Introduction to numerical computations on the GPU
|
|
|
- Kerrie Johns
- 5 years ago
- Views:
Transcription

1 Introduction to numerical computations on the GPU Lucian Covaci Tuesday 1 November 11 1
2 2 Outline: NVIDIA Tesla and Geforce video cards: architecture CUDA - C: programming framework (thread hierarchy and memory access) 2 very simple examples my work (kernel polynomial method): Thrust and Cusp libraries



3 Cuda enabled Nvidia GeForce and Tesla Tuesday 1 November 11 3

4 4

5 fastest supercomputer to date: Tianhe-1A (China) 14,336 Xeon X5670 processors and 7,168 Nvidia Tesla M2050 speed: theoretical peak performance of petaflops (4.7 million GFlops) Tuesday 1 November 11 5

6 6
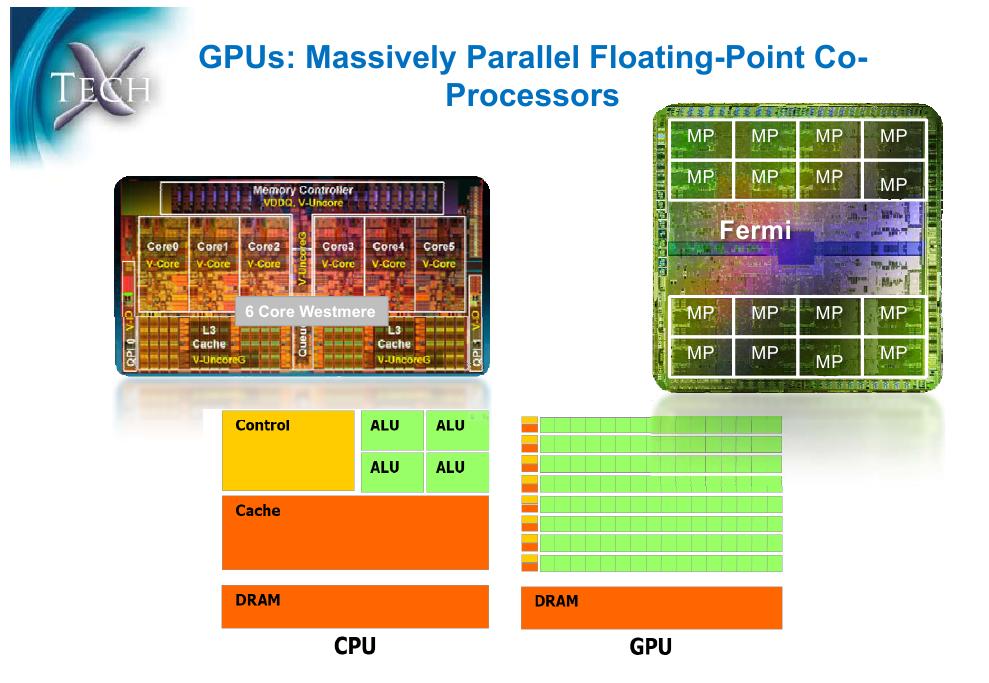
7 7

8 8

9 9

10 10

11 11

12 12

13 13

14 14

15 15

16 16 Cuda specifications (wikipedia)

17 17

18 18

19 19

20 20

21 21

22 22
23 23
24 24

25 25
26 26
27 27
28 28

29 29
30 30

31 31

32 32
33 33
34 34

35 35 Scientific computing on GPUs: GPGPU applications showcase on nvidia.com
36 36 Physics applications theoretical speedup vs. real speedup: parallelizable problem? single versus double precision computation best suited so far: visualization and imaging fluid dynamics (lattice Boltzmann simulations) molecular dynamics Monte Carlo simulations of spin systems wave packet dynamics in quantum mechanics (Chebyshev expansions) mean-field solutions of many body problems (KPM) many more to come... programming languages: C/C++, Fortran (PGI), Python, Matlab, Perl, Java, Mathematica
37 37 Let f :[ 1 : 1]!R; Set of orthogonal functions: h n mi = Z 1 1 Chebyshev polynomial expansion integrable function n = T n(x) p 1 x 2 p 1 x 2 n(x) m (x)dx h n mi = 1+ n0 2 n,m Chebyshev polynomials: T n (x) =cos[narccos(x)] T 0 (x) =1 T 1 (x) =x T n+1 =2xT n (x) T n 1 P Z 1 1 U n (x) =sin[(n + 1) arccos(x)]/ sin[narccos(x)] U 0 (x) =1 U 1 (x) =0 U n+1 =2xU n (x) U n 1 T n (y) (y x) p 1 y 2 dy = U n 1(x) Then any integrable function f(x), can be expressed as: f(x) = 1 p 1 x 2 [µ X µ n T n (x)]; µ n = n=1 Z 1 1 f(x)t n (x) dx
38 38 Expansion of the Green s function: G ij (!) = i p 1! 2 " µ 0 +2 # 1X µ n e in arccos(!) n=1 µ n = hi T n (H) ji where ji = c j" 0i for regular GF ji = c j# 0i for anomalous GF hi = h0 c i" define: j n i = T n (H) ji j 0 i = ji j 1 i = H ji j n+1 i = 2H j n i j n 1 i for each iteration step: µ n = hi j n i sparse matrix-vector multiplication choose i> and j> to obtain different components of the Green s function A. Weisse et al., Rev. Mod. Phys. 78, 275 (2006) L. Covaci, F. Peeters and M. Berciu, Phys. Rev. Lett. 105, (2010)
39 39 use Thrust and Cusp libraries to perform sparse matrix-vector multiplications and vector dot products on three Geforce GTX 580

40 40 Thrust CUDA library with interface resembling C++ Standard template library (e.g. define vector and map containers, use algorithms)

41 41 Cusp CUDA library for sparse linear algebra. It provides a high-level interface for manipulating sparse matrices and solving sparse linear systems. Cusp is based on Thrust.
42 42 Summary GPU hardware is optimized to run massively parallel grid of threads all performing the same computation (SIMD) not all algorithms can be speedup on the GPU basic ingredients for a fast code: ability to start a large number of threads on independent components of an array (linear algebra, molecular dynamics, grid partitioning for Monte Carlo on spin systems) minimize memory transfer between CPU and GPU
43 References nvidia.com for information on CUDA Cuda by Example, J. Sanders and E. Kandrot Online lecture notes from Harvard 2011 course information and examples on Thrust information and examples on Cusp Tuesday 1 November 11 43
Population annealing study of the frustrated Ising antiferromagnet on the stacked triangular lattice
 Population annealing study of the frustrated Ising antiferromagnet on the stacked triangular lattice Michal Borovský Department of Theoretical Physics and Astrophysics, University of P. J. Šafárik in Košice,
Population annealing study of the frustrated Ising antiferromagnet on the stacked triangular lattice Michal Borovský Department of Theoretical Physics and Astrophysics, University of P. J. Šafárik in Košice,
TR A Comparison of the Performance of SaP::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems
 for Solving Dense Banded Linear Systems") TR-0-07 A Comparison of the Performance of ::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems Ang Li, Omkar Deshmukh, Radu Serban, Dan Negrut May, 0 Abstract ::GPU is a
TR-0-07 A Comparison of the Performance of ::GPU and Intel s Math Kernel Library (MKL) for Solving Dense Banded Linear Systems Ang Li, Omkar Deshmukh, Radu Serban, Dan Negrut May, 0 Abstract ::GPU is a
arxiv: v1 [hep-lat] 7 Oct 2010
![arxiv: v1 [hep-lat] 7 Oct 2010](/thumbs/79/80346009.jpg "arxiv: v1 [hep-lat] 7 Oct 2010") arxiv:.486v [hep-lat] 7 Oct 2 Nuno Cardoso CFTP, Instituto Superior Técnico E-mail: nunocardoso@cftp.ist.utl.pt Pedro Bicudo CFTP, Instituto Superior Técnico E-mail: bicudo@ist.utl.pt We discuss the CUDA
arxiv:.486v [hep-lat] 7 Oct 2 Nuno Cardoso CFTP, Instituto Superior Técnico E-mail: nunocardoso@cftp.ist.utl.pt Pedro Bicudo CFTP, Instituto Superior Técnico E-mail: bicudo@ist.utl.pt We discuss the CUDA
Calculation of ground states of few-body nuclei using NVIDIA CUDA technology
 Calculation of ground states of few-body nuclei using NVIDIA CUDA technology M. A. Naumenko 1,a, V. V. Samarin 1, 1 Flerov Laboratory of Nuclear Reactions, Joint Institute for Nuclear Research, 6 Joliot-Curie
Calculation of ground states of few-body nuclei using NVIDIA CUDA technology M. A. Naumenko 1,a, V. V. Samarin 1, 1 Flerov Laboratory of Nuclear Reactions, Joint Institute for Nuclear Research, 6 Joliot-Curie
Accelerating linear algebra computations with hybrid GPU-multicore systems.
 Accelerating linear algebra computations with hybrid GPU-multicore systems. Marc Baboulin INRIA/Université Paris-Sud joint work with Jack Dongarra (University of Tennessee and Oak Ridge National Laboratory)
Accelerating linear algebra computations with hybrid GPU-multicore systems. Marc Baboulin INRIA/Université Paris-Sud joint work with Jack Dongarra (University of Tennessee and Oak Ridge National Laboratory)
Dense Arithmetic over Finite Fields with CUMODP
 Dense Arithmetic over Finite Fields with CUMODP Sardar Anisul Haque 1 Xin Li 2 Farnam Mansouri 1 Marc Moreno Maza 1 Wei Pan 3 Ning Xie 1 1 University of Western Ontario, Canada 2 Universidad Carlos III,
Dense Arithmetic over Finite Fields with CUMODP Sardar Anisul Haque 1 Xin Li 2 Farnam Mansouri 1 Marc Moreno Maza 1 Wei Pan 3 Ning Xie 1 1 University of Western Ontario, Canada 2 Universidad Carlos III,
Welcome to MCS 572. content and organization expectations of the course. definition and classification
 Welcome to MCS 572 1 About the Course content and organization expectations of the course 2 Supercomputing definition and classification 3 Measuring Performance speedup and efficiency Amdahl s Law Gustafson
Welcome to MCS 572 1 About the Course content and organization expectations of the course 2 Supercomputing definition and classification 3 Measuring Performance speedup and efficiency Amdahl s Law Gustafson
GPU acceleration of Newton s method for large systems of polynomial equations in double double and quad double arithmetic
 GPU acceleration of Newton s method for large systems of polynomial equations in double double and quad double arithmetic Jan Verschelde joint work with Xiangcheng Yu University of Illinois at Chicago
GPU acceleration of Newton s method for large systems of polynomial equations in double double and quad double arithmetic Jan Verschelde joint work with Xiangcheng Yu University of Illinois at Chicago
SPARSE SOLVERS POISSON EQUATION. Margreet Nool. November 9, 2015 FOR THE. CWI, Multiscale Dynamics
 SPARSE SOLVERS FOR THE POISSON EQUATION Margreet Nool CWI, Multiscale Dynamics November 9, 2015 OUTLINE OF THIS TALK 1 FISHPACK, LAPACK, PARDISO 2 SYSTEM OVERVIEW OF CARTESIUS 3 POISSON EQUATION 4 SOLVERS
SPARSE SOLVERS FOR THE POISSON EQUATION Margreet Nool CWI, Multiscale Dynamics November 9, 2015 OUTLINE OF THIS TALK 1 FISHPACK, LAPACK, PARDISO 2 SYSTEM OVERVIEW OF CARTESIUS 3 POISSON EQUATION 4 SOLVERS
Perm State University Research-Education Center Parallel and Distributed Computing
 Perm State University Research-Education Center Parallel and Distributed Computing A 25-minute Talk (S4493) at the GPU Technology Conference (GTC) 2014 MARCH 24-27, 2014 SAN JOSE, CA GPU-accelerated modeling
Perm State University Research-Education Center Parallel and Distributed Computing A 25-minute Talk (S4493) at the GPU Technology Conference (GTC) 2014 MARCH 24-27, 2014 SAN JOSE, CA GPU-accelerated modeling
Case Study: Quantum Chromodynamics
 Case Study: Quantum Chromodynamics Michael Clark Harvard University with R. Babich, K. Barros, R. Brower, J. Chen and C. Rebbi Outline Primer to QCD QCD on a GPU Mixed Precision Solvers Multigrid solver
Case Study: Quantum Chromodynamics Michael Clark Harvard University with R. Babich, K. Barros, R. Brower, J. Chen and C. Rebbi Outline Primer to QCD QCD on a GPU Mixed Precision Solvers Multigrid solver
GPU Computing Activities in KISTI
 International Advanced Research Workshop on High Performance Computing, Grids and Clouds 2010 June 21~June 25 2010, Cetraro, Italy HPC Infrastructure and GPU Computing Activities in KISTI Hongsuk Yi hsyi@kisti.re.kr
International Advanced Research Workshop on High Performance Computing, Grids and Clouds 2010 June 21~June 25 2010, Cetraro, Italy HPC Infrastructure and GPU Computing Activities in KISTI Hongsuk Yi hsyi@kisti.re.kr
APPLICATION OF CUDA TECHNOLOGY FOR CALCULATION OF GROUND STATES OF FEW-BODY NUCLEI BY FEYNMAN'S CONTINUAL INTEGRALS METHOD
 APPLICATION OF CUDA TECHNOLOGY FOR CALCULATION OF GROUND STATES OF FEW-BODY NUCLEI BY FEYNMAN'S CONTINUAL INTEGRALS METHOD M.A. Naumenko, V.V. Samarin Joint Institute for Nuclear Research, Dubna, Russia
APPLICATION OF CUDA TECHNOLOGY FOR CALCULATION OF GROUND STATES OF FEW-BODY NUCLEI BY FEYNMAN'S CONTINUAL INTEGRALS METHOD M.A. Naumenko, V.V. Samarin Joint Institute for Nuclear Research, Dubna, Russia
Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption. Langshi CHEN 1,2,3 Supervised by Serge PETITON 2
 1 / 23 Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption Langshi CHEN 1,2,3 Supervised by Serge PETITON 2 Maison de la Simulation Lille 1 University CNRS March 18, 2013
1 / 23 Parallel Asynchronous Hybrid Krylov Methods for Minimization of Energy Consumption Langshi CHEN 1,2,3 Supervised by Serge PETITON 2 Maison de la Simulation Lille 1 University CNRS March 18, 2013
Quantum Computer Simulation Using CUDA (Quantum Fourier Transform Algorithm)
") Quantum Computer Simulation Using CUDA (Quantum Fourier Transform Algorithm) Alexander Smith & Khashayar Khavari Department of Electrical and Computer Engineering University of Toronto April 15, 2009 Alexander
Quantum Computer Simulation Using CUDA (Quantum Fourier Transform Algorithm) Alexander Smith & Khashayar Khavari Department of Electrical and Computer Engineering University of Toronto April 15, 2009 Alexander
Algorithm for Sparse Approximate Inverse Preconditioners in the Conjugate Gradient Method
 Algorithm for Sparse Approximate Inverse Preconditioners in the Conjugate Gradient Method Ilya B. Labutin A.A. Trofimuk Institute of Petroleum Geology and Geophysics SB RAS, 3, acad. Koptyug Ave., Novosibirsk
Algorithm for Sparse Approximate Inverse Preconditioners in the Conjugate Gradient Method Ilya B. Labutin A.A. Trofimuk Institute of Petroleum Geology and Geophysics SB RAS, 3, acad. Koptyug Ave., Novosibirsk
Accelerating Linear Algebra on Heterogeneous Architectures of Multicore and GPUs using MAGMA and DPLASMA and StarPU Schedulers
 UT College of Engineering Tutorial Accelerating Linear Algebra on Heterogeneous Architectures of Multicore and GPUs using MAGMA and DPLASMA and StarPU Schedulers Stan Tomov 1, George Bosilca 1, and Cédric
UT College of Engineering Tutorial Accelerating Linear Algebra on Heterogeneous Architectures of Multicore and GPUs using MAGMA and DPLASMA and StarPU Schedulers Stan Tomov 1, George Bosilca 1, and Cédric
arxiv: v1 [physics.data-an] 19 Feb 2017
![arxiv: v1 [physics.data-an] 19 Feb 2017](/thumbs/89/98728028.jpg "arxiv: v1 [physics.data-an] 19 Feb 2017") arxiv:1703.03284v1 [physics.data-an] 19 Feb 2017 Model-independent partial wave analysis using a massively-parallel fitting framework L Sun 1, R Aoude 2, A C dos Reis 2, M Sokoloff 3 1 School of Physics
arxiv:1703.03284v1 [physics.data-an] 19 Feb 2017 Model-independent partial wave analysis using a massively-parallel fitting framework L Sun 1, R Aoude 2, A C dos Reis 2, M Sokoloff 3 1 School of Physics
Parallelism of MRT Lattice Boltzmann Method based on Multi-GPUs
 Parallelism of MRT Lattice Boltzmann Method based on Multi-GPUs 1 School of Information Engineering, China University of Geosciences (Beijing) Beijing, 100083, China E-mail: Yaolk1119@icloud.com Ailan
Parallelism of MRT Lattice Boltzmann Method based on Multi-GPUs 1 School of Information Engineering, China University of Geosciences (Beijing) Beijing, 100083, China E-mail: Yaolk1119@icloud.com Ailan
Real-time signal detection for pulsars and radio transients using GPUs
 Real-time signal detection for pulsars and radio transients using GPUs W. Armour, M. Giles, A. Karastergiou and C. Williams. University of Oxford. 15 th July 2013 1 Background of GPUs Why use GPUs? Influence
Real-time signal detection for pulsars and radio transients using GPUs W. Armour, M. Giles, A. Karastergiou and C. Williams. University of Oxford. 15 th July 2013 1 Background of GPUs Why use GPUs? Influence
Plaquette Renormalized Tensor Network States: Application to Frustrated Systems
 Workshop on QIS and QMP, Dec 20, 2009 Plaquette Renormalized Tensor Network States: Application to Frustrated Systems Ying-Jer Kao and Center for Quantum Science and Engineering Hsin-Chih Hsiao, Ji-Feng
Workshop on QIS and QMP, Dec 20, 2009 Plaquette Renormalized Tensor Network States: Application to Frustrated Systems Ying-Jer Kao and Center for Quantum Science and Engineering Hsin-Chih Hsiao, Ji-Feng
Research on GPU-accelerated algorithm in 3D finite difference neutron diffusion calculation method
 NUCLEAR SCIENCE AND TECHNIQUES 25, 0501 (14) Research on GPU-accelerated algorithm in 3D finite difference neutron diffusion calculation method XU Qi ( 徐琪 ), 1, YU Gang-Lin ( 余纲林 ), 1 WANG Kan ( 王侃 ),
NUCLEAR SCIENCE AND TECHNIQUES 25, 0501 (14) Research on GPU-accelerated algorithm in 3D finite difference neutron diffusion calculation method XU Qi ( 徐琪 ), 1, YU Gang-Lin ( 余纲林 ), 1 WANG Kan ( 王侃 ),
COMPARISON OF CPU AND GPU IMPLEMENTATIONS OF THE LATTICE BOLTZMANN METHOD
 XVIII International Conference on Water Resources CMWR 2010 J. Carrera (Ed) c CIMNE, Barcelona, 2010 COMPARISON OF CPU AND GPU IMPLEMENTATIONS OF THE LATTICE BOLTZMANN METHOD James.E. McClure, Jan F. Prins
XVIII International Conference on Water Resources CMWR 2010 J. Carrera (Ed) c CIMNE, Barcelona, 2010 COMPARISON OF CPU AND GPU IMPLEMENTATIONS OF THE LATTICE BOLTZMANN METHOD James.E. McClure, Jan F. Prins
On Portability, Performance and Scalability of a MPI OpenCL Lattice Boltzmann Code
 On Portability, Performance and Scalability of a MPI OpenCL Lattice Boltzmann Code E Calore, S F Schifano, R Tripiccione Enrico Calore INFN Ferrara, Italy 7 th Workshop on UnConventional High Performance
On Portability, Performance and Scalability of a MPI OpenCL Lattice Boltzmann Code E Calore, S F Schifano, R Tripiccione Enrico Calore INFN Ferrara, Italy 7 th Workshop on UnConventional High Performance
Parallelization of Molecular Dynamics (with focus on Gromacs) SeSE 2014 p.1/29
 SeSE 2014 p.1/29") Parallelization of Molecular Dynamics (with focus on Gromacs) SeSE 2014 p.1/29 Outline A few words on MD applications and the GROMACS package The main work in an MD simulation Parallelization Stream computing
Parallelization of Molecular Dynamics (with focus on Gromacs) SeSE 2014 p.1/29 Outline A few words on MD applications and the GROMACS package The main work in an MD simulation Parallelization Stream computing
INTENSIVE COMPUTATION. Annalisa Massini
 INTENSIVE COMPUTATION Annalisa Massini 2015-2016 Course topics The course will cover topics that are in some sense related to intensive computation: Matlab (an introduction) GPU (an introduction) Sparse
INTENSIVE COMPUTATION Annalisa Massini 2015-2016 Course topics The course will cover topics that are in some sense related to intensive computation: Matlab (an introduction) GPU (an introduction) Sparse
Multiphase Flow Simulations in Inclined Tubes with Lattice Boltzmann Method on GPU
 Multiphase Flow Simulations in Inclined Tubes with Lattice Boltzmann Method on GPU Khramtsov D.P., Nekrasov D.A., Pokusaev B.G. Department of Thermodynamics, Thermal Engineering and Energy Saving Technologies,
Multiphase Flow Simulations in Inclined Tubes with Lattice Boltzmann Method on GPU Khramtsov D.P., Nekrasov D.A., Pokusaev B.G. Department of Thermodynamics, Thermal Engineering and Energy Saving Technologies,
Outline Python, Numpy, and Matplotlib Making Models with Polynomials Making Models with Monte Carlo Error, Accuracy and Convergence Floating Point Mod
 Outline Python, Numpy, and Matplotlib Making Models with Polynomials Making Models with Monte Carlo Error, Accuracy and Convergence Floating Point Modeling the World with Arrays The World in a Vector What
Outline Python, Numpy, and Matplotlib Making Models with Polynomials Making Models with Monte Carlo Error, Accuracy and Convergence Floating Point Modeling the World with Arrays The World in a Vector What
Solution to Laplace Equation using Preconditioned Conjugate Gradient Method with Compressed Row Storage using MPI
 Solution to Laplace Equation using Preconditioned Conjugate Gradient Method with Compressed Row Storage using MPI Sagar Bhatt Person Number: 50170651 Department of Mechanical and Aerospace Engineering,
Solution to Laplace Equation using Preconditioned Conjugate Gradient Method with Compressed Row Storage using MPI Sagar Bhatt Person Number: 50170651 Department of Mechanical and Aerospace Engineering,
Level-3 BLAS on a GPU
 Level-3 BLAS on a GPU Picking the Low Hanging Fruit Francisco Igual 1 Gregorio Quintana-Ortí 1 Robert A. van de Geijn 2 1 Departamento de Ingeniería y Ciencia de los Computadores. University Jaume I. Castellón
Level-3 BLAS on a GPU Picking the Low Hanging Fruit Francisco Igual 1 Gregorio Quintana-Ortí 1 Robert A. van de Geijn 2 1 Departamento de Ingeniería y Ciencia de los Computadores. University Jaume I. Castellón
Direct Self-Consistent Field Computations on GPU Clusters
 Direct Self-Consistent Field Computations on GPU Clusters Guochun Shi, Volodymyr Kindratenko National Center for Supercomputing Applications University of Illinois at UrbanaChampaign Ivan Ufimtsev, Todd
Direct Self-Consistent Field Computations on GPU Clusters Guochun Shi, Volodymyr Kindratenko National Center for Supercomputing Applications University of Illinois at UrbanaChampaign Ivan Ufimtsev, Todd
Two case studies of Monte Carlo simulation on GPU
 Two case studies of Monte Carlo simulation on GPU National Institute for Computational Sciences University of Tennessee Seminar series on HPC, Feb. 27, 2014 Outline 1 Introduction 2 Discrete energy lattice
Two case studies of Monte Carlo simulation on GPU National Institute for Computational Sciences University of Tennessee Seminar series on HPC, Feb. 27, 2014 Outline 1 Introduction 2 Discrete energy lattice
Computational Physics Computerphysik
 Computational Physics Computerphysik Rainer Spurzem, Astronomisches Rechen-Institut Zentrum für Astronomie, Universität Heidelberg Ralf Klessen, Institut f. Theoretische Astrophysik, Zentrum für Astronomie,
Computational Physics Computerphysik Rainer Spurzem, Astronomisches Rechen-Institut Zentrum für Astronomie, Universität Heidelberg Ralf Klessen, Institut f. Theoretische Astrophysik, Zentrum für Astronomie,
Computers and Mathematics with Applications
 Computers and Mathematics with Applications 68 (2014) 1151 1160 Contents lists available at ScienceDirect Computers and Mathematics with Applications journal homepage: www.elsevier.com/locate/camwa A GPU
Computers and Mathematics with Applications 68 (2014) 1151 1160 Contents lists available at ScienceDirect Computers and Mathematics with Applications journal homepage: www.elsevier.com/locate/camwa A GPU
CRYPTOGRAPHIC COMPUTING
 CRYPTOGRAPHIC COMPUTING ON GPU Chen Mou Cheng Dept. Electrical Engineering g National Taiwan University January 16, 2009 COLLABORATORS Daniel Bernstein, UIC, USA Tien Ren Chen, Army Tanja Lange, TU Eindhoven,
CRYPTOGRAPHIC COMPUTING ON GPU Chen Mou Cheng Dept. Electrical Engineering g National Taiwan University January 16, 2009 COLLABORATORS Daniel Bernstein, UIC, USA Tien Ren Chen, Army Tanja Lange, TU Eindhoven,
GPU Acceleration of Cutoff Pair Potentials for Molecular Modeling Applications
 GPU Acceleration of Cutoff Pair Potentials for Molecular Modeling Applications Christopher Rodrigues, David J. Hardy, John E. Stone, Klaus Schulten, Wen-Mei W. Hwu University of Illinois at Urbana-Champaign
GPU Acceleration of Cutoff Pair Potentials for Molecular Modeling Applications Christopher Rodrigues, David J. Hardy, John E. Stone, Klaus Schulten, Wen-Mei W. Hwu University of Illinois at Urbana-Champaign
The Lattice Boltzmann Method for Laminar and Turbulent Channel Flows
 The Lattice Boltzmann Method for Laminar and Turbulent Channel Flows Vanja Zecevic, Michael Kirkpatrick and Steven Armfield Department of Aerospace Mechanical & Mechatronic Engineering The University of
The Lattice Boltzmann Method for Laminar and Turbulent Channel Flows Vanja Zecevic, Michael Kirkpatrick and Steven Armfield Department of Aerospace Mechanical & Mechatronic Engineering The University of
GPU Accelerated Markov Decision Processes in Crowd Simulation
 GPU Accelerated Markov Decision Processes in Crowd Simulation Sergio Ruiz Computer Science Department Tecnológico de Monterrey, CCM Mexico City, México sergio.ruiz.loza@itesm.mx Benjamín Hernández National
GPU Accelerated Markov Decision Processes in Crowd Simulation Sergio Ruiz Computer Science Department Tecnológico de Monterrey, CCM Mexico City, México sergio.ruiz.loza@itesm.mx Benjamín Hernández National
A CUDA Solver for Helmholtz Equation
 Journal of Computational Information Systems 11: 24 (2015) 7805 7812 Available at http://www.jofcis.com A CUDA Solver for Helmholtz Equation Mingming REN 1,2,, Xiaoguang LIU 1,2, Gang WANG 1,2 1 College
Journal of Computational Information Systems 11: 24 (2015) 7805 7812 Available at http://www.jofcis.com A CUDA Solver for Helmholtz Equation Mingming REN 1,2,, Xiaoguang LIU 1,2, Gang WANG 1,2 1 College
Multicore Parallelization of Determinant Quantum Monte Carlo Simulations
 Multicore Parallelization of Determinant Quantum Monte Carlo Simulations Andrés Tomás, Che-Rung Lee, Zhaojun Bai, Richard Scalettar UC Davis SIAM Conference on Computation Science & Engineering Reno, March
Multicore Parallelization of Determinant Quantum Monte Carlo Simulations Andrés Tomás, Che-Rung Lee, Zhaojun Bai, Richard Scalettar UC Davis SIAM Conference on Computation Science & Engineering Reno, March
Accelerating Quantum Chromodynamics Calculations with GPUs
 Accelerating Quantum Chromodynamics Calculations with GPUs Guochun Shi, Steven Gottlieb, Aaron Torok, Volodymyr Kindratenko NCSA & Indiana University National Center for Supercomputing Applications University
Accelerating Quantum Chromodynamics Calculations with GPUs Guochun Shi, Steven Gottlieb, Aaron Torok, Volodymyr Kindratenko NCSA & Indiana University National Center for Supercomputing Applications University
Efficient implementation of the overlap operator on multi-gpus
 Efficient implementation of the overlap operator on multi-gpus Andrei Alexandru Mike Lujan, Craig Pelissier, Ben Gamari, Frank Lee SAAHPC 2011 - University of Tennessee Outline Motivation Overlap operator
Efficient implementation of the overlap operator on multi-gpus Andrei Alexandru Mike Lujan, Craig Pelissier, Ben Gamari, Frank Lee SAAHPC 2011 - University of Tennessee Outline Motivation Overlap operator
The new challenges to Krylov subspace methods Yousef Saad Department of Computer Science and Engineering University of Minnesota
 The new challenges to Krylov subspace methods Yousef Saad Department of Computer Science and Engineering University of Minnesota SIAM Applied Linear Algebra Valencia, June 18-22, 2012 Introduction Krylov
The new challenges to Krylov subspace methods Yousef Saad Department of Computer Science and Engineering University of Minnesota SIAM Applied Linear Algebra Valencia, June 18-22, 2012 Introduction Krylov
New approaches to strongly interacting Fermi gases
 New approaches to strongly interacting Fermi gases Joaquín E. Drut The Ohio State University INT Program Simulations and Symmetries Seattle, March 2010 In collaboration with Timo A. Lähde Aalto University,
New approaches to strongly interacting Fermi gases Joaquín E. Drut The Ohio State University INT Program Simulations and Symmetries Seattle, March 2010 In collaboration with Timo A. Lähde Aalto University,
GPU accelerated Monte Carlo simulations of lattice spin models
 Available online at www.sciencedirect.com Physics Procedia 15 (2011) 92 96 GPU accelerated Monte Carlo simulations of lattice spin models M. Weigel, T. Yavors kii Institut für Physik, Johannes Gutenberg-Universität
Available online at www.sciencedirect.com Physics Procedia 15 (2011) 92 96 GPU accelerated Monte Carlo simulations of lattice spin models M. Weigel, T. Yavors kii Institut für Physik, Johannes Gutenberg-Universität
Introduction to Neural Networks
 Introduction to Neural Networks Philipp Koehn 4 April 205 Linear Models We used before weighted linear combination of feature values h j and weights λ j score(λ, d i ) = j λ j h j (d i ) Such models can
Introduction to Neural Networks Philipp Koehn 4 April 205 Linear Models We used before weighted linear combination of feature values h j and weights λ j score(λ, d i ) = j λ j h j (d i ) Such models can
Parallel Sparse Tensor Decompositions using HiCOO Format
 Figure sources: A brief survey of tensors by Berton Earnshaw and NVIDIA Tensor Cores Parallel Sparse Tensor Decompositions using HiCOO Format Jiajia Li, Jee Choi, Richard Vuduc May 8, 8 @ SIAM ALA 8 Outline
Figure sources: A brief survey of tensors by Berton Earnshaw and NVIDIA Tensor Cores Parallel Sparse Tensor Decompositions using HiCOO Format Jiajia Li, Jee Choi, Richard Vuduc May 8, 8 @ SIAM ALA 8 Outline
Heterogeneous programming for hybrid CPU-GPU systems: Lessons learned from computational chemistry
 Heterogeneous programming for hybrid CPU-GPU systems: Lessons learned from computational chemistry and Eugene DePrince Argonne National Laboratory (LCF and CNM) (Eugene moved to Georgia Tech last week)
Heterogeneous programming for hybrid CPU-GPU systems: Lessons learned from computational chemistry and Eugene DePrince Argonne National Laboratory (LCF and CNM) (Eugene moved to Georgia Tech last week)
Accelerating Model Reduction of Large Linear Systems with Graphics Processors
 Accelerating Model Reduction of Large Linear Systems with Graphics Processors P. Benner 1, P. Ezzatti 2, D. Kressner 3, E.S. Quintana-Ortí 4, Alfredo Remón 4 1 Max-Plank-Institute for Dynamics of Complex
Accelerating Model Reduction of Large Linear Systems with Graphics Processors P. Benner 1, P. Ezzatti 2, D. Kressner 3, E.S. Quintana-Ortí 4, Alfredo Remón 4 1 Max-Plank-Institute for Dynamics of Complex
Explore Computational Power of GPU in Electromagnetics and Micromagnetics
 Explore Computational Power of GPU in Electromagnetics and Micromagnetics Presenter: Sidi Fu, PhD candidate, UC San Diego Advisor: Prof. Vitaliy Lomakin Center of Magnetic Recording Research, Department
Explore Computational Power of GPU in Electromagnetics and Micromagnetics Presenter: Sidi Fu, PhD candidate, UC San Diego Advisor: Prof. Vitaliy Lomakin Center of Magnetic Recording Research, Department
Random Sampling for Short Lattice Vectors on Graphics Cards
 Random Sampling for Short Lattice Vectors on Graphics Cards Michael Schneider, Norman Göttert TU Darmstadt, Germany mischnei@cdc.informatik.tu-darmstadt.de CHES 2011, Nara September 2011 Michael Schneider
Random Sampling for Short Lattice Vectors on Graphics Cards Michael Schneider, Norman Göttert TU Darmstadt, Germany mischnei@cdc.informatik.tu-darmstadt.de CHES 2011, Nara September 2011 Michael Schneider
Lattice Boltzmann simulations on heterogeneous CPU-GPU clusters
 Lattice Boltzmann simulations on heterogeneous CPU-GPU clusters H. Köstler 2nd International Symposium Computer Simulations on GPU Freudenstadt, 29.05.2013 1 Contents Motivation walberla software concepts
Lattice Boltzmann simulations on heterogeneous CPU-GPU clusters H. Köstler 2nd International Symposium Computer Simulations on GPU Freudenstadt, 29.05.2013 1 Contents Motivation walberla software concepts
Lattice QCD at non-zero temperature and density
 Lattice QCD at non-zero temperature and density Frithjof Karsch Bielefeld University & Brookhaven National Laboratory QCD in a nutshell, non-perturbative physics, lattice-regularized QCD, Monte Carlo simulations
Lattice QCD at non-zero temperature and density Frithjof Karsch Bielefeld University & Brookhaven National Laboratory QCD in a nutshell, non-perturbative physics, lattice-regularized QCD, Monte Carlo simulations
Shortest Lattice Vector Enumeration on Graphics Cards
 Shortest Lattice Vector Enumeration on Graphics Cards Jens Hermans 1 Michael Schneider 2 Fréderik Vercauteren 1 Johannes Buchmann 2 Bart Preneel 1 1 K.U.Leuven 2 TU Darmstadt SHARCS - 10 September 2009
Shortest Lattice Vector Enumeration on Graphics Cards Jens Hermans 1 Michael Schneider 2 Fréderik Vercauteren 1 Johannes Buchmann 2 Bart Preneel 1 1 K.U.Leuven 2 TU Darmstadt SHARCS - 10 September 2009
Claude Tadonki. MINES ParisTech PSL Research University Centre de Recherche Informatique
 Claude Tadonki MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Monthly CRI Seminar MINES ParisTech - CRI June 06, 2016, Fontainebleau (France)
Claude Tadonki MINES ParisTech PSL Research University Centre de Recherche Informatique claude.tadonki@mines-paristech.fr Monthly CRI Seminar MINES ParisTech - CRI June 06, 2016, Fontainebleau (France)
Review for the Midterm Exam
 Review for the Midterm Exam 1 Three Questions of the Computational Science Prelim scaled speedup network topologies work stealing 2 The in-class Spring 2012 Midterm Exam pleasingly parallel computations
Review for the Midterm Exam 1 Three Questions of the Computational Science Prelim scaled speedup network topologies work stealing 2 The in-class Spring 2012 Midterm Exam pleasingly parallel computations
Antti-Pekka Hynninen, 5/10/2017, GTC2017, San Jose CA
 S7255: CUTT: A HIGH- PERFORMANCE TENSOR TRANSPOSE LIBRARY FOR GPUS Antti-Pekka Hynninen, 5/10/2017, GTC2017, San Jose CA MOTIVATION Tensor contractions are the most computationally intensive part of quantum
S7255: CUTT: A HIGH- PERFORMANCE TENSOR TRANSPOSE LIBRARY FOR GPUS Antti-Pekka Hynninen, 5/10/2017, GTC2017, San Jose CA MOTIVATION Tensor contractions are the most computationally intensive part of quantum
Hydra. A library for data analysis in massively parallel platforms. A. Augusto Alves Jr and Michael D. Sokoloff
 Hydra A library for data analysis in massively parallel platforms A. Augusto Alves Jr and Michael D. Sokoloff University of Cincinnati aalvesju@cern.ch Presented at NVIDIA s GPU Technology Conference,
Hydra A library for data analysis in massively parallel platforms A. Augusto Alves Jr and Michael D. Sokoloff University of Cincinnati aalvesju@cern.ch Presented at NVIDIA s GPU Technology Conference,
A Quantum Chemistry Domain-Specific Language for Heterogeneous Clusters
 A Quantum Chemistry Domain-Specific Language for Heterogeneous Clusters ANTONINO TUMEO, ORESTE VILLA Collaborators: Karol Kowalski, Sriram Krishnamoorthy, Wenjing Ma, Simone Secchi May 15, 2012 1 Outline!
A Quantum Chemistry Domain-Specific Language for Heterogeneous Clusters ANTONINO TUMEO, ORESTE VILLA Collaborators: Karol Kowalski, Sriram Krishnamoorthy, Wenjing Ma, Simone Secchi May 15, 2012 1 Outline!
Block AIR Methods. For Multicore and GPU. Per Christian Hansen Hans Henrik B. Sørensen. Technical University of Denmark
 Block AIR Methods For Multicore and GPU Per Christian Hansen Hans Henrik B. Sørensen Technical University of Denmark Model Problem and Notation Parallel-beam 3D tomography exact solution exact data noise
Block AIR Methods For Multicore and GPU Per Christian Hansen Hans Henrik B. Sørensen Technical University of Denmark Model Problem and Notation Parallel-beam 3D tomography exact solution exact data noise
GPU Acceleration of BCP Procedure for SAT Algorithms
 GPU Acceleration of BCP Procedure for SAT Algorithms Hironori Fujii 1 and Noriyuki Fujimoto 1 1 Graduate School of Science Osaka Prefecture University 1-1 Gakuencho, Nakaku, Sakai, Osaka 599-8531, Japan
GPU Acceleration of BCP Procedure for SAT Algorithms Hironori Fujii 1 and Noriyuki Fujimoto 1 1 Graduate School of Science Osaka Prefecture University 1-1 Gakuencho, Nakaku, Sakai, Osaka 599-8531, Japan
Graphics Card Computing for Materials Modelling
 Graphics Card Computing for Materials Modelling Case study: Analytic Bond Order Potentials B. Seiser, T. Hammerschmidt, R. Drautz, D. Pettifor Funded by EPSRC within the collaborative multi-scale project
Graphics Card Computing for Materials Modelling Case study: Analytic Bond Order Potentials B. Seiser, T. Hammerschmidt, R. Drautz, D. Pettifor Funded by EPSRC within the collaborative multi-scale project
A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures
 A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
A Massively Parallel Eigenvalue Solver for Small Matrices on Multicore and Manycore Architectures Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Multilevel low-rank approximation preconditioners Yousef Saad Department of Computer Science and Engineering University of Minnesota
 Multilevel low-rank approximation preconditioners Yousef Saad Department of Computer Science and Engineering University of Minnesota SIAM CSE Boston - March 1, 2013 First: Joint work with Ruipeng Li Work
Multilevel low-rank approximation preconditioners Yousef Saad Department of Computer Science and Engineering University of Minnesota SIAM CSE Boston - March 1, 2013 First: Joint work with Ruipeng Li Work
S0214 : GPU Based Stacking Sequence Generation For Composite Skins Using GA
 S0214 : GPU Based Stacking Sequence Generation For Composite Skins Using GA Date: 16th May 2012 Wed, 3pm to 3.25pm(Adv. Session) Sathyanarayana K., Manish Banga, and Ravi Kumar G. V. V. Engineering Services,
S0214 : GPU Based Stacking Sequence Generation For Composite Skins Using GA Date: 16th May 2012 Wed, 3pm to 3.25pm(Adv. Session) Sathyanarayana K., Manish Banga, and Ravi Kumar G. V. V. Engineering Services,
Tips Geared Towards R. Adam J. Suarez. Arpil 10, 2015
 Tips Geared Towards R Departments of Statistics North Carolina State University Arpil 10, 2015 1 / 30 Advantages of R As an interpretive and interactive language, developing an algorithm in R can be done
Tips Geared Towards R Departments of Statistics North Carolina State University Arpil 10, 2015 1 / 30 Advantages of R As an interpretive and interactive language, developing an algorithm in R can be done
Measuring freeze-out parameters on the Bielefeld GPU cluster
 Measuring freeze-out parameters on the Bielefeld GPU cluster Outline Fluctuations and the QCD phase diagram Fluctuations from Lattice QCD The Bielefeld hybrid GPU cluster Freeze-out conditions from QCD
Measuring freeze-out parameters on the Bielefeld GPU cluster Outline Fluctuations and the QCD phase diagram Fluctuations from Lattice QCD The Bielefeld hybrid GPU cluster Freeze-out conditions from QCD
上海超级计算中心 Shanghai Supercomputer Center. Lei Xu Shanghai Supercomputer Center San Jose
 上海超级计算中心 Shanghai Supercomputer Center Lei Xu Shanghai Supercomputer Center 03/26/2014 @GTC, San Jose Overview Introduction Fundamentals of the FDTD method Implementation of 3D UPML-FDTD algorithm on GPU
上海超级计算中心 Shanghai Supercomputer Center Lei Xu Shanghai Supercomputer Center 03/26/2014 @GTC, San Jose Overview Introduction Fundamentals of the FDTD method Implementation of 3D UPML-FDTD algorithm on GPU
arxiv: v1 [cs.ir] 8 Nov 2015
![arxiv: v1 [cs.ir] 8 Nov 2015](/thumbs/71/66141320.jpg "arxiv: v1 [cs.ir] 8 Nov 2015") Accelerating Recommender Systems using GPUs André Valente Rodrigues LIAAD - INESC TEC DCC - University of Porto Alípio Jorge LIAAD - INESC TEC DCC - University of Porto Inês Dutra CRACS - INESC TEC DCC
Accelerating Recommender Systems using GPUs André Valente Rodrigues LIAAD - INESC TEC DCC - University of Porto Alípio Jorge LIAAD - INESC TEC DCC - University of Porto Inês Dutra CRACS - INESC TEC DCC
Robust Preconditioned Conjugate Gradient for the GPU and Parallel Implementations
 Robust Preconditioned Conjugate Gradient for the GPU and Parallel Implementations Rohit Gupta, Martin van Gijzen, Kees Vuik GPU Technology Conference 2012, San Jose CA. GPU Technology Conference 2012,
Robust Preconditioned Conjugate Gradient for the GPU and Parallel Implementations Rohit Gupta, Martin van Gijzen, Kees Vuik GPU Technology Conference 2012, San Jose CA. GPU Technology Conference 2012,
Solving Lattice QCD systems of equations using mixed precision solvers on GPUs
 Solving Lattice QCD systems of equations using mixed precision solvers on GPUs M. A. Clark a,b, R. Babich c,d, K. Barros e,f, R. C. Brower c,d, C. Rebbi c,d arxiv:0911.3191v2 [hep-lat] 21 Dec 2009 a Harvard-Smithsonian
Solving Lattice QCD systems of equations using mixed precision solvers on GPUs M. A. Clark a,b, R. Babich c,d, K. Barros e,f, R. C. Brower c,d, C. Rebbi c,d arxiv:0911.3191v2 [hep-lat] 21 Dec 2009 a Harvard-Smithsonian
Mayer Sampling Monte Carlo Calculation of Virial. Coefficients on Graphics Processors
 Mayer Sampling Monte Carlo Calculation of Virial Coefficients on Graphics Processors Andrew J. Schultz, Vipin Chaudhary, David A. Kofke,, and Nathaniel S. Barlow Department of Chemical and Biological Engineering,
Mayer Sampling Monte Carlo Calculation of Virial Coefficients on Graphics Processors Andrew J. Schultz, Vipin Chaudhary, David A. Kofke,, and Nathaniel S. Barlow Department of Chemical and Biological Engineering,
Parallel Rabin-Karp Algorithm Implementation on GPU (preliminary version)
") Bulletin of Networking, Computing, Systems, and Software www.bncss.org, ISSN 2186-5140 Volume 7, Number 1, pages 28 32, January 2018 Parallel Rabin-Karp Algorithm Implementation on GPU (preliminary version)
Bulletin of Networking, Computing, Systems, and Software www.bncss.org, ISSN 2186-5140 Volume 7, Number 1, pages 28 32, January 2018 Parallel Rabin-Karp Algorithm Implementation on GPU (preliminary version)
Julian Merten. GPU Computing and Alternative Architecture
 Future Directions of Cosmological Simulations / Edinburgh 1 / 16 Julian Merten GPU Computing and Alternative Architecture Institut für Theoretische Astrophysik Zentrum für Astronomie Universität Heidelberg
Future Directions of Cosmological Simulations / Edinburgh 1 / 16 Julian Merten GPU Computing and Alternative Architecture Institut für Theoretische Astrophysik Zentrum für Astronomie Universität Heidelberg
Computing least squares condition numbers on hybrid multicore/gpu systems
 Computing least squares condition numbers on hybrid multicore/gpu systems M. Baboulin and J. Dongarra and R. Lacroix Abstract This paper presents an efficient computation for least squares conditioning
Computing least squares condition numbers on hybrid multicore/gpu systems M. Baboulin and J. Dongarra and R. Lacroix Abstract This paper presents an efficient computation for least squares conditioning
arxiv: v1 [hep-lat] 31 Oct 2015
![arxiv: v1 [hep-lat] 31 Oct 2015](/thumbs/74/71106348.jpg "arxiv: v1 [hep-lat] 31 Oct 2015") and Code Optimization arxiv:1511.00088v1 [hep-lat] 31 Oct 2015 Hwancheol Jeong, Sangbaek Lee, Weonjong Lee, Lattice Gauge Theory Research Center, CTP, and FPRD, Department of Physics and Astronomy, Seoul
and Code Optimization arxiv:1511.00088v1 [hep-lat] 31 Oct 2015 Hwancheol Jeong, Sangbaek Lee, Weonjong Lee, Lattice Gauge Theory Research Center, CTP, and FPRD, Department of Physics and Astronomy, Seoul
Interpolation with Radial Basis Functions on GPGPUs using CUDA
 Interpolation with Radial Basis Functions on GPGPUs using CUDA Gundolf Haase in coop. with: Dirk Martin [VRV Vienna] and Günter Offner [AVL Graz] Institute for Mathematics and Scientific Computing University
Interpolation with Radial Basis Functions on GPGPUs using CUDA Gundolf Haase in coop. with: Dirk Martin [VRV Vienna] and Günter Offner [AVL Graz] Institute for Mathematics and Scientific Computing University
GPU Computing with Applications in Digital Logic
 Tampere International Center for Signal Processing. TICSP series # 62 J. Astola, M. Kameyama, M. Lukac & R. S. Stanković (eds.) GPU Computing with Applications in Digital Logic Tampere International Center
Tampere International Center for Signal Processing. TICSP series # 62 J. Astola, M. Kameyama, M. Lukac & R. S. Stanković (eds.) GPU Computing with Applications in Digital Logic Tampere International Center
Jacobi-Based Eigenvalue Solver on GPU. Lung-Sheng Chien, NVIDIA
 Jacobi-Based Eigenvalue Solver on GPU Lung-Sheng Chien, NVIDIA lchien@nvidia.com Outline Symmetric eigenvalue solver Experiment Applications Conclusions Symmetric eigenvalue solver The standard form is
Jacobi-Based Eigenvalue Solver on GPU Lung-Sheng Chien, NVIDIA lchien@nvidia.com Outline Symmetric eigenvalue solver Experiment Applications Conclusions Symmetric eigenvalue solver The standard form is
Sparse LU Factorization on GPUs for Accelerating SPICE Simulation
 Nano-scale Integrated Circuit and System (NICS) Laboratory Sparse LU Factorization on GPUs for Accelerating SPICE Simulation Xiaoming Chen PhD Candidate Department of Electronic Engineering Tsinghua University,
Nano-scale Integrated Circuit and System (NICS) Laboratory Sparse LU Factorization on GPUs for Accelerating SPICE Simulation Xiaoming Chen PhD Candidate Department of Electronic Engineering Tsinghua University,
Available online at ScienceDirect. Procedia Engineering 61 (2013 ) 94 99
 94 99") Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 6 (203 ) 94 99 Parallel Computational Fluid Dynamics Conference (ParCFD203) Simulations of three-dimensional cavity flows with
Available online at www.sciencedirect.com ScienceDirect Procedia Engineering 6 (203 ) 94 99 Parallel Computational Fluid Dynamics Conference (ParCFD203) Simulations of three-dimensional cavity flows with
Optimization Techniques for Parallel Code 1. Parallel programming models
 Optimization Techniques for Parallel Code 1. Parallel programming models Sylvain Collange Inria Rennes Bretagne Atlantique http://www.irisa.fr/alf/collange/ sylvain.collange@inria.fr OPT - 2017 Goals of
Optimization Techniques for Parallel Code 1. Parallel programming models Sylvain Collange Inria Rennes Bretagne Atlantique http://www.irisa.fr/alf/collange/ sylvain.collange@inria.fr OPT - 2017 Goals of
Nuclear Physics and Computing: Exascale Partnerships. Juan Meza Senior Scientist Lawrence Berkeley National Laboratory
 Nuclear Physics and Computing: Exascale Partnerships Juan Meza Senior Scientist Lawrence Berkeley National Laboratory Nuclear Science and Exascale i Workshop held in DC to identify scientific challenges
Nuclear Physics and Computing: Exascale Partnerships Juan Meza Senior Scientist Lawrence Berkeley National Laboratory Nuclear Science and Exascale i Workshop held in DC to identify scientific challenges
A microsecond a day keeps the doctor away: Efficient GPU Molecular Dynamics with GROMACS
 GTC 20130319 A microsecond a day keeps the doctor away: Efficient GPU Molecular Dynamics with GROMACS Erik Lindahl erik.lindahl@scilifelab.se Molecular Dynamics Understand biology We re comfortably on
GTC 20130319 A microsecond a day keeps the doctor away: Efficient GPU Molecular Dynamics with GROMACS Erik Lindahl erik.lindahl@scilifelab.se Molecular Dynamics Understand biology We re comfortably on
Massively Parallel Jacobian Computation
 Massively Parallel Jacobian Computation by Wanqi Li A research paper presented to the University of Waterloo in partial ful llment of the requirement for the degree of Master of Mathematics in Computational
Massively Parallel Jacobian Computation by Wanqi Li A research paper presented to the University of Waterloo in partial ful llment of the requirement for the degree of Master of Mathematics in Computational
Bachelor-thesis: GPU-Acceleration of Linear Algebra using OpenCL
 Bachelor-thesis: GPU-Acceleration of Linear Algebra using OpenCL Andreas Falkenstrøm Mieritz s093065 September 13, 2012 Supervisors: Allan Ensig-Peter Karup Bernd Dammann IMM-B.Sc.-2012-30 Contents 1 Problem
Bachelor-thesis: GPU-Acceleration of Linear Algebra using OpenCL Andreas Falkenstrøm Mieritz s093065 September 13, 2012 Supervisors: Allan Ensig-Peter Karup Bernd Dammann IMM-B.Sc.-2012-30 Contents 1 Problem
SIMULATION OF ISING SPIN MODEL USING CUDA
 SIMULATION OF ISING SPIN MODEL USING CUDA MIRO JURIŠIĆ Supervisor: dr.sc. Dejan Vinković Split, November 2011 Master Thesis in Physics Department of Physics Faculty of Natural Sciences and Mathematics
SIMULATION OF ISING SPIN MODEL USING CUDA MIRO JURIŠIĆ Supervisor: dr.sc. Dejan Vinković Split, November 2011 Master Thesis in Physics Department of Physics Faculty of Natural Sciences and Mathematics
MURCIA: Fast parallel solvent accessible surface area calculation on GPUs and application to drug discovery and molecular visualization
 MURCIA: Fast parallel solvent accessible surface area calculation on GPUs and application to drug discovery and molecular visualization Eduardo J. Cepas Quiñonero Horacio Pérez-Sánchez Wolfgang Wenzel
MURCIA: Fast parallel solvent accessible surface area calculation on GPUs and application to drug discovery and molecular visualization Eduardo J. Cepas Quiñonero Horacio Pérez-Sánchez Wolfgang Wenzel
The Lattice Boltzmann Simulation on Multi-GPU Systems
 The Lattice Boltzmann Simulation on Multi-GPU Systems Thor Kristian Valderhaug Master of Science in Computer Science Submission date: June 2011 Supervisor: Anne Cathrine Elster, IDI Norwegian University
The Lattice Boltzmann Simulation on Multi-GPU Systems Thor Kristian Valderhaug Master of Science in Computer Science Submission date: June 2011 Supervisor: Anne Cathrine Elster, IDI Norwegian University
Verbundprojekt ELPA-AEO. Eigenwert-Löser für Petaflop-Anwendungen Algorithmische Erweiterungen und Optimierungen
 Verbundprojekt ELPA-AEO http://elpa-aeo.mpcdf.mpg.de Eigenwert-Löser für Petaflop-Anwendungen Algorithmische Erweiterungen und Optimierungen BMBF Projekt 01IH15001 Feb 2016 - Jan 2019 7. HPC-Statustagung,
Verbundprojekt ELPA-AEO http://elpa-aeo.mpcdf.mpg.de Eigenwert-Löser für Petaflop-Anwendungen Algorithmische Erweiterungen und Optimierungen BMBF Projekt 01IH15001 Feb 2016 - Jan 2019 7. HPC-Statustagung,
Introduction to Benchmark Test for Multi-scale Computational Materials Software
 Introduction to Benchmark Test for Multi-scale Computational Materials Software Shun Xu*, Jian Zhang, Zhong Jin xushun@sccas.cn Computer Network Information Center Chinese Academy of Sciences (IPCC member)
Introduction to Benchmark Test for Multi-scale Computational Materials Software Shun Xu*, Jian Zhang, Zhong Jin xushun@sccas.cn Computer Network Information Center Chinese Academy of Sciences (IPCC member)
MAGMA MIC 1.0: Linear Algebra Library for Intel Xeon Phi Coprocessors
 MAGMA MIC 1.0: Linear Algebra Library for Intel Xeon Phi Coprocessors J. Dongarra, M. Gates, A. Haidar, Y. Jia, K. Kabir, P. Luszczek, and S. Tomov University of Tennessee, Knoxville 05 / 03 / 2013 MAGMA:
MAGMA MIC 1.0: Linear Algebra Library for Intel Xeon Phi Coprocessors J. Dongarra, M. Gates, A. Haidar, Y. Jia, K. Kabir, P. Luszczek, and S. Tomov University of Tennessee, Knoxville 05 / 03 / 2013 MAGMA:
PLATFORM DEPENDENT EFFICIENCY OF A MONTE CARLO CODE FOR TISSUE NEUTRON DOSE ASSESSMENT
 RAD Conference Proceedings, vol., pp. 2-25, 206 www.rad-proceedings.org PLATFORM DEPENDENT EFFICIENCY OF A MONTE CARLO CODE FOR TISSUE NEUTRON DOSE ASSESSMENT Slobodan Milutinović, Filip Jeremić, Marko
RAD Conference Proceedings, vol., pp. 2-25, 206 www.rad-proceedings.org PLATFORM DEPENDENT EFFICIENCY OF A MONTE CARLO CODE FOR TISSUE NEUTRON DOSE ASSESSMENT Slobodan Milutinović, Filip Jeremić, Marko
A new multiplication algorithm for extended precision using floating-point expansions. Valentina Popescu, Jean-Michel Muller,Ping Tak Peter Tang
 A new multiplication algorithm for extended precision using floating-point expansions Valentina Popescu, Jean-Michel Muller,Ping Tak Peter Tang ARITH 23 July 2016 AMPAR CudA Multiple Precision ARithmetic
A new multiplication algorithm for extended precision using floating-point expansions Valentina Popescu, Jean-Michel Muller,Ping Tak Peter Tang ARITH 23 July 2016 AMPAR CudA Multiple Precision ARithmetic
Faster Kinetics: Accelerate Your Finite-Rate Combustion Simulation with GPUs
 Faster Kinetics: Accelerate Your Finite-Rate Combustion Simulation with GPUs Christopher P. Stone, Ph.D. Computational Science and Engineering, LLC Kyle Niemeyer, Ph.D. Oregon State University 2 Outline
Faster Kinetics: Accelerate Your Finite-Rate Combustion Simulation with GPUs Christopher P. Stone, Ph.D. Computational Science and Engineering, LLC Kyle Niemeyer, Ph.D. Oregon State University 2 Outline
Applications of Mathematical Economics
 Applications of Mathematical Economics Michael Curran Trinity College Dublin Overview Introduction. Data Preparation Filters. Dynamic Stochastic General Equilibrium Models: Sunspots and Blanchard-Kahn
Applications of Mathematical Economics Michael Curran Trinity College Dublin Overview Introduction. Data Preparation Filters. Dynamic Stochastic General Equilibrium Models: Sunspots and Blanchard-Kahn
ab initio Electronic Structure Calculations
 ab initio Electronic Structure Calculations New scalability frontiers using the BG/L Supercomputer C. Bekas, A. Curioni and W. Andreoni IBM, Zurich Research Laboratory Rueschlikon 8803, Switzerland ab
ab initio Electronic Structure Calculations New scalability frontiers using the BG/L Supercomputer C. Bekas, A. Curioni and W. Andreoni IBM, Zurich Research Laboratory Rueschlikon 8803, Switzerland ab
Population annealing and large scale simulations in statistical mechanics
 Population annealing and large scale simulations in statistical mechanics Lev Shchur 1,2[0000 0002 4191 1324], Lev Barash 1,3[0000 0002 2298 785X], Martin Weigel 4[0000 0002 0914 1147], and Wolfhard Janke
Population annealing and large scale simulations in statistical mechanics Lev Shchur 1,2[0000 0002 4191 1324], Lev Barash 1,3[0000 0002 2298 785X], Martin Weigel 4[0000 0002 0914 1147], and Wolfhard Janke
Parallel programming practices for the solution of Sparse Linear Systems (motivated by computational physics and graphics)
") Parallel programming practices for the solution of Sparse Linear Systems (motivated by computational physics and graphics) Eftychios Sifakis CS758 Guest Lecture - 19 Sept 2012 Introduction Linear systems
Parallel programming practices for the solution of Sparse Linear Systems (motivated by computational physics and graphics) Eftychios Sifakis CS758 Guest Lecture - 19 Sept 2012 Introduction Linear systems
Randomized Selection on the GPU. Laura Monroe, Joanne Wendelberger, Sarah Michalak Los Alamos National Laboratory
 Randomized Selection on the GPU Laura Monroe, Joanne Wendelberger, Sarah Michalak Los Alamos National Laboratory High Performance Graphics 2011 August 6, 2011 Top k Selection on GPU Output the top k keys
Randomized Selection on the GPU Laura Monroe, Joanne Wendelberger, Sarah Michalak Los Alamos National Laboratory High Performance Graphics 2011 August 6, 2011 Top k Selection on GPU Output the top k keys