Linear Models for Regression
|
|
|
- Avis Carson
- 5 years ago
- Views:
Transcription
1 Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea / 36
2 Outline Regression Least Squares Method Ridge Regression Least Mean Squares Recursive (Sequential) least squares Bias-Variance Dilemman Bayesian Linear Regression 2 / 36
3 Regression Regression aims at modeling the dependence of a response Y on a covariate X. In other words, the goal of regression is to predict the value of one or more continuous target variables y given the value of input vector x. The regression model is described by y = f (x) + ɛ. Terminology: x: input, independent variable, predictor, regressor, covariate y: output, dependent variable, response The dependence of a response on a covariate is captured via a conditional probability distribution, p(y x). Depending on f (x), Linear regression: f (x) = M j= w jφ j (x) + w. Kernel regression: f (x) = N i= w ik(x, x i ) + w. 3 / 36
4 Regression Function: Conditional Mean We consider the mean squared error and find the MMSE estiamte: E(f ) = y f (x) 2 = y f (x) 2 p(x, y)dxdy = y f (x) 2 p(x)p(y x)dxdy = p(x) y f (x) 2 p(y x)dy dx }{{} to be minimized [ f (x) y f (x) 2 p(y x)dy ] = f (x) = yp(y x)dy = y x. 4 / 36
5 Linear Regression Linear regression refers to a model in which the conditional mean of y given the value of x is an affine function of φ(x) f (x) = M w j φ j (x) + w φ (x) = w φ(x), j= where φ j (x) are known as basis functions and w = [w, w,..., w M ], φ = [φ, φ,..., φ M ]. By using nonlinear basis functions, we allow the function f (x) to be a nonlinear function of the input vector x (but a linear function of φ(x)). 5 / 36
6 Polynomial Regression: y t = M j= w jφ j (x t) = M j= w jx j t M = M = t t x x M = 3 M = 9 t t x x 6 / 36
7 Basis Functions Polynomial regression: φ j (x) = x j. Gaussian basis functions: φ j (x) = exp { x µ j 2 2σ 2 }. Spline basis functions: Piecewise polynomials (divide the input space up into regions and fit a different polynomial in each region). Many other possible basis functions: sigmoidal basis functions, hyperbolic tangent basis functions, Fourier basis, wavelet basis, and so on. 7 / 36
8 Least Squares Method Given a set of training data {(x t, y t )} N t=, we determine the weight vector w which minimizes E LS = 2 N t= { yt w φ(x t ) } 2 = 2 y Φw 2, where y = [y,..., y N ] and Φ R N (M+) is known as the design matrix with Φ tj = φ j (x t ), i.e., φ (x ) φ (x ) φ M (x ) φ (x 2 ) φ (x 2 ) φ M (x 2 ) Φ = φ (x N ) φ (x N ) φ M (x N ) 8 / 36
9 E LS w = leads to the normal equation that is of the form Φ Φw = Φ y. Thus, LS estimate of w is given by w LS = ( Φ Φ) Φ y = Φ y, where Φ is known as the Moore-Penrose pseudo-inverse. Φ Φ is known as the Gram matrix. 9 / 36
10 Maximum Likelihood We assume that the target variable y t is given by a deterministic function f (x t, w) = w φ(x t ) with additive Gaussian noise so that where ɛ N (, σ 2 I ). The log-likelihood is given by y = Φw + ɛ, L = log p(y Φ, w) = N log p(y t φ(x t ), w) t= = N 2 log σ2 N 2 log 2π σ 2 E LS. Therefore, under Gaussian noise assumption, w ML = w LS. / 36
11 Ridge Regression We consider the sum-of-squares error function with a Euclidean norm-based regularizer Solving E w E = y Φw 2 + λ } 2 {{} 2 w 2. }{{} LSfit regularizer = for w leads to w ridge = ( λi + Φ Φ) Φ y. / 36
12 Ridge Regression: MAP Perpective Recall the likelihood: p(y Φ, w) = N (y Φw, σ 2 I ). Assume a zero-mean Gaussian prior with covariance Σ for parameters w: Then the posterior over w, p(w y, Φ) = p(w) = N (w, Σ). p(y Φ, w)p(w), p(y Φ, w)p(w)dw is still Gaussian with mean and mode at ŵ = (σ 2 Σ + Φ Φ) Φ y. When Σ is proportional to identity, i.e., Σ = λ σ 2 I, this is called ridge regression. 2 / 36
13 Ridge Regression: Shrinkage Suppose that the SVD of the design matrix Φ R N (M+) has the form Φ = UDV, where D = diag(d,..., d M+ ). Using the SVD we write the least squares fitted vector as ( M+ Φw LS = Φ Φ Φ) Φ y = UU y = u i u i y, where U y are the coordinates of y with respect to the orthonormal basis U. The ridge solutions are ( Φw ridge = Φ λi + Φ Φ) Φ y i= M+ = UD(D 2 + λi ) DU di 2 y = u i di 2 + λ u i y. It shrinks the coordinates by the factors. A greater amount of d i 2 +λ shrinkage is applied to basis vectors with smaller di 2. d 2 i i= 3 / 36
