HEP Data Mining with TMVA
|
|
|
- Willis Lane
- 6 years ago
- Views:
Transcription
1 HEP Data Mining with TMVA ToolKit for Multivariate Analysis with ROOT Andreas Hoecker ( * ) (CERN) Seminar, IFJ Krakow, Feb 27, 2007 ( * ) on behalf of J. Stelzer, F. Tegenfeldt, H.+K. Voss, and many other contributors A. Hoecker: Data Mining with TMVA 1
2 a d v e r t i s e m e n t We (finally) have a Users Guide! Please check on tmva.sf.net for its imminent release TMVA Users Guide 68pp, incl. code examples to be submitted to arxiv:physics A. Hoecker: Data Mining with TMVA 2
3 Preliminary Remarks One example for Machine Learning : It is not so useful to let the machine learn what we know well, but let it do where we re bad: Set the goal (define signal and background ) H u m a n Determine discriminating variables Find appropriate control samples Develop machine learning algorithms M a c h i n e Train the algorithm Independently evaluate the algorithm Apply the algorithm to unknown data It is good to understand what the machine does but it is not mandatory! A. Hoecker: Data Mining with TMVA 3



4 Event Classification Suppose data sample with two types of events: H 0, H 1 We have found discriminating input variables x 1, x 2, What decision boundary should we use to select events of type H 1? Rectangular cuts? A linear boundary? A nonlinear one? x 2 H 1 H 1 x 2 x 2 H 1 H 0 H 0 H 0 x 1 x 1 x 1 How can we decide this in an optimal way? Let the machine learn it! A. Hoecker: Data Mining with TMVA 4
 multi-variable input information in a single scalar")
 0, y(h 1 ) 1 A.")
5 Multivariate Event Classification All multivariate classifiers have in common to condense (correlated) multi-variable input information in a single scalar output variable It is a R n R regression problem; classification is in fact a discretised regression y(h 0 ) 0, y(h 1 ) 1 A. Hoecker: Data Mining with TMVA 5
 Lifetime and flavour tagging (b-tagging, ) Parameter estimation (CP violation in B system, ) etc.")
6 Event Classification in High-Energy Physics (HEP) Most HEP analyses require discrimination of signal from background: Event level (Higgs searches, ) Cone level (Tau-vs-jet reconstruction, ) Track level (particle identification, ) Lifetime and flavour tagging (b-tagging, ) Parameter estimation (CP violation in B system, ) etc. The multivariate input information used for this has various sources Kinematic variables (masses, momenta, decay angles, ) Event properties (jet/lepton multiplicity, sum of charges, ) Event shape (sphericity, Fox-Wolfram moments, ) Detector response (silicon hits, de/dx, Cherenkov angle, shower profiles, muon hits, ) etc. Traditionally few powerful input variables were combined; new methods allow to use up to 100 and more variables w/o loss of classification power A. Hoecker: Data Mining with TMVA 6
7 Multivariate Classification Algorithms A large variety of multivariate classifiers (MVAs) exists T T r r a a d d i i t t i i o o n n a a l l Rectangular cuts (optimisation often by hand ) Projective likelihood (up to 2D) Linear discriminant analysis (χ 2 estimators, Fisher) Nonlinear discriminant analysis (Neural nets) V V a a r r i i a a n n t t s s Prior decorrelation of input variables (input to cuts and likelihood) Principal component analysis of input variables Multidimensional likelihood (kernel nearest neighbor methods) N N e e w w Decision trees with boosting and bagging, Random forests Rule-based learning machines Support vector machines Bayesian neural nets, and more general Committee classifiers A. Hoecker: Data Mining with TMVA 7
8 Multivariate Classification Algorithms How to dissipate (often diffuse) skepticism against the use of MVAs black boxes! Certainly, cuts are transparent, so if cuts are competitive (rarely the case) use them in presence of correlations, cuts loose transparency we should stop calling MVAs black boxes and understand how they behave what if the training samples incorrectly describe the data? Not good, but not necessarily a huge problem: performance on real data will be worse than training results however: bad training does not create a bias! only if the training efficiencies are used in data analysis bias optimized cuts are not in general less vulnerable to systematics (on the contrary!) how can one evaluate systematics? There is no principle difference in systematics evaluation between single variables discriminating and MVAs variables and MVA need control sample for MVA output (not necessarily for each input variable) A. Hoecker: Data Mining with TMVA 8
9 T M V A A. Hoecker: Data Mining with TMVA 9

10 What is TMVA The various classifiers have very different properties Ideally, all should be tested for a given problem Systematically choose the best performing classifier Comparisons between classifiers improves the understanding and takes away mysticism TMVA Toolkit for multivariate data analysis with ROOT Framework for parallel training, testing, evaluation and application of MV classifiers A large number of linear, nonlinear, likelihood and rule-based classifiers implemented Each classifier provides a ranking of the input variables The input variables can be decorrelated or projected upon their principal components Training results and full configuration are written to weight files and applied by a Reader Clear and simple user interface A. Hoecker: Data Mining with TMVA 10

11 TMVA Development and Distribution TMVA is a sourceforge (SF) package for world-wide access Home page. SF project page. View CVS Mailing list... ROOT class index. Very active project fast response time on feature requests Currently 4 main developers, and 24 registered contributors at SF ~ 700 downloads since March 2006 (not accounting cvs checkouts and ROOT users) Written in C++, relying on core ROOT functionality Full examples distributed with TMVA, including analysis macros and GUI Scripts are provided for TMVA use in ROOT macro, as C++ executable or with python Integrated and distributed with ROOT since ROOT v A. Hoecker: Data Mining with TMVA 11
12 T h e T M V A C l a s s i f i e r s Currently implemented classifiers : Rectangular cut optimisation Projective and multidimensional likelihood estimator Fisher and H-Matrix discriminants Artificial neural networks (three different multilayer perceptrons) Boosted/bagged decision trees with automatic node pruning RuleFit In work : Support vector machine Committee classifier A. Hoecker: Data Mining with TMVA 12
 into decorrelated variable space (x ) by: x = C 1 x")

13 Data Preprocessing: Decorrelation Commonly realised for all methods in TMVA (centrally in DataSet class) Removal of linear correlations by rotating input variables Determine square-root C of correlation matrix C, i.e., C = C C Compute C by diagonalising C: Transform original (x) into decorrelated variable space (x ) by: x = C 1 x Various ways to choose basis for decorrelation (also implemented PCA) Note that decorrelation is only complete, if Correlations are linear Input variables are Gaussian distributed Not very accurate conjecture in general = T T D = S CS C S DS original original SQRT SQRT derorr. derorr. PCA PCA derorr. derorr. A. Hoecker: Data Mining with TMVA 13
 xcut ievent 0,1 = x, x v Usually training files in TMVA do not contain realistic signal and background abundance Cannot optimize")
![for best significance Instead: scan in signal efficiency [0 1] and maximise background rejection From this scan, the best working](/docs-images/74/70079015/images/14-1.jpg "point (cuts) for any sig/bkg numbers can be derived Technical challenge: how to find optimal cuts MINUIT fails due to non-unique")

14 Rectangular Cut Optimisation Simplest method: cut in rectangular variable volume ( ) { } ( i ) { variables} ( v event xv,min v,max ) xcut ievent 0,1 = x, x v Usually training files in TMVA do not contain realistic signal and background abundance Cannot optimize for best significance Instead: scan in signal efficiency [0 1] and maximise background rejection From this scan, the best working point (cuts) for any sig/bkg numbers can be derived Technical challenge: how to find optimal cuts MINUIT fails due to non-unique solution space TMVA uses: Monte Carlo sampling, Genetics Algorithm, Simulated Annealing Huge speed improvement of volume search by sorting events in binary tree Cuts usually benefit from prior decorrelation of cut variables A. Hoecker: Data Mining with TMVA 14
15 Projective Likelihood Estimator (PDE Approach) Much liked in HEP: probability density estimators for each input variable combined in likelihood estimator Likelihood ratio for event i event y L ( i ) event = U k { species} PDFs { variables} k p signal k { variables} ( x ( i )) p U k k event ( x ( i )) k discriminating variables event Species: signal, background types PDE introduces fuzzy logic Ignores correlations between input variables Optimal approach if correlations are zero (or linear decorrelation) Otherwise: significant performance loss y L often strongly peaked 0,1: transform output (configurable) ( ) y y = ln y L L τ L A. Hoecker: Data Mining with TMVA 15

 with Gaussian smearing TMVA performs automatic validation of goodness-of-fit original distribution is Gaussian A.")
16 PDE Approach: Estimating PDF Kernels Technical challenge: how to estimate the PDF shapes 3 ways: parametric fitting (function) nonparametric fitting event counting Difficult to automate for arbitrary PDFs Easy to automate, can create artefacts/suppress information Automatic, unbiased, but suboptimal We have chosen to implement nonparametric fitting in TMVA Binned shape interpolation using spline functions (orders: 1, 2, 3, 5) Unbinned kernel density estimation (KDE) with Gaussian smearing TMVA performs automatic validation of goodness-of-fit original distribution is Gaussian A. Hoecker: Data Mining with TMVA 16
17 Multidimensional PDE Approach Use a single PDF per event class (sig, bkg), which spans N var dimensions PDE Range-Search: count number of signal and background events in vicinity of test event preset or adaptive volume defines vicinity Carli-Koblitz, NIM A501, 576 (2003) The signal estimator is then given by (simplified, full formula accounts for event weights and training population) x 2 ( ) y i V PDERS event, 0.14 H 1 PDE-RS ratio for event i event y PDERS (, V ) i = event chosen volume n S ns ( ievent, V ) ( i, V) + n ( i, V) event #signal events in V B event H 0 test event #background events in V x 1 Improve y PDERS estimate within V by using various N var -D kernel estimators Enhance speed of event counting in volume by binary tree search A. Hoecker: Data Mining with TMVA 17
 ( i ) y = F + x F Fi event 0 Fisher coefficients given by: k k { variables} N k event k (,, )")
18 Fisher Linear Discriminant Analysis (LDA) Well known, simple and elegant classifier LDA determines axis in the input variable hyperspace such that a projection of events onto this axis pushes signal and background as far away from each other as possible Classifier computation couldn t be simpler: ( i ) ( i ) y = F + x F Fi event 0 Fisher coefficients given by: k k { variables} N k event k (,, ) var 1 k S B F W x x = 1 Fisher coefficients, where W is sum C S + C B Fisher requires distinct sample means between signal and background Optimal classifier for linearly correlated Gaussian-distributed variables H-Matrix: poor man s version of Fisher discriminant A. Hoecker: Data Mining with TMVA 18
19 Nonlinear Analysis: Artificial Neural Networks Achieve nonlinear classifier response by activating output nodes using nonlinear weights Call nodes neurons and arrange them in series: Feed-forward Multilayer Perceptron N var discriminating input variables 1 input layer k hidden layers 1 ouput layer 1. i... N (0) x i = 1.. Nvar w 11 w 1j w ij 1. j. M M k x w w x ( k 1) x + 1,2 M k 1 ( k) ( k) ( k) ( k 1) j = A 0 j + ij i i = 1 2 output classes (signal and background) with: ( Activation function) Ax ( ) = 1+ x ( e ) 1 Weierstrass theorem: can approximate any continuous functions to arbitrary precision with a single hidden layer and an infinite number of neurons Three different multilayer perceptrons available in TMVA Adjust weights (=training) using back-propagation : For each training event compare desired and received MLP outputs {0,1}: ε = d r Correct weights, depending on ε and a learning rate η A. Hoecker: Data Mining with TMVA 19
20 Decision Trees Sequential application of cuts splits the data into nodes, where the final nodes (leafs) classify an event as signal or background A. Hoecker: Data Mining with TMVA 20
")


 Continue")


21 Decision Trees Sequential application of cuts splits the data into nodes, where the final nodes (leafs) classify an event as signal or background Growing a decision tree: Start with Root node Split training sample according to cut on best variable at this node Splitting criterion: e.g., maximum Gini-index : purity (1 purity) Continue splitting until min. number of events or max. purity reached Classify leaf node according to majority of events, or give weight; unknown test events are classified accordingly Bottom-up pruning of a decision tree Remove statistically insignificant nodes to reduce tree overtraining automatic in TMVA A. Hoecker: Data Mining with TMVA 21

22 Decision Trees Decision tree before pruning Decision tree after pruning Bottom-up pruning of a decision tree Remove statistically insignificant nodes to reduce tree overtraining automatic in TMVA A. Hoecker: Data Mining with TMVA 22
 deteriorate performance) Shortcomings: Instability: small changes in training sample can")
23 Boosted Decision Trees (BDT) Data mining with decision trees is popular in science (so far mostly outside of HEP) Advantages: Easy interpretation can always be represented in 2D tree Independent of monotonous variable transformations, immune against outliers Weak variables are ignored (and don t (much) deteriorate performance) Shortcomings: Instability: small changes in training sample can dramatically alter the tree structure Sensitivity to overtraining ( requires pruning) Boosted decision trees: combine forest of decision trees, with differently weighted events in each tree (trees can also be weighted), by majority vote e.g., AdaBoost : incorrectly classified events receive larger weight in next decision tree Bagging (instead of boosting): random event weights, resampling with replacement Boosting or bagging are means to create set of basis functions : the final classifier is linear combination (expansion) of these functions A. Hoecker: Data Mining with TMVA 23
 normalised discriminating event")
 Fast, rather robust and good performance One of the elementary cellular automaton rules (Wolfram 1983, 2002).")
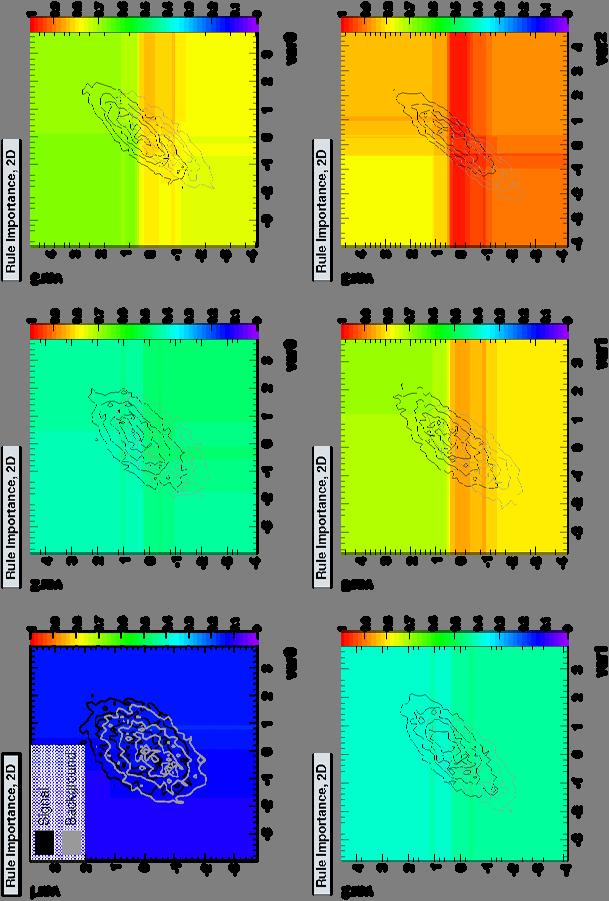
24 Predictive Learning via Rule Ensembles (RuleFit) Following RuleFit approach by Friedman-Popescu Friedman-Popescu, Tech Rep, Stat. Dpt, Stanford U., 2003 Model is linear combination of rules, where a rule is a sequence of cuts RuleFit classifier rules (cut sequence r m =1 if all cuts satisfied, =0 otherwise) normalised discriminating event variables nr y x = a + r x + b xˆ MR ( ) a ( ˆ) RF 0 m m k k m= 1 k= 1 Sum of rules Linear Fisher term The problem to solve is Create rule ensemble: use forest of decision trees Fit coefficients a m, b k : gradient direct regularization (Friedman et al.) Fast, rather robust and good performance One of the elementary cellular automaton rules (Wolfram 1983, 2002). It specifies the next color in a cell, depending on its color and its immediate neighbors. Its rule outcomes are encoded in the binary representation 30= A. Hoecker: Data Mining with TMVA 24
25 U s i n g T M V A A typical TMVA analysis consists of two main steps: 1. Training phase: training, testing and evaluation of classifiers using data samples with known signal and background composition 2. Application phase: using selected trained classifiers to classify unknown data samples Illustration of these steps with toy data samples A. Hoecker: Data Mining with TMVA 25
26 Code Flow for Training and Application Phases A. Hoecker: Data Mining with TMVA 26




27 Code Flow for Training and Application Phases Can Can be be ROOT ROOT scripts, scripts, C++ C++ executables executables or or python python scripts scripts (via (via PyROOT), PyROOT), or or any any other other high-level high-level language language that that interfaces interfaces with with ROOT ROOT A. Hoecker: Data Mining with TMVA 27


28 A Toy Example (idealized) Use data set with 4 linearly correlated Gaussian distributed variables: Rank : Variable : Separation : var3 : 3.834e+02 2 : var2 : 3.062e+02 3 : var1 : 1.097e+02 4 : var0 : 5.818e A. Hoecker: Data Mining with TMVA 28
29 Preprocessing the Input Variables Decorrelation of variables before training is useful for this example A. Hoecker: Data Mining with TMVA 29



30 Preprocessing the Input Variables Decorrelation of variables before training is useful for this example Similar distributions for PCA Note that in cases with non-gaussian distributions and/or nonlinear correlations decorrelation may do more harm than any good A. Hoecker: Data Mining with TMVA 30








31 Validating the Classifier Training Projective likelihood PDFs, MLP training, BDTs, TMVA GUI average no. of nodes before/after pruning: 4193 / 968 A. Hoecker: Data Mining with TMVA 31


32 Testing the Classifiers Classifier output distributions for independent test sample: A. Hoecker: Data Mining with TMVA 32
33 Testing the Classifiers Classifier output distributions for independent test sample: A. Hoecker: Data Mining with TMVA 33
34 Evaluating the Classifiers There is no unique way to express the performance of a classifier several benchmark quantities computed by TMVA Signal eff. at various background effs. (= 1 rejection) when cutting on classifier output The Separation: ( yˆ ( ) ˆ ( )) 2 S y yb y 1 2 yˆ ( y) + yˆ ( y) The discrimination Significance: The average of the signal μ-transform: Remark on overtraining S 2 2 ( y y ) σ + σ S B y, S y, B ( ˆ ( )) yμ y y dy (the μ-transform of a classifier yields a uniform background distribution, so that the signal shapes can be directly compared among the classifiers) B dy Occurs when classifier training has too few degrees of freedom because the classifier has too many adjustable parameters for too few training events Sensitivity to overtraining depends on classifier: e.g., Fisher weak, BDT strong Compare performance between training and test sample to detect overtraining Actively counteract overtraining: e.g., smooth likelihood PDFs, prune decision trees, S A. Hoecker: Data Mining with TMVA 34
35 Evaluating the Classifiers (taken from TMVA output ) Better classifier Check for overtraining Evaluation results ranked by best signal efficiency and purity (area) MVA Signal efficiency at bkg eff. (error): Sepa- @B=0.30 Area ration: cance: Fisher : 0.268(03) 0.653(03) 0.873(02) MLP : 0.266(03) 0.656(03) 0.873(02) LikelihoodD : 0.259(03) 0.649(03) 0.871(02) PDERS : 0.223(03) 0.628(03) 0.861(02) RuleFit : 0.196(03) 0.607(03) 0.845(02) HMatrix : 0.058(01) 0.622(03) 0.868(02) BDT : 0.154(02) 0.594(04) 0.838(03) CutsGA : 0.109(02) 1.000(00) 0.717(03) Likelihood : 0.086(02) 0.387(03) 0.677(03) Testing efficiency compared to training efficiency (overtraining check) MVA Signal efficiency: from test sample (from traing @B= Fisher : (0.275) (0.658) (0.873) MLP : (0.278) (0.658) (0.873) LikelihoodD : (0.273) (0.657) (0.872) PDERS : (0.389) (0.691) (0.881) RuleFit : (0.198) (0.616) (0.848) HMatrix : (0.060) (0.623) (0.868) BDT : (0.268) (0.736) (0.911) CutsGA : (0.123) (0.424) (0.715) Likelihood : (0.092) (0.379) (0.677) A. Hoecker: Data Mining with TMVA 35
36 Evaluating the Classifiers (taken from TMVA output ) Better classifier Check for overtraining Evaluation results ranked by best signal efficiency and purity (area) MVA Signal efficiency at bkg eff. (error): Sepa- @B=0.30 Area ration: cance: Fisher : 0.268(03) 0.653(03) 0.873(02) MLP : 0.266(03) 0.656(03) 0.873(02) LikelihoodD : 0.259(03) 0.649(03) 0.871(02) PDERS : 0.223(03) 0.628(03) 0.861(02) RuleFit : 0.196(03) 0.607(03) 0.845(02) HMatrix : 0.058(01) 0.622(03) 0.868(02) BDT : 0.154(02) 0.594(04) 0.838(03) CutsGA : 0.109(02) 1.000(00) 0.717(03) Likelihood : 0.086(02) 0.387(03) 0.677(03) Testing efficiency compared to training efficiency (overtraining check) MVA Signal efficiency: from test sample (from traing @B= Fisher : (0.275) (0.658) (0.873) MLP : (0.278) (0.658) (0.873) LikelihoodD : (0.273) (0.657) (0.872) PDERS : (0.389) (0.691) (0.881) RuleFit : (0.198) (0.616) (0.848) HMatrix : (0.060) (0.623) (0.868) BDT : (0.268) (0.736) (0.911) CutsGA : (0.123) (0.424) (0.715) Likelihood : (0.092) (0.379) (0.677) A. Hoecker: Data Mining with TMVA 36
37 Evaluating the Classifiers (with a single plot ) Smooth background rejection versus signal efficiency curve: (from cut on classifier output) A. Hoecker: Data Mining with TMVA 37

