Linear Dimensionality Reduction
|
|
|
- Paul Berry
- 5 years ago
- Views:
Transcription
1 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012)
2 Outline Outline I 1 Introduction 2 Principal Component Analysis 3 Factor Analysis 4 Multidimensional Scaling 5 Linear Discriminant Analysis
3 Why Dimensionality Reduction? The number of inputs (input dimensionality) often affects the time and space complexity of the learning algorithm. Eliminating an input saves the cost of extracting it. Simpler models are often more robust on small data sets. Simpler models are more interpretable, leading to simpler explanation. Data visualization in 2 or 3 dimensions facilitates the detection of structure and outliers.
4 Feature Selection vs. Extraction Feature selection: Choosing K < D important features and discarding the remaining D K. Subset selection algorithms Feature extraction: Projecting the original D dimensions to K (< D) new dimensions. Unsupervised methods (without using output information): Principal component analysis (PCA) Factor analysis (FA) Multidimensional scaling (MDS) Supervised methods (using output information): Linear discriminant analysis (LDA) The linear methods above also have nonlinear extensions.
5 Principal Component Analysis PCA finds a linear mapping from the D-dimensional input space to a K -dimensional space (K < D) with minimum information loss according to some criterion. Projection of x on the direction of w: z = w T x Finding the first principal component w 1 s.t. var(z 1 ) is maximized: var(z 1 ) = var(w T 1 x) = E[(w T 1 x w T 1 µ) 2 ] = E[w T 1 (x µ)(x µ) T w 1 ] = w T 1 E[(x µ)(x µ) T ]w 1 = w T 1 Σw 1 where cov(x) = E[(x µ)(x µ) T ] = Σ
6 Optimization Problem for First Principal Component Maximization of var(z 1 ) subject to w 1 = 1 can be solved as a constrained optimization problem using a Lagrange multiplier. Maximization of Lagrangian: w T 1 Σw 1 α(w T 1 w 1 1) Taking the derivative of the Lagrangian w.r.t. w 1 and setting it to 0, we get an eigenvalue equation for the first principal component w 1 : Σw 1 = αw 1 Because we have w T 1 Σw 1 = αw T 1 w 1 = α we choose the eigenvector with the largest eigenvalue for the variance to be maximum.
7 Optimization Problem for Second Principal Component The second principal component w 2 should also maximize the variance var(z 2 ), subject to the constraints that w 2 = 1 and that w 2 is orthogonal to w 1. Maximization of Lagrangian: w T 2 Σw 2 α(w T 2 w 2 1) β(w T 2 w 1 0) Taking the derivative of the Lagrangian w.r.t. w 2 and setting it to 0, we get the following equation:: 2Σw 2 2αw 2 βw 1 = 0 We can show that β = 0 and hence have this eigenvalue equation: Σw 2 = αw 2 implying that w 2 is the eigenvector of Σ with the second largest eigenvalue.
8 What PCA Does Transformation of data: z = W T (x m) where the columns of W are the eigenvectors of Σ and m is the sample mean. Centering the data at the origin and rotating the axes: If the variance on z 2 is too small, it can be ignored to reduce the dimensionality from 2 to 1.
9 How to Choose K Proportion of variance (PoV) explained: λ 1 + λ λ K λ 1 + λ λ D where λ i are sorted in descending order. Typically, stop at PoV > 0.9 Scree graph plotting PoV against K ; stop at elbow.
10 Scree Graph

11 Scatterplot in Lower-Dimensional Space
12 Factor Analysis FA assumes that there is a set of latent factors z j which when acting in combination to generate the observed variables x. The goal of FA is to characterize the dependency among the observed variables by means of a smaller number of factors. Problem settings: Sample X = {x (i) }: drawn from some unknown probability density with E[x] = µ and cov(x) = Σ. Factors z j with unit normals: E[z j ] = 0, var(z j ) = 1, cov(z j, z k ) = 0, j k. Noise sources ɛ i : E[ɛ j ] = 0, var(ɛ j ) = Ψ j, cov(ɛ j, ɛ k ) = 0, j k, cov(ɛ j, z k ) = 0. Each of the D input dimensions x j is expressed as a weighted sum of the K (< D) factors z k plus some residual error term: x j µ j = K k=1 v jkz k + ɛ j where v jk are called factor loadings. Without loss of generality, we assume that µ = 0.
13 Relationships between Factors and Input Dimensions The factor z k are independent unit normals that are stretched, rotated and translated to generate the inputs x.
14 PCA vs. FA The direction of FA is opposite to that of PCA: PCA (from x to z): z = W T (x µ) FA (from z to z): x µ = Vz + ɛ
15 Covariance Matrix Given that var(z k ) = 1 and var(ɛ j ) = Ψ j var(x j ) = K k=1 v 2 jk var(z k) + var(ɛ j ) = K k=1 v 2 jk + Ψ j where the first part ( K k=1 v jk 2 ) is the variance explained by the common factors and the second part (Ψ j ) is the variance specific to x j. Covariance matrix: where Ψ = diag(ψ j ) Σ = cov(x) = cov(vz + ɛ) = cov(vz) + cov(ɛ) = Vcov(z)V T + Ψ = VV T + Ψ
16 2-Factor Example Let ( x = (x 1, x 2 ) T v11 v V = 12 v 21 v 22 ) Since ( σ11 σ Σ = 12 σ 21 σ 22 we have ) ( ) ( = VV T v11 v +Ψ = 12 v11 v 21 v 21 v 22 v 12 v 22 σ 12 = cov(x 1, x 2 ) = v 11 v 21 + v 12 v 22 ) ( Ψ Ψ 2 ) If x 1 and x 2 have high covariance, then they are related through a factor: If it is the first factor, then v 11 and v 21 will both be high. If it is the second factor, then v 12 and v 22 will both be high. If x 1 and x 2 have low covariance, then they depend on different factors: In each of the products v 11 v 21 and v 12 v 22, one term will be high and the other will be low.
17 Factor Loadings Because cov(x 1, z 1 ) = cov(v 11 z 1 + v 12 z 2 + ɛ 1, z 1 ) = cov(v 11 z 1 ) = v 11 var(z 1 ) = v 11 and similarity, cov(x 1, z 2 ) = v 12 cov(x 2, z 1 ) = v 21 cov(x 2, z 2 ) = v 22 so we have cov(x, z) = V i.e., the factor loadings V represent the covariance between the variables and the factors.
18 Dimensionality Reduction Given S as the estimator of Σ, we want to find V and Ψ such that S = VV T + Ψ If there are only a few factors (i.e., K D), then we can get a simplified structure for S. The number of parameters is reduced from D(D + 1)/2 (for S) to DK + D (for VV T + Ψ). Special cases: Probabilistic PCA (PPCA): Ψ = ΨI (i.e., all Ψ j are equal) PCA: Ψ j = 0 For dimensionality reduction, FA offers no advantage over PCA except the interpretability of factors allowing the identification of common causes, a simple explanation, and knowledge extraction.
19 Multidimensional Scaling Problem formulation: Given the pairwise distances between pairs of points in some space (but the exact coordinates of the points and their dimensionality are unknown). We want to embed the points in a lower-dimensional space such that the pairwise distances in this space are as close as possible to those in the original space. The projection to the lower-dimensional space is not unique because the pairwise distances are invariant to such operations as translation, rotation and reflection.
20 MDS Embedding of Cities
21 Derivation Sample X = {x (i) R D } N i=1 Squared Euclidean distance between points r and s: d 2 rs = x (r) x (s) 2 = = D j=1 j=1 (x (r) j x (s) j ) 2 D D (x (r) j ) 2 2 x (r) j x (s) j + j=1 D (x (s) j ) 2 j=1 where b rs = or in matrix form: D j=1 = b rr + b ss 2b rs x (r) j x (s) j (dot product of x (r) and x (s) ) B = XX T
22 Derivation (2) Centering of data to constrain the solution: N = 0, i = 1,..., D i=1 x (i) j Summing up equation (1) on r, s and both r, s, and defining N T = b ii = (x (i) j ) 2 i=1 i j we get drs 2 = T + Nb ss r drs 2 = Nb rr + T s drs 2 = 2NT r s
23 Derivation (3) By defining d s 2 = 1 d 2 N rs, dr 2 = 1 d 2 N rs, d 2 = 1 N 2 and using equation (1), we get r s r s d 2 rs b rs = 1 2 (d 2 r + d 2 s d 2 d 2 rs) B = XX T is positive semidefinite, so it can be expressed as its spectral decomposition: B = CDC T = CD 1/2 D 1/2 C T = (CD 1/2 )(CD 1/2 ) T where C is the matrix whose columns are the eigenvectors of B and D 1/2 is the diagonal matrix whose diagonal elements are the square roots of the eigenvalues.
24 Projection to Lower-Dimensional Space If we ignore the eigenvector of B with very small eigenvalues (the eigenvalues of B = XX T are the same as the eigenvalues of X T X), CD 1/2 will only be a low-rank approximation of X. Let c k be the k eigenvectors chosen with corresponding eigenvalues λ k. New dimensions in k-dimensional embedding space: z (i) k = λ k c (i) k So the new coordinates of instance i are given by the ith elements of the eigenvectors after normalization.
25 Linear Discriminant Analysis Unlike PCA, FA and MDS, LDA is a supervised dimensionality reduction method. LDA is typically used with a classifier for classification problems. Goal: the classes are well-separated after projecting to a low-dimensional space by utilizing the label information (output information).
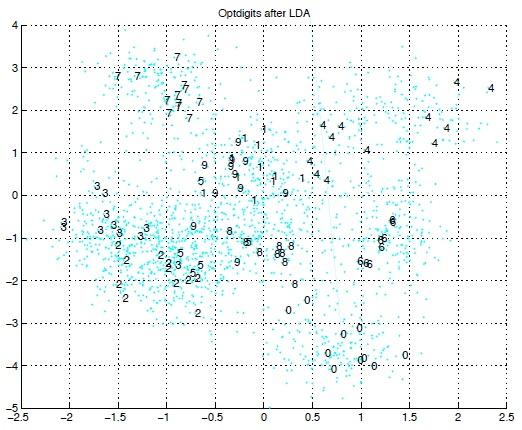
26 Example
27 2-Class Case Given sample X = {(x (i), y (i) )}, where y (i) = 1 if x (i) C 1 and y (i) = 0 if x (i) C 2. Find vector w on which the data are projected such that the examples from C 1 and C 2 are as well separated as possible. Projection of x onto w (dimensionality reduced from D to 1): z = w T x m j R D and m j = R are sample means of C j before and after projection: m 1 = m 2 = i wt x (i) y (i) i y = w T m (i) 1 i wt x (i) (1 y (i) ) i (1 y = w T m (i) 2 )
28 Projection
29 Between-Class Scatter Between-class scatter: (m 1 m 2 ) 2 = (w T m 1 w T m 2 ) 2 = w T (m 1 m 2 )(m 1 m 2 ) T w = w T S B w where S B = (m 1 m 2 )(m 1 m 2 ) T
30 Within-Class Scatter Within-class scatter: s 2 1 = i = i (w T x (i) m 1 ) 2 y (i) w T (x (i) m 1 )(x (i) m 1 ) T wy (i) = w T S 1 w where S 1 = i (x(i) m 1 )(x (i) m 1 ) T y (i). Similarly, s 2 2 = wt S 2 w with S 2 = i (x(i) m 2 )(x (i) m 2 ) T (1 y (i) ). So s s 2 2 = w T S W w where S W = S 1 + S 2.
31 Fisher s Linear Discriminant Fisher s linear discriminant refers to the vector w that maximizes the Fisher criterion (a.k.a. generalized Rayleigh quotient): J(w) = (m 1 m 2 ) 2 s s2 2 = wt S B w w T S W w Taking the derivative of J w.r.t. w and setting it to 0, we obtain the following generalized eigenvalue problem: S B w = λs W w or, if S W is nonsingular, an equivalent eigenvalue problem: S 1 W S Bw = λw
32 Fisher s Linear Discriminant (2) Alternatively, for the 2-class case, we note that S B w = (m 1 m 2 )(m 1 m 2 ) T w = c(m 1 m 2 ) for some constant c and hence S B w (also S W w) is in the same direction of m 1 m 2. So we get w = S 1 W (m 1 m 2 ) = (S 1 + S 2 ) 1 (m 1 m 2 ) The constant factor is irrelevant and hence is discarded.
33 K > 2 Classes Find the matrix W R D K such that z = W T x R K Within-class scatter matrix for class C k : S k = i y (i) k (x(i) m k )(x (i) m k ) T where y (i) k = 1 if x (i) C k and 0 otherwise. Total within-class scatter matrix: S W = K k=1 S k
34 K > 2 Classes (2) Between-class scatter matrix: S B = K N k (m k m)(m k m) T k=1 where m is the overall mean and N k = i y (i) k. The optimal solution is the matrix W that maximizes J(W) = Tr(WT S B W) Tr(W T S W W) which corresponds to the eigenvectors of S 1 W S B with the largest eigenvalues. Take k K 1: since S B is the sum of K rank-1 matrices and only K 1 of them are independent, S B has a maximum rank of K 1.
Data Mining. Dimensionality reduction. Hamid Beigy. Sharif University of Technology. Fall 1395
 Data Mining Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 42 Outline 1 Introduction 2 Feature selection
Data Mining Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 42 Outline 1 Introduction 2 Feature selection
Machine Learning. Dimensionality reduction. Hamid Beigy. Sharif University of Technology. Fall 1395
 Machine Learning Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1395 1 / 47 Table of contents 1 Introduction
Machine Learning Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1395 1 / 47 Table of contents 1 Introduction
Machine Learning 2nd Edition
 INTRODUCTION TO Lecture Slides for Machine Learning 2nd Edition ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://www.cs.tau.ac.il/~apartzin/machinelearning/ The MIT Press, 2010
INTRODUCTION TO Lecture Slides for Machine Learning 2nd Edition ETHEM ALPAYDIN, modified by Leonardo Bobadilla and some parts from http://www.cs.tau.ac.il/~apartzin/machinelearning/ The MIT Press, 2010
PCA and LDA. Man-Wai MAK
 PCA and LDA Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: S.J.D. Prince,Computer
PCA and LDA Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: S.J.D. Prince,Computer
PCA and LDA. Man-Wai MAK
 PCA and LDA Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: S.J.D. Prince,Computer
PCA and LDA Man-Wai MAK Dept. of Electronic and Information Engineering, The Hong Kong Polytechnic University enmwmak@polyu.edu.hk http://www.eie.polyu.edu.hk/ mwmak References: S.J.D. Prince,Computer
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
Principal Component Analysis and Linear Discriminant Analysis
 Principal Component Analysis and Linear Discriminant Analysis Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/29
Principal Component Analysis and Linear Discriminant Analysis Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/29
STATISTICAL LEARNING SYSTEMS
 STATISTICAL LEARNING SYSTEMS LECTURE 8: UNSUPERVISED LEARNING: FINDING STRUCTURE IN DATA Institute of Computer Science, Polish Academy of Sciences Ph. D. Program 2013/2014 Principal Component Analysis
STATISTICAL LEARNING SYSTEMS LECTURE 8: UNSUPERVISED LEARNING: FINDING STRUCTURE IN DATA Institute of Computer Science, Polish Academy of Sciences Ph. D. Program 2013/2014 Principal Component Analysis
Statistical Pattern Recognition
 Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Machine Learning (Spring 2012) Principal Component Analysis
 Principal Component Analysis") 1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
1-71 Machine Learning (Spring 1) Principal Component Analysis Yang Xu This note is partly based on Chapter 1.1 in Chris Bishop s book on PRML and the lecture slides on PCA written by Carlos Guestrin in
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015
 ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
CSC 411 Lecture 12: Principal Component Analysis
 CSC 411 Lecture 12: Principal Component Analysis Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 12-PCA 1 / 23 Overview Today we ll cover the first unsupervised
CSC 411 Lecture 12: Principal Component Analysis Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 12-PCA 1 / 23 Overview Today we ll cover the first unsupervised
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
Course 495: Advanced Statistical Machine Learning/Pattern Recognition
 Course 495: Advanced Statistical Machine Learning/Pattern Recognition Deterministic Component Analysis Goal (Lecture): To present standard and modern Component Analysis (CA) techniques such as Principal
Course 495: Advanced Statistical Machine Learning/Pattern Recognition Deterministic Component Analysis Goal (Lecture): To present standard and modern Component Analysis (CA) techniques such as Principal
Fisher s Linear Discriminant Analysis
 Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Dimensionality Reduction
 Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Lecture 7: Con3nuous Latent Variable Models
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 7: Con3nuous Latent Variable Models All lecture slides will be available as.pdf on the course website: http://www.cs.toronto.edu/~urtasun/courses/csc2515/
Lecture 13. Principal Component Analysis. Brett Bernstein. April 25, CDS at NYU. Brett Bernstein (CDS at NYU) Lecture 13 April 25, / 26
 Lecture 13 April 25, / 26") Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
Principal Component Analysis Brett Bernstein CDS at NYU April 25, 2017 Brett Bernstein (CDS at NYU) Lecture 13 April 25, 2017 1 / 26 Initial Question Intro Question Question Let S R n n be symmetric. 1
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 8 Continuous Latent Variable
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 8 Continuous Latent Variable
Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations.
 Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Nonlinear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Statistical Machine Learning
 Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Pattern Recognition 2
 Pattern Recognition 2 KNN,, Dr. Terence Sim School of Computing National University of Singapore Outline 1 2 3 4 5 Outline 1 2 3 4 5 The Bayes Classifier is theoretically optimum. That is, prob. of error
Pattern Recognition 2 KNN,, Dr. Terence Sim School of Computing National University of Singapore Outline 1 2 3 4 5 Outline 1 2 3 4 5 The Bayes Classifier is theoretically optimum. That is, prob. of error
Principle Components Analysis (PCA) Relationship Between a Linear Combination of Variables and Axes Rotation for PCA
 Relationship Between a Linear Combination of Variables and Axes Rotation for PCA") Principle Components Analysis (PCA) Relationship Between a Linear Combination of Variables and Axes Rotation for PCA Principle Components Analysis: Uses one group of variables (we will call this X) In
Principle Components Analysis (PCA) Relationship Between a Linear Combination of Variables and Axes Rotation for PCA Principle Components Analysis: Uses one group of variables (we will call this X) In
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Linear Algebra Methods for Data Mining
 Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 Linear Discriminant Analysis Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki Principal
Linear Algebra Methods for Data Mining Saara Hyvönen, Saara.Hyvonen@cs.helsinki.fi Spring 2007 Linear Discriminant Analysis Linear Algebra Methods for Data Mining, Spring 2007, University of Helsinki Principal
L11: Pattern recognition principles
 L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
L11: Pattern recognition principles Bayesian decision theory Statistical classifiers Dimensionality reduction Clustering This lecture is partly based on [Huang, Acero and Hon, 2001, ch. 4] Introduction
Data Mining and Analysis: Fundamental Concepts and Algorithms
 Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA
Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA
L26: Advanced dimensionality reduction
 L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
14 Singular Value Decomposition
 14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Dimension Reduction and Low-dimensional Embedding
 Dimension Reduction and Low-dimensional Embedding Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/26 Dimension
Dimension Reduction and Low-dimensional Embedding Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/26 Dimension
Machine Learning. B. Unsupervised Learning B.2 Dimensionality Reduction. Lars Schmidt-Thieme, Nicolas Schilling
 Machine Learning B. Unsupervised Learning B.2 Dimensionality Reduction Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University
Machine Learning B. Unsupervised Learning B.2 Dimensionality Reduction Lars Schmidt-Thieme, Nicolas Schilling Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University
Preprocessing & dimensionality reduction
 Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi
 presented by Hassan A. Kingravi") Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
December 20, MAA704, Multivariate analysis. Christopher Engström. Multivariate. analysis. Principal component analysis
 .. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
.. December 20, 2013 Todays lecture. (PCA) (PLS-R) (LDA) . (PCA) is a method often used to reduce the dimension of a large dataset to one of a more manageble size. The new dataset can then be used to make
1 Principal Components Analysis
 Lecture 3 and 4 Sept. 18 and Sept.20-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Principal Components Analysis Principal components analysis (PCA) is a very popular technique for
Lecture 3 and 4 Sept. 18 and Sept.20-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Principal Components Analysis Principal components analysis (PCA) is a very popular technique for
Dimensionality Reduction
 Dimensionality Reduction Le Song Machine Learning I CSE 674, Fall 23 Unsupervised learning Learning from raw (unlabeled, unannotated, etc) data, as opposed to supervised data where a classification of
Dimensionality Reduction Le Song Machine Learning I CSE 674, Fall 23 Unsupervised learning Learning from raw (unlabeled, unannotated, etc) data, as opposed to supervised data where a classification of
PCA & ICA. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
Principal Component Analysis
 Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach
 A First Dimensionality Reduction Approach") LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
MACHINE LEARNING. Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA
 1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
Computation. For QDA we need to calculate: Lets first consider the case that
 Computation For QDA we need to calculate: δ (x) = 1 2 log( Σ ) 1 2 (x µ ) Σ 1 (x µ ) + log(π ) Lets first consider the case that Σ = I,. This is the case where each distribution is spherical, around the
Computation For QDA we need to calculate: δ (x) = 1 2 log( Σ ) 1 2 (x µ ) Σ 1 (x µ ) + log(π ) Lets first consider the case that Σ = I,. This is the case where each distribution is spherical, around the
7. Variable extraction and dimensionality reduction
 7. Variable extraction and dimensionality reduction The goal of the variable selection in the preceding chapter was to find least useful variables so that it would be possible to reduce the dimensionality
7. Variable extraction and dimensionality reduction The goal of the variable selection in the preceding chapter was to find least useful variables so that it would be possible to reduce the dimensionality
LEC 3: Fisher Discriminant Analysis (FDA)
") LEC 3: Fisher Discriminant Analysis (FDA) A Supervised Dimensionality Reduction Approach Dr. Guangliang Chen February 18, 2016 Outline Motivation: PCA is unsupervised which does not use training labels
LEC 3: Fisher Discriminant Analysis (FDA) A Supervised Dimensionality Reduction Approach Dr. Guangliang Chen February 18, 2016 Outline Motivation: PCA is unsupervised which does not use training labels
Regularized Discriminant Analysis and Reduced-Rank LDA
 Regularized Discriminant Analysis and Reduced-Rank LDA Department of Statistics The Pennsylvania State University Email: jiali@stat.psu.edu Regularized Discriminant Analysis A compromise between LDA and
Regularized Discriminant Analysis and Reduced-Rank LDA Department of Statistics The Pennsylvania State University Email: jiali@stat.psu.edu Regularized Discriminant Analysis A compromise between LDA and
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA
, Factor Analysis, Mixtures of PPCA") Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inria.fr http://perception.inrialpes.fr/
Manifold Learning for Signal and Visual Processing Lecture 9: Probabilistic PCA (PPCA), Factor Analysis, Mixtures of PPCA Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inria.fr http://perception.inrialpes.fr/
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Principal Component Analysis & Factor Analysis. Psych 818 DeShon
 Principal Component Analysis & Factor Analysis Psych 818 DeShon Purpose Both are used to reduce the dimensionality of correlated measurements Can be used in a purely exploratory fashion to investigate
Principal Component Analysis & Factor Analysis Psych 818 DeShon Purpose Both are used to reduce the dimensionality of correlated measurements Can be used in a purely exploratory fashion to investigate
ECE 661: Homework 10 Fall 2014
 ECE 661: Homework 10 Fall 2014 This homework consists of the following two parts: (1) Face recognition with PCA and LDA for dimensionality reduction and the nearest-neighborhood rule for classification;
ECE 661: Homework 10 Fall 2014 This homework consists of the following two parts: (1) Face recognition with PCA and LDA for dimensionality reduction and the nearest-neighborhood rule for classification;
Maximum variance formulation
 12.1. Principal Component Analysis 561 Figure 12.2 Principal component analysis seeks a space of lower dimensionality, known as the principal subspace and denoted by the magenta line, such that the orthogonal
12.1. Principal Component Analysis 561 Figure 12.2 Principal component analysis seeks a space of lower dimensionality, known as the principal subspace and denoted by the magenta line, such that the orthogonal
LECTURE NOTE #11 PROF. ALAN YUILLE
 LECTURE NOTE #11 PROF. ALAN YUILLE 1. NonLinear Dimension Reduction Spectral Methods. The basic idea is to assume that the data lies on a manifold/surface in D-dimensional space, see figure (1) Perform
LECTURE NOTE #11 PROF. ALAN YUILLE 1. NonLinear Dimension Reduction Spectral Methods. The basic idea is to assume that the data lies on a manifold/surface in D-dimensional space, see figure (1) Perform
Principal Components Theory Notes
 Principal Components Theory Notes Charles J. Geyer August 29, 2007 1 Introduction These are class notes for Stat 5601 (nonparametrics) taught at the University of Minnesota, Spring 2006. This not a theory
Principal Components Theory Notes Charles J. Geyer August 29, 2007 1 Introduction These are class notes for Stat 5601 (nonparametrics) taught at the University of Minnesota, Spring 2006. This not a theory
Statistics for Applications. Chapter 9: Principal Component Analysis (PCA) 1/16
 1/16") Statistics for Applications Chapter 9: Principal Component Analysis (PCA) 1/16 Multivariate statistics and review of linear algebra (1) Let X be a d-dimensional random vector and X 1,..., X n be n independent
Statistics for Applications Chapter 9: Principal Component Analysis (PCA) 1/16 Multivariate statistics and review of linear algebra (1) Let X be a d-dimensional random vector and X 1,..., X n be n independent
Notes on Implementation of Component Analysis Techniques
 Notes on Implementation of Component Analysis Techniques Dr. Stefanos Zafeiriou January 205 Computing Principal Component Analysis Assume that we have a matrix of centered data observations X = [x µ,...,
Notes on Implementation of Component Analysis Techniques Dr. Stefanos Zafeiriou January 205 Computing Principal Component Analysis Assume that we have a matrix of centered data observations X = [x µ,...,
Principal Components Analysis. Sargur Srihari University at Buffalo
 Principal Components Analysis Sargur Srihari University at Buffalo 1 Topics Projection Pursuit Methods Principal Components Examples of using PCA Graphical use of PCA Multidimensional Scaling Srihari 2
Principal Components Analysis Sargur Srihari University at Buffalo 1 Topics Projection Pursuit Methods Principal Components Examples of using PCA Graphical use of PCA Multidimensional Scaling Srihari 2
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
Lecture 24: Principal Component Analysis. Aykut Erdem May 2016 Hacettepe University
 Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Unsupervised Learning: Dimensionality Reduction
 Unsupervised Learning: Dimensionality Reduction CMPSCI 689 Fall 2015 Sridhar Mahadevan Lecture 3 Outline In this lecture, we set about to solve the problem posed in the previous lecture Given a dataset,
Unsupervised Learning: Dimensionality Reduction CMPSCI 689 Fall 2015 Sridhar Mahadevan Lecture 3 Outline In this lecture, we set about to solve the problem posed in the previous lecture Given a dataset,
Mathematical foundations - linear algebra
 Mathematical foundations - linear algebra Andrea Passerini passerini@disi.unitn.it Machine Learning Vector space Definition (over reals) A set X is called a vector space over IR if addition and scalar
Mathematical foundations - linear algebra Andrea Passerini passerini@disi.unitn.it Machine Learning Vector space Definition (over reals) A set X is called a vector space over IR if addition and scalar
PCA and admixture models
 PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Principal Component Analysis Barnabás Póczos Contents Motivation PCA algorithms Applications Some of these slides are taken from Karl Booksh Research
Advanced Introduction to Machine Learning CMU-10715 Principal Component Analysis Barnabás Póczos Contents Motivation PCA algorithms Applications Some of these slides are taken from Karl Booksh Research
Principal Component Analysis
 CSci 5525: Machine Learning Dec 3, 2008 The Main Idea Given a dataset X = {x 1,..., x N } The Main Idea Given a dataset X = {x 1,..., x N } Find a low-dimensional linear projection The Main Idea Given
CSci 5525: Machine Learning Dec 3, 2008 The Main Idea Given a dataset X = {x 1,..., x N } The Main Idea Given a dataset X = {x 1,..., x N } Find a low-dimensional linear projection The Main Idea Given
LECTURE NOTE #10 PROF. ALAN YUILLE
 LECTURE NOTE #10 PROF. ALAN YUILLE 1. Principle Component Analysis (PCA) One way to deal with the curse of dimensionality is to project data down onto a space of low dimensions, see figure (1). Figure
LECTURE NOTE #10 PROF. ALAN YUILLE 1. Principle Component Analysis (PCA) One way to deal with the curse of dimensionality is to project data down onto a space of low dimensions, see figure (1). Figure
Revision: Chapter 1-6. Applied Multivariate Statistics Spring 2012
 Revision: Chapter 1-6 Applied Multivariate Statistics Spring 2012 Overview Cov, Cor, Mahalanobis, MV normal distribution Visualization: Stars plot, mosaic plot with shading Outlier: chisq.plot Missing
Revision: Chapter 1-6 Applied Multivariate Statistics Spring 2012 Overview Cov, Cor, Mahalanobis, MV normal distribution Visualization: Stars plot, mosaic plot with shading Outlier: chisq.plot Missing
PCA, Kernel PCA, ICA
 PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
Clustering VS Classification
 MCQ Clustering VS Classification 1. What is the relation between the distance between clusters and the corresponding class discriminability? a. proportional b. inversely-proportional c. no-relation Ans:
MCQ Clustering VS Classification 1. What is the relation between the distance between clusters and the corresponding class discriminability? a. proportional b. inversely-proportional c. no-relation Ans:
Data Analysis and Manifold Learning Lecture 6: Probabilistic PCA and Factor Analysis
 Data Analysis and Manifold Learning Lecture 6: Probabilistic PCA and Factor Analysis Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture
Data Analysis and Manifold Learning Lecture 6: Probabilistic PCA and Factor Analysis Radu Horaud INRIA Grenoble Rhone-Alpes, France Radu.Horaud@inrialpes.fr http://perception.inrialpes.fr/ Outline of Lecture
9.1 Orthogonal factor model.
 36 Chapter 9 Factor Analysis Factor analysis may be viewed as a refinement of the principal component analysis The objective is, like the PC analysis, to describe the relevant variables in study in terms
36 Chapter 9 Factor Analysis Factor analysis may be viewed as a refinement of the principal component analysis The objective is, like the PC analysis, to describe the relevant variables in study in terms
Feature selection and extraction Spectral domain quality estimation Alternatives
 Feature selection and extraction Error estimation Maa-57.3210 Data Classification and Modelling in Remote Sensing Markus Törmä markus.torma@tkk.fi Measurements Preprocessing: Remove random and systematic
Feature selection and extraction Error estimation Maa-57.3210 Data Classification and Modelling in Remote Sensing Markus Törmä markus.torma@tkk.fi Measurements Preprocessing: Remove random and systematic
Principal Component Analysis
 B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Applications of visual analytics, data types 3 Data sources and preparation Project 1 out 4
 Lecture Topic Projects 1 Intro, schedule, and logistics 2 Applications of visual analytics, data types 3 Data sources and preparation Project 1 out 4 Data reduction, similarity & distance, data augmentation
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Applications of visual analytics, data types 3 Data sources and preparation Project 1 out 4 Data reduction, similarity & distance, data augmentation
Dimensionality Reduction with Principal Component Analysis
 10 Dimensionality Reduction with Principal Component Analysis Working directly with high-dimensional data, such as images, comes with some difficulties: it is hard to analyze, interpretation is difficult,
10 Dimensionality Reduction with Principal Component Analysis Working directly with high-dimensional data, such as images, comes with some difficulties: it is hard to analyze, interpretation is difficult,
Unsupervised dimensionality reduction
 Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
Motivating the Covariance Matrix
 Motivating the Covariance Matrix Raúl Rojas Computer Science Department Freie Universität Berlin January 2009 Abstract This note reviews some interesting properties of the covariance matrix and its role
Motivating the Covariance Matrix Raúl Rojas Computer Science Department Freie Universität Berlin January 2009 Abstract This note reviews some interesting properties of the covariance matrix and its role
Factor Analysis (10/2/13)
") STA561: Probabilistic machine learning Factor Analysis (10/2/13) Lecturer: Barbara Engelhardt Scribes: Li Zhu, Fan Li, Ni Guan Factor Analysis Factor analysis is related to the mixture models we have studied.
STA561: Probabilistic machine learning Factor Analysis (10/2/13) Lecturer: Barbara Engelhardt Scribes: Li Zhu, Fan Li, Ni Guan Factor Analysis Factor analysis is related to the mixture models we have studied.
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Salvador Dalí, Galatea of the Spheres CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy and Lisa Zhang Some slides from Derek Hoiem and Alysha
Principal Component Analysis (PCA) Salvador Dalí, Galatea of the Spheres CSC411/2515: Machine Learning and Data Mining, Winter 2018 Michael Guerzhoy and Lisa Zhang Some slides from Derek Hoiem and Alysha
Lecture 4: Principal Component Analysis and Linear Dimension Reduction
 Lecture 4: Principal Component Analysis and Linear Dimension Reduction Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics University of Pittsburgh E-mail:
Lecture 4: Principal Component Analysis and Linear Dimension Reduction Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics University of Pittsburgh E-mail:
3.1. The probabilistic view of the principal component analysis.
 301 Chapter 3 Principal Components and Statistical Factor Models This chapter of introduces the principal component analysis (PCA), briefly reviews statistical factor models PCA is among the most popular
301 Chapter 3 Principal Components and Statistical Factor Models This chapter of introduces the principal component analysis (PCA), briefly reviews statistical factor models PCA is among the most popular
Principal Component Analysis (PCA) CSC411/2515 Tutorial
 CSC411/2515 Tutorial") Principal Component Analysis (PCA) CSC411/2515 Tutorial Harris Chan Based on previous tutorial slides by Wenjie Luo, Ladislav Rampasek University of Toronto hchan@cs.toronto.edu October 19th, 2017 (UofT)
Principal Component Analysis (PCA) CSC411/2515 Tutorial Harris Chan Based on previous tutorial slides by Wenjie Luo, Ladislav Rampasek University of Toronto hchan@cs.toronto.edu October 19th, 2017 (UofT)
Dimensionality Reduction: PCA. Nicholas Ruozzi University of Texas at Dallas
 Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Dimensionality Reduction: PCA Nicholas Ruozzi University of Texas at Dallas Eigenvalues λ is an eigenvalue of a matrix A R n n if the linear system Ax = λx has at least one non-zero solution If Ax = λx
Machine Learning - MT & 14. PCA and MDS
 Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)
Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)
Face Recognition. Face Recognition. Subspace-Based Face Recognition Algorithms. Application of Face Recognition
 ace Recognition Identify person based on the appearance of face CSED441:Introduction to Computer Vision (2017) Lecture10: Subspace Methods and ace Recognition Bohyung Han CSE, POSTECH bhhan@postech.ac.kr
ace Recognition Identify person based on the appearance of face CSED441:Introduction to Computer Vision (2017) Lecture10: Subspace Methods and ace Recognition Bohyung Han CSE, POSTECH bhhan@postech.ac.kr
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
Machine Learning (BSMC-GA 4439) Wenke Liu 02-01-2018 Biomedical data are usually high-dimensional Number of samples (n) is relatively small whereas number of features (p) can be large Sometimes p>>n Problems
Lecture 7 Spectral methods
 CSE 291: Unsupervised learning Spring 2008 Lecture 7 Spectral methods 7.1 Linear algebra review 7.1.1 Eigenvalues and eigenvectors Definition 1. A d d matrix M has eigenvalue λ if there is a d-dimensional
CSE 291: Unsupervised learning Spring 2008 Lecture 7 Spectral methods 7.1 Linear algebra review 7.1.1 Eigenvalues and eigenvectors Definition 1. A d d matrix M has eigenvalue λ if there is a d-dimensional
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 2017-2018 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 2017-2018 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI
IN Pratical guidelines for classification Evaluation Feature selection Principal component transform Anne Solberg
 IN 5520 30.10.18 Pratical guidelines for classification Evaluation Feature selection Principal component transform Anne Solberg (anne@ifi.uio.no) 30.10.18 IN 5520 1 Literature Practical guidelines of classification
IN 5520 30.10.18 Pratical guidelines for classification Evaluation Feature selection Principal component transform Anne Solberg (anne@ifi.uio.no) 30.10.18 IN 5520 1 Literature Practical guidelines of classification
Image Analysis & Retrieval. Lec 14. Eigenface and Fisherface
 Image Analysis & Retrieval Lec 14 Eigenface and Fisherface Zhu Li Dept of CSEE, UMKC Office: FH560E, Email: lizhu@umkc.edu, Ph: x 2346. http://l.web.umkc.edu/lizhu Z. Li, Image Analysis & Retrv, Spring
Image Analysis & Retrieval Lec 14 Eigenface and Fisherface Zhu Li Dept of CSEE, UMKC Office: FH560E, Email: lizhu@umkc.edu, Ph: x 2346. http://l.web.umkc.edu/lizhu Z. Li, Image Analysis & Retrv, Spring
7 Principal Component Analysis
 7 Principal Component Analysis This topic will build a series of techniques to deal with high-dimensional data. Unlike regression problems, our goal is not to predict a value (the y-coordinate), it is
7 Principal Component Analysis This topic will build a series of techniques to deal with high-dimensional data. Unlike regression problems, our goal is not to predict a value (the y-coordinate), it is
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Additional reading can be found from non-assessed exercises (week 8) in this course unit teaching page. Textbooks: Sect. 6.3 in [1] and Ch. 12 in [2] Outline Introduction
Principal Component Analysis (PCA) Additional reading can be found from non-assessed exercises (week 8) in this course unit teaching page. Textbooks: Sect. 6.3 in [1] and Ch. 12 in [2] Outline Introduction
Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis
 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis Alvina Goh Vision Reading Group 13 October 2005 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal
Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis Alvina Goh Vision Reading Group 13 October 2005 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal
Lecture 5 Supspace Tranformations Eigendecompositions, kernel PCA and CCA
 Lecture 5 Supspace Tranformations Eigendecompositions, kernel PCA and CCA Pavel Laskov 1 Blaine Nelson 1 1 Cognitive Systems Group Wilhelm Schickard Institute for Computer Science Universität Tübingen,
Lecture 5 Supspace Tranformations Eigendecompositions, kernel PCA and CCA Pavel Laskov 1 Blaine Nelson 1 1 Cognitive Systems Group Wilhelm Schickard Institute for Computer Science Universität Tübingen,
Machine detection of emotions: Feature Selection
 Machine detection of emotions: Feature Selection Final Degree Dissertation Degree in Mathematics Leire Santos Moreno Supervisor: Raquel Justo Blanco María Inés Torres Barañano Leioa, 31 August 2016 Contents
Machine detection of emotions: Feature Selection Final Degree Dissertation Degree in Mathematics Leire Santos Moreno Supervisor: Raquel Justo Blanco María Inés Torres Barañano Leioa, 31 August 2016 Contents
Dimension Reduction Techniques. Presented by Jie (Jerry) Yu
 Yu") Dimension Reduction Techniques Presented by Jie (Jerry) Yu Outline Problem Modeling Review of PCA and MDS Isomap Local Linear Embedding (LLE) Charting Background Advances in data collection and storage
Dimension Reduction Techniques Presented by Jie (Jerry) Yu Outline Problem Modeling Review of PCA and MDS Isomap Local Linear Embedding (LLE) Charting Background Advances in data collection and storage
What is Principal Component Analysis?
 What is Principal Component Analysis? Principal component analysis (PCA) Reduce the dimensionality of a data set by finding a new set of variables, smaller than the original set of variables Retains most
What is Principal Component Analysis? Principal component analysis (PCA) Reduce the dimensionality of a data set by finding a new set of variables, smaller than the original set of variables Retains most
Principal Component Analysis (PCA) Our starting point consists of T observations from N variables, which will be arranged in an T N matrix R,
 Our starting point consists of T observations from N variables, which will be arranged in an T N matrix R,") Principal Component Analysis (PCA) PCA is a widely used statistical tool for dimension reduction. The objective of PCA is to find common factors, the so called principal components, in form of linear combinations
Principal Component Analysis (PCA) PCA is a widely used statistical tool for dimension reduction. The objective of PCA is to find common factors, the so called principal components, in form of linear combinations
Advanced data analysis
 Advanced data analysis Akisato Kimura ( 木村昭悟 ) NTT Communication Science Laboratories E-mail: akisato@ieee.org Advanced data analysis 1. Introduction (Aug 20) 2. Dimensionality reduction (Aug 20,21) PCA,
Advanced data analysis Akisato Kimura ( 木村昭悟 ) NTT Communication Science Laboratories E-mail: akisato@ieee.org Advanced data analysis 1. Introduction (Aug 20) 2. Dimensionality reduction (Aug 20,21) PCA,
Introduction to Graphical Models
 Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic
Introduction to Graphical Models The 15 th Winter School of Statistical Physics POSCO International Center & POSTECH, Pohang 2018. 1. 9 (Tue.) Yung-Kyun Noh GENERALIZATION FOR PREDICTION 2 Probabilistic
Principal Components Analysis (PCA) and Singular Value Decomposition (SVD) with applications to Microarrays
 and Singular Value Decomposition (SVD) with applications to Microarrays") Principal Components Analysis (PCA) and Singular Value Decomposition (SVD) with applications to Microarrays Prof. Tesler Math 283 Fall 2015 Prof. Tesler Principal Components Analysis Math 283 / Fall 2015
Principal Components Analysis (PCA) and Singular Value Decomposition (SVD) with applications to Microarrays Prof. Tesler Math 283 Fall 2015 Prof. Tesler Principal Components Analysis Math 283 / Fall 2015