First Technical Course, European Centre for Soft Computing, Mieres, Spain. 4th July 2011
|
|
|
- Kerry Garrison
- 5 years ago
- Views:
Transcription
1 First Technical Course, European Centre for Soft Computing, Mieres, Spain. 4th July 2011 Linear
2 Given probabilities p(a), p(b), and the joint probability p(a, B), we can write the conditional probabilities p(b A) = p(a B) = p(a, B) p(a) p(a, B) p(b) Linear Eliminating p(a, B) gives p(b A) = p(a B)p(B) p(a)
3 In the context of model fitting, if we have data y and model parameters w, the terms in p(w y) = p(y w)p(w) p(y) are referred to as the prior, p(w), the likelihood, p(y w), and the posterior, p(w y). The probability p(y) is a normalisation term and can be found by marginalisation. For continuously valued parameters p(y) = p(y w)p(w)dw or for discrete parameters p(y) = i p(y w i )p(w i ) p(y) is referred to as the marginal likelihood or model evidence. Linear
 MRA can miss sizable Intracranial Aneurysms (IA) s but is non-invasive (top).")
4 Johnson et al (2001) consider Bayesian inference in for Magnetic Resonance Angiography (MRA). An Aneurysm is a localized, blood-filled balloon-like bulge in the wall of a blood vessel. They commonly occur in arteries at the base of the brain. There are two tests: (1) MRA can miss sizable Intracranial Aneurysms (IA) s but is non-invasive (top). (2) Intra-Arterial Digital Subtraction Angiography (DSA) (bottom) is the gold standard method for detecting IA but is an invasive procedure requiring local injection of a contrast agent via a tube inserted into the relevant artery. Linear
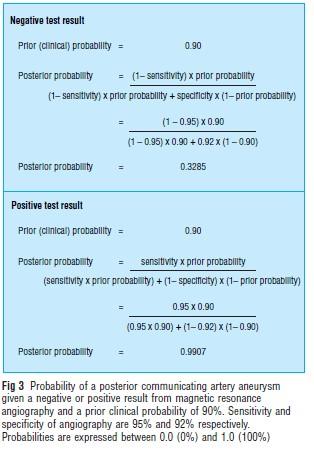
5 Given patient 1 s symptoms (oculomotor palsy), the prior probability of IA (prior to MRA) is believed to be 90%. For IAs bigger than 6mm MRA has a sensitivity and specificity of 95% and 92%. What then is the probability of IA given a negative MRA test result? Linear
6 The probability of IA given a negative test can be found from p(mra = 0 IA = 1)p(IA = 1) p(ia = 1 MRA = 0) = p(mra = 0 IA = 1)p(IA = 1) + p(mra = 0 IA = 0)p(IA = 0) where p(ia = 1) is the probability of IA prior to the MRA test. MRA test sensitivity and specificity are p(mra = 1 IA = 1) p(mra = 0 IA = 0) We have p(mra = 0 IA = 1) = 1 p(mra = 1 IA = 1) Linear
7 Linear

8 Linear A negative MRA cannot therefore be used to exclude a diagnosis of IA. In both reported cases IA was initially excluded, until other symptoms developed or other tests also proved negative.
9 For the prior (blue) we have m 0 = 20, λ 0 = 1 and for the likelihood (red) m D = 25 and λ D = 3. Linear Precision, λ, is inverse variance.
10 for Gaussians For a Gaussian prior with mean m 0 and precision λ 0, and a Gaussian likelihood with mean m D and precision λ D the posterior is Gaussian with λ = λ 0 + λ D m = λ 0 λ m 0 + λ D λ m D So, (1) precisions add and (2) the posterior mean is the sum of the prior and data means, but each weighted by their relative precision. Linear
11 for Gaussians For the prior (blue) m 0 = 20, λ 0 = 1 and the likelihood (red) m D = 25 and λ D = 3, the posterior (magenta) shows the posterior distribution with m = and λ = 4. Linear The posterior is closer to the likelihood because the likelihood has higher precision.
12 General Linear Model The General Linear Model (GLM) is given by y = Xw + e where y are data, X is a design matrix, and e are zero mean Gaussian errors with covariance V. The above equation implicitly defines the likelihood function p(y w) = N(y; Xw, C y ) where the Normal density is given by ( 1 N(x; µ, C) = (2π) N/2 exp 1 ) C 1/2 2 (x µ)t C 1 (x µ) Linear
13 Maximum Likelihood If we know C y then we can estimate w by maximising the likelihood or equivalently the log-likelihood L = N 2 log 2π 1 2 log C y 1 2 (y Xw)T Cy 1 (y Xw) We can compute the gradient with help from the Matrix Reference Manual dl dw = X T Cy 1 y X T Cy 1 Xw to zero. This leads to the solution ŵ ML = (X T C 1 y X) 1 X T C 1 y This is the Maximum Likelihood (ML) solution. y Linear

14 fmri time series analysis In software such as SPM or FSL brain mapping is implemented with the following method. At the ith voxel (volume element) we have time series y i Linear
15 fmri time series analysis In a standard analysis linear models are fitted separately at each voxel y i = Xw i + e i C y = Cov(e i ) is the error covariance and then the regression coefficients are computed using Maximum Likelihood (ML) estimation ŵ i = (X T C 1 y X) 1 X T C 1 The fitted responses are then ŷ i = Xŵ i y y i Linear
 1 t i = ŵ i")
16 Statistical Parametric Maps We can then test if effects are significantly non-zero. The uncertainty in the ML estimates is given by A t-score is then given by S = (X T Cy 1 X) 1 t i = ŵ i (k)/ S(k, k) Linear

17 The standard approach in SPM and FSL smooths the data, y, before fitting time series models at each voxel. This increases the SNR. Linear Top 3 views show original fmri images, bottom 3 views show data smoothed by a Gaussian kernel of width 6mm.
 was looking to find which brain regions show different responses for repeated and familiar stimuli in the context")
18 Generally, we are looking to test for multiple effects at each point in the brain. Linear Henson et al. (2002) was looking to find which brain regions show different responses for repeated and familiar stimuli in the context of face processing.
19 Generally, we are looking to test for multiple effects at each point in the brain. Linear
20 Generally, we are looking to test for multiple effects at each point in the brain. At voxel i y i = Xw i + e i where eg. X is as below and w i is a 4-element vector. Linear
 c = [1/4, 1/4, 1/4, 1/4].")
21 Contrast vectors c can then be used to test for specific effects µ c = c T ŵ i For example, to look at the average response to faces (regardless of type) c = [1/4, 1/4, 1/4, 1/4]. The uncertainty in the effect is then σ 2 c = c T Sc and a t-score is then given by t = µ c /σ c Linear
22 To look at the effect of repetition c = [1/2, 1/2, 1/2, 1/2]. Linear
23 Bayesian GLM A Bayesian GLM is defined as y = Xw + e 1 w = µ w + e 2 where the errors are zero mean Gaussian with covariances Cov[e 1 ] = C y and Cov[e 2 ] = C w. p(y w) = N(y; Xw, C y ) p(w) = N(w; µ w, C w ) Linear
24 GLM posterior The posterior density is (Bishop, 2006) p(w y) = N(w; m w, S w ) Sw 1 = X T Cy 1 X + Cw 1 m w = S w (X T Cy 1 y + Cw 1 µ w ) The posterior precision is the sum of the prior precision and the data precision. The posterior mean is a relative precision weighted combination of the data mean and the prior mean. Linear
25 Bayesian GLM with two parameters The prior has mean µ w = [0, 0] T (cross) and precision C 1 w = diag([1, 1]). Linear
26 Bayesian GLM with two parameters The likelihood has mean X T y = [3, 2] T (circle) and precision (X T C 1 y X) 1 = diag([10, 1]). Linear
27 Bayesian GLM with two parameters The posterior has mean m = [2.73, 1] T (cross) and precision S 1 w = diag([11, 2]). Linear
28 Bayesian GLM with two parameters In this example, the measurements are more informative about w 1 than w 2. This is reflected in the posterior distribution. Linear
29 Shrinkage Prior If µ w = 0 we have a shrinkage prior. Linear
 There is evidence that humans combine information in this optimal way (Doya et al 2006).")
30 Tennis From Wolpert and Ghahramani (2006) Linear p(w y) = N(m w, S w ) Sw 1 = X T Cy 1 X + Cw 1 m w = S w (X T Cy 1 y + Cw 1 µ w ) There is evidence that humans combine information in this optimal way (Doya et al 2006).

31 Time series models Usually, we wish to test for multiple experimental effects. At the ith spatial position y i = Xw i + e i where eg X is a T K design matrix as below and w i is a K = 4 element vector and y i is a T = 351 element time series Linear
32 Time series model for images We can write the model over all spatial positions i = 1..V as Y = XW + E where Y is an T V fmri data matrix, X is a V K design matrix, W is a K V matrix of regression coefficients, and E is an T V matrix of errors. The ith column of Y is the time series at the ith voxel. The ith column of W, w i, is the vector of regression coefficients at the ith voxel. Linear The kth row of W, w k, is a V -element vector. It contains the image of regression coefficients for the kth effect we are testing for.
33 We can define a spatial prior over each of the k = 1..K regression coefficient images p(w k α) = N(w k ; 0, αq w ) to capture our prior information that regression coefficients will be similar at nearby voxels, where the larger α produces smoother images. Linear The matrix Q w can be set to reflect different assumptions abouth the types of smoothness.
34 Laplacian Prior If we define a spatial kernel S with elements Linear Then z k = Sw k will be a vector of local discrepancies between neighbouring voxels. The quantity z T k z k = w T k ST Sw k is then the sum of squared discrepancies. A shrinkage prior on z k, that is one that encourages minimal discrepancy, is given by where Q 1 w = S T S. p(w k α k ) = N(w k ; 0, α k Q w )
 can have different smoothnesses.")
35 We define a spatio-temporal model where p(y, W ) = p(y W )p(w α) p(w α) = K p(w k α k ) k=1 Linear Different effects (eg first versus second presentation) can have different smoothnesses. For full generative model see Penny et al (2005).
36 Variational Bayes Given fmri data, the posterior distibution for the spatio-temporal model is Gaussian but the posterior covariance is of dimension VK VK which is too large to handle. Instead we use an approximate posterior that factorises over voxels q(w Y ) = q(w i Y ) i This approximate posterior can be fitted using the Variational Bayes (VB) framework (Bishop 2006, Penny et al. 2005). The VB method can also be used to estimate the prior precisions α. This is a special case of (see MEG example later). Linear
 Structural image (MRI) (b) ML applied to smooth data Y (c) Bayesian inference with Global shrinkage prior (Q w = I) (d)")
37 Results. (a) Structural image (MRI) (b) ML applied to smooth data Y (c) Bayesian inference with Global shrinkage prior (Q w = I) (d) Bayesian inference with Laplacian prior (Q w = S T S) Linear For (c) a Gaussian smoothing kernel of 8mm FWHM was used.
 (d) Bayesian inference with Laplacian prior (Q w = S T S)")
38 . (a) True activations (b) ML applied to smooth data (c) Bayesian inference with Global shrinkage prior (Q w = I) (d) Bayesian inference with Laplacian prior (Q w = S T S) Linear
39 Receiver Operating Characteristic Linear

40 is achieved through inversion of the linear model y = Xw + e (d 1) = (d p)(p 1) + (d 1) for MEG data, y with d sensors and p potential sources, w, lying perpendicular to the cortical surface. The lead field matrix is specified by X. For our example we have d = 274 and p = Linear The above equation is for a single time point.
41 Generative Likelihood Prior We let p(y w) = N(y; Xw, C y ) p(w) = N(w; 0, C w ) Linear C y = λ y Q 1 C w = λ w Q 2 For shrinkage priors Q 2 = I p, MAP estimation results in the minimum norm method of source reconstruction. This is implemented in SPM as the IID option
 method. Linear This is implemented in SPM as the COH option. Note, these are not location priors.")
42 Smoothness Priors For smoothness priors Q 2 = KK T corresponding to the operation of a Gaussian smoothing kernel, MAP estimation results something similar to the Low Resolution Tomography (LORETA) method. Linear This is implemented in SPM as the COH option. Note, these are not location priors.
43 Posterior Density From earlier we have where p(w y) = N(w; m w, S w ) S 1 w = X T Cy 1 X + Cw 1 m w = S w X T Cy 1 y However, S w is p p with p = 8192 so cannot be inverted easily. But we can use the matrix inversion lemma, also known as the Woodbury identity (Bishop, 2006) (A + BCD) 1 = A 1 A 1 B(C 1 + DA 1 B) 1 DA 1 to ensure that only d d matrices need inverting. Linear
44 Simulation Two sinusoidal sources were placed in bilateral auditory cortex and produced this MEG data (Barnes, 2010), comprising d = 274 time series (butterfly plot) Linear
45 LORETA We fix λ y = 1. Here we set λ w = Linear This shows the posterior mean activity for the 500 dipoles with the greatest power (over peristimulus time)

46 LORETA We fix λ y = 1. Here we set λ w = 0.1. Linear
47 LORETA We fix λ y = 1. Here we set λ w = 1. Linear
48 Hyperparameters, λ, can be estimated so as to maximise the model evidence. This forms the basis of Empirical Bayes. The marginal likelihood or model evidence is given by p(y λ) = p(y, w, λ)dw = p(y w, λ)p(w λ)dw The log model evidence is L(λ) = log p(y λ) For linear models this can be derived as in Bishop (2006) or as in my Maths for Brain Imaging notes. In this formulation λ are not treated as random variables. There is no prior on them. Linear
49 We iterate between finding the parameters w and hyperparameters λ. For linear Gaussian models this corresponds to computing the posterior over w S 1 w = X T Cy 1 X + Cw 1 m w = S w (X T Cy 1 y + Cw 1 µ w ) and then setting λ to maximise the model evidence. Linear ˆλ = arg max L(λ) λ These two steps are then iterated and can be thought of as E and M steps in an EM optimisation algorithm.
50 The model evidence is composed of sum squared precision weighted prediction errors and Occam factors L(λ) = 1 2 et y Cy 1 e y 1 2 log C y d log 2π et wcw 1 e w 1 2 log C w S w where λ is a vector of hyperparameters that parameterise the covariances C w = λ w Q w and C y = λ y Q y. The prediction errors are the difference between what is expected and what is observed e y = y Xm w e w = m w µ w Linear
51 For a Bayesian GLM y = Xw + e 1 w = µ w + e 2 with isotropic covariances (eg minimum norm source reconstruction) C y = λ y I N C w = λ w I p and d data points and p parameters. The equations for updating λ can be derived as shown in Chapter 10 of Bishop (2005). Linear
52 Well-determined parameters Define γ = p j=1 α j α j + ˆλ w where α j are eigenvalues of the data precision term X T Cy 1 X. If α j >> ˆλ w for all j then γ = p. Parameters have all been determined by the data. So γ is equivalent to number of well-determined parameters. Linear
53 M-Step Then 1 ˆλ w = et we w γ 1 ˆλ y = et y e y d γ Linear where the prediction errors are e y = y Xm w e w = m w µ w This effectively partitions the degrees of freedom in the data into those for estimating the prior and the likelihood. Setting λ to maximise the marginal likelihood produces unbiased estimates of variances whereas ML estimation produces biased estimates.
54 For a Bayesian GLM with covariances y = Xw + e 1 w = µ w + e 2 C y = i λ i Q i C w = i λ i Q i where Q are known covariance basis functions. The M-step is ˆλ = arg max L(λ) λ Linear
55 This maximisation is effected by first computing the gradient and curvature of L(λ) at the current parameter estimate, λ old j λ (i) = dl(λ) dλ(i) H λ (i, j) = d 2 L(λ) dλ(i)dλ(j) where i and j index the ith and jth parameters, j λ is the gradient vector and H λ is the curvature matrix. The new estimate is then given by λ new = λ old H 1 λ j λ Linear

56 Hyperparameters set using. Linear The minimum norm method, also implemented in SPM as the IID option.

57 Smoothness Priors Hyperparameters set using. Linear This is similar to the LORETA method, implemented in SPM as the COH option.
58 G. Barnes (2010) Localisation, SPM Manual, Chapter 35 C. Bishop (2006) Pattern Recognition and Machine Learning, Springer. K. Doya et al (2006) Bayesian Brain. Probabilistic approaches to neural coding. MIT Press. R. Henson (2003) Cerebral Cortex, 12: M. Johnson et al. (2001) BMJ 322, D. Mackay (2003) Information Theory, Inference and Learning Algorithms, Cambridge. W. Penny et al. (2007) time series analysis with spatial priors. Neuroimage 24, D. Wolpert and Z. Ghahramani (2004) In Gregory RL (ed) Oxford Companion to the Mind, OUP. Linear
Bayesian Inference. Will Penny. 24th February Bayesian Inference. Will Penny. Bayesian Inference. References
 24th February 2011 Given probabilities p(a), p(b), and the joint probability p(a, B), we can write the conditional probabilities p(b A) = p(a B) = p(a, B) p(a) p(a, B) p(b) Eliminating p(a, B) gives p(b
24th February 2011 Given probabilities p(a), p(b), and the joint probability p(a, B), we can write the conditional probabilities p(b A) = p(a B) = p(a, B) p(a) p(a, B) p(b) Eliminating p(a, B) gives p(b
Model Comparison. Course on Bayesian Inference, WTCN, UCL, February Model Comparison. Bayes rule for models. Linear Models. AIC and BIC.
