Lattice Boltzmann simulations on heterogeneous CPU-GPU clusters
|
|
|
- Abel Gregory
- 5 years ago
- Views:
Transcription
1 Lattice Boltzmann simulations on heterogeneous CPU-GPU clusters H. Köstler 2nd International Symposium Computer Simulations on GPU Freudenstadt,
2 Contents Motivation walberla software concepts LBM simulations on Tsubame Future Work 2




")




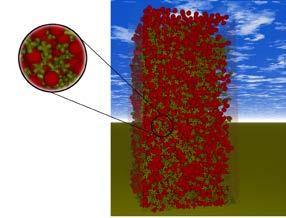

3 Computational Science and LSS Applications Multiphysics fluid, structure medical imaging laser USE_SweepSection( getlbmsweepuid() ){ USE_Sweep(){ swusefunction( LBM",sweep::LBMsweep,FS UIDSet::all(),hsCPU,BSUIDSet::all()); } USE_After(){ //Communication } } Computer Science HPC / hardware Performance engineering software engineering Applied Math LBM multigrid FEM numerics 3
4 Problems Hardware: Modern HPC clusters are massively parallel Intra-core, intra-node, and inter-node Software: Applications become more complex with increasing computational power More complex (physical) models Code development in interdisciplinary teams Algorithm: Many variants exist Components and parameters depend on computational domain or grid, type of problem, 4
5 Applications WALBERLA 5

6 walberla: parallel block-structured grid framework 6




7 GPU Geometric multigrid solver on Tsubame runtime in ms Computational Steering (VIPER) unknowns in million CFD, fluid-structure interaction 7
8 Boltzmann equation Mesoscopic approach to solving the Navier-Stokes equations Boltzmann equation describes the statistical distribution of one particle in a fluid f t + ζ f f is the probability distribution function (PDF), velocity, and Ω(f) is the change due to collision Models behavior of fluids in statistical physics Lattice Boltzmann Method (LBM) solves the discrete Boltzmann equation = Ω (f ) ζ the particle 8




9 Particulate Flow Simulation D3Q19 LBM cell Collide and Stream K. Iglberger F = m a M = J α simulation done by Ch. Feichtinger 9
10 CPU-GPU cluster software concepts WALBERLA 10

11 walberla: Block concept 11
12 walberla: Sweep concept 12

13 walberla: Communication concept 13

14 Overlapping of work and communication 14
15 WaLBerla: Subblocks Assumption: A block corresponds to a (shared-memory) compute node Can possibly be heterogeneous (CPU + GPU) Distributed memory communication (via MPI) is not required within one block Divide one block into subblocks of different sizes for (static) load balancing Subblocks map to (local) devices 15

16 Domain decomposition on one compute node 16
17 LBM Simulations on Tsubame 2.0 RESULTS 17

18 Tsubame 2.0 in Japan Compute nodes: 1442 Processor: Intel Xeon X5670 GPU: 3 x Nvidia Tesla M2050 LINPACK performance: 1.2 Petaflops Power consumption: 1.4 MW Interconnect: QDR Infiniband 18
19 Performance Model I Input Algorithm: LBM kernel Generic Implementation Hardware information (bandwidth, peak performance) Assumption t = t + max( t, t + t + t,, total comp, outer comp, inner buffer comm GPUCPU comm MPI ) Computation time limited by memory bandwidth and instruction throughput Communication time limited by network bandwidth and latency (for direct and collective communication) 19
20 Performance Model II Single node performance on Tsubame Machine balance B m = sustainable bandwidth peak performance Code balance B c = no. bytes loaded and stored no. executed FLOPS = Lightspeed estimate l = min 1, B B m c 20
21 Single Compute Node Performance I 21
22 Single Compute Node Performance II 22
23 Single Compute Node Performance III 23
24 Single Compute Node Performance IV 24
25 Weak scaling, 3 GPUs per node 25
26 Strong scaling, 3 GPUs per node 26

27 Test case: Packed bed of hollow cylinders 27
28 Porous media: 100x100x1536, 1D dom. decomp. 28
29 Porous media: 100x100x1536, 1D dom. decomp. 29
30 Porous media: 100x100x1536, 1D/2D/3D 30
31 Porous media: 256x256x3600, 1D/2D 31
32 Future Work Tests on Nvidia Kepler cluster Main focus in walberla currently on Juqueen and SuperMUC Programming paradigms on future HPC clusters? Code generation techniques to improve portability Dynamic load balancing 32
A Framework for Hybrid Parallel Flow Simulations with a Trillion Cells in Complex Geometries
 A Framework for Hybrid Parallel Flow Simulations with a Trillion Cells in Complex Geometries SC13, November 21 st 2013 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler, Ulrich
A Framework for Hybrid Parallel Flow Simulations with a Trillion Cells in Complex Geometries SC13, November 21 st 2013 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler, Ulrich
Parallel Simulations of Self-propelled Microorganisms
 Parallel Simulations of Self-propelled Microorganisms K. Pickl a,b M. Hofmann c T. Preclik a H. Köstler a A.-S. Smith b,d U. Rüde a,b ParCo 2013, Munich a Lehrstuhl für Informatik 10 (Systemsimulation),
Parallel Simulations of Self-propelled Microorganisms K. Pickl a,b M. Hofmann c T. Preclik a H. Köstler a A.-S. Smith b,d U. Rüde a,b ParCo 2013, Munich a Lehrstuhl für Informatik 10 (Systemsimulation),
Some thoughts about energy efficient application execution on NEC LX Series compute clusters
 Some thoughts about energy efficient application execution on NEC LX Series compute clusters G. Wellein, G. Hager, J. Treibig, M. Wittmann Erlangen Regional Computing Center & Department of Computer Science
Some thoughts about energy efficient application execution on NEC LX Series compute clusters G. Wellein, G. Hager, J. Treibig, M. Wittmann Erlangen Regional Computing Center & Department of Computer Science
Multiphase Flow Simulations in Inclined Tubes with Lattice Boltzmann Method on GPU
 Multiphase Flow Simulations in Inclined Tubes with Lattice Boltzmann Method on GPU Khramtsov D.P., Nekrasov D.A., Pokusaev B.G. Department of Thermodynamics, Thermal Engineering and Energy Saving Technologies,
Multiphase Flow Simulations in Inclined Tubes with Lattice Boltzmann Method on GPU Khramtsov D.P., Nekrasov D.A., Pokusaev B.G. Department of Thermodynamics, Thermal Engineering and Energy Saving Technologies,
On Portability, Performance and Scalability of a MPI OpenCL Lattice Boltzmann Code
 On Portability, Performance and Scalability of a MPI OpenCL Lattice Boltzmann Code E Calore, S F Schifano, R Tripiccione Enrico Calore INFN Ferrara, Italy 7 th Workshop on UnConventional High Performance
