Universität Dortmund UCHPC. Performance. Computing for Finite Element Simulations
|
|
|
- Ashlee Turner
- 5 years ago
- Views:
Transcription
 Institut für Angewandte Mathematik, TU Dortmund http://www.mathematik.tu-dortmund.de/ls3 http://www.featflow.de http://www.feast.")
1 technische universität dortmund Universität Dortmund fakultät für mathematik LS III (IAM) UCHPC UnConventional High Performance Computing for Finite Element Simulations S. Turek, Chr. Becker, S. Buijssen, D. Göddeke, H.Wobker (FEAST Group) Institut für Angewandte Mathematik, TU Dortmund
2 Motivation The free ride is over, paradigm shift in HPC: memory wall (in particular for sparse Linear Algebra problems) physical barriers (heat, power consumption, leaking voltage) applications no longer run faster automatically on newer hardware Heterogeneous hardware: commodity CPUs plus coprocessors graphics cards (GPU) Cell BE processor HPC accelerators (e.g. ClearSpeed) reconfigurable hardware (FPGA) Finite Element Methods (FEM) and Multigrid solvers: most flexible, efficient and accurate simulation tools for PDEs. 2

3 Aim of this Talk High Performance Computing meets Hardware-oriented Numerics on Unconventional Hardware for Finite Element Methods 3
4 1) Hardware-Oriented Numerics What is Hardware-Oriented Numerics? It is more than good Numerics and good Implementation on High Performance Computers Critical quantity: Total Numerical Efficiency 4
5 Total Numerical Efficiency High (guaranteed) accuracy for user-specific quantities with minimal #d.o.f. (~ N) via fast and robust solvers for a wide class of parameter variations with optimal numerical complexity (~ O(N)) while exploiting a significant percentage of the available huge sequential/ parallel GFLOP/s rates at the same time FEM Multigrid solvers with a posteriori error control for adaptive meshing are a candidate Is it easy to achieve high Total Numerical Efficiency? 5
6 Example: Fast Poisson Solvers Fast Multigrid Methods as general philosophy Optimized versions for scalar PDE problems ( Poisson problems) on general meshes should require ca FLOPs per unknown (in contrast to LAPACK for dense matrices with O(N 3 ) FLOPs) Problem size 10 6 : Much less than 1 sec on PC (???) Problem size : Less than 1 sec on PFLOP/s computer More realistic (and much harder) Criterion for Petascale Computing in Technical Simulations 6
7 Main Component: Sparse MV Application Sparse Matrix-Vector techniques ( indexed DAXPY ) DO 10 IROW=1,N DO 10 ICOL=KLD(IROW),KLD(IROW+1)-1 10 Y(IROW)=DA(ICOL)*X(KCOL(ICOL))+Y(IROW) Sparse Banded MV techniques on generalized TP grids 7
 r-adaptivity Unstructured macro mesh of tensor")
8 Grid Structure Fully adaptive grids Maximum flexibility Stochastic numbering Unstructured sparse matrices Indirect addressing, very slow. Locally structured grids Logical tensor product Fixedbanded matrix structure Direct addressing ( fast) r-adaptivity Unstructured macro mesh of tensor product subdomains 8
9 Generalized Tensorproduct Meshes 9
10 Generalized Tensorproduct Meshes 10

11 Generalized Tensorproduct Meshes with appropriate Fictitious Boundary techniques in FEATFLOW.. 11
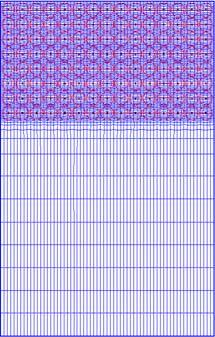
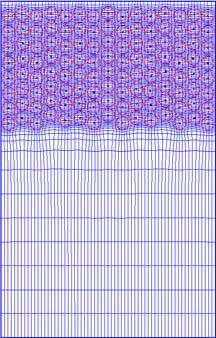
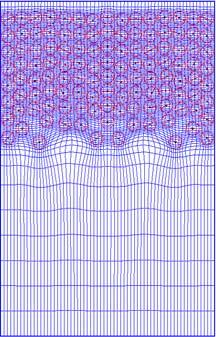


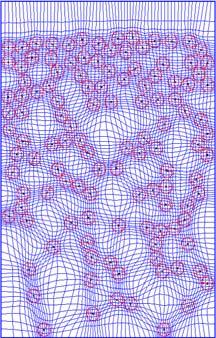

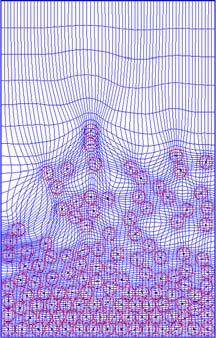
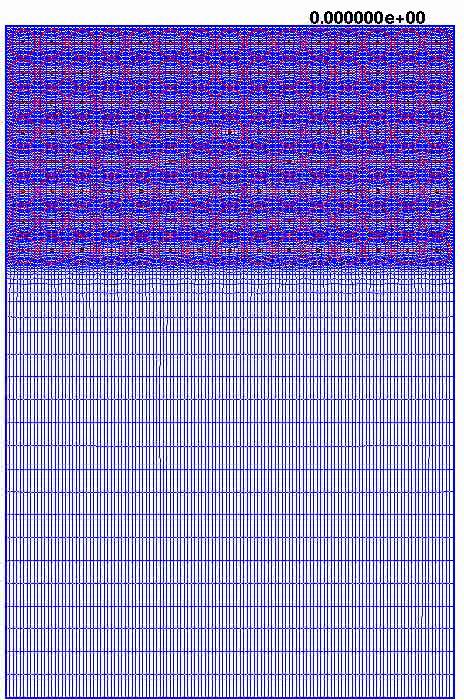
12 Generalized Tensorproduct Meshes.dynamic CFD problems.. 12
13 Example: SpMV on TP Grid F Opteron X2 2214, 2.2 GHz, 2x1 MB L2 cache, one thread F 50 vs. 550 MFLOP/s for interesting large problem size F Caching of coefficient vector, full streaming bandwidth for A F const: constant coefficients stencil 13
14 Observation I: Sparse MV Multiplication Numbering 4K DOF 66K DOF 1M DOF Stochastic Hierarchical Banded Stencil (const) In realistic scenarios, MFLOP/s rates are poor, and problem size dependent 14
 Speed-up of 100x for")

15 Observation II: Full CFD Simulations Speed-up (logscale) Speed-up of 100x for free in 10 years Stagnation for standard simulation tools on conventional hardware 15

16 Observation III: Parallel Performance Mesh partitioned into 32 subdomains Problems due to communication Numerical behavior vs. anisotropic meshes 1 P. 2 P. 4 P. 8 P. 16 P. 32 P. 64 P. %Comm. 10% 24% 36% 45% 47% 55% 56% # PPP-IT
17 Summary It is (almost) impossible to reach Single Processor Peak Performance with modern (= high numerical efficiency) FEM simulation tools Memory-intensive data/matrix/solver structures? Parallel Peak Performance with modern Numerics even harder, already for moderate processor numbers 17
 Dramatic improvement (factor 1000)")
18 Hardware-oriented Numerics (HwoN) FEM for 8 Mill. unknowns on general domain, 1 CPU, Poisson Problem in 2D Speed-up (logscale) Dramatic improvement (factor 1000) due to better Numerics AND better data structures/ algorithms 18
 FEASTSolid (CSM) FEASTLBM (SKALB Project)")
19 FEAST Realization of HwoN ScaRC solver: Combine advantages of (parallel) domain decomposition and multigrid methods Cascaded multigrid scheme Hide anisotropies locally to increase robustness Globally unstructured locally structured Low communication overhead FEAST applications: FEASTFlow (CFD) FEASTSolid (CSM) FEASTLBM (SKALB Project) 19
20 Solver Structure ScaRC Scalable Recursive Clustering F Minimal overlap by extended Dirichlet BCs F Hybrid multilevel domain decomposition method F Inspired by parallel MG( best of both worlds ) I Multiplicative vertically (between levels), global coarse grid problem (MG-like) I Additive horizontally: block-jacobi / Schwarz smoother (DD-like) F Hide local irregularities by MGs within the Schwarz smoother F Embed in Krylov to alleviate Block-Jacobi character 20
21 (Preliminary) State-of-the-Art Numerical efficiency? OK Parallel efficiency? OK (tested up to 256 CPUs on NEC SX-8, commodity clusters) Single processor efficiency? OK (for CPU) Peak efficiency? NO Special unconventional FEM Co-Processors 21
, 7")



22 2) UnConventional HPC Cell multicore processor (PS3), 7 synergistic processing 3.2 GHz, 218 GFLOP/s, 3.2 GHz GPU (NVIDIA GTX 285): GHz, GHz memory bus (160 GB/s) 1.06 TFLOP/s UnConventional High Performance Computing (UCHPC( UCHPC) 22


23 Why are GPUs and Cells so fast? CPUs devote most of the transistors to caches and data movement for general purpose applications GPUs and Cells are more transistor-efficient w.r.t. floating point operations 23
24 Bandwidth in a CPU/GPU Node 24




25 Benchmarks: FEM Building Blocks Typical performance of FEM building blocks SAXPY_C, SAXPY_V (variable coefficients), MV_V (9-point-stencil, Q1 elements), DOT 25
26 Example: SpMV on TP Grid 40 GFLOP/s, 140 GB/s with CUDA on GeForce GTX 280 only 13 GFLOP/s on 8800 GTX (90 GB/s peak) 26


27 Benchmarks: Complete Multigrid Solver Promising results, attempt to integrate GPUs as FEM Co-Processors 27
28 Multigrid on TP Grid Core2Duo (double) GTX 280 (mixed) Level time(s) MFLOP/s time(s) MFLOP/s speedup x x x x F Poisson on unitsquare, Dirichlet BCs, not only a matrix stencil F 1M DOF, multigrid, FE-accurate in less than 0.1 seconds! F 27x faster than CPU F 1.7x faster than pure double on GPU F 8800 GTX (correction loop on CPU): 0.44 seconds onlevel 10 28
29 Design Goals Include GPUs into FEAST without changes to application codes FEASTFLOW / FEASTSolid fundamental re-design of FEAST sacrificing either functionality or accuracy but with noteworthy speedups a reasonable amount of generality w.r.t. other co-processors and additional benefits in terms of space/power/etc. But: no --march=gpu/cell compiler switch 29
30 Integration Principles Isolate suitable parts Balance acceleration potential and acceleration effort Diverge code paths as late as possible Local MG solver Same interface for several co-processors Important benefit of minimally invasive approach: No changes to application code Co-processor code can be developed and tuned on a single node Entire MPI communication infrastructure remains unchanged 30

31 Minimally invasive integration global BiCGStab preconditioned by global multilevel (V 1+1) additively smoothed by for all Ω i : local multigrid coarse grid solver: UMFPACK Allouterwork:CPU,double Local MGs: GPU, single GPU is preconditioner Applicable to many co-processors 31




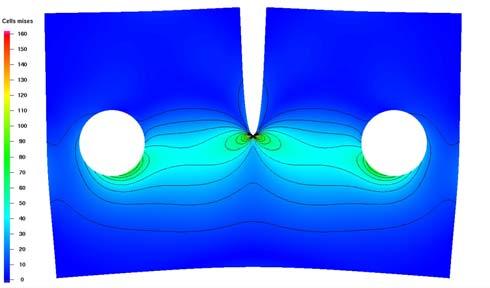
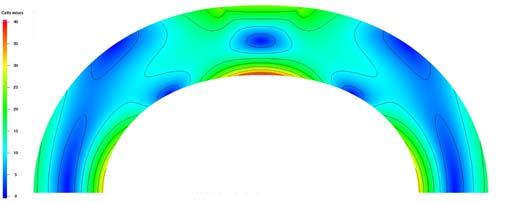
32 Show-Case: FEASTSolid Fundamental model problem: solid body of elastic, compressible material (e.g. steel) exposed to some external load 32
33 Linearised elasticity µ µ A11 A 12 u1 = f A 21 A 22 u µ 2 (2μ + λ) xx + μ yy (μ + λ) xy (μ + λ) yx μ xx +(2μ + λ) yy global multivariate BiCGStab block-preconditioned by Global multivariate multilevel (V 1+1) additively smoothed (block GS) by for all Ω i : solve A 11 c 1 = d 1 by local scalar multigrid update RHS: d 2 = d 2 A 21 c 1 for all Ω i : solve A 22 c 2 = d 2 by local scalar multigrid coarse grid solver: UMFPACK 33
34 Mixed precision approach single precision double precision Level Error Reduction Error Reduction E E E E E E E E E E E E E E E E E E F Poisson u = f on [0, 1] 2 with Dirichlet BCs, MG solver F Bilinear conforming Finite Elements (Q 1 )oncartesianmesh F Mixed precision solver: double precision Richardson, preconditioned with single precision MG ( gain one digit ) F Same results as entirely in double precision 34
35 Accuracy L 2 error against reference solution Same results for CPU and GPU expected error reduction independent of refinement and subdomain distribution 35
36 (Weak) Scalability F Outdated cluster, dual Xeon EM64T, F one NVIDIA Quadro FX 1400 per node (one generation behind the Xeons, 20 GB/s BW) F Poisson problem (left): up to 1.3B DOF, 160 nodes F Elasticity (right): up to 1B DOF, 128 nodes 36

37 Absolute Speedup F 16 nodes, Opteron X2 2214, F NVIDIA Quadro FX 5600 (76 GB/s BW), OpenGL F Problem size 128 M DOF F Dualcore 1.6x faster than singlecore F GPU 2.6x faster than singlecore, 1.6x than dual 37
38 Speedup Analysis Speedups in 'time to solution' for one GPU: 2.6x vs. Singlecore, 1.6x vs. Dualcore Amdahl's Law is lurking Local speedup of 9x and 5.5x by the GPU 2/3 of the solver accelerable => theoretical upper bound 3x Future work Three-way parallelism in our system: coarse-grained (MPI) medium-grained (heterogeneous resources within the node) fine-grained (compute cores in the GPU) Better interplay of resources within the node Adapt Hardware-oriented Numerics to increase accelerable part 38
, CUDA F Driven cavity and channel flow")
 Block-Schurcomplement preconditioner 1) approx.")
 update RHS: d 3 = d 3 + B(c 1, c 2 )")
39 Stationary Navier-Stokes A 11 A 12 B 1 A 21 A 22 B 2 u 1 u 2 = f 1 f 2 B 1 B 2 C p g F 4-node cluster F Opteron X F GeForce 8800 GTX (90 GB/s BW), CUDA F Driven cavity and channel flow around a cylinder fixed point iteration solving linearised subproblems with global BiCGStab (reduce initial residual by 1digit) Block-Schurcomplement preconditioner 1) approx. solve for velocities with global MG(V1+0), additively smoothed by for all Ω i :solve for u 1 with local MG for all Ω i :solve for u 2 with local MG 2) update RHS: d 3 = d 3 + B(c 1, c 2 ) 3) scale c 3 = (Mp L)d 3 39
40 Navier-Stokes results Speedup analysis R acc S local S total L9 L10 L9 L10 L9 L10 DC Re100 41% 46% 6x 12x 1.4x 1.8x DC Re250 56% 58% 5.5x 11.5x 1.9x 2.1x Channel flow 60% 6x 1.9x Important consequence: Ratio between assembly and linear solve changes significantly DC Re100 DC Re250 Channel flow plain accel. plain accel. plain accel. 29:71 50:48 11:89 25:75 13:87 26:74 40
41 Acceleration analysis Speedup analysis F Addition of GPUs increases resources F Correct model: strong scalability inside each node F Accelerable fraction of the elasticity solver: 2/3 F Remaining time spent in MPI and the outer solver Accelerable fraction R acc : 66% Local speedup S local : 9x Total speedup S total : 2.6x Theoretical limit S max : 3x 41
42 There is a Huge Potential for the Future But: High Performance Computing has to consider recent and future hardware trends, particularly for heterogeneous multicore architectures and massively parallel systems! The combination of Hardware-oriented Numerics and special Data Structures/Algorithms and Unconventional Hardware has to be used! or most of existing (academic/commercial) FEM software will be worthless in a few years! 42
 Jamaludin Mohd-Yusof, Patrick McCormick (Los Alamos National")
43 Acknowledgements FEAST Group (TU Dortmund) Robert Strzodka (Max Planck Center, Max Planck Institut Informatik) Jamaludin Mohd-Yusof, Patrick McCormick (Los Alamos National Laboratories) 43
- Part 4 - Multicore and Manycore Technology: Chances and Challenges. Vincent Heuveline
 - Part 4 - Multicore and Manycore Technology: Chances and Challenges Vincent Heuveline 1 Numerical Simulation of Tropical Cyclones Goal oriented adaptivity for tropical cyclones ~10⁴km ~1500km ~100km 2
- Part 4 - Multicore and Manycore Technology: Chances and Challenges Vincent Heuveline 1 Numerical Simulation of Tropical Cyclones Goal oriented adaptivity for tropical cyclones ~10⁴km ~1500km ~100km 2
FEM-Level Set Techniques for Multiphase Flow --- Some recent results
 FEM-Level Set Techniques for Multiphase Flow --- Some recent results ENUMATH09, Uppsala Stefan Turek, Otto Mierka, Dmitri Kuzmin, Shuren Hysing Institut für Angewandte Mathematik, TU Dortmund http://www.mathematik.tu-dortmund.de/ls3
FEM-Level Set Techniques for Multiphase Flow --- Some recent results ENUMATH09, Uppsala Stefan Turek, Otto Mierka, Dmitri Kuzmin, Shuren Hysing Institut für Angewandte Mathematik, TU Dortmund http://www.mathematik.tu-dortmund.de/ls3
Open-Source Parallel FE Software : FrontISTR -- Performance Considerations about B/F (Byte per Flop) of SpMV on K-Supercomputer and GPU-Clusters --
 of SpMV on K-Supercomputer and GPU-Clusters --") Parallel Processing for Energy Efficiency October 3, 2013 NTNU, Trondheim, Norway Open-Source Parallel FE Software : FrontISTR -- Performance Considerations about B/F (Byte per Flop) of SpMV on K-Supercomputer
Parallel Processing for Energy Efficiency October 3, 2013 NTNU, Trondheim, Norway Open-Source Parallel FE Software : FrontISTR -- Performance Considerations about B/F (Byte per Flop) of SpMV on K-Supercomputer
Efficient Multilevel Solvers and High Performance Computing Techniques for the Finite Element Simulation of Large-Scale Elasticity Problems
 Efficient Multilevel Solvers and High Performance Computing Techniques for the Finite Element Simulation of Large-Scale Elasticity Problems Dissertation zur Erlangung des Grades eines Doktors der Naturwissenschaften
Efficient Multilevel Solvers and High Performance Computing Techniques for the Finite Element Simulation of Large-Scale Elasticity Problems Dissertation zur Erlangung des Grades eines Doktors der Naturwissenschaften
Accelerating Linear Algebra on Heterogeneous Architectures of Multicore and GPUs using MAGMA and DPLASMA and StarPU Schedulers
 UT College of Engineering Tutorial Accelerating Linear Algebra on Heterogeneous Architectures of Multicore and GPUs using MAGMA and DPLASMA and StarPU Schedulers Stan Tomov 1, George Bosilca 1, and Cédric
UT College of Engineering Tutorial Accelerating Linear Algebra on Heterogeneous Architectures of Multicore and GPUs using MAGMA and DPLASMA and StarPU Schedulers Stan Tomov 1, George Bosilca 1, and Cédric
Solving PDEs with Multigrid Methods p.1
 Solving PDEs with Multigrid Methods Scott MacLachlan maclachl@colorado.edu Department of Applied Mathematics, University of Colorado at Boulder Solving PDEs with Multigrid Methods p.1 Support and Collaboration
Solving PDEs with Multigrid Methods Scott MacLachlan maclachl@colorado.edu Department of Applied Mathematics, University of Colorado at Boulder Solving PDEs with Multigrid Methods p.1 Support and Collaboration
Parallel Preconditioning Methods for Ill-conditioned Problems
 Parallel Preconditioning Methods for Ill-conditioned Problems Kengo Nakajima Information Technology Center, The University of Tokyo 2014 Conference on Advanced Topics and Auto Tuning in High Performance
Parallel Preconditioning Methods for Ill-conditioned Problems Kengo Nakajima Information Technology Center, The University of Tokyo 2014 Conference on Advanced Topics and Auto Tuning in High Performance
Lattice Boltzmann simulations on heterogeneous CPU-GPU clusters
 Lattice Boltzmann simulations on heterogeneous CPU-GPU clusters H. Köstler 2nd International Symposium Computer Simulations on GPU Freudenstadt, 29.05.2013 1 Contents Motivation walberla software concepts
Lattice Boltzmann simulations on heterogeneous CPU-GPU clusters H. Köstler 2nd International Symposium Computer Simulations on GPU Freudenstadt, 29.05.2013 1 Contents Motivation walberla software concepts
Accelerating linear algebra computations with hybrid GPU-multicore systems.
 Accelerating linear algebra computations with hybrid GPU-multicore systems. Marc Baboulin INRIA/Université Paris-Sud joint work with Jack Dongarra (University of Tennessee and Oak Ridge National Laboratory)
Accelerating linear algebra computations with hybrid GPU-multicore systems. Marc Baboulin INRIA/Université Paris-Sud joint work with Jack Dongarra (University of Tennessee and Oak Ridge National Laboratory)
Towards a highly-parallel PDE-Solver using Adaptive Sparse Grids on Compute Clusters
 Towards a highly-parallel PDE-Solver using Adaptive Sparse Grids on Compute Clusters HIM - Workshop on Sparse Grids and Applications Alexander Heinecke Chair of Scientific Computing May 18 th 2011 HIM
Towards a highly-parallel PDE-Solver using Adaptive Sparse Grids on Compute Clusters HIM - Workshop on Sparse Grids and Applications Alexander Heinecke Chair of Scientific Computing May 18 th 2011 HIM
Multilevel low-rank approximation preconditioners Yousef Saad Department of Computer Science and Engineering University of Minnesota
 Multilevel low-rank approximation preconditioners Yousef Saad Department of Computer Science and Engineering University of Minnesota SIAM CSE Boston - March 1, 2013 First: Joint work with Ruipeng Li Work
Multilevel low-rank approximation preconditioners Yousef Saad Department of Computer Science and Engineering University of Minnesota SIAM CSE Boston - March 1, 2013 First: Joint work with Ruipeng Li Work
Newton-Multigrid Least-Squares FEM for S-V-P Formulation of the Navier-Stokes Equations
 Newton-Multigrid Least-Squares FEM for S-V-P Formulation of the Navier-Stokes Equations A. Ouazzi, M. Nickaeen, S. Turek, and M. Waseem Institut für Angewandte Mathematik, LSIII, TU Dortmund, Vogelpothsweg
Newton-Multigrid Least-Squares FEM for S-V-P Formulation of the Navier-Stokes Equations A. Ouazzi, M. Nickaeen, S. Turek, and M. Waseem Institut für Angewandte Mathematik, LSIII, TU Dortmund, Vogelpothsweg
Solving PDEs with CUDA Jonathan Cohen
 Solving PDEs with CUDA Jonathan Cohen jocohen@nvidia.com NVIDIA Research PDEs (Partial Differential Equations) Big topic Some common strategies Focus on one type of PDE in this talk Poisson Equation Linear
Solving PDEs with CUDA Jonathan Cohen jocohen@nvidia.com NVIDIA Research PDEs (Partial Differential Equations) Big topic Some common strategies Focus on one type of PDE in this talk Poisson Equation Linear
Robust solution of Poisson-like problems with aggregation-based AMG
 Robust solution of Poisson-like problems with aggregation-based AMG Yvan Notay Université Libre de Bruxelles Service de Métrologie Nucléaire Paris, January 26, 215 Supported by the Belgian FNRS http://homepages.ulb.ac.be/
Robust solution of Poisson-like problems with aggregation-based AMG Yvan Notay Université Libre de Bruxelles Service de Métrologie Nucléaire Paris, January 26, 215 Supported by the Belgian FNRS http://homepages.ulb.ac.be/
FAS and Solver Performance
 FAS and Solver Performance Matthew Knepley Mathematics and Computer Science Division Argonne National Laboratory Fall AMS Central Section Meeting Chicago, IL Oct 05 06, 2007 M. Knepley (ANL) FAS AMS 07
FAS and Solver Performance Matthew Knepley Mathematics and Computer Science Division Argonne National Laboratory Fall AMS Central Section Meeting Chicago, IL Oct 05 06, 2007 M. Knepley (ANL) FAS AMS 07
A Space-Time Multigrid Solver Methodology for the Optimal Control of Time-Dependent Fluid Flow
 A Space-Time Multigrid Solver Methodology for the Optimal Control of Time-Dependent Fluid Flow Michael Köster, Michael Hinze, Stefan Turek Michael Köster Institute for Applied Mathematics TU Dortmund Trier,
A Space-Time Multigrid Solver Methodology for the Optimal Control of Time-Dependent Fluid Flow Michael Köster, Michael Hinze, Stefan Turek Michael Köster Institute for Applied Mathematics TU Dortmund Trier,
1. Fast Iterative Solvers of SLE
 1. Fast Iterative Solvers of crucial drawback of solvers discussed so far: they become slower if we discretize more accurate! now: look for possible remedies relaxation: explicit application of the multigrid
1. Fast Iterative Solvers of crucial drawback of solvers discussed so far: they become slower if we discretize more accurate! now: look for possible remedies relaxation: explicit application of the multigrid
Efficient multigrid solvers for mixed finite element discretisations in NWP models
 1/20 Efficient multigrid solvers for mixed finite element discretisations in NWP models Colin Cotter, David Ham, Lawrence Mitchell, Eike Hermann Müller *, Robert Scheichl * * University of Bath, Imperial
1/20 Efficient multigrid solvers for mixed finite element discretisations in NWP models Colin Cotter, David Ham, Lawrence Mitchell, Eike Hermann Müller *, Robert Scheichl * * University of Bath, Imperial
Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption. Langshi CHEN 1,2,3 Supervised by Serge PETITON 2
 1 / 23 Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption Langshi CHEN 1,2,3 Supervised by Serge PETITON 2 Maison de la Simulation Lille 1 University CNRS March 18, 2013
1 / 23 Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption Langshi CHEN 1,2,3 Supervised by Serge PETITON 2 Maison de la Simulation Lille 1 University CNRS March 18, 2013
Multipole-Based Preconditioners for Sparse Linear Systems.
 Multipole-Based Preconditioners for Sparse Linear Systems. Ananth Grama Purdue University. Supported by the National Science Foundation. Overview Summary of Contributions Generalized Stokes Problem Solenoidal
Multipole-Based Preconditioners for Sparse Linear Systems. Ananth Grama Purdue University. Supported by the National Science Foundation. Overview Summary of Contributions Generalized Stokes Problem Solenoidal
A High-Performance Parallel Hybrid Method for Large Sparse Linear Systems
 Outline A High-Performance Parallel Hybrid Method for Large Sparse Linear Systems Azzam Haidar CERFACS, Toulouse joint work with Luc Giraud (N7-IRIT, France) and Layne Watson (Virginia Polytechnic Institute,
Outline A High-Performance Parallel Hybrid Method for Large Sparse Linear Systems Azzam Haidar CERFACS, Toulouse joint work with Luc Giraud (N7-IRIT, France) and Layne Watson (Virginia Polytechnic Institute,
A User Friendly Toolbox for Parallel PDE-Solvers
 A User Friendly Toolbox for Parallel PDE-Solvers Gundolf Haase Institut for Mathematics and Scientific Computing Karl-Franzens University of Graz Manfred Liebmann Mathematics in Sciences Max-Planck-Institute
A User Friendly Toolbox for Parallel PDE-Solvers Gundolf Haase Institut for Mathematics and Scientific Computing Karl-Franzens University of Graz Manfred Liebmann Mathematics in Sciences Max-Planck-Institute
Welcome to MCS 572. content and organization expectations of the course. definition and classification
 Welcome to MCS 572 1 About the Course content and organization expectations of the course 2 Supercomputing definition and classification 3 Measuring Performance speedup and efficiency Amdahl s Law Gustafson
Welcome to MCS 572 1 About the Course content and organization expectations of the course 2 Supercomputing definition and classification 3 Measuring Performance speedup and efficiency Amdahl s Law Gustafson
Block AIR Methods. For Multicore and GPU. Per Christian Hansen Hans Henrik B. Sørensen. Technical University of Denmark
 Block AIR Methods For Multicore and GPU Per Christian Hansen Hans Henrik B. Sørensen Technical University of Denmark Model Problem and Notation Parallel-beam 3D tomography exact solution exact data noise
Block AIR Methods For Multicore and GPU Per Christian Hansen Hans Henrik B. Sørensen Technical University of Denmark Model Problem and Notation Parallel-beam 3D tomography exact solution exact data noise
Minisymposia 9 and 34: Avoiding Communication in Linear Algebra. Jim Demmel UC Berkeley bebop.cs.berkeley.edu
 Minisymposia 9 and 34: Avoiding Communication in Linear Algebra Jim Demmel UC Berkeley bebop.cs.berkeley.edu Motivation (1) Increasing parallelism to exploit From Top500 to multicores in your laptop Exponentially
Minisymposia 9 and 34: Avoiding Communication in Linear Algebra Jim Demmel UC Berkeley bebop.cs.berkeley.edu Motivation (1) Increasing parallelism to exploit From Top500 to multicores in your laptop Exponentially
Numerical analysis and a-posteriori error control for a new nonconforming quadrilateral linear finite element
 Numerical analysis and a-posteriori error control for a new nonconforming quadrilateral linear finite element M. Grajewski, J. Hron, S. Turek Matthias.Grajewski@math.uni-dortmund.de, jaroslav.hron@math.uni-dortmund.de,
Numerical analysis and a-posteriori error control for a new nonconforming quadrilateral linear finite element M. Grajewski, J. Hron, S. Turek Matthias.Grajewski@math.uni-dortmund.de, jaroslav.hron@math.uni-dortmund.de,
Algebraic Multigrid as Solvers and as Preconditioner
 Ò Algebraic Multigrid as Solvers and as Preconditioner Domenico Lahaye domenico.lahaye@cs.kuleuven.ac.be http://www.cs.kuleuven.ac.be/ domenico/ Department of Computer Science Katholieke Universiteit Leuven
Ò Algebraic Multigrid as Solvers and as Preconditioner Domenico Lahaye domenico.lahaye@cs.kuleuven.ac.be http://www.cs.kuleuven.ac.be/ domenico/ Department of Computer Science Katholieke Universiteit Leuven
Case Study: Quantum Chromodynamics
 Case Study: Quantum Chromodynamics Michael Clark Harvard University with R. Babich, K. Barros, R. Brower, J. Chen and C. Rebbi Outline Primer to QCD QCD on a GPU Mixed Precision Solvers Multigrid solver
Case Study: Quantum Chromodynamics Michael Clark Harvard University with R. Babich, K. Barros, R. Brower, J. Chen and C. Rebbi Outline Primer to QCD QCD on a GPU Mixed Precision Solvers Multigrid solver
ERLANGEN REGIONAL COMPUTING CENTER
 ERLANGEN REGIONAL COMPUTING CENTER Making Sense of Performance Numbers Georg Hager Erlangen Regional Computing Center (RRZE) Friedrich-Alexander-Universität Erlangen-Nürnberg OpenMPCon 2018 Barcelona,
ERLANGEN REGIONAL COMPUTING CENTER Making Sense of Performance Numbers Georg Hager Erlangen Regional Computing Center (RRZE) Friedrich-Alexander-Universität Erlangen-Nürnberg OpenMPCon 2018 Barcelona,
Claude Tadonki. MINES ParisTech PSL Research University Centre de Recherche Informatique
 Claude Tadonki MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Monthly CRI Seminar MINES ParisTech - CRI June 06, 2016, Fontainebleau (France)
Claude Tadonki MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Monthly CRI Seminar MINES ParisTech - CRI June 06, 2016, Fontainebleau (France)
Contents. Preface... xi. Introduction...
 Contents Preface... xi Introduction... xv Chapter 1. Computer Architectures... 1 1.1. Different types of parallelism... 1 1.1.1. Overlap, concurrency and parallelism... 1 1.1.2. Temporal and spatial parallelism
Contents Preface... xi Introduction... xv Chapter 1. Computer Architectures... 1 1.1. Different types of parallelism... 1 1.1.1. Overlap, concurrency and parallelism... 1 1.1.2. Temporal and spatial parallelism
SPARSE SOLVERS POISSON EQUATION. Margreet Nool. November 9, 2015 FOR THE. CWI, Multiscale Dynamics
 SPARSE SOLVERS FOR THE POISSON EQUATION Margreet Nool CWI, Multiscale Dynamics November 9, 2015 OUTLINE OF THIS TALK 1 FISHPACK, LAPACK, PARDISO 2 SYSTEM OVERVIEW OF CARTESIUS 3 POISSON EQUATION 4 SOLVERS
SPARSE SOLVERS FOR THE POISSON EQUATION Margreet Nool CWI, Multiscale Dynamics November 9, 2015 OUTLINE OF THIS TALK 1 FISHPACK, LAPACK, PARDISO 2 SYSTEM OVERVIEW OF CARTESIUS 3 POISSON EQUATION 4 SOLVERS
Improvements for Implicit Linear Equation Solvers
 Improvements for Implicit Linear Equation Solvers Roger Grimes, Bob Lucas, Clement Weisbecker Livermore Software Technology Corporation Abstract Solving large sparse linear systems of equations is often
Improvements for Implicit Linear Equation Solvers Roger Grimes, Bob Lucas, Clement Weisbecker Livermore Software Technology Corporation Abstract Solving large sparse linear systems of equations is often
Parallel programming practices for the solution of Sparse Linear Systems (motivated by computational physics and graphics)
") Parallel programming practices for the solution of Sparse Linear Systems (motivated by computational physics and graphics) Eftychios Sifakis CS758 Guest Lecture - 19 Sept 2012 Introduction Linear systems
Parallel programming practices for the solution of Sparse Linear Systems (motivated by computational physics and graphics) Eftychios Sifakis CS758 Guest Lecture - 19 Sept 2012 Introduction Linear systems
Acceleration of a Domain Decomposition Method for Advection-Diffusion Problems
 Acceleration of a Domain Decomposition Method for Advection-Diffusion Problems Gert Lube 1, Tobias Knopp 2, and Gerd Rapin 2 1 University of Göttingen, Institute of Numerical and Applied Mathematics (http://www.num.math.uni-goettingen.de/lube/)
Acceleration of a Domain Decomposition Method for Advection-Diffusion Problems Gert Lube 1, Tobias Knopp 2, and Gerd Rapin 2 1 University of Göttingen, Institute of Numerical and Applied Mathematics (http://www.num.math.uni-goettingen.de/lube/)
MARCH 24-27, 2014 SAN JOSE, CA
 MARCH 24-27, 2014 SAN JOSE, CA Sparse HPC on modern architectures Important scientific applications rely on sparse linear algebra HPCG a new benchmark proposal to complement Top500 (HPL) To solve A x =
MARCH 24-27, 2014 SAN JOSE, CA Sparse HPC on modern architectures Important scientific applications rely on sparse linear algebra HPCG a new benchmark proposal to complement Top500 (HPL) To solve A x =
Large-scale Electronic Structure Simulations with MVAPICH2 on Intel Knights Landing Manycore Processors
 Large-scale Electronic Structure Simulations with MVAPICH2 on Intel Knights Landing Manycore Processors Hoon Ryu, Ph.D. (E: elec1020@kisti.re.kr) Principal Researcher / Korea Institute of Science and Technology
Large-scale Electronic Structure Simulations with MVAPICH2 on Intel Knights Landing Manycore Processors Hoon Ryu, Ph.D. (E: elec1020@kisti.re.kr) Principal Researcher / Korea Institute of Science and Technology
On Portability, Performance and Scalability of a MPI OpenCL Lattice Boltzmann Code
 On Portability, Performance and Scalability of a MPI OpenCL Lattice Boltzmann Code E Calore, S F Schifano, R Tripiccione Enrico Calore INFN Ferrara, Italy 7 th Workshop on UnConventional High Performance
On Portability, Performance and Scalability of a MPI OpenCL Lattice Boltzmann Code E Calore, S F Schifano, R Tripiccione Enrico Calore INFN Ferrara, Italy 7 th Workshop on UnConventional High Performance
An Efficient FETI Implementation on Distributed Shared Memory Machines with Independent Numbers of Subdomains and Processors
 Contemporary Mathematics Volume 218, 1998 B 0-8218-0988-1-03024-7 An Efficient FETI Implementation on Distributed Shared Memory Machines with Independent Numbers of Subdomains and Processors Michel Lesoinne
Contemporary Mathematics Volume 218, 1998 B 0-8218-0988-1-03024-7 An Efficient FETI Implementation on Distributed Shared Memory Machines with Independent Numbers of Subdomains and Processors Michel Lesoinne
Scalable Domain Decomposition Preconditioners For Heterogeneous Elliptic Problems
 Scalable Domain Decomposition Preconditioners For Heterogeneous Elliptic Problems Pierre Jolivet, F. Hecht, F. Nataf, C. Prud homme Laboratoire Jacques-Louis Lions Laboratoire Jean Kuntzmann INRIA Rocquencourt
Scalable Domain Decomposition Preconditioners For Heterogeneous Elliptic Problems Pierre Jolivet, F. Hecht, F. Nataf, C. Prud homme Laboratoire Jacques-Louis Lions Laboratoire Jean Kuntzmann INRIA Rocquencourt
A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures
 A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Parallel PIPS-SBB Multi-level parallelism for 2-stage SMIPS. Lluís-Miquel Munguia, Geoffrey M. Oxberry, Deepak Rajan, Yuji Shinano
 Parallel PIPS-SBB Multi-level parallelism for 2-stage SMIPS Lluís-Miquel Munguia, Geoffrey M. Oxberry, Deepak Rajan, Yuji Shinano ... Our contribution PIPS-PSBB*: Multi-level parallelism for Stochastic
Parallel PIPS-SBB Multi-level parallelism for 2-stage SMIPS Lluís-Miquel Munguia, Geoffrey M. Oxberry, Deepak Rajan, Yuji Shinano ... Our contribution PIPS-PSBB*: Multi-level parallelism for Stochastic
Multigrid Methods and their application in CFD
 Multigrid Methods and their application in CFD Michael Wurst TU München 16.06.2009 1 Multigrid Methods Definition Multigrid (MG) methods in numerical analysis are a group of algorithms for solving differential
Multigrid Methods and their application in CFD Michael Wurst TU München 16.06.2009 1 Multigrid Methods Definition Multigrid (MG) methods in numerical analysis are a group of algorithms for solving differential
Schwarz-type methods and their application in geomechanics
 Schwarz-type methods and their application in geomechanics R. Blaheta, O. Jakl, K. Krečmer, J. Starý Institute of Geonics AS CR, Ostrava, Czech Republic E-mail: stary@ugn.cas.cz PDEMAMIP, September 7-11,
Schwarz-type methods and their application in geomechanics R. Blaheta, O. Jakl, K. Krečmer, J. Starý Institute of Geonics AS CR, Ostrava, Czech Republic E-mail: stary@ugn.cas.cz PDEMAMIP, September 7-11,
Accelerating Model Reduction of Large Linear Systems with Graphics Processors
 Accelerating Model Reduction of Large Linear Systems with Graphics Processors P. Benner 1, P. Ezzatti 2, D. Kressner 3, E.S. Quintana-Ortí 4, Alfredo Remón 4 1 Max-Plank-Institute for Dynamics of Complex
Accelerating Model Reduction of Large Linear Systems with Graphics Processors P. Benner 1, P. Ezzatti 2, D. Kressner 3, E.S. Quintana-Ortí 4, Alfredo Remón 4 1 Max-Plank-Institute for Dynamics of Complex
J.I. Aliaga 1 M. Bollhöfer 2 A.F. Martín 1 E.S. Quintana-Ortí 1. March, 2009
 Parallel Preconditioning of Linear Systems based on ILUPACK for Multithreaded Architectures J.I. Aliaga M. Bollhöfer 2 A.F. Martín E.S. Quintana-Ortí Deparment of Computer Science and Engineering, Univ.
Parallel Preconditioning of Linear Systems based on ILUPACK for Multithreaded Architectures J.I. Aliaga M. Bollhöfer 2 A.F. Martín E.S. Quintana-Ortí Deparment of Computer Science and Engineering, Univ.
Domain Decomposition-based contour integration eigenvalue solvers
 Domain Decomposition-based contour integration eigenvalue solvers Vassilis Kalantzis joint work with Yousef Saad Computer Science and Engineering Department University of Minnesota - Twin Cities, USA SIAM
Domain Decomposition-based contour integration eigenvalue solvers Vassilis Kalantzis joint work with Yousef Saad Computer Science and Engineering Department University of Minnesota - Twin Cities, USA SIAM
Algorithm for Sparse Approximate Inverse Preconditioners in the Conjugate Gradient Method
 Algorithm for Sparse Approximate Inverse Preconditioners in the Conjugate Gradient Method Ilya B. Labutin A.A. Trofimuk Institute of Petroleum Geology and Geophysics SB RAS, 3, acad. Koptyug Ave., Novosibirsk
Algorithm for Sparse Approximate Inverse Preconditioners in the Conjugate Gradient Method Ilya B. Labutin A.A. Trofimuk Institute of Petroleum Geology and Geophysics SB RAS, 3, acad. Koptyug Ave., Novosibirsk
Jacobi-Based Eigenvalue Solver on GPU. Lung-Sheng Chien, NVIDIA
 Jacobi-Based Eigenvalue Solver on GPU Lung-Sheng Chien, NVIDIA lchien@nvidia.com Outline Symmetric eigenvalue solver Experiment Applications Conclusions Symmetric eigenvalue solver The standard form is
Jacobi-Based Eigenvalue Solver on GPU Lung-Sheng Chien, NVIDIA lchien@nvidia.com Outline Symmetric eigenvalue solver Experiment Applications Conclusions Symmetric eigenvalue solver The standard form is
Some Geometric and Algebraic Aspects of Domain Decomposition Methods
 Some Geometric and Algebraic Aspects of Domain Decomposition Methods D.S.Butyugin 1, Y.L.Gurieva 1, V.P.Ilin 1,2, and D.V.Perevozkin 1 Abstract Some geometric and algebraic aspects of various domain decomposition
Some Geometric and Algebraic Aspects of Domain Decomposition Methods D.S.Butyugin 1, Y.L.Gurieva 1, V.P.Ilin 1,2, and D.V.Perevozkin 1 Abstract Some geometric and algebraic aspects of various domain decomposition
Solving Large Nonlinear Sparse Systems
 Solving Large Nonlinear Sparse Systems Fred W. Wubs and Jonas Thies Computational Mechanics & Numerical Mathematics University of Groningen, the Netherlands f.w.wubs@rug.nl Centre for Interdisciplinary
Solving Large Nonlinear Sparse Systems Fred W. Wubs and Jonas Thies Computational Mechanics & Numerical Mathematics University of Groningen, the Netherlands f.w.wubs@rug.nl Centre for Interdisciplinary
Faster Kinetics: Accelerate Your Finite-Rate Combustion Simulation with GPUs
 Faster Kinetics: Accelerate Your Finite-Rate Combustion Simulation with GPUs Christopher P. Stone, Ph.D. Computational Science and Engineering, LLC Kyle Niemeyer, Ph.D. Oregon State University 2 Outline
Faster Kinetics: Accelerate Your Finite-Rate Combustion Simulation with GPUs Christopher P. Stone, Ph.D. Computational Science and Engineering, LLC Kyle Niemeyer, Ph.D. Oregon State University 2 Outline
Petascale Quantum Simulations of Nano Systems and Biomolecules
 Petascale Quantum Simulations of Nano Systems and Biomolecules Emil Briggs North Carolina State University 1. Outline of real-space Multigrid (RMG) 2. Scalability and hybrid/threaded models 3. GPU acceleration
Petascale Quantum Simulations of Nano Systems and Biomolecules Emil Briggs North Carolina State University 1. Outline of real-space Multigrid (RMG) 2. Scalability and hybrid/threaded models 3. GPU acceleration
Incomplete Cholesky preconditioners that exploit the low-rank property
 anapov@ulb.ac.be ; http://homepages.ulb.ac.be/ anapov/ 1 / 35 Incomplete Cholesky preconditioners that exploit the low-rank property (theory and practice) Artem Napov Service de Métrologie Nucléaire, Université
anapov@ulb.ac.be ; http://homepages.ulb.ac.be/ anapov/ 1 / 35 Incomplete Cholesky preconditioners that exploit the low-rank property (theory and practice) Artem Napov Service de Métrologie Nucléaire, Université
Research on GPU-accelerated algorithm in 3D finite difference neutron diffusion calculation method
 NUCLEAR SCIENCE AND TECHNIQUES 25, 0501 (14) Research on GPU-accelerated algorithm in 3D finite difference neutron diffusion calculation method XU Qi ( 徐琪 ), 1, YU Gang-Lin ( 余纲林 ), 1 WANG Kan ( 王侃 ),
NUCLEAR SCIENCE AND TECHNIQUES 25, 0501 (14) Research on GPU-accelerated algorithm in 3D finite difference neutron diffusion calculation method XU Qi ( 徐琪 ), 1, YU Gang-Lin ( 余纲林 ), 1 WANG Kan ( 王侃 ),
Architecture Solutions for DDM Numerical Environment
 Architecture Solutions for DDM Numerical Environment Yana Gurieva 1 and Valery Ilin 1,2 1 Institute of Computational Mathematics and Mathematical Geophysics SB RAS, Novosibirsk, Russia 2 Novosibirsk State
Architecture Solutions for DDM Numerical Environment Yana Gurieva 1 and Valery Ilin 1,2 1 Institute of Computational Mathematics and Mathematical Geophysics SB RAS, Novosibirsk, Russia 2 Novosibirsk State
Discretization of PDEs and Tools for the Parallel Solution of the Resulting Systems
 Discretization of PDEs and Tools for the Parallel Solution of the Resulting Systems Stan Tomov Innovative Computing Laboratory Computer Science Department The University of Tennessee Wednesday April 4,
Discretization of PDEs and Tools for the Parallel Solution of the Resulting Systems Stan Tomov Innovative Computing Laboratory Computer Science Department The University of Tennessee Wednesday April 4,
Computing least squares condition numbers on hybrid multicore/gpu systems
 Computing least squares condition numbers on hybrid multicore/gpu systems M. Baboulin and J. Dongarra and R. Lacroix Abstract This paper presents an efficient computation for least squares conditioning
Computing least squares condition numbers on hybrid multicore/gpu systems M. Baboulin and J. Dongarra and R. Lacroix Abstract This paper presents an efficient computation for least squares conditioning
CRYPTOGRAPHIC COMPUTING
 CRYPTOGRAPHIC COMPUTING ON GPU Chen Mou Cheng Dept. Electrical Engineering g National Taiwan University January 16, 2009 COLLABORATORS Daniel Bernstein, UIC, USA Tien Ren Chen, Army Tanja Lange, TU Eindhoven,
CRYPTOGRAPHIC COMPUTING ON GPU Chen Mou Cheng Dept. Electrical Engineering g National Taiwan University January 16, 2009 COLLABORATORS Daniel Bernstein, UIC, USA Tien Ren Chen, Army Tanja Lange, TU Eindhoven,
ANR Project DEDALES Algebraic and Geometric Domain Decomposition for Subsurface Flow
 ANR Project DEDALES Algebraic and Geometric Domain Decomposition for Subsurface Flow Michel Kern Inria Paris Rocquencourt Maison de la Simulation C2S@Exa Days, Inria Paris Centre, Novembre 2016 M. Kern
ANR Project DEDALES Algebraic and Geometric Domain Decomposition for Subsurface Flow Michel Kern Inria Paris Rocquencourt Maison de la Simulation C2S@Exa Days, Inria Paris Centre, Novembre 2016 M. Kern
Efficient Augmented Lagrangian-type Preconditioning for the Oseen Problem using Grad-Div Stabilization
 Efficient Augmented Lagrangian-type Preconditioning for the Oseen Problem using Grad-Div Stabilization Timo Heister, Texas A&M University 2013-02-28 SIAM CSE 2 Setting Stationary, incompressible flow problems
Efficient Augmented Lagrangian-type Preconditioning for the Oseen Problem using Grad-Div Stabilization Timo Heister, Texas A&M University 2013-02-28 SIAM CSE 2 Setting Stationary, incompressible flow problems
Multilevel spectral coarse space methods in FreeFem++ on parallel architectures
 Multilevel spectral coarse space methods in FreeFem++ on parallel architectures Pierre Jolivet Laboratoire Jacques-Louis Lions Laboratoire Jean Kuntzmann DD 21, Rennes. June 29, 2012 In collaboration with
Multilevel spectral coarse space methods in FreeFem++ on parallel architectures Pierre Jolivet Laboratoire Jacques-Louis Lions Laboratoire Jean Kuntzmann DD 21, Rennes. June 29, 2012 In collaboration with
Toward black-box adaptive domain decomposition methods
 Toward black-box adaptive domain decomposition methods Frédéric Nataf Laboratory J.L. Lions (LJLL), CNRS, Alpines Inria and Univ. Paris VI joint work with Victorita Dolean (Univ. Nice Sophia-Antipolis)
Toward black-box adaptive domain decomposition methods Frédéric Nataf Laboratory J.L. Lions (LJLL), CNRS, Alpines Inria and Univ. Paris VI joint work with Victorita Dolean (Univ. Nice Sophia-Antipolis)
Accelerated Solvers for CFD
 Accelerated Solvers for CFD Co-Design of Hardware/Software for Predicting MAV Aerodynamics Eric de Sturler, Virginia Tech Mathematics Email: sturler@vt.edu Web: http://www.math.vt.edu/people/sturler Co-design
Accelerated Solvers for CFD Co-Design of Hardware/Software for Predicting MAV Aerodynamics Eric de Sturler, Virginia Tech Mathematics Email: sturler@vt.edu Web: http://www.math.vt.edu/people/sturler Co-design
Cactus Tools for Petascale Computing
 Cactus Tools for Petascale Computing Erik Schnetter Reno, November 2007 Gamma Ray Bursts ~10 7 km He Protoneutron Star Accretion Collapse to a Black Hole Jet Formation and Sustainment Fe-group nuclei Si
Cactus Tools for Petascale Computing Erik Schnetter Reno, November 2007 Gamma Ray Bursts ~10 7 km He Protoneutron Star Accretion Collapse to a Black Hole Jet Formation and Sustainment Fe-group nuclei Si
TR A Comparison of the Performance of SaP::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems
 for Solving Dense Banded Linear Systems") TR-0-07 A Comparison of the Performance of ::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems Ang Li, Omkar Deshmukh, Radu Serban, Dan Negrut May, 0 Abstract ::GPU is a
TR-0-07 A Comparison of the Performance of ::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems Ang Li, Omkar Deshmukh, Radu Serban, Dan Negrut May, 0 Abstract ::GPU is a
Massively parallel semi-lagrangian solution of the 6d Vlasov-Poisson problem
 Massively parallel semi-lagrangian solution of the 6d Vlasov-Poisson problem Katharina Kormann 1 Klaus Reuter 2 Markus Rampp 2 Eric Sonnendrücker 1 1 Max Planck Institut für Plasmaphysik 2 Max Planck Computing
Massively parallel semi-lagrangian solution of the 6d Vlasov-Poisson problem Katharina Kormann 1 Klaus Reuter 2 Markus Rampp 2 Eric Sonnendrücker 1 1 Max Planck Institut für Plasmaphysik 2 Max Planck Computing
Dune. Patrick Leidenberger. 13. May Distributed and Unified Numerics Environment. 13. May 2009
 13. May 2009 leidenberger@ifh.ee.ethz.ch 1 / 25 Dune Distributed and Unified Numerics Environment Patrick Leidenberger 13. May 2009 13. May 2009 leidenberger@ifh.ee.ethz.ch 2 / 25 Table of contents 1 Introduction
13. May 2009 leidenberger@ifh.ee.ethz.ch 1 / 25 Dune Distributed and Unified Numerics Environment Patrick Leidenberger 13. May 2009 13. May 2009 leidenberger@ifh.ee.ethz.ch 2 / 25 Table of contents 1 Introduction
FINDING PARALLELISM IN GENERAL-PURPOSE LINEAR PROGRAMMING
 FINDING PARALLELISM IN GENERAL-PURPOSE LINEAR PROGRAMMING Daniel Thuerck 1,2 (advisors Michael Goesele 1,2 and Marc Pfetsch 1 ) Maxim Naumov 3 1 Graduate School of Computational Engineering, TU Darmstadt
FINDING PARALLELISM IN GENERAL-PURPOSE LINEAR PROGRAMMING Daniel Thuerck 1,2 (advisors Michael Goesele 1,2 and Marc Pfetsch 1 ) Maxim Naumov 3 1 Graduate School of Computational Engineering, TU Darmstadt
Julian Merten. GPU Computing and Alternative Architecture
 Future Directions of Cosmological Simulations / Edinburgh 1 / 16 Julian Merten GPU Computing and Alternative Architecture Institut für Theoretische Astrophysik Zentrum für Astronomie Universität Heidelberg
Future Directions of Cosmological Simulations / Edinburgh 1 / 16 Julian Merten GPU Computing and Alternative Architecture Institut für Theoretische Astrophysik Zentrum für Astronomie Universität Heidelberg
Static-scheduling and hybrid-programming in SuperLU DIST on multicore cluster systems
 Static-scheduling and hybrid-programming in SuperLU DIST on multicore cluster systems Ichitaro Yamazaki University of Tennessee, Knoxville Xiaoye Sherry Li Lawrence Berkeley National Laboratory MS49: Sparse
Static-scheduling and hybrid-programming in SuperLU DIST on multicore cluster systems Ichitaro Yamazaki University of Tennessee, Knoxville Xiaoye Sherry Li Lawrence Berkeley National Laboratory MS49: Sparse
Leveraging Task-Parallelism in Energy-Efficient ILU Preconditioners
 Leveraging Task-Parallelism in Energy-Efficient ILU Preconditioners José I. Aliaga Leveraging task-parallelism in energy-efficient ILU preconditioners Universidad Jaime I (Castellón, Spain) José I. Aliaga
Leveraging Task-Parallelism in Energy-Efficient ILU Preconditioners José I. Aliaga Leveraging task-parallelism in energy-efficient ILU preconditioners Universidad Jaime I (Castellón, Spain) José I. Aliaga
All-electron density functional theory on Intel MIC: Elk
 All-electron density functional theory on Intel MIC: Elk W. Scott Thornton, R.J. Harrison Abstract We present the results of the porting of the full potential linear augmented plane-wave solver, Elk [1],
All-electron density functional theory on Intel MIC: Elk W. Scott Thornton, R.J. Harrison Abstract We present the results of the porting of the full potential linear augmented plane-wave solver, Elk [1],
Introduction to numerical computations on the GPU
 Introduction to numerical computations on the GPU Lucian Covaci http://lucian.covaci.org/cuda.pdf Tuesday 1 November 11 1 2 Outline: NVIDIA Tesla and Geforce video cards: architecture CUDA - C: programming
Introduction to numerical computations on the GPU Lucian Covaci http://lucian.covaci.org/cuda.pdf Tuesday 1 November 11 1 2 Outline: NVIDIA Tesla and Geforce video cards: architecture CUDA - C: programming
NVIDIA MPI-enabled Iterative Solvers for Large Scale Problems. Joe Eaton Manager, AmgX CUDA Library NVIDIA
 NVIDIA MPI-enabled Iterative Solvers for Large Scale Problems Joe Eaton Manager, AmgX CUDA Library NVIDIA ANSYS Fluent Fluent control flow Accelerate this first Non-linear iterations Assemble Linear System
NVIDIA MPI-enabled Iterative Solvers for Large Scale Problems Joe Eaton Manager, AmgX CUDA Library NVIDIA ANSYS Fluent Fluent control flow Accelerate this first Non-linear iterations Assemble Linear System
Utilisation de la compression low-rank pour réduire la complexité du solveur PaStiX
 Utilisation de la compression low-rank pour réduire la complexité du solveur PaStiX 26 Septembre 2018 - JCAD 2018 - Lyon Grégoire Pichon, Mathieu Faverge, Pierre Ramet, Jean Roman Outline 1. Context 2.
Utilisation de la compression low-rank pour réduire la complexité du solveur PaStiX 26 Septembre 2018 - JCAD 2018 - Lyon Grégoire Pichon, Mathieu Faverge, Pierre Ramet, Jean Roman Outline 1. Context 2.
Robust Preconditioned Conjugate Gradient for the GPU and Parallel Implementations
 Robust Preconditioned Conjugate Gradient for the GPU and Parallel Implementations Rohit Gupta, Martin van Gijzen, Kees Vuik GPU Technology Conference 2012, San Jose CA. GPU Technology Conference 2012,
Robust Preconditioned Conjugate Gradient for the GPU and Parallel Implementations Rohit Gupta, Martin van Gijzen, Kees Vuik GPU Technology Conference 2012, San Jose CA. GPU Technology Conference 2012,
Finite Element Methods with Linear B-Splines
 Finite Element Methods with Linear B-Splines K. Höllig, J. Hörner and M. Pfeil Universität Stuttgart Institut für Mathematische Methoden in den Ingenieurwissenschaften, Numerik und geometrische Modellierung
Finite Element Methods with Linear B-Splines K. Höllig, J. Hörner and M. Pfeil Universität Stuttgart Institut für Mathematische Methoden in den Ingenieurwissenschaften, Numerik und geometrische Modellierung
Nuclear Physics and Computing: Exascale Partnerships. Juan Meza Senior Scientist Lawrence Berkeley National Laboratory
 Nuclear Physics and Computing: Exascale Partnerships Juan Meza Senior Scientist Lawrence Berkeley National Laboratory Nuclear Science and Exascale i Workshop held in DC to identify scientific challenges
Nuclear Physics and Computing: Exascale Partnerships Juan Meza Senior Scientist Lawrence Berkeley National Laboratory Nuclear Science and Exascale i Workshop held in DC to identify scientific challenges
A model leading to self-consistent iteration computation with need for HP LA (e.g, diagonalization and orthogonalization)
") A model leading to self-consistent iteration computation with need for HP LA (e.g, diagonalization and orthogonalization) Schodinger equation: Hψ = Eψ Choose a basis set of wave functions Two cases: Orthonormal
A model leading to self-consistent iteration computation with need for HP LA (e.g, diagonalization and orthogonalization) Schodinger equation: Hψ = Eψ Choose a basis set of wave functions Two cases: Orthonormal
IMPLEMENTATION OF A PARALLEL AMG SOLVER
 IMPLEMENTATION OF A PARALLEL AMG SOLVER Tony Saad May 2005 http://tsaad.utsi.edu - tsaad@utsi.edu PLAN INTRODUCTION 2 min. MULTIGRID METHODS.. 3 min. PARALLEL IMPLEMENTATION PARTITIONING. 1 min. RENUMBERING...
IMPLEMENTATION OF A PARALLEL AMG SOLVER Tony Saad May 2005 http://tsaad.utsi.edu - tsaad@utsi.edu PLAN INTRODUCTION 2 min. MULTIGRID METHODS.. 3 min. PARALLEL IMPLEMENTATION PARTITIONING. 1 min. RENUMBERING...
Fine-grained Parallel Incomplete LU Factorization
 Fine-grained Parallel Incomplete LU Factorization Edmond Chow School of Computational Science and Engineering Georgia Institute of Technology Sparse Days Meeting at CERFACS June 5-6, 2014 Contribution
Fine-grained Parallel Incomplete LU Factorization Edmond Chow School of Computational Science and Engineering Georgia Institute of Technology Sparse Days Meeting at CERFACS June 5-6, 2014 Contribution
Scalable Hybrid Programming and Performance for SuperLU Sparse Direct Solver
 Scalable Hybrid Programming and Performance for SuperLU Sparse Direct Solver Sherry Li Lawrence Berkeley National Laboratory Piyush Sao Rich Vuduc Georgia Institute of Technology CUG 14, May 4-8, 14, Lugano,
Scalable Hybrid Programming and Performance for SuperLU Sparse Direct Solver Sherry Li Lawrence Berkeley National Laboratory Piyush Sao Rich Vuduc Georgia Institute of Technology CUG 14, May 4-8, 14, Lugano,
上海超级计算中心 Shanghai Supercomputer Center. Lei Xu Shanghai Supercomputer Center San Jose
 上海超级计算中心 Shanghai Supercomputer Center Lei Xu Shanghai Supercomputer Center 03/26/2014 @GTC, San Jose Overview Introduction Fundamentals of the FDTD method Implementation of 3D UPML-FDTD algorithm on GPU
上海超级计算中心 Shanghai Supercomputer Center Lei Xu Shanghai Supercomputer Center 03/26/2014 @GTC, San Jose Overview Introduction Fundamentals of the FDTD method Implementation of 3D UPML-FDTD algorithm on GPU
Multilevel Preconditioning of Graph-Laplacians: Polynomial Approximation of the Pivot Blocks Inverses
 Multilevel Preconditioning of Graph-Laplacians: Polynomial Approximation of the Pivot Blocks Inverses P. Boyanova 1, I. Georgiev 34, S. Margenov, L. Zikatanov 5 1 Uppsala University, Box 337, 751 05 Uppsala,
Multilevel Preconditioning of Graph-Laplacians: Polynomial Approximation of the Pivot Blocks Inverses P. Boyanova 1, I. Georgiev 34, S. Margenov, L. Zikatanov 5 1 Uppsala University, Box 337, 751 05 Uppsala,
Sparse LU Factorization on GPUs for Accelerating SPICE Simulation
 Nano-scale Integrated Circuit and System (NICS) Laboratory Sparse LU Factorization on GPUs for Accelerating SPICE Simulation Xiaoming Chen PhD Candidate Department of Electronic Engineering Tsinghua University,
Nano-scale Integrated Circuit and System (NICS) Laboratory Sparse LU Factorization on GPUs for Accelerating SPICE Simulation Xiaoming Chen PhD Candidate Department of Electronic Engineering Tsinghua University,
Recent advances in HPC with FreeFem++
 Recent advances in HPC with FreeFem++ Pierre Jolivet Laboratoire Jacques-Louis Lions Laboratoire Jean Kuntzmann Fourth workshop on FreeFem++ December 6, 2012 With F. Hecht, F. Nataf, C. Prud homme. Outline
Recent advances in HPC with FreeFem++ Pierre Jolivet Laboratoire Jacques-Louis Lions Laboratoire Jean Kuntzmann Fourth workshop on FreeFem++ December 6, 2012 With F. Hecht, F. Nataf, C. Prud homme. Outline
A SHORT NOTE COMPARING MULTIGRID AND DOMAIN DECOMPOSITION FOR PROTEIN MODELING EQUATIONS
 A SHORT NOTE COMPARING MULTIGRID AND DOMAIN DECOMPOSITION FOR PROTEIN MODELING EQUATIONS MICHAEL HOLST AND FAISAL SAIED Abstract. We consider multigrid and domain decomposition methods for the numerical
A SHORT NOTE COMPARING MULTIGRID AND DOMAIN DECOMPOSITION FOR PROTEIN MODELING EQUATIONS MICHAEL HOLST AND FAISAL SAIED Abstract. We consider multigrid and domain decomposition methods for the numerical
Measuring freeze-out parameters on the Bielefeld GPU cluster
 Measuring freeze-out parameters on the Bielefeld GPU cluster Outline Fluctuations and the QCD phase diagram Fluctuations from Lattice QCD The Bielefeld hybrid GPU cluster Freeze-out conditions from QCD
Measuring freeze-out parameters on the Bielefeld GPU cluster Outline Fluctuations and the QCD phase diagram Fluctuations from Lattice QCD The Bielefeld hybrid GPU cluster Freeze-out conditions from QCD
A Robust Preconditioned Iterative Method for the Navier-Stokes Equations with High Reynolds Numbers
 Applied and Computational Mathematics 2017; 6(4): 202-207 http://www.sciencepublishinggroup.com/j/acm doi: 10.11648/j.acm.20170604.18 ISSN: 2328-5605 (Print); ISSN: 2328-5613 (Online) A Robust Preconditioned
Applied and Computational Mathematics 2017; 6(4): 202-207 http://www.sciencepublishinggroup.com/j/acm doi: 10.11648/j.acm.20170604.18 ISSN: 2328-5605 (Print); ISSN: 2328-5613 (Online) A Robust Preconditioned
Parallel programming using MPI. Analysis and optimization. Bhupender Thakur, Jim Lupo, Le Yan, Alex Pacheco
 Parallel programming using MPI Analysis and optimization Bhupender Thakur, Jim Lupo, Le Yan, Alex Pacheco Outline l Parallel programming: Basic definitions l Choosing right algorithms: Optimal serial and
Parallel programming using MPI Analysis and optimization Bhupender Thakur, Jim Lupo, Le Yan, Alex Pacheco Outline l Parallel programming: Basic definitions l Choosing right algorithms: Optimal serial and
Scalable Non-blocking Preconditioned Conjugate Gradient Methods
 Scalable Non-blocking Preconditioned Conjugate Gradient Methods Paul Eller and William Gropp University of Illinois at Urbana-Champaign Department of Computer Science Supercomputing 16 Paul Eller and William
Scalable Non-blocking Preconditioned Conjugate Gradient Methods Paul Eller and William Gropp University of Illinois at Urbana-Champaign Department of Computer Science Supercomputing 16 Paul Eller and William
The Conjugate Gradient Method
 The Conjugate Gradient Method Classical Iterations We have a problem, We assume that the matrix comes from a discretization of a PDE. The best and most popular model problem is, The matrix will be as large
The Conjugate Gradient Method Classical Iterations We have a problem, We assume that the matrix comes from a discretization of a PDE. The best and most popular model problem is, The matrix will be as large
Jacobi-Davidson Eigensolver in Cusolver Library. Lung-Sheng Chien, NVIDIA
 Jacobi-Davidson Eigensolver in Cusolver Library Lung-Sheng Chien, NVIDIA lchien@nvidia.com Outline CuSolver library - cusolverdn: dense LAPACK - cusolversp: sparse LAPACK - cusolverrf: refactorization
Jacobi-Davidson Eigensolver in Cusolver Library Lung-Sheng Chien, NVIDIA lchien@nvidia.com Outline CuSolver library - cusolverdn: dense LAPACK - cusolversp: sparse LAPACK - cusolverrf: refactorization
Stabilization and Acceleration of Algebraic Multigrid Method
 Stabilization and Acceleration of Algebraic Multigrid Method Recursive Projection Algorithm A. Jemcov J.P. Maruszewski Fluent Inc. October 24, 2006 Outline 1 Need for Algorithm Stabilization and Acceleration
Stabilization and Acceleration of Algebraic Multigrid Method Recursive Projection Algorithm A. Jemcov J.P. Maruszewski Fluent Inc. October 24, 2006 Outline 1 Need for Algorithm Stabilization and Acceleration
Dense Arithmetic over Finite Fields with CUMODP
 Dense Arithmetic over Finite Fields with CUMODP Sardar Anisul Haque 1 Xin Li 2 Farnam Mansouri 1 Marc Moreno Maza 1 Wei Pan 3 Ning Xie 1 1 University of Western Ontario, Canada 2 Universidad Carlos III,
Dense Arithmetic over Finite Fields with CUMODP Sardar Anisul Haque 1 Xin Li 2 Farnam Mansouri 1 Marc Moreno Maza 1 Wei Pan 3 Ning Xie 1 1 University of Western Ontario, Canada 2 Universidad Carlos III,
Heterogeneous programming for hybrid CPU-GPU systems: Lessons learned from computational chemistry
 Heterogeneous programming for hybrid CPU-GPU systems: Lessons learned from computational chemistry and Eugene DePrince Argonne National Laboratory (LCF and CNM) (Eugene moved to Georgia Tech last week)
Heterogeneous programming for hybrid CPU-GPU systems: Lessons learned from computational chemistry and Eugene DePrince Argonne National Laboratory (LCF and CNM) (Eugene moved to Georgia Tech last week)
Lattice QCD with Domain Decomposition on Intel R Xeon Phi TM
 Lattice QCD with Domain Decomposition on Intel R Xeon Phi TM Co-Processors Simon Heybrock, Bálint Joó, Dhiraj D. Kalamkar, Mikhail Smelyanskiy, Karthikeyan Vaidyanathan, Tilo Wettig, and Pradeep Dubey
Lattice QCD with Domain Decomposition on Intel R Xeon Phi TM Co-Processors Simon Heybrock, Bálint Joó, Dhiraj D. Kalamkar, Mikhail Smelyanskiy, Karthikeyan Vaidyanathan, Tilo Wettig, and Pradeep Dubey
Discontinuous Galerkin methods for nonlinear elasticity
 Discontinuous Galerkin methods for nonlinear elasticity Preprint submitted to lsevier Science 8 January 2008 The goal of this paper is to introduce Discontinuous Galerkin (DG) methods for nonlinear elasticity
Discontinuous Galerkin methods for nonlinear elasticity Preprint submitted to lsevier Science 8 January 2008 The goal of this paper is to introduce Discontinuous Galerkin (DG) methods for nonlinear elasticity
An Efficient Low Memory Implicit DG Algorithm for Time Dependent Problems
 An Efficient Low Memory Implicit DG Algorithm for Time Dependent Problems P.-O. Persson and J. Peraire Massachusetts Institute of Technology 2006 AIAA Aerospace Sciences Meeting, Reno, Nevada January 9,
An Efficient Low Memory Implicit DG Algorithm for Time Dependent Problems P.-O. Persson and J. Peraire Massachusetts Institute of Technology 2006 AIAA Aerospace Sciences Meeting, Reno, Nevada January 9,