he Applications of Tensor Factorization in Inference, Clustering, Graph Theory, Coding and Visual Representation
|
|
|
- Adele Scarlett Fields
- 5 years ago
- Views:
Transcription
1 he Applications of Tensor Factorization in Inference, Clustering, Graph Theory, Coding and Visual Representation Amnon Shashua School of Computer Science & Eng. The Hebrew University
2 Matrix Factorization Algorithms: Low Rank Factorization Algorithms Principle Component Analysis (PCA) and its probabilistic versions (Buntine & Perttu, 2003 ; Tipping & Bishop, 1999), Latent Semantic Analysis (Deerwester et al., 1990), Probabilistic Latent Semantic Analysis (Hofmann, 1999), Maximum Margin Matrix Factorization (Srebro, Rennie & Jaakola, 2005) Non-negative Matrix Factorization NMF (Paatero & Tapper, 1994; Lee & Seung, 1999). All methods factorize the data into a lower dimensional space in order to introduces a compact basis which if set up appropriately can describe the original data in a concise manner. What are the possible interpretations of high dimensional (tensor) Decompositions under convex/simplex constraints? Hebrew University
3 Outline General Arrays: conditional independence, tensorrank, latent class models image coding, bag of visterms,.. Super-symmetric Arrays: clustering over hypergraphs multi-body segmentation, multi-object relighting, Partially Symmetric: Latent Clustering Models multiclass visual recognition with shared fragments.. Hebrew University 3
4 N-way array decompositions A rank=1 matrix G is represented by an outer-product of two vectors: A rank=1 tensor (n-way array) of n vectors is represented by an outer-product
5 N-way array decompositions A matrix G is of (at most) rank=k if it can be represented by a sum of k rank-1 matrices: A tensor G is (at most) rank=k if it can be represented by a sum of k rank-1 tensors: Example:
6 N-way array Symmetric Decompositions A symmetric rank=1 matrix G: A symmetric rank=k matrix G: A super-symmetric rank=1 tensor (n-way array), is represented by an outer-product of n copies of a single vector A super-symmetric tensor described as sum of k super-symmetric rank=1 tensors: is (at most) rank=k.
7 General Tensors Latent Class Models 7
8 Reduced Rank in Statistics Let and be two random variables taking values in the sets The statement is independent of, denoted by means: is a 2D array (a matrix) is a 1D array (a vector) is a 1D array (a vector) means that is a rank=1 matrix
9 Reduced Rank in Statistics Let be random variables taking values in the sets The statement means: is a n-way array (a tensor) is a 1D array (a vector) whose entries means that is a rank=1 tensor
10 Reduced Rank in Statistics Let be three random variables taking values in the sets The conditional independence statement means: Slice is a rank=1 matrix
11 Reduced Rank in Statistics: Latent Class Model Let Let be random variables taking values in the sets be a hidden random variable taking values in the set The observed joint probability n-way array is: A statement of the form About the n-way array translates to the algebraic statement having tensor-rank equal to
12 Reduced Rank in Statistics: Latent Class Model is a n-way array is a 1D array (a vector) is a rank-1 n-way array is a 1D array (a vector)

13 Reduced Rank in Statistics: Latent Class Model for n=2:

14 Reduced Rank in Statistics: Latent Class Model
15 Reduced Rank in Statistics: Latent Class Model when loss() is the relative-entropy: then the factorization above is called plsa (Hofmann 1999) Typical Algorithm: Expectation Maximization (EM)
16 Reduced Rank in Statistics: Latent Class Model The Expectation-Maximization algorithm introduces auxiliary tensors and alternates among the three sets of variables: Hadamard product. reduces to repeated application of projection onto probability simplex 16
17 Reduced Rank in Statistics: Latent Class Model An L2 version can be realized by replacing RE in the projection operation:
18 Reduced Rank in Statistics: Latent Class Model An equivalent representation: Non-negative Matrix Factorization (normalize columns of G)
19 (non-negative) Low Rank Decompositions Measurements (non-negative) Low Rank Decompositions The rank-1 blocks tend to represent local parts of the image class Hierarchical buildup of important parts 4 factors 8 factors 12 factors 16 factors 20 factors
20 (non-negative) Low Rank Decompositions Example: The swimmer Sample set (256) Non-negative Tensor Factorization NMF
21 Super-symmetric Decompositions Clustering over Hypergraphs Matrices 21
22 Clustering data into k groups: Pairwise Affinity input points input (pairwise) affinity value interpret as the probability that and are clustered together unknown class labels 22
23 Clustering data into k groups: Pairwise Affinity input points k=3 clusters, this point does not belong to any cluster in a hard sense. input (pairwise) affinity value interpret as the probability that and are clustered together unknown class labels A probabilistic view: probability that belongs to the j th cluster note: What is the (algebraic) relationship between the input matrix K and the desired G? 23
24 Clustering data into k groups: Pairwise Affinity Assume the following conditional independence statements: 24
25 Probabilistic Min-Cut A hard assignment requires that: where are the cardinalities of the clusters Proposition: the feasible set of matrices G that satisfy are of the form: equivalent to: Min-cut formulation 25
26 Relation to Spectral Clustering Add a balancing constraint: put together means that also, and means that n/k can be dropped. Relax the balancing constraint by replacing K with the closest doubly stochastic matrix K and ignore the non-negativity constraint: 26
27 Relation to Spectral Clustering Let Then: is the closest D.S. in L1 error norm. Normalized-Cuts Ratio-cuts Proposition: iterating with is converges to the closest D.S. in KL-div error measure. 27
28 New Normalization for Spectral Clustering where we are looking for the closest doubly-stochastic matrix in least-squares sense. 28
29 New Normalization for Spectral Clustering to find K as above, we break this into two subproblems: use the Von-Neumann successive projection lemma: 29

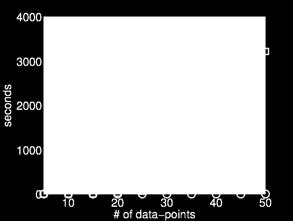
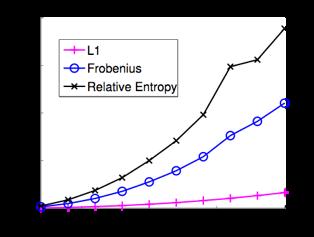
30 New Normalization for Spectral Clustering successive-projection vs. QP solver running time for the three normalizations 30


31 New Normalization for Spectral Clustering UCI Data-sets Cancer Data-sets 31
32 Super-symmetric Decompositions Clustering over Hypergraphs Tensors 32
33 Clustering data into k groups: Beyond Pairwise Affinity A model selection problem that is determined by n-1 points can be described by a factorization problem of n-way array (tensor). Example: clustering m points into k lines Input: Output: the probability that same model (line). belong to the the probability that the point belongs to the r th model (line) Under the independence assumption: is a 3-dimensional super-symmetric tensor of rank=4
34 Clustering data into k groups: Beyond Pairwise Affinity General setting: clusters are defined by n-1 dim subspaces, then for each n- tuple of points we define an affinity value where is the volume defined by the n-tuple. Input: the probability that belong to the same cluster Output: the probability that the point belongs to the r th cluster Assume the conditional independence: is a n-dimensional super-symmetric tensor of rank=k
35 Clustering data into k groups: Beyond Pairwise Affinity Hyper-stochastic constraint: under balancing requirement K is (scaled) hyper-stochastic: Theorem: for any non-negative super-symmetric tensor, iterating converges to a hyper-stochastic tensor.

36 Example: multi-body segmentation Model Selection 9-way array, each entry contains The probability that a choice of 9-tuple of points arise from the same model. Probability:
37 Example: visual recognition under changing illumination 4-way array, each entry contains The probability that a choice of 4 images Live in a 3D subspace. Model Selection
38 Partially-symmetric Decompositions Latent Clustering 38
39 Latent Clustering Model collection of data points context states probability that are clustered together given that small high i.e., the vector has a low entropy meaning that the contribution of the context variable to the pairwise affinity is far from uniform. pairwise affinities do not convey sufficient information. input triple-wise affinities
40 Latent Clustering Model Hypergraph representation G(V,E,w) Hyper-edge defined over triplets representing two data points and one context state (any order) undetermined means we have no information, i.e, we do not have access to the probability that three data points are clustered together...
41 Latent Clustering Model Cluster 1 Cluster k Hyper-edge.. Probability that the context state is Associated with the cluster Super-symmetric NTF Hypergraph clustering would provide means to cluster together points whose pairwise affinities are low, but there exists a subset of context states for which is high. Multiple copies of this block All the remaining entries are undefined In that case, a cluster would be formed containing the data points and the subset of context states.
42 Latent Clustering Model Multiple copies of this block All the remaining entries are undefined
43 Latent Clustering Model Multiple copies of this block All the remaining entries are undefined min D(K u r,h r q r=1 h r h r u r ) s.t. u r 0,h r 0, r h ri =1, r u rj =1
44 Latent Clustering Model: Application collection of image fragments from a large collection of images unlabeled images holding k object classes, one object per image Available info: # of obj classes k, each image contains only one instance from one (unknown) object class. Clustering Task: associate (probabilistically) fragments to object classes. Challenges: Clusters and obj classes are not the same thing. Generally, # of clusters is larger than # of obj classes. Also, the same cluster may be shared among a number of different classes. The probability that two fragments should belong to the same cluster may be low only because they appear together in a small subset of images small high
45 Images Examples 3 Classes of images: Cows Faces Cars

46 Fragments Examples

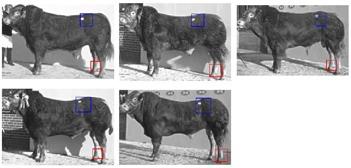

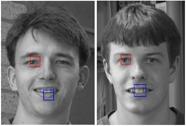
47 Examples of Representative Fragments
48 Leading Fragments Of Clusters Cluster 1 Cluster 2 Cluster 3 Cluster 4 Cluster 5 Cluster 6
49 Examples Of The Resulting Matrix G Rows
50 Examples Of The Resulting Matrix G Rows
 stop sign, (5) one way sign,(6) frontal view car,(7) side view car,(8) face,(9) computer mouse, (10) pedestrian dataset adapted from Torralba,Murphey and Freeman,")
51 Handling Multiple Object Classes Unlabeled set of segmented images, each containing an instance of some unknown object class from a collection of 10 classes: (1) Bottle, (2) can, (3) do not enter sign,(4) stop sign, (5) one way sign,(6) frontal view car,(7) side view car,(8) face,(9) computer mouse, (10) pedestrian dataset adapted from Torralba,Murphey and Freeman, CVPR04
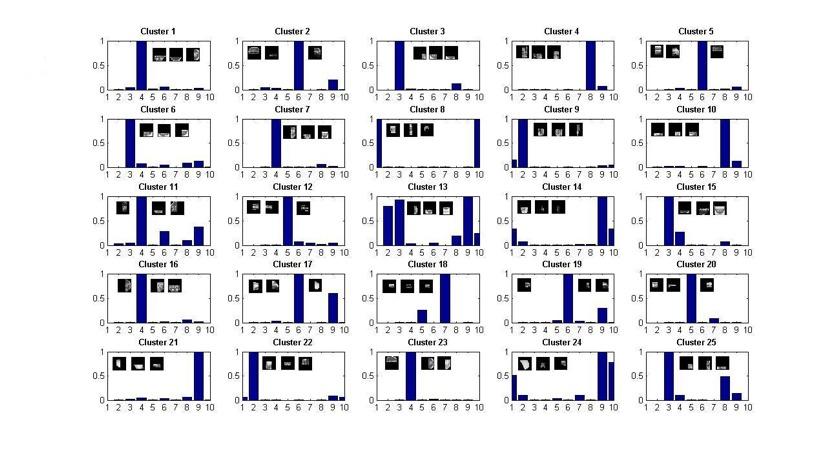
52 Clustering Fragments
53 From Clusters to Classes

54 Results A location which is associated with fragments voting consistently for the same object class will have high value in the corresponding voting map. Strongest hot-spots (local maximums) in the voting maps show the most probable locations of objects.