14 Least Mean Square (LMS) LMS is a gradient-descent method which minimizes the instantaneous error E t, where E LS = N E t = 2 t= N t= { y t w φ(x t)} 2. The gradient descent method leads to the updating rule for w that is of the form w w η E t { } w + η y t w φ(x t) φ(x t), where η > is a constant known as learning rate. 4 / 36
15 Recursive (Sequential) LS We introduce the forgetting factor λ to de-emphasize old samples, leading to the following error function E RLS = 2 t λ t i (y i φ i w t ) 2, i= where φ t = φ(x t). Solving E RLS w t = for w t leads to [ t ] [ t ] λ t i φ i φ i w t = λ t i y i φ i. i= i= 5 / 36
16 We define P t = r t = [ t ] λ t i φ i φ i, i= [ t ] λ t i y i φ i. i= With these definitions, we have w t = P tr t. The core idea of RLS is to apply the matrix inversion lemma to develop the sequential algorithm without matrix inversion. (A + BCD) = A A B(DA B + C ) DA. 6 / 36
17 The recursion for P t is given by [ t P t = λ t i φ i φ i = = λ i= ] [ t λ λ t i φ i φ i i= + φ t φ t ] [ P t Pt φ ] t φ t Pt. (matrix inversion lemma) λ + φ t P t φ t 7 / 36
18 Thus, the updating rule for w is given by w t = P tr t = [ P t Pt φ ] tφ t P t λ λ + φ t Pt φ [λr t + y tφ t ] t ] [y t φ t w t P t φ t = w t + λ + φ t Pt φ t }{{} gain } {{ } error. 8 / 36
19 Expected Loss The squared loss L is given by L(y, f (x)) = (f (x) y) 2. The expected loss is computed by E {L(y, f (x))} = (f (x) y) 2 p(x, y)dxdy = E {(f (x) E{y x} + E{y x} y) 2} = E {(f (x) E{y x}) 2 + (E{y x} y) 2} + 2E {(f (x) E{y x}) (E{y x} y)}. }{{} 9 / 36
20 The expected loss can be written as E {L(y, f (x))} = (f (x) E{y x}) 2 p(x)dx } {{ } first term + (E{y x} y) 2 p(x)dx. } {{ } second term The function f (x) appears only in the first term which will be minimized when f (x) = E{y x}. The second term is the variance of the distribution of y, averaged over x, representing the intrinsic variability of the target data and can be regarded as noise. Because it is independent of f (x), it represents the irreducible minimum value of the loss function. 2 / 36
21 Bias-Variance Decomposition Consider the integrand of the first term, which for a particular data set D takes the form (f (x; D) E{y x}) 2. Then we have { E D (f (x; D) E{y x}) 2} = (E D{f (x; D)} E{y x}) 2 }{{} (bias) { 2 + E D (f (x; D) E D{f (x; D)}) 2}. } {{ } variance expected loss = (bias) 2 + variance + noise. 2 / 36
22 Bias-Variance Dilemma There is a trade-off between bias and variance: flexible models: low bias but high variance rigid models: high bias but low variance The model with the optimal predictive capability is the one that leads to the best balance between bias and variance. 22 / 36
23 Example We consider the sinusoidal data set. We generate data sets, each containing N = 25 data points, independently from the sinusoidal curve h(x) = E{y x} = sin(2πx). The data sets are indexed by l =,..., L where L =. For each data set D (l), we fit a model with 24 Gaussian basis functions through a method of ridge regression to give a prediction function f (l) (x). f (x) = L (bias) 2 = N variance = N L f (l) (x), l= N [ f (xt) h(x ] 2 t), t= N t= L L l= [ f (l) (x t) f (x t)] / 36
24 Rigid model (st row) and flexible model (2nd row) low variance high bias high variance low bias 24 / 36
25 Bayesian Linear Regression The likelihood function is given by p(y Φ, w) = N p(y t φ t, w), t= where p(y t φ t, w) = N (y t w φ t, β ). Assuming Gaussian prior for w, i.e., p(w) = N (w µ, Σ ), the posterior distribution over w is again Gaussian that is of the form where p(w y, Φ) = N (w µ N, Σ N ), µ N = Σ N (Σ µ + βφ y), Σ N = Σ + βφ Φ. 25 / 36
26 For the sake of simplicity, we consider a particular form of Gaussian prior (zero mean isotropic Gaussian prior), p(w α) = N (w, α I ). Then the corresponding posterior distribution over w is given by where p(w y) = N (w µ N, Σ N ), µ N = βσ N Φ y, Σ N = αi + βφ Φ. 26 / 36
27 An Example of Sequential Bayesian Learning Consider a linear model y = w + w x where only two parameters are involved. Next slide illustrates the sequential nature of Bayesian learning, showing that the posterior distribution over parameters become sharper as more data points are observed. Left-hand column: likelihood, p(y x, w). Middle column: prior/posterior, p(w D t). Right-hand column: samples of function y = w + w x where w are drawn from the posterior. 27 / 36
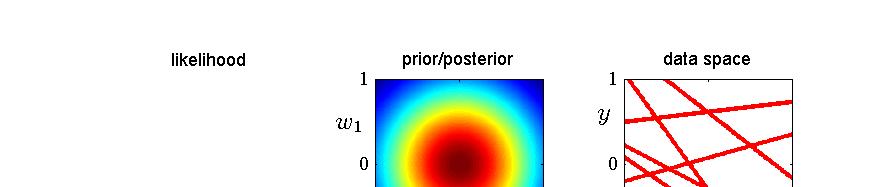
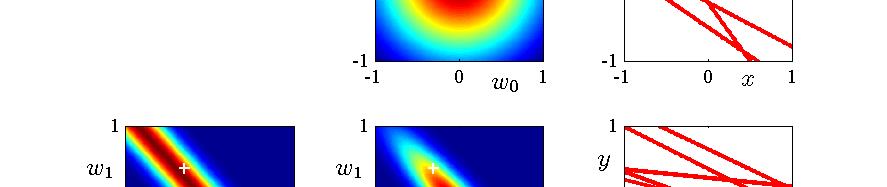
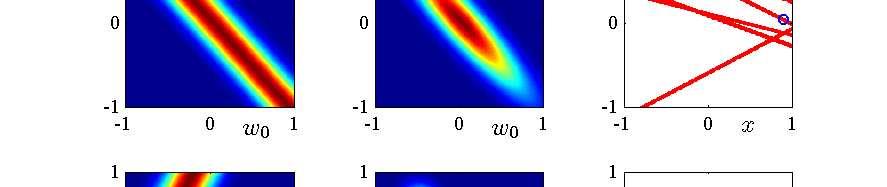
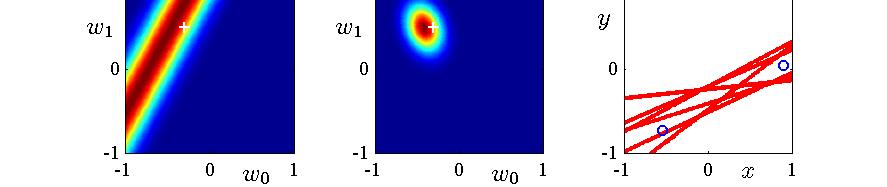
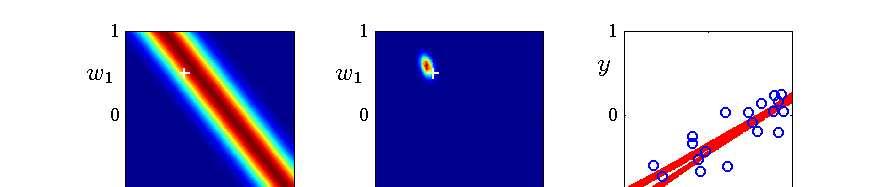
28 28 / 36
29 Predictive Distribution Make predictions of y for new values x (i.e, φ ). Let D = {Φ, y}. Then the predictive distribution is given by p(y φ, D, α, β) = p(y φ, w, β)p(w D, α, β)dw ( ) = N y µ N φ, σ2 N(x ), where µ N = βσ N Φ y, Σ N = αi + βφ Φ, σn(x 2 ) = + φ β Σ Nφ. }{{}}{{} uncertainty associated with parameters w noise on the data 29 / 36
30 Examples of Predictive Distributions t t x x t t x x 3 / 36
31 Plots of f (x; w) using samples from p(w y) t t x x t t x x 3 / 36
32 Bayesian Model Comparison Avoid the over-fitting associated with maximum likelihood by marginalizing over the model parameters instead of making point estimates of their values. Models can be compared directly on the training data, without the need for a validation set. Avoids the multiple training runs for each model associated with cross-validation. 32 / 36
33 Suppose that we wish to compare a set of L models, {M i } for i =,..., L. (a model refers to a probability distribution over the observed data D) Given a training set D, we then wish to evaluate the posterior distribution p(m i D) p(m i ) p(d M i ). }{{}}{{} prior evidence p(m i ) is a prior probability distribution to express our uncertainty. The data is generated from one of these models but we are uncertain which one. p(d M i ) is the model evidence which expresses the preference shown by the data for different models. This is also known as marginal likelihood, since it can be viewed as a likelihood function over the space of models, in which the parameters have been marginalized out. 33 / 36
34 Bayes factor is the ratio of model evidences for two models: p(d M i ) p(d M j ). Model selection: Choose the single most probable model. For a model governed by a set of parameters w, the model evidence is given by p(d M i ) = p(d w, M i )p(w M i )dw. 34 / 36
35 p(d) M M 2 M 3 D D M is the simplest and M 3 is the most complex. For the particular observed data set D, the model M 2 with intermediate complexity has the largest evidence. 35 / 36
36 Marginal Likelihood: Hyperparameter Estimation We estimate hyperparameters α and β through maximizing the marginal likelihood. The marginal likelihood is given by p(y Φ, α, β) = p(y Φ, w, β)p(w α)dw. Marginal likelihood maximization is illustrated in detail in Sec and / 36
Linear Models for Regression
 Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 254 Part V
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 254 Part V
Nonparameteric Regression:
 Nonparameteric Regression: Nadaraya-Watson Kernel Regression & Gaussian Process Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Nonparameteric Regression: Nadaraya-Watson Kernel Regression & Gaussian Process Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
 course textbook Pattern Recognition and Machine Learning by Christopher Bishop") Music and Machine Learning (IFT68 Winter 8) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
Music and Machine Learning (IFT68 Winter 8) Prof. Douglas Eck, Université de Montréal These slides follow closely the (English) course textbook Pattern Recognition and Machine Learning by Christopher Bishop
Linear Models for Regression
 Linear Models for Regression Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 3 of Pattern Recognition and Machine Learning by Bishop Chapter 3+5+6+7 of The Elements of Statistical Learning
Linear Models for Regression Machine Learning Torsten Möller Möller/Mori 1 Reading Chapter 3 of Pattern Recognition and Machine Learning by Bishop Chapter 3+5+6+7 of The Elements of Statistical Learning
Lecture 3. Linear Regression II Bastian Leibe RWTH Aachen
 Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Logistic Regression. Seungjin Choi
 Logistic Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Logistic Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Bayes Decision Theory
 Bayes Decision Theory Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr 1 / 16
Bayes Decision Theory Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr 1 / 16
Regression. Machine Learning and Pattern Recognition. Chris Williams. School of Informatics, University of Edinburgh.
