Back-Propagation Algorithm. Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples
|
|
|
- Carmel Phelps
- 5 years ago
- Views:
Transcription
1 Back-Propagation Algorithm Perceptron Gradient Descent Multilayered neural network Back-Propagation More on Back-Propagation Examples 1
2 Inner-product net =< w, x >= w x cos(θ) net = n i=1 w i x i A measure of the projection of one vector onto another Activation function o = f (net) = f ( w i x i ) n i=1 f (x) := sgn(x) = 1 if x 0 1 if x < 0 2
3 f (x) := ϕ(x) = 1 if x 0 0 if x < 0 1 if x 0.5 f (x) := ϕ(x) = x if 0.5 > x > if x 0.5 sigmoid function f (x) := σ(x) = 1 1+ e ( ax ) Gradient Descent To understand, consider simpler linear unit, where o = n i= 0 w i x i Let's learn w i that minimize the squared error, D={(x 1,t 1 ),(x 2,t 2 ),..,(x d,t d ),..,(x m,t m )} (t for target) 3

4 Error for different hypothesis, for w 0 and w 1 (dim 2) We want to move the weight vector in the direction that decrease E w i =w i +Δw i w=w+δw 4
5 Differentiating E Update rule for gradient decent Δw i = η d D (t d o d )x id 5
6 Stochastic Approximation to gradient descent Δw i = η(t o)x i The gradient decent training rule updates summing over all the training examples D Stochastic gradient approximates gradient decent by updating weights incrementally Calculate error for each example Known as delta-rule or LMS (last mean-square) weight update Adaline rule, used for adaptive filters Widroff and Hoff (1960) 6

7 XOR problem and Perceptron By Minsky and Papert in mid
8 Multi-layer Networks The limitations of simple perceptron do not apply to feed-forward networks with intermediate or hidden nonlinear units A network with just one hidden unit can represent any Boolean function The great power of multi-layer networks was realized long ago But it was only in the eighties it was shown how to make them learn Multiple layers of cascade linear units still produce only linear functions We search for networks capable of representing nonlinear functions Units should use nonlinear activation functions Examples of nonlinear activation functions 8
9 XOR-example 9

![[1986] Parallel Distributed Processing - Vol. 1 Foundations David E. Rumelhart, James L.](/docs-images/87/97038010/images/10-3.jpg "McClelland and the PDP Research Group What makes people smarter than computers?")
10 Back-propagation is a learning algorithm for multi-layer neural networks It was invented independently several times Bryson an Ho [1969] Werbos [1974] Parker [1985] Rumelhart et al. [1986] Parallel Distributed Processing - Vol. 1 Foundations David E. Rumelhart, James L. McClelland and the PDP Research Group What makes people smarter than computers? These volumes by a pioneering neurocomputing... 10
11 Back-propagation The algorithm gives a prescription for changing the weights w ij in any feedforward network to learn a training set of input output pairs {x d,t d } We consider a simple two-layer network x k x 1 x 2 x 3 x 4 x 5 11
12 Given the pattern x d the hidden unit j receives a net input net j d = k=1 d w jk x k and produces the output 5 V d j = f (net d j ) = f ( w jk x d k ) 5 k=1 Output unit i thus receives 3 net d i = W ij V d j = (W ij f ( w jk x d k )) j=1 j=1 k=1 And produce the final output 3 3 o d i = f (net d i ) = f ( W ij V d j ) = f ( (W ij f ( w jk x d k ))) j=1 j=1 k=
13 Out usual error function For l outputs and m input output pairs {x d,t d } E[ w ] = 1 2 m l d (t i o d i ) 2 d =1 i=1 In our example E becomes E[ w ] = 1 2 E[ w ] = 1 2 m 2 d =1 i=1 m 2 d (t i o d i ) 2 d =1 i=1 3 d (t i f ( W ij d f ( w jk x k ))) 2 E[w] is differentiable given f is differentiable Gradient descent can be applied j 5 k=1 13
14 For hidden-to-output connections the gradient descent rule gives: ΔW ij = η E = η W ij ΔW ij = η m d =1 m d =1 (t d i o d i ) f ' (net d d i ) V j (t d i o d i ) ( f ' (net d d i )) V j δ i d = f ' (net i d )(t i d o i d ) m d d ΔW ij = ηδ i V j d =1 For the input-to hidden connection w jk we must differentiate with respect to the w jk Using the chain rule we obtain Δw jk = η E = η w jk m d =1 d E V V j d j w jk 14
15 Δw jk = η m 2 d =1 i=1 (t i d δ i d = f ' (net i d )(t i d o i d ) Δw jk = η δ j d = f ' (net j d ) Δw jk = η m 2 d =1 i=1 m d =1 δ j d o i d ) f ' (net i d )W ij f ' (net j d ) x k d δ d i W ij f ' (net d d j ) x k x k d 2 d W ij δ i i=1 m d d ΔW ij = ηδ i V j d =1 Δw jk = η m d =1 δ j d x k d we have same form with a different definition of δ 15
16 In general, with an arbitrary number of layers, the back-propagation update rule has always the form Δw ij = η m d =1 δ output V input Where output and input refers to the connection concerned V stands for the appropriate input (hidden unit or real input, x d ) δ depends on the layer concerned By the equation δ d j = f ' (net d j ) 2 d W ij δ i allows us to determine for a given hidden unit V j in terms of the δ s of the unit o i The coefficient are usual forward, but the errors δ are propagated backward back-propagation i=1 16
17 We have to use a nonlinear differentiable activation function Examples: 1 f (x) = σ(x) = 1+ e ( α x) f ' (x) = σ ' (x) = α σ(x) (1 σ(x)) f (x) = tanh(α x) f ' (x) = α (1 f (x) 2 ) 17
18 Consider a network with M layers m=1,2,..,m V m i from the output of the ith unit of the mth layer V 0 i is a synonym for x i of the ith input Subscript m layers m s layers, not patterns W m ij mean connection from V j m-1 to V im Stochastic Back-Propagation Algorithm (mostly used) 1. Initialize the weights to small random values 2. Choose a pattern x d k and apply is to the input layer V0 k = xd k for all k 3. Propagate the signal through the network V m i = f (net m m i ) = f ( w ij V m 1 j ) 4. Compute the deltas for the output layer δ M i = f ' (net M i )(t d i V M i ) 5. Compute the deltas for the preceding layer for m=m,m-1,..2 δ m 1 i = f ' (net m 1 m m i ) δ j j 6. Update all connections Δw m ij = ηδ m m 1 i V j w new ij = w old ij + Δw ij 7. Goto 2 and repeat for the next pattern w ji j 18
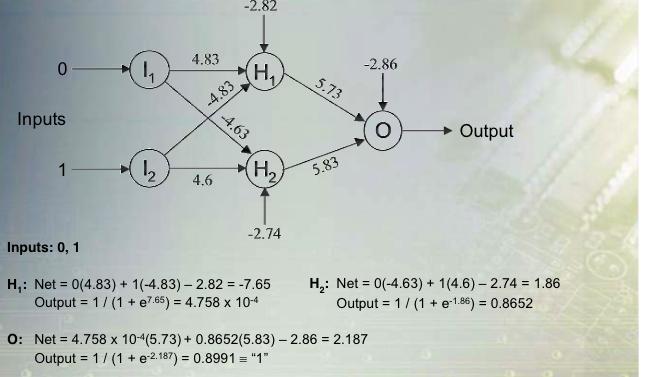
19 Example w 1 ={w 11 =0.1,w 12 =0.1,w 13 =0.1,w 14 =0.1,w 15 =0.1} w 2 ={w 21 =0.1,w 22 =0.1,w 23 =0.1,w 24 =0.1,w 25 =0.1} w 3 ={w 31 =0.1,w 32 =0.1,w 33 =0.1,w 34 =0.1,w 35 =0.1} W 1 ={W 11 =0.1,W 12 =0.1,W 13 =0.1} W 2 ={W 21 =0.1,W 22 =0.1,W 23 =0.1} X 1 ={1,1,0,0,0}; t 1 ={1,0} X 2 ={0,0,0,1,1}; t 1 ={0,1} f (x) = σ(x) = 1 1+ e ( x) f ' (x) = σ ' (x) = σ(x) (1 σ(x)) net = w 1k x k 5 k=1 net = w 2k x k 5 k=1 1 V 1 1 = f (net 1 1 ) = 1+ e net 1 1 net 1 1=1*0.1+1*0.1+0*0.1+0*0.1+0*0.1 V 1 1=f(net 1 1 )=1/(1+exp(-0.2))= V 1 2 = f (net 1 1 ) = 1+ e net 2 1 V 1 2=f(net 1 2 )=1/(1+exp(-0.2))= net = w 3k x k 5 k=1 1 V 1 3 = f (net 1 3 ) = 1+ e net 3 1 V 1 3=f(net 1 3 )=1/(1+exp(-0.2))=
20 3 net = W 1 j V j 1 o 1 1 = f (net 1 1 ) = 1+ e net 1 1 j=1 net 1 1= * * *0.1= o 1 1= f(net11)=1/(1+exp( ))= net = W 2 j V j j=1 1 o 1 2 = f (net 1 2 ) = 1+ e net 2 1 net 1 2= * * *0.1= o 1 2= f(net11)=1/(1+exp( ))= ΔW ij = η m (t d i o d i ) f ' (net d d i ) V j d =1 We will use stochastic gradient descent with η=1 ΔW ij = (t i o i ) f ' (net i )V j f ' (x) = σ ' (x) = σ(x) (1 σ(x)) ΔW ij = (t i o i )σ(net i )(1 σ(net i ))V j δ i = (t i o i )σ(net i )(1 σ(net i )) ΔW ij = δ i V j 20
21 δ 1 = (t 1 o 1 )σ(net 1 )(1 σ(net 1 )) ΔW 1 j = δ 1 V j δ 1 =( )*(1/(1+exp( )))*(1-(1/(1+exp( ))))= δ 2 = (t 2 o 2 )σ(net 2 )(1 σ(net 2 )) ΔW 2 j = δ 2 V j δ 2 =( )*(1/(1+exp( )))*(1-(1/(1+exp( ))))= Δw jk = δ i W ij f ' (net j ) x k i=1 2 Δw jk = δ i W ij σ(net j )(1 σ(net j )) x k i=1 δ j = σ(net j )(1 σ(net j )) Δw jk = δ j x k 2 W ij δ i i=1 21
22 2 δ 1 = σ(net 1 )(1 σ(net 1 )) W i1 δ i i=1 δ 1 = 1/(1+exp(- 0.2))*(1-1/(1+exp(- 0.2)))*(0.1* *( )) δ 1 = e-04 2 δ 2 = σ(net 2 )(1 σ(net 2 )) W i2 δ i i=1 δ 2 = e-04 δ 3 = σ(net 3 )(1 σ(net 3 )) i=1 δ 3 = e-04 2 W i3 δ i First Adaptation for x 1 (one epoch, adaptation over all training patterns, in our case x 1 x 2 ) Δw jk = δ j x k ΔW ij = δ i V j δ 1 = e-04 δ 1 = δ 2 = e-04 δ 2 = δ 3 = e-04 x 1 =1 v 1 = x 2 =1 v 2 = x 3 =0 v 3 = x 4 =0 x 5 =0 22
23 More on Back-Propagation Gradient descent over entire network weight vector Easily generalized to arbitrary directed graphs Will find a local, not necessarily global error minimum In practice, often works well (can run multiple times) Gradient descent can be very slow if η is to small, and can oscillate widely if η is to large Often include weight momentum α Δw pq (t +1) = η E w pq + α Δw pq (t) Momentum parameter α is chosen between 0 and 1, 0.9 is a good value 23
24 Minimizes error over training examples Will it generalize well Training can take thousands of iterations, it is slow! Using network after training is very fast 24
25 Convergence of Backpropagation Gradient descent to some local minimum Perhaps not global minimum... Add momentum Stochastic gradient descent Train multiple nets with different initial weights Nature of convergence Initialize weights near zero Therefore, initial networks near-linear Increasingly non-linear functions possible as training progresses 25
26 Expressive Capabilities of ANNs Boolean functions: Every boolean function can be represented by network with single hidden layer but might require exponential (in number of inputs) hidden units Continuous functions: Every bounded continuous function can be approximated with arbitrarily small error, by network with one hidden layer [Cybenko 1989; Hornik et al. 1989] Any function can be approximated to arbitrary accuracy by a network with two hidden layers [Cybenko 1988]. NETtalk Sejnowski et al
27 Prediction 27
28 28

29 Perceptron Gradient Descent Multi-layerd neural network Back-Propagation More on Back-Propagation Examples 29
30 RBF Networks, Support Vector Machines 30
Artificial Neural Networks
 Artificial Neural Networks Threshold units Gradient descent Multilayer networks Backpropagation Hidden layer representations Example: Face Recognition Advanced topics 1 Connectionist Models Consider humans:
Artificial Neural Networks Threshold units Gradient descent Multilayer networks Backpropagation Hidden layer representations Example: Face Recognition Advanced topics 1 Connectionist Models Consider humans:
Artificial Neural Networks
 Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Artificial Neural Networks 鮑興國 Ph.D. National Taiwan University of Science and Technology Outline Perceptrons Gradient descent Multi-layer networks Backpropagation Hidden layer representations Examples
Machine Learning
 Machine Learning 10-601 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 02/10/2016 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-601 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 02/10/2016 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Lecture 4: Perceptrons and Multilayer Perceptrons
 Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Lecture 4: Perceptrons and Multilayer Perceptrons Cognitive Systems II - Machine Learning SS 2005 Part I: Basic Approaches of Concept Learning Perceptrons, Artificial Neuronal Networks Lecture 4: Perceptrons
Artificial Neural Networks
 0 Artificial Neural Networks Based on Machine Learning, T Mitchell, McGRAW Hill, 1997, ch 4 Acknowledgement: The present slides are an adaptation of slides drawn by T Mitchell PLAN 1 Introduction Connectionist
0 Artificial Neural Networks Based on Machine Learning, T Mitchell, McGRAW Hill, 1997, ch 4 Acknowledgement: The present slides are an adaptation of slides drawn by T Mitchell PLAN 1 Introduction Connectionist
Machine Learning
 Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Lab 5: 16 th April Exercises on Neural Networks
 Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Lab 5: 16 th April 01 Exercises on Neural Networks 1. What are the values of weights w 0, w 1, and w for the perceptron whose decision surface is illustrated in the figure? Assume the surface crosses the
Radial Basis-Function Networks
 Raial Basis-Function Networks Back-Propagation Stochastic Back-Propagation Algorithm Step by Step Example Raial Basis-Function Networks Gaussian response function Location of center u Determining sigma
Raial Basis-Function Networks Back-Propagation Stochastic Back-Propagation Algorithm Step by Step Example Raial Basis-Function Networks Gaussian response function Location of center u Determining sigma
Introduction to Neural Networks
 Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
Introduction to Neural Networks What are (Artificial) Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning
100 inference steps doesn't seem like enough. Many neuron-like threshold switching units. Many weighted interconnections among units
 Connectionist Models Consider humans: Neuron switching time ~ :001 second Number of neurons ~ 10 10 Connections per neuron ~ 10 4 5 Scene recognition time ~ :1 second 100 inference steps doesn't seem like
Connectionist Models Consider humans: Neuron switching time ~ :001 second Number of neurons ~ 10 10 Connections per neuron ~ 10 4 5 Scene recognition time ~ :1 second 100 inference steps doesn't seem like
Multilayer Neural Networks
 Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Multilayer Neural Networks Multilayer Neural Networks Discriminant function flexibility NON-Linear But with sets of linear parameters at each layer Provably general function approximators for sufficient
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
4. Multilayer Perceptrons
 4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
4. Multilayer Perceptrons This is a supervised error-correction learning algorithm. 1 4.1 Introduction A multilayer feedforward network consists of an input layer, one or more hidden layers, and an output
y(x n, w) t n 2. (1)
 t n 2. (1)") Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Network training: Training a neural network involves determining the weight parameter vector w that minimizes a cost function. Given a training set comprising a set of input vector {x n }, n = 1,...N,
Multilayer Perceptrons and Backpropagation
 Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Neural networks. Chapter 20. Chapter 20 1
 Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Neural networks Chapter 20 Chapter 20 1 Outline Brains Neural networks Perceptrons Multilayer networks Applications of neural networks Chapter 20 2 Brains 10 11 neurons of > 20 types, 10 14 synapses, 1ms
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Chapter ML:VI (continued)
") Chapter ML:VI (continued) VI Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-64 Neural Networks STEIN 2005-2018 Definition 1 (Linear Separability)
Chapter ML:VI (continued) VI Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-64 Neural Networks STEIN 2005-2018 Definition 1 (Linear Separability)
Introduction to Artificial Neural Networks
 Facultés Universitaires Notre-Dame de la Paix 27 March 2007 Outline 1 Introduction 2 Fundamentals Biological neuron Artificial neuron Artificial Neural Network Outline 3 Single-layer ANN Perceptron Adaline
Facultés Universitaires Notre-Dame de la Paix 27 March 2007 Outline 1 Introduction 2 Fundamentals Biological neuron Artificial neuron Artificial Neural Network Outline 3 Single-layer ANN Perceptron Adaline
Supervised (BPL) verses Hybrid (RBF) Learning. By: Shahed Shahir
 verses Hybrid (RBF) Learning. By: Shahed Shahir") Supervised (BPL) verses Hybrid (RBF) Learning By: Shahed Shahir 1 Outline I. Introduction II. Supervised Learning III. Hybrid Learning IV. BPL Verses RBF V. Supervised verses Hybrid learning VI. Conclusion
Supervised (BPL) verses Hybrid (RBF) Learning By: Shahed Shahir 1 Outline I. Introduction II. Supervised Learning III. Hybrid Learning IV. BPL Verses RBF V. Supervised verses Hybrid learning VI. Conclusion
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Lecture 5: Logistic Regression. Neural Networks
 Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Lecture 5: Logistic Regression. Neural Networks Logistic regression Comparison with generative models Feed-forward neural networks Backpropagation Tricks for training neural networks COMP-652, Lecture
Pattern Classification
 Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Pattern Classification All materials in these slides were taen from Pattern Classification (2nd ed) by R. O. Duda,, P. E. Hart and D. G. Stor, John Wiley & Sons, 2000 with the permission of the authors
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Chapter ML:VI (continued)
") Chapter ML:VI (continued) VI. Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-56 Neural Networks STEIN 2005-2013 Definition 1 (Linear Separability)
Chapter ML:VI (continued) VI. Neural Networks Perceptron Learning Gradient Descent Multilayer Perceptron Radial asis Functions ML:VI-56 Neural Networks STEIN 2005-2013 Definition 1 (Linear Separability)
Artificial Neural Networks. Edward Gatt
 Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
Artificial Neural Networks Edward Gatt What are Neural Networks? Models of the brain and nervous system Highly parallel Process information much more like the brain than a serial computer Learning Very
Neural Networks and the Back-propagation Algorithm
 Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Neural Networks and the Back-propagation Algorithm Francisco S. Melo In these notes, we provide a brief overview of the main concepts concerning neural networks and the back-propagation algorithm. We closely
Plan. Perceptron Linear discriminant. Associative memories Hopfield networks Chaotic networks. Multilayer perceptron Backpropagation
 Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Introduction to Machine Learning
 Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
AI Programming CS F-20 Neural Networks
 AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
AI Programming CS662-2008F-20 Neural Networks David Galles Department of Computer Science University of San Francisco 20-0: Symbolic AI Most of this class has been focused on Symbolic AI Focus or symbols
Neural networks. Chapter 20, Section 5 1
 Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural networks Chapter 20, Section 5 Chapter 20, Section 5 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 20, Section 5 2 Brains 0 neurons of
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Gradient Descent Training Rule: The Details
 Gradient Descent Training Rule: The Details 1 For Perceptrons The whole idea behind gradient descent is to gradually, but consistently, decrease the output error by adjusting the weights. The trick is
Gradient Descent Training Rule: The Details 1 For Perceptrons The whole idea behind gradient descent is to gradually, but consistently, decrease the output error by adjusting the weights. The trick is
Part 8: Neural Networks
 METU Informatics Institute Min720 Pattern Classification ith Bio-Medical Applications Part 8: Neural Netors - INTRODUCTION: BIOLOGICAL VS. ARTIFICIAL Biological Neural Netors A Neuron: - A nerve cell as
METU Informatics Institute Min720 Pattern Classification ith Bio-Medical Applications Part 8: Neural Netors - INTRODUCTION: BIOLOGICAL VS. ARTIFICIAL Biological Neural Netors A Neuron: - A nerve cell as
Unit III. A Survey of Neural Network Model
 Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Unit III A Survey of Neural Network Model 1 Single Layer Perceptron Perceptron the first adaptive network architecture was invented by Frank Rosenblatt in 1957. It can be used for the classification of
Neural networks. Chapter 19, Sections 1 5 1
 Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
Neural networks Chapter 19, Sections 1 5 Chapter 19, Sections 1 5 1 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural networks Chapter 19, Sections 1 5 2 Brains 10
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Training Multi-Layer Neural Networks. - the Back-Propagation Method. (c) Marcin Sydow
 Marcin Sydow") Plan training single neuron with continuous activation function training 1-layer of continuous neurons training multi-layer network - back-propagation method single neuron with continuous activation function
Plan training single neuron with continuous activation function training 1-layer of continuous neurons training multi-layer network - back-propagation method single neuron with continuous activation function
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Computational Intelligence Winter Term 2017/18
 Computational Intelligence Winter Term 207/8 Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Plan for Today Single-Layer Perceptron Accelerated Learning
Computational Intelligence Winter Term 207/8 Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Plan for Today Single-Layer Perceptron Accelerated Learning
C1.2 Multilayer perceptrons
 Supervised Models C1.2 Multilayer perceptrons Luis B Almeida Abstract This section introduces multilayer perceptrons, which are the most commonly used type of neural network. The popular backpropagation
Supervised Models C1.2 Multilayer perceptrons Luis B Almeida Abstract This section introduces multilayer perceptrons, which are the most commonly used type of neural network. The popular backpropagation
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks. Chapter 18, Section 7. TB Artificial Intelligence. Slides from AIMA 1/ 21
 Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks Chapter 8, Section 7 TB Artificial Intelligence Slides from AIMA http://aima.cs.berkeley.edu / 2 Outline Brains Neural networks Perceptrons Multilayer perceptrons Applications of neural
Neural Networks. Fundamentals of Neural Networks : Architectures, Algorithms and Applications. L, Fausett, 1994
 Neural Networks Neural Networks Fundamentals of Neural Networks : Architectures, Algorithms and Applications. L, Fausett, 1994 An Introduction to Neural Networks (nd Ed). Morton, IM, 1995 Neural Networks
Neural Networks Neural Networks Fundamentals of Neural Networks : Architectures, Algorithms and Applications. L, Fausett, 1994 An Introduction to Neural Networks (nd Ed). Morton, IM, 1995 Neural Networks
Machine Learning. Neural Networks. Le Song. CSE6740/CS7641/ISYE6740, Fall Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Neural Networks Le Song Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 5 CB Learning highly non-linear functions f:
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Neural Networks Le Song Lecture 7, September 11, 2012 Based on slides from Eric Xing, CMU Reading: Chap. 5 CB Learning highly non-linear functions f:
Multilayer Perceptron = FeedForward Neural Network
 Multilayer Perceptron = FeedForward Neural Networ History Definition Classification = feedforward operation Learning = bacpropagation = local optimization in the space of weights Pattern Classification
Multilayer Perceptron = FeedForward Neural Networ History Definition Classification = feedforward operation Learning = bacpropagation = local optimization in the space of weights Pattern Classification
Neural Networks. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Neural Networks CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Perceptrons x 0 = 1 x 1 x 2 z = h w T x Output: z x D A perceptron
Computational Intelligence
 Plan for Today Single-Layer Perceptron Computational Intelligence Winter Term 00/ Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Accelerated Learning
Plan for Today Single-Layer Perceptron Computational Intelligence Winter Term 00/ Prof. Dr. Günter Rudolph Lehrstuhl für Algorithm Engineering (LS ) Fakultät für Informatik TU Dortmund Accelerated Learning
Backpropagation Neural Net
 Backpropagation Neural Net As is the case with most neural networks, the aim of Backpropagation is to train the net to achieve a balance between the ability to respond correctly to the input patterns that
Backpropagation Neural Net As is the case with most neural networks, the aim of Backpropagation is to train the net to achieve a balance between the ability to respond correctly to the input patterns that
Feedforward Neural Nets and Backpropagation
 Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Feedforward Neural Nets and Backpropagation Julie Nutini University of British Columbia MLRG September 28 th, 2016 1 / 23 Supervised Learning Roadmap Supervised Learning: Assume that we are given the features
Simple Neural Nets For Pattern Classification
 CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
Christian Mohr
 Christian Mohr 20.12.2011 Recurrent Networks Networks in which units may have connections to units in the same or preceding layers Also connections to the unit itself possible Already covered: Hopfield
Christian Mohr 20.12.2011 Recurrent Networks Networks in which units may have connections to units in the same or preceding layers Also connections to the unit itself possible Already covered: Hopfield
Introduction Neural Networks - Architecture Network Training Small Example - ZIP Codes Summary. Neural Networks - I. Henrik I Christensen
 Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Neural Networks - I Henrik I Christensen Robotics & Intelligent Machines @ GT Georgia Institute of Technology, Atlanta, GA 30332-0280 hic@cc.gatech.edu Henrik I Christensen (RIM@GT) Neural Networks 1 /
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Data Mining Part 5. Prediction
 Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
Data Mining Part 5. Prediction 5.5. Spring 2010 Instructor: Dr. Masoud Yaghini Outline How the Brain Works Artificial Neural Networks Simple Computing Elements Feed-Forward Networks Perceptrons (Single-layer,
CS 6501: Deep Learning for Computer Graphics. Basics of Neural Networks. Connelly Barnes
 CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
CS 6501: Deep Learning for Computer Graphics Basics of Neural Networks Connelly Barnes Overview Simple neural networks Perceptron Feedforward neural networks Multilayer perceptron and properties Autoencoders
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Input layer. Weight matrix [ ] Output layer
![Input layer. Weight matrix [ ] Output layer](/thumbs/94/121286844.jpg "Input layer. Weight matrix [ ] Output layer") MASSACHUSETTS INSTITUTE OF TECHNOLOGY Department of Electrical Engineering and Computer Science 6.034 Artificial Intelligence, Fall 2003 Recitation 10, November 4 th & 5 th 2003 Learning by perceptrons
MASSACHUSETTS INSTITUTE OF TECHNOLOGY Department of Electrical Engineering and Computer Science 6.034 Artificial Intelligence, Fall 2003 Recitation 10, November 4 th & 5 th 2003 Learning by perceptrons
Learning Neural Networks
 Learning Neural Networks Neural Networks can represent complex decision boundaries Variable size. Any boolean function can be represented. Hidden units can be interpreted as new features Deterministic
Learning Neural Networks Neural Networks can represent complex decision boundaries Variable size. Any boolean function can be represented. Hidden units can be interpreted as new features Deterministic
Multilayer Neural Networks
 Multilayer Neural Networks Introduction Goal: Classify objects by learning nonlinearity There are many problems for which linear discriminants are insufficient for minimum error In previous methods, the
Multilayer Neural Networks Introduction Goal: Classify objects by learning nonlinearity There are many problems for which linear discriminants are insufficient for minimum error In previous methods, the
Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions
 perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions") BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
Multilayer Perceptron
 Aprendizagem Automática Multilayer Perceptron Ludwig Krippahl Aprendizagem Automática Summary Perceptron and linear discrimination Multilayer Perceptron, nonlinear discrimination Backpropagation and training
Aprendizagem Automática Multilayer Perceptron Ludwig Krippahl Aprendizagem Automática Summary Perceptron and linear discrimination Multilayer Perceptron, nonlinear discrimination Backpropagation and training
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning Lesson 39 Neural Networks - III 12.4.4 Multi-Layer Perceptrons In contrast to perceptrons, multilayer networks can learn not only multiple decision boundaries, but the boundaries
Module 12 Machine Learning Lesson 39 Neural Networks - III 12.4.4 Multi-Layer Perceptrons In contrast to perceptrons, multilayer networks can learn not only multiple decision boundaries, but the boundaries
Master Recherche IAC TC2: Apprentissage Statistique & Optimisation
 Master Recherche IAC TC2: Apprentissage Statistique & Optimisation Alexandre Allauzen Anne Auger Michèle Sebag LIMSI LRI Oct. 4th, 2012 This course Bio-inspired algorithms Classical Neural Nets History
Master Recherche IAC TC2: Apprentissage Statistique & Optimisation Alexandre Allauzen Anne Auger Michèle Sebag LIMSI LRI Oct. 4th, 2012 This course Bio-inspired algorithms Classical Neural Nets History
Artificial Neural Networks. Q550: Models in Cognitive Science Lecture 5
 Artificial Neural Networks Q550: Models in Cognitive Science Lecture 5 "Intelligence is 10 million rules." --Doug Lenat The human brain has about 100 billion neurons. With an estimated average of one thousand
Artificial Neural Networks Q550: Models in Cognitive Science Lecture 5 "Intelligence is 10 million rules." --Doug Lenat The human brain has about 100 billion neurons. With an estimated average of one thousand
Last update: October 26, Neural networks. CMSC 421: Section Dana Nau
 Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Last update: October 26, 207 Neural networks CMSC 42: Section 8.7 Dana Nau Outline Applications of neural networks Brains Neural network units Perceptrons Multilayer perceptrons 2 Example Applications
Artificial Neural Networks
 Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
Introduction ANN in Action Final Observations Application: Poverty Detection Artificial Neural Networks Alvaro J. Riascos Villegas University of los Andes and Quantil July 6 2018 Artificial Neural Networks
Introduction to Natural Computation. Lecture 9. Multilayer Perceptrons and Backpropagation. Peter Lewis
 Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Introduction to Natural Computation Lecture 9 Multilayer Perceptrons and Backpropagation Peter Lewis 1 / 25 Overview of the Lecture Why multilayer perceptrons? Some applications of multilayer perceptrons.
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Supervised Learning in Neural Networks
 The Norwegian University of Science and Technology (NTNU Trondheim, Norway keithd@idi.ntnu.no March 7, 2011 Supervised Learning Constant feedback from an instructor, indicating not only right/wrong, but
The Norwegian University of Science and Technology (NTNU Trondheim, Norway keithd@idi.ntnu.no March 7, 2011 Supervised Learning Constant feedback from an instructor, indicating not only right/wrong, but
Unit 8: Introduction to neural networks. Perceptrons
 Unit 8: Introduction to neural networks. Perceptrons D. Balbontín Noval F. J. Martín Mateos J. L. Ruiz Reina A. Riscos Núñez Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
Unit 8: Introduction to neural networks. Perceptrons D. Balbontín Noval F. J. Martín Mateos J. L. Ruiz Reina A. Riscos Núñez Departamento de Ciencias de la Computación e Inteligencia Artificial Universidad
<Special Topics in VLSI> Learning for Deep Neural Networks (Back-propagation)
") Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
Learning for Deep Neural Networks (Back-propagation) Outline Summary of Previous Standford Lecture Universal Approximation Theorem Inference vs Training Gradient Descent Back-Propagation
The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt.
 1 The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt. The algorithm applies only to single layer models
1 The perceptron learning algorithm is one of the first procedures proposed for learning in neural network models and is mostly credited to Rosenblatt. The algorithm applies only to single layer models
NN V: The generalized delta learning rule
 NN V: The generalized delta learning rule We now focus on generalizing the delta learning rule for feedforward layered neural networks. The architecture of the two-layer network considered below is shown
NN V: The generalized delta learning rule We now focus on generalizing the delta learning rule for feedforward layered neural networks. The architecture of the two-layer network considered below is shown
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
CS:4420 Artificial Intelligence
 CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
CS:4420 Artificial Intelligence Spring 2018 Neural Networks Cesare Tinelli The University of Iowa Copyright 2004 18, Cesare Tinelli and Stuart Russell a a These notes were originally developed by Stuart
A Logarithmic Neural Network Architecture for Unbounded Non-Linear Function Approximation
 1 Introduction A Logarithmic Neural Network Architecture for Unbounded Non-Linear Function Approximation J Wesley Hines Nuclear Engineering Department The University of Tennessee Knoxville, Tennessee,
1 Introduction A Logarithmic Neural Network Architecture for Unbounded Non-Linear Function Approximation J Wesley Hines Nuclear Engineering Department The University of Tennessee Knoxville, Tennessee,
SPSS, University of Texas at Arlington. Topics in Machine Learning-EE 5359 Neural Networks
 Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Topics in Machine Learning-EE 5359 Neural Networks 1 The Perceptron Output: A perceptron is a function that maps D-dimensional vectors to real numbers. For notational convenience, we add a zero-th dimension
Radial-Basis Function Networks
 Radial-Basis Function etworks A function is radial basis () if its output depends on (is a non-increasing function of) the distance of the input from a given stored vector. s represent local receptors,
Radial-Basis Function etworks A function is radial basis () if its output depends on (is a non-increasing function of) the distance of the input from a given stored vector. s represent local receptors,
ECE 471/571 - Lecture 17. Types of NN. History. Back Propagation. Recurrent (feedback during operation) Feedforward
 Feedforward") ECE 47/57 - Lecture 7 Back Propagation Types of NN Recurrent (feedback during operation) n Hopfield n Kohonen n Associative memory Feedforward n No feedback during operation or testing (only during determination
ECE 47/57 - Lecture 7 Back Propagation Types of NN Recurrent (feedback during operation) n Hopfield n Kohonen n Associative memory Feedforward n No feedback during operation or testing (only during determination
Administration. Registration Hw3 is out. Lecture Captioning (Extra-Credit) Scribing lectures. Questions. Due on Thursday 10/6
 Scribing lectures. Questions. Due on Thursday 10/6") Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Need for Deep Networks Perceptron. Can only model linear functions. Kernel Machines. Non-linearity provided by kernels
 Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Need for Deep Networks Perceptron Can only model linear functions Kernel Machines Non-linearity provided by kernels Need to design appropriate kernels (possibly selecting from a set, i.e. kernel learning)
Machine Learning: Multi Layer Perceptrons
 Machine Learning: Multi Layer Perceptrons Prof. Dr. Martin Riedmiller Albert-Ludwigs-University Freiburg AG Maschinelles Lernen Machine Learning: Multi Layer Perceptrons p.1/61 Outline multi layer perceptrons
Machine Learning: Multi Layer Perceptrons Prof. Dr. Martin Riedmiller Albert-Ludwigs-University Freiburg AG Maschinelles Lernen Machine Learning: Multi Layer Perceptrons p.1/61 Outline multi layer perceptrons
Perceptron. Inner-product scalar Perceptron. XOR problem. Gradient descent Stochastic Approximation to gradient descent 5/10/10
 Perceptro Ier-product scalar Perceptro Perceptro learig rule XOR problem liear separable patters Gradiet descet Stochastic Approximatio to gradiet descet LMS Adalie 1 Ier-product et =< w, x >= w x cos(θ)
Perceptro Ier-product scalar Perceptro Perceptro learig rule XOR problem liear separable patters Gradiet descet Stochastic Approximatio to gradiet descet LMS Adalie 1 Ier-product et =< w, x >= w x cos(θ)
Radial-Basis Function Networks
 Radial-Basis Function etworks A function is radial () if its output depends on (is a nonincreasing function of) the distance of the input from a given stored vector. s represent local receptors, as illustrated
Radial-Basis Function etworks A function is radial () if its output depends on (is a nonincreasing function of) the distance of the input from a given stored vector. s represent local receptors, as illustrated
Neural networks COMS 4771
 Neural networks COMS 4771 1. Logistic regression Logistic regression Suppose X = R d and Y = {0, 1}. A logistic regression model is a statistical model where the conditional probability function has a
Neural networks COMS 4771 1. Logistic regression Logistic regression Suppose X = R d and Y = {0, 1}. A logistic regression model is a statistical model where the conditional probability function has a
Artificial Neural Networks (ANN)
") Artificial Neural Networks (ANN) Edmondo Trentin April 17, 2013 ANN: Definition The definition of ANN is given in 3.1 points. Indeed, an ANN is a machine that is completely specified once we define its:
Artificial Neural Networks (ANN) Edmondo Trentin April 17, 2013 ANN: Definition The definition of ANN is given in 3.1 points. Indeed, an ANN is a machine that is completely specified once we define its:
Deep Learning. Ali Ghodsi. University of Waterloo
 University of Waterloo Deep learning attempts to learn representations of data with multiple levels of abstraction. Deep learning usually refers to a set of algorithms and computational models that are
University of Waterloo Deep learning attempts to learn representations of data with multiple levels of abstraction. Deep learning usually refers to a set of algorithms and computational models that are
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Neural Networks and Deep Learning.
 Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
Neural Networks and Deep Learning www.cs.wisc.edu/~dpage/cs760/ 1 Goals for the lecture you should understand the following concepts perceptrons the perceptron training rule linear separability hidden
CS489/698: Intro to ML
 CS489/698: Intro to ML Lecture 03: Multi-layer Perceptron Outline Failure of Perceptron Neural Network Backpropagation Universal Approximator 2 Outline Failure of Perceptron Neural Network Backpropagation
CS489/698: Intro to ML Lecture 03: Multi-layer Perceptron Outline Failure of Perceptron Neural Network Backpropagation Universal Approximator 2 Outline Failure of Perceptron Neural Network Backpropagation
Neural Networks Lecture 4: Radial Bases Function Networks
 Neural Networks Lecture 4: Radial Bases Function Networks H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011. A. Talebi, Farzaneh Abdollahi
Neural Networks Lecture 4: Radial Bases Function Networks H.A Talebi Farzaneh Abdollahi Department of Electrical Engineering Amirkabir University of Technology Winter 2011. A. Talebi, Farzaneh Abdollahi
Neural Networks. Fundamentals Framework for distributed processing Network topologies Training of ANN s Notation Perceptron Back Propagation
 Neural Networks Fundamentals Framework for distributed processing Network topologies Training of ANN s Notation Perceptron Back Propagation Neural Networks Historical Perspective A first wave of interest
Neural Networks Fundamentals Framework for distributed processing Network topologies Training of ANN s Notation Perceptron Back Propagation Neural Networks Historical Perspective A first wave of interest
Multilayer Feedforward Networks. Berlin Chen, 2002
 Multilayer Feedforard Netors Berlin Chen, 00 Introduction The single-layer perceptron classifiers discussed previously can only deal ith linearly separable sets of patterns The multilayer netors to be
Multilayer Feedforard Netors Berlin Chen, 00 Introduction The single-layer perceptron classifiers discussed previously can only deal ith linearly separable sets of patterns The multilayer netors to be
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011!
 Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error
Artificial Neural Networks" and Nonparametric Methods" CMPSCI 383 Nov 17, 2011! 1 Todayʼs lecture" How the brain works (!)! Artificial neural networks! Perceptrons! Multilayer feed-forward networks! Error