55 Results
56 Summary Factorization of empirical joint distribution Factorization of symmetric forms Latent Class Model Probabilistic clustering. Factorization of partially-symmetric forms Latent clustering Further details in 56
57 END
Non-Negative Tensor Factorization with Applications to Statistics and Computer Vision
 Non-Negative Tensor Factorization with Applications to Statistics and Computer Vision Amnon Shashua shashua@cs.huji.ac.il School of Engineering and Computer Science, The Hebrew University of Jerusalem,
Non-Negative Tensor Factorization with Applications to Statistics and Computer Vision Amnon Shashua shashua@cs.huji.ac.il School of Engineering and Computer Science, The Hebrew University of Jerusalem,
A Unifying Approach to Hard and Probabilistic Clustering
 A Unifying Approach to Hard and Probabilistic Clustering Ron Zass and Amnon Shashua School of Engineering and Computer Science, The Hebrew University, Jerusalem 91904, Israel Abstract We derive the clustering
A Unifying Approach to Hard and Probabilistic Clustering Ron Zass and Amnon Shashua School of Engineering and Computer Science, The Hebrew University, Jerusalem 91904, Israel Abstract We derive the clustering
Doubly Stochastic Normalization for Spectral Clustering
 Doubly Stochastic Normalization for Spectral Clustering Ron Zass and Amnon Shashua Abstract In this paper we focus on the issue of normalization of the affinity matrix in spectral clustering. We show that
Doubly Stochastic Normalization for Spectral Clustering Ron Zass and Amnon Shashua Abstract In this paper we focus on the issue of normalization of the affinity matrix in spectral clustering. We show that
Multi-way Clustering Using Super-symmetric Non-negative Tensor Factorization
 Multi-way Clustering Using Super-symmetric Non-negative Tensor Factorization Amnon Shashua, Ron Zass, and Tamir Hazan School of Engineering and Computer Science, The Hebrew University, Jerusalem {shashua,
Multi-way Clustering Using Super-symmetric Non-negative Tensor Factorization Amnon Shashua, Ron Zass, and Tamir Hazan School of Engineering and Computer Science, The Hebrew University, Jerusalem {shashua,
Non-negative Matrix Factorization: Algorithms, Extensions and Applications
 Non-negative Matrix Factorization: Algorithms, Extensions and Applications Emmanouil Benetos www.soi.city.ac.uk/ sbbj660/ March 2013 Emmanouil Benetos Non-negative Matrix Factorization March 2013 1 / 25
Non-negative Matrix Factorization: Algorithms, Extensions and Applications Emmanouil Benetos www.soi.city.ac.uk/ sbbj660/ March 2013 Emmanouil Benetos Non-negative Matrix Factorization March 2013 1 / 25
Multi-way Clustering Using Super-symmetric Non-negative Tensor Factorization
 Multi-way Clustering Using Super-symmetric Non-negative Tensor Factorization Amnon Shashua Ron Zass and Tamir Hazan School of Engineering & Computer Science Hebrew University Jerusalem 994 Israel {shashuazasstamirr}@cs.huji.ac.il
Multi-way Clustering Using Super-symmetric Non-negative Tensor Factorization Amnon Shashua Ron Zass and Tamir Hazan School of Engineering & Computer Science Hebrew University Jerusalem 994 Israel {shashuazasstamirr}@cs.huji.ac.il
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Probabilistic Latent Semantic Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017
 COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
COMS 4721: Machine Learning for Data Science Lecture 18, 4/4/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University TOPIC MODELING MODELS FOR TEXT DATA
Matrix Factorization & Latent Semantic Analysis Review. Yize Li, Lanbo Zhang
 Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Matrix Factorization & Latent Semantic Analysis Review Yize Li, Lanbo Zhang Overview SVD in Latent Semantic Indexing Non-negative Matrix Factorization Probabilistic Latent Semantic Indexing Vector Space
Sparse Subspace Clustering
 Sparse Subspace Clustering Based on Sparse Subspace Clustering: Algorithm, Theory, and Applications by Elhamifar and Vidal (2013) Alex Gutierrez CSCI 8314 March 2, 2017 Outline 1 Motivation and Background
Sparse Subspace Clustering Based on Sparse Subspace Clustering: Algorithm, Theory, and Applications by Elhamifar and Vidal (2013) Alex Gutierrez CSCI 8314 March 2, 2017 Outline 1 Motivation and Background
Non-negative matrix factorization with fixed row and column sums
 Available online at www.sciencedirect.com Linear Algebra and its Applications 9 (8) 5 www.elsevier.com/locate/laa Non-negative matrix factorization with fixed row and column sums Ngoc-Diep Ho, Paul Van
Available online at www.sciencedirect.com Linear Algebra and its Applications 9 (8) 5 www.elsevier.com/locate/laa Non-negative matrix factorization with fixed row and column sums Ngoc-Diep Ho, Paul Van
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding
 Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Dan Oneaţă 1 Introduction Probabilistic Latent Semantic Analysis (plsa) is a technique from the category of topic models. Its main goal is to model cooccurrence information
Probabilistic Latent Semantic Analysis Dan Oneaţă 1 Introduction Probabilistic Latent Semantic Analysis (plsa) is a technique from the category of topic models. Its main goal is to model cooccurrence information
Data Mining and Matrices
 Data Mining and Matrices 6 Non-Negative Matrix Factorization Rainer Gemulla, Pauli Miettinen May 23, 23 Non-Negative Datasets Some datasets are intrinsically non-negative: Counters (e.g., no. occurrences
Data Mining and Matrices 6 Non-Negative Matrix Factorization Rainer Gemulla, Pauli Miettinen May 23, 23 Non-Negative Datasets Some datasets are intrinsically non-negative: Counters (e.g., no. occurrences
Note on Algorithm Differences Between Nonnegative Matrix Factorization And Probabilistic Latent Semantic Indexing
 Note on Algorithm Differences Between Nonnegative Matrix Factorization And Probabilistic Latent Semantic Indexing 1 Zhong-Yuan Zhang, 2 Chris Ding, 3 Jie Tang *1, Corresponding Author School of Statistics,
Note on Algorithm Differences Between Nonnegative Matrix Factorization And Probabilistic Latent Semantic Indexing 1 Zhong-Yuan Zhang, 2 Chris Ding, 3 Jie Tang *1, Corresponding Author School of Statistics,
Automatic Rank Determination in Projective Nonnegative Matrix Factorization
 Automatic Rank Determination in Projective Nonnegative Matrix Factorization Zhirong Yang, Zhanxing Zhu, and Erkki Oja Department of Information and Computer Science Aalto University School of Science and
Automatic Rank Determination in Projective Nonnegative Matrix Factorization Zhirong Yang, Zhanxing Zhu, and Erkki Oja Department of Information and Computer Science Aalto University School of Science and
Robustness of Principal Components
 PCA for Clustering An objective of principal components analysis is to identify linear combinations of the original variables that are useful in accounting for the variation in those original variables.
PCA for Clustering An objective of principal components analysis is to identify linear combinations of the original variables that are useful in accounting for the variation in those original variables.
Notes on Latent Semantic Analysis
 Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
Notes on Latent Semantic Analysis Costas Boulis 1 Introduction One of the most fundamental problems of information retrieval (IR) is to find all documents (and nothing but those) that are semantically
Star-Structured High-Order Heterogeneous Data Co-clustering based on Consistent Information Theory
 Star-Structured High-Order Heterogeneous Data Co-clustering based on Consistent Information Theory Bin Gao Tie-an Liu Wei-ing Ma Microsoft Research Asia 4F Sigma Center No. 49 hichun Road Beijing 00080
Star-Structured High-Order Heterogeneous Data Co-clustering based on Consistent Information Theory Bin Gao Tie-an Liu Wei-ing Ma Microsoft Research Asia 4F Sigma Center No. 49 hichun Road Beijing 00080
Fast Coordinate Descent methods for Non-Negative Matrix Factorization
 Fast Coordinate Descent methods for Non-Negative Matrix Factorization Inderjit S. Dhillon University of Texas at Austin SIAM Conference on Applied Linear Algebra Valencia, Spain June 19, 2012 Joint work
Fast Coordinate Descent methods for Non-Negative Matrix Factorization Inderjit S. Dhillon University of Texas at Austin SIAM Conference on Applied Linear Algebra Valencia, Spain June 19, 2012 Joint work
HYPERGRAPH BASED SEMI-SUPERVISED LEARNING ALGORITHMS APPLIED TO SPEECH RECOGNITION PROBLEM: A NOVEL APPROACH
 HYPERGRAPH BASED SEMI-SUPERVISED LEARNING ALGORITHMS APPLIED TO SPEECH RECOGNITION PROBLEM: A NOVEL APPROACH Hoang Trang 1, Tran Hoang Loc 1 1 Ho Chi Minh City University of Technology-VNU HCM, Ho Chi
HYPERGRAPH BASED SEMI-SUPERVISED LEARNING ALGORITHMS APPLIED TO SPEECH RECOGNITION PROBLEM: A NOVEL APPROACH Hoang Trang 1, Tran Hoang Loc 1 1 Ho Chi Minh City University of Technology-VNU HCM, Ho Chi
Statistical Machine Learning
 Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Principal Component Analysis
 Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
A Randomized Approach for Crowdsourcing in the Presence of Multiple Views
 A Randomized Approach for Crowdsourcing in the Presence of Multiple Views Presenter: Yao Zhou joint work with: Jingrui He - 1 - Roadmap Motivation Proposed framework: M2VW Experimental results Conclusion
A Randomized Approach for Crowdsourcing in the Presence of Multiple Views Presenter: Yao Zhou joint work with: Jingrui He - 1 - Roadmap Motivation Proposed framework: M2VW Experimental results Conclusion
PROBABILISTIC LATENT SEMANTIC ANALYSIS
 PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
PROBABILISTIC LATENT SEMANTIC ANALYSIS Lingjia Deng Revised from slides of Shuguang Wang Outline Review of previous notes PCA/SVD HITS Latent Semantic Analysis Probabilistic Latent Semantic Analysis Applications
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
CS145: INTRODUCTION TO DATA MINING Text Data: Topic Model Instructor: Yizhou Sun yzsun@cs.ucla.edu December 4, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification Clustering
Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text
 Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text Yi Zhang Machine Learning Department Carnegie Mellon University yizhang1@cs.cmu.edu Jeff Schneider The Robotics Institute
Learning the Semantic Correlation: An Alternative Way to Gain from Unlabeled Text Yi Zhang Machine Learning Department Carnegie Mellon University yizhang1@cs.cmu.edu Jeff Schneider The Robotics Institute
Solving Systems of Equations Row Reduction
 Solving Systems of Equations Row Reduction November 19, 2008 Though it has not been a primary topic of interest for us, the task of solving a system of linear equations has come up several times. For example,
Solving Systems of Equations Row Reduction November 19, 2008 Though it has not been a primary topic of interest for us, the task of solving a system of linear equations has come up several times. For example,
PCA and admixture models
 PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
Lecture 21: Spectral Learning for Graphical Models
 10-708: Probabilistic Graphical Models 10-708, Spring 2016 Lecture 21: Spectral Learning for Graphical Models Lecturer: Eric P. Xing Scribes: Maruan Al-Shedivat, Wei-Cheng Chang, Frederick Liu 1 Motivation
10-708: Probabilistic Graphical Models 10-708, Spring 2016 Lecture 21: Spectral Learning for Graphical Models Lecturer: Eric P. Xing Scribes: Maruan Al-Shedivat, Wei-Cheng Chang, Frederick Liu 1 Motivation
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Block Coordinate Descent for Regularized Multi-convex Optimization
 Block Coordinate Descent for Regularized Multi-convex Optimization Yangyang Xu and Wotao Yin CAAM Department, Rice University February 15, 2013 Multi-convex optimization Model definition Applications Outline