 Course on Bayesian Inference, WTCN, UCL, February 2013 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented
Course on Bayesian Inference, WTCN, UCL, February 2013 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented
A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y.
 (or hypothesis space ) can be updated to a posterior distribution after observing data y.") June 2nd 2011 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule p(m y) = p(y m)p(m)
June 2nd 2011 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule p(m y) = p(y m)p(m)
Will Penny. SPM for MEG/EEG, 15th May 2012
 SPM for MEG/EEG, 15th May 2012 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule
SPM for MEG/EEG, 15th May 2012 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule
Hierarchical Models. W.D. Penny and K.J. Friston. Wellcome Department of Imaging Neuroscience, University College London.
 Hierarchical Models W.D. Penny and K.J. Friston Wellcome Department of Imaging Neuroscience, University College London. February 28, 2003 1 Introduction Hierarchical models are central to many current
Hierarchical Models W.D. Penny and K.J. Friston Wellcome Department of Imaging Neuroscience, University College London. February 28, 2003 1 Introduction Hierarchical models are central to many current
Will Penny. SPM short course for M/EEG, London 2013
 SPM short course for M/EEG, London 2013 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure Bayes rule for models A prior distribution over model space p(m) (or hypothesis space ) can be updated
SPM short course for M/EEG, London 2013 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure Bayes rule for models A prior distribution over model space p(m) (or hypothesis space ) can be updated
Will Penny. SPM short course for M/EEG, London 2015
 SPM short course for M/EEG, London 2015 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure The model evidence is given by integrating out the dependence on model parameters p(y m) = p(y,
SPM short course for M/EEG, London 2015 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure The model evidence is given by integrating out the dependence on model parameters p(y m) = p(y,
Hierarchy. Will Penny. 24th March Hierarchy. Will Penny. Linear Models. Convergence. Nonlinear Models. References
 24th March 2011 Update Hierarchical Model Rao and Ballard (1999) presented a hierarchical model of visual cortex to show how classical and extra-classical Receptive Field (RF) effects could be explained
24th March 2011 Update Hierarchical Model Rao and Ballard (1999) presented a hierarchical model of visual cortex to show how classical and extra-classical Receptive Field (RF) effects could be explained
Will Penny. DCM short course, Paris 2012
 DCM short course, Paris 2012 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure Bayes rule for models A prior distribution over model space p(m) (or hypothesis space ) can be updated to a
DCM short course, Paris 2012 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure Bayes rule for models A prior distribution over model space p(m) (or hypothesis space ) can be updated to a
Linear Models for Regression
 Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Principles of DCM. Will Penny. 26th May Principles of DCM. Will Penny. Introduction. Differential Equations. Bayesian Estimation.
 26th May 2011 Dynamic Causal Modelling Dynamic Causal Modelling is a framework studying large scale brain connectivity by fitting differential equation models to brain imaging data. DCMs differ in their
26th May 2011 Dynamic Causal Modelling Dynamic Causal Modelling is a framework studying large scale brain connectivity by fitting differential equation models to brain imaging data. DCMs differ in their
Regularized Regression A Bayesian point of view
 Regularized Regression A Bayesian point of view Vincent MICHEL Director : Gilles Celeux Supervisor : Bertrand Thirion Parietal Team, INRIA Saclay Ile-de-France LRI, Université Paris Sud CEA, DSV, I2BM,
Regularized Regression A Bayesian point of view Vincent MICHEL Director : Gilles Celeux Supervisor : Bertrand Thirion Parietal Team, INRIA Saclay Ile-de-France LRI, Université Paris Sud CEA, DSV, I2BM,
M/EEG source analysis
 Jérémie Mattout Lyon Neuroscience Research Center Will it ever happen that mathematicians will know enough about the physiology of the brain, and neurophysiologists enough of mathematical discovery, for
Jérémie Mattout Lyon Neuroscience Research Center Will it ever happen that mathematicians will know enough about the physiology of the brain, and neurophysiologists enough of mathematical discovery, for
Bayesian Inference Course, WTCN, UCL, March 2013
 Bayesian Course, WTCN, UCL, March 2013 Shannon (1948) asked how much information is received when we observe a specific value of the variable x? If an unlikely event occurs then one would expect the information
Bayesian Course, WTCN, UCL, March 2013 Shannon (1948) asked how much information is received when we observe a specific value of the variable x? If an unlikely event occurs then one would expect the information
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Bayesian Linear Regression [DRAFT - In Progress]
![Bayesian Linear Regression [DRAFT - In Progress]](/thumbs/92/109828713.jpg "Bayesian Linear Regression [DRAFT - In Progress]") Bayesian Linear Regression [DRAFT - In Progress] David S. Rosenberg Abstract Here we develop some basics of Bayesian linear regression. Most of the calculations for this document come from the basic theory
Bayesian Linear Regression [DRAFT - In Progress] David S. Rosenberg Abstract Here we develop some basics of Bayesian linear regression. Most of the calculations for this document come from the basic theory
Wellcome Trust Centre for Neuroimaging, UCL, UK.
 Bayesian Inference Will Penny Wellcome Trust Centre for Neuroimaging, UCL, UK. SPM Course, Virginia Tech, January 2012 What is Bayesian Inference? (From Daniel Wolpert) Bayesian segmentation and normalisation
Bayesian Inference Will Penny Wellcome Trust Centre for Neuroimaging, UCL, UK. SPM Course, Virginia Tech, January 2012 What is Bayesian Inference? (From Daniel Wolpert) Bayesian segmentation and normalisation
Bayesian Inference: Principles and Practice 3. Sparse Bayesian Models and the Relevance Vector Machine
 Bayesian Inference: Principles and Practice 3. Sparse Bayesian Models and the Relevance Vector Machine Mike Tipping Gaussian prior Marginal prior: single α Independent α Cambridge, UK Lecture 3: Overview
Bayesian Inference: Principles and Practice 3. Sparse Bayesian Models and the Relevance Vector Machine Mike Tipping Gaussian prior Marginal prior: single α Independent α Cambridge, UK Lecture 3: Overview
Computer Vision Group Prof. Daniel Cremers. 2. Regression (cont.)
") Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 17. Bayesian inference; Bayesian regression Training == optimisation (?) Stages of learning & inference: Formulate model Regression
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 17. Bayesian inference; Bayesian regression Training == optimisation (?) Stages of learning & inference: Formulate model Regression
Bayesian inference J. Daunizeau
 Bayesian inference J. Daunizeau Brain and Spine Institute, Paris, France Wellcome Trust Centre for Neuroimaging, London, UK Overview of the talk 1 Probabilistic modelling and representation of uncertainty
Bayesian inference J. Daunizeau Brain and Spine Institute, Paris, France Wellcome Trust Centre for Neuroimaging, London, UK Overview of the talk 1 Probabilistic modelling and representation of uncertainty
Modelling temporal structure (in noise and signal)
") Modelling temporal structure (in noise and signal) Mark Woolrich, Christian Beckmann*, Salima Makni & Steve Smith FMRIB, Oxford *Imperial/FMRIB temporal noise: modelling temporal autocorrelation temporal
Modelling temporal structure (in noise and signal) Mark Woolrich, Christian Beckmann*, Salima Makni & Steve Smith FMRIB, Oxford *Imperial/FMRIB temporal noise: modelling temporal autocorrelation temporal
Bayesian inference J. Daunizeau
 Bayesian inference J. Daunizeau Brain and Spine Institute, Paris, France Wellcome Trust Centre for Neuroimaging, London, UK Overview of the talk 1 Probabilistic modelling and representation of uncertainty
Bayesian inference J. Daunizeau Brain and Spine Institute, Paris, France Wellcome Trust Centre for Neuroimaging, London, UK Overview of the talk 1 Probabilistic modelling and representation of uncertainty
An Introduction to Statistical and Probabilistic Linear Models
 An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
LINEAR MODELS FOR CLASSIFICATION. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
Bayesian Inference for the Multivariate Normal
 Bayesian Inference for the Multivariate Normal Will Penny Wellcome Trust Centre for Neuroimaging, University College, London WC1N 3BG, UK. November 28, 2014 Abstract Bayesian inference for the multivariate
Bayesian Inference for the Multivariate Normal Will Penny Wellcome Trust Centre for Neuroimaging, University College, London WC1N 3BG, UK. November 28, 2014 Abstract Bayesian inference for the multivariate
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
CS-E3210 Machine Learning: Basic Principles
 CS-E3210 Machine Learning: Basic Principles Lecture 4: Regression II slides by Markus Heinonen Department of Computer Science Aalto University, School of Science Autumn (Period I) 2017 1 / 61 Today s introduction
CS-E3210 Machine Learning: Basic Principles Lecture 4: Regression II slides by Markus Heinonen Department of Computer Science Aalto University, School of Science Autumn (Period I) 2017 1 / 61 Today s introduction
Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model
 Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model (& discussion on the GPLVM tech. report by Prof. N. Lawrence, 06) Andreas Damianou Department of Neuro- and Computer Science,
Tutorial on Gaussian Processes and the Gaussian Process Latent Variable Model (& discussion on the GPLVM tech. report by Prof. N. Lawrence, 06) Andreas Damianou Department of Neuro- and Computer Science,
Annealed Importance Sampling for Neural Mass Models
 for Neural Mass Models, UCL. WTCN, UCL, October 2015. Generative Model Behavioural or imaging data y. Likelihood p(y w, Γ). We have a Gaussian prior over model parameters p(w µ, Λ) = N (w; µ, Λ) Assume
for Neural Mass Models, UCL. WTCN, UCL, October 2015. Generative Model Behavioural or imaging data y. Likelihood p(y w, Γ). We have a Gaussian prior over model parameters p(w µ, Λ) = N (w; µ, Λ) Assume
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 3 Stochastic Gradients, Bayesian Inference, and Occam s Razor https://people.orie.cornell.edu/andrew/orie6741 Cornell University August
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 3 Stochastic Gradients, Bayesian Inference, and Occam s Razor https://people.orie.cornell.edu/andrew/orie6741 Cornell University August
COMS 4721: Machine Learning for Data Science Lecture 19, 4/6/2017
 COMS 4721: Machine Learning for Data Science Lecture 19, 4/6/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University PRINCIPAL COMPONENT ANALYSIS DIMENSIONALITY
COMS 4721: Machine Learning for Data Science Lecture 19, 4/6/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University PRINCIPAL COMPONENT ANALYSIS DIMENSIONALITY
> DEPARTMENT OF MATHEMATICS AND COMPUTER SCIENCE GRAVIS 2016 BASEL. Logistic Regression. Pattern Recognition 2016 Sandro Schönborn University of Basel
 Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Learning with Noisy Labels. Kate Niehaus Reading group 11-Feb-2014
 Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Probabilistic Graphical Models Lecture 20: Gaussian Processes
 Probabilistic Graphical Models Lecture 20: Gaussian Processes Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 30, 2015 1 / 53 What is Machine Learning? Machine learning algorithms
Probabilistic Graphical Models Lecture 20: Gaussian Processes Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 30, 2015 1 / 53 What is Machine Learning? Machine learning algorithms
Lecture 4: Probabilistic Learning
 DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
Part 2: Multivariate fmri analysis using a sparsifying spatio-temporal prior
 Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 2: Multivariate fmri analysis using a sparsifying spatio-temporal prior Tom Heskes joint work with Marcel van Gerven
Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 2: Multivariate fmri analysis using a sparsifying spatio-temporal prior Tom Heskes joint work with Marcel van Gerven
CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes
 CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes Roger Grosse Roger Grosse CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes 1 / 55 Adminis-Trivia Did everyone get my e-mail
CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes Roger Grosse Roger Grosse CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes 1 / 55 Adminis-Trivia Did everyone get my e-mail
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA
, Factor Analysis, Mixtures of PPCA") Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inria.fr http://perception.inrialpes.fr/
Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inria.fr http://perception.inrialpes.fr/
y Xw 2 2 y Xw λ w 2 2
 CS 189 Introduction to Machine Learning Spring 2018 Note 4 1 MLE and MAP for Regression (Part I) So far, we ve explored two approaches of the regression framework, Ordinary Least Squares and Ridge Regression:
CS 189 Introduction to Machine Learning Spring 2018 Note 4 1 MLE and MAP for Regression (Part I) So far, we ve explored two approaches of the regression framework, Ordinary Least Squares and Ridge Regression:
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
Machine Learning - MT & 5. Basis Expansion, Regularization, Validation
 Machine Learning - MT 2016 4 & 5. Basis Expansion, Regularization, Validation Varun Kanade University of Oxford October 19 & 24, 2016 Outline Basis function expansion to capture non-linear relationships
Machine Learning - MT 2016 4 & 5. Basis Expansion, Regularization, Validation Varun Kanade University of Oxford October 19 & 24, 2016 Outline Basis function expansion to capture non-linear relationships
Introduction: MLE, MAP, Bayesian reasoning (28/8/13)
") STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
STA561: Probabilistic machine learning Introduction: MLE, MAP, Bayesian reasoning (28/8/13) Lecturer: Barbara Engelhardt Scribes: K. Ulrich, J. Subramanian, N. Raval, J. O Hollaren 1 Classifiers In this
Bayesian Inference of Noise Levels in Regression
 Bayesian Inference of Noise Levels in Regression Christopher M. Bishop Microsoft Research, 7 J. J. Thomson Avenue, Cambridge, CB FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop
Bayesian Inference of Noise Levels in Regression Christopher M. Bishop Microsoft Research, 7 J. J. Thomson Avenue, Cambridge, CB FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop
Curve Fitting Re-visited, Bishop1.2.5
 Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Curve Fitting Re-visited, Bishop1.2.5 Maximum Likelihood Bishop 1.2.5 Model Likelihood differentiation p(t x, w, β) = Maximum Likelihood N N ( t n y(x n, w), β 1). (1.61) n=1 As we did in the case of the
Variational Approximate Inference in Latent Linear Models
 Variational Approximate Inference in Latent Linear Models Edward Arthur Lester Challis A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy of the
Variational Approximate Inference in Latent Linear Models Edward Arthur Lester Challis A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy of the
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
The General Linear Model (GLM)
") he General Linear Model (GLM) Klaas Enno Stephan ranslational Neuromodeling Unit (NU) Institute for Biomedical Engineering University of Zurich & EH Zurich Wellcome rust Centre for Neuroimaging Institute
he General Linear Model (GLM) Klaas Enno Stephan ranslational Neuromodeling Unit (NU) Institute for Biomedical Engineering University of Zurich & EH Zurich Wellcome rust Centre for Neuroimaging Institute
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
Lecture 3. Linear Regression II Bastian Leibe RWTH Aachen
 Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Lecture 4: Probabilistic Learning. Estimation Theory. Classification with Probability Distributions
 DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
Computer Vision Group Prof. Daniel Cremers. 9. Gaussian Processes - Regression
 Group Prof. Daniel Cremers 9. Gaussian Processes - Regression Repetition: Regularized Regression Before, we solved for w using the pseudoinverse. But: we can kernelize this problem as well! First step:
Group Prof. Daniel Cremers 9. Gaussian Processes - Regression Repetition: Regularized Regression Before, we solved for w using the pseudoinverse. But: we can kernelize this problem as well! First step:
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
Probabilistic & Bayesian deep learning. Andreas Damianou
 Probabilistic & Bayesian deep learning Andreas Damianou Amazon Research Cambridge, UK Talk at University of Sheffield, 19 March 2019 In this talk Not in this talk: CRFs, Boltzmann machines,... In this
Probabilistic & Bayesian deep learning Andreas Damianou Amazon Research Cambridge, UK Talk at University of Sheffield, 19 March 2019 In this talk Not in this talk: CRFs, Boltzmann machines,... In this
ADVANCED MACHINE LEARNING ADVANCED MACHINE LEARNING. Non-linear regression techniques Part - II
 1 Non-linear regression techniques Part - II Regression Algorithms in this Course Support Vector Machine Relevance Vector Machine Support vector regression Boosting random projections Relevance vector
1 Non-linear regression techniques Part - II Regression Algorithms in this Course Support Vector Machine Relevance Vector Machine Support vector regression Boosting random projections Relevance vector
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
The General Linear Model (GLM)
") The General Linear Model (GLM) Dr. Frederike Petzschner Translational Neuromodeling Unit (TNU) Institute for Biomedical Engineering, University of Zurich & ETH Zurich With many thanks for slides & images
The General Linear Model (GLM) Dr. Frederike Petzschner Translational Neuromodeling Unit (TNU) Institute for Biomedical Engineering, University of Zurich & ETH Zurich With many thanks for slides & images
Lecture 2: From Linear Regression to Kalman Filter and Beyond
 Lecture 2: From Linear Regression to Kalman Filter and Beyond Department of Biomedical Engineering and Computational Science Aalto University January 26, 2012 Contents 1 Batch and Recursive Estimation
Lecture 2: From Linear Regression to Kalman Filter and Beyond Department of Biomedical Engineering and Computational Science Aalto University January 26, 2012 Contents 1 Batch and Recursive Estimation
Gaussian Process Regression
 Gaussian Process Regression 4F1 Pattern Recognition, 21 Carl Edward Rasmussen Department of Engineering, University of Cambridge November 11th - 16th, 21 Rasmussen (Engineering, Cambridge) Gaussian Process
Gaussian Process Regression 4F1 Pattern Recognition, 21 Carl Edward Rasmussen Department of Engineering, University of Cambridge November 11th - 16th, 21 Rasmussen (Engineering, Cambridge) Gaussian Process
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Pattern Recognition and Machine Learning. Bishop Chapter 6: Kernel Methods
 Pattern Recognition and Machine Learning Chapter 6: Kernel Methods Vasil Khalidov Alex Kläser December 13, 2007 Training Data: Keep or Discard? Parametric methods (linear/nonlinear) so far: learn parameter
Pattern Recognition and Machine Learning Chapter 6: Kernel Methods Vasil Khalidov Alex Kläser December 13, 2007 Training Data: Keep or Discard? Parametric methods (linear/nonlinear) so far: learn parameter
An introduction to Bayesian inference and model comparison J. Daunizeau
 An introduction to Bayesian inference and model comparison J. Daunizeau ICM, Paris, France TNU, Zurich, Switzerland Overview of the talk An introduction to probabilistic modelling Bayesian model comparison
An introduction to Bayesian inference and model comparison J. Daunizeau ICM, Paris, France TNU, Zurich, Switzerland Overview of the talk An introduction to probabilistic modelling Bayesian model comparison
GWAS V: Gaussian processes
 GWAS V: Gaussian processes Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS V: Gaussian processes Summer 2011
GWAS V: Gaussian processes Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS V: Gaussian processes Summer 2011
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 13: Learning in Gaussian Graphical Models, Non-Gaussian Inference, Monte Carlo Methods Some figures
Latent Variable Models and EM Algorithm
 SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
SC4/SM8 Advanced Topics in Statistical Machine Learning Latent Variable Models and EM Algorithm Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/atsml/
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
TDA231. Logistic regression
 TDA231 Devdatt Dubhashi dubhashi@chalmers.se Dept. of Computer Science and Engg. Chalmers University February 19, 2016 Some data 5 x2 0 5 5 0 5 x 1 In the Bayes classifier, we built a model of each class
TDA231 Devdatt Dubhashi dubhashi@chalmers.se Dept. of Computer Science and Engg. Chalmers University February 19, 2016 Some data 5 x2 0 5 5 0 5 x 1 In the Bayes classifier, we built a model of each class
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 2: PROBABILITY DISTRIBUTIONS Parametric Distributions Basic building blocks: Need to determine given Representation: or? Recall Curve Fitting Binary Variables
Approximate Message Passing
 Approximate Message Passing Mohammad Emtiyaz Khan CS, UBC February 8, 2012 Abstract In this note, I summarize Sections 5.1 and 5.2 of Arian Maleki s PhD thesis. 1 Notation We denote scalars by small letters
Approximate Message Passing Mohammad Emtiyaz Khan CS, UBC February 8, 2012 Abstract In this note, I summarize Sections 5.1 and 5.2 of Arian Maleki s PhD thesis. 1 Notation We denote scalars by small letters
GAUSSIAN PROCESS REGRESSION
 GAUSSIAN PROCESS REGRESSION CSE 515T Spring 2015 1. BACKGROUND The kernel trick again... The Kernel Trick Consider again the linear regression model: y(x) = φ(x) w + ε, with prior p(w) = N (w; 0, Σ). The
GAUSSIAN PROCESS REGRESSION CSE 515T Spring 2015 1. BACKGROUND The kernel trick again... The Kernel Trick Consider again the linear regression model: y(x) = φ(x) w + ε, with prior p(w) = N (w; 0, Σ). The
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 305 Part VII
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 305 Part VII
Overview of SPM. Overview. Making the group inferences we want. Non-sphericity Beyond Ordinary Least Squares. Model estimation A word on power
 Group Inference, Non-sphericity & Covariance Components in SPM Alexa Morcom Edinburgh SPM course, April 011 Centre for Cognitive & Neural Systems/ Department of Psychology University of Edinburgh Overview
Group Inference, Non-sphericity & Covariance Components in SPM Alexa Morcom Edinburgh SPM course, April 011 Centre for Cognitive & Neural Systems/ Department of Psychology University of Edinburgh Overview
Lecture 1b: Linear Models for Regression
 Lecture 1b: Linear Models for Regression Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced
Lecture 1b: Linear Models for Regression Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced
Pattern Recognition and Machine Learning. Bishop Chapter 2: Probability Distributions
 Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Linear Models for Regression
 Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Midterm. Introduction to Machine Learning. CS 189 Spring Please do not open the exam before you are instructed to do so.
 CS 89 Spring 07 Introduction to Machine Learning Midterm Please do not open the exam before you are instructed to do so. The exam is closed book, closed notes except your one-page cheat sheet. Electronic
CS 89 Spring 07 Introduction to Machine Learning Midterm Please do not open the exam before you are instructed to do so. The exam is closed book, closed notes except your one-page cheat sheet. Electronic
Least Absolute Shrinkage is Equivalent to Quadratic Penalization
 Least Absolute Shrinkage is Equivalent to Quadratic Penalization Yves Grandvalet Heudiasyc, UMR CNRS 6599, Université de Technologie de Compiègne, BP 20.529, 60205 Compiègne Cedex, France Yves.Grandvalet@hds.utc.fr
Least Absolute Shrinkage is Equivalent to Quadratic Penalization Yves Grandvalet Heudiasyc, UMR CNRS 6599, Université de Technologie de Compiègne, BP 20.529, 60205 Compiègne Cedex, France Yves.Grandvalet@hds.utc.fr
CS8803: Statistical Techniques in Robotics Byron Boots. Hilbert Space Embeddings
 CS8803: Statistical Techniques in Robotics Byron Boots Hilbert Space Embeddings 1 Motivation CS8803: STR Hilbert Space Embeddings 2 Overview Multinomial Distributions Marginal, Joint, Conditional Sum,
CS8803: Statistical Techniques in Robotics Byron Boots Hilbert Space Embeddings 1 Motivation CS8803: STR Hilbert Space Embeddings 2 Overview Multinomial Distributions Marginal, Joint, Conditional Sum,
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
COM336: Neural Computing
 COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
Bayesian RL Seminar. Chris Mansley September 9, 2008
 Bayesian RL Seminar Chris Mansley September 9, 2008 Bayes Basic Probability One of the basic principles of probability theory, the chain rule, will allow us to derive most of the background material in
Bayesian RL Seminar Chris Mansley September 9, 2008 Bayes Basic Probability One of the basic principles of probability theory, the chain rule, will allow us to derive most of the background material in
Linear Regression and Discrimination
 Linear Regression and Discrimination Kernel-based Learning Methods Christian Igel Institut für Neuroinformatik Ruhr-Universität Bochum, Germany http://www.neuroinformatik.rub.de July 16, 2009 Christian
Linear Regression and Discrimination Kernel-based Learning Methods Christian Igel Institut für Neuroinformatik Ruhr-Universität Bochum, Germany http://www.neuroinformatik.rub.de July 16, 2009 Christian
Automated Segmentation of Low Light Level Imagery using Poisson MAP- MRF Labelling
 Automated Segmentation of Low Light Level Imagery using Poisson MAP- MRF Labelling Abstract An automated unsupervised technique, based upon a Bayesian framework, for the segmentation of low light level
Automated Segmentation of Low Light Level Imagery using Poisson MAP- MRF Labelling Abstract An automated unsupervised technique, based upon a Bayesian framework, for the segmentation of low light level
Lecture 2: From Linear Regression to Kalman Filter and Beyond
 Lecture 2: From Linear Regression to Kalman Filter and Beyond January 18, 2017 Contents 1 Batch and Recursive Estimation 2 Towards Bayesian Filtering 3 Kalman Filter and Bayesian Filtering and Smoothing
Lecture 2: From Linear Regression to Kalman Filter and Beyond January 18, 2017 Contents 1 Batch and Recursive Estimation 2 Towards Bayesian Filtering 3 Kalman Filter and Bayesian Filtering and Smoothing
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 2. Statistical Schools Adapted from slides by Ben Rubinstein Statistical Schools of Thought Remainder of lecture is to provide
STAT 518 Intro Student Presentation
 STAT 518 Intro Student Presentation Wen Wei Loh April 11, 2013 Title of paper Radford M. Neal [1999] Bayesian Statistics, 6: 475-501, 1999 What the paper is about Regression and Classification Flexible
STAT 518 Intro Student Presentation Wen Wei Loh April 11, 2013 Title of paper Radford M. Neal [1999] Bayesian Statistics, 6: 475-501, 1999 What the paper is about Regression and Classification Flexible
COMP 551 Applied Machine Learning Lecture 20: Gaussian processes
 COMP 55 Applied Machine Learning Lecture 2: Gaussian processes Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~hvanho2/comp55
COMP 55 Applied Machine Learning Lecture 2: Gaussian processes Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~hvanho2/comp55
PMR Learning as Inference
 Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Midterm exam CS 189/289, Fall 2015
 Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
SCUOLA DI SPECIALIZZAZIONE IN FISICA MEDICA. Sistemi di Elaborazione dell Informazione. Regressione. Ruggero Donida Labati
 SCUOLA DI SPECIALIZZAZIONE IN FISICA MEDICA Sistemi di Elaborazione dell Informazione Regressione Ruggero Donida Labati Dipartimento di Informatica via Bramante 65, 26013 Crema (CR), Italy http://homes.di.unimi.it/donida
SCUOLA DI SPECIALIZZAZIONE IN FISICA MEDICA Sistemi di Elaborazione dell Informazione Regressione Ruggero Donida Labati Dipartimento di Informatica via Bramante 65, 26013 Crema (CR), Italy http://homes.di.unimi.it/donida
Statistical Data Mining and Machine Learning Hilary Term 2016
 Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 143 Part IV
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 143 Part IV
Group Analysis. Lexicon. Hierarchical models Mixed effect models Random effect (RFX) models Components of variance
 models Components of variance") Group Analysis J. Daunizeau Institute of Empirical Research in Economics, Zurich, Switzerland Brain and Spine Institute, Paris, France SPM Course Edinburgh, April 2011 Image time-series Spatial filter
Group Analysis J. Daunizeau Institute of Empirical Research in Economics, Zurich, Switzerland Brain and Spine Institute, Paris, France SPM Course Edinburgh, April 2011 Image time-series Spatial filter
Multivariate Bayesian Linear Regression MLAI Lecture 11
 Multivariate Bayesian Linear Regression MLAI Lecture 11 Neil D. Lawrence Department of Computer Science Sheffield University 21st October 2012 Outline Univariate Bayesian Linear Regression Multivariate
Multivariate Bayesian Linear Regression MLAI Lecture 11 Neil D. Lawrence Department of Computer Science Sheffield University 21st October 2012 Outline Univariate Bayesian Linear Regression Multivariate