NON-TRIVIAL APPLICATIONS OF BOOSTING:
|
|
|
- Candice Bradford
- 6 years ago
- Views:
Transcription




1 NON-TRIVIAL APPLICATIONS OF BOOSTING: REWEIGHTING DISTRIBUTIONS WITH BDT, BOOSTING TO UNIFORMITY Alex Rogozhnikov YSDA, NRU HSE Heavy Flavour Data Mining workshop, Zurich,
2 BOOSTING a family of machine learning algorithms which convert weak learners to strong ones usually built over decision trees state-of-art results in many areas usually general-purpose implementations are used for classification and regression how can we get more by adapting boosting for our applications? 2
3 ADABOOST (ADAPTIVE BOOSTING) the first famous example of boosting building weak learners one-by-one, predictions are summed up: D(x) = j α j d j (x) each time increase weights of events incorrectly classified by tree d(x) w i w i exp ( αy i d( x i ))), y i = ±1 main idea: provide base estimator (weak learner) with information about which samples have higher importance 3

4 REWEIGHTING OF DISTRIBUTIONS Reweighting in HEP is used to minimize difference between real data (RD) and Monte-Carlo (MC) simulation. Known process is used, for which real data can be obtained. Goal of reweighting: assign weights to MC s.t. MC and RD distributions coincide: 4
5 APPLICATIONS BEYOND PHYSICS Introducing corrections to fight non-response bias: assigning higher weight to answers from groups with low response. See e.g. R. Kizilcec, "Reducing non-response bias with survey reweighting: Applications for online learning researchers", I'll talk in physical terms of original (MC) and target (RD) distributions, since this is applicable to any reweighting. 5
6 TYPICAL APPROACH Usually histogram reweighting is used: the variable(s) is splitted into bins, in each bin the weight of original distribution is multiplied by: w target, bin w original, bin, original distributions. multiplier bin = w target, bin w original, bin total weight of events in bin for target and 1. Simple and fast! 2. Very few (typically, one or two) variables 3. Reweighting one variable may bring disagreement in others 4. Which variable to use in reweighting? 6
 two")
7 COMPARING DISTRIBUTIONS i.e. to check the quality of reweighting one dimension: KS-test, CvM, Mann-Whitney (U-test) two or more dimensions? comparing 1d projections is not the way: 7
8 COMPARING DISTRIBUTIONS USING ML Final goal: define if the classifier discriminates RD and MC. Comparison shall be done using ML, output of classifier is 1-dimensional. Looking at ROC curve on a holdout: See also: J. Friedman, On Multivariate Goodness of Fit and Two Sample Testing,


9 REWEIGHTING WITH HISTOGRAMS: EXAMPLE Problems arise when there are too few events in bin. Those can be detected on a holdout. Issues: 1. few bins rule is rough 2. many bins rule is not reliable 9
10 REUSING ML CLASSIFIERS TO REWEIGHTING We need to estimate density ratio f 1 (x) f 0 (x) Classifier trained to discriminate MC and RD should reconstruct probabilities (x) and (x). p 0 p 1 So, for reweghting we can use p 1 (x) p 0 (x) f 1 (x) f 0 (x) able to reweight in many variables successfully tried in HEP, see D. Martschei et al, "Advanced event reweighting using multivariate analysis", 2012 poor reconstruction when ratio is too small / high slow 10
11 BETTER IDEA: Write ML algorithm to solve directly reweighting problem 1. Split space of variables in several large regions 2. Find this regions 'intellectually'! USING DECISION TREE TO FIND REGIONS 1. Tree splits the space of variables by orthogonal splits 2. Finding regions with high difference by maximizing symmetrized χ 2 : χ 2 ( w leaf, original w leaf, target ) 2 = leaf + w leaf, original w leaf, target 11

12 SYMMETRIZED BINNED χ 2 Finding optimal threshold to split variable into two bins: 12
13 BDT REWEIGHTER To train reweighter many times repeat following steps: 1. build a shallow tree to maximize symmetrized 2. compute predictions in leaves: leaf_pred = log w leaf, target 3. reweight distributions (compare with AdaBoost): w ={ w, w e pred, w leaf, original CHANGES COMPARED TO GBDT tree splitting criterion (MSE χ 2 ) different boosting procedure χ 2 if event from target (RD) distribution if event from original (MC) distribution 13
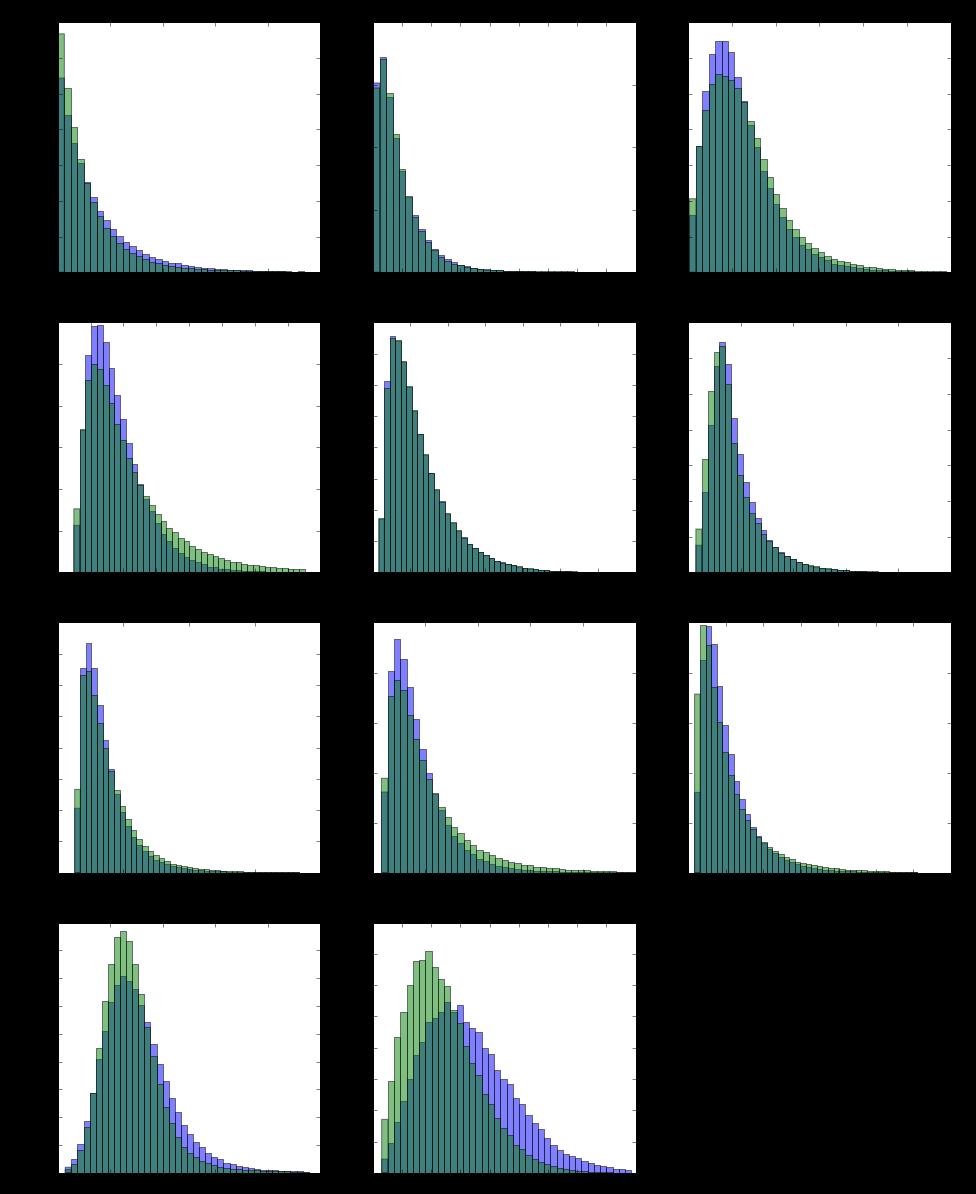
14 DEMONSTRATION original result of BDT reweighter 14
15 KS DISTANCES AFTER REWEIGHTING Bins reweighter uses only 2 last variables ( bins); ML and BDT use all variables Feature original bins reuse ML BDT reweighter Bplus_IPCHI2_OWNPV Bplus_ENDVERTEX_CHI Bplus_PT Bplus_P Bplus_TAU mu_min_pt mu_max_pt mu_max_p mu_min_p mu_max_track_chi2ndof nspdhits
16 COMPARING RESULTS WITH ML Using approach to distribution comparison described earlier. Reweighting two variables wasn't enough: 16
17 FEATURE IMPORTANCES Being a variation of GBDT, BDT reweighter is able to calculate feature importances. Two features used in reweighting with bins are indeed most important 17
18 BOOSTED REWEIGHTING uses each time few large bins is able to handle many variables requires less data (for same performance)... but slow SUMMARY ABOUT REWEIGHTING 1. Comparison of multidimensional distributions is ML problem 2. Reweighting of distributions is ML problem 18
19 RECALL: GRADIENT BOOSTING Gradient boosting greedily builds an ensemble of estimators (regressors) D(x) = j α j d j (x) by optimizing some loss function. Those could be: MSE: = i ( y i D( x i )) 2 AdaLoss: = i e y i D( x i ), y i = ±1 LogLoss: = i log(1 + e y i D( x i ) ), = ±1 Next estimator in series approximates gradient of loss in the space of functions. y i 19
20 BOOSTING TO UNIFORMITY Point of uniform boosting have constant efficiency (FPR/TPR) against some variable. Examples: flat background efficiency along mass flat signal efficiency for different flight time flat signal efficiency along Dalitz variables 20
 Goal: FPR = const for different regions in mass. Reminder: FPR background efficiency 21")
21 EXAMPLE: NON-FLAT BACKGROUND EFFICIENCY (FPR) ALONG MASS High correlation with mass will create from pure background false peaking signal (specially if we use mass sidebands for training) Goal: FPR = const for different regions in mass. Reminder: FPR background efficiency 21
22 BASIC APPROACH reduce the number of features used in training leave only the set of features, which do not give enough information to reconstruct mass of particle simple and works sometimes we have to lose much information Can we modify ML to use all features, but provide uniform background efficiency (FPR) along mass? 22
23 uboostbdt Aims to get FPR region = const. fix target efficiency (say threshold FPR target = 30%), find corresponding train a tree, its decision function d(x) increase weight for misclassification: w i w i exp( αy i d(x))) increase weight of signal events in regions with high FPR w i w i FPR region FPR target exp(β( )) FPR region This way we achieve threshold on training dataset. = 30% in all regions only for some 23
24 uboost uboost is an ensemble of uboostbdts, each uboostbdt uses own FPR target (all possible FPRs with step of 1%). uboostbdt returns 0 or 1 (passed or not the threshold corresponding to FPR target ), simple averaging is used to obtain predictions. drives to uniform selection very complex training many trees estimation of threshold in uboostbdt may be biased 24
25 MEASURING NON-UNIFORMITY difference in efficiency can be detected by analyzing distributions uniformity no dependence between mass and predictions Uniform predictions Non-uniform predictions (peak in highlighted region) 25
 F global (s) 2 d Fglobal (s)")
26 MEASURING NON-UNIFORMITY Sum up contributions from different regions in mass CvM = F region (s) F global (s) 2 d Fglobal (s) region 26
27 MINIMIZING NON-UNIFORMITY why not minimizing CvM inside with GB?... because we can't compute gradient ROC AUC, classification accuracy are not differentiable too also, minimizing CvM doesn't encounter classification problem: the minimum of CvM is achieved i.e. on a classifier with random predictions 27
28 FLATNESS LOSS (FL) Put an additional term in loss function which will penalize for nonuniformity = adaloss + c FL Flatness loss approximates (non-differentiable) CvM metrics: FL = F (s) ds region region F global (s) 2 2( (s) (s)) D( ) FL F region F global x i s=d( xi) 28
 when we train")



29 EXAMPLE (EFFICIENCY OVER BACKGROUND) when we train on a sideband using many features, we easily can run into problems all models use same features for discrimination, but AdaBoost got serious correlation with mass 29
30 BOOSTING SUMMARY powerful general-purpose algorithm most known applications: classification, regression and ranking widely used, considered to be well-studied can be adapted to different specific scientific problems EXAMPLES DEMONSTRATED TODAY: 1. reweighting of multidimensional distributions 2. boosting to uniformity These algorithms are available in hep_ml package (based on sklearn) 30
