Data Mining und Maschinelles Lernen
|
|
|
- Lynette Shaw
- 6 years ago
- Views:
Transcription
1 Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting Output Codes (ECOC)
2 Bias and Variance Decomposition Bias: the part of the error that is caused by bad model Variance: the part of the error that is caused by the data sample Bias-Variance Trade-off: algorithms that can easily adapt to any given decision boundary are very sensitive to small variations in the data and vice versa Models with a low bias often have a high variance e.g., nearest neighbor, unpruned decision trees Models with a low variance often have a high bias e.g., decision stump, linear model
3 Ensemble Classifiers IDEA: do not learn a single classifier but learn a set of classifiers combine the predictions of multiple classifiers MOTIVATION: reduce variance: results are less dependent on peculiarities of a single training set reduce bias: a combination of multiple classifiers may learn a more expressive concept class than a single classifier KEY STEP: formation of an ensemble of diverse classifiers from a single training set
4 Why do ensembles work? Suppose there are 25 base classifiers Each classifier has error rate, = 0.35 Assume classifiers are independent i.e., probability that a classifier makes a mistake does not depend on whether other classifiers made a mistake Note: in practice they are not independent! Probability that the ensemble classifier makes a wrong prediction The ensemble makes a wrong prediction if the majority of the classifiers makes a wrong prediction The probability that 13 or more classifiers err is i=13 i i 1 25 i 0.06

5 Bagging: General Idea
6 Generate Bootstrap Samples Generate new training sets using sampling with replacement (bootstrap samples) Original Data Bagging (Round 1) Bagging (Round 2) Bagging (Round 3) some examples may appear in more than one set some examples will appear more than once in a set for each set of size n, the probability that a given example appears in it is Pr x D i =1 1 1 n n i.e., on average, less than 2/3 of the examples appear in any single bootstrap sample
7 Bagging Algorithm for m = 1 to to t t // // t t number of of iterations a) draw (with replacement) a bootstrap sample D m of of the data b) b) learn a classifier C m from D m for each test example a) a) try all classifiers C m b) predict the class that receives the highest number of of votes variations are possible e.g., size of subset, sampling w/o replacement, etc. many related variants sampling of features, not instances learn a set of classifiers with different algorithms
8 Bagged Decision Trees from Hastie, Tibshirani, Friedman: The Elements of Statistical Learning, Springer Verlag 2001
9 Bagged Trees weighted voting voting from Hastie, Tibshirani, Friedman: The Elements of Statistical Learning, Springer Verlag 2001
10 Bagging with costs Bagging unpruned decision trees is known to produce good probability estimates Where, instead of voting, the individual classifiers' probability estimates Pr n ( j x) are averaged Pr j x = 1 t Pr n=1 n j x Note: this can also improve the error rate We can use this with minimum-expected cost approach for learning problems with costs predict class c with c=arg min i C i j Pr j x j Problem: not interpretable MetaCost re-labels training data using bagging with costs and then builds single tree (Domingos, 1997) t
11 Randomization Randomize the learning algorithm instead of the input data Some algorithms already have a random component eg. initial weights in neural net Most algorithms can be randomized, e.g. greedy algorithms: Pick from the N best options at random instead of always picking the best options Eg.: test selection in decision trees or rule learning Can be combined with bagging
12 Random Forests Combines bagging and random attribute subset selection: Build the tree from a bootstrap sample Instead of choosing the best split among all attributes, select the best split among a random subset of k attributes is equal to bagging when k equals the number of attributes There is a bias/variance tradeoff with k: The smaller k, the greater the reduction of variance but also the higher the increase of bias
13 Boosting Basic Idea: later classifiers focus on examples that were misclassified by earlier classifiers weight the predictions of the classifiers with their error Realization perform multiple iterations each time using different example weights weight update between iterations increase the weight of incorrectly classified examples this ensures that they will become more important in the next iterations (misclassification errors for these examples count more heavily) combine results of all iterations weighted by their respective error measures
14 Boosting Algorithm AdaBoost.M initialize example weights w i i = 1/N (i (i = 1..N) for m = 1 to to t t // // t t number of of iterations a) a) learn a classifier C m using the current example weights b) b) compute a weighted error estimate c) c) compute a classifier weight m = 1 2 ln 1 err m err m d) d) for all all correctly classified examples e i i :: w i w i e m e) e) for all all incorrectly classified examples e i i :: w i w i e m f) f) normalize the weights w i i so so that they sum to to for each test example a) a) try all all classifiers C m w err m = i of all incorrectly classified e i N wi i=1 = 1 because weights b) b) predict the class that receives the highest sum of of weights α m are normalized update weights so that sum of correctly classified examples equals sum of incorrectly classified examples
15 Illustration of the Weights Classifier Weights a m differences near 0 or 1 are emphasized Example Weights w i multiplier for correct and incorrect examples, depending on error
16 Boosting Error rate example boosting of decision stumps on simulated data from Hastie, Tibshirani, Friedman: The Elements of Statistical Learning, Springer Verlag 2001
17 Toy Example (taken from Verma & Thrun, Slides to CALD Course CMU , Machine Learning, Fall 2000) An Applet demonstrating AdaBoost
18 Round 1
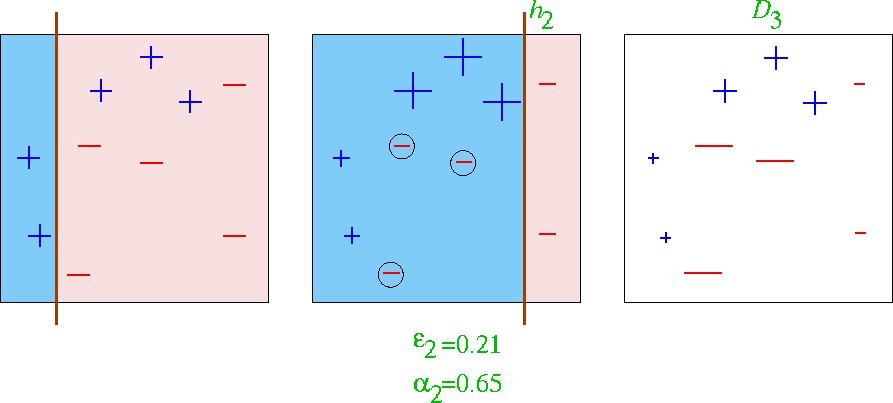
19 Round 2
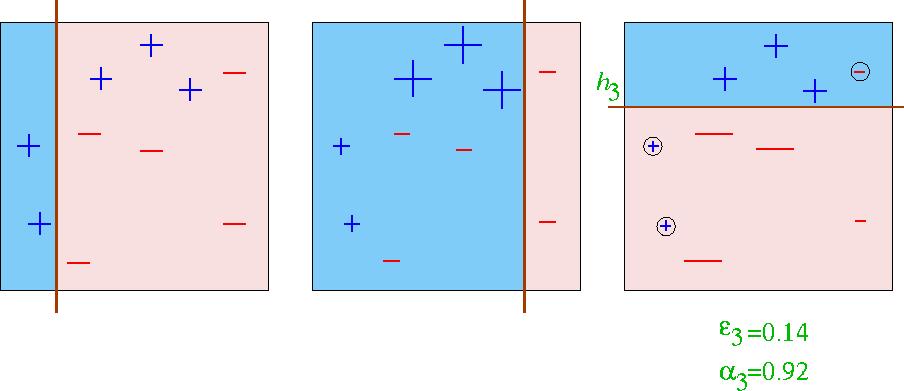
20 Round 3
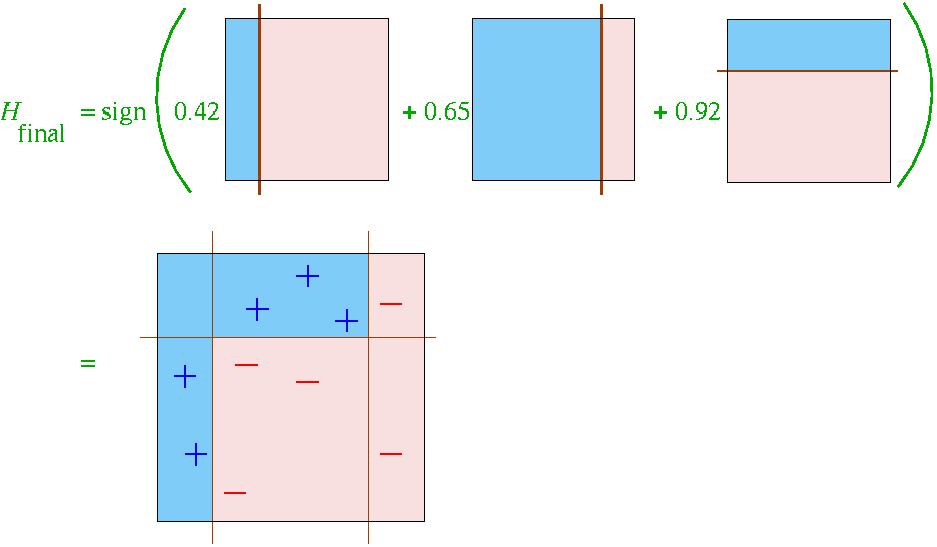
21 Final Hypothesis
22 Dealing with Weighted Examples Two possibilities ( cost-sensitive learning) directly example e i has weight w i number of examples n Þ total example weight n i=1 via sampling interpret the weights as probabilities examples with larger weights are more likely to be sampled assumptions sampling with replacement weights are well distributed in [0,1] learning algorithm sensible to varying numbers of identical examples in training data boosting can thus be used in very much the same way as bagging w i V2.1 J. Fürnkranz
23 Comparison Bagging/Boosting Bagging noise-tolerant produces better class probability estimates not so accurate statistical basis related to random sampling Boosting very susceptible to noise in the data produces rather bad class probability estimates if it works, it works really well based on learning theory (statistical interpretations are possible) related to windowing
24 Example from Hastie, Tibshirani, Friedman: The Elements of Statistical Learning, Springer Verlag 2001
25 Additive regression It turns out that boosting is a greedy algorithm for fitting additive models More specifically, implements forward stagewise additive modeling Same kind of algorithm for numeric prediction: 1.Build standard regression model (e.g. tree) 2.Gather residuals 3.learn model predicting residuals (e.g. tree) 4.goto 2. To predict, simply sum up individual predictions from all models
26 Combining Predictions voting each ensemble member votes for one of the classes predict the class with the highest number of vote (e.g., bagging) weighted voting make a weighted sum of the votes of the ensemble members weights typically depend on the classifiers confidence in its prediction (e.g., the estimated probability of the predicted class) on error estimates of the classifier (e.g., boosting) stacking Why not use a classifier for making the final decision? training material are the class labels of the training data and the (cross-validated) predictions of the ensemble members
27 Stacking Basic Idea: learn a function that combines the predictions of the individual classifiers Algorithm: train n different classifiers C 1...C n (the base classifiers) obtain predictions of the classifiers for the training examples form a new data set (the meta data) classes the same as the original dataset attributes one attribute for each base classifier value is the prediction of this classifier on the example train a separate classifier M (the meta classifier) This is better done with cross-validation!
28 Stacking (2) Example: Using a stacked classifier: try each of the classifiers C 1...C n form a feature vector consisting of their predictions submit these feature vectors to the meta classifier M
29 Error-correcting output codes (Dietterich & Bakiri, 1995) Class Binarization technique Multiclass problem binary problems Simple scheme: One-vs-all coding Idea: use error-correcting codes instead one code vector per class Prediction: base classifiers predict , true class =?? Use code words that have large pairwise Hamming distance d Can correct up to (d 1)/2 single-bit errors class a b c d class a b c d class vector class vector binary classifiers
30 More on ECOCs Two criteria : Row separation: minimum distance between rows Column separation: minimum distance between columns (and columns complements) Why? Because if columns are identical, base classifiers will likely make the same errors Error-correction is weakened if errors are correlated 3 classes only 2 3 possible columns (and 4 out of the 8 are complements) Cannot achieve row and column separation Only works for problems with > 3 classes
31 Exhaustive ECOCs Exhaustive code for k classes: Columns comprise every possible k-string except for complements and all-zero/one strings Each code word contains 2 k 1 1 bits Class 1: code word is all ones Class 2: 2 k 2 zeroes followed by 2 k 2 1 ones Class i : alternating runs of 2 k i 0s and 1s last run is one bit shorter than the others Exhaustive code, k = 4 class class vector a b c d
32 Extensions of ECOCs Many different coding strategies have been proposed exhaustive codes infeasible for large numbers of classes Number of columns increases exponentially Random code words have good error-correcting properties on average! Ternary ECOCs (Allwein et al., 2000) use three-valued codes -1/0/1, i.e., positive / ignore / negative this can, e.g., also model pairwise classification ECOCs don t work with NN classifier because the same neighbor(s) are used in all binary classifiers for making the prediction But: works if different attribute subsets are used to predict each output bit
33 Summary: Forming an Ensemble Modifying the data Subsampling bagging boosting feature subsets randomly feature samples Modifying the learning task pairwise classification / round robin learning error-correcting output codes Exploiting the algorithm characterisitics algorithms with random components neural networks randomizing algorithms randomized decision trees use multiple algorithms with different characteristics Exploiting problem characteristics e.g., hyperlink ensembles
Machine Learning. Ensemble Methods. Manfred Huber
 Machine Learning Ensemble Methods Manfred Huber 2015 1 Bias, Variance, Noise Classification errors have different sources Choice of hypothesis space and algorithm Training set Noise in the data The expected
Machine Learning Ensemble Methods Manfred Huber 2015 1 Bias, Variance, Noise Classification errors have different sources Choice of hypothesis space and algorithm Training set Noise in the data The expected
Learning with multiple models. Boosting.
 CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS7267 MACHINE LEARNING
 CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
VBM683 Machine Learning
 VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
Ensemble Methods. Charles Sutton Data Mining and Exploration Spring Friday, 27 January 12
 Ensemble Methods Charles Sutton Data Mining and Exploration Spring 2012 Bias and Variance Consider a regression problem Y = f(x)+ N(0, 2 ) With an estimate regression function ˆf, e.g., ˆf(x) =w > x Suppose
Ensemble Methods Charles Sutton Data Mining and Exploration Spring 2012 Bias and Variance Consider a regression problem Y = f(x)+ N(0, 2 ) With an estimate regression function ˆf, e.g., ˆf(x) =w > x Suppose
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers
 Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
PDEEC Machine Learning 2016/17
 PDEEC Machine Learning 2016/17 Lecture - Model assessment, selection and Ensemble Jaime S. Cardoso jaime.cardoso@inesctec.pt INESC TEC and Faculdade Engenharia, Universidade do Porto Nov. 07, 2017 1 /
PDEEC Machine Learning 2016/17 Lecture - Model assessment, selection and Ensemble Jaime S. Cardoso jaime.cardoso@inesctec.pt INESC TEC and Faculdade Engenharia, Universidade do Porto Nov. 07, 2017 1 /
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
Voting (Ensemble Methods)
") 1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
Variance Reduction and Ensemble Methods
 Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis
Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis
TDT4173 Machine Learning
 TDT4173 Machine Learning Lecture 9 Learning Classifiers: Bagging & Boosting Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline
TDT4173 Machine Learning Lecture 9 Learning Classifiers: Bagging & Boosting Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline
Ensembles of Classifiers.
 Ensembles of Classifiers www.biostat.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts ensemble bootstrap sample bagging boosting random forests error correcting
Ensembles of Classifiers www.biostat.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts ensemble bootstrap sample bagging boosting random forests error correcting
Ensembles. Léon Bottou COS 424 4/8/2010
 Ensembles Léon Bottou COS 424 4/8/2010 Readings T. G. Dietterich (2000) Ensemble Methods in Machine Learning. R. E. Schapire (2003): The Boosting Approach to Machine Learning. Sections 1,2,3,4,6. Léon
Ensembles Léon Bottou COS 424 4/8/2010 Readings T. G. Dietterich (2000) Ensemble Methods in Machine Learning. R. E. Schapire (2003): The Boosting Approach to Machine Learning. Sections 1,2,3,4,6. Léon
TDT4173 Machine Learning
 TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
From Binary to Multiclass Classification. CS 6961: Structured Prediction Spring 2018
 From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
CSE 151 Machine Learning. Instructor: Kamalika Chaudhuri
 CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Ensemble Learning How to combine multiple classifiers into a single one Works well if the classifiers are complementary This class: two types of
CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Ensemble Learning How to combine multiple classifiers into a single one Works well if the classifiers are complementary This class: two types of
Ensemble Methods: Jay Hyer
 Ensemble Methods: committee-based learning Jay Hyer linkedin.com/in/jayhyer @adatahead Overview Why Ensemble Learning? What is learning? How is ensemble learning different? Boosting Weak and Strong Learners
Ensemble Methods: committee-based learning Jay Hyer linkedin.com/in/jayhyer @adatahead Overview Why Ensemble Learning? What is learning? How is ensemble learning different? Boosting Weak and Strong Learners
Bias-Variance in Machine Learning
 Bias-Variance in Machine Learning Bias-Variance: Outline Underfitting/overfitting: Why are complex hypotheses bad? Simple example of bias/variance Error as bias+variance for regression brief comments on
Bias-Variance in Machine Learning Bias-Variance: Outline Underfitting/overfitting: Why are complex hypotheses bad? Simple example of bias/variance Error as bias+variance for regression brief comments on
Big Data Analytics. Special Topics for Computer Science CSE CSE Feb 24
 Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 8. Chapter 8. Classification: Basic Concepts
 Chapter 8. Chapter 8. Classification: Basic Concepts") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
AdaBoost. Lecturer: Authors: Center for Machine Perception Czech Technical University, Prague
 AdaBoost Lecturer: Jan Šochman Authors: Jan Šochman, Jiří Matas Center for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Motivation Presentation 2/17 AdaBoost with trees
AdaBoost Lecturer: Jan Šochman Authors: Jan Šochman, Jiří Matas Center for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Motivation Presentation 2/17 AdaBoost with trees
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Decision Trees. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Decision Trees Tobias Scheffer Decision Trees One of many applications: credit risk Employed longer than 3 months Positive credit
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Decision Trees Tobias Scheffer Decision Trees One of many applications: credit risk Employed longer than 3 months Positive credit
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Ensembles Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique Fédérale de Lausanne
Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Ensembles Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique Fédérale de Lausanne
Learning Theory Continued
 Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
Decision Trees: Overfitting
 Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring /
 Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Neural Networks and Ensemble Methods for Classification
 Neural Networks and Ensemble Methods for Classification NEURAL NETWORKS 2 Neural Networks A neural network is a set of connected input/output units (neurons) where each connection has a weight associated
Neural Networks and Ensemble Methods for Classification NEURAL NETWORKS 2 Neural Networks A neural network is a set of connected input/output units (neurons) where each connection has a weight associated
Learning Ensembles. 293S T. Yang. UCSB, 2017.
 Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
Stochastic Gradient Descent
 Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Ensemble learning 11/19/13. The wisdom of the crowds. Chapter 11. Ensemble methods. Ensemble methods
 The wisdom of the crowds Ensemble learning Sir Francis Galton discovered in the early 1900s that a collection of educated guesses can add up to very accurate predictions! Chapter 11 The paper in which
The wisdom of the crowds Ensemble learning Sir Francis Galton discovered in the early 1900s that a collection of educated guesses can add up to very accurate predictions! Chapter 11 The paper in which
BBM406 - Introduc0on to ML. Spring Ensemble Methods. Aykut Erdem Dept. of Computer Engineering HaceDepe University
 BBM406 - Introduc0on to ML Spring 2014 Ensemble Methods Aykut Erdem Dept. of Computer Engineering HaceDepe University 2 Slides adopted from David Sontag, Mehryar Mohri, Ziv- Bar Joseph, Arvind Rao, Greg
BBM406 - Introduc0on to ML Spring 2014 Ensemble Methods Aykut Erdem Dept. of Computer Engineering HaceDepe University 2 Slides adopted from David Sontag, Mehryar Mohri, Ziv- Bar Joseph, Arvind Rao, Greg
Ensemble Methods for Machine Learning
 Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
1 Handling of Continuous Attributes in C4.5. Algorithm
 .. Spring 2009 CSC 466: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Classification/Supervised Learning Potpourri Contents 1. C4.5. and continuous attributes: incorporating continuous
.. Spring 2009 CSC 466: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Classification/Supervised Learning Potpourri Contents 1. C4.5. and continuous attributes: incorporating continuous
10701/15781 Machine Learning, Spring 2007: Homework 2
 070/578 Machine Learning, Spring 2007: Homework 2 Due: Wednesday, February 2, beginning of the class Instructions There are 4 questions on this assignment The second question involves coding Do not attach
070/578 Machine Learning, Spring 2007: Homework 2 Due: Wednesday, February 2, beginning of the class Instructions There are 4 questions on this assignment The second question involves coding Do not attach
Boosting. Acknowledgment Slides are based on tutorials from Robert Schapire and Gunnar Raetsch
 . Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
. Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
MIRA, SVM, k-nn. Lirong Xia
 MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c /9/9 page 331 le-tex
 Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c15 2013/9/9 page 331 le-tex 331 15 Ensemble Learning The expression ensemble learning refers to a broad class
Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c15 2013/9/9 page 331 le-tex 331 15 Ensemble Learning The expression ensemble learning refers to a broad class
UVA CS 4501: Machine Learning
 UVA CS 4501: Machine Learning Lecture 21: Decision Tree / Random Forest / Ensemble Dr. Yanjun Qi University of Virginia Department of Computer Science Where are we? è Five major sections of this course
UVA CS 4501: Machine Learning Lecture 21: Decision Tree / Random Forest / Ensemble Dr. Yanjun Qi University of Virginia Department of Computer Science Where are we? è Five major sections of this course
A Brief Introduction to Adaboost
 A Brief Introduction to Adaboost Hongbo Deng 6 Feb, 2007 Some of the slides are borrowed from Derek Hoiem & Jan ˇSochman. 1 Outline Background Adaboost Algorithm Theory/Interpretations 2 What s So Good
A Brief Introduction to Adaboost Hongbo Deng 6 Feb, 2007 Some of the slides are borrowed from Derek Hoiem & Jan ˇSochman. 1 Outline Background Adaboost Algorithm Theory/Interpretations 2 What s So Good
Ensemble Methods and Random Forests
 Ensemble Methods and Random Forests Vaishnavi S May 2017 1 Introduction We have seen various analysis for classification and regression in the course. One of the common methods to reduce the generalization
Ensemble Methods and Random Forests Vaishnavi S May 2017 1 Introduction We have seen various analysis for classification and regression in the course. One of the common methods to reduce the generalization
Midterm Exam Solutions, Spring 2007
 1-71 Midterm Exam Solutions, Spring 7 1. Personal info: Name: Andrew account: E-mail address:. There should be 16 numbered pages in this exam (including this cover sheet). 3. You can use any material you
1-71 Midterm Exam Solutions, Spring 7 1. Personal info: Name: Andrew account: E-mail address:. There should be 16 numbered pages in this exam (including this cover sheet). 3. You can use any material you
Numerical Learning Algorithms
 Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Numerical Learning Algorithms Example SVM for Separable Examples.......................... Example SVM for Nonseparable Examples....................... 4 Example Gaussian Kernel SVM...............................
Lecture 13: Ensemble Methods
 Lecture 13: Ensemble Methods Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu 1 / 71 Outline 1 Bootstrap
Lecture 13: Ensemble Methods Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu 1 / 71 Outline 1 Bootstrap
Statistics and learning: Big Data
 Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees
Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees
Chapter 14 Combining Models
 Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
1/sqrt(B) convergence 1/B convergence B
 convergence 1/B convergence B") The Error Coding Method and PICTs Gareth James and Trevor Hastie Department of Statistics, Stanford University March 29, 1998 Abstract A new family of plug-in classication techniques has recently been
The Error Coding Method and PICTs Gareth James and Trevor Hastie Department of Statistics, Stanford University March 29, 1998 Abstract A new family of plug-in classication techniques has recently been
Multiclass Boosting with Repartitioning
 Multiclass Boosting with Repartitioning Ling Li Learning Systems Group, Caltech ICML 2006 Binary and Multiclass Problems Binary classification problems Y = { 1, 1} Multiclass classification problems Y
Multiclass Boosting with Repartitioning Ling Li Learning Systems Group, Caltech ICML 2006 Binary and Multiclass Problems Binary classification problems Y = { 1, 1} Multiclass classification problems Y
A Decision Stump. Decision Trees, cont. Boosting. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. October 1 st, 2007
 Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Bagging. Ryan Tibshirani Data Mining: / April Optional reading: ISL 8.2, ESL 8.7
 Bagging Ryan Tibshirani Data Mining: 36-462/36-662 April 23 2013 Optional reading: ISL 8.2, ESL 8.7 1 Reminder: classification trees Our task is to predict the class label y {1,... K} given a feature vector
Bagging Ryan Tibshirani Data Mining: 36-462/36-662 April 23 2013 Optional reading: ISL 8.2, ESL 8.7 1 Reminder: classification trees Our task is to predict the class label y {1,... K} given a feature vector
What makes good ensemble? CS789: Machine Learning and Neural Network. Introduction. More on diversity
 What makes good ensemble? CS789: Machine Learning and Neural Network Ensemble methods Jakramate Bootkrajang Department of Computer Science Chiang Mai University 1. A member of the ensemble is accurate.
What makes good ensemble? CS789: Machine Learning and Neural Network Ensemble methods Jakramate Bootkrajang Department of Computer Science Chiang Mai University 1. A member of the ensemble is accurate.
The Boosting Approach to. Machine Learning. Maria-Florina Balcan 10/31/2016
 The Boosting Approach to Machine Learning Maria-Florina Balcan 10/31/2016 Boosting General method for improving the accuracy of any given learning algorithm. Works by creating a series of challenge datasets
The Boosting Approach to Machine Learning Maria-Florina Balcan 10/31/2016 Boosting General method for improving the accuracy of any given learning algorithm. Works by creating a series of challenge datasets
Computational Learning Theory
 09s1: COMP9417 Machine Learning and Data Mining Computational Learning Theory May 20, 2009 Acknowledgement: Material derived from slides for the book Machine Learning, Tom M. Mitchell, McGraw-Hill, 1997
09s1: COMP9417 Machine Learning and Data Mining Computational Learning Theory May 20, 2009 Acknowledgement: Material derived from slides for the book Machine Learning, Tom M. Mitchell, McGraw-Hill, 1997
Analysis of the Performance of AdaBoost.M2 for the Simulated Digit-Recognition-Example
 Analysis of the Performance of AdaBoost.M2 for the Simulated Digit-Recognition-Example Günther Eibl and Karl Peter Pfeiffer Institute of Biostatistics, Innsbruck, Austria guenther.eibl@uibk.ac.at Abstract.
Analysis of the Performance of AdaBoost.M2 for the Simulated Digit-Recognition-Example Günther Eibl and Karl Peter Pfeiffer Institute of Biostatistics, Innsbruck, Austria guenther.eibl@uibk.ac.at Abstract.
Boosting & Deep Learning
 Boosting & Deep Learning Ensemble Learning n So far learning methods that learn a single hypothesis, chosen form a hypothesis space that is used to make predictions n Ensemble learning à select a collection
Boosting & Deep Learning Ensemble Learning n So far learning methods that learn a single hypothesis, chosen form a hypothesis space that is used to make predictions n Ensemble learning à select a collection
CART Classification and Regression Trees Trees can be viewed as basis expansions of simple functions. f(x) = c m 1(x R m )
 = c m 1(x R m )") CART Classification and Regression Trees Trees can be viewed as basis expansions of simple functions with R 1,..., R m R p disjoint. f(x) = M c m 1(x R m ) m=1 The CART algorithm is a heuristic, adaptive
CART Classification and Regression Trees Trees can be viewed as basis expansions of simple functions with R 1,..., R m R p disjoint. f(x) = M c m 1(x R m ) m=1 The CART algorithm is a heuristic, adaptive
1 Handling of Continuous Attributes in C4.5. Algorithm
 .. Spring 2009 CSC 466: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Classification/Supervised Learning Potpourri Contents 1. C4.5. and continuous attributes: incorporating continuous
.. Spring 2009 CSC 466: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Classification/Supervised Learning Potpourri Contents 1. C4.5. and continuous attributes: incorporating continuous
Combining Classifiers
 Cobining Classifiers Generic ethods of generating and cobining ultiple classifiers Bagging Boosting References: Duda, Hart & Stork, pg 475-480. Hastie, Tibsharini, Friedan, pg 246-256 and Chapter 10. http://www.boosting.org/
Cobining Classifiers Generic ethods of generating and cobining ultiple classifiers Bagging Boosting References: Duda, Hart & Stork, pg 475-480. Hastie, Tibsharini, Friedan, pg 246-256 and Chapter 10. http://www.boosting.org/
Boosting. Ryan Tibshirani Data Mining: / April Optional reading: ISL 8.2, ESL , 10.7, 10.13
 Boosting Ryan Tibshirani Data Mining: 36-462/36-662 April 25 2013 Optional reading: ISL 8.2, ESL 10.1 10.4, 10.7, 10.13 1 Reminder: classification trees Suppose that we are given training data (x i, y
Boosting Ryan Tibshirani Data Mining: 36-462/36-662 April 25 2013 Optional reading: ISL 8.2, ESL 10.1 10.4, 10.7, 10.13 1 Reminder: classification trees Suppose that we are given training data (x i, y
Recitation 9. Gradient Boosting. Brett Bernstein. March 30, CDS at NYU. Brett Bernstein (CDS at NYU) Recitation 9 March 30, / 14
 Recitation 9 March 30, / 14") Brett Bernstein CDS at NYU March 30, 2017 Brett Bernstein (CDS at NYU) Recitation 9 March 30, 2017 1 / 14 Initial Question Intro Question Question Suppose 10 different meteorologists have produced functions
Brett Bernstein CDS at NYU March 30, 2017 Brett Bernstein (CDS at NYU) Recitation 9 March 30, 2017 1 / 14 Initial Question Intro Question Question Suppose 10 different meteorologists have produced functions
Holdout and Cross-Validation Methods Overfitting Avoidance
 Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
Notation P(Y ) = X P(X, Y ) = X. P(Y X )P(X ) Teorema de Bayes: P(Y X ) = CIn/UFPE - Prof. Francisco de A. T. de Carvalho P(X )
 = X P(X, Y ) = X. P(Y X )P(X ) Teorema de Bayes: P(Y X ) = CIn/UFPE - Prof. Francisco de A. T. de Carvalho P(X )") Notation R n : feature space Y : class label set m : number of training examples D = {x i, y i } m i=1 (x i R n ; y i Y}: training data set H hipothesis space h : base classificer H : emsemble classifier
Notation R n : feature space Y : class label set m : number of training examples D = {x i, y i } m i=1 (x i R n ; y i Y}: training data set H hipothesis space h : base classificer H : emsemble classifier
Gradient Boosting (Continued)
") Gradient Boosting (Continued) David Rosenberg New York University April 4, 2016 David Rosenberg (New York University) DS-GA 1003 April 4, 2016 1 / 31 Boosting Fits an Additive Model Boosting Fits an Additive
Gradient Boosting (Continued) David Rosenberg New York University April 4, 2016 David Rosenberg (New York University) DS-GA 1003 April 4, 2016 1 / 31 Boosting Fits an Additive Model Boosting Fits an Additive
Linear and Logistic Regression. Dr. Xiaowei Huang
 Linear and Logistic Regression Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Two Classical Machine Learning Algorithms Decision tree learning K-nearest neighbor Model Evaluation Metrics
Linear and Logistic Regression Dr. Xiaowei Huang https://cgi.csc.liv.ac.uk/~xiaowei/ Up to now, Two Classical Machine Learning Algorithms Decision tree learning K-nearest neighbor Model Evaluation Metrics
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
Support Vector Machine, Random Forests, Boosting Based in part on slides from textbook, slides of Susan Holmes. December 2, 2012
 Support Vector Machine, Random Forests, Boosting Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Neural networks Neural network Another classifier (or regression technique)
Support Vector Machine, Random Forests, Boosting Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Neural networks Neural network Another classifier (or regression technique)
Outline: Ensemble Learning. Ensemble Learning. The Wisdom of Crowds. The Wisdom of Crowds - Really? Crowd wiser than any individual
 Outline: Ensemble Learning We will describe and investigate algorithms to Ensemble Learning Lecture 10, DD2431 Machine Learning A. Maki, J. Sullivan October 2014 train weak classifiers/regressors and how
Outline: Ensemble Learning We will describe and investigate algorithms to Ensemble Learning Lecture 10, DD2431 Machine Learning A. Maki, J. Sullivan October 2014 train weak classifiers/regressors and how
Machine Learning. Computational Learning Theory. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Computational Learning Theory Le Song Lecture 11, September 20, 2012 Based on Slides from Eric Xing, CMU Reading: Chap. 7 T.M book 1 Complexity of Learning
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Computational Learning Theory Le Song Lecture 11, September 20, 2012 Based on Slides from Eric Xing, CMU Reading: Chap. 7 T.M book 1 Complexity of Learning
Machine Learning Recitation 8 Oct 21, Oznur Tastan
 Machine Learning 10601 Recitation 8 Oct 21, 2009 Oznur Tastan Outline Tree representation Brief information theory Learning decision trees Bagging Random forests Decision trees Non linear classifier Easy
Machine Learning 10601 Recitation 8 Oct 21, 2009 Oznur Tastan Outline Tree representation Brief information theory Learning decision trees Bagging Random forests Decision trees Non linear classifier Easy
Boosting. CAP5610: Machine Learning Instructor: Guo-Jun Qi
 Boosting CAP5610: Machine Learning Instructor: Guo-Jun Qi Weak classifiers Weak classifiers Decision stump one layer decision tree Naive Bayes A classifier without feature correlations Linear classifier
Boosting CAP5610: Machine Learning Instructor: Guo-Jun Qi Weak classifiers Weak classifiers Decision stump one layer decision tree Naive Bayes A classifier without feature correlations Linear classifier
Error Limiting Reductions Between Classification Tasks
 Error Limiting Reductions Between Classification Tasks Keywords: supervised learning, reductions, classification Abstract We introduce a reduction-based model for analyzing supervised learning tasks. We
Error Limiting Reductions Between Classification Tasks Keywords: supervised learning, reductions, classification Abstract We introduce a reduction-based model for analyzing supervised learning tasks. We
BAGGING PREDICTORS AND RANDOM FOREST
 BAGGING PREDICTORS AND RANDOM FOREST DANA KANER M.SC. SEMINAR IN STATISTICS, MAY 2017 BAGIGNG PREDICTORS / LEO BREIMAN, 1996 RANDOM FORESTS / LEO BREIMAN, 2001 THE ELEMENTS OF STATISTICAL LEARNING (CHAPTERS
BAGGING PREDICTORS AND RANDOM FOREST DANA KANER M.SC. SEMINAR IN STATISTICS, MAY 2017 BAGIGNG PREDICTORS / LEO BREIMAN, 1996 RANDOM FORESTS / LEO BREIMAN, 2001 THE ELEMENTS OF STATISTICAL LEARNING (CHAPTERS
Machine Learning. Lecture 9: Learning Theory. Feng Li.
 Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Learning Theory. Machine Learning CSE546 Carlos Guestrin University of Washington. November 25, Carlos Guestrin
 Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
Chapter 18. Decision Trees and Ensemble Learning. Recall: Learning Decision Trees
 CSE 473 Chapter 18 Decision Trees and Ensemble Learning Recall: Learning Decision Trees Example: When should I wait for a table at a restaurant? Attributes (features) relevant to Wait? decision: 1. Alternate:
CSE 473 Chapter 18 Decision Trees and Ensemble Learning Recall: Learning Decision Trees Example: When should I wait for a table at a restaurant? Attributes (features) relevant to Wait? decision: 1. Alternate:
Learning from Examples
 Learning from Examples Data fitting Decision trees Cross validation Computational learning theory Linear classifiers Neural networks Nonparametric methods: nearest neighbor Support vector machines Ensemble
Learning from Examples Data fitting Decision trees Cross validation Computational learning theory Linear classifiers Neural networks Nonparametric methods: nearest neighbor Support vector machines Ensemble
Classification using stochastic ensembles
 July 31, 2014 Topics Introduction Topics Classification Application and classfication Classification and Regression Trees Stochastic ensemble methods Our application: USAID Poverty Assessment Tools Topics
July 31, 2014 Topics Introduction Topics Classification Application and classfication Classification and Regression Trees Stochastic ensemble methods Our application: USAID Poverty Assessment Tools Topics
Part I Week 7 Based in part on slides from textbook, slides of Susan Holmes
 Part I Week 7 Based in part on slides from textbook, slides of Susan Holmes Support Vector Machine, Random Forests, Boosting December 2, 2012 1 / 1 2 / 1 Neural networks Artificial Neural networks: Networks
Part I Week 7 Based in part on slides from textbook, slides of Susan Holmes Support Vector Machine, Random Forests, Boosting December 2, 2012 1 / 1 2 / 1 Neural networks Artificial Neural networks: Networks
Bagging and Other Ensemble Methods
 Bagging and Other Ensemble Methods Sargur N. Srihari srihari@buffalo.edu 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties as Constrained Optimization 3. Regularization and Underconstrained
Bagging and Other Ensemble Methods Sargur N. Srihari srihari@buffalo.edu 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties as Constrained Optimization 3. Regularization and Underconstrained
Importance Sampling: An Alternative View of Ensemble Learning. Jerome H. Friedman Bogdan Popescu Stanford University
 Importance Sampling: An Alternative View of Ensemble Learning Jerome H. Friedman Bogdan Popescu Stanford University 1 PREDICTIVE LEARNING Given data: {z i } N 1 = {y i, x i } N 1 q(z) y = output or response
Importance Sampling: An Alternative View of Ensemble Learning Jerome H. Friedman Bogdan Popescu Stanford University 1 PREDICTIVE LEARNING Given data: {z i } N 1 = {y i, x i } N 1 q(z) y = output or response
Logistic Regression and Boosting for Labeled Bags of Instances
 Logistic Regression and Boosting for Labeled Bags of Instances Xin Xu and Eibe Frank Department of Computer Science University of Waikato Hamilton, New Zealand {xx5, eibe}@cs.waikato.ac.nz Abstract. In
Logistic Regression and Boosting for Labeled Bags of Instances Xin Xu and Eibe Frank Department of Computer Science University of Waikato Hamilton, New Zealand {xx5, eibe}@cs.waikato.ac.nz Abstract. In
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Learning Binary Classifiers for Multi-Class Problem
 Research Memorandum No. 1010 September 28, 2006 Learning Binary Classifiers for Multi-Class Problem Shiro Ikeda The Institute of Statistical Mathematics 4-6-7 Minami-Azabu, Minato-ku, Tokyo, 106-8569,
Research Memorandum No. 1010 September 28, 2006 Learning Binary Classifiers for Multi-Class Problem Shiro Ikeda The Institute of Statistical Mathematics 4-6-7 Minami-Azabu, Minato-ku, Tokyo, 106-8569,
A Unified Bias-Variance Decomposition
 A Unified Bias-Variance Decomposition Pedro Domingos Department of Computer Science and Engineering University of Washington Box 352350 Seattle, WA 98185-2350, U.S.A. pedrod@cs.washington.edu Tel.: 206-543-4229
A Unified Bias-Variance Decomposition Pedro Domingos Department of Computer Science and Engineering University of Washington Box 352350 Seattle, WA 98185-2350, U.S.A. pedrod@cs.washington.edu Tel.: 206-543-4229
Understanding Generalization Error: Bounds and Decompositions
 CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet.
 or two-page (one side) crib sheet.") CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE
 MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
MIDTERM SOLUTIONS: FALL 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE March 28, 2012 The exam is closed book. You are allowed a double sided one page cheat sheet. Answer the questions in the spaces provided on
Oliver Dürr. Statistisches Data Mining (StDM) Woche 11. Institut für Datenanalyse und Prozessdesign Zürcher Hochschule für Angewandte Wissenschaften
 Woche 11. Institut für Datenanalyse und Prozessdesign Zürcher Hochschule für Angewandte Wissenschaften") Statistisches Data Mining (StDM) Woche 11 Oliver Dürr Institut für Datenanalyse und Prozessdesign Zürcher Hochschule für Angewandte Wissenschaften oliver.duerr@zhaw.ch Winterthur, 29 November 2016 1 Multitasking
Statistisches Data Mining (StDM) Woche 11 Oliver Dürr Institut für Datenanalyse und Prozessdesign Zürcher Hochschule für Angewandte Wissenschaften oliver.duerr@zhaw.ch Winterthur, 29 November 2016 1 Multitasking
Boosting: Foundations and Algorithms. Rob Schapire
 Boosting: Foundations and Algorithms Rob Schapire Example: Spam Filtering problem: filter out spam (junk email) gather large collection of examples of spam and non-spam: From: yoav@ucsd.edu Rob, can you
Boosting: Foundations and Algorithms Rob Schapire Example: Spam Filtering problem: filter out spam (junk email) gather large collection of examples of spam and non-spam: From: yoav@ucsd.edu Rob, can you
Decision Tree Learning Lecture 2
 Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
CS229 Supplemental Lecture notes
 CS229 Supplemental Lecture notes John Duchi 1 Boosting We have seen so far how to solve classification (and other) problems when we have a data representation already chosen. We now talk about a procedure,
CS229 Supplemental Lecture notes John Duchi 1 Boosting We have seen so far how to solve classification (and other) problems when we have a data representation already chosen. We now talk about a procedure,
CS 188: Artificial Intelligence. Outline
 CS 188: Artificial Intelligence Lecture 21: Perceptrons Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. Outline Generative vs. Discriminative Binary Linear Classifiers Perceptron Multi-class
CS 188: Artificial Intelligence Lecture 21: Perceptrons Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein. Outline Generative vs. Discriminative Binary Linear Classifiers Perceptron Multi-class
Proteomics and Variable Selection
 Proteomics and Variable Selection p. 1/55 Proteomics and Variable Selection Alex Lewin With thanks to Paul Kirk for some graphs Department of Epidemiology and Biostatistics, School of Public Health, Imperial
Proteomics and Variable Selection p. 1/55 Proteomics and Variable Selection Alex Lewin With thanks to Paul Kirk for some graphs Department of Epidemiology and Biostatistics, School of Public Health, Imperial
A Unified Bias-Variance Decomposition and its Applications
 A Unified ias-ariance Decomposition and its Applications Pedro Domingos pedrod@cs.washington.edu Department of Computer Science and Engineering, University of Washington, Seattle, WA 98195, U.S.A. Abstract
A Unified ias-ariance Decomposition and its Applications Pedro Domingos pedrod@cs.washington.edu Department of Computer Science and Engineering, University of Washington, Seattle, WA 98195, U.S.A. Abstract
Machine Learning Basics
 Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Low Bias Bagged Support Vector Machines
 Low Bias Bagged Support Vector Machines Giorgio Valentini Dipartimento di Scienze dell Informazione Università degli Studi di Milano, Italy valentini@dsi.unimi.it Thomas G. Dietterich Department of Computer
Low Bias Bagged Support Vector Machines Giorgio Valentini Dipartimento di Scienze dell Informazione Università degli Studi di Milano, Italy valentini@dsi.unimi.it Thomas G. Dietterich Department of Computer