Link Analysis. Stony Brook University CSE545, Fall 2016
|
|
|
- Dinah Berenice Knight
- 5 years ago
- Views:
Transcription
1 Link Analysis Stony Brook University CSE545, Fall 2016
2 The Web, circa 1998

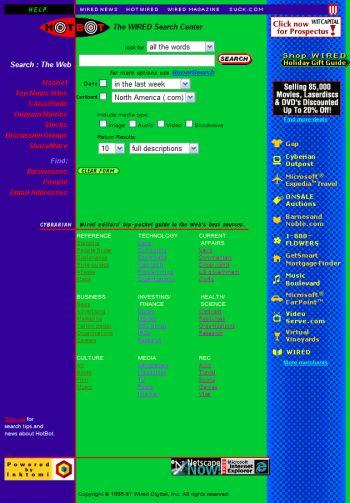

3 The Web, circa 1998
4 The Web, circa 1998 Match keywords, language (information retrieval) Explore directory
5 The Web, circa 1998 Easy to game with term spam Match keywords, language (information retrieval) Explore directory Time-consuming; Not open-ended

6 Enter PageRank...
7 Key Idea: Consider the citations of the website in addition to keywords.
8 Key Idea: Consider the citations of the website in addition to keywords. Who links to it? and what are their citations?
9 Key Idea: Consider the citations of the website in addition to keywords. Who links to it? and what are their citations? The Web as a directed graph:
10 Key Idea: Consider the citations of the website in addition to keywords. Who links to it? and what are their citations? Innovation 2: Not just own terms but what terms are used by citations?
11 Key Idea: Consider the citations of the website in addition to keywords. Flow Model: in-links as votes Innovation 2: Not just own terms but what terms are used by citations?
12 Key Idea: Consider the citations of the website in addition to keywords. Flow Model: in-links (citations) as votes But citations from important pages should count more. Use recursion to figure out if each page is important. Innovation 2: Not just own terms but what terms are used by citations?
 as votes But citations from important pages should count more.")
13 Key Idea: Consider the citations of the website in addition to keywords. Flow Model: in-links (citations) as votes But citations from important pages should count more. Use recursion to figure out if each page is important. Innovation 2: Not just own terms but what terms are used by citations?
14 Key Idea: Consider the citations of the website in addition to keywords. Flow Model: in-links (citations) as votes But citations from important pages should count more. How to compute? Each page (j) has an importance (i.e. rank, r j ) (n j is out-links ) Use recursion to figure out if each page is important. Innovation 2: Not just own terms but what terms are used by citations?
15 A C B D How to compute? Each page (j) has an importance (i.e. rank, r j ) (n j is out-links ) Innovation 2: Not just own terms but what terms are used by citations?
16 A C r A /1 B r B /4 r C /2 D r D = r A /1 + r B /4 + r C /2 How to compute? Each page (j) has an importance (i.e. rank, r j ) (n j is out-links ) Innovation 2: Not just own terms but what terms are used by citations?
17 A C B D How to compute? Each page (j) has an importance (i.e. rank, r j ) (n j is out-links ) Innovation 2: Not just own terms but what terms are used by citations?

 (n j is out-links )")
18 A B A system of equations? C How to compute? D Each page (j) has an importance (i.e. rank, r j ) (n j is out-links ) Innovation 2: Not just own terms but what terms are used by citations?
19 A B A system of equations? C How to compute? D Each page (j) has an importance (i.e. rank, r j ) (n j is out-links ) Innovation 2: Not just own terms but what terms are used by citations?
20 A B A system of equations? Provides intuition, but impractical to solve at scale. C D How to compute? Each page (j) has an importance (i.e. rank, r j ) (n j is out-links ) Innovation 2: Not just own terms but what terms are used by citations?
21 A C B D to \ from A B C D A 0 1/2 1 0 B 1/ /2 C 1/ /2 D 1/3 1/2 0 0 Transition Matrix, M
22 A C B D to \ from A B C D A 0 1/2 1 0 B 1/ /2 C 1/ /2 D 1/3 1/2 0 0 Transition Matrix, M To start: N=4 nodes, so r = [¼, ¼, ¼, ¼,]
23 A C B D to \ from A B C D A 0 1/2 1 0 B 1/ /2 C 1/ /2 D 1/3 1/2 0 0 Transition Matrix, M To start: N=4 nodes, so r = [¼, ¼, ¼, ¼,] after first iteration: M r = [3/8, 5/24, 5/24, 5/24]
24 A C B D to \ from A B C D A 0 1/2 1 0 B 1/ /2 C 1/ /2 D 1/3 1/2 0 0 Transition Matrix, M To start: N=4 nodes, so r = [¼, ¼, ¼, ¼,] after first iteration: M r = [3/8, 5/24, 5/24, 5/24] after second iteration: M(M r) = M 2 r = [15/48, 11/48, ]
25 A B Power iteration algorithm Initialize: r[0] = [1/N,, 1/N], r[-1]=[0,...,0] while (err_norm(r[t],r[t-1])>min_err): r[t+1] = M r[t] t+=1 solution = r[t] err_norm(v1, v2) = v1 - v2 #L1 norm C D to \ from A B C D A 0 1/2 1 0 B 1/ /2 C 1/ /2 D 1/3 1/2 0 0 Transition Matrix, M To start: N=4 nodes, so r = [¼, ¼, ¼, ¼,] after first iteration: M r = [3/8, 5/24, 5/24, 5/24] after second iteration: M(M r) = M 2 r = [15/48, 11/48, ]
26 A B Power iteration algorithm Initialize: r[0] = [1/N,, 1/N], r[-1]=[0,...,0] while (err_norm(r[t],r[t-1])>min_err): r[t+1] = M r[t] t+=1 solution = r[t] err_norm(v1, v2) = v1 - v2 #L1 norm C D to \ from A B C D A 0 1/2 1 0 B 1/ /2 C 1/ /2 D 1/3 1/2 0 0 Transition Matrix, M To start: N=4 nodes, so r = [¼, ¼, ¼, ¼,] after first iteration: M r = [3/8, 5/24, 5/24, 5/24] after second iteration: M(M r) = M 2 r = [15/48, 11/48, ]
27 Power iteration algorithm Initialize: r[0] = [1/N,, 1/N], r[-1]=[0,...,0] while (err_norm(r[t],r[t-1])>min_err): r[t+1] = M r[t] t+=1 solution = r[t] As err_norm gets smaller we are moving toward: r = M r We are actually just finding the eigenvector of M. err_norm(v1, v2) = v1 - v2 #L1 norm To start: N=4 nodes, so r = [¼, ¼, ¼, ¼,] after first iteration: M r = [3/8, 5/24, 5/24, 5/24] after second iteration: M(M r) = M 2 r = [15/48, 11/48, ]
28 Power iteration algorithm Initialize: r[0] = [1/N,, 1/N], r[-1]=[0,...,0] while (err_norm(r[t],r[t-1])>min_err): r[t+1] = M r[t] t+=1 solution = r[t] As err_norm gets smaller we are moving toward: r = M r We are actually just finding the eigenvector of M. x is an eigenvector of if: A x = x err_norm(v1, v2) = v1 - v2 #L1 norm To start: N=4 nodes, so r = [¼, ¼, ¼, ¼,] after first iteration: M r = [3/8, 5/24, 5/24, 5/24] after second iteration: M(M r) = M 2 r = [15/48, 11/48, ]
29 As err_norm gets smaller we are moving toward: r = M r Power iteration algorithm finds the... Initialize: r[0] = [1/N,, 1/N], r[-1]=[0,...,0] while (err_norm(r[t],r[t-1])>min_err): r[t+1] = M r[t] t+=1 solution = r[t] err_norm(v1, v2) = v1 - v2 #L1 norm We are actually just finding the eigenvector of M. x is an eigenvector of if: A x = x A = 1 since columns of M sum to 1. thus, 1r=Mr To start: N=4 nodes, so r = [¼, ¼, ¼, ¼,] after first iteration: M r = [3/8, 5/24, 5/24, 5/24] after second iteration: M(M r) = M 2 r = [15/48, 11/48, ]
30 As err_norm gets smaller we are moving toward: r = M r Power iteration algorithm finds the... Initialize: r[0] = [1/N,, 1/N], r[-1]=[0,...,0] while (err_norm(r[t],r[t-1])>min_err): r[t+1] = M r[t] t+=1 solution = r[t] err_norm(v1, v2) = v1 - v2 #L1 norm We are actually just finding the eigenvector of M. x is an eigenvector of if: A x = x A = 1 since columns of M sum to 1. thus, 1r=Mr To start: N=4 nodes, so r = [¼, ¼, ¼, ¼,] after first iteration: M r = [3/8, 5/24, 5/24, 5/24] after second iteration: M(M r) = M 2 r = [15/48, 11/48, ]
31 Power iteration algorithm Initialize: r[0] = [1/N,, 1/N], r[-1]=[0,...,0] while (err_norm(r[t],r[t-1])>min_err): r[t+1] = M r[t] t+=1 solution = r[t] err_norm(v1, v2) = v1 - v2 #L1 norm Where is surfer at time t+1? p(t+1) = M p(t) Suppose: p(t+1) = p(t), then p(t) is a stationary distribution of a random walk. Thus, r is a stationary distribution. Probability of being at given node.
32 aka 1st order Markov Process Rich probabilistic theory. One finding: Stationary distributions have a unique distribution if: Where is surfer at time t+1? p(t+1) = M p(t) Suppose: p(t+1) = p(t), then p(t) is a stationary distribution of a random walk. Thus, r is a stationary distribution. Probability of being at given node.
33 aka 1st order Markov Process Rich probabilistic theory. One finding: Stationary distributions have a unique distribution if: No dead-ends a node can t propagate its rank No spider traps set of nodes with no way out. Where is surfer at time t+1? p(t+1) = M p(t) Suppose: p(t+1) = p(t), then p(t) is a stationary distribution of a random walk. Thus, r is a stationary distribution. Probability of being at given node.
34 aka 1st order Markov Process Rich probabilistic theory. One finding: Stationary distributions have a unique distribution if: No dead-ends a node can t propagate its rank No spider traps set of nodes with no way out. (technically: it needs to be: stochastic, irreducible, and aperiodic ) Where is surfer at time t+1? p(t+1) = M p(t) Suppose: p(t+1) = p(t), then p(t) is a stationary distribution of a random walk. Thus, r is a stationary distribution. Probability of being at given node.
35 aka 1st order Markov Process Rich probabilistic theory. One finding: Stationary distributions have a unique distribution if: No dead-ends a node can t propagate its rank No spider traps set of nodes with no way out. A C B D to \ from A B C D A B 1/ C 1/ Where is surfer at time t+1? p(t+1) = M p(t) Suppose: p(t+1) = p(t), then p(t) is a stationary distribution of a random walk. Thus, r is a stationary distribution. Probability of being at given node. r would eventually converge to [0, 0, ]
36 aka 1st order Markov Process Rich probabilistic theory. One finding: Stationary distributions have a unique distribution if: No dead-ends a node can t propagate its rank No spider traps set of nodes with no way out. Where is surfer at time t+1? p(t+1) = M p(t) Suppose: p(t+1) = p(t), then p(t) is a stationary distribution of a random walk. Thus, r is a stationary distribution. Probability of being at given node. A B C D
37 aka 1st order Markov Process Rich probabilistic theory. One finding: Stationary distributions have a unique distribution if: No dead-ends a node can t propagate its rank No spider traps set of nodes with no way out. (technically: it needs to be: stochastic, irreducible, and aperiodic ) Where is surfer at time t+1? p(t+1) = M p(t) Suppose: p(t+1) = p(t), then p(t) is a stationary distribution of a random walk. Thus, r is a stationary distribution. Probability of being at given node. columns sum to 1 same node doesn t repeat at a regular interval non-zero chance of going to any another node
38 No dead-ends No spider traps The Google PageRank Formulation Add teleportation:at each step, two choices 1. Follow a random link (probability, = ~.85) 2. Teleport to a random node (probability, 1- ) A B C D
 2.")
39 No dead-ends No spider traps The Google PageRank Formulation Add teleportation:at each step, two choices 1. Follow a random link (probability, = ~.85) 2. Teleport to a random node (probability, 1- ) A B C D
40 No dead-ends No spider traps The Google PageRank Formulation Add teleportation chance at all nodes. i.e. at each step, two choices 1. Follow a random link (probability, = ~.85) 2. Teleport to a random node (probability, 1- ) Add teleportation from dead end with probability 1 A C B D to \ from A B C D A B 1/ C 1/ D 1/
41 No dead-ends No spider traps The Google PageRank Formulation Add teleportation chance at all nodes. i.e. at each step, two choices 1. Follow a random link (probability, = ~.85) 2. Teleport to a random node (probability, 1- ) Add teleportation from dead end with probability 1 A C B D to \ from A B C D A 0 ¼ 1 0 B 1/3 ¼ 0 1 C 1/3 ¼ 0 0 D 1/3 ¼ 0 0
42 No dead-ends No spider traps The Google PageRank Formulation Add teleportation chance at all nodes. i.e. at each step, two choices 1. Follow a random link (probability, = ~.85) 2. Teleport to a random node (probability, 1- ) Add teleportation from dead end with probability 1 to \ from A B C D (Brin and Page, 1998) A A C B D B 1/ C 1/ D 1/
43 No dead-ends No spider traps Flow Model The Google PageRank Formulation Add teleportation chance at all nodes. i.e. at each step, two choices 1. Follow a random link (probability, = ~.85) 2. Teleport to a random node (probability, 1- ) Add teleportation from dead end with probability 1 Matrix Model to \ from A B C D A B... (Brin and Page, 1998) A B A B 1/ C 1/ A ⅘*0 + ⅕*¼ ¼ B ⅘*⅓ + ⅕*¼ ¼ C ⅘*⅓ + ⅕*¼ ¼ assume = ⅘ C D D 1/ D ⅘*⅓ + ⅕*¼ ¼
44 No dead-ends No spider traps The Google PageRank Formulation Add teleportation chance at all nodes. i.e. at each step, two choices 1. Follow a random link (probability, = ~.85) 2. Teleport to a random node (probability, 1- ) Add teleportation from dead end with probability 1 Matrix Model To apply: run power iterations over M instead of M. A B... A ⅘*0 + ⅕*¼ ¼ B ⅘*⅓ + ⅕*¼ ¼ C ⅘*⅓ + ⅕*¼ ¼ D ⅘*⅓ + ⅕*¼ ¼ assume = ⅘
Link Mining PageRank. From Stanford C246
 Link Mining PageRank From Stanford C246 Broad Question: How to organize the Web? First try: Human curated Web dictionaries Yahoo, DMOZ LookSmart Second try: Web Search Information Retrieval investigates
Link Mining PageRank From Stanford C246 Broad Question: How to organize the Web? First try: Human curated Web dictionaries Yahoo, DMOZ LookSmart Second try: Web Search Information Retrieval investigates
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/7/2012 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 Web pages are not equally important www.joe-schmoe.com
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/7/2012 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 Web pages are not equally important www.joe-schmoe.com
Slide source: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University.
 Slide source: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org #1: C4.5 Decision Tree - Classification (61 votes) #2: K-Means - Clustering
Slide source: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org #1: C4.5 Decision Tree - Classification (61 votes) #2: K-Means - Clustering
Data and Algorithms of the Web
 Data and Algorithms of the Web Link Analysis Algorithms Page Rank some slides from: Anand Rajaraman, Jeffrey D. Ullman InfoLab (Stanford University) Link Analysis Algorithms Page Rank Hubs and Authorities
Data and Algorithms of the Web Link Analysis Algorithms Page Rank some slides from: Anand Rajaraman, Jeffrey D. Ullman InfoLab (Stanford University) Link Analysis Algorithms Page Rank Hubs and Authorities
0.1 Naive formulation of PageRank
 PageRank is a ranking system designed to find the best pages on the web. A webpage is considered good if it is endorsed (i.e. linked to) by other good webpages. The more webpages link to it, and the more
PageRank is a ranking system designed to find the best pages on the web. A webpage is considered good if it is endorsed (i.e. linked to) by other good webpages. The more webpages link to it, and the more
PageRank algorithm Hubs and Authorities. Data mining. Web Data Mining PageRank, Hubs and Authorities. University of Szeged.
 Web Data Mining PageRank, University of Szeged Why ranking web pages is useful? We are starving for knowledge It earns Google a bunch of money. How? How does the Web looks like? Big strongly connected
Web Data Mining PageRank, University of Szeged Why ranking web pages is useful? We are starving for knowledge It earns Google a bunch of money. How? How does the Web looks like? Big strongly connected
Slides based on those in:
 Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering
Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu November 16, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu November 16, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize/navigate it? First try: Human curated Web directories Yahoo, DMOZ, LookSmart
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize/navigate it? First try: Human curated Web directories Yahoo, DMOZ, LookSmart
1998: enter Link Analysis
 1998: enter Link Analysis uses hyperlink structure to focus the relevant set combine traditional IR score with popularity score Page and Brin 1998 Kleinberg Web Information Retrieval IR before the Web
1998: enter Link Analysis uses hyperlink structure to focus the relevant set combine traditional IR score with popularity score Page and Brin 1998 Kleinberg Web Information Retrieval IR before the Web
CS246: Mining Massive Datasets Jure Leskovec, Stanford University.
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu What is the structure of the Web? How is it organized? 2/7/2011 Jure Leskovec, Stanford C246: Mining Massive
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu What is the structure of the Web? How is it organized? 2/7/2011 Jure Leskovec, Stanford C246: Mining Massive
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides
 Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides
 Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Introduction to Data Mining
 Introduction to Data Mining Lecture #9: Link Analysis Seoul National University 1 In This Lecture Motivation for link analysis Pagerank: an important graph ranking algorithm Flow and random walk formulation
Introduction to Data Mining Lecture #9: Link Analysis Seoul National University 1 In This Lecture Motivation for link analysis Pagerank: an important graph ranking algorithm Flow and random walk formulation
DATA MINING LECTURE 13. Link Analysis Ranking PageRank -- Random walks HITS
 DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information
DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information
Online Social Networks and Media. Link Analysis and Web Search
 Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Link Analysis. Leonid E. Zhukov
 Link Analysis Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural Analysis and Visualization
Link Analysis Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural Analysis and Visualization
Link Analysis Ranking
 Link Analysis Ranking How do search engines decide how to rank your query results? Guess why Google ranks the query results the way it does How would you do it? Naïve ranking of query results Given query
Link Analysis Ranking How do search engines decide how to rank your query results? Guess why Google ranks the query results the way it does How would you do it? Naïve ranking of query results Given query
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu March 16, 2016 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu March 16, 2016 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Graph and Network Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Methods Learnt Classification Clustering Vector Data Text Data Recommender System Decision Tree; Naïve
CS249: ADVANCED DATA MINING Graph and Network Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Methods Learnt Classification Clustering Vector Data Text Data Recommender System Decision Tree; Naïve
Online Social Networks and Media. Link Analysis and Web Search
 Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Google PageRank. Francesco Ricci Faculty of Computer Science Free University of Bozen-Bolzano
 Google PageRank Francesco Ricci Faculty of Computer Science Free University of Bozen-Bolzano fricci@unibz.it 1 Content p Linear Algebra p Matrices p Eigenvalues and eigenvectors p Markov chains p Google
Google PageRank Francesco Ricci Faculty of Computer Science Free University of Bozen-Bolzano fricci@unibz.it 1 Content p Linear Algebra p Matrices p Eigenvalues and eigenvectors p Markov chains p Google
Updating PageRank. Amy Langville Carl Meyer
 Updating PageRank Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC SCCM 11/17/2003 Indexing Google Must index key terms on each page Robots crawl the web software
Updating PageRank Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC SCCM 11/17/2003 Indexing Google Must index key terms on each page Robots crawl the web software
Uncertainty and Randomization
 Uncertainty and Randomization The PageRank Computation in Google Roberto Tempo IEIIT-CNR Politecnico di Torino tempo@polito.it 1993: Robustness of Linear Systems 1993: Robustness of Linear Systems 16 Years
Uncertainty and Randomization The PageRank Computation in Google Roberto Tempo IEIIT-CNR Politecnico di Torino tempo@polito.it 1993: Robustness of Linear Systems 1993: Robustness of Linear Systems 16 Years
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Mark Schmidt University of British Columbia Winter 2019 Last Time: Monte Carlo Methods If we want to approximate expectations of random functions, E[g(x)] = g(x)p(x) or E[g(x)]