31 REFERENCES D. Martschei, M. Feindt, S. Honc, J. Wagner-Kuhr, Advanced event reweighting using multivariate analysis Reweighting with Boosted Decision Trees J. Stevens, M. Williams, uboost: A boosting method for producing uniform selection efficiencies from multivariate classifiers A. Rogozhnikov, A. Bukva, V. Gligorov, A. Ustyuzhanin, M. Williams, New approaches for boosting to uniformity Implementations of algorithms: github repository 31

32 32
Stochastic Gradient Descent
 Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
A Decision Stump. Decision Trees, cont. Boosting. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. October 1 st, 2007
 Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Advanced event reweighting using multivariate analysis
 Advanced event reweighting using multivariate analysis D Martschei, M Feindt, S Honc, J Wagner-Kuhr Institut für Experimentelle Kernphysik - Karlsruhe Institute of Technology KIT, DE E-mail: martschei@ekp.uni-karlsruhe.de
Advanced event reweighting using multivariate analysis D Martschei, M Feindt, S Honc, J Wagner-Kuhr Institut für Experimentelle Kernphysik - Karlsruhe Institute of Technology KIT, DE E-mail: martschei@ekp.uni-karlsruhe.de
Multivariate statistical methods and data mining in particle physics
 Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Ensemble Methods. Charles Sutton Data Mining and Exploration Spring Friday, 27 January 12
 Ensemble Methods Charles Sutton Data Mining and Exploration Spring 2012 Bias and Variance Consider a regression problem Y = f(x)+ N(0, 2 ) With an estimate regression function ˆf, e.g., ˆf(x) =w > x Suppose
Ensemble Methods Charles Sutton Data Mining and Exploration Spring 2012 Bias and Variance Consider a regression problem Y = f(x)+ N(0, 2 ) With an estimate regression function ˆf, e.g., ˆf(x) =w > x Suppose
Harrison B. Prosper. Bari Lectures
 Harrison B. Prosper Florida State University Bari Lectures 30, 31 May, 1 June 2016 Lectures on Multivariate Methods Harrison B. Prosper Bari, 2016 1 h Lecture 1 h Introduction h Classification h Grid Searches
Harrison B. Prosper Florida State University Bari Lectures 30, 31 May, 1 June 2016 Lectures on Multivariate Methods Harrison B. Prosper Bari, 2016 1 h Lecture 1 h Introduction h Classification h Grid Searches
Learning with multiple models. Boosting.
 CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS7267 MACHINE LEARNING
 CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
VBM683 Machine Learning
 VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
Gradient Boosting (Continued)
") Gradient Boosting (Continued) David Rosenberg New York University April 4, 2016 David Rosenberg (New York University) DS-GA 1003 April 4, 2016 1 / 31 Boosting Fits an Additive Model Boosting Fits an Additive
Gradient Boosting (Continued) David Rosenberg New York University April 4, 2016 David Rosenberg (New York University) DS-GA 1003 April 4, 2016 1 / 31 Boosting Fits an Additive Model Boosting Fits an Additive
Chapter 14 Combining Models
 Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet.
 or two-page (one side) crib sheet.") CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
Boosting. Ryan Tibshirani Data Mining: / April Optional reading: ISL 8.2, ESL , 10.7, 10.13
 Boosting Ryan Tibshirani Data Mining: 36-462/36-662 April 25 2013 Optional reading: ISL 8.2, ESL 10.1 10.4, 10.7, 10.13 1 Reminder: classification trees Suppose that we are given training data (x i, y
Boosting Ryan Tibshirani Data Mining: 36-462/36-662 April 25 2013 Optional reading: ISL 8.2, ESL 10.1 10.4, 10.7, 10.13 1 Reminder: classification trees Suppose that we are given training data (x i, y
Voting (Ensemble Methods)
") 1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
Class 4: Classification. Quaid Morris February 11 th, 2011 ML4Bio
 Class 4: Classification Quaid Morris February 11 th, 211 ML4Bio Overview Basic concepts in classification: overfitting, cross-validation, evaluation. Linear Discriminant Analysis and Quadratic Discriminant
Class 4: Classification Quaid Morris February 11 th, 211 ML4Bio Overview Basic concepts in classification: overfitting, cross-validation, evaluation. Linear Discriminant Analysis and Quadratic Discriminant
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Lecture 4 Discriminant Analysis, k-nearest Neighbors
 Lecture 4 Discriminant Analysis, k-nearest Neighbors Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se fredrik.lindsten@it.uu.se
Lecture 4 Discriminant Analysis, k-nearest Neighbors Fredrik Lindsten Division of Systems and Control Department of Information Technology Uppsala University. Email: fredrik.lindsten@it.uu.se fredrik.lindsten@it.uu.se
Learning Ensembles. 293S T. Yang. UCSB, 2017.
 Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
Machine Learning. Ensemble Methods. Manfred Huber
 Machine Learning Ensemble Methods Manfred Huber 2015 1 Bias, Variance, Noise Classification errors have different sources Choice of hypothesis space and algorithm Training set Noise in the data The expected
Machine Learning Ensemble Methods Manfred Huber 2015 1 Bias, Variance, Noise Classification errors have different sources Choice of hypothesis space and algorithm Training set Noise in the data The expected
Multivariate Analysis Techniques in HEP
 Multivariate Analysis Techniques in HEP Jan Therhaag IKTP Institutsseminar, Dresden, January 31 st 2013 Multivariate analysis in a nutshell Neural networks: Defeating the black box Boosted Decision Trees:
Multivariate Analysis Techniques in HEP Jan Therhaag IKTP Institutsseminar, Dresden, January 31 st 2013 Multivariate analysis in a nutshell Neural networks: Defeating the black box Boosted Decision Trees:
Advanced statistical methods for data analysis Lecture 1
 Advanced statistical methods for data analysis Lecture 1 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Advanced statistical methods for data analysis Lecture 1 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Multivariate Methods in Statistical Data Analysis
 Multivariate Methods in Statistical Data Analysis Web-Site: http://tmva.sourceforge.net/ See also: "TMVA - Toolkit for Multivariate Data Analysis, A. Hoecker, P. Speckmayer, J. Stelzer, J. Therhaag, E.
Multivariate Methods in Statistical Data Analysis Web-Site: http://tmva.sourceforge.net/ See also: "TMVA - Toolkit for Multivariate Data Analysis, A. Hoecker, P. Speckmayer, J. Stelzer, J. Therhaag, E.
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING
 EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: June 9, 2018, 09.00 14.00 RESPONSIBLE TEACHER: Andreas Svensson NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: June 9, 2018, 09.00 14.00 RESPONSIBLE TEACHER: Andreas Svensson NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
Decision Trees: Overfitting
 Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
Holdout and Cross-Validation Methods Overfitting Avoidance
 Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
Online Advertising is Big Business
 Online Advertising Online Advertising is Big Business Multiple billion dollar industry $43B in 2013 in USA, 17% increase over 2012 [PWC, Internet Advertising Bureau, April 2013] Higher revenue in USA
Online Advertising Online Advertising is Big Business Multiple billion dollar industry $43B in 2013 in USA, 17% increase over 2012 [PWC, Internet Advertising Bureau, April 2013] Higher revenue in USA
Multivariate Analysis for Setting the Limit with the ATLAS Detector
 Multivariate Analysis for Setting the Limit with the ATLAS B s! µ + µ Detector T. Alexopoulos, E. Gazis, S. Leontsinis - NTU Athens A.Cerri CERN International School of Subnuclear Physics 50 th Course
Multivariate Analysis for Setting the Limit with the ATLAS B s! µ + µ Detector T. Alexopoulos, E. Gazis, S. Leontsinis - NTU Athens A.Cerri CERN International School of Subnuclear Physics 50 th Course
Tuning the simulated response of the CMS detector to b-jets using Machine learning algorithms
 Tuning the simulated response of the CMS detector to b-jets using Machine learning algorithms ETH Zürich On behalf of the CMS Collaboration SPS Annual Meeting 2018 31st August 2018 EPFL, Lausanne 1 Motivation
Tuning the simulated response of the CMS detector to b-jets using Machine learning algorithms ETH Zürich On behalf of the CMS Collaboration SPS Annual Meeting 2018 31st August 2018 EPFL, Lausanne 1 Motivation
Statistics and learning: Big Data
 Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees
Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees
Ensemble Methods and Random Forests
 Ensemble Methods and Random Forests Vaishnavi S May 2017 1 Introduction We have seen various analysis for classification and regression in the course. One of the common methods to reduce the generalization
Ensemble Methods and Random Forests Vaishnavi S May 2017 1 Introduction We have seen various analysis for classification and regression in the course. One of the common methods to reduce the generalization
Motivating the Covariance Matrix
 Motivating the Covariance Matrix Raúl Rojas Computer Science Department Freie Universität Berlin January 2009 Abstract This note reviews some interesting properties of the covariance matrix and its role
Motivating the Covariance Matrix Raúl Rojas Computer Science Department Freie Universität Berlin January 2009 Abstract This note reviews some interesting properties of the covariance matrix and its role
Recitation 9. Gradient Boosting. Brett Bernstein. March 30, CDS at NYU. Brett Bernstein (CDS at NYU) Recitation 9 March 30, / 14
 Recitation 9 March 30, / 14") Brett Bernstein CDS at NYU March 30, 2017 Brett Bernstein (CDS at NYU) Recitation 9 March 30, 2017 1 / 14 Initial Question Intro Question Question Suppose 10 different meteorologists have produced functions
Brett Bernstein CDS at NYU March 30, 2017 Brett Bernstein (CDS at NYU) Recitation 9 March 30, 2017 1 / 14 Initial Question Intro Question Question Suppose 10 different meteorologists have produced functions
Face detection and recognition. Detection Recognition Sally
 Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Face detection and recognition Detection Recognition Sally Face detection & recognition Viola & Jones detector Available in open CV Face recognition Eigenfaces for face recognition Metric learning identification
Prediction of Citations for Academic Papers
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Data Mining. CS57300 Purdue University. Bruno Ribeiro. February 8, 2018
 Data Mining CS57300 Purdue University Bruno Ribeiro February 8, 2018 Decision trees Why Trees? interpretable/intuitive, popular in medical applications because they mimic the way a doctor thinks model
Data Mining CS57300 Purdue University Bruno Ribeiro February 8, 2018 Decision trees Why Trees? interpretable/intuitive, popular in medical applications because they mimic the way a doctor thinks model
Harrison B. Prosper. Bari Lectures
 Harrison B. Prosper Florida State University Bari Lectures 30, 31 May, 1 June 2016 Lectures on Multivariate Methods Harrison B. Prosper Bari, 2016 1 h Lecture 1 h Introduction h Classification h Grid Searches
Harrison B. Prosper Florida State University Bari Lectures 30, 31 May, 1 June 2016 Lectures on Multivariate Methods Harrison B. Prosper Bari, 2016 1 h Lecture 1 h Introduction h Classification h Grid Searches
Big Data Analytics. Special Topics for Computer Science CSE CSE Feb 24
 Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
Ensemble Methods. NLP ML Web! Fall 2013! Andrew Rosenberg! TA/Grader: David Guy Brizan
 Ensemble Methods NLP ML Web! Fall 2013! Andrew Rosenberg! TA/Grader: David Guy Brizan How do you make a decision? What do you want for lunch today?! What did you have last night?! What are your favorite
Ensemble Methods NLP ML Web! Fall 2013! Andrew Rosenberg! TA/Grader: David Guy Brizan How do you make a decision? What do you want for lunch today?! What did you have last night?! What are your favorite
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION
 SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
SUPERVISED LEARNING: INTRODUCTION TO CLASSIFICATION 1 Outline Basic terminology Features Training and validation Model selection Error and loss measures Statistical comparison Evaluation measures 2 Terminology
Advanced Machine Learning Practical 4b Solution: Regression (BLR, GPR & Gradient Boosting)
") Advanced Machine Learning Practical 4b Solution: Regression (BLR, GPR & Gradient Boosting) Professor: Aude Billard Assistants: Nadia Figueroa, Ilaria Lauzana and Brice Platerrier E-mails: aude.billard@epfl.ch,
Advanced Machine Learning Practical 4b Solution: Regression (BLR, GPR & Gradient Boosting) Professor: Aude Billard Assistants: Nadia Figueroa, Ilaria Lauzana and Brice Platerrier E-mails: aude.billard@epfl.ch,
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Announcements Kevin Jamieson
 Announcements My office hours TODAY 3:30 pm - 4:30 pm CSE 666 Poster Session - Pick one First poster session TODAY 4:30 pm - 7:30 pm CSE Atrium Second poster session December 12 4:30 pm - 7:30 pm CSE Atrium
Announcements My office hours TODAY 3:30 pm - 4:30 pm CSE 666 Poster Session - Pick one First poster session TODAY 4:30 pm - 7:30 pm CSE Atrium Second poster session December 12 4:30 pm - 7:30 pm CSE Atrium
Gradient Boosting, Continued
 Gradient Boosting, Continued David Rosenberg New York University December 26, 2016 David Rosenberg (New York University) DS-GA 1003 December 26, 2016 1 / 16 Review: Gradient Boosting Review: Gradient Boosting
Gradient Boosting, Continued David Rosenberg New York University December 26, 2016 David Rosenberg (New York University) DS-GA 1003 December 26, 2016 1 / 16 Review: Gradient Boosting Review: Gradient Boosting
Learning theory. Ensemble methods. Boosting. Boosting: history
 Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Decision Trees. CS57300 Data Mining Fall Instructor: Bruno Ribeiro
 Decision Trees CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Classification without Models Well, partially without a model } Today: Decision Trees 2015 Bruno Ribeiro 2 3 Why Trees? } interpretable/intuitive,
Decision Trees CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Classification without Models Well, partially without a model } Today: Decision Trees 2015 Bruno Ribeiro 2 3 Why Trees? } interpretable/intuitive,
Classification and Pattern Recognition
 Classification and Pattern Recognition Léon Bottou NEC Labs America COS 424 2/23/2010 The machine learning mix and match Goals Representation Capacity Control Operational Considerations Computational Considerations
Classification and Pattern Recognition Léon Bottou NEC Labs America COS 424 2/23/2010 The machine learning mix and match Goals Representation Capacity Control Operational Considerations Computational Considerations
Machine Learning Concepts in Chemoinformatics
 Machine Learning Concepts in Chemoinformatics Martin Vogt B-IT Life Science Informatics Rheinische Friedrich-Wilhelms-Universität Bonn BigChem Winter School 2017 25. October Data Mining in Chemoinformatics
Machine Learning Concepts in Chemoinformatics Martin Vogt B-IT Life Science Informatics Rheinische Friedrich-Wilhelms-Universität Bonn BigChem Winter School 2017 25. October Data Mining in Chemoinformatics
Machine Learning Linear Classification. Prof. Matteo Matteucci
 Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Machine Learning Linear Classification Prof. Matteo Matteucci Recall from the first lecture 2 X R p Regression Y R Continuous Output X R p Y {Ω 0, Ω 1,, Ω K } Classification Discrete Output X R p Y (X)
Evaluation. Albert Bifet. April 2012
 Evaluation Albert Bifet April 2012 COMP423A/COMP523A Data Stream Mining Outline 1. Introduction 2. Stream Algorithmics 3. Concept drift 4. Evaluation 5. Classification 6. Ensemble Methods 7. Regression
Evaluation Albert Bifet April 2012 COMP423A/COMP523A Data Stream Mining Outline 1. Introduction 2. Stream Algorithmics 3. Concept drift 4. Evaluation 5. Classification 6. Ensemble Methods 7. Regression
Evaluation. Andrea Passerini Machine Learning. Evaluation
 Andrea Passerini passerini@disi.unitn.it Machine Learning Basic concepts requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain
Andrea Passerini passerini@disi.unitn.it Machine Learning Basic concepts requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Ensembles Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique Fédérale de Lausanne
Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Ensembles Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique Fédérale de Lausanne
Data Mining Prof. Pabitra Mitra Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur
 Data Mining Prof. Pabitra Mitra Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Lecture 21 K - Nearest Neighbor V In this lecture we discuss; how do we evaluate the
Data Mining Prof. Pabitra Mitra Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Lecture 21 K - Nearest Neighbor V In this lecture we discuss; how do we evaluate the
Performance Evaluation
 Performance Evaluation Confusion Matrix: Detected Positive Negative Actual Positive A: True Positive B: False Negative Negative C: False Positive D: True Negative Recall or Sensitivity or True Positive
Performance Evaluation Confusion Matrix: Detected Positive Negative Actual Positive A: True Positive B: False Negative Negative C: False Positive D: True Negative Recall or Sensitivity or True Positive
Evaluation requires to define performance measures to be optimized
 Evaluation Basic concepts Evaluation requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain (generalization error) approximation
Evaluation Basic concepts Evaluation requires to define performance measures to be optimized Performance of learning algorithms cannot be evaluated on entire domain (generalization error) approximation
Support Vector Machine, Random Forests, Boosting Based in part on slides from textbook, slides of Susan Holmes. December 2, 2012
 Support Vector Machine, Random Forests, Boosting Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Neural networks Neural network Another classifier (or regression technique)
Support Vector Machine, Random Forests, Boosting Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Neural networks Neural network Another classifier (or regression technique)
Bagging and Other Ensemble Methods
 Bagging and Other Ensemble Methods Sargur N. Srihari srihari@buffalo.edu 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties as Constrained Optimization 3. Regularization and Underconstrained
Bagging and Other Ensemble Methods Sargur N. Srihari srihari@buffalo.edu 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties as Constrained Optimization 3. Regularization and Underconstrained
Performance Evaluation
 Performance Evaluation David S. Rosenberg Bloomberg ML EDU October 26, 2017 David S. Rosenberg (Bloomberg ML EDU) October 26, 2017 1 / 36 Baseline Models David S. Rosenberg (Bloomberg ML EDU) October 26,
Performance Evaluation David S. Rosenberg Bloomberg ML EDU October 26, 2017 David S. Rosenberg (Bloomberg ML EDU) October 26, 2017 1 / 36 Baseline Models David S. Rosenberg (Bloomberg ML EDU) October 26,
Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008)
") Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008) RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement
Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008) RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement
Linear Classifiers: Expressiveness
 Linear Classifiers: Expressiveness Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture outline Linear classifiers: Introduction What functions do linear classifiers express?
Linear Classifiers: Expressiveness Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture outline Linear classifiers: Introduction What functions do linear classifiers express?
Ensemble Methods for Machine Learning
 Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
Neural Networks and Ensemble Methods for Classification
 Neural Networks and Ensemble Methods for Classification NEURAL NETWORKS 2 Neural Networks A neural network is a set of connected input/output units (neurons) where each connection has a weight associated
Neural Networks and Ensemble Methods for Classification NEURAL NETWORKS 2 Neural Networks A neural network is a set of connected input/output units (neurons) where each connection has a weight associated
Introduction to Signal Detection and Classification. Phani Chavali
 Introduction to Signal Detection and Classification Phani Chavali Outline Detection Problem Performance Measures Receiver Operating Characteristics (ROC) F-Test - Test Linear Discriminant Analysis (LDA)
Introduction to Signal Detection and Classification Phani Chavali Outline Detection Problem Performance Measures Receiver Operating Characteristics (ROC) F-Test - Test Linear Discriminant Analysis (LDA)
Variance Reduction and Ensemble Methods
 Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis
Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Adaptive Crowdsourcing via EM with Prior
 Adaptive Crowdsourcing via EM with Prior Peter Maginnis and Tanmay Gupta May, 205 In this work, we make two primary contributions: derivation of the EM update for the shifted and rescaled beta prior and
Adaptive Crowdsourcing via EM with Prior Peter Maginnis and Tanmay Gupta May, 205 In this work, we make two primary contributions: derivation of the EM update for the shifted and rescaled beta prior and
Introduction to Supervised Learning. Performance Evaluation
 Introduction to Supervised Learning Performance Evaluation Marcelo S. Lauretto Escola de Artes, Ciências e Humanidades, Universidade de São Paulo marcelolauretto@usp.br Lima - Peru Performance Evaluation
Introduction to Supervised Learning Performance Evaluation Marcelo S. Lauretto Escola de Artes, Ciências e Humanidades, Universidade de São Paulo marcelolauretto@usp.br Lima - Peru Performance Evaluation
COMS 4771 Lecture Boosting 1 / 16
 COMS 4771 Lecture 12 1. Boosting 1 / 16 Boosting What is boosting? Boosting: Using a learning algorithm that provides rough rules-of-thumb to construct a very accurate predictor. 3 / 16 What is boosting?
COMS 4771 Lecture 12 1. Boosting 1 / 16 Boosting What is boosting? Boosting: Using a learning algorithm that provides rough rules-of-thumb to construct a very accurate predictor. 3 / 16 What is boosting?
Part I Week 7 Based in part on slides from textbook, slides of Susan Holmes
 Part I Week 7 Based in part on slides from textbook, slides of Susan Holmes Support Vector Machine, Random Forests, Boosting December 2, 2012 1 / 1 2 / 1 Neural networks Artificial Neural networks: Networks
Part I Week 7 Based in part on slides from textbook, slides of Susan Holmes Support Vector Machine, Random Forests, Boosting December 2, 2012 1 / 1 2 / 1 Neural networks Artificial Neural networks: Networks
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 8. Chapter 8. Classification: Basic Concepts
 Chapter 8. Chapter 8. Classification: Basic Concepts") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Online Advertising is Big Business
 Online Advertising Online Advertising is Big Business Multiple billion dollar industry $43B in 2013 in USA, 17% increase over 2012 [PWC, Internet Advertising Bureau, April 2013] Higher revenue in USA
Online Advertising Online Advertising is Big Business Multiple billion dollar industry $43B in 2013 in USA, 17% increase over 2012 [PWC, Internet Advertising Bureau, April 2013] Higher revenue in USA
PDEEC Machine Learning 2016/17
 PDEEC Machine Learning 2016/17 Lecture - Model assessment, selection and Ensemble Jaime S. Cardoso jaime.cardoso@inesctec.pt INESC TEC and Faculdade Engenharia, Universidade do Porto Nov. 07, 2017 1 /
PDEEC Machine Learning 2016/17 Lecture - Model assessment, selection and Ensemble Jaime S. Cardoso jaime.cardoso@inesctec.pt INESC TEC and Faculdade Engenharia, Universidade do Porto Nov. 07, 2017 1 /
Search for the very rare decays B s/d + - at LHCb
 Search for the very rare decays B s/d + - at LHCb Justine Serrano Centre de Physique des Particules de Marseille On behalf of the LHCb collaboration EPS-HEP, July 22 th 2011, Grenoble Bs2MuMu @ LHCb Justine
Search for the very rare decays B s/d + - at LHCb Justine Serrano Centre de Physique des Particules de Marseille On behalf of the LHCb collaboration EPS-HEP, July 22 th 2011, Grenoble Bs2MuMu @ LHCb Justine
Statistical Tools in Collider Experiments. Multivariate analysis in high energy physics
 Statistical Tools in Collider Experiments Multivariate analysis in high energy physics Lecture 3 Pauli Lectures - 08/02/2012 Nicolas Chanon - ETH Zürich 1 Outline 1.Introduction 2.Multivariate methods
Statistical Tools in Collider Experiments Multivariate analysis in high energy physics Lecture 3 Pauli Lectures - 08/02/2012 Nicolas Chanon - ETH Zürich 1 Outline 1.Introduction 2.Multivariate methods
Sparse Kernel Machines - SVM
 Sparse Kernel Machines - SVM Henrik I. Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I. Christensen (RIM@GT) Support
Sparse Kernel Machines - SVM Henrik I. Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I. Christensen (RIM@GT) Support
Hypothesis Evaluation
 Hypothesis Evaluation Machine Learning Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Hypothesis Evaluation Fall 1395 1 / 31 Table of contents 1 Introduction
Hypothesis Evaluation Machine Learning Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Hypothesis Evaluation Fall 1395 1 / 31 Table of contents 1 Introduction
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
Machine Learning Linear Models
 Machine Learning Linear Models Outline II - Linear Models 1. Linear Regression (a) Linear regression: History (b) Linear regression with Least Squares (c) Matrix representation and Normal Equation Method
Machine Learning Linear Models Outline II - Linear Models 1. Linear Regression (a) Linear regression: History (b) Linear regression with Least Squares (c) Matrix representation and Normal Equation Method
Chart types and when to use them
 APPENDIX A Chart types and when to use them Pie chart Figure illustration of pie chart 2.3 % 4.5 % Browser Usage for April 2012 18.3 % 38.3 % Internet Explorer Firefox Chrome Safari Opera 35.8 % Pie chart
APPENDIX A Chart types and when to use them Pie chart Figure illustration of pie chart 2.3 % 4.5 % Browser Usage for April 2012 18.3 % 38.3 % Internet Explorer Firefox Chrome Safari Opera 35.8 % Pie chart
Decision Trees. Machine Learning CSEP546 Carlos Guestrin University of Washington. February 3, 2014
 Decision Trees Machine Learning CSEP546 Carlos Guestrin University of Washington February 3, 2014 17 Linear separability n A dataset is linearly separable iff there exists a separating hyperplane: Exists
Decision Trees Machine Learning CSEP546 Carlos Guestrin University of Washington February 3, 2014 17 Linear separability n A dataset is linearly separable iff there exists a separating hyperplane: Exists
JEROME H. FRIEDMAN Department of Statistics and Stanford Linear Accelerator Center, Stanford University, Stanford, CA
 1 SEPARATING SIGNAL FROM BACKGROUND USING ENSEMBLES OF RULES JEROME H. FRIEDMAN Department of Statistics and Stanford Linear Accelerator Center, Stanford University, Stanford, CA 94305 E-mail: jhf@stanford.edu
1 SEPARATING SIGNAL FROM BACKGROUND USING ENSEMBLES OF RULES JEROME H. FRIEDMAN Department of Statistics and Stanford Linear Accelerator Center, Stanford University, Stanford, CA 94305 E-mail: jhf@stanford.edu
PCA FACE RECOGNITION
 PCA FACE RECOGNITION The slides are from several sources through James Hays (Brown); Srinivasa Narasimhan (CMU); Silvio Savarese (U. of Michigan); Shree Nayar (Columbia) including their own slides. Goal
PCA FACE RECOGNITION The slides are from several sources through James Hays (Brown); Srinivasa Narasimhan (CMU); Silvio Savarese (U. of Michigan); Shree Nayar (Columbia) including their own slides. Goal
CSE446: non-parametric methods Spring 2017
 CSE446: non-parametric methods Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Linear Regression: What can go wrong? What do we do if the bias is too strong? Might want
CSE446: non-parametric methods Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Linear Regression: What can go wrong? What do we do if the bias is too strong? Might want
Lecture 9: Classification, LDA
 Lecture 9: Classification, LDA Reading: Chapter 4 STATS 202: Data mining and analysis October 13, 2017 1 / 21 Review: Main strategy in Chapter 4 Find an estimate ˆP (Y X). Then, given an input x 0, we
Lecture 9: Classification, LDA Reading: Chapter 4 STATS 202: Data mining and analysis October 13, 2017 1 / 21 Review: Main strategy in Chapter 4 Find an estimate ˆP (Y X). Then, given an input x 0, we
Outline: Ensemble Learning. Ensemble Learning. The Wisdom of Crowds. The Wisdom of Crowds - Really? Crowd wiser than any individual
 Outline: Ensemble Learning We will describe and investigate algorithms to Ensemble Learning Lecture 10, DD2431 Machine Learning A. Maki, J. Sullivan October 2014 train weak classifiers/regressors and how
Outline: Ensemble Learning We will describe and investigate algorithms to Ensemble Learning Lecture 10, DD2431 Machine Learning A. Maki, J. Sullivan October 2014 train weak classifiers/regressors and how
A Brief Introduction to Adaboost
 A Brief Introduction to Adaboost Hongbo Deng 6 Feb, 2007 Some of the slides are borrowed from Derek Hoiem & Jan ˇSochman. 1 Outline Background Adaboost Algorithm Theory/Interpretations 2 What s So Good
A Brief Introduction to Adaboost Hongbo Deng 6 Feb, 2007 Some of the slides are borrowed from Derek Hoiem & Jan ˇSochman. 1 Outline Background Adaboost Algorithm Theory/Interpretations 2 What s So Good
Data Mining und Maschinelles Lernen
 Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Applied Multivariate and Longitudinal Data Analysis
 Applied Multivariate and Longitudinal Data Analysis Discriminant analysis and classification Ana-Maria Staicu SAS Hall 5220; 919-515-0644; astaicu@ncsu.edu 1 Consider the examples: An online banking service
Applied Multivariate and Longitudinal Data Analysis Discriminant analysis and classification Ana-Maria Staicu SAS Hall 5220; 919-515-0644; astaicu@ncsu.edu 1 Consider the examples: An online banking service
Lecture 9: Classification, LDA
 Lecture 9: Classification, LDA Reading: Chapter 4 STATS 202: Data mining and analysis Jonathan Taylor, 10/12 Slide credits: Sergio Bacallado 1 / 1 Review: Main strategy in Chapter 4 Find an estimate ˆP
Lecture 9: Classification, LDA Reading: Chapter 4 STATS 202: Data mining and analysis Jonathan Taylor, 10/12 Slide credits: Sergio Bacallado 1 / 1 Review: Main strategy in Chapter 4 Find an estimate ˆP
the tree till a class assignment is reached
 Decision Trees Decision Tree for Playing Tennis Prediction is done by sending the example down Prediction is done by sending the example down the tree till a class assignment is reached Definitions Internal
Decision Trees Decision Tree for Playing Tennis Prediction is done by sending the example down Prediction is done by sending the example down the tree till a class assignment is reached Definitions Internal
Boosting. CAP5610: Machine Learning Instructor: Guo-Jun Qi
 Boosting CAP5610: Machine Learning Instructor: Guo-Jun Qi Weak classifiers Weak classifiers Decision stump one layer decision tree Naive Bayes A classifier without feature correlations Linear classifier
Boosting CAP5610: Machine Learning Instructor: Guo-Jun Qi Weak classifiers Weak classifiers Decision stump one layer decision tree Naive Bayes A classifier without feature correlations Linear classifier
Lecture 9: Classification, LDA
 Lecture 9: Classification, LDA Reading: Chapter 4 STATS 202: Data mining and analysis October 13, 2017 1 / 21 Review: Main strategy in Chapter 4 Find an estimate ˆP (Y X). Then, given an input x 0, we
Lecture 9: Classification, LDA Reading: Chapter 4 STATS 202: Data mining and analysis October 13, 2017 1 / 21 Review: Main strategy in Chapter 4 Find an estimate ˆP (Y X). Then, given an input x 0, we
StatPatternRecognition: A C++ Package for Multivariate Classification of HEP Data. Ilya Narsky, Caltech
 StatPatternRecognition: A C++ Package for Multivariate Classification of HEP Data Ilya Narsky, Caltech Motivation Introduction advanced classification tools in a convenient C++ package for HEP researchers
StatPatternRecognition: A C++ Package for Multivariate Classification of HEP Data Ilya Narsky, Caltech Motivation Introduction advanced classification tools in a convenient C++ package for HEP researchers
W vs. QCD Jet Tagging at the Large Hadron Collider
 W vs. QCD Jet Tagging at the Large Hadron Collider Bryan Anenberg: anenberg@stanford.edu; CS229 December 13, 2013 Problem Statement High energy collisions of protons at the Large Hadron Collider (LHC)
W vs. QCD Jet Tagging at the Large Hadron Collider Bryan Anenberg: anenberg@stanford.edu; CS229 December 13, 2013 Problem Statement High energy collisions of protons at the Large Hadron Collider (LHC)
Machine Learning & Data Mining
 Group M L D Machine Learning M & Data Mining Chapter 7 Decision Trees Xin-Shun Xu @ SDU School of Computer Science and Technology, Shandong University Top 10 Algorithm in DM #1: C4.5 #2: K-Means #3: SVM
Group M L D Machine Learning M & Data Mining Chapter 7 Decision Trees Xin-Shun Xu @ SDU School of Computer Science and Technology, Shandong University Top 10 Algorithm in DM #1: C4.5 #2: K-Means #3: SVM
6.867 Machine Learning
 6.867 Machine Learning Problem Set 2 Due date: Wednesday October 6 Please address all questions and comments about this problem set to 6867-staff@csail.mit.edu. You will need to use MATLAB for some of
6.867 Machine Learning Problem Set 2 Due date: Wednesday October 6 Please address all questions and comments about this problem set to 6867-staff@csail.mit.edu. You will need to use MATLAB for some of
Boosting Methods: Why They Can Be Useful for High-Dimensional Data
 New URL: http://www.r-project.org/conferences/dsc-2003/ Proceedings of the 3rd International Workshop on Distributed Statistical Computing (DSC 2003) March 20 22, Vienna, Austria ISSN 1609-395X Kurt Hornik,
New URL: http://www.r-project.org/conferences/dsc-2003/ Proceedings of the 3rd International Workshop on Distributed Statistical Computing (DSC 2003) March 20 22, Vienna, Austria ISSN 1609-395X Kurt Hornik,
CLASSIFICATION METHODS FOR MAGIC TELESCOPE IMAGES ON A PIXEL-BY-PIXEL BASE. 1 Introduction
 CLASSIFICATION METHODS FOR MAGIC TELESCOPE IMAGES ON A PIXEL-BY-PIXEL BASE CONSTANTINO MALAGÓN Departamento de Ingeniería Informática, Univ. Antonio de Nebrija, 28040 Madrid, Spain. JUAN ABEL BARRIO 2,
CLASSIFICATION METHODS FOR MAGIC TELESCOPE IMAGES ON A PIXEL-BY-PIXEL BASE CONSTANTINO MALAGÓN Departamento de Ingeniería Informática, Univ. Antonio de Nebrija, 28040 Madrid, Spain. JUAN ABEL BARRIO 2,