Basic Principles of Unsupervised and Unsupervised
|
|
|
- Lesley George
- 5 years ago
- Views:
Transcription
1 Basic Principles of Unsupervised and Unsupervised Learning Toward Deep Learning Shun ichi Amari (RIKEN Brain Science Institute) collaborators: R. Karakida, M. Okada (U. Tokyo)
2 Deep Learning Self Organization + Supervised Learning RBM: Restricted Boltzmann Machine Auto Encoder, Recurrent Net Dropout Contrastive divergence
3 Simple Hebbian Self Organization
4 self organization of
5 Equillibrium
6 Equillibrium: special cases
7 Two and many clusters
8 Dynamics of self organization
9 Lyapunov Function
10 Further Problems Distributed small clusters; large clusters Mutual interactions among h neurons neural field Localized receptive fields invariance
11 Boltzmann Machine
12 RBM: Restricted Boltzmann Machine
13 RBM
14 Self Organization
15 Interaction of Hidden Neurons
16
17 Recurrent Net (Auto Encoder)
18 Recurrent Net Self Organization
19 Gaussian RBM is easy Higher order interactions Gram Charlier expansion
20 Gaussian Boltzmann Machine
21 Equilibrium Solution
22 Equilibrium Solution General Solution diagonalized by You can choose m( k) eigen values form Stable Solution the case of m = k
23 Contrastive Divergence RBM 2 layered probabilistic neural network No connections within layers Visible v W Hidden h How to train RBM Maximum Likelihood (ML) learning is hard Sampling Input Equilibrium Many iterations of Gibbs Sampling demand too much computational time 23
24 Contrastive Divergence Solution
25 Solution General Solution Stable Solution = k the same analytical form with maximum likelihood regardless of n
26 Simulation Each Layer : 10 Neurons Input: 10 dim. Gaussian Distribution Mean = 0, Variance[0.2, 0.4,, 2], Covariance = 0 ML Extracted Eigenvalue Extracted Eigenvalue Input Eigenvalues Extracted Eigenvalues
27 Bayesian Duality in Exponential Family Data x Parameter (higher order concepts) Curved exponential family
28 RBM = h, x = Wv x = v = hw
29 Two Manifolds
30 Geometry of CDn (contrastive divergence)
31 Bernoulli Gaussian RBM ICA R. Karakida
32 Equilibrium Analysis: Results Assumption of Input s: Independent and nonnegative sources B: N N orthogonal matrix ICA (independent Component Analysis) Solutions If, ML and CD learning have the following stable solutions: W s Space CD Solutions Mean value: Model variance : σ ML Solutions ICA 32
33 Simulation The number of Neurons: N = M = 2, σ = 1/2 Sources p (s) Uniform Distribution Mixing Input CD ICA Solution Output Independent sources are extracted in G B RBM 33
34 Supervised Learning Multilayer perceptron Back prop learning Singularity!! Natural Gradient Solves Difficulty
35 Mathematical Neurons w x y wx h i i x y ( u) u
36 Multilayer Perceptrons y v i wi x w 1 x x ( x1, x2,..., x n ) x y f x v w x, i i ( w,..., w ; v,..., v ) 1 m 1 m
