Mixture of Gaussians Models
|
|
|
- Francis Booker
- 5 years ago
- Views:
Transcription
1 Mixture of Gaussians Models
2 Outline Inference, Learning, and Maximum Likelihood Why Mixtures? Why Gaussians? Building up to the Mixture of Gaussians Single Gaussians Fully-Observed Mixtures Hidden Mixtures
3 Perception Involves Inference and Learning Must infer the hidden causes, α, of sensory data, x Sensory data: air pressure wave frequency composition, patterns of electromagnetic radiation Hidden causes: proverbial tigers in bushes, lecture slides, sentences Must learn the correct model for the relationship between hidden causes and sensory data Models will be parameterized, with parameters θ We will use quality of prediction as our figure of merit


4 Generative models inference explanation or prediction
5 Maximum Likelihood and Maximum a Posteriori The model parameters θ that make the data most probable are called the maximum likelihood parameters or hidden causes α or causes INFERENCE LEARNING
6 In practice, we maximize log-likelihoods Taking logs doesn t change the answer Logs turn multiplication into addition Logs turn many natural operations on probabilities into linear algebra operations Negative log probabilities arise naturally in information theory

7 The Maximum Likelihood Answer Depends on Model Class
8 Outline Inference, Learning, and Maximum Likelihood Why Mixtures? Why Gaussians? Building up to the Mixture of Gaussians Single Gaussians Fully-Observed Mixtures Hidden Mixtures
9 Why Mixtures?
10 What is a Mixture Model? DATA LIKELIHOOD PRIOR This is precisely analogous to using a basis to approximate a vector

11 Example Mixture Datasets Mixtures of Uniforms Spike-And-Gaussian Mixtures Mixtures of Gaussians
12 Why Gaussians?

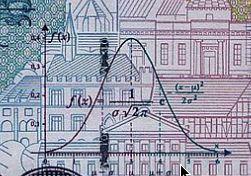
13 Why Gaussians? Wikipedia
14 Why Gaussians? An unhelpfully terse answer. Gaussians satisfy a particular differential equation: From this differential equation, all the properties of the Gaussian family can be derived without solving for the explicit form. Gaussians are isotropic, Fourier transform of a Gaussian is a Gaussian, sum of Gaussian RVs is Gaussian, Central Limit Theorem See this blogpost for details:
15 Why Gaussians? Gaussians are everywhere, thanks to the Central Limit Theorem Gaussians are the maximum entropy distribution with a given center (mean) and spread (std dev) Inference on Gaussians is linear algebra
16 Central Limit Theorem Statistics: adding up independent random variables with finite variances results in a Gaussian distribution Science: if we assume that many small, independent random factors produce the noise in our results, we should see a Gaussian distribution
17 Central Limit Theorem in Action
18 Central Limit Theorem in Action
19 Why Gaussians? Gaussians are everywhere, thanks to the Central Limit Theorem Gaussians are the maximum entropy distribution with a given center (mean) and spread (std dev) Inference on Gaussians is linear algebra
20 Gaussians are a natural MAXENT distribution The principle of maximum entropy (MAXENT) will be covered in detail later Teaser: MAXENT maps statistics of data to probability distributions in a principled, faithful manner For the most common choice of statistic, mean ± s.d., the MAXENT is a Gaussian
21 Why Gaussians? Gaussians are everywhere, thanks to the Central Limit Theorem Gaussians are the maximum entropy distribution with a given center (mean) and spread (std dev) Inference on Gaussians is linear algebra
22 Inference with Gaussians is just linear algebra The log-probabilities of a Gaussian are a negative-definite quadratic form Quadratic forms can be mapped onto matrices So solving an inference problem becomes solving a linear algebra problem Linear algebra is the Scottie Pippen of mathematics
23 Outline Inference, Learning, and Maximum Likelihood Why Mixtures? Why Gaussians? Building up to the Mixture of Gaussians Single Gaussians Fully-Observed Mixtures Hidden Mixtures
24 What is a Gaussian Mixture Model? DATA LIKELIHOOD PRIOR Example
25 Maximum Likelihood for Gaussian Mixture Models Plan of Attack: ML for a single Gaussian ML for a fully-observed mixture ML for a hidden mixture

26 Maximum Likelihood for a Single Gaussian
27 Maximum Likelihood for a Single Gaussian
28 Maximum Likelihood for a Single Gaussian By a similar argument:
29 Maximum Likelihood for Gaussian Mixture Models Plan of Attack: ML for a single Gaussian ML for a fully-observed mixture ML for a hidden mixture
30 Maximum Likelihood for Fully-Observed Mixture Observed Mixture means we receive datapoints (x,α). Examples: classification (discrete), regression (continuous) Cats Dogs Memming Wordpress Blog
31 Maximum Likelihood for Fully-Observed Mixture For each mixture element, the problem is exactly the same - what are the parameters of a single Gaussian? Because we know which mixture each data point came from, we can solve all these problems separately, using the same method as for a single Gaussian. How do we figure out the mixture weights w?
