An Introduction to Independent Components Analysis (ICA)
|
|
|
- Penelope Griffin
- 6 years ago
- Views:
Transcription

")


1 An Introduction to Independent Components Analysis (ICA) Anish R. Shah, CFA Northfield Information Services Newport Jun 6,
2 Overview of Talk Review principal components Introduce independent components 2
3 Part I: Principal Components Analysis (PCA) At each step, PCA finds the direction that explains li the most remaining i variation iti 3





4 1 st principal component of a cylinder 4


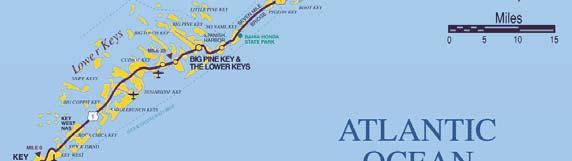
5 PCA on the Florida Keys 5
")

6 Principal components of 2 years of annual mutual fund returns 30 Returns of top (by 10 yr return) US diversified mutual funds 1 outlier excluded
7 Principal Component Analysis (PCA) Setup: Centered observations x 1.. x n Each observation is a vector of length t eg e.g. x 1 = IBM s monthly returns for the past 5 years (t = 60) x 1 = location of 1 acre of the Florida Keys (t = 2) x 1 = pixel intensities of a digital photo (t = 10 6 ) Centering happens by subtractingoff a) the mean of each observation (e.g. for stock covariance model) or b) the centroid of the set of observations (e.g. Florida Keys) Goal: Find the linear model that minimizes the squared error between the model and the data Think of regressing many stocks against a single independent variable PCA finds the independent variable that explains the most on average 7
8 PCA (cont.) Consider the familiar linear model x i(t) = β i y(t) + error Regression SE i = squared error for observation i= t=1..m [x i (t) β i y(t)] 2 Given y and x, regression sets β to minimize squared error: β i* = x it y/ y T y PCA TSE = total squared error over all observations = i=1..n SE i PCA finds the vector y (and the β i s) that minimize TSE To get the next component, repeat on the residuals {x i β i y} 8
9 PC s come from eigenvectors of the matrix of 2 nd moments C = X T X = (n n) matrix of 2 nd moments across t C i,j = s=1..t x i (s) x j (s) e.g. the co movement between securities i& j across time C = X X T = (t t) matrix of 2 nd moments across n C i,j = k=1..n x k (i) x k (j) e.g. the co movement between periods i& j across securities C d C h h i l d ildh C and C have the same non zero eigenvalues and yield the same PC s i.e. covariance of 5000 stocks over 60 months can be analyzed as a matrix instead of a
10 PC s come from eigenvectors of the matrix of 2 nd moments (cont.) X = (t n) matrix of observations C = X T X (size n n) C= X X T (size t t) λ i = the i th largest eigenvalue of C or C v i = (n 1) normalized eigenvector of C corresponding to λ i v i = (t 1) normalized eigenvector of C corresponding to λ i C = i λ i v i v T i C = i λ i v i v T i v i = X T v i / (λ i ) ½ v i = X v i / (λ i ) ½ p i = (t 1) i th normalized principal component = v i = X v i / (λ i ) ½ e i = (n 1) exposures to the component = X T v i = (λ i ) ½ v i Average squared error explained by the component = λ i / (t n) 10
11 PCA (cont.) More volatile observations have greater impact in determining components To counteract, t reweight: iht x i (t) w i x i (t) e.g. w i = 1 / x i maximizes average correlation w i = sqrt(mkt cap i ) weights squared error by cap Exposures for the original observations are the reweighted observation s exposures divided by the weight 2 views of PCA a low dimensional representation of something high dimensional, e.g. stock return covariance a way to separate features from noise, e.g. extracting the structural part of stock returns PCAyields factorsuncorrelated with each other 11
 = x and g(x)")

12 Uncorrelated doesn t mean independent f(x) = x and g(x) = x 2 f and g uncorrelated, but g = f




13 An application: face recognition Training Start with a large # of pictures of faces Calculate the PC s of this set called eigenfaces For each person, take a reference photo and calculate its loadings on the PC s Model in operation Person looks into camera. The image s eigenface loadings are compared to the reference photo s Image Source: AT&T Laboratories Cambridge 13
14 Part II: Independent Components Goal: extract the signals driving a process Cocktail party problem separate the sound of several talkers into individual voices Stock market ktreturns extract tsignals that t investors use to price securities, fit predictive model for profit Cichocki, Stansell, Leonowicz, & Buck. "Independent variable selection: Application of independent component analysisto forecasting a stock index", Journal of Asset Management, v6(4) Dec 2005 Back & Weigand. A first application of independent component analysis to extracting structure from stock returns, International Journal of Neural Systems, v8(4) Aug




15 6/9/2008 An example: Observe 4 linear combinations of 4 signals 15



16 6/9/2008 Principal Components 16



17 6/9/2008 Independent Components 17
18 ICA Independent Component Analysis Similar Setup Assume there exist independent signals S = [s 1 (t),, s n (t)] Observe only linear combinations of them, X(t) = A S(t) Both A and S are unknown! A is called the mixing matrix Goal Recover the original signals S(t) from X(t) ie. find a linear transformation L, ideally A 1, such that LX(t) = S(t) (up to scale and permutation) 18
19 ICA Basic idea First get rid of correlation whitening Apply a linear transformation N to decorrelate and normalize the signals: (NX) T NX= I. Let Z = NX The whitening transformation isn t unique any rotation of whitened signals is white: W rotation W T W = I (WZ) T (WZ) = Z T (W T W)Z = Z T Z = I Principal components are one source of whitened signals Then address higher order dependence Find a rotation W that makes the whitened signals independent, d i.e. the columns of WZ independent d The optimization problem is minimize W dep(wz) where dep(m) is a measure of the dependency between the columns of M st s.t. W T W = I (W is a rotation) 19
20 Notions of independence: 1. Nonlineardecorrelation Signals are already decorrelated by whitening E[u v] = E[u] E[v] Know that for independent signals u & v, E[g(u) h(v)] = E[g(u)] E[h(v)] for all g, h Are there functions ĝ & ĥ whose nonlinearity captures most of the higher order dependence? Ans: How well a particular function works depends on the shape of the data distribution ss tails dep(m) = magnitude of the difference between E[ĝ ĥ] and E[ĝ] E[ĥ] when ĝ & ĥ are applied to the columns of M 20
21 Notions of independence: 2. Non Gaussianity Model is X = AS wherethe columns ofs areindependent Central limit theorem says adding things together makes them more Gaussian Unmixed signals should be less Gaussian 21
22 A measure of non Gaussianity: Kurtosis Kurtosis 4 th centered moment / squared variance A measure of the mass in the distribution s tails Highly influenced by outliers Takes values from 0 to,, Gaussian is 3 Excess Kurtosis = Kurtosis 3 Takes values from 3 to, Gaussian is 0 Maximize the absolute value to find non Gaussian dep(m) = 11 excess kurtosis ofcolumns ofm 22
23 Background: Information theory (Shannon 1948) Entropy H(X) = p(x) log p(x) # of bits needed to encode X Differential Entropy h(x) = p(x) log p(x) dx For a given variance, Gaussians maximize differential entropy Kullback Leibler Divergence (Relative Entropy) D(p q) = p(x) log [p(x)/q(x)] 0 Mutual Information I(X,Y) = D[ p(x,y) p(x) p(y) ] = avg # of bits X tells about Y = avg # of bits Y tells about X I(X,Y) = 0 X & Y independent d 23
24 A measure of non Gaussianity: Negentropy Negentropy Shortfall in entropy relative to a Gaussian with the same variance Useful because scale invariant To evaluate, need probability distribution Estimate densities by expansions around a Gaussian density Cumulant (moment) based (Edgeworth, Gram Charlier) sensitive to outliers By non polynomial functions, eg. x exp( x 2 /2), tanh(x) more robust, but choice of functions depends d on the tails Maximize an approximation of negentropy dep(m) = 1 negentropyof columns of M 24
25 Mutual information Minimize the mutual information among the signals dep(m) = mutual information of columns of M After manipulating and constraining the signals to be uncorrelated, minimizing mutual information is maximizing negentropy 25
26 Another characterization: Maximum likelihood Recall model X = As let B = A 1 p(x) = det(b) i p i (b it X) Find demixing matrix B that maximizes the likelihood of the observations X First need an (inexact) model of the p s, similar to density approximation for negentropy 26
27 Connections to Human Wiring ICA can be characterized as sparse coding How can signals be represented compactly (each signal loading on a few of the factors) while retaining as much information as possible? A neuron codes only a few messages and rarely fires Edges are the independent components in pictures of nature Our visual system is built to detect edges 27
28 Summary Incredibly clever and powerful tool for extracting ti information F d l i l f Fundamental can motivate results from many different starting points 28
29 References Hyvärinen, A, J Karhunen, and E Oja. Independent Component Analysis Stone, James. Independent Component Analysis: A Tutorial Introduction Bishop, Christopher. Pattern Recognition and Machine Learning Shawe Taylor, J and N Cristianini. Kernel Methods for Pattern Analysis
Independent Component Analysis. PhD Seminar Jörgen Ungh
 Independent Component Analysis PhD Seminar Jörgen Ungh Agenda Background a motivater Independence ICA vs. PCA Gaussian data ICA theory Examples Background & motivation The cocktail party problem Bla bla
Independent Component Analysis PhD Seminar Jörgen Ungh Agenda Background a motivater Independence ICA vs. PCA Gaussian data ICA theory Examples Background & motivation The cocktail party problem Bla bla
Dimensionality Reduction. CS57300 Data Mining Fall Instructor: Bruno Ribeiro
 Dimensionality Reduction CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Visualize high dimensional data (and understand its Geometry) } Project the data into lower dimensional spaces }
Dimensionality Reduction CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Visualize high dimensional data (and understand its Geometry) } Project the data into lower dimensional spaces }
CIFAR Lectures: Non-Gaussian statistics and natural images
 CIFAR Lectures: Non-Gaussian statistics and natural images Dept of Computer Science University of Helsinki, Finland Outline Part I: Theory of ICA Definition and difference to PCA Importance of non-gaussianity
CIFAR Lectures: Non-Gaussian statistics and natural images Dept of Computer Science University of Helsinki, Finland Outline Part I: Theory of ICA Definition and difference to PCA Importance of non-gaussianity
Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts I-II
 Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts I-II Gatsby Unit University College London 27 Feb 2017 Outline Part I: Theory of ICA Definition and difference
Gatsby Theoretical Neuroscience Lectures: Non-Gaussian statistics and natural images Parts I-II Gatsby Unit University College London 27 Feb 2017 Outline Part I: Theory of ICA Definition and difference
Independent Component Analysis
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 1 Introduction Indepent
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 1 Introduction Indepent
Independent Component Analysis
 1 Independent Component Analysis Background paper: http://www-stat.stanford.edu/ hastie/papers/ica.pdf 2 ICA Problem X = AS where X is a random p-vector representing multivariate input measurements. S
1 Independent Component Analysis Background paper: http://www-stat.stanford.edu/ hastie/papers/ica.pdf 2 ICA Problem X = AS where X is a random p-vector representing multivariate input measurements. S
Independent Component Analysis (ICA) Bhaskar D Rao University of California, San Diego
 Bhaskar D Rao University of California, San Diego") Independent Component Analysis (ICA) Bhaskar D Rao University of California, San Diego Email: brao@ucsdedu References 1 Hyvarinen, A, Karhunen, J, & Oja, E (2004) Independent component analysis (Vol 46)
Independent Component Analysis (ICA) Bhaskar D Rao University of California, San Diego Email: brao@ucsdedu References 1 Hyvarinen, A, Karhunen, J, & Oja, E (2004) Independent component analysis (Vol 46)
Independent Component Analysis and Its Applications. By Qing Xue, 10/15/2004
 Independent Component Analysis and Its Applications By Qing Xue, 10/15/2004 Outline Motivation of ICA Applications of ICA Principles of ICA estimation Algorithms for ICA Extensions of basic ICA framework
Independent Component Analysis and Its Applications By Qing Xue, 10/15/2004 Outline Motivation of ICA Applications of ICA Principles of ICA estimation Algorithms for ICA Extensions of basic ICA framework
PCA & ICA. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Independent Component Analysis Barnabás Póczos Independent Component Analysis 2 Independent Component Analysis Model original signals Observations (Mixtures)
Advanced Introduction to Machine Learning CMU-10715 Independent Component Analysis Barnabás Póczos Independent Component Analysis 2 Independent Component Analysis Model original signals Observations (Mixtures)
Independent Component Analysis. Contents
 Contents Preface xvii 1 Introduction 1 1.1 Linear representation of multivariate data 1 1.1.1 The general statistical setting 1 1.1.2 Dimension reduction methods 2 1.1.3 Independence as a guiding principle
Contents Preface xvii 1 Introduction 1 1.1 Linear representation of multivariate data 1 1.1.1 The general statistical setting 1 1.1.2 Dimension reduction methods 2 1.1.3 Independence as a guiding principle
Introduction to Independent Component Analysis. Jingmei Lu and Xixi Lu. Abstract
 Final Project 2//25 Introduction to Independent Component Analysis Abstract Independent Component Analysis (ICA) can be used to solve blind signal separation problem. In this article, we introduce definition
Final Project 2//25 Introduction to Independent Component Analysis Abstract Independent Component Analysis (ICA) can be used to solve blind signal separation problem. In this article, we introduce definition
MTTS1 Dimensionality Reduction and Visualization Spring 2014 Jaakko Peltonen
 MTTS1 Dimensionality Reduction and Visualization Spring 2014 Jaakko Peltonen Lecture 3: Linear feature extraction Feature extraction feature extraction: (more general) transform the original to (k < d).
MTTS1 Dimensionality Reduction and Visualization Spring 2014 Jaakko Peltonen Lecture 3: Linear feature extraction Feature extraction feature extraction: (more general) transform the original to (k < d).
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
STATS 306B: Unsupervised Learning Spring Lecture 12 May 7
 STATS 306B: Unsupervised Learning Spring 2014 Lecture 12 May 7 Lecturer: Lester Mackey Scribe: Lan Huong, Snigdha Panigrahi 12.1 Beyond Linear State Space Modeling Last lecture we completed our discussion
STATS 306B: Unsupervised Learning Spring 2014 Lecture 12 May 7 Lecturer: Lester Mackey Scribe: Lan Huong, Snigdha Panigrahi 12.1 Beyond Linear State Space Modeling Last lecture we completed our discussion
Fundamentals of Principal Component Analysis (PCA), Independent Component Analysis (ICA), and Independent Vector Analysis (IVA)
, Independent Component Analysis (ICA), and Independent Vector Analysis (IVA)") Fundamentals of Principal Component Analysis (PCA),, and Independent Vector Analysis (IVA) Dr Mohsen Naqvi Lecturer in Signal and Information Processing, School of Electrical and Electronic Engineering,
Fundamentals of Principal Component Analysis (PCA),, and Independent Vector Analysis (IVA) Dr Mohsen Naqvi Lecturer in Signal and Information Processing, School of Electrical and Electronic Engineering,
HST.582J/6.555J/16.456J
 Blind Source Separation: PCA & ICA HST.582J/6.555J/16.456J Gari D. Clifford gari [at] mit. edu http://www.mit.edu/~gari G. D. Clifford 2005-2009 What is BSS? Assume an observation (signal) is a linear
Blind Source Separation: PCA & ICA HST.582J/6.555J/16.456J Gari D. Clifford gari [at] mit. edu http://www.mit.edu/~gari G. D. Clifford 2005-2009 What is BSS? Assume an observation (signal) is a linear
Principal Component Analysis
 Principal Component Analysis Introduction Consider a zero mean random vector R n with autocorrelation matri R = E( T ). R has eigenvectors q(1),,q(n) and associated eigenvalues λ(1) λ(n). Let Q = [ q(1)
Principal Component Analysis Introduction Consider a zero mean random vector R n with autocorrelation matri R = E( T ). R has eigenvectors q(1),,q(n) and associated eigenvalues λ(1) λ(n). Let Q = [ q(1)
Lecture'12:' SSMs;'Independent'Component'Analysis;' Canonical'Correla;on'Analysis'
 Lecture'12:' SSMs;'Independent'Component'Analysis;' Canonical'Correla;on'Analysis' Lester'Mackey' May'7,'2014' ' Stats'306B:'Unsupervised'Learning' Beyond'linearity'in'state'space'modeling' Credit:'Alex'Simma'
Lecture'12:' SSMs;'Independent'Component'Analysis;' Canonical'Correla;on'Analysis' Lester'Mackey' May'7,'2014' ' Stats'306B:'Unsupervised'Learning' Beyond'linearity'in'state'space'modeling' Credit:'Alex'Simma'
Separation of Different Voices in Speech using Fast Ica Algorithm
 Volume-6, Issue-6, November-December 2016 International Journal of Engineering and Management Research Page Number: 364-368 Separation of Different Voices in Speech using Fast Ica Algorithm Dr. T.V.P Sundararajan
Volume-6, Issue-6, November-December 2016 International Journal of Engineering and Management Research Page Number: 364-368 Separation of Different Voices in Speech using Fast Ica Algorithm Dr. T.V.P Sundararajan
Independent Component Analysis (ICA)
") Independent Component Analysis (ICA) Université catholique de Louvain (Belgium) Machine Learning Group http://www.dice.ucl ucl.ac.be/.ac.be/mlg/ 1 Overview Uncorrelation vs Independence Blind source separation
Independent Component Analysis (ICA) Université catholique de Louvain (Belgium) Machine Learning Group http://www.dice.ucl ucl.ac.be/.ac.be/mlg/ 1 Overview Uncorrelation vs Independence Blind source separation
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
HST.582J / 6.555J / J Biomedical Signal and Image Processing Spring 2007
 MIT OpenCourseWare http://ocw.mit.edu HST.582J / 6.555J / 16.456J Biomedical Signal and Image Processing Spring 2007 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
MIT OpenCourseWare http://ocw.mit.edu HST.582J / 6.555J / 16.456J Biomedical Signal and Image Processing Spring 2007 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
Introduction PCA classic Generative models Beyond and summary. PCA, ICA and beyond
 PCA, ICA and beyond Summer School on Manifold Learning in Image and Signal Analysis, August 17-21, 2009, Hven Technical University of Denmark (DTU) & University of Copenhagen (KU) August 18, 2009 Motivation
PCA, ICA and beyond Summer School on Manifold Learning in Image and Signal Analysis, August 17-21, 2009, Hven Technical University of Denmark (DTU) & University of Copenhagen (KU) August 18, 2009 Motivation
Machine learning - HT Maximum Likelihood
 Machine learning - HT 2016 3. Maximum Likelihood Varun Kanade University of Oxford January 27, 2016 Outline Probabilistic Framework Formulate linear regression in the language of probability Introduce
Machine learning - HT 2016 3. Maximum Likelihood Varun Kanade University of Oxford January 27, 2016 Outline Probabilistic Framework Formulate linear regression in the language of probability Introduce
Natural Image Statistics
 Natural Image Statistics A probabilistic approach to modelling early visual processing in the cortex Dept of Computer Science Early visual processing LGN V1 retina From the eye to the primary visual cortex
Natural Image Statistics A probabilistic approach to modelling early visual processing in the cortex Dept of Computer Science Early visual processing LGN V1 retina From the eye to the primary visual cortex
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
BANA 7046 Data Mining I Lecture 6. Other Data Mining Algorithms 1
 BANA 7046 Data Mining I Lecture 6. Other Data Mining Algorithms 1 Shaobo Li University of Cincinnati 1 Partially based on Hastie, et al. (2009) ESL, and James, et al. (2013) ISLR Data Mining I Lecture
BANA 7046 Data Mining I Lecture 6. Other Data Mining Algorithms 1 Shaobo Li University of Cincinnati 1 Partially based on Hastie, et al. (2009) ESL, and James, et al. (2013) ISLR Data Mining I Lecture
Linear Factor Models. Sargur N. Srihari
 Linear Factor Models Sargur N. srihari@cedar.buffalo.edu 1 Topics in Linear Factor Models Linear factor model definition 1. Probabilistic PCA and Factor Analysis 2. Independent Component Analysis (ICA)
Linear Factor Models Sargur N. srihari@cedar.buffalo.edu 1 Topics in Linear Factor Models Linear factor model definition 1. Probabilistic PCA and Factor Analysis 2. Independent Component Analysis (ICA)
Independent Component Analysis and Unsupervised Learning
 Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien National Cheng Kung University TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent
Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien National Cheng Kung University TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent
Different Estimation Methods for the Basic Independent Component Analysis Model
 Washington University in St. Louis Washington University Open Scholarship Arts & Sciences Electronic Theses and Dissertations Arts & Sciences Winter 12-2018 Different Estimation Methods for the Basic Independent
Washington University in St. Louis Washington University Open Scholarship Arts & Sciences Electronic Theses and Dissertations Arts & Sciences Winter 12-2018 Different Estimation Methods for the Basic Independent
Principal Component Analysis vs. Independent Component Analysis for Damage Detection
 6th European Workshop on Structural Health Monitoring - Fr..D.4 Principal Component Analysis vs. Independent Component Analysis for Damage Detection D. A. TIBADUIZA, L. E. MUJICA, M. ANAYA, J. RODELLAR
6th European Workshop on Structural Health Monitoring - Fr..D.4 Principal Component Analysis vs. Independent Component Analysis for Damage Detection D. A. TIBADUIZA, L. E. MUJICA, M. ANAYA, J. RODELLAR
Independent Component Analysis and Unsupervised Learning. Jen-Tzung Chien
 Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent voices Nonparametric likelihood
Independent Component Analysis and Unsupervised Learning Jen-Tzung Chien TABLE OF CONTENTS 1. Independent Component Analysis 2. Case Study I: Speech Recognition Independent voices Nonparametric likelihood
Unsupervised learning: beyond simple clustering and PCA
 Unsupervised learning: beyond simple clustering and PCA Liza Rebrova Self organizing maps (SOM) Goal: approximate data points in R p by a low-dimensional manifold Unlike PCA, the manifold does not have
Unsupervised learning: beyond simple clustering and PCA Liza Rebrova Self organizing maps (SOM) Goal: approximate data points in R p by a low-dimensional manifold Unlike PCA, the manifold does not have
CPSC 340: Machine Learning and Data Mining. Sparse Matrix Factorization Fall 2018
 CPSC 340: Machine Learning and Data Mining Sparse Matrix Factorization Fall 2018 Last Time: PCA with Orthogonal/Sequential Basis When k = 1, PCA has a scaling problem. When k > 1, have scaling, rotation,
CPSC 340: Machine Learning and Data Mining Sparse Matrix Factorization Fall 2018 Last Time: PCA with Orthogonal/Sequential Basis When k = 1, PCA has a scaling problem. When k > 1, have scaling, rotation,
Estimation of information-theoretic quantities
 Estimation of information-theoretic quantities Liam Paninski Gatsby Computational Neuroscience Unit University College London http://www.gatsby.ucl.ac.uk/ liam liam@gatsby.ucl.ac.uk November 16, 2004 Some
Estimation of information-theoretic quantities Liam Paninski Gatsby Computational Neuroscience Unit University College London http://www.gatsby.ucl.ac.uk/ liam liam@gatsby.ucl.ac.uk November 16, 2004 Some
Unsupervised Machine Learning and Data Mining. DS 5230 / DS Fall Lecture 7. Jan-Willem van de Meent
 Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Gaussian with mean ( µ ) and standard deviation ( σ)
 and standard deviation ( σ)") Slide from Pieter Abbeel Gaussian with mean ( µ ) and standard deviation ( σ) 10/6/16 CSE-571: Robotics X ~ N( µ, σ ) Y ~ N( aµ + b, a σ ) Y = ax + b + + + + 1 1 1 1 1 1 1 1 1 1, ~ ) ( ) ( ), ( ~ ), (
Slide from Pieter Abbeel Gaussian with mean ( µ ) and standard deviation ( σ) 10/6/16 CSE-571: Robotics X ~ N( µ, σ ) Y ~ N( aµ + b, a σ ) Y = ax + b + + + + 1 1 1 1 1 1 1 1 1 1, ~ ) ( ) ( ), ( ~ ), (
Independent Component Analysis
 Independent Component Analysis Seungjin Choi Department of Computer Science Pohang University of Science and Technology, Korea seungjin@postech.ac.kr March 4, 2009 1 / 78 Outline Theory and Preliminaries
Independent Component Analysis Seungjin Choi Department of Computer Science Pohang University of Science and Technology, Korea seungjin@postech.ac.kr March 4, 2009 1 / 78 Outline Theory and Preliminaries
Computer Vision Group Prof. Daniel Cremers. 2. Regression (cont.)
") Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
Prof. Daniel Cremers 2. Regression (cont.) Regression with MLE (Rep.) Assume that y is affected by Gaussian noise : t = f(x, w)+ where Thus, we have p(t x, w, )=N (t; f(x, w), 2 ) 2 Maximum A-Posteriori
20 Unsupervised Learning and Principal Components Analysis (PCA)
") 116 Jonathan Richard Shewchuk 20 Unsupervised Learning and Principal Components Analysis (PCA) UNSUPERVISED LEARNING We have sample points, but no labels! No classes, no y-values, nothing to predict. Goal:
116 Jonathan Richard Shewchuk 20 Unsupervised Learning and Principal Components Analysis (PCA) UNSUPERVISED LEARNING We have sample points, but no labels! No classes, no y-values, nothing to predict. Goal:
Tutorial on Blind Source Separation and Independent Component Analysis
 Tutorial on Blind Source Separation and Independent Component Analysis Lucas Parra Adaptive Image & Signal Processing Group Sarnoff Corporation February 09, 2002 Linear Mixtures... problem statement...
Tutorial on Blind Source Separation and Independent Component Analysis Lucas Parra Adaptive Image & Signal Processing Group Sarnoff Corporation February 09, 2002 Linear Mixtures... problem statement...
Mining Big Data Using Parsimonious Factor and Shrinkage Methods
 Mining Big Data Using Parsimonious Factor and Shrinkage Methods Hyun Hak Kim 1 and Norman Swanson 2 1 Bank of Korea and 2 Rutgers University ECB Workshop on using Big Data for Forecasting and Statistics
Mining Big Data Using Parsimonious Factor and Shrinkage Methods Hyun Hak Kim 1 and Norman Swanson 2 1 Bank of Korea and 2 Rutgers University ECB Workshop on using Big Data for Forecasting and Statistics
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
COMS 4721: Machine Learning for Data Science Lecture 19, 4/6/2017
 COMS 4721: Machine Learning for Data Science Lecture 19, 4/6/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University PRINCIPAL COMPONENT ANALYSIS DIMENSIONALITY
COMS 4721: Machine Learning for Data Science Lecture 19, 4/6/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University PRINCIPAL COMPONENT ANALYSIS DIMENSIONALITY
COMP 551 Applied Machine Learning Lecture 13: Dimension reduction and feature selection
 COMP 551 Applied Machine Learning Lecture 13: Dimension reduction and feature selection Instructor: Herke van Hoof (herke.vanhoof@cs.mcgill.ca) Based on slides by:, Jackie Chi Kit Cheung Class web page:
COMP 551 Applied Machine Learning Lecture 13: Dimension reduction and feature selection Instructor: Herke van Hoof (herke.vanhoof@cs.mcgill.ca) Based on slides by:, Jackie Chi Kit Cheung Class web page:
An Improved Cumulant Based Method for Independent Component Analysis
 An Improved Cumulant Based Method for Independent Component Analysis Tobias Blaschke and Laurenz Wiskott Institute for Theoretical Biology Humboldt University Berlin Invalidenstraße 43 D - 0 5 Berlin Germany
An Improved Cumulant Based Method for Independent Component Analysis Tobias Blaschke and Laurenz Wiskott Institute for Theoretical Biology Humboldt University Berlin Invalidenstraße 43 D - 0 5 Berlin Germany
Slide11 Haykin Chapter 10: Information-Theoretic Models
 Slide11 Haykin Chapter 10: Information-Theoretic Models CPSC 636-600 Instructor: Yoonsuck Choe Spring 2015 ICA section is heavily derived from Aapo Hyvärinen s ICA tutorial: http://www.cis.hut.fi/aapo/papers/ijcnn99_tutorialweb/.
Slide11 Haykin Chapter 10: Information-Theoretic Models CPSC 636-600 Instructor: Yoonsuck Choe Spring 2015 ICA section is heavily derived from Aapo Hyvärinen s ICA tutorial: http://www.cis.hut.fi/aapo/papers/ijcnn99_tutorialweb/.
Machine Learning. Dimensionality reduction. Hamid Beigy. Sharif University of Technology. Fall 1395
 Machine Learning Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1395 1 / 47 Table of contents 1 Introduction
Machine Learning Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1395 1 / 47 Table of contents 1 Introduction
Dimensionality Reduction
 Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Recursive Generalized Eigendecomposition for Independent Component Analysis
 Recursive Generalized Eigendecomposition for Independent Component Analysis Umut Ozertem 1, Deniz Erdogmus 1,, ian Lan 1 CSEE Department, OGI, Oregon Health & Science University, Portland, OR, USA. {ozertemu,deniz}@csee.ogi.edu
Recursive Generalized Eigendecomposition for Independent Component Analysis Umut Ozertem 1, Deniz Erdogmus 1,, ian Lan 1 CSEE Department, OGI, Oregon Health & Science University, Portland, OR, USA. {ozertemu,deniz}@csee.ogi.edu
Principal Component Analysis (PCA) CSC411/2515 Tutorial
 CSC411/2515 Tutorial") Principal Component Analysis (PCA) CSC411/2515 Tutorial Harris Chan Based on previous tutorial slides by Wenjie Luo, Ladislav Rampasek University of Toronto hchan@cs.toronto.edu October 19th, 2017 (UofT)
Principal Component Analysis (PCA) CSC411/2515 Tutorial Harris Chan Based on previous tutorial slides by Wenjie Luo, Ladislav Rampasek University of Toronto hchan@cs.toronto.edu October 19th, 2017 (UofT)
Bayesian Linear Regression [DRAFT - In Progress]
![Bayesian Linear Regression [DRAFT - In Progress]](/thumbs/92/109828713.jpg "Bayesian Linear Regression [DRAFT - In Progress]") Bayesian Linear Regression [DRAFT - In Progress] David S. Rosenberg Abstract Here we develop some basics of Bayesian linear regression. Most of the calculations for this document come from the basic theory
Bayesian Linear Regression [DRAFT - In Progress] David S. Rosenberg Abstract Here we develop some basics of Bayesian linear regression. Most of the calculations for this document come from the basic theory
Independent Component Analysis
 Independent Component Analysis James V. Stone November 4, 24 Sheffield University, Sheffield, UK Keywords: independent component analysis, independence, blind source separation, projection pursuit, complexity
Independent Component Analysis James V. Stone November 4, 24 Sheffield University, Sheffield, UK Keywords: independent component analysis, independence, blind source separation, projection pursuit, complexity
Dimension Reduction (PCA, ICA, CCA, FLD,
 Dimension Reduction (PCA, ICA, CCA, FLD, Topic Models) Yi Zhang 10-701, Machine Learning, Spring 2011 April 6 th, 2011 Parts of the PCA slides are from previous 10-701 lectures 1 Outline Dimension reduction
Dimension Reduction (PCA, ICA, CCA, FLD, Topic Models) Yi Zhang 10-701, Machine Learning, Spring 2011 April 6 th, 2011 Parts of the PCA slides are from previous 10-701 lectures 1 Outline Dimension reduction
Independent Components Analysis
 CS229 Lecture notes Andrew Ng Part XII Independent Components Analysis Our next topic is Independent Components Analysis (ICA). Similar to PCA, this will find a new basis in which to represent our data.
CS229 Lecture notes Andrew Ng Part XII Independent Components Analysis Our next topic is Independent Components Analysis (ICA). Similar to PCA, this will find a new basis in which to represent our data.
Independent Component Analysis
 Chapter 5 Independent Component Analysis Part I: Introduction and applications Motivation Skillikorn chapter 7 2 Cocktail party problem Did you see that Have you heard So, yesterday this guy I said, darling
Chapter 5 Independent Component Analysis Part I: Introduction and applications Motivation Skillikorn chapter 7 2 Cocktail party problem Did you see that Have you heard So, yesterday this guy I said, darling
Dimensionality Reduction and Principle Components Analysis
 Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
Dimensionality Reduction and Principle Components Analysis 1 Outline What is dimensionality reduction? Principle Components Analysis (PCA) Example (Bishop, ch 12) PCA vs linear regression PCA as a mixture
Learning features by contrasting natural images with noise
 Learning features by contrasting natural images with noise Michael Gutmann 1 and Aapo Hyvärinen 12 1 Dept. of Computer Science and HIIT, University of Helsinki, P.O. Box 68, FIN-00014 University of Helsinki,
Learning features by contrasting natural images with noise Michael Gutmann 1 and Aapo Hyvärinen 12 1 Dept. of Computer Science and HIIT, University of Helsinki, P.O. Box 68, FIN-00014 University of Helsinki,
Independent Component Analysis and Its Application on Accelerator Physics
 Independent Component Analysis and Its Application on Accelerator Physics Xiaoying Pang LA-UR-12-20069 ICA and PCA Similarities: Blind source separation method (BSS) no model Observed signals are linear
Independent Component Analysis and Its Application on Accelerator Physics Xiaoying Pang LA-UR-12-20069 ICA and PCA Similarities: Blind source separation method (BSS) no model Observed signals are linear
CPSC 340: Machine Learning and Data Mining. More PCA Fall 2017
 CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
A GUIDE TO INDEPENDENT COMPONENT ANALYSIS Theory and Practice
 CONTROL ENGINEERING LABORATORY A GUIDE TO INDEPENDENT COMPONENT ANALYSIS Theory and Practice Jelmer van Ast and Mika Ruusunen Report A No 3, March 004 University of Oulu Control Engineering Laboratory
CONTROL ENGINEERING LABORATORY A GUIDE TO INDEPENDENT COMPONENT ANALYSIS Theory and Practice Jelmer van Ast and Mika Ruusunen Report A No 3, March 004 University of Oulu Control Engineering Laboratory
Neural coding Ecological approach to sensory coding: efficient adaptation to the natural environment
 Neural coding Ecological approach to sensory coding: efficient adaptation to the natural environment Jean-Pierre Nadal CNRS & EHESS Laboratoire de Physique Statistique (LPS, UMR 8550 CNRS - ENS UPMC Univ.
Neural coding Ecological approach to sensory coding: efficient adaptation to the natural environment Jean-Pierre Nadal CNRS & EHESS Laboratoire de Physique Statistique (LPS, UMR 8550 CNRS - ENS UPMC Univ.
CSC2515 Winter 2015 Introduction to Machine Learning. Lecture 2: Linear regression
 CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
CSC2515 Winter 2015 Introduction to Machine Learning Lecture 2: Linear regression All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/csc2515_winter15.html
Efficient Coding. Odelia Schwartz 2017
 Efficient Coding Odelia Schwartz 2017 1 Levels of modeling Descriptive (what) Mechanistic (how) Interpretive (why) 2 Levels of modeling Fitting a receptive field model to experimental data (e.g., using
Efficient Coding Odelia Schwartz 2017 1 Levels of modeling Descriptive (what) Mechanistic (how) Interpretive (why) 2 Levels of modeling Fitting a receptive field model to experimental data (e.g., using
PATTERN RECOGNITION AND MACHINE LEARNING
 PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
PATTERN RECOGNITION AND MACHINE LEARNING Chapter 1. Introduction Shuai Huang April 21, 2014 Outline 1 What is Machine Learning? 2 Curve Fitting 3 Probability Theory 4 Model Selection 5 The curse of dimensionality
Course 495: Advanced Statistical Machine Learning/Pattern Recognition
 Course 495: Advanced Statistical Machine Learning/Pattern Recognition Goal (Lecture): To present Probabilistic Principal Component Analysis (PPCA) using both Maximum Likelihood (ML) and Expectation Maximization
Course 495: Advanced Statistical Machine Learning/Pattern Recognition Goal (Lecture): To present Probabilistic Principal Component Analysis (PPCA) using both Maximum Likelihood (ML) and Expectation Maximization
Introduction to Information Theory. Uncertainty. Entropy. Surprisal. Joint entropy. Conditional entropy. Mutual information.
 L65 Dept. of Linguistics, Indiana University Fall 205 Information theory answers two fundamental questions in communication theory: What is the ultimate data compression? What is the transmission rate
L65 Dept. of Linguistics, Indiana University Fall 205 Information theory answers two fundamental questions in communication theory: What is the ultimate data compression? What is the transmission rate
Dept. of Linguistics, Indiana University Fall 2015
 L645 Dept. of Linguistics, Indiana University Fall 2015 1 / 28 Information theory answers two fundamental questions in communication theory: What is the ultimate data compression? What is the transmission
L645 Dept. of Linguistics, Indiana University Fall 2015 1 / 28 Information theory answers two fundamental questions in communication theory: What is the ultimate data compression? What is the transmission
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 12 Jan-Willem van de Meent (credit: Yijun Zhao, Percy Liang) DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Linear Dimensionality
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 12 Jan-Willem van de Meent (credit: Yijun Zhao, Percy Liang) DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Linear Dimensionality
FEATURE EXTRACTION USING SUPERVISED INDEPENDENT COMPONENT ANALYSIS BY MAXIMIZING CLASS DISTANCE
 FEATURE EXTRACTION USING SUPERVISED INDEPENDENT COMPONENT ANALYSIS BY MAXIMIZING CLASS DISTANCE Yoshinori Sakaguchi*, Seiichi Ozawa*, and Manabu Kotani** *Graduate School of Science and Technology, Kobe
FEATURE EXTRACTION USING SUPERVISED INDEPENDENT COMPONENT ANALYSIS BY MAXIMIZING CLASS DISTANCE Yoshinori Sakaguchi*, Seiichi Ozawa*, and Manabu Kotani** *Graduate School of Science and Technology, Kobe
Unsupervised Learning Methods
 Structural Health Monitoring Using Statistical Pattern Recognition Unsupervised Learning Methods Keith Worden and Graeme Manson Presented by Keith Worden The Structural Health Monitoring Process 1. Operational
Structural Health Monitoring Using Statistical Pattern Recognition Unsupervised Learning Methods Keith Worden and Graeme Manson Presented by Keith Worden The Structural Health Monitoring Process 1. Operational
Dimension reduction, PCA & eigenanalysis Based in part on slides from textbook, slides of Susan Holmes. October 3, Statistics 202: Data Mining
 Dimension reduction, PCA & eigenanalysis Based in part on slides from textbook, slides of Susan Holmes October 3, 2012 1 / 1 Combinations of features Given a data matrix X n p with p fairly large, it can
Dimension reduction, PCA & eigenanalysis Based in part on slides from textbook, slides of Susan Holmes October 3, 2012 1 / 1 Combinations of features Given a data matrix X n p with p fairly large, it can
Nonlinear reverse-correlation with synthesized naturalistic noise
 Cognitive Science Online, Vol1, pp1 7, 2003 http://cogsci-onlineucsdedu Nonlinear reverse-correlation with synthesized naturalistic noise Hsin-Hao Yu Department of Cognitive Science University of California
Cognitive Science Online, Vol1, pp1 7, 2003 http://cogsci-onlineucsdedu Nonlinear reverse-correlation with synthesized naturalistic noise Hsin-Hao Yu Department of Cognitive Science University of California
Unsupervised Neural Nets
 Unsupervised Neural Nets (and ICA) Lyle Ungar (with contributions from Quoc Le, Socher & Manning) Lyle Ungar, University of Pennsylvania Semi-Supervised Learning Hypothesis:%P(c x)%can%be%more%accurately%computed%using%
Unsupervised Neural Nets (and ICA) Lyle Ungar (with contributions from Quoc Le, Socher & Manning) Lyle Ungar, University of Pennsylvania Semi-Supervised Learning Hypothesis:%P(c x)%can%be%more%accurately%computed%using%
STA 4273H: Sta-s-cal Machine Learning
 STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
STA 4273H: Sta-s-cal Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistical Sciences! rsalakhu@cs.toronto.edu! h0p://www.cs.utoronto.ca/~rsalakhu/ Lecture 2 In our
EECS490: Digital Image Processing. Lecture #26
 Lecture #26 Moments; invariant moments Eigenvector, principal component analysis Boundary coding Image primitives Image representation: trees, graphs Object recognition and classes Minimum distance classifiers
Lecture #26 Moments; invariant moments Eigenvector, principal component analysis Boundary coding Image primitives Image representation: trees, graphs Object recognition and classes Minimum distance classifiers
MACHINE LEARNING. Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA
 1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
Basic Principles of Unsupervised and Unsupervised
 Basic Principles of Unsupervised and Unsupervised Learning Toward Deep Learning Shun ichi Amari (RIKEN Brain Science Institute) collaborators: R. Karakida, M. Okada (U. Tokyo) Deep Learning Self Organization
Basic Principles of Unsupervised and Unsupervised Learning Toward Deep Learning Shun ichi Amari (RIKEN Brain Science Institute) collaborators: R. Karakida, M. Okada (U. Tokyo) Deep Learning Self Organization
New Approximations of Differential Entropy for Independent Component Analysis and Projection Pursuit
 New Approximations of Differential Entropy for Independent Component Analysis and Projection Pursuit Aapo Hyvarinen Helsinki University of Technology Laboratory of Computer and Information Science P.O.
New Approximations of Differential Entropy for Independent Component Analysis and Projection Pursuit Aapo Hyvarinen Helsinki University of Technology Laboratory of Computer and Information Science P.O.
Lecture 7: Con3nuous Latent Variable Models
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
Independent Component Analysis of Incomplete Data
 Independent Component Analysis of Incomplete Data Max Welling Markus Weber California Institute of Technology 136-93 Pasadena, CA 91125 fwelling,rmwg@vision.caltech.edu Keywords: EM, Missing Data, ICA
Independent Component Analysis of Incomplete Data Max Welling Markus Weber California Institute of Technology 136-93 Pasadena, CA 91125 fwelling,rmwg@vision.caltech.edu Keywords: EM, Missing Data, ICA
Eigenfaces. Face Recognition Using Principal Components Analysis
 Eigenfaces Face Recognition Using Principal Components Analysis M. Turk, A. Pentland, "Eigenfaces for Recognition", Journal of Cognitive Neuroscience, 3(1), pp. 71-86, 1991. Slides : George Bebis, UNR
Eigenfaces Face Recognition Using Principal Components Analysis M. Turk, A. Pentland, "Eigenfaces for Recognition", Journal of Cognitive Neuroscience, 3(1), pp. 71-86, 1991. Slides : George Bebis, UNR
Lecture 11: Continuous-valued signals and differential entropy
 Lecture 11: Continuous-valued signals and differential entropy Biology 429 Carl Bergstrom September 20, 2008 Sources: Parts of today s lecture follow Chapter 8 from Cover and Thomas (2007). Some components
Lecture 11: Continuous-valued signals and differential entropy Biology 429 Carl Bergstrom September 20, 2008 Sources: Parts of today s lecture follow Chapter 8 from Cover and Thomas (2007). Some components
Classification. The goal: map from input X to a label Y. Y has a discrete set of possible values. We focused on binary Y (values 0 or 1).
.") Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
Regression and PCA Classification The goal: map from input X to a label Y. Y has a discrete set of possible values We focused on binary Y (values 0 or 1). But we also discussed larger number of classes
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 2 - Spring 2017 Lecture 4 Jan-Willem van de Meent (credit: Yijun Zhao, Arthur Gretton Rasmussen & Williams, Percy Liang) Kernel Regression Basis function regression
Data Mining Techniques CS 6220 - Section 2 - Spring 2017 Lecture 4 Jan-Willem van de Meent (credit: Yijun Zhao, Arthur Gretton Rasmussen & Williams, Percy Liang) Kernel Regression Basis function regression
Principal Component Analysis CS498
 Principal Component Analysis CS498 Today s lecture Adaptive Feature Extraction Principal Component Analysis How, why, when, which A dual goal Find a good representation The features part Reduce redundancy
Principal Component Analysis CS498 Today s lecture Adaptive Feature Extraction Principal Component Analysis How, why, when, which A dual goal Find a good representation The features part Reduce redundancy
Machine learning for pervasive systems Classification in high-dimensional spaces
 Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Higher Order Statistics
 Higher Order Statistics Matthias Hennig Neural Information Processing School of Informatics, University of Edinburgh February 12, 2018 1 0 Based on Mark van Rossum s and Chris Williams s old NIP slides
Higher Order Statistics Matthias Hennig Neural Information Processing School of Informatics, University of Edinburgh February 12, 2018 1 0 Based on Mark van Rossum s and Chris Williams s old NIP slides
Statistical and Learning Techniques in Computer Vision Lecture 1: Random Variables Jens Rittscher and Chuck Stewart
 Statistical and Learning Techniques in Computer Vision Lecture 1: Random Variables Jens Rittscher and Chuck Stewart 1 Motivation Imaging is a stochastic process: If we take all the different sources of
Statistical and Learning Techniques in Computer Vision Lecture 1: Random Variables Jens Rittscher and Chuck Stewart 1 Motivation Imaging is a stochastic process: If we take all the different sources of
Ch. 8 Math Preliminaries for Lossy Coding. 8.5 Rate-Distortion Theory
 Ch. 8 Math Preliminaries for Lossy Coding 8.5 Rate-Distortion Theory 1 Introduction Theory provide insight into the trade between Rate & Distortion This theory is needed to answer: What do typical R-D
Ch. 8 Math Preliminaries for Lossy Coding 8.5 Rate-Distortion Theory 1 Introduction Theory provide insight into the trade between Rate & Distortion This theory is needed to answer: What do typical R-D
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Additional reading can be found from non-assessed exercises (week 8) in this course unit teaching page. Textbooks: Sect. 6.3 in [1] and Ch. 12 in [2] Outline Introduction
Principal Component Analysis (PCA) Additional reading can be found from non-assessed exercises (week 8) in this course unit teaching page. Textbooks: Sect. 6.3 in [1] and Ch. 12 in [2] Outline Introduction
Independent component analysis: algorithms and applications
 PERGAMON Neural Networks 13 (2000) 411 430 Invited article Independent component analysis: algorithms and applications A. Hyvärinen, E. Oja* Neural Networks Research Centre, Helsinki University of Technology,
PERGAMON Neural Networks 13 (2000) 411 430 Invited article Independent component analysis: algorithms and applications A. Hyvärinen, E. Oja* Neural Networks Research Centre, Helsinki University of Technology,
Discriminative Direction for Kernel Classifiers
 Discriminative Direction for Kernel Classifiers Polina Golland Artificial Intelligence Lab Massachusetts Institute of Technology Cambridge, MA 02139 polina@ai.mit.edu Abstract In many scientific and engineering
Discriminative Direction for Kernel Classifiers Polina Golland Artificial Intelligence Lab Massachusetts Institute of Technology Cambridge, MA 02139 polina@ai.mit.edu Abstract In many scientific and engineering
PROPERTIES OF THE EMPIRICAL CHARACTERISTIC FUNCTION AND ITS APPLICATION TO TESTING FOR INDEPENDENCE. Noboru Murata
 ' / PROPERTIES OF THE EMPIRICAL CHARACTERISTIC FUNCTION AND ITS APPLICATION TO TESTING FOR INDEPENDENCE Noboru Murata Waseda University Department of Electrical Electronics and Computer Engineering 3--
' / PROPERTIES OF THE EMPIRICAL CHARACTERISTIC FUNCTION AND ITS APPLICATION TO TESTING FOR INDEPENDENCE Noboru Murata Waseda University Department of Electrical Electronics and Computer Engineering 3--
Blind Source Separation Using Artificial immune system
 American Journal of Engineering Research (AJER) e-issn : 2320-0847 p-issn : 2320-0936 Volume-03, Issue-02, pp-240-247 www.ajer.org Research Paper Open Access Blind Source Separation Using Artificial immune
American Journal of Engineering Research (AJER) e-issn : 2320-0847 p-issn : 2320-0936 Volume-03, Issue-02, pp-240-247 www.ajer.org Research Paper Open Access Blind Source Separation Using Artificial immune
CS 4495 Computer Vision Principle Component Analysis
 CS 4495 Computer Vision Principle Component Analysis (and it s use in Computer Vision) Aaron Bobick School of Interactive Computing Administrivia PS6 is out. Due *** Sunday, Nov 24th at 11:55pm *** PS7
CS 4495 Computer Vision Principle Component Analysis (and it s use in Computer Vision) Aaron Bobick School of Interactive Computing Administrivia PS6 is out. Due *** Sunday, Nov 24th at 11:55pm *** PS7
Deriving Principal Component Analysis (PCA)
") -0 Mathematical Foundations for Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deriving Principal Component Analysis (PCA) Matt Gormley Lecture 11 Oct.
-0 Mathematical Foundations for Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deriving Principal Component Analysis (PCA) Matt Gormley Lecture 11 Oct.
Subspace Methods for Visual Learning and Recognition
 This is a shortened version of the tutorial given at the ECCV 2002, Copenhagen, and ICPR 2002, Quebec City. Copyright 2002 by Aleš Leonardis, University of Ljubljana, and Horst Bischof, Graz University
This is a shortened version of the tutorial given at the ECCV 2002, Copenhagen, and ICPR 2002, Quebec City. Copyright 2002 by Aleš Leonardis, University of Ljubljana, and Horst Bischof, Graz University
Independent Component Analysis and FastICA. Copyright Changwei Xiong June last update: July 7, 2016
 Independent Component Analysis and FastICA Copyright Changwei Xiong 016 June 016 last update: July 7, 016 TABLE OF CONTENTS Table of Contents...1 1. Introduction.... Independence by Non-gaussianity....1.
Independent Component Analysis and FastICA Copyright Changwei Xiong 016 June 016 last update: July 7, 016 TABLE OF CONTENTS Table of Contents...1 1. Introduction.... Independence by Non-gaussianity....1.