Bias-Variance in Machine Learning
|
|
|
- Marjory Sanders
- 6 years ago
- Views:
Transcription
1 Bias-Variance in Machine Learning
2 Bias-Variance: Outline Underfitting/overfitting: Why are complex hypotheses bad? Simple example of bias/variance Error as bias+variance for regression brief comments on how it extends to classification Measuring bias, variance and error Bagging - a way to reduce variance Bias-variance for classification



3 Bias/Variance is a Way to Understand Overfitting and Underfitting high error too simple too complex Error/Loss on an unseen test set D test Error/Loss on training set D train simple classifier complex classifier 3
4 Bias-Variance: An Example
5 Example Tom Dietterich, Oregon St
6 Example Tom Dietterich, Oregon St Same experiment, repeated: with 50 samples of 20 points each
 è Error 1 Fix: more expressive")

7 noise is similar to error 1 The true function f can t be fit perfectly with hypotheses from our class H (lines) è Error 1 Fix: more expressive set of hypotheses H We don t get the best hypothesis from H because of noise/small sample size è Error 2 Fix: less expressive set of hypotheses H
8 Bias-Variance Decomposition: Regression
9 Bias and variance for regression For regression, we can easily decompose the error of the learned model into two parts: bias (error 1) and variance (error 2) Bias: the class of models can t fit the data. Fix: a more expressive model class. Variance: the class of models could fit the data, but doesn t because it s hard to fit. Fix: a less expressive model class.
10 Bias Variance decomposition of error E {( ( ) ( )) } 2 f x +ε h D, ε D x dataset and noise true function Fix test case x, then do this experiment: 1. Draw size n sample D=(x 1,y 1 ),.(x n,y n ) 2. Train linear regressor h D using D 3. Draw one test example (x, f(x)+ε) learned from D 4. Measure squared error of h D on that example x What s the expected error? 10 noise
11 Bias Variance decomposition of error Notation - to simplify this f f (x)+ε yˆ = yˆ D h D ( x) E { D,ε ( f (x)+ε h D (x)) 2 } dataset and noise true function noise learned from D h E D { h ( x)} D long-term expectation of learner s prediction on this x averaged over many data sets D 11
12 Bias Variance decomposition of error E { D,ε ( f ŷ) 2 } = E { ([ f h]+[h ŷ] ) 2 } = E { [ f h] 2 +[h ŷ] 2 + 2[ f h][h ŷ] } = E { [ f h] 2 +[h ŷ] 2 + 2[ fh fŷ h 2 + hŷ] } h ED{ hd ( x)} yˆ = yˆ D hd ( x) f f (x)+ε = E[( f h) 2 ]+ E[(h ŷ) 2 ]+ 2( E[ fh] E[ fŷ] E[h 2 ]+ E[hŷ] ) E D,ε {( f (x)+ε)* E D { h D (x)}} { } = E D,ε ( f (x)+ε)* h D (x) { { }} E D,ε E D { h D (x)}* E D h D (x) { } = E D,ε E D { h D (x)}* h D (x)
13 Bias Variance decomposition of error E { D,ε ( f ŷ) 2 } = E { ([ f h]+[h ŷ] ) 2 } = E { [ f h] 2 +[h ŷ] 2 + 2[ f h][h ŷ] } = E[( f h) 2 ]+ E[(h ŷ) 2 ] h ED{ hd ( x)} yˆ = yˆ D hd ( x) f f (x)+ε Squared difference between best possible prediction for x, f(x), and our long-term expectation for what the learner will do if we averaged over many datasets D, E D [h D (x)] 13 BIAS 2 VARIANCE Squared difference btwn our longterm expectation for the learners performance, E D [h D (x)], and what we expect in a representative run on a dataset D (hat y)
14 x=5 variance bias
15 Bias-variance decomposition This is something real that you can (approximately) measure experimentally if you have synthetic data Different learners and model classes have different tradeoffs large bias/small variance: few features, highly regularized, highly pruned decision trees, large-k k- NN small bias/high variance: many features, less regularization, unpruned trees, small-k k-nn
16 Bias-Variance Decomposition: Classification
17 A generalization of bias-variance decomposition to other loss functions Arbitrary real-valued loss L(y,y ) But L(y,y )=L(y,y), L(y,y)=0, and L(y,y )!=0 if y!=y Define optimal prediction : y* = argmin y L(t,y ) Define main prediction of learner y m =y m,d = argmin y E D {L(y,y )} Define bias of learner : Bias(x)=L(y*,y m ) Define variance of learner Var(x)=E D [L(y m,y)] Define noise for x : N(x) = E t [L(t,y*)] m= D Claim: E D,t [L(t,y) = c 1 N(x)+Bias(x)+c 2 Var(x) where c 1 =Pr D [y=y*] - 1 c 2 =1 if y m =y*, -1 else For 0/1 loss, the main prediction is the most common class predicted by h D (x), weighting h s by Pr(D) Domingos, A Unified Bias-Variance Decomposition and its Applications, ICML 2000
18 Bias and variance For classification, we can also decompose the error of a learned classifier into two terms: bias and variance Bias: the class of models can t fit the data. Fix: a more expressive model class. Variance: the class of models could fit the data, but doesn t because it s hard to fit. Fix: a less expressive model class.
19 Bias-Variance Decomposition: Measuring
20 Bias-variance decomposition This is something real that you can (approximately) measure experimentally if you have synthetic data or if you re clever You need to somehow approximate E D {h D (x)} I.e., construct many variants of the dataset D
21 Background: Bootstrap sampling Input: dataset D Output: many variants of D: D 1,,D T For t=1,.,t: D t = { } For i=1 D : Pick (x,y) uniformly at random from D (i.e., with replacement) and add it to D t Some examples never get picked (~37%) Some are picked 2x, 3x,.
22 Measuring Bias-Variance with Bootstrap sampling Create B bootstrap variants of D (approximate many draws of D) For each bootstrap dataset T b is the dataset; U b are the out of bag examples Train a hypothesis h b on T b Test h b on each x in U b Now for each (x,y) example we have many predictions h 1 (x),h 2 (x),. so we can estimate (ignoring noise) variance: ordinary variance of h 1 (x),.,h n (x) bias: average(h 1 (x),,h n (x)) - y
23 Applying Bias-Variance Analysis By measuring the bias and variance on a problem, we can determine how to improve our model If bias is high, we need to allow our model to be more complex If variance is high, we need to reduce the complexity of the model Bias-variance analysis also suggests a way to reduce variance: bagging (later) 23
24 Bagging
25 Bootstrap Aggregation (Bagging) Use the bootstrap to create B variants of D Learn a classifier from each variant Vote the learned classifiers to predict on a test example


26 Bagging (bootstrap aggregation) Breaking it down: input: dataset D and YFCL Note that you can use any learner you like! output: a classifier h D-BAG use bootstrap to construct variants D 1,,D T for t=1,,t: train YFCL on D t to get h t You can also test h t on the out of bag examples to classify x with h D-BAG classify x with h 1,.,h T and predict the most frequently predicted class for x (majority vote)
27 Experiments Freund and Schapire

28 Bagged, minimally pruned decision trees
29


30 Generally, bagged decision trees outperform the linear classifier eventually if the data is large enough and clean enough.
31 Bagging (bootstrap aggregation) Experimentally: especially with minimal pruning: decision trees have low bias but high variance. bagging usually improves performance for decision trees and similar methods It reduces variance without increasing the bias (much).
32 More detail on bias-variance and bagging for classification Thanks Tom Dietterich MLSS 2014
33 A generalization of bias-variance decomposition to other loss functions Arbitrary real-valued loss L(y,y ) But L(y,y )=L(y,y), L(y,y)=0, and L(y,y )!=0 if y!=y Define optimal prediction : y* = argmin y L(t,y ) Define main prediction of learner y m =y m,d = argmin y E D {L(y,y )} Define bias of learner : Bias(x)=L(y*,y m ) Define variance of learner Var(x)=E D [L(y m,y)] Define noise for x : N(x) = E t [L(t,y*)] m= D Claim: E D,t [L(t,y) = c 1 N(x)+Bias(x)+c 2 Var(x) where c 1 =Pr D [y=y*] - 1 c 2 =1 if y m =y*, -1 else For 0/1 loss, the main prediction is the most common class predicted by h D (x), weighting h s by Pr(D) Domingos, A Unified Bias-Variance Decomposition and its Applications, ICML 2000
34 More detail on Domingos s model Noisy channel: y i = noise(f(x i )) f(x i ) is true label of x i Noise noise(.) may change y à y h=h D is learned hypothesis from D={(x 1,y 1 ), (x m,y m )} for test case (x*,y*), and predicted label h(x*), loss is L(h(x*),y*) For instance, L(h(x*),y*) = 1 if error, else 0
35 More detail on Domingos s model We want to decompose E D,P {L(h(x*),y*)} where m is size of D, (x*,y*)~p Main prediction of learner is y m (x*) y m (x*) = argmin y E D,P {L(h(x*),y )} y m (x*) = most common h D (x*) among all possible D s, weighted by Pr(D) Bias is B(x*) = L(y m (x*), f(x*)) Variance is V(x*) = E D,P {L(h D (x*), y m (x*) ) Noise is N(x*)= L(y*, f(x*))
36 More detail on Domingos s model We want to decompose E D,P {L(h(x*),y*)} Main prediction of learner is y m (x*) most common h D (x*) over D s for 0/1 loss Bias is B(x*) = L(y m (x*), f(x*)) main prediction vs true label Variance is V(x*) = E D,P {L(h D (x*), y m (x*) ) this hypothesis vs main prediction Noise is N(x*)= L(y*, f(x*)) true label vs observed label
37 More detail on Domingos s model We will decompose E D,P {L(h(x*),y*)} into Bias is B(x*) = L(y m (x*), f(x*)) main prediction vs true label this is 0/1, not a random variable Variance is V(x*) = E D,P {L(h D (x*), y m (x*) ) this hypothesis vs main prediction Noise is N(x*)= L(y*, f(x*)) true label vs observed label

38 Case analysis of error





39 Analysis of error: unbiased case Variance but no noise Main prediction is correct Noise but no variance



40 Analysis of error: biased case No noise, no variance Main prediction is wrong Noise and variance




41 Analysis of error: overall Hopefully we ll be in this case more often, if we ve chosen a good classifier Interaction terms are usually small




42 Analysis of error: without noise which is hard to estimate anyway Vb Vu As with regression, we can experimentally approximately measure bias and variance with bootstrap replicates Typically break variance down into biased variance, Vb, and unbiased variance, Vu.
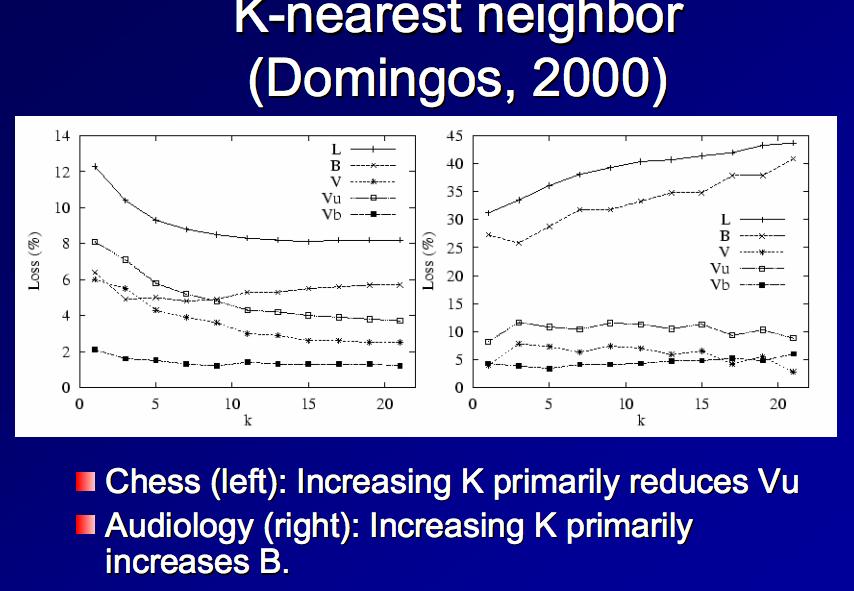
43 K-NN Experiments
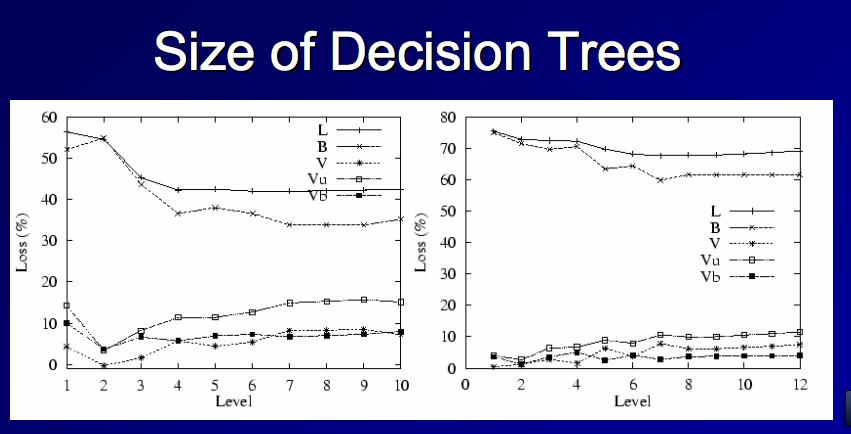
44 Tree Experiments



45 Tree stump experiments (depth 2) Bias is reduced (!)



46 Large tree experiments (depth 10) Bias is not changed much Variance is reduced
CS7267 MACHINE LEARNING
 CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
CS7267 MACHINE LEARNING ENSEMBLE LEARNING Ref: Dr. Ricardo Gutierrez-Osuna at TAMU, and Aarti Singh at CMU Mingon Kang, Ph.D. Computer Science, Kennesaw State University Definition of Ensemble Learning
Ensemble Methods for Machine Learning
 Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
Machine Learning. Ensemble Methods. Manfred Huber
 Machine Learning Ensemble Methods Manfred Huber 2015 1 Bias, Variance, Noise Classification errors have different sources Choice of hypothesis space and algorithm Training set Noise in the data The expected
Machine Learning Ensemble Methods Manfred Huber 2015 1 Bias, Variance, Noise Classification errors have different sources Choice of hypothesis space and algorithm Training set Noise in the data The expected
Learning with multiple models. Boosting.
 CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
Low Bias Bagged Support Vector Machines
 Low Bias Bagged Support Vector Machines Giorgio Valentini Dipartimento di Scienze dell Informazione Università degli Studi di Milano, Italy valentini@dsi.unimi.it Thomas G. Dietterich Department of Computer
Low Bias Bagged Support Vector Machines Giorgio Valentini Dipartimento di Scienze dell Informazione Università degli Studi di Milano, Italy valentini@dsi.unimi.it Thomas G. Dietterich Department of Computer
Data Mining und Maschinelles Lernen
 Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Voting (Ensemble Methods)
") 1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
Introduction to Machine Learning Fall 2017 Note 5. 1 Overview. 2 Metric
 CS 189 Introduction to Machine Learning Fall 2017 Note 5 1 Overview Recall from our previous note that for a fixed input x, our measurement Y is a noisy measurement of the true underlying response f x):
CS 189 Introduction to Machine Learning Fall 2017 Note 5 1 Overview Recall from our previous note that for a fixed input x, our measurement Y is a noisy measurement of the true underlying response f x):
Stochastic Gradient Descent
 Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
VBM683 Machine Learning
 VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
VBM683 Machine Learning Pinar Duygulu Slides are adapted from Dhruv Batra Bias is the algorithm's tendency to consistently learn the wrong thing by not taking into account all the information in the data
CSE 151 Machine Learning. Instructor: Kamalika Chaudhuri
 CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Ensemble Learning How to combine multiple classifiers into a single one Works well if the classifiers are complementary This class: two types of
CSE 151 Machine Learning Instructor: Kamalika Chaudhuri Ensemble Learning How to combine multiple classifiers into a single one Works well if the classifiers are complementary This class: two types of
ECE 5984: Introduction to Machine Learning
 ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
ECE 5984: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting Readings: Murphy 16.4; Hastie 16 Dhruv Batra Virginia Tech Administrativia HW3 Due: April 14, 11:55pm You will implement
Variance Reduction and Ensemble Methods
 Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis
Variance Reduction and Ensemble Methods Nicholas Ruozzi University of Texas at Dallas Based on the slides of Vibhav Gogate and David Sontag Last Time PAC learning Bias/variance tradeoff small hypothesis
A Decision Stump. Decision Trees, cont. Boosting. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. October 1 st, 2007
 Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
What makes good ensemble? CS789: Machine Learning and Neural Network. Introduction. More on diversity
 What makes good ensemble? CS789: Machine Learning and Neural Network Ensemble methods Jakramate Bootkrajang Department of Computer Science Chiang Mai University 1. A member of the ensemble is accurate.
What makes good ensemble? CS789: Machine Learning and Neural Network Ensemble methods Jakramate Bootkrajang Department of Computer Science Chiang Mai University 1. A member of the ensemble is accurate.
Classifier Performance. Assessment and Improvement
 Classifier Performance Assessment and Improvement Error Rates Define the Error Rate function Q( ω ˆ,ω) = δ( ω ˆ ω) = 1 if ω ˆ ω = 0 0 otherwise When training a classifier, the Apparent error rate (or Test
Classifier Performance Assessment and Improvement Error Rates Define the Error Rate function Q( ω ˆ,ω) = δ( ω ˆ ω) = 1 if ω ˆ ω = 0 0 otherwise When training a classifier, the Apparent error rate (or Test
Linear Regression. Machine Learning CSE546 Kevin Jamieson University of Washington. Oct 5, Kevin Jamieson 1
 Linear Regression Machine Learning CSE546 Kevin Jamieson University of Washington Oct 5, 2017 1 The regression problem Given past sales data on zillow.com, predict: y = House sale price from x = {# sq.
