BBM406 - Introduc0on to ML. Spring Ensemble Methods. Aykut Erdem Dept. of Computer Engineering HaceDepe University
|
|
|
- Rose Lucas
- 5 years ago
- Views:
Transcription
1 BBM406 - Introduc0on to ML Spring 2014 Ensemble Methods Aykut Erdem Dept. of Computer Engineering HaceDepe University
2 2 Slides adopted from David Sontag, Mehryar Mohri, Ziv- Bar Joseph, Arvind Rao, Greg Shakhnarovich, Rob Schapire, Tommi Jaakkola, Jan Sochman and Jiri Matters Today Ensemble Methods - - Bagging Boos0ng

3 Bias/Variance Tradeoff Bias/Variance&Tradeoff& Hastie, Tibshirani, Friedman Elements of Statistical Learning

4 Bias/Variance Tradeoff Graphical illustration of bias and variance. roe.com/docs/biasvariance.html 4
5 Figh0ng the bias- variance tradeoff Simple (a.k.a. weak) learners are good - - e.g., naïve Bayes, logis0c regression, decision stumps (or shallow decision trees) Low variance, don t usually overfit Simple (a.k.a. weak) learners are bad High bias, can t solve hard learning problems 5
6 Reduce Variance Without Increasing Bias Averaging reduces variance: (when prediction are independent) Average models to reduce model variance One problem: - - Only one training set Where do mul0ple models come from? 6
7 Bagging (Bootstrap Aggrega0ng) Leo Breiman (1994) Take repeated bootstrap samples from training set D. Bootstrap sampling: Given set D containing N training examples, create D by drawing N examples at random with replacement from D. Bagging: - Create k bootstrap samples D 1... D k. - Train dis0nct classifier on each D i. - Classify new instance by majority vote / average. 7
8 Bagging Best case: In prac0ce: - models are correlated, so reduc0on is smaller than 1/N - variance of models trained on fewer training cases usually somewhat larger 8

9 Bagging Example 9

10 CART* decision boundary * A decision tree learning algorithm; very similar to ID3 10
11 100 bagged trees Shades of blue/red indicate strength of vote for par0cular classifica0on 11
12 Reduce Bias 2 and Decrease Variance? Bagging reduces variance by averaging Bagging has lidle effect on bias Can we average and reduce bias? Yes: Boos0ng 12
13 Boos0ng Ideas Main idea: use weak learner to create strong learner. Ensemble method: combine base classifiers returned by weak learner. Finding simple rela0vely accurate base classifiers olen not hard. But, how should base classifiers be combined? 13
14 Example: How May I Help You? Goal: automa0cally categorize type of call requested by phone customer (Collect, CallingCard, PersonToPerson, etc.) - yes I d like to place a collect call long distance please (Collect) - operator I need to make a call but I need to bill it to my office (ThirdNumber) - yes I d like to place a call on my master card please (CallingCard) - I just called a number in sioux city and I musta rang the wrong number because I got the wrong party and I would like to have that taken off of my bill (BillingCredit) Observa;on: - - easy to find rules of thumb that are olen correct e.g.: IF card occurs in uderance THEN predict CallingCard hard to find single highly accurate predic0on rule [Gorin et al.] 14
15 Boos0ng: Intui0on Instead of learning a single (weak) classifier, learn many weak classifiers that are good at different parts of the input space Output class: (Weighted) vote of each classifier Classifiers that are most sure will vote with more convic0on Classifiers will be most sure about a par0cular part of the space On average, do beder than single classifier But how do you??? - - force classifiers to learn about different parts of the input space? weigh the votes of different classifiers? 15
16 Boos0ng [Schapire, 1989] Idea: given a weak learner, run it mul0ple 0mes on (reweighted) training data, then let the learned classifiers vote On each itera0on t: - weight each training example by how incorrectly it was classified - Learn a hypothesis h t - A strength for this hypothesis a t Final classifier: - A linear combina0on of the votes of the different classifiers weighted by their strength Prac;cally useful Theore;cally interes;ng 16
17 Boos0ng: Intui0on Want to pick weak classifiers that contribute something to the ensemble Greedy algorithm: for m=1,...,m Pick a weak classifier h m Adjust weights: misclassified examples get heavier α m set according to weighted error of h m 17
18 Boos0ng: Intui0on Want to pick weak classifiers that contribute something to the ensemble Greedy algorithm: for m=1,...,m Pick a weak classifier h m Adjust weights: misclassified examples get heavier α m set according to weighted error of h m 18
19 Boos0ng: Intui0on Want to pick weak classifiers that contribute something to the ensemble Greedy algorithm: for m=1,...,m Pick a weak classifier h m Adjust weights: misclassified examples get heavier α m set according to weighted error of h m 19
20 Boos0ng: Intui0on Want to pick weak classifiers that contribute something to the ensemble Greedy algorithm: for m=1,...,m Pick a weak classifier h m Adjust weights: misclassified examples get heavier α m set according to weighted error of h m 20
21 Boos0ng: Intui0on Want to pick weak classifiers that contribute something to the ensemble Greedy algorithm: for m=1,...,m Pick a weak classifier h m Adjust weights: misclassified examples get heavier α m set according to weighted error of h m 21
22 Boos0ng: Intui0on Want to pick weak classifiers that contribute something to the ensemble Greedy algorithm: for m=1,...,m Pick a weak classifier h m Adjust weights: misclassified examples get heavier α m set according to weighted error of h m 22
23 Boos0ng: Intui0on Want to pick weak classifiers that contribute something to the ensemble Greedy algorithm: for m=1,...,m Pick a weak classifier h m Adjust weights: misclassified examples get heavier α m set according to weighted error of h m 23
24 First Boos0ng Algorithms [Schapire 89]: - first provable boos0ng algorithm [Freund 90]: - op0mal algorithm that boosts by majority [Drucker, Schapire & Simard 92]: - first experiments using boos0ng - limited by prac0cal drawbacks [Freund & Schapire 95]: - introduced AdaBoost algorithm - strong prac0cal advantages over previous boos0ng algorithms 24
25 The AdaBoost Algorithm 25
26 Toy Example Minimize the error weak hypotheses = ver0cal or horizontal half- planes 26
27 Round 1 h 1 D 2 ε 1 =0.30 α 1 =
28 Round 2 h 2 D 3 ε 2 =0.21 α 2 =
29 Round 3 h 3 ε 3 =0.14 α 3 =
30 Final Hypothesis H = sign final = 30
31 Voted combina0on of classifiers The general problem here is to try to combine many simple weak classifiers into a single strong classifier We consider voted combina0ons of simple binary ±1 component classifiers where the (non- nega0ve) votes α i can be used to emphasize component classifiers that are more reliable than others 31

32 Components: Decision stumps Consider the following simple family of component classifiers genera0ng ±1 labels: where These are called decision stumps. Each decision stump pays aden0on to only a single component of the input vector 32
33 Voted combina0ons (cont d.) We need to define a loss func0on for the combina0on so we can determine which new component h(x; θ) to add and how many votes it should receive While there are many op0ons for the loss func0on we consider here only a simple exponen0al loss 33
34 Modularity, errors, and loss Consider adding the m th component: 34
35 Modularity, errors, and loss Consider adding the m th component: 35
 should op0mize a weighted loss (weighted towards mistakes). 36")
36 Modularity, errors, and loss Consider adding the m th component: So at the m th itera0on the new component (and the votes) should op0mize a weighted loss (weighted towards mistakes). 36
 To increase modularity we d like to further decouple the op0miza0on of h(x; θ m ) from the associated votes α m To this end we")
37 Empirical exponen0al loss (cont d.) To increase modularity we d like to further decouple the op0miza0on of h(x; θ m ) from the associated votes α m To this end we select h(x; θ m ) that op0mizes the rate at which the loss would decrease as a func0on of α m 37
 We find that minimizes We can also normalize the")
38 Empirical exponen0al loss (cont d.) We find that minimizes We can also normalize the weights: so that 38
39 Empirical exponen0al loss (cont d.) We find that minimizes where is subsequently chosen to minimize 39

40 The AdaBoost Algorithm 40
41 The AdaBoost Algorithm Given: (x 1,y 1 ),...,(x m,y m ); x i 2 X,y i 2 { 1, +1} 41
42 The AdaBoost Algorithm Given: (x 1,y 1 ),...,(x m,y m ); x i 2 X,y i 2 { 1, +1} Initialise weights D 1 (i) =1/m 42
43 The AdaBoost Algorithm Given: (x 1,y 1 ),...,(x m,y m ); x i 2 X,y i 2 { 1, +1} Initialise weights D 1 (i) =1/m For t =1,..., T : Find ht = arg min P j = m D t (i)jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t =1 43
44 The AdaBoost Algorithm Given: (x 1,y 1 ),...,(x m,y m ); x i 2 X,y i 2 { 1, +1} Initialise weights D 1 (i) =1/m For t =1,..., T : Find ht = arg min P j = m D t (i)jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t =1 Set t = 12 log(1 t t ) 44
45 The AdaBoost Algorithm Given: (x 1,y 1 ),...,(x m,y m ); x i 2 X,y i 2 { 1, +1} Initialise weights D 1 (i) =1/m For t =1,..., T : Find ht = arg min P j = m D t (i)jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t =1 Set t = Update 12 log(1 t t ) D t+1 (i) = D t(i)exp( t y i h t (x i )) Z t where Z t is normalisation factor 45
46 The AdaBoost Algorithm Given: (x 1,y 1 ),...,(x m,y m ); x i 2 X,y i 2 { 1, +1} Initialise weights D 1 (i) =1/m For t =1,..., T : Find ht = arg min P j = m D t (i)jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t =1 Set t = Update 12 log(1 t t ) D t+1 (i) = D t(i)exp( t y i h t (x i )) Z t where Z t is normalisation factor Output the final classifier: H(x) =sign TX t h t (x) t=1 training error step 46
47 The AdaBoost Algorithm Given: (x 1,y 1 ),...,(x m,y m ); x i 2 X,y i 2 { 1, +1} Initialise weights D 1 (i) =1/m For t =1,..., T : Find ht = arg min P j = m D t (i)jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t =2 Set t = Update 12 log(1 t t ) D t+1 (i) = D t(i)exp( t y i h t (x i )) Z t where Z t is normalisation factor Output the final classifier: H(x) =sign TX t h t (x) t=1 training error step 47
jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t =3 Set t = Update 12 log(1 t t ) D t+1 (i) = D t(i)exp( t y i h t (x i )) Z t where Z t is normalisation")
48 The AdaBoost Algorithm Given: (x 1,y 1 ),...,(x m,y m ); x i 2 X,y i 2 { 1, +1} Initialise weights D 1 (i) =1/m For t =1,..., T : Find ht = arg min P j = m D t (i)jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t =3 Set t = Update 12 log(1 t t ) D t+1 (i) = D t(i)exp( t y i h t (x i )) Z t where Z t is normalisation factor Output the final classifier: H(x) =sign TX t h t (x) t=1 training error step 48
jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t =4 Set t = Update 12 log(1 t t ) D t+1 (i) = D t(i)exp( t y i h t (x i )) Z t where Z t is normalisation")
49 The AdaBoost Algorithm Given: (x 1,y 1 ),...,(x m,y m ); x i 2 X,y i 2 { 1, +1} Initialise weights D 1 (i) =1/m For t =1,..., T : Find ht = arg min P j = m D t (i)jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t =4 Set t = Update 12 log(1 t t ) D t+1 (i) = D t(i)exp( t y i h t (x i )) Z t where Z t is normalisation factor Output the final classifier: H(x) =sign TX t h t (x) t=1 training error step 49
50 The AdaBoost Algorithm Given: (x 1,y 1 ),...,(x m,y m ); x i 2 X,y i 2 { 1, +1} Initialise weights D 1 (i) =1/m For t =1,..., T : Find ht = arg min P j = m D t (i)jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t =5 Set t = Update 12 log(1 t t ) D t+1 (i) = D t(i)exp( t y i h t (x i )) Z t where Z t is normalisation factor Output the final classifier: H(x) =sign TX t h t (x) t=1 training error step 50
jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t =6 Set t = Update 12 log(1 t t ) D t+1 (i) = D t(i)exp( t y i h t (x i )) Z t where Z t is normalisation")
51 The AdaBoost Algorithm Given: (x 1,y 1 ),...,(x m,y m ); x i 2 X,y i 2 { 1, +1} Initialise weights D 1 (i) =1/m For t =1,..., T : Find ht = arg min P j = m D t (i)jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t =6 Set t = Update 12 log(1 t t ) D t+1 (i) = D t(i)exp( t y i h t (x i )) Z t where Z t is normalisation factor Output the final classifier: H(x) =sign TX t h t (x) t=1 training error step 51
52 The AdaBoost Algorithm Given: (x 1,y 1 ),...,(x m,y m ); x i 2 X,y i 2 { 1, +1} Initialise weights D 1 (i) =1/m For t =1,..., T : Find ht = arg min P j = m D t (i)jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t =7 Set t = Update 12 log(1 t t ) D t+1 (i) = D t(i)exp( t y i h t (x i )) Z t where Z t is normalisation factor Output the final classifier: H(x) =sign TX t h t (x) t=1 training error step 52
53 The AdaBoost Algorithm Given: (x 1,y 1 ),...,(x m,y m ); x i 2 X,y i 2 { 1, +1} Initialise weights D 1 (i) =1/m For t =1,..., T : Find ht = arg min P j = m D t (i)jy i 6= h j (x i )K h j 2H i=1 If t 1/2 then stop t = 40 Set t = Update 12 log(1 t t ) D t+1 (i) = D t(i)exp( t y i h t (x i )) Z t where Z t is normalisation factor Output the final classifier: H(x) =sign TX t h t (x) t=1 training error step 53

54 Reweigh0ng 54

55 Reweigh0ng 55
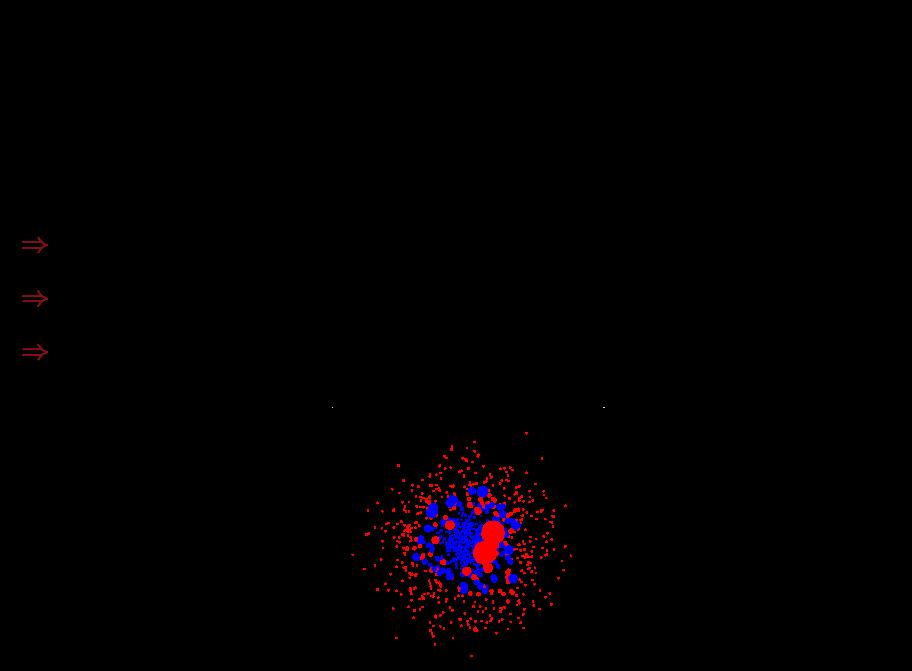

56 Reweigh0ng 56
57 Boos0ng results Digit recogni0on test error training error error # rounds Boos0ng olen (but not always) - - Robust to overfivng Test set error decreases even aler training error is zero [Schapire, 1989] 57
58 Applica0on: Detec0ng Faces Problem: find faces in photograph or movie Weak classifiers: detect light/dark rectangle in image Many clever tricks to make extremely fast and accurate [Viola & Jones] 58
59 Boos0ng vs. Logis0c Regression Logis+c$regression:$ Minimize$log$loss$ Minimize+log+loss+ Boos+ng:$ Minimize+exp+loss+ Minimize$exp$loss$ Define$$ Define++ $ $ $ where$x re+x +predefined+ j $predefined$ where$h e+ t (x)$defined$ +defined+dyna features$(linear$classifier)$ Jointly$op+mize$over$all$ weights$w 0,w 1,w 2, $ $ Define++ Define$ $ dynamically$to$fit$data$$ (not$a$$linear$classifier)$ Weights$α t $learned$per$ itera+on$t$incrementally$ 59
60 Boos0ng vs. Bagging Bagging: Resample data points Weight of each classifier is the same Only variance reduc0on Boos0ng: Reweights data points (modifies their distribu0on) Weight is dependent on classifier s accuracy Both bias and variance reduced learning rule becomes more complex with itera0ons 60
Boos$ng Can we make dumb learners smart?
 Boos$ng Can we make dumb learners smart? Aarti Singh Machine Learning 10-601 Nov 29, 2011 Slides Courtesy: Carlos Guestrin, Freund & Schapire 1 Why boost weak learners? Goal: Automa'cally categorize type
Boos$ng Can we make dumb learners smart? Aarti Singh Machine Learning 10-601 Nov 29, 2011 Slides Courtesy: Carlos Guestrin, Freund & Schapire 1 Why boost weak learners? Goal: Automa'cally categorize type
Voting (Ensemble Methods)
") 1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
Stochastic Gradient Descent
 Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
AdaBoost. Lecturer: Authors: Center for Machine Perception Czech Technical University, Prague
 AdaBoost Lecturer: Jan Šochman Authors: Jan Šochman, Jiří Matas Center for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Motivation Presentation 2/17 AdaBoost with trees
AdaBoost Lecturer: Jan Šochman Authors: Jan Šochman, Jiří Matas Center for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Motivation Presentation 2/17 AdaBoost with trees
CS7267 MACHINE LEARNING
 CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
A Decision Stump. Decision Trees, cont. Boosting. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. October 1 st, 2007
 Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Machine Learning. Ensemble Methods. Manfred Huber
 Machine Learning Ensemble Methods Manfred Huber 2015 1 Bias, Variance, Noise Classification errors have different sources Choice of hypothesis space and algorithm Training set Noise in the data The expected
Machine Learning Ensemble Methods Manfred Huber 2015 1 Bias, Variance, Noise Classification errors have different sources Choice of hypothesis space and algorithm Training set Noise in the data The expected
Boosting: Foundations and Algorithms. Rob Schapire
 Boosting: Foundations and Algorithms Rob Schapire Example: Spam Filtering problem: filter out spam (junk email) gather large collection of examples of spam and non-spam: From: yoav@ucsd.edu Rob, can you
Boosting: Foundations and Algorithms Rob Schapire Example: Spam Filtering problem: filter out spam (junk email) gather large collection of examples of spam and non-spam: From: yoav@ucsd.edu Rob, can you
VBM683 Machine Learning
 VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
Ensemble Methods for Machine Learning
 Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
Data Mining und Maschinelles Lernen
 Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Ensemble Methods. Charles Sutton Data Mining and Exploration Spring Friday, 27 January 12
 Ensemble Methods Charles Sutton Data Mining and Exploration Spring 2012 Bias and Variance Consider a regression problem Y = f(x)+ N(0, 2 ) With an estimate regression function ˆf, e.g., ˆf(x) =w > x Suppose
Ensemble Methods Charles Sutton Data Mining and Exploration Spring 2012 Bias and Variance Consider a regression problem Y = f(x)+ N(0, 2 ) With an estimate regression function ˆf, e.g., ˆf(x) =w > x Suppose
Boosting. Acknowledgment Slides are based on tutorials from Robert Schapire and Gunnar Raetsch
 . Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
. Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
Learning with multiple models. Boosting.
 CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
Background. Adaptive Filters and Machine Learning. Bootstrap. Combining models. Boosting and Bagging. Poltayev Rassulzhan
 Adaptive Filters and Machine Learning Boosting and Bagging Background Poltayev Rassulzhan rasulzhan@gmail.com Resampling Bootstrap We are using training set and different subsets in order to validate results
Adaptive Filters and Machine Learning Boosting and Bagging Background Poltayev Rassulzhan rasulzhan@gmail.com Resampling Bootstrap We are using training set and different subsets in order to validate results
An overview of Boosting. Yoav Freund UCSD
 An overview of Boosting Yoav Freund UCSD Plan of talk Generative vs. non-generative modeling Boosting Alternating decision trees Boosting and over-fitting Applications 2 Toy Example Computer receives telephone
An overview of Boosting Yoav Freund UCSD Plan of talk Generative vs. non-generative modeling Boosting Alternating decision trees Boosting and over-fitting Applications 2 Toy Example Computer receives telephone
A Brief Introduction to Adaboost
 A Brief Introduction to Adaboost Hongbo Deng 6 Feb, 2007 Some of the slides are borrowed from Derek Hoiem & Jan ˇSochman. 1 Outline Background Adaboost Algorithm Theory/Interpretations 2 What s So Good
A Brief Introduction to Adaboost Hongbo Deng 6 Feb, 2007 Some of the slides are borrowed from Derek Hoiem & Jan ˇSochman. 1 Outline Background Adaboost Algorithm Theory/Interpretations 2 What s So Good
COMP 562: Introduction to Machine Learning
 COMP 562: Introduction to Machine Learning Lecture 20 : Support Vector Machines, Kernels Mahmoud Mostapha 1 Department of Computer Science University of North Carolina at Chapel Hill mahmoudm@cs.unc.edu
COMP 562: Introduction to Machine Learning Lecture 20 : Support Vector Machines, Kernels Mahmoud Mostapha 1 Department of Computer Science University of North Carolina at Chapel Hill mahmoudm@cs.unc.edu
Outline: Ensemble Learning. Ensemble Learning. The Wisdom of Crowds. The Wisdom of Crowds - Really? Crowd wiser than any individual
 Outline: Ensemble Learning We will describe and investigate algorithms to Ensemble Learning Lecture 10, DD2431 Machine Learning A. Maki, J. Sullivan October 2014 train weak classifiers/regressors and how
Outline: Ensemble Learning We will describe and investigate algorithms to Ensemble Learning Lecture 10, DD2431 Machine Learning A. Maki, J. Sullivan October 2014 train weak classifiers/regressors and how
The AdaBoost algorithm =1/n for i =1,...,n 1) At the m th iteration we find (any) classifier h(x; ˆθ m ) for which the weighted classification error m
 At the m th iteration we find (any) classifier h(x; ˆθ m ) for which the weighted classification error m") ) Set W () i The AdaBoost algorithm =1/n for i =1,...,n 1) At the m th iteration we find (any) classifier h(x; ˆθ m ) for which the weighted classification error m m =.5 1 n W (m 1) i y i h(x i ; 2 ˆθ
) Set W () i The AdaBoost algorithm =1/n for i =1,...,n 1) At the m th iteration we find (any) classifier h(x; ˆθ m ) for which the weighted classification error m m =.5 1 n W (m 1) i y i h(x i ; 2 ˆθ
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring /
 Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Boosting & Deep Learning
 Boosting & Deep Learning Ensemble Learning n So far learning methods that learn a single hypothesis, chosen form a hypothesis space that is used to make predictions n Ensemble learning à select a collection
Boosting & Deep Learning Ensemble Learning n So far learning methods that learn a single hypothesis, chosen form a hypothesis space that is used to make predictions n Ensemble learning à select a collection
Boosting. CAP5610: Machine Learning Instructor: Guo-Jun Qi
 Boosting CAP5610: Machine Learning Instructor: Guo-Jun Qi Weak classifiers Weak classifiers Decision stump one layer decision tree Naive Bayes A classifier without feature correlations Linear classifier
Boosting CAP5610: Machine Learning Instructor: Guo-Jun Qi Weak classifiers Weak classifiers Decision stump one layer decision tree Naive Bayes A classifier without feature correlations Linear classifier
Variance Reduction and Ensemble Methods
 Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis
Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis
Learning Ensembles. 293S T. Yang. UCSB, 2017.
 Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
Ensemble Methods: Jay Hyer
 Ensemble Methods: committee-based learning Jay Hyer linkedin.com/in/jayhyer @adatahead Overview Why Ensemble Learning? What is learning? How is ensemble learning different? Boosting Weak and Strong Learners
Ensemble Methods: committee-based learning Jay Hyer linkedin.com/in/jayhyer @adatahead Overview Why Ensemble Learning? What is learning? How is ensemble learning different? Boosting Weak and Strong Learners
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Decision Trees. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Decision Trees Tobias Scheffer Decision Trees One of many applications: credit risk Employed longer than 3 months Positive credit
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Decision Trees Tobias Scheffer Decision Trees One of many applications: credit risk Employed longer than 3 months Positive credit
Hierarchical Boosting and Filter Generation
 January 29, 2007 Plan Combining Classifiers Boosting Neural Network Structure of AdaBoost Image processing Hierarchical Boosting Hierarchical Structure Filters Combining Classifiers Combining Classifiers
January 29, 2007 Plan Combining Classifiers Boosting Neural Network Structure of AdaBoost Image processing Hierarchical Boosting Hierarchical Structure Filters Combining Classifiers Combining Classifiers
Learning theory. Ensemble methods. Boosting. Boosting: history
 Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Data Warehousing & Data Mining
 13. Meta-Algorithms for Classification Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 13.
13. Meta-Algorithms for Classification Data Warehousing & Data Mining Wolf-Tilo Balke Silviu Homoceanu Institut für Informationssysteme Technische Universität Braunschweig http://www.ifis.cs.tu-bs.de 13.
CSE 151 Machine Learning. Instructor: Kamalika Chaudhuri
 CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Ensemble Learning How to combine multiple classifiers into a single one Works well if the classifiers are complementary This class: two types of
CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Ensemble Learning How to combine multiple classifiers into a single one Works well if the classifiers are complementary This class: two types of
Ensembles. Léon Bottou COS 424 4/8/2010
 Ensembles Léon Bottou COS 424 4/8/2010 Readings T. G. Dietterich (2000) Ensemble Methods in Machine Learning. R. E. Schapire (2003): The Boosting Approach to Machine Learning. Sections 1,2,3,4,6. Léon
Ensembles Léon Bottou COS 424 4/8/2010 Readings T. G. Dietterich (2000) Ensemble Methods in Machine Learning. R. E. Schapire (2003): The Boosting Approach to Machine Learning. Sections 1,2,3,4,6. Léon
Bias-Variance in Machine Learning
 Bias-Variance in Machine Learning Bias-Variance: Outline Underfitting/overfitting: Why are complex hypotheses bad? Simple example of bias/variance Error as bias+variance for regression brief comments on
Bias-Variance in Machine Learning Bias-Variance: Outline Underfitting/overfitting: Why are complex hypotheses bad? Simple example of bias/variance Error as bias+variance for regression brief comments on
Decision Trees: Overfitting
 Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
Introduction to Boosting and Joint Boosting
 Introduction to Boosting and Learning Systems Group, Caltech 2005/04/26, Presentation in EE150 Boosting and Outline Introduction to Boosting 1 Introduction to Boosting Intuition of Boosting Adaptive Boosting
Introduction to Boosting and Learning Systems Group, Caltech 2005/04/26, Presentation in EE150 Boosting and Outline Introduction to Boosting 1 Introduction to Boosting Intuition of Boosting Adaptive Boosting
Bias/variance tradeoff, Model assessment and selec+on
 Applied induc+ve learning Bias/variance tradeoff, Model assessment and selec+on Pierre Geurts Department of Electrical Engineering and Computer Science University of Liège October 29, 2012 1 Supervised
Applied induc+ve learning Bias/variance tradeoff, Model assessment and selec+on Pierre Geurts Department of Electrical Engineering and Computer Science University of Liège October 29, 2012 1 Supervised
CS229 Supplemental Lecture notes
 CS229 Supplemental Lecture notes John Duchi 1 Boosting We have seen so far how to solve classification (and other) problems when we have a data representation already chosen. We now talk about a procedure,
CS229 Supplemental Lecture notes John Duchi 1 Boosting We have seen so far how to solve classification (and other) problems when we have a data representation already chosen. We now talk about a procedure,
Linear Regression with mul2ple variables. Mul2ple features. Machine Learning
 Linear Regression with mul2ple variables Mul2ple features Machine Learning Mul4ple features (variables). Size (feet 2 ) Price ($1000) 2104 460 1416 232 1534 315 852 178 Mul4ple features (variables). Size
Linear Regression with mul2ple variables Mul2ple features Machine Learning Mul4ple features (variables). Size (feet 2 ) Price ($1000) 2104 460 1416 232 1534 315 852 178 Mul4ple features (variables). Size
COMS 4721: Machine Learning for Data Science Lecture 13, 3/2/2017
 COMS 4721: Machine Learning for Data Science Lecture 13, 3/2/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University BOOSTING Robert E. Schapire and Yoav
COMS 4721: Machine Learning for Data Science Lecture 13, 3/2/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University BOOSTING Robert E. Schapire and Yoav
The Boosting Approach to. Machine Learning. Maria-Florina Balcan 10/31/2016
 The Boosting Approach to Machine Learning Maria-Florina Balcan 10/31/2016 Boosting General method for improving the accuracy of any given learning algorithm. Works by creating a series of challenge datasets
The Boosting Approach to Machine Learning Maria-Florina Balcan 10/31/2016 Boosting General method for improving the accuracy of any given learning algorithm. Works by creating a series of challenge datasets
Big Data Analytics. Special Topics for Computer Science CSE CSE Feb 24
 Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
What makes good ensemble? CS789: Machine Learning and Neural Network. Introduction. More on diversity
 What makes good ensemble? CS789: Machine Learning and Neural Network Ensemble methods Jakramate Bootkrajang Department of Computer Science Chiang Mai University 1. A member of the ensemble is accurate.
What makes good ensemble? CS789: Machine Learning and Neural Network Ensemble methods Jakramate Bootkrajang Department of Computer Science Chiang Mai University 1. A member of the ensemble is accurate.
Midterm Exam Solutions, Spring 2007
 1-71 Midterm Exam Solutions, Spring 7 1. Personal info: Name: Andrew account: E-mail address:. There should be 16 numbered pages in this exam (including this cover sheet). 3. You can use any material you
1-71 Midterm Exam Solutions, Spring 7 1. Personal info: Name: Andrew account: E-mail address:. There should be 16 numbered pages in this exam (including this cover sheet). 3. You can use any material you
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
Chapter 14 Combining Models
 Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
M1 Apprentissage. Michèle Sebag Benoit Barbot LRI LSV. 13 janvier 2014
 M1 Apprentissage Michèle Sebag Benoit Barbot LRI LSV 13 janvier 2014 Empirical assessment Motivations Which algorithm for which data? Which hyper-parameters? Caruana et al, 08 Crossing the chasm Note on
M1 Apprentissage Michèle Sebag Benoit Barbot LRI LSV 13 janvier 2014 Empirical assessment Motivations Which algorithm for which data? Which hyper-parameters? Caruana et al, 08 Crossing the chasm Note on
Statistics and learning: Big Data
 Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees
Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees
CSE446: Linear Regression Regulariza5on Bias / Variance Tradeoff Winter 2015
 CSE446: Linear Regression Regulariza5on Bias / Variance Tradeoff Winter 2015 Luke ZeElemoyer Slides adapted from Carlos Guestrin Predic5on of con5nuous variables Billionaire says: Wait, that s not what
CSE446: Linear Regression Regulariza5on Bias / Variance Tradeoff Winter 2015 Luke ZeElemoyer Slides adapted from Carlos Guestrin Predic5on of con5nuous variables Billionaire says: Wait, that s not what
Bagging. Ryan Tibshirani Data Mining: / April Optional reading: ISL 8.2, ESL 8.7
 Bagging Ryan Tibshirani Data Mining: 36-462/36-662 April 23 2013 Optional reading: ISL 8.2, ESL 8.7 1 Reminder: classification trees Our task is to predict the class label y {1,... K} given a feature vector
Bagging Ryan Tibshirani Data Mining: 36-462/36-662 April 23 2013 Optional reading: ISL 8.2, ESL 8.7 1 Reminder: classification trees Our task is to predict the class label y {1,... K} given a feature vector
Announcements Kevin Jamieson
 Announcements My office hours TODAY 3:30 pm - 4:30 pm CSE 666 Poster Session - Pick one First poster session TODAY 4:30 pm - 7:30 pm CSE Atrium Second poster session December 12 4:30 pm - 7:30 pm CSE Atrium
Announcements My office hours TODAY 3:30 pm - 4:30 pm CSE 666 Poster Session - Pick one First poster session TODAY 4:30 pm - 7:30 pm CSE Atrium Second poster session December 12 4:30 pm - 7:30 pm CSE Atrium
Recitation 9. Gradient Boosting. Brett Bernstein. March 30, CDS at NYU. Brett Bernstein (CDS at NYU) Recitation 9 March 30, / 14
 Recitation 9 March 30, / 14") Brett Bernstein CDS at NYU March 30, 2017 Brett Bernstein (CDS at NYU) Recitation 9 March 30, 2017 1 / 14 Initial Question Intro Question Question Suppose 10 different meteorologists have produced functions
Brett Bernstein CDS at NYU March 30, 2017 Brett Bernstein (CDS at NYU) Recitation 9 March 30, 2017 1 / 14 Initial Question Intro Question Question Suppose 10 different meteorologists have produced functions
Introduction to Machine Learning Lecture 11. Mehryar Mohri Courant Institute and Google Research
 Introduction to Machine Learning Lecture 11 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Boosting Mehryar Mohri - Introduction to Machine Learning page 2 Boosting Ideas Main idea:
Introduction to Machine Learning Lecture 11 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Boosting Mehryar Mohri - Introduction to Machine Learning page 2 Boosting Ideas Main idea:
Chapter 18. Decision Trees and Ensemble Learning. Recall: Learning Decision Trees
 CSE 473 Chapter 18 Decision Trees and Ensemble Learning Recall: Learning Decision Trees Example: When should I wait for a table at a restaurant? Attributes (features) relevant to Wait? decision: 1. Alternate:
CSE 473 Chapter 18 Decision Trees and Ensemble Learning Recall: Learning Decision Trees Example: When should I wait for a table at a restaurant? Attributes (features) relevant to Wait? decision: 1. Alternate:
Machine Learning 2nd Edi7on
 Lecture Slides for INTRODUCTION TO Machine Learning 2nd Edi7on CHAPTER 9: Decision Trees ETHEM ALPAYDIN The MIT Press, 2010 Edited and expanded for CS 4641 by Chris Simpkins alpaydin@boun.edu.tr h1p://www.cmpe.boun.edu.tr/~ethem/i2ml2e
Lecture Slides for INTRODUCTION TO Machine Learning 2nd Edi7on CHAPTER 9: Decision Trees ETHEM ALPAYDIN The MIT Press, 2010 Edited and expanded for CS 4641 by Chris Simpkins alpaydin@boun.edu.tr h1p://www.cmpe.boun.edu.tr/~ethem/i2ml2e
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
Analysis of the Performance of AdaBoost.M2 for the Simulated Digit-Recognition-Example
 Analysis of the Performance of AdaBoost.M2 for the Simulated Digit-Recognition-Example Günther Eibl and Karl Peter Pfeiffer Institute of Biostatistics, Innsbruck, Austria guenther.eibl@uibk.ac.at Abstract.
Analysis of the Performance of AdaBoost.M2 for the Simulated Digit-Recognition-Example Günther Eibl and Karl Peter Pfeiffer Institute of Biostatistics, Innsbruck, Austria guenther.eibl@uibk.ac.at Abstract.
Ensemble learning 11/19/13. The wisdom of the crowds. Chapter 11. Ensemble methods. Ensemble methods
 The wisdom of the crowds Ensemble learning Sir Francis Galton discovered in the early 1900s that a collection of educated guesses can add up to very accurate predictions! Chapter 11 The paper in which
The wisdom of the crowds Ensemble learning Sir Francis Galton discovered in the early 1900s that a collection of educated guesses can add up to very accurate predictions! Chapter 11 The paper in which
CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on
 CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on Professor Wei-Min Shen Week 13.1 and 13.2 1 Status Check Extra credits? Announcement Evalua/on process will start soon
CSCI 360 Introduc/on to Ar/ficial Intelligence Week 2: Problem Solving and Op/miza/on Professor Wei-Min Shen Week 13.1 and 13.2 1 Status Check Extra credits? Announcement Evalua/on process will start soon
TDT4173 Machine Learning
 TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
TDT4173 Machine Learning Lecture 3 Bagging & Boosting + SVMs Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline 1 Ensemble-methods
Empirical Risk Minimization Algorithms
 Empirical Risk Minimization Algorithms Tirgul 2 Part I November 2016 Reminder Domain set, X : the set of objects that we wish to label. Label set, Y : the set of possible labels. A prediction rule, h:
Empirical Risk Minimization Algorithms Tirgul 2 Part I November 2016 Reminder Domain set, X : the set of objects that we wish to label. Label set, Y : the set of possible labels. A prediction rule, h:
TDT4173 Machine Learning
 TDT4173 Machine Learning Lecture 9 Learning Classifiers: Bagging & Boosting Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline
TDT4173 Machine Learning Lecture 9 Learning Classifiers: Bagging & Boosting Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline
Ensembles of Classifiers.