32 Bonus: We Can Now Classify Unlabeled Datapoints We can label new datapoints x with a corresponding α using our model This is the key idea behind supervised learning approaches in general. How do we label them? Max Likelihood method - find the closest mean (in z-score units), that s our label Fully Bayesian method - maintain a distribution over the labels - p(α x ; θ) Dogs Cats Memming Wordpress Blog
33 Maximum Likelihood for Gaussian Mixture Models Plan of Attack: ML for a single Gaussian ML for a fully-observed mixture ML for a hidden mixture


34 Hidden Variables Example: Spike Sorting Martinez, Quiran Quiroga, et al., 2009 Journal of Neuroscience Methods
35 Maximum Likelihood for Models with Hidden Variables p(x μ,σ,α) is the same, but now we don t have the labels α. Problem: if we had the labels, we could find the parameters (just as before), and if we had the parameters, we could compute the labels (again, just as before). It s a chicken-and-egg problem! Solution: let s just make-believe we have the parameters.

36 Our Clustering Algorithm on Spike Sorting Wikipedia
37 Our Clustering Algorithm on Spike Sorting Wikipedia
38 The K-Means Algorithm 1. Make up K values for the means of the clusters 2. Assign datapoints to clusters Usually initialized randomly Each datapoint is assigned to the nearest cluster Update the cluster means to the new empirical means Repeat 2-4.
39 Issues with K-Means 1. Cluster assignment step (inference) is not Bayesian 2. Small changes in data can cause big changes in behavior
40 Soft Clustering? Bishop - PRML
41 Expectation-Maximization for Means Make up K values for the means (E) Infer p(α x) for each x and α (M) Update the means via weighted average a. 4. Weight the contribution of datapoint x by p(α x) Repeat 2-4.
42 Full Expectation-Maximization Make up K values for the means, covariances, and mixture weights (E) Infer p(α x) for each x and α (M) Update the parameters with weighted averages a. 4. Weight the contribution of datapoint x by p(α x) Repeat 2-4.
43 E-Step: Bayes Rule for Inference
44 M-Step: Direct Maximization
45 Bonus Slides: Information Geometry
46 A Geometric View All Probability Distributions Family of Model Distributions
47 Geometry of MLE All Probability Distributions Family of Model Distributions (here, Gaussians with different means)
48 Geometry of EM Family of Data Labelings (same p(x), different p(a x)) All Probability Distributions Family of Model Distributions
49 Family of Data Labelings E-Step: Inference M-Step: Learning Family of Model Distributions
Gaussian Mixture Models, Expectation Maximization
 Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Gaussian Mixture Models, Expectation Maximization Instructor: Jessica Wu Harvey Mudd College The instructor gratefully acknowledges Andrew Ng (Stanford), Andrew Moore (CMU), Eric Eaton (UPenn), David Kauchak
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a
 Lecture 20.a") Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Parametric Unsupervised Learning Expectation Maximization (EM) Lecture 20.a Some slides are due to Christopher Bishop Limitations of K-means Hard assignments of data points to clusters small shift of a
Data Preprocessing. Cluster Similarity
 1 Cluster Similarity Similarity is most often measured with the help of a distance function. The smaller the distance, the more similar the data objects (points). A function d: M M R is a distance on M
1 Cluster Similarity Similarity is most often measured with the help of a distance function. The smaller the distance, the more similar the data objects (points). A function d: M M R is a distance on M
Parametric Models. Dr. Shuang LIANG. School of Software Engineering TongJi University Fall, 2012
 Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Parametric Models Dr. Shuang LIANG School of Software Engineering TongJi University Fall, 2012 Today s Topics Maximum Likelihood Estimation Bayesian Density Estimation Today s Topics Maximum Likelihood
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 The Generative Model POV We think of the data as being generated from some process. We assume
Expectation Maximization Algorithm
 Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
Expectation Maximization Algorithm Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein, Luke Zettlemoyer and Dan Weld The Evils of Hard Assignments? Clusters
Machine Learning for Data Science (CS4786) Lecture 12
 Lecture 12") Machine Learning for Data Science (CS4786) Lecture 12 Gaussian Mixture Models Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016fa/ Back to K-means Single link is sensitive to outliners We
Machine Learning for Data Science (CS4786) Lecture 12 Gaussian Mixture Models Course Webpage : http://www.cs.cornell.edu/courses/cs4786/2016fa/ Back to K-means Single link is sensitive to outliners We
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project
 Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Chapter 3: Maximum-Likelihood & Bayesian Parameter Estimation (part 1)
") HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
HW 1 due today Parameter Estimation Biometrics CSE 190 Lecture 7 Today s lecture was on the blackboard. These slides are an alternative presentation of the material. CSE190, Winter10 CSE190, Winter10 Chapter
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
Statistical learning. Chapter 20, Sections 1 4 1
 Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Statistical learning Chapter 20, Sections 1 4 Chapter 20, Sections 1 4 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Mixtures of Gaussians continued
 Mixtures of Gaussians continued Machine Learning CSE446 Carlos Guestrin University of Washington May 17, 2013 1 One) bad case for k-means n Clusters may overlap n Some clusters may be wider than others
Mixtures of Gaussians continued Machine Learning CSE446 Carlos Guestrin University of Washington May 17, 2013 1 One) bad case for k-means n Clusters may overlap n Some clusters may be wider than others
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
ECE521 week 3: 23/26 January 2017
 ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
ECE521 week 3: 23/26 January 2017 Outline Probabilistic interpretation of linear regression - Maximum likelihood estimation (MLE) - Maximum a posteriori (MAP) estimation Bias-variance trade-off Linear
CSE446: Clustering and EM Spring 2017
 CSE446: Clustering and EM Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin, Dan Klein, and Luke Zettlemoyer Clustering systems: Unsupervised learning Clustering Detect patterns in unlabeled
CSE446: Clustering and EM Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin, Dan Klein, and Luke Zettlemoyer Clustering systems: Unsupervised learning Clustering Detect patterns in unlabeled
MIXTURE MODELS AND EM
 Last updated: November 6, 212 MIXTURE MODELS AND EM Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis,
Last updated: November 6, 212 MIXTURE MODELS AND EM Credits 2 Some of these slides were sourced and/or modified from: Christopher Bishop, Microsoft UK Simon Prince, University College London Sergios Theodoridis,
Linear Models for Classification
 Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
Linear Models for Classification Oliver Schulte - CMPT 726 Bishop PRML Ch. 4 Classification: Hand-written Digit Recognition CHINE INTELLIGENCE, VOL. 24, NO. 24, APRIL 2002 x i = t i = (0, 0, 0, 1, 0, 0,
K-Means and Gaussian Mixture Models
 K-Means and Gaussian Mixture Models David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 42 K-Means Clustering K-Means Clustering David
K-Means and Gaussian Mixture Models David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 42 K-Means Clustering K-Means Clustering David
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Pattern Recognition. Parameter Estimation of Probability Density Functions
 Pattern Recognition Parameter Estimation of Probability Density Functions Classification Problem (Review) The classification problem is to assign an arbitrary feature vector x F to one of c classes. The
Pattern Recognition Parameter Estimation of Probability Density Functions Classification Problem (Review) The classification problem is to assign an arbitrary feature vector x F to one of c classes. The
SYDE 372 Introduction to Pattern Recognition. Probability Measures for Classification: Part I
 SYDE 372 Introduction to Pattern Recognition Probability Measures for Classification: Part I Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 Why use probability
SYDE 372 Introduction to Pattern Recognition Probability Measures for Classification: Part I Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 Why use probability
COM336: Neural Computing
 COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
COM336: Neural Computing http://www.dcs.shef.ac.uk/ sjr/com336/ Lecture 2: Density Estimation Steve Renals Department of Computer Science University of Sheffield Sheffield S1 4DP UK email: s.renals@dcs.shef.ac.uk
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Expectation Maximization Mark Schmidt University of British Columbia Winter 2018 Last Time: Learning with MAR Values We discussed learning with missing at random values in data:
CPSC 540: Machine Learning Expectation Maximization Mark Schmidt University of British Columbia Winter 2018 Last Time: Learning with MAR Values We discussed learning with missing at random values in data:
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
Expectation Maximization
 Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Expectation Maximization Aaron C. Courville Université de Montréal Note: Material for the slides is taken directly from a presentation prepared by Christopher M. Bishop Learning in DAGs Two things could
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Lior Wolf 2014-15 We know that X ~ B(n,p), but we do not know p. We get a random sample from X, a
Introduction to Bayesian Learning. Machine Learning Fall 2018
 Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Introduction to Bayesian Learning Machine Learning Fall 2018 1 What we have seen so far What does it mean to learn? Mistake-driven learning Learning by counting (and bounding) number of mistakes PAC learnability
Clustering K-means. Clustering images. Machine Learning CSE546 Carlos Guestrin University of Washington. November 4, 2014.
 Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Clustering K-means Machine Learning CSE546 Carlos Guestrin University of Washington November 4, 2014 1 Clustering images Set of Images [Goldberger et al.] 2 1 K-means Randomly initialize k centers µ (0)
Probabilistic Machine Learning. Industrial AI Lab.
 Probabilistic Machine Learning Industrial AI Lab. Probabilistic Linear Regression Outline Probabilistic Classification Probabilistic Clustering Probabilistic Dimension Reduction 2 Probabilistic Linear
Probabilistic Machine Learning Industrial AI Lab. Probabilistic Linear Regression Outline Probabilistic Classification Probabilistic Clustering Probabilistic Dimension Reduction 2 Probabilistic Linear
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Intro. ANN & Fuzzy Systems. Lecture 15. Pattern Classification (I): Statistical Formulation
: Statistical Formulation") Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Lecture 15. Pattern Classification (I): Statistical Formulation Outline Statistical Pattern Recognition Maximum Posterior Probability (MAP) Classifier Maximum Likelihood (ML) Classifier K-Nearest Neighbor
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Introduction to Machine Learning Midterm Exam Solutions
 10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
Introduction to Machine Learning. Maximum Likelihood and Bayesian Inference. Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf
 1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
1 Introduction to Machine Learning Maximum Likelihood and Bayesian Inference Lecturers: Eran Halperin, Yishay Mansour, Lior Wolf 2013-14 We know that X ~ B(n,p), but we do not know p. We get a random sample
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Gaussian Mixture Models
 Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
K-means. Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University. November 19 th, Carlos Guestrin 1
 EM Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University November 19 th, 2007 2005-2007 Carlos Guestrin 1 K-means 1. Ask user how many clusters they d like. e.g. k=5 2. Randomly guess
EM Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University November 19 th, 2007 2005-2007 Carlos Guestrin 1 K-means 1. Ask user how many clusters they d like. e.g. k=5 2. Randomly guess
Lecture : Probabilistic Machine Learning
 Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Lecture : Probabilistic Machine Learning Riashat Islam Reasoning and Learning Lab McGill University September 11, 2018 ML : Many Methods with Many Links Modelling Views of Machine Learning Machine Learning
Introduction to Machine Learning Midterm Exam
 10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
Machine Learning for Signal Processing Bayes Classification and Regression
 Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning for Signal Processing Bayes Classification and Regression Instructor: Bhiksha Raj 11755/18797 1 Recap: KNN A very effective and simple way of performing classification Simple model: For
Machine Learning. Lecture 4: Regularization and Bayesian Statistics. Feng Li. https://funglee.github.io
 Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Machine Learning Lecture 4: Regularization and Bayesian Statistics Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 207 Overfitting Problem
Statistical learning. Chapter 20, Sections 1 3 1
 Statistical learning Chapter 20, Sections 1 3 Chapter 20, Sections 1 3 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Statistical learning Chapter 20, Sections 1 3 Chapter 20, Sections 1 3 1 Outline Bayesian learning Maximum a posteriori and maximum likelihood learning Bayes net learning ML parameter learning with complete
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 25: Markov Chain Monte Carlo (MCMC) Course Review and Advanced Topics Many figures courtesy Kevin
Computer Vision Group Prof. Daniel Cremers. 3. Regression
 Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
Prof. Daniel Cremers 3. Regression Categories of Learning (Rep.) Learnin g Unsupervise d Learning Clustering, density estimation Supervised Learning learning from a training data set, inference on the
CMU-Q Lecture 24:
 CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
CMU-Q 15-381 Lecture 24: Supervised Learning 2 Teacher: Gianni A. Di Caro SUPERVISED LEARNING Hypotheses space Hypothesis function Labeled Given Errors Performance criteria Given a collection of input
Machine Learning Lecture 2
 Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
Machine Perceptual Learning and Sensory Summer Augmented 15 Computing Many slides adapted from B. Schiele Machine Learning Lecture 2 Probability Density Estimation 16.04.2015 Bastian Leibe RWTH Aachen
Expectation Maximization
 Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
Expectation Maximization Bishop PRML Ch. 9 Alireza Ghane c Ghane/Mori 4 6 8 4 6 8 4 6 8 4 6 8 5 5 5 5 5 5 4 6 8 4 4 6 8 4 5 5 5 5 5 5 µ, Σ) α f Learningscale is slightly Parameters is slightly larger larger
CSE 546 Final Exam, Autumn 2013
 CSE 546 Final Exam, Autumn 0. Personal info: Name: Student ID: E-mail address:. There should be 5 numbered pages in this exam (including this cover sheet).. You can use any material you brought: any book,
CSE 546 Final Exam, Autumn 0. Personal info: Name: Student ID: E-mail address:. There should be 5 numbered pages in this exam (including this cover sheet).. You can use any material you brought: any book,
STATS 306B: Unsupervised Learning Spring Lecture 2 April 2
 STATS 306B: Unsupervised Learning Spring 2014 Lecture 2 April 2 Lecturer: Lester Mackey Scribe: Junyang Qian, Minzhe Wang 2.1 Recap In the last lecture, we formulated our working definition of unsupervised
STATS 306B: Unsupervised Learning Spring 2014 Lecture 2 April 2 Lecturer: Lester Mackey Scribe: Junyang Qian, Minzhe Wang 2.1 Recap In the last lecture, we formulated our working definition of unsupervised
Lecture 6: Gaussian Mixture Models (GMM)
") Helsinki Institute for Information Technology Lecture 6: Gaussian Mixture Models (GMM) Pedram Daee 3.11.2015 Outline Gaussian Mixture Models (GMM) Models Model families and parameters Parameter learning
Helsinki Institute for Information Technology Lecture 6: Gaussian Mixture Models (GMM) Pedram Daee 3.11.2015 Outline Gaussian Mixture Models (GMM) Models Model families and parameters Parameter learning
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 2: Bayesian Basics https://people.orie.cornell.edu/andrew/orie6741 Cornell University August 25, 2016 1 / 17 Canonical Machine Learning
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Introduction to Machine Learning Spring 2018 Note 18
 CS 189 Introduction to Machine Learning Spring 2018 Note 18 1 Gaussian Discriminant Analysis Recall the idea of generative models: we classify an arbitrary datapoint x with the class label that maximizes
CS 189 Introduction to Machine Learning Spring 2018 Note 18 1 Gaussian Discriminant Analysis Recall the idea of generative models: we classify an arbitrary datapoint x with the class label that maximizes
Bayesian Methods: Naïve Bayes
 Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
Bayesian Methods: aïve Bayes icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Last Time Parameter learning Learning the parameter of a simple coin flipping model Prior
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Latent Variable Models and Expectation Maximization
 Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Lecture 4: Probabilistic Learning. Estimation Theory. Classification with Probability Distributions
 DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
DD2431 Autumn, 2014 1 2 3 Classification with Probability Distributions Estimation Theory Classification in the last lecture we assumed we new: P(y) Prior P(x y) Lielihood x2 x features y {ω 1,..., ω K
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Week 5: Logistic Regression & Neural Networks
