CS 277: Data Mining. Mining Web Link Structure. CS 277: Data Mining Lectures Analyzing Web Link Structure Padhraic Smyth, UC Irvine
|
|
|
- Britton Nash
- 6 years ago
- Views:
Transcription
1 CS 277: Data Mining Mining Web Link Structure
2 Class Presentations In-class, Tuesday and Thursday next week 2-person teams: 6 minutes, up to 6 slides, 3 minutes/slides each person 1-person teams 4 minutes, up to 4 slides Powerpoint or PDF is fine Needs to be ed by 12 noon on the day of presentation Order of presentations will be announced later in the week
3 Web Mining Web = a potentially enormous data set for data mining 3 primary aspects of Web mining 1. Web page content e.g., clustering Web pages based on their text content 2. Web connectivity e.g., characterizing distributions on path lengths between pages e.g., determining importance of pages from graph structure 3. Web usage e.g., understanding user behavior from Web logs All 3 are interconnected/interdependent E.g., Google (and most search engines) use both content and connectivity These slides: Web connectivity
4 The Web Graph G = (V, E) V = set of all Web pages E = set of all hyperlinks Number of nodes? Difficult to estimate Crawling the Web is highly non-trivial > 10 billion Number of edges? E = O( V ) i.e., mean number of outlinks per page is a small constant
5 The Web Graph The Web graph is inherently dynamic nodes and edges are continually appearing and disappearing Interested in general properties of the Web graph What is the distribution of the number of in-links and out-links? What is the distribution of number of pages per site? Typically power-laws for many of these distributions How far apart are 2 randomly selected pages on the Web? What is the average distance between 2 random pages? And so on
6 Social Networks Social networks = graphs V = set of actors (e.g., students in a class) E = set of interactions (e.g., collaborations) Typically small graphs, e.g., V = 10 or 50 Long history of social network analysis (e.g. at UCI) Quantitative data analysis techniques that can automatically extract structure or information from graphs E.g., who is the most important actor in a network? E.g., are there clusters in the network? Comprehensive reference: S. Wasserman and K. Faust, Social Network Analysis, Cambridge University Press, 1994.
7 Node Importance in Social Networks General idea is that some nodes are more important than others in terms of the structure of the graph In a directed graph, in-degree may be a useful indicator of importance e.g., for a citation network among authors (or papers) in-degree is the number of citations => importance However: in-degree is only a first-order measure in that it implicitly assumes that all edges are of equal importance
8 Recursive Notions of Node Importance w ij = weight of link from node i to node j assume Σ j w ij = 1 and weights are non-negative e.g., default choice: w ij = 1/outdegree(i) more outlinks => less importance attached to each Define r j = importance of node j in a directed graph r j = Σ i w ij r i i,j = 1,.n Importance of a node is a weighted sum of the importance of nodes that point to it Makes intuitive sense Leads to a set of recursive linear equations
9 Simple Example
10 Simple Example
11 Simple Example Weight matrix W
12 Matrix-Vector form Recall r j = importance of node j r j = Σ i w ij r i i,j = 1,.n e.g., r 2 = 1 r r r r 4 = dot product of r vector with column 2 of W Let r = n x 1 vector of importance values for the n nodes Let W = n x n matrix of link weights => we can rewrite the importance equations as r = W T r
13 Eigenvector Formulation Need to solve the importance equations for unknown r, with known W r = W T r We recognize this as a standard eigenvalue problem, i.e., A r = λ r (where A = W T) with λ = an eigenvalue = 1 and r = the eigenvector corresponding to λ = 1
14 Need to solve for r in Eigenvector Formulation (W T λ I) r = 0 Note: W is a stochastic matrix, i.e., rows are non-negative and sum to 1 Results from linear algebra tell us that: (a) Since W is a stochastic matrix, W and W T have the same eigenvectors/eigenvalues (b) The largest of these eigenvalues λ is always 1 (c) the vector r corresponds to the eigenvector corresponding to the largest eigenvector of W (or W T )
15 Solution for the Simple Example Solving for the eigenvector of W we get r = [ ] 1 Results are quite intuitive, e.g., 2 is most important W
16 PageRank Algorithm: Applying this idea to the Web 1. Crawl the Web to get nodes (pages) and links (hyperlinks) [highly non-trivial problem!] 2. Weights from each page = 1/(# of outlinks) 3. Solve for the eigenvector r (for λ = 1) of the weight matrix Computational Problem: Solving an eigenvector equation scales as O(n 3 ) For the entire Web graph n > 10 billion (!!) So direct solution is not feasible Can use the power method (iterative) r (k+1) = W T r (k) for k=1,2,..
17 Power Method for solving for r r (k+1) = W T r (k) Define a suitable starting vector r (1) e.g., all entries 1/n, or all entries = indegree(node)/ E, etc Each iteration is matrix-vector multiplication =>O(n 2 ) - problematic? no: since W is highly sparse (Web pages have limited outdegree), each iteration is effectively O(n) For sparse W, the iterations typically converge quite quickly: - rate of convergence depends on the spectral gap -> how quickly does error(k) = (λ 2 / λ 1 ) k go to 0 as a function of k? -> if λ 2 is close to 1 (= λ 1 ) then convergence is slow - empirically: Web graph with 300 million pages -> 50 iterations to convergence (Brin and Page, 1998)
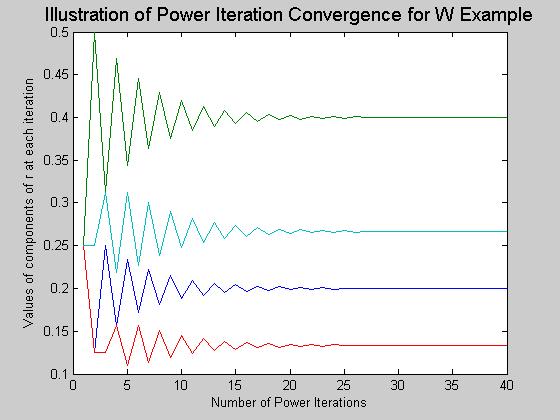
18
19 Basic Principles of Markov Chains Discrete-time finite-state first-order Markov chain, K states Transition matrix A = K x K matrix Entry a ij = P( state t = j state t-1 = i), i, j = 1, K Rows sum to 1 (since Σ j P( state t = j state t-1 = i) = 1) Note that P(state..) only depends on state t-1 P 0 = initial state probability = P(state 0 = i), i = 1, K


20 Simple Example of a Markov Chain K = A = P 0 = [1/3 1/3 1/3] 3 0.6
21 Steady-State (Equilibrium) Distribution for a Markov Chain Irreducibility: A Markov chain is irreducible if there is a directed path from any node to any other node Steady-state distribution π for an irreducible Markov chain*: π i = probability that in the long run, chain is in state I The π s are solutions to π = A t π Note that this is exactly the same as our earlier recursive equations for node importance in a graph! *Note: technically, for a meaningful solution to exist for π, A must be both irreducible and aperiodic
22 Markov Chain Interpretation of PageRank W is a stochastic matrix (rows sum to 1) by definition can interpret W as defining the transition probabilities in a Markov chain w ij = probability of transitioning from node i to node j Markov chain interpretation: r = W T r -> these are the solutions of the steady-state probabilities for a Markov chain page importance steady-state Markov probabilities eigenvector