38 Evaluating the Classifiers (with a single plot ) Smooth background rejection versus signal efficiency curve: (from cut on classifier output) Note: Nearly All Realistic Use Cases are Much More Difficult Than This One Note: Nearly All Realistic Use Cases are Much More Difficult Than This One A. Hoecker: Data Mining with TMVA 38
39 Remarks Additional information provided during the TMVA training phase Classifiers provide specific ranking of input variables Correlation matrix and classification overlap matrix for classifiers: if two classifiers have similar performance, but significant non-overlapping classifications combine them! Such a combination of classifiers is denoted a Committee classifier : currently under development (BDTs and RuleFit are committees of base learners, Bayesian ANNs are committees of ANNs, etc) PDFs for the classifier outputs can be used to derive signal probabilities: P MVA ( i ) event = f ˆ SyS( ievent ) fyˆ ( i ) + 1 f yˆ ( i ) ( ) S S event S B event, with f the signal fraction in sample S All classifiers write ROOT and text weight files for configuration and training results feeds the application phase (Reader) A. Hoecker: Data Mining with TMVA 39
40 M o r e T o y E x a m p l e s A. Hoecker: Data Mining with TMVA 40

 Linear correlations (opposite for")
 A.")
41 More Toys: Linear-, Cross-, Circular Correlations Illustrate the behaviour of linear and nonlinear classifiers Linear correlations (same for signal and background) Linear correlations (opposite for signal and background) Circular correlations (same for signal and background) A. Hoecker: Data Mining with TMVA 41




42 How does linear decorrelation affect strongly nonlinear cases? Original correlations A. Hoecker: Data Mining with TMVA 42
43 How does linear decorrelation affect strongly nonlinear cases? SQRT decorrelation A. Hoecker: Data Mining with TMVA 43
44 How does linear decorrelation affect strongly nonlinear cases? PCA decorrelation A. Hoecker: Data Mining with TMVA 44

")
 Circular correlations (same for signal")
45 Weight Variables by Classifier Performance How well do the classifier resolve the various correlation patterns? Linear correlations (same for signal and background) Linear correlations (opposite for signal and background) Circular correlations (same for signal and background) A. Hoecker: Data Mining with TMVA 45
46 Weight Variables by Classifier Performance How well do the classifier resolve the various correlation patterns? Linear correlations (same for signal and background) Linear correlations (opposite for signal and background) Circular correlations (same for signal and background) A. Hoecker: Data Mining with TMVA 46
47 Weight Variables by Classifier Performance How well do the classifier resolve the various correlation patterns? Linear correlations (same for signal and background) Linear correlations (opposite for signal and background) Circular correlations (same for signal and background) A. Hoecker: Data Mining with TMVA 47
48 Weight Variables by Classifier Performance How well do the classifier resolve the various correlation patterns? Linear correlations (same for signal and background) Linear correlations (opposite for signal and background) Circular correlations (same for signal and background) A. Hoecker: Data Mining with TMVA 48
49 Weight Variables by Classifier Performance How well do the classifier resolve the various correlation patterns? Linear correlations (same for signal and background) Linear correlations (opposite for signal and background) Circular correlations (same for signal and background) A. Hoecker: Data Mining with TMVA 49
50 Weight Variables by Classifier Performance How well do the classifier resolve the various correlation patterns? Linear correlations (same for signal and background) Linear correlations (opposite for signal and background) Circular correlations (same for signal and background) A. Hoecker: Data Mining with TMVA 50
51 Weight Variables by Classifier Performance How well do the classifier resolve the various correlation patterns? Linear correlations (same for signal and background) Linear correlations (opposite for signal and background) Circular correlations (same for signal and background) A. Hoecker: Data Mining with TMVA 51

52 Final Classifier Performance Background rejection versus signal efficiency curve: Linear Cross Circular Example A. Hoecker: Data Mining with TMVA 52
53 Stability with Respect to Irrelevant Variables Toy example with 2 discriminating and 4 non-discriminating variables? A. Hoecker: Data Mining with TMVA 53
54 Stability with Respect to Irrelevant Variables Toy example with 2 discriminating and 4 non-discriminating variables? use use only only two two discriminant discriminant variables variables in in classifiers classifiers A. Hoecker: Data Mining with TMVA 54



55 Stability with Respect to Irrelevant Variables Toy example with 2 discriminating and 4 non-discriminating variables? use use only all only all discriminant discriminant two two discriminant discriminant variables variables in in classifiers classifiers A. Hoecker: Data Mining with TMVA 55

56 S u m m a r y & P l a n s A. Hoecker: Data Mining with TMVA 56
57 Summary of the Classifiers and their Properties Classifiers Criteria Rectangular Cuts Projective Likelihood Multi-D PDERS H-Matrix Fisher MLP BDT RuleFit Speed Performance Robustness no / linear correlations nonlinear correlations Course of dimensionality Clarity Training Response Overtraining Weak input variables A. Hoecker: Data Mining with TMVA 57
58 S u m m a r y & P l a n s TMVA unifies highly customizable and performing multivariate classification algorithms in a single user-friendly framework This ensures most objective classifier comparisons, and simplifies their use TMVA is available on tmva.sf.net, and in ROOT ( 5.11/03) A typical TMVA analysis requires user interaction with a Factory (for the classifier training) and a Reader (for the classifier application) ROOT Macros are provided for the display of the evaluation results Forthcoming: Imminent: TMVA version with new features (together with a detailed Users Guide) Support Vector Machine (M. Wolter & A. Zemla) Bayesian classifiers Committee method A. Hoecker: Data Mining with TMVA 58

59 C o p y r i g h t s & C r e d i t s TMVA is open source! Use & redistribution of source permitted according to terms in BSD license Several similar data mining efforts with rising importance in most fields of science and industry Important for HEP: Parallelised MVA training and evaluation pioneered by Cornelius package (BABAR) Also frequently used: StatPatternRecognition package by I. Narsky Many implementations of individual classifiers exist Acknowledgments: The fast development of TMVA would not have been possible without the contribution and feedback from many developers and users to whom we are indebted. We thank in particular the CERN Summer students Matt Jachowski (Stanford) for the implementation of TMVA's new MLP neural network, and Yair Mahalalel (Tel Aviv) for a significant improvement of PDERS. We are grateful to Doug Applegate, Kregg Arms, Ren\'e Brun and the ROOT team, Tancredi Carli, Elzbieta Richter-Was, Vincent Tisserand and Marcin Wolter for helpful conversations. A. Hoecker: Data Mining with TMVA 59
Multivariate Data Analysis with TMVA
 Multivariate Data Analysis with TMVA Andreas Hoecker ( * ) (CERN) Statistical Tools Workshop, DESY, Germany, June 19, 2008 ( * ) On behalf of the present core team: A. Hoecker, P. Speckmayer, J. Stelzer,
Multivariate Data Analysis with TMVA Andreas Hoecker ( * ) (CERN) Statistical Tools Workshop, DESY, Germany, June 19, 2008 ( * ) On behalf of the present core team: A. Hoecker, P. Speckmayer, J. Stelzer,
Multivariate Methods in Statistical Data Analysis
 Multivariate Methods in Statistical Data Analysis Web-Site: http://tmva.sourceforge.net/ See also: "TMVA - Toolkit for Multivariate Data Analysis, A. Hoecker, P. Speckmayer, J. Stelzer, J. Therhaag, E.
Multivariate Methods in Statistical Data Analysis Web-Site: http://tmva.sourceforge.net/ See also: "TMVA - Toolkit for Multivariate Data Analysis, A. Hoecker, P. Speckmayer, J. Stelzer, J. Therhaag, E.
Multivariate Data Analysis Techniques
 Multivariate Data Analysis Techniques Andreas Hoecker (CERN) Workshop on Statistics, Karlsruhe, Germany, Oct 12 14, 2009 O u t l i n e Introduction to multivariate classification and regression Multivariate
Multivariate Data Analysis Techniques Andreas Hoecker (CERN) Workshop on Statistics, Karlsruhe, Germany, Oct 12 14, 2009 O u t l i n e Introduction to multivariate classification and regression Multivariate
Multivariate Analysis, TMVA, and Artificial Neural Networks
 http://tmva.sourceforge.net/ Multivariate Analysis, TMVA, and Artificial Neural Networks Matt Jachowski jachowski@stanford.edu 1 Multivariate Analysis Techniques dedicated to analysis of data with multiple
http://tmva.sourceforge.net/ Multivariate Analysis, TMVA, and Artificial Neural Networks Matt Jachowski jachowski@stanford.edu 1 Multivariate Analysis Techniques dedicated to analysis of data with multiple
The Toolkit for Multivariate Data Analysis, TMVA 4
 7th International Conference on Computing in High Energy and Nuclear Physics (CHEP9) IOP Publishing Journal of Physics: Conference Series 29 (2) 3257 doi:.88/742-6596/29/3/3257 The Toolkit for Multivariate
7th International Conference on Computing in High Energy and Nuclear Physics (CHEP9) IOP Publishing Journal of Physics: Conference Series 29 (2) 3257 doi:.88/742-6596/29/3/3257 The Toolkit for Multivariate
Statistical Tools in Collider Experiments. Multivariate analysis in high energy physics
 Statistical Tools in Collider Experiments Multivariate analysis in high energy physics Pauli Lectures - 06/0/01 Nicolas Chanon - ETH Zürich 1 Main goals of these lessons - Have an understanding of what
Statistical Tools in Collider Experiments Multivariate analysis in high energy physics Pauli Lectures - 06/0/01 Nicolas Chanon - ETH Zürich 1 Main goals of these lessons - Have an understanding of what
StatPatternRecognition: A C++ Package for Multivariate Classification of HEP Data. Ilya Narsky, Caltech
 StatPatternRecognition: A C++ Package for Multivariate Classification of HEP Data Ilya Narsky, Caltech Motivation Introduction advanced classification tools in a convenient C++ package for HEP researchers
StatPatternRecognition: A C++ Package for Multivariate Classification of HEP Data Ilya Narsky, Caltech Motivation Introduction advanced classification tools in a convenient C++ package for HEP researchers
Statistical Methods in Particle Physics
 Statistical Methods in Particle Physics 8. Multivariate Analysis Prof. Dr. Klaus Reygers (lectures) Dr. Sebastian Neubert (tutorials) Heidelberg University WS 2017/18 Multi-Variate Classification Consider
Statistical Methods in Particle Physics 8. Multivariate Analysis Prof. Dr. Klaus Reygers (lectures) Dr. Sebastian Neubert (tutorials) Heidelberg University WS 2017/18 Multi-Variate Classification Consider
Optimization of tau identification in ATLAS experiment using multivariate tools
 Optimization of tau identification in ATLAS experiment using multivariate tools Marcin Wolter a, Andrzej Zemła a,b a Institute of Nuclear Physics PAN, Kraków b Jagiellonian University, Kraków ACAT 2007,
Optimization of tau identification in ATLAS experiment using multivariate tools Marcin Wolter a, Andrzej Zemła a,b a Institute of Nuclear Physics PAN, Kraków b Jagiellonian University, Kraków ACAT 2007,
Machine learning approaches to the Higgs boson self coupling
 Machine learning approaches to the Higgs boson self coupling 6 JUNE ICHEP 2018 @ COEX SEOUL JUBIN PARK (CHONNAM NATIONAL UNIVERSITY) COLLABORATED WITH JUNG CHANG, KINGMAN CHEUNG, JAE SIK LEE, CHIH-TING
Machine learning approaches to the Higgs boson self coupling 6 JUNE ICHEP 2018 @ COEX SEOUL JUBIN PARK (CHONNAM NATIONAL UNIVERSITY) COLLABORATED WITH JUNG CHANG, KINGMAN CHEUNG, JAE SIK LEE, CHIH-TING
Applied Statistics. Multivariate Analysis - part II. Troels C. Petersen (NBI) Statistics is merely a quantization of common sense 1
 Statistics is merely a quantization of common sense 1") Applied Statistics Multivariate Analysis - part II Troels C. Petersen (NBI) Statistics is merely a quantization of common sense 1 Fisher Discriminant You want to separate two types/classes (A and B) of
Applied Statistics Multivariate Analysis - part II Troels C. Petersen (NBI) Statistics is merely a quantization of common sense 1 Fisher Discriminant You want to separate two types/classes (A and B) of
Statistical Methods for Particle Physics Lecture 2: statistical tests, multivariate methods
 Statistical Methods for Particle Physics Lecture 2: statistical tests, multivariate methods www.pp.rhul.ac.uk/~cowan/stat_aachen.html Graduierten-Kolleg RWTH Aachen 10-14 February 2014 Glen Cowan Physics
Statistical Methods for Particle Physics Lecture 2: statistical tests, multivariate methods www.pp.rhul.ac.uk/~cowan/stat_aachen.html Graduierten-Kolleg RWTH Aachen 10-14 February 2014 Glen Cowan Physics
Multivariate statistical methods and data mining in particle physics
 Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Multivariate Data Analysis and Machine Learning in High Energy Physics (III)
") Multivariate Data Analysis and Machine Learning in High Energy Physics (III) Helge Voss (MPI K, Heidelberg) Graduierten-Kolleg, Freiburg, 11.5-15.5, 2009 Outline Summary of last lecture 1-dimensional Likelihood:
Multivariate Data Analysis and Machine Learning in High Energy Physics (III) Helge Voss (MPI K, Heidelberg) Graduierten-Kolleg, Freiburg, 11.5-15.5, 2009 Outline Summary of last lecture 1-dimensional Likelihood:
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Advanced statistical methods for data analysis Lecture 2
 Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Particle Identification at LHCb. IML Workshop. April 10, 2018
 Particle Identification at LHCb Miriam Lucio, on behalf of the LHCb Collaboration IML Workshop April 10, 2018 M. Lucio Particle Identification at LHCb April 10, 2018 1 Outline 1 Introduction 2 Neutral
Particle Identification at LHCb Miriam Lucio, on behalf of the LHCb Collaboration IML Workshop April 10, 2018 M. Lucio Particle Identification at LHCb April 10, 2018 1 Outline 1 Introduction 2 Neutral
Multivariate Analysis Techniques in HEP
 Multivariate Analysis Techniques in HEP Jan Therhaag IKTP Institutsseminar, Dresden, January 31 st 2013 Multivariate analysis in a nutshell Neural networks: Defeating the black box Boosted Decision Trees:
Multivariate Analysis Techniques in HEP Jan Therhaag IKTP Institutsseminar, Dresden, January 31 st 2013 Multivariate analysis in a nutshell Neural networks: Defeating the black box Boosted Decision Trees:
Statistical Tools in Collider Experiments. Multivariate analysis in high energy physics
 Statistical Tools in Collider Experiments Multivariate analysis in high energy physics Lecture 3 Pauli Lectures - 08/02/2012 Nicolas Chanon - ETH Zürich 1 Outline 1.Introduction 2.Multivariate methods
Statistical Tools in Collider Experiments Multivariate analysis in high energy physics Lecture 3 Pauli Lectures - 08/02/2012 Nicolas Chanon - ETH Zürich 1 Outline 1.Introduction 2.Multivariate methods
Advanced statistical methods for data analysis Lecture 1
 Advanced statistical methods for data analysis Lecture 1 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Advanced statistical methods for data analysis Lecture 1 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008)
") Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008) RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement
Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008) RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement
Lecture 2. G. Cowan Lectures on Statistical Data Analysis Lecture 2 page 1
 Lecture 2 1 Probability (90 min.) Definition, Bayes theorem, probability densities and their properties, catalogue of pdfs, Monte Carlo 2 Statistical tests (90 min.) general concepts, test statistics,
Lecture 2 1 Probability (90 min.) Definition, Bayes theorem, probability densities and their properties, catalogue of pdfs, Monte Carlo 2 Statistical tests (90 min.) general concepts, test statistics,
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Tuning the simulated response of the CMS detector to b-jets using Machine learning algorithms
 Tuning the simulated response of the CMS detector to b-jets using Machine learning algorithms ETH Zürich On behalf of the CMS Collaboration SPS Annual Meeting 2018 31st August 2018 EPFL, Lausanne 1 Motivation
Tuning the simulated response of the CMS detector to b-jets using Machine learning algorithms ETH Zürich On behalf of the CMS Collaboration SPS Annual Meeting 2018 31st August 2018 EPFL, Lausanne 1 Motivation
Boosted Decision Trees and Applications
 EPJ Web of Conferences, 24 (23) DOI:./ epjconf/ 2324 C Owned by the authors, published by EDP Sciences, 23 Boosted Decision Trees and Applications Yann COADOU CPPM, Aix-Marseille UniversitNRS/IN2P3, Marseille,
EPJ Web of Conferences, 24 (23) DOI:./ epjconf/ 2324 C Owned by the authors, published by EDP Sciences, 23 Boosted Decision Trees and Applications Yann COADOU CPPM, Aix-Marseille UniversitNRS/IN2P3, Marseille,
Statistical Data Analysis Stat 2: Monte Carlo Method, Statistical Tests
 Statistical Data Analysis Stat 2: Monte Carlo Method, Statistical Tests London Postgraduate Lectures on Particle Physics; University of London MSci course PH4515 Glen Cowan Physics Department Royal Holloway,
Statistical Data Analysis Stat 2: Monte Carlo Method, Statistical Tests London Postgraduate Lectures on Particle Physics; University of London MSci course PH4515 Glen Cowan Physics Department Royal Holloway,
Hypothesis testing:power, test statistic CMS:
 Hypothesis testing:power, test statistic The more sensitive the test, the better it can discriminate between the null and the alternative hypothesis, quantitatively, maximal power In order to achieve this
Hypothesis testing:power, test statistic The more sensitive the test, the better it can discriminate between the null and the alternative hypothesis, quantitatively, maximal power In order to achieve this
The search for standard model Higgs boson in ZH l + l b b channel at DØ
 The search for standard model Higgs boson in ZH l + l b b channel at DØ University of Science and Technology of China E-mail: pengj@fnal.gov on behalf of the DØ collaboration We present a search for the
The search for standard model Higgs boson in ZH l + l b b channel at DØ University of Science and Technology of China E-mail: pengj@fnal.gov on behalf of the DØ collaboration We present a search for the
Holdout and Cross-Validation Methods Overfitting Avoidance
 Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Search for a diffuse cosmic neutrino flux with ANTARES using track and cascade events
 Search for a diffuse cosmic neutrino flux with ANTARES using track and cascade events Jutta Schnabel on behalf of the ANTARES collaboration Erlangen Centre for Astroparticle Physics, Erwin-Rommel Str.
Search for a diffuse cosmic neutrino flux with ANTARES using track and cascade events Jutta Schnabel on behalf of the ANTARES collaboration Erlangen Centre for Astroparticle Physics, Erwin-Rommel Str.
Functional Preprocessing for Multilayer Perceptrons
 Functional Preprocessing for Multilayer Perceptrons Fabrice Rossi and Brieuc Conan-Guez Projet AxIS, INRIA, Domaine de Voluceau, Rocquencourt, B.P. 105 78153 Le Chesnay Cedex, France CEREMADE, UMR CNRS
Functional Preprocessing for Multilayer Perceptrons Fabrice Rossi and Brieuc Conan-Guez Projet AxIS, INRIA, Domaine de Voluceau, Rocquencourt, B.P. 105 78153 Le Chesnay Cedex, France CEREMADE, UMR CNRS
W vs. QCD Jet Tagging at the Large Hadron Collider
 W vs. QCD Jet Tagging at the Large Hadron Collider Bryan Anenberg: anenberg@stanford.edu; CS229 December 13, 2013 Problem Statement High energy collisions of protons at the Large Hadron Collider (LHC)
W vs. QCD Jet Tagging at the Large Hadron Collider Bryan Anenberg: anenberg@stanford.edu; CS229 December 13, 2013 Problem Statement High energy collisions of protons at the Large Hadron Collider (LHC)
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Statistical Methods for Particle Physics Lecture 2: multivariate methods
 Statistical Methods for Particle Physics Lecture 2: multivariate methods http://indico.ihep.ac.cn/event/4902/ istep 2015 Shandong University, Jinan August 11-19, 2015 Glen Cowan ( 谷林 科恩 ) Physics Department
Statistical Methods for Particle Physics Lecture 2: multivariate methods http://indico.ihep.ac.cn/event/4902/ istep 2015 Shandong University, Jinan August 11-19, 2015 Glen Cowan ( 谷林 科恩 ) Physics Department
Harrison B. Prosper. Bari Lectures
 Harrison B. Prosper Florida State University Bari Lectures 30, 31 May, 1 June 2016 Lectures on Multivariate Methods Harrison B. Prosper Bari, 2016 1 h Lecture 1 h Introduction h Classification h Grid Searches
Harrison B. Prosper Florida State University Bari Lectures 30, 31 May, 1 June 2016 Lectures on Multivariate Methods Harrison B. Prosper Bari, 2016 1 h Lecture 1 h Introduction h Classification h Grid Searches
A Decision Stump. Decision Trees, cont. Boosting. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. October 1 st, 2007
 Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
NON-TRIVIAL APPLICATIONS OF BOOSTING:
 NON-TRIVIAL APPLICATIONS OF BOOSTING: REWEIGHTING DISTRIBUTIONS WITH BDT, BOOSTING TO UNIFORMITY Alex Rogozhnikov YSDA, NRU HSE Heavy Flavour Data Mining workshop, Zurich, 2016 1 BOOSTING a family of machine
NON-TRIVIAL APPLICATIONS OF BOOSTING: REWEIGHTING DISTRIBUTIONS WITH BDT, BOOSTING TO UNIFORMITY Alex Rogozhnikov YSDA, NRU HSE Heavy Flavour Data Mining workshop, Zurich, 2016 1 BOOSTING a family of machine
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING
 EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: June 9, 2018, 09.00 14.00 RESPONSIBLE TEACHER: Andreas Svensson NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: June 9, 2018, 09.00 14.00 RESPONSIBLE TEACHER: Andreas Svensson NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
Boosted hadronic object identification using jet substructure in ATLAS Run-2
 Boosted hadronic object identification using jet substructure in ATLAS Run-2 Emma Winkels on behalf of the ATLAS collaboration HEPMAD18 Outline Jets and jet substructure Top and W tagging H bb tagging
Boosted hadronic object identification using jet substructure in ATLAS Run-2 Emma Winkels on behalf of the ATLAS collaboration HEPMAD18 Outline Jets and jet substructure Top and W tagging H bb tagging
Algorithm-Independent Learning Issues
 Algorithm-Independent Learning Issues Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2007 c 2007, Selim Aksoy Introduction We have seen many learning
Algorithm-Independent Learning Issues Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2007 c 2007, Selim Aksoy Introduction We have seen many learning
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
PATTERN CLASSIFICATION
 PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
Classification for High Dimensional Problems Using Bayesian Neural Networks and Dirichlet Diffusion Trees
 Classification for High Dimensional Problems Using Bayesian Neural Networks and Dirichlet Diffusion Trees Rafdord M. Neal and Jianguo Zhang Presented by Jiwen Li Feb 2, 2006 Outline Bayesian view of feature
Classification for High Dimensional Problems Using Bayesian Neural Networks and Dirichlet Diffusion Trees Rafdord M. Neal and Jianguo Zhang Presented by Jiwen Li Feb 2, 2006 Outline Bayesian view of feature
Statistics for the LHC Lecture 1: Introduction
 Statistics for the LHC Lecture 1: Introduction Academic Training Lectures CERN, 14 17 June, 2010 indico.cern.ch/conferencedisplay.py?confid=77830 Glen Cowan Physics Department Royal Holloway, University
Statistics for the LHC Lecture 1: Introduction Academic Training Lectures CERN, 14 17 June, 2010 indico.cern.ch/conferencedisplay.py?confid=77830 Glen Cowan Physics Department Royal Holloway, University
Data Mining und Maschinelles Lernen
 Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
How to find a Higgs boson. Jonathan Hays QMUL 12 th October 2012
 How to find a Higgs boson Jonathan Hays QMUL 12 th October 2012 Outline Introducing the scalar boson Experimental overview Where and how to search Higgs properties Prospects and summary 12/10/2012 2 The
How to find a Higgs boson Jonathan Hays QMUL 12 th October 2012 Outline Introducing the scalar boson Experimental overview Where and how to search Higgs properties Prospects and summary 12/10/2012 2 The
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Advanced Statistical Methods: Beyond Linear Regression
 Advanced Statistical Methods: Beyond Linear Regression John R. Stevens Utah State University Notes 3. Statistical Methods II Mathematics Educators Worshop 28 March 2009 1 http://www.stat.usu.edu/~jrstevens/pcmi
Advanced Statistical Methods: Beyond Linear Regression John R. Stevens Utah State University Notes 3. Statistical Methods II Mathematics Educators Worshop 28 March 2009 1 http://www.stat.usu.edu/~jrstevens/pcmi
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Chapter 14 Combining Models
 Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Learning from Examples
 Learning from Examples Data fitting Decision trees Cross validation Computational learning theory Linear classifiers Neural networks Nonparametric methods: nearest neighbor Support vector machines Ensemble
Learning from Examples Data fitting Decision trees Cross validation Computational learning theory Linear classifiers Neural networks Nonparametric methods: nearest neighbor Support vector machines Ensemble
CS7267 MACHINE LEARNING
 CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
Neural Networks and Ensemble Methods for Classification
 Neural Networks and Ensemble Methods for Classification NEURAL NETWORKS 2 Neural Networks A neural network is a set of connected input/output units (neurons) where each connection has a weight associated
Neural Networks and Ensemble Methods for Classification NEURAL NETWORKS 2 Neural Networks A neural network is a set of connected input/output units (neurons) where each connection has a weight associated
Final Exam, Machine Learning, Spring 2009
 Name: Andrew ID: Final Exam, 10701 Machine Learning, Spring 2009 - The exam is open-book, open-notes, no electronics other than calculators. - The maximum possible score on this exam is 100. You have 3
Name: Andrew ID: Final Exam, 10701 Machine Learning, Spring 2009 - The exam is open-book, open-notes, no electronics other than calculators. - The maximum possible score on this exam is 100. You have 3
Physics with Tau Lepton Final States in ATLAS. Felix Friedrich on behalf of the ATLAS Collaboration
 Physics with Tau Lepton Final States in ATLAS on behalf of the ATLAS Collaboration HEP 2012, Valparaiso (Chile), 06.01.2012 The Tau Lepton m τ = 1.8 GeV, heaviest lepton cτ = 87 μm, short lifetime hadronic
Physics with Tau Lepton Final States in ATLAS on behalf of the ATLAS Collaboration HEP 2012, Valparaiso (Chile), 06.01.2012 The Tau Lepton m τ = 1.8 GeV, heaviest lepton cτ = 87 μm, short lifetime hadronic
Lecture 16: Small Sample Size Problems (Covariance Estimation) Many thanks to Carlos Thomaz who authored the original version of these slides
 Many thanks to Carlos Thomaz who authored the original version of these slides") Lecture 16: Small Sample Size Problems (Covariance Estimation) Many thanks to Carlos Thomaz who authored the original version of these slides Intelligent Data Analysis and Probabilistic Inference Lecture
Lecture 16: Small Sample Size Problems (Covariance Estimation) Many thanks to Carlos Thomaz who authored the original version of these slides Intelligent Data Analysis and Probabilistic Inference Lecture
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 4: Vector Data: Decision Tree Instructor: Yizhou Sun yzsun@cs.ucla.edu October 10, 2017 Methods to Learn Vector Data Set Data Sequence Data Text Data Classification Clustering
CS145: INTRODUCTION TO DATA MINING 4: Vector Data: Decision Tree Instructor: Yizhou Sun yzsun@cs.ucla.edu October 10, 2017 Methods to Learn Vector Data Set Data Sequence Data Text Data Classification Clustering
Decision Trees: Overfitting
 Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Studies of b b gluon and c c vertices Λ. Abstract
 SLAC PUB 8661 October 2000 Studies of b b gluon and c c vertices Λ Toshinori Abe Stanford Linear Accelerator Center, Stanford University, Stanford, CA 94309 Representing the SLD Collaboration Abstract
SLAC PUB 8661 October 2000 Studies of b b gluon and c c vertices Λ Toshinori Abe Stanford Linear Accelerator Center, Stanford University, Stanford, CA 94309 Representing the SLD Collaboration Abstract
Combination of M-Estimators and Neural Network Model to Analyze Inside/Outside Bark Tree Diameters
 Combination of M-Estimators and Neural Network Model to Analyze Inside/Outside Bark Tree Diameters Kyriaki Kitikidou, Elias Milios, Lazaros Iliadis, and Minas Kaymakis Democritus University of Thrace,
Combination of M-Estimators and Neural Network Model to Analyze Inside/Outside Bark Tree Diameters Kyriaki Kitikidou, Elias Milios, Lazaros Iliadis, and Minas Kaymakis Democritus University of Thrace,
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers
 Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
THE MULTIPLICIY JUMP! FINDING B S IN MULTI-TEV JETS W/O TRACKS
 1 THE MULTIPLICIY JUMP! FINDING B S IN MULTI-TEV JETS W/O TRACKS TODD HUFFMAN, OXFORD UNIVERSITY THOMAS RUSSELL, CURRENTLY @ BLOOMBERG L.P. JEFF TSENG, OXFORD UNIVERSITY ARXIV:1701.06832 ALSO: 2016 J.PHYS.
1 THE MULTIPLICIY JUMP! FINDING B S IN MULTI-TEV JETS W/O TRACKS TODD HUFFMAN, OXFORD UNIVERSITY THOMAS RUSSELL, CURRENTLY @ BLOOMBERG L.P. JEFF TSENG, OXFORD UNIVERSITY ARXIV:1701.06832 ALSO: 2016 J.PHYS.
Statistical Methods for Particle Physics Tutorial on multivariate methods
 Statistical Methods for Particle Physics Tutorial on multivariate methods http://indico.ihep.ac.cn/event/4902/ istep 2015 Shandong University, Jinan August 11-19, 2015 Glen Cowan ( 谷林 科恩 ) Physics Department
Statistical Methods for Particle Physics Tutorial on multivariate methods http://indico.ihep.ac.cn/event/4902/ istep 2015 Shandong University, Jinan August 11-19, 2015 Glen Cowan ( 谷林 科恩 ) Physics Department
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
PoS(ICHEP2012)238. Search for B 0 s µ + µ and other exclusive B decays with the ATLAS detector. Paolo Iengo
238. Search for B 0 s µ + µ and other exclusive B decays with the ATLAS detector. Paolo Iengo") Search for B s µ + µ and other exclusive B decays with the ATLAS detector. On behalf of the ATLAS Collaboration INFN Naples, Italy E-mail: paolo.iengo@cern.ch The ATLAS experiment, collecting data in pp
Search for B s µ + µ and other exclusive B decays with the ATLAS detector. On behalf of the ATLAS Collaboration INFN Naples, Italy E-mail: paolo.iengo@cern.ch The ATLAS experiment, collecting data in pp
UVA CS 4501: Machine Learning
 UVA CS 4501: Machine Learning Lecture 21: Decision Tree / Random Forest / Ensemble Dr. Yanjun Qi University of Virginia Department of Computer Science Where are we? è Five major sections of this course
UVA CS 4501: Machine Learning Lecture 21: Decision Tree / Random Forest / Ensemble Dr. Yanjun Qi University of Virginia Department of Computer Science Where are we? è Five major sections of this course
Lecture 3: Pattern Classification. Pattern classification
 EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Artificial Intelligence Roman Barták
 Artificial Intelligence Roman Barták Department of Theoretical Computer Science and Mathematical Logic Introduction We will describe agents that can improve their behavior through diligent study of their
Artificial Intelligence Roman Barták Department of Theoretical Computer Science and Mathematical Logic Introduction We will describe agents that can improve their behavior through diligent study of their
MLPR: Logistic Regression and Neural Networks
 MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition Amos Storkey Amos Storkey MLPR: Logistic Regression and Neural Networks 1/28 Outline 1 Logistic Regression 2 Multi-layer
MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition Amos Storkey Amos Storkey MLPR: Logistic Regression and Neural Networks 1/28 Outline 1 Logistic Regression 2 Multi-layer
Artificial Neural Networks
 Artificial Neural Networks Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Knowledge
Artificial Neural Networks Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Knowledge
Outline. MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition. Which is the correct model? Recap.
 Outline MLPR: and Neural Networks Machine Learning and Pattern Recognition 2 Amos Storkey Amos Storkey MLPR: and Neural Networks /28 Recap Amos Storkey MLPR: and Neural Networks 2/28 Which is the correct
Outline MLPR: and Neural Networks Machine Learning and Pattern Recognition 2 Amos Storkey Amos Storkey MLPR: and Neural Networks /28 Recap Amos Storkey MLPR: and Neural Networks 2/28 Which is the correct
Numerical Learning Algorithms
 Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Importance Sampling: An Alternative View of Ensemble Learning. Jerome H. Friedman Bogdan Popescu Stanford University
 Importance Sampling: An Alternative View of Ensemble Learning Jerome H. Friedman Bogdan Popescu Stanford University 1 PREDICTIVE LEARNING Given data: {z i } N 1 = {y i, x i } N 1 q(z) y = output or response
Importance Sampling: An Alternative View of Ensemble Learning Jerome H. Friedman Bogdan Popescu Stanford University 1 PREDICTIVE LEARNING Given data: {z i } N 1 = {y i, x i } N 1 q(z) y = output or response
ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92
 ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92 BIOLOGICAL INSPIRATIONS Some numbers The human brain contains about 10 billion nerve cells (neurons) Each neuron is connected to the others through 10000
ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92 BIOLOGICAL INSPIRATIONS Some numbers The human brain contains about 10 billion nerve cells (neurons) Each neuron is connected to the others through 10000
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
Bagging and Other Ensemble Methods
 Bagging and Other Ensemble Methods Sargur N. Srihari srihari@buffalo.edu 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties as Constrained Optimization 3. Regularization and Underconstrained
Bagging and Other Ensemble Methods Sargur N. Srihari srihari@buffalo.edu 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties as Constrained Optimization 3. Regularization and Underconstrained
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Stochastic Gradient Descent
 Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Boosted Top Tagging with Neural Networks
 Boosted Top Tagging with Neural Networks Maxim Perelstein Cornell CMS Group Physics Retreat, March 5 2015 Based on work with Leo Almeida, Mihailo Backovic, Mathieu Cliche, Seung Lee [arxiv:1501.05968 +
Boosted Top Tagging with Neural Networks Maxim Perelstein Cornell CMS Group Physics Retreat, March 5 2015 Based on work with Leo Almeida, Mihailo Backovic, Mathieu Cliche, Seung Lee [arxiv:1501.05968 +
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology SE lecture revision 2013 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology SE lecture revision 2013 Outline 1. Bayesian classification
Classification: The rest of the story
 U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
Artificial Neural Networks Examination, June 2005
 Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Learning with multiple models. Boosting.
 CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
Artificial Neural Networks Examination, June 2004
 Artificial Neural Networks Examination, June 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Artificial Neural Networks Examination, June 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Jet Identification in QCD Samples at DØ
 Jet Identification in QCD Samples at DØ Zachary D. Hodge Austin Peay State University Columbia University Nevis Laboratories July 3, 2008 Abstract The jets of b-hadrons and gluons in QCD Monte Carlo samples
Jet Identification in QCD Samples at DØ Zachary D. Hodge Austin Peay State University Columbia University Nevis Laboratories July 3, 2008 Abstract The jets of b-hadrons and gluons in QCD Monte Carlo samples
Learning Methods for Linear Detectors
 Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2011/2012 Lesson 20 27 April 2012 Contents Learning Methods for Linear Detectors Learning Linear Detectors...2
Intelligent Systems: Reasoning and Recognition James L. Crowley ENSIMAG 2 / MoSIG M1 Second Semester 2011/2012 Lesson 20 27 April 2012 Contents Learning Methods for Linear Detectors Learning Linear Detectors...2
Data Mining. Preamble: Control Application. Industrial Researcher s Approach. Practitioner s Approach. Example. Example. Goal: Maintain T ~Td
 Data Mining Andrew Kusiak 2139 Seamans Center Iowa City, Iowa 52242-1527 Preamble: Control Application Goal: Maintain T ~Td Tel: 319-335 5934 Fax: 319-335 5669 andrew-kusiak@uiowa.edu http://www.icaen.uiowa.edu/~ankusiak
Data Mining Andrew Kusiak 2139 Seamans Center Iowa City, Iowa 52242-1527 Preamble: Control Application Goal: Maintain T ~Td Tel: 319-335 5934 Fax: 319-335 5669 andrew-kusiak@uiowa.edu http://www.icaen.uiowa.edu/~ankusiak
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
Lecture 7: DecisionTrees
 Lecture 7: DecisionTrees What are decision trees? Brief interlude on information theory Decision tree construction Overfitting avoidance Regression trees COMP-652, Lecture 7 - September 28, 2009 1 Recall:
Lecture 7: DecisionTrees What are decision trees? Brief interlude on information theory Decision tree construction Overfitting avoidance Regression trees COMP-652, Lecture 7 - September 28, 2009 1 Recall:
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely