Brief Introduction of Machine Learning Techniques for Content Analysis
|
|
|
- Alisha Lucas
- 5 years ago
- Views:
Transcription
1 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20
2 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM)
3 Overview 3 Any computer program that can improve its performance at some task through experience (or training) can be called a learning program. During early days, computer scientists developed learning algorithms based on heuristics and insights into human reasoning mechanisms. Decision tree, Neuro-scientists attempted to devise learning methods by imitating the structure of human brains. Y. Gong and W. Xu, Machine Learning for Multimedia Content Analysis, Springer, 2007
4 Basic Statistical Learning Problems 4 Many learning tasks can be formulated as one of the following two problems. Regression: X: input variable, Y: output variable. Infer a function f(x) so that given a value of x of the input variable X, y = f(x) is a good predication of the true value y of the output variable Y.
5 Basic Statistical Learning Problems 5 Classification: Assume that a random variable X can belong to one of a finite set of classes C={1,2,,K}. Given the value x of variable X, infer its class label l=g(x), where. It is also of great interest to estimate the probability P(k x) that X belongs to class k,. In fact both the regression and classification problems can be formulated using the same framework.
6 6 Categorizations of Machine Learning Techniques Unsupervised vs. Supervised For inferring the functions f(x) and g(x), if pairs of training data (x i,y i ) or (x i, l i ), i= 1,,N are available, then the inference process is called supervised learning. Most regression methods are supervised learning. Unsupervised methods strive to automatically partition a given data set into the predefined number of clusters also called clustering.
7 7 Categorizations of Machine Learning Techniques Generative Models vs. Discriminative Models Discriminative models strive to learn P(k x) directly from the training set without the attempt to modeling the observation x. Generative models compute P(k x) by first modeling the class-conditional probabilities P(x k) as well as the class probabilities P(k) Posterior prob. likelihood Priori prob.
8 Categorizations of Machine Learning 8 Techniques Generative models: Naïve Bayes, Bayesian Networks, Gaussian Mixture Models (GMM), Hidden Markov Models (HMM), Discriminative models: Neural Networks, Support Vector Machines (SVM), Maximum Entropy Models (MEM), Conditional Random Fields (CRF),
9 9 Categorizations of Machine Learning Techniques Models for Simple Data vs. Models for Complex Data Complex data: consist of sub-entities that are strongly related one to another E.g. a beach scene usually composed of a blue sky on top, an ocean in the middle, and a sand beach at the bottom For simple: Naïve Bayes, GMM, NN, SVM For complex: BN, HMM, MEM, CRF, M 3 -net
10 10 Categorizations of Machine Learning Techniques Model Identification vs. Model Prediction Model identification: to discover an existing Law of Nature The model identification paradigm is an ill-posed problems, and is annoyed by the curse of dimensionality. The goal of model predication is to predict events well, but not necessarily through the identification of the model of events.
11 11 Gaussian Mixture Model Wei-Ta Chu 2008/11/20

12 Introduction 12 By using a sufficient number of Gaussians, and by adjusting their means and covariances as well as the coefficients in the linear combinations, almost any continuous density can be approximated to arbitrary accuracy. C.M. Bishop, Pattern Recognition and Machine Learning, Springer, 2006


13 Introduction 13 Consider a superposition of K Gaussian densities Each Gaussian density is called a component of the mixture and has its own mean and covariance.
14 Introduction 14 From the sum and product rules, the marginal density is given by We can view as the prior probability of picking the kth component, and the density as the probability of x conditioned on k:
15 Introduction 15 FromBaye stheorem, the posterior probability p(k x) is given by Gaussian mixture distribution is governed by parameters. One way to set these parameters is to use maximum likelihood. Assume that different mixtures are independent and identically distributed
16 Introduction 16 In case of a single variable x, the Gaussian distribution is in the form For a D-dimensional vector x, the multivariate Gaussian distribution takes the form



17 Maximizing Likelihood 17 Setting the derivative of with respect to the means of the Gaussian components to zero The mean for the kth Gaussian component is obtained by taking a weighted mean of all of the points in the data set, in which the weighting factor for data point is given by the posterior probability

18 Maximizing Likelihood 18 Setting the derivative of with respect to the covariance of the Gaussian components to zero Each data point weighted by the corresponding posterior probability
19 Maximizing Likelihood 19 Maximize with respect to the mixing coefficients Constraint: the sum of mixing coefficients is one Using Lagrange multiplier and maximizing the following quantity If we multiply both sides by and sum over k making use of the constraint, we find. Using this to eliminate and rearranging we obtain Mixing coefficient of the kth component is given by the average responsibility which that component takes for explaining the data points
20 20 Expectation-Maximization (EM) Algorithm We first choose some initial values for the means, covariances, and mixing coefficients. Expectation step (E step) Use the current parameters to evaluate the posterior probabilities Maximization step (M step) Re-estimate the means, covariances, and mixing coefficients Each update to the parameters resulting from an E step followed by an M step is guaranteed to increase the log likelihood function.

21 Example 21


22 EM for Gaussian Mixtures 22

23 Case Study 23 Jiang, et al. A new method to segment playfield and its applications in match analysis in sports video, In Proc. of ACM MM, pp , 2004.

24 Case Study 24 The condition density of a pixel belongs to the playfield region is modeled with M Gaussian densities:
25 Related Resources 25 GMMBAYES - Bayesian Classifier and Gaussian Mixture Model ToolBox gmmbayestb/ Netlab Matlab toolboxes collection
26 26 Hidden Markov Model Wei-Ta Chu 2008/11/20

27 Markov Model Chain rule 27 Assume that each of the condition distributions is independent of all previous observations except the most recent, we obtain the first-order Markov chain. First-order Markov chain Second-order Markov chain C.M. Bishop, Pattern Recognition and Machine Learning, Springer, 2006
28 Example 28 What s the probability that the weather for eight consecutive days is sun-sun-sun-rain-rain-sun-cloudy-sun? rain sunny 3 cloudy L. Rabiner and B.-H. Juang, Fundamentals of Speech Recognition, Prentice-Hall, 1993 L. Rabiner, A tutorial on hidden Markov models and selected applications in speech recognition, Proceedings of IEEE, vol. 77, no. 2, pp , 1989.
29 Coin-Toss Model 29 You are in a room with a curtain through which you cannot see that is happening. On the other side of the curtain is another person who is performing a coin tossing experiment (using one or more coins). The person will not tell you which coin he selects at any time; he will only tell you the result of each coin flip. A typical observation sequence would be The question is: how do we build an model to explain the observed sequence of head and tails?
30 Coin-Toss Model 30 P(H) 1-P(H) Head 1-P(H) 1 2 P(H) Tail 1-coin model (Observable Markov Model) a 11 a 22 1-a a coins model (Hidden Markov Model) P(H) = P 1 P(T) =1- P 1 P(H) = P 2 P(T) =1- P 2
31 Coin-Toss Model 31 a 11 a 22 a a 21 3-coins model (Hidden Markov Model) a a 13 a a 23 3 a 33 State 1 State 2 State 3 P(H) = P 1 P(H) = P 2 P(H) = P 3 P(T) =1- P 1 P(T) =1- P 2 P(T) =1- P 3
32 Elements of HMM 32 N: the number of states in the model M: the number of distinct observation symbols per state The state-transition probability A={a ij } The observation symbol probability distribution B={b j (k)} The initial state distribution To describe an HMM, we usually use the compact notation
33 Three Basic Problems of HMM 33 Problem 1: Probability Evaluation How do we compute the probability that the observed sequence was produced by the model? Scoring how well a given model matches a given observation sequence.
34 Three Basic Problems of HMM 34 Problem 2: Optimal State Sequence Attempt to uncover the hidden part of the model that is, to find the corect state sequence. For practical situations, we usually use an optimality criterion to solve this problem as best as possible.
35 Three Basic Problems of HMM 35 Problem 3: Parameter Estimation Attempt to optimize the model parameters to best describe how a given observation sequence comes about. The observation sequence used to adjust the model parameters is called a training sequence because it is used to train the HMM.
36 Solution to Problem 1 36 There are N T possible state sequences Consider one fixed-state sequence The prob. of the observation sequence given the state sequence Where we have assumed statistical independence of observations, thus we get
37 Solution to Problem 1 37 The prob. of such state sequence can be written as The joint prob. of O and q, i.e., the prob. that O and q occur simultaneously, is simply the product of the above terms The prob. of O is obtained by summing this joint prob. over all possible state sequences q, giving
38 Solution to Problem 1 38 The Forward Procedure The prob. of the partial observation sequence o 1,o 2,,o t (until time t) and state i at time t, given the model We solve for it inductively 1. Initialization 2. Induction 3. Termination
39 Solution to Problem 1 39 The Forward Procedure Require on the order of N 2 T calculations, rather than 2TN T as required by the direction calculation.
40 40 The Backward Procedure The prob. of partial observation sequence from t+1 to the end, given state i at time t and the model 1. Initialization 2. Induction
41 Solution to Problem 2 41 We define the quantity Which is the best score (highest probability) along a single path, at time t, which accounts for the first t observations and ends in state i. By induction we have
42 Solution to Problem 2 42 The Viterbi Algorithm 1. Initialization 2. Recursion 3. Termination 4. Path (state sequence) backtracking The major difference between Viterbi and the forward procedure is the maximization over previous states.
43 Solution to Problem 3 43 Choose such that its likelihood,, is locally maximized using an iterative procedure such as the Baum- Welch algorithm (also known as EM algorithm or forwardbackward algorithm) Define the prob. of being in state i at time t, and state j at time t+1, given the model and the observation sequence.
44 Solution to Problem 3 44 The prob. of being in state i at time t, given the observation sequence O and the model
45 Solution to Problem 3 45
46 Types of HMMs 46 Ergodic Left-right Parallel path left-right
47 Case Study 47 Features Field descriptor Edge descriptor Grass and sand Player height Peng, et al. Extract highlights from basebal game video with hidden Markov models, In Proc. of ICIP, vol. 1, pp , 2002.
48 Related Resources 48 Hidden Markov Model (HMM) Toolbox for Matlab html The General Hidden Markov Model library (GHMM) HTK Speech Recognition Toolkit
49 49 Support Vector Machine Wei-Ta Chu 2008/11/20
50 Introduction Linearly Separable Data 50 For a linearly separable data set S, there exists a hyperplane that satisfies all the points in S Y. Gong and W. Xu, Machine Learning for Multimedia Content Analysis, Springer, 2007

51 Introduction 51 Rescale (w,b) so that the closet points to the hyperplane satisfy. This normalization leads to the canonical form for SVM
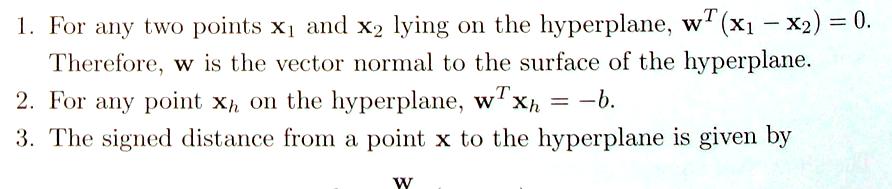

52 Properties 52

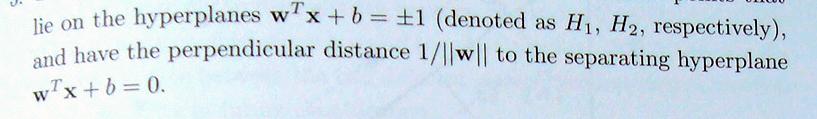
53 Properties 53
54 54 The goal of SVM is to find the pair of hyperplanes H1, H2 that maximize the margin, subject to the constraints This can be formulated as the constrained optimization problem:

55 55 Introduction Linearly Non-Separable Data When the SVM derived above is applied to non-separable data sets, some data points could be at a distance on the wrong side. We transform the constraint to The SVM for non-separable case can be casted as the optimization problem:
56 General Idea 56 General idea: the original input space can always be mapped to some higher-dimensional feature space where the training set is separable: Φ: x φ(x)
57 Optimization Problem 57 Use Lagrange multiplier method to find the optimal solution transform the original problem to a dual problem Kernel trick We don t realy find the mapping function, but to use a kernel function to find the inner product of data points in the higher-dimensional space.
58 Related Resources 58 LIBSVM
59 References 59 L. Rabiner, A tutorial on hidden Markov models and selected applications in speech recognition, Proceedings of IEEE, vol. 77, no. 2, pp , Statistical Data Mining Tutorials, Tutorial Slides by Andrew Moore: Jiang, et al. A new method to segment playfield and its applications in match analysis in sports video, In Proc. of ACM MM, pp , Peng, et al. Extract highlights from basebal game video with hidden Markov models, In Proc. of ICIP, vol. 1, pp , LIBSVM,
60 References 60 Hidden Markov Model (HMM) Toolbox for Matlab The General Hidden Markov Model library (GHMM) HTK Speech Recognition Toolkit
61 Next Week 61 Introduction to Audio and Music
L23: hidden Markov models
 L23: hidden Markov models Discrete Markov processes Hidden Markov models Forward and Backward procedures The Viterbi algorithm This lecture is based on [Rabiner and Juang, 1993] Introduction to Speech
L23: hidden Markov models Discrete Markov processes Hidden Markov models Forward and Backward procedures The Viterbi algorithm This lecture is based on [Rabiner and Juang, 1993] Introduction to Speech
Lecture 11: Hidden Markov Models
 Lecture 11: Hidden Markov Models Cognitive Systems - Machine Learning Cognitive Systems, Applied Computer Science, Bamberg University slides by Dr. Philip Jackson Centre for Vision, Speech & Signal Processing
Lecture 11: Hidden Markov Models Cognitive Systems - Machine Learning Cognitive Systems, Applied Computer Science, Bamberg University slides by Dr. Philip Jackson Centre for Vision, Speech & Signal Processing
Introduction to Machine Learning Midterm, Tues April 8
 Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Hidden Markov Model. Ying Wu. Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208
 Hidden Markov Model Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/19 Outline Example: Hidden Coin Tossing Hidden
Hidden Markov Model Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/19 Outline Example: Hidden Coin Tossing Hidden
Hidden Markov Models. Aarti Singh Slides courtesy: Eric Xing. Machine Learning / Nov 8, 2010
 Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Hidden Markov Models. By Parisa Abedi. Slides courtesy: Eric Xing
 Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
Conditional Random Field
 Introduction Linear-Chain General Specific Implementations Conclusions Corso di Elaborazione del Linguaggio Naturale Pisa, May, 2011 Introduction Linear-Chain General Specific Implementations Conclusions
