Multivariate Data Analysis and Machine Learning in High Energy Physics (III)
|
|
|
- Cynthia Nicholson
- 6 years ago
- Views:
Transcription
 Graduierten-Kolleg, Freiburg, 11.5-15.5, 2009")
1 Multivariate Data Analysis and Machine Learning in High Energy Physics (III) Helge Voss (MPI K, Heidelberg) Graduierten-Kolleg, Freiburg, , 2009
2 Outline Summary of last lecture 1-dimensional Likelihood: data preprocessing decorrelation Recap of Fisher s Discriminant Neural Networks Helge Voss 2
3 What we ve learned yesterday: Neyman Pearson: Actually he states the obvious if you think about it: if you want to know to which probability an event with measured variables x is either signal or background, use the ratio between the true probability between observing an event with x from either signal or background. Who is surprised that this is the best you can do? Unfortunately we basically never have access to the true probability density : hence we try to either estimate the PDF S (x) and PDF B (x) using Kernel Density Estimator/Mulitdimensional likelihood (effectively averages of the PDF over regions of the variable space, derived from training events) curse of dimensionality!! or neglect correlations and use 1-dimensional PDF s no problems with dimensionality or try a different approach of directly determining hyperplanes in the feature space that separate signal and background events. There is no magic, you still need to tune parameters (e.g size of the region you want to average over in PDF estimate) in order to get good results. Helge Voss 3
 { variables} event C p i (x i, k ) event discriminating variables Classes: signal, background types If the correlations between variables is really")
4 4 Naïve Bayesian Classifier often called: (projective or 1D) Likelihood If correlations between variables are weak: D p( x) p i( x) i= 0 Likelihood ratio for event event yx ( ) = PDE, k event i PDFs { sse } { variables} C cla s i signal p i (x i, k ) { variables} event C p i (x i, k ) event discriminating variables Classes: signal, background types If the correlations between variables is really negligible, this classifier is perfect (simple, robust, performing) If not, you seriously loose performance How can we fix this? var i


![i, x j ]=E[ x i x j ] E[ x](/docs-images/71/65818287/images/5-2.jpg "i ]E[ x j ] 0 (i j)")

5 What if there are correlations? 5 Typically correlations are present: C ij =cov[ x i, x j ]=E[ x i x j ] E[ x i ]E[ x j ] 0 (i j) pre-processing: choose set of linear transformed input variables for which C ij = 0 (i j)
6 Decorrelation 6 Determine square-root C of correlation matrix C, i.e., C = C C T T compute C by diagonalising C: D = S CS C = S DS transformation from original (x) in de-correlated variable space (x ) by: x = C 1x Attention. This is is able to eliminate only linear correlations!!


7 Decorrelation 7 Determine square-root C of correlation matrix C, i.e., C = C C T T compute C by diagonalising C: D = S CS C = S DS transformation from original (x) in de-correlated variable space (x ) by: x = C 1x Attention. This is is able to eliminate only linear correlations!!
8 Decorrelation: Principal Component Analysis 8 PCA is typically used to: reduce dimensionality of a problem find the most dominant features in your distribution by transforming The eigenvectors of the covariance matrix with the largest eigenvalues correspond to the dimensions that have the strongest correlation in the data set. Along these axis the variance is largest sort the eigenvectors according to their eigenvalues Dataset is transformed in variable space along these eigenvectors Along the first dimension the data show the largest features, the smallest features are found in the last dimension. ( i ) x ( i ) PC ( k ) k event v event v v v { variables} { variab } x = x v, k les Principle Component (PC) of variable k sample means Matrix of eigenvectors V obey the relation: eigenvector CV = DV PCA eliminates correlations! correlation matrix diagonalised square root of C
9 How to Apply the Pre-Processing Transformation? Helge Voss 9 In general: the decorrelation for signal and background variables is different however: for a test event we don t know beforehand if it is signal or background.? What do we do? for likelihood ratio, decorrelate signal and background independently y L ( i ) event = k { variables} k { variables} p S k ( x ( i )) event B ( ( i )) + ( x ( i )) S k k event k k k k p x p { variables} event y trans L ( i ) event = k { variables} p S k S( ˆ S pk T xk( ievent )) k { variables} ( ˆS B ( event )) ( ˆB T xk i + pk T xk( ievent) ) k { variables} for other estimators, one need to decide on one of the two

10 10 Decorrelation at Work Example: linear correlated Gaussians decorrelation works to 100% 1-D Likelihood on decorrelated sample give best possible performance compare also the effect on the MVA-output variable! correlated variables: after decorrelation (note the different scale on the y-axis sorry)


11 Limitations of the Decorrelation 11 in cases with non-gaussian distributions and/or nonlinear correlations, the decorrelation needs to be treated with care How does linear decorrelation affect cases where correlations between signal and background differ? Original correlations Signal Background
12 Limitations of the Decorrelation 12 in cases with non-gaussian distributions and/or nonlinear correlations, the decorrelation needs to be treated with care How does linear decorrelation affect cases where correlations between signal and background differ? Original correlations SQRT decorrelation Signal Background

13 Limitations of the Decorrelation 13 in cases with non-gaussian distributions and/or nonlinear correlations, the decorrelation needs to be treated with care How does linear decorrelation affect strongly nonlinear cases? Original correlations Signal Background
14 Limitations of the Decorrelation 14 in cases with non-gaussian distributions and/or nonlinear correlations, the decorrelation needs to be treated with care How does linear decorrelation affect strongly nonlinear cases? Original correlations SQRT decorrelation Signal Background Watch out before you used decorrelation blindly!!
15 Gaussian-isation 15 Improve decorrelation by pre-gaussianisation of variables First: transformation to achieve uniform (flat) distribution: flat k ( i ) event ( i ) ( x ) event x k { variabl } x = p dx, k es Rarity transform of variable k Measured value PDF of variable k The integral can be solved in an unbinned way by event counting, or by creating non-parametric PDFs (see later for likelihood section) k k k Second: make Gaussian via inverse error function: erf x at ( ) x ( ) Gauss 1 fl k event ( x) 2 = e π ( k event ), { } i = 2 erf 2 i 1 k variables x 0 t 2 dt Third: decorrelate (and iterate this procedure)
16 Gaussian-isation 16 Background Signal Background Signal -Original -Original - - Gaussianised Gaussianised We cannot simultaneously Gaussianise both signal and background?!
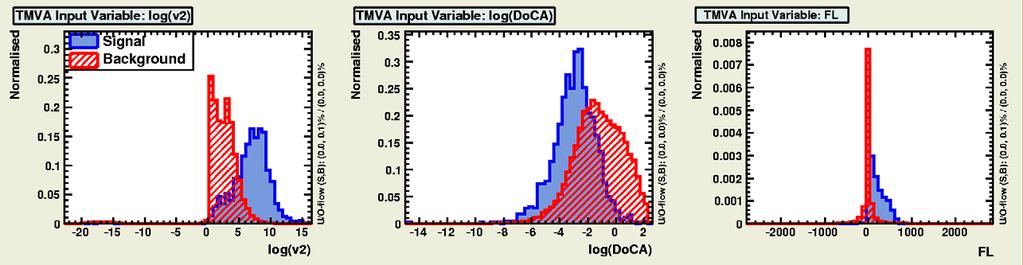
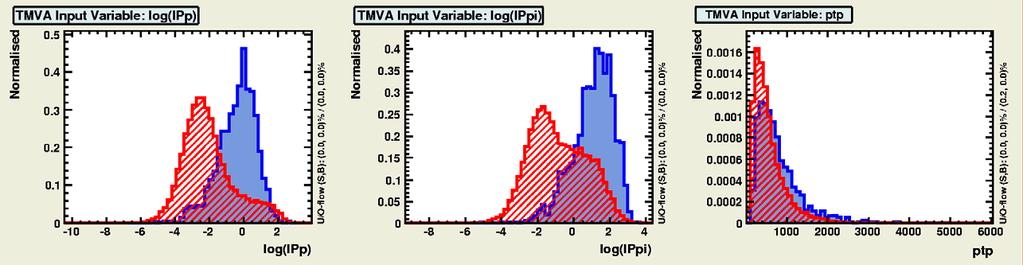
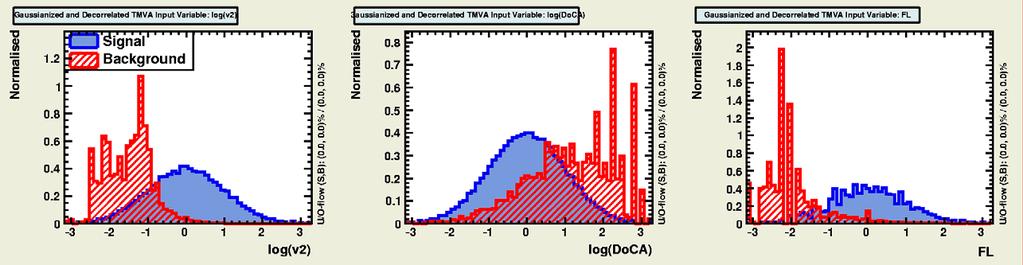
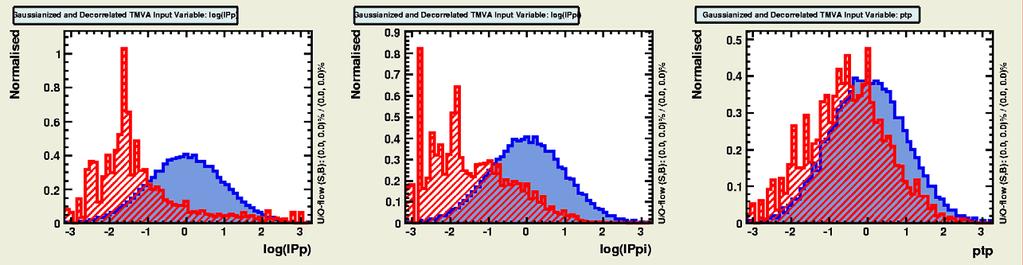
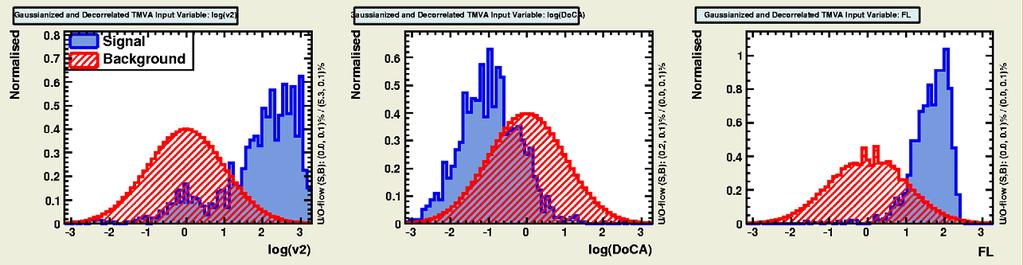
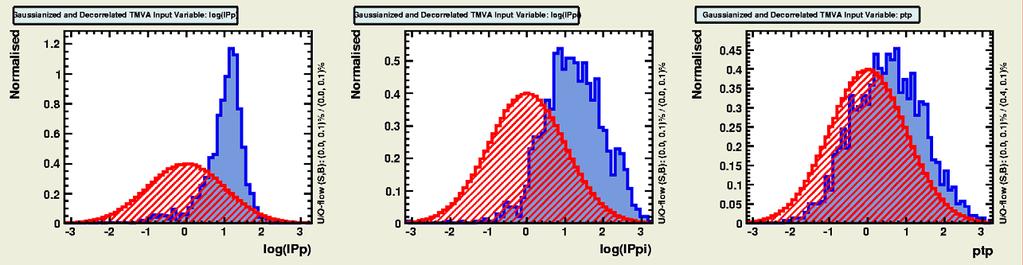
17 Gaussian-isation 17 Background Signal Background Signal -Original -Original - - Gaussianised Gaussianised We cannot simultaneously Gaussianise both signal and background?!
18 Linear Discriminant ( {({})wii1})18 If non parametric methods like k-nearest-neighbour or Kernel Density Estimators suffer from lack of training data curse of dimensionality slow response time need to evaluate the whole training data for every test event use of parametric models y(x) to fit to the training data yx=x,.,xd 1M ii=0i out: these lines are NOT the linear function =Watch y(x), wh(x) Linear Discriminant: yx=x,.,x=w+i.e. any linear function of the input variables: 1D0 Dgiving rise to linear decision boundaries i=xh1 x 2 How do we determine the weights w that do best?? H 0 but rather the decision boundary given by y(x)=const. x 1
 Maximise the separation between the two classes S and B minimise overlap of the distribution y S (x) and y B (x) maximise the distance between the two mean values of the classes minimise the")
19 19 Helge Voss Fisher s Linear Discriminant 0 + Di=1y(x={x,.,x})=y(x,w)=wwxHow do we determine the weights w that do best?? y(x) Maximise the separation between the two classes S and B minimise overlap of the distribution y S (x) and y B (x) maximise the distance between the two mean values of the classes minimise the variance within each class y S (x) y B (x) maximise B S 2 B S 2 2 y y (E(y ) - E(y )) J(w) = σ + σ TTwBw"inbetween"variance==wWw"within"variancenote: these quantities can be calculated from the training data -1wSB J(w)=0 w W(x-x)the Fisher coefficients

20 Linear Discriminant and non linear correlations Helge Voss 20 assume the following non-linear correlated data: the Linear discriminant obviousl doesn t do a very good job here: Of course, these can easily de-correlated: here: linear discriminator works perfectly on de-correlated data var 0 = var 0 + var1 l 2 2 var 0 = var1 atan var1


21 Linear Discriminant with Quadratic input: 21 A simple extension of the linear decision boundary to quadratic decision boundary: while: var0 var1 var0 * var0 var1 * var1 var0 * var1 linear decision boundaries in var0,var1 quadratic decision boundaries in var0,var1 Performance of Fisher Discriminant: with quadratic input: Fisher Fisher with decorrelated variables Fisher with quadratic input
22 Training Classifiers and Loss-Function All classifiers (KNN,Likelihood,Fisher) could be calculated and didn t require parameter fitting Other classifiers provide a set of basis functions (or model) that need to optimally adjusted to find the appropriate separating hyperplane(surface) Let x R n be a random variable (i.e. our observables) and y(x) y a real valued output variable with joint distribution Pr(x,y) regression y value 1 for signal, y 0 for background classification we are looking for a function y(x) that predicts y given certain input variables: y(x):r n R: Loss function: L(y,y(x)) penalizes errors made in the prediction: EPE(y(x)) = E(y y(x)) 2 squared error loss, typical loss function used in regression by conditioning on x we can write: EPE(y(x)) = E( y-y(x) ) misclassification error, typical loss function for classification problems Helge Voss 22
23 Neural Networks 23 naturally, if we want to go the arbitrary non-linear decision boundaries, y(x) needs to be constructed in any non-linear fashion y(x)= M i ( w ) ih i(x) Think of h i (x) as a set of basis functions If h(x) is sufficiently general (i.e. non linear), a linear combination of enough basis function should allow to describe any possible discriminating function y(x) K.Weierstrass Theorem: proves just that previous statement. Imagine you chose h i (x) to be such that: y(x)= w A w + w x 1 D A(x)= M D 0i i0 ij j i j=1 1-e x : the sigmoid function y(x) = a linear combination of non linear functions of of linear combination of the input data Now we only need to find the appropriate weights w
24 Neural Networks: Multilayer Perceptron MLP 24 But before talking about the weights, let s try to interpret the formula as a Neural Network: D var discriminating input variables as input + 1 offset input layer hidden layer ouput layer 1. i. w j1 w ij w 11 w 1j 1. j. k... output: y(x)= w A w + w x M 0i i0 D ij j i j=1 Activation function e.g. sigmoid: Ax ( ) = 1+ x ( e ) 1 D or tanh D+1 M 1 Nodes in hidden layer represent the activation functions whose arguments are linear combinations of input variables non-linear response to the input The output is a linear combination of the output of the activation functions at the internal nodes Input to the layers from preceding nodes only feed forward network (no backward loops) It is straightforward to extend this to several input layers
25 Neural Networks: Multilayer Perceptron MLP 25 But before talking about the weights, let s try to interpret the formula as a Neural Network: D var discriminating input variables as input + 1 offset input layer hidden layer ouput layer 1. i. w j1 w ij w 11 w 1j 1. j. k... output: y(x)= w A w + w x M 0i i0 D ij j i j=1 Activation function e.g. sigmoid: Ax ( ) = 1+ x ( e ) 1 D or tanh D+1 M 1 nodes neurons links(weights) synapses Neural network: try to simulate reactions of a brain to certain stimulus (input data)
26 Neural Network Training forc=26 idea: using the training events adjust the weights such, that y(x) 0 for background events y(x) 1 for signal events how do we adjust? minimize Loss function: yevents i 2 where ( C) i L(w) = (y(x ) y(c)) i.e. use usual sum of squares 0f 1signal=or. C=backgrpredicted true event type event type y(x) is a very wiggly function with many local minima. A global overall fit in the many parameters is possible but not the most efficient method to train neural networks back propagation (learn from experience, gradually adjust your perception to match reality online learning (learn event by event -- not only at the end of your life from all experience)
27 Neural Network Training back-propagation and online learning () 27 start with random weights adjust weights in each step a bit in the direction of the steepest descend of the Loss - function L n 1 n w w η η learning rate = i + = + LwwM for weights connected to output nodes = D i j=1 L w 0i D = y(x)-y(c) A w + w x j=1 ( ) i0 ij j for weights connected to output nodes a bit more complicated formula note: all these gradients are easily calculated from the training event L(w) (y(x ) y(c)) y(x)= w A w + w x 0i i0 ij j 2 training is repeated n-times over the whole training data sample. how often?? for online learning, the training events should be mixed randomly, otherwise you first steer in a wrong direction from which it is afterwards hard to get out again!
28 Overtraining 28 training is repeated n-times over the whole training data sample. how often?? it seems intuitive that this boundary will give better results in another statistically independent data set than that one x 2 S x 2 S B B stop training before you learn statistical fluctuations in the data x 1 verify on independent test sample possible overtraining is concern for every tunable parameter α of classifiers: Smoothing parameter, n-nodes classificaion error x 1 test sample training sample training cycles α
29 29 Cross Validation many (all) classifiers have tuning parameters α that need to be controlled against overtraining number of training cycles, number of nodes (neural net) smoothing parameter h (kernel density estimator). the more free parameter a classifier has to adjust internally more prone to overtraining more training data better training results division of data set into training and test sample reduces the training data Cross Validation: divide the data sample into say 5 sub-sets Train Test Train Test Train Test Test Train Train Test train 5 classifiers: y i (x,α) : i=1,..5, classifier y i (x,α) is trained without the i-th sub sample calculate the test error: events 1 CV( α) = L(y i(x k, α)) L : loss function N events choose tuning parameter α for which CV(α) is minimum and train the final classifier using all data k
30 30 What is the best Network Architecture? Theoretically a single hidden layer is enough for any problem, provided one allows for sufficient number of nodes. (K.Weierstrass theorem) Relatively little is known concerning advantages and disadvantages of using a single hidden layer with many nodes over many hidden layers with fewer nodes. The mathematics and approximation theory of the MLP model with more than one hdden layer is not very well understood. nonetheless there seems to be reason to conjecture that the two hidden layer model may be significantly more promising than the single hidden layer model (Glen Cowan) A.Pinkus, Approximation theory of the MLP model with neural networks, Acta Numerica (1999),pp Typically in high-energy physics, non-linearities are reasonably simple, in many cases 1 layer with a larger number of nodes should be enough but it might well be worth trying more layers (and less nodes in each layer)
Advanced statistical methods for data analysis Lecture 2
 Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Learning from Data: Multi-layer Perceptrons
 Learning from Data: Multi-layer Perceptrons Amos Storkey, School of Informatics University of Edinburgh Semester, 24 LfD 24 Layered Neural Networks Background Single Neurons Relationship to logistic regression.
Learning from Data: Multi-layer Perceptrons Amos Storkey, School of Informatics University of Edinburgh Semester, 24 LfD 24 Layered Neural Networks Background Single Neurons Relationship to logistic regression.
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Statistical Methods in Particle Physics
 Statistical Methods in Particle Physics 8. Multivariate Analysis Prof. Dr. Klaus Reygers (lectures) Dr. Sebastian Neubert (tutorials) Heidelberg University WS 2017/18 Multi-Variate Classification Consider
Statistical Methods in Particle Physics 8. Multivariate Analysis Prof. Dr. Klaus Reygers (lectures) Dr. Sebastian Neubert (tutorials) Heidelberg University WS 2017/18 Multi-Variate Classification Consider
Multivariate Analysis, TMVA, and Artificial Neural Networks
 http://tmva.sourceforge.net/ Multivariate Analysis, TMVA, and Artificial Neural Networks Matt Jachowski jachowski@stanford.edu 1 Multivariate Analysis Techniques dedicated to analysis of data with multiple
http://tmva.sourceforge.net/ Multivariate Analysis, TMVA, and Artificial Neural Networks Matt Jachowski jachowski@stanford.edu 1 Multivariate Analysis Techniques dedicated to analysis of data with multiple
1 What a Neural Network Computes
 Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Multilayer Perceptrons and Backpropagation
 Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Lecture 2. G. Cowan Lectures on Statistical Data Analysis Lecture 2 page 1
 Lecture 2 1 Probability (90 min.) Definition, Bayes theorem, probability densities and their properties, catalogue of pdfs, Monte Carlo 2 Statistical tests (90 min.) general concepts, test statistics,
Lecture 2 1 Probability (90 min.) Definition, Bayes theorem, probability densities and their properties, catalogue of pdfs, Monte Carlo 2 Statistical tests (90 min.) general concepts, test statistics,
Intelligent Systems Discriminative Learning, Neural Networks
 Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
18.6 Regression and Classification with Linear Models
 18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Multivariate statistical methods and data mining in particle physics
 Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Multivariate statistical methods and data mining in particle physics RHUL Physics www.pp.rhul.ac.uk/~cowan Academic Training Lectures CERN 16 19 June, 2008 1 Outline Statement of the problem Some general
Applied Statistics. Multivariate Analysis - part II. Troels C. Petersen (NBI) Statistics is merely a quantization of common sense 1
 Statistics is merely a quantization of common sense 1") Applied Statistics Multivariate Analysis - part II Troels C. Petersen (NBI) Statistics is merely a quantization of common sense 1 Fisher Discriminant You want to separate two types/classes (A and B) of
Applied Statistics Multivariate Analysis - part II Troels C. Petersen (NBI) Statistics is merely a quantization of common sense 1 Fisher Discriminant You want to separate two types/classes (A and B) of
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
AI Programming CS F-20 Neural Networks
 AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
Linear Models for Classification
 Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Classification with Perceptrons. Reading:
 Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Artificial Neural Networks
 Artificial Neural Networks Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Knowledge
Artificial Neural Networks Stephan Dreiseitl University of Applied Sciences Upper Austria at Hagenberg Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support Knowledge
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
MLPR: Logistic Regression and Neural Networks
 MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition Amos Storkey Amos Storkey MLPR: Logistic Regression and Neural Networks 1/28 Outline 1 Logistic Regression 2 Multi-layer
MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition Amos Storkey Amos Storkey MLPR: Logistic Regression and Neural Networks 1/28 Outline 1 Logistic Regression 2 Multi-layer
Outline. MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition. Which is the correct model? Recap.
 Outline MLPR: and Neural Networks Machine Learning and Pattern Recognition 2 Amos Storkey Amos Storkey MLPR: and Neural Networks /28 Recap Amos Storkey MLPR: and Neural Networks 2/28 Which is the correct
Outline MLPR: and Neural Networks Machine Learning and Pattern Recognition 2 Amos Storkey Amos Storkey MLPR: and Neural Networks /28 Recap Amos Storkey MLPR: and Neural Networks 2/28 Which is the correct
Statistical Methods for Particle Physics Lecture 2: multivariate methods
 Statistical Methods for Particle Physics Lecture 2: multivariate methods http://indico.ihep.ac.cn/event/4902/ istep 2015 Shandong University, Jinan August 11-19, 2015 Glen Cowan ( 谷林 科恩 ) Physics Department
Statistical Methods for Particle Physics Lecture 2: multivariate methods http://indico.ihep.ac.cn/event/4902/ istep 2015 Shandong University, Jinan August 11-19, 2015 Glen Cowan ( 谷林 科恩 ) Physics Department
Linear Classification. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Linear Classification CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Example of Linear Classification Red points: patterns belonging
Linear Classification CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Example of Linear Classification Red points: patterns belonging
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Lecture 3: Pattern Classification. Pattern classification
 EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
EE E68: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mitures and
Week 5: Logistic Regression & Neural Networks
 Week 5: Logistic Regression & Neural Networks Instructor: Sergey Levine 1 Summary: Logistic Regression In the previous lecture, we covered logistic regression. To recap, logistic regression models and
Week 5: Logistic Regression & Neural Networks Instructor: Sergey Levine 1 Summary: Logistic Regression In the previous lecture, we covered logistic regression. To recap, logistic regression models and
Computational statistics
 Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers
 Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Lecture 3: Pattern Classification
 EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
EE E6820: Speech & Audio Processing & Recognition Lecture 3: Pattern Classification 1 2 3 4 5 The problem of classification Linear and nonlinear classifiers Probabilistic classification Gaussians, mixtures
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
Multivariate Analysis Techniques in HEP
 Multivariate Analysis Techniques in HEP Jan Therhaag IKTP Institutsseminar, Dresden, January 31 st 2013 Multivariate analysis in a nutshell Neural networks: Defeating the black box Boosted Decision Trees:
Multivariate Analysis Techniques in HEP Jan Therhaag IKTP Institutsseminar, Dresden, January 31 st 2013 Multivariate analysis in a nutshell Neural networks: Defeating the black box Boosted Decision Trees:
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
The Bayes classifier
 The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
The Bayes classifier Consider where is a random vector in is a random variable (depending on ) Let be a classifier with probability of error/risk given by The Bayes classifier (denoted ) is the optimal
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS
 CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
CS 179: LECTURE 16 MODEL COMPLEXITY, REGULARIZATION, AND CONVOLUTIONAL NETS LAST TIME Intro to cudnn Deep neural nets using cublas and cudnn TODAY Building a better model for image classification Overfitting
Mining Classification Knowledge
 Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Mining Classification Knowledge Remarks on NonSymbolic Methods JERZY STEFANOWSKI Institute of Computing Sciences, Poznań University of Technology COST Doctoral School, Troina 2008 Outline 1. Bayesian classification
Classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
Classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Topics Discriminant functions Logistic regression Perceptron Generative models Generative vs. discriminative
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Multilayer Perceptron = FeedForward Neural Network
 Multilayer Perceptron = FeedForward Neural Networ History Definition Classification = feedforward operation Learning = bacpropagation = local optimization in the space of weights Pattern Classification
Multilayer Perceptron = FeedForward Neural Networ History Definition Classification = feedforward operation Learning = bacpropagation = local optimization in the space of weights Pattern Classification
Mark Gales October y (x) x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.
 x 1. x 2 y (x) Inputs. Outputs. x d. y (x) Second Output layer layer. layer.") University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
University of Cambridge Engineering Part IIB & EIST Part II Paper I0: Advanced Pattern Processing Handouts 4 & 5: Multi-Layer Perceptron: Introduction and Training x y (x) Inputs x 2 y (x) 2 Outputs x
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Multi-layer Neural Networks
 Multi-layer Neural Networks Steve Renals Informatics 2B Learning and Data Lecture 13 8 March 2011 Informatics 2B: Learning and Data Lecture 13 Multi-layer Neural Networks 1 Overview Multi-layer neural
Multi-layer Neural Networks Steve Renals Informatics 2B Learning and Data Lecture 13 8 March 2011 Informatics 2B: Learning and Data Lecture 13 Multi-layer Neural Networks 1 Overview Multi-layer neural
Multivariate Data Analysis Techniques
 Multivariate Data Analysis Techniques Andreas Hoecker (CERN) Workshop on Statistics, Karlsruhe, Germany, Oct 12 14, 2009 O u t l i n e Introduction to multivariate classification and regression Multivariate
Multivariate Data Analysis Techniques Andreas Hoecker (CERN) Workshop on Statistics, Karlsruhe, Germany, Oct 12 14, 2009 O u t l i n e Introduction to multivariate classification and regression Multivariate
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Classification: The rest of the story
 U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
U NIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN CS598 Machine Learning for Signal Processing Classification: The rest of the story 3 October 2017 Today s lecture Important things we haven t covered yet Fisher
Statistical Methods for Particle Physics Lecture 2: statistical tests, multivariate methods
 Statistical Methods for Particle Physics Lecture 2: statistical tests, multivariate methods www.pp.rhul.ac.uk/~cowan/stat_aachen.html Graduierten-Kolleg RWTH Aachen 10-14 February 2014 Glen Cowan Physics
Statistical Methods for Particle Physics Lecture 2: statistical tests, multivariate methods www.pp.rhul.ac.uk/~cowan/stat_aachen.html Graduierten-Kolleg RWTH Aachen 10-14 February 2014 Glen Cowan Physics
Hypothesis testing:power, test statistic CMS:
 Hypothesis testing:power, test statistic The more sensitive the test, the better it can discriminate between the null and the alternative hypothesis, quantitatively, maximal power In order to achieve this
Hypothesis testing:power, test statistic The more sensitive the test, the better it can discriminate between the null and the alternative hypothesis, quantitatively, maximal power In order to achieve this
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones
 Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Introduction to machine learning and pattern recognition Lecture 2 Coryn Bailer-Jones http://www.mpia.de/homes/calj/mlpr_mpia2008.html 1 1 Last week... supervised and unsupervised methods need adaptive
Kernel Methods. Barnabás Póczos
 Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Notes on Discriminant Functions and Optimal Classification
 Notes on Discriminant Functions and Optimal Classification Padhraic Smyth, Department of Computer Science University of California, Irvine c 2017 1 Discriminant Functions Consider a classification problem
Notes on Discriminant Functions and Optimal Classification Padhraic Smyth, Department of Computer Science University of California, Irvine c 2017 1 Discriminant Functions Consider a classification problem
Machine Learning 2nd Edition
 INTRODUCTION TO Lecture Slides for Machine Learning 2nd Edition ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://www.cs.tau.ac.il/~apartzin/machinelearning/ The MIT Press, 2010
INTRODUCTION TO Lecture Slides for Machine Learning 2nd Edition ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://www.cs.tau.ac.il/~apartzin/machinelearning/ The MIT Press, 2010
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Introduction Neural Networks - Architecture Network Training Small Example - ZIP Codes Summary. Neural Networks - I. Henrik I Christensen
 Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Feature Engineering, Model Evaluations
 Feature Engineering, Model Evaluations Giri Iyengar Cornell University gi43@cornell.edu Feb 5, 2018 Giri Iyengar (Cornell Tech) Feature Engineering Feb 5, 2018 1 / 35 Overview 1 ETL 2 Feature Engineering
Feature Engineering, Model Evaluations Giri Iyengar Cornell University gi43@cornell.edu Feb 5, 2018 Giri Iyengar (Cornell Tech) Feature Engineering Feb 5, 2018 1 / 35 Overview 1 ETL 2 Feature Engineering
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
Introduction to Neural Networks
 Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
ESS2222. Lecture 4 Linear model
 ESS2222 Lecture 4 Linear model Hosein Shahnas University of Toronto, Department of Earth Sciences, 1 Outline Logistic Regression Predicting Continuous Target Variables Support Vector Machine (Some Details)
ESS2222 Lecture 4 Linear model Hosein Shahnas University of Toronto, Department of Earth Sciences, 1 Outline Logistic Regression Predicting Continuous Target Variables Support Vector Machine (Some Details)
Introduction to Neural Networks
 CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
CUONG TUAN NGUYEN SEIJI HOTTA MASAKI NAKAGAWA Tokyo University of Agriculture and Technology Copyright by Nguyen, Hotta and Nakagawa 1 Pattern classification Which category of an input? Example: Character
Linear discriminant functions
 Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
Data Mining. Linear & nonlinear classifiers. Hamid Beigy. Sharif University of Technology. Fall 1396
 Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Pattern Classification
 Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Machine Learning 2017
 Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
Machine Learning 2017 Volker Roth Department of Mathematics & Computer Science University of Basel 21st March 2017 Volker Roth (University of Basel) Machine Learning 2017 21st March 2017 1 / 41 Section
Probabilistic classification CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2016
 Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Probabilistic classification CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2016 Topics Probabilistic approach Bayes decision theory Generative models Gaussian Bayes classifier
Learning from Data Logistic Regression
 Learning from Data Logistic Regression Copyright David Barber 2-24. Course lecturer: Amos Storkey a.storkey@ed.ac.uk Course page : http://www.anc.ed.ac.uk/ amos/lfd/ 2.9.8.7.6.5.4.3.2...2.3.4.5.6.7.8.9
Learning from Data Logistic Regression Copyright David Barber 2-24. Course lecturer: Amos Storkey a.storkey@ed.ac.uk Course page : http://www.anc.ed.ac.uk/ amos/lfd/ 2.9.8.7.6.5.4.3.2...2.3.4.5.6.7.8.9
Feed-forward Network Functions
 Feed-forward Network Functions Sargur Srihari Topics 1. Extension of linear models 2. Feed-forward Network Functions 3. Weight-space symmetries 2 Recap of Linear Models Linear Models for Regression, Classification
Feed-forward Network Functions Sargur Srihari Topics 1. Extension of linear models 2. Feed-forward Network Functions 3. Weight-space symmetries 2 Recap of Linear Models Linear Models for Regression, Classification
CSC321 Lecture 8: Optimization
 CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
CSC321 Lecture 8: Optimization Roger Grosse Roger Grosse CSC321 Lecture 8: Optimization 1 / 26 Overview We ve talked a lot about how to compute gradients. What do we actually do with them? Today s lecture:
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
A summary of Deep Learning without Poor Local Minima
 A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
A summary of Deep Learning without Poor Local Minima by Kenji Kawaguchi MIT oral presentation at NIPS 2016 Learning Supervised (or Predictive) learning Learn a mapping from inputs x to outputs y, given
Classification. Sandro Cumani. Politecnico di Torino
 Politecnico di Torino Outline Generative model: Gaussian classifier (Linear) discriminative model: logistic regression (Non linear) discriminative model: neural networks Gaussian Classifier We want to
Politecnico di Torino Outline Generative model: Gaussian classifier (Linear) discriminative model: logistic regression (Non linear) discriminative model: neural networks Gaussian Classifier We want to
Machine Learning (CS 567) Lecture 5
 Lecture 5") Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 5 Time: T-Th 5:00pm - 6:20pm Location: GFS 118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning Lecture 10
 Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Lecture 3 Feedforward Networks and Backpropagation
 Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
Lecture 3 Feedforward Networks and Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 3, 2017 Things we will look at today Recap of Logistic Regression
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
Bits of Machine Learning Part 1: Supervised Learning
 Bits of Machine Learning Part 1: Supervised Learning Alexandre Proutiere and Vahan Petrosyan KTH (The Royal Institute of Technology) Outline of the Course 1. Supervised Learning Regression and Classification
Bits of Machine Learning Part 1: Supervised Learning Alexandre Proutiere and Vahan Petrosyan KTH (The Royal Institute of Technology) Outline of the Course 1. Supervised Learning Regression and Classification
Backpropagation Introduction to Machine Learning. Matt Gormley Lecture 12 Feb 23, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 12 Feb 23, 2018 1 Neural Networks Outline
AN INTRODUCTION TO NEURAL NETWORKS. Scott Kuindersma November 12, 2009
 AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Natural Language Processing. Classification. Features. Some Definitions. Classification. Feature Vectors. Classification I. Dan Klein UC Berkeley
 Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Midterm: CS 6375 Spring 2018
 Midterm: CS 6375 Spring 2018 The exam is closed book (1 cheat sheet allowed). Answer the questions in the spaces provided on the question sheets. If you run out of room for an answer, use an additional
Midterm: CS 6375 Spring 2018 The exam is closed book (1 cheat sheet allowed). Answer the questions in the spaces provided on the question sheets. If you run out of room for an answer, use an additional
The classifier. Theorem. where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know
 The Bayes classifier Theorem The classifier satisfies where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know Alternatively, since the maximum it is
The Bayes classifier Theorem The classifier satisfies where the min is over all possible classifiers. To calculate the Bayes classifier/bayes risk, we need to know Alternatively, since the maximum it is
The classifier. Linear discriminant analysis (LDA) Example. Challenges for LDA
 Example. Challenges for LDA") The Bayes classifier Linear discriminant analysis (LDA) Theorem The classifier satisfies In linear discriminant analysis (LDA), we make the (strong) assumption that where the min is over all possible classifiers.
The Bayes classifier Linear discriminant analysis (LDA) Theorem The classifier satisfies In linear discriminant analysis (LDA), we make the (strong) assumption that where the min is over all possible classifiers.
The Multi-Layer Perceptron
 EC 6430 Pattern Recognition and Analysis Monsoon 2011 Lecture Notes - 6 The Multi-Layer Perceptron Single layer networks have limitations in terms of the range of functions they can represent. Multi-layer
EC 6430 Pattern Recognition and Analysis Monsoon 2011 Lecture Notes - 6 The Multi-Layer Perceptron Single layer networks have limitations in terms of the range of functions they can represent. Multi-layer
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
9 Classification. 9.1 Linear Classifiers
 9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive