Unsupervised Neural Nets
|
|
|
- Amy Marsh
- 5 years ago
- Views:
Transcription
 Lyle Ungar, University of")
1 Unsupervised Neural Nets (and ICA) Lyle Ungar (with contributions from Quoc Le, Socher & Manning) Lyle Ungar, University of Pennsylvania
2 Semi-Supervised Learning Hypothesis:%P(c x)%can%be%more%accurately%computed%using% shared%structure%with%p(x)%% purely% supervised% from Socher and Manning 2
3 Semi-Supervised Learning Hypothesis:%P(c x)%can%be%more%accurately%computed%using% shared%structure%with%p(x)%% semij% supervised% from Socher and Manning 3

4 Unsupervised Neural Nets u Autoencoders l Take same image as input and output n often adding noise to the input l Learn weights to minimize the reconstruction error l Avoid perfect fitting n Pass through a bottleneck n Impose sparsity w Dropout n Add noise to the input u Generalize PCA or ICA Autoencoders_and_Sparsity
5 Independent Components Analysis (ICA) u Given observations X, find W such that components s j of S = XW are as independent of each other as possible l E.g. have maximum KL-divergence or low mutual information l Alternatively, find directions in X that are most skewed n farthest from Gaussian l Usually mean center and whiten the data (make unit covariance) first n whiten: (X T X) -1/2 X u Very similar to PCA l But the loss function is not quadratic l So optimization cannot be done by SVD
6 Independent Components Analysis (ICA) u Given observations X, find W and S such that components s j of S = XW are as independent of each other as possible l S k = sources should be independent u Reconstruct X ~ (XW)W + = SW + l S like principle components l W + like loadings l x ~ Σ j s j w j + u Auto-encoder nonlinear generalization that encodes X as S and then decodes it
7 Reconstruction ICA (RICA) u Reconstruction ICA: find W to minimize l Reconstruction error n X - SW + 2 = X - (XW)W + 2 And minimize l Mutual information between sources S = XW I(s 1, s 2...s k ) = H(y) = k H(s i ) H(s) i 1 p(y)log p(y)dy Difference between the entropy of each source s i and the entropy of all of them together Note: this is a bit more complex than it looks, as we have real numbers, not distributions
8 Mutual information I(y 1,y 2, y m ) = KL(p(y 1,y 2, y m ) p(y 1 )p(y 2 )...p(y m )) 8
 l Use for semi-supervised learning http://theanalyticsstore.")
9 Unsupervised Neural Nets u Auto-encoders l Take same image as input and output n often adding noise to the input l Learn weights to minimize the reconstruction error l This can be done repeatedly (reconstructing features) l Use for semi-supervised learning


10 PCA = Linear Manifold = Linear Auto-Encoder from Socher and Manning 10
11 The Manifold Learning Hypothesis from Socher and Manning 11
12 Auto-Encoders are like nonlinear PCA from Socher and Manning 12
13 Stacking for deep learning from Socher and Manning 13
14 Stacking for deep learning Now learn to reconstruct the features (using more abstract ones) from Socher and Manning 14
15 Stacking for deep learning u Recurse many layers deep u Can be used to initialize supervised learning from Socher and Manning 15
16 Tera-scale deep learning Quoc%V.%Le% Stanford%University%and%Google% Now at google









17 Joint%work%with% Kai%Chen% Greg%Corrado% Jeff%Dean% MaQhieu%Devin% Rajat%Monga% Andrew%Ng% Marc Aurelio% Ranzato% Paul%Tucker% Ke%Yang% AddiNonal% Thanks:% Samy%Bengio,%Zhenghao%Chen,%Tom%Dean,%Pangwei%Koh,% Mark%Mao,%Jiquan%Ngiam,%Patrick%Nguyen,%Andrew%Saxe,% Mark%Segal,%Jon%Shlens,%%Vincent%Vanhouke,%%Xiaoyun%Wu,%% Peng%Xe,%Serena%Yeung,%Will%Zou%

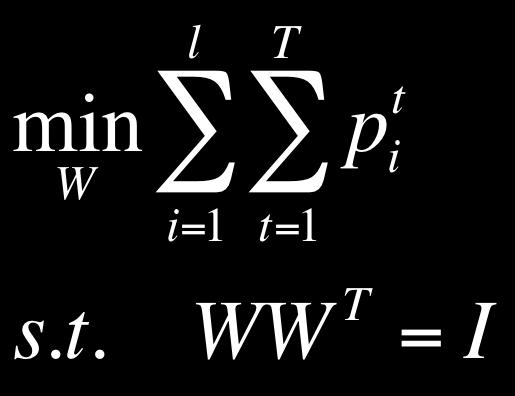
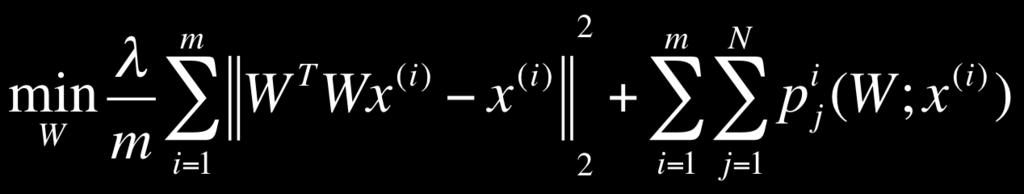