Introduction Linear-Chain General Specific Implementations Conclusions Corso di Elaborazione del Linguaggio Naturale Pisa, May, 2011 Introduction Linear-Chain General Specific Implementations Conclusions
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Lecture 3: Machine learning, classification, and generative models
 EE E6820: Speech & Audio Processing & Recognition Lecture 3: Machine learning, classification, and generative models 1 Classification 2 Generative models 3 Gaussian models Michael Mandel
EE E6820: Speech & Audio Processing & Recognition Lecture 3: Machine learning, classification, and generative models 1 Classification 2 Generative models 3 Gaussian models Michael Mandel
Hidden Markov Models (HMM) and Support Vector Machine (SVM)
 and Support Vector Machine (SVM)") Hidden Markov Models (HMM) and Support Vector Machine (SVM) Professor Joongheon Kim School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea 1 Hidden Markov Models (HMM)
Hidden Markov Models (HMM) and Support Vector Machine (SVM) Professor Joongheon Kim School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea 1 Hidden Markov Models (HMM)
Hidden Markov Models
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
More on HMMs and other sequence models. Intro to NLP - ETHZ - 18/03/2013
 More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Overview of Statistical Tools. Statistical Inference. Bayesian Framework. Modeling. Very simple case. Things are usually more complicated
 Fall 3 Computer Vision Overview of Statistical Tools Statistical Inference Haibin Ling Observation inference Decision Prior knowledge http://www.dabi.temple.edu/~hbling/teaching/3f_5543/index.html Bayesian
Fall 3 Computer Vision Overview of Statistical Tools Statistical Inference Haibin Ling Observation inference Decision Prior knowledge http://www.dabi.temple.edu/~hbling/teaching/3f_5543/index.html Bayesian
Chapter 4 Dynamic Bayesian Networks Fall Jin Gu, Michael Zhang
 Chapter 4 Dynamic Bayesian Networks 2016 Fall Jin Gu, Michael Zhang Reviews: BN Representation Basic steps for BN representations Define variables Define the preliminary relations between variables Check
Chapter 4 Dynamic Bayesian Networks 2016 Fall Jin Gu, Michael Zhang Reviews: BN Representation Basic steps for BN representations Define variables Define the preliminary relations between variables Check
Hidden Markov Models (HMMs)
") Hidden Markov Models (HMMs) Reading Assignments R. Duda, P. Hart, and D. Stork, Pattern Classification, John-Wiley, 2nd edition, 2001 (section 3.10, hard-copy). L. Rabiner, "A tutorial on HMMs and selected
Hidden Markov Models (HMMs) Reading Assignments R. Duda, P. Hart, and D. Stork, Pattern Classification, John-Wiley, 2nd edition, 2001 (section 3.10, hard-copy). L. Rabiner, "A tutorial on HMMs and selected
Hidden Markov Models. Dr. Naomi Harte
 Hidden Markov Models Dr. Naomi Harte The Talk Hidden Markov Models What are they? Why are they useful? The maths part Probability calculations Training optimising parameters Viterbi unseen sequences Real
Hidden Markov Models Dr. Naomi Harte The Talk Hidden Markov Models What are they? Why are they useful? The maths part Probability calculations Training optimising parameters Viterbi unseen sequences Real
Hidden Markov Models
 Hidden Markov Models Dr Philip Jackson Centre for Vision, Speech & Signal Processing University of Surrey, UK 1 3 2 http://www.ee.surrey.ac.uk/personal/p.jackson/isspr/ Outline 1. Recognizing patterns
Hidden Markov Models Dr Philip Jackson Centre for Vision, Speech & Signal Processing University of Surrey, UK 1 3 2 http://www.ee.surrey.ac.uk/personal/p.jackson/isspr/ Outline 1. Recognizing patterns
Hidden Markov Models
 Hidden Markov Models Lecture Notes Speech Communication 2, SS 2004 Erhard Rank/Franz Pernkopf Signal Processing and Speech Communication Laboratory Graz University of Technology Inffeldgasse 16c, A-8010
Hidden Markov Models Lecture Notes Speech Communication 2, SS 2004 Erhard Rank/Franz Pernkopf Signal Processing and Speech Communication Laboratory Graz University of Technology Inffeldgasse 16c, A-8010
Hidden Markov Models. Ivan Gesteira Costa Filho IZKF Research Group Bioinformatics RWTH Aachen Adapted from:
 Hidden Markov Models Ivan Gesteira Costa Filho IZKF Research Group Bioinformatics RWTH Aachen Adapted from: www.ioalgorithms.info Outline CG-islands The Fair Bet Casino Hidden Markov Model Decoding Algorithm
Hidden Markov Models Ivan Gesteira Costa Filho IZKF Research Group Bioinformatics RWTH Aachen Adapted from: www.ioalgorithms.info Outline CG-islands The Fair Bet Casino Hidden Markov Model Decoding Algorithm
Sequence labeling. Taking collective a set of interrelated instances x 1,, x T and jointly labeling them
 HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
Data Mining in Bioinformatics HMM
 Data Mining in Bioinformatics HMM Microarray Problem: Major Objective n Major Objective: Discover a comprehensive theory of life s organization at the molecular level 2 1 Data Mining in Bioinformatics
Data Mining in Bioinformatics HMM Microarray Problem: Major Objective n Major Objective: Discover a comprehensive theory of life s organization at the molecular level 2 1 Data Mining in Bioinformatics
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
An Introduction to Bioinformatics Algorithms Hidden Markov Models
 Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
Parametric Models Part III: Hidden Markov Models
 Parametric Models Part III: Hidden Markov Models Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2014 CS 551, Spring 2014 c 2014, Selim Aksoy (Bilkent
Parametric Models Part III: Hidden Markov Models Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2014 CS 551, Spring 2014 c 2014, Selim Aksoy (Bilkent
Hidden Markov Models Hamid R. Rabiee
 Hidden Markov Models Hamid R. Rabiee 1 Hidden Markov Models (HMMs) In the previous slides, we have seen that in many cases the underlying behavior of nature could be modeled as a Markov process. However
Hidden Markov Models Hamid R. Rabiee 1 Hidden Markov Models (HMMs) In the previous slides, we have seen that in many cases the underlying behavior of nature could be modeled as a Markov process. However
Hidden Markov Models
 Hidden Markov Models CI/CI(CS) UE, SS 2015 Christian Knoll Signal Processing and Speech Communication Laboratory Graz University of Technology June 23, 2015 CI/CI(CS) SS 2015 June 23, 2015 Slide 1/26 Content
Hidden Markov Models CI/CI(CS) UE, SS 2015 Christian Knoll Signal Processing and Speech Communication Laboratory Graz University of Technology June 23, 2015 CI/CI(CS) SS 2015 June 23, 2015 Slide 1/26 Content
Statistical Methods for NLP
 Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
Hidden Markov Models
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 19 Nov. 5, 2018 1 Reminders Homework
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 19 Nov. 5, 2018 1 Reminders Homework
Advanced Data Science
 Advanced Data Science Dr. Kira Radinsky Slides Adapted from Tom M. Mitchell Agenda Topics Covered: Time series data Markov Models Hidden Markov Models Dynamic Bayes Nets Additional Reading: Bishop: Chapter
Advanced Data Science Dr. Kira Radinsky Slides Adapted from Tom M. Mitchell Agenda Topics Covered: Time series data Markov Models Hidden Markov Models Dynamic Bayes Nets Additional Reading: Bishop: Chapter
Hidden Markov Models
 Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
Hidden Markov Models Outline 1. CG-Islands 2. The Fair Bet Casino 3. Hidden Markov Model 4. Decoding Algorithm 5. Forward-Backward Algorithm 6. Profile HMMs 7. HMM Parameter Estimation 8. Viterbi Training
10. Hidden Markov Models (HMM) for Speech Processing. (some slides taken from Glass and Zue course)
 for Speech Processing. (some slides taken from Glass and Zue course)") 10. Hidden Markov Models (HMM) for Speech Processing (some slides taken from Glass and Zue course) Definition of an HMM The HMM are powerful statistical methods to characterize the observed samples of
10. Hidden Markov Models (HMM) for Speech Processing (some slides taken from Glass and Zue course) Definition of an HMM The HMM are powerful statistical methods to characterize the observed samples of
A brief introduction to Conditional Random Fields
 A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
Human Mobility Pattern Prediction Algorithm using Mobile Device Location and Time Data
 Human Mobility Pattern Prediction Algorithm using Mobile Device Location and Time Data 0. Notations Myungjun Choi, Yonghyun Ro, Han Lee N = number of states in the model T = length of observation sequence
Human Mobility Pattern Prediction Algorithm using Mobile Device Location and Time Data 0. Notations Myungjun Choi, Yonghyun Ro, Han Lee N = number of states in the model T = length of observation sequence
Hidden Markov Modelling
 Hidden Markov Modelling Introduction Problem formulation Forward-Backward algorithm Viterbi search Baum-Welch parameter estimation Other considerations Multiple observation sequences Phone-based models
Hidden Markov Modelling Introduction Problem formulation Forward-Backward algorithm Viterbi search Baum-Welch parameter estimation Other considerations Multiple observation sequences Phone-based models
ECE662: Pattern Recognition and Decision Making Processes: HW TWO
 ECE662: Pattern Recognition and Decision Making Processes: HW TWO Purdue University Department of Electrical and Computer Engineering West Lafayette, INDIANA, USA Abstract. In this report experiments are
ECE662: Pattern Recognition and Decision Making Processes: HW TWO Purdue University Department of Electrical and Computer Engineering West Lafayette, INDIANA, USA Abstract. In this report experiments are
Constrained Optimization and Support Vector Machines
 Constrained Optimization and Support Vector Machines Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/
Constrained Optimization and Support Vector Machines Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/
CS 136a Lecture 7 Speech Recognition Architecture: Training models with the Forward backward algorithm
 + September13, 2016 Professor Meteer CS 136a Lecture 7 Speech Recognition Architecture: Training models with the Forward backward algorithm Thanks to Dan Jurafsky for these slides + ASR components n Feature
+ September13, 2016 Professor Meteer CS 136a Lecture 7 Speech Recognition Architecture: Training models with the Forward backward algorithm Thanks to Dan Jurafsky for these slides + ASR components n Feature
A Gentle Tutorial of the EM Algorithm and its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models
 A Gentle Tutorial of the EM Algorithm and its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models Jeff A. Bilmes (bilmes@cs.berkeley.edu) International Computer Science Institute
A Gentle Tutorial of the EM Algorithm and its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models Jeff A. Bilmes (bilmes@cs.berkeley.edu) International Computer Science Institute
Final Examination CS 540-2: Introduction to Artificial Intelligence
 Final Examination CS 540-2: Introduction to Artificial Intelligence May 7, 2017 LAST NAME: SOLUTIONS FIRST NAME: Problem Score Max Score 1 14 2 10 3 6 4 10 5 11 6 9 7 8 9 10 8 12 12 8 Total 100 1 of 11
Final Examination CS 540-2: Introduction to Artificial Intelligence May 7, 2017 LAST NAME: SOLUTIONS FIRST NAME: Problem Score Max Score 1 14 2 10 3 6 4 10 5 11 6 9 7 8 9 10 8 12 12 8 Total 100 1 of 11
Hidden Markov Models Part 2: Algorithms
 Hidden Markov Models Part 2: Algorithms CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Hidden Markov Model An HMM consists of:
Hidden Markov Models Part 2: Algorithms CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 Hidden Markov Model An HMM consists of:
What s an HMM? Extraction with Finite State Machines e.g. Hidden Markov Models (HMMs) Hidden Markov Models (HMMs) for Information Extraction
 Hidden Markov Models (HMMs) for Information Extraction") Hidden Markov Models (HMMs) for Information Extraction Daniel S. Weld CSE 454 Extraction with Finite State Machines e.g. Hidden Markov Models (HMMs) standard sequence model in genomics, speech, NLP, What
Hidden Markov Models (HMMs) for Information Extraction Daniel S. Weld CSE 454 Extraction with Finite State Machines e.g. Hidden Markov Models (HMMs) standard sequence model in genomics, speech, NLP, What
We Live in Exciting Times. CSCI-567: Machine Learning (Spring 2019) Outline. Outline. ACM (an international computing research society) has named
 Outline. Outline. ACM (an international computing research society) has named") We Live in Exciting Times ACM (an international computing research society) has named CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Apr. 2, 2019 Yoshua Bengio,
We Live in Exciting Times ACM (an international computing research society) has named CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Apr. 2, 2019 Yoshua Bengio,
Multiscale Systems Engineering Research Group
 Hidden Markov Model Prof. Yan Wang Woodruff School of Mechanical Engineering Georgia Institute of echnology Atlanta, GA 30332, U.S.A. yan.wang@me.gatech.edu Learning Objectives o familiarize the hidden
Hidden Markov Model Prof. Yan Wang Woodruff School of Mechanical Engineering Georgia Institute of echnology Atlanta, GA 30332, U.S.A. yan.wang@me.gatech.edu Learning Objectives o familiarize the hidden
Shankar Shivappa University of California, San Diego April 26, CSE 254 Seminar in learning algorithms
 Recognition of Visual Speech Elements Using Adaptively Boosted Hidden Markov Models. Say Wei Foo, Yong Lian, Liang Dong. IEEE Transactions on Circuits and Systems for Video Technology, May 2004. Shankar
Recognition of Visual Speech Elements Using Adaptively Boosted Hidden Markov Models. Say Wei Foo, Yong Lian, Liang Dong. IEEE Transactions on Circuits and Systems for Video Technology, May 2004. Shankar
Introduction to Graphical Models
 Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic
Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic
Hidden Markov Models and Gaussian Mixture Models
 Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 23&27 January 2014 ASR Lectures 4&5 Hidden Markov Models and Gaussian
Hidden Markov Models and Gaussian Mixture Models Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 4&5 23&27 January 2014 ASR Lectures 4&5 Hidden Markov Models and Gaussian
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES. Supervised Learning
 LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
Qualifier: CS 6375 Machine Learning Spring 2015
 Qualifier: CS 6375 Machine Learning Spring 2015 The exam is closed book. You are allowed to use two double-sided cheat sheets and a calculator. If you run out of room for an answer, use an additional sheet
Qualifier: CS 6375 Machine Learning Spring 2015 The exam is closed book. You are allowed to use two double-sided cheat sheets and a calculator. If you run out of room for an answer, use an additional sheet
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
HMM part 1. Dr Philip Jackson
 Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. HMM part 1 Dr Philip Jackson Probability fundamentals Markov models State topology diagrams Hidden Markov models -
Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. HMM part 1 Dr Philip Jackson Probability fundamentals Markov models State topology diagrams Hidden Markov models -
Advanced Introduction to Machine Learning
 10-715 Advanced Introduction to Machine Learning Homework Due Oct 15, 10.30 am Rules Please follow these guidelines. Failure to do so, will result in loss of credit. 1. Homework is due on the due date
10-715 Advanced Introduction to Machine Learning Homework Due Oct 15, 10.30 am Rules Please follow these guidelines. Failure to do so, will result in loss of credit. 1. Homework is due on the due date
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Robert Collins CSE586 CSE 586, Spring 2015 Computer Vision II
 CSE 586, Spring 2015 Computer Vision II Hidden Markov Model and Kalman Filter Recall: Modeling Time Series State-Space Model: You have a Markov chain of latent (unobserved) states Each state generates
CSE 586, Spring 2015 Computer Vision II Hidden Markov Model and Kalman Filter Recall: Modeling Time Series State-Space Model: You have a Markov chain of latent (unobserved) states Each state generates
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Hidden Markov Models
 Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Machine Learning for Structured Prediction
 Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Machine Learning Overview
 Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Recent Advances in Bayesian Inference Techniques
 Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
Recent Advances in Bayesian Inference Techniques Christopher M. Bishop Microsoft Research, Cambridge, U.K. research.microsoft.com/~cmbishop SIAM Conference on Data Mining, April 2004 Abstract Bayesian
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Master 2 Informatique Probabilistic Learning and Data Analysis
 Master 2 Informatique Probabilistic Learning and Data Analysis Faicel Chamroukhi Maître de Conférences USTV, LSIS UMR CNRS 7296 email: chamroukhi@univ-tln.fr web: chamroukhi.univ-tln.fr 2013/2014 Faicel
Master 2 Informatique Probabilistic Learning and Data Analysis Faicel Chamroukhi Maître de Conférences USTV, LSIS UMR CNRS 7296 email: chamroukhi@univ-tln.fr web: chamroukhi.univ-tln.fr 2013/2014 Faicel
O 3 O 4 O 5. q 3. q 4. Transition
 Hidden Markov Models Hidden Markov models (HMM) were developed in the early part of the 1970 s and at that time mostly applied in the area of computerized speech recognition. They are first described in
Hidden Markov Models Hidden Markov models (HMM) were developed in the early part of the 1970 s and at that time mostly applied in the area of computerized speech recognition. They are first described in
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
CS 6375 Machine Learning
 CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
CS 6375 Machine Learning Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Course Info. Instructor: Nicholas Ruozzi Office: ECSS 3.409 Office hours: Tues.
Be able to define the following terms and answer basic questions about them:
 CS440/ECE448 Section Q Fall 2017 Final Review Be able to define the following terms and answer basic questions about them: Probability o Random variables, axioms of probability o Joint, marginal, conditional
CS440/ECE448 Section Q Fall 2017 Final Review Be able to define the following terms and answer basic questions about them: Probability o Random variables, axioms of probability o Joint, marginal, conditional
Lecture 3: ASR: HMMs, Forward, Viterbi
 Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Original slides by Dan Jurafsky CS 224S / LINGUIST 285 Spoken Language Processing Andrew Maas Stanford University Spring 2017 Lecture 3: ASR: HMMs, Forward, Viterbi Fun informative read on phonetics The
Recall: Modeling Time Series. CSE 586, Spring 2015 Computer Vision II. Hidden Markov Model and Kalman Filter. Modeling Time Series
 Recall: Modeling Time Series CSE 586, Spring 2015 Computer Vision II Hidden Markov Model and Kalman Filter State-Space Model: You have a Markov chain of latent (unobserved) states Each state generates
Recall: Modeling Time Series CSE 586, Spring 2015 Computer Vision II Hidden Markov Model and Kalman Filter State-Space Model: You have a Markov chain of latent (unobserved) states Each state generates
Lecture 15. Probabilistic Models on Graph
 Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
An Introduction to Bioinformatics Algorithms Hidden Markov Models
 Hidden Markov Models Hidden Markov Models Outline CG-islands The Fair Bet Casino Hidden Markov Model Decoding Algorithm Forward-Backward Algorithm Profile HMMs HMM Parameter Estimation Viterbi training
Hidden Markov Models Hidden Markov Models Outline CG-islands The Fair Bet Casino Hidden Markov Model Decoding Algorithm Forward-Backward Algorithm Profile HMMs HMM Parameter Estimation Viterbi training
Statistical Sequence Recognition and Training: An Introduction to HMMs
 Statistical Sequence Recognition and Training: An Introduction to HMMs EECS 225D Nikki Mirghafori nikki@icsi.berkeley.edu March 7, 2005 Credit: many of the HMM slides have been borrowed and adapted, with
Statistical Sequence Recognition and Training: An Introduction to HMMs EECS 225D Nikki Mirghafori nikki@icsi.berkeley.edu March 7, 2005 Credit: many of the HMM slides have been borrowed and adapted, with
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Machine Learning Support Vector Machines. Prof. Matteo Matteucci
 Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Pattern Recognition 2018 Support Vector Machines
 Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
Support Vector Machines (SVM) in bioinformatics. Day 1: Introduction to SVM
 in bioinformatics. Day 1: Introduction to SVM") 1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
Information Extraction from Text
 Information Extraction from Text Jing Jiang Chapter 2 from Mining Text Data (2012) Presented by Andrew Landgraf, September 13, 2013 1 What is Information Extraction? Goal is to discover structured information
Information Extraction from Text Jing Jiang Chapter 2 from Mining Text Data (2012) Presented by Andrew Landgraf, September 13, 2013 1 What is Information Extraction? Goal is to discover structured information
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Statistical Learning Reading Assignments
 Statistical Learning Reading Assignments S. Gong et al. Dynamic Vision: From Images to Face Recognition, Imperial College Press, 2001 (Chapt. 3, hard copy). T. Evgeniou, M. Pontil, and T. Poggio, "Statistical
Statistical Learning Reading Assignments S. Gong et al. Dynamic Vision: From Images to Face Recognition, Imperial College Press, 2001 (Chapt. 3, hard copy). T. Evgeniou, M. Pontil, and T. Poggio, "Statistical
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
HIDDEN MARKOV MODELS
 HIDDEN MARKOV MODELS Outline CG-islands The Fair Bet Casino Hidden Markov Model Decoding Algorithm Forward-Backward Algorithm Profile HMMs HMM Parameter Estimation Viterbi training Baum-Welch algorithm
HIDDEN MARKOV MODELS Outline CG-islands The Fair Bet Casino Hidden Markov Model Decoding Algorithm Forward-Backward Algorithm Profile HMMs HMM Parameter Estimation Viterbi training Baum-Welch algorithm
Expectation Maximization (EM)
") Expectation Maximization (EM) The Expectation Maximization (EM) algorithm is one approach to unsupervised, semi-supervised, or lightly supervised learning. In this kind of learning either no labels are
Expectation Maximization (EM) The Expectation Maximization (EM) algorithm is one approach to unsupervised, semi-supervised, or lightly supervised learning. In this kind of learning either no labels are
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
Plan for today. ! Part 1: (Hidden) Markov models. ! Part 2: String matching and read mapping
 Markov models. ! Part 2: String matching and read mapping") Plan for today! Part 1: (Hidden) Markov models! Part 2: String matching and read mapping! 2.1 Exact algorithms! 2.2 Heuristic methods for approximate search (Hidden) Markov models Why consider probabilistics
Plan for today! Part 1: (Hidden) Markov models! Part 2: String matching and read mapping! 2.1 Exact algorithms! 2.2 Heuristic methods for approximate search (Hidden) Markov models Why consider probabilistics
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Probabilistic Time Series Classification
 Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Random Field Models for Applications in Computer Vision
 Random Field Models for Applications in Computer Vision Nazre Batool Post-doctorate Fellow, Team AYIN, INRIA Sophia Antipolis Outline Graphical Models Generative vs. Discriminative Classifiers Markov Random
Random Field Models for Applications in Computer Vision Nazre Batool Post-doctorate Fellow, Team AYIN, INRIA Sophia Antipolis Outline Graphical Models Generative vs. Discriminative Classifiers Markov Random
STA414/2104. Lecture 11: Gaussian Processes. Department of Statistics
 STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
STA414/2104 Lecture 11: Gaussian Processes Department of Statistics www.utstat.utoronto.ca Delivered by Mark Ebden with thanks to Russ Salakhutdinov Outline Gaussian Processes Exam review Course evaluations
p L yi z n m x N n xi
 y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen
y i z n x n N x i Overview Directed and undirected graphs Conditional independence Exact inference Latent variables and EM Variational inference Books statistical perspective Graphical Models, S. Lauritzen