound 32

33 The New Lower Bound Apply mean field assumption 33


34 The Benefit of Independence The integrals get simpler In fact, these go away 34

35 Optimizing the Lower Bound 35
 Use")

36 Optimal q θ (θ) Use Lagrange multipliers constraint 36

37 Optimal q z (z) Use Lagrange multipliers constraint 37

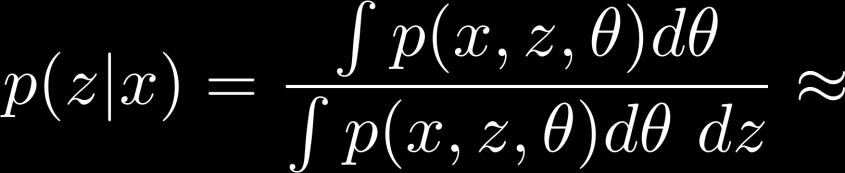

38 The Approximation q p 38


39 Estimating Parameters Now we have our approximation q We need to compute the expectations Use EM-like procedure, alternating between the two It was hard to do this for p(z,θ x) It s (hopefully) easy for q(z,θ) if we ve defined p to make use of conjugacy and if we ve chosen the right constraint for q 39
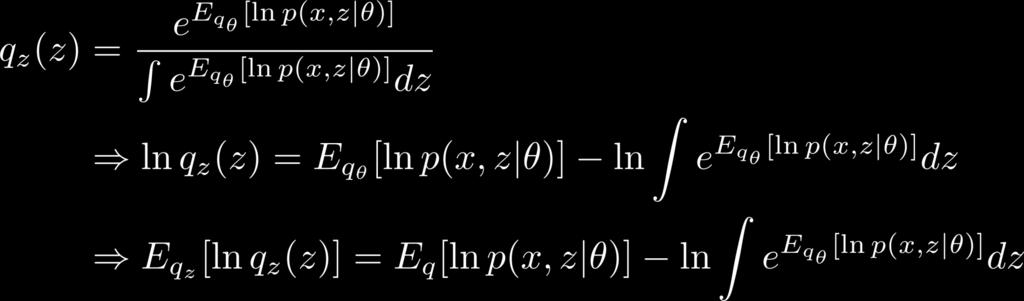
40 Calculating F 40
 So, we really only need two more expectations 41")
41 Calculating F As a side effect of inference, we already have It s the log of the normalization constant for q(z) So, we really only need two more expectations 41
42 Uses for F We can often use F in cases where we would normally use the log likelihood Measuring convergence No guarantee to maximize likelihood, but we do have F Others Model selection Choose the model with the highest lower bound Selecting the number of clusters Pick the number that gives us the highest lower bound Parameter optimization Again, optimize the lower bound w.r.t. the parameters 42
43 Worked Example Dirichlet-Multinomial Mixture Model 43

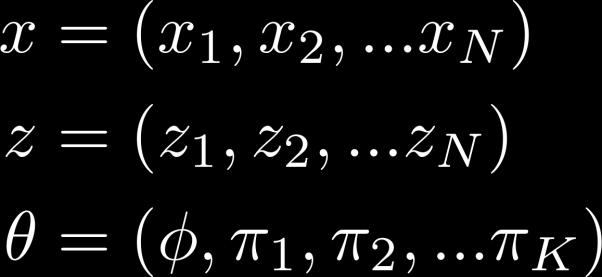
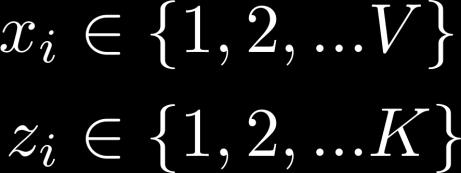
44 Dirichlet-Multinomial Mixture Model α φ β z π K x N 44

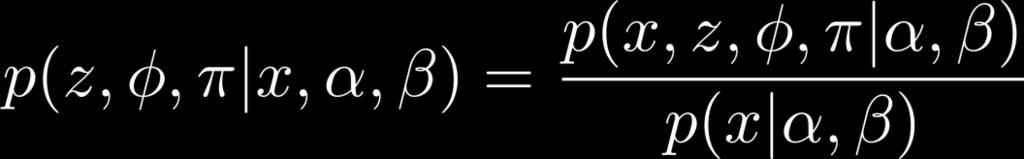
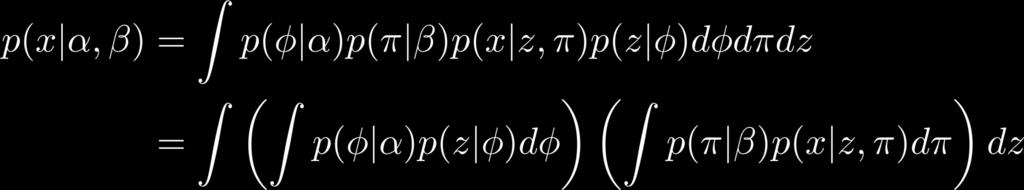
45 The Intractable Integral 45

