On Top-k Structural. Similarity Search. Pei Lee, Laks V.S. Lakshmanan University of British Columbia Vancouver, BC, Canada
|
|
|
- Cecil Cameron
- 5 years ago
- Views:
Transcription



1 On Top-k Structural 1 Similarity Search Pei Lee, Laks V.S. Lakshmanan University of British Columbia Vancouver, BC, Canada Jeffrey Xu Yu Chinese University of Hong Kong Hong Kong, China 2014/10/14 Pei Lee, ICDE 2012,

2 What s structural similarity? 2 Graph structures are ubiquitous Social networks, citation networks, web graphs, etc Problem Statement
3 What s structural similarity? 3 Structural similarity: the pairwise similarity between nodes in a graph How f to quantify d b the g similarity between u and v? e u c a v h Problem Definition: Input: G( V, E), u V, v V Output: S( u, v) Intuition: two nodes are similar, if their neighbors are similar Do you remember PageRank s intuition? Problem Statement A node is important, if this node is referenced by many other important nodes

4 What s top-k structural similarity search? 4 I am a node in a huge graph with millions of nodes I want to find top-k similar nodes with me But I definitely do not want to compare with every node I hope the accuracy of results is guaranteed. Problem Definition: Input: G( V, E), v V, k Output: Top- k similar nodes for Problem Statement v
5 Existing Structural Similarity Measures 5 Neighbor-based approaches Jaccard Coefficient, Cosine Similarity, Pearson correlation, Co-citation, etc Cons: no neighbors, no similarity! Meeting-based approaches SimRank (Jeh & Widom, KDD 02) P-Rank (Zhao et.al, CIKM 09) (by extending SimRank) Cons: high computational cost Not designed for top-k similarity search Related Work
6 SimRank & P-Rank 6 SimRank: two nodes are similar, if they are referenced by similar nodes b u a c v S( a, a) 1 S( b, c) S( u, v) Pairwise iterative form: 0 < C < 1 C Sn 1( u, v) Sn( i, j) I( u) I( v) Matrix form: S T n1 CWSnW In-neighbors ii ( u) ji ( v) Correction matrix Related Work Transition matrix P-Rank: two nodes are similar, if they are related with similar nodes 0 < λ < 1 S ( u, v) C S ( i, j) (1 ) C S ( i, j) n1 n n I( u) I( v) ii ( u) ji ( v) O( u) O( v) io ( u) jo ( v) SimRank Reversed SimRank
7 Top-k similarity search: challenges 7 Matrix-based approach: Offline: compute a V -by- V similarity matrix SimRank/P-Rank takes O( E 2 ) time, which degenerate to O( V 4 ) in the worst case Space cost: hard to store this huge similarity matrix Vector-based approach: Offline: compute a vector with length V Takes O( V D 2n ) time in the worst case, where n is the iteration number, D is the average edge degree All these approaches need to access the whole graph to find the exact top-k similar nodes Challenges
8 Contributions 8 Transform the computation of pairwise similarity on graph G to the computation of authority on G G, based on a propagation & aggregation process; Propose TopSim, a local top-k structural similarity search algorithm that avoids accessing the whole graph while the accuracy is guaranteed. Propose Trun-TopSim-SM and Prio-TopSim-SM, which are two approximations allowing us to trade accuracy for speed. Contributions
9 Structural similarity computation 9 Similarity Score Propagation & Aggregation Similarity Path Single random walk on G G Coupling random walk on G
10 Product of graphs: G G 10 Given G(V, E), G G is defined as For node u and v in G, uv is a node in G G For edge (u, u ) and (v, v ) in G, (uv, u v ) is an edge in G G b a cb cc uu ec vu c d v bd ce uv ee ea u e G da aa vv dd ae G G Each node pair in G will be a node in G G Each edge pair in G will be an edge in G G No need to materialize G G: only conceptually exists to facilitate analysis
11 Coupling random walk 11 Coupling random walk: two random surfers walk simultaneously and follow the same edge direction Surf1, Surf2 SimRank: S(u, v) is the first meeting probability of two random surfers starting from u and v respectively and following backward links. Coupling random walk on G can be equivalently transformed as a single random walk on G G b a cc uu ec cb vu c d v bd ce uv ee ea u e G da aa vv dd ae G G
12 Compute similarity based on coupling random walk 12 We actually transform a similarity ranking problem on G into an authority ranking problem on G G R(uv) = S(u, v) Initialization: R(uv) = 1 is fixed if u = v (uv is a source node) R(uv) = 0 if u v and R(uv) will be updated (uv is a target node) A propagation & Aggregation process Propagation: nodes propagate their authority to their neighbors following random walk steps Aggregation: nodes receive and aggregate the authorities that are propagated-in from their neighbors.
13 Compute S(u,v)? 13 Similarity path: a path from source node to target node without going by source nodes cc uu ec cb vu bd ce uv ee ea vv da aa dd ae Probability of a transition step: Similarity:
14 Compute S(u,v): example 14 If we only consider 3 steps C = cc uu ec cb vu Path 1: (ee, uv) P(ee, uv) = 0.5 bd ce uv 1 ee ea da aa 1 vv 1 dd 1 ae Path 2: (aa, bd, ce, uv) P(aa, bd, ce, uv) = 0.5*1*0.5 = 0.25 S 3 (u,v) = P(ee, uv)*c + P(aa, bd, ce, uv)*c 3 = 0.281

15 Length bound for similarity paths 15 How many steps should take to guarantee the accuracy? Accuracy loss upper bound: TopSim: find top k similar nodes for a node v Start from v and explore neighbors in G as candidates step by step; Stop until the following condition is satisfied: TopSim can guarantee all theoretical top k similar nodes are explored.