On Portability, Performance and Scalability of a MPI OpenCL Lattice Boltzmann Code E Calore, S F Schifano, R Tripiccione Enrico Calore INFN Ferrara, Italy 7 th Workshop on UnConventional High Performance
COMPARISON OF CPU AND GPU IMPLEMENTATIONS OF THE LATTICE BOLTZMANN METHOD
 XVIII International Conference on Water Resources CMWR 2010 J. Carrera (Ed) c CIMNE, Barcelona, 2010 COMPARISON OF CPU AND GPU IMPLEMENTATIONS OF THE LATTICE BOLTZMANN METHOD James.E. McClure, Jan F. Prins
XVIII International Conference on Water Resources CMWR 2010 J. Carrera (Ed) c CIMNE, Barcelona, 2010 COMPARISON OF CPU AND GPU IMPLEMENTATIONS OF THE LATTICE BOLTZMANN METHOD James.E. McClure, Jan F. Prins
A simple Concept for the Performance Analysis of Cluster-Computing
 A simple Concept for the Performance Analysis of Cluster-Computing H. Kredel 1, S. Richling 2, J.P. Kruse 3, E. Strohmaier 4, H.G. Kruse 1 1 IT-Center, University of Mannheim, Germany 2 IT-Center, University
A simple Concept for the Performance Analysis of Cluster-Computing H. Kredel 1, S. Richling 2, J.P. Kruse 3, E. Strohmaier 4, H.G. Kruse 1 1 IT-Center, University of Mannheim, Germany 2 IT-Center, University
The Lattice Boltzmann Simulation on Multi-GPU Systems
 The Lattice Boltzmann Simulation on Multi-GPU Systems Thor Kristian Valderhaug Master of Science in Computer Science Submission date: June 2011 Supervisor: Anne Cathrine Elster, IDI Norwegian University
The Lattice Boltzmann Simulation on Multi-GPU Systems Thor Kristian Valderhaug Master of Science in Computer Science Submission date: June 2011 Supervisor: Anne Cathrine Elster, IDI Norwegian University
Parallelism of MRT Lattice Boltzmann Method based on Multi-GPUs
 Parallelism of MRT Lattice Boltzmann Method based on Multi-GPUs 1 School of Information Engineering, China University of Geosciences (Beijing) Beijing, 100083, China E-mail: Yaolk1119@icloud.com Ailan
Parallelism of MRT Lattice Boltzmann Method based on Multi-GPUs 1 School of Information Engineering, China University of Geosciences (Beijing) Beijing, 100083, China E-mail: Yaolk1119@icloud.com Ailan
Solving RODEs on GPU clusters
 HIGH TEA @ SCIENCE Solving RODEs on GPU clusters Christoph Riesinger Technische Universität München March 4, 206 HIGH TEA @ SCIENCE, March 4, 206 Motivation - Parallel Computing HIGH TEA @ SCIENCE, March
HIGH TEA @ SCIENCE Solving RODEs on GPU clusters Christoph Riesinger Technische Universität München March 4, 206 HIGH TEA @ SCIENCE, March 4, 206 Motivation - Parallel Computing HIGH TEA @ SCIENCE, March
Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption. Langshi CHEN 1,2,3 Supervised by Serge PETITON 2
 1 / 23 Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption Langshi CHEN 1,2,3 Supervised by Serge PETITON 2 Maison de la Simulation Lille 1 University CNRS March 18, 2013
1 / 23 Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption Langshi CHEN 1,2,3 Supervised by Serge PETITON 2 Maison de la Simulation Lille 1 University CNRS March 18, 2013
Open-Source Parallel FE Software : FrontISTR -- Performance Considerations about B/F (Byte per Flop) of SpMV on K-Supercomputer and GPU-Clusters --
 of SpMV on K-Supercomputer and GPU-Clusters --") Parallel Processing for Energy Efficiency October 3, 2013 NTNU, Trondheim, Norway Open-Source Parallel FE Software : FrontISTR -- Performance Considerations about B/F (Byte per Flop) of SpMV on K-Supercomputer
Parallel Processing for Energy Efficiency October 3, 2013 NTNU, Trondheim, Norway Open-Source Parallel FE Software : FrontISTR -- Performance Considerations about B/F (Byte per Flop) of SpMV on K-Supercomputer
The Green Index (TGI): A Metric for Evalua:ng Energy Efficiency in HPC Systems
: A Metric for Evalua:ng Energy Efficiency in HPC Systems") The Green Index (TGI): A Metric for Evalua:ng Energy Efficiency in HPC Systems Wu Feng and Balaji Subramaniam Metrics for Energy Efficiency Energy- Delay Product (EDP) Used primarily in circuit design
The Green Index (TGI): A Metric for Evalua:ng Energy Efficiency in HPC Systems Wu Feng and Balaji Subramaniam Metrics for Energy Efficiency Energy- Delay Product (EDP) Used primarily in circuit design
Performance Analysis of a List-Based Lattice-Boltzmann Kernel
 Performance Analysis of a List-Based Lattice-Boltzmann Kernel First Talk MuCoSim, 29. June 2016 Michael Hußnätter RRZE HPC Group Friedrich-Alexander University of Erlangen-Nuremberg Outline Lattice Boltzmann
Performance Analysis of a List-Based Lattice-Boltzmann Kernel First Talk MuCoSim, 29. June 2016 Michael Hußnätter RRZE HPC Group Friedrich-Alexander University of Erlangen-Nuremberg Outline Lattice Boltzmann
Efficient implementation of the overlap operator on multi-gpus
 Efficient implementation of the overlap operator on multi-gpus Andrei Alexandru Mike Lujan, Craig Pelissier, Ben Gamari, Frank Lee SAAHPC 2011 - University of Tennessee Outline Motivation Overlap operator
Efficient implementation of the overlap operator on multi-gpus Andrei Alexandru Mike Lujan, Craig Pelissier, Ben Gamari, Frank Lee SAAHPC 2011 - University of Tennessee Outline Motivation Overlap operator
Applications of Lattice Boltzmann Methods
 Applications of Lattice Boltzmann Methods Dominik Bartuschat, Martin Bauer, Simon Bogner, Christian Godenschwager, Florian Schornbaum, Ulrich Rüde Erlangen, Germany March 1, 2016 NUMET 2016 D.Bartuschat,
Applications of Lattice Boltzmann Methods Dominik Bartuschat, Martin Bauer, Simon Bogner, Christian Godenschwager, Florian Schornbaum, Ulrich Rüde Erlangen, Germany March 1, 2016 NUMET 2016 D.Bartuschat,
上海超级计算中心 Shanghai Supercomputer Center. Lei Xu Shanghai Supercomputer Center San Jose
 上海超级计算中心 Shanghai Supercomputer Center Lei Xu Shanghai Supercomputer Center 03/26/2014 @GTC, San Jose Overview Introduction Fundamentals of the FDTD method Implementation of 3D UPML-FDTD algorithm on GPU
上海超级计算中心 Shanghai Supercomputer Center Lei Xu Shanghai Supercomputer Center 03/26/2014 @GTC, San Jose Overview Introduction Fundamentals of the FDTD method Implementation of 3D UPML-FDTD algorithm on GPU
Multiscale simulations of complex fluid rheology
 Multiscale simulations of complex fluid rheology Michael P. Howard, Athanassios Z. Panagiotopoulos Department of Chemical and Biological Engineering, Princeton University Arash Nikoubashman Institute of
Multiscale simulations of complex fluid rheology Michael P. Howard, Athanassios Z. Panagiotopoulos Department of Chemical and Biological Engineering, Princeton University Arash Nikoubashman Institute of
- Part 4 - Multicore and Manycore Technology: Chances and Challenges. Vincent Heuveline
 - Part 4 - Multicore and Manycore Technology: Chances and Challenges Vincent Heuveline 1 Numerical Simulation of Tropical Cyclones Goal oriented adaptivity for tropical cyclones ~10⁴km ~1500km ~100km 2
- Part 4 - Multicore and Manycore Technology: Chances and Challenges Vincent Heuveline 1 Numerical Simulation of Tropical Cyclones Goal oriented adaptivity for tropical cyclones ~10⁴km ~1500km ~100km 2
GPU Acceleration of Cutoff Pair Potentials for Molecular Modeling Applications
 GPU Acceleration of Cutoff Pair Potentials for Molecular Modeling Applications Christopher Rodrigues, David J. Hardy, John E. Stone, Klaus Schulten, Wen-Mei W. Hwu University of Illinois at Urbana-Champaign
GPU Acceleration of Cutoff Pair Potentials for Molecular Modeling Applications Christopher Rodrigues, David J. Hardy, John E. Stone, Klaus Schulten, Wen-Mei W. Hwu University of Illinois at Urbana-Champaign
Parallelization of Molecular Dynamics (with focus on Gromacs) SeSE 2014 p.1/29
 SeSE 2014 p.1/29") Parallelization of Molecular Dynamics (with focus on Gromacs) SeSE 2014 p.1/29 Outline A few words on MD applications and the GROMACS package The main work in an MD simulation Parallelization Stream computing
Parallelization of Molecular Dynamics (with focus on Gromacs) SeSE 2014 p.1/29 Outline A few words on MD applications and the GROMACS package The main work in an MD simulation Parallelization Stream computing
Simulation of Lid-driven Cavity Flow by Parallel Implementation of Lattice Boltzmann Method on GPUs
 Simulation of Lid-driven Cavity Flow by Parallel Implementation of Lattice Boltzmann Method on GPUs S. Berat Çelik 1, Cüneyt Sert 2, Barbaros ÇETN 3 1,2 METU, Mechanical Engineering, Ankara, TURKEY 3 METU-NCC,
Simulation of Lid-driven Cavity Flow by Parallel Implementation of Lattice Boltzmann Method on GPUs S. Berat Çelik 1, Cüneyt Sert 2, Barbaros ÇETN 3 1,2 METU, Mechanical Engineering, Ankara, TURKEY 3 METU-NCC,
Cactus Tools for Petascale Computing
 Cactus Tools for Petascale Computing Erik Schnetter Reno, November 2007 Gamma Ray Bursts ~10 7 km He Protoneutron Star Accretion Collapse to a Black Hole Jet Formation and Sustainment Fe-group nuclei Si
Cactus Tools for Petascale Computing Erik Schnetter Reno, November 2007 Gamma Ray Bursts ~10 7 km He Protoneutron Star Accretion Collapse to a Black Hole Jet Formation and Sustainment Fe-group nuclei Si
Scalable Hybrid Programming and Performance for SuperLU Sparse Direct Solver
 Scalable Hybrid Programming and Performance for SuperLU Sparse Direct Solver Sherry Li Lawrence Berkeley National Laboratory Piyush Sao Rich Vuduc Georgia Institute of Technology CUG 14, May 4-8, 14, Lugano,
Scalable Hybrid Programming and Performance for SuperLU Sparse Direct Solver Sherry Li Lawrence Berkeley National Laboratory Piyush Sao Rich Vuduc Georgia Institute of Technology CUG 14, May 4-8, 14, Lugano,
Welcome to MCS 572. content and organization expectations of the course. definition and classification
 Welcome to MCS 572 1 About the Course content and organization expectations of the course 2 Supercomputing definition and classification 3 Measuring Performance speedup and efficiency Amdahl s Law Gustafson
Welcome to MCS 572 1 About the Course content and organization expectations of the course 2 Supercomputing definition and classification 3 Measuring Performance speedup and efficiency Amdahl s Law Gustafson
Measuring freeze-out parameters on the Bielefeld GPU cluster
 Measuring freeze-out parameters on the Bielefeld GPU cluster Outline Fluctuations and the QCD phase diagram Fluctuations from Lattice QCD The Bielefeld hybrid GPU cluster Freeze-out conditions from QCD
Measuring freeze-out parameters on the Bielefeld GPU cluster Outline Fluctuations and the QCD phase diagram Fluctuations from Lattice QCD The Bielefeld hybrid GPU cluster Freeze-out conditions from QCD
Scalable and Power-Efficient Data Mining Kernels
 Scalable and Power-Efficient Data Mining Kernels Alok Choudhary, John G. Searle Professor Dept. of Electrical Engineering and Computer Science and Professor, Kellogg School of Management Director of the
Scalable and Power-Efficient Data Mining Kernels Alok Choudhary, John G. Searle Professor Dept. of Electrical Engineering and Computer Science and Professor, Kellogg School of Management Director of the
Performance Evaluation of Scientific Applications on POWER8
 Performance Evaluation of Scientific Applications on POWER8 2014 Nov 16 Andrew V. Adinetz 1, Paul F. Baumeister 1, Hans Böttiger 3, Thorsten Hater 1, Thilo Maurer 3, Dirk Pleiter 1, Wolfram Schenck 4,
Performance Evaluation of Scientific Applications on POWER8 2014 Nov 16 Andrew V. Adinetz 1, Paul F. Baumeister 1, Hans Böttiger 3, Thorsten Hater 1, Thilo Maurer 3, Dirk Pleiter 1, Wolfram Schenck 4,
Using AmgX to accelerate a PETSc-based immersed-boundary method code
 29th International Conference on Parallel Computational Fluid Dynamics May 15-17, 2017; Glasgow, Scotland Using AmgX to accelerate a PETSc-based immersed-boundary method code Olivier Mesnard, Pi-Yueh Chuang,
29th International Conference on Parallel Computational Fluid Dynamics May 15-17, 2017; Glasgow, Scotland Using AmgX to accelerate a PETSc-based immersed-boundary method code Olivier Mesnard, Pi-Yueh Chuang,
A Quantum Chemistry Domain-Specific Language for Heterogeneous Clusters
 A Quantum Chemistry Domain-Specific Language for Heterogeneous Clusters ANTONINO TUMEO, ORESTE VILLA Collaborators: Karol Kowalski, Sriram Krishnamoorthy, Wenjing Ma, Simone Secchi May 15, 2012 1 Outline!
A Quantum Chemistry Domain-Specific Language for Heterogeneous Clusters ANTONINO TUMEO, ORESTE VILLA Collaborators: Karol Kowalski, Sriram Krishnamoorthy, Wenjing Ma, Simone Secchi May 15, 2012 1 Outline!
On the Use of a Many core Processor for Computational Fluid Dynamics Simulations
 On the Use of a Many core Processor for Computational Fluid Dynamics Simulations Sebastian Raase, Tomas Nordström Halmstad University, Sweden {sebastian.raase,tomas.nordstrom} @ hh.se Preface based on
On the Use of a Many core Processor for Computational Fluid Dynamics Simulations Sebastian Raase, Tomas Nordström Halmstad University, Sweden {sebastian.raase,tomas.nordstrom} @ hh.se Preface based on
More Science per Joule: Bottleneck Computing
 More Science per Joule: Bottleneck Computing Georg Hager Erlangen Regional Computing Center (RRZE) University of Erlangen-Nuremberg Germany PPAM 2013 September 9, 2013 Warsaw, Poland Motivation (1): Scalability
More Science per Joule: Bottleneck Computing Georg Hager Erlangen Regional Computing Center (RRZE) University of Erlangen-Nuremberg Germany PPAM 2013 September 9, 2013 Warsaw, Poland Motivation (1): Scalability
Universität Dortmund UCHPC. Performance. Computing for Finite Element Simulations
 technische universität dortmund Universität Dortmund fakultät für mathematik LS III (IAM) UCHPC UnConventional High Performance Computing for Finite Element Simulations S. Turek, Chr. Becker, S. Buijssen,
technische universität dortmund Universität Dortmund fakultät für mathematik LS III (IAM) UCHPC UnConventional High Performance Computing for Finite Element Simulations S. Turek, Chr. Becker, S. Buijssen,
Research on GPU-accelerated algorithm in 3D finite difference neutron diffusion calculation method
 NUCLEAR SCIENCE AND TECHNIQUES 25, 0501 (14) Research on GPU-accelerated algorithm in 3D finite difference neutron diffusion calculation method XU Qi ( 徐琪 ), 1, YU Gang-Lin ( 余纲林 ), 1 WANG Kan ( 王侃 ),
NUCLEAR SCIENCE AND TECHNIQUES 25, 0501 (14) Research on GPU-accelerated algorithm in 3D finite difference neutron diffusion calculation method XU Qi ( 徐琪 ), 1, YU Gang-Lin ( 余纲林 ), 1 WANG Kan ( 王侃 ),
GPU Computing Activities in KISTI
 International Advanced Research Workshop on High Performance Computing, Grids and Clouds 2010 June 21~June 25 2010, Cetraro, Italy HPC Infrastructure and GPU Computing Activities in KISTI Hongsuk Yi hsyi@kisti.re.kr
International Advanced Research Workshop on High Performance Computing, Grids and Clouds 2010 June 21~June 25 2010, Cetraro, Italy HPC Infrastructure and GPU Computing Activities in KISTI Hongsuk Yi hsyi@kisti.re.kr
TR A Comparison of the Performance of SaP::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems
 for Solving Dense Banded Linear Systems") TR-0-07 A Comparison of the Performance of ::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems Ang Li, Omkar Deshmukh, Radu Serban, Dan Negrut May, 0 Abstract ::GPU is a
TR-0-07 A Comparison of the Performance of ::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems Ang Li, Omkar Deshmukh, Radu Serban, Dan Negrut May, 0 Abstract ::GPU is a
Petascale Quantum Simulations of Nano Systems and Biomolecules
 Petascale Quantum Simulations of Nano Systems and Biomolecules Emil Briggs North Carolina State University 1. Outline of real-space Multigrid (RMG) 2. Scalability and hybrid/threaded models 3. GPU acceleration
Petascale Quantum Simulations of Nano Systems and Biomolecules Emil Briggs North Carolina State University 1. Outline of real-space Multigrid (RMG) 2. Scalability and hybrid/threaded models 3. GPU acceleration
Two case studies of Monte Carlo simulation on GPU
 Two case studies of Monte Carlo simulation on GPU National Institute for Computational Sciences University of Tennessee Seminar series on HPC, Feb. 27, 2014 Outline 1 Introduction 2 Discrete energy lattice
Two case studies of Monte Carlo simulation on GPU National Institute for Computational Sciences University of Tennessee Seminar series on HPC, Feb. 27, 2014 Outline 1 Introduction 2 Discrete energy lattice
A hierarchical Model for the Analysis of Efficiency and Speed-up of Multi-Core Cluster-Computers
 A hierarchical Model for the Analysis of Efficiency and Speed-up of Multi-Core Cluster-Computers H. Kredel 1, H. G. Kruse 1 retired, S. Richling2 1 IT-Center, University of Mannheim, Germany 2 IT-Center,
A hierarchical Model for the Analysis of Efficiency and Speed-up of Multi-Core Cluster-Computers H. Kredel 1, H. G. Kruse 1 retired, S. Richling2 1 IT-Center, University of Mannheim, Germany 2 IT-Center,
Lattice Quantum Chromodynamics on the MIC architectures
 Lattice Quantum Chromodynamics on the MIC architectures Piotr Korcyl Universität Regensburg Intel MIC Programming Workshop @ LRZ 28 June 2017 Piotr Korcyl Lattice Quantum Chromodynamics on the MIC 1/ 25
Lattice Quantum Chromodynamics on the MIC architectures Piotr Korcyl Universität Regensburg Intel MIC Programming Workshop @ LRZ 28 June 2017 Piotr Korcyl Lattice Quantum Chromodynamics on the MIC 1/ 25
Claude Tadonki. MINES ParisTech PSL Research University Centre de Recherche Informatique
 Claude Tadonki MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Monthly CRI Seminar MINES ParisTech - CRI June 06, 2016, Fontainebleau (France)
Claude Tadonki MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Monthly CRI Seminar MINES ParisTech - CRI June 06, 2016, Fontainebleau (France)
Weather Research and Forecasting (WRF) Performance Benchmark and Profiling. July 2012
 Performance Benchmark and Profiling. July 2012") Weather Research and Forecasting (WRF) Performance Benchmark and Profiling July 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell,
Weather Research and Forecasting (WRF) Performance Benchmark and Profiling July 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell,
Introduction to numerical computations on the GPU
 Introduction to numerical computations on the GPU Lucian Covaci http://lucian.covaci.org/cuda.pdf Tuesday 1 November 11 1 2 Outline: NVIDIA Tesla and Geforce video cards: architecture CUDA - C: programming
Introduction to numerical computations on the GPU Lucian Covaci http://lucian.covaci.org/cuda.pdf Tuesday 1 November 11 1 2 Outline: NVIDIA Tesla and Geforce video cards: architecture CUDA - C: programming
A CPU-GPU Hybrid Implementation and Model-Driven Scheduling of the Fast Multipole Method
 A CPU-GPU Hybrid Implementation and Model-Driven Scheduling of the Fast Multipole Method Jee Choi 1, Aparna Chandramowlishwaran 3, Kamesh Madduri 4, and Richard Vuduc 2 1 ECE, Georgia Tech 2 CSE, Georgia
A CPU-GPU Hybrid Implementation and Model-Driven Scheduling of the Fast Multipole Method Jee Choi 1, Aparna Chandramowlishwaran 3, Kamesh Madduri 4, and Richard Vuduc 2 1 ECE, Georgia Tech 2 CSE, Georgia
Antti-Pekka Hynninen, 5/10/2017, GTC2017, San Jose CA
 S7255: CUTT: A HIGH- PERFORMANCE TENSOR TRANSPOSE LIBRARY FOR GPUS Antti-Pekka Hynninen, 5/10/2017, GTC2017, San Jose CA MOTIVATION Tensor contractions are the most computationally intensive part of quantum
S7255: CUTT: A HIGH- PERFORMANCE TENSOR TRANSPOSE LIBRARY FOR GPUS Antti-Pekka Hynninen, 5/10/2017, GTC2017, San Jose CA MOTIVATION Tensor contractions are the most computationally intensive part of quantum
Efficient multigrid solvers for mixed finite element discretisations in NWP models
 1/20 Efficient multigrid solvers for mixed finite element discretisations in NWP models Colin Cotter, David Ham, Lawrence Mitchell, Eike Hermann Müller *, Robert Scheichl * * University of Bath, Imperial
1/20 Efficient multigrid solvers for mixed finite element discretisations in NWP models Colin Cotter, David Ham, Lawrence Mitchell, Eike Hermann Müller *, Robert Scheichl * * University of Bath, Imperial
Nuclear Physics and Computing: Exascale Partnerships. Juan Meza Senior Scientist Lawrence Berkeley National Laboratory
 Nuclear Physics and Computing: Exascale Partnerships Juan Meza Senior Scientist Lawrence Berkeley National Laboratory Nuclear Science and Exascale i Workshop held in DC to identify scientific challenges
Nuclear Physics and Computing: Exascale Partnerships Juan Meza Senior Scientist Lawrence Berkeley National Laboratory Nuclear Science and Exascale i Workshop held in DC to identify scientific challenges
Case Study: Quantum Chromodynamics
 Case Study: Quantum Chromodynamics Michael Clark Harvard University with R. Babich, K. Barros, R. Brower, J. Chen and C. Rebbi Outline Primer to QCD QCD on a GPU Mixed Precision Solvers Multigrid solver
Case Study: Quantum Chromodynamics Michael Clark Harvard University with R. Babich, K. Barros, R. Brower, J. Chen and C. Rebbi Outline Primer to QCD QCD on a GPU Mixed Precision Solvers Multigrid solver
Performance Evaluation of MPI on Weather and Hydrological Models
 NCAR/RAL Performance Evaluation of MPI on Weather and Hydrological Models Alessandro Fanfarillo elfanfa@ucar.edu August 8th 2018 Cheyenne - NCAR Supercomputer Cheyenne is a 5.34-petaflops, high-performance
NCAR/RAL Performance Evaluation of MPI on Weather and Hydrological Models Alessandro Fanfarillo elfanfa@ucar.edu August 8th 2018 Cheyenne - NCAR Supercomputer Cheyenne is a 5.34-petaflops, high-performance
ERLANGEN REGIONAL COMPUTING CENTER
 ERLANGEN REGIONAL COMPUTING CENTER Making Sense of Performance Numbers Georg Hager Erlangen Regional Computing Center (RRZE) Friedrich-Alexander-Universität Erlangen-Nürnberg OpenMPCon 2018 Barcelona,
ERLANGEN REGIONAL COMPUTING CENTER Making Sense of Performance Numbers Georg Hager Erlangen Regional Computing Center (RRZE) Friedrich-Alexander-Universität Erlangen-Nürnberg OpenMPCon 2018 Barcelona,
A Stochastic-based Optimized Schwarz Method for the Gravimetry Equations on GPU Clusters
 A Stochastic-based Optimized Schwarz Method for the Gravimetry Equations on GPU Clusters Abal-Kassim Cheik Ahamed and Frédéric Magoulès Introduction By giving another way to see beneath the Earth, gravimetry
A Stochastic-based Optimized Schwarz Method for the Gravimetry Equations on GPU Clusters Abal-Kassim Cheik Ahamed and Frédéric Magoulès Introduction By giving another way to see beneath the Earth, gravimetry
Unraveling the mysteries of quarks with hundreds of GPUs. Ron Babich NVIDIA
 Unraveling the mysteries of quarks with hundreds of GPUs Ron Babich NVIDIA Collaborators and QUDA developers Kip Barros (LANL) Rich Brower (Boston University) Mike Clark (NVIDIA) Justin Foley (University
Unraveling the mysteries of quarks with hundreds of GPUs Ron Babich NVIDIA Collaborators and QUDA developers Kip Barros (LANL) Rich Brower (Boston University) Mike Clark (NVIDIA) Justin Foley (University
Efficient Molecular Dynamics on Heterogeneous Architectures in GROMACS
 Efficient Molecular Dynamics on Heterogeneous Architectures in GROMACS Berk Hess, Szilárd Páll KTH Royal Institute of Technology GTC 2012 GROMACS: fast, scalable, free Classical molecular dynamics package
Efficient Molecular Dynamics on Heterogeneous Architectures in GROMACS Berk Hess, Szilárd Páll KTH Royal Institute of Technology GTC 2012 GROMACS: fast, scalable, free Classical molecular dynamics package
The Fast Multipole Method in molecular dynamics
 The Fast Multipole Method in molecular dynamics Berk Hess KTH Royal Institute of Technology, Stockholm, Sweden ADAC6 workshop Zurich, 20-06-2018 Slide BioExcel Slide Molecular Dynamics of biomolecules
The Fast Multipole Method in molecular dynamics Berk Hess KTH Royal Institute of Technology, Stockholm, Sweden ADAC6 workshop Zurich, 20-06-2018 Slide BioExcel Slide Molecular Dynamics of biomolecules
Unsteady CFD for Automotive Aerodynamics
 Unsteady CFD for Automotive Aerodynamics T. Indinger, B. Schnepf, P. Nathen, M. Peichl, TU München, Institute of Aerodynamics and Fluid Mechanics Prof. Dr.-Ing. N.A. Adams Outline 2 Motivation Applications
Unsteady CFD for Automotive Aerodynamics T. Indinger, B. Schnepf, P. Nathen, M. Peichl, TU München, Institute of Aerodynamics and Fluid Mechanics Prof. Dr.-Ing. N.A. Adams Outline 2 Motivation Applications
Direct Self-Consistent Field Computations on GPU Clusters
 Direct Self-Consistent Field Computations on GPU Clusters Guochun Shi, Volodymyr Kindratenko National Center for Supercomputing Applications University of Illinois at UrbanaChampaign Ivan Ufimtsev, Todd
Direct Self-Consistent Field Computations on GPU Clusters Guochun Shi, Volodymyr Kindratenko National Center for Supercomputing Applications University of Illinois at UrbanaChampaign Ivan Ufimtsev, Todd
Breaking Computational Barriers: Multi-GPU High-Order RBF Kernel Problems with Millions of Points
 Breaking Computational Barriers: Multi-GPU High-Order RBF Kernel Problems with Millions of Points Michael Griebel Christian Rieger Peter Zaspel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität
Breaking Computational Barriers: Multi-GPU High-Order RBF Kernel Problems with Millions of Points Michael Griebel Christian Rieger Peter Zaspel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität
Accelerating incompressible fluid flow simulations on hybrid CPU/GPU systems
 Accelerating incompressible fluid flow simulations on hybrid CPU/GPU systems Yushan Wang 1, Marc Baboulin 1,2, Karl Rupp 3,4, Yann Fraigneau 1,5, Olivier Le Maître 1,5 1 Université Paris-Sud, France 2
Accelerating incompressible fluid flow simulations on hybrid CPU/GPU systems Yushan Wang 1, Marc Baboulin 1,2, Karl Rupp 3,4, Yann Fraigneau 1,5, Olivier Le Maître 1,5 1 Université Paris-Sud, France 2
The Lattice Boltzmann Method for Laminar and Turbulent Channel Flows
 The Lattice Boltzmann Method for Laminar and Turbulent Channel Flows Vanja Zecevic, Michael Kirkpatrick and Steven Armfield Department of Aerospace Mechanical & Mechatronic Engineering The University of
The Lattice Boltzmann Method for Laminar and Turbulent Channel Flows Vanja Zecevic, Michael Kirkpatrick and Steven Armfield Department of Aerospace Mechanical & Mechatronic Engineering The University of
Domain Decomposition-based contour integration eigenvalue solvers
 Domain Decomposition-based contour integration eigenvalue solvers Vassilis Kalantzis joint work with Yousef Saad Computer Science and Engineering Department University of Minnesota - Twin Cities, USA SIAM
Domain Decomposition-based contour integration eigenvalue solvers Vassilis Kalantzis joint work with Yousef Saad Computer Science and Engineering Department University of Minnesota - Twin Cities, USA SIAM
Video: Lenovo, NVIDIA & Beckman Coulter showcase healthcare solutions
 Video: Lenovo, NVIDIA & Beckman Coulter showcase healthcare solutions http://www.youtube.com/watch?v=ldjif9u6zms 2 Lenovo ThinkStation 3 LENOVO THINKSTATION RELIABLE AND POWERFUL Lenovo ThinkStation S30
Video: Lenovo, NVIDIA & Beckman Coulter showcase healthcare solutions http://www.youtube.com/watch?v=ldjif9u6zms 2 Lenovo ThinkStation 3 LENOVO THINKSTATION RELIABLE AND POWERFUL Lenovo ThinkStation S30
High-performance processing and development with Madagascar. July 24, 2010 Madagascar development team
 High-performance processing and development with Madagascar July 24, 2010 Madagascar development team Outline 1 HPC terminology and frameworks 2 Utilizing data parallelism 3 HPC development with Madagascar
High-performance processing and development with Madagascar July 24, 2010 Madagascar development team Outline 1 HPC terminology and frameworks 2 Utilizing data parallelism 3 HPC development with Madagascar
Faster Kinetics: Accelerate Your Finite-Rate Combustion Simulation with GPUs
 Faster Kinetics: Accelerate Your Finite-Rate Combustion Simulation with GPUs Christopher P. Stone, Ph.D. Computational Science and Engineering, LLC Kyle Niemeyer, Ph.D. Oregon State University 2 Outline
Faster Kinetics: Accelerate Your Finite-Rate Combustion Simulation with GPUs Christopher P. Stone, Ph.D. Computational Science and Engineering, LLC Kyle Niemeyer, Ph.D. Oregon State University 2 Outline
Tuning And Understanding MILC Performance In Cray XK6 GPU Clusters. Mike Showerman, Guochun Shi Steven Gottlieb
 Tuning And Understanding MILC Performance In Cray XK6 GPU Clusters Mike Showerman, Guochun Shi Steven Gottlieb Outline Background Lattice QCD and MILC GPU and Cray XK6 node architecture Implementation
Tuning And Understanding MILC Performance In Cray XK6 GPU Clusters Mike Showerman, Guochun Shi Steven Gottlieb Outline Background Lattice QCD and MILC GPU and Cray XK6 node architecture Implementation
Using a CUDA-Accelerated PGAS Model on a GPU Cluster for Bioinformatics
 Using a CUDA-Accelerated PGAS Model on a GPU Cluster for Bioinformatics Jorge González-Domínguez Parallel and Distributed Architectures Group Johannes Gutenberg University of Mainz, Germany j.gonzalez@uni-mainz.de
Using a CUDA-Accelerated PGAS Model on a GPU Cluster for Bioinformatics Jorge González-Domínguez Parallel and Distributed Architectures Group Johannes Gutenberg University of Mainz, Germany j.gonzalez@uni-mainz.de
Performance Analysis of Parallel Alternating Directions Algorithm for Time Dependent Problems
 Performance Analysis of Parallel Alternating Directions Algorithm for Time Dependent Problems Ivan Lirkov 1, Marcin Paprzycki 2, and Maria Ganzha 2 1 Institute of Information and Communication Technologies,
Performance Analysis of Parallel Alternating Directions Algorithm for Time Dependent Problems Ivan Lirkov 1, Marcin Paprzycki 2, and Maria Ganzha 2 1 Institute of Information and Communication Technologies,
Efficient Parallelization of Molecular Dynamics Simulations on Hybrid CPU/GPU Supercoputers
 Efficient Parallelization of Molecular Dynamics Simulations on Hybrid CPU/GPU Supercoputers Jaewoon Jung (RIKEN, RIKEN AICS) Yuji Sugita (RIKEN, RIKEN AICS, RIKEN QBiC, RIKEN ithes) Molecular Dynamics
Efficient Parallelization of Molecular Dynamics Simulations on Hybrid CPU/GPU Supercoputers Jaewoon Jung (RIKEN, RIKEN AICS) Yuji Sugita (RIKEN, RIKEN AICS, RIKEN QBiC, RIKEN ithes) Molecular Dynamics
Analysis of the Efficiency PETSc and PETIGA Libraries in Solving the Problem of Crystal Growth
 Analysis of the Efficiency PETSc and PETIGA Libraries in Solving the Problem of Crystal Growth Ilya Starodumov 1, Evgeny Pavlyuk 1, Leonid Klyuev 2, Maxim Kovalenko 3, and Anton Medyankin 1 1 Ural Federal
Analysis of the Efficiency PETSc and PETIGA Libraries in Solving the Problem of Crystal Growth Ilya Starodumov 1, Evgeny Pavlyuk 1, Leonid Klyuev 2, Maxim Kovalenko 3, and Anton Medyankin 1 1 Ural Federal
Performance and Energy Analysis of the Iterative Solution of Sparse Linear Systems on Multicore and Manycore Architectures
 Performance and Energy Analysis of the Iterative Solution of Sparse Linear Systems on Multicore and Manycore Architectures José I. Aliaga Performance and Energy Analysis of the Iterative Solution of Sparse
Performance and Energy Analysis of the Iterative Solution of Sparse Linear Systems on Multicore and Manycore Architectures José I. Aliaga Performance and Energy Analysis of the Iterative Solution of Sparse
GPU acceleration of Newton s method for large systems of polynomial equations in double double and quad double arithmetic
 GPU acceleration of Newton s method for large systems of polynomial equations in double double and quad double arithmetic Jan Verschelde joint work with Xiangcheng Yu University of Illinois at Chicago
GPU acceleration of Newton s method for large systems of polynomial equations in double double and quad double arithmetic Jan Verschelde joint work with Xiangcheng Yu University of Illinois at Chicago
Pore Scale Analysis of Oil Shale/Sands Pyrolysis
 Pore Scale Analysis of Oil Shale/Sands Pyrolysis C.L. Lin, J.D. Miller, and C.H. Hsieh Department of Metallurgical Engineering College of Mines and Earth Sciences University of Utah Outlines Introduction
Pore Scale Analysis of Oil Shale/Sands Pyrolysis C.L. Lin, J.D. Miller, and C.H. Hsieh Department of Metallurgical Engineering College of Mines and Earth Sciences University of Utah Outlines Introduction
Gas Turbine Technologies Torino (Italy) 26 January 2006
 26 January 2006") Pore Scale Mesoscopic Modeling of Reactive Mixtures in the Porous Media for SOFC Application: Physical Model, Numerical Code Development and Preliminary Validation Michele CALI, Pietro ASINARI Dipartimento
Pore Scale Mesoscopic Modeling of Reactive Mixtures in the Porous Media for SOFC Application: Physical Model, Numerical Code Development and Preliminary Validation Michele CALI, Pietro ASINARI Dipartimento
Dynamic Scheduling for Work Agglomeration on Heterogeneous Clusters
 Dynamic Scheduling for Work Agglomeration on Heterogeneous Clusters Jonathan Lifflander, G. Carl Evans, Anshu Arya, Laxmikant Kale University of Illinois Urbana-Champaign May 25, 2012 Work is overdecomposed
Dynamic Scheduling for Work Agglomeration on Heterogeneous Clusters Jonathan Lifflander, G. Carl Evans, Anshu Arya, Laxmikant Kale University of Illinois Urbana-Champaign May 25, 2012 Work is overdecomposed
Verbundprojekt ELPA-AEO. Eigenwert-Löser für Petaflop-Anwendungen Algorithmische Erweiterungen und Optimierungen
 Verbundprojekt ELPA-AEO http://elpa-aeo.mpcdf.mpg.de Eigenwert-Löser für Petaflop-Anwendungen Algorithmische Erweiterungen und Optimierungen BMBF Projekt 01IH15001 Feb 2016 - Jan 2019 7. HPC-Statustagung,
Verbundprojekt ELPA-AEO http://elpa-aeo.mpcdf.mpg.de Eigenwert-Löser für Petaflop-Anwendungen Algorithmische Erweiterungen und Optimierungen BMBF Projekt 01IH15001 Feb 2016 - Jan 2019 7. HPC-Statustagung,
High-Performance Computing, Planet Formation & Searching for Extrasolar Planets
 High-Performance Computing, Planet Formation & Searching for Extrasolar Planets Eric B. Ford (UF Astronomy) Research Computing Day September 29, 2011 Postdocs: A. Boley, S. Chatterjee, A. Moorhead, M.
High-Performance Computing, Planet Formation & Searching for Extrasolar Planets Eric B. Ford (UF Astronomy) Research Computing Day September 29, 2011 Postdocs: A. Boley, S. Chatterjee, A. Moorhead, M.
SPARSE SOLVERS POISSON EQUATION. Margreet Nool. November 9, 2015 FOR THE. CWI, Multiscale Dynamics
 SPARSE SOLVERS FOR THE POISSON EQUATION Margreet Nool CWI, Multiscale Dynamics November 9, 2015 OUTLINE OF THIS TALK 1 FISHPACK, LAPACK, PARDISO 2 SYSTEM OVERVIEW OF CARTESIUS 3 POISSON EQUATION 4 SOLVERS
SPARSE SOLVERS FOR THE POISSON EQUATION Margreet Nool CWI, Multiscale Dynamics November 9, 2015 OUTLINE OF THIS TALK 1 FISHPACK, LAPACK, PARDISO 2 SYSTEM OVERVIEW OF CARTESIUS 3 POISSON EQUATION 4 SOLVERS
First, a look at using OpenACC on WRF subroutine advance_w dynamics routine
 First, a look at using OpenACC on WRF subroutine advance_w dynamics routine Second, an estimate of WRF multi-node performance on Cray XK6 with GPU accelerators Based on performance of WRF kernels, what
First, a look at using OpenACC on WRF subroutine advance_w dynamics routine Second, an estimate of WRF multi-node performance on Cray XK6 with GPU accelerators Based on performance of WRF kernels, what
A model leading to self-consistent iteration computation with need for HP LA (e.g, diagonalization and orthogonalization)
") A model leading to self-consistent iteration computation with need for HP LA (e.g, diagonalization and orthogonalization) Schodinger equation: Hψ = Eψ Choose a basis set of wave functions Two cases: Orthonormal
A model leading to self-consistent iteration computation with need for HP LA (e.g, diagonalization and orthogonalization) Schodinger equation: Hψ = Eψ Choose a basis set of wave functions Two cases: Orthonormal
A microsecond a day keeps the doctor away: Efficient GPU Molecular Dynamics with GROMACS
 GTC 20130319 A microsecond a day keeps the doctor away: Efficient GPU Molecular Dynamics with GROMACS Erik Lindahl erik.lindahl@scilifelab.se Molecular Dynamics Understand biology We re comfortably on
GTC 20130319 A microsecond a day keeps the doctor away: Efficient GPU Molecular Dynamics with GROMACS Erik Lindahl erik.lindahl@scilifelab.se Molecular Dynamics Understand biology We re comfortably on
Discretization of PDEs and Tools for the Parallel Solution of the Resulting Systems
 Discretization of PDEs and Tools for the Parallel Solution of the Resulting Systems Stan Tomov Innovative Computing Laboratory Computer Science Department The University of Tennessee Wednesday April 4,
Discretization of PDEs and Tools for the Parallel Solution of the Resulting Systems Stan Tomov Innovative Computing Laboratory Computer Science Department The University of Tennessee Wednesday April 4,
Lattice-Boltzmann vs. Navier-Stokes simulation of particulate flows
 Lattice-Boltzmann vs. Navier-Stokes simulation of particulate flows Amir Eshghinejadfard, Abouelmagd Abdelsamie, Dominique Thévenin University of Magdeburg, Germany 14th Workshop on Two-Phase Flow Predictions
Lattice-Boltzmann vs. Navier-Stokes simulation of particulate flows Amir Eshghinejadfard, Abouelmagd Abdelsamie, Dominique Thévenin University of Magdeburg, Germany 14th Workshop on Two-Phase Flow Predictions
Practical Combustion Kinetics with CUDA
 Funded by: U.S. Department of Energy Vehicle Technologies Program Program Manager: Gurpreet Singh & Leo Breton Practical Combustion Kinetics with CUDA GPU Technology Conference March 20, 2015 Russell Whitesides
Funded by: U.S. Department of Energy Vehicle Technologies Program Program Manager: Gurpreet Singh & Leo Breton Practical Combustion Kinetics with CUDA GPU Technology Conference March 20, 2015 Russell Whitesides
Block AIR Methods. For Multicore and GPU. Per Christian Hansen Hans Henrik B. Sørensen. Technical University of Denmark
 Block AIR Methods For Multicore and GPU Per Christian Hansen Hans Henrik B. Sørensen Technical University of Denmark Model Problem and Notation Parallel-beam 3D tomography exact solution exact data noise
Block AIR Methods For Multicore and GPU Per Christian Hansen Hans Henrik B. Sørensen Technical University of Denmark Model Problem and Notation Parallel-beam 3D tomography exact solution exact data noise
QR Factorization of Tall and Skinny Matrices in a Grid Computing Environment
 QR Factorization of Tall and Skinny Matrices in a Grid Computing Environment Emmanuel AGULLO (INRIA / LaBRI) Camille COTI (Iowa State University) Jack DONGARRA (University of Tennessee) Thomas HÉRAULT
QR Factorization of Tall and Skinny Matrices in a Grid Computing Environment Emmanuel AGULLO (INRIA / LaBRI) Camille COTI (Iowa State University) Jack DONGARRA (University of Tennessee) Thomas HÉRAULT
arxiv: v1 [hep-lat] 7 Oct 2010
![arxiv: v1 [hep-lat] 7 Oct 2010](/thumbs/79/80346009.jpg "arxiv: v1 [hep-lat] 7 Oct 2010") arxiv:.486v [hep-lat] 7 Oct 2 Nuno Cardoso CFTP, Instituto Superior Técnico E-mail: nunocardoso@cftp.ist.utl.pt Pedro Bicudo CFTP, Instituto Superior Técnico E-mail: bicudo@ist.utl.pt We discuss the CUDA
arxiv:.486v [hep-lat] 7 Oct 2 Nuno Cardoso CFTP, Instituto Superior Técnico E-mail: nunocardoso@cftp.ist.utl.pt Pedro Bicudo CFTP, Instituto Superior Técnico E-mail: bicudo@ist.utl.pt We discuss the CUDA
Computers and Mathematics with Applications
 Computers and Mathematics with Applications 67 (014) 445 451 Contents lists available at ScienceDirect Computers and Mathematics with Applications journal homepage: www.elsevier.com/locate/camwa GPU accelerated
Computers and Mathematics with Applications 67 (014) 445 451 Contents lists available at ScienceDirect Computers and Mathematics with Applications journal homepage: www.elsevier.com/locate/camwa GPU accelerated
Piz Daint & Piz Kesch : from general purpose supercomputing to an appliance for weather forecasting. Thomas C. Schulthess
 Piz Daint & Piz Kesch : from general purpose supercomputing to an appliance for weather forecasting Thomas C. Schulthess 1 Cray XC30 with 5272 hybrid, GPU accelerated compute nodes Piz Daint Compute node:
Piz Daint & Piz Kesch : from general purpose supercomputing to an appliance for weather forecasting Thomas C. Schulthess 1 Cray XC30 with 5272 hybrid, GPU accelerated compute nodes Piz Daint Compute node:
Quantum Chemical Calculations by Parallel Computer from Commodity PC Components
 Nonlinear Analysis: Modelling and Control, 2007, Vol. 12, No. 4, 461 468 Quantum Chemical Calculations by Parallel Computer from Commodity PC Components S. Bekešienė 1, S. Sėrikovienė 2 1 Institute of
Nonlinear Analysis: Modelling and Control, 2007, Vol. 12, No. 4, 461 468 Quantum Chemical Calculations by Parallel Computer from Commodity PC Components S. Bekešienė 1, S. Sėrikovienė 2 1 Institute of
Available online at ScienceDirect. Procedia Engineering 61 (2013 ) 94 99
 94 99") Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 6 (203 ) 94 99 Parallel Computational Fluid Dynamics Conference (ParCFD203) Simulations of three-dimensional cavity flows with
Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 6 (203 ) 94 99 Parallel Computational Fluid Dynamics Conference (ParCFD203) Simulations of three-dimensional cavity flows with
Multilevel low-rank approximation preconditioners Yousef Saad Department of Computer Science and Engineering University of Minnesota
 Multilevel low-rank approximation preconditioners Yousef Saad Department of Computer Science and Engineering University of Minnesota SIAM CSE Boston - March 1, 2013 First: Joint work with Ruipeng Li Work
Multilevel low-rank approximation preconditioners Yousef Saad Department of Computer Science and Engineering University of Minnesota SIAM CSE Boston - March 1, 2013 First: Joint work with Ruipeng Li Work
CRYSTAL in parallel: replicated and distributed (MPP) data. Why parallel?
 data. Why parallel?") CRYSTAL in parallel: replicated and distributed (MPP) data Roberto Orlando Dipartimento di Chimica Università di Torino Via Pietro Giuria 5, 10125 Torino (Italy) roberto.orlando@unito.it 1 Why parallel?
CRYSTAL in parallel: replicated and distributed (MPP) data Roberto Orlando Dipartimento di Chimica Università di Torino Via Pietro Giuria 5, 10125 Torino (Italy) roberto.orlando@unito.it 1 Why parallel?
Information Sciences Institute 22 June 2012 Bob Lucas, Gene Wagenbreth, Dan Davis, Roger Grimes and
 Accelerating the Multifrontal Method Information Sciences Institute 22 June 2012 Bob Lucas, Gene Wagenbreth, Dan Davis, Roger Grimes {rflucas,genew,ddavis}@isi.edu and grimes@lstc.com 3D Finite Element
Accelerating the Multifrontal Method Information Sciences Institute 22 June 2012 Bob Lucas, Gene Wagenbreth, Dan Davis, Roger Grimes {rflucas,genew,ddavis}@isi.edu and grimes@lstc.com 3D Finite Element
Static-scheduling and hybrid-programming in SuperLU DIST on multicore cluster systems
 Static-scheduling and hybrid-programming in SuperLU DIST on multicore cluster systems Ichitaro Yamazaki University of Tennessee, Knoxville Xiaoye Sherry Li Lawrence Berkeley National Laboratory MS49: Sparse
Static-scheduling and hybrid-programming in SuperLU DIST on multicore cluster systems Ichitaro Yamazaki University of Tennessee, Knoxville Xiaoye Sherry Li Lawrence Berkeley National Laboratory MS49: Sparse
Accelerating linear algebra computations with hybrid GPU-multicore systems.
 Accelerating linear algebra computations with hybrid GPU-multicore systems. Marc Baboulin INRIA/Université Paris-Sud joint work with Jack Dongarra (University of Tennessee and Oak Ridge National Laboratory)
Accelerating linear algebra computations with hybrid GPU-multicore systems. Marc Baboulin INRIA/Université Paris-Sud joint work with Jack Dongarra (University of Tennessee and Oak Ridge National Laboratory)
Heterogeneous programming for hybrid CPU-GPU systems: Lessons learned from computational chemistry
 Heterogeneous programming for hybrid CPU-GPU systems: Lessons learned from computational chemistry and Eugene DePrince Argonne National Laboratory (LCF and CNM) (Eugene moved to Georgia Tech last week)
Heterogeneous programming for hybrid CPU-GPU systems: Lessons learned from computational chemistry and Eugene DePrince Argonne National Laboratory (LCF and CNM) (Eugene moved to Georgia Tech last week)
A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures
 A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
arxiv: v1 [cs.dc] 4 Sep 2014
![arxiv: v1 [cs.dc] 4 Sep 2014](/thumbs/93/114366338.jpg "arxiv: v1 [cs.dc] 4 Sep 2014") and NVIDIA R GPUs arxiv:1409.1510v1 [cs.dc] 4 Sep 2014 O. Kaczmarek, C. Schmidt and P. Steinbrecher Fakultät für Physik, Universität Bielefeld, D-33615 Bielefeld, Germany E-mail: okacz, schmidt, p.steinbrecher@physik.uni-bielefeld.de
and NVIDIA R GPUs arxiv:1409.1510v1 [cs.dc] 4 Sep 2014 O. Kaczmarek, C. Schmidt and P. Steinbrecher Fakultät für Physik, Universität Bielefeld, D-33615 Bielefeld, Germany E-mail: okacz, schmidt, p.steinbrecher@physik.uni-bielefeld.de
PERFORMANCE METRICS. Mahdi Nazm Bojnordi. CS/ECE 6810: Computer Architecture. Assistant Professor School of Computing University of Utah
 PERFORMANCE METRICS Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Jan. 17 th : Homework 1 release (due on Jan.
PERFORMANCE METRICS Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Jan. 17 th : Homework 1 release (due on Jan.
Massively parallel semi-lagrangian solution of the 6d Vlasov-Poisson problem
 Massively parallel semi-lagrangian solution of the 6d Vlasov-Poisson problem Katharina Kormann 1 Klaus Reuter 2 Markus Rampp 2 Eric Sonnendrücker 1 1 Max Planck Institut für Plasmaphysik 2 Max Planck Computing
Massively parallel semi-lagrangian solution of the 6d Vlasov-Poisson problem Katharina Kormann 1 Klaus Reuter 2 Markus Rampp 2 Eric Sonnendrücker 1 1 Max Planck Institut für Plasmaphysik 2 Max Planck Computing
Simulation of floating bodies with lattice Boltzmann
 Simulation of floating bodies with lattice Boltzmann by Simon Bogner, 17.11.2011, Lehrstuhl für Systemsimulation, Friedrich-Alexander Universität Erlangen 1 Simulation of floating bodies with lattice Boltzmann
Simulation of floating bodies with lattice Boltzmann by Simon Bogner, 17.11.2011, Lehrstuhl für Systemsimulation, Friedrich-Alexander Universität Erlangen 1 Simulation of floating bodies with lattice Boltzmann