46 The Mean Field Assumption 46
47 Optimizing F Apply Lagrange multipliers just like example 2 In this case, we have simply replaced z, x, and θ with vectors The math is exactly the same But we need to find the expectations we skipped before Plug in the Dirichlet and multinomial distributions 47
48 Optimal q(z,θ) Borrowed from example 2 See slides All we need to do is apply the particulars of the Mixture model 48
 49")
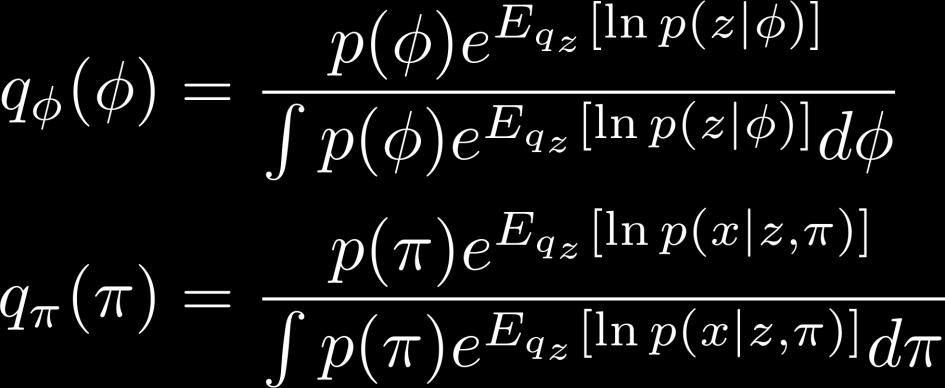
49 Optimal q θ (θ) 49

50 Optimal q φ (φ): The Expectation 50

51 Dirichlet Distribution 51

52 Optimal q φ (φ): The Numerator 52
:")
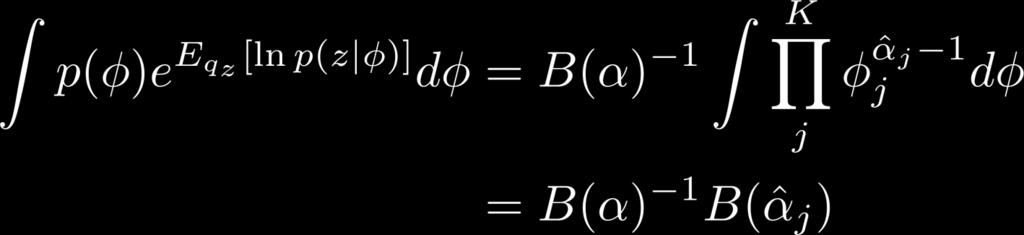
53 Optimal q φ (φ): The Normalization 53

54 Optimal q φ (φ): Conjugacy Helps 54
55 Optimal q π (π) q(π) is essentially the same as q(φ) The only difference is that there are multiple π s So, q(π) should be a product of Dirichlets 55

56 Optimal q π (π): The Expectation 56

57 Optimal q π (π): The Numerator 57
:")
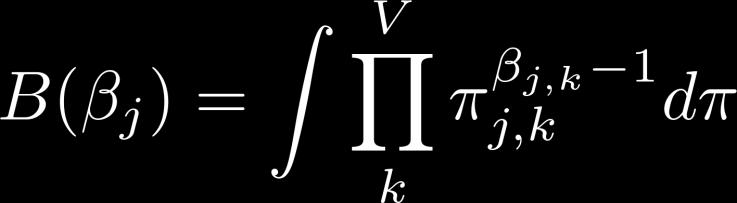
58 Optimal q π (π): The Denominator 58
:")

59 Optimal q π (π): Putting Them Together 59


60 A Useful Standard Result The digamma function The expectation under a Dirichlet of the log of an individual component of a Dirichlet random variable 60

61 Optimal q z (z) Again, borrowed from example 2 See slides Here, we plug in the model definition 61
62 Optimal q z (z) First, let s work with the simpler multinomial distribution Side effect: a kind of estimate for the multinomial parameter vector 62
:")
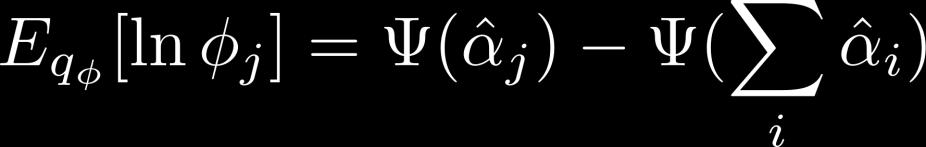
63 Optimal q z (z): The Expectations 63
64 Optimal q z (z): The Expectations Now, let s work with the product of multinomials Side effect: a kind of set of multinomial parameter vectors This is essentialy the same math required for HMMs and PCFGs 64

65 Optimal q z (z): The Expectations 65
:")

66 Optimal q z (z): Putting It Together 66



67 Implications of Assumption We should get the same result with an even weaker assumption 67
68 Inference E-Step : Expected Counts Topic counts Topic-word pair counts M-Step : The Proportions Topic j Topic-word pair j-k 68

69 Calculating F Also borrowed from example 2 See slides But we adapt it for the mixture model 69
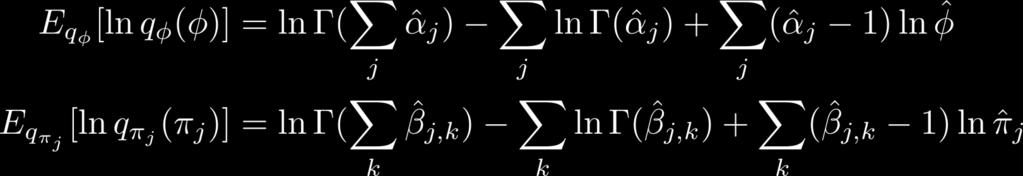
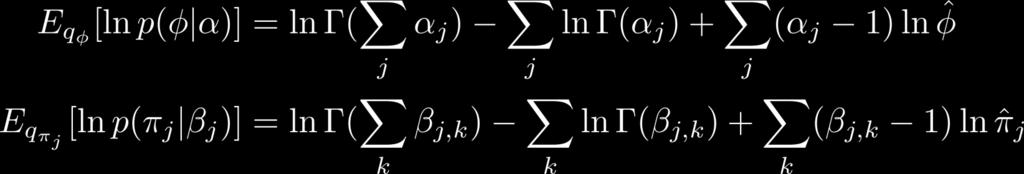
70 Calculating F 70

71 Calculating F: The Normalization Constant By product of computing 71
Lecture 8: Graphical models for Text
 Lecture 8: Graphical models for Text 4F13: Machine Learning Joaquin Quiñonero-Candela and Carl Edward Rasmussen Department of Engineering University of Cambridge http://mlg.eng.cam.ac.uk/teaching/4f13/
Lecture 8: Graphical models for Text 4F13: Machine Learning Joaquin Quiñonero-Candela and Carl Edward Rasmussen Department of Engineering University of Cambridge http://mlg.eng.cam.ac.uk/teaching/4f13/
13: Variational inference II
 10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
10-708: Probabilistic Graphical Models, Spring 2015 13: Variational inference II Lecturer: Eric P. Xing Scribes: Ronghuo Zheng, Zhiting Hu, Yuntian Deng 1 Introduction We started to talk about variational
Study Notes on the Latent Dirichlet Allocation
 Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
The Expectation Maximization or EM algorithm
 The Expectation Maximization or EM algorithm Carl Edward Rasmussen November 15th, 2017 Carl Edward Rasmussen The EM algorithm November 15th, 2017 1 / 11 Contents notation, objective the lower bound functional,
The Expectation Maximization or EM algorithm Carl Edward Rasmussen November 15th, 2017 Carl Edward Rasmussen The EM algorithm November 15th, 2017 1 / 11 Contents notation, objective the lower bound functional,
Quantitative Biology II Lecture 4: Variational Methods
 10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
Latent Dirichlet Allocation (LDA)
") Latent Dirichlet Allocation (LDA) D. Blei, A. Ng, and M. Jordan. Journal of Machine Learning Research, 3:993-1022, January 2003. Following slides borrowed ant then heavily modified from: Jonathan Huang
Latent Dirichlet Allocation (LDA) D. Blei, A. Ng, and M. Jordan. Journal of Machine Learning Research, 3:993-1022, January 2003. Following slides borrowed ant then heavily modified from: Jonathan Huang
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Variational Inference. Sargur Srihari
 Variational Inference Sargur srihari@cedar.buffalo.edu 1 Plan of discussion We first describe inference with PGMs and the intractability of exact inference Then give a taxonomy of inference algorithms
Variational Inference Sargur srihari@cedar.buffalo.edu 1 Plan of discussion We first describe inference with PGMs and the intractability of exact inference Then give a taxonomy of inference algorithms
Posterior Regularization
 Posterior Regularization 1 Introduction One of the key challenges in probabilistic structured learning, is the intractability of the posterior distribution, for fast inference. There are numerous methods
Posterior Regularization 1 Introduction One of the key challenges in probabilistic structured learning, is the intractability of the posterior distribution, for fast inference. There are numerous methods
CS Lecture 18. Topic Models and LDA
 CS 6347 Lecture 18 Topic Models and LDA (some slides by David Blei) Generative vs. Discriminative Models Recall that, in Bayesian networks, there could be many different, but equivalent models of the same
CS 6347 Lecture 18 Topic Models and LDA (some slides by David Blei) Generative vs. Discriminative Models Recall that, in Bayesian networks, there could be many different, but equivalent models of the same
Computer Vision Group Prof. Daniel Cremers. 6. Mixture Models and Expectation-Maximization
 Prof. Daniel Cremers 6. Mixture Models and Expectation-Maximization Motivation Often the introduction of latent (unobserved) random variables into a model can help to express complex (marginal) distributions
Prof. Daniel Cremers 6. Mixture Models and Expectation-Maximization Motivation Often the introduction of latent (unobserved) random variables into a model can help to express complex (marginal) distributions
EM & Variational Bayes
 EM & Variational Bayes Hanxiao Liu September 9, 2014 1 / 19 Outline 1. EM Algorithm 1.1 Introduction 1.2 Example: Mixture of vmfs 2. Variational Bayes 2.1 Introduction 2.2 Example: Bayesian Mixture of
EM & Variational Bayes Hanxiao Liu September 9, 2014 1 / 19 Outline 1. EM Algorithm 1.1 Introduction 1.2 Example: Mixture of vmfs 2. Variational Bayes 2.1 Introduction 2.2 Example: Bayesian Mixture of
Latent Variable View of EM. Sargur Srihari
 Latent Variable View of EM Sargur srihari@cedar.buffalo.edu 1 Examples of latent variables 1. Mixture Model Joint distribution is p(x,z) We don t have values for z 2. Hidden Markov Model A single time
Latent Variable View of EM Sargur srihari@cedar.buffalo.edu 1 Examples of latent variables 1. Mixture Model Joint distribution is p(x,z) We don t have values for z 2. Hidden Markov Model A single time
Gaussian Mixture Models
 Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Variational Scoring of Graphical Model Structures
 Variational Scoring of Graphical Model Structures Matthew J. Beal Work with Zoubin Ghahramani & Carl Rasmussen, Toronto. 15th September 2003 Overview Bayesian model selection Approximations using Variational
Variational Scoring of Graphical Model Structures Matthew J. Beal Work with Zoubin Ghahramani & Carl Rasmussen, Toronto. 15th September 2003 Overview Bayesian model selection Approximations using Variational
Lecture 13 : Variational Inference: Mean Field Approximation
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
The Particle Filter. PD Dr. Rudolph Triebel Computer Vision Group. Machine Learning for Computer Vision
 The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
The Particle Filter Non-parametric implementation of Bayes filter Represents the belief (posterior) random state samples. by a set of This representation is approximate. Can represent distributions that
CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection
 CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection (non-examinable material) Matthew J. Beal February 27, 2004 www.variational-bayes.org Bayesian Model Selection
CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection (non-examinable material) Matthew J. Beal February 27, 2004 www.variational-bayes.org Bayesian Model Selection
Note 1: Varitional Methods for Latent Dirichlet Allocation
 Technical Note Series Spring 2013 Note 1: Varitional Methods for Latent Dirichlet Allocation Version 1.0 Wayne Xin Zhao batmanfly@gmail.com Disclaimer: The focus of this note was to reorganie the content
Technical Note Series Spring 2013 Note 1: Varitional Methods for Latent Dirichlet Allocation Version 1.0 Wayne Xin Zhao batmanfly@gmail.com Disclaimer: The focus of this note was to reorganie the content
Linear Dynamical Systems
 Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Linear Dynamical Systems Sargur N. srihari@cedar.buffalo.edu Machine Learning Course: http://www.cedar.buffalo.edu/~srihari/cse574/index.html Two Models Described by Same Graph Latent variables Observations
Expectation maximization tutorial
 Expectation maximization tutorial Octavian Ganea November 18, 2016 1/1 Today Expectation - maximization algorithm Topic modelling 2/1 ML & MAP Observed data: X = {x 1, x 2... x N } 3/1 ML & MAP Observed
Expectation maximization tutorial Octavian Ganea November 18, 2016 1/1 Today Expectation - maximization algorithm Topic modelling 2/1 ML & MAP Observed data: X = {x 1, x 2... x N } 3/1 ML & MAP Observed
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu October 19, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu October 19, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
LDA with Amortized Inference
 LDA with Amortied Inference Nanbo Sun Abstract This report describes how to frame Latent Dirichlet Allocation LDA as a Variational Auto- Encoder VAE and use the Amortied Variational Inference AVI to optimie
LDA with Amortied Inference Nanbo Sun Abstract This report describes how to frame Latent Dirichlet Allocation LDA as a Variational Auto- Encoder VAE and use the Amortied Variational Inference AVI to optimie
Lecture 10. Announcement. Mixture Models II. Topics of This Lecture. This Lecture: Advanced Machine Learning. Recap: GMMs as Latent Variable Models
 Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Advanced Machine Learning Lecture 10 Mixture Models II 30.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ Announcement Exercise sheet 2 online Sampling Rejection Sampling Importance
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Two Useful Bounds for Variational Inference
 Two Useful Bounds for Variational Inference John Paisley Department of Computer Science Princeton University, Princeton, NJ jpaisley@princeton.edu Abstract We review and derive two lower bounds on the
Two Useful Bounds for Variational Inference John Paisley Department of Computer Science Princeton University, Princeton, NJ jpaisley@princeton.edu Abstract We review and derive two lower bounds on the
Unsupervised Learning
 Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
A Note on the Expectation-Maximization (EM) Algorithm
 Algorithm") A Note on the Expectation-Maximization (EM) Algorithm ChengXiang Zhai Department of Computer Science University of Illinois at Urbana-Champaign March 11, 2007 1 Introduction The Expectation-Maximization
A Note on the Expectation-Maximization (EM) Algorithm ChengXiang Zhai Department of Computer Science University of Illinois at Urbana-Champaign March 11, 2007 1 Introduction The Expectation-Maximization
Expectation Maximization
 Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
Expectation Maximization Algorithm
 Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Expectation Maximization and Mixtures of Gaussians
 Statistical Machine Learning Notes 10 Expectation Maximiation and Mixtures of Gaussians Instructor: Justin Domke Contents 1 Introduction 1 2 Preliminary: Jensen s Inequality 2 3 Expectation Maximiation
Statistical Machine Learning Notes 10 Expectation Maximiation and Mixtures of Gaussians Instructor: Justin Domke Contents 1 Introduction 1 2 Preliminary: Jensen s Inequality 2 3 Expectation Maximiation
MACHINE LEARNING AND PATTERN RECOGNITION Fall 2006, Lecture 8: Latent Variables, EM Yann LeCun
 Y. LeCun: Machine Learning and Pattern Recognition p. 1/? MACHINE LEARNING AND PATTERN RECOGNITION Fall 2006, Lecture 8: Latent Variables, EM Yann LeCun The Courant Institute, New York University http://yann.lecun.com
Y. LeCun: Machine Learning and Pattern Recognition p. 1/? MACHINE LEARNING AND PATTERN RECOGNITION Fall 2006, Lecture 8: Latent Variables, EM Yann LeCun The Courant Institute, New York University http://yann.lecun.com
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
ECE 5984: Introduction to Machine Learning Topics: (Finish) Expectation Maximization Principal Component Analysis (PCA) Readings: Barber 15.1-15.4 Dhruv Batra Virginia Tech Administrativia Poster Presentation:
Mixture Models and Expectation-Maximization
 Mixture Models and Expectation-Maximiation David M. Blei March 9, 2012 EM for mixtures of multinomials The graphical model for a mixture of multinomials π d x dn N D θ k K How should we fit the parameters?
Mixture Models and Expectation-Maximiation David M. Blei March 9, 2012 EM for mixtures of multinomials The graphical model for a mixture of multinomials π d x dn N D θ k K How should we fit the parameters?
STATS 306B: Unsupervised Learning Spring Lecture 3 April 7th
 STATS 306B: Unsupervised Learning Spring 2014 Lecture 3 April 7th Lecturer: Lester Mackey Scribe: Jordan Bryan, Dangna Li 3.1 Recap: Gaussian Mixture Modeling In the last lecture, we discussed the Gaussian
STATS 306B: Unsupervised Learning Spring 2014 Lecture 3 April 7th Lecturer: Lester Mackey Scribe: Jordan Bryan, Dangna Li 3.1 Recap: Gaussian Mixture Modeling In the last lecture, we discussed the Gaussian
Mixtures of Gaussians. Sargur Srihari
 Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Mixtures of Gaussians Sargur srihari@cedar.buffalo.edu 1 9. Mixture Models and EM 0. Mixture Models Overview 1. K-Means Clustering 2. Mixtures of Gaussians 3. An Alternative View of EM 4. The EM Algorithm
Maximum Likelihood (ML), Expectation Maximization (EM) Pieter Abbeel UC Berkeley EECS
, Expectation Maximization (EM) Pieter Abbeel UC Berkeley EECS") Maximum Likelihood (ML), Expectation Maximization (EM) Pieter Abbeel UC Berkeley EECS Many slides adapted from Thrun, Burgard and Fox, Probabilistic Robotics Outline Maximum likelihood (ML) Priors, and
Maximum Likelihood (ML), Expectation Maximization (EM) Pieter Abbeel UC Berkeley EECS Many slides adapted from Thrun, Burgard and Fox, Probabilistic Robotics Outline Maximum likelihood (ML) Priors, and
Series 6, May 14th, 2018 (EM Algorithm and Semi-Supervised Learning)
") Exercises Introduction to Machine Learning SS 2018 Series 6, May 14th, 2018 (EM Algorithm and Semi-Supervised Learning) LAS Group, Institute for Machine Learning Dept of Computer Science, ETH Zürich Prof
Exercises Introduction to Machine Learning SS 2018 Series 6, May 14th, 2018 (EM Algorithm and Semi-Supervised Learning) LAS Group, Institute for Machine Learning Dept of Computer Science, ETH Zürich Prof
Technical Details about the Expectation Maximization (EM) Algorithm
 Algorithm") Technical Details about the Expectation Maximization (EM Algorithm Dawen Liang Columbia University dliang@ee.columbia.edu February 25, 2015 1 Introduction Maximum Lielihood Estimation (MLE is widely used
Technical Details about the Expectation Maximization (EM Algorithm Dawen Liang Columbia University dliang@ee.columbia.edu February 25, 2015 1 Introduction Maximum Lielihood Estimation (MLE is widely used
Probabilistic Time Series Classification
 Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Latent Variable Models
 Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Latent Variable Models Stefano Ermon, Aditya Grover Stanford University Lecture 5 Stefano Ermon, Aditya Grover (AI Lab) Deep Generative Models Lecture 5 1 / 31 Recap of last lecture 1 Autoregressive models:
Motif representation using position weight matrix
 Motif representation using position weight matrix Xiaohui Xie University of California, Irvine Motif representation using position weight matrix p.1/31 Position weight matrix Position weight matrix representation
Motif representation using position weight matrix Xiaohui Xie University of California, Irvine Motif representation using position weight matrix p.1/31 Position weight matrix Position weight matrix representation
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
An Introduction to Expectation-Maximization
 An Introduction to Expectation-Maximization Dahua Lin Abstract This notes reviews the basics about the Expectation-Maximization EM) algorithm, a popular approach to perform model estimation of the generative
An Introduction to Expectation-Maximization Dahua Lin Abstract This notes reviews the basics about the Expectation-Maximization EM) algorithm, a popular approach to perform model estimation of the generative
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Auto-Encoding Variational Bayes
 Auto-Encoding Variational Bayes Diederik P Kingma, Max Welling June 18, 2018 Diederik P Kingma, Max Welling Auto-Encoding Variational Bayes June 18, 2018 1 / 39 Outline 1 Introduction 2 Variational Lower
Auto-Encoding Variational Bayes Diederik P Kingma, Max Welling June 18, 2018 Diederik P Kingma, Max Welling Auto-Encoding Variational Bayes June 18, 2018 1 / 39 Outline 1 Introduction 2 Variational Lower
A minimalist s exposition of EM
 A minimalist s exposition of EM Karl Stratos 1 What EM optimizes Let O, H be a random variables representing the space of samples. Let be the parameter of a generative model with an associated probability
A minimalist s exposition of EM Karl Stratos 1 What EM optimizes Let O, H be a random variables representing the space of samples. Let be the parameter of a generative model with an associated probability
Bayesian Inference and MCMC
 Bayesian Inference and MCMC Aryan Arbabi Partly based on MCMC slides from CSC412 Fall 2018 1 / 18 Bayesian Inference - Motivation Consider we have a data set D = {x 1,..., x n }. E.g each x i can be the
Bayesian Inference and MCMC Aryan Arbabi Partly based on MCMC slides from CSC412 Fall 2018 1 / 18 Bayesian Inference - Motivation Consider we have a data set D = {x 1,..., x n }. E.g each x i can be the
The Expectation-Maximization Algorithm
 1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
Probabilistic Graphical Models for Image Analysis - Lecture 4
 Probabilistic Graphical Models for Image Analysis - Lecture 4 Stefan Bauer 12 October 2018 Max Planck ETH Center for Learning Systems Overview 1. Repetition 2. α-divergence 3. Variational Inference 4.
Probabilistic Graphical Models for Image Analysis - Lecture 4 Stefan Bauer 12 October 2018 Max Planck ETH Center for Learning Systems Overview 1. Repetition 2. α-divergence 3. Variational Inference 4.
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Pattern Recognition and Machine Learning. Bishop Chapter 9: Mixture Models and EM
 Pattern Recognition and Machine Learning Chapter 9: Mixture Models and EM Thomas Mensink Jakob Verbeek October 11, 27 Le Menu 9.1 K-means clustering Getting the idea with a simple example 9.2 Mixtures
Pattern Recognition and Machine Learning Chapter 9: Mixture Models and EM Thomas Mensink Jakob Verbeek October 11, 27 Le Menu 9.1 K-means clustering Getting the idea with a simple example 9.2 Mixtures
Clustering K-means. Machine Learning CSE546. Sham Kakade University of Washington. November 15, Review: PCA Start: unsupervised learning
 Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Clustering K-means Machine Learning CSE546 Sham Kakade University of Washington November 15, 2016 1 Announcements: Project Milestones due date passed. HW3 due on Monday It ll be collaborative HW2 grades
Expectation Maximization
 Expectation Maximization Machine Learning CSE546 Carlos Guestrin University of Washington November 13, 2014 1 E.M.: The General Case E.M. widely used beyond mixtures of Gaussians The recipe is the same
Expectation Maximization Machine Learning CSE546 Carlos Guestrin University of Washington November 13, 2014 1 E.M.: The General Case E.M. widely used beyond mixtures of Gaussians The recipe is the same
Algorithms for Variational Learning of Mixture of Gaussians
 Algorithms for Variational Learning of Mixture of Gaussians Instructors: Tapani Raiko and Antti Honkela Bayes Group Adaptive Informatics Research Center 28.08.2008 Variational Bayesian Inference Mixture
Algorithms for Variational Learning of Mixture of Gaussians Instructors: Tapani Raiko and Antti Honkela Bayes Group Adaptive Informatics Research Center 28.08.2008 Variational Bayesian Inference Mixture
Clustering, K-Means, EM Tutorial
 Clustering, K-Means, EM Tutorial Kamyar Ghasemipour Parts taken from Shikhar Sharma, Wenjie Luo, and Boris Ivanovic s tutorial slides, as well as lecture notes Organization: Clustering Motivation K-Means
Clustering, K-Means, EM Tutorial Kamyar Ghasemipour Parts taken from Shikhar Sharma, Wenjie Luo, and Boris Ivanovic s tutorial slides, as well as lecture notes Organization: Clustering Motivation K-Means
Gaussian Mixture Models, Expectation Maximization
 Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu November 3, 2015 Methods to Learn Matrix Data Text Data Set Data Sequence Data Time Series Graph
CS6220: DATA MINING TECHNIQUES Matrix Data: Clustering: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu November 3, 2015 Methods to Learn Matrix Data Text Data Set Data Sequence Data Time Series Graph
Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures
 17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
Expectation Propagation Algorithm
 Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Clustering and Gaussian Mixture Models
 Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Bayesian Methods for Machine Learning
 Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Bayesian Methods for Machine Learning CS 584: Big Data Analytics Material adapted from Radford Neal s tutorial (http://ftp.cs.utoronto.ca/pub/radford/bayes-tut.pdf), Zoubin Ghahramni (http://hunch.net/~coms-4771/zoubin_ghahramani_bayesian_learning.pdf),
Variational Message Passing. By John Winn, Christopher M. Bishop Presented by Andy Miller
 Variational Message Passing By John Winn, Christopher M. Bishop Presented by Andy Miller Overview Background Variational Inference Conjugate-Exponential Models Variational Message Passing Messages Univariate
Variational Message Passing By John Winn, Christopher M. Bishop Presented by Andy Miller Overview Background Variational Inference Conjugate-Exponential Models Variational Message Passing Messages Univariate
Latent Dirichlet Bayesian Co-Clustering
 Latent Dirichlet Bayesian Co-Clustering Pu Wang 1, Carlotta Domeniconi 1, and athryn Blackmond Laskey 1 Department of Computer Science Department of Systems Engineering and Operations Research George Mason
Latent Dirichlet Bayesian Co-Clustering Pu Wang 1, Carlotta Domeniconi 1, and athryn Blackmond Laskey 1 Department of Computer Science Department of Systems Engineering and Operations Research George Mason
Lecture 6: Gaussian Mixture Models (GMM)
") Helsinki Institute for Information Technology Lecture 6: Gaussian Mixture Models (GMM) Pedram Daee 3.11.2015 Outline Gaussian Mixture Models (GMM) Models Model families and parameters Parameter learning
Helsinki Institute for Information Technology Lecture 6: Gaussian Mixture Models (GMM) Pedram Daee 3.11.2015 Outline Gaussian Mixture Models (GMM) Models Model families and parameters Parameter learning
Deep Variational Inference. FLARE Reading Group Presentation Wesley Tansey 9/28/2016
 Deep Variational Inference FLARE Reading Group Presentation Wesley Tansey 9/28/2016 What is Variational Inference? What is Variational Inference? Want to estimate some distribution, p*(x) p*(x) What is
Deep Variational Inference FLARE Reading Group Presentation Wesley Tansey 9/28/2016 What is Variational Inference? What is Variational Inference? Want to estimate some distribution, p*(x) p*(x) What is
Part 1: Expectation Propagation
 Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Lecture 8 Learning Sequence Motif Models Using Expectation Maximization (EM) Colin Dewey February 14, 2008
 Colin Dewey February 14, 2008") Lecture 8 Learning Sequence Motif Models Using Expectation Maximization (EM) Colin Dewey February 14, 2008 1 Sequence Motifs what is a sequence motif? a sequence pattern of biological significance typically
Lecture 8 Learning Sequence Motif Models Using Expectation Maximization (EM) Colin Dewey February 14, 2008 1 Sequence Motifs what is a sequence motif? a sequence pattern of biological significance typically
Latent Variable Models and EM Algorithm
 SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
Generative and Discriminative Approaches to Graphical Models CMSC Topics in AI
 Generative and Discriminative Approaches to Graphical Models CMSC 35900 Topics in AI Lecture 2 Yasemin Altun January 26, 2007 Review of Inference on Graphical Models Elimination algorithm finds single
Generative and Discriminative Approaches to Graphical Models CMSC 35900 Topics in AI Lecture 2 Yasemin Altun January 26, 2007 Review of Inference on Graphical Models Elimination algorithm finds single
EM-algorithm for motif discovery
 EM-algorithm for motif discovery Xiaohui Xie University of California, Irvine EM-algorithm for motif discovery p.1/19 Position weight matrix Position weight matrix representation of a motif with width
EM-algorithm for motif discovery Xiaohui Xie University of California, Irvine EM-algorithm for motif discovery p.1/19 Position weight matrix Position weight matrix representation of a motif with width
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Learning MN Parameters with Approximation. Sargur Srihari
 Learning MN Parameters with Approximation Sargur srihari@cedar.buffalo.edu 1 Topics Iterative exact learning of MN parameters Difficulty with exact methods Approximate methods Approximate Inference Belief
Learning MN Parameters with Approximation Sargur srihari@cedar.buffalo.edu 1 Topics Iterative exact learning of MN parameters Difficulty with exact methods Approximate methods Approximate Inference Belief
IEOR E4570: Machine Learning for OR&FE Spring 2015 c 2015 by Martin Haugh. The EM Algorithm
 IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017
 COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University SOFT CLUSTERING VS HARD CLUSTERING
COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University SOFT CLUSTERING VS HARD CLUSTERING
an introduction to bayesian inference
 with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
Programming Assignment 4: Image Completion using Mixture of Bernoullis
 Programming Assignment 4: Image Completion using Mixture of Bernoullis Deadline: Tuesday, April 4, at 11:59pm TA: Renie Liao (csc321ta@cs.toronto.edu) Submission: You must submit two files through MarkUs
Programming Assignment 4: Image Completion using Mixture of Bernoullis Deadline: Tuesday, April 4, at 11:59pm TA: Renie Liao (csc321ta@cs.toronto.edu) Submission: You must submit two files through MarkUs
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
MCMC and Gibbs Sampling. Kayhan Batmanghelich
 MCMC and Gibbs Sampling Kayhan Batmanghelich 1 Approaches to inference l Exact inference algorithms l l l The elimination algorithm Message-passing algorithm (sum-product, belief propagation) The junction
MCMC and Gibbs Sampling Kayhan Batmanghelich 1 Approaches to inference l Exact inference algorithms l l l The elimination algorithm Message-passing algorithm (sum-product, belief propagation) The junction
Directed Probabilistic Graphical Models CMSC 678 UMBC
 Directed Probabilistic Graphical Models CMSC 678 UMBC Announcement 1: Assignment 3 Due Wednesday April 11 th, 11:59 AM Any questions? Announcement 2: Progress Report on Project Due Monday April 16 th,
Directed Probabilistic Graphical Models CMSC 678 UMBC Announcement 1: Assignment 3 Due Wednesday April 11 th, 11:59 AM Any questions? Announcement 2: Progress Report on Project Due Monday April 16 th,
Cheng Soon Ong & Christian Walder. Canberra February June 2017
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2017 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 679 Part XIX
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2017 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 679 Part XIX
Non-Parametric Bayes
 Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Non-Parametric Bayes Mark Schmidt UBC Machine Learning Reading Group January 2016 Current Hot Topics in Machine Learning Bayesian learning includes: Gaussian processes. Approximate inference. Bayesian
Note for plsa and LDA-Version 1.1
 Note for plsa and LDA-Version 1.1 Wayne Xin Zhao March 2, 2011 1 Disclaimer In this part of PLSA, I refer to [4, 5, 1]. In LDA part, I refer to [3, 2]. Due to the limit of my English ability, in some place,
Note for plsa and LDA-Version 1.1 Wayne Xin Zhao March 2, 2011 1 Disclaimer In this part of PLSA, I refer to [4, 5, 1]. In LDA part, I refer to [3, 2]. Due to the limit of my English ability, in some place,
Expectation-Maximization (EM) algorithm
 algorithm") I529: Machine Learning in Bioinformatics (Spring 2017) Expectation-Maximization (EM) algorithm Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2017 Contents Introduce
I529: Machine Learning in Bioinformatics (Spring 2017) Expectation-Maximization (EM) algorithm Yuzhen Ye School of Informatics and Computing Indiana University, Bloomington Spring 2017 Contents Introduce
ECE521 Tutorial 11. Topic Review. ECE521 Winter Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides. ECE521 Tutorial 11 / 4
 ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
Variational Inference and Learning. Sargur N. Srihari
 Variational Inference and Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics in Approximate Inference Task of Inference Intractability in Inference 1. Inference as Optimization 2. Expectation Maximization
Variational Inference and Learning Sargur N. srihari@cedar.buffalo.edu 1 Topics in Approximate Inference Task of Inference Intractability in Inference 1. Inference as Optimization 2. Expectation Maximization
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Latent Variable Models and EM algorithm
 Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Gibbs Sampling. Héctor Corrada Bravo. University of Maryland, College Park, USA CMSC 644:
 Gibbs Sampling Héctor Corrada Bravo University of Maryland, College Park, USA CMSC 644: 2019 03 27 Latent semantic analysis Documents as mixtures of topics (Hoffman 1999) 1 / 60 Latent semantic analysis
Gibbs Sampling Héctor Corrada Bravo University of Maryland, College Park, USA CMSC 644: 2019 03 27 Latent semantic analysis Documents as mixtures of topics (Hoffman 1999) 1 / 60 Latent semantic analysis
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 9: Variational Inference Relaxations Volkan Cevher, Matthias Seeger Ecole Polytechnique Fédérale de Lausanne 24/10/2011 (EPFL) Graphical Models 24/10/2011 1 / 15
Probabilistic Graphical Models Lecture 9: Variational Inference Relaxations Volkan Cevher, Matthias Seeger Ecole Polytechnique Fédérale de Lausanne 24/10/2011 (EPFL) Graphical Models 24/10/2011 1 / 15
Statistical Pattern Recognition
 Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Statistical Pattern Recognition Expectation Maximization (EM) and Mixture Models Hamid R. Rabiee Jafar Muhammadi, Mohammad J. Hosseini Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2 Agenda Expectation-maximization
Unsupervised Learning
 2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
2018 EE448, Big Data Mining, Lecture 7 Unsupervised Learning Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html ML Problem Setting First build and
The Expectation Maximization Algorithm
 The Expectation Maximization Algorithm Frank Dellaert College of Computing, Georgia Institute of Technology Technical Report number GIT-GVU-- February Abstract This note represents my attempt at explaining
The Expectation Maximization Algorithm Frank Dellaert College of Computing, Georgia Institute of Technology Technical Report number GIT-GVU-- February Abstract This note represents my attempt at explaining
Week 3: The EM algorithm
 Week 3: The EM algorithm Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London Term 1, Autumn 2005 Mixtures of Gaussians Data: Y = {y 1... y N } Latent
Week 3: The EM algorithm Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London Term 1, Autumn 2005 Mixtures of Gaussians Data: Y = {y 1... y N } Latent
Bayesian Analysis for Natural Language Processing Lecture 2
 Bayesian Analysis for Natural Language Processing Lecture 2 Shay Cohen February 4, 2013 Administrativia The class has a mailing list: coms-e6998-11@cs.columbia.edu Need two volunteers for leading a discussion
Bayesian Analysis for Natural Language Processing Lecture 2 Shay Cohen February 4, 2013 Administrativia The class has a mailing list: coms-e6998-11@cs.columbia.edu Need two volunteers for leading a discussion