 Regression Machine Learning and Pattern Recognition Chris Williams School of Informatics, University of Edinburgh September 24 (All of the slides in this course have been adapted from previous versions
Regression Machine Learning and Pattern Recognition Chris Williams School of Informatics, University of Edinburgh September 24 (All of the slides in this course have been adapted from previous versions
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Bayesian Linear Regression. Sargur Srihari
 Bayesian Linear Regression Sargur srihari@cedar.buffalo.edu Topics in Bayesian Regression Recall Max Likelihood Linear Regression Parameter Distribution Predictive Distribution Equivalent Kernel 2 Linear
Bayesian Linear Regression Sargur srihari@cedar.buffalo.edu Topics in Bayesian Regression Recall Max Likelihood Linear Regression Parameter Distribution Predictive Distribution Equivalent Kernel 2 Linear
SCUOLA DI SPECIALIZZAZIONE IN FISICA MEDICA. Sistemi di Elaborazione dell Informazione. Regressione. Ruggero Donida Labati
 SCUOLA DI SPECIALIZZAZIONE IN FISICA MEDICA Sistemi di Elaborazione dell Informazione Regressione Ruggero Donida Labati Dipartimento di Informatica via Bramante 65, 26013 Crema (CR), Italy http://homes.di.unimi.it/donida
SCUOLA DI SPECIALIZZAZIONE IN FISICA MEDICA Sistemi di Elaborazione dell Informazione Regressione Ruggero Donida Labati Dipartimento di Informatica via Bramante 65, 26013 Crema (CR), Italy http://homes.di.unimi.it/donida
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
Relevance Vector Machines
 LUT February 21, 2011 Support Vector Machines Model / Regression Marginal Likelihood Regression Relevance vector machines Exercise Support Vector Machines The relevance vector machine (RVM) is a bayesian
LUT February 21, 2011 Support Vector Machines Model / Regression Marginal Likelihood Regression Relevance vector machines Exercise Support Vector Machines The relevance vector machine (RVM) is a bayesian
Kernel Principal Component Analysis
 Kernel Principal Component Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Kernel Principal Component Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Linear Models for Regression. Sargur Srihari
 Linear Models for Regression Sargur srihari@cedar.buffalo.edu 1 Topics in Linear Regression What is regression? Polynomial Curve Fitting with Scalar input Linear Basis Function Models Maximum Likelihood
Linear Models for Regression Sargur srihari@cedar.buffalo.edu 1 Topics in Linear Regression What is regression? Polynomial Curve Fitting with Scalar input Linear Basis Function Models Maximum Likelihood
Outline Lecture 2 2(32)
") Outline Lecture (3), Lecture Linear Regression and Classification it is our firm belief that an understanding of linear models is essential for understanding nonlinear ones Thomas Schön Division of Automatic
Outline Lecture (3), Lecture Linear Regression and Classification it is our firm belief that an understanding of linear models is essential for understanding nonlinear ones Thomas Schön Division of Automatic
Outline lecture 2 2(30)
") Outline lecture 2 2(3), Lecture 2 Linear Regression it is our firm belief that an understanding of linear models is essential for understanding nonlinear ones Thomas Schön Division of Automatic Control
Outline lecture 2 2(3), Lecture 2 Linear Regression it is our firm belief that an understanding of linear models is essential for understanding nonlinear ones Thomas Schön Division of Automatic Control
Bayesian methods in economics and finance
 1/26 Bayesian methods in economics and finance Linear regression: Bayesian model selection and sparsity priors Linear Regression 2/26 Linear regression Model for relationship between (several) independent
1/26 Bayesian methods in economics and finance Linear regression: Bayesian model selection and sparsity priors Linear Regression 2/26 Linear regression Model for relationship between (several) independent
The evolution from MLE to MAP to Bayesian Learning
 The evolution from MLE to MAP to Bayesian Learning Zhe Li January 13, 2015 1 The evolution from MLE to MAP to Bayesian Based on the linear regression, we illustrate the evolution from Maximum Loglikelihood
The evolution from MLE to MAP to Bayesian Learning Zhe Li January 13, 2015 1 The evolution from MLE to MAP to Bayesian Based on the linear regression, we illustrate the evolution from Maximum Loglikelihood
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 3 Stochastic Gradients, Bayesian Inference, and Occam s Razor https://people.orie.cornell.edu/andrew/orie6741 Cornell University August
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 3 Stochastic Gradients, Bayesian Inference, and Occam s Razor https://people.orie.cornell.edu/andrew/orie6741 Cornell University August
Computer Vision Group Prof. Daniel Cremers. 3. Regression
 Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Bayesian Gaussian / Linear Models. Read Sections and 3.3 in the text by Bishop
 Bayesian Gaussian / Linear Models Read Sections 2.3.3 and 3.3 in the text by Bishop Multivariate Gaussian Model with Multivariate Gaussian Prior Suppose we model the observed vector b as having a multivariate
Bayesian Gaussian / Linear Models Read Sections 2.3.3 and 3.3 in the text by Bishop Multivariate Gaussian Model with Multivariate Gaussian Prior Suppose we model the observed vector b as having a multivariate
Overfitting, Bias / Variance Analysis
 Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Overfitting, Bias / Variance Analysis Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 8, 207 / 40 Outline Administration 2 Review of last lecture 3 Basic
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes
 CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes Roger Grosse Roger Grosse CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes 1 / 55 Adminis-Trivia Did everyone get my e-mail
CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes Roger Grosse Roger Grosse CSC2541 Lecture 2 Bayesian Occam s Razor and Gaussian Processes 1 / 55 Adminis-Trivia Did everyone get my e-mail
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
Introduction to Machine Learning
 Introduction to Machine Learning Linear Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Introduction to Machine Learning Linear Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1
Pattern Recognition and Machine Learning. Bishop Chapter 6: Kernel Methods
 Pattern Recognition and Machine Learning Chapter 6: Kernel Methods Vasil Khalidov Alex Kläser December 13, 2007 Training Data: Keep or Discard? Parametric methods (linear/nonlinear) so far: learn parameter
Pattern Recognition and Machine Learning Chapter 6: Kernel Methods Vasil Khalidov Alex Kläser December 13, 2007 Training Data: Keep or Discard? Parametric methods (linear/nonlinear) so far: learn parameter
Machine Learning - MT & 5. Basis Expansion, Regularization, Validation
 Machine Learning - MT 2016 4 & 5. Basis Expansion, Regularization, Validation Varun Kanade University of Oxford October 19 & 24, 2016 Outline Basis function expansion to capture non-linear relationships
Machine Learning - MT 2016 4 & 5. Basis Expansion, Regularization, Validation Varun Kanade University of Oxford October 19 & 24, 2016 Outline Basis function expansion to capture non-linear relationships
Computer Vision Group Prof. Daniel Cremers. 2. Regression (cont.)
") Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak
 Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak 1 Introduction. Random variables During the course we are interested in reasoning about considered phenomenon. In other words,
Introduction to Systems Analysis and Decision Making Prepared by: Jakub Tomczak 1 Introduction. Random variables During the course we are interested in reasoning about considered phenomenon. In other words,
Lecture 4: Types of errors. Bayesian regression models. Logistic regression
 Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Information Theory Primer:
 Information Theory Primer: Entropy, KL Divergence, Mutual Information, Jensen s inequality Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Information Theory Primer: Entropy, KL Divergence, Mutual Information, Jensen s inequality Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Bayesian Learning. Tobias Scheffer, Niels Landwehr
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning Tobias Scheffer, Niels Landwehr Remember: Normal Distribution Distribution over x. Density function with parameters
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning Tobias Scheffer, Niels Landwehr Remember: Normal Distribution Distribution over x. Density function with parameters
Linear Models for Regression CS534
 Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
Linear Models for Regression CS534 Prediction Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict the
Lecture 5: GPs and Streaming regression
 Lecture 5: GPs and Streaming regression Gaussian Processes Information gain Confidence intervals COMP-652 and ECSE-608, Lecture 5 - September 19, 2017 1 Recall: Non-parametric regression Input space X
Lecture 5: GPs and Streaming regression Gaussian Processes Information gain Confidence intervals COMP-652 and ECSE-608, Lecture 5 - September 19, 2017 1 Recall: Non-parametric regression Input space X
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Overview c 1 What is? 2 Definition Outlines 3 Examples of 4 Related Fields Overview Linear Regression Linear Classification Neural Networks Kernel Met
 c Outlines Statistical Group and College of Engineering and Computer Science Overview Linear Regression Linear Classification Neural Networks Kernel Methods and SVM Mixture Models and EM Resources More
c Outlines Statistical Group and College of Engineering and Computer Science Overview Linear Regression Linear Classification Neural Networks Kernel Methods and SVM Mixture Models and EM Resources More
Lecture 2 Machine Learning Review
 Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
Linear Regression (continued)
") Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Ridge Regression. Mohammad Emtiyaz Khan EPFL Oct 1, 2015
 Ridge Regression Mohammad Emtiyaz Khan EPFL Oct, 205 Mohammad Emtiyaz Khan 205 Motivation Linear models can be too limited and usually underfit. One way is to use nonlinear basis functions instead. Nonlinear
Ridge Regression Mohammad Emtiyaz Khan EPFL Oct, 205 Mohammad Emtiyaz Khan 205 Motivation Linear models can be too limited and usually underfit. One way is to use nonlinear basis functions instead. Nonlinear
Modeling Data with Linear Combinations of Basis Functions. Read Chapter 3 in the text by Bishop
 Modeling Data with Linear Combinations of Basis Functions Read Chapter 3 in the text by Bishop A Type of Supervised Learning Problem We want to model data (x 1, t 1 ),..., (x N, t N ), where x i is a vector
Modeling Data with Linear Combinations of Basis Functions Read Chapter 3 in the text by Bishop A Type of Supervised Learning Problem We want to model data (x 1, t 1 ),..., (x N, t N ), where x i is a vector
CSci 8980: Advanced Topics in Graphical Models Gaussian Processes
 CSci 8980: Advanced Topics in Graphical Models Gaussian Processes Instructor: Arindam Banerjee November 15, 2007 Gaussian Processes Outline Gaussian Processes Outline Parametric Bayesian Regression Gaussian
CSci 8980: Advanced Topics in Graphical Models Gaussian Processes Instructor: Arindam Banerjee November 15, 2007 Gaussian Processes Outline Gaussian Processes Outline Parametric Bayesian Regression Gaussian
Introduction to Machine Learning
 Introduction to Machine Learning Logistic Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Introduction to Machine Learning Logistic Regression Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
ECE521 Tutorial 2. Regression, GPs, Assignment 1. ECE521 Winter Credits to Alireza Makhzani, Alex Schwing, Rich Zemel for the slides.
 ECE521 Tutorial 2 Regression, GPs, Assignment 1 ECE521 Winter 2016 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel for the slides. ECE521 Tutorial 2 ECE521 Winter 2016 Credits to Alireza / 3 Outline
ECE521 Tutorial 2 Regression, GPs, Assignment 1 ECE521 Winter 2016 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel for the slides. ECE521 Tutorial 2 ECE521 Winter 2016 Credits to Alireza / 3 Outline
Direct Learning: Linear Classification. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Direct Learning: Linear Classification Logistic regression models for classification problem We consider two class problem: Y {0, 1}. The Bayes rule for the classification is I(P(Y = 1 X = x) > 1/2) so
Direct Learning: Linear Classification Logistic regression models for classification problem We consider two class problem: Y {0, 1}. The Bayes rule for the classification is I(P(Y = 1 X = x) > 1/2) so
Linear Regression and Discrimination
 Linear Regression and Discrimination Kernel-based Learning Methods Christian Igel Institut für Neuroinformatik Ruhr-Universität Bochum, Germany http://www.neuroinformatik.rub.de July 16, 2009 Christian
Linear Regression and Discrimination Kernel-based Learning Methods Christian Igel Institut für Neuroinformatik Ruhr-Universität Bochum, Germany http://www.neuroinformatik.rub.de July 16, 2009 Christian
Bias-Variance Trade-off in ML. Sargur Srihari
 Bias-Variance Trade-off in ML Sargur srihari@cedar.buffalo.edu 1 Bias-Variance Decomposition 1. Model Complexity in Linear Regression 2. Point estimate Bias-Variance in Statistics 3. Bias-Variance in Regression
Bias-Variance Trade-off in ML Sargur srihari@cedar.buffalo.edu 1 Bias-Variance Decomposition 1. Model Complexity in Linear Regression 2. Point estimate Bias-Variance in Statistics 3. Bias-Variance in Regression
Least Squares Regression
 CIS 50: Machine Learning Spring 08: Lecture 4 Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may not cover all the
CIS 50: Machine Learning Spring 08: Lecture 4 Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may or may not cover all the
Midterm. Introduction to Machine Learning. CS 189 Spring Please do not open the exam before you are instructed to do so.
 CS 89 Spring 07 Introduction to Machine Learning Midterm Please do not open the exam before you are instructed to do so. The exam is closed book, closed notes except your one-page cheat sheet. Electronic
CS 89 Spring 07 Introduction to Machine Learning Midterm Please do not open the exam before you are instructed to do so. The exam is closed book, closed notes except your one-page cheat sheet. Electronic
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
LINEAR MODELS FOR CLASSIFICATION. J. Elder CSE 6390/PSYC 6225 Computational Modeling of Visual Perception
 LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
LINEAR MODELS FOR CLASSIFICATION Classification: Problem Statement 2 In regression, we are modeling the relationship between a continuous input variable x and a continuous target variable t. In classification,
Lecture 1b: Linear Models for Regression
 Lecture 1b: Linear Models for Regression Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced
Lecture 1b: Linear Models for Regression Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced
Fisher s Linear Discriminant Analysis
 Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
First Technical Course, European Centre for Soft Computing, Mieres, Spain. 4th July 2011
 First Technical Course, European Centre for Soft Computing, Mieres, Spain. 4th July 2011 Linear Given probabilities p(a), p(b), and the joint probability p(a, B), we can write the conditional probabilities
First Technical Course, European Centre for Soft Computing, Mieres, Spain. 4th July 2011 Linear Given probabilities p(a), p(b), and the joint probability p(a, B), we can write the conditional probabilities
CS540 Machine learning Lecture 5
 CS540 Machine learning Lecture 5 1 Last time Basis functions for linear regression Normal equations QR SVD - briefly 2 This time Geometry of least squares (again) SVD more slowly LMS Ridge regression 3
CS540 Machine learning Lecture 5 1 Last time Basis functions for linear regression Normal equations QR SVD - briefly 2 This time Geometry of least squares (again) SVD more slowly LMS Ridge regression 3
Linear Regression Linear Regression with Shrinkage
 Linear Regression Linear Regression ith Shrinkage Introduction Regression means predicting a continuous (usually scalar) output y from a vector of continuous inputs (features) x. Example: Predicting vehicle
Linear Regression Linear Regression ith Shrinkage Introduction Regression means predicting a continuous (usually scalar) output y from a vector of continuous inputs (features) x. Example: Predicting vehicle
Linear Regression. CSL603 - Fall 2017 Narayanan C Krishnan
 Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression CSL603 - Fall 2017 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis Regularization
Linear Regression. CSL465/603 - Fall 2016 Narayanan C Krishnan
 Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Linear Regression CSL465/603 - Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Outline Univariate regression Multivariate regression Probabilistic view of regression Loss functions Bias-Variance analysis
Linear Regression Linear Regression with Shrinkage
 Linear Regression Linear Regression ith Shrinkage Introduction Regression means predicting a continuous (usually scalar) output y from a vector of continuous inputs (features) x. Example: Predicting vehicle
Linear Regression Linear Regression ith Shrinkage Introduction Regression means predicting a continuous (usually scalar) output y from a vector of continuous inputs (features) x. Example: Predicting vehicle
Expectation Maximization
 Expectation Maximization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr 1 /
Expectation Maximization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr 1 /
DATA MINING AND MACHINE LEARNING. Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane
 DATA MINING AND MACHINE LEARNING Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Linear models for regression Regularized
DATA MINING AND MACHINE LEARNING Lecture 4: Linear models for regression and classification Lecturer: Simone Scardapane Academic Year 2016/2017 Table of contents Linear models for regression Regularized
Machine Learning. 7. Logistic and Linear Regression
 Sapienza University of Rome, Italy - Machine Learning (27/28) University of Rome La Sapienza Master in Artificial Intelligence and Robotics Machine Learning 7. Logistic and Linear Regression Luca Iocchi,
Sapienza University of Rome, Italy - Machine Learning (27/28) University of Rome La Sapienza Master in Artificial Intelligence and Robotics Machine Learning 7. Logistic and Linear Regression Luca Iocchi,
GWAS IV: Bayesian linear (variance component) models
 models") GWAS IV: Bayesian linear (variance component) models Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS IV: Bayesian
GWAS IV: Bayesian linear (variance component) models Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS IV: Bayesian
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Gaussian Processes for Machine Learning
 Gaussian Processes for Machine Learning Carl Edward Rasmussen Max Planck Institute for Biological Cybernetics Tübingen, Germany carl@tuebingen.mpg.de Carlos III, Madrid, May 2006 The actual science of
Gaussian Processes for Machine Learning Carl Edward Rasmussen Max Planck Institute for Biological Cybernetics Tübingen, Germany carl@tuebingen.mpg.de Carlos III, Madrid, May 2006 The actual science of
Computer Vision Group Prof. Daniel Cremers. 9. Gaussian Processes - Regression
 Group Prof. Daniel Cremers 9. Gaussian Processes - Regression Repetition: Regularized Regression Before, we solved for w using the pseudoinverse. But: we can kernelize this problem as well! First step:
Group Prof. Daniel Cremers 9. Gaussian Processes - Regression Repetition: Regularized Regression Before, we solved for w using the pseudoinverse. But: we can kernelize this problem as well! First step:
σ(a) = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =
 = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =") Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Linear Regression (9/11/13)
") STA561: Probabilistic machine learning Linear Regression (9/11/13) Lecturer: Barbara Engelhardt Scribes: Zachary Abzug, Mike Gloudemans, Zhuosheng Gu, Zhao Song 1 Why use linear regression? Figure 1: Scatter
STA561: Probabilistic machine learning Linear Regression (9/11/13) Lecturer: Barbara Engelhardt Scribes: Zachary Abzug, Mike Gloudemans, Zhuosheng Gu, Zhao Song 1 Why use linear regression? Figure 1: Scatter
Gaussian processes and bayesian optimization Stanisław Jastrzębski. kudkudak.github.io kudkudak
 Gaussian processes and bayesian optimization Stanisław Jastrzębski kudkudak.github.io kudkudak Plan Goal: talk about modern hyperparameter optimization algorithms Bayes reminder: equivalent linear regression
Gaussian processes and bayesian optimization Stanisław Jastrzębski kudkudak.github.io kudkudak Plan Goal: talk about modern hyperparameter optimization algorithms Bayes reminder: equivalent linear regression
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Lecture 2: From Linear Regression to Kalman Filter and Beyond
 Lecture 2: From Linear Regression to Kalman Filter and Beyond Department of Biomedical Engineering and Computational Science Aalto University January 26, 2012 Contents 1 Batch and Recursive Estimation
Lecture 2: From Linear Regression to Kalman Filter and Beyond Department of Biomedical Engineering and Computational Science Aalto University January 26, 2012 Contents 1 Batch and Recursive Estimation
Artificial Neural Networks
 Artificial Neural Networks Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Knowledge
Artificial Neural Networks Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Knowledge
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Machine Learning. Bayesian Regression & Classification. Marc Toussaint U Stuttgart
 Machine Learning Bayesian Regression & Classification learning as inference, Bayesian Kernel Ridge regression & Gaussian Processes, Bayesian Kernel Logistic Regression & GP classification, Bayesian Neural
Machine Learning Bayesian Regression & Classification learning as inference, Bayesian Kernel Ridge regression & Gaussian Processes, Bayesian Kernel Logistic Regression & GP classification, Bayesian Neural
Overview. Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation
 Overview Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation Probabilistic Interpretation: Linear Regression Assume output y is generated
Overview Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation Probabilistic Interpretation: Linear Regression Assume output y is generated
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Computer Vision Group Prof. Daniel Cremers. 4. Gaussian Processes - Regression
 Group Prof. Daniel Cremers 4. Gaussian Processes - Regression Definition (Rep.) Definition: A Gaussian process is a collection of random variables, any finite number of which have a joint Gaussian distribution.
Group Prof. Daniel Cremers 4. Gaussian Processes - Regression Definition (Rep.) Definition: A Gaussian process is a collection of random variables, any finite number of which have a joint Gaussian distribution.
Linear regression example Simple linear regression: f(x) = ϕ(x)t w w ~ N(0, ) The mean and covariance are given by E[f(x)] = ϕ(x)e[w] = 0.
![Linear regression example Simple linear regression: f(x) = ϕ(x)t w w ~ N(0, ) The mean and covariance are given by E[f(x)] = ϕ(x)e[w] = 0.](/thumbs/95/123587665.jpg "Linear regression example Simple linear regression: f(x) = ϕ(x)t w w ~ N(0, ) The mean and covariance are given by E[f(x)] = ϕ(x)e[w] = 0.") Gaussian Processes Gaussian Process Stochastic process: basically, a set of random variables. may be infinite. usually related in some way. Gaussian process: each variable has a Gaussian distribution every
Gaussian Processes Gaussian Process Stochastic process: basically, a set of random variables. may be infinite. usually related in some way. Gaussian process: each variable has a Gaussian distribution every
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Slides modified from: PATTERN RECOGNITION AND MACHINE LEARNING CHRISTOPHER M. BISHOP
 Slides modified from: PATTERN RECOGNITION AND MACHINE LEARNING CHRISTOPHER M. BISHOP Predic?ve Distribu?on (1) Predict t for new values of x by integra?ng over w: where The Evidence Approxima?on (1) The
Slides modified from: PATTERN RECOGNITION AND MACHINE LEARNING CHRISTOPHER M. BISHOP Predic?ve Distribu?on (1) Predict t for new values of x by integra?ng over w: where The Evidence Approxima?on (1) The
Introduction to Bayesian Statistics
 School of Computing & Communication, UTS January, 207 Random variables Pre-university: A number is just a fixed value. When we talk about probabilities: When X is a continuous random variable, it has a
School of Computing & Communication, UTS January, 207 Random variables Pre-university: A number is just a fixed value. When we talk about probabilities: When X is a continuous random variable, it has a
Mathematical Formulation of Our Example
 Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Mathematical Formulation of Our Example We define two binary random variables: open and, where is light on or light off. Our question is: What is? Computer Vision 1 Combining Evidence Suppose our robot
Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods.
 Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods. Linear models for classification Logistic regression Gradient descent and second-order methods
Lecture 5: Linear models for classification. Logistic regression. Gradient Descent. Second-order methods. Linear models for classification Logistic regression Gradient descent and second-order methods
Manifold Learning: Theory and Applications to HRI
 Manifold Learning: Theory and Applications to HRI Seungjin Choi Department of Computer Science Pohang University of Science and Technology, Korea seungjin@postech.ac.kr August 19, 2008 1 / 46 Greek Philosopher
Manifold Learning: Theory and Applications to HRI Seungjin Choi Department of Computer Science Pohang University of Science and Technology, Korea seungjin@postech.ac.kr August 19, 2008 1 / 46 Greek Philosopher
COMS 4771 Introduction to Machine Learning. James McInerney Adapted from slides by Nakul Verma
 COMS 4771 Introduction to Machine Learning James McInerney Adapted from slides by Nakul Verma Announcements HW1: Please submit as a group Watch out for zero variance features (Q5) HW2 will be released
COMS 4771 Introduction to Machine Learning James McInerney Adapted from slides by Nakul Verma Announcements HW1: Please submit as a group Watch out for zero variance features (Q5) HW2 will be released
Advanced Machine Learning Practical 4b Solution: Regression (BLR, GPR & Gradient Boosting)
") Advanced Machine Learning Practical 4b Solution: Regression (BLR, GPR & Gradient Boosting) Professor: Aude Billard Assistants: Nadia Figueroa, Ilaria Lauzana and Brice Platerrier E-mails: aude.billard@epfl.ch,
Advanced Machine Learning Practical 4b Solution: Regression (BLR, GPR & Gradient Boosting) Professor: Aude Billard Assistants: Nadia Figueroa, Ilaria Lauzana and Brice Platerrier E-mails: aude.billard@epfl.ch,
Pattern Recognition and Machine Learning. Bishop Chapter 2: Probability Distributions
 Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Pattern Recognition and Machine Learning Chapter 2: Probability Distributions Cécile Amblard Alex Kläser Jakob Verbeek October 11, 27 Probability Distributions: General Density Estimation: given a finite
Least Squares Estimation Namrata Vaswani,
 Least Squares Estimation Namrata Vaswani, namrata@iastate.edu Least Squares Estimation 1 Recall: Geometric Intuition for Least Squares Minimize J(x) = y Hx 2 Solution satisfies: H T H ˆx = H T y, i.e.
Least Squares Estimation Namrata Vaswani, namrata@iastate.edu Least Squares Estimation 1 Recall: Geometric Intuition for Least Squares Minimize J(x) = y Hx 2 Solution satisfies: H T H ˆx = H T y, i.e.
Least Squares Regression
 E0 70 Machine Learning Lecture 4 Jan 7, 03) Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in the lecture. They are not a substitute
E0 70 Machine Learning Lecture 4 Jan 7, 03) Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in the lecture. They are not a substitute
CSCI567 Machine Learning (Fall 2014)
") CSCI567 Machine Learning (Fall 24) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu October 2, 24 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 24) October 2, 24 / 24 Outline Review
CSCI567 Machine Learning (Fall 24) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu October 2, 24 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 24) October 2, 24 / 24 Outline Review