 Ensembles of Classifiers www.biostat.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts ensemble bootstrap sample bagging boosting random forests error correcting
Ensembles of Classifiers www.biostat.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts ensemble bootstrap sample bagging boosting random forests error correcting
Learning Theory, Overfi1ng, Bias Variance Decomposi9on
 Learning Theory, Overfi1ng, Bias Variance Decomposi9on Machine Learning 10-601B Seyoung Kim Many of these slides are derived from Tom Mitchell, Ziv- 1 Bar Joseph. Thanks! Any(!) learner that outputs a
Learning Theory, Overfi1ng, Bias Variance Decomposi9on Machine Learning 10-601B Seyoung Kim Many of these slides are derived from Tom Mitchell, Ziv- 1 Bar Joseph. Thanks! Any(!) learner that outputs a
Combining Classifiers
 Cobining Classifiers Generic ethods of generating and cobining ultiple classifiers Bagging Boosting References: Duda, Hart & Stork, pg 475-480. Hastie, Tibsharini, Friedan, pg 246-256 and Chapter 10. http://www.boosting.org/
Cobining Classifiers Generic ethods of generating and cobining ultiple classifiers Bagging Boosting References: Duda, Hart & Stork, pg 475-480. Hastie, Tibsharini, Friedan, pg 246-256 and Chapter 10. http://www.boosting.org/
Decision Trees Lecture 12
 Decision Trees Lecture 12 David Sontag New York University Slides adapted from Luke Zettlemoyer, Carlos Guestrin, and Andrew Moore Machine Learning in the ER Physician documentation Triage Information
Decision Trees Lecture 12 David Sontag New York University Slides adapted from Luke Zettlemoyer, Carlos Guestrin, and Andrew Moore Machine Learning in the ER Physician documentation Triage Information
Dr. Ulas Bagci
 CAP5415-Computer Vision Lecture 18-Face Recogni;on Dr. Ulas Bagci bagci@ucf.edu 1 Lecture 18 Face Detec;on and Recogni;on Detec;on Recogni;on Sally 2 Why wasn t Massachusetss Bomber iden6fied by the Massachuse8s
CAP5415-Computer Vision Lecture 18-Face Recogni;on Dr. Ulas Bagci bagci@ucf.edu 1 Lecture 18 Face Detec;on and Recogni;on Detec;on Recogni;on Sally 2 Why wasn t Massachusetss Bomber iden6fied by the Massachuse8s
CS 484 Data Mining. Classification 7. Some slides are from Professor Padhraic Smyth at UC Irvine
 CS 484 Data Mining Classification 7 Some slides are from Professor Padhraic Smyth at UC Irvine Bayesian Belief networks Conditional independence assumption of Naïve Bayes classifier is too strong. Allows
CS 484 Data Mining Classification 7 Some slides are from Professor Padhraic Smyth at UC Irvine Bayesian Belief networks Conditional independence assumption of Naïve Bayes classifier is too strong. Allows
10701/15781 Machine Learning, Spring 2007: Homework 2
 070/578 Machine Learning, Spring 2007: Homework 2 Due: Wednesday, February 2, beginning of the class Instructions There are 4 questions on this assignment The second question involves coding Do not attach
070/578 Machine Learning, Spring 2007: Homework 2 Due: Wednesday, February 2, beginning of the class Instructions There are 4 questions on this assignment The second question involves coding Do not attach
CS 6140: Machine Learning Spring What We Learned Last Week 2/26/16
 Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Sign
Logis@cs CS 6140: Machine Learning Spring 2016 Instructor: Lu Wang College of Computer and Informa@on Science Northeastern University Webpage: www.ccs.neu.edu/home/luwang Email: luwang@ccs.neu.edu Sign
Lecture 8. Instructor: Haipeng Luo
 Lecture 8 Instructor: Haipeng Luo Boosting and AdaBoost In this lecture we discuss the connection between boosting and online learning. Boosting is not only one of the most fundamental theories in machine
Lecture 8 Instructor: Haipeng Luo Boosting and AdaBoost In this lecture we discuss the connection between boosting and online learning. Boosting is not only one of the most fundamental theories in machine
COMS 4771 Lecture Boosting 1 / 16
 COMS 4771 Lecture 12 1. Boosting 1 / 16 Boosting What is boosting? Boosting: Using a learning algorithm that provides rough rules-of-thumb to construct a very accurate predictor. 3 / 16 What is boosting?
COMS 4771 Lecture 12 1. Boosting 1 / 16 Boosting What is boosting? Boosting: Using a learning algorithm that provides rough rules-of-thumb to construct a very accurate predictor. 3 / 16 What is boosting?
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers
 Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c /9/9 page 331 le-tex
 Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c15 2013/9/9 page 331 le-tex 331 15 Ensemble Learning The expression ensemble learning refers to a broad class
Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c15 2013/9/9 page 331 le-tex 331 15 Ensemble Learning The expression ensemble learning refers to a broad class
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
Large-Margin Thresholded Ensembles for Ordinal Regression
 Large-Margin Thresholded Ensembles for Ordinal Regression Hsuan-Tien Lin (accepted by ALT 06, joint work with Ling Li) Learning Systems Group, Caltech Workshop Talk in MLSS 2006, Taipei, Taiwan, 07/25/2006
Large-Margin Thresholded Ensembles for Ordinal Regression Hsuan-Tien Lin (accepted by ALT 06, joint work with Ling Li) Learning Systems Group, Caltech Workshop Talk in MLSS 2006, Taipei, Taiwan, 07/25/2006
Discriminative v. generative
 Discriminative v. generative Naive Bayes 2 Naive Bayes P (x ij,y i )= Y i P (y i ) Y j P (x ij y i ) P (y i =+)=p MLE: max P (x ij,y i ) a j,b j,p p = 1 N P [yi =+] P (x ij =1 y i = ) = a j P (x ij =1
Discriminative v. generative Naive Bayes 2 Naive Bayes P (x ij,y i )= Y i P (y i ) Y j P (x ij y i ) P (y i =+)=p MLE: max P (x ij,y i ) a j,b j,p p = 1 N P [yi =+] P (x ij =1 y i = ) = a j P (x ij =1
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 8. Chapter 8. Classification: Basic Concepts
 Chapter 8. Chapter 8. Classification: Basic Concepts") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 8 1 Chapter 8. Classification: Basic Concepts Classification: Basic Concepts Decision Tree Induction Bayes Classification Methods Rule-Based Classification
2 Upper-bound of Generalization Error of AdaBoost
 COS 511: Theoretical Machine Learning Lecturer: Rob Schapire Lecture #10 Scribe: Haipeng Zheng March 5, 2008 1 Review of AdaBoost Algorithm Here is the AdaBoost Algorithm: input: (x 1,y 1 ),...,(x m,y
COS 511: Theoretical Machine Learning Lecturer: Rob Schapire Lecture #10 Scribe: Haipeng Zheng March 5, 2008 1 Review of AdaBoost Algorithm Here is the AdaBoost Algorithm: input: (x 1,y 1 ),...,(x m,y
10-701/ Machine Learning - Midterm Exam, Fall 2010
 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Ensembles Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique Fédérale de Lausanne
Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Ensembles Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique Fédérale de Lausanne
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Boosting: Algorithms and Applications
 Boosting: Algorithms and Applications Lecture 11, ENGN 4522/6520, Statistical Pattern Recognition and Its Applications in Computer Vision ANU 2 nd Semester, 2008 Chunhua Shen, NICTA/RSISE Boosting Definition
Boosting: Algorithms and Applications Lecture 11, ENGN 4522/6520, Statistical Pattern Recognition and Its Applications in Computer Vision ANU 2 nd Semester, 2008 Chunhua Shen, NICTA/RSISE Boosting Definition
Theory and Applications of Boosting. Rob Schapire
 Theory and Applications of Boosting Rob Schapire Example: How May I Help You? [Gorin et al.] goal: automatically categorize type of call requested by phone customer (Collect, CallingCard, PersonToPerson,
Theory and Applications of Boosting Rob Schapire Example: How May I Help You? [Gorin et al.] goal: automatically categorize type of call requested by phone customer (Collect, CallingCard, PersonToPerson,
Dan Roth 461C, 3401 Walnut
 CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
CIS 519/419 Applied Machine Learning www.seas.upenn.edu/~cis519 Dan Roth danroth@seas.upenn.edu http://www.cis.upenn.edu/~danroth/ 461C, 3401 Walnut Slides were created by Dan Roth (for CIS519/419 at Penn
Lecture 13: Ensemble Methods
 Lecture 13: Ensemble Methods Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu 1 / 71 Outline 1 Bootstrap
Lecture 13: Ensemble Methods Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu 1 / 71 Outline 1 Bootstrap
Machine Learning, Midterm Exam
 10-601 Machine Learning, Midterm Exam Instructors: Tom Mitchell, Ziv Bar-Joseph Wednesday 12 th December, 2012 There are 9 questions, for a total of 100 points. This exam has 20 pages, make sure you have
10-601 Machine Learning, Midterm Exam Instructors: Tom Mitchell, Ziv Bar-Joseph Wednesday 12 th December, 2012 There are 9 questions, for a total of 100 points. This exam has 20 pages, make sure you have
Adaptive Boosting of Neural Networks for Character Recognition
 Adaptive Boosting of Neural Networks for Character Recognition Holger Schwenk Yoshua Bengio Dept. Informatique et Recherche Opérationnelle Université de Montréal, Montreal, Qc H3C-3J7, Canada fschwenk,bengioyg@iro.umontreal.ca
Adaptive Boosting of Neural Networks for Character Recognition Holger Schwenk Yoshua Bengio Dept. Informatique et Recherche Opérationnelle Université de Montréal, Montreal, Qc H3C-3J7, Canada fschwenk,bengioyg@iro.umontreal.ca
SPECIAL INVITED PAPER
 The Annals of Statistics 2000, Vol. 28, No. 2, 337 407 SPECIAL INVITED PAPER ADDITIVE LOGISTIC REGRESSION: A STATISTICAL VIEW OF BOOSTING By Jerome Friedman, 1 Trevor Hastie 2 3 and Robert Tibshirani 2
The Annals of Statistics 2000, Vol. 28, No. 2, 337 407 SPECIAL INVITED PAPER ADDITIVE LOGISTIC REGRESSION: A STATISTICAL VIEW OF BOOSTING By Jerome Friedman, 1 Trevor Hastie 2 3 and Robert Tibshirani 2
Boosting. Ryan Tibshirani Data Mining: / April Optional reading: ISL 8.2, ESL , 10.7, 10.13
 Boosting Ryan Tibshirani Data Mining: 36-462/36-662 April 25 2013 Optional reading: ISL 8.2, ESL 10.1 10.4, 10.7, 10.13 1 Reminder: classification trees Suppose that we are given training data (x i, y
Boosting Ryan Tibshirani Data Mining: 36-462/36-662 April 25 2013 Optional reading: ISL 8.2, ESL 10.1 10.4, 10.7, 10.13 1 Reminder: classification trees Suppose that we are given training data (x i, y
Bagging and Other Ensemble Methods
 Bagging and Other Ensemble Methods Sargur N. Srihari srihari@buffalo.edu 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties as Constrained Optimization 3. Regularization and Underconstrained
Bagging and Other Ensemble Methods Sargur N. Srihari srihari@buffalo.edu 1 Regularization Strategies 1. Parameter Norm Penalties 2. Norm Penalties as Constrained Optimization 3. Regularization and Underconstrained
Classification: The rest of the story
 U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
A Gentle Introduction to Gradient Boosting. Cheng Li College of Computer and Information Science Northeastern University
 A Gentle Introduction to Gradient Boosting Cheng Li chengli@ccs.neu.edu College of Computer and Information Science Northeastern University Gradient Boosting a powerful machine learning algorithm it can
A Gentle Introduction to Gradient Boosting Cheng Li chengli@ccs.neu.edu College of Computer and Information Science Northeastern University Gradient Boosting a powerful machine learning algorithm it can
Robotics 2. AdaBoost for People and Place Detection. Kai Arras, Cyrill Stachniss, Maren Bennewitz, Wolfram Burgard
 Robotics 2 AdaBoost for People and Place Detection Kai Arras, Cyrill Stachniss, Maren Bennewitz, Wolfram Burgard v.1.1, Kai Arras, Jan 12, including material by Luciano Spinello and Oscar Martinez Mozos
Robotics 2 AdaBoost for People and Place Detection Kai Arras, Cyrill Stachniss, Maren Bennewitz, Wolfram Burgard v.1.1, Kai Arras, Jan 12, including material by Luciano Spinello and Oscar Martinez Mozos
Monte Carlo Theory as an Explanation of Bagging and Boosting
 Monte Carlo Theory as an Explanation of Bagging and Boosting Roberto Esposito Università di Torino C.so Svizzera 185, Torino, Italy esposito@di.unito.it Lorenza Saitta Università del Piemonte Orientale
Monte Carlo Theory as an Explanation of Bagging and Boosting Roberto Esposito Università di Torino C.so Svizzera 185, Torino, Italy esposito@di.unito.it Lorenza Saitta Università del Piemonte Orientale
1 Handling of Continuous Attributes in C4.5. Algorithm
 .. Spring 2009 CSC 466: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Classification/Supervised Learning Potpourri Contents 1. C4.5. and continuous attributes: incorporating continuous
.. Spring 2009 CSC 466: Knowledge Discovery from Data Alexander Dekhtyar.. Data Mining: Classification/Supervised Learning Potpourri Contents 1. C4.5. and continuous attributes: incorporating continuous
BAGGING PREDICTORS AND RANDOM FOREST
 BAGGING PREDICTORS AND RANDOM FOREST DANA KANER M.SC. SEMINAR IN STATISTICS, MAY 2017 BAGIGNG PREDICTORS / LEO BREIMAN, 1996 RANDOM FORESTS / LEO BREIMAN, 2001 THE ELEMENTS OF STATISTICAL LEARNING (CHAPTERS
BAGGING PREDICTORS AND RANDOM FOREST DANA KANER M.SC. SEMINAR IN STATISTICS, MAY 2017 BAGIGNG PREDICTORS / LEO BREIMAN, 1996 RANDOM FORESTS / LEO BREIMAN, 2001 THE ELEMENTS OF STATISTICAL LEARNING (CHAPTERS
PDEEC Machine Learning 2016/17
 PDEEC Machine Learning 2016/17 Lecture - Model assessment, selection and Ensemble Jaime S. Cardoso jaime.cardoso@inesctec.pt INESC TEC and Faculdade Engenharia, Universidade do Porto Nov. 07, 2017 1 /
PDEEC Machine Learning 2016/17 Lecture - Model assessment, selection and Ensemble Jaime S. Cardoso jaime.cardoso@inesctec.pt INESC TEC and Faculdade Engenharia, Universidade do Porto Nov. 07, 2017 1 /