 Week 5: Logistic Regression & Neural Networks Instructor: Sergey Levine 1 Summary: Logistic Regression In the previous lecture, we covered logistic regression. To recap, logistic regression models and
Week 5: Logistic Regression & Neural Networks Instructor: Sergey Levine 1 Summary: Logistic Regression In the previous lecture, we covered logistic regression. To recap, logistic regression models and
MACHINE LEARNING ADVANCED MACHINE LEARNING
 MACHINE LEARNING ADVANCED MACHINE LEARNING Recap of Important Notions on Estimation of Probability Density Functions 2 2 MACHINE LEARNING Overview Definition pdf Definition joint, condition, marginal,
MACHINE LEARNING ADVANCED MACHINE LEARNING Recap of Important Notions on Estimation of Probability Density Functions 2 2 MACHINE LEARNING Overview Definition pdf Definition joint, condition, marginal,
Learning Objectives. c D. Poole and A. Mackworth 2010 Artificial Intelligence, Lecture 7.2, Page 1
 Learning Objectives At the end of the class you should be able to: identify a supervised learning problem characterize how the prediction is a function of the error measure avoid mixing the training and
Learning Objectives At the end of the class you should be able to: identify a supervised learning problem characterize how the prediction is a function of the error measure avoid mixing the training and
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Heeyoul (Henry) Choi. Dept. of Computer Science Texas A&M University
 Choi. Dept. of Computer Science Texas A&M University") Heeyoul (Henry) Choi Dept. of Computer Science Texas A&M University hchoi@cs.tamu.edu Introduction Speaker Adaptation Eigenvoice Comparison with others MAP, MLLR, EMAP, RMP, CAT, RSW Experiments Future
Heeyoul (Henry) Choi Dept. of Computer Science Texas A&M University hchoi@cs.tamu.edu Introduction Speaker Adaptation Eigenvoice Comparison with others MAP, MLLR, EMAP, RMP, CAT, RSW Experiments Future
STA414/2104 Statistical Methods for Machine Learning II
 STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
STA414/2104 Statistical Methods for Machine Learning II Murat A. Erdogdu & David Duvenaud Department of Computer Science Department of Statistical Sciences Lecture 3 Slide credits: Russ Salakhutdinov Announcements
Final Exam, Fall 2002
 15-781 Final Exam, Fall 22 1. Write your name and your andrew email address below. Name: Andrew ID: 2. There should be 17 pages in this exam (excluding this cover sheet). 3. If you need more room to work
15-781 Final Exam, Fall 22 1. Write your name and your andrew email address below. Name: Andrew ID: 2. There should be 17 pages in this exam (excluding this cover sheet). 3. If you need more room to work
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
A brief introduction to Conditional Random Fields
 A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
Gentle Introduction to Infinite Gaussian Mixture Modeling
 Gentle Introduction to Infinite Gaussian Mixture Modeling with an application in neuroscience By Frank Wood Rasmussen, NIPS 1999 Neuroscience Application: Spike Sorting Important in neuroscience and for
Gentle Introduction to Infinite Gaussian Mixture Modeling with an application in neuroscience By Frank Wood Rasmussen, NIPS 1999 Neuroscience Application: Spike Sorting Important in neuroscience and for
Introduction to Machine Learning Midterm, Tues April 8
 Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Clustering with k-means and Gaussian mixture distributions
 Clustering with k-means and Gaussian mixture distributions Machine Learning and Category Representation 2012-2013 Jakob Verbeek, ovember 23, 2012 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.12.13
Clustering with k-means and Gaussian mixture distributions Machine Learning and Category Representation 2012-2013 Jakob Verbeek, ovember 23, 2012 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.12.13
CS-E3210 Machine Learning: Basic Principles
 CS-E3210 Machine Learning: Basic Principles Lecture 4: Regression II slides by Markus Heinonen Department of Computer Science Aalto University, School of Science Autumn (Period I) 2017 1 / 61 Today s introduction
CS-E3210 Machine Learning: Basic Principles Lecture 4: Regression II slides by Markus Heinonen Department of Computer Science Aalto University, School of Science Autumn (Period I) 2017 1 / 61 Today s introduction
Probabilistic Graphical Models for Image Analysis - Lecture 1
 Probabilistic Graphical Models for Image Analysis - Lecture 1 Alexey Gronskiy, Stefan Bauer 21 September 2018 Max Planck ETH Center for Learning Systems Overview 1. Motivation - Why Graphical Models 2.
Probabilistic Graphical Models for Image Analysis - Lecture 1 Alexey Gronskiy, Stefan Bauer 21 September 2018 Max Planck ETH Center for Learning Systems Overview 1. Motivation - Why Graphical Models 2.
CSE 473: Artificial Intelligence Autumn Topics
 CSE 473: Artificial Intelligence Autumn 2014 Bayesian Networks Learning II Dan Weld Slides adapted from Jack Breese, Dan Klein, Daphne Koller, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 473 Topics
CSE 473: Artificial Intelligence Autumn 2014 Bayesian Networks Learning II Dan Weld Slides adapted from Jack Breese, Dan Klein, Daphne Koller, Stuart Russell, Andrew Moore & Luke Zettlemoyer 1 473 Topics
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering with k-means and Gaussian mixture distributions
 Clustering with k-means and Gaussian mixture distributions Machine Learning and Object Recognition 2017-2018 Jakob Verbeek Clustering Finding a group structure in the data Data in one cluster similar to
Clustering with k-means and Gaussian mixture distributions Machine Learning and Object Recognition 2017-2018 Jakob Verbeek Clustering Finding a group structure in the data Data in one cluster similar to
Lecture 4: Probabilistic Learning
 DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
DD2431 Autumn, 2015 1 Maximum Likelihood Methods Maximum A Posteriori Methods Bayesian methods 2 Classification vs Clustering Heuristic Example: K-means Expectation Maximization 3 Maximum Likelihood Methods
Bayesian Learning (II)
") Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayesian Learning (II) Niels Landwehr Overview Probabilities, expected values, variance Basic concepts of Bayesian learning MAP
Machine Learning. Gaussian Mixture Models. Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall
 Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 Discriminative vs Generative Models Discriminative: Just learn a decision boundary between your
Machine Learning Gaussian Mixture Models Zhiyao Duan & Bryan Pardo, Machine Learning: EECS 349 Fall 2012 1 Discriminative vs Generative Models Discriminative: Just learn a decision boundary between your
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Latent Variable Models and Expectation Maximization
 Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Latent Variable Models and Expectation Maximization Oliver Schulte - CMPT 726 Bishop PRML Ch. 9 2 4 6 8 1 12 14 16 18 2 4 6 8 1 12 14 16 18 5 1 15 2 25 5 1 15 2 25 2 4 6 8 1 12 14 2 4 6 8 1 12 14 5 1 15
Bayesian Machine Learning
 Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Bayesian Machine Learning Andrew Gordon Wilson ORIE 6741 Lecture 4 Occam s Razor, Model Construction, and Directed Graphical Models https://people.orie.cornell.edu/andrew/orie6741 Cornell University September
Midterm: CS 6375 Spring 2018
 Midterm: CS 6375 Spring 2018 The exam is closed book (1 cheat sheet allowed). Answer the questions in the spaces provided on the question sheets. If you run out of room for an answer, use an additional
Midterm: CS 6375 Spring 2018 The exam is closed book (1 cheat sheet allowed). Answer the questions in the spaces provided on the question sheets. If you run out of room for an answer, use an additional
Semi-supervised Learning
 Semi-supervised Learning Introduction Supervised learning: x r, y r R r=1 E.g.x r : image, y r : class labels Semi-supervised learning: x r, y r r=1 R, x u R+U u=r A set of unlabeled data, usually U >>
Semi-supervised Learning Introduction Supervised learning: x r, y r R r=1 E.g.x r : image, y r : class labels Semi-supervised learning: x r, y r r=1 R, x u R+U u=r A set of unlabeled data, usually U >>
Logistics. Naïve Bayes & Expectation Maximization. 573 Schedule. Coming Soon. Estimation Models. Topics
 Logistics Naïve Bayes & Expectation Maximization CSE 7 eam Meetings Midterm Open book, notes Studying See AIMA exercises Daniel S. Weld Daniel S. Weld 7 Schedule Selected opics Coming Soon Selected opics
Logistics Naïve Bayes & Expectation Maximization CSE 7 eam Meetings Midterm Open book, notes Studying See AIMA exercises Daniel S. Weld Daniel S. Weld 7 Schedule Selected opics Coming Soon Selected opics
Support Vector Machines. CAP 5610: Machine Learning Instructor: Guo-Jun QI
 Support Vector Machines CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Linear Classifier Naive Bayes Assume each attribute is drawn from Gaussian distribution with the same variance Generative model:
Support Vector Machines CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Linear Classifier Naive Bayes Assume each attribute is drawn from Gaussian distribution with the same variance Generative model:
Review and Motivation
 Review and Motivation We can model and visualize multimodal datasets by using multiple unimodal (Gaussian-like) clusters. K-means gives us a way of partitioning points into N clusters. Once we know which
Review and Motivation We can model and visualize multimodal datasets by using multiple unimodal (Gaussian-like) clusters. K-means gives us a way of partitioning points into N clusters. Once we know which
Density Estimation. Seungjin Choi
 Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Density Estimation Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr http://mlg.postech.ac.kr/
Least Squares Regression
 E0 70 Machine Learning Lecture 4 Jan 7, 03) Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in the lecture. They are not a substitute
E0 70 Machine Learning Lecture 4 Jan 7, 03) Least Squares Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in the lecture. They are not a substitute
Clustering and Gaussian Mixture Models
 Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Expectation maximization
 Expectation maximization Subhransu Maji CMSCI 689: Machine Learning 14 April 2015 Motivation Suppose you are building a naive Bayes spam classifier. After your are done your boss tells you that there is
Expectation maximization Subhransu Maji CMSCI 689: Machine Learning 14 April 2015 Motivation Suppose you are building a naive Bayes spam classifier. After your are done your boss tells you that there is
CS181 Midterm 2 Practice Solutions
 CS181 Midterm 2 Practice Solutions 1. Convergence of -Means Consider Lloyd s algorithm for finding a -Means clustering of N data, i.e., minimizing the distortion measure objective function J({r n } N n=1,
CS181 Midterm 2 Practice Solutions 1. Convergence of -Means Consider Lloyd s algorithm for finding a -Means clustering of N data, i.e., minimizing the distortion measure objective function J({r n } N n=1,
y Xw 2 2 y Xw λ w 2 2
 CS 189 Introduction to Machine Learning Spring 2018 Note 4 1 MLE and MAP for Regression (Part I) So far, we ve explored two approaches of the regression framework, Ordinary Least Squares and Ridge Regression:
CS 189 Introduction to Machine Learning Spring 2018 Note 4 1 MLE and MAP for Regression (Part I) So far, we ve explored two approaches of the regression framework, Ordinary Least Squares and Ridge Regression:
Bayesian Networks Structure Learning (cont.)
") Koller & Friedman Chapters (handed out): Chapter 11 (short) Chapter 1: 1.1, 1., 1.3 (covered in the beginning of semester) 1.4 (Learning parameters for BNs) Chapter 13: 13.1, 13.3.1, 13.4.1, 13.4.3 (basic
Koller & Friedman Chapters (handed out): Chapter 11 (short) Chapter 1: 1.1, 1., 1.3 (covered in the beginning of semester) 1.4 (Learning parameters for BNs) Chapter 13: 13.1, 13.3.1, 13.4.1, 13.4.3 (basic
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Machine Learning for Signal Processing Bayes Classification
 Machine Learning for Signal Processing Bayes Classification Class 16. 24 Oct 2017 Instructor: Bhiksha Raj - Abelino Jimenez 11755/18797 1 Recap: KNN A very effective and simple way of performing classification
Machine Learning for Signal Processing Bayes Classification Class 16. 24 Oct 2017 Instructor: Bhiksha Raj - Abelino Jimenez 11755/18797 1 Recap: KNN A very effective and simple way of performing classification
STA 414/2104, Spring 2014, Practice Problem Set #1
 STA 44/4, Spring 4, Practice Problem Set # Note: these problems are not for credit, and not to be handed in Question : Consider a classification problem in which there are two real-valued inputs, and,
STA 44/4, Spring 4, Practice Problem Set # Note: these problems are not for credit, and not to be handed in Question : Consider a classification problem in which there are two real-valued inputs, and,
Introduction to Graphical Models
 Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic
Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic