Will Penny. SPM short course for M/EEG, London 2013
|
|
|
- Phyllis Floyd
- 5 years ago
- Views:
Transcription
1 SPM short course for M/EEG, London 2013
2 Ten Simple Rules Stephan et al. Neuroimage, 2010
3 Model Structure
4 Bayes rule for models A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule p(m y) = p(y m)p(m) p(y) where p(y m) is referred to as the evidence for model m and the denominator is given by p(y) = m p(y m )p(m )
5 Bayes Factors The Bayes factor for model j versus i is the ratio of model evidences p(y m = j) B ji = p(y m = i) We have B ij = 1 B ji
6 Posterior Model Probability Given equal priors, p(m = i) = p(m = j) the posterior model probability is p(m = i y) = = = = = p(y m = i) p(y m = i) + p(y m = j) p(y m=j) p(y m=i) B ji exp(log B ji ) exp( log B ij )
7 Posterior Model Probability Hence p(m = i y) = σ(log B ij ) where is the Bayes factor for model i versus model j and σ(x) = is the sigmoid function exp( x)
8 The posterior model probability is a sigmoidal function of the log Bayes factor p(m = i y) = σ(log B ij )
9 The posterior model probability is a sigmoidal function of the log Bayes factor p(m = i y) = σ(log B ij ) Kass and Raftery, JASA, 1995.
10 Odds Ratios If we don t have uniform priors one can work with odds ratios. The prior and posterior odds ratios are defined as π 0 ij = π ij = p(m = i) p(m = j) p(m = i y) p(m = j y) resepectively, and are related by the Bayes Factor π ij = B ij π 0 ij eg. priors odds of 2 and Bayes factor of 10 leads posterior odds of 20. An odds ratio of 20 is 20-1 ON in bookmakers parlance.
11 Model Evidence The model evidence is not, in general, straightforward to compute since computing it involves integrating out the dependence on model parameters p(y m) = p(y, θ m)dθ = p(y θ, m)p(θ m)dθ Because we have marginalised over θ the evidence is also known as the marginal likelihood. But for linear, Gaussian models there is an analytic solution.
12 For y = Xw + e where X is a design matrix and w are now regression coefficients. For prior mean µ w, prior covariance C w, observation noise covariance C y the posterior distribution is given by S 1 w = X T Cy 1 X + Cw 1 ( ) m w = S w X T Cy 1 y + Cw 1 µ w
13 Parameter
14 Structure
15 Model Evidence The log model evidence comprises sum squared precision weighted prediction errors and Occam factors log p(y m) = 1 2 et y Cy 1 e y 1 2 log C y N y et wcw 1 e w 1 2 log C w S w log 2π where prediction errors are the difference between what is expected and what is observed e y = y Xm w e w = m w µ w Bishop, Pattern Recognition and Machine Learning, 2006
16 Accuracy and The log evidence for model m can be split into an accuracy and a complexity term where and log p(y m) = Accuracy(m) (m) Accuracy(m) = 1 2 et y Cy 1 e y 1 2 log C y N y log 2π 2 (m) = 1 2 et wcw 1 e w log C w S w KL(prior posterior)
17 Small KL
18 Medium KL
19 Big KL
20 For nonlinear models, we replace the true posterior with the approximate posterior (m w, S w ), and the previous expression becomes an approximation to the log model evidence called the (negative) Free Energy where F = 1 2 et y Cy 1 e y 1 2 log C y N y et wcw 1 e w 1 2 log C w S w e y = y g(m w ) e w = m w µ w log 2π and g(m w ) is the DCM prediction. This is used to approximate the model evidence for DCMs. Penny, Neuroimage, 2011.
21 Bayes rule for models A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule p(m y) = p(y m)p(m) p(y)
22
. The probability for any single model can become very small esp.")
23 Posterior Model Probabilities Say we ve fitted 8 DCMs and get the following distribution over models Similar models share probability mass (dilution). The probability for any single model can become very small esp. for large model spaces.

24 Model Assign model m to family f eg. first four to family one, second four to family two. The posterior family probability is then p(f y) = m S f p(m y)
25 Different Sized If we have K families, then to avoid bias in family inference we wish to have a uniform prior at the family level p(f ) = 1 K The prior family probability is related to the prior model probability p(f ) = m S f p(m) where the sum is over all N f models in family f. So we set p(m) = 1 KN f for all models in family f before computing p(m y). This allows us to have families with unequal numbers of models. Penny et al. PLOS-CB, 2010.
26 Different Sized So say we have two families. We want a prior for each family of p(f ) = 0.5. If family one has N 1 = 2 models and family two has N 2 = 8 models, then we set p(m) = = 0.25 for all models in family one and for all models in family two. p(m) = = These are then used in Bayes rule for models p(m y) = p(y m)p(m) p(y)
27
28 Each DCM.mat file stores the posterior mean (DCM.Ep) and covariance (DCM.Cp) for each fitted model. This defines the posterior mean over parameters for that model, p(θ m, y). This can then be combined with the posterior model probabilities p(m y) to compute a posterior over parameters p(θ y) = m = m p(θ, m y) p(θ m, y)p(m y) which is independent of model assumptions (within the chosen set). Here, we marginalise over m. The sum over m could be restricted to eg. models within the winning family.
29 The distribution p(θ y) can be gotten by sampling; sample m from p(m y), then sample θ from p(θ m, y). If a connection doesn t exist for model m the relevant samples are set to zero.
30 Group Parameter If ith subject has posterior mean value m i we can use these in Summary Statistic approach for group parameter inference (eg two-sample t-tests for control versus patient inferences). eg P to A connection in controls: 0.20, 0.12, 0.32, 0.11, 0.01,... eg P to A connection in patients: 0.50, 0.42, 0.22, 0.71, 0.31,... Two sample t-test shows the P to A connection is stronger in patients than controls (p < 0.05).
31 Fixed Effects BMS
32 Fixed Effects BMS Two models, twenty subjects. log p(y m) = N log p(y n m) n=1 The Group Bayes Factor (GBF) is B ij = N Bij(n)
33 Random Effects BMS
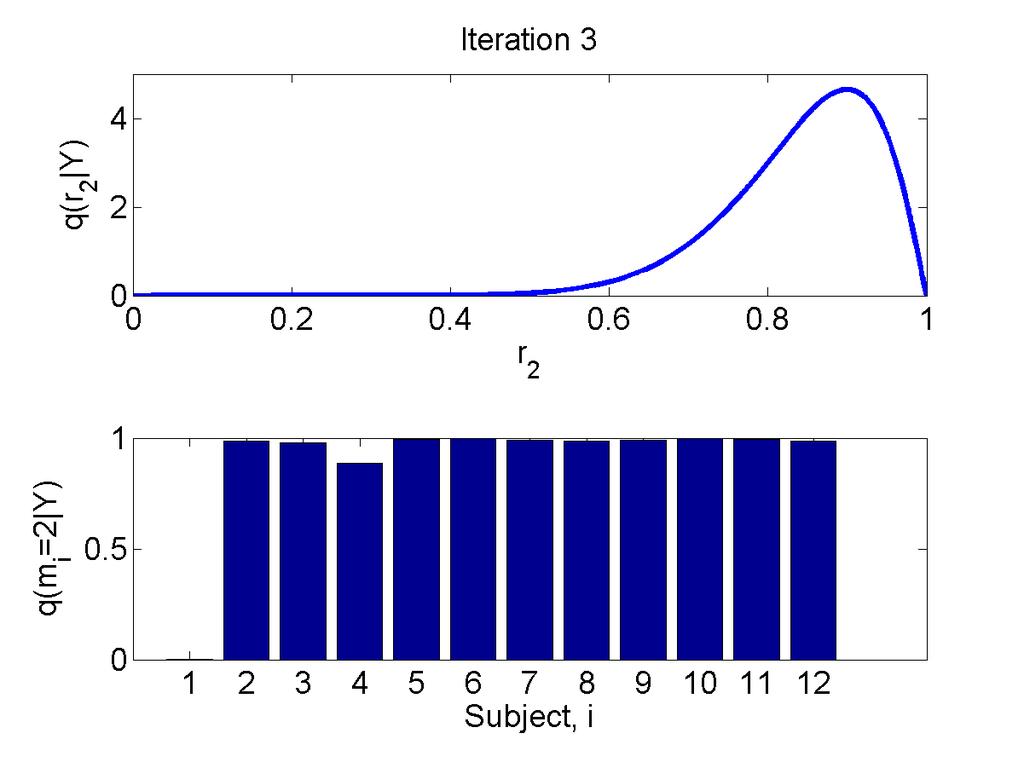
34 Random Effects BMS Stephan et al. J. Neurosci, /12=92% subjects favour model 2. GBF = 15 in favour of model 1. FFX inference does not agree with the majority of subjects.
35 Log Bayes Factor in favour of model 2 log p(y i m i = 2) p(y i m i = 1)
36 Model frequencies r k, model assignments m i, subject data y i. Approximate posterior q(r, m Y ) = q(r Y )q(m Y ) Stephan et al, Neuroimage, 2009.
37
38
39
40
41
42 Random Effects 11/12=92% subjects favoured model 2. E[r 2 Y ] = 0.84 p(r 2 > r 1 Y ) = 0.99 where the latter is called the exceedance probability.
43 Dependence on Comparison Set The ranking of models from RFX inference can depend on the comparison set. Say we have two models with 7 subjects prefering model 1 and 10 ten subjects preferring model 2. The model frequencies are r 1 = 7/17 = 0.41 and r 2 = 10/17 = Now say we add a third model which is similar to the second, and that 4 of the subjects that used to prefer model 2 now prefer model 3. The model frequencies are now r 1 = 7/17 = 0.41, r 2 = 6/17 = 0.35 and r 3 = 4/17 = This is like voting in elections. Penny et al. PLOS-CB, 2010.
44 Bayesian Parameter
45 Bayesian Parameter If for the ith subject the posterior mean and precision are µ i and Λ i Three subjects shown.
46 Bayesian Parameter If for the ith subject the posterior mean and precision are µ i and Λ i then the posterior mean and precision for the group are Λ = N i=1 Λ i N µ = Λ 1 Λ i µ i i=1 Kasses et al, Neuroimage, This is a FFX analysis where each subject adds to the posterior precision.
47 Bayesian Parameter Λ = N i=1 Λ i N µ = Λ 1 Λ i µ i i=1
48 Informative Priors If for the ith subject the posterior mean and precision are µ i and Λ i then the posterior mean and precision for the group are Λ = N Λ i (N 1)Λ 0 i=1 ( N ) µ = Λ 1 Λ i µ i (N 1)Λ 0 µ 0 i=1 Formulae augmented to accomodate non-zero priors Λ 0 and µ 0.
49
50 If ith subject has posterior mean value m i we can use these in Summary Statistic approach for group parameter inference (eg two-sample t-tests for control versus patient inferences). eg P to A connection in controls: 0.20, 0.12, 0.32, 0.11, 0.01,... eg P to A connection in patients: 0.50, 0.42, 0.22, 0.71, 0.31,... Two sample t-test shows the P to A connection is stronger in patients than controls (p < 0.05). Or one sample t-tests if we have a single group. RFX is more conservative than BPA.
51 C. Bishop (2006) Pattern Recognition and Machine Learning. Springer. A. Gelman et al. (1995) Bayesian Data Analysis. Chapman and Hall. W. Penny (2011) Comparing Dynamic Causal Models using AIC, BIC and Free Energy. Neuroimage Available online 27 July W. Penny et al (2010) Comparing of Dynamic Causal Models. PLoS CB, 6(3). A Raftery (1995) Bayesian model selection in social research. In Marsden, P (Ed) Sociological Methodology, , Cambridge. K Stephan et al (2009). Bayesian model selection for group studies. Neuroimage, 46(4):
Will Penny. DCM short course, Paris 2012
 DCM short course, Paris 2012 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure Bayes rule for models A prior distribution over model space p(m) (or hypothesis space ) can be updated to a
DCM short course, Paris 2012 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure Bayes rule for models A prior distribution over model space p(m) (or hypothesis space ) can be updated to a
Will Penny. SPM short course for M/EEG, London 2015
 SPM short course for M/EEG, London 2015 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure The model evidence is given by integrating out the dependence on model parameters p(y m) = p(y,
SPM short course for M/EEG, London 2015 Ten Simple Rules Stephan et al. Neuroimage, 2010 Model Structure The model evidence is given by integrating out the dependence on model parameters p(y m) = p(y,
Will Penny. SPM for MEG/EEG, 15th May 2012
 SPM for MEG/EEG, 15th May 2012 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule
SPM for MEG/EEG, 15th May 2012 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule
Model Comparison. Course on Bayesian Inference, WTCN, UCL, February Model Comparison. Bayes rule for models. Linear Models. AIC and BIC.
 Course on Bayesian Inference, WTCN, UCL, February 2013 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented
Course on Bayesian Inference, WTCN, UCL, February 2013 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented
A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y.
 (or hypothesis space ) can be updated to a posterior distribution after observing data y.") June 2nd 2011 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule p(m y) = p(y m)p(m)
June 2nd 2011 A prior distribution over model space p(m) (or hypothesis space ) can be updated to a posterior distribution after observing data y. This is implemented using Bayes rule p(m y) = p(y m)p(m)
Wellcome Trust Centre for Neuroimaging, UCL, UK.
 Bayesian Inference Will Penny Wellcome Trust Centre for Neuroimaging, UCL, UK. SPM Course, Virginia Tech, January 2012 What is Bayesian Inference? (From Daniel Wolpert) Bayesian segmentation and normalisation
Bayesian Inference Will Penny Wellcome Trust Centre for Neuroimaging, UCL, UK. SPM Course, Virginia Tech, January 2012 What is Bayesian Inference? (From Daniel Wolpert) Bayesian segmentation and normalisation
Bayesian Inference Course, WTCN, UCL, March 2013
 Bayesian Course, WTCN, UCL, March 2013 Shannon (1948) asked how much information is received when we observe a specific value of the variable x? If an unlikely event occurs then one would expect the information
Bayesian Course, WTCN, UCL, March 2013 Shannon (1948) asked how much information is received when we observe a specific value of the variable x? If an unlikely event occurs then one would expect the information
Lecture 6: Model Checking and Selection
 Lecture 6: Model Checking and Selection Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 27, 2014 Model selection We often have multiple modeling choices that are equally sensible: M 1,, M T. Which
Lecture 6: Model Checking and Selection Melih Kandemir melih.kandemir@iwr.uni-heidelberg.de May 27, 2014 Model selection We often have multiple modeling choices that are equally sensible: M 1,, M T. Which
Bayesian inference. Justin Chumbley ETH and UZH. (Thanks to Jean Denizeau for slides)
") Bayesian inference Justin Chumbley ETH and UZH (Thanks to Jean Denizeau for slides) Overview of the talk Introduction: Bayesian inference Bayesian model comparison Group-level Bayesian model selection
Bayesian inference Justin Chumbley ETH and UZH (Thanks to Jean Denizeau for slides) Overview of the talk Introduction: Bayesian inference Bayesian model comparison Group-level Bayesian model selection
David Giles Bayesian Econometrics
 9. Model Selection - Theory David Giles Bayesian Econometrics One nice feature of the Bayesian analysis is that we can apply it to drawing inferences about entire models, not just parameters. Can't do
9. Model Selection - Theory David Giles Bayesian Econometrics One nice feature of the Bayesian analysis is that we can apply it to drawing inferences about entire models, not just parameters. Can't do
Bayesian Inference for the Multivariate Normal
 Bayesian Inference for the Multivariate Normal Will Penny Wellcome Trust Centre for Neuroimaging, University College, London WC1N 3BG, UK. November 28, 2014 Abstract Bayesian inference for the multivariate
Bayesian Inference for the Multivariate Normal Will Penny Wellcome Trust Centre for Neuroimaging, University College, London WC1N 3BG, UK. November 28, 2014 Abstract Bayesian inference for the multivariate
7. Estimation and hypothesis testing. Objective. Recommended reading
 7. Estimation and hypothesis testing Objective In this chapter, we show how the election of estimators can be represented as a decision problem. Secondly, we consider the problem of hypothesis testing
7. Estimation and hypothesis testing Objective In this chapter, we show how the election of estimators can be represented as a decision problem. Secondly, we consider the problem of hypothesis testing
SCUOLA DI SPECIALIZZAZIONE IN FISICA MEDICA. Sistemi di Elaborazione dell Informazione. Regressione. Ruggero Donida Labati
 SCUOLA DI SPECIALIZZAZIONE IN FISICA MEDICA Sistemi di Elaborazione dell Informazione Regressione Ruggero Donida Labati Dipartimento di Informatica via Bramante 65, 26013 Crema (CR), Italy http://homes.di.unimi.it/donida
SCUOLA DI SPECIALIZZAZIONE IN FISICA MEDICA Sistemi di Elaborazione dell Informazione Regressione Ruggero Donida Labati Dipartimento di Informatica via Bramante 65, 26013 Crema (CR), Italy http://homes.di.unimi.it/donida
First Technical Course, European Centre for Soft Computing, Mieres, Spain. 4th July 2011
 First Technical Course, European Centre for Soft Computing, Mieres, Spain. 4th July 2011 Linear Given probabilities p(a), p(b), and the joint probability p(a, B), we can write the conditional probabilities
First Technical Course, European Centre for Soft Computing, Mieres, Spain. 4th July 2011 Linear Given probabilities p(a), p(b), and the joint probability p(a, B), we can write the conditional probabilities
Expectation Propagation for Approximate Bayesian Inference
 Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
Expectation Propagation for Approximate Bayesian Inference José Miguel Hernández Lobato Universidad Autónoma de Madrid, Computer Science Department February 5, 2007 1/ 24 Bayesian Inference Inference Given
How to build an automatic statistician
 How to build an automatic statistician James Robert Lloyd 1, David Duvenaud 1, Roger Grosse 2, Joshua Tenenbaum 2, Zoubin Ghahramani 1 1: Department of Engineering, University of Cambridge, UK 2: Massachusetts
How to build an automatic statistician James Robert Lloyd 1, David Duvenaud 1, Roger Grosse 2, Joshua Tenenbaum 2, Zoubin Ghahramani 1 1: Department of Engineering, University of Cambridge, UK 2: Massachusetts
An introduction to Bayesian inference and model comparison J. Daunizeau
 An introduction to Bayesian inference and model comparison J. Daunizeau ICM, Paris, France TNU, Zurich, Switzerland Overview of the talk An introduction to probabilistic modelling Bayesian model comparison
An introduction to Bayesian inference and model comparison J. Daunizeau ICM, Paris, France TNU, Zurich, Switzerland Overview of the talk An introduction to probabilistic modelling Bayesian model comparison
Bayesian Inference. Chris Mathys Wellcome Trust Centre for Neuroimaging UCL. London SPM Course
 Bayesian Inference Chris Mathys Wellcome Trust Centre for Neuroimaging UCL London SPM Course Thanks to Jean Daunizeau and Jérémie Mattout for previous versions of this talk A spectacular piece of information
Bayesian Inference Chris Mathys Wellcome Trust Centre for Neuroimaging UCL London SPM Course Thanks to Jean Daunizeau and Jérémie Mattout for previous versions of this talk A spectacular piece of information
Bayesian inference J. Daunizeau
 Bayesian inference J. Daunizeau Brain and Spine Institute, Paris, France Wellcome Trust Centre for Neuroimaging, London, UK Overview of the talk 1 Probabilistic modelling and representation of uncertainty
Bayesian inference J. Daunizeau Brain and Spine Institute, Paris, France Wellcome Trust Centre for Neuroimaging, London, UK Overview of the talk 1 Probabilistic modelling and representation of uncertainty
Bayesian model selection: methodology, computation and applications
 Bayesian model selection: methodology, computation and applications David Nott Department of Statistics and Applied Probability National University of Singapore Statistical Genomics Summer School Program
Bayesian model selection: methodology, computation and applications David Nott Department of Statistics and Applied Probability National University of Singapore Statistical Genomics Summer School Program
Principles of DCM. Will Penny. 26th May Principles of DCM. Will Penny. Introduction. Differential Equations. Bayesian Estimation.
 26th May 2011 Dynamic Causal Modelling Dynamic Causal Modelling is a framework studying large scale brain connectivity by fitting differential equation models to brain imaging data. DCMs differ in their
26th May 2011 Dynamic Causal Modelling Dynamic Causal Modelling is a framework studying large scale brain connectivity by fitting differential equation models to brain imaging data. DCMs differ in their
Bayesian inference J. Daunizeau
 Bayesian inference J. Daunizeau Brain and Spine Institute, Paris, France Wellcome Trust Centre for Neuroimaging, London, UK Overview of the talk 1 Probabilistic modelling and representation of uncertainty
Bayesian inference J. Daunizeau Brain and Spine Institute, Paris, France Wellcome Trust Centre for Neuroimaging, London, UK Overview of the talk 1 Probabilistic modelling and representation of uncertainty
DCM: Advanced topics. Klaas Enno Stephan. SPM Course Zurich 06 February 2015
 DCM: Advanced topics Klaas Enno Stephan SPM Course Zurich 06 February 205 Overview DCM a generative model Evolution of DCM for fmri Bayesian model selection (BMS) Translational Neuromodeling Generative
DCM: Advanced topics Klaas Enno Stephan SPM Course Zurich 06 February 205 Overview DCM a generative model Evolution of DCM for fmri Bayesian model selection (BMS) Translational Neuromodeling Generative
Dynamic Causal Models
 Dynamic Causal Models V1 SPC Will Penny V1 SPC V5 V5 Olivier David, Karl Friston, Lee Harrison, Andrea Mechelli, Klaas Stephan Wellcome Department of Imaging Neuroscience, ION, UCL, UK. Mathematics in
Dynamic Causal Models V1 SPC Will Penny V1 SPC V5 V5 Olivier David, Karl Friston, Lee Harrison, Andrea Mechelli, Klaas Stephan Wellcome Department of Imaging Neuroscience, ION, UCL, UK. Mathematics in
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Overview. Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation
 Overview Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation Probabilistic Interpretation: Linear Regression Assume output y is generated
Overview Probabilistic Interpretation of Linear Regression Maximum Likelihood Estimation Bayesian Estimation MAP Estimation Probabilistic Interpretation: Linear Regression Assume output y is generated
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Dynamic Causal Modelling for EEG and MEG. Stefan Kiebel
 Dynamic Causal Modelling for EEG and MEG Stefan Kiebel Overview 1 M/EEG analysis 2 Dynamic Causal Modelling Motivation 3 Dynamic Causal Modelling Generative model 4 Bayesian inference 5 Applications Overview
Dynamic Causal Modelling for EEG and MEG Stefan Kiebel Overview 1 M/EEG analysis 2 Dynamic Causal Modelling Motivation 3 Dynamic Causal Modelling Generative model 4 Bayesian inference 5 Applications Overview
σ(a) = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =
 = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =") Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 3 Stochastic Gradients, Bayesian Inference, and Occam s Razor https://people.orie.cornell.edu/andrew/orie6741 Cornell University August
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 3 Stochastic Gradients, Bayesian Inference, and Occam s Razor https://people.orie.cornell.edu/andrew/orie6741 Cornell University August
Lecture 2: From Linear Regression to Kalman Filter and Beyond
 Lecture 2: From Linear Regression to Kalman Filter and Beyond January 18, 2017 Contents 1 Batch and Recursive Estimation 2 Towards Bayesian Filtering 3 Kalman Filter and Bayesian Filtering and Smoothing
Lecture 2: From Linear Regression to Kalman Filter and Beyond January 18, 2017 Contents 1 Batch and Recursive Estimation 2 Towards Bayesian Filtering 3 Kalman Filter and Bayesian Filtering and Smoothing
Lecture 2: From Linear Regression to Kalman Filter and Beyond
 Lecture 2: From Linear Regression to Kalman Filter and Beyond Department of Biomedical Engineering and Computational Science Aalto University January 26, 2012 Contents 1 Batch and Recursive Estimation
Lecture 2: From Linear Regression to Kalman Filter and Beyond Department of Biomedical Engineering and Computational Science Aalto University January 26, 2012 Contents 1 Batch and Recursive Estimation
Multivariate Bayesian Linear Regression MLAI Lecture 11
 Multivariate Bayesian Linear Regression MLAI Lecture 11 Neil D. Lawrence Department of Computer Science Sheffield University 21st October 2012 Outline Univariate Bayesian Linear Regression Multivariate
Multivariate Bayesian Linear Regression MLAI Lecture 11 Neil D. Lawrence Department of Computer Science Sheffield University 21st October 2012 Outline Univariate Bayesian Linear Regression Multivariate
Bayesian Learning. HT2015: SC4 Statistical Data Mining and Machine Learning. Maximum Likelihood Principle. The Bayesian Learning Framework
 HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
HT5: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Maximum Likelihood Principle A generative model for
Chapter 35: Bayesian model selection and averaging
 Chapter 35: Bayesian model selection and averaging W.D. Penny, J.Mattout and N. Trujillo-Barreto May 10, 2006 Introduction In Chapter 11 we described how Bayesian inference can be applied to hierarchical
Chapter 35: Bayesian model selection and averaging W.D. Penny, J.Mattout and N. Trujillo-Barreto May 10, 2006 Introduction In Chapter 11 we described how Bayesian inference can be applied to hierarchical
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Lecture 4: Probabilistic Learning. Estimation Theory. Classification with Probability Distributions
 DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
Approximate Inference using MCMC
 Approximate Inference using MCMC 9.520 Class 22 Ruslan Salakhutdinov BCS and CSAIL, MIT 1 Plan 1. Introduction/Notation. 2. Examples of successful Bayesian models. 3. Basic Sampling Algorithms. 4. Markov
Approximate Inference using MCMC 9.520 Class 22 Ruslan Salakhutdinov BCS and CSAIL, MIT 1 Plan 1. Introduction/Notation. 2. Examples of successful Bayesian models. 3. Basic Sampling Algorithms. 4. Markov
Bayesian Inference in Neural Networks
 1 Bayesian Inference in Neural Networks Bayesian Inference in Neural Networks Robert L. Paige Saturday, January 12, 2002 with Ronald W. Butler, Colorado State University Biometrika (2001) Vol. 88, Issue
1 Bayesian Inference in Neural Networks Bayesian Inference in Neural Networks Robert L. Paige Saturday, January 12, 2002 with Ronald W. Butler, Colorado State University Biometrika (2001) Vol. 88, Issue
Comparing Families of Dynamic Causal Models
 Comparing Families of Dynamic Causal Models Will D. Penny 1 *, Klaas E. Stephan 1,2, Jean Daunizeau 1, Maria J. Rosa 1, Karl J. Friston 1, Thomas M. Schofield 1, Alex P. Leff 1 1 Wellcome Trust Centre
Comparing Families of Dynamic Causal Models Will D. Penny 1 *, Klaas E. Stephan 1,2, Jean Daunizeau 1, Maria J. Rosa 1, Karl J. Friston 1, Thomas M. Schofield 1, Alex P. Leff 1 1 Wellcome Trust Centre
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA
 PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA Contents in latter part Linear Dynamical Systems What is different from HMM? Kalman filter Its strength and limitation Particle Filter
PATTERN RECOGNITION AND MACHINE LEARNING CHAPTER 13: SEQUENTIAL DATA Contents in latter part Linear Dynamical Systems What is different from HMM? Kalman filter Its strength and limitation Particle Filter
GWAS IV: Bayesian linear (variance component) models
 models") GWAS IV: Bayesian linear (variance component) models Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS IV: Bayesian
GWAS IV: Bayesian linear (variance component) models Dr. Oliver Stegle Christoh Lippert Prof. Dr. Karsten Borgwardt Max-Planck-Institutes Tübingen, Germany Tübingen Summer 2011 Oliver Stegle GWAS IV: Bayesian
GAUSSIAN PROCESS REGRESSION
 GAUSSIAN PROCESS REGRESSION CSE 515T Spring 2015 1. BACKGROUND The kernel trick again... The Kernel Trick Consider again the linear regression model: y(x) = φ(x) w + ε, with prior p(w) = N (w; 0, Σ). The
GAUSSIAN PROCESS REGRESSION CSE 515T Spring 2015 1. BACKGROUND The kernel trick again... The Kernel Trick Consider again the linear regression model: y(x) = φ(x) w + ε, with prior p(w) = N (w; 0, Σ). The
Dynamic Causal Modelling for EEG/MEG: principles J. Daunizeau
 Dynamic Causal Modelling for EEG/MEG: principles J. Daunizeau Motivation, Brain and Behaviour group, ICM, Paris, France Overview 1 DCM: introduction 2 Dynamical systems theory 3 Neural states dynamics
Dynamic Causal Modelling for EEG/MEG: principles J. Daunizeau Motivation, Brain and Behaviour group, ICM, Paris, France Overview 1 DCM: introduction 2 Dynamical systems theory 3 Neural states dynamics
Bayes Factors, posterior predictives, short intro to RJMCMC. Thermodynamic Integration
 Bayes Factors, posterior predictives, short intro to RJMCMC Thermodynamic Integration Dave Campbell 2016 Bayesian Statistical Inference P(θ Y ) P(Y θ)π(θ) Once you have posterior samples you can compute
Bayes Factors, posterior predictives, short intro to RJMCMC Thermodynamic Integration Dave Campbell 2016 Bayesian Statistical Inference P(θ Y ) P(Y θ)π(θ) Once you have posterior samples you can compute
John Ashburner. Wellcome Trust Centre for Neuroimaging, UCL Institute of Neurology, 12 Queen Square, London WC1N 3BG, UK.
 FOR MEDICAL IMAGING John Ashburner Wellcome Trust Centre for Neuroimaging, UCL Institute of Neurology, 12 Queen Square, London WC1N 3BG, UK. PIPELINES V MODELS PROBABILITY THEORY MEDICAL IMAGE COMPUTING
FOR MEDICAL IMAGING John Ashburner Wellcome Trust Centre for Neuroimaging, UCL Institute of Neurology, 12 Queen Square, London WC1N 3BG, UK. PIPELINES V MODELS PROBABILITY THEORY MEDICAL IMAGE COMPUTING
Lecture 4: Probabilistic Learning
 DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
Bayesian RL Seminar. Chris Mansley September 9, 2008
 Bayesian RL Seminar Chris Mansley September 9, 2008 Bayes Basic Probability One of the basic principles of probability theory, the chain rule, will allow us to derive most of the background material in
Bayesian RL Seminar Chris Mansley September 9, 2008 Bayes Basic Probability One of the basic principles of probability theory, the chain rule, will allow us to derive most of the background material in
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Lecture 3. Linear Regression II Bastian Leibe RWTH Aachen
 Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Advanced Machine Learning Lecture 3 Linear Regression II 02.11.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
DEPARTMENT OF COMPUTER SCIENCE Autumn Semester MACHINE LEARNING AND ADAPTIVE INTELLIGENCE
 Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Data Provided: None DEPARTMENT OF COMPUTER SCIENCE Autumn Semester 203 204 MACHINE LEARNING AND ADAPTIVE INTELLIGENCE 2 hours Answer THREE of the four questions. All questions carry equal weight. Figures
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Bayesian Learning. Tobias Scheffer, Niels Landwehr
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning Tobias Scheffer, Niels Landwehr Remember: Normal Distribution Distribution over x. Density function with parameters
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning Tobias Scheffer, Niels Landwehr Remember: Normal Distribution Distribution over x. Density function with parameters
Parameter Estimation. William H. Jefferys University of Texas at Austin Parameter Estimation 7/26/05 1
 Parameter Estimation William H. Jefferys University of Texas at Austin bill@bayesrules.net Parameter Estimation 7/26/05 1 Elements of Inference Inference problems contain two indispensable elements: Data
Parameter Estimation William H. Jefferys University of Texas at Austin bill@bayesrules.net Parameter Estimation 7/26/05 1 Elements of Inference Inference problems contain two indispensable elements: Data
An Introduction to Statistical and Probabilistic Linear Models
 An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
An Introduction to Statistical and Probabilistic Linear Models Maximilian Mozes Proseminar Data Mining Fakultät für Informatik Technische Universität München June 07, 2017 Introduction In statistical learning
Hierarchical Models & Bayesian Model Selection
 Hierarchical Models & Bayesian Model Selection Geoffrey Roeder Departments of Computer Science and Statistics University of British Columbia Jan. 20, 2016 Contact information Please report any typos or
Hierarchical Models & Bayesian Model Selection Geoffrey Roeder Departments of Computer Science and Statistics University of British Columbia Jan. 20, 2016 Contact information Please report any typos or
1 Bayesian Linear Regression (BLR)
") Statistical Techniques in Robotics (STR, S15) Lecture#10 (Wednesday, February 11) Lecturer: Byron Boots Gaussian Properties, Bayesian Linear Regression 1 Bayesian Linear Regression (BLR) In linear regression,
Statistical Techniques in Robotics (STR, S15) Lecture#10 (Wednesday, February 11) Lecturer: Byron Boots Gaussian Properties, Bayesian Linear Regression 1 Bayesian Linear Regression (BLR) In linear regression,
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Part 1: Expectation Propagation
 Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Chalmers Machine Learning Summer School Approximate message passing and biomedicine Part 1: Expectation Propagation Tom Heskes Machine Learning Group, Institute for Computing and Information Sciences Radboud
Probabilistic Models for Learning Data Representations. Andreas Damianou
 Probabilistic Models for Learning Data Representations Andreas Damianou Department of Computer Science, University of Sheffield, UK IBM Research, Nairobi, Kenya, 23/06/2015 Sheffield SITraN Outline Part
Probabilistic Models for Learning Data Representations Andreas Damianou Department of Computer Science, University of Sheffield, UK IBM Research, Nairobi, Kenya, 23/06/2015 Sheffield SITraN Outline Part
STA 414/2104, Spring 2014, Practice Problem Set #1
 STA 44/4, Spring 4, Practice Problem Set # Note: these problems are not for credit, and not to be handed in Question : Consider a classification problem in which there are two real-valued inputs, and,
STA 44/4, Spring 4, Practice Problem Set # Note: these problems are not for credit, and not to be handed in Question : Consider a classification problem in which there are two real-valued inputs, and,
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Linear Regression and Discrimination
 Linear Regression and Discrimination Kernel-based Learning Methods Christian Igel Institut für Neuroinformatik Ruhr-Universität Bochum, Germany http://www.neuroinformatik.rub.de July 16, 2009 Christian
Linear Regression and Discrimination Kernel-based Learning Methods Christian Igel Institut für Neuroinformatik Ruhr-Universität Bochum, Germany http://www.neuroinformatik.rub.de July 16, 2009 Christian
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
ST440/540: Applied Bayesian Statistics. (9) Model selection and goodness-of-fit checks
 Model selection and goodness-of-fit checks") (9) Model selection and goodness-of-fit checks Objectives In this module we will study methods for model comparisons and checking for model adequacy For model comparisons there are a finite number of candidate
(9) Model selection and goodness-of-fit checks Objectives In this module we will study methods for model comparisons and checking for model adequacy For model comparisons there are a finite number of candidate
Computer Vision Group Prof. Daniel Cremers. 2. Regression (cont.)
") Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Learning Gaussian Process Models from Uncertain Data
 Learning Gaussian Process Models from Uncertain Data Patrick Dallaire, Camille Besse, and Brahim Chaib-draa DAMAS Laboratory, Computer Science & Software Engineering Department, Laval University, Canada
Learning Gaussian Process Models from Uncertain Data Patrick Dallaire, Camille Besse, and Brahim Chaib-draa DAMAS Laboratory, Computer Science & Software Engineering Department, Laval University, Canada
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Empirical Bayes, Hierarchical Bayes Mark Schmidt University of British Columbia Winter 2017 Admin Assignment 5: Due April 10. Project description on Piazza. Final details coming
CPSC 540: Machine Learning Empirical Bayes, Hierarchical Bayes Mark Schmidt University of British Columbia Winter 2017 Admin Assignment 5: Due April 10. Project description on Piazza. Final details coming
Machine Learning Basics Lecture 7: Multiclass Classification. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 7: Multiclass Classification Princeton University COS 495 Instructor: Yingyu Liang Example: image classification indoor Indoor outdoor Example: image classification (multiclass)
Machine Learning Basics Lecture 7: Multiclass Classification Princeton University COS 495 Instructor: Yingyu Liang Example: image classification indoor Indoor outdoor Example: image classification (multiclass)
Gaussian Processes (10/16/13)
") STA561: Probabilistic machine learning Gaussian Processes (10/16/13) Lecturer: Barbara Engelhardt Scribes: Changwei Hu, Di Jin, Mengdi Wang 1 Introduction In supervised learning, we observe some inputs
STA561: Probabilistic machine learning Gaussian Processes (10/16/13) Lecturer: Barbara Engelhardt Scribes: Changwei Hu, Di Jin, Mengdi Wang 1 Introduction In supervised learning, we observe some inputs
Introduction Generalization Overview of the main methods Resources. Pattern Recognition. Bertrand Thirion and John Ashburner
 Definitions Classification and Regression Curse of Dimensionality Some key concepts Definitions Classification and Regression Curse of Dimensionality supervised learning: The data comes with additional
Definitions Classification and Regression Curse of Dimensionality Some key concepts Definitions Classification and Regression Curse of Dimensionality supervised learning: The data comes with additional
Hypothesis Testing. Econ 690. Purdue University. Justin L. Tobias (Purdue) Testing 1 / 33
 Testing 1 / 33") Hypothesis Testing Econ 690 Purdue University Justin L. Tobias (Purdue) Testing 1 / 33 Outline 1 Basic Testing Framework 2 Testing with HPD intervals 3 Example 4 Savage Dickey Density Ratio 5 Bartlett
Hypothesis Testing Econ 690 Purdue University Justin L. Tobias (Purdue) Testing 1 / 33 Outline 1 Basic Testing Framework 2 Testing with HPD intervals 3 Example 4 Savage Dickey Density Ratio 5 Bartlett
Machine Learning CSE546 Carlos Guestrin University of Washington. September 30, 2013
 Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
An introduction to Variational calculus in Machine Learning
 n introduction to Variational calculus in Machine Learning nders Meng February 2004 1 Introduction The intention of this note is not to give a full understanding of calculus of variations since this area
n introduction to Variational calculus in Machine Learning nders Meng February 2004 1 Introduction The intention of this note is not to give a full understanding of calculus of variations since this area
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Probabilistic Graphical Models Lecture 20: Gaussian Processes
 Probabilistic Graphical Models Lecture 20: Gaussian Processes Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 30, 2015 1 / 53 What is Machine Learning? Machine learning algorithms
Probabilistic Graphical Models Lecture 20: Gaussian Processes Andrew Gordon Wilson www.cs.cmu.edu/~andrewgw Carnegie Mellon University March 30, 2015 1 / 53 What is Machine Learning? Machine learning algorithms
y Xw 2 2 y Xw λ w 2 2
 CS 189 Introduction to Machine Learning Spring 2018 Note 4 1 MLE and MAP for Regression (Part I) So far, we ve explored two approaches of the regression framework, Ordinary Least Squares and Ridge Regression:
CS 189 Introduction to Machine Learning Spring 2018 Note 4 1 MLE and MAP for Regression (Part I) So far, we ve explored two approaches of the regression framework, Ordinary Least Squares and Ridge Regression:
Week 5: Logistic Regression & Neural Networks
 Week 5: Logistic Regression & Neural Networks Instructor: Sergey Levine 1 Summary: Logistic Regression In the previous lecture, we covered logistic regression. To recap, logistic regression models and
Week 5: Logistic Regression & Neural Networks Instructor: Sergey Levine 1 Summary: Logistic Regression In the previous lecture, we covered logistic regression. To recap, logistic regression models and
Bayesian Gaussian / Linear Models. Read Sections and 3.3 in the text by Bishop
 Bayesian Gaussian / Linear Models Read Sections 2.3.3 and 3.3 in the text by Bishop Multivariate Gaussian Model with Multivariate Gaussian Prior Suppose we model the observed vector b as having a multivariate
Bayesian Gaussian / Linear Models Read Sections 2.3.3 and 3.3 in the text by Bishop Multivariate Gaussian Model with Multivariate Gaussian Prior Suppose we model the observed vector b as having a multivariate
Lecture 6: Graphical Models: Learning
 Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Lecture 6: Graphical Models: Learning 4F13: Machine Learning Zoubin Ghahramani and Carl Edward Rasmussen Department of Engineering, University of Cambridge February 3rd, 2010 Ghahramani & Rasmussen (CUED)
Probabilistic & Bayesian deep learning. Andreas Damianou
 Probabilistic & Bayesian deep learning Andreas Damianou Amazon Research Cambridge, UK Talk at University of Sheffield, 19 March 2019 In this talk Not in this talk: CRFs, Boltzmann machines,... In this
Probabilistic & Bayesian deep learning Andreas Damianou Amazon Research Cambridge, UK Talk at University of Sheffield, 19 March 2019 In this talk Not in this talk: CRFs, Boltzmann machines,... In this
November 2002 STA Random Effects Selection in Linear Mixed Models
 November 2002 STA216 1 Random Effects Selection in Linear Mixed Models November 2002 STA216 2 Introduction It is common practice in many applications to collect multiple measurements on a subject. Linear
November 2002 STA216 1 Random Effects Selection in Linear Mixed Models November 2002 STA216 2 Introduction It is common practice in many applications to collect multiple measurements on a subject. Linear
Bayesian Linear Regression [DRAFT - In Progress]
![Bayesian Linear Regression [DRAFT - In Progress]](/thumbs/92/109828713.jpg "Bayesian Linear Regression [DRAFT - In Progress]") Bayesian Linear Regression [DRAFT - In Progress] David S. Rosenberg Abstract Here we develop some basics of Bayesian linear regression. Most of the calculations for this document come from the basic theory
Bayesian Linear Regression [DRAFT - In Progress] David S. Rosenberg Abstract Here we develop some basics of Bayesian linear regression. Most of the calculations for this document come from the basic theory
Estimating the marginal likelihood with Integrated nested Laplace approximation (INLA)
") Estimating the marginal likelihood with Integrated nested Laplace approximation (INLA) arxiv:1611.01450v1 [stat.co] 4 Nov 2016 Aliaksandr Hubin Department of Mathematics, University of Oslo and Geir Storvik
Estimating the marginal likelihood with Integrated nested Laplace approximation (INLA) arxiv:1611.01450v1 [stat.co] 4 Nov 2016 Aliaksandr Hubin Department of Mathematics, University of Oslo and Geir Storvik
Assessing Regime Uncertainty Through Reversible Jump McMC
 Assessing Regime Uncertainty Through Reversible Jump McMC August 14, 2008 1 Introduction Background Research Question 2 The RJMcMC Method McMC RJMcMC Algorithm Dependent Proposals Independent Proposals
Assessing Regime Uncertainty Through Reversible Jump McMC August 14, 2008 1 Introduction Background Research Question 2 The RJMcMC Method McMC RJMcMC Algorithm Dependent Proposals Independent Proposals
Statistical Machine Learning Lecture 8: Markov Chain Monte Carlo Sampling
 1 / 27 Statistical Machine Learning Lecture 8: Markov Chain Monte Carlo Sampling Melih Kandemir Özyeğin University, İstanbul, Turkey 2 / 27 Monte Carlo Integration The big question : Evaluate E p(z) [f(z)]
1 / 27 Statistical Machine Learning Lecture 8: Markov Chain Monte Carlo Sampling Melih Kandemir Özyeğin University, İstanbul, Turkey 2 / 27 Monte Carlo Integration The big question : Evaluate E p(z) [f(z)]
Should all Machine Learning be Bayesian? Should all Bayesian models be non-parametric?
 Should all Machine Learning be Bayesian? Should all Bayesian models be non-parametric? Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/
Should all Machine Learning be Bayesian? Should all Bayesian models be non-parametric? Zoubin Ghahramani Department of Engineering University of Cambridge, UK zoubin@eng.cam.ac.uk http://learning.eng.cam.ac.uk/zoubin/
Computer Vision Group Prof. Daniel Cremers. 3. Regression
 Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Intelligent Systems I
 Intelligent Systems I 00 INTRODUCTION Stefan Harmeling & Philipp Hennig 24. October 2013 Max Planck Institute for Intelligent Systems Dptmt. of Empirical Inference Which Card? Opening Experiment Which
Intelligent Systems I 00 INTRODUCTION Stefan Harmeling & Philipp Hennig 24. October 2013 Max Planck Institute for Intelligent Systems Dptmt. of Empirical Inference Which Card? Opening Experiment Which
Gaussian Processes for Machine Learning
 Gaussian Processes for Machine Learning Carl Edward Rasmussen Max Planck Institute for Biological Cybernetics Tübingen, Germany carl@tuebingen.mpg.de Carlos III, Madrid, May 2006 The actual science of
Gaussian Processes for Machine Learning Carl Edward Rasmussen Max Planck Institute for Biological Cybernetics Tübingen, Germany carl@tuebingen.mpg.de Carlos III, Madrid, May 2006 The actual science of
Gaussian Process Regression
 Gaussian Process Regression 4F1 Pattern Recognition, 21 Carl Edward Rasmussen Department of Engineering, University of Cambridge November 11th - 16th, 21 Rasmussen (Engineering, Cambridge) Gaussian Process
Gaussian Process Regression 4F1 Pattern Recognition, 21 Carl Edward Rasmussen Department of Engineering, University of Cambridge November 11th - 16th, 21 Rasmussen (Engineering, Cambridge) Gaussian Process
ST 740: Model Selection
 ST 740: Model Selection Alyson Wilson Department of Statistics North Carolina State University November 25, 2013 A. Wilson (NCSU Statistics) Model Selection November 25, 2013 1 / 29 Formal Bayesian Model
ST 740: Model Selection Alyson Wilson Department of Statistics North Carolina State University November 25, 2013 A. Wilson (NCSU Statistics) Model Selection November 25, 2013 1 / 29 Formal Bayesian Model
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Machine Learning - MT & 5. Basis Expansion, Regularization, Validation
 Machine Learning - MT 2016 4 & 5. Basis Expansion, Regularization, Validation Varun Kanade University of Oxford October 19 & 24, 2016 Outline Basis function expansion to capture non-linear relationships
Machine Learning - MT 2016 4 & 5. Basis Expansion, Regularization, Validation Varun Kanade University of Oxford October 19 & 24, 2016 Outline Basis function expansion to capture non-linear relationships
Reconstruction of individual patient data for meta analysis via Bayesian approach
 Reconstruction of individual patient data for meta analysis via Bayesian approach Yusuke Yamaguchi, Wataru Sakamoto and Shingo Shirahata Graduate School of Engineering Science, Osaka University Masashi
Reconstruction of individual patient data for meta analysis via Bayesian approach Yusuke Yamaguchi, Wataru Sakamoto and Shingo Shirahata Graduate School of Engineering Science, Osaka University Masashi
CSC321 Lecture 18: Learning Probabilistic Models
 CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
CSC321 Lecture 18: Learning Probabilistic Models Roger Grosse Roger Grosse CSC321 Lecture 18: Learning Probabilistic Models 1 / 25 Overview So far in this course: mainly supervised learning Language modeling
Lecture 3: Pattern Classification. Pattern classification
 EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
PMR Learning as Inference
 Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Outline PMR Learning as Inference Probabilistic Modelling and Reasoning Amos Storkey Modelling 2 The Exponential Family 3 Bayesian Sets School of Informatics, University of Edinburgh Amos Storkey PMR Learning
Model Selection for Gaussian Processes
 Institute for Adaptive and Neural Computation School of Informatics,, UK December 26 Outline GP basics Model selection: covariance functions and parameterizations Criteria for model selection Marginal
Institute for Adaptive and Neural Computation School of Informatics,, UK December 26 Outline GP basics Model selection: covariance functions and parameterizations Criteria for model selection Marginal
CS-E3210 Machine Learning: Basic Principles
 CS-E3210 Machine Learning: Basic Principles Lecture 4: Regression II slides by Markus Heinonen Department of Computer Science Aalto University, School of Science Autumn (Period I) 2017 1 / 61 Today s introduction
CS-E3210 Machine Learning: Basic Principles Lecture 4: Regression II slides by Markus Heinonen Department of Computer Science Aalto University, School of Science Autumn (Period I) 2017 1 / 61 Today s introduction