The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt.
|
|
|
- Kelley Haynes
- 5 years ago
- Views:
Transcription
1 1
2 The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt. The algorithm applies only to single layer models of discrete cells. That is, cells that have a step threshold function. 2

3 3
4 For a single neuron j, with p inputs let the weights be defined by a vector: W = [w j,0, w j,1, w j,2,..., w j, p ] for convenience, let w i = w j,i The weighted sum then becomes S = S j = p i=0 w i x i The output of the unit y j is +1 if S 0 and -1 if S < 0. X k is a p length vector of real numbers corresponding to the p inputs. For perceptron learning, the inputs must belong to the set {+1, -1, 0} C k is the correct response or classification for the input pattern and will have a value of either +1 or -1 (Actually, it can be any boolean representation, but we use bipolar). Note that C k can be a vector also. In that case there would be a separate neuron for each component of the vector. 4
5 The goal of the perceptron learning algorithm is to find a weight vector that correctly classifies all input vectors. That is, for each input pattern X k used in training, the neuron(s) must generate the required output C k, for the corresponding input. 5
6 Consider when p=2. This can be shown to be the problem of finding a hyperplane (which in this 2D case is a line) which correctly categorizes the inputs. WX = w 0 + w 1 x 1 + w 2 x 2 equation of a straight line. x WX=0 - The weight vector must correctly satisfy all inputs (x 1, x 2 ) x2 6
7 Bias Term : Analogy with a straight line A popular form for the equation of a straight line is y = mx + c Here m is the gradient of the line and c is the point at which the line intersects the y axis. When c is zero, the line intersects the origin. Without a bias term, the hyperplane arrived at by the neural net is restricted to intersect the origin. This can be problematic and in many cases may prevent a solution from being found, even though the problem is linearly separable. Thus it is useful to add a bias term to each neuron. The bias is analogous to c in y = mx + c 7
8 A bias term will in effect turn a three input problem into a four input problem, where the additional input is the bias term regarded as a weight from an input which is always +1. When implementing a neural net, it is recommended to include in the weighted sum for each neuron, a weight from an input that is always 1. 8
9 A neuron computes the weighted sum of its inputs S=W.X k S will be zero for any data point represented by vector X k that is normal to w. I.e. any point lying on the decision boundary will generate a zero weighted sum. Thus the weight vector is normal to the decision boundary. S is the projection of X k onto w. A perceptron is a special kind of neuron that thresholds the weighted sum using a step threshold function. Data points falling one side of the decision boundary have a negative projection and those falling the other side have a positive projection. So our perceptron is computing what is known in mathematics, as the scalar product or dot product of two vectors. You all know that right? J 9
10 The perceptron learning algorithm is very simple indeed. The goal is to arrive at a weight vector w which correctly classifies all samples in the training set. This is the stopping criteria. A weight update step involves selecting a training sample that is not correctly classified and changing the weights according to the term in step 3 above. Since for perceptron leaning C k is actually a scalar that is either +1 or -1, the weight update step effectively is either adding or subtracting the example vector X k from the current weight vector. That s it! Note of course, the assumption is that the problem is linearly separable. That is that a linear hyperplane can be found that separates all positively classified samples from negatively samples. 10
11 Each training example corresponds to a vector on a sphere as does the weight vector. (Note with the biploar representation, the Cartesian length of all input vectors is the same. This is not true for the binary representation). The scalar product W.X k is the projection of the weight vector onto the example vector. The projection may be positive or negative. The goal is to find a W which has a positive projection for X k classified as C k = +1 and a negative projection for all C k =
12 The modification in step 3 will always cause the weight vector to move closer to examples that should be positive and further from examples that should be negatively classified. The proof of this theory is beyond the scope of this lecture and it is not intuitively obvious. For a formal proof to this theory, the reader is referred to the textbook by Fausett, recommended for this course. 12
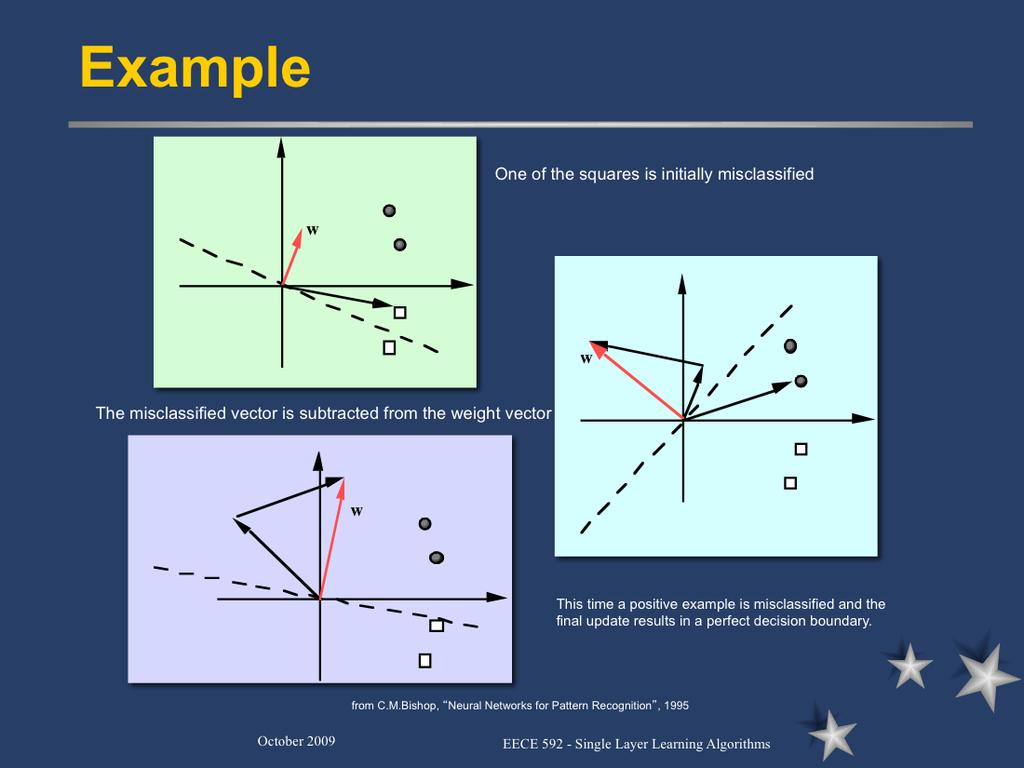
13 13
14 Problems The perceptron learning algorithm is poorly behaved when presented with a non-separable set of training examples. For example, when learning the XOR relationship, the best set of weights that could be hoped for is: w 0 (bias) = +1, w 1 = +1, w 2 = +1 which correctly classifies 3 out of the four training examples. This is not so bad. The problem is when the algorithm attempts to learn a misclassified example, it is not unusual for the algorithm to change the weights to a new configuration, eg. w 0 (bias) = 0, w 1 = +0, w 2 = +0 which classify none of the training set correctly! Thus after a given number of iterations, there is no guarantee of the quality of the weights. The Pocket algorithm Gallant has proposed a solution to this which called the Pocket algorithm. This works by pocketing the best set of weights encountered so far. The best or most optimal are those weights which classify as many of the training set as possible. 14
15 Widrow and Hoff (circa 1970s) presented a famous learning algorithm based upon least mean square errors, now known as the LMS algorithm or the delta rule. As the name suggests, the approach is based upon minimizing the squared error as a means of learning and provides an alternative to the perceptron learning algorithm for single layer neural net models. Whereas perceptron learning approaches aim to find an optimal weight vector capable of correctly classifying the training set, the delta rule can be used with continuous valued cells and gradient descent to reach a minimized error for a particular problem. Given a training set of N examples, the total error in the net can be represented as : E = E k = 1 (C k S k ) 2 2 N N Where S k is the weighted sum for pattern k and C k is the correct output for that pattern. Note that cells for the delta rule typically use a linear threshold function (such as the identity function). 15
16 As the diagram shows, the delta rule is capable of reaching a better solution than perceptron learning. In this case, better means better generalization. 16
17 In this example, the delta rule over emphasizes a far-out point resulting in a solution that misclassifies many points. This point may even be spurious. So the Perceptron learning algorithm (Gallant s pocketing variant) fares better than the Delta rule in this case. 17
 then the error E for this pattern is E(W k ) = 1 2 (Sk C k ) 2 The trick is determining how to update the weight so that it results in a reduction in the")
18 Suppose for example X k the correct output is C k but the actual output is the weighted sum W k.x k = (S k ) then the error E for this pattern is E(W k ) = 1 2 (Sk C k ) 2 The trick is determining how to update the weight so that it results in a reduction in the overall computed error E for all patterns k. For this we apply gradient descent. 18

19 So the point b is computed by moving along the negative gradient as computed at a. This distance moved is given by the step size ρ. In general the gradient of a multivariate function is given by the vector of partial differentials along each dimension. 19
20 Gradient descent is defined as minimization of E over all patterns k. 20
21 The idea is to make a change in the weight that will cause the total error E to decrease. I.e. we want the weight change to be in the direction of the negative gradient of E with to the negative of the error as measured on the current pattern with respect to each weight. Lets start with the definition of gradient descent: Δ k w j Ek w j leading to E k w j = E k S k S k w j where S k is the output for the k th pattern. Since the delta rule uses linear elements, S k = W k.x k S k Then = X k and also w j E k S k = (C k S k ) and then Δ k w j = ρδ k X k Where δ k = (C k S k ) and ρ is the gradient step size which we use to remove the constant of proportionality. W * = W + ρδx 21
22 The definition of gradient descent suggests that the Δw is computed from all training patterns prior to actually changing the weights. This is referred to as batch mode training since the weight updates from each training pattern are batched up and a single update made once the entire training set has been presented. In practice however, an alternative form is used. In this case, following presentation of each and every training pattern, a weight update is computed and applied immediately. This approach performs the updates in an online manner and is a form of stochastic gradient descent. Stochastic because the next weight change may not necessarily be in the direction of the negative gradient and maybe in any random direction. The approach works because on average, the update will be in the right direction. 22
23 Widrow and Hoff used the delta rule to train weights for a discrete single cell model which they called the ADALINE - ADAptive LINear Element. Note that the term ADALINE was originally an abbreviation for adaptive linear neuron, however Widrow & Hoff acknowledged that activity in neural network was not in fashion and opted to not use it feeling that their work may not be received favourably as a result! 23
24 Comparing the ADALINE to Perceptron learning, it turns out that Perceptron learning is a less general form of gradient descent that uses a constant step size: W * = W ± X where the sign is the same as (C S) For separable training sets, Perceptron learning guarantees finding an optimal solution, whereas the Widrow and Hoff approach will tend to asymptotically converge. The Widrow and Hoff algorithm is however likely to find a solution that generalizes better. Also, for non-separable training sets, the Widrow and Hoff rule is stable unlike Perceptron learning. 24
Chapter 2 Single Layer Feedforward Networks
 Chapter 2 Single Layer Feedforward Networks By Rosenblatt (1962) Perceptrons For modeling visual perception (retina) A feedforward network of three layers of units: Sensory, Association, and Response Learning
Chapter 2 Single Layer Feedforward Networks By Rosenblatt (1962) Perceptrons For modeling visual perception (retina) A feedforward network of three layers of units: Sensory, Association, and Response Learning
Simple Neural Nets For Pattern Classification
 CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
ADALINE for Pattern Classification
 POLYTECHNIC UNIVERSITY Department of Computer and Information Science ADALINE for Pattern Classification K. Ming Leung Abstract: A supervised learning algorithm known as the Widrow-Hoff rule, or the Delta
POLYTECHNIC UNIVERSITY Department of Computer and Information Science ADALINE for Pattern Classification K. Ming Leung Abstract: A supervised learning algorithm known as the Widrow-Hoff rule, or the Delta
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
The Perceptron Algorithm 1
 CS 64: Machine Learning Spring 5 College of Computer and Information Science Northeastern University Lecture 5 March, 6 Instructor: Bilal Ahmed Scribe: Bilal Ahmed & Virgil Pavlu Introduction The Perceptron
CS 64: Machine Learning Spring 5 College of Computer and Information Science Northeastern University Lecture 5 March, 6 Instructor: Bilal Ahmed Scribe: Bilal Ahmed & Virgil Pavlu Introduction The Perceptron
Single layer NN. Neuron Model
 Single layer NN We consider the simple architecture consisting of just one neuron. Generalization to a single layer with more neurons as illustrated below is easy because: M M The output units are independent
Single layer NN We consider the simple architecture consisting of just one neuron. Generalization to a single layer with more neurons as illustrated below is easy because: M M The output units are independent
Linear Discrimination Functions
 Laurea Magistrale in Informatica Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari November 4, 2009 Outline Linear models Gradient descent Perceptron Minimum square error approach
Laurea Magistrale in Informatica Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari November 4, 2009 Outline Linear models Gradient descent Perceptron Minimum square error approach
Least Mean Squares Regression
 Least Mean Squares Regression Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture Overview Linear classifiers What functions do linear classifiers express? Least Squares Method
Least Mean Squares Regression Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Lecture Overview Linear classifiers What functions do linear classifiers express? Least Squares Method
PMR5406 Redes Neurais e Lógica Fuzzy Aula 3 Single Layer Percetron
 PMR5406 Redes Neurais e Aula 3 Single Layer Percetron Baseado em: Neural Networks, Simon Haykin, Prentice-Hall, 2 nd edition Slides do curso por Elena Marchiori, Vrije Unviersity Architecture We consider
PMR5406 Redes Neurais e Aula 3 Single Layer Percetron Baseado em: Neural Networks, Simon Haykin, Prentice-Hall, 2 nd edition Slides do curso por Elena Marchiori, Vrije Unviersity Architecture We consider
In the Name of God. Lecture 11: Single Layer Perceptrons
 1 In the Name of God Lecture 11: Single Layer Perceptrons Perceptron: architecture We consider the architecture: feed-forward NN with one layer It is sufficient to study single layer perceptrons with just
1 In the Name of God Lecture 11: Single Layer Perceptrons Perceptron: architecture We consider the architecture: feed-forward NN with one layer It is sufficient to study single layer perceptrons with just
Engineering Part IIB: Module 4F10 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers
 Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Engineering Part IIB: Module 4F0 Statistical Pattern Processing Lecture 5: Single Layer Perceptrons & Estimating Linear Classifiers Phil Woodland: pcw@eng.cam.ac.uk Michaelmas 202 Engineering Part IIB:
Vote. Vote on timing for night section: Option 1 (what we have now) Option 2. Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9
 Option 2. Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9") Vote Vote on timing for night section: Option 1 (what we have now) Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9 Option 2 Lecture, 6:10-7 10 minute break Lecture, 7:10-8 10 minute break Tutorial,
Vote Vote on timing for night section: Option 1 (what we have now) Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9 Option 2 Lecture, 6:10-7 10 minute break Lecture, 7:10-8 10 minute break Tutorial,
The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural
 learning techniques for neural") 1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
1 2 The error-backpropagation algorithm is one of the most important and widely used (and some would say wildly used) learning techniques for neural networks. First we will look at the algorithm itself
Lecture 6. Notes on Linear Algebra. Perceptron
 Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
Lecture 6. Notes on Linear Algebra. Perceptron COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Andrey Kan Copyright: University of Melbourne This lecture Notes on linear algebra Vectors
The Perceptron Algorithm
 The Perceptron Algorithm Greg Grudic Greg Grudic Machine Learning Questions? Greg Grudic Machine Learning 2 Binary Classification A binary classifier is a mapping from a set of d inputs to a single output
The Perceptron Algorithm Greg Grudic Greg Grudic Machine Learning Questions? Greg Grudic Machine Learning 2 Binary Classification A binary classifier is a mapping from a set of d inputs to a single output
Least Mean Squares Regression. Machine Learning Fall 2018
 Least Mean Squares Regression Machine Learning Fall 2018 1 Where are we? Least Squares Method for regression Examples The LMS objective Gradient descent Incremental/stochastic gradient descent Exercises
Least Mean Squares Regression Machine Learning Fall 2018 1 Where are we? Least Squares Method for regression Examples The LMS objective Gradient descent Incremental/stochastic gradient descent Exercises
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
CSC321 Lecture 4 The Perceptron Algorithm
 CSC321 Lecture 4 The Perceptron Algorithm Roger Grosse and Nitish Srivastava January 17, 2017 Roger Grosse and Nitish Srivastava CSC321 Lecture 4 The Perceptron Algorithm January 17, 2017 1 / 1 Recap:
CSC321 Lecture 4 The Perceptron Algorithm Roger Grosse and Nitish Srivastava January 17, 2017 Roger Grosse and Nitish Srivastava CSC321 Lecture 4 The Perceptron Algorithm January 17, 2017 1 / 1 Recap:
Linear models: the perceptron and closest centroid algorithms. D = {(x i,y i )} n i=1. x i 2 R d 9/3/13. Preliminaries. Chapter 1, 7.
} n i=1. x i 2 R d 9/3/13. Preliminaries. Chapter 1, 7.") Preliminaries Linear models: the perceptron and closest centroid algorithms Chapter 1, 7 Definition: The Euclidean dot product beteen to vectors is the expression d T x = i x i The dot product is also
Preliminaries Linear models: the perceptron and closest centroid algorithms Chapter 1, 7 Definition: The Euclidean dot product beteen to vectors is the expression d T x = i x i The dot product is also
Artificial Neural Networks Examination, June 2005
 Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
Artificial Neural Networks Examination, June 2005 Instructions There are SIXTY questions. (The pass mark is 30 out of 60). For each question, please select a maximum of ONE of the given answers (either
More about the Perceptron
 More about the Perceptron CMSC 422 MARINE CARPUAT marine@cs.umd.edu Credit: figures by Piyush Rai and Hal Daume III Recap: Perceptron for binary classification Classifier = hyperplane that separates positive
More about the Perceptron CMSC 422 MARINE CARPUAT marine@cs.umd.edu Credit: figures by Piyush Rai and Hal Daume III Recap: Perceptron for binary classification Classifier = hyperplane that separates positive
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Last updated: Oct 22, 2012 LINEAR CLASSIFIERS Problems 2 Please do Problem 8.3 in the textbook. We will discuss this in class. Classification: Problem Statement 3 In regression, we are modeling the relationship
Unit III. A Survey of Neural Network Model
 Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
The Perceptron algorithm
 The Perceptron algorithm Tirgul 3 November 2016 Agnostic PAC Learnability A hypothesis class H is agnostic PAC learnable if there exists a function m H : 0,1 2 N and a learning algorithm with the following
The Perceptron algorithm Tirgul 3 November 2016 Agnostic PAC Learnability A hypothesis class H is agnostic PAC learnable if there exists a function m H : 0,1 2 N and a learning algorithm with the following
CSC321 Lecture 4: Learning a Classifier
 CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 28 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 28 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
Preliminaries. Definition: The Euclidean dot product between two vectors is the expression. i=1
 90 8 80 7 70 6 60 0 8/7/ Preliminaries Preliminaries Linear models and the perceptron algorithm Chapters, T x + b < 0 T x + b > 0 Definition: The Euclidean dot product beteen to vectors is the expression
90 8 80 7 70 6 60 0 8/7/ Preliminaries Preliminaries Linear models and the perceptron algorithm Chapters, T x + b < 0 T x + b > 0 Definition: The Euclidean dot product beteen to vectors is the expression
Classification with Perceptrons. Reading:
 Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
Classification with Perceptrons Reading: Chapters 1-3 of Michael Nielsen's online book on neural networks covers the basics of perceptrons and multilayer neural networks We will cover material in Chapters
CSC242: Intro to AI. Lecture 21
 CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
CSC242: Intro to AI Lecture 21 Administrivia Project 4 (homeworks 18 & 19) due Mon Apr 16 11:59PM Posters Apr 24 and 26 You need an idea! You need to present it nicely on 2-wide by 4-high landscape pages
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
CSE 417T: Introduction to Machine Learning. Lecture 11: Review. Henry Chai 10/02/18
 CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
CSE 417T: Introduction to Machine Learning Lecture 11: Review Henry Chai 10/02/18 Unknown Target Function!: # % Training data Formal Setup & = ( ), + ),, ( -, + - Learning Algorithm 2 Hypothesis Set H
Intelligent Systems Discriminative Learning, Neural Networks
 Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Intelligent Systems Discriminative Learning, Neural Networks Carsten Rother, Dmitrij Schlesinger WS2014/2015, Outline 1. Discriminative learning 2. Neurons and linear classifiers: 1) Perceptron-Algorithm
Unit 8: Introduction to neural networks. Perceptrons
 Unit 8: Introduction to neural networks. Perceptrons D. Balbontín Noval F. J. Martín Mateos J. L. Ruiz Reina A. Riscos Núñez Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
Unit 8: Introduction to neural networks. Perceptrons D. Balbontín Noval F. J. Martín Mateos J. L. Ruiz Reina A. Riscos Núñez Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Chapter ML:VI. VI. Neural Networks. Perceptron Learning Gradient Descent Multilayer Perceptron Radial Basis Functions
 Chapter ML:VI VI. Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-1 Neural Networks STEIN 2005-2018 The iological Model Simplified model of a neuron:
Chapter ML:VI VI. Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-1 Neural Networks STEIN 2005-2018 The iological Model Simplified model of a neuron:
Revision: Neural Network
 Revision: Neural Network Exercise 1 Tell whether each of the following statements is true or false by checking the appropriate box. Statement True False a) A perceptron is guaranteed to perfectly learn
Revision: Neural Network Exercise 1 Tell whether each of the following statements is true or false by checking the appropriate box. Statement True False a) A perceptron is guaranteed to perfectly learn
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
CE213 Artificial Intelligence Lecture 14
 CE213 Artificial Intelligence Lecture 14 Neural Networks: Part 2 Learning Rules -Hebb Rule - Perceptron Rule -Delta Rule Neural Networks Using Linear Units [ Difficulty warning: equations! ] 1 Learning
CE213 Artificial Intelligence Lecture 14 Neural Networks: Part 2 Learning Rules -Hebb Rule - Perceptron Rule -Delta Rule Neural Networks Using Linear Units [ Difficulty warning: equations! ] 1 Learning
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Linear discriminant functions
 Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
Andrea Passerini passerini@disi.unitn.it Machine Learning Discriminative learning Discriminative vs generative Generative learning assumes knowledge of the distribution governing the data Discriminative
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
CSC321 Lecture 4: Learning a Classifier
 CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 31 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 31 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
Artificial Neural Networks The Introduction
 Artificial Neural Networks The Introduction 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001 00100000
Artificial Neural Networks The Introduction 01001110 01100101 01110101 01110010 01101111 01101110 01101111 01110110 01100001 00100000 01110011 01101011 01110101 01110000 01101001 01101110 01100001 00100000
Linear models and the perceptron algorithm
 8/5/6 Preliminaries Linear models and the perceptron algorithm Chapters, 3 Definition: The Euclidean dot product beteen to vectors is the expression dx T x = i x i The dot product is also referred to as
8/5/6 Preliminaries Linear models and the perceptron algorithm Chapters, 3 Definition: The Euclidean dot product beteen to vectors is the expression dx T x = i x i The dot product is also referred to as
Optimization and Gradient Descent
 Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Introduction to Neural Networks
 Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Neural Networks. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Linear smoother. ŷ = S y. where s ij = s ij (x) e.g. s ij = diag(l i (x))
 e.g. s ij = diag(l i (x))") Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Linear smoother ŷ = S y where s ij = s ij (x) e.g. s ij = diag(l i (x)) 2 Online Learning: LMS and Perceptrons Partially adapted from slides by Ryan Gabbard and Mitch Marcus (and lots original slides by
Lecture 4. 1 Learning Non-Linear Classifiers. 2 The Kernel Trick. CS-621 Theory Gems September 27, 2012
 CS-62 Theory Gems September 27, 22 Lecture 4 Lecturer: Aleksander Mądry Scribes: Alhussein Fawzi Learning Non-Linear Classifiers In the previous lectures, we have focused on finding linear classifiers,
CS-62 Theory Gems September 27, 22 Lecture 4 Lecturer: Aleksander Mądry Scribes: Alhussein Fawzi Learning Non-Linear Classifiers In the previous lectures, we have focused on finding linear classifiers,
Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011!
 Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011! 1 Todayʼs topics" Learning from Examples: brief review! Univariate Linear Regression! Batch gradient descent! Stochastic gradient
Regression and Classification" with Linear Models" CMPSCI 383 Nov 15, 2011! 1 Todayʼs topics" Learning from Examples: brief review! Univariate Linear Regression! Batch gradient descent! Stochastic gradient
Multilayer Perceptron
 Aprendizagem Automática Multilayer Perceptron Ludwig Krippahl Aprendizagem Automática Summary Perceptron and linear discrimination Multilayer Perceptron, nonlinear discrimination Backpropagation and training
Aprendizagem Automática Multilayer Perceptron Ludwig Krippahl Aprendizagem Automática Summary Perceptron and linear discrimination Multilayer Perceptron, nonlinear discrimination Backpropagation and training
SPSS, University of Texas at Arlington. Topics in Machine Learning-EE 5359 Neural Networks
 Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions
 perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions") BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Linear Classification. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Linear Classification CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Example of Linear Classification Red points: patterns belonging
Linear Classification CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Example of Linear Classification Red points: patterns belonging
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Artificial Neural Networks Examination, June 2004
 Artificial Neural Networks Examination, June 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Artificial Neural Networks Examination, June 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Lab 5: 16 th April Exercises on Neural Networks
 Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Introduction to Artificial Neural Networks
 Facultés Universitaires Notre-Dame de la Paix 27 March 2007 Outline 1 Introduction 2 Fundamentals Biological neuron Artificial neuron Artificial Neural Network Outline 3 Single-layer ANN Perceptron Adaline
Facultés Universitaires Notre-Dame de la Paix 27 March 2007 Outline 1 Introduction 2 Fundamentals Biological neuron Artificial neuron Artificial Neural Network Outline 3 Single-layer ANN Perceptron Adaline
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Neural Networks Lecture 2:Single Layer Classifiers
 Neural Networks Lecture 2:Single Layer Classifiers H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011. A. Talebi, Farzaneh Abdollahi Neural
Neural Networks Lecture 2:Single Layer Classifiers H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011. A. Talebi, Farzaneh Abdollahi Neural
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Linear Discriminant Functions
 Linear Discriminant Functions Linear discriminant functions and decision surfaces Definition It is a function that is a linear combination of the components of g() = t + 0 () here is the eight vector and
Linear Discriminant Functions Linear discriminant functions and decision surfaces Definition It is a function that is a linear combination of the components of g() = t + 0 () here is the eight vector and
Machine Learning and Data Mining. Linear classification. Kalev Kask
 Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Multilayer Neural Networks
 Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Chapter 9: The Perceptron
 Chapter 9: The Perceptron 9.1 INTRODUCTION At this point in the book, we have completed all of the exercises that we are going to do with the James program. These exercises have shown that distributed
Chapter 9: The Perceptron 9.1 INTRODUCTION At this point in the book, we have completed all of the exercises that we are going to do with the James program. These exercises have shown that distributed
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Artificial Neural Networks Examination, March 2004
 Artificial Neural Networks Examination, March 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
Artificial Neural Networks Examination, March 2004 Instructions There are SIXTY questions (worth up to 60 marks). The exam mark (maximum 60) will be added to the mark obtained in the laborations (maximum
AN INTRODUCTION TO NEURAL NETWORKS. Scott Kuindersma November 12, 2009
 AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
Back-Propagation Algorithm. Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples
 Back-Propagation Algorithm Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples 1 Inner-product net =< w, x >= w x cos(θ) net = n i=1 w i x i A measure
Back-Propagation Algorithm Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples 1 Inner-product net =< w, x >= w x cos(θ) net = n i=1 w i x i A measure
Kernelized Perceptron Support Vector Machines
 Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Machine Learning Lecture 10
 Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Machine Learning Lecture 10 Neural Networks 26.11.2018 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Today s Topic Deep Learning 2 Course Outline Fundamentals Bayes
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
Machine Learning Basics Lecture 3: Perceptron. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 3: Perceptron Princeton University COS 495 Instructor: Yingyu Liang Perceptron Overview Previous lectures: (Principle for loss function) MLE to derive loss Example: linear
Machine Learning Basics Lecture 3: Perceptron Princeton University COS 495 Instructor: Yingyu Liang Perceptron Overview Previous lectures: (Principle for loss function) MLE to derive loss Example: linear
A Course in Machine Learning
 A Course in Machine Learning Hal Daumé III 3 THE PERCEPTRON Learning Objectives: Describe the biological motivation behind the perceptron. Classify learning algorithms based on whether they are error-driven
A Course in Machine Learning Hal Daumé III 3 THE PERCEPTRON Learning Objectives: Describe the biological motivation behind the perceptron. Classify learning algorithms based on whether they are error-driven
Notes on Back Propagation in 4 Lines
 Notes on Back Propagation in 4 Lines Lili Mou moull12@sei.pku.edu.cn March, 2015 Congratulations! You are reading the clearest explanation of forward and backward propagation I have ever seen. In this
Notes on Back Propagation in 4 Lines Lili Mou moull12@sei.pku.edu.cn March, 2015 Congratulations! You are reading the clearest explanation of forward and backward propagation I have ever seen. In this
Input layer. Weight matrix [ ] Output layer
![Input layer. Weight matrix [ ] Output layer](/thumbs/94/121286844.jpg "Input layer. Weight matrix [ ] Output layer") MASSACHUSETTS INSTITUTE OF TECHNOLOGY Department of Electrical Engineering and Computer Science 6.034 Artificial Intelligence, Fall 2003 Recitation 10, November 4 th & 5 th 2003 Learning by perceptrons
MASSACHUSETTS INSTITUTE OF TECHNOLOGY Department of Electrical Engineering and Computer Science 6.034 Artificial Intelligence, Fall 2003 Recitation 10, November 4 th & 5 th 2003 Learning by perceptrons
The Perceptron Algorithm
 The Perceptron Algorithm Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Outline The Perceptron Algorithm Perceptron Mistake Bound Variants of Perceptron 2 Where are we? The Perceptron
The Perceptron Algorithm Machine Learning Spring 2018 The slides are mainly from Vivek Srikumar 1 Outline The Perceptron Algorithm Perceptron Mistake Bound Variants of Perceptron 2 Where are we? The Perceptron
Pattern Classification
 Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Administration. Registration Hw3 is out. Lecture Captioning (Extra-Credit) Scribing lectures. Questions. Due on Thursday 10/6
 Scribing lectures. Questions. Due on Thursday 10/6") Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
9 Classification. 9.1 Linear Classifiers
 9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
Support Vector Machines
 Support Vector Machines Hypothesis Space variable size deterministic continuous parameters Learning Algorithm linear and quadratic programming eager batch SVMs combine three important ideas Apply optimization
Support Vector Machines Hypothesis Space variable size deterministic continuous parameters Learning Algorithm linear and quadratic programming eager batch SVMs combine three important ideas Apply optimization
Learning from Data Logistic Regression
 Learning from Data Logistic Regression Copyright David Barber 2-24. Course lecturer: Amos Storkey a.storkey@ed.ac.uk Course page : http://www.anc.ed.ac.uk/ amos/lfd/ 2.9.8.7.6.5.4.3.2...2.3.4.5.6.7.8.9
Learning from Data Logistic Regression Copyright David Barber 2-24. Course lecturer: Amos Storkey a.storkey@ed.ac.uk Course page : http://www.anc.ed.ac.uk/ amos/lfd/ 2.9.8.7.6.5.4.3.2...2.3.4.5.6.7.8.9
Neural Networks and Deep Learning.
 Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Linear Models for Classification
 Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Νεςπο-Ασαυήρ Υπολογιστική Neuro-Fuzzy Computing
 Νεςπο-Ασαυήρ Υπολογιστική Neuro-Fuzzy Computing ΗΥ418 Διδάσκων Δημήτριος Κατσαρός @ Τμ. ΗΜΜΥ Πανεπιστήμιο Θεσσαλίαρ Διάλεξη 4η 1 Perceptron s convergence 2 Proof of convergence Suppose that we have n training
Νεςπο-Ασαυήρ Υπολογιστική Neuro-Fuzzy Computing ΗΥ418 Διδάσκων Δημήτριος Κατσαρός @ Τμ. ΗΜΜΥ Πανεπιστήμιο Θεσσαλίαρ Διάλεξη 4η 1 Perceptron s convergence 2 Proof of convergence Suppose that we have n training
Minimax risk bounds for linear threshold functions
 CS281B/Stat241B (Spring 2008) Statistical Learning Theory Lecture: 3 Minimax risk bounds for linear threshold functions Lecturer: Peter Bartlett Scribe: Hao Zhang 1 Review We assume that there is a probability
CS281B/Stat241B (Spring 2008) Statistical Learning Theory Lecture: 3 Minimax risk bounds for linear threshold functions Lecturer: Peter Bartlett Scribe: Hao Zhang 1 Review We assume that there is a probability
Linear Regression. S. Sumitra
 Linear Regression S Sumitra Notations: x i : ith data point; x T : transpose of x; x ij : ith data point s jth attribute Let {(x 1, y 1 ), (x, y )(x N, y N )} be the given data, x i D and y i Y Here D
Linear Regression S Sumitra Notations: x i : ith data point; x T : transpose of x; x ij : ith data point s jth attribute Let {(x 1, y 1 ), (x, y )(x N, y N )} be the given data, x i D and y i Y Here D
Multilayer Perceptron = FeedForward Neural Network
 Multilayer Perceptron = FeedForward Neural Networ History Definition Classification = feedforward operation Learning = bacpropagation = local optimization in the space of weights Pattern Classification
Multilayer Perceptron = FeedForward Neural Networ History Definition Classification = feedforward operation Learning = bacpropagation = local optimization in the space of weights Pattern Classification
Lecture 4: Linear predictors and the Perceptron
 Lecture 4: Linear predictors and the Perceptron Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 4 1 / 34 Inductive Bias Inductive bias is critical to prevent overfitting.
Lecture 4: Linear predictors and the Perceptron Introduction to Learning and Analysis of Big Data Kontorovich and Sabato (BGU) Lecture 4 1 / 34 Inductive Bias Inductive bias is critical to prevent overfitting.