16 16 TopSim
} SM(a) = {(e, 1/8)} SM(v) = {(u, 1/32)} SimMap SM(u) = {(key, value)} key is the node visited by Surf2 on step i when Surf1 visits the node u value = S i")
17 SimMap 17 Observation: many similarity paths are overlapped 3 c c Example: f d e u b a g v h b a u Similarity paths v Start from c SM(b) = {(d, 1/2), (f, 1/2)} SM(a) = {(e, 1/8)} SM(v) = {(u, 1/32)} SimMap SM(u) = {(key, value)} key is the node visited by Surf2 on step i when Surf1 visits the node u value = S i (key, u)
18 TopSim based on SimMaps 18 Start from v and find source nodes at each step From level n-1 to 0 Let Surf1 start from source node and walk to node v Let Surf2 start from the same source node and put the visited nodes into SimMaps When level=0, Surf1 visits v, Surf2 will exactly visits the similar nodes of v in the same step 3 c 2 f d b g 1 e a h 0 u v
19 Algorithms 19 Algrithms Quality Performance TopSim Accurate Slow if not sparse TopSim-SM Accurate More efficient than TopSim Trun-TopSim-SM Trade accuracy for speed More efficient than TopSim-SM Prio-TopSim-SM Trade accuracy for speed More efficient than TopSim-SM

20 TopSim approximations for Scalefree graphs 20 Scale-free graphs Some nodes have very high degree Web graphs, citation networks, etc Random surfers will be trapped by high degree nodes The size of SimMaps will be exploded Revisit the transition probabilities: a n
21 TopSim approximations 21 Basic idea: Only consider similarity paths with higher probability Truncated TopSim-SM If P(u 0 u 0,, u i v i ) < η, stop and ignore this path Prioritized TopSim-SM Set a buffer size H Only expand top H nodes in SimMaps: If SM(u) > H, set SM(u) = H. See accuracy and complexity analysis in paper
22 Experiments 22 Datasets Arxiv High Energy Physics paper citation network, including 34,546 nodes and 421,578 edges DBLP co-author graph, with 0.92M nodes, 6.1M edges DBLP citation network, with 1.5M papers and 2.1M citations Live Journal social network, with 4.84M users and 68.99M friendship ties C = 0.5, η = 0.001, H = 100
23 Accuracy of similarity scores 23 Accuracy ratio Accuracy loss
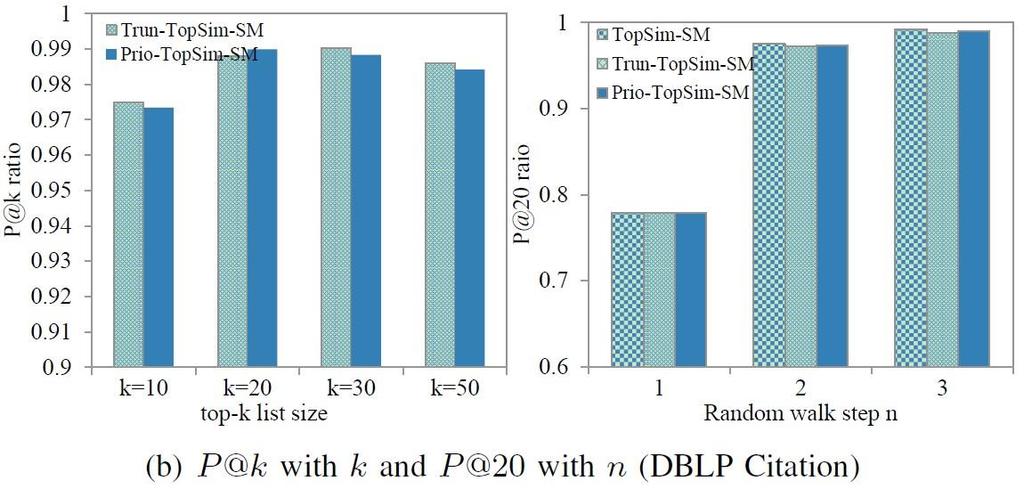
24 24

25 25 Kendall Tau distance
26 Running time with different node sizes and node degrees 26 TopSim algorithms are not sensitive to the graph size TopSim approximations are not sensitive to high degree nodes
27 27 Running time and accessed nodes
28 Conclusion 28 We transform a similarity problem on graph G into an authority ranking problem on the product graph G G; We propose a family of TopSim methods that produce both the exact and approximate top-k results while accessing a small portion of the graph; Our algorithms work with both SimRank and P-Rank under the same top k framework. Questions?
Cross-lingual and temporal Wikipedia analysis
 MTA SZTAKI Data Mining and Search Group June 14, 2013 Supported by the EC FET Open project New tools and algorithms for directed network analysis (NADINE No 288956) Table of Contents 1 Link prediction
MTA SZTAKI Data Mining and Search Group June 14, 2013 Supported by the EC FET Open project New tools and algorithms for directed network analysis (NADINE No 288956) Table of Contents 1 Link prediction
ECEN 689 Special Topics in Data Science for Communications Networks
 ECEN 689 Special Topics in Data Science for Communications Networks Nick Duffield Department of Electrical & Computer Engineering Texas A&M University Lecture 8 Random Walks, Matrices and PageRank Graphs
ECEN 689 Special Topics in Data Science for Communications Networks Nick Duffield Department of Electrical & Computer Engineering Texas A&M University Lecture 8 Random Walks, Matrices and PageRank Graphs
Web Structure Mining Nodes, Links and Influence
 Web Structure Mining Nodes, Links and Influence 1 Outline 1. Importance of nodes 1. Centrality 2. Prestige 3. Page Rank 4. Hubs and Authority 5. Metrics comparison 2. Link analysis 3. Influence model 1.
Web Structure Mining Nodes, Links and Influence 1 Outline 1. Importance of nodes 1. Centrality 2. Prestige 3. Page Rank 4. Hubs and Authority 5. Metrics comparison 2. Link analysis 3. Influence model 1.
DATA MINING LECTURE 13. Link Analysis Ranking PageRank -- Random walks HITS
 DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information
DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information
Online Social Networks and Media. Link Analysis and Web Search
 Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Link Analysis Ranking
 Link Analysis Ranking How do search engines decide how to rank your query results? Guess why Google ranks the query results the way it does How would you do it? Naïve ranking of query results Given query
Link Analysis Ranking How do search engines decide how to rank your query results? Guess why Google ranks the query results the way it does How would you do it? Naïve ranking of query results Given query
Online Social Networks and Media. Link Analysis and Web Search
 Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Node Centrality and Ranking on Networks
 Node Centrality and Ranking on Networks Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Social
Node Centrality and Ranking on Networks Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Social
Link Analysis. Stony Brook University CSE545, Fall 2016
 Link Analysis Stony Brook University CSE545, Fall 2016 The Web, circa 1998 The Web, circa 1998 The Web, circa 1998 Match keywords, language (information retrieval) Explore directory The Web, circa 1998
Link Analysis Stony Brook University CSE545, Fall 2016 The Web, circa 1998 The Web, circa 1998 The Web, circa 1998 Match keywords, language (information retrieval) Explore directory The Web, circa 1998
Link Mining PageRank. From Stanford C246
 Link Mining PageRank From Stanford C246 Broad Question: How to organize the Web? First try: Human curated Web dictionaries Yahoo, DMOZ LookSmart Second try: Web Search Information Retrieval investigates
Link Mining PageRank From Stanford C246 Broad Question: How to organize the Web? First try: Human curated Web dictionaries Yahoo, DMOZ LookSmart Second try: Web Search Information Retrieval investigates
Model Reduction for Edge-Weighted Personalized PageRank
 Model Reduction for Edge-Weighted Personalized PageRank David Bindel Mar 2, 2015 David Bindel SCAN Mar 2, 2015 1 / 29 The PageRank Model Surfer follows random link (probability α) or teleports to random
Model Reduction for Edge-Weighted Personalized PageRank David Bindel Mar 2, 2015 David Bindel SCAN Mar 2, 2015 1 / 29 The PageRank Model Surfer follows random link (probability α) or teleports to random
CS 277: Data Mining. Mining Web Link Structure. CS 277: Data Mining Lectures Analyzing Web Link Structure Padhraic Smyth, UC Irvine
 CS 277: Data Mining Mining Web Link Structure Class Presentations In-class, Tuesday and Thursday next week 2-person teams: 6 minutes, up to 6 slides, 3 minutes/slides each person 1-person teams 4 minutes,
CS 277: Data Mining Mining Web Link Structure Class Presentations In-class, Tuesday and Thursday next week 2-person teams: 6 minutes, up to 6 slides, 3 minutes/slides each person 1-person teams 4 minutes,
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Graph and Network Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Methods Learnt Classification Clustering Vector Data Text Data Recommender System Decision Tree; Naïve
CS249: ADVANCED DATA MINING Graph and Network Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Methods Learnt Classification Clustering Vector Data Text Data Recommender System Decision Tree; Naïve
Communities Via Laplacian Matrices. Degree, Adjacency, and Laplacian Matrices Eigenvectors of Laplacian Matrices
 Communities Via Laplacian Matrices Degree, Adjacency, and Laplacian Matrices Eigenvectors of Laplacian Matrices The Laplacian Approach As with betweenness approach, we want to divide a social graph into
Communities Via Laplacian Matrices Degree, Adjacency, and Laplacian Matrices Eigenvectors of Laplacian Matrices The Laplacian Approach As with betweenness approach, we want to divide a social graph into
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu March 16, 2016 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu March 16, 2016 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
New Coding System of Grid Squares in the Republic of Indonesia
 September14, 2006 New Coding System of Grid Squares in the Republic of Indonesia Current coding system of grid squares in the Republic of Indonesia is based on similar
September14, 2006 New Coding System of Grid Squares in the Republic of Indonesia Current coding system of grid squares in the Republic of Indonesia is based on similar
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides
 Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
To Randomize or Not To
 To Randomize or Not To Randomize: Space Optimal Summaries for Hyperlink Analysis Tamás Sarlós, Eötvös University and Computer and Automation Institute, Hungarian Academy of Sciences Joint work with András
To Randomize or Not To Randomize: Space Optimal Summaries for Hyperlink Analysis Tamás Sarlós, Eötvös University and Computer and Automation Institute, Hungarian Academy of Sciences Joint work with András
Complex Social System, Elections. Introduction to Network Analysis 1
 Complex Social System, Elections Introduction to Network Analysis 1 Complex Social System, Network I person A voted for B A is more central than B if more people voted for A In-degree centrality index
Complex Social System, Elections Introduction to Network Analysis 1 Complex Social System, Network I person A voted for B A is more central than B if more people voted for A In-degree centrality index
Overlapping Community Detection at Scale: A Nonnegative Matrix Factorization Approach
 Overlapping Community Detection at Scale: A Nonnegative Matrix Factorization Approach Author: Jaewon Yang, Jure Leskovec 1 1 Venue: WSDM 2013 Presenter: Yupeng Gu 1 Stanford University 1 Background Community
Overlapping Community Detection at Scale: A Nonnegative Matrix Factorization Approach Author: Jaewon Yang, Jure Leskovec 1 1 Venue: WSDM 2013 Presenter: Yupeng Gu 1 Stanford University 1 Background Community
CS533 Fall 2017 HW5 Solutions. CS533 Information Retrieval Fall HW5 Solutions
 CS533 Information Retrieval Fall 2017 HW5 Solutions Q1 a) For λ = 1, we select documents based on similarity Thus, d 1> d 2> d 4> d 3 Start with d 1, S = {d1} R\S = { d 2, d 4, d 3} MMR(d 2) = 0.7 Maximum.
CS533 Information Retrieval Fall 2017 HW5 Solutions Q1 a) For λ = 1, we select documents based on similarity Thus, d 1> d 2> d 4> d 3 Start with d 1, S = {d1} R\S = { d 2, d 4, d 3} MMR(d 2) = 0.7 Maximum.
Point-of-Interest Recommendations: Learning Potential Check-ins from Friends
 Point-of-Interest Recommendations: Learning Potential Check-ins from Friends Huayu Li, Yong Ge +, Richang Hong, Hengshu Zhu University of North Carolina at Charlotte + University of Arizona Hefei University
Point-of-Interest Recommendations: Learning Potential Check-ins from Friends Huayu Li, Yong Ge +, Richang Hong, Hengshu Zhu University of North Carolina at Charlotte + University of Arizona Hefei University
1998: enter Link Analysis
 1998: enter Link Analysis uses hyperlink structure to focus the relevant set combine traditional IR score with popularity score Page and Brin 1998 Kleinberg Web Information Retrieval IR before the Web
1998: enter Link Analysis uses hyperlink structure to focus the relevant set combine traditional IR score with popularity score Page and Brin 1998 Kleinberg Web Information Retrieval IR before the Web
Link Analysis. Leonid E. Zhukov
 Link Analysis Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural Analysis and Visualization
Link Analysis Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural Analysis and Visualization
OLAK: An Efficient Algorithm to Prevent Unraveling in Social Networks. Fan Zhang 1, Wenjie Zhang 2, Ying Zhang 1, Lu Qin 1, Xuemin Lin 2
 OLAK: An Efficient Algorithm to Prevent Unraveling in Social Networks Fan Zhang 1, Wenjie Zhang 2, Ying Zhang 1, Lu Qin 1, Xuemin Lin 2 1 University of Technology Sydney, Computer 2 University Science
OLAK: An Efficient Algorithm to Prevent Unraveling in Social Networks Fan Zhang 1, Wenjie Zhang 2, Ying Zhang 1, Lu Qin 1, Xuemin Lin 2 1 University of Technology Sydney, Computer 2 University Science
Slides based on those in:
 Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering
Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering
Lab 8: Measuring Graph Centrality - PageRank. Monday, November 5 CompSci 531, Fall 2018
 Lab 8: Measuring Graph Centrality - PageRank Monday, November 5 CompSci 531, Fall 2018 Outline Measuring Graph Centrality: Motivation Random Walks, Markov Chains, and Stationarity Distributions Google
Lab 8: Measuring Graph Centrality - PageRank Monday, November 5 CompSci 531, Fall 2018 Outline Measuring Graph Centrality: Motivation Random Walks, Markov Chains, and Stationarity Distributions Google
Computing PageRank using Power Extrapolation
 Computing PageRank using Power Extrapolation Taher Haveliwala, Sepandar Kamvar, Dan Klein, Chris Manning, and Gene Golub Stanford University Abstract. We present a novel technique for speeding up the computation
Computing PageRank using Power Extrapolation Taher Haveliwala, Sepandar Kamvar, Dan Klein, Chris Manning, and Gene Golub Stanford University Abstract. We present a novel technique for speeding up the computation
Dynamical SimRank search on time-varying networks
 The VLDB Journal 28) 27:79 4 https://doi.org/.7/s778-7-488-z REGULAR PAPER Dynamical SimRank search on time-varying networks Weiren Yu Xuemin Lin 2 Wenjie Zhang 2 Julie A. McCann 3 Received: 22 November
The VLDB Journal 28) 27:79 4 https://doi.org/.7/s778-7-488-z REGULAR PAPER Dynamical SimRank search on time-varying networks Weiren Yu Xuemin Lin 2 Wenjie Zhang 2 Julie A. McCann 3 Received: 22 November
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/7/2012 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 Web pages are not equally important www.joe-schmoe.com
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/7/2012 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 Web pages are not equally important www.joe-schmoe.com
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides
 Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Axiomatic Analysis of Co-occurrence Similarity Functions
 Axiomatic Analysis of Co-occurrence Similarity Functions U Kang Mikhail Bilenko Dengyong Zhou Christos Faloutsos February 202 CMU-CS-2-02 School of Computer Science Carnegie Mellon University Pittsburgh,
Axiomatic Analysis of Co-occurrence Similarity Functions U Kang Mikhail Bilenko Dengyong Zhou Christos Faloutsos February 202 CMU-CS-2-02 School of Computer Science Carnegie Mellon University Pittsburgh,
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize/navigate it? First try: Human curated Web directories Yahoo, DMOZ, LookSmart
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize/navigate it? First try: Human curated Web directories Yahoo, DMOZ, LookSmart
Large-scale Collaborative Ranking in Near-Linear Time
 Large-scale Collaborative Ranking in Near-Linear Time Liwei Wu Depts of Statistics and Computer Science UC Davis KDD 17, Halifax, Canada August 13-17, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
Large-scale Collaborative Ranking in Near-Linear Time Liwei Wu Depts of Statistics and Computer Science UC Davis KDD 17, Halifax, Canada August 13-17, 2017 Joint work with Cho-Jui Hsieh and James Sharpnack
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu November 16, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu November 16, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS246: Mining Massive Datasets Jure Leskovec, Stanford University.
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu What is the structure of the Web? How is it organized? 2/7/2011 Jure Leskovec, Stanford C246: Mining Massive
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu What is the structure of the Web? How is it organized? 2/7/2011 Jure Leskovec, Stanford C246: Mining Massive
Introduction to Data Mining
 Introduction to Data Mining Lecture #9: Link Analysis Seoul National University 1 In This Lecture Motivation for link analysis Pagerank: an important graph ranking algorithm Flow and random walk formulation
Introduction to Data Mining Lecture #9: Link Analysis Seoul National University 1 In This Lecture Motivation for link analysis Pagerank: an important graph ranking algorithm Flow and random walk formulation
Node similarity and classification
 Node similarity and classification Davide Mottin, Anton Tsitsulin HassoPlattner Institute Graph Mining course Winter Semester 2017 Acknowledgements Some part of this lecture is taken from: http://web.eecs.umich.edu/~dkoutra/tut/icdm14.html
Node similarity and classification Davide Mottin, Anton Tsitsulin HassoPlattner Institute Graph Mining course Winter Semester 2017 Acknowledgements Some part of this lecture is taken from: http://web.eecs.umich.edu/~dkoutra/tut/icdm14.html
Intelligent Data Analysis. PageRank. School of Computer Science University of Birmingham
 Intelligent Data Analysis PageRank Peter Tiňo School of Computer Science University of Birmingham Information Retrieval on the Web Most scoring methods on the Web have been derived in the context of Information
Intelligent Data Analysis PageRank Peter Tiňo School of Computer Science University of Birmingham Information Retrieval on the Web Most scoring methods on the Web have been derived in the context of Information
arxiv: v1 [cs.si] 13 Dec 2011
![arxiv: v1 [cs.si] 13 Dec 2011](/thumbs/85/91895128.jpg "arxiv: v1 [cs.si] 13 Dec 2011") Measuring Tie Strength in Implicit Social Networks Mangesh Gupte Department of Computer Science Rutgers University Piscataway, NJ 08854 mangesh@cs.rutgers.edu Tina Eliassi-Rad Department of Computer Science
Measuring Tie Strength in Implicit Social Networks Mangesh Gupte Department of Computer Science Rutgers University Piscataway, NJ 08854 mangesh@cs.rutgers.edu Tina Eliassi-Rad Department of Computer Science
Cutting Graphs, Personal PageRank and Spilling Paint
 Graphs and Networks Lecture 11 Cutting Graphs, Personal PageRank and Spilling Paint Daniel A. Spielman October 3, 2013 11.1 Disclaimer These notes are not necessarily an accurate representation of what
Graphs and Networks Lecture 11 Cutting Graphs, Personal PageRank and Spilling Paint Daniel A. Spielman October 3, 2013 11.1 Disclaimer These notes are not necessarily an accurate representation of what
Axiomatic Analysis of Co-occurrence Similarity Functions
 Axiomatic Analysis of Co-occurrence Similarity Functions U Kang Mikhail Bilenko Dengyong Zhou Christos Faloutsos February 202 CMU-CS-2-02 School of Computer Science Carnegie Mellon University Pittsburgh,
Axiomatic Analysis of Co-occurrence Similarity Functions U Kang Mikhail Bilenko Dengyong Zhou Christos Faloutsos February 202 CMU-CS-2-02 School of Computer Science Carnegie Mellon University Pittsburgh,
Outline for today. Information Retrieval. Cosine similarity between query and document. tf-idf weighting
 Outline for today Information Retrieval Efficient Scoring and Ranking Recap on ranked retrieval Jörg Tiedemann jorg.tiedemann@lingfil.uu.se Department of Linguistics and Philology Uppsala University Efficient
Outline for today Information Retrieval Efficient Scoring and Ranking Recap on ranked retrieval Jörg Tiedemann jorg.tiedemann@lingfil.uu.se Department of Linguistics and Philology Uppsala University Efficient
Slide source: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University.
 Slide source: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org #1: C4.5 Decision Tree - Classification (61 votes) #2: K-Means - Clustering
Slide source: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org #1: C4.5 Decision Tree - Classification (61 votes) #2: K-Means - Clustering
Kristina Lerman USC Information Sciences Institute
 Rethinking Network Structure Kristina Lerman USC Information Sciences Institute Università della Svizzera Italiana, December 16, 2011 Measuring network structure Central nodes Community structure Strength
Rethinking Network Structure Kristina Lerman USC Information Sciences Institute Università della Svizzera Italiana, December 16, 2011 Measuring network structure Central nodes Community structure Strength
ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties
 ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties Prof. James She james.she@ust.hk 1 Last lecture 2 Selected works from Tutorial
ELEC6910Q Analytics and Systems for Social Media and Big Data Applications Lecture 3 Centrality, Similarity, and Strength Ties Prof. James She james.she@ust.hk 1 Last lecture 2 Selected works from Tutorial
Idea: Select and rank nodes w.r.t. their relevance or interestingness in large networks.
 Graph Databases and Linked Data So far: Obects are considered as iid (independent and identical diributed) the meaning of obects depends exclusively on the description obects do not influence each other
Graph Databases and Linked Data So far: Obects are considered as iid (independent and identical diributed) the meaning of obects depends exclusively on the description obects do not influence each other
Node and Link Analysis
 Node and Link Analysis Leonid E. Zhukov School of Applied Mathematics and Information Science National Research University Higher School of Economics 10.02.2014 Leonid E. Zhukov (HSE) Lecture 5 10.02.2014
Node and Link Analysis Leonid E. Zhukov School of Applied Mathematics and Information Science National Research University Higher School of Economics 10.02.2014 Leonid E. Zhukov (HSE) Lecture 5 10.02.2014
Overlapping Communities
 Overlapping Communities Davide Mottin HassoPlattner Institute Graph Mining course Winter Semester 2017 Acknowledgements Most of this lecture is taken from: http://web.stanford.edu/class/cs224w/slides GRAPH
Overlapping Communities Davide Mottin HassoPlattner Institute Graph Mining course Winter Semester 2017 Acknowledgements Most of this lecture is taken from: http://web.stanford.edu/class/cs224w/slides GRAPH
Link Prediction. Eman Badr Mohammed Saquib Akmal Khan
 Link Prediction Eman Badr Mohammed Saquib Akmal Khan 11-06-2013 Link Prediction Which pair of nodes should be connected? Applications Facebook friend suggestion Recommendation systems Monitoring and controlling
Link Prediction Eman Badr Mohammed Saquib Akmal Khan 11-06-2013 Link Prediction Which pair of nodes should be connected? Applications Facebook friend suggestion Recommendation systems Monitoring and controlling
PageRank algorithm Hubs and Authorities. Data mining. Web Data Mining PageRank, Hubs and Authorities. University of Szeged.
 Web Data Mining PageRank, University of Szeged Why ranking web pages is useful? We are starving for knowledge It earns Google a bunch of money. How? How does the Web looks like? Big strongly connected
Web Data Mining PageRank, University of Szeged Why ranking web pages is useful? We are starving for knowledge It earns Google a bunch of money. How? How does the Web looks like? Big strongly connected
LINK ANALYSIS. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 LINK ANALYSIS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Retrieval evaluation Link analysis Models
LINK ANALYSIS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Retrieval evaluation Link analysis Models
CSI 445/660 Part 6 (Centrality Measures for Networks) 6 1 / 68
 6 1 / 68") CSI 445/660 Part 6 (Centrality Measures for Networks) 6 1 / 68 References 1 L. Freeman, Centrality in Social Networks: Conceptual Clarification, Social Networks, Vol. 1, 1978/1979, pp. 215 239. 2 S. Wasserman
CSI 445/660 Part 6 (Centrality Measures for Networks) 6 1 / 68 References 1 L. Freeman, Centrality in Social Networks: Conceptual Clarification, Social Networks, Vol. 1, 1978/1979, pp. 215 239. 2 S. Wasserman
A Note on Google s PageRank
 A Note on Google s PageRank According to Google, google-search on a given topic results in a listing of most relevant web pages related to the topic. Google ranks the importance of webpages according to
A Note on Google s PageRank According to Google, google-search on a given topic results in a listing of most relevant web pages related to the topic. Google ranks the importance of webpages according to
Degree Distribution: The case of Citation Networks
 Network Analysis Degree Distribution: The case of Citation Networks Papers (in almost all fields) refer to works done earlier on same/related topics Citations A network can be defined as Each node is
Network Analysis Degree Distribution: The case of Citation Networks Papers (in almost all fields) refer to works done earlier on same/related topics Citations A network can be defined as Each node is
0.1 Naive formulation of PageRank
 PageRank is a ranking system designed to find the best pages on the web. A webpage is considered good if it is endorsed (i.e. linked to) by other good webpages. The more webpages link to it, and the more
PageRank is a ranking system designed to find the best pages on the web. A webpage is considered good if it is endorsed (i.e. linked to) by other good webpages. The more webpages link to it, and the more
Google PageRank. Francesco Ricci Faculty of Computer Science Free University of Bozen-Bolzano
 Google PageRank Francesco Ricci Faculty of Computer Science Free University of Bozen-Bolzano fricci@unibz.it 1 Content p Linear Algebra p Matrices p Eigenvalues and eigenvectors p Markov chains p Google
Google PageRank Francesco Ricci Faculty of Computer Science Free University of Bozen-Bolzano fricci@unibz.it 1 Content p Linear Algebra p Matrices p Eigenvalues and eigenvectors p Markov chains p Google
Data and Algorithms of the Web
 Data and Algorithms of the Web Link Analysis Algorithms Page Rank some slides from: Anand Rajaraman, Jeffrey D. Ullman InfoLab (Stanford University) Link Analysis Algorithms Page Rank Hubs and Authorities
Data and Algorithms of the Web Link Analysis Algorithms Page Rank some slides from: Anand Rajaraman, Jeffrey D. Ullman InfoLab (Stanford University) Link Analysis Algorithms Page Rank Hubs and Authorities
IR: Information Retrieval
 / 44 IR: Information Retrieval FIB, Master in Innovation and Research in Informatics Slides by Marta Arias, José Luis Balcázar, Ramon Ferrer-i-Cancho, Ricard Gavaldá Department of Computer Science, UPC
/ 44 IR: Information Retrieval FIB, Master in Innovation and Research in Informatics Slides by Marta Arias, José Luis Balcázar, Ramon Ferrer-i-Cancho, Ricard Gavaldá Department of Computer Science, UPC
Updating PageRank. Amy Langville Carl Meyer
 Updating PageRank Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC SCCM 11/17/2003 Indexing Google Must index key terms on each page Robots crawl the web software
Updating PageRank Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC SCCM 11/17/2003 Indexing Google Must index key terms on each page Robots crawl the web software
A Nearly Sublinear Approximation to exp{p}e i for Large Sparse Matrices from Social Networks
 A Nearly Sublinear Approximation to exp{p}e i for Large Sparse Matrices from Social Networks Kyle Kloster and David F. Gleich Purdue University December 14, 2013 Supported by NSF CAREER 1149756-CCF Kyle
A Nearly Sublinear Approximation to exp{p}e i for Large Sparse Matrices from Social Networks Kyle Kloster and David F. Gleich Purdue University December 14, 2013 Supported by NSF CAREER 1149756-CCF Kyle
TopPPR: Top-k Personalized PageRank Queries with Precision Guarantees on Large Graphs
 TopPPR: Top-k Personalized PageRank Queries with Precision Guarantees on Large Graphs Zhewei Wei School of Infromation, Renmin University of China zhewei@ruc.edu.cn Sibo Wang University of Queensland sibo.wang@uq.edu.au
TopPPR: Top-k Personalized PageRank Queries with Precision Guarantees on Large Graphs Zhewei Wei School of Infromation, Renmin University of China zhewei@ruc.edu.cn Sibo Wang University of Queensland sibo.wang@uq.edu.au
Link Analysis Information Retrieval and Data Mining. Prof. Matteo Matteucci
 Link Analysis Information Retrieval and Data Mining Prof. Matteo Matteucci Hyperlinks for Indexing and Ranking 2 Page A Hyperlink Page B Intuitions The anchor text might describe the target page B Anchor
Link Analysis Information Retrieval and Data Mining Prof. Matteo Matteucci Hyperlinks for Indexing and Ranking 2 Page A Hyperlink Page B Intuitions The anchor text might describe the target page B Anchor
Determining the Diameter of Small World Networks
 Determining the Diameter of Small World Networks Frank W. Takes & Walter A. Kosters Leiden University, The Netherlands CIKM 2011 October 2, 2011 Glasgow, UK NWO COMPASS project (grant #12.0.92) 1 / 30
Determining the Diameter of Small World Networks Frank W. Takes & Walter A. Kosters Leiden University, The Netherlands CIKM 2011 October 2, 2011 Glasgow, UK NWO COMPASS project (grant #12.0.92) 1 / 30
Computing Trusted Authority Scores in Peer-to-Peer Web Search Networks
 Computing Trusted Authority Scores in Peer-to-Peer Web Search Networks Josiane Xavier Parreira, Debora Donato, Carlos Castillo, Gerhard Weikum Max-Planck Institute for Informatics Yahoo! Research May 8,
Computing Trusted Authority Scores in Peer-to-Peer Web Search Networks Josiane Xavier Parreira, Debora Donato, Carlos Castillo, Gerhard Weikum Max-Planck Institute for Informatics Yahoo! Research May 8,
Centrality Measures. Leonid E. Zhukov
 Centrality Measures Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Network Science Leonid E.
Centrality Measures Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Network Science Leonid E.
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu Intro sessions to SNAP C++ and SNAP.PY: SNAP.PY: Friday 9/27, 4:5 5:30pm in Gates B03 SNAP
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu Intro sessions to SNAP C++ and SNAP.PY: SNAP.PY: Friday 9/27, 4:5 5:30pm in Gates B03 SNAP
Page rank computation HPC course project a.y
 Page rank computation HPC course project a.y. 2015-16 Compute efficient and scalable Pagerank MPI, Multithreading, SSE 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and
Page rank computation HPC course project a.y. 2015-16 Compute efficient and scalable Pagerank MPI, Multithreading, SSE 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and
Part III: Traveling salesman problems
 Transportation Logistics Part III: Traveling salesman problems c R.F. Hartl, S.N. Parragh 1/282 Motivation Motivation Why do we study the TSP? c R.F. Hartl, S.N. Parragh 2/282 Motivation Motivation Why
Transportation Logistics Part III: Traveling salesman problems c R.F. Hartl, S.N. Parragh 1/282 Motivation Motivation Why do we study the TSP? c R.F. Hartl, S.N. Parragh 2/282 Motivation Motivation Why
Analysis of an Optimal Measurement Index Based on the Complex Network
 BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 16, No 5 Special Issue on Application of Advanced Computing and Simulation in Information Systems Sofia 2016 Print ISSN: 1311-9702;
BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 16, No 5 Special Issue on Application of Advanced Computing and Simulation in Information Systems Sofia 2016 Print ISSN: 1311-9702;
DS504/CS586: Big Data Analytics Graph Mining II
 Welcome to DS504/CS586: Big Data Analytics Graph Mining II Prof. Yanhua Li Time: 6-8:50PM Thursday Location: AK233 Spring 2018 v Course Project I has been graded. Grading was based on v 1. Project report
Welcome to DS504/CS586: Big Data Analytics Graph Mining II Prof. Yanhua Li Time: 6-8:50PM Thursday Location: AK233 Spring 2018 v Course Project I has been graded. Grading was based on v 1. Project report
Item Recommendation for Emerging Online Businesses
 Item Recommendation for Emerging Online Businesses Chun-Ta Lu Sihong Xie Weixiang Shao Lifang He Philip S. Yu University of Illinois at Chicago Presenter: Chun-Ta Lu New Online Businesses Emerge Rapidly
Item Recommendation for Emerging Online Businesses Chun-Ta Lu Sihong Xie Weixiang Shao Lifang He Philip S. Yu University of Illinois at Chicago Presenter: Chun-Ta Lu New Online Businesses Emerge Rapidly
Two Proofs of Commute Time being Proportional to Effective Resistance
 Two Proofs of Commute Time being Proportional to Effective Resistance Sandeep Nuckchady Report for Prof. Peter Winkler February 17, 2013 Abstract Chandra et al. have shown that the effective resistance,
Two Proofs of Commute Time being Proportional to Effective Resistance Sandeep Nuckchady Report for Prof. Peter Winkler February 17, 2013 Abstract Chandra et al. have shown that the effective resistance,
Data Mining Recitation Notes Week 3
 Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
Web Ranking. Classification (manual, automatic) Link Analysis (today s lesson)
 Link Analysis (today s lesson)") Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
Recommendation Systems
 Recommendation Systems Pawan Goyal CSE, IITKGP October 21, 2014 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 21, 2014 1 / 52 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Recommendation Systems Pawan Goyal CSE, IITKGP October 21, 2014 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 21, 2014 1 / 52 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Query Independent Scholarly Article Ranking
 Query Independent Scholarly Article Ranking Shuai Ma, Chen Gong, Renjun Hu, Dongsheng Luo, Chunming Hu and Jinpeng Huai SKLSDE Lab, Beihang University, Beijing, China Beijing Advanced Innovation Center
Query Independent Scholarly Article Ranking Shuai Ma, Chen Gong, Renjun Hu, Dongsheng Luo, Chunming Hu and Jinpeng Huai SKLSDE Lab, Beihang University, Beijing, China Beijing Advanced Innovation Center
UpdatingtheStationary VectorofaMarkovChain. Amy Langville Carl Meyer
 UpdatingtheStationary VectorofaMarkovChain Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC NSMC 9/4/2003 Outline Updating and Pagerank Aggregation Partitioning
UpdatingtheStationary VectorofaMarkovChain Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC NSMC 9/4/2003 Outline Updating and Pagerank Aggregation Partitioning
Data Mining and Matrices
 Data Mining and Matrices 10 Graphs II Rainer Gemulla, Pauli Miettinen Jul 4, 2013 Link analysis The web as a directed graph Set of web pages with associated textual content Hyperlinks between webpages
Data Mining and Matrices 10 Graphs II Rainer Gemulla, Pauli Miettinen Jul 4, 2013 Link analysis The web as a directed graph Set of web pages with associated textual content Hyperlinks between webpages
Heat Kernel Based Community Detection
 Heat Kernel Based Community Detection Joint with David F. Gleich, (Purdue), supported by" NSF CAREER 1149756-CCF Kyle Kloster! Purdue University! Local Community Detection Given seed(s) S in G, find a
Heat Kernel Based Community Detection Joint with David F. Gleich, (Purdue), supported by" NSF CAREER 1149756-CCF Kyle Kloster! Purdue University! Local Community Detection Given seed(s) S in G, find a
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Mark Schmidt University of British Columbia Winter 2019 Last Time: Monte Carlo Methods If we want to approximate expectations of random functions, E[g(x)] = g(x)p(x) or E[g(x)]
CPSC 540: Machine Learning Mark Schmidt University of British Columbia Winter 2019 Last Time: Monte Carlo Methods If we want to approximate expectations of random functions, E[g(x)] = g(x)p(x) or E[g(x)]
PageRank. Ryan Tibshirani /36-662: Data Mining. January Optional reading: ESL 14.10
 PageRank Ryan Tibshirani 36-462/36-662: Data Mining January 24 2012 Optional reading: ESL 14.10 1 Information retrieval with the web Last time we learned about information retrieval. We learned how to
PageRank Ryan Tibshirani 36-462/36-662: Data Mining January 24 2012 Optional reading: ESL 14.10 1 Information retrieval with the web Last time we learned about information retrieval. We learned how to
11 The Max-Product Algorithm
 Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms for Inference Fall 2014 11 The Max-Product Algorithm In the previous lecture, we introduced
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms for Inference Fall 2014 11 The Max-Product Algorithm In the previous lecture, we introduced
Personal PageRank and Spilling Paint
 Graphs and Networks Lecture 11 Personal PageRank and Spilling Paint Daniel A. Spielman October 7, 2010 11.1 Overview These lecture notes are not complete. The paint spilling metaphor is due to Berkhin
Graphs and Networks Lecture 11 Personal PageRank and Spilling Paint Daniel A. Spielman October 7, 2010 11.1 Overview These lecture notes are not complete. The paint spilling metaphor is due to Berkhin
Recommendation Systems
 Recommendation Systems Pawan Goyal CSE, IITKGP October 29-30, 2015 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 29-30, 2015 1 / 61 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
Recommendation Systems Pawan Goyal CSE, IITKGP October 29-30, 2015 Pawan Goyal (IIT Kharagpur) Recommendation Systems October 29-30, 2015 1 / 61 Recommendation System? Pawan Goyal (IIT Kharagpur) Recommendation
CMPS 6630: Introduction to Computational Biology and Bioinformatics. Structure Comparison
 CMPS 6630: Introduction to Computational Biology and Bioinformatics Structure Comparison Protein Structure Comparison Motivation Understand sequence and structure variability Understand Domain architecture
CMPS 6630: Introduction to Computational Biology and Bioinformatics Structure Comparison Protein Structure Comparison Motivation Understand sequence and structure variability Understand Domain architecture
Uncertainty and Randomization
 Uncertainty and Randomization The PageRank Computation in Google Roberto Tempo IEIIT-CNR Politecnico di Torino tempo@polito.it 1993: Robustness of Linear Systems 1993: Robustness of Linear Systems 16 Years
Uncertainty and Randomization The PageRank Computation in Google Roberto Tempo IEIIT-CNR Politecnico di Torino tempo@polito.it 1993: Robustness of Linear Systems 1993: Robustness of Linear Systems 16 Years
DS504/CS586: Big Data Analytics Graph Mining II
 Welcome to DS504/CS586: Big Data Analytics Graph Mining II Prof. Yanhua Li Time: 6:00pm 8:50pm Mon. and Wed. Location: SL105 Spring 2016 Reading assignments We will increase the bar a little bit Please
Welcome to DS504/CS586: Big Data Analytics Graph Mining II Prof. Yanhua Li Time: 6:00pm 8:50pm Mon. and Wed. Location: SL105 Spring 2016 Reading assignments We will increase the bar a little bit Please
Hyperlinked-Induced Topic Search (HITS) identifies. authorities as good content sources (~high indegree) HITS [Kleinberg 99] considers a web page
![Hyperlinked-Induced Topic Search (HITS) identifies. authorities as good content sources (~high indegree) HITS [Kleinberg 99] considers a web page](/thumbs/95/125556981.jpg "Hyperlinked-Induced Topic Search (HITS) identifies. authorities as good content sources (~high indegree) HITS [Kleinberg 99] considers a web page") IV.3 HITS Hyperlinked-Induced Topic Search (HITS) identifies authorities as good content sources (~high indegree) hubs as good link sources (~high outdegree) HITS [Kleinberg 99] considers a web page a
IV.3 HITS Hyperlinked-Induced Topic Search (HITS) identifies authorities as good content sources (~high indegree) hubs as good link sources (~high outdegree) HITS [Kleinberg 99] considers a web page a
Strong Localization in Personalized PageRank Vectors
 Strong Localization in Personalized PageRank Vectors Huda Nassar 1, Kyle Kloster 2, and David F. Gleich 1 1 Purdue University, Computer Science Department 2 Purdue University, Mathematics Department {hnassar,kkloste,dgleich}@purdue.edu
Strong Localization in Personalized PageRank Vectors Huda Nassar 1, Kyle Kloster 2, and David F. Gleich 1 1 Purdue University, Computer Science Department 2 Purdue University, Mathematics Department {hnassar,kkloste,dgleich}@purdue.edu
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 21: Review Jan-Willem van de Meent Schedule Topics for Exam Pre-Midterm Probability Information Theory Linear Regression Classification Clustering
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 21: Review Jan-Willem van de Meent Schedule Topics for Exam Pre-Midterm Probability Information Theory Linear Regression Classification Clustering
Asymmetric Correlation Regularized Matrix Factorization for Web Service Recommendation
 Asymmetric Correlation Regularized Matrix Factorization for Web Service Recommendation Qi Xie, Shenglin Zhao, Zibin Zheng, Jieming Zhu and Michael R. Lyu School of Computer Science and Technology, Southwest
Asymmetric Correlation Regularized Matrix Factorization for Web Service Recommendation Qi Xie, Shenglin Zhao, Zibin Zheng, Jieming Zhu and Michael R. Lyu School of Computer Science and Technology, Southwest
Edge-Weighted Personalized PageRank: Breaking a Decade-Old Performance Barrier
 Edge-Weighted Personalized PageRank: Breaking a Decade-Old Performance Barrier W. Xie D. Bindel A. Demers J. Gehrke 12 Aug 2015 W. Xie, D. Bindel, A. Demers, J. Gehrke KDD2015 12 Aug 2015 1 / 1 PageRank
Edge-Weighted Personalized PageRank: Breaking a Decade-Old Performance Barrier W. Xie D. Bindel A. Demers J. Gehrke 12 Aug 2015 W. Xie, D. Bindel, A. Demers, J. Gehrke KDD2015 12 Aug 2015 1 / 1 PageRank
Online Sampling of High Centrality Individuals in Social Networks
 Online Sampling of High Centrality Individuals in Social Networks Arun S. Maiya and Tanya Y. Berger-Wolf Department of Computer Science University of Illinois at Chicago 85 S. Morgan, Chicago, IL 667,
Online Sampling of High Centrality Individuals in Social Networks Arun S. Maiya and Tanya Y. Berger-Wolf Department of Computer Science University of Illinois at Chicago 85 S. Morgan, Chicago, IL 667,
Structural Link Analysis and Prediction in Microblogs
 Structural Link Analysis and Prediction in Microblogs Dawei Yin Liangjie Hong Brian D. Davison Department of Computer Science & Engineering, Lehigh University Bethlehem, PA 18015 USA {day207, lih307, davison}@cse.lehigh.edu
Structural Link Analysis and Prediction in Microblogs Dawei Yin Liangjie Hong Brian D. Davison Department of Computer Science & Engineering, Lehigh University Bethlehem, PA 18015 USA {day207, lih307, davison}@cse.lehigh.edu
PageRank: The Math-y Version (Or, What To Do When You Can t Tear Up Little Pieces of Paper)
") PageRank: The Math-y Version (Or, What To Do When You Can t Tear Up Little Pieces of Paper) In class, we saw this graph, with each node representing people who are following each other on Twitter: Our
PageRank: The Math-y Version (Or, What To Do When You Can t Tear Up Little Pieces of Paper) In class, we saw this graph, with each node representing people who are following each other on Twitter: Our
IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 6, NO. 1, JANUARY Static and Dynamic Structural Correlations in Graphs
 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 6, NO. 1, JANUARY 27 1 Static and Dynamic Structural Correlations in Graphs Jian Wu, Ziyu Guan, Qing Zhang, Ambuj Singh, Xifeng Yan Abstract Real-life
IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 6, NO. 1, JANUARY 27 1 Static and Dynamic Structural Correlations in Graphs Jian Wu, Ziyu Guan, Qing Zhang, Ambuj Singh, Xifeng Yan Abstract Real-life
Large Graph Mining: Power Tools and a Practitioner s guide
 Large Graph Mining: Power Tools and a Practitioner s guide Task 3: Recommendations & proximity Faloutsos, Miller & Tsourakakis CMU KDD'09 Faloutsos, Miller, Tsourakakis P3-1 Outline Introduction Motivation
Large Graph Mining: Power Tools and a Practitioner s guide Task 3: Recommendations & proximity Faloutsos, Miller & Tsourakakis CMU KDD'09 Faloutsos, Miller, Tsourakakis P3-1 Outline Introduction Motivation
Lecture: Local Spectral Methods (2 of 4) 19 Computing spectral ranking with the push procedure
 19 Computing spectral ranking with the push procedure") Stat260/CS294: Spectral Graph Methods Lecture 19-04/02/2015 Lecture: Local Spectral Methods (2 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Stat260/CS294: Spectral Graph Methods Lecture 19-04/02/2015 Lecture: Local Spectral Methods (2 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide