GPU Computing Activities in KISTI
|
|
|
- Gary McBride
- 5 years ago
- Views:
Transcription
1 International Advanced Research Workshop on High Performance Computing, Grids and Clouds 2010 June 21~June , Cetraro, Italy HPC Infrastructure and GPU Computing Activities in KISTI Hongsuk Yi kr
2 Outline HPC infrastructure and activities in KISTI Heterogeneous Computing with GPU What is the scalability Heterogeneous Computing with MPI+CUDA HPC2010_Italy_2

 Multi-GPU programming Scientific Cloud")


3 Where is KISTI? KISTI is responsible for national cyber-infrastructure of Korea Mission is enable Discovery through National Projects I will don t talk about, today Grid Project (2002~2009) ~ K*Grid HPC Infrastructure & e-science Project (2005 ~) Multi-GPU programming Scientific Cloud Computing (2009~) Research Network Project (2005~) Cyber- infrastructure Environment Keep securing/providing g world-class supercomputing systems Computing /Network Resource Help Korea research communities to be equipped with proper knowledge of Cyber-infra. Validate newly emerging concepts, ideas, tools, and systems K*Grid, Scientific Cloud Testbed Center Value-adding Center Make best use of what the center has, to create new values Heterogeneous Computing_3






4 History of Supercomputers in Korea Time for new multi-petaflops System in Korea Exa Peta Ham GF Nobel 02 4 TF Tera ea T3E GF SUN TF Giga IBM 9 30 TF Mega SX5 02 SX6 03 2GF 88 16GF 93 80GF 160GF HPC2010_Italy_4
5 HPC ACT of Korea HPC ACT has been started from 2004 The ACT is currently awaiting the approval of the National Assembly Purpose To provide for a well coordinated national program to ensure continued Korea role in HPC and its applications by improving the coordination of supercomputing resource on HPC maximizing the effectiveness of the Korea s networks research (KREONET) We can make more contribution by expanding support for National agenda research program in the field of computational science, and development of cyber-infrastructure environment, ad well as applications of extreme scale computation HPC2010_Italy_5






6 NCRC National Core Research Center for Computational Science and Technology Budget ~ 10M$ Sep. 2010~ (not yet completely determined) Application Domains Energy transformation by quantum simulation Migration of pollution by air including yellow sand New material for Energy HPC2010_Italy_6
7 Supercomputing Resource (Tachyon) Tachyon-II is the 15 th ranked in Top500 (June, 2010) Sun Blade x6048, Intel Nehalem procs~26,232 (Memory~157 TB ) Peak ~ 307 Tflops (Sustained Peak 274 Tflops) Providing about 30% of whole computing capacity for public research in Korea Users form 200 institutes in Korea Utilization : 70~80% Little room for large scale grand challenge problems Chemistry Earth/Weather Mechanics Physics Electronics Oh Others HPC2010_Italy_7
8 User Support and Applications Support code optimization and parallelization We optimize and parallelize user s code. Performance improvements from - 5 times to more than 1,000-fold Year Optimization Parallelization User s Application through Grand Challenge Problems Magnetic control of edge spins by K. S. Kim, Nature Nanotech. 3, 408 (2008) Hydrogen Storage Materials by J. Ihm, Phys. Rev. Lett. 97, (2006) HPC2010_Italy_8
")



")

")
9 Supercomputing Resource (GAIA) GAIA-II is SMP Cluster 393th in Top500, IBMPOWER65GH GHz, Power 595, Number of Procs ~ 1,536 (64 cores/node) Rpeak~30.7 Tflops (Sustained Peak 23.3 Tflops) Memory (8.7 TB) HPC2010_Italy_9
10 Hybrid Programming : Multi-Zone NPB GAIA-2 (IBM p6 5GHz) Big memory ~16GB/cores Bin-packing algorithm The size of zones varies ~20 BT-MZ with class F Memory required ~ 5 TB MPI+OpenMP Programming Performance ~ 4.5TF (15%) HPC2010_Italy_10






11 GPU computing for visualization All KISTI s visualization systems have direct connection to GLORIAD, whose bandwidth is 10 Gbps Visualization Computer Total number of nodes ±150 CPU #ofcpu cores Total memory TB GPU Model NVIDIA Quadro FX 5600 # of GPUs 96 + Netw ork Interconnectio n External network 20 Gbps Gbps HPC2010_Italy_11


")




12 GPU Computing Activities KSCSE (Korea Society for Computational Sciences and Engineering) Establish as a new computing society in 2009 Support GPU computing Forum and workshop 200 participants, two days, May 2010, Seoul Open for international collaboration on the extreme scale computing HPC2010_Italy_12


, D870, GTX280")
13 Heterogeneous Computing Testbed Heterogeneous Computing System refer to system that use a variety of different types of computational units. A computational unit could be a GPU, co-processor, FPGA KISTI Heterogeneous GPU Testbed NVIDIA 2* S1070 (8 GPUs), D870, GTX280 PCI-e : 16x HPC2010_Italy_13
14 Performance Benefit of GPU Computing The ratio of operations to elements transfer : O(N) Matrix-Matrix Multiplication Operation N 3, Transfer 3xN 2,,Scaling O(N) Matrix-Matrix Addition Operation N 2, Transfer 3xN 2, Scaling O(1) NVIDA GTX280 (Peak 933 GHz) 40% Efficiency 6x Matrix-Matrix Multiplication C= AxB HPC2010_Italy_14






15 Image Compression Using SVD SVD is an important factoriz ation of matrix with many applications in signal p rocessing and statistics. culasgesvd() by using CULA RBG full color 2048x2048 total 4,194,304 pixels Original 12, KB 1 Rank 12 KB 10 Rank 120 KB 50 Rank 600 KB 80 Rank 960 KB 100 Rank 1,200 KB HPC2010_Italy_15
 Divide")

 Hy Ex Hz (i+1,j,k) Hx Ey (i+1, j+1, k+1) (i+1,j+1,k)")
16 3D FDTD on GPU H t 300 Finite-Difference Time-Domain Time domain simulation: FDTD, Frequency domain simulation: FEM, (i,j,k+1) Divide both space and time into discrete grids BEM,.. 3D FDTD Benchmark Results Memory ~ 988 MB, Grid~300x300x240 1 E E t By Q. Park and K. Kim, Korea Univ. 1 H J Ez (i,j,k) Hy Ex Hz (i+1,j,k) Hx Ey (i+1, j+1, k+1) (i+1,j+1,k) Intel Opt 9800GF GTX280 GTX480 C1060 HPC2010_Italy_16
![RNG and Monte Carlo Algorithm Ising Model Model and probability weight E L J i, j 1 ij s s i j H L i 1 s i 1 p exp [ E / kb T ] ZT ( ) 1000 MC steps and](/docs-images/93/111614967/images/17-2.jpg "512 threads per block independent of block number and (tx=512, ty=1,by=1), bx Size of the warp ~32 and the number of thread block ~ 30 warp")
17 RNG and Monte Carlo Algorithm Ising Model Model and probability weight E L J i, j 1 ij s s i j H L i 1 s i 1 p exp [ E / kb T ] ZT ( ) 1000 MC steps and 512 threads per block independent of block number and (tx=512, ty=1,by=1), bx Size of the warp ~32 and the number of thread block ~ 30 warp HPC2010_Italy_17





")
18 Performance of Ising Model on a GPU Use the checkerboard decomposition to avoid the read/write conflicts the spin field and the seed values of the RNGs Divide the spin on the lattice into blocks on the GPU. Example for a (20x16) lattice HPC2010_Italy_18







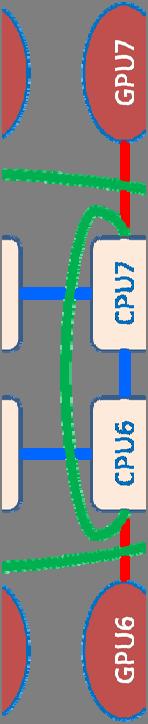

19 MPI Virtual Topology + CUDA Model VT is weak scaling problem The problem size grows in direct proportion to the num. of cores Using PBC with MPI_Sendrecv() e Intel Nehalem 8 cores + Nvidia Tesla C1060*8GPUs PCI-E cables HPC2010_Italy_19



20 Heterogeneous Communication Pattern PCIe InfiniBand PCIe GPU CPU1 --- CPU > GPU2 There is an extra cudamemcopy() involved in message passing HPC2010_Italy_20
21 GPU scaling Issues Achieving good scaling is more difficult with GPUs The kernels are much faster so the MPI communication becomes a larger faction of the overall execution time HPC2010_Italy_21
22 Summary HPC ACT of Korea is in progress The act is awaiting the approval of the Korea assembly Time for heterogeneous petaflops system in Korea Consider too many things, power, space, user s ability of porting In the MPI+CUDA model, achieving good scaling is more difficult than pure MPI since the kernels are still faster on the GPU There is an another communication over head between CPU and GPUs HPC2010_Italy_22
23 Q&A Thank You! HPC2010_Italy_23
Introduction to numerical computations on the GPU
 Introduction to numerical computations on the GPU Lucian Covaci http://lucian.covaci.org/cuda.pdf Tuesday 1 November 11 1 2 Outline: NVIDIA Tesla and Geforce video cards: architecture CUDA - C: programming
Introduction to numerical computations on the GPU Lucian Covaci http://lucian.covaci.org/cuda.pdf Tuesday 1 November 11 1 2 Outline: NVIDIA Tesla and Geforce video cards: architecture CUDA - C: programming
Stochastic Modelling of Electron Transport on different HPC architectures
 Stochastic Modelling of Electron Transport on different HPC architectures www.hp-see.eu E. Atanassov, T. Gurov, A. Karaivan ova Institute of Information and Communication Technologies Bulgarian Academy
Stochastic Modelling of Electron Transport on different HPC architectures www.hp-see.eu E. Atanassov, T. Gurov, A. Karaivan ova Institute of Information and Communication Technologies Bulgarian Academy
Direct Self-Consistent Field Computations on GPU Clusters
 Direct Self-Consistent Field Computations on GPU Clusters Guochun Shi, Volodymyr Kindratenko National Center for Supercomputing Applications University of Illinois at UrbanaChampaign Ivan Ufimtsev, Todd
Direct Self-Consistent Field Computations on GPU Clusters Guochun Shi, Volodymyr Kindratenko National Center for Supercomputing Applications University of Illinois at UrbanaChampaign Ivan Ufimtsev, Todd
Population annealing study of the frustrated Ising antiferromagnet on the stacked triangular lattice
 Population annealing study of the frustrated Ising antiferromagnet on the stacked triangular lattice Michal Borovský Department of Theoretical Physics and Astrophysics, University of P. J. Šafárik in Košice,
Population annealing study of the frustrated Ising antiferromagnet on the stacked triangular lattice Michal Borovský Department of Theoretical Physics and Astrophysics, University of P. J. Šafárik in Košice,
Two case studies of Monte Carlo simulation on GPU
 Two case studies of Monte Carlo simulation on GPU National Institute for Computational Sciences University of Tennessee Seminar series on HPC, Feb. 27, 2014 Outline 1 Introduction 2 Discrete energy lattice
Two case studies of Monte Carlo simulation on GPU National Institute for Computational Sciences University of Tennessee Seminar series on HPC, Feb. 27, 2014 Outline 1 Introduction 2 Discrete energy lattice
Lattice Boltzmann simulations on heterogeneous CPU-GPU clusters
 Lattice Boltzmann simulations on heterogeneous CPU-GPU clusters H. Köstler 2nd International Symposium Computer Simulations on GPU Freudenstadt, 29.05.2013 1 Contents Motivation walberla software concepts
Lattice Boltzmann simulations on heterogeneous CPU-GPU clusters H. Köstler 2nd International Symposium Computer Simulations on GPU Freudenstadt, 29.05.2013 1 Contents Motivation walberla software concepts
arxiv: v1 [hep-lat] 31 Oct 2015
![arxiv: v1 [hep-lat] 31 Oct 2015](/thumbs/74/71106348.jpg "arxiv: v1 [hep-lat] 31 Oct 2015") and Code Optimization arxiv:1511.00088v1 [hep-lat] 31 Oct 2015 Hwancheol Jeong, Sangbaek Lee, Weonjong Lee, Lattice Gauge Theory Research Center, CTP, and FPRD, Department of Physics and Astronomy, Seoul
and Code Optimization arxiv:1511.00088v1 [hep-lat] 31 Oct 2015 Hwancheol Jeong, Sangbaek Lee, Weonjong Lee, Lattice Gauge Theory Research Center, CTP, and FPRD, Department of Physics and Astronomy, Seoul
Massively scalable computing method to tackle large eigenvalue problems for nanoelectronics modeling
 2019 Intel extreme Performance Users Group (IXPUG) meeting Massively scalable computing method to tackle large eigenvalue problems for nanoelectronics modeling Hoon Ryu, Ph.D. (E: elec1020@kisti.re.kr)
2019 Intel extreme Performance Users Group (IXPUG) meeting Massively scalable computing method to tackle large eigenvalue problems for nanoelectronics modeling Hoon Ryu, Ph.D. (E: elec1020@kisti.re.kr)
Plaquette Renormalized Tensor Network States: Application to Frustrated Systems
 Workshop on QIS and QMP, Dec 20, 2009 Plaquette Renormalized Tensor Network States: Application to Frustrated Systems Ying-Jer Kao and Center for Quantum Science and Engineering Hsin-Chih Hsiao, Ji-Feng
Workshop on QIS and QMP, Dec 20, 2009 Plaquette Renormalized Tensor Network States: Application to Frustrated Systems Ying-Jer Kao and Center for Quantum Science and Engineering Hsin-Chih Hsiao, Ji-Feng
Claude Tadonki. MINES ParisTech PSL Research University Centre de Recherche Informatique
 Claude Tadonki MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Monthly CRI Seminar MINES ParisTech - CRI June 06, 2016, Fontainebleau (France)
Claude Tadonki MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Monthly CRI Seminar MINES ParisTech - CRI June 06, 2016, Fontainebleau (France)
On Portability, Performance and Scalability of a MPI OpenCL Lattice Boltzmann Code
 On Portability, Performance and Scalability of a MPI OpenCL Lattice Boltzmann Code E Calore, S F Schifano, R Tripiccione Enrico Calore INFN Ferrara, Italy 7 th Workshop on UnConventional High Performance
On Portability, Performance and Scalability of a MPI OpenCL Lattice Boltzmann Code E Calore, S F Schifano, R Tripiccione Enrico Calore INFN Ferrara, Italy 7 th Workshop on UnConventional High Performance
Parallelization of Molecular Dynamics (with focus on Gromacs) SeSE 2014 p.1/29
 SeSE 2014 p.1/29") Parallelization of Molecular Dynamics (with focus on Gromacs) SeSE 2014 p.1/29 Outline A few words on MD applications and the GROMACS package The main work in an MD simulation Parallelization Stream computing
Parallelization of Molecular Dynamics (with focus on Gromacs) SeSE 2014 p.1/29 Outline A few words on MD applications and the GROMACS package The main work in an MD simulation Parallelization Stream computing
上海超级计算中心 Shanghai Supercomputer Center. Lei Xu Shanghai Supercomputer Center San Jose
 上海超级计算中心 Shanghai Supercomputer Center Lei Xu Shanghai Supercomputer Center 03/26/2014 @GTC, San Jose Overview Introduction Fundamentals of the FDTD method Implementation of 3D UPML-FDTD algorithm on GPU
上海超级计算中心 Shanghai Supercomputer Center Lei Xu Shanghai Supercomputer Center 03/26/2014 @GTC, San Jose Overview Introduction Fundamentals of the FDTD method Implementation of 3D UPML-FDTD algorithm on GPU
A Quantum Chemistry Domain-Specific Language for Heterogeneous Clusters
 A Quantum Chemistry Domain-Specific Language for Heterogeneous Clusters ANTONINO TUMEO, ORESTE VILLA Collaborators: Karol Kowalski, Sriram Krishnamoorthy, Wenjing Ma, Simone Secchi May 15, 2012 1 Outline!
A Quantum Chemistry Domain-Specific Language for Heterogeneous Clusters ANTONINO TUMEO, ORESTE VILLA Collaborators: Karol Kowalski, Sriram Krishnamoorthy, Wenjing Ma, Simone Secchi May 15, 2012 1 Outline!
Open-Source Parallel FE Software : FrontISTR -- Performance Considerations about B/F (Byte per Flop) of SpMV on K-Supercomputer and GPU-Clusters --
 of SpMV on K-Supercomputer and GPU-Clusters --") Parallel Processing for Energy Efficiency October 3, 2013 NTNU, Trondheim, Norway Open-Source Parallel FE Software : FrontISTR -- Performance Considerations about B/F (Byte per Flop) of SpMV on K-Supercomputer
Parallel Processing for Energy Efficiency October 3, 2013 NTNU, Trondheim, Norway Open-Source Parallel FE Software : FrontISTR -- Performance Considerations about B/F (Byte per Flop) of SpMV on K-Supercomputer
Large-scale Electronic Structure Simulations with MVAPICH2 on Intel Knights Landing Manycore Processors
 Large-scale Electronic Structure Simulations with MVAPICH2 on Intel Knights Landing Manycore Processors Hoon Ryu, Ph.D. (E: elec1020@kisti.re.kr) Principal Researcher / Korea Institute of Science and Technology
Large-scale Electronic Structure Simulations with MVAPICH2 on Intel Knights Landing Manycore Processors Hoon Ryu, Ph.D. (E: elec1020@kisti.re.kr) Principal Researcher / Korea Institute of Science and Technology
arxiv: v1 [hep-lat] 7 Oct 2010
![arxiv: v1 [hep-lat] 7 Oct 2010](/thumbs/79/80346009.jpg "arxiv: v1 [hep-lat] 7 Oct 2010") arxiv:.486v [hep-lat] 7 Oct 2 Nuno Cardoso CFTP, Instituto Superior Técnico E-mail: nunocardoso@cftp.ist.utl.pt Pedro Bicudo CFTP, Instituto Superior Técnico E-mail: bicudo@ist.utl.pt We discuss the CUDA
arxiv:.486v [hep-lat] 7 Oct 2 Nuno Cardoso CFTP, Instituto Superior Técnico E-mail: nunocardoso@cftp.ist.utl.pt Pedro Bicudo CFTP, Instituto Superior Técnico E-mail: bicudo@ist.utl.pt We discuss the CUDA
Tuning And Understanding MILC Performance In Cray XK6 GPU Clusters. Mike Showerman, Guochun Shi Steven Gottlieb
 Tuning And Understanding MILC Performance In Cray XK6 GPU Clusters Mike Showerman, Guochun Shi Steven Gottlieb Outline Background Lattice QCD and MILC GPU and Cray XK6 node architecture Implementation
Tuning And Understanding MILC Performance In Cray XK6 GPU Clusters Mike Showerman, Guochun Shi Steven Gottlieb Outline Background Lattice QCD and MILC GPU and Cray XK6 node architecture Implementation
Welcome to MCS 572. content and organization expectations of the course. definition and classification
 Welcome to MCS 572 1 About the Course content and organization expectations of the course 2 Supercomputing definition and classification 3 Measuring Performance speedup and efficiency Amdahl s Law Gustafson
Welcome to MCS 572 1 About the Course content and organization expectations of the course 2 Supercomputing definition and classification 3 Measuring Performance speedup and efficiency Amdahl s Law Gustafson
Julian Merten. GPU Computing and Alternative Architecture
 Future Directions of Cosmological Simulations / Edinburgh 1 / 16 Julian Merten GPU Computing and Alternative Architecture Institut für Theoretische Astrophysik Zentrum für Astronomie Universität Heidelberg
Future Directions of Cosmological Simulations / Edinburgh 1 / 16 Julian Merten GPU Computing and Alternative Architecture Institut für Theoretische Astrophysik Zentrum für Astronomie Universität Heidelberg
High-Performance Computing and Groundbreaking Applications
 INSTITUTE OF INFORMATION AND COMMUNICATION TECHNOLOGIES BULGARIAN ACADEMY OF SCIENCE High-Performance Computing and Groundbreaking Applications Svetozar Margenov Institute of Information and Communication
INSTITUTE OF INFORMATION AND COMMUNICATION TECHNOLOGIES BULGARIAN ACADEMY OF SCIENCE High-Performance Computing and Groundbreaking Applications Svetozar Margenov Institute of Information and Communication
Shortest Lattice Vector Enumeration on Graphics Cards
 Shortest Lattice Vector Enumeration on Graphics Cards Jens Hermans 1 Michael Schneider 2 Fréderik Vercauteren 1 Johannes Buchmann 2 Bart Preneel 1 1 K.U.Leuven 2 TU Darmstadt SHARCS - 10 September 2009
Shortest Lattice Vector Enumeration on Graphics Cards Jens Hermans 1 Michael Schneider 2 Fréderik Vercauteren 1 Johannes Buchmann 2 Bart Preneel 1 1 K.U.Leuven 2 TU Darmstadt SHARCS - 10 September 2009
Performance evaluation of scalable optoelectronics application on large-scale Knights Landing cluster
 Performance evaluation of scalable optoelectronics application on large-scale Knights Landing cluster Yuta Hirokawa Graduate School of Systems and Information Engineering, University of Tsukuba hirokawa@hpcs.cs.tsukuba.ac.jp
Performance evaluation of scalable optoelectronics application on large-scale Knights Landing cluster Yuta Hirokawa Graduate School of Systems and Information Engineering, University of Tsukuba hirokawa@hpcs.cs.tsukuba.ac.jp
Massively scalable computing method to tackle large eigenvalue problems for nanoelectronics modeling
 2019 Intel extreme Performance Users Group (IXPUG) meeting Massively scalable computing method to tackle large eigenvalue problems for nanoelectronics modeling Hoon Ryu, Ph.D. (E: elec1020@kisti.re.kr)
2019 Intel extreme Performance Users Group (IXPUG) meeting Massively scalable computing method to tackle large eigenvalue problems for nanoelectronics modeling Hoon Ryu, Ph.D. (E: elec1020@kisti.re.kr)
Performance Evaluation of MPI on Weather and Hydrological Models
 NCAR/RAL Performance Evaluation of MPI on Weather and Hydrological Models Alessandro Fanfarillo elfanfa@ucar.edu August 8th 2018 Cheyenne - NCAR Supercomputer Cheyenne is a 5.34-petaflops, high-performance
NCAR/RAL Performance Evaluation of MPI on Weather and Hydrological Models Alessandro Fanfarillo elfanfa@ucar.edu August 8th 2018 Cheyenne - NCAR Supercomputer Cheyenne is a 5.34-petaflops, high-performance
The Green Index (TGI): A Metric for Evalua:ng Energy Efficiency in HPC Systems
: A Metric for Evalua:ng Energy Efficiency in HPC Systems") The Green Index (TGI): A Metric for Evalua:ng Energy Efficiency in HPC Systems Wu Feng and Balaji Subramaniam Metrics for Energy Efficiency Energy- Delay Product (EDP) Used primarily in circuit design
The Green Index (TGI): A Metric for Evalua:ng Energy Efficiency in HPC Systems Wu Feng and Balaji Subramaniam Metrics for Energy Efficiency Energy- Delay Product (EDP) Used primarily in circuit design
Monte Carlo Methods for Electron Transport: Scalability Study
 Monte Carlo Methods for Electron Transport: Scalability Study www.hp-see.eu Aneta Karaivanova (Joint work with E. Atanassov and T. Gurov) Institute of Information and Communication Technologies Bulgarian
Monte Carlo Methods for Electron Transport: Scalability Study www.hp-see.eu Aneta Karaivanova (Joint work with E. Atanassov and T. Gurov) Institute of Information and Communication Technologies Bulgarian
Janus: FPGA Based System for Scientific Computing Filippo Mantovani
 Janus: FPGA Based System for Scientific Computing Filippo Mantovani Physics Department Università degli Studi di Ferrara Ferrara, 28/09/2009 Overview: 1. The physical problem: - Ising model and Spin Glass
Janus: FPGA Based System for Scientific Computing Filippo Mantovani Physics Department Università degli Studi di Ferrara Ferrara, 28/09/2009 Overview: 1. The physical problem: - Ising model and Spin Glass
Deutscher Wetterdienst
 Deutscher Wetterdienst The Enhanced DWD-RAPS Suite Testing Computers, Compilers and More? Ulrich Schättler, Florian Prill, Harald Anlauf Deutscher Wetterdienst Research and Development Deutscher Wetterdienst
Deutscher Wetterdienst The Enhanced DWD-RAPS Suite Testing Computers, Compilers and More? Ulrich Schättler, Florian Prill, Harald Anlauf Deutscher Wetterdienst Research and Development Deutscher Wetterdienst
Accelerating linear algebra computations with hybrid GPU-multicore systems.
 Accelerating linear algebra computations with hybrid GPU-multicore systems. Marc Baboulin INRIA/Université Paris-Sud joint work with Jack Dongarra (University of Tennessee and Oak Ridge National Laboratory)
Accelerating linear algebra computations with hybrid GPU-multicore systems. Marc Baboulin INRIA/Université Paris-Sud joint work with Jack Dongarra (University of Tennessee and Oak Ridge National Laboratory)
A Data Communication Reliability and Trustability Study for Cluster Computing
 A Data Communication Reliability and Trustability Study for Cluster Computing Speaker: Eduardo Colmenares Midwestern State University Wichita Falls, TX HPC Introduction Relevant to a variety of sciences,
A Data Communication Reliability and Trustability Study for Cluster Computing Speaker: Eduardo Colmenares Midwestern State University Wichita Falls, TX HPC Introduction Relevant to a variety of sciences,
Towards a highly-parallel PDE-Solver using Adaptive Sparse Grids on Compute Clusters
 Towards a highly-parallel PDE-Solver using Adaptive Sparse Grids on Compute Clusters HIM - Workshop on Sparse Grids and Applications Alexander Heinecke Chair of Scientific Computing May 18 th 2011 HIM
Towards a highly-parallel PDE-Solver using Adaptive Sparse Grids on Compute Clusters HIM - Workshop on Sparse Grids and Applications Alexander Heinecke Chair of Scientific Computing May 18 th 2011 HIM
Reliability at Scale
 Reliability at Scale Intelligent Storage Workshop 5 James Nunez Los Alamos National lab LA-UR-07-0828 & LA-UR-06-0397 May 15, 2007 A Word about scale Petaflop class machines LLNL Blue Gene 350 Tflops 128k
Reliability at Scale Intelligent Storage Workshop 5 James Nunez Los Alamos National lab LA-UR-07-0828 & LA-UR-06-0397 May 15, 2007 A Word about scale Petaflop class machines LLNL Blue Gene 350 Tflops 128k
Accelerating Linear Algebra on Heterogeneous Architectures of Multicore and GPUs using MAGMA and DPLASMA and StarPU Schedulers
 UT College of Engineering Tutorial Accelerating Linear Algebra on Heterogeneous Architectures of Multicore and GPUs using MAGMA and DPLASMA and StarPU Schedulers Stan Tomov 1, George Bosilca 1, and Cédric
UT College of Engineering Tutorial Accelerating Linear Algebra on Heterogeneous Architectures of Multicore and GPUs using MAGMA and DPLASMA and StarPU Schedulers Stan Tomov 1, George Bosilca 1, and Cédric
Some thoughts about energy efficient application execution on NEC LX Series compute clusters
 Some thoughts about energy efficient application execution on NEC LX Series compute clusters G. Wellein, G. Hager, J. Treibig, M. Wittmann Erlangen Regional Computing Center & Department of Computer Science
Some thoughts about energy efficient application execution on NEC LX Series compute clusters G. Wellein, G. Hager, J. Treibig, M. Wittmann Erlangen Regional Computing Center & Department of Computer Science
The QMC Petascale Project
 The QMC Petascale Project Richard G. Hennig What will a petascale computer look like? What are the limitations of current QMC algorithms for petascale computers? How can Quantum Monte Carlo algorithms
The QMC Petascale Project Richard G. Hennig What will a petascale computer look like? What are the limitations of current QMC algorithms for petascale computers? How can Quantum Monte Carlo algorithms
Improvement of MPAS on the Integration Speed and the Accuracy
 ICAS2017 Annecy, France Improvement of MPAS on the Integration Speed and the Accuracy Wonsu Kim, Ji-Sun Kang, Jae Youp Kim, and Minsu Joh Disaster Management HPC Technology Research Center, Korea Institute
ICAS2017 Annecy, France Improvement of MPAS on the Integration Speed and the Accuracy Wonsu Kim, Ji-Sun Kang, Jae Youp Kim, and Minsu Joh Disaster Management HPC Technology Research Center, Korea Institute
Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption. Langshi CHEN 1,2,3 Supervised by Serge PETITON 2
 1 / 23 Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption Langshi CHEN 1,2,3 Supervised by Serge PETITON 2 Maison de la Simulation Lille 1 University CNRS March 18, 2013
1 / 23 Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption Langshi CHEN 1,2,3 Supervised by Serge PETITON 2 Maison de la Simulation Lille 1 University CNRS March 18, 2013
Calculation of ground states of few-body nuclei using NVIDIA CUDA technology
 Calculation of ground states of few-body nuclei using NVIDIA CUDA technology M. A. Naumenko 1,a, V. V. Samarin 1, 1 Flerov Laboratory of Nuclear Reactions, Joint Institute for Nuclear Research, 6 Joliot-Curie
Calculation of ground states of few-body nuclei using NVIDIA CUDA technology M. A. Naumenko 1,a, V. V. Samarin 1, 1 Flerov Laboratory of Nuclear Reactions, Joint Institute for Nuclear Research, 6 Joliot-Curie
Extreme scale simulations of high-temperature superconductivity. Thomas C. Schulthess
 Extreme scale simulations of high-temperature superconductivity Thomas C. Schulthess T [K] Superconductivity: a state of matter with zero electrical resistivity Heike Kamerlingh Onnes (1853-1926) Discovery
Extreme scale simulations of high-temperature superconductivity Thomas C. Schulthess T [K] Superconductivity: a state of matter with zero electrical resistivity Heike Kamerlingh Onnes (1853-1926) Discovery
Weather Research and Forecasting (WRF) Performance Benchmark and Profiling. July 2012
 Performance Benchmark and Profiling. July 2012") Weather Research and Forecasting (WRF) Performance Benchmark and Profiling July 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell,
Weather Research and Forecasting (WRF) Performance Benchmark and Profiling July 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell,
Heterogeneous programming for hybrid CPU-GPU systems: Lessons learned from computational chemistry
 Heterogeneous programming for hybrid CPU-GPU systems: Lessons learned from computational chemistry and Eugene DePrince Argonne National Laboratory (LCF and CNM) (Eugene moved to Georgia Tech last week)
Heterogeneous programming for hybrid CPU-GPU systems: Lessons learned from computational chemistry and Eugene DePrince Argonne National Laboratory (LCF and CNM) (Eugene moved to Georgia Tech last week)
Multiphase Flow Simulations in Inclined Tubes with Lattice Boltzmann Method on GPU
 Multiphase Flow Simulations in Inclined Tubes with Lattice Boltzmann Method on GPU Khramtsov D.P., Nekrasov D.A., Pokusaev B.G. Department of Thermodynamics, Thermal Engineering and Energy Saving Technologies,
Multiphase Flow Simulations in Inclined Tubes with Lattice Boltzmann Method on GPU Khramtsov D.P., Nekrasov D.A., Pokusaev B.G. Department of Thermodynamics, Thermal Engineering and Energy Saving Technologies,
GPU-based computation of the Monte Carlo simulation of classical spin systems
 Perspectives of GPU Computing in Physics and Astrophysics, Sapienza University of Rome, Rome, Italy, September 15-17, 2014 GPU-based computation of the Monte Carlo simulation of classical spin systems
Perspectives of GPU Computing in Physics and Astrophysics, Sapienza University of Rome, Rome, Italy, September 15-17, 2014 GPU-based computation of the Monte Carlo simulation of classical spin systems
Parallel Sparse Tensor Decompositions using HiCOO Format
 Figure sources: A brief survey of tensors by Berton Earnshaw and NVIDIA Tensor Cores Parallel Sparse Tensor Decompositions using HiCOO Format Jiajia Li, Jee Choi, Richard Vuduc May 8, 8 @ SIAM ALA 8 Outline
Figure sources: A brief survey of tensors by Berton Earnshaw and NVIDIA Tensor Cores Parallel Sparse Tensor Decompositions using HiCOO Format Jiajia Li, Jee Choi, Richard Vuduc May 8, 8 @ SIAM ALA 8 Outline
Measuring freeze-out parameters on the Bielefeld GPU cluster
 Measuring freeze-out parameters on the Bielefeld GPU cluster Outline Fluctuations and the QCD phase diagram Fluctuations from Lattice QCD The Bielefeld hybrid GPU cluster Freeze-out conditions from QCD
Measuring freeze-out parameters on the Bielefeld GPU cluster Outline Fluctuations and the QCD phase diagram Fluctuations from Lattice QCD The Bielefeld hybrid GPU cluster Freeze-out conditions from QCD
Accelerating Model Reduction of Large Linear Systems with Graphics Processors
 Accelerating Model Reduction of Large Linear Systems with Graphics Processors P. Benner 1, P. Ezzatti 2, D. Kressner 3, E.S. Quintana-Ortí 4, Alfredo Remón 4 1 Max-Plank-Institute for Dynamics of Complex
Accelerating Model Reduction of Large Linear Systems with Graphics Processors P. Benner 1, P. Ezzatti 2, D. Kressner 3, E.S. Quintana-Ortí 4, Alfredo Remón 4 1 Max-Plank-Institute for Dynamics of Complex
Performance of WRF using UPC
 Performance of WRF using UPC Hee-Sik Kim and Jong-Gwan Do * Cray Korea ABSTRACT: The Weather Research and Forecasting (WRF) model is a next-generation mesoscale numerical weather prediction system. We
Performance of WRF using UPC Hee-Sik Kim and Jong-Gwan Do * Cray Korea ABSTRACT: The Weather Research and Forecasting (WRF) model is a next-generation mesoscale numerical weather prediction system. We
SPARSE SOLVERS POISSON EQUATION. Margreet Nool. November 9, 2015 FOR THE. CWI, Multiscale Dynamics
 SPARSE SOLVERS FOR THE POISSON EQUATION Margreet Nool CWI, Multiscale Dynamics November 9, 2015 OUTLINE OF THIS TALK 1 FISHPACK, LAPACK, PARDISO 2 SYSTEM OVERVIEW OF CARTESIUS 3 POISSON EQUATION 4 SOLVERS
SPARSE SOLVERS FOR THE POISSON EQUATION Margreet Nool CWI, Multiscale Dynamics November 9, 2015 OUTLINE OF THIS TALK 1 FISHPACK, LAPACK, PARDISO 2 SYSTEM OVERVIEW OF CARTESIUS 3 POISSON EQUATION 4 SOLVERS
Multi-GPU Simulations of the Infinite Universe
 () Multi-GPU of the Infinite with with G. Rácz, I. Szapudi & L. Dobos Physics of Complex Systems Department Eötvös Loránd University, Budapest June 22, 2018, Budapest, Hungary Outline 1 () 2 () Concordance
() Multi-GPU of the Infinite with with G. Rácz, I. Szapudi & L. Dobos Physics of Complex Systems Department Eötvös Loránd University, Budapest June 22, 2018, Budapest, Hungary Outline 1 () 2 () Concordance
Accelerating Quantum Chromodynamics Calculations with GPUs
 Accelerating Quantum Chromodynamics Calculations with GPUs Guochun Shi, Steven Gottlieb, Aaron Torok, Volodymyr Kindratenko NCSA & Indiana University National Center for Supercomputing Applications University
Accelerating Quantum Chromodynamics Calculations with GPUs Guochun Shi, Steven Gottlieb, Aaron Torok, Volodymyr Kindratenko NCSA & Indiana University National Center for Supercomputing Applications University
Piz Daint & Piz Kesch : from general purpose supercomputing to an appliance for weather forecasting. Thomas C. Schulthess
 Piz Daint & Piz Kesch : from general purpose supercomputing to an appliance for weather forecasting Thomas C. Schulthess 1 Cray XC30 with 5272 hybrid, GPU accelerated compute nodes Piz Daint Compute node:
Piz Daint & Piz Kesch : from general purpose supercomputing to an appliance for weather forecasting Thomas C. Schulthess 1 Cray XC30 with 5272 hybrid, GPU accelerated compute nodes Piz Daint Compute node:
Performance Evaluation of Scientific Applications on POWER8
 Performance Evaluation of Scientific Applications on POWER8 2014 Nov 16 Andrew V. Adinetz 1, Paul F. Baumeister 1, Hans Böttiger 3, Thorsten Hater 1, Thilo Maurer 3, Dirk Pleiter 1, Wolfram Schenck 4,
Performance Evaluation of Scientific Applications on POWER8 2014 Nov 16 Andrew V. Adinetz 1, Paul F. Baumeister 1, Hans Böttiger 3, Thorsten Hater 1, Thilo Maurer 3, Dirk Pleiter 1, Wolfram Schenck 4,
Multicore Parallelization of Determinant Quantum Monte Carlo Simulations
 Multicore Parallelization of Determinant Quantum Monte Carlo Simulations Andrés Tomás, Che-Rung Lee, Zhaojun Bai, Richard Scalettar UC Davis SIAM Conference on Computation Science & Engineering Reno, March
Multicore Parallelization of Determinant Quantum Monte Carlo Simulations Andrés Tomás, Che-Rung Lee, Zhaojun Bai, Richard Scalettar UC Davis SIAM Conference on Computation Science & Engineering Reno, March
Dark Energy and Massive Neutrino Universe Covariances
 Dark Energy and Massive Neutrino Universe Covariances (DEMNUniCov) Carmelita Carbone Physics Dept, Milan University & INAF-Brera Collaborators: M. Calabrese, M. Zennaro, G. Fabbian, J. Bel November 30
Dark Energy and Massive Neutrino Universe Covariances (DEMNUniCov) Carmelita Carbone Physics Dept, Milan University & INAF-Brera Collaborators: M. Calabrese, M. Zennaro, G. Fabbian, J. Bel November 30
Klaus Schulten Department of Physics and Theoretical and Computational Biophysics Group University of Illinois at Urbana-Champaign
 Klaus Schulten Department of Physics and Theoretical and Computational Biophysics Group University of Illinois at Urbana-Champaign GTC, San Jose Convention Center, CA Sept. 20 23, 2010 GPU and the Computational
Klaus Schulten Department of Physics and Theoretical and Computational Biophysics Group University of Illinois at Urbana-Champaign GTC, San Jose Convention Center, CA Sept. 20 23, 2010 GPU and the Computational
Cyclops Tensor Framework
 Cyclops Tensor Framework Edgar Solomonik Department of EECS, Computer Science Division, UC Berkeley March 17, 2014 1 / 29 Edgar Solomonik Cyclops Tensor Framework 1/ 29 Definition of a tensor A rank r
Cyclops Tensor Framework Edgar Solomonik Department of EECS, Computer Science Division, UC Berkeley March 17, 2014 1 / 29 Edgar Solomonik Cyclops Tensor Framework 1/ 29 Definition of a tensor A rank r
An Implementation of SPELT(31, 4, 96, 96, (32, 16, 8))
)") An Implementation of SPELT(31, 4, 96, 96, (32, 16, 8)) Tung Chou January 5, 2012 QUAD Stream cipher. Security relies on MQ (Multivariate Quadratics). QUAD The Provably-secure QUAD(q, n, r) Stream Cipher
An Implementation of SPELT(31, 4, 96, 96, (32, 16, 8)) Tung Chou January 5, 2012 QUAD Stream cipher. Security relies on MQ (Multivariate Quadratics). QUAD The Provably-secure QUAD(q, n, r) Stream Cipher
COMPARISON OF CPU AND GPU IMPLEMENTATIONS OF THE LATTICE BOLTZMANN METHOD
 XVIII International Conference on Water Resources CMWR 2010 J. Carrera (Ed) c CIMNE, Barcelona, 2010 COMPARISON OF CPU AND GPU IMPLEMENTATIONS OF THE LATTICE BOLTZMANN METHOD James.E. McClure, Jan F. Prins
XVIII International Conference on Water Resources CMWR 2010 J. Carrera (Ed) c CIMNE, Barcelona, 2010 COMPARISON OF CPU AND GPU IMPLEMENTATIONS OF THE LATTICE BOLTZMANN METHOD James.E. McClure, Jan F. Prins
Universität Dortmund UCHPC. Performance. Computing for Finite Element Simulations
 technische universität dortmund Universität Dortmund fakultät für mathematik LS III (IAM) UCHPC UnConventional High Performance Computing for Finite Element Simulations S. Turek, Chr. Becker, S. Buijssen,
technische universität dortmund Universität Dortmund fakultät für mathematik LS III (IAM) UCHPC UnConventional High Performance Computing for Finite Element Simulations S. Turek, Chr. Becker, S. Buijssen,
TR A Comparison of the Performance of SaP::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems
 for Solving Dense Banded Linear Systems") TR-0-07 A Comparison of the Performance of ::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems Ang Li, Omkar Deshmukh, Radu Serban, Dan Negrut May, 0 Abstract ::GPU is a
TR-0-07 A Comparison of the Performance of ::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems Ang Li, Omkar Deshmukh, Radu Serban, Dan Negrut May, 0 Abstract ::GPU is a
Review for the Midterm Exam
 Review for the Midterm Exam 1 Three Questions of the Computational Science Prelim scaled speedup network topologies work stealing 2 The in-class Spring 2012 Midterm Exam pleasingly parallel computations
Review for the Midterm Exam 1 Three Questions of the Computational Science Prelim scaled speedup network topologies work stealing 2 The in-class Spring 2012 Midterm Exam pleasingly parallel computations
Acceleration of WRF on the GPU
 Acceleration of WRF on the GPU Daniel Abdi, Sam Elliott, Iman Gohari Don Berchoff, Gene Pache, John Manobianco TempoQuest 1434 Spruce Street Boulder, CO 80302 720 726 9032 TempoQuest.com THE WORLD S FASTEST
Acceleration of WRF on the GPU Daniel Abdi, Sam Elliott, Iman Gohari Don Berchoff, Gene Pache, John Manobianco TempoQuest 1434 Spruce Street Boulder, CO 80302 720 726 9032 TempoQuest.com THE WORLD S FASTEST
Perm State University Research-Education Center Parallel and Distributed Computing
 Perm State University Research-Education Center Parallel and Distributed Computing A 25-minute Talk (S4493) at the GPU Technology Conference (GTC) 2014 MARCH 24-27, 2014 SAN JOSE, CA GPU-accelerated modeling
Perm State University Research-Education Center Parallel and Distributed Computing A 25-minute Talk (S4493) at the GPU Technology Conference (GTC) 2014 MARCH 24-27, 2014 SAN JOSE, CA GPU-accelerated modeling
Petascale Quantum Simulations of Nano Systems and Biomolecules
 Petascale Quantum Simulations of Nano Systems and Biomolecules Emil Briggs North Carolina State University 1. Outline of real-space Multigrid (RMG) 2. Scalability and hybrid/threaded models 3. GPU acceleration
Petascale Quantum Simulations of Nano Systems and Biomolecules Emil Briggs North Carolina State University 1. Outline of real-space Multigrid (RMG) 2. Scalability and hybrid/threaded models 3. GPU acceleration
The Blue Gene/P at Jülich Case Study & Optimization. W.Frings, Forschungszentrum Jülich,
 The Blue Gene/P at Jülich Case Study & Optimization W.Frings, Forschungszentrum Jülich, 26.08.2008 Jugene Case-Studies: Overview Case Study: PEPC Case Study: racoon Case Study: QCD CPU0CPU3 CPU1CPU2 2
The Blue Gene/P at Jülich Case Study & Optimization W.Frings, Forschungszentrum Jülich, 26.08.2008 Jugene Case-Studies: Overview Case Study: PEPC Case Study: racoon Case Study: QCD CPU0CPU3 CPU1CPU2 2
The Memory Intensive System
 DiRAC@Durham The Memory Intensive System The DiRAC-2.5x Memory Intensive system at Durham in partnership with Dell Dr Lydia Heck, Technical Director ICC HPC and DiRAC Technical Manager 1 DiRAC Who we are:
DiRAC@Durham The Memory Intensive System The DiRAC-2.5x Memory Intensive system at Durham in partnership with Dell Dr Lydia Heck, Technical Director ICC HPC and DiRAC Technical Manager 1 DiRAC Who we are:
Improving the solar cells efficiency of metal Sulfide thin-film nanostructure via first principle calculations
 Improving the solar cells efficiency of metal Sulfide thin-film nanostructure via first principle calculations Alwaleed Adllan Abusin, PhD Elzina Bala Africa City of Technology Agenda INTRODUCTION TO HIGH-PERFORMANCE
Improving the solar cells efficiency of metal Sulfide thin-film nanostructure via first principle calculations Alwaleed Adllan Abusin, PhD Elzina Bala Africa City of Technology Agenda INTRODUCTION TO HIGH-PERFORMANCE
CRYPTOGRAPHIC COMPUTING
 CRYPTOGRAPHIC COMPUTING ON GPU Chen Mou Cheng Dept. Electrical Engineering g National Taiwan University January 16, 2009 COLLABORATORS Daniel Bernstein, UIC, USA Tien Ren Chen, Army Tanja Lange, TU Eindhoven,
CRYPTOGRAPHIC COMPUTING ON GPU Chen Mou Cheng Dept. Electrical Engineering g National Taiwan University January 16, 2009 COLLABORATORS Daniel Bernstein, UIC, USA Tien Ren Chen, Army Tanja Lange, TU Eindhoven,
HYCOM and Navy ESPC Future High Performance Computing Needs. Alan J. Wallcraft. COAPS Short Seminar November 6, 2017
 HYCOM and Navy ESPC Future High Performance Computing Needs Alan J. Wallcraft COAPS Short Seminar November 6, 2017 Forecasting Architectural Trends 3 NAVY OPERATIONAL GLOBAL OCEAN PREDICTION Trend is higher
HYCOM and Navy ESPC Future High Performance Computing Needs Alan J. Wallcraft COAPS Short Seminar November 6, 2017 Forecasting Architectural Trends 3 NAVY OPERATIONAL GLOBAL OCEAN PREDICTION Trend is higher
Reflecting on the Goal and Baseline of Exascale Computing
 Reflecting on the Goal and Baseline of Exascale Computing Thomas C. Schulthess!1 Tracking supercomputer performance over time? Linpack benchmark solves: Ax = b!2 Tracking supercomputer performance over
Reflecting on the Goal and Baseline of Exascale Computing Thomas C. Schulthess!1 Tracking supercomputer performance over time? Linpack benchmark solves: Ax = b!2 Tracking supercomputer performance over
Distributed Processing of the Lattice in Monte Carlo Simulations of the Ising Type Spin Model
 CMST 21(3) 117-121 (2015) DOI:10.12921/cmst.2015.21.03.002 Distributed Processing of the Lattice in Monte Carlo Simulations of the Ising Type Spin Model Szymon Murawski *, Grzegorz Musiał, Grzegorz Pawłowski
CMST 21(3) 117-121 (2015) DOI:10.12921/cmst.2015.21.03.002 Distributed Processing of the Lattice in Monte Carlo Simulations of the Ising Type Spin Model Szymon Murawski *, Grzegorz Musiał, Grzegorz Pawłowski
Solving RODEs on GPU clusters
 HIGH TEA @ SCIENCE Solving RODEs on GPU clusters Christoph Riesinger Technische Universität München March 4, 206 HIGH TEA @ SCIENCE, March 4, 206 Motivation - Parallel Computing HIGH TEA @ SCIENCE, March
HIGH TEA @ SCIENCE Solving RODEs on GPU clusters Christoph Riesinger Technische Universität München March 4, 206 HIGH TEA @ SCIENCE, March 4, 206 Motivation - Parallel Computing HIGH TEA @ SCIENCE, March
ACCELERATING WEATHER PREDICTION WITH NVIDIA GPUS
 ACCELERATING WEATHER PREDICTION WITH NVIDIA GPUS Alan Gray, Developer Technology Engineer, NVIDIA ECMWF 18th Workshop on high performance computing in meteorology, 28 th September 2018 ESCAPE NVIDIA s
ACCELERATING WEATHER PREDICTION WITH NVIDIA GPUS Alan Gray, Developer Technology Engineer, NVIDIA ECMWF 18th Workshop on high performance computing in meteorology, 28 th September 2018 ESCAPE NVIDIA s
APPLICATION OF CUDA TECHNOLOGY FOR CALCULATION OF GROUND STATES OF FEW-BODY NUCLEI BY FEYNMAN'S CONTINUAL INTEGRALS METHOD
 APPLICATION OF CUDA TECHNOLOGY FOR CALCULATION OF GROUND STATES OF FEW-BODY NUCLEI BY FEYNMAN'S CONTINUAL INTEGRALS METHOD M.A. Naumenko, V.V. Samarin Joint Institute for Nuclear Research, Dubna, Russia
APPLICATION OF CUDA TECHNOLOGY FOR CALCULATION OF GROUND STATES OF FEW-BODY NUCLEI BY FEYNMAN'S CONTINUAL INTEGRALS METHOD M.A. Naumenko, V.V. Samarin Joint Institute for Nuclear Research, Dubna, Russia
Verbundprojekt ELPA-AEO. Eigenwert-Löser für Petaflop-Anwendungen Algorithmische Erweiterungen und Optimierungen
 Verbundprojekt ELPA-AEO http://elpa-aeo.mpcdf.mpg.de Eigenwert-Löser für Petaflop-Anwendungen Algorithmische Erweiterungen und Optimierungen BMBF Projekt 01IH15001 Feb 2016 - Jan 2019 7. HPC-Statustagung,
Verbundprojekt ELPA-AEO http://elpa-aeo.mpcdf.mpg.de Eigenwert-Löser für Petaflop-Anwendungen Algorithmische Erweiterungen und Optimierungen BMBF Projekt 01IH15001 Feb 2016 - Jan 2019 7. HPC-Statustagung,
Quantum computing with superconducting qubits Towards useful applications
 Quantum computing with superconducting qubits Towards useful applications Stefan Filipp IBM Research Zurich Switzerland Forum Teratec 2018 June 20, 2018 Palaiseau, France Why Quantum Computing? Why now?
Quantum computing with superconducting qubits Towards useful applications Stefan Filipp IBM Research Zurich Switzerland Forum Teratec 2018 June 20, 2018 Palaiseau, France Why Quantum Computing? Why now?
Performance Analysis of Lattice QCD Application with APGAS Programming Model
 Performance Analysis of Lattice QCD Application with APGAS Programming Model Koichi Shirahata 1, Jun Doi 2, Mikio Takeuchi 2 1: Tokyo Institute of Technology 2: IBM Research - Tokyo Programming Models
Performance Analysis of Lattice QCD Application with APGAS Programming Model Koichi Shirahata 1, Jun Doi 2, Mikio Takeuchi 2 1: Tokyo Institute of Technology 2: IBM Research - Tokyo Programming Models
Performance and Application of Observation Sensitivity to Global Forecasts on the KMA Cray XE6
 Performance and Application of Observation Sensitivity to Global Forecasts on the KMA Cray XE6 Sangwon Joo, Yoonjae Kim, Hyuncheol Shin, Eunhee Lee, Eunjung Kim (Korea Meteorological Administration) Tae-Hun
Performance and Application of Observation Sensitivity to Global Forecasts on the KMA Cray XE6 Sangwon Joo, Yoonjae Kim, Hyuncheol Shin, Eunhee Lee, Eunjung Kim (Korea Meteorological Administration) Tae-Hun
A Framework for Hybrid Parallel Flow Simulations with a Trillion Cells in Complex Geometries
 A Framework for Hybrid Parallel Flow Simulations with a Trillion Cells in Complex Geometries SC13, November 21 st 2013 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler, Ulrich
A Framework for Hybrid Parallel Flow Simulations with a Trillion Cells in Complex Geometries SC13, November 21 st 2013 Christian Godenschwager, Florian Schornbaum, Martin Bauer, Harald Köstler, Ulrich
Listening for thunder beyond the clouds
 Listening for thunder beyond the clouds Using the grid to analyse gravitational wave data Ra Inta The Australian National University Overview 1. Gravitational wave (GW) observatories 2. Analysis of continuous
Listening for thunder beyond the clouds Using the grid to analyse gravitational wave data Ra Inta The Australian National University Overview 1. Gravitational wave (GW) observatories 2. Analysis of continuous
Investigation of an Unusual Phase Transition Freezing on heating of liquid solution
 Investigation of an Unusual Phase Transition Freezing on heating of liquid solution Calin Gabriel Floare National Institute for R&D of Isotopic and Molecular Technologies, Cluj-Napoca, Romania Max von
Investigation of an Unusual Phase Transition Freezing on heating of liquid solution Calin Gabriel Floare National Institute for R&D of Isotopic and Molecular Technologies, Cluj-Napoca, Romania Max von
High-Performance Scientific Computing
 High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org
High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org
Targeting Extreme Scale Computational Challenges with Heterogeneous Systems
 Targeting Extreme Scale Computational Challenges with Heterogeneous Systems Oreste Villa, Antonino Tumeo Pacific Northwest Na/onal Laboratory (PNNL) 1 Introduction! PNNL Laboratory Directed Research &
Targeting Extreme Scale Computational Challenges with Heterogeneous Systems Oreste Villa, Antonino Tumeo Pacific Northwest Na/onal Laboratory (PNNL) 1 Introduction! PNNL Laboratory Directed Research &
Scalable and Power-Efficient Data Mining Kernels
 Scalable and Power-Efficient Data Mining Kernels Alok Choudhary, John G. Searle Professor Dept. of Electrical Engineering and Computer Science and Professor, Kellogg School of Management Director of the
Scalable and Power-Efficient Data Mining Kernels Alok Choudhary, John G. Searle Professor Dept. of Electrical Engineering and Computer Science and Professor, Kellogg School of Management Director of the
Using a CUDA-Accelerated PGAS Model on a GPU Cluster for Bioinformatics
 Using a CUDA-Accelerated PGAS Model on a GPU Cluster for Bioinformatics Jorge González-Domínguez Parallel and Distributed Architectures Group Johannes Gutenberg University of Mainz, Germany j.gonzalez@uni-mainz.de
Using a CUDA-Accelerated PGAS Model on a GPU Cluster for Bioinformatics Jorge González-Domínguez Parallel and Distributed Architectures Group Johannes Gutenberg University of Mainz, Germany j.gonzalez@uni-mainz.de
Performance of the fusion code GYRO on three four generations of Crays. Mark Fahey University of Tennessee, Knoxville
 Performance of the fusion code GYRO on three four generations of Crays Mark Fahey mfahey@utk.edu University of Tennessee, Knoxville Contents Introduction GYRO Overview Benchmark Problem Test Platforms
Performance of the fusion code GYRO on three four generations of Crays Mark Fahey mfahey@utk.edu University of Tennessee, Knoxville Contents Introduction GYRO Overview Benchmark Problem Test Platforms
Parallel Simulations of Self-propelled Microorganisms
 Parallel Simulations of Self-propelled Microorganisms K. Pickl a,b M. Hofmann c T. Preclik a H. Köstler a A.-S. Smith b,d U. Rüde a,b ParCo 2013, Munich a Lehrstuhl für Informatik 10 (Systemsimulation),
Parallel Simulations of Self-propelled Microorganisms K. Pickl a,b M. Hofmann c T. Preclik a H. Köstler a A.-S. Smith b,d U. Rüde a,b ParCo 2013, Munich a Lehrstuhl für Informatik 10 (Systemsimulation),
CRYSTAL in parallel: replicated and distributed (MPP) data. Why parallel?
 data. Why parallel?") CRYSTAL in parallel: replicated and distributed (MPP) data Roberto Orlando Dipartimento di Chimica Università di Torino Via Pietro Giuria 5, 10125 Torino (Italy) roberto.orlando@unito.it 1 Why parallel?
CRYSTAL in parallel: replicated and distributed (MPP) data Roberto Orlando Dipartimento di Chimica Università di Torino Via Pietro Giuria 5, 10125 Torino (Italy) roberto.orlando@unito.it 1 Why parallel?
Utility Maximizing Routing to Data Centers
 0-0 Utility Maximizing Routing to Data Centers M. Sarwat, J. Shin and S. Kapoor (Presented by J. Shin) Sep 26, 2011 Sep 26, 2011 1 Outline 1. Problem Definition - Data Center Allocation 2. How to construct
0-0 Utility Maximizing Routing to Data Centers M. Sarwat, J. Shin and S. Kapoor (Presented by J. Shin) Sep 26, 2011 Sep 26, 2011 1 Outline 1. Problem Definition - Data Center Allocation 2. How to construct
SP-CNN: A Scalable and Programmable CNN-based Accelerator. Dilan Manatunga Dr. Hyesoon Kim Dr. Saibal Mukhopadhyay
 SP-CNN: A Scalable and Programmable CNN-based Accelerator Dilan Manatunga Dr. Hyesoon Kim Dr. Saibal Mukhopadhyay Motivation Power is a first-order design constraint, especially for embedded devices. Certain
SP-CNN: A Scalable and Programmable CNN-based Accelerator Dilan Manatunga Dr. Hyesoon Kim Dr. Saibal Mukhopadhyay Motivation Power is a first-order design constraint, especially for embedded devices. Certain
Jacobi-Based Eigenvalue Solver on GPU. Lung-Sheng Chien, NVIDIA
 Jacobi-Based Eigenvalue Solver on GPU Lung-Sheng Chien, NVIDIA lchien@nvidia.com Outline Symmetric eigenvalue solver Experiment Applications Conclusions Symmetric eigenvalue solver The standard form is
Jacobi-Based Eigenvalue Solver on GPU Lung-Sheng Chien, NVIDIA lchien@nvidia.com Outline Symmetric eigenvalue solver Experiment Applications Conclusions Symmetric eigenvalue solver The standard form is
Data analysis of massive data sets a Planck example
 Data analysis of massive data sets a Planck example Radek Stompor (APC) LOFAR workshop, Meudon, 29/03/06 Outline 1. Planck mission; 2. Planck data set; 3. Planck data analysis plan and challenges; 4. Planck
Data analysis of massive data sets a Planck example Radek Stompor (APC) LOFAR workshop, Meudon, 29/03/06 Outline 1. Planck mission; 2. Planck data set; 3. Planck data analysis plan and challenges; 4. Planck
Nuclear Physics and Computing: Exascale Partnerships. Juan Meza Senior Scientist Lawrence Berkeley National Laboratory
 Nuclear Physics and Computing: Exascale Partnerships Juan Meza Senior Scientist Lawrence Berkeley National Laboratory Nuclear Science and Exascale i Workshop held in DC to identify scientific challenges
Nuclear Physics and Computing: Exascale Partnerships Juan Meza Senior Scientist Lawrence Berkeley National Laboratory Nuclear Science and Exascale i Workshop held in DC to identify scientific challenges
CMOS Ising Computer to Help Optimize Social Infrastructure Systems
 FEATURED ARTICLES Taking on Future Social Issues through Open Innovation Information Science for Greater Industrial Efficiency CMOS Ising Computer to Help Optimize Social Infrastructure Systems As the
FEATURED ARTICLES Taking on Future Social Issues through Open Innovation Information Science for Greater Industrial Efficiency CMOS Ising Computer to Help Optimize Social Infrastructure Systems As the
N-body Simulations. On GPU Clusters
 N-body Simulations On GPU Clusters Laxmikant Kale Filippo Gioachin Pritish Jetley Thomas Quinn Celso Mendes Graeme Lufkin Amit Sharma Joachim Stadel Lukasz Wesolowski James Wadsley Edgar Solomonik Fabio
N-body Simulations On GPU Clusters Laxmikant Kale Filippo Gioachin Pritish Jetley Thomas Quinn Celso Mendes Graeme Lufkin Amit Sharma Joachim Stadel Lukasz Wesolowski James Wadsley Edgar Solomonik Fabio
Case Study: Quantum Chromodynamics
 Case Study: Quantum Chromodynamics Michael Clark Harvard University with R. Babich, K. Barros, R. Brower, J. Chen and C. Rebbi Outline Primer to QCD QCD on a GPU Mixed Precision Solvers Multigrid solver
Case Study: Quantum Chromodynamics Michael Clark Harvard University with R. Babich, K. Barros, R. Brower, J. Chen and C. Rebbi Outline Primer to QCD QCD on a GPU Mixed Precision Solvers Multigrid solver
Benchmark of the CPMD code on CRESCO HPC Facilities for Numerical Simulation of a Magnesium Nanoparticle.
 Benchmark of the CPMD code on CRESCO HPC Facilities for Numerical Simulation of a Magnesium Nanoparticle. Simone Giusepponi a), Massimo Celino b), Salvatore Podda a), Giovanni Bracco a), Silvio Migliori
Benchmark of the CPMD code on CRESCO HPC Facilities for Numerical Simulation of a Magnesium Nanoparticle. Simone Giusepponi a), Massimo Celino b), Salvatore Podda a), Giovanni Bracco a), Silvio Migliori
GPU acceleration of Newton s method for large systems of polynomial equations in double double and quad double arithmetic
 GPU acceleration of Newton s method for large systems of polynomial equations in double double and quad double arithmetic Jan Verschelde joint work with Xiangcheng Yu University of Illinois at Chicago
GPU acceleration of Newton s method for large systems of polynomial equations in double double and quad double arithmetic Jan Verschelde joint work with Xiangcheng Yu University of Illinois at Chicago
ab initio Electronic Structure Calculations
 ab initio Electronic Structure Calculations New scalability frontiers using the BG/L Supercomputer C. Bekas, A. Curioni and W. Andreoni IBM, Zurich Research Laboratory Rueschlikon 8803, Switzerland ab
ab initio Electronic Structure Calculations New scalability frontiers using the BG/L Supercomputer C. Bekas, A. Curioni and W. Andreoni IBM, Zurich Research Laboratory Rueschlikon 8803, Switzerland ab