Overlapping Community Detection at Scale: A Nonnegative Matrix Factorization Approach
|
|
|
- Irene Turner
- 5 years ago
- Views:
Transcription
1 Overlapping Community Detection at Scale: A Nonnegative Matrix Factorization Approach Author: Jaewon Yang, Jure Leskovec 1 1 Venue: WSDM 2013 Presenter: Yupeng Gu 1 Stanford University 1
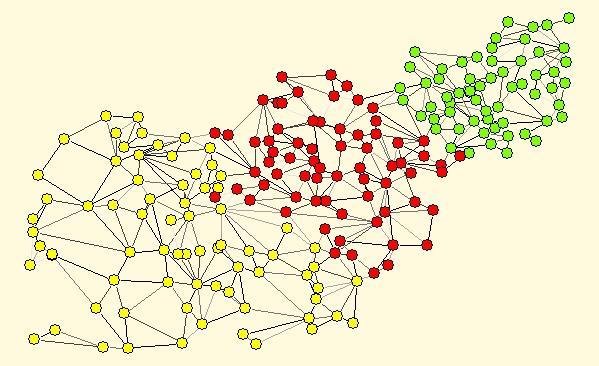
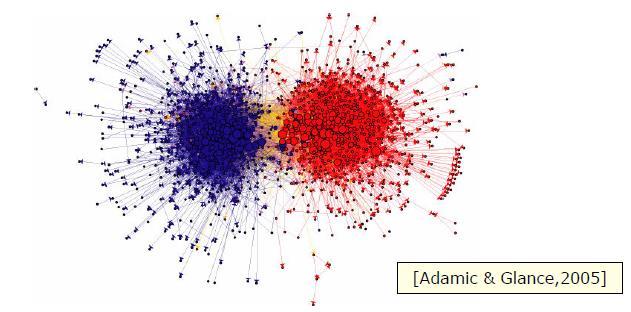
2 Background Community 2
3 Background Community Overlap 3
4 Background Communities are everywhere in networks, especially in large social networks. 4
5 Background Communities are everywhere in networks, especially in large social networks. Nodes can belong to multiple communities simultaneously, which leads to overlapping community structure. 5

6 Background Communities are everywhere in networks, especially in large social networks. Nodes can belong to multiple communities simultaneously, which leads to overlapping community structure. In traditional methods, it is assumed that overlaps between communities are sparsely connected. 6
7 Background Communities are everywhere in networks, especially in large social networks. Nodes can belong to multiple communities simultaneously, which leads to overlapping community structure. In traditional methods, it is assumed that overlaps between communities are sparsely connected. More communities a pair of nodes shares, the more likely they are connected in the network. 7

8 Background Communities are everywhere in networks, especially in large social networks. Nodes can belong to multiple communities simultaneously, which leads to overlapping community structure. In traditional methods, it is assumed that overlaps between communities are sparsely connected. More communities a pair of nodes shares, the more likely they are connected in the network. 8
9 Cluster Affiliation Model The social/information network is assumed to be undirected and unweighted. They represent node community memberships with a bipartite affiliation network. Communities Nodes 9
10 Cluster Affiliation Model The social/information network is assumed to be undirected and unweighted. They represent node community memberships with a bipartite affiliation network. F ua u 10
11 Notations Notations G(V, E) N B(V, C, M) C M K F R N K Meanings Network Total number of nodes, V = N Bipartite affiliation network Set of communities Node community affiliations Total number of communities, C = K Affiliation factor matrix 11
12 Cluster Affiliation Model for Big Networks ( BIGCLAM ) The process of generating network G(V, E) given a bipartite community affiliation B(V, C, M): B(V, C, M) Communities C F uc F vc Nodes u v Nonnegative weight F uc 12
13 Cluster Affiliation Model for Big Networks ( BIGCLAM ) The process of generating network G(V, E) given a bipartite community affiliation B(V, C, M): B(V, C, M) Communities Nodes F uc u C F vc v F uc u C? F vc v Larger F uc is more likely to generate links (inside C). F uc = 0 will not affect the link generation probabilities. Nonnegative weight F uc Community connects its members with probability 1 e F uc F vc 13
14 Cluster Affiliation Model for Big Networks ( BIGCLAM ) The process of generating network G(V, E) given a bipartite community affiliation B(V, C, M): B(V, C, M) Communities C C p u, v = 1 exp( F u T F v ) F uc F vc F uc F vc F u is a weight vector for node u: F u = F u Nodes u v u? v Nonnegative weight F uc Community connects its members with probability 1 e F uc F vc 14
15 Probabilistic Interpretation In the generation process, we have an undirected weighted network where pairs of nodes u, v have a latent interaction of non-negative strength X uv In the observed graph G(V, E), u, v is connected if X uv > 0 15
16 Probabilistic Interpretation In the generation process, we have an undirected weighted network where pairs of nodes u, v have a latent interaction of non-negative strength X uv In the observed graph G(V, E), u, v is connected if X uv > 0 u, v generate an interaction of strength X c uv within community c (using a Poisson distribution with mean F uc F vc ) Then the total amount of interaction X uv = c X uv X c uv ~Pois F uc F vc X uv ~Pois c F uc F vc pr X uv 0 = 1 exp( F T u F v ) c 16
17 Probabilistic Interpretation Which kind of nodes is likely to have a high degree? Answer: Node u with larger F uc is more likely to be connected to other members of c 1 e F uc F vc F uc F uc = 0 p c u, v = 0 for all v C 17
18 Probabilistic Interpretation Which pair of nodes is likely to have a link? Answer: Pair of nodes that share multiple community memberships receive multiple chances to create a link. A p u, v = 1 e F ua F va F ua F va u v 18
19 Probabilistic Interpretation Which pair of nodes is likely to have a link? Answer: Pair of nodes that share multiple community memberships receive multiple chances to create a link. A B p u, v = 1 e F ua F va F ub F ua u F va v F vb p u, v = 1 e F ua F va F ub F vb 1 e F ua F va 19
20 Background Part Edges between pair of nodes u, v that do not share any common communities (=0?) p u, v = ε, where ε is the background edge probability (between a random pair of nodes) ε = 2 E / V ( V 1)
21 Community Detection Given an undirected network G(V, E), detect K communities by finding the most likely affiliation factor matrix F to the underlying network G by maximizing the likelihood l F = log P(G F): where l F = u,v E F = arg max F 0 l(f) log(1 exp F u T F v ) (u,v) E F u T F v 21
22 A variant of nonnegative matrix factorization (NMF): learn F R N K that best approximates the adjacency matrix A of a given network G. F = arg min F 0 D(A, f FFT ) where loss function D = l(f) and link function f = 1 exp( ) 22
23 Optimization where l F = u,v E F = arg max F 0 l(f) log(1 exp F u T F v ) (u,v) E F u T F v Update F u with the other F v fixed (convex). After each update, F u is projected into a space of non-negative vectors: F uc = max(f uc, 0). Each step requires O( N u ) time. 23
24 Community Affiliations Whether u belongs to community c or not? Criterion: ignore the membership of u to c if F uc is below some threshold δ. ε 1 exp( δ 2 ) δ = log(1 ε) 10 5 ~
25 Number of communities Reserve 20% of node pairs as a hold out set. The K with the maximum hold out likelihood will be chosen as the number of communities. 25
26 Experimental results 26
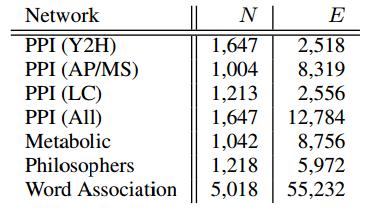
27 Data Description They collected 6 large social and information networks where nodes explicitly state their community memberships. (Defining ground-truth communities will also help quantitatively evaluate the performance) LiveJournal, Friendster, Orkut, YouTube: Nodes: users, edges: friendship Groups are formed over specific interests/hobbies etc. DBLP Nodes: authors, edges: co-authorship Communities: publication venues Amazon Nodes: products, edges connect commonly co-purchased products Each node belongs to one or more hierarchically product categories 27

28 Data Description Some statistics N: number of nodes E: number of edges C: number of communities S: average community size A: community memberships per node 28
 when the pair share two")
29 Data Overview Ground-truth communities heavily overlap: on average 95% of all communities overlap with at least one other community. How the edge probability changes as k increases: The edge probability increases by 10 4 (from 10 5 to 10 1 ) when the pair share two communities 29
30 Evaluation Measures Runtime comparison 30
31 Evaluation Measures F-1 score F-1 score = 31
32 Evaluation Measures Omega Index C uv is the set of ground truth communities u and v share. 32
33 Evaluation Measures NMI (normalized mutual information) Accuracy in the number of communities ( 1) 33

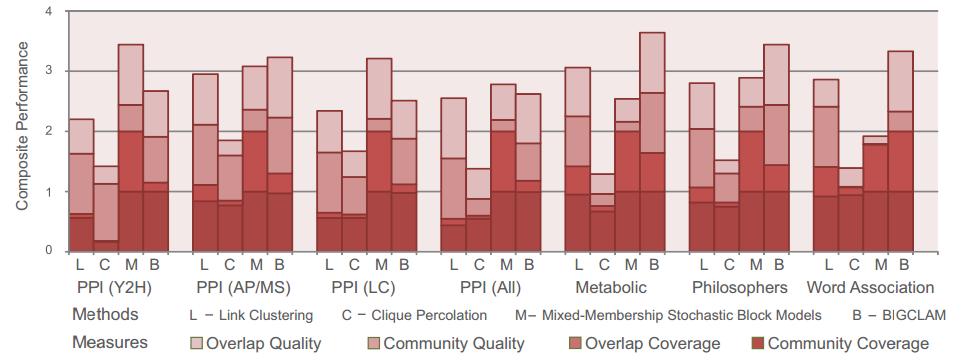
34 Experimental results Composite performance of six datasets Scores of methods are scaled: the best performing method achieves the score of 1. 34
35 Experimental results 35
36 Conclusion A novel large scale community detection method A set of networks with explicit ground-truth labels for nodes Overlaps of communities are more connected 36
Overlapping Communities
 Overlapping Communities Davide Mottin HassoPlattner Institute Graph Mining course Winter Semester 2017 Acknowledgements Most of this lecture is taken from: http://web.stanford.edu/class/cs224w/slides GRAPH
Overlapping Communities Davide Mottin HassoPlattner Institute Graph Mining course Winter Semester 2017 Acknowledgements Most of this lecture is taken from: http://web.stanford.edu/class/cs224w/slides GRAPH
Jure Leskovec Joint work with Jaewon Yang, Julian McAuley
 Jure Leskovec (@jure) Joint work with Jaewon Yang, Julian McAuley Given a network, find communities! Sets of nodes with common function, role or property 2 3 Q: How and why do communities form? A: Strength
Jure Leskovec (@jure) Joint work with Jaewon Yang, Julian McAuley Given a network, find communities! Sets of nodes with common function, role or property 2 3 Q: How and why do communities form? A: Strength
Communities Via Laplacian Matrices. Degree, Adjacency, and Laplacian Matrices Eigenvectors of Laplacian Matrices
 Communities Via Laplacian Matrices Degree, Adjacency, and Laplacian Matrices Eigenvectors of Laplacian Matrices The Laplacian Approach As with betweenness approach, we want to divide a social graph into
Communities Via Laplacian Matrices Degree, Adjacency, and Laplacian Matrices Eigenvectors of Laplacian Matrices The Laplacian Approach As with betweenness approach, we want to divide a social graph into
Nonparametric Bayesian Matrix Factorization for Assortative Networks
 Nonparametric Bayesian Matrix Factorization for Assortative Networks Mingyuan Zhou IROM Department, McCombs School of Business Department of Statistics and Data Sciences The University of Texas at Austin
Nonparametric Bayesian Matrix Factorization for Assortative Networks Mingyuan Zhou IROM Department, McCombs School of Business Department of Statistics and Data Sciences The University of Texas at Austin
Heat Kernel Based Community Detection
 Heat Kernel Based Community Detection Joint with David F. Gleich, (Purdue), supported by" NSF CAREER 1149756-CCF Kyle Kloster! Purdue University! Local Community Detection Given seed(s) S in G, find a
Heat Kernel Based Community Detection Joint with David F. Gleich, (Purdue), supported by" NSF CAREER 1149756-CCF Kyle Kloster! Purdue University! Local Community Detection Given seed(s) S in G, find a
1 Matrix notation and preliminaries from spectral graph theory
 Graph clustering (or community detection or graph partitioning) is one of the most studied problems in network analysis. One reason for this is that there are a variety of ways to define a cluster or community.
Graph clustering (or community detection or graph partitioning) is one of the most studied problems in network analysis. One reason for this is that there are a variety of ways to define a cluster or community.
The Ties that Bind Characterizing Classes by Attributes and Social Ties
 The Ties that Bind WWW April, 2017, Bryan Perozzi*, Leman Akoglu Stony Brook University *Now at Google. Introduction Outline Our problem: Characterizing Community Differences Proposed Method Experimental
The Ties that Bind WWW April, 2017, Bryan Perozzi*, Leman Akoglu Stony Brook University *Now at Google. Introduction Outline Our problem: Characterizing Community Differences Proposed Method Experimental
Link Prediction. Eman Badr Mohammed Saquib Akmal Khan
 Link Prediction Eman Badr Mohammed Saquib Akmal Khan 11-06-2013 Link Prediction Which pair of nodes should be connected? Applications Facebook friend suggestion Recommendation systems Monitoring and controlling
Link Prediction Eman Badr Mohammed Saquib Akmal Khan 11-06-2013 Link Prediction Which pair of nodes should be connected? Applications Facebook friend suggestion Recommendation systems Monitoring and controlling
RaRE: Social Rank Regulated Large-scale Network Embedding
 RaRE: Social Rank Regulated Large-scale Network Embedding Authors: Yupeng Gu 1, Yizhou Sun 1, Yanen Li 2, Yang Yang 3 04/26/2018 The Web Conference, 2018 1 University of California, Los Angeles 2 Snapchat
RaRE: Social Rank Regulated Large-scale Network Embedding Authors: Yupeng Gu 1, Yizhou Sun 1, Yanen Li 2, Yang Yang 3 04/26/2018 The Web Conference, 2018 1 University of California, Los Angeles 2 Snapchat
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu Non-overlapping vs. overlapping communities 11/10/2010 Jure Leskovec, Stanford CS224W: Social
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu Non-overlapping vs. overlapping communities 11/10/2010 Jure Leskovec, Stanford CS224W: Social
Nonnegative Matrix Factorization Clustering on Multiple Manifolds
 Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10) Nonnegative Matrix Factorization Clustering on Multiple Manifolds Bin Shen, Luo Si Department of Computer Science,
Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10) Nonnegative Matrix Factorization Clustering on Multiple Manifolds Bin Shen, Luo Si Department of Computer Science,
Project in Computational Game Theory: Communities in Social Networks
 Project in Computational Game Theory: Communities in Social Networks Eldad Rubinstein November 11, 2012 1 Presentation of the Original Paper 1.1 Introduction In this section I present the article [1].
Project in Computational Game Theory: Communities in Social Networks Eldad Rubinstein November 11, 2012 1 Presentation of the Original Paper 1.1 Introduction In this section I present the article [1].
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec Stanford University Jure Leskovec, Stanford University http://cs224w.stanford.edu Task: Find coalitions in signed networks Incentives: European
CS224W: Social and Information Network Analysis Jure Leskovec Stanford University Jure Leskovec, Stanford University http://cs224w.stanford.edu Task: Find coalitions in signed networks Incentives: European
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu Intro sessions to SNAP C++ and SNAP.PY: SNAP.PY: Friday 9/27, 4:5 5:30pm in Gates B03 SNAP
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu Intro sessions to SNAP C++ and SNAP.PY: SNAP.PY: Friday 9/27, 4:5 5:30pm in Gates B03 SNAP
Densest subgraph computation and applications in finding events on social media
 Densest subgraph computation and applications in finding events on social media Oana Denisa Balalau advised by Mauro Sozio Télécom ParisTech, Institut Mines Télécom December 4, 2015 1 / 28 Table of Contents
Densest subgraph computation and applications in finding events on social media Oana Denisa Balalau advised by Mauro Sozio Télécom ParisTech, Institut Mines Télécom December 4, 2015 1 / 28 Table of Contents
Final Exam, Machine Learning, Spring 2009
 Name: Andrew ID: Final Exam, 10701 Machine Learning, Spring 2009 - The exam is open-book, open-notes, no electronics other than calculators. - The maximum possible score on this exam is 100. You have 3
Name: Andrew ID: Final Exam, 10701 Machine Learning, Spring 2009 - The exam is open-book, open-notes, no electronics other than calculators. - The maximum possible score on this exam is 100. You have 3
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project
 Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Performance Comparison of K-Means and Expectation Maximization with Gaussian Mixture Models for Clustering EE6540 Final Project Devin Cornell & Sushruth Sastry May 2015 1 Abstract In this article, we explore
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Learning in Bayesian Networks
 Learning in Bayesian Networks Florian Markowetz Max-Planck-Institute for Molecular Genetics Computational Molecular Biology Berlin Berlin: 20.06.2002 1 Overview 1. Bayesian Networks Stochastic Networks
Learning in Bayesian Networks Florian Markowetz Max-Planck-Institute for Molecular Genetics Computational Molecular Biology Berlin Berlin: 20.06.2002 1 Overview 1. Bayesian Networks Stochastic Networks
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
GraphRNN: A Deep Generative Model for Graphs (24 Feb 2018)
") GraphRNN: A Deep Generative Model for Graphs (24 Feb 2018) Jiaxuan You, Rex Ying, Xiang Ren, William L. Hamilton, Jure Leskovec Presented by: Jesse Bettencourt and Harris Chan March 9, 2018 University
GraphRNN: A Deep Generative Model for Graphs (24 Feb 2018) Jiaxuan You, Rex Ying, Xiang Ren, William L. Hamilton, Jure Leskovec Presented by: Jesse Bettencourt and Harris Chan March 9, 2018 University
The University of Texas at Austin Department of Electrical and Computer Engineering. EE381V: Large Scale Learning Spring 2013.
 The University of Texas at Austin Department of Electrical and Computer Engineering EE381V: Large Scale Learning Spring 2013 Assignment 1 Caramanis/Sanghavi Due: Thursday, Feb. 7, 2013. (Problems 1 and
The University of Texas at Austin Department of Electrical and Computer Engineering EE381V: Large Scale Learning Spring 2013 Assignment 1 Caramanis/Sanghavi Due: Thursday, Feb. 7, 2013. (Problems 1 and
MLCC Clustering. Lorenzo Rosasco UNIGE-MIT-IIT
 MLCC 2018 - Clustering Lorenzo Rosasco UNIGE-MIT-IIT About this class We will consider an unsupervised setting, and in particular the problem of clustering unlabeled data into coherent groups. MLCC 2018
MLCC 2018 - Clustering Lorenzo Rosasco UNIGE-MIT-IIT About this class We will consider an unsupervised setting, and in particular the problem of clustering unlabeled data into coherent groups. MLCC 2018
Lifted and Constrained Sampling of Attributed Graphs with Generative Network Models
 Lifted and Constrained Sampling of Attributed Graphs with Generative Network Models Jennifer Neville Departments of Computer Science and Statistics Purdue University (joint work with Pablo Robles Granda,
Lifted and Constrained Sampling of Attributed Graphs with Generative Network Models Jennifer Neville Departments of Computer Science and Statistics Purdue University (joint work with Pablo Robles Granda,
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University
 CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu 10/24/2012 Jure Leskovec, Stanford CS224W: Social and Information Network Analysis, http://cs224w.stanford.edu
CS224W: Social and Information Network Analysis Jure Leskovec, Stanford University http://cs224w.stanford.edu 10/24/2012 Jure Leskovec, Stanford CS224W: Social and Information Network Analysis, http://cs224w.stanford.edu
Determining the Diameter of Small World Networks
 Determining the Diameter of Small World Networks Frank W. Takes & Walter A. Kosters Leiden University, The Netherlands CIKM 2011 October 2, 2011 Glasgow, UK NWO COMPASS project (grant #12.0.92) 1 / 30
Determining the Diameter of Small World Networks Frank W. Takes & Walter A. Kosters Leiden University, The Netherlands CIKM 2011 October 2, 2011 Glasgow, UK NWO COMPASS project (grant #12.0.92) 1 / 30
Mining of Massive Datasets Jure Leskovec, AnandRajaraman, Jeff Ullman Stanford University
 Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit
A brief introduction to Conditional Random Fields
 A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
Nonnegative Matrix Factorization
 Nonnegative Matrix Factorization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Nonnegative Matrix Factorization Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Multi-Task Clustering using Constrained Symmetric Non-Negative Matrix Factorization
 Multi-Task Clustering using Constrained Symmetric Non-Negative Matrix Factorization Samir Al-Stouhi Chandan K. Reddy Abstract Researchers have attempted to improve the quality of clustering solutions through
Multi-Task Clustering using Constrained Symmetric Non-Negative Matrix Factorization Samir Al-Stouhi Chandan K. Reddy Abstract Researchers have attempted to improve the quality of clustering solutions through
Quiz 3. Please write your name in the upper corner of each page. Problem Points Grade. Total 100 Q3-1
 6.045J/18.400J: Automata, Computability and Complexity April 28, 2004 Quiz 3 Prof. Nancy Lynch, Nati Srebro Susan Hohenberger Please write your name in the upper corner of each page. Problem Points Grade
6.045J/18.400J: Automata, Computability and Complexity April 28, 2004 Quiz 3 Prof. Nancy Lynch, Nati Srebro Susan Hohenberger Please write your name in the upper corner of each page. Problem Points Grade
Applying Latent Dirichlet Allocation to Group Discovery in Large Graphs
 Lawrence Livermore National Laboratory Applying Latent Dirichlet Allocation to Group Discovery in Large Graphs Keith Henderson and Tina Eliassi-Rad keith@llnl.gov and eliassi@llnl.gov This work was performed
Lawrence Livermore National Laboratory Applying Latent Dirichlet Allocation to Group Discovery in Large Graphs Keith Henderson and Tina Eliassi-Rad keith@llnl.gov and eliassi@llnl.gov This work was performed
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Prediction Instructor: Yizhou Sun yzsun@ccs.neu.edu September 14, 2014 Today s Schedule Course Project Introduction Linear Regression Model Decision Tree 2 Methods
CS6220: DATA MINING TECHNIQUES Matrix Data: Prediction Instructor: Yizhou Sun yzsun@ccs.neu.edu September 14, 2014 Today s Schedule Course Project Introduction Linear Regression Model Decision Tree 2 Methods
Lecture 6: Gaussian Mixture Models (GMM)
") Helsinki Institute for Information Technology Lecture 6: Gaussian Mixture Models (GMM) Pedram Daee 3.11.2015 Outline Gaussian Mixture Models (GMM) Models Model families and parameters Parameter learning
Helsinki Institute for Information Technology Lecture 6: Gaussian Mixture Models (GMM) Pedram Daee 3.11.2015 Outline Gaussian Mixture Models (GMM) Models Model families and parameters Parameter learning
DS504/CS586: Big Data Analytics Graph Mining II
 Welcome to DS504/CS586: Big Data Analytics Graph Mining II Prof. Yanhua Li Time: 6:00pm 8:50pm Mon. and Wed. Location: SL105 Spring 2016 Reading assignments We will increase the bar a little bit Please
Welcome to DS504/CS586: Big Data Analytics Graph Mining II Prof. Yanhua Li Time: 6:00pm 8:50pm Mon. and Wed. Location: SL105 Spring 2016 Reading assignments We will increase the bar a little bit Please
A Nearly Sublinear Approximation to exp{p}e i for Large Sparse Matrices from Social Networks
 A Nearly Sublinear Approximation to exp{p}e i for Large Sparse Matrices from Social Networks Kyle Kloster and David F. Gleich Purdue University December 14, 2013 Supported by NSF CAREER 1149756-CCF Kyle
A Nearly Sublinear Approximation to exp{p}e i for Large Sparse Matrices from Social Networks Kyle Kloster and David F. Gleich Purdue University December 14, 2013 Supported by NSF CAREER 1149756-CCF Kyle
Data Mining Techniques
 Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Data Mining Techniques CS 622 - Section 2 - Spring 27 Pre-final Review Jan-Willem van de Meent Feedback Feedback https://goo.gl/er7eo8 (also posted on Piazza) Also, please fill out your TRACE evaluations!
Study Notes on the Latent Dirichlet Allocation
 Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Study Notes on the Latent Dirichlet Allocation Xugang Ye 1. Model Framework A word is an element of dictionary {1,,}. A document is represented by a sequence of words: =(,, ), {1,,}. A corpus is a collection
Chapter 5-2: Clustering
 Chapter 5-2: Clustering Jilles Vreeken Revision 1, November 20 th typo s fixed: dendrogram Revision 2, December 10 th clarified: we do consider a point x as a member of its own ε-neighborhood 12 Nov 2015
Chapter 5-2: Clustering Jilles Vreeken Revision 1, November 20 th typo s fixed: dendrogram Revision 2, December 10 th clarified: we do consider a point x as a member of its own ε-neighborhood 12 Nov 2015
SIGNAL DETECTION ON GRAPHS: BERNOULLI NOISE MODEL. Carnegie Mellon University, Pittsburgh, PA, USA
 SIGNAL DETECTION ON GRAPHS: BERNOULLI NOISE MODEL Siheng Chen 1,2, Yaoqing Yang 1, Aarti Singh 2, Jelena Kovačević 1,3 1 Dept. of ECE, 2 Dept. of ML, 3 Dept. of BME, Carnegie Mellon University, Pittsburgh,
SIGNAL DETECTION ON GRAPHS: BERNOULLI NOISE MODEL Siheng Chen 1,2, Yaoqing Yang 1, Aarti Singh 2, Jelena Kovačević 1,3 1 Dept. of ECE, 2 Dept. of ML, 3 Dept. of BME, Carnegie Mellon University, Pittsburgh,
Unified Modeling of User Activities on Social Networking Sites
 Unified Modeling of User Activities on Social Networking Sites Himabindu Lakkaraju IBM Research - India Manyata Embassy Business Park Bangalore, Karnataka - 5645 klakkara@in.ibm.com Angshu Rai IBM Research
Unified Modeling of User Activities on Social Networking Sites Himabindu Lakkaraju IBM Research - India Manyata Embassy Business Park Bangalore, Karnataka - 5645 klakkara@in.ibm.com Angshu Rai IBM Research
Graphical Models for Collaborative Filtering
 Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
Graphical Models for Collaborative Filtering Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Sequence modeling HMM, Kalman Filter, etc.: Similarity: the same graphical model topology,
JOINT PROBABILISTIC INFERENCE OF CAUSAL STRUCTURE
 JOINT PROBABILISTIC INFERENCE OF CAUSAL STRUCTURE Dhanya Sridhar Lise Getoor U.C. Santa Cruz KDD Workshop on Causal Discovery August 14 th, 2016 1 Outline Motivation Problem Formulation Our Approach Preliminary
JOINT PROBABILISTIC INFERENCE OF CAUSAL STRUCTURE Dhanya Sridhar Lise Getoor U.C. Santa Cruz KDD Workshop on Causal Discovery August 14 th, 2016 1 Outline Motivation Problem Formulation Our Approach Preliminary
L 2,1 Norm and its Applications
 L 2, Norm and its Applications Yale Chang Introduction According to the structure of the constraints, the sparsity can be obtained from three types of regularizers for different purposes.. Flat Sparsity.
L 2, Norm and its Applications Yale Chang Introduction According to the structure of the constraints, the sparsity can be obtained from three types of regularizers for different purposes.. Flat Sparsity.
Stat 315c: Introduction
 Stat 315c: Introduction Art B. Owen Stanford Statistics Art B. Owen (Stanford Statistics) Stat 315c: Introduction 1 / 14 Stat 315c Analysis of Transposable Data Usual Statistics Setup there s Y (we ll
Stat 315c: Introduction Art B. Owen Stanford Statistics Art B. Owen (Stanford Statistics) Stat 315c: Introduction 1 / 14 Stat 315c Analysis of Transposable Data Usual Statistics Setup there s Y (we ll
25 : Graphical induced structured input/output models
 10-708: Probabilistic Graphical Models 10-708, Spring 2013 25 : Graphical induced structured input/output models Lecturer: Eric P. Xing Scribes: Meghana Kshirsagar (mkshirsa), Yiwen Chen (yiwenche) 1 Graph
10-708: Probabilistic Graphical Models 10-708, Spring 2013 25 : Graphical induced structured input/output models Lecturer: Eric P. Xing Scribes: Meghana Kshirsagar (mkshirsa), Yiwen Chen (yiwenche) 1 Graph
On Top-k Structural. Similarity Search. Pei Lee, Laks V.S. Lakshmanan University of British Columbia Vancouver, BC, Canada
 On Top-k Structural 1 Similarity Search Pei Lee, Laks V.S. Lakshmanan University of British Columbia Vancouver, BC, Canada Jeffrey Xu Yu Chinese University of Hong Kong Hong Kong, China 2014/10/14 Pei
On Top-k Structural 1 Similarity Search Pei Lee, Laks V.S. Lakshmanan University of British Columbia Vancouver, BC, Canada Jeffrey Xu Yu Chinese University of Hong Kong Hong Kong, China 2014/10/14 Pei
a Short Introduction
 Collaborative Filtering in Recommender Systems: a Short Introduction Norm Matloff Dept. of Computer Science University of California, Davis matloff@cs.ucdavis.edu December 3, 2016 Abstract There is a strong
Collaborative Filtering in Recommender Systems: a Short Introduction Norm Matloff Dept. of Computer Science University of California, Davis matloff@cs.ucdavis.edu December 3, 2016 Abstract There is a strong
APPLICATIONS OF MINING HETEROGENEOUS INFORMATION NETWORKS
 APPLICATIONS OF MINING HETEROGENEOUS INFORMATION NETWORKS Yizhou Sun College of Computer and Information Science Northeastern University yzsun@ccs.neu.edu July 25, 2015 Heterogeneous Information Networks
APPLICATIONS OF MINING HETEROGENEOUS INFORMATION NETWORKS Yizhou Sun College of Computer and Information Science Northeastern University yzsun@ccs.neu.edu July 25, 2015 Heterogeneous Information Networks
Networks and Their Spectra
 Networks and Their Spectra Victor Amelkin University of California, Santa Barbara Department of Computer Science victor@cs.ucsb.edu December 4, 2017 1 / 18 Introduction Networks (= graphs) are everywhere.
Networks and Their Spectra Victor Amelkin University of California, Santa Barbara Department of Computer Science victor@cs.ucsb.edu December 4, 2017 1 / 18 Introduction Networks (= graphs) are everywhere.
GLAD: Group Anomaly Detection in Social Media Analysis
 GLAD: Group Anomaly Detection in Social Media Analysis Poster #: 1150 Rose Yu, Xinran He and Yan Liu University of Southern California Group Anomaly Detection Anomalous phenomenon in social media data
GLAD: Group Anomaly Detection in Social Media Analysis Poster #: 1150 Rose Yu, Xinran He and Yan Liu University of Southern California Group Anomaly Detection Anomalous phenomenon in social media data
Linear Models for Regression CS534
 Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
A Dimensionality Reduction Framework for Detection of Multiscale Structure in Heterogeneous Networks
 Shen HW, Cheng XQ, Wang YZ et al. A dimensionality reduction framework for detection of multiscale structure in heterogeneous networks. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 27(2): 341 357 Mar. 2012.
Shen HW, Cheng XQ, Wang YZ et al. A dimensionality reduction framework for detection of multiscale structure in heterogeneous networks. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 27(2): 341 357 Mar. 2012.
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding
 Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Large-Scale Feature Learning with Spike-and-Slab Sparse Coding Ian J. Goodfellow, Aaron Courville, Yoshua Bengio ICML 2012 Presented by Xin Yuan January 17, 2013 1 Outline Contributions Spike-and-Slab
Fast Algorithms for Pseudoarboricity
 Fast Algorithms for Pseudoarboricity Meeting on Algorithm Engineering and Experiments ALENEX 2016 Markus Blumenstock Institute of Computer Science, University of Mainz January 10th, 2016 Pseudotrees Orientations
Fast Algorithms for Pseudoarboricity Meeting on Algorithm Engineering and Experiments ALENEX 2016 Markus Blumenstock Institute of Computer Science, University of Mainz January 10th, 2016 Pseudotrees Orientations
PathSelClus: Integrating Meta-Path Selection with User-Guided Object Clustering in Heterogeneous Information Networks
 PathSelClus: Integrating Meta-Path Selection with User-Guided Object Clustering in Heterogeneous Information Networks YIZHOU SUN, BRANDON NORICK, and JIAWEI HAN, University of Illinois at Urbana-Champaign
PathSelClus: Integrating Meta-Path Selection with User-Guided Object Clustering in Heterogeneous Information Networks YIZHOU SUN, BRANDON NORICK, and JIAWEI HAN, University of Illinois at Urbana-Champaign
Clustering and Gaussian Mixture Models
 Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
Clustering and Gaussian Mixture Models Piyush Rai IIT Kanpur Probabilistic Machine Learning (CS772A) Jan 25, 2016 Probabilistic Machine Learning (CS772A) Clustering and Gaussian Mixture Models 1 Recap
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Matrix Data: Prediction Instructor: Yizhou Sun yzsun@ccs.neu.edu September 21, 2015 Announcements TA Monisha s office hour has changed to Thursdays 10-12pm, 462WVH (the same
CS6220: DATA MINING TECHNIQUES Matrix Data: Prediction Instructor: Yizhou Sun yzsun@ccs.neu.edu September 21, 2015 Announcements TA Monisha s office hour has changed to Thursdays 10-12pm, 462WVH (the same
Time-Sensitive Dirichlet Process Mixture Models
 Time-Sensitive Dirichlet Process Mixture Models Xiaojin Zhu Zoubin Ghahramani John Lafferty May 25 CMU-CALD-5-4 School of Computer Science Carnegie Mellon University Pittsburgh, PA 523 Abstract We introduce
Time-Sensitive Dirichlet Process Mixture Models Xiaojin Zhu Zoubin Ghahramani John Lafferty May 25 CMU-CALD-5-4 School of Computer Science Carnegie Mellon University Pittsburgh, PA 523 Abstract We introduce
Data Preprocessing. Cluster Similarity
 1 Cluster Similarity Similarity is most often measured with the help of a distance function. The smaller the distance, the more similar the data objects (points). A function d: M M R is a distance on M
1 Cluster Similarity Similarity is most often measured with the help of a distance function. The smaller the distance, the more similar the data objects (points). A function d: M M R is a distance on M
Exact Algorithms for Dominating Induced Matching Based on Graph Partition
 Exact Algorithms for Dominating Induced Matching Based on Graph Partition Mingyu Xiao School of Computer Science and Engineering University of Electronic Science and Technology of China Chengdu 611731,
Exact Algorithms for Dominating Induced Matching Based on Graph Partition Mingyu Xiao School of Computer Science and Engineering University of Electronic Science and Technology of China Chengdu 611731,
6.867 Machine learning, lecture 23 (Jaakkola)
") Lecture topics: Markov Random Fields Probabilistic inference Markov Random Fields We will briefly go over undirected graphical models or Markov Random Fields (MRFs) as they will be needed in the context
Lecture topics: Markov Random Fields Probabilistic inference Markov Random Fields We will briefly go over undirected graphical models or Markov Random Fields (MRFs) as they will be needed in the context
NETWORKS (a.k.a. graphs) are important data structures
 are important data structures") PREPRINT Mixed-Order Spectral Clustering for Networks Yan Ge, Haiping Lu, and Pan Peng arxiv:82.040v [cs.lg] 25 Dec 208 Abstract Clustering is fundamental for gaining insights from complex networks, and
PREPRINT Mixed-Order Spectral Clustering for Networks Yan Ge, Haiping Lu, and Pan Peng arxiv:82.040v [cs.lg] 25 Dec 208 Abstract Clustering is fundamental for gaining insights from complex networks, and
Local Lanczos Spectral Approximation for Community Detection
 Local Lanczos Spectral Approximation for Community Detection Pan Shi 1, Kun He 1( ), David Bindel 2, John E. Hopcroft 2 1 Huazhong University of Science and Technology, Wuhan, China {panshi,brooklet60}@hust.edu.cn
Local Lanczos Spectral Approximation for Community Detection Pan Shi 1, Kun He 1( ), David Bindel 2, John E. Hopcroft 2 1 Huazhong University of Science and Technology, Wuhan, China {panshi,brooklet60}@hust.edu.cn
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Learning from Sensor Data: Set II. Behnaam Aazhang J.S. Abercombie Professor Electrical and Computer Engineering Rice University
 Learning from Sensor Data: Set II Behnaam Aazhang J.S. Abercombie Professor Electrical and Computer Engineering Rice University 1 6. Data Representation The approach for learning from data Probabilistic
Learning from Sensor Data: Set II Behnaam Aazhang J.S. Abercombie Professor Electrical and Computer Engineering Rice University 1 6. Data Representation The approach for learning from data Probabilistic
Introduction to Logistic Regression
 Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
Introduction to Logistic Regression Guy Lebanon Binary Classification Binary classification is the most basic task in machine learning, and yet the most frequent. Binary classifiers often serve as the
An Efficient reconciliation algorithm for social networks
 An Efficient reconciliation algorithm for social networks Silvio Lattanzi (Google Research NY) Joint work with: Nitish Korula (Google Research NY) ICERM Stochastic Graph Models Outline Graph reconciliation
An Efficient reconciliation algorithm for social networks Silvio Lattanzi (Google Research NY) Joint work with: Nitish Korula (Google Research NY) ICERM Stochastic Graph Models Outline Graph reconciliation
CS224W: Analysis of Networks Jure Leskovec, Stanford University
 Announcements: Please fill HW Survey Weekend Office Hours starting this weekend (Hangout only) Proposal: Can use 1 late period CS224W: Analysis of Networks Jure Leskovec, Stanford University http://cs224w.stanford.edu
Announcements: Please fill HW Survey Weekend Office Hours starting this weekend (Hangout only) Proposal: Can use 1 late period CS224W: Analysis of Networks Jure Leskovec, Stanford University http://cs224w.stanford.edu
STATS 306B: Unsupervised Learning Spring Lecture 2 April 2
 STATS 306B: Unsupervised Learning Spring 2014 Lecture 2 April 2 Lecturer: Lester Mackey Scribe: Junyang Qian, Minzhe Wang 2.1 Recap In the last lecture, we formulated our working definition of unsupervised
STATS 306B: Unsupervised Learning Spring 2014 Lecture 2 April 2 Lecturer: Lester Mackey Scribe: Junyang Qian, Minzhe Wang 2.1 Recap In the last lecture, we formulated our working definition of unsupervised
Discovering molecular pathways from protein interaction and ge
 Discovering molecular pathways from protein interaction and gene expression data 9-4-2008 Aim To have a mechanism for inferring pathways from gene expression and protein interaction data. Motivation Why
Discovering molecular pathways from protein interaction and gene expression data 9-4-2008 Aim To have a mechanism for inferring pathways from gene expression and protein interaction data. Motivation Why
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Point-of-Interest Recommendations: Learning Potential Check-ins from Friends
 Point-of-Interest Recommendations: Learning Potential Check-ins from Friends Huayu Li, Yong Ge +, Richang Hong, Hengshu Zhu University of North Carolina at Charlotte + University of Arizona Hefei University
Point-of-Interest Recommendations: Learning Potential Check-ins from Friends Huayu Li, Yong Ge +, Richang Hong, Hengshu Zhu University of North Carolina at Charlotte + University of Arizona Hefei University
Mixed Membership Stochastic Blockmodels
 Mixed Membership Stochastic Blockmodels Journal of Machine Learning Research, 2008 by E.M. Airoldi, D.M. Blei, S.E. Fienberg, E.P. Xing as interpreted by Ted Westling STAT 572 Final Talk May 8, 2014 Ted
Mixed Membership Stochastic Blockmodels Journal of Machine Learning Research, 2008 by E.M. Airoldi, D.M. Blei, S.E. Fienberg, E.P. Xing as interpreted by Ted Westling STAT 572 Final Talk May 8, 2014 Ted
Linear Models for Regression CS534
 Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
Linear Models for Regression CS534 Example Regression Problems Predict housing price based on House size, lot size, Location, # of rooms Predict stock price based on Price history of the past month Predict
CA-SVM: Communication-Avoiding Support Vector Machines on Distributed System
 CA-SVM: Communication-Avoiding Support Vector Machines on Distributed System Yang You 1, James Demmel 1, Kent Czechowski 2, Le Song 2, Richard Vuduc 2 UC Berkeley 1, Georgia Tech 2 Yang You (Speaker) James
CA-SVM: Communication-Avoiding Support Vector Machines on Distributed System Yang You 1, James Demmel 1, Kent Czechowski 2, Le Song 2, Richard Vuduc 2 UC Berkeley 1, Georgia Tech 2 Yang You (Speaker) James
On Defining and Computing Communities
 AU Herning Aarhus University martino@hih.au.dk UPF, Barcelona, November 29th 2012 Zacharys Karate Club 25 26 12 5 17 7 11 28 32 6 24 27 29 20 1 22 9 30 34 3 2 13 15 33 4 14 18 16 31 8 21 10 23 19 A community
AU Herning Aarhus University martino@hih.au.dk UPF, Barcelona, November 29th 2012 Zacharys Karate Club 25 26 12 5 17 7 11 28 32 6 24 27 29 20 1 22 9 30 34 3 2 13 15 33 4 14 18 16 31 8 21 10 23 19 A community
Analysis & Generative Model for Trust Networks
 Analysis & Generative Model for Trust Networks Pranav Dandekar Management Science & Engineering Stanford University Stanford, CA 94305 ppd@stanford.edu ABSTRACT Trust Networks are a specific kind of social
Analysis & Generative Model for Trust Networks Pranav Dandekar Management Science & Engineering Stanford University Stanford, CA 94305 ppd@stanford.edu ABSTRACT Trust Networks are a specific kind of social
Supporting Statistical Hypothesis Testing Over Graphs
 Supporting Statistical Hypothesis Testing Over Graphs Jennifer Neville Departments of Computer Science and Statistics Purdue University (joint work with Tina Eliassi-Rad, Brian Gallagher, Sergey Kirshner,
Supporting Statistical Hypothesis Testing Over Graphs Jennifer Neville Departments of Computer Science and Statistics Purdue University (joint work with Tina Eliassi-Rad, Brian Gallagher, Sergey Kirshner,
DS504/CS586: Big Data Analytics Graph Mining II
 Welcome to DS504/CS586: Big Data Analytics Graph Mining II Prof. Yanhua Li Time: 6-8:50PM Thursday Location: AK233 Spring 2018 v Course Project I has been graded. Grading was based on v 1. Project report
Welcome to DS504/CS586: Big Data Analytics Graph Mining II Prof. Yanhua Li Time: 6-8:50PM Thursday Location: AK233 Spring 2018 v Course Project I has been graded. Grading was based on v 1. Project report
Lecture 11: Unsupervised Machine Learning
 CSE517A Machine Learning Spring 2018 Lecture 11: Unsupervised Machine Learning Instructor: Marion Neumann Scribe: Jingyu Xin Reading: fcml Ch6 (Intro), 6.2 (k-means), 6.3 (Mixture Models); [optional]:
CSE517A Machine Learning Spring 2018 Lecture 11: Unsupervised Machine Learning Instructor: Marion Neumann Scribe: Jingyu Xin Reading: fcml Ch6 (Intro), 6.2 (k-means), 6.3 (Mixture Models); [optional]:
Massive-scale estimation of exponential-family random graph models with local dependence
 Massive-scale estimation of exponential-family random graph models with local dependence Sergii Babkin Michael Schweinberger arxiv:1703.09301v1 [stat.co] 27 Mar 2017 Abstract A flexible approach to modeling
Massive-scale estimation of exponential-family random graph models with local dependence Sergii Babkin Michael Schweinberger arxiv:1703.09301v1 [stat.co] 27 Mar 2017 Abstract A flexible approach to modeling
Mixed Membership Stochastic Blockmodels
 Mixed Membership Stochastic Blockmodels (2008) Edoardo M. Airoldi, David M. Blei, Stephen E. Fienberg and Eric P. Xing Herrissa Lamothe Princeton University Herrissa Lamothe (Princeton University) Mixed
Mixed Membership Stochastic Blockmodels (2008) Edoardo M. Airoldi, David M. Blei, Stephen E. Fienberg and Eric P. Xing Herrissa Lamothe Princeton University Herrissa Lamothe (Princeton University) Mixed
Networks as vectors of their motif frequencies and 2-norm distance as a measure of similarity
 Networks as vectors of their motif frequencies and 2-norm distance as a measure of similarity CS322 Project Writeup Semih Salihoglu Stanford University 353 Serra Street Stanford, CA semih@stanford.edu
Networks as vectors of their motif frequencies and 2-norm distance as a measure of similarity CS322 Project Writeup Semih Salihoglu Stanford University 353 Serra Street Stanford, CA semih@stanford.edu
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Graph and Network Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Methods Learnt Classification Clustering Vector Data Text Data Recommender System Decision Tree; Naïve
CS249: ADVANCED DATA MINING Graph and Network Instructor: Yizhou Sun yzsun@cs.ucla.edu May 31, 2017 Methods Learnt Classification Clustering Vector Data Text Data Recommender System Decision Tree; Naïve
Probabilistic Graphical Models
 Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
Probabilistic Graphical Models Brown University CSCI 295-P, Spring 213 Prof. Erik Sudderth Lecture 11: Inference & Learning Overview, Gaussian Graphical Models Some figures courtesy Michael Jordan s draft
Mining Newsgroups Using Networks Arising From Social Behavior by Rakesh Agrawal et al. Presented by Will Lee
 Mining Newsgroups Using Networks Arising From Social Behavior by Rakesh Agrawal et al. Presented by Will Lee wwlee1@uiuc.edu September 28, 2004 Motivation IR on newsgroups is challenging due to lack of
Mining Newsgroups Using Networks Arising From Social Behavior by Rakesh Agrawal et al. Presented by Will Lee wwlee1@uiuc.edu September 28, 2004 Motivation IR on newsgroups is challenging due to lack of
25 : Graphical induced structured input/output models
 10-708: Probabilistic Graphical Models 10-708, Spring 2016 25 : Graphical induced structured input/output models Lecturer: Eric P. Xing Scribes: Raied Aljadaany, Shi Zong, Chenchen Zhu Disclaimer: A large
10-708: Probabilistic Graphical Models 10-708, Spring 2016 25 : Graphical induced structured input/output models Lecturer: Eric P. Xing Scribes: Raied Aljadaany, Shi Zong, Chenchen Zhu Disclaimer: A large
arxiv: v1 [cs.dm] 26 Apr 2010
![arxiv: v1 [cs.dm] 26 Apr 2010](/thumbs/73/68325063.jpg "arxiv: v1 [cs.dm] 26 Apr 2010") A Simple Polynomial Algorithm for the Longest Path Problem on Cocomparability Graphs George B. Mertzios Derek G. Corneil arxiv:1004.4560v1 [cs.dm] 26 Apr 2010 Abstract Given a graph G, the longest path
A Simple Polynomial Algorithm for the Longest Path Problem on Cocomparability Graphs George B. Mertzios Derek G. Corneil arxiv:1004.4560v1 [cs.dm] 26 Apr 2010 Abstract Given a graph G, the longest path
Conditional Random Field
 Introduction Linear-Chain General Specific Implementations Conclusions Corso di Elaborazione del Linguaggio Naturale Pisa, May, 2011 Introduction Linear-Chain General Specific Implementations Conclusions
Introduction Linear-Chain General Specific Implementations Conclusions Corso di Elaborazione del Linguaggio Naturale Pisa, May, 2011 Introduction Linear-Chain General Specific Implementations Conclusions
Kristina Lerman USC Information Sciences Institute
 Rethinking Network Structure Kristina Lerman USC Information Sciences Institute Università della Svizzera Italiana, December 16, 2011 Measuring network structure Central nodes Community structure Strength
Rethinking Network Structure Kristina Lerman USC Information Sciences Institute Università della Svizzera Italiana, December 16, 2011 Measuring network structure Central nodes Community structure Strength
Data Mining and Matrices
 Data Mining and Matrices 08 Boolean Matrix Factorization Rainer Gemulla, Pauli Miettinen June 13, 2013 Outline 1 Warm-Up 2 What is BMF 3 BMF vs. other three-letter abbreviations 4 Binary matrices, tiles,
Data Mining and Matrices 08 Boolean Matrix Factorization Rainer Gemulla, Pauli Miettinen June 13, 2013 Outline 1 Warm-Up 2 What is BMF 3 BMF vs. other three-letter abbreviations 4 Binary matrices, tiles,
Reconstruction in the Generalized Stochastic Block Model
 Reconstruction in the Generalized Stochastic Block Model Marc Lelarge 1 Laurent Massoulié 2 Jiaming Xu 3 1 INRIA-ENS 2 INRIA-Microsoft Research Joint Centre 3 University of Illinois, Urbana-Champaign GDR
Reconstruction in the Generalized Stochastic Block Model Marc Lelarge 1 Laurent Massoulié 2 Jiaming Xu 3 1 INRIA-ENS 2 INRIA-Microsoft Research Joint Centre 3 University of Illinois, Urbana-Champaign GDR
Modelling self-organizing networks
 Paweł Department of Mathematics, Ryerson University, Toronto, ON Cargese Fall School on Random Graphs (September 2015) Outline 1 Introduction 2 Spatial Preferred Attachment (SPA) Model 3 Future work Multidisciplinary
Paweł Department of Mathematics, Ryerson University, Toronto, ON Cargese Fall School on Random Graphs (September 2015) Outline 1 Introduction 2 Spatial Preferred Attachment (SPA) Model 3 Future work Multidisciplinary
6.047 / Computational Biology: Genomes, Networks, Evolution Fall 2008
 MIT OpenCourseWare http://ocw.mit.edu 6.047 / 6.878 Computational Biology: Genomes, etworks, Evolution Fall 2008 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
MIT OpenCourseWare http://ocw.mit.edu 6.047 / 6.878 Computational Biology: Genomes, etworks, Evolution Fall 2008 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
Efficient Subgraph Matching by Postponing Cartesian Products. Matthias Barkowsky
 Efficient Subgraph Matching by Postponing Cartesian Products Matthias Barkowsky 5 Subgraph Isomorphism - Approaches search problem: find all embeddings of a query graph in a data graph NP-hard, but can
Efficient Subgraph Matching by Postponing Cartesian Products Matthias Barkowsky 5 Subgraph Isomorphism - Approaches search problem: find all embeddings of a query graph in a data graph NP-hard, but can
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Maximum likelihood with coarse data. robust optimisation
 based on robust optimisation Romain Guillaume, Inés Couso, Didier Dubois IRIT, Université Toulouse, France, Universidad de Oviedo, Gijon (Spain) July 10, 2017 Contents Introduction 1 Introduction 2 3 4
based on robust optimisation Romain Guillaume, Inés Couso, Didier Dubois IRIT, Université Toulouse, France, Universidad de Oviedo, Gijon (Spain) July 10, 2017 Contents Introduction 1 Introduction 2 3 4
On the Equivalence of Nonnegative Matrix Factorization and Spectral Clustering
 On the Equivalence of Nonnegative Matrix Factorization and Spectral Clustering Chris Ding, Xiaofeng He, Horst D. Simon Published on SDM 05 Hongchang Gao Outline NMF NMF Kmeans NMF Spectral Clustering NMF
On the Equivalence of Nonnegative Matrix Factorization and Spectral Clustering Chris Ding, Xiaofeng He, Horst D. Simon Published on SDM 05 Hongchang Gao Outline NMF NMF Kmeans NMF Spectral Clustering NMF