Block Coordinate Descent for Regularized Multi-convex Optimization Yangyang Xu and Wotao Yin CAAM Department, Rice University February 15, 2013 Multi-convex optimization Model definition Applications Outline
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Coding the Matrix Index - Version 0
 0 vector, [definition]; (2.4.1): 68 2D geometry, transformations in, [lab]; (4.15.0): 196-200 A T (matrix A transpose); (4.5.4): 157 absolute value, complex number; (1.4.1): 43 abstract/abstracting, over
0 vector, [definition]; (2.4.1): 68 2D geometry, transformations in, [lab]; (4.15.0): 196-200 A T (matrix A transpose); (4.5.4): 157 absolute value, complex number; (1.4.1): 43 abstract/abstracting, over
Expressive Efficiency and Inductive Bias of Convolutional Networks:
 Expressive Efficiency and Inductive Bias of Convolutional Networks: Analysis & Design via Hierarchical Tensor Decompositions Nadav Cohen The Hebrew University of Jerusalem AAAI Spring Symposium Series
Expressive Efficiency and Inductive Bias of Convolutional Networks: Analysis & Design via Hierarchical Tensor Decompositions Nadav Cohen The Hebrew University of Jerusalem AAAI Spring Symposium Series
From Binary to Multiclass Classification. CS 6961: Structured Prediction Spring 2018
 From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
Expressive Efficiency and Inductive Bias of Convolutional Networks:
 Expressive Efficiency and Inductive Bias of Convolutional Networks: Analysis & Design via Hierarchical Tensor Decompositions Nadav Cohen The Hebrew University of Jerusalem AAAI Spring Symposium Series
Expressive Efficiency and Inductive Bias of Convolutional Networks: Analysis & Design via Hierarchical Tensor Decompositions Nadav Cohen The Hebrew University of Jerusalem AAAI Spring Symposium Series
Spectral Clustering using Multilinear SVD
 Spectral Clustering using Multilinear SVD Analysis, Approximations and Applications Debarghya Ghoshdastidar, Ambedkar Dukkipati Dept. of Computer Science & Automation Indian Institute of Science Clustering:
Spectral Clustering using Multilinear SVD Analysis, Approximations and Applications Debarghya Ghoshdastidar, Ambedkar Dukkipati Dept. of Computer Science & Automation Indian Institute of Science Clustering:
Finding normalized and modularity cuts by spectral clustering. Ljubjana 2010, October
 Finding normalized and modularity cuts by spectral clustering Marianna Bolla Institute of Mathematics Budapest University of Technology and Economics marib@math.bme.hu Ljubjana 2010, October Outline Find
Finding normalized and modularity cuts by spectral clustering Marianna Bolla Institute of Mathematics Budapest University of Technology and Economics marib@math.bme.hu Ljubjana 2010, October Outline Find
Temporal Multi-View Inconsistency Detection for Network Traffic Analysis
 WWW 15 Florence, Italy Temporal Multi-View Inconsistency Detection for Network Traffic Analysis Houping Xiao 1, Jing Gao 1, Deepak Turaga 2, Long Vu 2, and Alain Biem 2 1 Department of Computer Science
WWW 15 Florence, Italy Temporal Multi-View Inconsistency Detection for Network Traffic Analysis Houping Xiao 1, Jing Gao 1, Deepak Turaga 2, Long Vu 2, and Alain Biem 2 1 Department of Computer Science
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 218 Outlines Overview Introduction Linear Algebra Probability Linear Regression 1
Nonnegative Matrix Factorization
 Nonnegative Matrix Factorization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Nonnegative Matrix Factorization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Latent Semantic Analysis. Hongning Wang
 Latent Semantic Analysis Hongning Wang CS@UVa VS model in practice Document and query are represented by term vectors Terms are not necessarily orthogonal to each other Synonymy: car v.s. automobile Polysemy:
Latent Semantic Analysis Hongning Wang CS@UVa VS model in practice Document and query are represented by term vectors Terms are not necessarily orthogonal to each other Synonymy: car v.s. automobile Polysemy:
Dynamic P n to P n Alignment
 Dynamic P n to P n Alignment Amnon Shashua and Lior Wolf School of Engineering and Computer Science, the Hebrew University of Jerusalem, Jerusalem, 91904, Israel {shashua,lwolf}@cs.huji.ac.il We introduce
Dynamic P n to P n Alignment Amnon Shashua and Lior Wolf School of Engineering and Computer Science, the Hebrew University of Jerusalem, Jerusalem, 91904, Israel {shashua,lwolf}@cs.huji.ac.il We introduce
CPSC 340: Machine Learning and Data Mining. More PCA Fall 2017
 CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
CPSC 340: Machine Learning and Data Mining More PCA Fall 2017 Admin Assignment 4: Due Friday of next week. No class Monday due to holiday. There will be tutorials next week on MAP/PCA (except Monday).
Joint Factor Analysis for Speaker Verification
 Joint Factor Analysis for Speaker Verification Mengke HU ASPITRG Group, ECE Department Drexel University mengke.hu@gmail.com October 12, 2012 1/37 Outline 1 Speaker Verification Baseline System Session
Joint Factor Analysis for Speaker Verification Mengke HU ASPITRG Group, ECE Department Drexel University mengke.hu@gmail.com October 12, 2012 1/37 Outline 1 Speaker Verification Baseline System Session
Learning with Matrix Factorizations
 Learning with Matrix Factorizations Nati Srebro Department of Electrical Engineering and Computer Science Massachusetts Institute of Technology Adviser: Tommi Jaakkola (MIT) Committee: Alan Willsky (MIT),
Learning with Matrix Factorizations Nati Srebro Department of Electrical Engineering and Computer Science Massachusetts Institute of Technology Adviser: Tommi Jaakkola (MIT) Committee: Alan Willsky (MIT),
Randomized Algorithms
 Randomized Algorithms Saniv Kumar, Google Research, NY EECS-6898, Columbia University - Fall, 010 Saniv Kumar 9/13/010 EECS6898 Large Scale Machine Learning 1 Curse of Dimensionality Gaussian Mixture Models
Randomized Algorithms Saniv Kumar, Google Research, NY EECS-6898, Columbia University - Fall, 010 Saniv Kumar 9/13/010 EECS6898 Large Scale Machine Learning 1 Curse of Dimensionality Gaussian Mixture Models
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Variable Latent Semantic Indexing
 Variable Latent Semantic Indexing Prabhakar Raghavan Yahoo! Research Sunnyvale, CA November 2005 Joint work with A. Dasgupta, R. Kumar, A. Tomkins. Yahoo! Research. Outline 1 Introduction 2 Background
Variable Latent Semantic Indexing Prabhakar Raghavan Yahoo! Research Sunnyvale, CA November 2005 Joint work with A. Dasgupta, R. Kumar, A. Tomkins. Yahoo! Research. Outline 1 Introduction 2 Background
Tensor Methods for Feature Learning
 Tensor Methods for Feature Learning Anima Anandkumar U.C. Irvine Feature Learning For Efficient Classification Find good transformations of input for improved classification Figures used attributed to
Tensor Methods for Feature Learning Anima Anandkumar U.C. Irvine Feature Learning For Efficient Classification Find good transformations of input for improved classification Figures used attributed to
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
Matrix factorization models for patterns beyond blocks. Pauli Miettinen 18 February 2016
 Matrix factorization models for patterns beyond blocks 18 February 2016 What does a matrix factorization do?? A = U V T 2 For SVD that s easy! 3 Inner-product interpretation Element (AB) ij is the inner
Matrix factorization models for patterns beyond blocks 18 February 2016 What does a matrix factorization do?? A = U V T 2 For SVD that s easy! 3 Inner-product interpretation Element (AB) ij is the inner
A randomized algorithm for approximating the SVD of a matrix
 A randomized algorithm for approximating the SVD of a matrix Joint work with Per-Gunnar Martinsson (U. of Colorado) and Vladimir Rokhlin (Yale) Mark Tygert Program in Applied Mathematics Yale University
A randomized algorithm for approximating the SVD of a matrix Joint work with Per-Gunnar Martinsson (U. of Colorado) and Vladimir Rokhlin (Yale) Mark Tygert Program in Applied Mathematics Yale University
Latent Semantic Analysis. Hongning Wang
 Latent Semantic Analysis Hongning Wang CS@UVa Recap: vector space model Represent both doc and query by concept vectors Each concept defines one dimension K concepts define a high-dimensional space Element
Latent Semantic Analysis Hongning Wang CS@UVa Recap: vector space model Represent both doc and query by concept vectors Each concept defines one dimension K concepts define a high-dimensional space Element
Clustering with k-means and Gaussian mixture distributions
 Clustering with k-means and Gaussian mixture distributions Machine Learning and Category Representation 2012-2013 Jakob Verbeek, ovember 23, 2012 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.12.13
Clustering with k-means and Gaussian mixture distributions Machine Learning and Category Representation 2012-2013 Jakob Verbeek, ovember 23, 2012 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.12.13
Lecture 7: Con3nuous Latent Variable Models
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
Learning Gaussian Graphical Models with Unknown Group Sparsity
 Learning Gaussian Graphical Models with Unknown Group Sparsity Kevin Murphy Ben Marlin Depts. of Statistics & Computer Science Univ. British Columbia Canada Connections Graphical models Density estimation
Learning Gaussian Graphical Models with Unknown Group Sparsity Kevin Murphy Ben Marlin Depts. of Statistics & Computer Science Univ. British Columbia Canada Connections Graphical models Density estimation
Maximum Margin Matrix Factorization
 Maximum Margin Matrix Factorization Nati Srebro Toyota Technological Institute Chicago Joint work with Noga Alon Tel-Aviv Yonatan Amit Hebrew U Alex d Aspremont Princeton Michael Fink Hebrew U Tommi Jaakkola
Maximum Margin Matrix Factorization Nati Srebro Toyota Technological Institute Chicago Joint work with Noga Alon Tel-Aviv Yonatan Amit Hebrew U Alex d Aspremont Princeton Michael Fink Hebrew U Tommi Jaakkola
Lecture 13. Principal Component Analysis. Brett Bernstein. April 25, CDS at NYU. Brett Bernstein (CDS at NYU) Lecture 13 April 25, / 26
 Lecture 13 April 25, / 26") Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Structure in Data. A major objective in data analysis is to identify interesting features or structure in the data.
 Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Expectation Maximization
 Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
chapter 12 MORE MATRIX ALGEBRA 12.1 Systems of Linear Equations GOALS
 chapter MORE MATRIX ALGEBRA GOALS In Chapter we studied matrix operations and the algebra of sets and logic. We also made note of the strong resemblance of matrix algebra to elementary algebra. The reader
chapter MORE MATRIX ALGEBRA GOALS In Chapter we studied matrix operations and the algebra of sets and logic. We also made note of the strong resemblance of matrix algebra to elementary algebra. The reader
26 : Spectral GMs. Lecturer: Eric P. Xing Scribes: Guillermo A Cidre, Abelino Jimenez G.
 10-708: Probabilistic Graphical Models, Spring 2015 26 : Spectral GMs Lecturer: Eric P. Xing Scribes: Guillermo A Cidre, Abelino Jimenez G. 1 Introduction A common task in machine learning is to work with
10-708: Probabilistic Graphical Models, Spring 2015 26 : Spectral GMs Lecturer: Eric P. Xing Scribes: Guillermo A Cidre, Abelino Jimenez G. 1 Introduction A common task in machine learning is to work with
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation)
") Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
Kernel Density Topic Models: Visual Topics Without Visual Words
 Kernel Density Topic Models: Visual Topics Without Visual Words Konstantinos Rematas K.U. Leuven ESAT-iMinds krematas@esat.kuleuven.be Mario Fritz Max Planck Institute for Informatics mfrtiz@mpi-inf.mpg.de
Kernel Density Topic Models: Visual Topics Without Visual Words Konstantinos Rematas K.U. Leuven ESAT-iMinds krematas@esat.kuleuven.be Mario Fritz Max Planck Institute for Informatics mfrtiz@mpi-inf.mpg.de
sublinear time low-rank approximation of positive semidefinite matrices Cameron Musco (MIT) and David P. Woodru (CMU)
 and David P. Woodru (CMU)") sublinear time low-rank approximation of positive semidefinite matrices Cameron Musco (MIT) and David P. Woodru (CMU) 0 overview Our Contributions: 1 overview Our Contributions: A near optimal low-rank
sublinear time low-rank approximation of positive semidefinite matrices Cameron Musco (MIT) and David P. Woodru (CMU) 0 overview Our Contributions: 1 overview Our Contributions: A near optimal low-rank
CPSC 340: Machine Learning and Data Mining. Sparse Matrix Factorization Fall 2018
 CPSC 340: Machine Learning and Data Mining Sparse Matrix Factorization Fall 2018 Last Time: PCA with Orthogonal/Sequential Basis When k = 1, PCA has a scaling problem. When k > 1, have scaling, rotation,
CPSC 340: Machine Learning and Data Mining Sparse Matrix Factorization Fall 2018 Last Time: PCA with Orthogonal/Sequential Basis When k = 1, PCA has a scaling problem. When k > 1, have scaling, rotation,
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 2 - Spring 2017 Lecture 6 Jan-Willem van de Meent (credit: Yijun Zhao, Chris Bishop, Andrew Moore, Hastie et al.) Project Project Deadlines 3 Feb: Form teams of
Data Mining Techniques CS 6220 - Section 2 - Spring 2017 Lecture 6 Jan-Willem van de Meent (credit: Yijun Zhao, Chris Bishop, Andrew Moore, Hastie et al.) Project Project Deadlines 3 Feb: Form teams of
K-Means and Gaussian Mixture Models
 K-Means and Gaussian Mixture Models David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 42 K-Means Clustering K-Means Clustering David
K-Means and Gaussian Mixture Models David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 42 K-Means Clustering K-Means Clustering David
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Machine learning for pervasive systems Classification in high-dimensional spaces
 Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Machine learning for pervasive systems Classification in high-dimensional spaces Department of Communications and Networking Aalto University, School of Electrical Engineering stephan.sigg@aalto.fi Version
Expectation Maximization
 Expectation Maximization Machine Learning CSE546 Carlos Guestrin University of Washington November 13, 2014 1 E.M.: The General Case E.M. widely used beyond mixtures of Gaussians The recipe is the same
Expectation Maximization Machine Learning CSE546 Carlos Guestrin University of Washington November 13, 2014 1 E.M.: The General Case E.M. widely used beyond mixtures of Gaussians The recipe is the same
Unsupervised Machine Learning and Data Mining. DS 5230 / DS Fall Lecture 7. Jan-Willem van de Meent
 Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Machine Learning Basics
 Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Security and Fairness of Deep Learning Machine Learning Basics Anupam Datta CMU Spring 2019 Image Classification Image Classification Image classification pipeline Input: A training set of N images, each
Mixture of Gaussians Models
 Mixture of Gaussians Models Outline Inference, Learning, and Maximum Likelihood Why Mixtures? Why Gaussians? Building up to the Mixture of Gaussians Single Gaussians Fully-Observed Mixtures Hidden Mixtures
Mixture of Gaussians Models Outline Inference, Learning, and Maximum Likelihood Why Mixtures? Why Gaussians? Building up to the Mixture of Gaussians Single Gaussians Fully-Observed Mixtures Hidden Mixtures
Orthogonal Nonnegative Matrix Factorization: Multiplicative Updates on Stiefel Manifolds
 Orthogonal Nonnegative Matrix Factorization: Multiplicative Updates on Stiefel Manifolds Jiho Yoo and Seungjin Choi Department of Computer Science Pohang University of Science and Technology San 31 Hyoja-dong,
Orthogonal Nonnegative Matrix Factorization: Multiplicative Updates on Stiefel Manifolds Jiho Yoo and Seungjin Choi Department of Computer Science Pohang University of Science and Technology San 31 Hyoja-dong,
Linear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Principal Component Analysis 3 Factor Analysis
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Principal Component Analysis 3 Factor Analysis
Boosting Dilated Convolutional Networks with Mixed Tensor Decompositions
 Boosting Dilated Convolutional Networks with Mixed Tensor Decompositions Nadav Cohen Ronen Tamari Amnon Shashua Institute for Advanced Study Hebrew University of Jerusalem International Conference on Learning
Boosting Dilated Convolutional Networks with Mixed Tensor Decompositions Nadav Cohen Ronen Tamari Amnon Shashua Institute for Advanced Study Hebrew University of Jerusalem International Conference on Learning
Eigenvalue Problems Computation and Applications
 Eigenvalue ProblemsComputation and Applications p. 1/36 Eigenvalue Problems Computation and Applications Che-Rung Lee cherung@gmail.com National Tsing Hua University Eigenvalue ProblemsComputation and
Eigenvalue ProblemsComputation and Applications p. 1/36 Eigenvalue Problems Computation and Applications Che-Rung Lee cherung@gmail.com National Tsing Hua University Eigenvalue ProblemsComputation and
Machine Learning Techniques for Computer Vision
 Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Machine Learning Techniques for Computer Vision Part 2: Unsupervised Learning Microsoft Research Cambridge x 3 1 0.5 0.2 0 0.5 0.3 0 0.5 1 ECCV 2004, Prague x 2 x 1 Overview of Part 2 Mixture models EM
Undirected Graphical Models
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
CS 231A Section 1: Linear Algebra & Probability Review
 CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
CS 231A Section 1: Linear Algebra & Probability Review. Kevin Tang
 CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Classification: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu September 21, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
CS6220: DATA MINING TECHNIQUES Matrix Data: Classification: Part 2 Instructor: Yizhou Sun yzsun@ccs.neu.edu September 21, 2014 Methods to Learn Matrix Data Set Data Sequence Data Time Series Graph & Network
Probabilistic Time Series Classification
 Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Probabilistic Latent Variable Models as Non-Negative Factorizations
 1 Probabilistic Latent Variable Models as Non-Negative Factorizations Madhusudana Shashanka, Bhiksha Raj, Paris Smaragdis Abstract In this paper, we present a family of probabilistic latent variable models
1 Probabilistic Latent Variable Models as Non-Negative Factorizations Madhusudana Shashanka, Bhiksha Raj, Paris Smaragdis Abstract In this paper, we present a family of probabilistic latent variable models
Latent Variable Models and EM algorithm
 Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Latent Variable Models and EM algorithm SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic 3.1 Clustering and Mixture Modelling K-means and hierarchical clustering are non-probabilistic
Quantum Computing Lecture 2. Review of Linear Algebra
 Quantum Computing Lecture 2 Review of Linear Algebra Maris Ozols Linear algebra States of a quantum system form a vector space and their transformations are described by linear operators Vector spaces
Quantum Computing Lecture 2 Review of Linear Algebra Maris Ozols Linear algebra States of a quantum system form a vector space and their transformations are described by linear operators Vector spaces
Uncorrelated Multilinear Principal Component Analysis through Successive Variance Maximization
 Uncorrelated Multilinear Principal Component Analysis through Successive Variance Maximization Haiping Lu 1 K. N. Plataniotis 1 A. N. Venetsanopoulos 1,2 1 Department of Electrical & Computer Engineering,
Uncorrelated Multilinear Principal Component Analysis through Successive Variance Maximization Haiping Lu 1 K. N. Plataniotis 1 A. N. Venetsanopoulos 1,2 1 Department of Electrical & Computer Engineering,
Bruce Hendrickson Discrete Algorithms & Math Dept. Sandia National Labs Albuquerque, New Mexico Also, CS Department, UNM
 Latent Semantic Analysis and Fiedler Retrieval Bruce Hendrickson Discrete Algorithms & Math Dept. Sandia National Labs Albuquerque, New Mexico Also, CS Department, UNM Informatics & Linear Algebra Eigenvectors
Latent Semantic Analysis and Fiedler Retrieval Bruce Hendrickson Discrete Algorithms & Math Dept. Sandia National Labs Albuquerque, New Mexico Also, CS Department, UNM Informatics & Linear Algebra Eigenvectors
Codes on graphs. Chapter Elementary realizations of linear block codes
 Chapter 11 Codes on graphs In this chapter we will introduce the subject of codes on graphs. This subject forms an intellectual foundation for all known classes of capacity-approaching codes, including
Chapter 11 Codes on graphs In this chapter we will introduce the subject of codes on graphs. This subject forms an intellectual foundation for all known classes of capacity-approaching codes, including
High-Rank Matrix Completion and Subspace Clustering with Missing Data
 High-Rank Matrix Completion and Subspace Clustering with Missing Data Authors: Brian Eriksson, Laura Balzano and Robert Nowak Presentation by Wang Yuxiang 1 About the authors
High-Rank Matrix Completion and Subspace Clustering with Missing Data Authors: Brian Eriksson, Laura Balzano and Robert Nowak Presentation by Wang Yuxiang 1 About the authors
Lecture Notes 1: Vector spaces
 Optimization-based data analysis Fall 2017 Lecture Notes 1: Vector spaces In this chapter we review certain basic concepts of linear algebra, highlighting their application to signal processing. 1 Vector
Optimization-based data analysis Fall 2017 Lecture Notes 1: Vector spaces In this chapter we review certain basic concepts of linear algebra, highlighting their application to signal processing. 1 Vector
Data Mining and Matrices
 Data Mining and Matrices 05 Semi-Discrete Decomposition Rainer Gemulla, Pauli Miettinen May 16, 2013 Outline 1 Hunting the Bump 2 Semi-Discrete Decomposition 3 The Algorithm 4 Applications SDD alone SVD
Data Mining and Matrices 05 Semi-Discrete Decomposition Rainer Gemulla, Pauli Miettinen May 16, 2013 Outline 1 Hunting the Bump 2 Semi-Discrete Decomposition 3 The Algorithm 4 Applications SDD alone SVD
Fantope Regularization in Metric Learning
 Fantope Regularization in Metric Learning CVPR 2014 Marc T. Law (LIP6, UPMC), Nicolas Thome (LIP6 - UPMC Sorbonne Universités), Matthieu Cord (LIP6 - UPMC Sorbonne Universités), Paris, France Introduction
Fantope Regularization in Metric Learning CVPR 2014 Marc T. Law (LIP6, UPMC), Nicolas Thome (LIP6 - UPMC Sorbonne Universités), Matthieu Cord (LIP6 - UPMC Sorbonne Universités), Paris, France Introduction
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering