Multivariate Analysis Techniques in HEP
|
|
|
- Mitchell Patterson
- 6 years ago
- Views:
Transcription



1 Multivariate Analysis Techniques in HEP Jan Therhaag IKTP Institutsseminar, Dresden, January 31 st 2013
2 Multivariate analysis in a nutshell Neural networks: Defeating the black box Boosted Decision Trees: Crowd wisdom 2

3 Separating signal and background taking optimal decisions Nomenclature: Think of an event as an ensemble of measured features (variables) Best separation of signal and background is based on likelihood ratio Problem 1: Usually no analytical expression for is available resort to MC and histograms Problem 2: We are not dealing with one variable, but with many curse of dimensionality kicks in 3




4 Separating signal and background MVA to the rescue Goal: examine MC and condense all relevant variables into one optimal discriminator reconstruction of the optimal decision boundary Must be flexible enough to model the underlying distributions Must be rigid enough to deal with sparsely populated regions 4

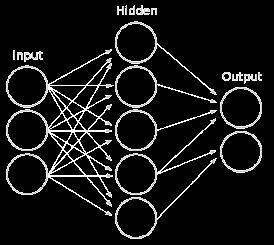
5 5
6 * * Adapted from Zamora-López et al. (2010). 6

7 * * Adapted from Zamora-López et al. (2010). 7

8 The Problem x 2 x 1 8
9 The single neuron as a classifier 9
 Perform a linear fit to this discrete function Define the decision boundary by x 1")
10 A simple approach: Assign discrete values to the classes x 2 (here: blue = -1, orange = 1) Perform a linear fit to this discrete function Define the decision boundary by x 1 10
11 Now consider the sigmoid transformation: 7! has values in [0,1] and can be interpreted as the probability p(orange x) (then obviously p(blue x) = 1- p(orange x) = ) 11
12 We have just invented the neuron! 1 1 x 1 w 1 w 0 x 1 w 1 w 0 x N w N x N w N neuron is called the activity of the neuron, while is called the activation most of the time, we will only consider the activity neuron behavior is entirely controlled by the weights w={w 0, w N } 12
13 Possible realizations of the neuron - the weight space 13
14 The training proceeds via minimization of the error function E(w) The neuron learns via gradient descent E (! ) " < " opt * a)! min! * from LeCun, Bottou, Orr, Mueller: Efficient BackProp, Neural Networks: tricks of the trade, Springer
15 The training proceeds via minimization of the error function E(w) The neuron learns via gradient descent 15
16 From neurons to networks 16
17 The universal approximation theorem Let be a non-constant, bounded, and monotone-increasing continuous function. Let denote the space of continuous functions on the D- dimensional hypercube. Then, for any given function and there exist an integer M and sets of real constants where and such that is an approximation of, that is 17
18 The universal approximation theorem Let be a non-constant, bounded, and monotone-increasing continuous function. Let denote the space of continuous functions on the D- dimensional hypercube. Then, for any given function and there exist an integer M and sets of real constants where and such that is an approximation of, that is Simple version: You can build any continuous function from neurons! 18
19 This architecture is known as feedforward networks Neurons are organized in layers The output of a neuron in one layer becomes the input for the neurons in the next layer z j 19
20 Any continuous function can be approximated with arbitratry precision Function complexity is determined by number of hidden units (neurons) and characteristic magnitude of weights z 1 z 2 z 3 output training data 1 input, 1 output, 3 hidden neurons 20
21 Overtraining in neural networks A network with many neurons may adapt too well to the training data NN with 10 hidden units 21

22 Overtraining in neural networks A network with many neurons may adapt too well to the training data Test data may be used to monitor convergence / stop training But training data is valuable, especially in high dimensional problems Undesirable effects may develop locally before a satisfactory global configuration is found Network size may be limited But complexity of problem is often not known beforehand NN with 10 hidden units 22
23 Regularization by weight decay Penalizing large weights explicitly avoids overtraining complexity is not limited from the start decision boundaries are smoothened weights connecting inputs to hidden neurons Left: w/o weight decay, Right: weight decay 23


24 Regularization by weight decay Penalizing large weights explicitly avoids overtraining complexity is not limited from the start decision boundaries are smoothened weights connecting inputs to hidden neurons Left: w/o weight decay, Right: weight decay NN with 10 hidden units and α=
25 Bayesian neural networks 25
26 Network training as inference Reminder: The output of a neuron may be interpreted as a probability This is our old error function, remember? 26
27 Network training as inference Reminder: The output of a neuron may be interpreted as a probability Similarly, we can interpret the weight decay term as a log probability distribution for w Looks like a Gaussian 27
28 Network training as inference Reminder: The output of a neuron may be interpreted as a probability Similarly, we can interpret the weight decay term as a log probability distribution for w likelihood prior normalization 28
29 29
30 Optimal network complexity Let s take another look at the posterior for the network parameters w: We want: 30
31 Optimal network complexity Let s take another look at the posterior for the network parameters w: We want: The optimal regularization can be found by evaluating the evidence for a given α: 31
32 The evidence framework The integral involved in the evaluation of the evidence is analytically intractable 32
33 The evidence framework The integral involved in the evaluation of the evidence is analytically intractable Way out: Laplace approximation Consider Taylor expand around maximum with This is exact if f(x) is Gaussian! 33
34 The evidence framework Occam terms 34
35 The evidence framework model complexity model complexity 35
36 The evidence framework model complexity NN with 8 hidden neurons model complexity green: optimal decision boundary black: result obtained w/o regularization red: after optimizing α using the evidence 36
37 Input variable relevance determination In a real-life HEP problem, it may not be obvious which variables have predictive power Good variables may be automatically selected if we allow for individual regularization of the input weights useless variables have their weights reduced including more variables does not hurt overall performance Strategy known as Automatic Relevance Determination (ARD) 37
38 Decision trees and boosting 38
39 Decision trees and boosting a perfect match (?) Decision trees are a natural extension of binary cuts most events are not exactly background-/signal-like but share properties of both classes instead of discarding events that fail one criterion, look at remaining criteria to classify them correctly Boosting refers to the process of combining several weak learners into a powerful one very general approach, not limited to decision trees helps to stabilize classifier performance by smoothing out statistical features embodies the principles of crowd wisdom and majority vote...but what makes BDT so popular in HEP? 39
40 Growing a decision tree 1. The root node of the tree corresponds to the full sample of events 2. Sort all events by each variable 3. Go through sorted lists and find best split value for each variable figure of merit is purity of signal/background in the two subsamples generated by the split 4. Select variable which provides the best split 5. Create two branches which contain the events passing/failing the optimal split identified in step 4 6. Repeat recursively from step 2, using new nodes created in step 5 as starting point variables may be used more than once 7. Stop when stopping criterion is reached maximum number of nodes, minimum number of events in final node, etc. 40

41 Consider a sample of events (signal +background) which is described by three variables (,, ) Growing a decision tree example* Sort all events by each variable * adapted from Y. Coadou s talk at SOS
 GeV, separation = 3 GeV, separation = 5 GeV, separation = 0.7 Split events: Pass or fail GeV * adapted from Y.")
42 Consider a sample of events (signal +background) which is described by three variables (,, ) Growing a decision tree example* Sort all events by each variable Look for best split in each variable (arbitrary units) GeV, separation = 3 GeV, separation = 5 GeV, separation = 0.7 Split events: Pass or fail GeV * adapted from Y. Coadou s talk at SOS
 GeV, separation = 3 GeV, separation = 5 GeV, separation = 0.7 Split events: Pass or fail GeV Repeat recursively * adapted from Y.")
43 Consider a sample of events (signal +background) which is described by three variables (,, ) Growing a decision tree example* Sort all events by each variable Look for best split in each variable (arbitrary units) GeV, separation = 3 GeV, separation = 5 GeV, separation = 0.7 Split events: Pass or fail GeV Repeat recursively * adapted from Y. Coadou s talk at SOS
44 Variables to consider -> see next slide Measure of separation Growing a decision tree adjustable parameters maximize purity -> minimize impurity misclassification error cross entropy Gini index note: significance is not a good figure of merit arbitrary unit Split criterion Misclas. error Entropy Gini Criterion to declare a terminal node ( leaf ) minimum amount of events in leaf perfect purity already reached in leaf no split offers sufficient improvement (careful!) maximum number of nodes/depth of tree reached signal purity Continuous or binary output for each event can return purity of terminal leaf or just assign each event to the class which dominates in the terminal leaf Seems confusing but will see there are preferred choices when boosting comes into play 44
45 Strengths of decision trees Non-informative variables do not disturb tree performance no useful split -> never used Duplicate variables do not change the tree Order of training events does not matter Order of variables does not matter Continuous and discrete variables are handled in the same manner Monotonous transformations of variables leave tree unchanged rescaling, unit change etc. Good immunity against outliers 45
46 Strengths/limitations of decision trees Non-informative variables do not disturb tree performance no useful split -> never used Duplicate variables do not change the tree Order of training events does not matter Order of variables does not matter Continuous and discrete variables are handled in the same manner Monotonous transformations of variables leave tree unchanged rescaling, unit change etc. Good immunity against outliers Output is discrete as many values as terminal nodes Instability: Small changes in training sample can lead to very different tree structure Need deep trees to map complex features of the input space statistics in sub-regions created by the tree becomes small classifier picks up fluctuations overtraining occurs Identification of powerful variables is not straightforward one variable may shadow a correlated one sometimes a less beneficial split may lead to a very powerful one later 46
: Train classifier T1 on N events Train T2 on N different events, half of which misclassified by T1 Train T3 on events where T1 and T3 disagree Final classification is")
47 Boosting exploiting the wisdom of crowds Idea: Creating a single powerful classifier is hard, but creating many simple ones is easy -> combine several weak learners to form a powerful one First proposal by Schapire (1990): Train classifier T1 on N events Train T2 on N different events, half of which misclassified by T1 Train T3 on events where T1 and T3 disagree Final classification is majority vote of T1, T2, T3 Incorporation of new ideas by Freund led to the invention of AdaBoost (1996) continues to be the boosting algorithm most widely used in HEP BDT = decision trees + AdaBoost 47
48 AdaBoost 1. Train classifier on training sample with event weights 4. Increase weights of misclassified events 2. Calculate misclassification rate 5. Train classifier on reweighted sample and repeat steps Derive tree weight 6. Final classification function after M iterations is signal background current tree weighted sum of trees 1st tree 10th tree 150th tree 48
: converges to zero for <0.5 prone to overtraining?")

49 AdaBoost + decision trees = great off-the-shelf performance Can be shown that misclassification rate of the final classifier is bounded (on the training sample!): converges to zero for <0.5 prone to overtraining? In practice, best test performance is reached when the base learners are weak slower convergence but little overtraining many classifiers needed -> fast base learner is desirable Trees are perfectly suited for combination with AdaBoost misclassification rate can be adjusted by tree depth small trees are very robust fast to train almost no tuning necessary discrete output structure of trees is smoothened by averaging 49
50 AdaBoost a closer look Boosting: basis function (e.g. decision tree) Neural net: basis function (neuron) Both learning approaches can be understood as an additive expansion, but boosting is a greedy algorithm, i.e. it determines one term at a time, leaving the other terms untouched. -> boosting is computationally less expensive 50
51 AdaBoost a closer look Generally, an additive expansion takes the form These models are optimized by minimizing a loss function on the training data are the parameters of the base learner (split variables and values for trees, weights for neurons etc.) computationally expensive, only feasible in particular cases (neural networks, etc.) AdaBoost is an example for approximation by forward stagewise additive modeling: 1. Initialize 2. For k=1 to M: 1. Compute 2. Set 51
52 AdaBoost can we do better? It turns out that the loss function minimized by AdaBoost is exponential loss L(y, f(x)) exp. loss assume / for correctly classified / misclassified events large penalty for misclassified events sensitive to outliers and noisy settings binomial deviance asymptote Other loss functions may be better suited consider binomial deviance: y f(x) asymptotically linear for large negative margin better balance in spreading the influence among the data 52
53 Gradient boosting No reweighting prescription similar to AdaBoost exists for loss functions other than exponential loss Example: y=1 if, y=-1 otherwise Best approximation to minimize general loss functions: Calculate gradient of the loss function with respect to grow next tree to minimize the least squares error between the tree output and the gradient value at each training data point Gradient boosting Test Error Stumps 10 Node 100 Node Adaboost Number of Terms To be fair: I ve never seen that dramatic differences in HEP classification problems. (but seems to perform better in regression tasks) 53
54 References and further reading Figures taken from: (if not stated otherwise) David MacKay: Information Theory, Inference and Learning Algorithms Cambridge University Press 2003 Christopher Bishop: Pattern Recognition and Machine Learning Springer 2006 Hastie, Tibshirani, Friedman: The Elements of Statistical Learning, 2 nd Ed. Springer 2009 These books are also recommended for further reading 54
55 BACKUP 55
56 The training proceeds via minimization of the error function E(w) 56
57 The training proceeds via minimization of the error function E(w) The neuron learns via gradient descent Weight space * Move in weight space: Examples may be learned all at once (batch learning) or one-by-one (online learning) Going through the training data once is called an epoch * from LeCun, Bottou, Orr, Mueller: Efficient BackProp, Neural Networks: tricks of the trade, Springer
58 Overtraining Diverging weights may lead to overfitting Probabilities assigned by the neuron are too confident 58
59 Overtraining Diverging weights may lead to overfitting E(w) Probabilities assigned by the neuron are too confident 59
60 Very simple approach: stop after a fixed number of iterations (early stopping) and how to avoid it Next to simple approach: Monitor convergence with test sample 60
61 Very simple approach: stop after a fixed number of iterations (early stopping) and how to avoid it Next to simple approach: Monitor convergence with test sample Principled approach: Introduce regularization weight decay term 61
62 and how to avoid it Very simple approach: stop after a fixed number of iterations (early stopping) w0 w1 w w0 w1 w w0 w1 w2 Next to simple approach: Monitor convergence with test sample Principled approach: Introduce regularization weight decay term 62
63 From neuron training to network training - backpropagation Remember: training the network means minimizing the error function E(w) Recall the single neuron: It turns out that: with and ± k = y k t k for output neurons else While input information is always propagated forward, errors are propagated backwards! 63
64 Network complexity vs. regularization Figure: Typical function with H=400 and weights randomly sampled from Gaussians with standard deviations In the limit of H! 1, (H = number of hidden units), function complexity is entirely determined by the typical size of the weights Output How much regularization do we need? 64
65 Summary Neurons and Networks A feedforward neural net is comprised of neurons arranged in layers It can approximate any continuous function to arbitrary precision Training of a neural net can be accomplished efficiently via backpropagation (see Backup) The complexity of the function represented by the NN is controlled by the typical size of the weights 65
66 The evidence framework 66
67 The evidence framework plugin expressions for likelihood and prior 67
68 The evidence framework use Laplace approximation 68
69 The evidence framework perform Gaussian integral 69
70 Predictions and confidence Goal: Predict class of new data point Standard approach: Calculate the network s output using the most probable value obtained in training 70
71 Predictions and confidence Goal: Predict class of new data point Standard approach: Calculate the network s output using the most probable value obtained in training Problem: Shouldn t we be less confident about points in sparsely populated regions? 71
72 Using the posterior to make predictions Instead of using, we can also exploit the full information in the posterior 72
73 Using the posterior to make predictions Instead of using, we can also exploit the full information in the posterior 73
74 Using the posterior to make predictions Instead of using, we can also exploit the full information in the posterior 74
75 Using the posterior to make predictions NN with 8 hidden neurons, α optimized using evidence left: using to make predictions right: prediction using Gaussian approximation to the posterior 75
76 Summary Bayesian NN Neural network training may be interpreted as an inference task Evaluating the evidence allows to determine the optimal amount of regularization model complexity Using independent regularization parameters for different input variables can help to select relevant inputs (ARD) model complexity Using the full posterior to make predictions naturally embodies uncertainties (see Backup) 76
77 Practical hints for NN users* * based on recommendations given in LeCun, Bottou, Orr, Mueller: Efficient BackProp Neural Networks: tricks of the trade, Springer
78 Prefer online- over batch learning Neural Networks good practice avoids redundancy (useful in HEP) -> speed improvement may help to avoid local minima Weight space
79 Prefer online- over batch learning Neural Networks good practice Shuffle the input samples networks learns more efficiently if successive samples are not from the same class 79
80 Prefer online- over batch learning Neural Networks good practice Shuffle the input samples Subtract the mean from the input variables Non-zero means create large eigenvalues in the Hessian matrix of the error function Eigenvalues of H determine the speed convergence E (! ) " < " opt E (! ) " = " opt E (! ) " = " opt a)! min! b)! min!! E (! ) E (! )! c! min " > " opt " > 2 " opt de/d!! c)! min! d)! min! d E(! c ) d!! c! min #! 80
81 Prefer online- over batch learning Neural Networks good practice Shuffle the input samples Subtract the means from the input variables Normalize the variances of the input variables Large spread in variation between input variables will produce a very eccentric error surface Eigenvalues will vary strongly in size 81
82 Prefer online- over batch learning Neural Networks good practice Shuffle the input samples Subtract the means from the input variables Normalize the variances of the input variables Decorrelate the input variables (at least if your NN does feature adaptive learning rates) For decorrelated inputs, eigenvectors of H point in direction of the coordinates Individual learning rates based on the different eigenvalues may be assigned 82
83 Neural network software to play with NeuroBayes: * proprietary software implementing a Bayesian neural network * efficient automatic preprocessing * very fast TMVA MLP: * open source, included in ROOT * regularization can be optionally turned on, uses approximations for evidence shown here * next version can directly interface to NeuroBayes * complete manual available from tmva.sourceforge.net 83
84 Summary Decision Trees and Boosting Single decision trees are robust with respect to variable choice and transformations, but unstable with respect to statistical features of the training data Boosting combines several weak learners into a powerful one works best with small trees has good out-of-the-box performance AdaBoost is an example of forward stagewise additive modeling minimizes exponential loss L(y, f(x)) exp. loss binomial deviance asymptote Some shortcomings of AdaBoost can be cured by choosing a different loss function leads to gradient boosting algorithm y f(x) 84
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Advanced statistical methods for data analysis Lecture 2
 Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Statistical Methods in Particle Physics
 Statistical Methods in Particle Physics 8. Multivariate Analysis Prof. Dr. Klaus Reygers (lectures) Dr. Sebastian Neubert (tutorials) Heidelberg University WS 2017/18 Multi-Variate Classification Consider
Statistical Methods in Particle Physics 8. Multivariate Analysis Prof. Dr. Klaus Reygers (lectures) Dr. Sebastian Neubert (tutorials) Heidelberg University WS 2017/18 Multi-Variate Classification Consider
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Data Mining und Maschinelles Lernen
 Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Data Mining und Maschinelles Lernen Ensemble Methods Bias-Variance Trade-off Basic Idea of Ensembles Bagging Basic Algorithm Bagging with Costs Randomization Random Forests Boosting Stacking Error-Correcting
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Statistics and learning: Big Data
 Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees
Statistics and learning: Big Data Learning Decision Trees and an Introduction to Boosting Sébastien Gadat Toulouse School of Economics February 2017 S. Gadat (TSE) SAD 2013 1 / 30 Keywords Decision trees
Machine Learning Lecture 10
 Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008)
") Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008) RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement
Multivariate statistical methods and data mining in particle physics Lecture 4 (19 June, 2008) RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Multivariate Methods in Statistical Data Analysis
 Multivariate Methods in Statistical Data Analysis Web-Site: http://tmva.sourceforge.net/ See also: "TMVA - Toolkit for Multivariate Data Analysis, A. Hoecker, P. Speckmayer, J. Stelzer, J. Therhaag, E.
Multivariate Methods in Statistical Data Analysis Web-Site: http://tmva.sourceforge.net/ See also: "TMVA - Toolkit for Multivariate Data Analysis, A. Hoecker, P. Speckmayer, J. Stelzer, J. Therhaag, E.
MODULE -4 BAYEIAN LEARNING
 MODULE -4 BAYEIAN LEARNING CONTENT Introduction Bayes theorem Bayes theorem and concept learning Maximum likelihood and Least Squared Error Hypothesis Maximum likelihood Hypotheses for predicting probabilities
MODULE -4 BAYEIAN LEARNING CONTENT Introduction Bayes theorem Bayes theorem and concept learning Maximum likelihood and Least Squared Error Hypothesis Maximum likelihood Hypotheses for predicting probabilities
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Gradient Boosting (Continued)
") Gradient Boosting (Continued) David Rosenberg New York University April 4, 2016 David Rosenberg (New York University) DS-GA 1003 April 4, 2016 1 / 31 Boosting Fits an Additive Model Boosting Fits an Additive
Gradient Boosting (Continued) David Rosenberg New York University April 4, 2016 David Rosenberg (New York University) DS-GA 1003 April 4, 2016 1 / 31 Boosting Fits an Additive Model Boosting Fits an Additive
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Ensemble Methods. Charles Sutton Data Mining and Exploration Spring Friday, 27 January 12
 Ensemble Methods Charles Sutton Data Mining and Exploration Spring 2012 Bias and Variance Consider a regression problem Y = f(x)+ N(0, 2 ) With an estimate regression function ˆf, e.g., ˆf(x) =w > x Suppose
Ensemble Methods Charles Sutton Data Mining and Exploration Spring 2012 Bias and Variance Consider a regression problem Y = f(x)+ N(0, 2 ) With an estimate regression function ˆf, e.g., ˆf(x) =w > x Suppose
Boosting. Ryan Tibshirani Data Mining: / April Optional reading: ISL 8.2, ESL , 10.7, 10.13
 Boosting Ryan Tibshirani Data Mining: 36-462/36-662 April 25 2013 Optional reading: ISL 8.2, ESL 10.1 10.4, 10.7, 10.13 1 Reminder: classification trees Suppose that we are given training data (x i, y
Boosting Ryan Tibshirani Data Mining: 36-462/36-662 April 25 2013 Optional reading: ISL 8.2, ESL 10.1 10.4, 10.7, 10.13 1 Reminder: classification trees Suppose that we are given training data (x i, y
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring /
 Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Machine Learning Ensemble Learning I Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi Spring 2015 http://ce.sharif.edu/courses/93-94/2/ce717-1 / Agenda Combining Classifiers Empirical view Theoretical
Machine Learning Lecture 14
 Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 14 Tricks of the Trade 07.12.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
10-701/ Machine Learning, Fall
 0-70/5-78 Machine Learning, Fall 2003 Homework 2 Solution If you have questions, please contact Jiayong Zhang .. (Error Function) The sum-of-squares error is the most common training
0-70/5-78 Machine Learning, Fall 2003 Homework 2 Solution If you have questions, please contact Jiayong Zhang .. (Error Function) The sum-of-squares error is the most common training
Harrison B. Prosper. Bari Lectures
 Harrison B. Prosper Florida State University Bari Lectures 30, 31 May, 1 June 2016 Lectures on Multivariate Methods Harrison B. Prosper Bari, 2016 1 h Lecture 1 h Introduction h Classification h Grid Searches
Harrison B. Prosper Florida State University Bari Lectures 30, 31 May, 1 June 2016 Lectures on Multivariate Methods Harrison B. Prosper Bari, 2016 1 h Lecture 1 h Introduction h Classification h Grid Searches
Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c /9/9 page 331 le-tex
 Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c15 2013/9/9 page 331 le-tex 331 15 Ensemble Learning The expression ensemble learning refers to a broad class
Frank C Porter and Ilya Narsky: Statistical Analysis Techniques in Particle Physics Chap. c15 2013/9/9 page 331 le-tex 331 15 Ensemble Learning The expression ensemble learning refers to a broad class
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
Chapter 14 Combining Models
 Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Chapter 14 Combining Models T-61.62 Special Course II: Pattern Recognition and Machine Learning Spring 27 Laboratory of Computer and Information Science TKK April 3th 27 Outline Independent Mixing Coefficients
Learning with multiple models. Boosting.
 CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
CS 2750 Machine Learning Lecture 21 Learning with multiple models. Boosting. Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Learning with multiple models: Approach 2 Approach 2: use multiple models
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Boosting Methods: Why They Can Be Useful for High-Dimensional Data
 New URL: http://www.r-project.org/conferences/dsc-2003/ Proceedings of the 3rd International Workshop on Distributed Statistical Computing (DSC 2003) March 20 22, Vienna, Austria ISSN 1609-395X Kurt Hornik,
New URL: http://www.r-project.org/conferences/dsc-2003/ Proceedings of the 3rd International Workshop on Distributed Statistical Computing (DSC 2003) March 20 22, Vienna, Austria ISSN 1609-395X Kurt Hornik,
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
A Brief Introduction to Adaboost
 A Brief Introduction to Adaboost Hongbo Deng 6 Feb, 2007 Some of the slides are borrowed from Derek Hoiem & Jan ˇSochman. 1 Outline Background Adaboost Algorithm Theory/Interpretations 2 What s So Good
A Brief Introduction to Adaboost Hongbo Deng 6 Feb, 2007 Some of the slides are borrowed from Derek Hoiem & Jan ˇSochman. 1 Outline Background Adaboost Algorithm Theory/Interpretations 2 What s So Good
Learning theory. Ensemble methods. Boosting. Boosting: history
 Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Learning theory Probability distribution P over X {0, 1}; let (X, Y ) P. We get S := {(x i, y i )} n i=1, an iid sample from P. Ensemble methods Goal: Fix ɛ, δ (0, 1). With probability at least 1 δ (over
Linear Classification. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Linear Classification CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Example of Linear Classification Red points: patterns belonging
Linear Classification CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Example of Linear Classification Red points: patterns belonging
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Stochastic Gradient Descent
 Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Statistical Machine Learning from Data
 January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
Mark Gales October y (x) x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.
 x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.") University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
Generalized Boosted Models: A guide to the gbm package
 Generalized Boosted Models: A guide to the gbm package Greg Ridgeway April 15, 2006 Boosting takes on various forms with different programs using different loss functions, different base models, and different
Generalized Boosted Models: A guide to the gbm package Greg Ridgeway April 15, 2006 Boosting takes on various forms with different programs using different loss functions, different base models, and different
Multivariate statistical methods and data mining in particle physics
 Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
CS6375: Machine Learning Gautam Kunapuli. Decision Trees
 Gautam Kunapuli Example: Restaurant Recommendation Example: Develop a model to recommend restaurants to users depending on their past dining experiences. Here, the features are cost (x ) and the user s
Gautam Kunapuli Example: Restaurant Recommendation Example: Develop a model to recommend restaurants to users depending on their past dining experiences. Here, the features are cost (x ) and the user s
CART Classification and Regression Trees Trees can be viewed as basis expansions of simple functions. f(x) = c m 1(x R m )
 = c m 1(x R m )") CART Classification and Regression Trees Trees can be viewed as basis expansions of simple functions with R 1,..., R m R p disjoint. f(x) = M c m 1(x R m ) m=1 The CART algorithm is a heuristic, adaptive
CART Classification and Regression Trees Trees can be viewed as basis expansions of simple functions with R 1,..., R m R p disjoint. f(x) = M c m 1(x R m ) m=1 The CART algorithm is a heuristic, adaptive
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Hierarchical Boosting and Filter Generation
 January 29, 2007 Plan Combining Classifiers Boosting Neural Network Structure of AdaBoost Image processing Hierarchical Boosting Hierarchical Structure Filters Combining Classifiers Combining Classifiers
January 29, 2007 Plan Combining Classifiers Boosting Neural Network Structure of AdaBoost Image processing Hierarchical Boosting Hierarchical Structure Filters Combining Classifiers Combining Classifiers
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
StatPatternRecognition: A C++ Package for Multivariate Classification of HEP Data. Ilya Narsky, Caltech
 StatPatternRecognition: A C++ Package for Multivariate Classification of HEP Data Ilya Narsky, Caltech Motivation Introduction advanced classification tools in a convenient C++ package for HEP researchers
StatPatternRecognition: A C++ Package for Multivariate Classification of HEP Data Ilya Narsky, Caltech Motivation Introduction advanced classification tools in a convenient C++ package for HEP researchers
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet.
 or two-page (one side) crib sheet.") CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
CS 189 Spring 013 Introduction to Machine Learning Final You have 3 hours for the exam. The exam is closed book, closed notes except your one-page (two sides) or two-page (one side) crib sheet. Please
Announcements Kevin Jamieson
 Announcements My office hours TODAY 3:30 pm - 4:30 pm CSE 666 Poster Session - Pick one First poster session TODAY 4:30 pm - 7:30 pm CSE Atrium Second poster session December 12 4:30 pm - 7:30 pm CSE Atrium
Announcements My office hours TODAY 3:30 pm - 4:30 pm CSE 666 Poster Session - Pick one First poster session TODAY 4:30 pm - 7:30 pm CSE Atrium Second poster session December 12 4:30 pm - 7:30 pm CSE Atrium
Machine Learning Lecture 12
 Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
PATTERN CLASSIFICATION
 PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
the tree till a class assignment is reached
 Decision Trees Decision Tree for Playing Tennis Prediction is done by sending the example down Prediction is done by sending the example down the tree till a class assignment is reached Definitions Internal
Decision Trees Decision Tree for Playing Tennis Prediction is done by sending the example down Prediction is done by sending the example down the tree till a class assignment is reached Definitions Internal
Links between Perceptrons, MLPs and SVMs
 Links between Perceptrons, MLPs and SVMs Ronan Collobert Samy Bengio IDIAP, Rue du Simplon, 19 Martigny, Switzerland Abstract We propose to study links between three important classification algorithms:
Links between Perceptrons, MLPs and SVMs Ronan Collobert Samy Bengio IDIAP, Rue du Simplon, 19 Martigny, Switzerland Abstract We propose to study links between three important classification algorithms:
Learning Ensembles. 293S T. Yang. UCSB, 2017.
 Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
Learning Ensembles 293S T. Yang. UCSB, 2017. Outlines Learning Assembles Random Forest Adaboost Training data: Restaurant example Examples described by attribute values (Boolean, discrete, continuous)
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Natural Language Processing. Classification. Features. Some Definitions. Classification. Feature Vectors. Classification I. Dan Klein UC Berkeley
 Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Comparison of Modern Stochastic Optimization Algorithms
 Comparison of Modern Stochastic Optimization Algorithms George Papamakarios December 214 Abstract Gradient-based optimization methods are popular in machine learning applications. In large-scale problems,
Comparison of Modern Stochastic Optimization Algorithms George Papamakarios December 214 Abstract Gradient-based optimization methods are popular in machine learning applications. In large-scale problems,
Ensemble Methods for Machine Learning
 Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
Ensemble Methods for Machine Learning COMBINING CLASSIFIERS: ENSEMBLE APPROACHES Common Ensemble classifiers Bagging/Random Forests Bucket of models Stacking Boosting Ensemble classifiers we ve studied
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017
 COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Boosted Decision Trees and Applications
 EPJ Web of Conferences, 24 (23) DOI:./ epjconf/ 2324 C Owned by the authors, published by EDP Sciences, 23 Boosted Decision Trees and Applications Yann COADOU CPPM, Aix-Marseille UniversitNRS/IN2P3, Marseille,
EPJ Web of Conferences, 24 (23) DOI:./ epjconf/ 2324 C Owned by the authors, published by EDP Sciences, 23 Boosted Decision Trees and Applications Yann COADOU CPPM, Aix-Marseille UniversitNRS/IN2P3, Marseille,
Neural Networks and Ensemble Methods for Classification
 Neural Networks and Ensemble Methods for Classification NEURAL NETWORKS 2 Neural Networks A neural network is a set of connected input/output units (neurons) where each connection has a weight associated
Neural Networks and Ensemble Methods for Classification NEURAL NETWORKS 2 Neural Networks A neural network is a set of connected input/output units (neurons) where each connection has a weight associated
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING
 EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: August 30, 2018, 14.00 19.00 RESPONSIBLE TEACHER: Niklas Wahlström NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: August 30, 2018, 14.00 19.00 RESPONSIBLE TEACHER: Niklas Wahlström NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
Vasil Khalidov & Miles Hansard. C.M. Bishop s PRML: Chapter 5; Neural Networks
 C.M. Bishop s PRML: Chapter 5; Neural Networks Introduction The aim is, as before, to find useful decompositions of the target variable; t(x) = y(x, w) + ɛ(x) (3.7) t(x n ) and x n are the observations,
C.M. Bishop s PRML: Chapter 5; Neural Networks Introduction The aim is, as before, to find useful decompositions of the target variable; t(x) = y(x, w) + ɛ(x) (3.7) t(x n ) and x n are the observations,
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Logistic Regression. COMP 527 Danushka Bollegala
 Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Logistic Regression COMP 527 Danushka Bollegala Binary Classification Given an instance x we must classify it to either positive (1) or negative (0) class We can use {1,-1} instead of {1,0} but we will
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
σ(a) = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =
 = a N (x; 0, 1 2 ) dx. σ(a) = Φ(a) =") Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Until now we have always worked with likelihoods and prior distributions that were conjugate to each other, allowing the computation of the posterior distribution to be done in closed form. Unfortunately,
Lecture 4: Types of errors. Bayesian regression models. Logistic regression
 Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
Lecture 4: Types of errors. Bayesian regression models. Logistic regression A Bayesian interpretation of regularization Bayesian vs maximum likelihood fitting more generally COMP-652 and ECSE-68, Lecture
Ensembles. Léon Bottou COS 424 4/8/2010
 Ensembles Léon Bottou COS 424 4/8/2010 Readings T. G. Dietterich (2000) Ensemble Methods in Machine Learning. R. E. Schapire (2003): The Boosting Approach to Machine Learning. Sections 1,2,3,4,6. Léon
Ensembles Léon Bottou COS 424 4/8/2010 Readings T. G. Dietterich (2000) Ensemble Methods in Machine Learning. R. E. Schapire (2003): The Boosting Approach to Machine Learning. Sections 1,2,3,4,6. Léon
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Computational statistics
 Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
> DEPARTMENT OF MATHEMATICS AND COMPUTER SCIENCE GRAVIS 2016 BASEL. Logistic Regression. Pattern Recognition 2016 Sandro Schönborn University of Basel
 Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
Logistic Regression Pattern Recognition 2016 Sandro Schönborn University of Basel Two Worlds: Probabilistic & Algorithmic We have seen two conceptual approaches to classification: data class density estimation
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Midterm exam CS 189/289, Fall 2015
 Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
Midterm exam CS 189/289, Fall 2015 You have 80 minutes for the exam. Total 100 points: 1. True/False: 36 points (18 questions, 2 points each). 2. Multiple-choice questions: 24 points (8 questions, 3 points
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING
 EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: June 9, 2018, 09.00 14.00 RESPONSIBLE TEACHER: Andreas Svensson NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
EXAM IN STATISTICAL MACHINE LEARNING STATISTISK MASKININLÄRNING DATE AND TIME: June 9, 2018, 09.00 14.00 RESPONSIBLE TEACHER: Andreas Svensson NUMBER OF PROBLEMS: 5 AIDING MATERIAL: Calculator, mathematical
Regularization in Neural Networks
 Regularization in Neural Networks Sargur Srihari 1 Topics in Neural Network Regularization What is regularization? Methods 1. Determining optimal number of hidden units 2. Use of regularizer in error function
Regularization in Neural Networks Sargur Srihari 1 Topics in Neural Network Regularization What is regularization? Methods 1. Determining optimal number of hidden units 2. Use of regularizer in error function
Recitation 9. Gradient Boosting. Brett Bernstein. March 30, CDS at NYU. Brett Bernstein (CDS at NYU) Recitation 9 March 30, / 14
 Recitation 9 March 30, / 14") Brett Bernstein CDS at NYU March 30, 2017 Brett Bernstein (CDS at NYU) Recitation 9 March 30, 2017 1 / 14 Initial Question Intro Question Question Suppose 10 different meteorologists have produced functions
Brett Bernstein CDS at NYU March 30, 2017 Brett Bernstein (CDS at NYU) Recitation 9 March 30, 2017 1 / 14 Initial Question Intro Question Question Suppose 10 different meteorologists have produced functions
AI Programming CS F-20 Neural Networks
 AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014 Exam policy: This exam allows two one-page, two-sided cheat sheets (i.e. 4 sides); No other materials. Time: 2 hours. Be sure to write
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014 Exam policy: This exam allows two one-page, two-sided cheat sheets (i.e. 4 sides); No other materials. Time: 2 hours. Be sure to write
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
COMP 551 Applied Machine Learning Lecture 21: Bayesian optimisation
 COMP 55 Applied Machine Learning Lecture 2: Bayesian optimisation Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp55 Unless otherwise noted, all material posted
COMP 55 Applied Machine Learning Lecture 2: Bayesian optimisation Associate Instructor: (herke.vanhoof@mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp55 Unless otherwise noted, all material posted
A Decision Stump. Decision Trees, cont. Boosting. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. October 1 st, 2007
 Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Decision Trees, cont. Boosting Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 1 st, 2007 1 A Decision Stump 2 1 The final tree 3 Basic Decision Tree Building Summarized
Voting (Ensemble Methods)
") 1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
1 2 Voting (Ensemble Methods) Instead of learning a single classifier, learn many weak classifiers that are good at different parts of the data Output class: (Weighted) vote of each classifier Classifiers
ECE 5424: Introduction to Machine Learning
 ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
ECE 5424: Introduction to Machine Learning Topics: Ensemble Methods: Bagging, Boosting PAC Learning Readings: Murphy 16.4;; Hastie 16 Stefan Lee Virginia Tech Fighting the bias-variance tradeoff Simple
Neural Networks. Bishop PRML Ch. 5. Alireza Ghane. Feed-forward Networks Network Training Error Backpropagation Applications
 Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Neural Networks Bishop PRML Ch. 5 Alireza Ghane Neural Networks Alireza Ghane / Greg Mori 1 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of
Reconnaissance d objetsd et vision artificielle
 Reconnaissance d objetsd et vision artificielle http://www.di.ens.fr/willow/teaching/recvis09 Lecture 6 Face recognition Face detection Neural nets Attention! Troisième exercice de programmation du le
Reconnaissance d objetsd et vision artificielle http://www.di.ens.fr/willow/teaching/recvis09 Lecture 6 Face recognition Face detection Neural nets Attention! Troisième exercice de programmation du le
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!!
 CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
CSE 190 Fall 2015 Midterm DO NOT TURN THIS PAGE UNTIL YOU ARE TOLD TO START!!!! November 18, 2015 THE EXAM IS CLOSED BOOK. Once the exam has started, SORRY, NO TALKING!!! No, you can t even say see ya
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
day month year documentname/initials 1
 ECE471-571 Pattern Recognition Lecture 13 Decision Tree Hairong Qi, Gonzalez Family Professor Electrical Engineering and Computer Science University of Tennessee, Knoxville http://www.eecs.utk.edu/faculty/qi
ECE471-571 Pattern Recognition Lecture 13 Decision Tree Hairong Qi, Gonzalez Family Professor Electrical Engineering and Computer Science University of Tennessee, Knoxville http://www.eecs.utk.edu/faculty/qi
Self Supervised Boosting
 Self Supervised Boosting Max Welling, Richard S. Zemel, and Geoffrey E. Hinton Department of omputer Science University of Toronto 1 King s ollege Road Toronto, M5S 3G5 anada Abstract Boosting algorithms
Self Supervised Boosting Max Welling, Richard S. Zemel, and Geoffrey E. Hinton Department of omputer Science University of Toronto 1 King s ollege Road Toronto, M5S 3G5 anada Abstract Boosting algorithms
Algorithm-Independent Learning Issues
 Algorithm-Independent Learning Issues Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2007 c 2007, Selim Aksoy Introduction We have seen many learning
Algorithm-Independent Learning Issues Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2007 c 2007, Selim Aksoy Introduction We have seen many learning