23 The Random Surfer Interpretation Recall that for the Web model, we set w ij = 1/outdegree(i) Thus, in using W for computing importance of Web pages, this is equivalent to a model where: We have a random surfer who surfs the Web for an infinitely long time At each page the surfer randomly selects an outlink to the next page importance of a page = fraction of visits the surfer makes to that page this is intuitive: pages that have better connectivity will be visited more often

24 Potential Problems Page 1 is a sink (no outlink) Pages 3 and 4 are also sinks (no outlink from the system) Markov chain theory tells us that no steady-state solution exists - depending on where you start you will end up at 1 or {3, 4} Markov chain is reducible 4
25 Making the Web Graph Irreducible One simple solution to our problem is to modify the Markov chain: With probability α the random surfer jumps to any random page in the system (with probability of 1/n, conditioned on such a jump) With probability 1-α the random surfer selects an outlink (randomly from the set of available outlinks) The resulting transition graph is fully connected => Markov system is irreducible => steady-state solutions exist Typically α is chosen to be between 0.1 and 0.2 in practice But now the graph is dense! However, power iterations can be written as: r (k+1) = (1- α) W T r (k) + (α/n) 1 T Complexity is still O(n) per iteration for sparse W
26 The PageRank Algorithm S. Brin and L. Page, The anatomy of a large-scale hypertextual search engine, in Proceedings of the 7 th WWW Conference, PageRank = the method on the previous slide, applied to the entire Web graph Crawl the Web Store both connectivity and content Calculate (off-line) the pagerank r for each Web page using the power iteration method How can this be used to answer Web queries: Terms in the search query are used to limit the set of pages of possible interest Pages are then ordered for the user via precomputed pageranks The Google search engine combines r with text-based measures This was the first demonstration that link information could be used for content-based search on the Web
 in their rankings TFIDF is a state-of-the-art search method (at the time) that does not use any link structure")
27 Link Structure helps in Web Search Singhal and Kaszkiel, WWW Conference, 2001 SE1, etc, indicate different (anonymized) commercial search engines, all using link structure (e.g., PageRank) in their rankings TFIDF is a state-of-the-art search method (at the time) that does not use any link structure
28 PageRank architecture at Google Ranking of pages more important than exact values of p i Pre-compute and store the PageRank of each page. PageRank independent of any query or textual content. Ranking scheme combines PageRank with textual match Unpublished Many empirical parameters and human effort Criticism : Ad-hoc coupling of query relevance and graph importance Massive engineering effort Continually crawling the Web and updating page ranks
29 Link Manipulation
30
31 Conclusions PageRank algorithm was the first algorithm for link-based search Many extensions and improvements since then See papers on class Web page Same idea used in social networks for determining importance Real-world search involves many other aspects besides PageRank E.g., use of logistic regression for ranking Learns how to predict relevance of page (represented by bag of words) relative to a query, using historical click data See paper by Joachims on class Web page Additional slides (optional) HITS algorithm, Kleinberg, 1998
32 ADDITIONAL OPTIONAL SLIDES
33 PageRank: Limitations rich get richer syndrome not as democratic as originally (nobly) claimed certainly not 1 vote per WWW citizen also: crawling frequency tends to be based on pagerank for detailed grumblings, see etc. not query-sensitive random walk same regardless of query topic whereas real random surfer has some topic interests non-uniform jumping vector needed would enable personalization (but requires faster eigenvector convergence) Topic of ongoing research ad hoc mix of PageRank & keyword match score done in two steps for efficiency, not quality motivations
34 HITS: Hub and Authority Rankings J. Kleinberg, Authorative sources in a hyperlinked environment, Proceedings of ACM SODA Conference, HITS Hypertext Induced Topic Selection Every page u has two distinct measures of merit, its hub score h[u] and its authority score a[u]. Recursive quantitative definitions of hub and authority scores Relies on query-time processing To select base set Vq of links for query q constructed by selecting a sub-graph R from the Web (root set) relevant to the query selecting any node u which neighbors any r \in R via an inbound or outbound edge (expanded set) To deduce hubs and authorities that exist in a sub-graph of the Web
35 Authority and Hubness a(1) = h(2) + h(3) + h(4) h(1) = a(5) + a(6) + a(7)
36 Authority and Hubness Convergence Recursive dependency: a(v) Σ h(w) w Є pa[v] h(v) Σ a(w) w Є ch[v] Using Linear Algebra, we can prove: a(v) and h(v) converge
37 Find a base subgraph: Start with a root set R {1, 2, 3, 4} HITS Example {1, 2, 3, 4} - nodes relevant to the topic Expand the root set R to include all the children and a fixed number of parents of nodes in R A new set S (base subgraph)
38 HITS Example Results Authority Hubness Authority and hubness weights
39 randomly deleted 30% of papers Stability of HITS vs PageRank (5 trials) HITS PageRank
40 HITS vs PageRank: Stability e.g. [Ng & Zheng & Jordan, IJCAI-01 & SIGIR-01] HITS can be very sensitive to change in small fraction of nodes/edges in link structure PageRank much more stable, due to random jumps propose HITS as bidirectional random walk with probability d, randomly (p=1/n) jump to a node with probability d-1: odd timestep: take random outlink from current node even timestep: go backward on random inlink of node this HITS variant seems much more stable as d increased issue: tuning d (d=1 most stable but useless for ranking)


41 Recommended Books
CS47300: Web Information Search and Management
 CS473: Web Information Search and Management Using Graph Structure for Retrieval Prof. Chris Clifton 24 September 218 Material adapted from slides created by Dr. Rong Jin (formerly Michigan State, now
CS473: Web Information Search and Management Using Graph Structure for Retrieval Prof. Chris Clifton 24 September 218 Material adapted from slides created by Dr. Rong Jin (formerly Michigan State, now
CS54701 Information Retrieval. Link Analysis. Luo Si. Department of Computer Science Purdue University. Borrowed Slides from Prof.
 CS54701 Information Retrieval Link Analysis Luo Si Department of Computer Science Purdue University Borrowed Slides from Prof. Rong Jin (MSU) Citation Analysis Web Structure Web is a graph Each web site
CS54701 Information Retrieval Link Analysis Luo Si Department of Computer Science Purdue University Borrowed Slides from Prof. Rong Jin (MSU) Citation Analysis Web Structure Web is a graph Each web site
Introduction to Search Engine Technology Introduction to Link Structure Analysis. Ronny Lempel Yahoo Labs, Haifa
 Introduction to Search Engine Technology Introduction to Link Structure Analysis Ronny Lempel Yahoo Labs, Haifa Outline Anchor-text indexing Mathematical Background Motivation for link structure analysis
Introduction to Search Engine Technology Introduction to Link Structure Analysis Ronny Lempel Yahoo Labs, Haifa Outline Anchor-text indexing Mathematical Background Motivation for link structure analysis
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize/navigate it? First try: Human curated Web directories Yahoo, DMOZ, LookSmart
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu How to organize/navigate it? First try: Human curated Web directories Yahoo, DMOZ, LookSmart
Online Social Networks and Media. Link Analysis and Web Search
 Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Link Analysis Ranking
 Link Analysis Ranking How do search engines decide how to rank your query results? Guess why Google ranks the query results the way it does How would you do it? Naïve ranking of query results Given query
Link Analysis Ranking How do search engines decide how to rank your query results? Guess why Google ranks the query results the way it does How would you do it? Naïve ranking of query results Given query
DATA MINING LECTURE 13. Link Analysis Ranking PageRank -- Random walks HITS
 DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information
DATA MINING LECTURE 3 Link Analysis Ranking PageRank -- Random walks HITS How to organize the web First try: Manually curated Web Directories How to organize the web Second try: Web Search Information
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/7/2012 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 Web pages are not equally important www.joe-schmoe.com
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 2/7/2012 Jure Leskovec, Stanford C246: Mining Massive Datasets 2 Web pages are not equally important www.joe-schmoe.com
Link Analysis Information Retrieval and Data Mining. Prof. Matteo Matteucci
 Link Analysis Information Retrieval and Data Mining Prof. Matteo Matteucci Hyperlinks for Indexing and Ranking 2 Page A Hyperlink Page B Intuitions The anchor text might describe the target page B Anchor
Link Analysis Information Retrieval and Data Mining Prof. Matteo Matteucci Hyperlinks for Indexing and Ranking 2 Page A Hyperlink Page B Intuitions The anchor text might describe the target page B Anchor
Link Analysis. Leonid E. Zhukov
 Link Analysis Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural Analysis and Visualization
Link Analysis Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Structural Analysis and Visualization
Data Mining and Matrices
 Data Mining and Matrices 10 Graphs II Rainer Gemulla, Pauli Miettinen Jul 4, 2013 Link analysis The web as a directed graph Set of web pages with associated textual content Hyperlinks between webpages
Data Mining and Matrices 10 Graphs II Rainer Gemulla, Pauli Miettinen Jul 4, 2013 Link analysis The web as a directed graph Set of web pages with associated textual content Hyperlinks between webpages
LINK ANALYSIS. Dr. Gjergji Kasneci Introduction to Information Retrieval WS
 LINK ANALYSIS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Retrieval evaluation Link analysis Models
LINK ANALYSIS Dr. Gjergji Kasneci Introduction to Information Retrieval WS 2012-13 1 Outline Intro Basics of probability and information theory Retrieval models Retrieval evaluation Link analysis Models
Link Analysis. Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze
 Link Analysis Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 The Web as a Directed Graph Page A Anchor hyperlink Page B Assumption 1: A hyperlink between pages
Link Analysis Reference: Introduction to Information Retrieval by C. Manning, P. Raghavan, H. Schutze 1 The Web as a Directed Graph Page A Anchor hyperlink Page B Assumption 1: A hyperlink between pages
IR: Information Retrieval
 / 44 IR: Information Retrieval FIB, Master in Innovation and Research in Informatics Slides by Marta Arias, José Luis Balcázar, Ramon Ferrer-i-Cancho, Ricard Gavaldá Department of Computer Science, UPC
/ 44 IR: Information Retrieval FIB, Master in Innovation and Research in Informatics Slides by Marta Arias, José Luis Balcázar, Ramon Ferrer-i-Cancho, Ricard Gavaldá Department of Computer Science, UPC
Lab 8: Measuring Graph Centrality - PageRank. Monday, November 5 CompSci 531, Fall 2018
 Lab 8: Measuring Graph Centrality - PageRank Monday, November 5 CompSci 531, Fall 2018 Outline Measuring Graph Centrality: Motivation Random Walks, Markov Chains, and Stationarity Distributions Google
Lab 8: Measuring Graph Centrality - PageRank Monday, November 5 CompSci 531, Fall 2018 Outline Measuring Graph Centrality: Motivation Random Walks, Markov Chains, and Stationarity Distributions Google
Online Social Networks and Media. Link Analysis and Web Search
 Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
Online Social Networks and Media Link Analysis and Web Search How to Organize the Web First try: Human curated Web directories Yahoo, DMOZ, LookSmart How to organize the web Second try: Web Search Information
How does Google rank webpages?
 Linear Algebra Spring 016 How does Google rank webpages? Dept. of Internet and Multimedia Eng. Konkuk University leehw@konkuk.ac.kr 1 Background on search engines Outline HITS algorithm (Jon Kleinberg)
Linear Algebra Spring 016 How does Google rank webpages? Dept. of Internet and Multimedia Eng. Konkuk University leehw@konkuk.ac.kr 1 Background on search engines Outline HITS algorithm (Jon Kleinberg)
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu November 16, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu November 16, 2015 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
ECEN 689 Special Topics in Data Science for Communications Networks
 ECEN 689 Special Topics in Data Science for Communications Networks Nick Duffield Department of Electrical & Computer Engineering Texas A&M University Lecture 8 Random Walks, Matrices and PageRank Graphs
ECEN 689 Special Topics in Data Science for Communications Networks Nick Duffield Department of Electrical & Computer Engineering Texas A&M University Lecture 8 Random Walks, Matrices and PageRank Graphs
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu March 16, 2016 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data Instructor: Yizhou Sun yzsun@ccs.neu.edu March 16, 2016 Methods to Learn Classification Clustering Frequent Pattern Mining Matrix Data Decision
PageRank. Ryan Tibshirani /36-662: Data Mining. January Optional reading: ESL 14.10
 PageRank Ryan Tibshirani 36-462/36-662: Data Mining January 24 2012 Optional reading: ESL 14.10 1 Information retrieval with the web Last time we learned about information retrieval. We learned how to
PageRank Ryan Tibshirani 36-462/36-662: Data Mining January 24 2012 Optional reading: ESL 14.10 1 Information retrieval with the web Last time we learned about information retrieval. We learned how to
Web Ranking. Classification (manual, automatic) Link Analysis (today s lesson)
 Link Analysis (today s lesson)") Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
1998: enter Link Analysis
 1998: enter Link Analysis uses hyperlink structure to focus the relevant set combine traditional IR score with popularity score Page and Brin 1998 Kleinberg Web Information Retrieval IR before the Web
1998: enter Link Analysis uses hyperlink structure to focus the relevant set combine traditional IR score with popularity score Page and Brin 1998 Kleinberg Web Information Retrieval IR before the Web
Data Mining Recitation Notes Week 3
 Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
Data Mining Recitation Notes Week 3 Jack Rae January 28, 2013 1 Information Retrieval Given a set of documents, pull the (k) most similar document(s) to a given query. 1.1 Setup Say we have D documents
Page rank computation HPC course project a.y
 Page rank computation HPC course project a.y. 2015-16 Compute efficient and scalable Pagerank MPI, Multithreading, SSE 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and
Page rank computation HPC course project a.y. 2015-16 Compute efficient and scalable Pagerank MPI, Multithreading, SSE 1 PageRank PageRank is a link analysis algorithm, named after Brin & Page [1], and
0.1 Naive formulation of PageRank
 PageRank is a ranking system designed to find the best pages on the web. A webpage is considered good if it is endorsed (i.e. linked to) by other good webpages. The more webpages link to it, and the more
PageRank is a ranking system designed to find the best pages on the web. A webpage is considered good if it is endorsed (i.e. linked to) by other good webpages. The more webpages link to it, and the more
A Note on Google s PageRank
 A Note on Google s PageRank According to Google, google-search on a given topic results in a listing of most relevant web pages related to the topic. Google ranks the importance of webpages according to
A Note on Google s PageRank According to Google, google-search on a given topic results in a listing of most relevant web pages related to the topic. Google ranks the importance of webpages according to
Information Retrieval and Search. Web Linkage Mining. Miłosz Kadziński
 Web Linkage Analysis D24 D4 : Web Linkage Mining Miłosz Kadziński Institute of Computing Science Poznan University of Technology, Poland www.cs.put.poznan.pl/mkadzinski/wpi Web mining: Web Mining Discovery
Web Linkage Analysis D24 D4 : Web Linkage Mining Miłosz Kadziński Institute of Computing Science Poznan University of Technology, Poland www.cs.put.poznan.pl/mkadzinski/wpi Web mining: Web Mining Discovery
Hyperlinked-Induced Topic Search (HITS) identifies. authorities as good content sources (~high indegree) HITS [Kleinberg 99] considers a web page
![Hyperlinked-Induced Topic Search (HITS) identifies. authorities as good content sources (~high indegree) HITS [Kleinberg 99] considers a web page](/thumbs/95/125556981.jpg "Hyperlinked-Induced Topic Search (HITS) identifies. authorities as good content sources (~high indegree) HITS [Kleinberg 99] considers a web page") IV.3 HITS Hyperlinked-Induced Topic Search (HITS) identifies authorities as good content sources (~high indegree) hubs as good link sources (~high outdegree) HITS [Kleinberg 99] considers a web page a
IV.3 HITS Hyperlinked-Induced Topic Search (HITS) identifies authorities as good content sources (~high indegree) hubs as good link sources (~high outdegree) HITS [Kleinberg 99] considers a web page a
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Graph and Network Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Methods Learnt Classification Clustering Vector Data Text Data Recommender System Decision Tree; Naïve
CS249: ADVANCED DATA MINING Graph and Network Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Methods Learnt Classification Clustering Vector Data Text Data Recommender System Decision Tree; Naïve
As it is not necessarily possible to satisfy this equation, we just ask for a solution to the more general equation
 Graphs and Networks Page 1 Lecture 2, Ranking 1 Tuesday, September 12, 2006 1:14 PM I. II. I. How search engines work: a. Crawl the web, creating a database b. Answer query somehow, e.g. grep. (ex. Funk
Graphs and Networks Page 1 Lecture 2, Ranking 1 Tuesday, September 12, 2006 1:14 PM I. II. I. How search engines work: a. Crawl the web, creating a database b. Answer query somehow, e.g. grep. (ex. Funk
Computing PageRank using Power Extrapolation
 Computing PageRank using Power Extrapolation Taher Haveliwala, Sepandar Kamvar, Dan Klein, Chris Manning, and Gene Golub Stanford University Abstract. We present a novel technique for speeding up the computation
Computing PageRank using Power Extrapolation Taher Haveliwala, Sepandar Kamvar, Dan Klein, Chris Manning, and Gene Golub Stanford University Abstract. We present a novel technique for speeding up the computation
Google PageRank. Francesco Ricci Faculty of Computer Science Free University of Bozen-Bolzano
 Google PageRank Francesco Ricci Faculty of Computer Science Free University of Bozen-Bolzano fricci@unibz.it 1 Content p Linear Algebra p Matrices p Eigenvalues and eigenvectors p Markov chains p Google
Google PageRank Francesco Ricci Faculty of Computer Science Free University of Bozen-Bolzano fricci@unibz.it 1 Content p Linear Algebra p Matrices p Eigenvalues and eigenvectors p Markov chains p Google
CS246: Mining Massive Datasets Jure Leskovec, Stanford University.
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu What is the structure of the Web? How is it organized? 2/7/2011 Jure Leskovec, Stanford C246: Mining Massive
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu What is the structure of the Web? How is it organized? 2/7/2011 Jure Leskovec, Stanford C246: Mining Massive
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides
 Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
MultiRank and HAR for Ranking Multi-relational Data, Transition Probability Tensors, and Multi-Stochastic Tensors
 MultiRank and HAR for Ranking Multi-relational Data, Transition Probability Tensors, and Multi-Stochastic Tensors Michael K. Ng Centre for Mathematical Imaging and Vision and Department of Mathematics
MultiRank and HAR for Ranking Multi-relational Data, Transition Probability Tensors, and Multi-Stochastic Tensors Michael K. Ng Centre for Mathematical Imaging and Vision and Department of Mathematics
Google Page Rank Project Linear Algebra Summer 2012
 Google Page Rank Project Linear Algebra Summer 2012 How does an internet search engine, like Google, work? In this project you will discover how the Page Rank algorithm works to give the most relevant
Google Page Rank Project Linear Algebra Summer 2012 How does an internet search engine, like Google, work? In this project you will discover how the Page Rank algorithm works to give the most relevant
Lecture 12: Link Analysis for Web Retrieval
 Lecture 12: Link Analysis for Web Retrieval Trevor Cohn COMP90042, 2015, Semester 1 What we ll learn in this lecture The web as a graph Page-rank method for deriving the importance of pages Hubs and authorities
Lecture 12: Link Analysis for Web Retrieval Trevor Cohn COMP90042, 2015, Semester 1 What we ll learn in this lecture The web as a graph Page-rank method for deriving the importance of pages Hubs and authorities
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides
 Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Thanks to Jure Leskovec, Stanford and Panayiotis Tsaparas, Univ. of Ioannina for slides Web Search: How to Organize the Web? Ranking Nodes on Graphs Hubs and Authorities PageRank How to Solve PageRank
Intelligent Data Analysis. PageRank. School of Computer Science University of Birmingham
 Intelligent Data Analysis PageRank Peter Tiňo School of Computer Science University of Birmingham Information Retrieval on the Web Most scoring methods on the Web have been derived in the context of Information
Intelligent Data Analysis PageRank Peter Tiňo School of Computer Science University of Birmingham Information Retrieval on the Web Most scoring methods on the Web have been derived in the context of Information
PageRank algorithm Hubs and Authorities. Data mining. Web Data Mining PageRank, Hubs and Authorities. University of Szeged.
 Web Data Mining PageRank, University of Szeged Why ranking web pages is useful? We are starving for knowledge It earns Google a bunch of money. How? How does the Web looks like? Big strongly connected
Web Data Mining PageRank, University of Szeged Why ranking web pages is useful? We are starving for knowledge It earns Google a bunch of money. How? How does the Web looks like? Big strongly connected
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 6: Numerical Linear Algebra: Applications in Machine Learning Cho-Jui Hsieh UC Davis April 27, 2017 Principal Component Analysis Principal
STA141C: Big Data & High Performance Statistical Computing Lecture 6: Numerical Linear Algebra: Applications in Machine Learning Cho-Jui Hsieh UC Davis April 27, 2017 Principal Component Analysis Principal
Link Analysis. Stony Brook University CSE545, Fall 2016
 Link Analysis Stony Brook University CSE545, Fall 2016 The Web, circa 1998 The Web, circa 1998 The Web, circa 1998 Match keywords, language (information retrieval) Explore directory The Web, circa 1998
Link Analysis Stony Brook University CSE545, Fall 2016 The Web, circa 1998 The Web, circa 1998 The Web, circa 1998 Match keywords, language (information retrieval) Explore directory The Web, circa 1998
Data and Algorithms of the Web
 Data and Algorithms of the Web Link Analysis Algorithms Page Rank some slides from: Anand Rajaraman, Jeffrey D. Ullman InfoLab (Stanford University) Link Analysis Algorithms Page Rank Hubs and Authorities
Data and Algorithms of the Web Link Analysis Algorithms Page Rank some slides from: Anand Rajaraman, Jeffrey D. Ullman InfoLab (Stanford University) Link Analysis Algorithms Page Rank Hubs and Authorities
Slides based on those in:
 Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering
Spyros Kontogiannis & Christos Zaroliagis Slides based on those in: http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering
IS4200/CS6200 Informa0on Retrieval. PageRank Con+nued. with slides from Hinrich Schütze and Chris6na Lioma
 IS4200/CS6200 Informa0on Retrieval PageRank Con+nued with slides from Hinrich Schütze and Chris6na Lioma Exercise: Assump0ons underlying PageRank Assump0on 1: A link on the web is a quality signal the
IS4200/CS6200 Informa0on Retrieval PageRank Con+nued with slides from Hinrich Schütze and Chris6na Lioma Exercise: Assump0ons underlying PageRank Assump0on 1: A link on the web is a quality signal the
Calculating Web Page Authority Using the PageRank Algorithm
 Jacob Miles Prystowsky and Levi Gill Math 45, Fall 2005 1 Introduction 1.1 Abstract In this document, we examine how the Google Internet search engine uses the PageRank algorithm to assign quantitatively
Jacob Miles Prystowsky and Levi Gill Math 45, Fall 2005 1 Introduction 1.1 Abstract In this document, we examine how the Google Internet search engine uses the PageRank algorithm to assign quantitatively
Web Structure Mining Nodes, Links and Influence
 Web Structure Mining Nodes, Links and Influence 1 Outline 1. Importance of nodes 1. Centrality 2. Prestige 3. Page Rank 4. Hubs and Authority 5. Metrics comparison 2. Link analysis 3. Influence model 1.
Web Structure Mining Nodes, Links and Influence 1 Outline 1. Importance of nodes 1. Centrality 2. Prestige 3. Page Rank 4. Hubs and Authority 5. Metrics comparison 2. Link analysis 3. Influence model 1.
1 Searching the World Wide Web
 Hubs and Authorities in a Hyperlinked Environment 1 Searching the World Wide Web Because diverse users each modify the link structure of the WWW within a relatively small scope by creating web-pages on
Hubs and Authorities in a Hyperlinked Environment 1 Searching the World Wide Web Because diverse users each modify the link structure of the WWW within a relatively small scope by creating web-pages on
Link Mining PageRank. From Stanford C246
 Link Mining PageRank From Stanford C246 Broad Question: How to organize the Web? First try: Human curated Web dictionaries Yahoo, DMOZ LookSmart Second try: Web Search Information Retrieval investigates
Link Mining PageRank From Stanford C246 Broad Question: How to organize the Web? First try: Human curated Web dictionaries Yahoo, DMOZ LookSmart Second try: Web Search Information Retrieval investigates
Complex Social System, Elections. Introduction to Network Analysis 1
 Complex Social System, Elections Introduction to Network Analysis 1 Complex Social System, Network I person A voted for B A is more central than B if more people voted for A In-degree centrality index
Complex Social System, Elections Introduction to Network Analysis 1 Complex Social System, Network I person A voted for B A is more central than B if more people voted for A In-degree centrality index
Inf 2B: Ranking Queries on the WWW
 Inf B: Ranking Queries on the WWW Kyriakos Kalorkoti School of Informatics University of Edinburgh Queries Suppose we have an Inverted Index for a set of webpages. Disclaimer Not really the scenario of
Inf B: Ranking Queries on the WWW Kyriakos Kalorkoti School of Informatics University of Edinburgh Queries Suppose we have an Inverted Index for a set of webpages. Disclaimer Not really the scenario of
Math 304 Handout: Linear algebra, graphs, and networks.
 Math 30 Handout: Linear algebra, graphs, and networks. December, 006. GRAPHS AND ADJACENCY MATRICES. Definition. A graph is a collection of vertices connected by edges. A directed graph is a graph all
Math 30 Handout: Linear algebra, graphs, and networks. December, 006. GRAPHS AND ADJACENCY MATRICES. Definition. A graph is a collection of vertices connected by edges. A directed graph is a graph all
6.207/14.15: Networks Lecture 7: Search on Networks: Navigation and Web Search
 6.207/14.15: Networks Lecture 7: Search on Networks: Navigation and Web Search Daron Acemoglu and Asu Ozdaglar MIT September 30, 2009 1 Networks: Lecture 7 Outline Navigation (or decentralized search)
6.207/14.15: Networks Lecture 7: Search on Networks: Navigation and Web Search Daron Acemoglu and Asu Ozdaglar MIT September 30, 2009 1 Networks: Lecture 7 Outline Navigation (or decentralized search)
eigenvalues, markov matrices, and the power method
 eigenvalues, markov matrices, and the power method Slides by Olson. Some taken loosely from Jeff Jauregui, Some from Semeraro L. Olson Department of Computer Science University of Illinois at Urbana-Champaign
eigenvalues, markov matrices, and the power method Slides by Olson. Some taken loosely from Jeff Jauregui, Some from Semeraro L. Olson Department of Computer Science University of Illinois at Urbana-Champaign
Slide source: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University.
 Slide source: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org #1: C4.5 Decision Tree - Classification (61 votes) #2: K-Means - Clustering
Slide source: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org #1: C4.5 Decision Tree - Classification (61 votes) #2: K-Means - Clustering
Pr[positive test virus] Pr[virus] Pr[positive test] = Pr[positive test] = Pr[positive test]
![Pr[positive test virus] Pr[virus] Pr[positive test] = Pr[positive test] = Pr[positive test]](/thumbs/77/74699650.jpg "Pr[positive test virus] Pr[virus] Pr[positive test] = Pr[positive test] = Pr[positive test]") 146 Probability Pr[virus] = 0.00001 Pr[no virus] = 0.99999 Pr[positive test virus] = 0.99 Pr[positive test no virus] = 0.01 Pr[virus positive test] = Pr[positive test virus] Pr[virus] = 0.99 0.00001 =
146 Probability Pr[virus] = 0.00001 Pr[no virus] = 0.99999 Pr[positive test virus] = 0.99 Pr[positive test no virus] = 0.01 Pr[virus positive test] = Pr[positive test virus] Pr[virus] = 0.99 0.00001 =
Uncertainty and Randomization
 Uncertainty and Randomization The PageRank Computation in Google Roberto Tempo IEIIT-CNR Politecnico di Torino tempo@polito.it 1993: Robustness of Linear Systems 1993: Robustness of Linear Systems 16 Years
Uncertainty and Randomization The PageRank Computation in Google Roberto Tempo IEIIT-CNR Politecnico di Torino tempo@polito.it 1993: Robustness of Linear Systems 1993: Robustness of Linear Systems 16 Years
Web Ranking. Classification (manual, automatic) Link Analysis (today s lesson)
 Link Analysis (today s lesson)") Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
Link Analysis Web Ranking Documents on the web are first ranked according to their relevance vrs the query Additional ranking methods are needed to cope with huge amount of information Additional ranking
The Second Eigenvalue of the Google Matrix
 The Second Eigenvalue of the Google Matrix Taher H. Haveliwala and Sepandar D. Kamvar Stanford University {taherh,sdkamvar}@cs.stanford.edu Abstract. We determine analytically the modulus of the second
The Second Eigenvalue of the Google Matrix Taher H. Haveliwala and Sepandar D. Kamvar Stanford University {taherh,sdkamvar}@cs.stanford.edu Abstract. We determine analytically the modulus of the second
Algebraic Representation of Networks
 Algebraic Representation of Networks 0 1 2 1 1 0 0 1 2 0 0 1 1 1 1 1 Hiroki Sayama sayama@binghamton.edu Describing networks with matrices (1) Adjacency matrix A matrix with rows and columns labeled by
Algebraic Representation of Networks 0 1 2 1 1 0 0 1 2 0 0 1 1 1 1 1 Hiroki Sayama sayama@binghamton.edu Describing networks with matrices (1) Adjacency matrix A matrix with rows and columns labeled by
CS 3750 Advanced Machine Learning. Applications of SVD and PCA (LSA and Link analysis) Cem Akkaya
 Cem Akkaya") CS 375 Advanced Machine Learning Applications of SVD and PCA (LSA and Link analysis) Cem Akkaya Outline SVD and LSI Kleinberg s Algorithm PageRank Algorithm Vector Space Model Vector space model represents
CS 375 Advanced Machine Learning Applications of SVD and PCA (LSA and Link analysis) Cem Akkaya Outline SVD and LSI Kleinberg s Algorithm PageRank Algorithm Vector Space Model Vector space model represents
The Google Markov Chain: convergence speed and eigenvalues
 U.U.D.M. Project Report 2012:14 The Google Markov Chain: convergence speed and eigenvalues Fredrik Backåker Examensarbete i matematik, 15 hp Handledare och examinator: Jakob Björnberg Juni 2012 Department
U.U.D.M. Project Report 2012:14 The Google Markov Chain: convergence speed and eigenvalues Fredrik Backåker Examensarbete i matematik, 15 hp Handledare och examinator: Jakob Björnberg Juni 2012 Department
Updating PageRank. Amy Langville Carl Meyer
 Updating PageRank Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC SCCM 11/17/2003 Indexing Google Must index key terms on each page Robots crawl the web software
Updating PageRank Amy Langville Carl Meyer Department of Mathematics North Carolina State University Raleigh, NC SCCM 11/17/2003 Indexing Google Must index key terms on each page Robots crawl the web software
CSI 445/660 Part 6 (Centrality Measures for Networks) 6 1 / 68
 6 1 / 68") CSI 445/660 Part 6 (Centrality Measures for Networks) 6 1 / 68 References 1 L. Freeman, Centrality in Social Networks: Conceptual Clarification, Social Networks, Vol. 1, 1978/1979, pp. 215 239. 2 S. Wasserman
CSI 445/660 Part 6 (Centrality Measures for Networks) 6 1 / 68 References 1 L. Freeman, Centrality in Social Networks: Conceptual Clarification, Social Networks, Vol. 1, 1978/1979, pp. 215 239. 2 S. Wasserman
Degree Distribution: The case of Citation Networks
 Network Analysis Degree Distribution: The case of Citation Networks Papers (in almost all fields) refer to works done earlier on same/related topics Citations A network can be defined as Each node is
Network Analysis Degree Distribution: The case of Citation Networks Papers (in almost all fields) refer to works done earlier on same/related topics Citations A network can be defined as Each node is
Application. Stochastic Matrices and PageRank
 Application Stochastic Matrices and PageRank Stochastic Matrices Definition A square matrix A is stochastic if all of its entries are nonnegative, and the sum of the entries of each column is. We say A
Application Stochastic Matrices and PageRank Stochastic Matrices Definition A square matrix A is stochastic if all of its entries are nonnegative, and the sum of the entries of each column is. We say A
Graph Models The PageRank Algorithm
 Graph Models The PageRank Algorithm Anna-Karin Tornberg Mathematical Models, Analysis and Simulation Fall semester, 2013 The PageRank Algorithm I Invented by Larry Page and Sergey Brin around 1998 and
Graph Models The PageRank Algorithm Anna-Karin Tornberg Mathematical Models, Analysis and Simulation Fall semester, 2013 The PageRank Algorithm I Invented by Larry Page and Sergey Brin around 1998 and
Cross-lingual and temporal Wikipedia analysis
 MTA SZTAKI Data Mining and Search Group June 14, 2013 Supported by the EC FET Open project New tools and algorithms for directed network analysis (NADINE No 288956) Table of Contents 1 Link prediction
MTA SZTAKI Data Mining and Search Group June 14, 2013 Supported by the EC FET Open project New tools and algorithms for directed network analysis (NADINE No 288956) Table of Contents 1 Link prediction
Wiki Definition. Reputation Systems I. Outline. Introduction to Reputations. Yury Lifshits. HITS, PageRank, SALSA, ebay, EigenTrust, VKontakte
 Reputation Systems I HITS, PageRank, SALSA, ebay, EigenTrust, VKontakte Yury Lifshits Wiki Definition Reputation is the opinion (more technically, a social evaluation) of the public toward a person, a
Reputation Systems I HITS, PageRank, SALSA, ebay, EigenTrust, VKontakte Yury Lifshits Wiki Definition Reputation is the opinion (more technically, a social evaluation) of the public toward a person, a
MAE 298, Lecture 8 Feb 4, Web search and decentralized search on small-worlds
 MAE 298, Lecture 8 Feb 4, 2008 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in a file-sharing
MAE 298, Lecture 8 Feb 4, 2008 Web search and decentralized search on small-worlds Search for information Assume some resource of interest is stored at the vertices of a network: Web pages Files in a file-sharing
Applications to network analysis: Eigenvector centrality indices Lecture notes
 Applications to network analysis: Eigenvector centrality indices Lecture notes Dario Fasino, University of Udine (Italy) Lecture notes for the second part of the course Nonnegative and spectral matrix
Applications to network analysis: Eigenvector centrality indices Lecture notes Dario Fasino, University of Udine (Italy) Lecture notes for the second part of the course Nonnegative and spectral matrix
Lecture: Local Spectral Methods (1 of 4)
") Stat260/CS294: Spectral Graph Methods Lecture 18-03/31/2015 Lecture: Local Spectral Methods (1 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
Stat260/CS294: Spectral Graph Methods Lecture 18-03/31/2015 Lecture: Local Spectral Methods (1 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough. They provide
How works. or How linear algebra powers the search engine. M. Ram Murty, FRSC Queen s Research Chair Queen s University
 How works or How linear algebra powers the search engine M. Ram Murty, FRSC Queen s Research Chair Queen s University From: gomath.com/geometry/ellipse.php Metric mishap causes loss of Mars orbiter
How works or How linear algebra powers the search engine M. Ram Murty, FRSC Queen s Research Chair Queen s University From: gomath.com/geometry/ellipse.php Metric mishap causes loss of Mars orbiter
Lecture 7 Mathematics behind Internet Search
 CCST907 Hidden Order in Daily Life: A Mathematical Perspective Lecture 7 Mathematics behind Internet Search Dr. S. P. Yung (907A) Dr. Z. Hua (907B) Department of Mathematics, HKU Outline Google is the
CCST907 Hidden Order in Daily Life: A Mathematical Perspective Lecture 7 Mathematics behind Internet Search Dr. S. P. Yung (907A) Dr. Z. Hua (907B) Department of Mathematics, HKU Outline Google is the
Hub, Authority and Relevance Scores in Multi-Relational Data for Query Search
 Hub, Authority and Relevance Scores in Multi-Relational Data for Query Search Xutao Li 1 Michael Ng 2 Yunming Ye 1 1 Department of Computer Science, Shenzhen Graduate School, Harbin Institute of Technology,
Hub, Authority and Relevance Scores in Multi-Relational Data for Query Search Xutao Li 1 Michael Ng 2 Yunming Ye 1 1 Department of Computer Science, Shenzhen Graduate School, Harbin Institute of Technology,
Faloutsos, Tong ICDE, 2009
 Large Graph Mining: Patterns, Tools and Case Studies Christos Faloutsos Hanghang Tong CMU Copyright: Faloutsos, Tong (29) 2-1 Outline Part 1: Patterns Part 2: Matrix and Tensor Tools Part 3: Proximity
Large Graph Mining: Patterns, Tools and Case Studies Christos Faloutsos Hanghang Tong CMU Copyright: Faloutsos, Tong (29) 2-1 Outline Part 1: Patterns Part 2: Matrix and Tensor Tools Part 3: Proximity
6.207/14.15: Networks Lectures 4, 5 & 6: Linear Dynamics, Markov Chains, Centralities
 6.207/14.15: Networks Lectures 4, 5 & 6: Linear Dynamics, Markov Chains, Centralities 1 Outline Outline Dynamical systems. Linear and Non-linear. Convergence. Linear algebra and Lyapunov functions. Markov
6.207/14.15: Networks Lectures 4, 5 & 6: Linear Dynamics, Markov Chains, Centralities 1 Outline Outline Dynamical systems. Linear and Non-linear. Convergence. Linear algebra and Lyapunov functions. Markov
SUPPLEMENTARY MATERIALS TO THE PAPER: ON THE LIMITING BEHAVIOR OF PARAMETER-DEPENDENT NETWORK CENTRALITY MEASURES
 SUPPLEMENTARY MATERIALS TO THE PAPER: ON THE LIMITING BEHAVIOR OF PARAMETER-DEPENDENT NETWORK CENTRALITY MEASURES MICHELE BENZI AND CHRISTINE KLYMKO Abstract This document contains details of numerical
SUPPLEMENTARY MATERIALS TO THE PAPER: ON THE LIMITING BEHAVIOR OF PARAMETER-DEPENDENT NETWORK CENTRALITY MEASURES MICHELE BENZI AND CHRISTINE KLYMKO Abstract This document contains details of numerical
Finding central nodes in large networks
 Finding central nodes in large networks Nelly Litvak University of Twente Eindhoven University of Technology, The Netherlands Woudschoten Conference 2017 Complex networks Networks: Internet, WWW, social
Finding central nodes in large networks Nelly Litvak University of Twente Eindhoven University of Technology, The Netherlands Woudschoten Conference 2017 Complex networks Networks: Internet, WWW, social
Spectral Graph Theory and You: Matrix Tree Theorem and Centrality Metrics
 Spectral Graph Theory and You: and Centrality Metrics Jonathan Gootenberg March 11, 2013 1 / 19 Outline of Topics 1 Motivation Basics of Spectral Graph Theory Understanding the characteristic polynomial
Spectral Graph Theory and You: and Centrality Metrics Jonathan Gootenberg March 11, 2013 1 / 19 Outline of Topics 1 Motivation Basics of Spectral Graph Theory Understanding the characteristic polynomial
DOMINANT VECTORS APPLICATION TO INFORMATION EXTRACTION IN LARGE GRAPHS. Laure NINOVE OF NONNEGATIVE MATRICES
 UNIVERSITÉ CATHOLIQUE DE LOUVAIN ÉCOLE POLYTECHNIQUE DE LOUVAIN DÉPARTEMENT D INGÉNIERIE MATHÉMATIQUE DOMINANT VECTORS OF NONNEGATIVE MATRICES APPLICATION TO INFORMATION EXTRACTION IN LARGE GRAPHS Laure
UNIVERSITÉ CATHOLIQUE DE LOUVAIN ÉCOLE POLYTECHNIQUE DE LOUVAIN DÉPARTEMENT D INGÉNIERIE MATHÉMATIQUE DOMINANT VECTORS OF NONNEGATIVE MATRICES APPLICATION TO INFORMATION EXTRACTION IN LARGE GRAPHS Laure
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Mark Schmidt University of British Columbia Winter 2019 Last Time: Monte Carlo Methods If we want to approximate expectations of random functions, E[g(x)] = g(x)p(x) or E[g(x)]
CPSC 540: Machine Learning Mark Schmidt University of British Columbia Winter 2019 Last Time: Monte Carlo Methods If we want to approximate expectations of random functions, E[g(x)] = g(x)p(x) or E[g(x)]
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Mark Schmidt University of British Columbia Winter 2018 Last Time: Monte Carlo Methods If we want to approximate expectations of random functions, E[g(x)] = g(x)p(x) or E[g(x)]
CPSC 540: Machine Learning Mark Schmidt University of British Columbia Winter 2018 Last Time: Monte Carlo Methods If we want to approximate expectations of random functions, E[g(x)] = g(x)p(x) or E[g(x)]
Links between Kleinberg s hubs and authorities, correspondence analysis, and Markov chains
 Links between Kleinberg s hubs and authorities, correspondence analysis, and Markov chains Francois Fouss, Jean-Michel Renders & Marco Saerens Université Catholique de Louvain and Xerox Research Center
Links between Kleinberg s hubs and authorities, correspondence analysis, and Markov chains Francois Fouss, Jean-Michel Renders & Marco Saerens Université Catholique de Louvain and Xerox Research Center
Complex Networks CSYS/MATH 303, Spring, Prof. Peter Dodds
 Complex Networks CSYS/MATH 303, Spring, 2011 Prof. Peter Dodds Department of Mathematics & Statistics Center for Complex Systems Vermont Advanced Computing Center University of Vermont Licensed under the
Complex Networks CSYS/MATH 303, Spring, 2011 Prof. Peter Dodds Department of Mathematics & Statistics Center for Complex Systems Vermont Advanced Computing Center University of Vermont Licensed under the
Idea: Select and rank nodes w.r.t. their relevance or interestingness in large networks.
 Graph Databases and Linked Data So far: Obects are considered as iid (independent and identical diributed) the meaning of obects depends exclusively on the description obects do not influence each other
Graph Databases and Linked Data So far: Obects are considered as iid (independent and identical diributed) the meaning of obects depends exclusively on the description obects do not influence each other
Node and Link Analysis
 Node and Link Analysis Leonid E. Zhukov School of Applied Mathematics and Information Science National Research University Higher School of Economics 10.02.2014 Leonid E. Zhukov (HSE) Lecture 5 10.02.2014
Node and Link Analysis Leonid E. Zhukov School of Applied Mathematics and Information Science National Research University Higher School of Economics 10.02.2014 Leonid E. Zhukov (HSE) Lecture 5 10.02.2014
MPageRank: The Stability of Web Graph
 Vietnam Journal of Mathematics 37:4(2009) 475-489 VAST 2009 MPageRank: The Stability of Web Graph Le Trung Kien 1, Le Trung Hieu 2, Tran Loc Hung 1, and Le Anh Vu 3 1 Department of Mathematics, College
Vietnam Journal of Mathematics 37:4(2009) 475-489 VAST 2009 MPageRank: The Stability of Web Graph Le Trung Kien 1, Le Trung Hieu 2, Tran Loc Hung 1, and Le Anh Vu 3 1 Department of Mathematics, College
Mathematical Properties & Analysis of Google s PageRank
 Mathematical Properties & Analysis of Google s PageRank Ilse Ipsen North Carolina State University, USA Joint work with Rebecca M. Wills Cedya p.1 PageRank An objective measure of the citation importance
Mathematical Properties & Analysis of Google s PageRank Ilse Ipsen North Carolina State University, USA Joint work with Rebecca M. Wills Cedya p.1 PageRank An objective measure of the citation importance
Data Mining and Analysis: Fundamental Concepts and Algorithms
 Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA
Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA
Node Centrality and Ranking on Networks
 Node Centrality and Ranking on Networks Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Social
Node Centrality and Ranking on Networks Leonid E. Zhukov School of Data Analysis and Artificial Intelligence Department of Computer Science National Research University Higher School of Economics Social
The Static Absorbing Model for the Web a
 Journal of Web Engineering, Vol. 0, No. 0 (2003) 000 000 c Rinton Press The Static Absorbing Model for the Web a Vassilis Plachouras University of Glasgow Glasgow G12 8QQ UK vassilis@dcs.gla.ac.uk Iadh
Journal of Web Engineering, Vol. 0, No. 0 (2003) 000 000 c Rinton Press The Static Absorbing Model for the Web a Vassilis Plachouras University of Glasgow Glasgow G12 8QQ UK vassilis@dcs.gla.ac.uk Iadh
Some relationships between Kleinberg s hubs and authorities, correspondence analysis, and the Salsa algorithm
 Some relationships between Kleinberg s hubs and authorities, correspondence analysis, and the Salsa algorithm François Fouss 1, Jean-Michel Renders 2 & Marco Saerens 1 {saerens,fouss}@isys.ucl.ac.be, jean-michel.renders@xrce.xerox.com
Some relationships between Kleinberg s hubs and authorities, correspondence analysis, and the Salsa algorithm François Fouss 1, Jean-Michel Renders 2 & Marco Saerens 1 {saerens,fouss}@isys.ucl.ac.be, jean-michel.renders@xrce.xerox.com
Introduction to Data Mining
 Introduction to Data Mining Lecture #9: Link Analysis Seoul National University 1 In This Lecture Motivation for link analysis Pagerank: an important graph ranking algorithm Flow and random walk formulation
Introduction to Data Mining Lecture #9: Link Analysis Seoul National University 1 In This Lecture Motivation for link analysis Pagerank: an important graph ranking algorithm Flow and random walk formulation
Kristina Lerman USC Information Sciences Institute
 Rethinking Network Structure Kristina Lerman USC Information Sciences Institute Università della Svizzera Italiana, December 16, 2011 Measuring network structure Central nodes Community structure Strength
Rethinking Network Structure Kristina Lerman USC Information Sciences Institute Università della Svizzera Italiana, December 16, 2011 Measuring network structure Central nodes Community structure Strength
Applications. Nonnegative Matrices: Ranking
 Applications of Nonnegative Matrices: Ranking and Clustering Amy Langville Mathematics Department College of Charleston Hamilton Institute 8/7/2008 Collaborators Carl Meyer, N. C. State University David
Applications of Nonnegative Matrices: Ranking and Clustering Amy Langville Mathematics Department College of Charleston Hamilton Institute 8/7/2008 Collaborators Carl Meyer, N. C. State University David
Spectral Graph Theory Tools. Analysis of Complex Networks
 Spectral Graph Theory Tools for the Department of Mathematics and Computer Science Emory University Atlanta, GA 30322, USA Acknowledgments Christine Klymko (Emory) Ernesto Estrada (Strathclyde, UK) Support:
Spectral Graph Theory Tools for the Department of Mathematics and Computer Science Emory University Atlanta, GA 30322, USA Acknowledgments Christine Klymko (Emory) Ernesto Estrada (Strathclyde, UK) Support:
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
DS504/CS586: Big Data Analytics Graph Mining II
 Welcome to DS504/CS586: Big Data Analytics Graph Mining II Prof. Yanhua Li Time: 6-8:50PM Thursday Location: AK233 Spring 2018 v Course Project I has been graded. Grading was based on v 1. Project report
Welcome to DS504/CS586: Big Data Analytics Graph Mining II Prof. Yanhua Li Time: 6-8:50PM Thursday Location: AK233 Spring 2018 v Course Project I has been graded. Grading was based on v 1. Project report