Bayesian Inference Course, WTCN, UCL, March 2013
|
|
|
- Stephany Andrews
- 5 years ago
- Views:
Transcription
1 Bayesian Course, WTCN, UCL, March 2013
2 Shannon (1948) asked how much information is received when we observe a specific value of the variable x? If an unlikely event occurs then one would expect the information to be greater. So information must be inversely proportional to p(x), and monotonic. Shannon also wanted a definition of information such that if x and y are independent then the total information would sum h(x i, y j ) = h(x i ) + h(y j ) Given that we know that in this case then we must have p(x i, y j ) = p(x i )p(y j ) h(x i ) = log 1 p(x i ) This is the self-information or surprise.
3 The entropy of a random variable is the average surprise. For discrete variables H(x) = p(x i ) log 1 p(x i ) i The uniform distribution has maximum entropy. A single peak has minimum entropy. We define 0 log 0 = 0 If we take logs to the base 2, entropy is measured in bits.
4 Source Coding Theorem Assigning code-words of length h(x i ) to each symbol x i results in the maximum rate of information transfer in a noiseless channel. This is the Source Coding Theorem (Shannon, 1948). h(x i ) = log 1 p(x i ) If channel is noisy, see Noisy Channel Coding Theorem (Mackay, 2003)
5 Prefix Codes No code-word is a prefix of another. Use number of bits b(x i ) = ceil(h(x i )). We have h(x i ) = log 2 1 p(x i ) b(x i ) = log 2 1 q(x i ) Hence, each code-word has equivalent q(x i ) = 2 b(x i ) i p(x i ) h(x i ) b(x i ) q(x i ) CodeWord
6 Relative Average length of code word B(x) = i = i H(x) = i = i p(x i )b(x i ) p(x i ) log 1 q(x i ) = 2.65bits p(x i )h(x i ) p(x i ) log 1 p(x i ) = 2.20bits Difference is relative entropy KL(p q) = B(x) H(x) = p(x i ) log p(x i) q(x i ) i = 0.45bits
7 Continuous Variables For continuous variables the (differential) entropy is H(x) = p(x) log 1 p(x) dx Out of all distributions with mean m and standard deviation σ the Gaussian distribution has the maximum entropy. This is H(x) = 1 2 (1 + log 2π) + 1 log σ2 2
8 Relative We can write the Kullback-Liebler (KL) divergence KL[q p] = q(x) log q(x) p(x) dx as a difference in entropies KL(q p) = q(x) log 1 p(x) dx q(x) log 1 q(x) dx This is the average surprise assuming information is encoded under p(x) minus the average surprise under q(x). Its the extra number of bits/nats required to transmit messages.
9 Univariate For p(x) = N(x; µ p, σ 2 p) q(x) = N(x; µ q, σ 2 q) we have KL(q p) = (µ q µ p ) 2 2σ 2 p log ( σ 2 p σ 2 q ) + σ2 q 2σ 2 p 1 2
10 Multivariate For we have p(x) = N(x; µ p, C p ) q(x) = N(x; µ q, C q ) KL(q p) = 1 2 et C 1 p e log C p C q Tr ( C 1 p C q ) d 2 where d = dim(x) and e = µ q µ p
11 For densities q(x) and p(x) the Relative or Kullback-Liebler (KL) divergence from q to p is KL[q p] = q(x) log q(x) p(x) dx The KL-divergence satisfies Gibbs inequality with equality only if q = p. KL[q p] 0 In general KL[q p] KL[p q], so KL is not a distance measure.
12 Different Variance - KL[q p] = If σ q σ p then KL(q p) KL(p q) q(x) log q(x) p(x) dx Here KL(q p) = 0.32 but KL(p q) = 0.81.
13 Same Variance - Symmetry If σ q = σ p then KL(q p) = KL(p q) eg. distributions that just have a different mean Here KL(q p) = KL(p q) = 0.12.
14 Approximating multimodal with unimodal We approximate the density p (blue), which is a Gaussian mixture, with a Gaussian density q (red). Left Mode Right Mode Moment Matched KL(q,p) KL(p,q) Minimising either KL produces the moment-matched solution.
15 Approximate Bayesian True posterior p (blue), approximate posterior q (red). Gaussian approx at mode is a Laplace approximation. Left Mode Right Mode Moment Matched KL(q,p) KL(p,q) Minimising either KL produces the moment-matched solution.
16 Distant Modes We approximate the density p (blue), which is a Gaussian mixture, with a Gaussian density q (red). Left Mode Right Mode Moment Matched KL(q,p) KL(p,q) Minimising KL(q p) produces mode-seeking. Minimising KL(p q) produces moment-matching.
. Minimising KL(q p) therefore seems desirable, but how do we do it if we don t know p?")
17 Multiple dimensions In higher dimensional spaces, unless modes are very close, minimising KL(p q) produces moment-matching (a) and minimising KL(q p) produces mode-seeking (b and c). Minimising KL(q p) therefore seems desirable, but how do we do it if we don t know p? Figure from Bishop, Pattern Recognition and Machine Learning, 2006
18 Joint Probability p(y, θ) = p(y θ 3, θ 4 )p(θ 3 θ 2, θ 1 )p(θ 1 )p(θ 2 )p(θ 4 ) Energy E = log p(y, θ)
19 Given a probabilistic model of some data, the log of the evidence can be written as log p(y ) = q(θ) log p(y )dθ p(y, θ) = q(θ) log p(θ Y ) dθ [ ] p(y, θ)q(θ) = q(θ) log dθ q(θ)p(θ Y ) [ ] p(y, θ) = q(θ) log dθ q(θ) [ ] q(θ) + q(θ) log dθ p(θ Y ) where q(θ) is the approximate posterior. Hence log p(y ) = F + KL(q(θ) p(θ Y ))
20 Free Energy We have F = q(θ) log p(y, θ) q(θ) dθ which in statistical physics is known as the variational free energy. We can write F = q(θ) log p(y, θ)dθ q(θ) log 1 q(θ) dθ This is an energy term, minus an entropy term, hence free energy.
21 Free Energy Because KL is always positive, due to the Gibbs inequality, F provides a lower bound on the model evidence. Moreover, because KL is zero when two densities are the same, F will become equal to the model evidence when q(θ) is equal to the true posterior. For this reason q(θ) can be viewed as an approximate posterior. log p(y ) = F + KL[q(θ) p(θ Y )]
22 To obtain a practical learning algorithm we must also ensure that the integrals in F are tractable. One generic procedure for attaining this goal is to assume that the approximating density factorizes over groups of parameters. In physics, this is known as the mean field approximation. Thus, we consider: q(θ) = i q(θ i ) where θ i is the ith group of parameters. We can also write this as q(θ) = q(θ i )q(θ \i ) where θ \i denotes all parameters not in the ith group.
23 We define the variational energy for the ith partition as I(θ i ) = q(θ \i ) log p(y, θ)dθ \i It is the Energy averaged over other ensembles. Then the free energy is minimised when q(θ i ) = exp[i(θ i)] Z where Z is the normalisation factor needed to make q(θ i ) a valid probability distribution. For proof see Bishop (2006) or SPM book. Think of above two equations as an approximate version of Bayes rule.
24 For q(z) = q(z 1 )q(z 2 ) minimising KL(q, p) where p is green and q is red produces left plot, where minimising KL(p, q) produces right plot. Hence minimising free energy produces approximations on left rather than right. That is, uncertainty is underestimated. See Minka (2005) for other divergences.
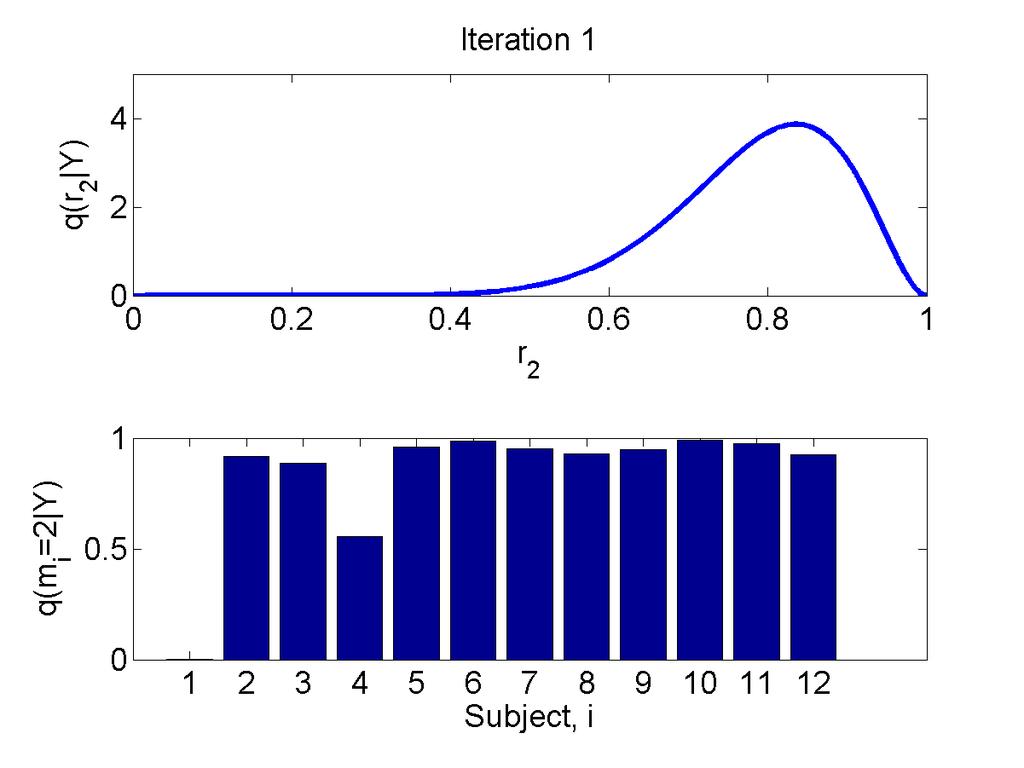
25 Example Approximate posteriors Update q(m Y ): Update q(r Y ): q(r Y ) = Dir(r; α) q(m Y ) = N K i=1 k=1 g m ik ik u ik = exp log p(y i k) + ψ(α k ) ψ(α k ) k g ik = u ik k u ik α k = α 0 k + i g ik Sufficient statistics of approximate posteriors are coupled. Update and iterate - see later.
26 has been applied to Hidden Markov Models (Mackay, Cambridge, 1997) Graphical Models (Jordan, Machine Learning, 1999) Logistic Regression (Jaakola and Jordan, Stats and Computing, 2000) Gaussian Mixture Models, (Attias, UAI, 1999) Independent Component Analysis, (Attias, UAI, 1999) Dynamic Trees, (Storkey, UAI, 2000)
27 Relevance Vector Machines, (Bishop and Tipping, 2000) Linear Dynamical Systems (Ghahramani and Beal, NIPS, 2001) Nonlinear Autoregressive Models (Roberts and Penny, IEEE SP, 2002) Canonical Correlation Analysis (Wang, IEEE TNN, 2007) Dynamic Causal Models (Friston, Neuroimage, 2007) Nonlinear Dynamic Systems (Daunizeau, PRL, 2009)
, as measured by KL-divergence.")
28 We can write F = q(θ) log p(y θ)dθ + q(θ) log q(θ) p(θ) dθ Replace point estimate θ with an ensemble q(θ). Keep parameters θ imprecise by penalizing distance from a prior p(θ), as measured by KL-divergence. See Hinton and van Camp, COLT, 1993
29 We can write F = q(θ) log p(y θ)dθ + F = q(θ) log p(y θ)dθ F = Accuracy Complexity q(θ) log q(θ) p(θ) dθ q(θ) log q(θ) p(θ) dθ
30 The negative free energy, being an approximation to the model evidence, can also be used for model comparison. See for example Graphical models (Beal, PhD Gatsby, 2003) Linear dynamical systems (Ghahramani and Beal, NIPS, 2001) Nonlinear autoregressive models (Roberts and Penny, IEEE SP, 2002) Hidden Markov Models (Valente and Wellekens, ICSLP 2004) Dynamic Causal Models (Penny, Neuroimage, 2011)
31 Log Bayes Factor in favour of model 2 log p(y i m i = 2) p(y i m i = 1)
32 Model frequencies r k, model assignments m i, subject data y i. Approximate posterior q(r, m Y ) = q(r Y )q(m Y ) Stephan, Neuroimage, 2009.
33 Approximate posteriors Update q(m Y ): Update q(r Y ): q(r Y ) = Dir(r; α) q(m Y ) = N K i=1 k=1 g m ik ik u ik = exp log p(y i k) + ψ(α k ) ψ(α k ) k g ik = u ik k u ik α k = α 0 k + i g ik Here log p(y i k) is the entry in the log evidence table from the ith subject (row) and kth model (column). The quantity g ik is the posterior probability that subject i used the kth model.
34
35
36
37
38
39 VB for generic models Winn and Bishop, Message Passing, JLMR, 2005 Wainwright and Jordan, A Principle for Graphical Models, 2005 Friston et al. Dynamic Expectation Maximisation, Neuroimage, 2008 For more see
40 : KL-Divergence: Energy: H(θ) = KL[q p] = q(θ) log 1 q(θ) dθ q(θ) log q(θ) p(θ) dθ E = log p(y, θ) Free Energy is Energy minus : F = q(θ) log p(y, θ)dθ is Negative Free Energy + KL: q(θ) log 1 q(θ) dθ log p(y m) = F + KL(q(θ) p(θ Y )) Negative Free Energy is Accuracy minus Complexity: F = q(θ) log p(y θ)dθ q(θ) log q(θ) p(θ) dθ
41 M. Beal (2003) PhD Thesis. Gatsby Computational Neuroscience Unit, UCL. C. Bishop (2006) Pattern Recognition and Machine Learning, Springer. G. Deco et al. (2008) The Dynamic Brain: From Spiking Neurons to Neural Masses and Cortical Fields. PLoS CB 4(8), e D. Mackay (2003), and Learning Algorithms, Cambridge. T. Minka et al. (2005) Divergence Measures and Message Passing. Microsoft Research Cambridge. S. Roberts and W. Penny (2002). for generalised autoregressive models. IEEE transactions on signal processing. 50(9), W. Penny (2006). In SPM Book, Elsevier. D. Valente and C. Wellekens (2004) Scoring unknown speaker clustering: VB versus BIC. ICSLP 2004, Korea.
Model Comparison. Course on Bayesian Inference, WTCN, UCL, February Model Comparison. Bayes rule for models. Linear Models. AIC and BIC.
 Course on Bayesian Inference, WTCN, UCL, February 2013 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented
Course on Bayesian Inference, WTCN, UCL, February 2013 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented
Expectation Propagation Algorithm
 Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Expectation Propagation Algorithm 1 Shuang Wang School of Electrical and Computer Engineering University of Oklahoma, Tulsa, OK, 74135 Email: {shuangwang}@ou.edu This note contains three parts. First,
Unsupervised Learning
 Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Unsupervised Learning Bayesian Model Comparison Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent Systems, Dept Computer Science University College
Foundations of Statistical Inference
 Foundations of Statistical Inference Julien Berestycki Department of Statistics University of Oxford MT 2016 Julien Berestycki (University of Oxford) SB2a MT 2016 1 / 32 Lecture 14 : Variational Bayes
Foundations of Statistical Inference Julien Berestycki Department of Statistics University of Oxford MT 2016 Julien Berestycki (University of Oxford) SB2a MT 2016 1 / 32 Lecture 14 : Variational Bayes
Variational Principal Components
 Variational Principal Components Christopher M. Bishop Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop In Proceedings
Variational Principal Components Christopher M. Bishop Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/ cmbishop In Proceedings
CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection
 CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection (non-examinable material) Matthew J. Beal February 27, 2004 www.variational-bayes.org Bayesian Model Selection
CSC2535: Computation in Neural Networks Lecture 7: Variational Bayesian Learning & Model Selection (non-examinable material) Matthew J. Beal February 27, 2004 www.variational-bayes.org Bayesian Model Selection
Statistical Machine Learning Lectures 4: Variational Bayes
 1 / 29 Statistical Machine Learning Lectures 4: Variational Bayes Melih Kandemir Özyeğin University, İstanbul, Turkey 2 / 29 Synonyms Variational Bayes Variational Inference Variational Bayesian Inference
1 / 29 Statistical Machine Learning Lectures 4: Variational Bayes Melih Kandemir Özyeğin University, İstanbul, Turkey 2 / 29 Synonyms Variational Bayes Variational Inference Variational Bayesian Inference
A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y.
 (or hypothesis space ) can be updated to a posterior distribution after observing data y.") June 2nd 2011 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule p(m y) = p(y m)p(m)
June 2nd 2011 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule p(m y) = p(y m)p(m)
Will Penny. SPM short course for M/EEG, London 2013
 SPM short course for M/EEG, London 2013 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure Bayes rule for models A prior distribution over model space p(m) (or hypothesis space ) can be updated
SPM short course for M/EEG, London 2013 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure Bayes rule for models A prior distribution over model space p(m) (or hypothesis space ) can be updated
Will Penny. DCM short course, Paris 2012
 DCM short course, Paris 2012 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure Bayes rule for models A prior distribution over model space p(m) (or hypothesis space ) can be updated to a
DCM short course, Paris 2012 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure Bayes rule for models A prior distribution over model space p(m) (or hypothesis space ) can be updated to a
Variational Scoring of Graphical Model Structures
 Variational Scoring of Graphical Model Structures Matthew J. Beal Work with Zoubin Ghahramani & Carl Rasmussen, Toronto. 15th September 2003 Overview Bayesian model selection Approximations using Variational
Variational Scoring of Graphical Model Structures Matthew J. Beal Work with Zoubin Ghahramani & Carl Rasmussen, Toronto. 15th September 2003 Overview Bayesian model selection Approximations using Variational
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 7 Approximate
Sparse Bayesian Logistic Regression with Hierarchical Prior and Variational Inference
 Sparse Bayesian Logistic Regression with Hierarchical Prior and Variational Inference Shunsuke Horii Waseda University s.horii@aoni.waseda.jp Abstract In this paper, we present a hierarchical model which
Sparse Bayesian Logistic Regression with Hierarchical Prior and Variational Inference Shunsuke Horii Waseda University s.horii@aoni.waseda.jp Abstract In this paper, we present a hierarchical model which
An Information Theoretic Interpretation of Variational Inference based on the MDL Principle and the Bits-Back Coding Scheme
 An Information Theoretic Interpretation of Variational Inference based on the MDL Principle and the Bits-Back Coding Scheme Ghassen Jerfel April 2017 As we will see during this talk, the Bayesian and information-theoretic
An Information Theoretic Interpretation of Variational Inference based on the MDL Principle and the Bits-Back Coding Scheme Ghassen Jerfel April 2017 As we will see during this talk, the Bayesian and information-theoretic
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Will Penny. SPM short course for M/EEG, London 2015
 SPM short course for M/EEG, London 2015 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure The model evidence is given by integrating out the dependence on model parameters p(y m) = p(y,
SPM short course for M/EEG, London 2015 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure The model evidence is given by integrating out the dependence on model parameters p(y m) = p(y,
An introduction to Variational calculus in Machine Learning
 n introduction to Variational calculus in Machine Learning nders Meng February 2004 1 Introduction The intention of this note is not to give a full understanding of calculus of variations since this area
n introduction to Variational calculus in Machine Learning nders Meng February 2004 1 Introduction The intention of this note is not to give a full understanding of calculus of variations since this area
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2
 Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Approximate Inference Part 1 of 2 Tom Minka Microsoft Research, Cambridge, UK Machine Learning Summer School 2009 http://mlg.eng.cam.ac.uk/mlss09/ 1 Bayesian paradigm Consistent use of probability theory
Will Penny. SPM for MEG/EEG, 15th May 2012
 SPM for MEG/EEG, 15th May 2012 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule
SPM for MEG/EEG, 15th May 2012 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule
Expectation Maximization
 Expectation Maximization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr 1 /
Expectation Maximization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr 1 /
The Variational Gaussian Approximation Revisited
 The Variational Gaussian Approximation Revisited Manfred Opper Cédric Archambeau March 16, 2009 Abstract The variational approximation of posterior distributions by multivariate Gaussians has been much
The Variational Gaussian Approximation Revisited Manfred Opper Cédric Archambeau March 16, 2009 Abstract The variational approximation of posterior distributions by multivariate Gaussians has been much
Understanding Covariance Estimates in Expectation Propagation
 Understanding Covariance Estimates in Expectation Propagation William Stephenson Department of EECS Massachusetts Institute of Technology Cambridge, MA 019 wtstephe@csail.mit.edu Tamara Broderick Department
Understanding Covariance Estimates in Expectation Propagation William Stephenson Department of EECS Massachusetts Institute of Technology Cambridge, MA 019 wtstephe@csail.mit.edu Tamara Broderick Department
Expectation propagation as a way of life
 Expectation propagation as a way of life Yingzhen Li Department of Engineering Feb. 2014 Yingzhen Li (Department of Engineering) Expectation propagation as a way of life Feb. 2014 1 / 9 Reference This
Expectation propagation as a way of life Yingzhen Li Department of Engineering Feb. 2014 Yingzhen Li (Department of Engineering) Expectation propagation as a way of life Feb. 2014 1 / 9 Reference This
CSC 2541: Bayesian Methods for Machine Learning
 CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 10 Alternatives to Monte Carlo Computation Since about 1990, Markov chain Monte Carlo has been the dominant
CSC 2541: Bayesian Methods for Machine Learning Radford M. Neal, University of Toronto, 2011 Lecture 10 Alternatives to Monte Carlo Computation Since about 1990, Markov chain Monte Carlo has been the dominant
Lecture 6: Graphical Models: Learning
 Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Probabilistic and Bayesian Machine Learning
 Probabilistic and Bayesian Machine Learning Day 4: Expectation and Belief Propagation Yee Whye Teh ywteh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London http://www.gatsby.ucl.ac.uk/
Probabilistic and Bayesian Machine Learning Day 4: Expectation and Belief Propagation Yee Whye Teh ywteh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London http://www.gatsby.ucl.ac.uk/
Part 1: Expectation Propagation
 Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Week 3: The EM algorithm
 Week 3: The EM algorithm Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London Term 1, Autumn 2005 Mixtures of Gaussians Data: Y = {y 1... y N } Latent
Week 3: The EM algorithm Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London Term 1, Autumn 2005 Mixtures of Gaussians Data: Y = {y 1... y N } Latent
13 : Variational Inference: Loopy Belief Propagation and Mean Field
 10-708: Probabilistic Graphical Models 10-708, Spring 2012 13 : Variational Inference: Loopy Belief Propagation and Mean Field Lecturer: Eric P. Xing Scribes: Peter Schulam and William Wang 1 Introduction
10-708: Probabilistic Graphical Models 10-708, Spring 2012 13 : Variational Inference: Loopy Belief Propagation and Mean Field Lecturer: Eric P. Xing Scribes: Peter Schulam and William Wang 1 Introduction
The Variational Bayesian EM Algorithm for Incomplete Data: with Application to Scoring Graphical Model Structures
 BAYESIAN STATISTICS 7, pp. 000 000 J. M. Bernardo, M. J. Bayarri, J. O. Berger, A. P. Dawid, D. Heckerman, A. F. M. Smith and M. West (Eds.) c Oxford University Press, 2003 The Variational Bayesian EM
BAYESIAN STATISTICS 7, pp. 000 000 J. M. Bernardo, M. J. Bayarri, J. O. Berger, A. P. Dawid, D. Heckerman, A. F. M. Smith and M. West (Eds.) c Oxford University Press, 2003 The Variational Bayesian EM
Machine Learning Summer School
 Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Machine Learning Summer School Lecture 3: Learning parameters and structure Zoubin Ghahramani zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/ Department of Engineering University of Cambridge,
Expectation Propagation in Dynamical Systems
 Expectation Propagation in Dynamical Systems Marc Peter Deisenroth Joint Work with Shakir Mohamed (UBC) August 10, 2012 Marc Deisenroth (TU Darmstadt) EP in Dynamical Systems 1 Motivation Figure : Complex
Expectation Propagation in Dynamical Systems Marc Peter Deisenroth Joint Work with Shakir Mohamed (UBC) August 10, 2012 Marc Deisenroth (TU Darmstadt) EP in Dynamical Systems 1 Motivation Figure : Complex
Variational Bayes. A key quantity in Bayesian inference is the marginal likelihood of a set of data D given a model M
 A key quantity in Bayesian inference is the marginal likelihood of a set of data D given a model M PD M = PD θ, MPθ Mdθ Lecture 14 : Variational Bayes where θ are the parameters of the model and Pθ M is
A key quantity in Bayesian inference is the marginal likelihood of a set of data D given a model M PD M = PD θ, MPθ Mdθ Lecture 14 : Variational Bayes where θ are the parameters of the model and Pθ M is
Machine Learning Srihari. Information Theory. Sargur N. Srihari
 Information Theory Sargur N. Srihari 1 Topics 1. Entropy as an Information Measure 1. Discrete variable definition Relationship to Code Length 2. Continuous Variable Differential Entropy 2. Maximum Entropy
Information Theory Sargur N. Srihari 1 Topics 1. Entropy as an Information Measure 1. Discrete variable definition Relationship to Code Length 2. Continuous Variable Differential Entropy 2. Maximum Entropy
Variational Inference. Sargur Srihari
 Variational Inference Sargur srihari@cedar.buffalo.edu 1 Plan of discussion We first describe inference with PGMs and the intractability of exact inference Then give a taxonomy of inference algorithms
Variational Inference Sargur srihari@cedar.buffalo.edu 1 Plan of discussion We first describe inference with PGMs and the intractability of exact inference Then give a taxonomy of inference algorithms
Deterministic Approximation Methods in Bayesian Inference
 Deterministic Approximation Methods in Bayesian Inference Tobias Plötz Department of Computer Science Technical University of Darmstadt 64289 Darmstadt t_ploetz@rbg.informatik.tu-darmstadt.de Abstract
Deterministic Approximation Methods in Bayesian Inference Tobias Plötz Department of Computer Science Technical University of Darmstadt 64289 Darmstadt t_ploetz@rbg.informatik.tu-darmstadt.de Abstract
Expectation Propagation for Approximate Bayesian Inference
 Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
Variational Methods in Bayesian Deconvolution
 PHYSTAT, SLAC, Stanford, California, September 8-, Variational Methods in Bayesian Deconvolution K. Zarb Adami Cavendish Laboratory, University of Cambridge, UK This paper gives an introduction to the
PHYSTAT, SLAC, Stanford, California, September 8-, Variational Methods in Bayesian Deconvolution K. Zarb Adami Cavendish Laboratory, University of Cambridge, UK This paper gives an introduction to the
Principles of DCM. Will Penny. 26th May Principles of DCM. Will Penny. Introduction. Differential Equations. Bayesian Estimation.
 26th May 2011 Dynamic Causal Modelling Dynamic Causal Modelling is a framework studying large scale brain connectivity by fitting differential equation models to brain imaging data. DCMs differ in their
26th May 2011 Dynamic Causal Modelling Dynamic Causal Modelling is a framework studying large scale brain connectivity by fitting differential equation models to brain imaging data. DCMs differ in their
Information Theory in Intelligent Decision Making
 Information Theory in Intelligent Decision Making Adaptive Systems and Algorithms Research Groups School of Computer Science University of Hertfordshire, United Kingdom June 7, 2015 Information Theory
Information Theory in Intelligent Decision Making Adaptive Systems and Algorithms Research Groups School of Computer Science University of Hertfordshire, United Kingdom June 7, 2015 Information Theory
Unsupervised Learning
 Unsupervised Learning Week 1: Introduction, Statistical Basics, and a bit of Information Theory Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent
Unsupervised Learning Week 1: Introduction, Statistical Basics, and a bit of Information Theory Zoubin Ghahramani zoubin@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc in Intelligent
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
Probabilistic Graphical Models Lecture 11 CRFs, Exponential Family CS/CNS/EE 155 Andreas Krause Announcements Homework 2 due today Project milestones due next Monday (Nov 9) About half the work should
G8325: Variational Bayes
 G8325: Variational Bayes Vincent Dorie Columbia University Wednesday, November 2nd, 2011 bridge Variational University Bayes Press 2003. On-screen viewing permitted. Printing not permitted. http://www.c
G8325: Variational Bayes Vincent Dorie Columbia University Wednesday, November 2nd, 2011 bridge Variational University Bayes Press 2003. On-screen viewing permitted. Printing not permitted. http://www.c
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Lecture 13 : Variational Inference: Mean Field Approximation
 10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
10-708: Probabilistic Graphical Models 10-708, Spring 2017 Lecture 13 : Variational Inference: Mean Field Approximation Lecturer: Willie Neiswanger Scribes: Xupeng Tong, Minxing Liu 1 Problem Setup 1.1
IEOR E4570: Machine Learning for OR&FE Spring 2015 c 2015 by Martin Haugh. The EM Algorithm
 IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
IEOR E4570: Machine Learning for OR&FE Spring 205 c 205 by Martin Haugh The EM Algorithm The EM algorithm is used for obtaining maximum likelihood estimates of parameters when some of the data is missing.
Lecture 2: From Linear Regression to Kalman Filter and Beyond
 Lecture 2: From Linear Regression to Kalman Filter and Beyond January 18, 2017 Contents 1 Batch and Recursive Estimation 2 Towards Bayesian Filtering 3 Kalman Filter and Bayesian Filtering and Smoothing
Lecture 2: From Linear Regression to Kalman Filter and Beyond January 18, 2017 Contents 1 Batch and Recursive Estimation 2 Towards Bayesian Filtering 3 Kalman Filter and Bayesian Filtering and Smoothing
U-Likelihood and U-Updating Algorithms: Statistical Inference in Latent Variable Models
 U-Likelihood and U-Updating Algorithms: Statistical Inference in Latent Variable Models Jaemo Sung 1, Sung-Yang Bang 1, Seungjin Choi 1, and Zoubin Ghahramani 2 1 Department of Computer Science, POSTECH,
U-Likelihood and U-Updating Algorithms: Statistical Inference in Latent Variable Models Jaemo Sung 1, Sung-Yang Bang 1, Seungjin Choi 1, and Zoubin Ghahramani 2 1 Department of Computer Science, POSTECH,
Expectation Propagation in Factor Graphs: A Tutorial
 DRAFT: Version 0.1, 28 October 2005. Do not distribute. Expectation Propagation in Factor Graphs: A Tutorial Charles Sutton October 28, 2005 Abstract Expectation propagation is an important variational
DRAFT: Version 0.1, 28 October 2005. Do not distribute. Expectation Propagation in Factor Graphs: A Tutorial Charles Sutton October 28, 2005 Abstract Expectation propagation is an important variational
Machine Learning Techniques for Computer Vision
 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
3. If a choice is broken down into two successive choices, the original H should be the weighted sum of the individual values of H.
 Appendix A Information Theory A.1 Entropy Shannon (Shanon, 1948) developed the concept of entropy to measure the uncertainty of a discrete random variable. Suppose X is a discrete random variable that
Appendix A Information Theory A.1 Entropy Shannon (Shanon, 1948) developed the concept of entropy to measure the uncertainty of a discrete random variable. Suppose X is a discrete random variable that
Bayesian Machine Learning - Lecture 7
 Bayesian Machine Learning - Lecture 7 Guido Sanguinetti Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh gsanguin@inf.ed.ac.uk March 4, 2015 Today s lecture 1
Bayesian Machine Learning - Lecture 7 Guido Sanguinetti Institute for Adaptive and Neural Computation School of Informatics University of Edinburgh gsanguin@inf.ed.ac.uk March 4, 2015 Today s lecture 1
Non-linear Bayesian Image Modelling
 Non-linear Bayesian Image Modelling Christopher M. Bishop 1 and John M. Winn 2 1 Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/
Non-linear Bayesian Image Modelling Christopher M. Bishop 1 and John M. Winn 2 1 Microsoft Research 7 J. J. Thomson Avenue, Cambridge, CB3 0FB, U.K. cmbishop@microsoft.com http://research.microsoft.com/
Graphical models: parameter learning
 Graphical models: parameter learning Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London London WC1N 3AR, England http://www.gatsby.ucl.ac.uk/ zoubin/ zoubin@gatsby.ucl.ac.uk
Graphical models: parameter learning Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London London WC1N 3AR, England http://www.gatsby.ucl.ac.uk/ zoubin/ zoubin@gatsby.ucl.ac.uk
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 9: Expectation Maximiation (EM) Algorithm, Learning in Undirected Graphical Models Some figures courtesy
Probabilistic Graphical Models Brown University CSCI 2950-P, Spring 2013 Prof. Erik Sudderth Lecture 9: Expectation Maximiation (EM) Algorithm, Learning in Undirected Graphical Models Some figures courtesy
Hierarchy. Will Penny. 24th March Hierarchy. Will Penny. Linear Models. Convergence. Nonlinear Models. References
 24th March 2011 Update Hierarchical Model Rao and Ballard (1999) presented a hierarchical model of visual cortex to show how classical and extra-classical Receptive Field (RF) effects could be explained
24th March 2011 Update Hierarchical Model Rao and Ballard (1999) presented a hierarchical model of visual cortex to show how classical and extra-classical Receptive Field (RF) effects could be explained
Probabilistic Graphical Models
 Probabilistic Graphical Models Lecture 9: Variational Inference Relaxations Volkan Cevher, Matthias Seeger Ecole Polytechnique Fédérale de Lausanne 24/10/2011 (EPFL) Graphical Models 24/10/2011 1 / 15
Probabilistic Graphical Models Lecture 9: Variational Inference Relaxations Volkan Cevher, Matthias Seeger Ecole Polytechnique Fédérale de Lausanne 24/10/2011 (EPFL) Graphical Models 24/10/2011 1 / 15
Information Theory. David Rosenberg. June 15, New York University. David Rosenberg (New York University) DS-GA 1003 June 15, / 18
 DS-GA 1003 June 15, / 18") Information Theory David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 18 A Measure of Information? Consider a discrete random variable
Information Theory David Rosenberg New York University June 15, 2015 David Rosenberg (New York University) DS-GA 1003 June 15, 2015 1 / 18 A Measure of Information? Consider a discrete random variable
Phase Diagram Study on Variational Bayes Learning of Bernoulli Mixture
 009 Technical Report on Information-Based Induction Sciences 009 (IBIS009) Phase Diagram Study on Variational Bayes Learning of Bernoulli Mixture Daisue Kaji Sumio Watanabe Abstract: Variational Bayes
009 Technical Report on Information-Based Induction Sciences 009 (IBIS009) Phase Diagram Study on Variational Bayes Learning of Bernoulli Mixture Daisue Kaji Sumio Watanabe Abstract: Variational Bayes
The Minimum Message Length Principle for Inductive Inference
 The Principle for Inductive Inference Centre for Molecular, Environmental, Genetic & Analytic (MEGA) Epidemiology School of Population Health University of Melbourne University of Helsinki, August 25,
The Principle for Inductive Inference Centre for Molecular, Environmental, Genetic & Analytic (MEGA) Epidemiology School of Population Health University of Melbourne University of Helsinki, August 25,
Statistical Approaches to Learning and Discovery
 Statistical Approaches to Learning and Discovery Bayesian Model Selection Zoubin Ghahramani & Teddy Seidenfeld zoubin@cs.cmu.edu & teddy@stat.cmu.edu CALD / CS / Statistics / Philosophy Carnegie Mellon
Statistical Approaches to Learning and Discovery Bayesian Model Selection Zoubin Ghahramani & Teddy Seidenfeld zoubin@cs.cmu.edu & teddy@stat.cmu.edu CALD / CS / Statistics / Philosophy Carnegie Mellon
an introduction to bayesian inference
 with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
with an application to network analysis http://jakehofman.com january 13, 2010 motivation would like models that: provide predictive and explanatory power are complex enough to describe observed phenomena
Probabilistic Graphical Models Lecture 17: Markov chain Monte Carlo
 Probabilistic Graphical Models Lecture 17: Markov chain Monte Carlo Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 18, 2015 1 / 45 Resources and Attribution Image credits,
Probabilistic Graphical Models Lecture 17: Markov chain Monte Carlo Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 18, 2015 1 / 45 Resources and Attribution Image credits,
Stochastic Variational Inference
 Stochastic Variational Inference David M. Blei Princeton University (DRAFT: DO NOT CITE) December 8, 2011 We derive a stochastic optimization algorithm for mean field variational inference, which we call
Stochastic Variational Inference David M. Blei Princeton University (DRAFT: DO NOT CITE) December 8, 2011 We derive a stochastic optimization algorithm for mean field variational inference, which we call
Non-conjugate Variational Message Passing for Multinomial and Binary Regression
 Non-conjugate Variational Message Passing for Multinomial and Binary Regression David A. Knowles Department of Engineering University of Cambridge Thomas P. Minka Microsoft Research Cambridge, UK Abstract
Non-conjugate Variational Message Passing for Multinomial and Binary Regression David A. Knowles Department of Engineering University of Cambridge Thomas P. Minka Microsoft Research Cambridge, UK Abstract
PROBABILITY AND INFORMATION THEORY. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 PROBABILITY AND INFORMATION THEORY Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Probability space Rules of probability
PROBABILITY AND INFORMATION THEORY Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Probability space Rules of probability
Expectation Maximization
 Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
Variational Inference (11/04/13)
") STA561: Probabilistic machine learning Variational Inference (11/04/13) Lecturer: Barbara Engelhardt Scribes: Matt Dickenson, Alireza Samany, Tracy Schifeling 1 Introduction In this lecture we will further
STA561: Probabilistic machine learning Variational Inference (11/04/13) Lecturer: Barbara Engelhardt Scribes: Matt Dickenson, Alireza Samany, Tracy Schifeling 1 Introduction In this lecture we will further
Cheng Soon Ong & Christian Walder. Canberra February June 2017
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2017 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 679 Part XIX
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2017 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 679 Part XIX
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Information Theory. Coding and Information Theory. Information Theory Textbooks. Entropy
 Coding and Information Theory Chris Williams, School of Informatics, University of Edinburgh Overview What is information theory? Entropy Coding Information Theory Shannon (1948): Information theory is
Coding and Information Theory Chris Williams, School of Informatics, University of Edinburgh Overview What is information theory? Entropy Coding Information Theory Shannon (1948): Information theory is
Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures
 17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
17th Europ. Conf. on Machine Learning, Berlin, Germany, 2006. Variational Bayesian Dirichlet-Multinomial Allocation for Exponential Family Mixtures Shipeng Yu 1,2, Kai Yu 2, Volker Tresp 2, and Hans-Peter
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Latent Variable Models and EM algorithm
 Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Learning with Noisy Labels. Kate Niehaus Reading group 11-Feb-2014
 Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Variational inference in the conjugate-exponential family
 Variational inference in the conjugate-exponential family Matthew J. Beal Work with Zoubin Ghahramani Gatsby Computational Neuroscience Unit August 2000 Abstract Variational inference in the conjugate-exponential
Variational inference in the conjugate-exponential family Matthew J. Beal Work with Zoubin Ghahramani Gatsby Computational Neuroscience Unit August 2000 Abstract Variational inference in the conjugate-exponential
Lecture 1a: Basic Concepts and Recaps
 Lecture 1a: Basic Concepts and Recaps Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced
Lecture 1a: Basic Concepts and Recaps Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced
Lecture 1b: Linear Models for Regression
 Lecture 1b: Linear Models for Regression Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced
Lecture 1b: Linear Models for Regression Cédric Archambeau Centre for Computational Statistics and Machine Learning Department of Computer Science University College London c.archambeau@cs.ucl.ac.uk Advanced
The Expectation-Maximization Algorithm
 1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
1/29 EM & Latent Variable Models Gaussian Mixture Models EM Theory The Expectation-Maximization Algorithm Mihaela van der Schaar Department of Engineering Science University of Oxford MLE for Latent Variable
Information Theory Primer:
 Information Theory Primer: Entropy, KL Divergence, Mutual Information, Jensen s inequality Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
Information Theory Primer: Entropy, KL Divergence, Mutual Information, Jensen s inequality Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro,
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Variational Learning : From exponential families to multilinear systems
 Variational Learning : From exponential families to multilinear systems Ananth Ranganathan th February 005 Abstract This note aims to give a general overview of variational inference on graphical models.
Variational Learning : From exponential families to multilinear systems Ananth Ranganathan th February 005 Abstract This note aims to give a general overview of variational inference on graphical models.
Probabilistic and Bayesian Machine Learning
 Probabilistic and Bayesian Machine Learning Lecture 1: Introduction to Probabilistic Modelling Yee Whye Teh ywteh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London Why a
Probabilistic and Bayesian Machine Learning Lecture 1: Introduction to Probabilistic Modelling Yee Whye Teh ywteh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit University College London Why a
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Widths. Center Fluctuations. Centers. Centers. Widths
 Radial Basis Functions: a Bayesian treatment David Barber Bernhard Schottky Neural Computing Research Group Department of Applied Mathematics and Computer Science Aston University, Birmingham B4 7ET, U.K.
Radial Basis Functions: a Bayesian treatment David Barber Bernhard Schottky Neural Computing Research Group Department of Applied Mathematics and Computer Science Aston University, Birmingham B4 7ET, U.K.
Lecture 2: From Linear Regression to Kalman Filter and Beyond
 Lecture 2: From Linear Regression to Kalman Filter and Beyond Department of Biomedical Engineering and Computational Science Aalto University January 26, 2012 Contents 1 Batch and Recursive Estimation
Lecture 2: From Linear Regression to Kalman Filter and Beyond Department of Biomedical Engineering and Computational Science Aalto University January 26, 2012 Contents 1 Batch and Recursive Estimation
Lecture 6: Model Checking and Selection
 Lecture 6: Model Checking and Selection Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 27, 2014 Model selection We often have multiple modeling choices that are equally sensible: M 1,, M T. Which
Lecture 6: Model Checking and Selection Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 27, 2014 Model selection We often have multiple modeling choices that are equally sensible: M 1,, M T. Which
Large-scale Ordinal Collaborative Filtering
 Large-scale Ordinal Collaborative Filtering Ulrich Paquet, Blaise Thomson, and Ole Winther Microsoft Research Cambridge, University of Cambridge, Technical University of Denmark ulripa@microsoft.com,brmt2@cam.ac.uk,owi@imm.dtu.dk
Large-scale Ordinal Collaborative Filtering Ulrich Paquet, Blaise Thomson, and Ole Winther Microsoft Research Cambridge, University of Cambridge, Technical University of Denmark ulripa@microsoft.com,brmt2@cam.ac.uk,owi@imm.dtu.dk
Bioinformatics: Biology X
 Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA Model Building/Checking, Reverse Engineering, Causality Outline 1 Bayesian Interpretation of Probabilities 2 Where (or of what)
Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA Model Building/Checking, Reverse Engineering, Causality Outline 1 Bayesian Interpretation of Probabilities 2 Where (or of what)
NONLINEAR INDEPENDENT FACTOR ANALYSIS BY HIERARCHICAL MODELS
 NONLINEAR INDEPENDENT FACTOR ANALYSIS BY HIERARCHICAL MODELS Harri Valpola, Tomas Östman and Juha Karhunen Helsinki University of Technology, Neural Networks Research Centre P.O. Box 5400, FIN-02015 HUT,
NONLINEAR INDEPENDENT FACTOR ANALYSIS BY HIERARCHICAL MODELS Harri Valpola, Tomas Östman and Juha Karhunen Helsinki University of Technology, Neural Networks Research Centre P.O. Box 5400, FIN-02015 HUT,
First Technical Course, European Centre for Soft Computing, Mieres, Spain. 4th July 2011
 First Technical Course, European Centre for Soft Computing, Mieres, Spain. 4th July 2011 Linear Given probabilities p(a), p(b), and the joint probability p(a, B), we can write the conditional probabilities
First Technical Course, European Centre for Soft Computing, Mieres, Spain. 4th July 2011 Linear Given probabilities p(a), p(b), and the joint probability p(a, B), we can write the conditional probabilities
Bayesian Hidden Markov Models and Extensions
 Bayesian Hidden Markov Models and Extensions Zoubin Ghahramani Department of Engineering University of Cambridge joint work with Matt Beal, Jurgen van Gael, Yunus Saatci, Tom Stepleton, Yee Whye Teh Modeling
Bayesian Hidden Markov Models and Extensions Zoubin Ghahramani Department of Engineering University of Cambridge joint work with Matt Beal, Jurgen van Gael, Yunus Saatci, Tom Stepleton, Yee Whye Teh Modeling
Integrated Non-Factorized Variational Inference
 Integrated Non-Factorized Variational Inference Shaobo Han, Xuejun Liao and Lawrence Carin Duke University February 27, 2014 S. Han et al. Integrated Non-Factorized Variational Inference February 27, 2014
Integrated Non-Factorized Variational Inference Shaobo Han, Xuejun Liao and Lawrence Carin Duke University February 27, 2014 S. Han et al. Integrated Non-Factorized Variational Inference February 27, 2014
Quantitative Biology II Lecture 4: Variational Methods
 10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
10 th March 2015 Quantitative Biology II Lecture 4: Variational Methods Gurinder Singh Mickey Atwal Center for Quantitative Biology Cold Spring Harbor Laboratory Image credit: Mike West Summary Approximate
COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017
 COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University SOFT CLUSTERING VS HARD CLUSTERING
COMS 4721: Machine Learning for Data Science Lecture 16, 3/28/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University SOFT CLUSTERING VS HARD CLUSTERING
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 305 Part VII
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 (Many figures from C. M. Bishop, "Pattern Recognition and ") 1of 305 Part VII
Active and Semi-supervised Kernel Classification
 Active and Semi-supervised Kernel Classification Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London Work done in collaboration with Xiaojin Zhu (CMU), John Lafferty (CMU),
Active and Semi-supervised Kernel Classification Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London Work done in collaboration with Xiaojin Zhu (CMU), John Lafferty (CMU),