37 Multilayer Perceptron neuromanifold () x space of functions S y f x, θ v i w i x θ v, v ; w, w 1 m 1, m
38 Backpropagation ---gradient learning x x examples :,,, training set y1 1 y t t 1 l( y, x; ) y f x, 2 log p y, x; 2 l( yt, xt; t) t t f x, v w x i i
39 Flaws of MLP slow convergence : Plateau error local minima Boosting and Bagging; SVM
40 Parameter Space vs Function Space

41 Singularity of MLP example
42 Geometry of singular model y v wx n v v w 0 W
43 singularities
44 Gaussian mixture ;,, 1 p x v w w v x w v x w x exp x singular : w w, v 1v v w 1 w 2
45 Steepest Direction---Natural Gradient l( ) l l l,, 1 n 1 l G l 2 d i j d d Gd = G d d ij lx (, y; ) t t t t t
46 Natural Gradient max dl l d l d 2 1 l G l lx (, y; ) t t t t t
47 Adaptive Natural Gradient
48 Learning, Estimation, and Model Selection x: x; Egen D p0 y p y E train Dpemp y x; E E gen gen d 2n E train d n d :dimension
49
50
51
52 Coordinate Transformation u w2 w1 : u0 v1w1 v2w2 w w w v v v1 v2 v v v2 v1 z z 1 v



53 Singular lines in the parameter space
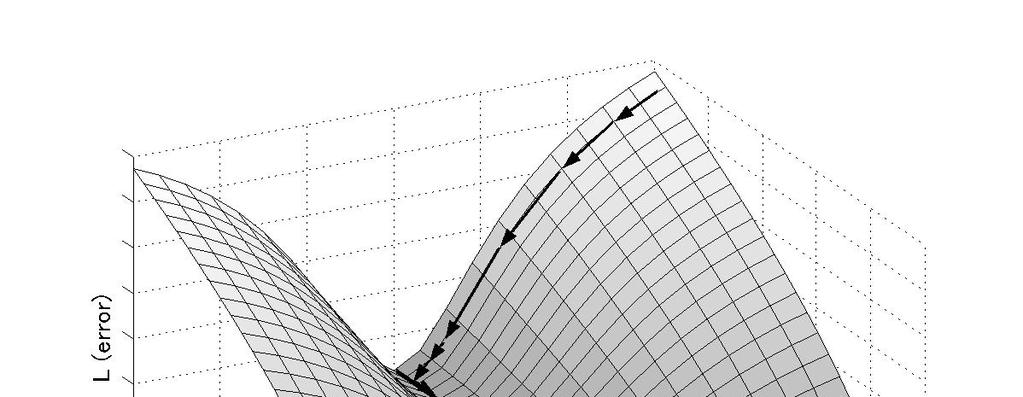
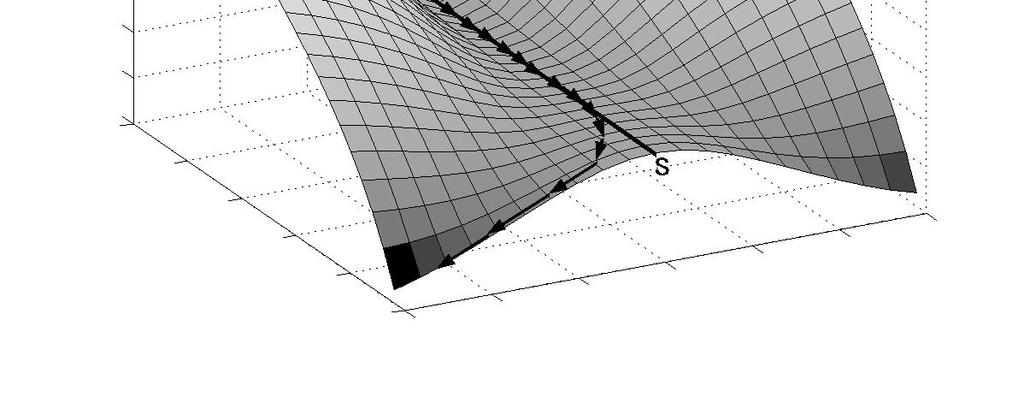
54 Learning Trajectory near the singularity

55 Milnor attractor
56 Dynamic vector fields: Redundant case
57 Dynamics of Learning : Trajectories log z l z z l v h v z h z z z h v z c z u u u u u
58 Dynamic vector fields: General case ( z <1 part stable)



59 Dynamic vector fields: General case ( z >1 part stable )


60 Fig. 2: trajectories
UNSUPERVISED LEARNING
 UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
Introduction to Neural Networks
 Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Non-Convex Optimization in Machine Learning. Jan Mrkos AIC
 Non-Convex Optimization in Machine Learning Jan Mrkos AIC The Plan 1. Introduction 2. Non convexity 3. (Some) optimization approaches 4. Speed and stuff? Neural net universal approximation Theorem (1989):
Non-Convex Optimization in Machine Learning Jan Mrkos AIC The Plan 1. Introduction 2. Non convexity 3. (Some) optimization approaches 4. Speed and stuff? Neural net universal approximation Theorem (1989):
Neural Networks. Mark van Rossum. January 15, School of Informatics, University of Edinburgh 1 / 28
 1 / 28 Neural Networks Mark van Rossum School of Informatics, University of Edinburgh January 15, 2018 2 / 28 Goals: Understand how (recurrent) networks behave Find a way to teach networks to do a certain
1 / 28 Neural Networks Mark van Rossum School of Informatics, University of Edinburgh January 15, 2018 2 / 28 Goals: Understand how (recurrent) networks behave Find a way to teach networks to do a certain
Greedy Layer-Wise Training of Deep Networks
 Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
Deep unsupervised learning
 Deep unsupervised learning Advanced data-mining Yongdai Kim Department of Statistics, Seoul National University, South Korea Unsupervised learning In machine learning, there are 3 kinds of learning paradigm.
Deep unsupervised learning Advanced data-mining Yongdai Kim Department of Statistics, Seoul National University, South Korea Unsupervised learning In machine learning, there are 3 kinds of learning paradigm.
Plan. Perceptron Linear discriminant. Associative memories Hopfield networks Chaotic networks. Multilayer perceptron Backpropagation
 Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, Spis treści
 Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
Deep learning / Ian Goodfellow, Yoshua Bengio and Aaron Courville. - Cambridge, MA ; London, 2017 Spis treści Website Acknowledgments Notation xiii xv xix 1 Introduction 1 1.1 Who Should Read This Book?
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
Statistical Learning Theory. Part I 5. Deep Learning
 Statistical Learning Theory Part I 5. Deep Learning Sumio Watanabe Tokyo Institute of Technology Review : Supervised Learning Training Data X 1, X 2,, X n q(x,y) =q(x)q(y x) Information Source Y 1, Y 2,,
Statistical Learning Theory Part I 5. Deep Learning Sumio Watanabe Tokyo Institute of Technology Review : Supervised Learning Training Data X 1, X 2,, X n q(x,y) =q(x)q(y x) Information Source Y 1, Y 2,,
COMP9444 Neural Networks and Deep Learning 11. Boltzmann Machines. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 11. Boltzmann Machines COMP9444 17s2 Boltzmann Machines 1 Outline Content Addressable Memory Hopfield Network Generative Models Boltzmann Machine Restricted Boltzmann
COMP9444 Neural Networks and Deep Learning 11. Boltzmann Machines COMP9444 17s2 Boltzmann Machines 1 Outline Content Addressable Memory Hopfield Network Generative Models Boltzmann Machine Restricted Boltzmann
Index. Santanu Pattanayak 2017 S. Pattanayak, Pro Deep Learning with TensorFlow,
 Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
Index A Activation functions, neuron/perceptron binary threshold activation function, 102 103 linear activation function, 102 rectified linear unit, 106 sigmoid activation function, 103 104 SoftMax activation
PATTERN CLASSIFICATION
 PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
Reading Group on Deep Learning Session 4 Unsupervised Neural Networks
 Reading Group on Deep Learning Session 4 Unsupervised Neural Networks Jakob Verbeek & Daan Wynen 206-09-22 Jakob Verbeek & Daan Wynen Unsupervised Neural Networks Outline Autoencoders Restricted) Boltzmann
Reading Group on Deep Learning Session 4 Unsupervised Neural Networks Jakob Verbeek & Daan Wynen 206-09-22 Jakob Verbeek & Daan Wynen Unsupervised Neural Networks Outline Autoencoders Restricted) Boltzmann
Unsupervised Neural Nets
 Unsupervised Neural Nets (and ICA) Lyle Ungar (with contributions from Quoc Le, Socher & Manning) Lyle Ungar, University of Pennsylvania Semi-Supervised Learning Hypothesis:%P(c x)%can%be%more%accurately%computed%using%
Unsupervised Neural Nets (and ICA) Lyle Ungar (with contributions from Quoc Le, Socher & Manning) Lyle Ungar, University of Pennsylvania Semi-Supervised Learning Hypothesis:%P(c x)%can%be%more%accurately%computed%using%
Lecture 10. Neural networks and optimization. Machine Learning and Data Mining November Nando de Freitas UBC. Nonlinear Supervised Learning
 Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Lecture 0 Neural networks and optimization Machine Learning and Data Mining November 2009 UBC Gradient Searching for a good solution can be interpreted as looking for a minimum of some error (loss) function
Deep Neural Networks
 Deep Neural Networks DT2118 Speech and Speaker Recognition Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 45 Outline State-to-Output Probability Model Artificial Neural Networks Perceptron Multi
Deep Neural Networks DT2118 Speech and Speaker Recognition Giampiero Salvi KTH/CSC/TMH giampi@kth.se VT 2015 1 / 45 Outline State-to-Output Probability Model Artificial Neural Networks Perceptron Multi
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Lecture 16 Deep Neural Generative Models
 Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Lecture 16 Deep Neural Generative Models CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 22, 2017 Approach so far: We have considered simple models and then constructed
Deep Learning Srihari. Deep Belief Nets. Sargur N. Srihari
 Deep Belief Nets Sargur N. Srihari srihari@cedar.buffalo.edu Topics 1. Boltzmann machines 2. Restricted Boltzmann machines 3. Deep Belief Networks 4. Deep Boltzmann machines 5. Boltzmann machines for continuous
Deep Belief Nets Sargur N. Srihari srihari@cedar.buffalo.edu Topics 1. Boltzmann machines 2. Restricted Boltzmann machines 3. Deep Belief Networks 4. Deep Boltzmann machines 5. Boltzmann machines for continuous
Deep Learning. What Is Deep Learning? The Rise of Deep Learning. Long History (in Hind Sight)
") CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
How to do backpropagation in a brain
 How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
How to do backpropagation in a brain Geoffrey Hinton Canadian Institute for Advanced Research & University of Toronto & Google Inc. Prelude I will start with three slides explaining a popular type of deep
Lecture 14: Deep Generative Learning
 Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Generative Modeling CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 14: Deep Generative Learning Density estimation Reconstructing probability density function using samples Bohyung Han
Course Structure. Psychology 452 Week 12: Deep Learning. Chapter 8 Discussion. Part I: Deep Learning: What and Why? Rufus. Rufus Processed By Fetch
 Psychology 452 Week 12: Deep Learning What Is Deep Learning? Preliminary Ideas (that we already know!) The Restricted Boltzmann Machine (RBM) Many Layers of RBMs Pros and Cons of Deep Learning Course Structure
Psychology 452 Week 12: Deep Learning What Is Deep Learning? Preliminary Ideas (that we already know!) The Restricted Boltzmann Machine (RBM) Many Layers of RBMs Pros and Cons of Deep Learning Course Structure
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Deep Learning. What Is Deep Learning? The Rise of Deep Learning. Long History (in Hind Sight)
") CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
Learning Deep Architectures for AI. Part II - Vijay Chakilam
 Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Learning Deep Architectures for AI - Yoshua Bengio Part II - Vijay Chakilam Limitations of Perceptron x1 W, b 0,1 1,1 y x2 weight plane output =1 output =0 There is no value for W and b such that the model
Restricted Boltzmann Machines for Collaborative Filtering
 Restricted Boltzmann Machines for Collaborative Filtering Authors: Ruslan Salakhutdinov Andriy Mnih Geoffrey Hinton Benjamin Schwehn Presentation by: Ioan Stanculescu 1 Overview The Netflix prize problem
Restricted Boltzmann Machines for Collaborative Filtering Authors: Ruslan Salakhutdinov Andriy Mnih Geoffrey Hinton Benjamin Schwehn Presentation by: Ioan Stanculescu 1 Overview The Netflix prize problem
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks
 Lecture 5: Artificial Neural Networks") Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Statistical Machine Learning (BE4M33SSU) Lecture 5: Artificial Neural Networks Jan Drchal Czech Technical University in Prague Faculty of Electrical Engineering Department of Computer Science Topics covered
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Regularization in Neural Networks
 Regularization in Neural Networks Sargur Srihari 1 Topics in Neural Network Regularization What is regularization? Methods 1. Determining optimal number of hidden units 2. Use of regularizer in error function
Regularization in Neural Networks Sargur Srihari 1 Topics in Neural Network Regularization What is regularization? Methods 1. Determining optimal number of hidden units 2. Use of regularizer in error function
Hopfield Networks and Boltzmann Machines. Christian Borgelt Artificial Neural Networks and Deep Learning 296
 Hopfield Networks and Boltzmann Machines Christian Borgelt Artificial Neural Networks and Deep Learning 296 Hopfield Networks A Hopfield network is a neural network with a graph G = (U,C) that satisfies
Hopfield Networks and Boltzmann Machines Christian Borgelt Artificial Neural Networks and Deep Learning 296 Hopfield Networks A Hopfield network is a neural network with a graph G = (U,C) that satisfies
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Unsupervised Learning
 CS 3750 Advanced Machine Learning hkc6@pitt.edu Unsupervised Learning Data: Just data, no labels Goal: Learn some underlying hidden structure of the data P(, ) P( ) Principle Component Analysis (Dimensionality
CS 3750 Advanced Machine Learning hkc6@pitt.edu Unsupervised Learning Data: Just data, no labels Goal: Learn some underlying hidden structure of the data P(, ) P( ) Principle Component Analysis (Dimensionality
Part 2. Representation Learning Algorithms
 53 Part 2 Representation Learning Algorithms 54 A neural network = running several logistic regressions at the same time If we feed a vector of inputs through a bunch of logis;c regression func;ons, then
53 Part 2 Representation Learning Algorithms 54 A neural network = running several logistic regressions at the same time If we feed a vector of inputs through a bunch of logis;c regression func;ons, then
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Learning to Disentangle Factors of Variation with Manifold Learning
 Learning to Disentangle Factors of Variation with Manifold Learning Scott Reed Kihyuk Sohn Yuting Zhang Honglak Lee University of Michigan, Department of Electrical Engineering and Computer Science 08
Learning to Disentangle Factors of Variation with Manifold Learning Scott Reed Kihyuk Sohn Yuting Zhang Honglak Lee University of Michigan, Department of Electrical Engineering and Computer Science 08
CSC321 Lecture 20: Autoencoders
 CSC321 Lecture 20: Autoencoders Roger Grosse Roger Grosse CSC321 Lecture 20: Autoencoders 1 / 16 Overview Latent variable models so far: mixture models Boltzmann machines Both of these involve discrete
CSC321 Lecture 20: Autoencoders Roger Grosse Roger Grosse CSC321 Lecture 20: Autoencoders 1 / 16 Overview Latent variable models so far: mixture models Boltzmann machines Both of these involve discrete
Probabilistic & Unsupervised Learning
 Probabilistic & Unsupervised Learning Week 2: Latent Variable Models Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College
Probabilistic & Unsupervised Learning Week 2: Latent Variable Models Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, and MSc ML/CSML, Dept Computer Science University College
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Statistical learning. Chapter 20, Sections 1 4 1
 Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Neural Networks Lecture 4: Radial Bases Function Networks
 Neural Networks Lecture 4: Radial Bases Function Networks H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011. A. Talebi, Farzaneh Abdollahi
Neural Networks Lecture 4: Radial Bases Function Networks H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011. A. Talebi, Farzaneh Abdollahi
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
Variational Autoencoders
 Variational Autoencoders Recap: Story so far A classification MLP actually comprises two components A feature extraction network that converts the inputs into linearly separable features Or nearly linearly
Variational Autoencoders Recap: Story so far A classification MLP actually comprises two components A feature extraction network that converts the inputs into linearly separable features Or nearly linearly
Robust Classification using Boltzmann machines by Vasileios Vasilakakis
 Robust Classification using Boltzmann machines by Vasileios Vasilakakis The scope of this report is to propose an architecture of Boltzmann machines that could be used in the context of classification,
Robust Classification using Boltzmann machines by Vasileios Vasilakakis The scope of this report is to propose an architecture of Boltzmann machines that could be used in the context of classification,
Introduction to Restricted Boltzmann Machines
 Introduction to Restricted Boltzmann Machines Ilija Bogunovic and Edo Collins EPFL {ilija.bogunovic,edo.collins}@epfl.ch October 13, 2014 Introduction Ingredients: 1. Probabilistic graphical models (undirected,
Introduction to Restricted Boltzmann Machines Ilija Bogunovic and Edo Collins EPFL {ilija.bogunovic,edo.collins}@epfl.ch October 13, 2014 Introduction Ingredients: 1. Probabilistic graphical models (undirected,
Natural Gradient Learning for Over- and Under-Complete Bases in ICA
 NOTE Communicated by Jean-François Cardoso Natural Gradient Learning for Over- and Under-Complete Bases in ICA Shun-ichi Amari RIKEN Brain Science Institute, Wako-shi, Hirosawa, Saitama 351-01, Japan Independent
NOTE Communicated by Jean-François Cardoso Natural Gradient Learning for Over- and Under-Complete Bases in ICA Shun-ichi Amari RIKEN Brain Science Institute, Wako-shi, Hirosawa, Saitama 351-01, Japan Independent
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Deep Learning: a gentle introduction
 Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
Deep Learning: a gentle introduction Jamal Atif jamal.atif@dauphine.fr PSL, Université Paris-Dauphine, LAMSADE February 8, 206 Jamal Atif (Université Paris-Dauphine) Deep Learning February 8, 206 / Why
ESANN'2003 proceedings - European Symposium on Artificial Neural Networks Bruges (Belgium), April 2003, d-side publi., ISBN X, pp.
, April 2003, d-side publi., ISBN X, pp.") On different ensembles of kernel machines Michiko Yamana, Hiroyuki Nakahara, Massimiliano Pontil, and Shun-ichi Amari Λ Abstract. We study some ensembles of kernel machines. Each machine is first trained
On different ensembles of kernel machines Michiko Yamana, Hiroyuki Nakahara, Massimiliano Pontil, and Shun-ichi Amari Λ Abstract. We study some ensembles of kernel machines. Each machine is first trained
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 8 Continuous Latent Variable
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 8 Continuous Latent Variable
1. A discrete-time recurrent network is described by the following equation: y(n + 1) = A y(n) + B x(n)
 = A y(n) + B x(n)") Neuro-Fuzzy, Revision questions June, 25. A discrete-time recurrent network is described by the following equation: y(n + ) = A y(n) + B x(n) where A =.7.5.4.6, B = 2 (a) Sketch the dendritic and signal-flow
Neuro-Fuzzy, Revision questions June, 25. A discrete-time recurrent network is described by the following equation: y(n + ) = A y(n) + B x(n) where A =.7.5.4.6, B = 2 (a) Sketch the dendritic and signal-flow
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Classification. The goal: map from input X to a label Y. Y has a discrete set of possible values. We focused on binary Y (values 0 or 1).
.") Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
Neural Networks. Hopfield Nets and Auto Associators Fall 2017
 Neural Networks Hopfield Nets and Auto Associators Fall 2017 1 Story so far Neural networks for computation All feedforward structures But what about.. 2 Loopy network Θ z = ቊ +1 if z > 0 1 if z 0 y i
Neural Networks Hopfield Nets and Auto Associators Fall 2017 1 Story so far Neural networks for computation All feedforward structures But what about.. 2 Loopy network Θ z = ቊ +1 if z > 0 1 if z 0 y i
Error Empirical error. Generalization error. Time (number of iteration)
") Submitted to Neural Networks. Dynamics of Batch Learning in Multilayer Networks { Overrealizability and Overtraining { Kenji Fukumizu The Institute of Physical and Chemical Research (RIKEN) E-mail: fuku@brain.riken.go.jp
Submitted to Neural Networks. Dynamics of Batch Learning in Multilayer Networks { Overrealizability and Overtraining { Kenji Fukumizu The Institute of Physical and Chemical Research (RIKEN) E-mail: fuku@brain.riken.go.jp
Using Kernel PCA for Initialisation of Variational Bayesian Nonlinear Blind Source Separation Method
 Using Kernel PCA for Initialisation of Variational Bayesian Nonlinear Blind Source Separation Method Antti Honkela 1, Stefan Harmeling 2, Leo Lundqvist 1, and Harri Valpola 1 1 Helsinki University of Technology,
Using Kernel PCA for Initialisation of Variational Bayesian Nonlinear Blind Source Separation Method Antti Honkela 1, Stefan Harmeling 2, Leo Lundqvist 1, and Harri Valpola 1 1 Helsinki University of Technology,
Deep Feedforward Networks. Seung-Hoon Na Chonbuk National University
 Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Deep Feedforward Networks Seung-Hoon Na Chonbuk National University Neural Network: Types Feedforward neural networks (FNN) = Deep feedforward networks = multilayer perceptrons (MLP) No feedback connections
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts III-IV
 Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts III-IV Aapo Hyvärinen Gatsby Unit University College London Part III: Estimation of unnormalized models Often,
Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts III-IV Aapo Hyvärinen Gatsby Unit University College London Part III: Estimation of unnormalized models Often,
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Artificial Neural Networks Examination, June 2005
 Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
= w 2. w 1. B j. A j. C + j1j2
 Local Minima and Plateaus in Multilayer Neural Networks Kenji Fukumizu and Shun-ichi Amari Brain Science Institute, RIKEN Hirosawa 2-, Wako, Saitama 35-098, Japan E-mail: ffuku, amarig@brain.riken.go.jp
Local Minima and Plateaus in Multilayer Neural Networks Kenji Fukumizu and Shun-ichi Amari Brain Science Institute, RIKEN Hirosawa 2-, Wako, Saitama 35-098, Japan E-mail: ffuku, amarig@brain.riken.go.jp
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
Statistical Machine Learning from Data
 January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
Statistical Machine Learning from Data
 January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Other Artificial Neural Networks Samy Bengio IDIAP Research Institute, Martigny, Switzerland,
January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Other Artificial Neural Networks Samy Bengio IDIAP Research Institute, Martigny, Switzerland,
Immediate Reward Reinforcement Learning for Projective Kernel Methods
 ESANN'27 proceedings - European Symposium on Artificial Neural Networks Bruges (Belgium), 25-27 April 27, d-side publi., ISBN 2-9337-7-2. Immediate Reward Reinforcement Learning for Projective Kernel Methods
ESANN'27 proceedings - European Symposium on Artificial Neural Networks Bruges (Belgium), 25-27 April 27, d-side publi., ISBN 2-9337-7-2. Immediate Reward Reinforcement Learning for Projective Kernel Methods
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
Deep Neural Networks
 Universidad Autónoma de Madrid Escuela Politécnica Superior - Departamento de Ingeniería Informática Facultad de Ciencias - Departamento de Matemáticas Deep Neural Networks Master s thesis presented to
Universidad Autónoma de Madrid Escuela Politécnica Superior - Departamento de Ingeniería Informática Facultad de Ciencias - Departamento de Matemáticas Deep Neural Networks Master s thesis presented to
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014 Exam policy: This exam allows two one-page, two-sided cheat sheets (i.e. 4 sides); No other materials. Time: 2 hours. Be sure to write
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014 Exam policy: This exam allows two one-page, two-sided cheat sheets (i.e. 4 sides); No other materials. Time: 2 hours. Be sure to write
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Variational Inference via Stochastic Backpropagation
 Variational Inference via Stochastic Backpropagation Kai Fan February 27, 2016 Preliminaries Stochastic Backpropagation Variational Auto-Encoding Related Work Summary Outline Preliminaries Stochastic Backpropagation
Variational Inference via Stochastic Backpropagation Kai Fan February 27, 2016 Preliminaries Stochastic Backpropagation Variational Auto-Encoding Related Work Summary Outline Preliminaries Stochastic Backpropagation
Discriminative Learning of Sum-Product Networks. Robert Gens Pedro Domingos
 Discriminative Learning of Sum-Product Networks Robert Gens Pedro Domingos X1 X1 X1 X1 X2 X2 X2 X2 X3 X3 X3 X3 X4 X4 X4 X4 X5 X5 X5 X5 X6 X6 X6 X6 Distributions X 1 X 1 X 1 X 1 X 2 X 2 X 2 X 2 X 3 X 3
Discriminative Learning of Sum-Product Networks Robert Gens Pedro Domingos X1 X1 X1 X1 X2 X2 X2 X2 X3 X3 X3 X3 X4 X4 X4 X4 X5 X5 X5 X5 X6 X6 X6 X6 Distributions X 1 X 1 X 1 X 1 X 2 X 2 X 2 X 2 X 3 X 3
Neural Networks. Bishop PRML Ch. 5. Alireza Ghane. Feed-forward Networks Network Training Error Backpropagation Applications
 Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Machine Learning Basics III
 Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Kyle Reing University of Southern California April 18, 2018
 Renormalization Group and Information Theory Kyle Reing University of Southern California April 18, 2018 Overview Renormalization Group Overview Information Theoretic Preliminaries Real Space Mutual Information
Renormalization Group and Information Theory Kyle Reing University of Southern California April 18, 2018 Overview Renormalization Group Overview Information Theoretic Preliminaries Real Space Mutual Information
Speaker Representation and Verification Part II. by Vasileios Vasilakakis
 Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Speaker Representation and Verification Part II by Vasileios Vasilakakis Outline -Approaches of Neural Networks in Speaker/Speech Recognition -Feed-Forward Neural Networks -Training with Back-propagation
Lecture 5: Recurrent Neural Networks
 1/25 Lecture 5: Recurrent Neural Networks Nima Mohajerin University of Waterloo WAVE Lab nima.mohajerin@uwaterloo.ca July 4, 2017 2/25 Overview 1 Recap 2 RNN Architectures for Learning Long Term Dependencies
1/25 Lecture 5: Recurrent Neural Networks Nima Mohajerin University of Waterloo WAVE Lab nima.mohajerin@uwaterloo.ca July 4, 2017 2/25 Overview 1 Recap 2 RNN Architectures for Learning Long Term Dependencies
Learning Energy-Based Models of High-Dimensional Data
 Learning Energy-Based Models of High-Dimensional Data Geoffrey Hinton Max Welling Yee-Whye Teh Simon Osindero www.cs.toronto.edu/~hinton/energybasedmodelsweb.htm Discovering causal structure as a goal
Learning Energy-Based Models of High-Dimensional Data Geoffrey Hinton Max Welling Yee-Whye Teh Simon Osindero www.cs.toronto.edu/~hinton/energybasedmodelsweb.htm Discovering causal structure as a goal
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Chapter 20. Deep Generative Models
 Peng et al.: Deep Learning and Practice 1 Chapter 20 Deep Generative Models Peng et al.: Deep Learning and Practice 2 Generative Models Models that are able to Provide an estimate of the probability distribution
Peng et al.: Deep Learning and Practice 1 Chapter 20 Deep Generative Models Peng et al.: Deep Learning and Practice 2 Generative Models Models that are able to Provide an estimate of the probability distribution
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Normalization Techniques
 Normalization Techniques Devansh Arpit Normalization Techniques 1 / 39 Table of Contents 1 Introduction 2 Motivation 3 Batch Normalization 4 Normalization Propagation 5 Weight Normalization 6 Layer Normalization
Normalization Techniques Devansh Arpit Normalization Techniques 1 / 39 Table of Contents 1 Introduction 2 Motivation 3 Batch Normalization 4 Normalization Propagation 5 Weight Normalization 6 Layer Normalization
Local minima and plateaus in hierarchical structures of multilayer perceptrons
 Neural Networks PERGAMON Neural Networks 13 (2000) 317 327 Contributed article Local minima and plateaus in hierarchical structures of multilayer perceptrons www.elsevier.com/locate/neunet K. Fukumizu*,
Neural Networks PERGAMON Neural Networks 13 (2000) 317 327 Contributed article Local minima and plateaus in hierarchical structures of multilayer perceptrons www.elsevier.com/locate/neunet K. Fukumizu*,
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
A summary of Deep Learning without Poor Local Minima
 A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
Hierarchy. Will Penny. 24th March Hierarchy. Will Penny. Linear Models. Convergence. Nonlinear Models. References
 24th March 2011 Update Hierarchical Model Rao and Ballard (1999) presented a hierarchical model of visual cortex to show how classical and extra-classical Receptive Field (RF) effects could be explained
24th March 2011 Update Hierarchical Model Rao and Ballard (1999) presented a hierarchical model of visual cortex to show how classical and extra-classical Receptive Field (RF) effects could be explained