CPSC 540: Machine Learning Mark Schmidt University of British Columbia Winter 2019 Last Time: Monte Carlo Methods If we want to approximate expectations of random functions, E[g(x)] = g(x)p(x) or E[g(x)]
ECEN 689 Special Topics in Data Science for Communications Networks
 ECEN 689 Special Topics in Data Science for Communications Networks Nick Duffield Department of Electrical & Computer Engineering Texas A&M University Lecture 8 Random Walks, Matrices and PageRank Graphs
ECEN 689 Special Topics in Data Science for Communications Networks Nick Duffield Department of Electrical & Computer Engineering Texas A&M University Lecture 8 Random Walks, Matrices and PageRank Graphs
Lecture 12: Link Analysis for Web Retrieval
 Lecture 12: Link Analysis for Web Retrieval Trevor Cohn COMP90042, 2015, Semester 1 What we ll learn in this lecture The web as a graph Page-rank method for deriving the importance of pages Hubs and authorities
Lecture 12: Link Analysis for Web Retrieval Trevor Cohn COMP90042, 2015, Semester 1 What we ll learn in this lecture The web as a graph Page-rank method for deriving the importance of pages Hubs and authorities
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University We ve had our first HC cases. Please, please, please, before you do anything that might violate the HC, talk to me or a TA to make sure it is legitimate. It is much
Jeffrey D. Ullman Stanford University We ve had our first HC cases. Please, please, please, before you do anything that might violate the HC, talk to me or a TA to make sure it is legitimate. It is much
Graph Models The PageRank Algorithm
 Graph Models The PageRank Algorithm Anna-Karin Tornberg Mathematical Models, Analysis and Simulation Fall semester, 2013 The PageRank Algorithm I Invented by Larry Page and Sergey Brin around 1998 and
Graph Models The PageRank Algorithm Anna-Karin Tornberg Mathematical Models, Analysis and Simulation Fall semester, 2013 The PageRank Algorithm I Invented by Larry Page and Sergey Brin around 1998 and
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Mark Schmidt University of British Columbia Winter 2018 Last Time: Monte Carlo Methods If we want to approximate expectations of random functions, E[g(x)] = g(x)p(x) or E[g(x)]
CPSC 540: Machine Learning Mark Schmidt University of British Columbia Winter 2018 Last Time: Monte Carlo Methods If we want to approximate expectations of random functions, E[g(x)] = g(x)p(x) or E[g(x)]
Introduction to Search Engine Technology Introduction to Link Structure Analysis. Ronny Lempel Yahoo Labs, Haifa
 Introduction to Search Engine Technology Introduction to Link Structure Analysis Ronny Lempel Yahoo Labs, Haifa Outline Anchor-text indexing Mathematical Background Motivation for link structure analysis
Introduction to Search Engine Technology Introduction to Link Structure Analysis Ronny Lempel Yahoo Labs, Haifa Outline Anchor-text indexing Mathematical Background Motivation for link structure analysis
Today. Next lecture. (Ch 14) Markov chains and hidden Markov models
 Markov chains and hidden Markov models") Today (Ch 14) Markov chains and hidden Markov models Graphical representation Transition probability matrix Propagating state distributions The stationary distribution Next lecture (Ch 14) Markov chains
Today (Ch 14) Markov chains and hidden Markov models Graphical representation Transition probability matrix Propagating state distributions The stationary distribution Next lecture (Ch 14) Markov chains
Computing PageRank using Power Extrapolation
 Computing PageRank using Power Extrapolation Taher Haveliwala, Sepandar Kamvar, Dan Klein, Chris Manning, and Gene Golub Stanford University Abstract. We present a novel technique for speeding up the computation
Computing PageRank using Power Extrapolation Taher Haveliwala, Sepandar Kamvar, Dan Klein, Chris Manning, and Gene Golub Stanford University Abstract. We present a novel technique for speeding up the computation
A Note on Google s PageRank
 A Note on Google s PageRank According to Google, google-search on a given topic results in a listing of most relevant web pages related to the topic. Google ranks the importance of webpages according to
A Note on Google s PageRank According to Google, google-search on a given topic results in a listing of most relevant web pages related to the topic. Google ranks the importance of webpages according to
Web Ranking. Classification (manual, automatic) Link Analysis (today s lesson)
 Link Analysis (today s lesson)") Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
Information Retrieval and Search. Web Linkage Mining. Miłosz Kadziński
 Web Linkage Analysis D24 D4 : Web Linkage Mining Miłosz Kadziński Institute of Computing Science Poznan University of Technology, Poland www.cs.put.poznan.pl/mkadzinski/wpi Web mining: Web Mining Discovery
Web Linkage Analysis D24 D4 : Web Linkage Mining Miłosz Kadziński Institute of Computing Science Poznan University of Technology, Poland www.cs.put.poznan.pl/mkadzinski/wpi Web mining: Web Mining Discovery
How works. or How linear algebra powers the search engine. M. Ram Murty, FRSC Queen s Research Chair Queen s University
 How works or How linear algebra powers the search engine M. Ram Murty, FRSC Queen s Research Chair Queen s University From: gomath.com/geometry/ellipse.php Metric mishap causes loss of Mars orbiter
How works or How linear algebra powers the search engine M. Ram Murty, FRSC Queen s Research Chair Queen s University From: gomath.com/geometry/ellipse.php Metric mishap causes loss of Mars orbiter
Pseudocode for calculating Eigenfactor TM Score and Article Influence TM Score using data from Thomson-Reuters Journal Citations Reports
 Pseudocode for calculating Eigenfactor TM Score and Article Influence TM Score using data from Thomson-Reuters Journal Citations Reports Jevin West and Carl T. Bergstrom November 25, 2008 1 Overview There
Pseudocode for calculating Eigenfactor TM Score and Article Influence TM Score using data from Thomson-Reuters Journal Citations Reports Jevin West and Carl T. Bergstrom November 25, 2008 1 Overview There
Data Mining and Matrices
 Data Mining and Matrices 10 Graphs II Rainer Gemulla, Pauli Miettinen Jul 4, 2013 Link analysis The web as a directed graph Set of web pages with associated textual content Hyperlinks between webpages
Data Mining and Matrices 10 Graphs II Rainer Gemulla, Pauli Miettinen Jul 4, 2013 Link analysis The web as a directed graph Set of web pages with associated textual content Hyperlinks between webpages
LINK ANALYSIS. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 LINK ANALYSIS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Retrieval evaluation Link analysis Models
LINK ANALYSIS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Retrieval evaluation Link analysis Models
Pr[positive test virus] Pr[virus] Pr[positive test] = Pr[positive test] = Pr[positive test]
![Pr[positive test virus] Pr[virus] Pr[positive test] = Pr[positive test] = Pr[positive test]](/thumbs/77/74699650.jpg "Pr[positive test virus] Pr[virus] Pr[positive test] = Pr[positive test] = Pr[positive test]") 146 Probability Pr[virus] = 0.00001 Pr[no virus] = 0.99999 Pr[positive test virus] = 0.99 Pr[positive test no virus] = 0.01 Pr[virus positive test] = Pr[positive test virus] Pr[virus] = 0.99 0.00001 =
146 Probability Pr[virus] = 0.00001 Pr[no virus] = 0.99999 Pr[positive test virus] = 0.99 Pr[positive test no virus] = 0.01 Pr[virus positive test] = Pr[positive test virus] Pr[virus] = 0.99 0.00001 =
IS4200/CS6200 Informa0on Retrieval. PageRank Con+nued. with slides from Hinrich Schütze and Chris6na Lioma
 IS4200/CS6200 Informa0on Retrieval PageRank Con+nued with slides from Hinrich Schütze and Chris6na Lioma Exercise: Assump0ons underlying PageRank Assump0on 1: A link on the web is a quality signal the
IS4200/CS6200 Informa0on Retrieval PageRank Con+nued with slides from Hinrich Schütze and Chris6na Lioma Exercise: Assump0ons underlying PageRank Assump0on 1: A link on the web is a quality signal the
Inf 2B: Ranking Queries on the WWW
 Inf B: Ranking Queries on the WWW Kyriakos Kalorkoti School of Informatics University of Edinburgh Queries Suppose we have an Inverted Index for a set of webpages. Disclaimer Not really the scenario of
Inf B: Ranking Queries on the WWW Kyriakos Kalorkoti School of Informatics University of Edinburgh Queries Suppose we have an Inverted Index for a set of webpages. Disclaimer Not really the scenario of
CS 277: Data Mining. Mining Web Link Structure. CS 277: Data Mining Lectures Analyzing Web Link Structure Padhraic Smyth, UC Irvine
 CS 277: Data Mining Mining Web Link Structure Class Presentations In-class, Tuesday and Thursday next week 2-person teams: 6 minutes, up to 6 slides, 3 minutes/slides each person 1-person teams 4 minutes,
CS 277: Data Mining Mining Web Link Structure Class Presentations In-class, Tuesday and Thursday next week 2-person teams: 6 minutes, up to 6 slides, 3 minutes/slides each person 1-person teams 4 minutes,
Link Analysis. Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze
 Link Analysis Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 The Web as a Directed Graph Page A Anchor hyperlink Page B Assumption 1: A hyperlink between pages
Link Analysis Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 The Web as a Directed Graph Page A Anchor hyperlink Page B Assumption 1: A hyperlink between pages
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University 2 Web pages are important if people visit them a lot. But we can t watch everybody using the Web. A good surrogate for visiting pages is to assume people follow links
Jeffrey D. Ullman Stanford University 2 Web pages are important if people visit them a lot. But we can t watch everybody using the Web. A good surrogate for visiting pages is to assume people follow links
IR: Information Retrieval
 / 44 IR: Information Retrieval FIB, Master in Innovation and Research in Informatics Slides by Marta Arias, José Luis Balcázar, Ramon Ferrer-i-Cancho, Ricard Gavaldá Department of Computer Science, UPC
/ 44 IR: Information Retrieval FIB, Master in Innovation and Research in Informatics Slides by Marta Arias, José Luis Balcázar, Ramon Ferrer-i-Cancho, Ricard Gavaldá Department of Computer Science, UPC
The Theory behind PageRank
 The Theory behind PageRank Mauro Sozio Telecom ParisTech May 21, 2014 Mauro Sozio (LTCI TPT) The Theory behind PageRank May 21, 2014 1 / 19 A Crash Course on Discrete Probability Events and Probability
The Theory behind PageRank Mauro Sozio Telecom ParisTech May 21, 2014 Mauro Sozio (LTCI TPT) The Theory behind PageRank May 21, 2014 1 / 19 A Crash Course on Discrete Probability Events and Probability
The Second Eigenvalue of the Google Matrix
 The Second Eigenvalue of the Google Matrix Taher H. Haveliwala and Sepandar D. Kamvar Stanford University {taherh,sdkamvar}@cs.stanford.edu Abstract. We determine analytically the modulus of the second
The Second Eigenvalue of the Google Matrix Taher H. Haveliwala and Sepandar D. Kamvar Stanford University {taherh,sdkamvar}@cs.stanford.edu Abstract. We determine analytically the modulus of the second
CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University
 CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University TheFind.com Large set of products (~6GB compressed) For each product A=ributes Related products Craigslist About 3 weeks of data
CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University TheFind.com Large set of products (~6GB compressed) For each product A=ributes Related products Craigslist About 3 weeks of data
Google Page Rank Project Linear Algebra Summer 2012
 Google Page Rank Project Linear Algebra Summer 2012 How does an internet search engine, like Google, work? In this project you will discover how the Page Rank algorithm works to give the most relevant
Google Page Rank Project Linear Algebra Summer 2012 How does an internet search engine, like Google, work? In this project you will discover how the Page Rank algorithm works to give the most relevant
COMPSCI 514: Algorithms for Data Science
 COMPSCI 514: Algorithms for Data Science Arya Mazumdar University of Massachusetts at Amherst Fall 2018 Lecture 4 Markov Chain & Pagerank Homework Announcement Show your work in the homework Write the
COMPSCI 514: Algorithms for Data Science Arya Mazumdar University of Massachusetts at Amherst Fall 2018 Lecture 4 Markov Chain & Pagerank Homework Announcement Show your work in the homework Write the
Page rank computation HPC course project a.y
 Page rank computation HPC course project a.y. 2015-16 Compute efficient and scalable Pagerank MPI, Multithreading, SSE 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and
Page rank computation HPC course project a.y. 2015-16 Compute efficient and scalable Pagerank MPI, Multithreading, SSE 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and
arxiv:cond-mat/ v1 3 Sep 2004
 Effects of Community Structure on Search and Ranking in Information Networks Huafeng Xie 1,3, Koon-Kiu Yan 2,3, Sergei Maslov 3 1 New Media Lab, The Graduate Center, CUNY New York, NY 10016, USA 2 Department
Effects of Community Structure on Search and Ranking in Information Networks Huafeng Xie 1,3, Koon-Kiu Yan 2,3, Sergei Maslov 3 1 New Media Lab, The Graduate Center, CUNY New York, NY 10016, USA 2 Department
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Statistical Problem. . We may have an underlying evolving system. (new state) = f(old state, noise) Input data: series of observations X 1, X 2 X t
 = f(old state, noise) Input data: series of observations X 1, X 2 X t") Markov Chains. Statistical Problem. We may have an underlying evolving system (new state) = f(old state, noise) Input data: series of observations X 1, X 2 X t Consecutive speech feature vectors are related
Markov Chains. Statistical Problem. We may have an underlying evolving system (new state) = f(old state, noise) Input data: series of observations X 1, X 2 X t Consecutive speech feature vectors are related
Web Ranking. Classification (manual, automatic) Link Analysis (today s lesson)
 Link Analysis (today s lesson)") Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
Lab 8: Measuring Graph Centrality - PageRank. Monday, November 5 CompSci 531, Fall 2018
 Lab 8: Measuring Graph Centrality - PageRank Monday, November 5 CompSci 531, Fall 2018 Outline Measuring Graph Centrality: Motivation Random Walks, Markov Chains, and Stationarity Distributions Google
Lab 8: Measuring Graph Centrality - PageRank Monday, November 5 CompSci 531, Fall 2018 Outline Measuring Graph Centrality: Motivation Random Walks, Markov Chains, and Stationarity Distributions Google
PageRank. Ryan Tibshirani /36-662: Data Mining. January Optional reading: ESL 14.10
 PageRank Ryan Tibshirani 36-462/36-662: Data Mining January 24 2012 Optional reading: ESL 14.10 1 Information retrieval with the web Last time we learned about information retrieval. We learned how to
PageRank Ryan Tibshirani 36-462/36-662: Data Mining January 24 2012 Optional reading: ESL 14.10 1 Information retrieval with the web Last time we learned about information retrieval. We learned how to
Calculating Web Page Authority Using the PageRank Algorithm
 Jacob Miles Prystowsky and Levi Gill Math 45, Fall 2005 1 Introduction 1.1 Abstract In this document, we examine how the Google Internet search engine uses the PageRank algorithm to assign quantitatively
Jacob Miles Prystowsky and Levi Gill Math 45, Fall 2005 1 Introduction 1.1 Abstract In this document, we examine how the Google Internet search engine uses the PageRank algorithm to assign quantitatively
Web Structure Mining Nodes, Links and Influence
 Web Structure Mining Nodes, Links and Influence 1 Outline 1. Importance of nodes 1. Centrality 2. Prestige 3. Page Rank 4. Hubs and Authority 5. Metrics comparison 2. Link analysis 3. Influence model 1.
Web Structure Mining Nodes, Links and Influence 1 Outline 1. Importance of nodes 1. Centrality 2. Prestige 3. Page Rank 4. Hubs and Authority 5. Metrics comparison 2. Link analysis 3. Influence model 1.
Data Mining Recitation Notes Week 3
 Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
MATH36001 Perron Frobenius Theory 2015
 MATH361 Perron Frobenius Theory 215 In addition to saying something useful, the Perron Frobenius theory is elegant. It is a testament to the fact that beautiful mathematics eventually tends to be useful,
MATH361 Perron Frobenius Theory 215 In addition to saying something useful, the Perron Frobenius theory is elegant. It is a testament to the fact that beautiful mathematics eventually tends to be useful,
Applications. Nonnegative Matrices: Ranking
 Applications of Nonnegative Matrices: Ranking and Clustering Amy Langville Mathematics Department College of Charleston Hamilton Institute 8/7/2008 Collaborators Carl Meyer, N. C. State University David
Applications of Nonnegative Matrices: Ranking and Clustering Amy Langville Mathematics Department College of Charleston Hamilton Institute 8/7/2008 Collaborators Carl Meyer, N. C. State University David
INTRODUCTION TO MCMC AND PAGERANK. Eric Vigoda Georgia Tech. Lecture for CS 6505
 INTRODUCTION TO MCMC AND PAGERANK Eric Vigoda Georgia Tech Lecture for CS 6505 1 MARKOV CHAIN BASICS 2 ERGODICITY 3 WHAT IS THE STATIONARY DISTRIBUTION? 4 PAGERANK 5 MIXING TIME 6 PREVIEW OF FURTHER TOPICS
INTRODUCTION TO MCMC AND PAGERANK Eric Vigoda Georgia Tech Lecture for CS 6505 1 MARKOV CHAIN BASICS 2 ERGODICITY 3 WHAT IS THE STATIONARY DISTRIBUTION? 4 PAGERANK 5 MIXING TIME 6 PREVIEW OF FURTHER TOPICS
Analysis and Computation of Google s PageRank
 Analysis and Computation of Google s PageRank Ilse Ipsen North Carolina State University, USA Joint work with Rebecca S. Wills ANAW p.1 PageRank An objective measure of the citation importance of a web
Analysis and Computation of Google s PageRank Ilse Ipsen North Carolina State University, USA Joint work with Rebecca S. Wills ANAW p.1 PageRank An objective measure of the citation importance of a web
On the mathematical background of Google PageRank algorithm
 Working Paper Series Department of Economics University of Verona On the mathematical background of Google PageRank algorithm Alberto Peretti, Alberto Roveda WP Number: 25 December 2014 ISSN: 2036-2919
Working Paper Series Department of Economics University of Verona On the mathematical background of Google PageRank algorithm Alberto Peretti, Alberto Roveda WP Number: 25 December 2014 ISSN: 2036-2919
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 6: Numerical Linear Algebra: Applications in Machine Learning Cho-Jui Hsieh UC Davis April 27, 2017 Principal Component Analysis Principal
STA141C: Big Data & High Performance Statistical Computing Lecture 6: Numerical Linear Algebra: Applications in Machine Learning Cho-Jui Hsieh UC Davis April 27, 2017 Principal Component Analysis Principal
Outline for today. Information Retrieval. Cosine similarity between query and document. tf-idf weighting
 Outline for today Information Retrieval Efficient Scoring and Ranking Recap on ranked retrieval Jörg Tiedemann jorg.tiedemann@lingfil.uu.se Department of Linguistics and Philology Uppsala University Efficient
Outline for today Information Retrieval Efficient Scoring and Ranking Recap on ranked retrieval Jörg Tiedemann jorg.tiedemann@lingfil.uu.se Department of Linguistics and Philology Uppsala University Efficient
As it is not necessarily possible to satisfy this equation, we just ask for a solution to the more general equation
 Graphs and Networks Page 1 Lecture 2, Ranking 1 Tuesday, September 12, 2006 1:14 PM I. II. I. How search engines work: a. Crawl the web, creating a database b. Answer query somehow, e.g. grep. (ex. Funk
Graphs and Networks Page 1 Lecture 2, Ranking 1 Tuesday, September 12, 2006 1:14 PM I. II. I. How search engines work: a. Crawl the web, creating a database b. Answer query somehow, e.g. grep. (ex. Funk
UpdatingtheStationary VectorofaMarkovChain. Amy Langville Carl Meyer
 UpdatingtheStationary VectorofaMarkovChain Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC NSMC 9/4/2003 Outline Updating and Pagerank Aggregation Partitioning
UpdatingtheStationary VectorofaMarkovChain Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC NSMC 9/4/2003 Outline Updating and Pagerank Aggregation Partitioning
Wiki Definition. Reputation Systems I. Outline. Introduction to Reputations. Yury Lifshits. HITS, PageRank, SALSA, ebay, EigenTrust, VKontakte
 Reputation Systems I HITS, PageRank, SALSA, ebay, EigenTrust, VKontakte Yury Lifshits Wiki Definition Reputation is the opinion (more technically, a social evaluation) of the public toward a person, a
Reputation Systems I HITS, PageRank, SALSA, ebay, EigenTrust, VKontakte Yury Lifshits Wiki Definition Reputation is the opinion (more technically, a social evaluation) of the public toward a person, a
Entropy Rate of Stochastic Processes
 Entropy Rate of Stochastic Processes Timo Mulder tmamulder@gmail.com Jorn Peters jornpeters@gmail.com February 8, 205 The entropy rate of independent and identically distributed events can on average be
Entropy Rate of Stochastic Processes Timo Mulder tmamulder@gmail.com Jorn Peters jornpeters@gmail.com February 8, 205 The entropy rate of independent and identically distributed events can on average be
COMS 4771 Probabilistic Reasoning via Graphical Models. Nakul Verma
 COMS 4771 Probabilistic Reasoning via Graphical Models Nakul Verma Last time Dimensionality Reduction Linear vs non-linear Dimensionality Reduction Principal Component Analysis (PCA) Non-linear methods
COMS 4771 Probabilistic Reasoning via Graphical Models Nakul Verma Last time Dimensionality Reduction Linear vs non-linear Dimensionality Reduction Principal Component Analysis (PCA) Non-linear methods
Node Centrality and Ranking on Networks
 Node Centrality and Ranking on Networks Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Social
Node Centrality and Ranking on Networks Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Social
INTRODUCTION TO MCMC AND PAGERANK. Eric Vigoda Georgia Tech. Lecture for CS 6505
 INTRODUCTION TO MCMC AND PAGERANK Eric Vigoda Georgia Tech Lecture for CS 6505 1 MARKOV CHAIN BASICS 2 ERGODICITY 3 WHAT IS THE STATIONARY DISTRIBUTION? 4 PAGERANK 5 MIXING TIME 6 PREVIEW OF FURTHER TOPICS
INTRODUCTION TO MCMC AND PAGERANK Eric Vigoda Georgia Tech Lecture for CS 6505 1 MARKOV CHAIN BASICS 2 ERGODICITY 3 WHAT IS THE STATIONARY DISTRIBUTION? 4 PAGERANK 5 MIXING TIME 6 PREVIEW OF FURTHER TOPICS
Mathematical Properties & Analysis of Google s PageRank
 Mathematical Properties & Analysis of Google s PageRank Ilse Ipsen North Carolina State University, USA Joint work with Rebecca M. Wills Cedya p.1 PageRank An objective measure of the citation importance
Mathematical Properties & Analysis of Google s PageRank Ilse Ipsen North Carolina State University, USA Joint work with Rebecca M. Wills Cedya p.1 PageRank An objective measure of the citation importance
MAE 298, Lecture 8 Feb 4, Web search and decentralized search on small-worlds
 MAE 298, Lecture 8 Feb 4, 2008 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in a file-sharing
MAE 298, Lecture 8 Feb 4, 2008 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in a file-sharing
Machine Learning CPSC 340. Tutorial 12
 Machine Learning CPSC 340 Tutorial 12 Random Walk on Graph Page Rank Algorithm Label Propagation on Graph Assume a strongly connected graph G = (V, A) Label Propagation on Graph Assume a strongly connected
Machine Learning CPSC 340 Tutorial 12 Random Walk on Graph Page Rank Algorithm Label Propagation on Graph Assume a strongly connected graph G = (V, A) Label Propagation on Graph Assume a strongly connected
How does Google rank webpages?
 Linear Algebra Spring 016 How does Google rank webpages? Dept. of Internet and Multimedia Eng. Konkuk University leehw@konkuk.ac.kr 1 Background on search engines Outline HITS algorithm (Jon Kleinberg)
Linear Algebra Spring 016 How does Google rank webpages? Dept. of Internet and Multimedia Eng. Konkuk University leehw@konkuk.ac.kr 1 Background on search engines Outline HITS algorithm (Jon Kleinberg)
Analysis of Google s PageRank
 Analysis of Google s PageRank Ilse Ipsen North Carolina State University Joint work with Rebecca M. Wills AN05 p.1 PageRank An objective measure of the citation importance of a web page [Brin & Page 1998]
Analysis of Google s PageRank Ilse Ipsen North Carolina State University Joint work with Rebecca M. Wills AN05 p.1 PageRank An objective measure of the citation importance of a web page [Brin & Page 1998]
Link Analysis Information Retrieval and Data Mining. Prof. Matteo Matteucci
 Link Analysis Information Retrieval and Data Mining Prof. Matteo Matteucci Hyperlinks for Indexing and Ranking 2 Page A Hyperlink Page B Intuitions The anchor text might describe the target page B Anchor
Link Analysis Information Retrieval and Data Mining Prof. Matteo Matteucci Hyperlinks for Indexing and Ranking 2 Page A Hyperlink Page B Intuitions The anchor text might describe the target page B Anchor
Node and Link Analysis
 Node and Link Analysis Leonid E. Zhukov School of Applied Mathematics and Information Science National Research University Higher School of Economics 10.02.2014 Leonid E. Zhukov (HSE) Lecture 5 10.02.2014
Node and Link Analysis Leonid E. Zhukov School of Applied Mathematics and Information Science National Research University Higher School of Economics 10.02.2014 Leonid E. Zhukov (HSE) Lecture 5 10.02.2014
eigenvalues, markov matrices, and the power method
 eigenvalues, markov matrices, and the power method Slides by Olson. Some taken loosely from Jeff Jauregui, Some from Semeraro L. Olson Department of Computer Science University of Illinois at Urbana-Champaign
eigenvalues, markov matrices, and the power method Slides by Olson. Some taken loosely from Jeff Jauregui, Some from Semeraro L. Olson Department of Computer Science University of Illinois at Urbana-Champaign
Updating Markov Chains Carl Meyer Amy Langville
 Updating Markov Chains Carl Meyer Amy Langville Department of Mathematics North Carolina State University Raleigh, NC A. A. Markov Anniversary Meeting June 13, 2006 Intro Assumptions Very large irreducible
Updating Markov Chains Carl Meyer Amy Langville Department of Mathematics North Carolina State University Raleigh, NC A. A. Markov Anniversary Meeting June 13, 2006 Intro Assumptions Very large irreducible
Lesson Plan. AM 121: Introduction to Optimization Models and Methods. Lecture 17: Markov Chains. Yiling Chen SEAS. Stochastic process Markov Chains
 AM : Introduction to Optimization Models and Methods Lecture 7: Markov Chains Yiling Chen SEAS Lesson Plan Stochastic process Markov Chains n-step probabilities Communicating states, irreducibility Recurrent
AM : Introduction to Optimization Models and Methods Lecture 7: Markov Chains Yiling Chen SEAS Lesson Plan Stochastic process Markov Chains n-step probabilities Communicating states, irreducibility Recurrent
Application. Stochastic Matrices and PageRank
 Application Stochastic Matrices and PageRank Stochastic Matrices Definition A square matrix A is stochastic if all of its entries are nonnegative, and the sum of the entries of each column is. We say A
Application Stochastic Matrices and PageRank Stochastic Matrices Definition A square matrix A is stochastic if all of its entries are nonnegative, and the sum of the entries of each column is. We say A
LEARNING DYNAMIC SYSTEMS: MARKOV MODELS
 LEARNING DYNAMIC SYSTEMS: MARKOV MODELS Markov Process and Markov Chains Hidden Markov Models Kalman Filters Types of dynamic systems Problem of future state prediction Predictability Observability Easily
LEARNING DYNAMIC SYSTEMS: MARKOV MODELS Markov Process and Markov Chains Hidden Markov Models Kalman Filters Types of dynamic systems Problem of future state prediction Predictability Observability Easily
Course 495: Advanced Statistical Machine Learning/Pattern Recognition
 Course 495: Advanced Statistical Machine Learning/Pattern Recognition Lecturer: Stefanos Zafeiriou Goal (Lectures): To present discrete and continuous valued probabilistic linear dynamical systems (HMMs
Course 495: Advanced Statistical Machine Learning/Pattern Recognition Lecturer: Stefanos Zafeiriou Goal (Lectures): To present discrete and continuous valued probabilistic linear dynamical systems (HMMs
Convex Optimization CMU-10725
 Convex Optimization CMU-10725 Simulated Annealing Barnabás Póczos & Ryan Tibshirani Andrey Markov Markov Chains 2 Markov Chains Markov chain: Homogen Markov chain: 3 Markov Chains Assume that the state
Convex Optimization CMU-10725 Simulated Annealing Barnabás Póczos & Ryan Tibshirani Andrey Markov Markov Chains 2 Markov Chains Markov chain: Homogen Markov chain: 3 Markov Chains Assume that the state
Computer Engineering II Solution to Exercise Sheet Chapter 12
 Distributed Computing FS 07 Prof. R. Wattenhofer Computer Engineering II Solution to Exercise Sheet Chapter Quiz Questions a) Yes, by using states that consist of the current and the previous value in
Distributed Computing FS 07 Prof. R. Wattenhofer Computer Engineering II Solution to Exercise Sheet Chapter Quiz Questions a) Yes, by using states that consist of the current and the previous value in
Lecture 14: Random Walks, Local Graph Clustering, Linear Programming
 CSE 521: Design and Analysis of Algorithms I Winter 2017 Lecture 14: Random Walks, Local Graph Clustering, Linear Programming Lecturer: Shayan Oveis Gharan 3/01/17 Scribe: Laura Vonessen Disclaimer: These
CSE 521: Design and Analysis of Algorithms I Winter 2017 Lecture 14: Random Walks, Local Graph Clustering, Linear Programming Lecturer: Shayan Oveis Gharan 3/01/17 Scribe: Laura Vonessen Disclaimer: These
MultiRank and HAR for Ranking Multi-relational Data, Transition Probability Tensors, and Multi-Stochastic Tensors
 MultiRank and HAR for Ranking Multi-relational Data, Transition Probability Tensors, and Multi-Stochastic Tensors Michael K. Ng Centre for Mathematical Imaging and Vision and Department of Mathematics
MultiRank and HAR for Ranking Multi-relational Data, Transition Probability Tensors, and Multi-Stochastic Tensors Michael K. Ng Centre for Mathematical Imaging and Vision and Department of Mathematics
Algebraic Representation of Networks
 Algebraic Representation of Networks 0 1 2 1 1 0 0 1 2 0 0 1 1 1 1 1 Hiroki Sayama sayama@binghamton.edu Describing networks with matrices (1) Adjacency matrix A matrix with rows and columns labeled by
Algebraic Representation of Networks 0 1 2 1 1 0 0 1 2 0 0 1 1 1 1 1 Hiroki Sayama sayama@binghamton.edu Describing networks with matrices (1) Adjacency matrix A matrix with rows and columns labeled by
1 Searching the World Wide Web
 Hubs and Authorities in a Hyperlinked Environment 1 Searching the World Wide Web Because diverse users each modify the link structure of the WWW within a relatively small scope by creating web-pages on
Hubs and Authorities in a Hyperlinked Environment 1 Searching the World Wide Web Because diverse users each modify the link structure of the WWW within a relatively small scope by creating web-pages on
Intelligent Data Analysis. PageRank. School of Computer Science University of Birmingham
 Intelligent Data Analysis PageRank Peter Tiňo School of Computer Science University of Birmingham Information Retrieval on the Web Most scoring methods on the Web have been derived in the context of Information
Intelligent Data Analysis PageRank Peter Tiňo School of Computer Science University of Birmingham Information Retrieval on the Web Most scoring methods on the Web have been derived in the context of Information
Complex Social System, Elections. Introduction to Network Analysis 1
 Complex Social System, Elections Introduction to Network Analysis 1 Complex Social System, Network I person A voted for B A is more central than B if more people voted for A In-degree centrality index
Complex Social System, Elections Introduction to Network Analysis 1 Complex Social System, Network I person A voted for B A is more central than B if more people voted for A In-degree centrality index
The PageRank Computation in Google: Randomization and Ergodicity
 The PageRank Computation in Google: Randomization and Ergodicity Roberto Tempo CNR-IEIIT Consiglio Nazionale delle Ricerche Politecnico di Torino roberto.tempo@polito.it Randomization over Networks - 1
The PageRank Computation in Google: Randomization and Ergodicity Roberto Tempo CNR-IEIIT Consiglio Nazionale delle Ricerche Politecnico di Torino roberto.tempo@polito.it Randomization over Networks - 1
Summary: A Random Walks View of Spectral Segmentation, by Marina Meila (University of Washington) and Jianbo Shi (Carnegie Mellon University)
 and Jianbo Shi (Carnegie Mellon University)") Summary: A Random Walks View of Spectral Segmentation, by Marina Meila (University of Washington) and Jianbo Shi (Carnegie Mellon University) The authors explain how the NCut algorithm for graph bisection
Summary: A Random Walks View of Spectral Segmentation, by Marina Meila (University of Washington) and Jianbo Shi (Carnegie Mellon University) The authors explain how the NCut algorithm for graph bisection
Finding central nodes in large networks
 Finding central nodes in large networks Nelly Litvak University of Twente Eindhoven University of Technology, The Netherlands Woudschoten Conference 2017 Complex networks Networks: Internet, WWW, social
Finding central nodes in large networks Nelly Litvak University of Twente Eindhoven University of Technology, The Netherlands Woudschoten Conference 2017 Complex networks Networks: Internet, WWW, social