Reward-modulated inference
|
|
|
- Ashlyn Doyle
- 5 years ago
- Views:
Transcription
1 Buck Shlegeris Matthew Alger COMP3740, 2014
2 Outline Supervised, unsupervised, and reinforcement learning Neural nets RMI Results with RMI
3 Types of machine learning supervised unsupervised reinforcement

4 MNIST
5 Supervised learning Given some pairs (x, f (x)), approximate f.
6 Supervised learning Given some pairs (x, f (x)), approximate f. classification
7 Supervised learning Given some pairs (x, f (x)), approximate f. classification regression
8 Supervised learning Given some pairs (x, f (x)), approximate f. classification regression prediction
9 Unsupervised learning Given data, find patterns.
10 Unsupervised learning Given data, find patterns. Goal is to increase likelihood of observed data.
11 Unsupervised learning Given data, find patterns. Goal is to increase likelihood of observed data. Related to compression
12 Unsupervised learning Given data, find patterns. Goal is to increase likelihood of observed data. Related to compression This is useful as a preprocessing step.
13 Reinforcement learning You see some stuff, and get some reward. What do you want to do?
14 Reinforcement learning You see some stuff, and get some reward. What do you want to do? Way more general much harder make assumptions.
15 Reinforcement learning You see some stuff, and get some reward. What do you want to do? Way more general much harder make assumptions. Stationary
16 Reinforcement learning You see some stuff, and get some reward. What do you want to do? Way more general much harder make assumptions. Stationary MDP
17 Reinforcement learning You see some stuff, and get some reward. What do you want to do? Way more general much harder make assumptions. Stationary MDP Value estimation? (Use supervised prediction?)
18 Reinforcement learning You see some stuff, and get some reward. What do you want to do? Way more general much harder make assumptions. Stationary MDP Value estimation? (Use supervised prediction?) Explore vs exploit?
19 Reinforcement learning You see some stuff, and get some reward. What do you want to do? Way more general much harder make assumptions. Stationary MDP Value estimation? (Use supervised prediction?) Explore vs exploit? Preprocessing somehow?
20 Neural nets What s a nice class of functions from R n to R m?
21 Neural nets f ( x) = W x + b (1)
22 Neural nets f ( x) = W x + b (1) Let s use the name θ for our model, the combination of W and b.
23 Logistic regression P(Y = i θ, x) = s(w x + b)i (2) (s rescales vectors in R n to have an L1 norm of 1.)
24 Logistic regression P(Y = i θ, x) = s(w x + b)i (2) (s rescales vectors in R n to have an L1 norm of 1.) prediction(θ, x) = argmax(p(y = i θ, x)) (3) i
25 Logistic regression L(θ, x, y) = log(s(w x + b)y ) (4)
26 Logistic regression L(θ, x, y) = log(s(w x + b)y ) (4) Overfitting?
27 Logistic regression L(θ, x, y) = log(s(w x + b)y ) (4) Overfitting? L(θ, x, y) = log(s(w x + b)y ) R(θ) (5)
28 Logistic regression L(θ, x, y) = log(s(w x + b)y ) (4) Overfitting? L(θ, x, y) = log(s(w x + b)y ) R(θ) (5) What if instead of a single input vector x and single label y, we had a whole list of inputs D and a vector of labels y?
29 Logistic regression L(θ, x, y) = log(s(w x + b)y ) (4) Overfitting? L(θ, x, y) = log(s(w x + b)y ) R(θ) (5) What if instead of a single input vector x and single label y, we had a whole list of inputs D and a vector of labels y? L(θ, D, y) = L(θ, D i, y i ) R(θ) (6) i D
30 Logistic regression θ (D, y) =
31 Logistic regression θ (D, y) = argmin (L(θ, D, y)) (7) θ
32 Logistic regression θ (D, y) = argmin (L(θ, D, y)) (7) θ θ (R x y R y ), so good luck finding that analytically
33 Logistic regression
34 Logistic regression Gradient descent while last update was bigger than ɛ do W new W α L(θ,D, y) W end while
35 Logistic regression Stochastic gradient descent for input x and label y (D, y) do w W α L(θ, x,y) W end for
36 Logistic regression Only linearly separable things can be separated!
 s(ws(w 2 x + b2 ) + b) = s(w h +")
37 Multilayer perceptron Logistic regression Multilayer perceptron s(w x + b) s(ws(w 2 x + b2 ) + b) = s(w h + b)
38 Multilayer perceptron Why stop at 1 layer?

39 Multilayer perceptron Why stop at 1 layer?
40 Autoencoders
41 Autoencoders x = s(w s(w 2 x + b2 ) + b) (8)
 + b) (8) L(θ, x) = x x")
42 Autoencoders x = s(w s(w 2 x + b2 ) + b) (8) L(θ, x) = x x (9)
43 Denoising autoencoders (das)
44 Denoising autoencoders (das) s(w s(w 2 n( x) + b2 ) + b) (10) (where n is a stochastic noise function)
45 Denoising autoencoders (das)
 + b) (11)")
46 Denoising autoencoders (das) s(w s(w 2 x + b2 ) + b) (11)

47 Denoising autoencoders (das)
48 Denoising autoencoders (das)

49 Denoising autoencoders (das)

50 Denoising autoencoders (das)
51 Denoising autoencoders (das) L(θ, x, y) = log(s(w x + b)y ) (12)
52 Denoising autoencoders (das) L(θ, x, y) = log(s(w x + b)y ) (12) L(θ, x) = x x (13)
53 Denoising autoencoders (das) L(θ, x, y) = log(s(w x + b)y ) (12) L(θ, x) = x x (13) How do we mix between these?
54 Reward modulation Add a time-varying modulation function λ(t):
55 Reward modulation Add a time-varying modulation function λ(t): L(θ, x, y) = λ(t) supervised cost + (1 λ(t)) unsupervised cost (14)
56 Reward modulation Add a time-varying modulation function λ(t): L(θ, x, y) = λ(t) supervised cost + (1 λ(t)) unsupervised cost (14) ( ) ( ) L(θ, x, y) = λ(t) log(s(w x + b)y ) + (1 λ(t)) x x (15)
57 Reward modulation Motivations: Information theory
58 Reward modulation Motivations: Information theory Fine tuning
59 Reward modulation Motivations: Information theory Fine tuning Extreme learning
60 Reward modulation Questions:
61 Reward modulation Questions: Does it improve performance on problems?
62 Reward modulation Questions: Does it improve performance on problems? How should we vary reward modulation?
63 Reward modulation Questions: Does it improve performance on problems? How should we vary reward modulation?
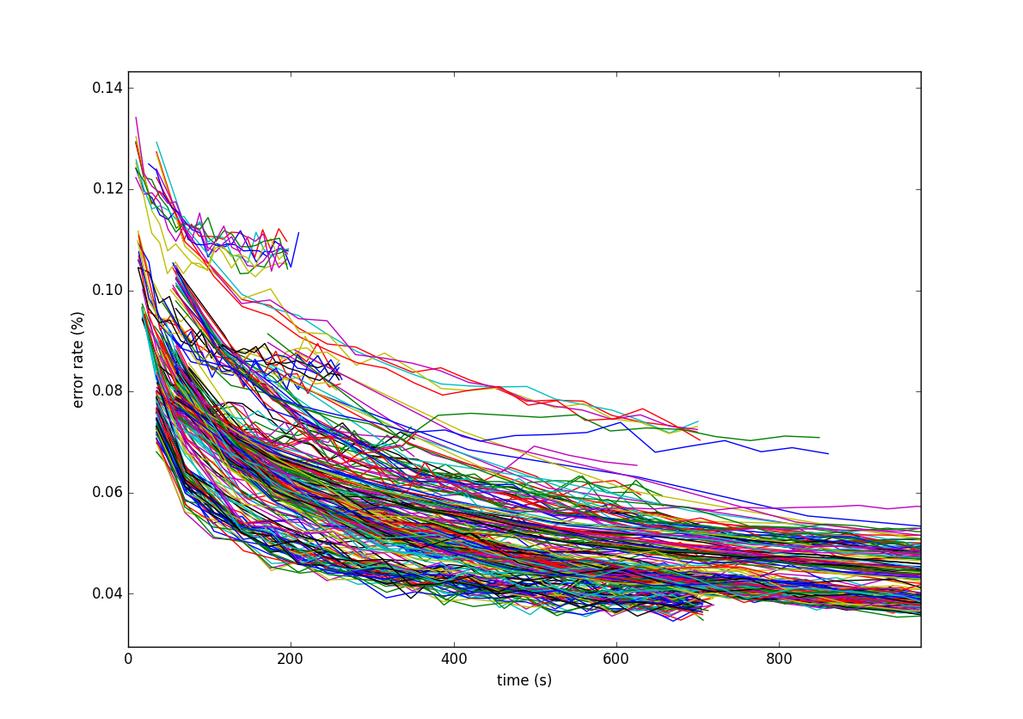
64 Results
65 Hyperparameters
66 Hyperparameters
67 Hyperparameters
68 Classification problem Error rate p = 0 p = 1 p = 2 p = 4 p = 10 p = 15 p = Epochs Figure: Step reward modulation with λ = 0 if t < p, and λ = 0 otherwise.
69 Classification problem 10 2 λ = t λ = t 2 Error rate 6 4 λ = t 4 λ = t 10 λ = t 20 λ = t 40 λ = t Epochs Figure: Linear reward modulation with different changes in λ.
70 Classification problem 10 2 Error rate 6 4 λ = t λ = t λ = t λ = t λ = t λ = t λ = t λ = t Epochs Figure: Hyperbolic reward modulation with different changes in λ.
71 Contextual bandit no results yet.
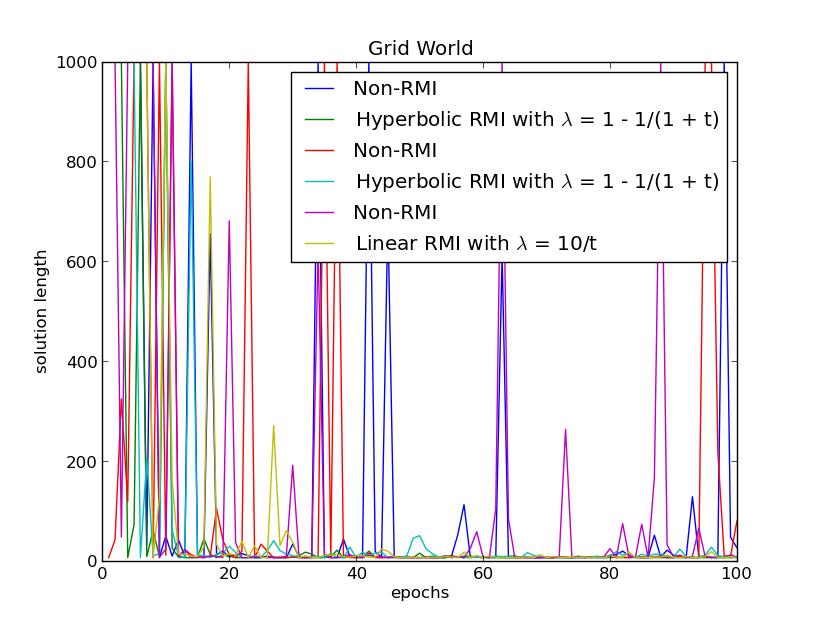
72 MDP
73 Conclusions
74 Conclusions RMI works on classification (maybe because it s like fine-tuning)
75 Conclusions RMI works on classification (maybe because it s like fine-tuning) Haven t got contextual bandit results yet.
76 Conclusions RMI works on classification (maybe because it s like fine-tuning) Haven t got contextual bandit results yet. Works nicely on grid world for some reason, more MDP data to come.
Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011!
 Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011! 1 Todayʼs topics" Learning from Examples: brief review! Univariate Linear Regression! Batch gradient descent! Stochastic gradient
Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011! 1 Todayʼs topics" Learning from Examples: brief review! Univariate Linear Regression! Batch gradient descent! Stochastic gradient
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
ECS171: Machine Learning Lecture 4: Optimization (LFD 3.3, SGD) Cho-Jui Hsieh UC Davis Jan 22, 2018 Gradient descent Optimization Goal: find the minimizer of a function min f (w) w For now we assume f
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
UNSUPERVISED LEARNING
 UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
Machine Learning Basics: Maximum Likelihood Estimation
 Machine Learning Basics: Maximum Likelihood Estimation Sargur N. srihari@cedar.buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics 1. Learning
Machine Learning Basics: Maximum Likelihood Estimation Sargur N. srihari@cedar.buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics 1. Learning
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Lecture 10. Neural networks and optimization. Machine Learning and Data Mining November Nando de Freitas UBC. Nonlinear Supervised Learning
 Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Course Structure. Psychology 452 Week 12: Deep Learning. Chapter 8 Discussion. Part I: Deep Learning: What and Why? Rufus. Rufus Processed By Fetch
 Psychology 452 Week 12: Deep Learning What Is Deep Learning? Preliminary Ideas (that we already know!) The Restricted Boltzmann Machine (RBM) Many Layers of RBMs Pros and Cons of Deep Learning Course Structure
Psychology 452 Week 12: Deep Learning What Is Deep Learning? Preliminary Ideas (that we already know!) The Restricted Boltzmann Machine (RBM) Many Layers of RBMs Pros and Cons of Deep Learning Course Structure
Variational Autoencoder
 Variational Autoencoder Göker Erdo gan August 8, 2017 The variational autoencoder (VA) [1] is a nonlinear latent variable model with an efficient gradient-based training procedure based on variational
Variational Autoencoder Göker Erdo gan August 8, 2017 The variational autoencoder (VA) [1] is a nonlinear latent variable model with an efficient gradient-based training procedure based on variational
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Learning Deep Architectures for AI. Part II - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Classification: Logistic Regression from Data
 Classification: Logistic Regression from Data Machine Learning: Jordan Boyd-Graber University of Colorado Boulder LECTURE 3 Slides adapted from Emily Fox Machine Learning: Jordan Boyd-Graber Boulder Classification:
Classification: Logistic Regression from Data Machine Learning: Jordan Boyd-Graber University of Colorado Boulder LECTURE 3 Slides adapted from Emily Fox Machine Learning: Jordan Boyd-Graber Boulder Classification:
Logistic Regression Trained with Different Loss Functions. Discussion
 Logistic Regression Trained with Different Loss Functions Discussion CS640 Notations We restrict our discussions to the binary case. g(z) = g (z) = g(z) z h w (x) = g(wx) = + e z = g(z)( g(z)) + e wx =
Logistic Regression Trained with Different Loss Functions Discussion CS640 Notations We restrict our discussions to the binary case. g(z) = g (z) = g(z) z h w (x) = g(wx) = + e z = g(z)( g(z)) + e wx =
CSCI567 Machine Learning (Fall 2014)
") CSCI567 Machine Learning (Fall 24) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu October 2, 24 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 24) October 2, 24 / 24 Outline Review
CSCI567 Machine Learning (Fall 24) Drs. Sha & Liu {feisha,yanliu.cs}@usc.edu October 2, 24 Drs. Sha & Liu ({feisha,yanliu.cs}@usc.edu) CSCI567 Machine Learning (Fall 24) October 2, 24 / 24 Outline Review
CS260: Machine Learning Algorithms
 CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
ECS171: Machine Learning
 ECS171: Machine Learning Lecture 3: Linear Models I (LFD 3.2, 3.3) Cho-Jui Hsieh UC Davis Jan 17, 2018 Linear Regression (LFD 3.2) Regression Classification: Customer record Yes/No Regression: predicting
ECS171: Machine Learning Lecture 3: Linear Models I (LFD 3.2, 3.3) Cho-Jui Hsieh UC Davis Jan 17, 2018 Linear Regression (LFD 3.2) Regression Classification: Customer record Yes/No Regression: predicting
Statistical Data Mining and Machine Learning Hilary Term 2016
 Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
TTIC 31230, Fundamentals of Deep Learning David McAllester, Winter Multiclass Logistic Regression. Multilayer Perceptrons (MLPs)
") TTIC 31230, Fundamentals of Deep Learning David McAllester, Winter 2018 Multiclass Logistic Regression Multilayer Perceptrons (MLPs) Stochastic Gradient Descent (SGD) 1 Multiclass Classification We consider
TTIC 31230, Fundamentals of Deep Learning David McAllester, Winter 2018 Multiclass Logistic Regression Multilayer Perceptrons (MLPs) Stochastic Gradient Descent (SGD) 1 Multiclass Classification We consider
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks
 Lecture 5: Artificial Neural Networks") Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Linear Regression (continued)
") Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Logistic Regression. William Cohen
 Logistic Regression William Cohen 1 Outline Quick review classi5ication, naïve Bayes, perceptrons new result for naïve Bayes Learning as optimization Logistic regression via gradient ascent Over5itting
Logistic Regression William Cohen 1 Outline Quick review classi5ication, naïve Bayes, perceptrons new result for naïve Bayes Learning as optimization Logistic regression via gradient ascent Over5itting
Importance Reweighting Using Adversarial-Collaborative Training
 Importance Reweighting Using Adversarial-Collaborative Training Yifan Wu yw4@andrew.cmu.edu Tianshu Ren tren@andrew.cmu.edu Lidan Mu lmu@andrew.cmu.edu Abstract We consider the problem of reweighting a
Importance Reweighting Using Adversarial-Collaborative Training Yifan Wu yw4@andrew.cmu.edu Tianshu Ren tren@andrew.cmu.edu Lidan Mu lmu@andrew.cmu.edu Abstract We consider the problem of reweighting a
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions
 perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions") BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Artificial Neural Networks 2
 CSC2515 Machine Learning Sam Roweis Artificial Neural s 2 We saw neural nets for classification. Same idea for regression. ANNs are just adaptive basis regression machines of the form: y k = j w kj σ(b
CSC2515 Machine Learning Sam Roweis Artificial Neural s 2 We saw neural nets for classification. Same idea for regression. ANNs are just adaptive basis regression machines of the form: y k = j w kj σ(b
Speaker Representation and Verification Part II. by Vasileios Vasilakakis
 Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Linear Models for Classification
 Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Variations of Logistic Regression with Stochastic Gradient Descent
 Variations of Logistic Regression with Stochastic Gradient Descent Panqu Wang(pawang@ucsd.edu) Phuc Xuan Nguyen(pxn002@ucsd.edu) January 26, 2012 Abstract In this paper, we extend the traditional logistic
Variations of Logistic Regression with Stochastic Gradient Descent Panqu Wang(pawang@ucsd.edu) Phuc Xuan Nguyen(pxn002@ucsd.edu) January 26, 2012 Abstract In this paper, we extend the traditional logistic
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 5
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 5 Slides adapted from Jordan Boyd-Graber, Tom Mitchell, Ziv Bar-Joseph Machine Learning: Chenhao Tan Boulder 1 of 27 Quiz question For
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 5 Slides adapted from Jordan Boyd-Graber, Tom Mitchell, Ziv Bar-Joseph Machine Learning: Chenhao Tan Boulder 1 of 27 Quiz question For
Machine Learning 4771
 Machine Learning 4771 Instructor: Tony Jebara Topic 7 Unsupervised Learning Statistical Perspective Probability Models Discrete & Continuous: Gaussian, Bernoulli, Multinomial Maimum Likelihood Logistic
Machine Learning 4771 Instructor: Tony Jebara Topic 7 Unsupervised Learning Statistical Perspective Probability Models Discrete & Continuous: Gaussian, Bernoulli, Multinomial Maimum Likelihood Logistic
Empirical Risk Minimization
 Empirical Risk Minimization Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Introduction PAC learning ERM in practice 2 General setting Data X the input space and Y the output space
Empirical Risk Minimization Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Introduction PAC learning ERM in practice 2 General setting Data X the input space and Y the output space
Probabilistic Machine Learning. Industrial AI Lab.
 Probabilistic Machine Learning Industrial AI Lab. Probabilistic Linear Regression Outline Probabilistic Classification Probabilistic Clustering Probabilistic Dimension Reduction 2 Probabilistic Linear
Probabilistic Machine Learning Industrial AI Lab. Probabilistic Linear Regression Outline Probabilistic Classification Probabilistic Clustering Probabilistic Dimension Reduction 2 Probabilistic Linear
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
Classification with Perceptrons. Reading:
 Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Contents. 1 Introduction. 1.1 History of Optimization ALG-ML SEMINAR LISSA: LINEAR TIME SECOND-ORDER STOCHASTIC ALGORITHM FEBRUARY 23, 2016
 ALG-ML SEMINAR LISSA: LINEAR TIME SECOND-ORDER STOCHASTIC ALGORITHM FEBRUARY 23, 2016 LECTURERS: NAMAN AGARWAL AND BRIAN BULLINS SCRIBE: KIRAN VODRAHALLI Contents 1 Introduction 1 1.1 History of Optimization.....................................
ALG-ML SEMINAR LISSA: LINEAR TIME SECOND-ORDER STOCHASTIC ALGORITHM FEBRUARY 23, 2016 LECTURERS: NAMAN AGARWAL AND BRIAN BULLINS SCRIBE: KIRAN VODRAHALLI Contents 1 Introduction 1 1.1 History of Optimization.....................................
Machine Learning Support Vector Machines. Prof. Matteo Matteucci
 Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
CSC321 Lecture 8: Optimization
 CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CS229 Supplemental Lecture notes
 CS229 Supplemental Lecture notes John Duchi Binary classification In binary classification problems, the target y can take on at only two values. In this set of notes, we show how to model this problem
CS229 Supplemental Lecture notes John Duchi Binary classification In binary classification problems, the target y can take on at only two values. In this set of notes, we show how to model this problem
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS16
 SS16") COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS6 Lecture 3: Classification with Logistic Regression Advanced optimization techniques Underfitting & Overfitting Model selection (Training-
COMPUTATIONAL INTELLIGENCE (INTRODUCTION TO MACHINE LEARNING) SS6 Lecture 3: Classification with Logistic Regression Advanced optimization techniques Underfitting & Overfitting Model selection (Training-
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Greedy Layer-Wise Training of Deep Networks
 Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Classification for High Dimensional Problems Using Bayesian Neural Networks and Dirichlet Diffusion Trees
 Classification for High Dimensional Problems Using Bayesian Neural Networks and Dirichlet Diffusion Trees Rafdord M. Neal and Jianguo Zhang Presented by Jiwen Li Feb 2, 2006 Outline Bayesian view of feature
Classification for High Dimensional Problems Using Bayesian Neural Networks and Dirichlet Diffusion Trees Rafdord M. Neal and Jianguo Zhang Presented by Jiwen Li Feb 2, 2006 Outline Bayesian view of feature
Learning From Data Lecture 15 Reflecting on Our Path - Epilogue to Part I
 Learning From Data Lecture 15 Reflecting on Our Path - Epilogue to Part I What We Did The Machine Learning Zoo Moving Forward M Magdon-Ismail CSCI 4100/6100 recap: Three Learning Principles Scientist 2
Learning From Data Lecture 15 Reflecting on Our Path - Epilogue to Part I What We Did The Machine Learning Zoo Moving Forward M Magdon-Ismail CSCI 4100/6100 recap: Three Learning Principles Scientist 2
Plan. Perceptron Linear discriminant. Associative memories Hopfield networks Chaotic networks. Multilayer perceptron Backpropagation
 Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Distirbutional robustness, regularizing variance, and adversaries
 Distirbutional robustness, regularizing variance, and adversaries John Duchi Based on joint work with Hongseok Namkoong and Aman Sinha Stanford University November 2017 Motivation We do not want machine-learned
Distirbutional robustness, regularizing variance, and adversaries John Duchi Based on joint work with Hongseok Namkoong and Aman Sinha Stanford University November 2017 Motivation We do not want machine-learned
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Online Learning and Sequential Decision Making
 Online Learning and Sequential Decision Making Emilie Kaufmann CNRS & CRIStAL, Inria SequeL, emilie.kaufmann@univ-lille.fr Research School, ENS Lyon, Novembre 12-13th 2018 Emilie Kaufmann Online Learning
Online Learning and Sequential Decision Making Emilie Kaufmann CNRS & CRIStAL, Inria SequeL, emilie.kaufmann@univ-lille.fr Research School, ENS Lyon, Novembre 12-13th 2018 Emilie Kaufmann Online Learning
Artificial Neural Networks (ANN)
") Artificial Neural Networks (ANN) Edmondo Trentin April 17, 2013 ANN: Definition The definition of ANN is given in 3.1 points. Indeed, an ANN is a machine that is completely specified once we define its:
Artificial Neural Networks (ANN) Edmondo Trentin April 17, 2013 ANN: Definition The definition of ANN is given in 3.1 points. Indeed, an ANN is a machine that is completely specified once we define its:
Machine Learning Basics: Stochastic Gradient Descent. Sargur N. Srihari
 Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Machine Learning Basics: Stochastic Gradient Descent Sargur N. srihari@cedar.buffalo.edu 1 Topics 1. Learning Algorithms 2. Capacity, Overfitting and Underfitting 3. Hyperparameters and Validation Sets
Logistic Regression Logistic
 Case Study 1: Estimating Click Probabilities L2 Regularization for Logistic Regression Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 10 th,
Case Study 1: Estimating Click Probabilities L2 Regularization for Logistic Regression Machine Learning/Statistics for Big Data CSE599C1/STAT592, University of Washington Carlos Guestrin January 10 th,
Machine Learning. Regression-Based Classification & Gaussian Discriminant Analysis. Manfred Huber
 Machine Learning Regression-Based Classification & Gaussian Discriminant Analysis Manfred Huber 2015 1 Logistic Regression Linear regression provides a nice representation and an efficient solution to
Machine Learning Regression-Based Classification & Gaussian Discriminant Analysis Manfred Huber 2015 1 Logistic Regression Linear regression provides a nice representation and an efficient solution to
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux INRIA 8 Nov 2011 Nicolas Le Roux (INRIA) Neural networks and optimization 8 Nov 2011 1 / 80 1 Introduction 2 Linear classifier 3 Convolutional neural networks
Neural networks and optimization Nicolas Le Roux INRIA 8 Nov 2011 Nicolas Le Roux (INRIA) Neural networks and optimization 8 Nov 2011 1 / 80 1 Introduction 2 Linear classifier 3 Convolutional neural networks
Classification: Logistic Regression from Data
 Classification: Logistic Regression from Data Machine Learning: Alvin Grissom II University of Colorado Boulder Slides adapted from Emily Fox Machine Learning: Alvin Grissom II Boulder Classification:
Classification: Logistic Regression from Data Machine Learning: Alvin Grissom II University of Colorado Boulder Slides adapted from Emily Fox Machine Learning: Alvin Grissom II Boulder Classification:
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Non-Convex Optimization in Machine Learning. Jan Mrkos AIC
 Non-Convex Optimization in Machine Learning Jan Mrkos AIC The Plan 1. Introduction 2. Non convexity 3. (Some) optimization approaches 4. Speed and stuff? Neural net universal approximation Theorem (1989):
Non-Convex Optimization in Machine Learning Jan Mrkos AIC The Plan 1. Introduction 2. Non convexity 3. (Some) optimization approaches 4. Speed and stuff? Neural net universal approximation Theorem (1989):
Unsupervised Neural Nets
 Unsupervised Neural Nets (and ICA) Lyle Ungar (with contributions from Quoc Le, Socher & Manning) Lyle Ungar, University of Pennsylvania Semi-Supervised Learning Hypothesis:%P(c x)%can%be%more%accurately%computed%using%
Unsupervised Neural Nets (and ICA) Lyle Ungar (with contributions from Quoc Le, Socher & Manning) Lyle Ungar, University of Pennsylvania Semi-Supervised Learning Hypothesis:%P(c x)%can%be%more%accurately%computed%using%
Towards stability and optimality in stochastic gradient descent
 Towards stability and optimality in stochastic gradient descent Panos Toulis, Dustin Tran and Edoardo M. Airoldi August 26, 2016 Discussion by Ikenna Odinaka Duke University Outline Introduction 1 Introduction
Towards stability and optimality in stochastic gradient descent Panos Toulis, Dustin Tran and Edoardo M. Airoldi August 26, 2016 Discussion by Ikenna Odinaka Duke University Outline Introduction 1 Introduction
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning
 CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
Machine Learning Linear Models
 Machine Learning Linear Models Outline II - Linear Models 1. Linear Regression (a) Linear regression: History (b) Linear regression with Least Squares (c) Matrix representation and Normal Equation Method
Machine Learning Linear Models Outline II - Linear Models 1. Linear Regression (a) Linear regression: History (b) Linear regression with Least Squares (c) Matrix representation and Normal Equation Method
Machine Learning and Data Mining. Linear classification. Kalev Kask
 Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
Linear Models in Machine Learning
 CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
Neural Networks and Deep Learning.
 Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Logistic Regression Introduction to Machine Learning. Matt Gormley Lecture 8 Feb. 12, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
Introduction to Machine Learning
 Introduction to Machine Learning Machine Learning: Jordan Boyd-Graber University of Maryland LOGISTIC REGRESSION FROM TEXT Slides adapted from Emily Fox Machine Learning: Jordan Boyd-Graber UMD Introduction
Introduction to Machine Learning Machine Learning: Jordan Boyd-Graber University of Maryland LOGISTIC REGRESSION FROM TEXT Slides adapted from Emily Fox Machine Learning: Jordan Boyd-Graber UMD Introduction
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
April 9, Depto. de Ing. de Sistemas e Industrial Universidad Nacional de Colombia, Bogotá. Linear Classification Models. Fabio A. González Ph.D.
 Depto. de Ing. de Sistemas e Industrial Universidad Nacional de Colombia, Bogotá April 9, 2018 Content 1 2 3 4 Outline 1 2 3 4 problems { C 1, y(x) threshold predict(x) = C 2, y(x) < threshold, with threshold
Depto. de Ing. de Sistemas e Industrial Universidad Nacional de Colombia, Bogotá April 9, 2018 Content 1 2 3 4 Outline 1 2 3 4 problems { C 1, y(x) threshold predict(x) = C 2, y(x) < threshold, with threshold
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Part of the slides are adapted from Ziko Kolter
 Part of the slides are adapted from Ziko Kolter OUTLINE 1 Supervised learning: classification........................................................ 2 2 Non-linear regression/classification, overfitting,
Part of the slides are adapted from Ziko Kolter OUTLINE 1 Supervised learning: classification........................................................ 2 2 Non-linear regression/classification, overfitting,
CSC321 Lecture 7: Optimization
 CSC321 Lecture 7: Optimization Roger Grosse Roger Grosse CSC321 Lecture 7: Optimization 1 / 25 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 7: Optimization Roger Grosse Roger Grosse CSC321 Lecture 7: Optimization 1 / 25 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
Denoising Autoencoders
 Denoising Autoencoders Oliver Worm, Daniel Leinfelder 20.11.2013 Oliver Worm, Daniel Leinfelder Denoising Autoencoders 20.11.2013 1 / 11 Introduction Poor initialisation can lead to local minima 1986 -
Denoising Autoencoders Oliver Worm, Daniel Leinfelder 20.11.2013 Oliver Worm, Daniel Leinfelder Denoising Autoencoders 20.11.2013 1 / 11 Introduction Poor initialisation can lead to local minima 1986 -
Linear Models for Regression
 Linear Models for Regression CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 The Regression Problem Training data: A set of input-output
Linear Models for Regression CSE 4309 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 The Regression Problem Training data: A set of input-output
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/xilnmn Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/xilnmn Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
Loss Functions, Decision Theory, and Linear Models
 Loss Functions, Decision Theory, and Linear Models CMSC 678 UMBC January 31 st, 2018 Some slides adapted from Hamed Pirsiavash Logistics Recap Piazza (ask & answer questions): https://piazza.com/umbc/spring2018/cmsc678
Loss Functions, Decision Theory, and Linear Models CMSC 678 UMBC January 31 st, 2018 Some slides adapted from Hamed Pirsiavash Logistics Recap Piazza (ask & answer questions): https://piazza.com/umbc/spring2018/cmsc678
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Neural Networks. Haiming Zhou. Division of Statistics Northern Illinois University.
 Neural Networks Haiming Zhou Division of Statistics Northern Illinois University zhouh@niu.edu Neural Networks The term neural network has evolved to encompass a large class of models and learning methods.
Neural Networks Haiming Zhou Division of Statistics Northern Illinois University zhouh@niu.edu Neural Networks The term neural network has evolved to encompass a large class of models and learning methods.
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation