Manifold Learning: Theory and Applications to HRI
|
|
|
- Claud Ball
- 5 years ago
- Views:
Transcription
1 Manifold Learning: Theory and Applications to HRI Seungjin Choi Department of Computer Science Pohang University of Science and Technology, Korea August 19, / 46
2 Greek Philosopher said... Heraclitus: Old days You can never step in the same river twice. Heraclitus: Now You can never see the same face twice. 2 / 46

3 Manifold Ways of Perception: Seung and Lee / 46
4 Manifold Learning: Example 1 Fingers extension Wrist rotation 4 / 46

5 Manifold Learning: Example 2 5 / 46

6 Manifold Learning: Example 3 6 / 46

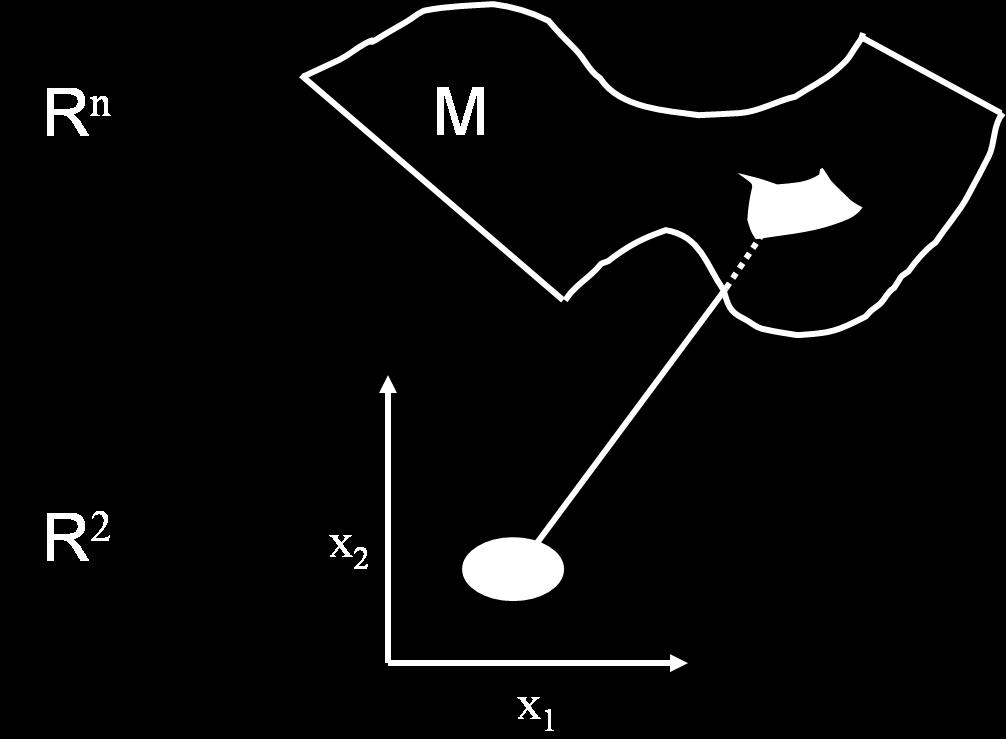
7 Why Manifold? 7 / 46
8 Principal Component Analysis (PCA) Given a data matrix X = [x 1,..., x N ] R m N, PCA aims at finding a linear orthogonal transformation W (W W = I) such that tr{yy } is maximized, where Y = W X. It turns out that W corresponds to first n eigenvectors of the data covariance matrix C = 1 N (XH)(XH), where H = I 1 N 1 N1 N W = U R m n where C UDU (eigen-decomposition). 8 / 46
9 PCA: An Example 9 / 46
10 Learning in Feature Space It is important to choose a representation that matches the specific learning problem. Change the representation of the data! x = x 1. x m φ(x) = φ 1 (x). φ r (x) φ : R m F (feature space) Feature space is {φ(x) x X }. (could infinite dimensional space, i.e., r = ) 10 / 46
11 Why a Nonlinear Mapping? 11 / 46
12 What is a Kernel? Consider a nonlinear mapping φ : R m F(feature space), where φ(x) = [φ 1 (x),..., φ r (x)] (r could be infinite). Definition (Kernel) A kernel is a function k such that for all x, y X k(x, y) = φ(x), φ(y), where φ is a mapping from X to an (inner product) feature space F (dot product space). 12 / 46
13 Various Kernels Polynomial kernel k(x, y) = x, y d RBF kernel } x y 2 k(x, y) = exp { 2σ 2 Sigmoid kernel k(x, y) = tanh (κ x, y + θ), for suitable values of gain κ and threshold θ. 13 / 46
14 Reproducing Kernels Define a map φ φ : x k(, x). Reproducing kernels satisfy k(, x), f = f (x) k(, x), k(, y) = k(x, y) φ(x), φ(y) = k(x, y). 14 / 46
15 RKHS and Kernels Theorem This theorem relates kernels and RKHS a) For every RKHS there exits a unique, positive definite function called the reproducing kernel (RK) b) Conversely for every positive definite function k on X X there is a unique RKHS with k as its RK 15 / 46
16 Mercer s Theorem Theorem (Mercer) If k is a continuous symmetric kernel of a positive integral operator T, i.e., (T f )(y) = k(x, y)f (x)dx with C C C k(x, y)f (x)f (y)dxdy 0 for all f L 2(C) (C begin a compact subset of R m ), then it can be expanded in a uniformly convergent series (on C C) in terms of T s eigenfunctions ϕ j and positive eigenvalues λ j, k(x, y) = r λ j ϕ j (x)ϕ j (y), j=1 where r is the number of positive eigenvalues. 16 / 46
17 PCA: Using Dot Products Given a set of data (with zero mean), x k R m, k = 1,..., N, the sample covariance matrix C is given by C = 1 N N j=1 x jx j. For PCA, one has to solve the eigenvalue equation Cv = λv. Note that Cv = 1 N = 1 N N x j x j v j=1 N x j, v x j. j=1 This implies that all solutions v with λ 0 must lie in the span of x 1,..., x N. Hence Cv = λv is equivalent to λ x k, v = x k, Cv. 17 / 46
18 PCA in Feature Space Consider a nonlinear mapping φ : R m F(feature space). Assume N k=1 φ(x k) = 0. The covariance matrix C in the feature space F is C = 1 N N φ(x j )φ (x j ). j=1 Like PCA, one has to solve the eigenvalue problem λv = CV. Again, all solutions V with λ 0 lie in the span of φ(x 1 ),..., φ(x N ), which leads to λ φ(x k ), V = φ(x k ), CV, k = 1,..., N, 18 / 46
19 PCA in Feature Space (Cont d) There exits coefficients {α i } such that N V = α i φ(x i ). i=1 Substitute this relation into λ φ(x k ), V = φ(x k ), CV to obtain N λ α i φ(x k ), φ(x i ) i=1 = 1 N for k = 1,..., N. N N α i φ(x k ), φ(x j ) φ(x j ), φ(x i ), i=1 j=1 19 / 46
20 PCA in Feature Space (Cont d) Define an N N matrix K by [K] ij = K ij = φ(x i ), φ(x j ). Then, we have λnkα = K 2 α, which is further simplified as Nλα = Kα, for nonzero eigenvalues. 20 / 46
21 Normalization Let λ 1, s λ N denote the eigenvalues of K and α 1,..., α N their corresponding eigenvectors, with λ p being the first nonzero eigenvalue. We normalize α p,..., α N by requiring that the corresponding vectors in F be normalized, i.e., V k, V k = 1, k = p,..., N, leading to N N αi k φ(x i ), αj k φ(x j ) = 1 i=1 j=1 αi k αj k K ij = 1 i j α k, Kα k = 1 λ k α k, α k = / 46
22 Compute Nonlinear Components In linear PCA, principal components are extracted by projecting the data x onto the eigenvectors v k of the covariance matrix C, i.e., v k, x. In kernel PCA, we also project x onto the eigenvectors V k of C, i.e., V k, φ(x) = = N αi k φ(x i ), φ(x) i=1 N αi k k(x i, x). i=1 22 / 46
23 Centering in Feature Space Define φ(x t ) = φ(x t ) 1 N N l=1 φ(x l). Then we have K ij = φ(xi ), φ(x j ) = φ(x i ) 1 N φ(x l ), φ(x j ) 1 N φ(x k ) N N l=1 k=1 = K ij 1 K ik 1 K lj + 1 N N N 2 K lk. Therefore, the centered Kernel matrix is given by k K = K 1 N N K K1 N N + 1 N N K1 N N. l l k 23 / 46
24 Algorithm Outline: Kernel PCA 1 Given a set of m-dimensional training data {x k }, k = 1,..., N, we compute the kernel matrix K R N N = [k(x i, x j )]. 2 Carry out centering in feature space for N k=1 φ(x k) = 0, K = K 1 N N K K1 N N + 1 N N K1 N N, where 1 N N = N.... R N N Solve the eigenvalue problem Nλα = Kα and normalize α k such that α k, α k = 1 λ k. 4 For a test pattern x, we extract a nonlinear component via V k, x = N αi k k(x i, x). i=1 24 / 46
25 Toy Example Eigenvalue= Eigenvalue= Eigenvalue= Eigenvalue= Eigenvalue= Eigenvalue= Eigenvalue= Eigenvalue= / 46
26 Multidimensional Scaling (MDS) Let {x t R m } N t=1 be given data points and {y t R n } N t=1 be the lower-dimensional images of x t. Let δ ij be the distance (dissimilarity) between x i and x j and d ij be the distance between y i and y j. The aim of MDS is to find a configuration of lower-dimensional images, such that the distances {d ij } match the dissimilarities {δ ij } as well as possible. 26 / 46
27 Algorithm Outline: Classical Scaling 1 Obtain dissimilarities {δ ij = x i x j }. 2 Compute the matrix A = [ 1 2 δ2 ij]. 3 Construct the Gram matrix B = H AH R N N where H = I 1 N 1 N1 N is the centering matrix. 4 Rank-n approximation of B is given by B = V 1 Λ 1 V 1 = Y Y, where V 1 R N n and Λ 1 R n n. 5 The coordinate of N points in the n-dimensional Euclidean space are given by Y = V 1 Λ R n N = [y 1,..., y N ]. That is, each column y i R n in Y is an embedding of x i. 27 / 46
28 Properties of Centering Matrix 1 H = I 1 N 1 N1 N 2 [HX] ij = X ij 1 N N k=1 X kj (column-wise centering) 3 [XH] ij = X ij 1 N N k=1 X ik (row-wise centering) 4 H 2 = HH = H (idempotent) 28 / 46
29 Core Idea: B = X X = H AH One can easily show that B ij = (x i x) (x j x) = x i x j x i x x x j + x x = 1 2 δ2 ij 1 δij 2 1 δij N N N 2 One the other hand [ [ ] ( H AH = I 1 ij N 1 N1 N = i j ) ( A I 1 ) ] N 1 N1 N i ij j δ 2 ij. [ A 1 N 1 N1 N A 1 N A1 N1 N + 1 N 2 1 N1 N A1 N 1 N = [A] ij 1 N A j 1 N A i + 1 N 2 A. ] ij 29 / 46
30 Relation to PCA One can easily prove that the classical scaling solution is nothing but the projection of centered data onto normalized principal directions: Λ 1 2 V }{{} = Λ 1 2 U XH, where U = XHV. MDS Note that V is the eigenvector matrix of B: BV = VΛ, HX XHV = VΛ, (XH)HX XHV = (XH)VΛ, NC XHV }{{} U = XHV }{{} Λ, U where C = 1 N (XH)(XH) is the covariance matrix. 30 / 46
31 Consider U = XHV R m n. Projecting centered data XH onto principal directions U yields Therefore we have Projection property U XH = V HX XH = V B = ΛV. Λ 1 2 U XH = Λ 1 2 V. PCA defines a mapping from the original space to the principal coordinates. Given a new data point, its projection onto the principal coordinate defined by the original N data points, can be computed as y = Λ 1 2 U x. 31 / 46
32 Isomap: Tenenbaum et al., Construct a neighborhood graph (k-nn or ɛ-ball). 2 Compute geodesic distances, D ij with D 2 = [ D 2 ij] R N N. 3 Construct a Gram matrix K(D 2 ) = 1 2 HD2 H. 4 Compute top n eigenvectors of K, i.e., K = V 1 Λ 1 V 1, where V 1 R N n and Λ 1 R n n. 5 The coordinate of N points in the n-dimensional Euclidean space are given by Y = V 1 Λ R n N = [y 1,..., y N ]. 32 / 46
33 Kernel Isomap: Choi and Choi, Construct a neighborhood graph (k-nn or ɛ-ball). 2 Compute geodesic distances, D ij with D 2 = [ D 2 ij] R N N. 3 Construct a Gram matrix K(D 2 ) = 1 2 HD2 H. 4 Compute the largest eigenvalue, c, of the matrix [ 0 2K(D 2 ] ), I 4K(D) and construct a Mercer kernel matrix K = K(D 2 ) + 2cK(D) c2 H, where K is guaranteed to be positive semidefinite for c c. 5 Compute top n eigenvectors of K, i.e., K = V 1 Λ 1 V 1, where V 1 R N n and Λ 1 R n n. 6 The coordinate of N points in the n-dimensional Euclidean space are given by Y = V 1 Λ R n N = [y 1,..., y N ]. 33 / 46
34 Kernel Isomap: An Example Noisy Swiss Roll, Isomap, Kernel Isomap, Kernel Isomap with projection. 34 / 46
35 Locally Linear Embedding (LLE): Roweis and Saul, / 46
36 Algorithm Outline: LLE 1 Determine weights {W ij } such that arg min Wij i x i j W ijx j 2, subject to W ij = 0 if x j / N i, j W ij = 1. 2 Fix {W ij } and optimize the coordinates y i via minimizing the embedding cost function: J (y) = i y i j W ij y j 2, with two constraints i y i = 0 and 1 N yi y i = I. 36 / 46
37 Algorithm Outline: Laplacian Eigenmap 1 Construct a neighborhood graph. 2 Choose edge weights W ij W ij = { e x x i j 2 σ if nodes i and i are connected, 0 otherwise. 3 Solve the generalized eigenvalue problem Lv i = λ i Dv i, where D is degree matrix which is a diagonal matrix with diagonal entries D ii = j W ij and L = D W is graph Laplacian. Eigenvalues are 0 = λ 0 λ 1 λ N 1. 4 Low-dimensional embedding Y R n N is given by Y = [v 1,..., v n ]. 37 / 46
38 Optimal Embedding Consider a embedding from x i R m to y i R. A reasonable criterion for choosing a good map is to minimize the following objective function: where L = D W. J = 1 (y i y j ) 2 W ij 2 = y L y, Therefore the minimization problem reduces to finding subject to y D y = 1. i arg min y L y, y j 38 / 46
39 Locality Preserving Projection (LPP): He and Niyogi, 2003 Consider a linear mapping y i = Ψ x i in the framework of Laplacian eigenmap, where Ψ R m n. Then the mapping Ψ is determined by solving { } arg min tr Ψ Ψ XLX Ψ, subject to Ψ XDX Ψ = I. 39 / 46

40 Manifolds of Spatial Hearing: Choi and Choi, / 46

41 Laplcianfaces: He et al., / 46
42 Manifolds of Human Motion: Elgammal and Lee, / 46
 43 /")
43 Manifolds of Human Motion (Cont d) 43 / 46

44 Human Emotion in HRI: Ho et al., / 46
 45 /")
45 Human Emotion in HRI (Cont d) 45 / 46
 46 /")
46 Human Emotion in HRI (Cont d) 46 / 46
Kernel Principal Component Analysis
 Kernel Principal Component Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Kernel Principal Component Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Unsupervised dimensionality reduction
 Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
Non-linear Dimensionality Reduction
 Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis
 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis Alvina Goh Vision Reading Group 13 October 2005 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal
Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis Alvina Goh Vision Reading Group 13 October 2005 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal
Nonlinear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
LECTURE NOTE #11 PROF. ALAN YUILLE
 LECTURE NOTE #11 PROF. ALAN YUILLE 1. NonLinear Dimension Reduction Spectral Methods. The basic idea is to assume that the data lies on a manifold/surface in D-dimensional space, see figure (1) Perform
LECTURE NOTE #11 PROF. ALAN YUILLE 1. NonLinear Dimension Reduction Spectral Methods. The basic idea is to assume that the data lies on a manifold/surface in D-dimensional space, see figure (1) Perform
Lecture 10: Dimension Reduction Techniques
 Lecture 10: Dimension Reduction Techniques Radu Balan Department of Mathematics, AMSC, CSCAMM and NWC University of Maryland, College Park, MD April 17, 2018 Input Data It is assumed that there is a set
Lecture 10: Dimension Reduction Techniques Radu Balan Department of Mathematics, AMSC, CSCAMM and NWC University of Maryland, College Park, MD April 17, 2018 Input Data It is assumed that there is a set
Laplacian Eigenmaps for Dimensionality Reduction and Data Representation
 Introduction and Data Representation Mikhail Belkin & Partha Niyogi Department of Electrical Engieering University of Minnesota Mar 21, 2017 1/22 Outline Introduction 1 Introduction 2 3 4 Connections to
Introduction and Data Representation Mikhail Belkin & Partha Niyogi Department of Electrical Engieering University of Minnesota Mar 21, 2017 1/22 Outline Introduction 1 Introduction 2 3 4 Connections to
Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations.
 Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Nonlinear Dimensionality Reduction
 Nonlinear Dimensionality Reduction Piyush Rai CS5350/6350: Machine Learning October 25, 2011 Recap: Linear Dimensionality Reduction Linear Dimensionality Reduction: Based on a linear projection of the
Nonlinear Dimensionality Reduction Piyush Rai CS5350/6350: Machine Learning October 25, 2011 Recap: Linear Dimensionality Reduction Linear Dimensionality Reduction: Based on a linear projection of the
Advanced Machine Learning & Perception
 Advanced Machine Learning & Perception Instructor: Tony Jebara Topic 2 Nonlinear Manifold Learning Multidimensional Scaling (MDS) Locally Linear Embedding (LLE) Beyond Principal Components Analysis (PCA)
Advanced Machine Learning & Perception Instructor: Tony Jebara Topic 2 Nonlinear Manifold Learning Multidimensional Scaling (MDS) Locally Linear Embedding (LLE) Beyond Principal Components Analysis (PCA)
Nonlinear Dimensionality Reduction. Jose A. Costa
 Nonlinear Dimensionality Reduction Jose A. Costa Mathematics of Information Seminar, Dec. Motivation Many useful of signals such as: Image databases; Gene expression microarrays; Internet traffic time
Nonlinear Dimensionality Reduction Jose A. Costa Mathematics of Information Seminar, Dec. Motivation Many useful of signals such as: Image databases; Gene expression microarrays; Internet traffic time
Fisher s Linear Discriminant Analysis
 Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Dimension Reduction Techniques. Presented by Jie (Jerry) Yu
 Yu") Dimension Reduction Techniques Presented by Jie (Jerry) Yu Outline Problem Modeling Review of PCA and MDS Isomap Local Linear Embedding (LLE) Charting Background Advances in data collection and storage
Dimension Reduction Techniques Presented by Jie (Jerry) Yu Outline Problem Modeling Review of PCA and MDS Isomap Local Linear Embedding (LLE) Charting Background Advances in data collection and storage
Dimension Reduction and Low-dimensional Embedding
 Dimension Reduction and Low-dimensional Embedding Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/26 Dimension
Dimension Reduction and Low-dimensional Embedding Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/26 Dimension
Data dependent operators for the spatial-spectral fusion problem
 Data dependent operators for the spatial-spectral fusion problem Wien, December 3, 2012 Joint work with: University of Maryland: J. J. Benedetto, J. A. Dobrosotskaya, T. Doster, K. W. Duke, M. Ehler, A.
Data dependent operators for the spatial-spectral fusion problem Wien, December 3, 2012 Joint work with: University of Maryland: J. J. Benedetto, J. A. Dobrosotskaya, T. Doster, K. W. Duke, M. Ehler, A.
DIMENSION REDUCTION. min. j=1
 DIMENSION REDUCTION 1 Principal Component Analysis (PCA) Principal components analysis (PCA) finds low dimensional approximations to the data by projecting the data onto linear subspaces. Let X R d and
DIMENSION REDUCTION 1 Principal Component Analysis (PCA) Principal components analysis (PCA) finds low dimensional approximations to the data by projecting the data onto linear subspaces. Let X R d and
Manifold Learning and it s application
 Manifold Learning and it s application Nandan Dubey SE367 Outline 1 Introduction Manifold Examples image as vector Importance Dimension Reduction Techniques 2 Linear Methods PCA Example MDS Perception
Manifold Learning and it s application Nandan Dubey SE367 Outline 1 Introduction Manifold Examples image as vector Importance Dimension Reduction Techniques 2 Linear Methods PCA Example MDS Perception
Apprentissage non supervisée
 Apprentissage non supervisée Cours 3 Higher dimensions Jairo Cugliari Master ECD 2015-2016 From low to high dimension Density estimation Histograms and KDE Calibration can be done automacally But! Let
Apprentissage non supervisée Cours 3 Higher dimensions Jairo Cugliari Master ECD 2015-2016 From low to high dimension Density estimation Histograms and KDE Calibration can be done automacally But! Let
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA
 Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
CSE 291. Assignment Spectral clustering versus k-means. Out: Wed May 23 Due: Wed Jun 13
 CSE 291. Assignment 3 Out: Wed May 23 Due: Wed Jun 13 3.1 Spectral clustering versus k-means Download the rings data set for this problem from the course web site. The data is stored in MATLAB format as
CSE 291. Assignment 3 Out: Wed May 23 Due: Wed Jun 13 3.1 Spectral clustering versus k-means Download the rings data set for this problem from the course web site. The data is stored in MATLAB format as
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi
 presented by Hassan A. Kingravi") Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Data-dependent representations: Laplacian Eigenmaps
 Data-dependent representations: Laplacian Eigenmaps November 4, 2015 Data Organization and Manifold Learning There are many techniques for Data Organization and Manifold Learning, e.g., Principal Component
Data-dependent representations: Laplacian Eigenmaps November 4, 2015 Data Organization and Manifold Learning There are many techniques for Data Organization and Manifold Learning, e.g., Principal Component
Nonlinear Methods. Data often lies on or near a nonlinear low-dimensional curve aka manifold.
 Nonlinear Methods Data often lies on or near a nonlinear low-dimensional curve aka manifold. 27 Laplacian Eigenmaps Linear methods Lower-dimensional linear projection that preserves distances between all
Nonlinear Methods Data often lies on or near a nonlinear low-dimensional curve aka manifold. 27 Laplacian Eigenmaps Linear methods Lower-dimensional linear projection that preserves distances between all
Locality Preserving Projections
 Locality Preserving Projections Xiaofei He Department of Computer Science The University of Chicago Chicago, IL 60637 xiaofei@cs.uchicago.edu Partha Niyogi Department of Computer Science The University
Locality Preserving Projections Xiaofei He Department of Computer Science The University of Chicago Chicago, IL 60637 xiaofei@cs.uchicago.edu Partha Niyogi Department of Computer Science The University
Unsupervised Learning Techniques Class 07, 1 March 2006 Andrea Caponnetto
 Unsupervised Learning Techniques 9.520 Class 07, 1 March 2006 Andrea Caponnetto About this class Goal To introduce some methods for unsupervised learning: Gaussian Mixtures, K-Means, ISOMAP, HLLE, Laplacian
Unsupervised Learning Techniques 9.520 Class 07, 1 March 2006 Andrea Caponnetto About this class Goal To introduce some methods for unsupervised learning: Gaussian Mixtures, K-Means, ISOMAP, HLLE, Laplacian
Laplacian Eigenmaps for Dimensionality Reduction and Data Representation
 Laplacian Eigenmaps for Dimensionality Reduction and Data Representation Neural Computation, June 2003; 15 (6):1373-1396 Presentation for CSE291 sp07 M. Belkin 1 P. Niyogi 2 1 University of Chicago, Department
Laplacian Eigenmaps for Dimensionality Reduction and Data Representation Neural Computation, June 2003; 15 (6):1373-1396 Presentation for CSE291 sp07 M. Belkin 1 P. Niyogi 2 1 University of Chicago, Department
Dimensionality Reduction AShortTutorial
 Dimensionality Reduction AShortTutorial Ali Ghodsi Department of Statistics and Actuarial Science University of Waterloo Waterloo, Ontario, Canada, 2006 c Ali Ghodsi, 2006 Contents 1 An Introduction to
Dimensionality Reduction AShortTutorial Ali Ghodsi Department of Statistics and Actuarial Science University of Waterloo Waterloo, Ontario, Canada, 2006 c Ali Ghodsi, 2006 Contents 1 An Introduction to
Data Mining. Dimensionality reduction. Hamid Beigy. Sharif University of Technology. Fall 1395
 Data Mining Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 42 Outline 1 Introduction 2 Feature selection
Data Mining Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 42 Outline 1 Introduction 2 Feature selection
Statistical Pattern Recognition
 Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Nonlinear Manifold Learning Summary
 Nonlinear Manifold Learning 6.454 Summary Alexander Ihler ihler@mit.edu October 6, 2003 Abstract Manifold learning is the process of estimating a low-dimensional structure which underlies a collection
Nonlinear Manifold Learning 6.454 Summary Alexander Ihler ihler@mit.edu October 6, 2003 Abstract Manifold learning is the process of estimating a low-dimensional structure which underlies a collection
Robust Laplacian Eigenmaps Using Global Information
 Manifold Learning and its Applications: Papers from the AAAI Fall Symposium (FS-9-) Robust Laplacian Eigenmaps Using Global Information Shounak Roychowdhury ECE University of Texas at Austin, Austin, TX
Manifold Learning and its Applications: Papers from the AAAI Fall Symposium (FS-9-) Robust Laplacian Eigenmaps Using Global Information Shounak Roychowdhury ECE University of Texas at Austin, Austin, TX
Data Mining II. Prof. Dr. Karsten Borgwardt, Department Biosystems, ETH Zürich. Basel, Spring Semester 2016 D-BSSE
 D-BSSE Data Mining II Prof. Dr. Karsten Borgwardt, Department Biosystems, ETH Zürich Basel, Spring Semester 2016 D-BSSE Karsten Borgwardt Data Mining II Course, Basel Spring Semester 2016 2 / 117 Our course
D-BSSE Data Mining II Prof. Dr. Karsten Borgwardt, Department Biosystems, ETH Zürich Basel, Spring Semester 2016 D-BSSE Karsten Borgwardt Data Mining II Course, Basel Spring Semester 2016 2 / 117 Our course
L26: Advanced dimensionality reduction
 L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
Kernel methods for comparing distributions, measuring dependence
 Kernel methods for comparing distributions, measuring dependence Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Principal component analysis Given a set of M centered observations
Kernel methods for comparing distributions, measuring dependence Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Principal component analysis Given a set of M centered observations
Intrinsic Structure Study on Whale Vocalizations
 1 2015 DCLDE Conference Intrinsic Structure Study on Whale Vocalizations Yin Xian 1, Xiaobai Sun 2, Yuan Zhang 3, Wenjing Liao 3 Doug Nowacek 1,4, Loren Nolte 1, Robert Calderbank 1,2,3 1 Department of
1 2015 DCLDE Conference Intrinsic Structure Study on Whale Vocalizations Yin Xian 1, Xiaobai Sun 2, Yuan Zhang 3, Wenjing Liao 3 Doug Nowacek 1,4, Loren Nolte 1, Robert Calderbank 1,2,3 1 Department of
Distance Preservation - Part 2
 Distance Preservation - Part 2 Graph Distances Niko Vuokko October 9th 2007 NLDR Seminar Outline Introduction Geodesic and graph distances From linearity to nonlinearity Isomap Geodesic NLM Curvilinear
Distance Preservation - Part 2 Graph Distances Niko Vuokko October 9th 2007 NLDR Seminar Outline Introduction Geodesic and graph distances From linearity to nonlinearity Isomap Geodesic NLM Curvilinear
Statistical Machine Learning
 Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Principal Component Analysis
 CSci 5525: Machine Learning Dec 3, 2008 The Main Idea Given a dataset X = {x 1,..., x N } The Main Idea Given a dataset X = {x 1,..., x N } Find a low-dimensional linear projection The Main Idea Given
CSci 5525: Machine Learning Dec 3, 2008 The Main Idea Given a dataset X = {x 1,..., x N } The Main Idea Given a dataset X = {x 1,..., x N } Find a low-dimensional linear projection The Main Idea Given
Global (ISOMAP) versus Local (LLE) Methods in Nonlinear Dimensionality Reduction
 versus Local (LLE) Methods in Nonlinear Dimensionality Reduction") Global (ISOMAP) versus Local (LLE) Methods in Nonlinear Dimensionality Reduction A presentation by Evan Ettinger on a Paper by Vin de Silva and Joshua B. Tenenbaum May 12, 2005 Outline Introduction The
Global (ISOMAP) versus Local (LLE) Methods in Nonlinear Dimensionality Reduction A presentation by Evan Ettinger on a Paper by Vin de Silva and Joshua B. Tenenbaum May 12, 2005 Outline Introduction The
Kernel-Based Contrast Functions for Sufficient Dimension Reduction
 Kernel-Based Contrast Functions for Sufficient Dimension Reduction Michael I. Jordan Departments of Statistics and EECS University of California, Berkeley Joint work with Kenji Fukumizu and Francis Bach
Kernel-Based Contrast Functions for Sufficient Dimension Reduction Michael I. Jordan Departments of Statistics and EECS University of California, Berkeley Joint work with Kenji Fukumizu and Francis Bach
Manifold Learning: From Linear to nonlinear. Presenter: Wei-Lun (Harry) Chao Date: April 26 and May 3, 2012 At: AMMAI 2012
 Chao Date: April 26 and May 3, 2012 At: AMMAI 2012") Manifold Learning: From Linear to nonlinear Presenter: Wei-Lun (Harry) Chao Date: April 26 and May 3, 2012 At: AMMAI 2012 1 Preview Goal: Dimensionality Classification reduction and clustering Main idea:
Manifold Learning: From Linear to nonlinear Presenter: Wei-Lun (Harry) Chao Date: April 26 and May 3, 2012 At: AMMAI 2012 1 Preview Goal: Dimensionality Classification reduction and clustering Main idea:
PCA, Kernel PCA, ICA
 PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
Kernel Methods. Machine Learning A W VO
 Kernel Methods Machine Learning A 708.063 07W VO Outline 1. Dual representation 2. The kernel concept 3. Properties of kernels 4. Examples of kernel machines Kernel PCA Support vector regression (Relevance
Kernel Methods Machine Learning A 708.063 07W VO Outline 1. Dual representation 2. The kernel concept 3. Properties of kernels 4. Examples of kernel machines Kernel PCA Support vector regression (Relevance
DS-GA 1002 Lecture notes 0 Fall Linear Algebra. These notes provide a review of basic concepts in linear algebra.
 DS-GA 1002 Lecture notes 0 Fall 2016 Linear Algebra These notes provide a review of basic concepts in linear algebra. 1 Vector spaces You are no doubt familiar with vectors in R 2 or R 3, i.e. [ ] 1.1
DS-GA 1002 Lecture notes 0 Fall 2016 Linear Algebra These notes provide a review of basic concepts in linear algebra. 1 Vector spaces You are no doubt familiar with vectors in R 2 or R 3, i.e. [ ] 1.1
The Kernel Trick. Robert M. Haralick. Computer Science, Graduate Center City University of New York
 The Kernel Trick Robert M. Haralick Computer Science, Graduate Center City University of New York Outline SVM Classification < (x 1, c 1 ),..., (x Z, c Z ) > is the training data c 1,..., c Z { 1, 1} specifies
The Kernel Trick Robert M. Haralick Computer Science, Graduate Center City University of New York Outline SVM Classification < (x 1, c 1 ),..., (x Z, c Z ) > is the training data c 1,..., c Z { 1, 1} specifies
EECS 275 Matrix Computation
 EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 23 1 / 27 Overview
EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 23 1 / 27 Overview
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen PCA. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen PCA Tobias Scheffer Overview Principal Component Analysis (PCA) Kernel-PCA Fisher Linear Discriminant Analysis t-sne 2 PCA: Motivation
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen PCA Tobias Scheffer Overview Principal Component Analysis (PCA) Kernel-PCA Fisher Linear Discriminant Analysis t-sne 2 PCA: Motivation
Lecture: Some Practical Considerations (3 of 4)
") Stat260/CS294: Spectral Graph Methods Lecture 14-03/10/2015 Lecture: Some Practical Considerations (3 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough.
Stat260/CS294: Spectral Graph Methods Lecture 14-03/10/2015 Lecture: Some Practical Considerations (3 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough.
Advances in Manifold Learning Presented by: Naku Nak l Verm r a June 10, 2008
 Advances in Manifold Learning Presented by: Nakul Verma June 10, 008 Outline Motivation Manifolds Manifold Learning Random projection of manifolds for dimension reduction Introduction to random projections
Advances in Manifold Learning Presented by: Nakul Verma June 10, 008 Outline Motivation Manifolds Manifold Learning Random projection of manifolds for dimension reduction Introduction to random projections
ISSN: (Online) Volume 3, Issue 5, May 2015 International Journal of Advance Research in Computer Science and Management Studies
 Volume 3, Issue 5, May 2015 International Journal of Advance Research in Computer Science and Management Studies") ISSN: 2321-7782 (Online) Volume 3, Issue 5, May 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online at:
ISSN: 2321-7782 (Online) Volume 3, Issue 5, May 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online at:
Dimensionality Reduction:
 Dimensionality Reduction: From Data Representation to General Framework Dong XU School of Computer Engineering Nanyang Technological University, Singapore What is Dimensionality Reduction? PCA LDA Examples:
Dimensionality Reduction: From Data Representation to General Framework Dong XU School of Computer Engineering Nanyang Technological University, Singapore What is Dimensionality Reduction? PCA LDA Examples:
Data Analysis and Manifold Learning Lecture 3: Graphs, Graph Matrices, and Graph Embeddings
 Data Analysis and Manifold Learning Lecture 3: Graphs, Graph Matrices, and Graph Embeddings Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline
Data Analysis and Manifold Learning Lecture 3: Graphs, Graph Matrices, and Graph Embeddings Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline
Spectral Clustering. by HU Pili. June 16, 2013
 Spectral Clustering by HU Pili June 16, 2013 Outline Clustering Problem Spectral Clustering Demo Preliminaries Clustering: K-means Algorithm Dimensionality Reduction: PCA, KPCA. Spectral Clustering Framework
Spectral Clustering by HU Pili June 16, 2013 Outline Clustering Problem Spectral Clustering Demo Preliminaries Clustering: K-means Algorithm Dimensionality Reduction: PCA, KPCA. Spectral Clustering Framework
SPECTRAL CLUSTERING AND KERNEL PRINCIPAL COMPONENT ANALYSIS ARE PURSUING GOOD PROJECTIONS
 SPECTRAL CLUSTERING AND KERNEL PRINCIPAL COMPONENT ANALYSIS ARE PURSUING GOOD PROJECTIONS VIKAS CHANDRAKANT RAYKAR DECEMBER 5, 24 Abstract. We interpret spectral clustering algorithms in the light of unsupervised
SPECTRAL CLUSTERING AND KERNEL PRINCIPAL COMPONENT ANALYSIS ARE PURSUING GOOD PROJECTIONS VIKAS CHANDRAKANT RAYKAR DECEMBER 5, 24 Abstract. We interpret spectral clustering algorithms in the light of unsupervised
Functional Analysis Review
 Outline 9.520: Statistical Learning Theory and Applications February 8, 2010 Outline 1 2 3 4 Vector Space Outline A vector space is a set V with binary operations +: V V V and : R V V such that for all
Outline 9.520: Statistical Learning Theory and Applications February 8, 2010 Outline 1 2 3 4 Vector Space Outline A vector space is a set V with binary operations +: V V V and : R V V such that for all
Learning gradients: prescriptive models
 Department of Statistical Science Institute for Genome Sciences & Policy Department of Computer Science Duke University May 11, 2007 Relevant papers Learning Coordinate Covariances via Gradients. Sayan
Department of Statistical Science Institute for Genome Sciences & Policy Department of Computer Science Duke University May 11, 2007 Relevant papers Learning Coordinate Covariances via Gradients. Sayan
Dimensionality Reduction: A Comparative Review
 Tilburg centre for Creative Computing P.O. Box 90153 Tilburg University 5000 LE Tilburg, The Netherlands http://www.uvt.nl/ticc Email: ticc@uvt.nl Copyright c Laurens van der Maaten, Eric Postma, and Jaap
Tilburg centre for Creative Computing P.O. Box 90153 Tilburg University 5000 LE Tilburg, The Netherlands http://www.uvt.nl/ticc Email: ticc@uvt.nl Copyright c Laurens van der Maaten, Eric Postma, and Jaap
Statistical and Computational Analysis of Locality Preserving Projection
 Statistical and Computational Analysis of Locality Preserving Projection Xiaofei He xiaofei@cs.uchicago.edu Department of Computer Science, University of Chicago, 00 East 58th Street, Chicago, IL 60637
Statistical and Computational Analysis of Locality Preserving Projection Xiaofei He xiaofei@cs.uchicago.edu Department of Computer Science, University of Chicago, 00 East 58th Street, Chicago, IL 60637
Learning a Kernel Matrix for Nonlinear Dimensionality Reduction
 Learning a Kernel Matrix for Nonlinear Dimensionality Reduction Kilian Q. Weinberger kilianw@cis.upenn.edu Fei Sha feisha@cis.upenn.edu Lawrence K. Saul lsaul@cis.upenn.edu Department of Computer and Information
Learning a Kernel Matrix for Nonlinear Dimensionality Reduction Kilian Q. Weinberger kilianw@cis.upenn.edu Fei Sha feisha@cis.upenn.edu Lawrence K. Saul lsaul@cis.upenn.edu Department of Computer and Information
Kernel Methods in Machine Learning
 Kernel Methods in Machine Learning Autumn 2015 Lecture 1: Introduction Juho Rousu ICS-E4030 Kernel Methods in Machine Learning 9. September, 2015 uho Rousu (ICS-E4030 Kernel Methods in Machine Learning)
Kernel Methods in Machine Learning Autumn 2015 Lecture 1: Introduction Juho Rousu ICS-E4030 Kernel Methods in Machine Learning 9. September, 2015 uho Rousu (ICS-E4030 Kernel Methods in Machine Learning)
Novelty Detection. Cate Welch. May 14, 2015
 Novelty Detection Cate Welch May 14, 2015 1 Contents 1 Introduction 2 11 The Four Fundamental Subspaces 2 12 The Spectral Theorem 4 1 The Singular Value Decomposition 5 2 The Principal Components Analysis
Novelty Detection Cate Welch May 14, 2015 1 Contents 1 Introduction 2 11 The Four Fundamental Subspaces 2 12 The Spectral Theorem 4 1 The Singular Value Decomposition 5 2 The Principal Components Analysis
Data Mining and Analysis: Fundamental Concepts and Algorithms
 Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA
Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA
Reproducing Kernel Hilbert Spaces
 Reproducing Kernel Hilbert Spaces Lorenzo Rosasco 9.520 Class 03 February 9, 2011 About this class Goal In this class we continue our journey in the world of RKHS. We discuss the Mercer theorem which gives
Reproducing Kernel Hilbert Spaces Lorenzo Rosasco 9.520 Class 03 February 9, 2011 About this class Goal In this class we continue our journey in the world of RKHS. We discuss the Mercer theorem which gives
Chapter 3 Transformations
 Chapter 3 Transformations An Introduction to Optimization Spring, 2014 Wei-Ta Chu 1 Linear Transformations A function is called a linear transformation if 1. for every and 2. for every If we fix the bases
Chapter 3 Transformations An Introduction to Optimization Spring, 2014 Wei-Ta Chu 1 Linear Transformations A function is called a linear transformation if 1. for every and 2. for every If we fix the bases
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach
 A First Dimensionality Reduction Approach") LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
MACHINE LEARNING. Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA
 1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
Kernel Method: Data Analysis with Positive Definite Kernels
 Kernel Method: Data Analysis with Positive Definite Kernels 2. Positive Definite Kernel and Reproducing Kernel Hilbert Space Kenji Fukumizu The Institute of Statistical Mathematics. Graduate University
Kernel Method: Data Analysis with Positive Definite Kernels 2. Positive Definite Kernel and Reproducing Kernel Hilbert Space Kenji Fukumizu The Institute of Statistical Mathematics. Graduate University
Learning a kernel matrix for nonlinear dimensionality reduction
 University of Pennsylvania ScholarlyCommons Departmental Papers (CIS) Department of Computer & Information Science 7-4-2004 Learning a kernel matrix for nonlinear dimensionality reduction Kilian Q. Weinberger
University of Pennsylvania ScholarlyCommons Departmental Papers (CIS) Department of Computer & Information Science 7-4-2004 Learning a kernel matrix for nonlinear dimensionality reduction Kilian Q. Weinberger
Learning on Graphs and Manifolds. CMPSCI 689 Sridhar Mahadevan U.Mass Amherst
 Learning on Graphs and Manifolds CMPSCI 689 Sridhar Mahadevan U.Mass Amherst Outline Manifold learning is a relatively new area of machine learning (2000-now). Main idea Model the underlying geometry of
Learning on Graphs and Manifolds CMPSCI 689 Sridhar Mahadevan U.Mass Amherst Outline Manifold learning is a relatively new area of machine learning (2000-now). Main idea Model the underlying geometry of
CIS 520: Machine Learning Oct 09, Kernel Methods
 CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
Lecture 7: Positive Semidefinite Matrices
 Lecture 7: Positive Semidefinite Matrices Rajat Mittal IIT Kanpur The main aim of this lecture note is to prepare your background for semidefinite programming. We have already seen some linear algebra.
Lecture 7: Positive Semidefinite Matrices Rajat Mittal IIT Kanpur The main aim of this lecture note is to prepare your background for semidefinite programming. We have already seen some linear algebra.
Dimensionality Reduction
 Dimensionality Reduction Neil D. Lawrence neill@cs.man.ac.uk Mathematics for Data Modelling University of Sheffield January 23rd 28 Neil Lawrence () Dimensionality Reduction Data Modelling School 1 / 7
Dimensionality Reduction Neil D. Lawrence neill@cs.man.ac.uk Mathematics for Data Modelling University of Sheffield January 23rd 28 Neil Lawrence () Dimensionality Reduction Data Modelling School 1 / 7
Gaussian Process Latent Random Field
 Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10) Gaussian Process Latent Random Field Guoqiang Zhong, Wu-Jun Li, Dit-Yan Yeung, Xinwen Hou, Cheng-Lin Liu National Laboratory
Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10) Gaussian Process Latent Random Field Guoqiang Zhong, Wu-Jun Li, Dit-Yan Yeung, Xinwen Hou, Cheng-Lin Liu National Laboratory
10-701/ Recitation : Kernels
 10-701/15-781 Recitation : Kernels Manojit Nandi February 27, 2014 Outline Mathematical Theory Banach Space and Hilbert Spaces Kernels Commonly Used Kernels Kernel Theory One Weird Kernel Trick Representer
10-701/15-781 Recitation : Kernels Manojit Nandi February 27, 2014 Outline Mathematical Theory Banach Space and Hilbert Spaces Kernels Commonly Used Kernels Kernel Theory One Weird Kernel Trick Representer
Certifying the Global Optimality of Graph Cuts via Semidefinite Programming: A Theoretic Guarantee for Spectral Clustering
 Certifying the Global Optimality of Graph Cuts via Semidefinite Programming: A Theoretic Guarantee for Spectral Clustering Shuyang Ling Courant Institute of Mathematical Sciences, NYU Aug 13, 2018 Joint
Certifying the Global Optimality of Graph Cuts via Semidefinite Programming: A Theoretic Guarantee for Spectral Clustering Shuyang Ling Courant Institute of Mathematical Sciences, NYU Aug 13, 2018 Joint
Linear Models for Regression
 Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
A Duality View of Spectral Methods for Dimensionality Reduction
 Lin Xiao lxiao@caltech.edu Center for the Mathematics of Information, California Institute of Technology, Pasadena, CA 91125, USA Jun Sun sunjun@stanford.edu Stephen Boyd boyd@stanford.edu Department of
Lin Xiao lxiao@caltech.edu Center for the Mathematics of Information, California Institute of Technology, Pasadena, CA 91125, USA Jun Sun sunjun@stanford.edu Stephen Boyd boyd@stanford.edu Department of
Linear Models for Regression
 Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Linear Models for Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Preprocessing & dimensionality reduction
 Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
Manifold Estimation, Hidden Structure and Dimension Reduction
 Manifold Estimation, Hidden Structure and Dimension Reduction We consider two related problems: (i) estimating low dimensional structure (ii) using low dimensional approximations for dimension reduction.
Manifold Estimation, Hidden Structure and Dimension Reduction We consider two related problems: (i) estimating low dimensional structure (ii) using low dimensional approximations for dimension reduction.
14 Singular Value Decomposition
 14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Machine Learning. Data visualization and dimensionality reduction. Eric Xing. Lecture 7, August 13, Eric Xing Eric CMU,
 Eric Xing Eric Xing @ CMU, 2006-2010 1 Machine Learning Data visualization and dimensionality reduction Eric Xing Lecture 7, August 13, 2010 Eric Xing Eric Xing @ CMU, 2006-2010 2 Text document retrieval/labelling
Eric Xing Eric Xing @ CMU, 2006-2010 1 Machine Learning Data visualization and dimensionality reduction Eric Xing Lecture 7, August 13, 2010 Eric Xing Eric Xing @ CMU, 2006-2010 2 Text document retrieval/labelling
Principal Component Analysis
 Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Spectral Clustering. Spectral Clustering? Two Moons Data. Spectral Clustering Algorithm: Bipartioning. Spectral methods
 Spectral Clustering Seungjin Choi Department of Computer Science POSTECH, Korea seungjin@postech.ac.kr 1 Spectral methods Spectral Clustering? Methods using eigenvectors of some matrices Involve eigen-decomposition
Spectral Clustering Seungjin Choi Department of Computer Science POSTECH, Korea seungjin@postech.ac.kr 1 Spectral methods Spectral Clustering? Methods using eigenvectors of some matrices Involve eigen-decomposition
Kernel Discriminant Analysis for Regression Problems
 Kernel Discriminant Analysis for Regression Problems 1 Nojun Kwak Abstract In this paper, we propose a nonlinear feature extraction method for regression problems to reduce the dimensionality of the input
Kernel Discriminant Analysis for Regression Problems 1 Nojun Kwak Abstract In this paper, we propose a nonlinear feature extraction method for regression problems to reduce the dimensionality of the input
Machine Learning. Dimensionality reduction. Hamid Beigy. Sharif University of Technology. Fall 1395
 Machine Learning Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1395 1 / 47 Table of contents 1 Introduction
Machine Learning Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1395 1 / 47 Table of contents 1 Introduction
The Laplacian PDF Distance: A Cost Function for Clustering in a Kernel Feature Space
 The Laplacian PDF Distance: A Cost Function for Clustering in a Kernel Feature Space Robert Jenssen, Deniz Erdogmus 2, Jose Principe 2, Torbjørn Eltoft Department of Physics, University of Tromsø, Norway
The Laplacian PDF Distance: A Cost Function for Clustering in a Kernel Feature Space Robert Jenssen, Deniz Erdogmus 2, Jose Principe 2, Torbjørn Eltoft Department of Physics, University of Tromsø, Norway
Kernel Methods. Barnabás Póczos
 Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Lecture 6 Sept Data Visualization STAT 442 / 890, CM 462
 Lecture 6 Sept. 25-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Dual PCA It turns out that the singular value decomposition also allows us to formulate the principle components
Lecture 6 Sept. 25-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Dual PCA It turns out that the singular value decomposition also allows us to formulate the principle components
A Duality View of Spectral Methods for Dimensionality Reduction
 A Duality View of Spectral Methods for Dimensionality Reduction Lin Xiao 1 Jun Sun 2 Stephen Boyd 3 May 3, 2006 1 Center for the Mathematics of Information, California Institute of Technology, Pasadena,
A Duality View of Spectral Methods for Dimensionality Reduction Lin Xiao 1 Jun Sun 2 Stephen Boyd 3 May 3, 2006 1 Center for the Mathematics of Information, California Institute of Technology, Pasadena,
Lecture 3: Review of Linear Algebra
 ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters, transforms,
ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters, transforms,
Spectral Dimensionality Reduction
 Spectral Dimensionality Reduction Yoshua Bengio, Olivier Delalleau, Nicolas Le Roux Jean-François Paiement, Pascal Vincent, and Marie Ouimet Département d Informatique et Recherche Opérationnelle Centre
Spectral Dimensionality Reduction Yoshua Bengio, Olivier Delalleau, Nicolas Le Roux Jean-François Paiement, Pascal Vincent, and Marie Ouimet Département d Informatique et Recherche Opérationnelle Centre
Nonparameteric Regression:
 Nonparameteric Regression: Nadaraya-Watson Kernel Regression & Gaussian Process Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Nonparameteric Regression: Nadaraya-Watson Kernel Regression & Gaussian Process Regression Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Dimensionality Reduction: A Comparative Review
 Dimensionality Reduction: A Comparative Review L.J.P. van der Maaten, E.O. Postma, H.J. van den Herik MICC, Maastricht University, P.O. Box 616, 6200 MD Maastricht, The Netherlands. Abstract In recent
Dimensionality Reduction: A Comparative Review L.J.P. van der Maaten, E.O. Postma, H.J. van den Herik MICC, Maastricht University, P.O. Box 616, 6200 MD Maastricht, The Netherlands. Abstract In recent
Kernel Methods. Jean-Philippe Vert Last update: Jan Jean-Philippe Vert (Mines ParisTech) 1 / 444
 1 / 444") Kernel Methods Jean-Philippe Vert Jean-Philippe.Vert@mines.org Last update: Jan 2015 Jean-Philippe Vert (Mines ParisTech) 1 / 444 What we know how to solve Jean-Philippe Vert (Mines ParisTech) 2 / 444
Kernel Methods Jean-Philippe Vert Jean-Philippe.Vert@mines.org Last update: Jan 2015 Jean-Philippe Vert (Mines ParisTech) 1 / 444 What we know how to solve Jean-Philippe Vert (Mines ParisTech) 2 / 444
Lecture 3: Review of Linear Algebra
 ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak, scribe: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters,
ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak, scribe: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters,
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
Vectors To begin, let us describe an element of the state space as a point with numerical coordinates, that is x 1. x 2. x =
 Linear Algebra Review Vectors To begin, let us describe an element of the state space as a point with numerical coordinates, that is x 1 x x = 2. x n Vectors of up to three dimensions are easy to diagram.
Linear Algebra Review Vectors To begin, let us describe an element of the state space as a point with numerical coordinates, that is x 1 x x = 2. x n Vectors of up to three dimensions are easy to diagram.