18 TICA:% Warning: this x and W are the transpose of what we use ReconstrucNon%ICA:% Equivalence%between%Sparse%Coding,%Autoencoders,%RBMs%and%ICA% Build%deep%architecture%by%treaNng%the%output%of%one%layer%as%input%to% another%layer% Le,%et%al.,%ICA$with$Reconstruc1on$Cost$for$Efficient$Overcomplete$Feature$Learning.%NIPS%2011%

19 Visualization of features learned Most%are%% local%features%
20 Challenges%with%1000s%of%machines%
21 Asynchronous%Parallel%SGDs% Parameter%server% Le,%et%al.,%Building$high>level$features$using$large>scale$unsupervised$learning.%ICML%2012%
22 Local%recepNve%field%networks% Machine%#1% Machine%#2% Machine%#3% Machine%#4% RICA%features% Image% Le,%et%al.,%Tiled$Convolu1onal$Neural$Networks.%NIPS%2010%
23 10%million%200x200%images%% 1%billion%parameters%
%for%1%week% % 1.")

24 Training% RICA% RICA% Dataset:%10%million%200x200%unlabeled%images%%from%YouTube/Web% % Train%on%2000%machines%(16000%cores)%for%1%week% % 1.15%billion%parameters% \ 100x%larger%than%previously%reported%% \ Small%compared%to%visual%cortex% % RICA% Image% Le,%et%al.,%Building$high>level$features$using$large>scale$unsupervised$learning.%ICML%2012%


25 The%face%neuron% Top%sNmuli%from%the%test%set% OpNmal%sNmulus%% by%numerical%opnmizanon% Le,%et%al.,%Building$high>level$features$using$large>scale$unsupervised$learning.%ICML%2012%


26 The cat neuron Top%sNmuli%from%the%test%set% OpNmal%sNmulus%% by%numerical%opnmizanon% Le,%et%al.,%Building$high>level$features$using$large>scale$unsupervised$learning.%ICML%2012%
27 What you should know u Supervised neural nets l Generalize logistic regression l Often have built-in structure n local receptive fields, max pooling l Usually solved by minibatch stochastic gradient descent n With chain rule ( backpropagation ), u Unsupervised neural nets l Generalize PCA or ICA l Generally learn an overcomplete basis l Often trained recursively as nonlinear autoencoders l Used in semi-supervised learning n Or to initialize supervised deep nets
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
UNSUPERVISED LEARNING
 UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
CSC321 Lecture 20: Autoencoders
 CSC321 Lecture 20: Autoencoders Roger Grosse Roger Grosse CSC321 Lecture 20: Autoencoders 1 / 16 Overview Latent variable models so far: mixture models Boltzmann machines Both of these involve discrete
CSC321 Lecture 20: Autoencoders Roger Grosse Roger Grosse CSC321 Lecture 20: Autoencoders 1 / 16 Overview Latent variable models so far: mixture models Boltzmann machines Both of these involve discrete
Basic Principles of Unsupervised and Unsupervised
 Basic Principles of Unsupervised and Unsupervised Learning Toward Deep Learning Shun ichi Amari (RIKEN Brain Science Institute) collaborators: R. Karakida, M. Okada (U. Tokyo) Deep Learning Self Organization
Basic Principles of Unsupervised and Unsupervised Learning Toward Deep Learning Shun ichi Amari (RIKEN Brain Science Institute) collaborators: R. Karakida, M. Okada (U. Tokyo) Deep Learning Self Organization
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Greedy Layer-Wise Training of Deep Networks
 Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Statistical Learning Theory. Part I 5. Deep Learning
 Statistical Learning Theory Part I 5. Deep Learning Sumio Watanabe Tokyo Institute of Technology Review : Supervised Learning Training Data X 1, X 2,, X n q(x,y) =q(x)q(y x) Information Source Y 1, Y 2,,
Statistical Learning Theory Part I 5. Deep Learning Sumio Watanabe Tokyo Institute of Technology Review : Supervised Learning Training Data X 1, X 2,, X n q(x,y) =q(x)q(y x) Information Source Y 1, Y 2,,
Deep Generative Models. (Unsupervised Learning)
") Deep Generative Models (Unsupervised Learning) CEng 783 Deep Learning Fall 2017 Emre Akbaş Reminders Next week: project progress demos in class Describe your problem/goal What you have done so far What
Deep Generative Models (Unsupervised Learning) CEng 783 Deep Learning Fall 2017 Emre Akbaş Reminders Next week: project progress demos in class Describe your problem/goal What you have done so far What
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
The XOR problem. Machine learning for vision. The XOR problem. The XOR problem. x 1 x 2. x 2. x 1. Fall Roland Memisevic
 The XOR problem Fall 2013 x 2 Lecture 9, February 25, 2015 x 1 The XOR problem The XOR problem x 1 x 2 x 2 x 1 (picture adapted from Bishop 2006) It s the features, stupid It s the features, stupid The
The XOR problem Fall 2013 x 2 Lecture 9, February 25, 2015 x 1 The XOR problem The XOR problem x 1 x 2 x 2 x 1 (picture adapted from Bishop 2006) It s the features, stupid It s the features, stupid The
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Regularization Introduction to Machine Learning. Matt Gormley Lecture 10 Feb. 19, 2018
 1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
Machine Learning for Computer Vision 8. Neural Networks and Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group INTRODUCTION Nonlinear Coordinate Transformation http://cs.stanford.edu/people/karpathy/convnetjs/
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Lecture 14: Deep Generative Learning
 Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
A Unified Energy-Based Framework for Unsupervised Learning
 A Unified Energy-Based Framework for Unsupervised Learning Marc Aurelio Ranzato Y-Lan Boureau Sumit Chopra Yann LeCun Courant Insitute of Mathematical Sciences New York University, New York, NY 10003 Abstract
A Unified Energy-Based Framework for Unsupervised Learning Marc Aurelio Ranzato Y-Lan Boureau Sumit Chopra Yann LeCun Courant Insitute of Mathematical Sciences New York University, New York, NY 10003 Abstract
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
Part 2. Representation Learning Algorithms
 53 Part 2 Representation Learning Algorithms 54 A neural network = running several logistic regressions at the same time If we feed a vector of inputs through a bunch of logis;c regression func;ons, then
53 Part 2 Representation Learning Algorithms 54 A neural network = running several logistic regressions at the same time If we feed a vector of inputs through a bunch of logis;c regression func;ons, then
Machine Learning Basics: Maximum Likelihood Estimation
 Machine Learning Basics: Maximum Likelihood Estimation Sargur N. srihari@cedar.buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics 1. Learning
Machine Learning Basics: Maximum Likelihood Estimation Sargur N. srihari@cedar.buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics 1. Learning
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
RegML 2018 Class 8 Deep learning
 RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x
RegML 2018 Class 8 Deep learning Lorenzo Rosasco UNIGE-MIT-IIT June 18, 2018 Supervised vs unsupervised learning? So far we have been thinking of learning schemes made in two steps f(x) = w, Φ(x) F, x
Administration. Registration Hw3 is out. Lecture Captioning (Extra-Credit) Scribing lectures. Questions. Due on Thursday 10/6
 Scribing lectures. Questions. Due on Thursday 10/6") Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Lecture 10. Neural networks and optimization. Machine Learning and Data Mining November Nando de Freitas UBC. Nonlinear Supervised Learning
 Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Index. Santanu Pattanayak 2017 S. Pattanayak, Pro Deep Learning with TensorFlow,
 Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Stochastic Backpropagation, Variational Inference, and Semi-Supervised Learning
 Stochastic Backpropagation, Variational Inference, and Semi-Supervised Learning Diederik (Durk) Kingma Danilo J. Rezende (*) Max Welling Shakir Mohamed (**) Stochastic Gradient Variational Inference Bayesian
Stochastic Backpropagation, Variational Inference, and Semi-Supervised Learning Diederik (Durk) Kingma Danilo J. Rezende (*) Max Welling Shakir Mohamed (**) Stochastic Gradient Variational Inference Bayesian
TUTORIAL PART 1 Unsupervised Learning
 TUTORIAL PART 1 Unsupervised Learning Marc'Aurelio Ranzato Department of Computer Science Univ. of Toronto ranzato@cs.toronto.edu Co-organizers: Honglak Lee, Yoshua Bengio, Geoff Hinton, Yann LeCun, Andrew
TUTORIAL PART 1 Unsupervised Learning Marc'Aurelio Ranzato Department of Computer Science Univ. of Toronto ranzato@cs.toronto.edu Co-organizers: Honglak Lee, Yoshua Bengio, Geoff Hinton, Yann LeCun, Andrew
Neural Networks and Deep Learning.
 Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Reward-modulated inference
 Buck Shlegeris Matthew Alger COMP3740, 2014 Outline Supervised, unsupervised, and reinforcement learning Neural nets RMI Results with RMI Types of machine learning supervised unsupervised reinforcement
Buck Shlegeris Matthew Alger COMP3740, 2014 Outline Supervised, unsupervised, and reinforcement learning Neural nets RMI Results with RMI Types of machine learning supervised unsupervised reinforcement
Neural Networks. Mark van Rossum. January 15, School of Informatics, University of Edinburgh 1 / 28
 1 / 28 Neural Networks Mark van Rossum School of Informatics, University of Edinburgh January 15, 2018 2 / 28 Goals: Understand how (recurrent) networks behave Find a way to teach networks to do a certain
1 / 28 Neural Networks Mark van Rossum School of Informatics, University of Edinburgh January 15, 2018 2 / 28 Goals: Understand how (recurrent) networks behave Find a way to teach networks to do a certain
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Convolutional Neural Networks. Srikumar Ramalingam
 Convolutional Neural Networks Srikumar Ramalingam Reference Many of the slides are prepared using the following resources: neuralnetworksanddeeplearning.com (mainly Chapter 6) http://cs231n.github.io/convolutional-networks/
Convolutional Neural Networks Srikumar Ramalingam Reference Many of the slides are prepared using the following resources: neuralnetworksanddeeplearning.com (mainly Chapter 6) http://cs231n.github.io/convolutional-networks/
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Lecture 16 Deep Neural Generative Models
 Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
Unsupervised Learning
 CS 3750 Advanced Machine Learning hkc6@pitt.edu Unsupervised Learning Data: Just data, no labels Goal: Learn some underlying hidden structure of the data P(, ) P( ) Principle Component Analysis (Dimensionality
CS 3750 Advanced Machine Learning hkc6@pitt.edu Unsupervised Learning Data: Just data, no labels Goal: Learn some underlying hidden structure of the data P(, ) P( ) Principle Component Analysis (Dimensionality
BACKPROPAGATION. Neural network training optimization problem. Deriving backpropagation
 BACKPROPAGATION Neural network training optimization problem min J(w) w The application of gradient descent to this problem is called backpropagation. Backpropagation is gradient descent applied to J(w)
BACKPROPAGATION Neural network training optimization problem min J(w) w The application of gradient descent to this problem is called backpropagation. Backpropagation is gradient descent applied to J(w)
Deep unsupervised learning
 Deep unsupervised learning Advanced data-mining Yongdai Kim Department of Statistics, Seoul National University, South Korea Unsupervised learning In machine learning, there are 3 kinds of learning paradigm.
Deep unsupervised learning Advanced data-mining Yongdai Kim Department of Statistics, Seoul National University, South Korea Unsupervised learning In machine learning, there are 3 kinds of learning paradigm.
WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY,
 WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY, WITH IMPLICATIONS FOR TRAINING Sanjeev Arora, Yingyu Liang & Tengyu Ma Department of Computer Science Princeton University Princeton, NJ 08540, USA {arora,yingyul,tengyu}@cs.princeton.edu
WHY ARE DEEP NETS REVERSIBLE: A SIMPLE THEORY, WITH IMPLICATIONS FOR TRAINING Sanjeev Arora, Yingyu Liang & Tengyu Ma Department of Computer Science Princeton University Princeton, NJ 08540, USA {arora,yingyul,tengyu}@cs.princeton.edu
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
PCA & ICA. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Course Structure. Psychology 452 Week 12: Deep Learning. Chapter 8 Discussion. Part I: Deep Learning: What and Why? Rufus. Rufus Processed By Fetch
 Psychology 452 Week 12: Deep Learning What Is Deep Learning? Preliminary Ideas (that we already know!) The Restricted Boltzmann Machine (RBM) Many Layers of RBMs Pros and Cons of Deep Learning Course Structure
Psychology 452 Week 12: Deep Learning What Is Deep Learning? Preliminary Ideas (that we already know!) The Restricted Boltzmann Machine (RBM) Many Layers of RBMs Pros and Cons of Deep Learning Course Structure
Loss Functions and Optimization. Lecture 3-1
 Lecture 3: Loss Functions and Optimization Lecture 3-1 Administrative: Live Questions We ll use Zoom to take questions from remote students live-streaming the lecture Check Piazza for instructions and
Lecture 3: Loss Functions and Optimization Lecture 3-1 Administrative: Live Questions We ll use Zoom to take questions from remote students live-streaming the lecture Check Piazza for instructions and
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS
 CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
An efficient way to learn deep generative models
 An efficient way to learn deep generative models Geoffrey Hinton Canadian Institute for Advanced Research & Department of Computer Science University of Toronto Joint work with: Ruslan Salakhutdinov, Yee-Whye
An efficient way to learn deep generative models Geoffrey Hinton Canadian Institute for Advanced Research & Department of Computer Science University of Toronto Joint work with: Ruslan Salakhutdinov, Yee-Whye
Deep Learning for Natural Language Processing
 Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Mathematical Tools for Neuroscience (NEU 314) Princeton University, Spring 2016 Jonathan Pillow. Homework 8: Logistic Regression & Information Theory
 Princeton University, Spring 2016 Jonathan Pillow. Homework 8: Logistic Regression & Information Theory") Mathematical Tools for Neuroscience (NEU 34) Princeton University, Spring 206 Jonathan Pillow Homework 8: Logistic Regression & Information Theory Due: Tuesday, April 26, 9:59am Optimization Toolbox One
Mathematical Tools for Neuroscience (NEU 34) Princeton University, Spring 206 Jonathan Pillow Homework 8: Logistic Regression & Information Theory Due: Tuesday, April 26, 9:59am Optimization Toolbox One
Feature Design. Feature Design. Feature Design. & Deep Learning
 Artificial Intelligence and its applications Lecture 9 & Deep Learning Professor Daniel Yeung danyeung@ieee.org Dr. Patrick Chan patrickchan@ieee.org South China University of Technology, China Appropriately
Artificial Intelligence and its applications Lecture 9 & Deep Learning Professor Daniel Yeung danyeung@ieee.org Dr. Patrick Chan patrickchan@ieee.org South China University of Technology, China Appropriately
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Machine Learning Basics: Stochastic Gradient Descent. Sargur N. Srihari
 Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Connecting Machine Learning with Shallow Neural Networks
 Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Connecting Machine Learning with Shallow Neural Networks Neural Networks and Deep Learning, Springer, 2018 Chapter 2, Section 2.1 Neural
Charu C. Aggarwal IBM T J Watson Research Center Yorktown Heights, NY Connecting Machine Learning with Shallow Neural Networks Neural Networks and Deep Learning, Springer, 2018 Chapter 2, Section 2.1 Neural
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory Announcements Be making progress on your projects! Three Types of Learning Unsupervised Supervised Reinforcement
Variational Autoencoders (VAEs)
") September 26 & October 3, 2017 Section 1 Preliminaries Kullback-Leibler divergence KL divergence (continuous case) p(x) andq(x) are two density distributions. Then the KL-divergence is defined as Z KL(p
September 26 & October 3, 2017 Section 1 Preliminaries Kullback-Leibler divergence KL divergence (continuous case) p(x) andq(x) are two density distributions. Then the KL-divergence is defined as Z KL(p
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
Auto-Encoding Variational Bayes
 Auto-Encoding Variational Bayes Diederik P Kingma, Max Welling June 18, 2018 Diederik P Kingma, Max Welling Auto-Encoding Variational Bayes June 18, 2018 1 / 39 Outline 1 Introduction 2 Variational Lower
Auto-Encoding Variational Bayes Diederik P Kingma, Max Welling June 18, 2018 Diederik P Kingma, Max Welling Auto-Encoding Variational Bayes June 18, 2018 1 / 39 Outline 1 Introduction 2 Variational Lower
Neural Networks. Bishop PRML Ch. 5. Alireza Ghane. Feed-forward Networks Network Training Error Backpropagation Applications
 Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Bayesian Semi-supervised Learning with Deep Generative Models
 Bayesian Semi-supervised Learning with Deep Generative Models Jonathan Gordon Department of Engineering Cambridge University jg801@cam.ac.uk José Miguel Hernández-Lobato Department of Engineering Cambridge
Bayesian Semi-supervised Learning with Deep Generative Models Jonathan Gordon Department of Engineering Cambridge University jg801@cam.ac.uk José Miguel Hernández-Lobato Department of Engineering Cambridge
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts III-IV
 Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts III-IV Aapo Hyvärinen Gatsby Unit University College London Part III: Estimation of unnormalized models Often,
Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts III-IV Aapo Hyvärinen Gatsby Unit University College London Part III: Estimation of unnormalized models Often,
Natural Image Statistics
 Natural Image Statistics A probabilistic approach to modelling early visual processing in the cortex Dept of Computer Science Early visual processing LGN V1 retina From the eye to the primary visual cortex
Natural Image Statistics A probabilistic approach to modelling early visual processing in the cortex Dept of Computer Science Early visual processing LGN V1 retina From the eye to the primary visual cortex
Learning Deep Architectures
 Learning Deep Architectures Yoshua Bengio, U. Montreal Microsoft Cambridge, U.K. July 7th, 2009, Montreal Thanks to: Aaron Courville, Pascal Vincent, Dumitru Erhan, Olivier Delalleau, Olivier Breuleux,
Learning Deep Architectures Yoshua Bengio, U. Montreal Microsoft Cambridge, U.K. July 7th, 2009, Montreal Thanks to: Aaron Courville, Pascal Vincent, Dumitru Erhan, Olivier Delalleau, Olivier Breuleux,
Learning From Data Lecture 15 Reflecting on Our Path - Epilogue to Part I
 Learning From Data Lecture 15 Reflecting on Our Path - Epilogue to Part I What We Did The Machine Learning Zoo Moving Forward M Magdon-Ismail CSCI 4100/6100 recap: Three Learning Principles Scientist 2
Learning From Data Lecture 15 Reflecting on Our Path - Epilogue to Part I What We Did The Machine Learning Zoo Moving Forward M Magdon-Ismail CSCI 4100/6100 recap: Three Learning Principles Scientist 2
Classification. The goal: map from input X to a label Y. Y has a discrete set of possible values. We focused on binary Y (values 0 or 1).
.") Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
Loss Functions and Optimization. Lecture 3-1
 Lecture 3: Loss Functions and Optimization Lecture 3-1 Administrative Assignment 1 is released: http://cs231n.github.io/assignments2017/assignment1/ Due Thursday April 20, 11:59pm on Canvas (Extending
Lecture 3: Loss Functions and Optimization Lecture 3-1 Administrative Assignment 1 is released: http://cs231n.github.io/assignments2017/assignment1/ Due Thursday April 20, 11:59pm on Canvas (Extending
Learning Deep Architectures for AI. Part II - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Dimensionality Reduction and Principle Components Analysis
 Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
Bits of Machine Learning Part 1: Supervised Learning
 Bits of Machine Learning Part 1: Supervised Learning Alexandre Proutiere and Vahan Petrosyan KTH (The Royal Institute of Technology) Outline of the Course 1. Supervised Learning Regression and Classification
Bits of Machine Learning Part 1: Supervised Learning Alexandre Proutiere and Vahan Petrosyan KTH (The Royal Institute of Technology) Outline of the Course 1. Supervised Learning Regression and Classification
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Techniques
 Machine Learning Techniques ( 機器學習技法 ) Lecture 13: Deep Learning Hsuan-Tien Lin ( 林軒田 ) htlin@csie.ntu.edu.tw Department of Computer Science & Information Engineering National Taiwan University ( 國立台灣大學資訊工程系
Machine Learning Techniques ( 機器學習技法 ) Lecture 13: Deep Learning Hsuan-Tien Lin ( 林軒田 ) htlin@csie.ntu.edu.tw Department of Computer Science & Information Engineering National Taiwan University ( 國立台灣大學資訊工程系
Learning features by contrasting natural images with noise
 Learning features by contrasting natural images with noise Michael Gutmann 1 and Aapo Hyvärinen 12 1 Dept. of Computer Science and HIIT, University of Helsinki, P.O. Box 68, FIN-00014 University of Helsinki,
Learning features by contrasting natural images with noise Michael Gutmann 1 and Aapo Hyvärinen 12 1 Dept. of Computer Science and HIIT, University of Helsinki, P.O. Box 68, FIN-00014 University of Helsinki,
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014 Exam policy: This exam allows two one-page, two-sided cheat sheets (i.e. 4 sides); No other materials. Time: 2 hours. Be sure to write
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014 Exam policy: This exam allows two one-page, two-sided cheat sheets (i.e. 4 sides); No other materials. Time: 2 hours. Be sure to write
Neural Network Tutorial & Application in Nuclear Physics. Weiguang Jiang ( 蒋炜光 ) UTK / ORNL
 UTK / ORNL") Neural Network Tutorial & Application in Nuclear Physics Weiguang Jiang ( 蒋炜光 ) UTK / ORNL Machine Learning Logistic Regression Gaussian Processes Neural Network Support vector machine Random Forest Genetic
Neural Network Tutorial & Application in Nuclear Physics Weiguang Jiang ( 蒋炜光 ) UTK / ORNL Machine Learning Logistic Regression Gaussian Processes Neural Network Support vector machine Random Forest Genetic
Linear Factor Models. Deep Learning Decal. Hosted by Machine Learning at Berkeley
 Linear Factor Models Deep Learning Decal Hosted by Machine Learning at Berkeley 1 Overview Agenda Background Linear Factor Models Probabilistic PCA Independent Component Analysis Slow Feature Analysis
Linear Factor Models Deep Learning Decal Hosted by Machine Learning at Berkeley 1 Overview Agenda Background Linear Factor Models Probabilistic PCA Independent Component Analysis Slow Feature Analysis
Supervised Learning. George Konidaris
 Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Learning with Singular Vectors
 Learning with Singular Vectors CIS 520 Lecture 30 October 2015 Barry Slaff Based on: CIS 520 Wiki Materials Slides by Jia Li (PSU) Works cited throughout Overview Linear regression: Given X, Y find w:
Learning with Singular Vectors CIS 520 Lecture 30 October 2015 Barry Slaff Based on: CIS 520 Wiki Materials Slides by Jia Li (PSU) Works cited throughout Overview Linear regression: Given X, Y find w:
An Introduction to Independent Components Analysis (ICA)
") An Introduction to Independent Components Analysis (ICA) Anish R. Shah, CFA Northfield Information Services Anish@northinfo.com Newport Jun 6, 2008 1 Overview of Talk Review principal components Introduce
An Introduction to Independent Components Analysis (ICA) Anish R. Shah, CFA Northfield Information Services Anish@northinfo.com Newport Jun 6, 2008 1 Overview of Talk Review principal components Introduce
Machine Learning. Regression-Based Classification & Gaussian Discriminant Analysis. Manfred Huber
 Machine Learning Regression-Based Classification & Gaussian Discriminant Analysis Manfred Huber 2015 1 Logistic Regression Linear regression provides a nice representation and an efficient solution to
Machine Learning Regression-Based Classification & Gaussian Discriminant Analysis Manfred Huber 2015 1 Logistic Regression Linear regression provides a nice representation and an efficient solution to
Deep Learning Basics Lecture 8: Autoencoder & DBM. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 8: Autoencoder & DBM Princeton University COS 495 Instructor: Yingyu Liang Autoencoder Autoencoder Neural networks trained to attempt to copy its input to its output Contain
Deep Learning Basics Lecture 8: Autoencoder & DBM Princeton University COS 495 Instructor: Yingyu Liang Autoencoder Autoencoder Neural networks trained to attempt to copy its input to its output Contain
Agenda. Digit Classification using CNN Digit Classification using SAE Visualization: Class models, filters and saliency 2 DCT
 versus 1 Agenda Deep Learning: Motivation Learning: Backpropagation Deep architectures I: Convolutional Neural Networks (CNN) Deep architectures II: Stacked Auto Encoders (SAE) Caffe Deep Learning Toolbox:
versus 1 Agenda Deep Learning: Motivation Learning: Backpropagation Deep architectures I: Convolutional Neural Networks (CNN) Deep architectures II: Stacked Auto Encoders (SAE) Caffe Deep Learning Toolbox:
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!!
 CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
Introduction to Machine learning
 Introduction to Machine learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Examples 1 Examples 1 WaveNet
Introduction to Machine learning Some slides and images are taken from: David Wolfe Corne Wikipedia Geoffrey A. Hinton https://www.macs.hw.ac.uk/~dwcorne/teaching/introdl.ppt Examples 1 Examples 1 WaveNet
Autoencoders and Score Matching. Based Models. Kevin Swersky Marc Aurelio Ranzato David Buchman Benjamin M. Marlin Nando de Freitas
 On for Energy Based Models Kevin Swersky Marc Aurelio Ranzato David Buchman Benjamin M. Marlin Nando de Freitas Toronto Machine Learning Group Meeting, 2011 Motivation Models Learning Goal: Unsupervised
On for Energy Based Models Kevin Swersky Marc Aurelio Ranzato David Buchman Benjamin M. Marlin Nando de Freitas Toronto Machine Learning Group Meeting, 2011 Motivation Models Learning Goal: Unsupervised
Denoising Autoencoders
 Denoising Autoencoders Oliver Worm, Daniel Leinfelder 20.11.2013 Oliver Worm, Daniel Leinfelder Denoising Autoencoders 20.11.2013 1 / 11 Introduction Poor initialisation can lead to local minima 1986 -
Denoising Autoencoders Oliver Worm, Daniel Leinfelder 20.11.2013 Oliver Worm, Daniel Leinfelder Denoising Autoencoders 20.11.2013 1 / 11 Introduction Poor initialisation can lead to local minima 1986 -
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Higher Order Statistics
 Higher Order Statistics Matthias Hennig Neural Information Processing School of Informatics, University of Edinburgh February 12, 2018 1 0 Based on Mark van Rossum s and Chris Williams s old NIP slides
Higher Order Statistics Matthias Hennig Neural Information Processing School of Informatics, University of Edinburgh February 12, 2018 1 0 Based on Mark van Rossum s and Chris Williams s old NIP slides
COMP 551 Applied Machine Learning Lecture 13: Dimension reduction and feature selection
 COMP 551 Applied Machine Learning Lecture 13: Dimension reduction and feature selection Instructor: Herke van Hoof (herke.vanhoof@cs.mcgill.ca) Based on slides by:, Jackie Chi Kit Cheung Class web page:
COMP 551 Applied Machine Learning Lecture 13: Dimension reduction and feature selection Instructor: Herke van Hoof (herke.vanhoof@cs.mcgill.ca) Based on slides by:, Jackie Chi Kit Cheung Class web page: