In the Name of God. Lectures 15&16: Radial Basis Function Networks
|
|
|
- Terence Patrick
- 6 years ago
- Views:
Transcription


1 1 In the Name of God Lectures 15&16: Radial Basis Function Networks
2 Some Historical Notes Learning is equivalent to finding a surface in a multidimensional space that provides a best fit to the training data. Cover (1965): A pattern-classification problem cast in a high-dimensional space is more likely to be linearly separable than in a low-dimensional space. Powell (1985): Radial-basis functions were introduced in the solution of the real multivariate interpolation problem. Broomhead and Lowe (1988) were the first to exploit the use of radial-basis functions in the design of neural networks. Mhaskar, Niyogi and Girosi (1996): The dimension of the hidden space is directly related to the capacity of the network to approximate a smooth input-output mapping (the higher h the dimension i of the hidden space, the more accurate the approximation will be).
3 Radial-Basis Function Networks In its most basic form Radial-Basis Function (RBF) network involves three layers with entirely different roles. The input layer is made up of source nodes that connect the network to its environment. The second layer, the only hidden layer, applies a nonlinear transformation from the input space to the hidden space. The output layer is linear, supplying the response of the network to the activation pattern applied to the input layer.
4 Radial-Basis Function Networks They are Feedforward neural networks compute activations at the hidden neurons using an exponential of a [Euclidean] distance measure between the input vector and a prototype t vector that characterizes the signal function at a hidden neuron. Originally introduced into the literature for the purpose p of interpolation of data points on a finite training set
5 In MLP
6 In RBFN
7 Architecture x 1 h 1 x 2 h 2 W 1 2 W 2 x 3 h 3 W 3 f(x) W m x n h m Input layer Hidden layer Output layer
8 Three layers Input layer Source nodes that connect to the network of its environment Hidden layer Hidden units provide a set of basis functions High dimensionality Output layer Linear combination of hidden functions
9 Linear Models A linear model for a function f(x) takes the form: The model f(.) is expressed as a linear combination of a set of m basis functions. The freedom to choose different values for the weights, derives the flexibility of f(.), its ability to fit many different functions. Any set of functions can be used as the basis set, however, models containing only basis functions drawn from one particular class have a special interest. h(x) is mostly Gaussian function
10 Special Base Functions Classical statistics - polynomials base functions: Signal processing applications - combinations of sinusoidal waves (Fourier series): Artificial neural networks (particularly in multi-layer perceptrons) - logistic functions:
11 Example the straight line A linear model of the form: f(x) = ax + b Which has two basis functions: h 1 (x) = 1, h 2 (x) = x Its weights are: w 1 = b, w 2 = a
12 Radial Functions Characteristic feature - their response decreases (or increases) monotonically with distance from a central point. The center, the distance scale, and the precise shape of the radial function are parameters of the model, all fixed if it is linear. Typical radial functions are: The Gaussian RBF (monotonically decreases with distance from the center). A multiquadric RBF (monotonically increases with distance from the center).
13 Radial functions Gaussian RBF: c: center, r: radius 2 ( x c) ) exp 2 h( x) r Multiquadric RBF h( x) r 2 ( x r c) 2 monotonically decreases with distance from center monotonically increases with distance from center
14 Radial Functions Gaussian RBF multiqradric i RBF
15 Cover s Theorem A complex pattern-classification problem cast in high-dimensional space nonlinearly is more likely to be linearly separable than in a low dimensional space (Cover, 1965)
16 Introduction to Cover s Theorem Let X denote a set of N patterns (points) x1, 1 x2, 2 x 3,, x N Each point is assigned to one of two classes: X + and X - This dichotomy is separable if there exists a surface that t separates these two classes of points.
17 Introduction to Cover s Theorem For each pattern x X define the vector: ( x) ( x), ( x),..., ( x) T 1 2 The vector (x) maps points in a p-dimensional input space into corresponding points in a new space of dimension m. Each i ( x) is a hidden function, i.e., a hidden unit m
18 Introduction to Cover s Theorem A dichotomy {X +,X - } is said to be φ-separable if there exist an m-dimensional vector w such that we may write (Cover, 1965): w T φ(x) 0, x X + w T φ(x) < 0, x X - The hyperplane defined by w T φ(x) = 0, is the separating surface between the two classes. Given a set of patterns X in an input space of arbitrary dimension p, we can usually find a nonlinear mapping φ(x) of high enough dimension m such that we have linear separability in the φ space.
19 Examples of φ-separable Dichotomies Linearly Separable Spherically Separable Quadrically Separable
20 Back to the XOR Problem Recall that in the XOR problem, there are four patterns (points), namely, (0,0),(0,1),(1,0),(1,1), (00)(01)(10)(11) in a two dimensional input space. We would like to construct a pattern classifier that produces the output 0 for the input patterns (0,0),(1,1) and the output 1 for the input patterns (0,1),(1,0). We will define a pair of Gaussian hidden functions as follows: x t ( x) e, t x t 2 2 ( x ) e, t 2 2
21 Back to the XOR Problem Using the later pair of Gaussian hidden functions, the input patterns are mapped onto the φ 1 - φ 2 plane, and now the input points can be linearly separable as required. φ 2 φ 2 (0,0) (0,1) (1,0) (1,1) φ 1
22 Interpolation Problem Assume a domain X and a range Y taken to be metric space, and that is related by a fixed but unknown mapping f. The problem of reconstructing the mapping f is said to be well-posed if three conditions are satisfied: Existence: For every input vector x H, there does exist an output y=f(x), where y H. Uniqueness: For any pair of input vectors x,t H, we have f(x)=f(t) f(t) if, and only if x=t. Continuity: (=stability) for any >0 there exists = ( ) such that the condition x (x,t)< implies that y (f(x),f(t))<, f(t))< where (.,.) ) is the symbol for distance between the two arguments in their respective spaces.
23 Interpolation Problem Given T = {X d k } X n k, k} k, dk Solving the interpolation problem means finding the map f(x k ) = d k, k = 1,,Q (target points are scalars for simplicity of exposition) RBFN assumes a set of exactly Q non-linear basis functions φ( X - X i ) Map is generated using a superposition of these N F( x) w ( x x ) i 1 i i
24 Application of Interpolation in Signal Processing Converting digital signals to continuous signal Up-sampling
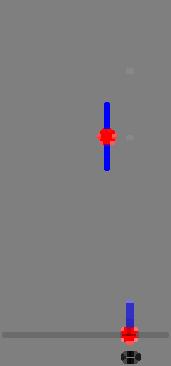
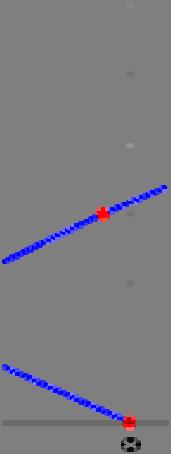



25 Uniqueness of Interpolation Problem Nearest-neighbor interpolation Linear interpolation
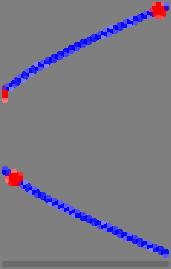


26 Regularized Interpolation Has Unique Answer
27 Exact Interpolation Equation Interpolation conditions Matrix definitions Yields a compact matrix equation
28 Michelli Functions Gaussian functions Multiquadrics Inverse multiquadrics
29 Solving the Interpolation Problem Choosing correctly ensures invertibility: W = -1 D Solution is a set of weights such that the interpolating surface generated passes through exactly every data point Common form of is the localized Gaussian basis function with center and spread
30 Radial Basis Function Network x 1 1 x 2 2 x n Q
31 Interpolation Example Assume a noisy data scatter of Q = 10 data points Generator: 2sin(x) +x In the graphs that follow: data scatter (indicated by small triangles) is shown along the generating function (the fine line) interpolation shown by the thick line = 1 =
32 Derivative Square Function = 1 = 0.3
33 Notes Making the spread factor smaller makes the function increasingly non-smooth being able to achieve a 100 per cent mapping accuracy on the ten data points rather than smoothness of the interpolation Quantify the oscillatory behavior of the interpolants by considering their derivatives Taking the derivative of the function Square it (to make it positive everywhere) Measure the areas under the curves Provides a nice measure of the non-smoothness the greater the area, the more non-smooth the function!
34 Problems Oscillatory behavior is highly undesirable for proper generalization Better generalization is achievable with smoother functions which are fitted to noisy data Number of basis functions in the expansion is equal to the number of data points! Not possible to have for real-world datasets, which can be extremely large Computational and storage requirements for them can explode very quickly
35 The RBFN Solution Choose the number of basis functions to be some number q < Q No longer restrict the centers of the basis functions to be fixed to the data point values. Now made trainable parameters of the model Spreads of each of the basis functions is permitted to be different and trainable. Learning can be done either by supervised or unsupervised techniques A bias is included in the final linear superposition Assume centers and spreads of the basis functions are optimized and fixed Proceed to determine the hidden output neuron weights using the procedure adopted in the interpolation case
36 Solving the Problem in a Least Squares Sense To formalize this, consider interpolating a set of data points with a number q < Q Then, Introduce the notion of error since the interpolation is not exact Input Centre
37 Compute the Optimal Weights Differentiating w.r.t. w i and setting it equal to zero Then, This yields Equation solved using singular value decomposition where Pseudo-inverse (is not square: q Q)
38 More generalization Straightforward to include a bias term w 0 into the approximation equation Basis function is generally chosen to be the Gaussian RBFs can be generalized to include arbitrary covariance matrices K i Universal approximator RBFNs have the best approximation property The set of approximating functions that RBFNs are capable of generating, there is one function that has the minimum approximation error for any given function which has to be approximated



39 RBFN Classifier to Solve the XOR Problem Will serve to show how a bias term is included at the output linear neuron RBFN classifier is assumed to have two basis functions centered at data points 1 and 4 The basis functions
40 RBFN Classifier to Solve the XOR Problem +1 x 1 1 w 1 w 2 f x 2 2 Basis functions centered at data points 1 and 4 We have the D, W, vectors and matrices as shown alongside Pseudo inverse and weight vector
41 Ill-Posed and Well-Posed Problems Ill-posed problems originally identified by Hadamard in the context t of partial differential equations. Problems are well-posed if their solutions satisfy three conditions: they exist they are unique they depend continuously on the data set Problems that are not well-posed are ill-posed Example differentiation is an ill-posed problem because some solutions need not depend continuously on the data inverse kinematics problem which maps external real-world movements into an internal coordinate system is also an ill- posed problem
42 Approximation Problem is Ill-Posed The solution to the problem is not unique Sufficient i data is not available to reconstruct t the mapping uniquely Data points are generally noisy The solution to the ill-posed approximation problem lies in regularization essentially requires the introduction of certain constraints that impose a restriction on the solution space Necessarily problem dependent Regularization techniques impose smoothness constraints on the approximating set of functions Some degree of smoothness is necessary for the representative function since it has to be robust against noise
43 Regularization Theory Assume training data T generated by random sampling of fthe function Regularization techniques replace the standard error minimization problem with minimization of a regularization risk functional The main idea behind regularization is to stabilize the solution by means of prior information This is done by including a function in the cost function Only a small number of candidate solutions will minimize this functional These functional terms are called the regularization terms Typically, the functional measure for the smoothness of the function
44 Tikhonov Functional Regularization risk functional comprises two terms error function smoothness functional intuitively iti appealing to consider using function derivatives to characterize smoothness The smoothness functional is expressed as P is a linear differential e operator, is a norm The regularization risk functional to be minimized is regularization parameter
, of a linear differential operator L is any solution of LG(x, s) = δ(x-s), where δ is Dirac delta function) Linear weighted sum of Q Green s")
45 Solving the Euler Lagrange System See complete solution in the textbook! Yields the final solution (Green's function, G(x, s), of a linear differential operator L is any solution of LG(x, s) = δ(x-s), where δ is Dirac delta function) Linear weighted sum of Q Green s functions centered at the data points X i The regularization solution uses Q Green s functions in a weighted summation The nature of the chosen Green s function depends on the kind of differential operator P chosen for the regularization term of R r
46 Solving for Weights Starting point Evaluate the equation at each data point Introduce matrix notation
47 Euclidean Norm Dependence If the differential operator P is rotationally invariant translationally invariant Then, the Green s function G(X,Y) depends only on the Euclidean norm of the difference of the vectors Then,
48 Multivariate Gaussian is a Green s Function Gaussian function defined by is a Green s function defined by the self-adjoint differential operator The final minimizer is then,
49 Desirable Properties of Regularization Networks The regularization network is a universal approximator, that can approximate any multivariate continuous function arbitrarily well, given sufficiently large number of hidden units. The approximation shows the best approximation property (best coefficients i will be found). The solution is optimal: it will minimize the cost functional ( F).
50 Generalized Radial Basis Function Network We now proceed to generalize the RBFN in two steps Reduce the Number of Basis Functions, Use Non-Data Centers Use a Weighted Norm
51 Reduce the Number of Basis Functions, Use Non-Data Centers The approximating function is Interested in minimizing the regualrized risk Simplifying the first term Using the matrix substitutions yields
52 Reduce the Number of Basis Functions, Use Non-Data Centers Simplifying the second term Use the properties of the adjoint of the differential operator and Green s function where Finally And the optimal weights W are obtained as
53 Using a Weighted Norm Replace the standard Euclidean norm by S is a norm-weighting matrix of proper dimension Substituting into the Gaussian yields where K is the covariance matrix With K = 2 I is a restricted form
54 Generalized Radial Basis Function Network Some propertiesp Fewer than Q basis functions (remember Q is the number of samples) A weighted norm to compute distances, which manifests itself as a general covariance matrix A bias weight at the output neuron Tunable weights, centers, and covariance matrices
55 Estimating the parameters Weights wi : already discussed (more next). Regularization parameter : Minimize averaged squared error. Use generalized cross-validation. RBF centers: Randomly select fixed centers. Self-organized selection. Supervised selection.
56 Estimating the Regularization parameter Minimize average squared error: For a fixed, for all Q inputs, calculate the squared error between the true function value and the estimated RBF network output using the. Find the optimal that minimizes this error. Problem: This requires knowledge of the true function values. Generalized cross-validation: Use leave-one-out cross validation. With a fixed, for all Q inputs, find the difference between the target value (from the training set) and the predicted value from the leaveone-out-trained network. This approach depends only on the training set.
57 Selection of the RBF forward selection starts with an empty subset adds one basis function at a time most reduces the sum-squared-error until some chosen criterion stops backward elimination i starts with the full subset removes one basis function at a time least increases the sum-squared-error until the chosen criterion stops decreasing
58 Number of radial basis neurons By designer Max of neurons = number of patterns Min of neurons = ( experimentally determined) More neurons More complex, but smaller tolerance
59 Learning strategies Two levels of Learning Center and spread learning (or determination) Output layer Weights Learning Make # ( parameters) as small as possible Principles of Dimensionality
60 Various learning strategies how the centers of the radial-basis functions of the network are specified. 1. Fixed centers selected at random 2. Self-organized selection of centers 3. Supervised selection of centers
61 Fixed centers selected at random Fixed RBFs of the hidden units The locations of the centers may be chosen randomly from the training dataset We can use different values of centers and widths for each radial basis function -> experimentation ti with training i data is needed d
62 Fixed centers selected at random Only output layer weight is needed to be learned Obtain the value of the output layer weight by pseudo-inverse method Main problem Requires a large training set for a satisfactory level of performance
63 Self-organized selection of centers Hybrid learning self-organized learning to estimate the centers of RBFs in hidden layer supervised learning to estimate t the linear weights of the output layer Self-organized learning of centers by means of clustering Supervised learning of output weights by LMS algorithm (pseudo-inverse method)
64 Self-organized selection of centers k-means clustering
65 Supervised selection of centers All free parameters of the network are changed by supervised learning process 1 E e, e d F ( x ) d w ( n) G( x ) 2 Ci N M 2 * j j j j j i j i j 1 i 1 Use error correction learning LMS to adjust all RBF parameters to minimize the error cost function: Linear weights (output layer): ( n) wi( n 1) wi( n) 1 w( n) Position of centers (hidden layer): i( n 1) i( n) 2 i Width of centers (hidden layer): 1 1 K ( n 1) K ( n) i i i ( n) t ( n) 3 1 i ( n) ( n)
66 Learning formula Linear weights (output layer) N ( n) E( n) ej( n) G( j i( n) C ) i wi ( n) x wi ( n 1) wi ( n) 1, i 1,2,..., M j 1 w ( n) Positions of centers (hidden layer) N ' 1 i j j i C i j i j 1 En ( ) 2 w ( n) e ( n) G ( ( n) ) K [ ( n)] i ( n) x x t i i En ( ) i( n 1) i( n) 2, i 1, 2,..., M ( n) i Spreads of centers (hidden layer) 1 i N ' i( ) j( ) ( j i( ) C ) ( ) i ji j K ( n 1) K ( n ) i i 3 Ki En ( ) w n e n G x n Q n Q ( ) [ ( )][ ( )] T ji n xj i n xj i n K ( n) E( n) 3 1 ( n)
67 Testing and Comparison Tested Adaptive Center RBF against Fixed Center RBF Made use of the cost function given below Analyze differences between two networks Cost Function 1 E 2 N 2 e j j 1 e d F*( x ) d wg( x t ) j j j j i j i C i 1 M i
68 Function Approximation "Plateau" function y = f(x1,x2) used in this example. The data are sampled in the domain - 1<x1<1, -1<x2<1. G. Bugmann, et all, "CLASSIFICATION USING NETWORKS OF NORMALIZED RADIAL BASIS FUNCTIONS", ICAPR 1998.


69 Function Approximation A) Function of a standard RBF net trained on 70 points sampled from Plateau function. Parameters: σ = 0.21, 021 Average RMS error < 0.04 after 30 epochs. 50 hidden nodes B) Function of a standard RBF net with σ = Figure produced for the purpose of indicating the positions of the 70 training i data.
70 Comparison of RBF and MLP RBF has a single hidden layer, while MLP can have many In MLP, hidden and output neurons have the same underlying function. In RBF, they are specialized into distinct functions In RBF, the output layer is linear, but in MLP, all neurons are nonlinear The hidden neurons in RBF calculate the Euclidean norm of the input vector and the center, while in MLP the inner product of the input vector and the weight vector is calculated l MLPs construct global approximations to nonlinear input output mapping. RBF uses exponentially decaying localized nonlinearities (e.g. Gaussians) to construct local approximations to nonlinear input output mappings
71 Locally linear models U = [U 1, U 2,, U p ]: inputs M: number of Locally Linear Model (LLMs) neurons w ij: denotes the LLM parameters of the i-th neuron The validity functions are chosen as normalized Gaussians Normalization is necessary for a proper interpretation of validity functions






72 Locally linear models
73 Locally Linear Model Tree (LoLiMoT) learning algorithm (Nelles 2001) 1. Start with an initial model: Construct the validity functions for the initially given input space partitioning and estimate the LLM parameters. Set M to the initial number of LLMs. If no input space partitioning is available a priori, then set M=1 and start t with a single LLM, which h in fact is a global l linear model since its validity function covers the whole input space with Φ 1 (x) = 1
74 Locally Linear Model Tree (LoLiMoT) learning algorithm (Nelles 2001) 2. Find worst LLM: Calculate a local loss function for each of the i = 1,..., M LLMs. The local loss functions can be computed by weighing the squared model errors with the degree of validity of the corresponding local model according to: Find the worst performing LLM, that is max i (I i ), and denote k as the index of this worst LLM
75 Locally Linear Model Tree (LoLiMoT) learning algorithm (Nelles 2001) 3. Check all divisions: The k-th LLM is considered for further refinement. The hyper-rectangle rectangle of this LLM is split into two halves with an axis-orthogonal split. Divisions in all dimensions are tried. For each division dim=1,,p the following steps are carried out: a. Construction of the multidimensional MFs for both hyperrectangles b. Construction of all validity functions c. Local estimation of the rule consequent parameters for both newly generated LLMs d. Calculation of the loss function for the current overall model
76 Locally Linear Model Tree (LoLiMoT) learning algorithm (Nelles 2001) Initial global linear model Split along x1 or x2 Pick split that minimizes model error (residual)
77 Reading S Haykin, Neural Networks: A Comprehensive y, p Foundation, 2007 (Chapter 6).
Slide05 Haykin Chapter 5: Radial-Basis Function Networks
 Slide5 Haykin Chapter 5: Radial-Basis Function Networks CPSC 636-6 Instructor: Yoonsuck Choe Spring Learning in MLP Supervised learning in multilayer perceptrons: Recursive technique of stochastic approximation,
Slide5 Haykin Chapter 5: Radial-Basis Function Networks CPSC 636-6 Instructor: Yoonsuck Choe Spring Learning in MLP Supervised learning in multilayer perceptrons: Recursive technique of stochastic approximation,
Neural Networks Lecture 4: Radial Bases Function Networks
 Neural Networks Lecture 4: Radial Bases Function Networks H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011. A. Talebi, Farzaneh Abdollahi
Neural Networks Lecture 4: Radial Bases Function Networks H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011. A. Talebi, Farzaneh Abdollahi
ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92
 ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92 BIOLOGICAL INSPIRATIONS Some numbers The human brain contains about 10 billion nerve cells (neurons) Each neuron is connected to the others through 10000
ARTIFICIAL NEURAL NETWORKS گروه مطالعاتي 17 بهار 92 BIOLOGICAL INSPIRATIONS Some numbers The human brain contains about 10 billion nerve cells (neurons) Each neuron is connected to the others through 10000
Radial Basis Function Networks. Ravi Kaushik Project 1 CSC Neural Networks and Pattern Recognition
 Radial Basis Function Networks Ravi Kaushik Project 1 CSC 84010 Neural Networks and Pattern Recognition History Radial Basis Function (RBF) emerged in late 1980 s as a variant of artificial neural network.
Radial Basis Function Networks Ravi Kaushik Project 1 CSC 84010 Neural Networks and Pattern Recognition History Radial Basis Function (RBF) emerged in late 1980 s as a variant of artificial neural network.
Radial Basis Function (RBF) Networks
 Networks") CSE 5526: Introduction to Neural Networks Radial Basis Function (RBF) Networks 1 Function approximation We have been using MLPs as pattern classifiers But in general, they are function approximators Depending
CSE 5526: Introduction to Neural Networks Radial Basis Function (RBF) Networks 1 Function approximation We have been using MLPs as pattern classifiers But in general, they are function approximators Depending
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
Lecture - 24 Radial Basis Function Networks: Cover s Theorem
 Neural Network and Applications Prof. S. Sengupta Department of Electronic and Electrical Communication Engineering Indian Institute of Technology, Kharagpur Lecture - 24 Radial Basis Function Networks:
Neural Network and Applications Prof. S. Sengupta Department of Electronic and Electrical Communication Engineering Indian Institute of Technology, Kharagpur Lecture - 24 Radial Basis Function Networks:
Radial-Basis Function Networks
 Radial-Basis Function etworks A function is radial () if its output depends on (is a nonincreasing function of) the distance of the input from a given stored vector. s represent local receptors, as illustrated
Radial-Basis Function etworks A function is radial () if its output depends on (is a nonincreasing function of) the distance of the input from a given stored vector. s represent local receptors, as illustrated
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
In the Name of God. Lecture 11: Single Layer Perceptrons
 1 In the Name of God Lecture 11: Single Layer Perceptrons Perceptron: architecture We consider the architecture: feed-forward NN with one layer It is sufficient to study single layer perceptrons with just
1 In the Name of God Lecture 11: Single Layer Perceptrons Perceptron: architecture We consider the architecture: feed-forward NN with one layer It is sufficient to study single layer perceptrons with just
Vorlesung Neuronale Netze - Radiale-Basisfunktionen (RBF)-Netze -
-Netze -") Vorlesung Neuronale Netze - Radiale-Basisfunktionen (RBF)-Netze - SS 004 Holger Fröhlich (abg. Vorl. von S. Kaushik¹) Lehrstuhl Rechnerarchitektur, Prof. Dr. A. Zell ¹www.cse.iitd.ernet.in/~saroj Radial
Vorlesung Neuronale Netze - Radiale-Basisfunktionen (RBF)-Netze - SS 004 Holger Fröhlich (abg. Vorl. von S. Kaushik¹) Lehrstuhl Rechnerarchitektur, Prof. Dr. A. Zell ¹www.cse.iitd.ernet.in/~saroj Radial
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Radial-Basis Function Networks
 Radial-Basis Function etworks A function is radial basis () if its output depends on (is a non-increasing function of) the distance of the input from a given stored vector. s represent local receptors,
Radial-Basis Function etworks A function is radial basis () if its output depends on (is a non-increasing function of) the distance of the input from a given stored vector. s represent local receptors,
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
COMP9444: Neural Networks. Vapnik Chervonenkis Dimension, PAC Learning and Structural Risk Minimization
 : Neural Networks Vapnik Chervonenkis Dimension, PAC Learning and Structural Risk Minimization 11s2 VC-dimension and PAC-learning 1 How good a classifier does a learner produce? Training error is the precentage
: Neural Networks Vapnik Chervonenkis Dimension, PAC Learning and Structural Risk Minimization 11s2 VC-dimension and PAC-learning 1 How good a classifier does a learner produce? Training error is the precentage
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
18.6 Regression and Classification with Linear Models
 18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
18.6 Regression and Classification with Linear Models 352 The hypothesis space of linear functions of continuous-valued inputs has been used for hundreds of years A univariate linear function (a straight
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Lecture Notes 1: Vector spaces
 Optimization-based data analysis Fall 2017 Lecture Notes 1: Vector spaces In this chapter we review certain basic concepts of linear algebra, highlighting their application to signal processing. 1 Vector
Optimization-based data analysis Fall 2017 Lecture Notes 1: Vector spaces In this chapter we review certain basic concepts of linear algebra, highlighting their application to signal processing. 1 Vector
Statistical Pattern Recognition
 Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Linear vs Non-linear classifier. CS789: Machine Learning and Neural Network. Introduction
 Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Radial Basis Functions Networks to hybrid neuro-genetic RBFΝs in Financial Evaluation of Corporations
 Radial Basis Functions Networks to hybrid neuro-genetic RBFΝs in Financial Evaluation of Corporations Loukeris Nikolaos University of Essex Email: nikosloukeris@gmail.com Abstract:- Financial management
Radial Basis Functions Networks to hybrid neuro-genetic RBFΝs in Financial Evaluation of Corporations Loukeris Nikolaos University of Essex Email: nikosloukeris@gmail.com Abstract:- Financial management
Linear Models for Regression. Sargur Srihari
 Linear Models for Regression Sargur srihari@cedar.buffalo.edu 1 Topics in Linear Regression What is regression? Polynomial Curve Fitting with Scalar input Linear Basis Function Models Maximum Likelihood
Linear Models for Regression Sargur srihari@cedar.buffalo.edu 1 Topics in Linear Regression What is regression? Polynomial Curve Fitting with Scalar input Linear Basis Function Models Maximum Likelihood
ADAPTIVE NEURO-FUZZY INFERENCE SYSTEMS
 ADAPTIVE NEURO-FUZZY INFERENCE SYSTEMS RBFN and TS systems Equivalent if the following hold: Both RBFN and TS use same aggregation method for output (weighted sum or weighted average) Number of basis functions
ADAPTIVE NEURO-FUZZY INFERENCE SYSTEMS RBFN and TS systems Equivalent if the following hold: Both RBFN and TS use same aggregation method for output (weighted sum or weighted average) Number of basis functions
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Advanced statistical methods for data analysis Lecture 2
 Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
Advanced statistical methods for data analysis Lecture 2 RHUL Physics www.pp.rhul.ac.uk/~cowan Universität Mainz Klausurtagung des GK Eichtheorien exp. Tests... Bullay/Mosel 15 17 September, 2008 1 Outline
9.2 Support Vector Machines 159
 9.2 Support Vector Machines 159 9.2.3 Kernel Methods We have all the tools together now to make an exciting step. Let us summarize our findings. We are interested in regularized estimation problems of
9.2 Support Vector Machines 159 9.2.3 Kernel Methods We have all the tools together now to make an exciting step. Let us summarize our findings. We are interested in regularized estimation problems of
CIS 520: Machine Learning Oct 09, Kernel Methods
 CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
Plan of Class 4. Radial Basis Functions with moving centers. Projection Pursuit Regression and ridge. Principal Component Analysis: basic ideas
 Plan of Class 4 Radial Basis Functions with moving centers Multilayer Perceptrons Projection Pursuit Regression and ridge functions approximation Principal Component Analysis: basic ideas Radial Basis
Plan of Class 4 Radial Basis Functions with moving centers Multilayer Perceptrons Projection Pursuit Regression and ridge functions approximation Principal Component Analysis: basic ideas Radial Basis
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Feedforward Neural Nets and Backpropagation
 Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Unit III. A Survey of Neural Network Model
 Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
Linear Regression and Its Applications
 Linear Regression and Its Applications Predrag Radivojac October 13, 2014 Given a data set D = {(x i, y i )} n the objective is to learn the relationship between features and the target. We usually start
Linear Regression and Its Applications Predrag Radivojac October 13, 2014 Given a data set D = {(x i, y i )} n the objective is to learn the relationship between features and the target. We usually start
Artificial Neural Networks Examination, March 2004
 Artificial Neural Networks Examination, March 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Artificial Neural Networks Examination, March 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Learning from Examples
 Learning from Examples Data fitting Decision trees Cross validation Computational learning theory Linear classifiers Neural networks Nonparametric methods: nearest neighbor Support vector machines Ensemble
Learning from Examples Data fitting Decision trees Cross validation Computational learning theory Linear classifiers Neural networks Nonparametric methods: nearest neighbor Support vector machines Ensemble
NN V: The generalized delta learning rule
 NN V: The generalized delta learning rule We now focus on generalizing the delta learning rule for feedforward layered neural networks. The architecture of the two-layer network considered below is shown
NN V: The generalized delta learning rule We now focus on generalizing the delta learning rule for feedforward layered neural networks. The architecture of the two-layer network considered below is shown
Artificial Neural Networks Examination, June 2005
 Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Introduction to Neural Networks: Structure and Training
 Introduction to Neural Networks: Structure and Training Professor Q.J. Zhang Department of Electronics Carleton University, Ottawa, Canada www.doe.carleton.ca/~qjz, qjz@doe.carleton.ca A Quick Illustration
Introduction to Neural Networks: Structure and Training Professor Q.J. Zhang Department of Electronics Carleton University, Ottawa, Canada www.doe.carleton.ca/~qjz, qjz@doe.carleton.ca A Quick Illustration
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Radial-Basis Function Networks. Radial-Basis Function Networks
 Radial-Basis Function Networks November 00 Michel Verleysen Radial-Basis Function Networks - Radial-Basis Function Networks p Origin: Cover s theorem p Interpolation problem p Regularization theory p Generalized
Radial-Basis Function Networks November 00 Michel Verleysen Radial-Basis Function Networks - Radial-Basis Function Networks p Origin: Cover s theorem p Interpolation problem p Regularization theory p Generalized
Single layer NN. Neuron Model
 Single layer NN We consider the simple architecture consisting of just one neuron. Generalization to a single layer with more neurons as illustrated below is easy because: M M The output units are independent
Single layer NN We consider the simple architecture consisting of just one neuron. Generalization to a single layer with more neurons as illustrated below is easy because: M M The output units are independent
Computational Intelligence Lecture 3: Simple Neural Networks for Pattern Classification
 Computational Intelligence Lecture 3: Simple Neural Networks for Pattern Classification Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Fall 2011 arzaneh Abdollahi
Computational Intelligence Lecture 3: Simple Neural Networks for Pattern Classification Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Fall 2011 arzaneh Abdollahi
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Christian Mohr
 Christian Mohr 20.12.2011 Recurrent Networks Networks in which units may have connections to units in the same or preceding layers Also connections to the unit itself possible Already covered: Hopfield
Christian Mohr 20.12.2011 Recurrent Networks Networks in which units may have connections to units in the same or preceding layers Also connections to the unit itself possible Already covered: Hopfield
Intelligent Systems Discriminative Learning, Neural Networks
 Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Artificial Neural Networks. Edward Gatt
 Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska. NEURAL NETWORKS Learning
 LECTURE NOTES Professor Anita Wasilewska. NEURAL NETWORKS Learning") CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Learning Neural Networks Classifier Short Presentation INPUT: classification data, i.e. it contains an classification (class) attribute.
CSE 352 (AI) LECTURE NOTES Professor Anita Wasilewska NEURAL NETWORKS Learning Neural Networks Classifier Short Presentation INPUT: classification data, i.e. it contains an classification (class) attribute.
Beyond the Point Cloud: From Transductive to Semi-Supervised Learning
 Beyond the Point Cloud: From Transductive to Semi-Supervised Learning Vikas Sindhwani, Partha Niyogi, Mikhail Belkin Andrew B. Goldberg goldberg@cs.wisc.edu Department of Computer Sciences University of
Beyond the Point Cloud: From Transductive to Semi-Supervised Learning Vikas Sindhwani, Partha Niyogi, Mikhail Belkin Andrew B. Goldberg goldberg@cs.wisc.edu Department of Computer Sciences University of
On Ridge Functions. Allan Pinkus. September 23, Technion. Allan Pinkus (Technion) Ridge Function September 23, / 27
 Ridge Function September 23, / 27") On Ridge Functions Allan Pinkus Technion September 23, 2013 Allan Pinkus (Technion) Ridge Function September 23, 2013 1 / 27 Foreword In this lecture we will survey a few problems and properties associated
On Ridge Functions Allan Pinkus Technion September 23, 2013 Allan Pinkus (Technion) Ridge Function September 23, 2013 1 / 27 Foreword In this lecture we will survey a few problems and properties associated
CS798: Selected topics in Machine Learning
 CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
FORMULATION OF THE LEARNING PROBLEM
 FORMULTION OF THE LERNING PROBLEM MIM RGINSKY Now that we have seen an informal statement of the learning problem, as well as acquired some technical tools in the form of concentration inequalities, we
FORMULTION OF THE LERNING PROBLEM MIM RGINSKY Now that we have seen an informal statement of the learning problem, as well as acquired some technical tools in the form of concentration inequalities, we
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Ch.8 Neural Networks
 Ch.8 Neural Networks Hantao Zhang http://www.cs.uiowa.edu/ hzhang/c145 The University of Iowa Department of Computer Science Artificial Intelligence p.1/?? Brains as Computational Devices Motivation: Algorithms
Ch.8 Neural Networks Hantao Zhang http://www.cs.uiowa.edu/ hzhang/c145 The University of Iowa Department of Computer Science Artificial Intelligence p.1/?? Brains as Computational Devices Motivation: Algorithms
Artificial Neural Networks 2
 CSC2515 Machine Learning Sam Roweis Artificial Neural s 2 We saw neural nets for classification. Same idea for regression. ANNs are just adaptive basis regression machines of the form: y k = j w kj σ(b
CSC2515 Machine Learning Sam Roweis Artificial Neural s 2 We saw neural nets for classification. Same idea for regression. ANNs are just adaptive basis regression machines of the form: y k = j w kj σ(b
Multilayer Neural Networks
 Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Kernel Methods. Charles Elkan October 17, 2007
 Kernel Methods Charles Elkan elkan@cs.ucsd.edu October 17, 2007 Remember the xor example of a classification problem that is not linearly separable. If we map every example into a new representation, then
Kernel Methods Charles Elkan elkan@cs.ucsd.edu October 17, 2007 Remember the xor example of a classification problem that is not linearly separable. If we map every example into a new representation, then
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
APPENDIX A. Background Mathematics. A.1 Linear Algebra. Vector algebra. Let x denote the n-dimensional column vector with components x 1 x 2.
 APPENDIX A Background Mathematics A. Linear Algebra A.. Vector algebra Let x denote the n-dimensional column vector with components 0 x x 2 B C @. A x n Definition 6 (scalar product). The scalar product
APPENDIX A Background Mathematics A. Linear Algebra A.. Vector algebra Let x denote the n-dimensional column vector with components 0 x x 2 B C @. A x n Definition 6 (scalar product). The scalar product
L20: MLPs, RBFs and SPR Bayes discriminants and MLPs The role of MLP hidden units Bayes discriminants and RBFs Comparison between MLPs and RBFs
 L0: MLPs, RBFs and SPR Bayes discriminants and MLPs The role of MLP hidden units Bayes discriminants and RBFs Comparison between MLPs and RBFs CSCE 666 Pattern Analysis Ricardo Gutierrez-Osuna CSE@TAMU
L0: MLPs, RBFs and SPR Bayes discriminants and MLPs The role of MLP hidden units Bayes discriminants and RBFs Comparison between MLPs and RBFs CSCE 666 Pattern Analysis Ricardo Gutierrez-Osuna CSE@TAMU
The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt.
 1 The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt. The algorithm applies only to single layer models
1 The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt. The algorithm applies only to single layer models
EE613 Machine Learning for Engineers. Kernel methods Support Vector Machines. jean-marc odobez 2015
 EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
Lecture 2 Machine Learning Review
 Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Lecture 2 Machine Learning Review CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago March 29, 2017 Things we will look at today Formal Setup for Supervised Learning Things
Why is Deep Learning so effective?
 Ma191b Winter 2017 Geometry of Neuroscience The unreasonable effectiveness of deep learning This lecture is based entirely on the paper: Reference: Henry W. Lin and Max Tegmark, Why does deep and cheap
Ma191b Winter 2017 Geometry of Neuroscience The unreasonable effectiveness of deep learning This lecture is based entirely on the paper: Reference: Henry W. Lin and Max Tegmark, Why does deep and cheap
Computational statistics
 Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Computational statistics Lecture 3: Neural networks Thierry Denœux 5 March, 2016 Neural networks A class of learning methods that was developed separately in different fields statistics and artificial
Gaussian Processes (10/16/13)
") STA561: Probabilistic machine learning Gaussian Processes (10/16/13) Lecturer: Barbara Engelhardt Scribes: Changwei Hu, Di Jin, Mengdi Wang 1 Introduction In supervised learning, we observe some inputs
STA561: Probabilistic machine learning Gaussian Processes (10/16/13) Lecturer: Barbara Engelhardt Scribes: Changwei Hu, Di Jin, Mengdi Wang 1 Introduction In supervised learning, we observe some inputs
Brief Introduction of Machine Learning Techniques for Content Analysis
 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 What a Neural Network Computes
 Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Neural Networks 1 What a Neural Network Computes To begin with, we will discuss fully connected feed-forward neural networks, also known as multilayer perceptrons. A feedforward neural network consists
Linear Regression (continued)
") Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA
 Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
Gaussian processes. Chuong B. Do (updated by Honglak Lee) November 22, 2008
 November 22, 2008") Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Gaussian processes Chuong B Do (updated by Honglak Lee) November 22, 2008 Many of the classical machine learning algorithms that we talked about during the first half of this course fit the following pattern:
Neural Nets Supervised learning
 6.034 Artificial Intelligence Big idea: Learning as acquiring a function on feature vectors Background Nearest Neighbors Identification Trees Neural Nets Neural Nets Supervised learning y s(z) w w 0 w
6.034 Artificial Intelligence Big idea: Learning as acquiring a function on feature vectors Background Nearest Neighbors Identification Trees Neural Nets Neural Nets Supervised learning y s(z) w w 0 w
MIT 9.520/6.860, Fall 2017 Statistical Learning Theory and Applications. Class 19: Data Representation by Design
 MIT 9.520/6.860, Fall 2017 Statistical Learning Theory and Applications Class 19: Data Representation by Design What is data representation? Let X be a data-space X M (M) F (M) X A data representation
MIT 9.520/6.860, Fall 2017 Statistical Learning Theory and Applications Class 19: Data Representation by Design What is data representation? Let X be a data-space X M (M) F (M) X A data representation
MATH 590: Meshfree Methods
 MATH 590: Meshfree Methods Chapter 33: Adaptive Iteration Greg Fasshauer Department of Applied Mathematics Illinois Institute of Technology Fall 2010 fasshauer@iit.edu MATH 590 Chapter 33 1 Outline 1 A
MATH 590: Meshfree Methods Chapter 33: Adaptive Iteration Greg Fasshauer Department of Applied Mathematics Illinois Institute of Technology Fall 2010 fasshauer@iit.edu MATH 590 Chapter 33 1 Outline 1 A
CHAPTER IX Radial Basis Function Networks
 Ugur HAICI - METU EEE - ANKARA 2/2/2005 CHAPTER IX Radial Basis Function Networks Introduction Radial basis function (RBF) networks are feed-forward networks trained using a supervised training algorithm.
Ugur HAICI - METU EEE - ANKARA 2/2/2005 CHAPTER IX Radial Basis Function Networks Introduction Radial basis function (RBF) networks are feed-forward networks trained using a supervised training algorithm.
POWER SYSTEM DYNAMIC SECURITY ASSESSMENT CLASSICAL TO MODERN APPROACH
 Abstract POWER SYSTEM DYNAMIC SECURITY ASSESSMENT CLASSICAL TO MODERN APPROACH A.H.M.A.Rahim S.K.Chakravarthy Department of Electrical Engineering K.F. University of Petroleum and Minerals Dhahran. Dynamic
Abstract POWER SYSTEM DYNAMIC SECURITY ASSESSMENT CLASSICAL TO MODERN APPROACH A.H.M.A.Rahim S.K.Chakravarthy Department of Electrical Engineering K.F. University of Petroleum and Minerals Dhahran. Dynamic
Hand Written Digit Recognition using Kalman Filter
 International Journal of Electronics and Communication Engineering. ISSN 0974-2166 Volume 5, Number 4 (2012), pp. 425-434 International Research Publication House http://www.irphouse.com Hand Written Digit
International Journal of Electronics and Communication Engineering. ISSN 0974-2166 Volume 5, Number 4 (2012), pp. 425-434 International Research Publication House http://www.irphouse.com Hand Written Digit
Linear Algebra Massoud Malek
 CSUEB Linear Algebra Massoud Malek Inner Product and Normed Space In all that follows, the n n identity matrix is denoted by I n, the n n zero matrix by Z n, and the zero vector by θ n An inner product
CSUEB Linear Algebra Massoud Malek Inner Product and Normed Space In all that follows, the n n identity matrix is denoted by I n, the n n zero matrix by Z n, and the zero vector by θ n An inner product
Artificial neural networks
 Artificial neural networks Chapter 8, Section 7 Artificial Intelligence, spring 203, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 8, Section 7 Outline Brains Neural
Artificial neural networks Chapter 8, Section 7 Artificial Intelligence, spring 203, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 8, Section 7 Outline Brains Neural
Motivating the Covariance Matrix
 Motivating the Covariance Matrix Raúl Rojas Computer Science Department Freie Universität Berlin January 2009 Abstract This note reviews some interesting properties of the covariance matrix and its role
Motivating the Covariance Matrix Raúl Rojas Computer Science Department Freie Universität Berlin January 2009 Abstract This note reviews some interesting properties of the covariance matrix and its role
Learning from Data: Multi-layer Perceptrons
 Learning from Data: Multi-layer Perceptrons Amos Storkey, School of Informatics University of Edinburgh Semester, 24 LfD 24 Layered Neural Networks Background Single Neurons Relationship to logistic regression.
Learning from Data: Multi-layer Perceptrons Amos Storkey, School of Informatics University of Edinburgh Semester, 24 LfD 24 Layered Neural Networks Background Single Neurons Relationship to logistic regression.
A Logarithmic Neural Network Architecture for Unbounded Non-Linear Function Approximation
 1 Introduction A Logarithmic Neural Network Architecture for Unbounded Non-Linear Function Approximation J Wesley Hines Nuclear Engineering Department The University of Tennessee Knoxville, Tennessee,
1 Introduction A Logarithmic Neural Network Architecture for Unbounded Non-Linear Function Approximation J Wesley Hines Nuclear Engineering Department The University of Tennessee Knoxville, Tennessee,
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD
 ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
ARTIFICIAL NEURAL NETWORK PART I HANIEH BORHANAZAD WHAT IS A NEURAL NETWORK? The simplest definition of a neural network, more properly referred to as an 'artificial' neural network (ANN), is provided
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
CSCI5654 (Linear Programming, Fall 2013) Lectures Lectures 10,11 Slide# 1
 Lectures Lectures 10,11 Slide# 1") CSCI5654 (Linear Programming, Fall 2013) Lectures 10-12 Lectures 10,11 Slide# 1 Today s Lecture 1. Introduction to norms: L 1,L 2,L. 2. Casting absolute value and max operators. 3. Norm minimization problems.
CSCI5654 (Linear Programming, Fall 2013) Lectures 10-12 Lectures 10,11 Slide# 1 Today s Lecture 1. Introduction to norms: L 1,L 2,L. 2. Casting absolute value and max operators. 3. Norm minimization problems.
Back-Propagation Algorithm. Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples
 Back-Propagation Algorithm Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples 1 Inner-product net =< w, x >= w x cos(θ) net = n i=1 w i x i A measure
Back-Propagation Algorithm Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples 1 Inner-product net =< w, x >= w x cos(θ) net = n i=1 w i x i A measure
PATTERN CLASSIFICATION
 PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS
PATTERN CLASSIFICATION Second Edition Richard O. Duda Peter E. Hart David G. Stork A Wiley-lnterscience Publication JOHN WILEY & SONS, INC. New York Chichester Weinheim Brisbane Singapore Toronto CONTENTS