Linear Regression Machine Learning CSE546 Kevin Jamieson University of Washington Oct 5, 2017 1 The regression problem Given past sales data on zillow.com, predict: y = House sale price from x = {# sq.
Machine Learning Recitation 8 Oct 21, Oznur Tastan
 Machine Learning 10601 Recitation 8 Oct 21, 2009 Oznur Tastan Outline Tree representation Brief information theory Learning decision trees Bagging Random forests Decision trees Non linear classifier Easy
Machine Learning 10601 Recitation 8 Oct 21, 2009 Oznur Tastan Outline Tree representation Brief information theory Learning decision trees Bagging Random forests Decision trees Non linear classifier Easy
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Ensembles Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique Fédérale de Lausanne
Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Ensembles Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique Fédérale de Lausanne
Ensembles of Classifiers.
 Ensembles of Classifiers www.biostat.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts ensemble bootstrap sample bagging boosting random forests error correcting
Ensembles of Classifiers www.biostat.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts ensemble bootstrap sample bagging boosting random forests error correcting
Learning Theory. Machine Learning CSE546 Carlos Guestrin University of Washington. November 25, Carlos Guestrin
 Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
Learning Theory Machine Learning CSE546 Carlos Guestrin University of Washington November 25, 2013 Carlos Guestrin 2005-2013 1 What now n We have explored many ways of learning from data n But How good
Machine Learning CSE546 Sham Kakade University of Washington. Oct 4, What about continuous variables?
 Linear Regression Machine Learning CSE546 Sham Kakade University of Washington Oct 4, 2016 1 What about continuous variables? Billionaire says: If I am measuring a continuous variable, what can you do
Linear Regression Machine Learning CSE546 Sham Kakade University of Washington Oct 4, 2016 1 What about continuous variables? Billionaire says: If I am measuring a continuous variable, what can you do
Machine Learning CSE546 Carlos Guestrin University of Washington. September 30, What about continuous variables?
 Linear Regression Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2014 1 What about continuous variables? n Billionaire says: If I am measuring a continuous variable, what
Linear Regression Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2014 1 What about continuous variables? n Billionaire says: If I am measuring a continuous variable, what
Boos$ng Can we make dumb learners smart?
 Boos$ng Can we make dumb learners smart? Aarti Singh Machine Learning 10-601 Nov 29, 2011 Slides Courtesy: Carlos Guestrin, Freund & Schapire 1 Why boost weak learners? Goal: Automa'cally categorize type
Boos$ng Can we make dumb learners smart? Aarti Singh Machine Learning 10-601 Nov 29, 2011 Slides Courtesy: Carlos Guestrin, Freund & Schapire 1 Why boost weak learners? Goal: Automa'cally categorize type
A Unified Bias-Variance Decomposition
 A Unified Bias-Variance Decomposition Pedro Domingos Department of Computer Science and Engineering University of Washington Box 352350 Seattle, WA 98185-2350, U.S.A. pedrod@cs.washington.edu Tel.: 206-543-4229
A Unified Bias-Variance Decomposition Pedro Domingos Department of Computer Science and Engineering University of Washington Box 352350 Seattle, WA 98185-2350, U.S.A. pedrod@cs.washington.edu Tel.: 206-543-4229
A Brief Introduction to Adaboost
 A Brief Introduction to Adaboost Hongbo Deng 6 Feb, 2007 Some of the slides are borrowed from Derek Hoiem & Jan ˇSochman. 1 Outline Background Adaboost Algorithm Theory/Interpretations 2 What s So Good
A Brief Introduction to Adaboost Hongbo Deng 6 Feb, 2007 Some of the slides are borrowed from Derek Hoiem & Jan ˇSochman. 1 Outline Background Adaboost Algorithm Theory/Interpretations 2 What s So Good
Machine Learning CSE546 Carlos Guestrin University of Washington. September 30, 2013
 Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
Bayesian Methods Machine Learning CSE546 Carlos Guestrin University of Washington September 30, 2013 1 What about prior n Billionaire says: Wait, I know that the thumbtack is close to 50-50. What can you
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring /
 Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Low Bias Bagged Support Vector Machines
 Low Bias Bagged Support Vector Machines Giorgio Valentini Dipartimento di Scienze dell Informazione, Università degli Studi di Milano, Italy INFM, Istituto Nazionale per la Fisica della Materia, Italy.
Low Bias Bagged Support Vector Machines Giorgio Valentini Dipartimento di Scienze dell Informazione, Università degli Studi di Milano, Italy INFM, Istituto Nazionale per la Fisica della Materia, Italy.
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers
 Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Decision Tree Learning Lecture 2
 Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
Machine Learning Coms-4771 Decision Tree Learning Lecture 2 January 28, 2008 Two Types of Supervised Learning Problems (recap) Feature (input) space X, label (output) space Y. Unknown distribution D over
Day 3: Classification, logistic regression
 Day 3: Classification, logistic regression Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 20 June 2018 Topics so far Supervised
Day 3: Classification, logistic regression Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 20 June 2018 Topics so far Supervised
A Unified Bias-Variance Decomposition and its Applications
 A Unified ias-ariance Decomposition and its Applications Pedro Domingos pedrod@cs.washington.edu Department of Computer Science and Engineering, University of Washington, Seattle, WA 98195, U.S.A. Abstract
A Unified ias-ariance Decomposition and its Applications Pedro Domingos pedrod@cs.washington.edu Department of Computer Science and Engineering, University of Washington, Seattle, WA 98195, U.S.A. Abstract
Machine Learning
 Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 1, 2011 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 1, 2011 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Understanding Generalization Error: Bounds and Decompositions
 CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
CIS 520: Machine Learning Spring 2018: Lecture 11 Understanding Generalization Error: Bounds and Decompositions Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the
Lecture 3: Decision Trees
 Lecture 3: Decision Trees Cognitive Systems - Machine Learning Part I: Basic Approaches of Concept Learning ID3, Information Gain, Overfitting, Pruning last change November 26, 2014 Ute Schmid (CogSys,
Lecture 3: Decision Trees Cognitive Systems - Machine Learning Part I: Basic Approaches of Concept Learning ID3, Information Gain, Overfitting, Pruning last change November 26, 2014 Ute Schmid (CogSys,
Ensemble Methods and Random Forests
 Ensemble Methods and Random Forests Vaishnavi S May 2017 1 Introduction We have seen various analysis for classification and regression in the course. One of the common methods to reduce the generalization
Ensemble Methods and Random Forests Vaishnavi S May 2017 1 Introduction We have seen various analysis for classification and regression in the course. One of the common methods to reduce the generalization
Boosting & Deep Learning
 Boosting & Deep Learning Ensemble Learning n So far learning methods that learn a single hypothesis, chosen form a hypothesis space that is used to make predictions n Ensemble learning à select a collection
Boosting & Deep Learning Ensemble Learning n So far learning methods that learn a single hypothesis, chosen form a hypothesis space that is used to make predictions n Ensemble learning à select a collection
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 4, 2015 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 4, 2015 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
COMS 4721: Machine Learning for Data Science Lecture 13, 3/2/2017
 COMS 4721: Machine Learning for Data Science Lecture 13, 3/2/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University BOOSTING Robert E. Schapire and Yoav
COMS 4721: Machine Learning for Data Science Lecture 13, 3/2/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University BOOSTING Robert E. Schapire and Yoav
Bias-Variance Tradeoff
 What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
Decision Trees. Machine Learning CSEP546 Carlos Guestrin University of Washington. February 3, 2014
 Decision Trees Machine Learning CSEP546 Carlos Guestrin University of Washington February 3, 2014 17 Linear separability n A dataset is linearly separable iff there exists a separating hyperplane: Exists
Decision Trees Machine Learning CSEP546 Carlos Guestrin University of Washington February 3, 2014 17 Linear separability n A dataset is linearly separable iff there exists a separating hyperplane: Exists
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University October 11, 2012 Today: Computational Learning Theory Probably Approximately Coorrect (PAC) learning theorem
Ensemble learning 11/19/13. The wisdom of the crowds. Chapter 11. Ensemble methods. Ensemble methods
 The wisdom of the crowds Ensemble learning Sir Francis Galton discovered in the early 1900s that a collection of educated guesses can add up to very accurate predictions! Chapter 11 The paper in which
The wisdom of the crowds Ensemble learning Sir Francis Galton discovered in the early 1900s that a collection of educated guesses can add up to very accurate predictions! Chapter 11 The paper in which
Linear Classifiers: Expressiveness
 Linear Classifiers: Expressiveness Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture outline Linear classifiers: Introduction What functions do linear classifiers express?
Linear Classifiers: Expressiveness Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture outline Linear classifiers: Introduction What functions do linear classifiers express?
COMS 4771 Regression. Nakul Verma
 COMS 4771 Regression Nakul Verma Last time Support Vector Machines Maximum Margin formulation Constrained Optimization Lagrange Duality Theory Convex Optimization SVM dual and Interpretation How get the
COMS 4771 Regression Nakul Verma Last time Support Vector Machines Maximum Margin formulation Constrained Optimization Lagrange Duality Theory Convex Optimization SVM dual and Interpretation How get the
12 Statistical Justifications; the Bias-Variance Decomposition
 Statistical Justifications; the Bias-Variance Decomposition 65 12 Statistical Justifications; the Bias-Variance Decomposition STATISTICAL JUSTIFICATIONS FOR REGRESSION [So far, I ve talked about regression
Statistical Justifications; the Bias-Variance Decomposition 65 12 Statistical Justifications; the Bias-Variance Decomposition STATISTICAL JUSTIFICATIONS FOR REGRESSION [So far, I ve talked about regression
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Learning Ensembles. 293S T. Yang. UCSB, 2017.
 Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
Notes on Machine Learning for and
 Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Learning = improving with experience Improve over task T (e.g, Classification, control tasks) with respect
Notes on Machine Learning for 16.410 and 16.413 (Notes adapted from Tom Mitchell and Andrew Moore.) Learning = improving with experience Improve over task T (e.g, Classification, control tasks) with respect
Boosting. Acknowledgment Slides are based on tutorials from Robert Schapire and Gunnar Raetsch
 . Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
. Machine Learning Boosting Prof. Dr. Martin Riedmiller AG Maschinelles Lernen und Natürlichsprachliche Systeme Institut für Informatik Technische Fakultät Albert-Ludwigs-Universität Freiburg riedmiller@informatik.uni-freiburg.de
Stephen Scott.
 1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
1 / 35 (Adapted from Ethem Alpaydin and Tom Mitchell) sscott@cse.unl.edu In Homework 1, you are (supposedly) 1 Choosing a data set 2 Extracting a test set of size > 30 3 Building a tree on the training
IEEE TRANSACTIONS ON SYSTEMS, MAN AND CYBERNETICS - PART B 1
 IEEE TRANSACTIONS ON SYSTEMS, MAN AND CYBERNETICS - PART B 1 1 2 IEEE TRANSACTIONS ON SYSTEMS, MAN AND CYBERNETICS - PART B 2 An experimental bias variance analysis of SVM ensembles based on resampling
IEEE TRANSACTIONS ON SYSTEMS, MAN AND CYBERNETICS - PART B 1 1 2 IEEE TRANSACTIONS ON SYSTEMS, MAN AND CYBERNETICS - PART B 2 An experimental bias variance analysis of SVM ensembles based on resampling
Introduction to Machine Learning Lecture 11. Mehryar Mohri Courant Institute and Google Research
 Introduction to Machine Learning Lecture 11 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Boosting Mehryar Mohri - Introduction to Machine Learning page 2 Boosting Ideas Main idea:
Introduction to Machine Learning Lecture 11 Mehryar Mohri Courant Institute and Google Research mohri@cims.nyu.edu Boosting Mehryar Mohri - Introduction to Machine Learning page 2 Boosting Ideas Main idea:
Cross Validation & Ensembling
 Cross Validation & Ensembling Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) CV & Ensembling Machine Learning
Cross Validation & Ensembling Shan-Hung Wu shwu@cs.nthu.edu.tw Department of Computer Science, National Tsing Hua University, Taiwan Machine Learning Shan-Hung Wu (CS, NTHU) CV & Ensembling Machine Learning
Ensembles. Léon Bottou COS 424 4/8/2010
 Ensembles Léon Bottou COS 424 4/8/2010 Readings T. G. Dietterich (2000) Ensemble Methods in Machine Learning. R. E. Schapire (2003): The Boosting Approach to Machine Learning. Sections 1,2,3,4,6. Léon
Ensembles Léon Bottou COS 424 4/8/2010 Readings T. G. Dietterich (2000) Ensemble Methods in Machine Learning. R. E. Schapire (2003): The Boosting Approach to Machine Learning. Sections 1,2,3,4,6. Léon
Decision Trees. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. February 5 th, Carlos Guestrin 1
 Decision Trees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 5 th, 2007 2005-2007 Carlos Guestrin 1 Linear separability A dataset is linearly separable iff 9 a separating
Decision Trees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 5 th, 2007 2005-2007 Carlos Guestrin 1 Linear separability A dataset is linearly separable iff 9 a separating
Introduction to Machine Learning
 Introduction to Machine Learning Thomas G. Dietterich tgd@eecs.oregonstate.edu 1 Outline What is Machine Learning? Introduction to Supervised Learning: Linear Methods Overfitting, Regularization, and the
Introduction to Machine Learning Thomas G. Dietterich tgd@eecs.oregonstate.edu 1 Outline What is Machine Learning? Introduction to Supervised Learning: Linear Methods Overfitting, Regularization, and the
Boosting. Ryan Tibshirani Data Mining: / April Optional reading: ISL 8.2, ESL , 10.7, 10.13
 Boosting Ryan Tibshirani Data Mining: 36-462/36-662 April 25 2013 Optional reading: ISL 8.2, ESL 10.1 10.4, 10.7, 10.13 1 Reminder: classification trees Suppose that we are given training data (x i, y
Boosting Ryan Tibshirani Data Mining: 36-462/36-662 April 25 2013 Optional reading: ISL 8.2, ESL 10.1 10.4, 10.7, 10.13 1 Reminder: classification trees Suppose that we are given training data (x i, y
Lecture 24: Other (Non-linear) Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof. Ganesh Ramakrishnan
 Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof. Ganesh Ramakrishnan") Lecture 24: Other (Non-linear) Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof Ganesh Ramakrishnan October 20, 2016 1 / 25 Decision Trees: Cascade of step
Lecture 24: Other (Non-linear) Classifiers: Decision Tree Learning, Boosting, and Support Vector Classification Instructor: Prof Ganesh Ramakrishnan October 20, 2016 1 / 25 Decision Trees: Cascade of step
BBM406 - Introduc0on to ML. Spring Ensemble Methods. Aykut Erdem Dept. of Computer Engineering HaceDepe University
 BBM406 - Introduc0on to ML Spring 2014 Ensemble Methods Aykut Erdem Dept. of Computer Engineering HaceDepe University 2 Slides adopted from David Sontag, Mehryar Mohri, Ziv- Bar Joseph, Arvind Rao, Greg
BBM406 - Introduc0on to ML Spring 2014 Ensemble Methods Aykut Erdem Dept. of Computer Engineering HaceDepe University 2 Slides adopted from David Sontag, Mehryar Mohri, Ziv- Bar Joseph, Arvind Rao, Greg
COMP 551 Applied Machine Learning Lecture 3: Linear regression (cont d)
") COMP 551 Applied Machine Learning Lecture 3: Linear regression (cont d) Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless
COMP 551 Applied Machine Learning Lecture 3: Linear regression (cont d) Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless
Classification: Decision Trees
 Classification: Decision Trees These slides were assembled by Byron Boots, with grateful acknowledgement to Eric Eaton and the many others who made their course materials freely available online. Feel
Classification: Decision Trees These slides were assembled by Byron Boots, with grateful acknowledgement to Eric Eaton and the many others who made their course materials freely available online. Feel
Announcements Kevin Jamieson
 Announcements My office hours TODAY 3:30 pm - 4:30 pm CSE 666 Poster Session - Pick one First poster session TODAY 4:30 pm - 7:30 pm CSE Atrium Second poster session December 12 4:30 pm - 7:30 pm CSE Atrium
Announcements My office hours TODAY 3:30 pm - 4:30 pm CSE 666 Poster Session - Pick one First poster session TODAY 4:30 pm - 7:30 pm CSE Atrium Second poster session December 12 4:30 pm - 7:30 pm CSE Atrium
Learning Theory Continued
 Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
Learning Theory Continued Machine Learning CSE446 Carlos Guestrin University of Washington May 13, 2013 1 A simple setting n Classification N data points Finite number of possible hypothesis (e.g., dec.
Statistical and Computational Learning Theory
 Statistical and Computational Learning Theory Fundamental Question: Predict Error Rates Given: Find: The space H of hypotheses The number and distribution of the training examples S The complexity of the
Statistical and Computational Learning Theory Fundamental Question: Predict Error Rates Given: Find: The space H of hypotheses The number and distribution of the training examples S The complexity of the
Logistic Regression. William Cohen
 Logistic Regression William Cohen 1 Outline Quick review classi5ication, naïve Bayes, perceptrons new result for naïve Bayes Learning as optimization Logistic regression via gradient ascent Over5itting
Logistic Regression William Cohen 1 Outline Quick review classi5ication, naïve Bayes, perceptrons new result for naïve Bayes Learning as optimization Logistic regression via gradient ascent Over5itting
Probability and Statistical Decision Theory
 Tufts COMP 135: Introduction to Machine Learning https://www.cs.tufts.edu/comp/135/2019s/ Probability and Statistical Decision Theory Many slides attributable to: Erik Sudderth (UCI) Prof. Mike Hughes
Tufts COMP 135: Introduction to Machine Learning https://www.cs.tufts.edu/comp/135/2019s/ Probability and Statistical Decision Theory Many slides attributable to: Erik Sudderth (UCI) Prof. Mike Hughes
RANDOMIZING OUTPUTS TO INCREASE PREDICTION ACCURACY
 1 RANDOMIZING OUTPUTS TO INCREASE PREDICTION ACCURACY Leo Breiman Statistics Department University of California Berkeley, CA. 94720 leo@stat.berkeley.edu Technical Report 518, May 1, 1998 abstract Bagging
1 RANDOMIZING OUTPUTS TO INCREASE PREDICTION ACCURACY Leo Breiman Statistics Department University of California Berkeley, CA. 94720 leo@stat.berkeley.edu Technical Report 518, May 1, 1998 abstract Bagging
Evaluating Hypotheses
 Evaluating Hypotheses IEEE Expert, October 1996 1 Evaluating Hypotheses Sample error, true error Confidence intervals for observed hypothesis error Estimators Binomial distribution, Normal distribution,
Evaluating Hypotheses IEEE Expert, October 1996 1 Evaluating Hypotheses Sample error, true error Confidence intervals for observed hypothesis error Estimators Binomial distribution, Normal distribution,
TDT4173 Machine Learning
 TDT4173 Machine Learning Lecture 9 Learning Classifiers: Bagging & Boosting Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline
TDT4173 Machine Learning Lecture 9 Learning Classifiers: Bagging & Boosting Norwegian University of Science and Technology Helge Langseth IT-VEST 310 helgel@idi.ntnu.no 1 TDT4173 Machine Learning Outline
Machine Learning. Lecture 9: Learning Theory. Feng Li.
 Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
Machine Learning Lecture 9: Learning Theory Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Why Learning Theory How can we tell
EECS 349: Machine Learning Bryan Pardo
 EECS 349: Machine Learning Bryan Pardo Topic: Concept Learning 1 Concept Learning Much of learning involves acquiring general concepts from specific training examples Concept: subset of objects from some
EECS 349: Machine Learning Bryan Pardo Topic: Concept Learning 1 Concept Learning Much of learning involves acquiring general concepts from specific training examples Concept: subset of objects from some
Deconstructing Data Science
 econstructing ata Science avid Bamman, UC Berkeley Info 290 Lecture 6: ecision trees & random forests Feb 2, 2016 Linear regression eep learning ecision trees Ordinal regression Probabilistic graphical
econstructing ata Science avid Bamman, UC Berkeley Info 290 Lecture 6: ecision trees & random forests Feb 2, 2016 Linear regression eep learning ecision trees Ordinal regression Probabilistic graphical
Learning Theory, Overfi1ng, Bias Variance Decomposi9on
 Learning Theory, Overfi1ng, Bias Variance Decomposi9on Machine Learning 10-601B Seyoung Kim Many of these slides are derived from Tom Mitchell, Ziv- 1 Bar Joseph. Thanks! Any(!) learner that outputs a
Learning Theory, Overfi1ng, Bias Variance Decomposi9on Machine Learning 10-601B Seyoung Kim Many of these slides are derived from Tom Mitchell, Ziv- 1 Bar Joseph. Thanks! Any(!) learner that outputs a
Bagging. Ryan Tibshirani Data Mining: / April Optional reading: ISL 8.2, ESL 8.7
 Bagging Ryan Tibshirani Data Mining: 36-462/36-662 April 23 2013 Optional reading: ISL 8.2, ESL 8.7 1 Reminder: classification trees Our task is to predict the class label y {1,... K} given a feature vector
Bagging Ryan Tibshirani Data Mining: 36-462/36-662 April 23 2013 Optional reading: ISL 8.2, ESL 8.7 1 Reminder: classification trees Our task is to predict the class label y {1,... K} given a feature vector
CSE446: Linear Regression Regulariza5on Bias / Variance Tradeoff Winter 2015
 CSE446: Linear Regression Regulariza5on Bias / Variance Tradeoff Winter 2015 Luke ZeElemoyer Slides adapted from Carlos Guestrin Predic5on of con5nuous variables Billionaire says: Wait, that s not what
CSE446: Linear Regression Regulariza5on Bias / Variance Tradeoff Winter 2015 Luke ZeElemoyer Slides adapted from Carlos Guestrin Predic5on of con5nuous variables Billionaire says: Wait, that s not what
Question of the Day? Machine Learning 2D1431. Training Examples for Concept Enjoy Sport. Outline. Lecture 3: Concept Learning
 Question of the Day? Machine Learning 2D43 Lecture 3: Concept Learning What row of numbers comes next in this series? 2 2 22 322 3222 Outline Training Examples for Concept Enjoy Sport Learning from examples
Question of the Day? Machine Learning 2D43 Lecture 3: Concept Learning What row of numbers comes next in this series? 2 2 22 322 3222 Outline Training Examples for Concept Enjoy Sport Learning from examples
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Decision Trees: Overfitting
 Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
Decision Trees: Overfitting Emily Fox University of Washington January 30, 2017 Decision tree recap Loan status: Root 22 18 poor 4 14 Credit? Income? excellent 9 0 3 years 0 4 Fair 9 4 Term? 5 years 9
cxx ab.ec Warm up OH 2 ax 16 0 axtb Fix any a, b, c > What is the x 2 R that minimizes ax 2 + bx + c
 Warm up D cai.yo.ie p IExrL9CxsYD Sglx.Ddl f E Luo fhlexi.si dbll Fix any a, b, c > 0. 1. What is the x 2 R that minimizes ax 2 + bx + c x a b Ta OH 2 ax 16 0 x 1 Za fhkxiiso3ii draulx.h dp.d 2. What is
Warm up D cai.yo.ie p IExrL9CxsYD Sglx.Ddl f E Luo fhlexi.si dbll Fix any a, b, c > 0. 1. What is the x 2 R that minimizes ax 2 + bx + c x a b Ta OH 2 ax 16 0 x 1 Za fhkxiiso3ii draulx.h dp.d 2. What is
Variance and Bias for General Loss Functions
 Machine Learning, 51, 115 135, 2003 c 2003 Kluwer Academic Publishers. Manufactured in The Netherlands. Variance and Bias for General Loss Functions GARETH M. JAMES Marshall School of Business, University
Machine Learning, 51, 115 135, 2003 c 2003 Kluwer Academic Publishers. Manufactured in The Netherlands. Variance and Bias for General Loss Functions GARETH M. JAMES Marshall School of Business, University
CS 543 Page 1 John E. Boon, Jr.
 CS 543 Machine Learning Spring 2010 Lecture 05 Evaluating Hypotheses I. Overview A. Given observed accuracy of a hypothesis over a limited sample of data, how well does this estimate its accuracy over
CS 543 Machine Learning Spring 2010 Lecture 05 Evaluating Hypotheses I. Overview A. Given observed accuracy of a hypothesis over a limited sample of data, how well does this estimate its accuracy over
Hypothesis Evaluation
 Hypothesis Evaluation Machine Learning Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Hypothesis Evaluation Fall 1395 1 / 31 Table of contents 1 Introduction
Hypothesis Evaluation Machine Learning Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Hypothesis Evaluation Fall 1395 1 / 31 Table of contents 1 Introduction
Perceptron. Subhransu Maji. CMPSCI 689: Machine Learning. 3 February February 2015
 Perceptron Subhransu Maji CMPSCI 689: Machine Learning 3 February 2015 5 February 2015 So far in the class Decision trees Inductive bias: use a combination of small number of features Nearest neighbor
Perceptron Subhransu Maji CMPSCI 689: Machine Learning 3 February 2015 5 February 2015 So far in the class Decision trees Inductive bias: use a combination of small number of features Nearest neighbor
CS 6375 Machine Learning
 CS 6375 Machine Learning Decision Trees Instructor: Yang Liu 1 Supervised Classifier X 1 X 2. X M Ref class label 2 1 Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short}
CS 6375 Machine Learning Decision Trees Instructor: Yang Liu 1 Supervised Classifier X 1 X 2. X M Ref class label 2 1 Three variables: Attribute 1: Hair = {blond, dark} Attribute 2: Height = {tall, short}
AdaBoost. Lecturer: Authors: Center for Machine Perception Czech Technical University, Prague
 AdaBoost Lecturer: Jan Šochman Authors: Jan Šochman, Jiří Matas Center for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Motivation Presentation 2/17 AdaBoost with trees
AdaBoost Lecturer: Jan Šochman Authors: Jan Šochman, Jiří Matas Center for Machine Perception Czech Technical University, Prague http://cmp.felk.cvut.cz Motivation Presentation 2/17 AdaBoost with trees
Big Data Analytics. Special Topics for Computer Science CSE CSE Feb 24
 Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
Big Data Analytics Special Topics for Computer Science CSE 4095-001 CSE 5095-005 Feb 24 Fei Wang Associate Professor Department of Computer Science and Engineering fei_wang@uconn.edu Prediction III Goal
Concept Learning Mitchell, Chapter 2. CptS 570 Machine Learning School of EECS Washington State University
 Concept Learning Mitchell, Chapter 2 CptS 570 Machine Learning School of EECS Washington State University Outline Definition General-to-specific ordering over hypotheses Version spaces and the candidate
Concept Learning Mitchell, Chapter 2 CptS 570 Machine Learning School of EECS Washington State University Outline Definition General-to-specific ordering over hypotheses Version spaces and the candidate
COMS 4771 Introduction to Machine Learning. James McInerney Adapted from slides by Nakul Verma
 COMS 4771 Introduction to Machine Learning James McInerney Adapted from slides by Nakul Verma Announcements HW1: Please submit as a group Watch out for zero variance features (Q5) HW2 will be released
COMS 4771 Introduction to Machine Learning James McInerney Adapted from slides by Nakul Verma Announcements HW1: Please submit as a group Watch out for zero variance features (Q5) HW2 will be released
Machine Learning Gaussian Naïve Bayes Big Picture
 Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 27, 2011 Today: Naïve Bayes Big Picture Logistic regression Gradient ascent Generative discriminative
Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 27, 2011 Today: Naïve Bayes Big Picture Logistic regression Gradient ascent Generative discriminative
Recitation 9. Gradient Boosting. Brett Bernstein. March 30, CDS at NYU. Brett Bernstein (CDS at NYU) Recitation 9 March 30, / 14
 Recitation 9 March 30, / 14") Brett Bernstein CDS at NYU March 30, 2017 Brett Bernstein (CDS at NYU) Recitation 9 March 30, 2017 1 / 14 Initial Question Intro Question Question Suppose 10 different meteorologists have produced functions
Brett Bernstein CDS at NYU March 30, 2017 Brett Bernstein (CDS at NYU) Recitation 9 March 30, 2017 1 / 14 Initial Question Intro Question Question Suppose 10 different meteorologists have produced functions
Holdout and Cross-Validation Methods Overfitting Avoidance
 Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
Holdout and Cross-Validation Methods Overfitting Avoidance Decision Trees Reduce error pruning Cost-complexity pruning Neural Networks Early stopping Adjusting Regularizers via Cross-Validation Nearest
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Classification: The rest of the story
 U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
Generalization, Overfitting, and Model Selection
 Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
Generalization, Overfitting, and Model Selection Sample Complexity Results for Supervised Classification Maria-Florina (Nina) Balcan 10/03/2016 Two Core Aspects of Machine Learning Algorithm Design. How
MIRA, SVM, k-nn. Lirong Xia
 MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output