Mixed Effects Models
|
|
|
- Barnaby Richard
- 5 years ago
- Views:
Transcription
1 Mixed Effects Models What is the effect of X on Y What is the effect of an independent variable on the dependent variable Independent variables are fixed factors. We want to measure their effect Random factors are variables who effect we don't want to measure, but we know it may be there. We want to eliminate it. Participants are random factors. Test items are random factors. Example of Participant affecting the outcome Research Question: What influences people to use or not use that in a sentence? Examples: I knew (that) he wouldn't show up. There are a lot of things (that) we don't know. Dependent Variable: that or no-that Independent Variables (fixed factors: Tense: past or present Sex: M, F Age 3-way: old, middle-aged, young Occupation: student, white collar, blue collar Random factor: participant Outcome without random effect of participant Tense (4.49e-32) Occ (5.97e-07) Age.3way (0.0044) Sex (0.132) Outcome with participant as random factor Tense (2.18e-31) Occ ( ) Age.3way (0.216) Sex (0.849)
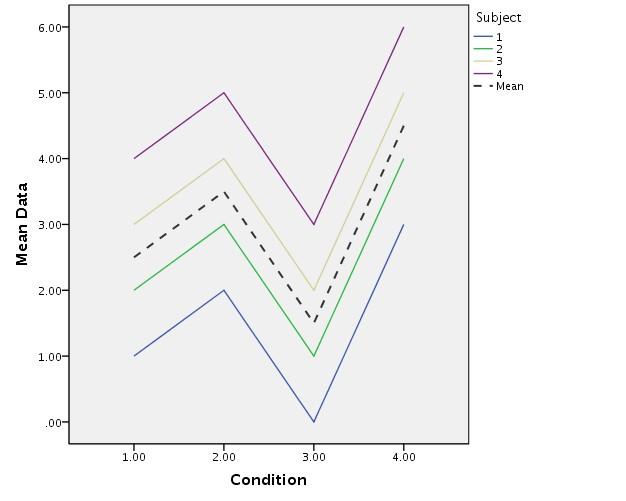
2 Why does age become insignificant? Some participants were deleting that much more or less than others in their age group, which made it look like age was a factor, in reality, it was caused by a few individuals that were outliers. Repeated Measures Correlation, Chi square, independent t-test, ANOVA assume independence of (lack of correlation between) the measurements. This assumption would be violated if: 1 A single person is measured more than once Correlation of language proficiency and number of year in country. Same person's data added more than once influences outcome too much Measurements of one person's VOT to many different words taken 2 A single person belongs to more than one test group Three groups: highly fluent, intermediate, low One person is put into two different groups Linguistic data often uses repeated measurements 1 What is the effect of X on VOT? There are 10 participants, and measurements of their VOTs to many different words is taken (Participant is a random factor. We aren't interested in differences between participants) 2 What is the effect of pronunciation training on foreign accent Three groups: no pronunciation training, training X, training Y. 20 native speakers rate all members of each group on degree of accent (Rater is a random factor. We don't care about differences between raters) We aren't interested in differences in the random factor, but we must acknowledge they exist and account for them statistically, or the results are not valid!
3 Example: end up VERBing Research question: what is the effect of time on the use of end up VERBing? Dependent variable: # of end up VERBing per mission Independent variable: time Random factor: corpus (which is the subject here. It is measured several times) Time 0 is 1930s and Time 50 is 2000s (quadratic to make data linear) Regression line is best fit, predicted values Good fit if dots are close, bad if they are far away Difference between data points and regression line are residuals (What the model doesn't explain)
4 Let's pretend that there are no repeated measures only decade as a factor MODEL 1 (no compensation for repeated measures) Open end up VERBing. Analyze > Mixed Models > Linear > Continue. Put end up verbing in the dependent variable box and Decade square in the covariate box. Click on fixed and then on DecadeSq. Move it to the Model box by clicking on Add > Continue > OK Total number of parameter is 3 (from Model Dimension box) Type III Tests of Fixed Effects a Source Numerator df Denominator df F Intercept DecadeSq
5 Information Criteria a -2 Restricted Log Likelihood Akaike's Information Criterion (AIC) Hurvich and Tsai's Criterion (AICC) Bozdogan's Criterion (CAIC) Schwarz's Bayesian Criterion (BIC) Restricted log Likelihood Same as deviance in Rbrul Used to compare models Smaller is better Can use to perform log likelihood test BIC Used to compare models Smaller is better Cannot use to perform log likelihood test Formula: Calculate the -2LL of model X minus the -2LL of model Y. Look up the resulting difference in a Chi square chart by the difference in degrees of freedom between each model. -2LL degrees of freedom Model Model difference At df=1 the -2LL must be or greater to be significant at p <.05.
6
7 Notice that there is lots of correlation (lack of independence) between the corpora. Time is always higher than the rest, GoogleUK is always lower. Let's factor in subject (corpus) as a random effect by allowing each to have its own regression line. Now the residuals are measured from the data point to the individual corpus regression line. They are smaller. The individual regression lines differ in two aspects: Intercept: their average distance from the overall mean. Where they intersect with the Y axis at zero (too hard to see here). Slope: how the slant of the individual line varies from the overall regression line. Time has a steeper slope and GoogleUK has a less steep slope. There may be interaction between the intercept and the slope. Here lower intercepts are correlated with flatter slopes and higher intercepts are correlated with steeper slopes.
8 MODEL 2 (adding a random intercept) Results Analyze > Mixed Models > Linear. Move Corpus to Subjects box > Contine. Put end up verbing in the dependent variable box, Corpus in Factors box, and Decade square in the covariate box. Click on fixed and then on DecadeSq. Move it to the Model box by clicking on Add > Continue. Click on Random, then Corpus and Add to move it to the Combinations Box. Check Include Intercept. Change Covariance Type to Scaled Identity > Continue > OK. The model has a random intercept for each corpus. The regression line for each corpus is parallel to the overall regression line. Decade is still significant Information Criteria a -2 Restricted Log Likelihood Akaike's Information Criterion (AIC) Hurvich and Tsai's Criterion (AICC) Bozdogan's Criterion (CAIC) Schwarz's Bayesian Criterion (BIC) Chi square chart -2LL degrees of freedom Model Model difference At df=1 the -2LL must be or greater to be significant at p <.05. Model 2 is more complex, but has a better fit. Adding random intercepts improves fit.
9 In chart, the slope differs by corpus. Random slope may fit better
10 MODEL 3 (random slope) Analyze > Mixed Models > Linear. Move Corpus to Subjects box > Continue. Put end up verbing in the dependent variable box, Corpus in Factors box, and Decade square in the covariate box. Click on fixed and then on DecadeSq. Move it to the Model box by clicking on Add > Continue. Click on Random, then DecadeSq and Add to move it to the Model Box. Check Include Intercept. Click on Corpus and move to Combinations box with the arrow. Change Covariance Type to Scaled Identity > Continue > OK. Degrees of freedom (Parameters) = 4 Chi square chart -2LL degrees of freedom Model Model difference 62 0 At df=1(or 0) the -2LL must be or greater to be significant at p <.05. Model 3 is better fit. Decade is no longer significant! p =.052. It is the differences in corpora that cause the effect. Information Criteria a -2 Restricted Log Likelihood Akaike's Information Criterion (AIC) Hurvich and Tsai's Criterion (AICC) Bozdogan's Criterion (CAIC) Schwarz's Bayesian Criterion (BIC)
11 Practice Winter and Bergen (2012) contend that language comprehension does not uniquely involve language mechanisms but perceptual systems as well. The hypothesize that when processing a sentence that describes an object at a distance, that produces a mental image of the object that can affect the perception of a picture of that object. Their participants read sentences that described objects that were either near (e.g. While you're milking the cow it starts mooing) or far away (e.g. Across the field, the cow starts mooing). Afterwards, they were shown a picture and asked to respond yes if it matched the preceding sentence, or no if it did not. Of course, not all of the trials involved matches between sentences and picture. However, when there was a match there were actually two kinds of matching pictures: one showed the object close up and the other far away. The difference was in the size of the object in the picture. Large objects are perceived to be closer than small objects. When participants heard a sentence about a cow, they should answer yes to a picture of a cow regardless of whether the cow is depicted as being close or far away. However, the authors hypothesized that the participants would respond more quickly when the distance in the sentence matched the distance in the picture, and more slowly when there was a mismatch. This experiment involves repeated measures because each participant belongs to each of the four groups that were contrasted: far sentence, small object; far sentence, large object, close sentence, small object; close sentence, large object. In addition, each subject gave multiple responses in each of the four groups. Dependent variable: reaction time in seconds (RTinSeconds) Independent variable: Condition (far/big, far/small, near/big, near/small) Random factor: Subject Download these data. Model 1-Pretend there are no repeated measures. See if reaction time is influenced by condition. (Note: Condition in this case is a categorical variable. Put it in the factor box. Only numeric variables go in the covariate box) What are the results for condition? How many parameters (degrees of freedom)? What is the -2LL? What is the BIC?
12 What are the results for condition? not significant How many parameters (degrees of freedom)? 5 What is the -2LL? You can't use this model since it doesn't account for repeated measures What is the BIC? Model 2-Repeat the analysis, but this time give each subject a random intercept. See if reaction time is influenced by condition. (Note: Condition in this case is a categorical variable. Put it in the factor box. Only numeric variables go in the covariate box) What are the results for condition? How many parameters (degrees of freedom)? What is the -2LL? What is the BIC? Use a log likelihood test to see if this is a better model.
13 What are the results for condition? not significant How many parameters (degrees of freedom)? 6 What is the -2LL? What is the BIC? Use a log likelihood test to see if this is a better model. Model 3-Repeat the analysis, but this time give each subject a random slope. See if reaction time is influenced by condition. (Note: Condition in this case is a categorical variable. Put it in the factor box. Only numeric variables go in the covariate box) What are the results for condition? How many parameters (degrees of freedom)? What is the -2LL? What is the BIC? Use a log likelihood test to see if this is a better model.
14 What are the results for condition? not significant How many parameters (degrees of freedom)? 6 What is the -2LL? What is the BIC? Use a log likelihood test to see if this is a better model. No, it is worse Model 4-Repeat the analysis, but this time give each test item a random intercept. See if reaction time is influenced by condition. (Note: Condition in this case is a categorical variable. Put it in the factor box. Only numeric variables go in the covariate box) What are the results for condition? How many parameters (degrees of freedom)? What is the -2LL? What is the BIC? Use a log likelihood test to see if this is a better model compared to Model 1.
15 What are the results for condition? not significant How many parameters (degrees of freedom)? 6 What is the -2LL? What is the BIC? Use a log likelihood test to see if this is a better model compared to Model 1. Model Model Significantly smaller. Adding 1 df is justifiable.
16 Model 5-Repeat the analysis, but this time give each test item a random slope. See if reaction time is influenced by condition. (Note: Condition in this case is a categorical variable. Put it in the factor box. Only numeric variables go in the covariate box) What are the results for condition? How many parameters (degrees of freedom)? What is the -2LL? What is the BIC? Use a log likelihood test to see if this is a better model compared to Model 4.
17 What are the results for condition? not significant How many parameters (degrees of freedom)? 6 What is the -2LL? What is the BIC? Use a log likelihood test to see if this is a better model compared to Model 4. Model Model (assume 1) No significant difference, BIC got bigger, so random slope doesn't help get a better fit.
18 Using the Syntax Editor Menus are confusing. You are not sure what you are doing. The syntax editor is easier to modify. Let's start by using the menus, then see what they give us as syntax. Analyze > Mixed Models > Linear. Move Subject to Subjects box > Continue. Put RtinSeconds in the dependent variable box and Condition and Subject in the Factors box. Click on Fixed and then on Condition. Move it to the Model box by clicking on Add > Continue. Click on Random, then Condition and Add to move it to the Model Box. Check Include Intercept. Click on Subject and move to Combinations box with the arrow. Change Covariance Type to Scaled Identity > Continue > Paste (This puts it into the syntax editor). Syntax The variables in our model are in green MIXED RTinSeconds BY Subject CONDITION /CRITERIA=CIN(95) MXITER(100) MXSTEP(10) SCORING(1) SINGULAR( ) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE( , ABSOLUTE) /FIXED=CONDITION SSTYPE(3) /METHOD=REML /RANDOM=INTERCEPT CONDITION SUBJECT(Subject) COVTYPE(ID). MIXED: run a mixed effects model RtinSeconds: dependent variable BY: specifies the categorical independent variables Subject CONDITION: the categorical independent variables (both fixed and random) WITH: specifies the numeric independent variables (there are none so there is no WITH here) /CRITERIA=CIN(95) MXITER(100) MXSTEP(10) SCORING(1) SINGULAR( ) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE( , ABSOLUTE): Directions to the computer on how to run the analysis. /FIXED: What the fixed effects are. CONDITION: the independent variable
19 SSTYPE(3): More directions to the computer. /METHOD=REML: More directions to the computer /RANDOM: What the random effects are INTERCEPT: calculate the intercept CONDITION SUBJECT(Subject): Calculate a random slope for each subject across each of the test conditions in CONDITION. COVTYPE(ID): Type of variance covariance matrix (Scaled identity). We'll talk about it. It is very important to put a period at the end of the syntax Random slope /RANDOM=INTERCEPT CONDITION SUBJECT(Subject) COVTYPE(ID). Random intercept /RANDOM=INTERCEPT SUBJECT(Subject) COVTYPE(ID). Running the syntax Highlight all of the syntax and press the green arrow. Look at the results in the Output window. Changing the syntax You can add and delete variables by deleting of typing them in the correct place. Practice 1 Change the syntax so that it runs a random intercept model 2 Change the syntax so that it runs a random intercept model with ITEM as the random factor instead of Subject. 3 We found that a random intercept for test item and a random intercept for subject produced a better model fit. Make a model that contains both random of these factors together. Compare the outcome to Models 2 and 4 above using a log likelihood test.

20 If each of these data points came from different people we wouldn't assume that there would be any correlation between any two points. We would measure the residuals to the overall predicted regression line.

21 When one person provides more than one data point, chances are that his/her responses to one item or at one point in time are correlated. To account for this we include a random factor. When this is done the residuals are measured to the individual's predicted response (the individual's regression line).
22 The repeated statement We can sometimes fit a model even better by providing information about how the residuals are structured. A covariance structure contains two kinds of data. First, it specifies information about any correlations that exist between repeated measurements. Second, it indicates what the variance of those measurements is like across time, or across experimental condition. Two graphs above, the variance goes up over time and the covariance get larger from one decade to the next. (Covariance is unstandardized correlation. It isn't +1 to -1, but given in the units of measurement.) 1930s 1940s 1950s 1960s 1970s 1980s 1990s 2000s 1930s s s s s s s s The covariance of a covariance is the variance and appears in bold along the diagonal. If we did a correlation they would all be 1. ARH1 Heterogenous first-order autoregressive This means the variance changes over time (or conditions), and the covariance does also. It assumes that the covariance between two adjacent decades is more similar that between more distant ones.
23 CS Compound symmetry The variance is about the same across time (or condition) and the covariance is about the same. 1930s 1940s 1950s 1960s 1970s 1980s 1990s 2000s 1930s s s s s s s s 1654
24
 and there is no")
25 ID Scaled Identity The variance is the same across time (or conditions) and there is no covariance.
26
27 Common covariance structures. Covariance Structure Variance across repeated measures Covariance across repeated measures Acronym Compound Symmetry Constant Constant CS Heterogenous Compound Symmetry Different Constant CSH Unstructured Different Different UN Autoregressive Constant Closer measurements are more correlated than distant ones. Heterogenous Autoregressive Different Covariance grow smaller with each successive measurement. Toeplitz Constant Adjacent measurements have same covariance, but covariance is smaller for nonadjacent measurements. Identity Constant None ID AR1 ARH1 Diagonal Different None DIAG TP Other covariance structures: TPH, CSR, AD1, FA1, FAH1, HF, UNR Which one do you use? The one that fits best.
28 Practice 1 Open these data. 2 Open the syntax editor and paste in the code below. File > New > Syntax. MIXED Score WITH Decade /CRITERIA=CIN(95) MXITER(100) MXSTEP(10) SCORING(1) SINGULAR( ) HCONVERGE(0, ABSOLUTE) LCONVERGE(0, ABSOLUTE) PCONVERGE( , ABSOLUTE) /FIXED=Decade SSTYPE(3) /METHOD=REML /RANDOM=INTERCEPT Decade SUBJECT(Subject) COVTYPE(ID). This is a random slope model. 3 Run this model and note the number of parameters, the -2LL, and the BIC. 4 Modify the syntax to run a random intercept model. Determine which is a better fit. 5 Add the random statement to the end and be sure to delete unnecessary periods. Run this model. /REPEATED=Decade SUBJECT(Subject) COVTYPE(DIAG). 6 Try the model with different covariance structures to see which give the best fit.
Step 2: Select Analyze, Mixed Models, and Linear.
 Example 1a. 20 employees were given a mood questionnaire on Monday, Wednesday and again on Friday. The data will be first be analyzed using a Covariance Pattern model. Step 1: Copy Example1.sav data file
Example 1a. 20 employees were given a mood questionnaire on Monday, Wednesday and again on Friday. The data will be first be analyzed using a Covariance Pattern model. Step 1: Copy Example1.sav data file
over Time line for the means). Specifically, & covariances) just a fixed variance instead. PROC MIXED: to 1000 is default) list models with TYPE=VC */
. Specifically, & covariances) just a fixed variance instead. PROC MIXED: to 1000 is default) list models with TYPE=VC */") CLP 944 Example 4 page 1 Within-Personn Fluctuation in Symptom Severity over Time These data come from a study of weekly fluctuation in psoriasis severity. There was no intervention and no real reason
CLP 944 Example 4 page 1 Within-Personn Fluctuation in Symptom Severity over Time These data come from a study of weekly fluctuation in psoriasis severity. There was no intervention and no real reason
Biostatistics 301A. Repeated measurement analysis (mixed models)
") B a s i c S t a t i s t i c s F o r D o c t o r s Singapore Med J 2004 Vol 45(10) : 456 CME Article Biostatistics 301A. Repeated measurement analysis (mixed models) Y H Chan Faculty of Medicine National
B a s i c S t a t i s t i c s F o r D o c t o r s Singapore Med J 2004 Vol 45(10) : 456 CME Article Biostatistics 301A. Repeated measurement analysis (mixed models) Y H Chan Faculty of Medicine National
Describing Within-Person Fluctuation over Time using Alternative Covariance Structures
 Describing Within-Person Fluctuation over Time using Alternative Covariance Structures Today s Class: The Big Picture ACS models using the R matrix only Introducing the G, Z, and V matrices ACS models
Describing Within-Person Fluctuation over Time using Alternative Covariance Structures Today s Class: The Big Picture ACS models using the R matrix only Introducing the G, Z, and V matrices ACS models
Introduction to Within-Person Analysis and RM ANOVA
 Introduction to Within-Person Analysis and RM ANOVA Today s Class: From between-person to within-person ANOVAs for longitudinal data Variance model comparisons using 2 LL CLP 944: Lecture 3 1 The Two Sides
Introduction to Within-Person Analysis and RM ANOVA Today s Class: From between-person to within-person ANOVAs for longitudinal data Variance model comparisons using 2 LL CLP 944: Lecture 3 1 The Two Sides
Daniel J. Bauer & Patrick J. Curran
 GET FILE='C:\Users\dan\Dropbox\SRA\antisocial.sav'. >Warning # 5281. Command name: GET FILE >SPSS Statistics is running in Unicode encoding mode. This file is encoded in >a locale-specific (code page)
GET FILE='C:\Users\dan\Dropbox\SRA\antisocial.sav'. >Warning # 5281. Command name: GET FILE >SPSS Statistics is running in Unicode encoding mode. This file is encoded in >a locale-specific (code page)
Class Notes: Week 8. Probit versus Logit Link Functions and Count Data
 Ronald Heck Class Notes: Week 8 1 Class Notes: Week 8 Probit versus Logit Link Functions and Count Data This week we ll take up a couple of issues. The first is working with a probit link function. While
Ronald Heck Class Notes: Week 8 1 Class Notes: Week 8 Probit versus Logit Link Functions and Count Data This week we ll take up a couple of issues. The first is working with a probit link function. While
An Introduction to Path Analysis
 An Introduction to Path Analysis PRE 905: Multivariate Analysis Lecture 10: April 15, 2014 PRE 905: Lecture 10 Path Analysis Today s Lecture Path analysis starting with multivariate regression then arriving
An Introduction to Path Analysis PRE 905: Multivariate Analysis Lecture 10: April 15, 2014 PRE 905: Lecture 10 Path Analysis Today s Lecture Path analysis starting with multivariate regression then arriving
An Introduction to Mplus and Path Analysis
 An Introduction to Mplus and Path Analysis PSYC 943: Fundamentals of Multivariate Modeling Lecture 10: October 30, 2013 PSYC 943: Lecture 10 Today s Lecture Path analysis starting with multivariate regression
An Introduction to Mplus and Path Analysis PSYC 943: Fundamentals of Multivariate Modeling Lecture 10: October 30, 2013 PSYC 943: Lecture 10 Today s Lecture Path analysis starting with multivariate regression
Review of CLDP 944: Multilevel Models for Longitudinal Data
 Review of CLDP 944: Multilevel Models for Longitudinal Data Topics: Review of general MLM concepts and terminology Model comparisons and significance testing Fixed and random effects of time Significance
Review of CLDP 944: Multilevel Models for Longitudinal Data Topics: Review of general MLM concepts and terminology Model comparisons and significance testing Fixed and random effects of time Significance
SAS Syntax and Output for Data Manipulation:
 CLP 944 Example 5 page 1 Practice with Fixed and Random Effects of Time in Modeling Within-Person Change The models for this example come from Hoffman (2015) chapter 5. We will be examining the extent
CLP 944 Example 5 page 1 Practice with Fixed and Random Effects of Time in Modeling Within-Person Change The models for this example come from Hoffman (2015) chapter 5. We will be examining the extent
Subject-specific observed profiles of log(fev1) vs age First 50 subjects in Six Cities Study
 vs age First 50 subjects in Six Cities Study") Subject-specific observed profiles of log(fev1) vs age First 50 subjects in Six Cities Study 1.4 0.0-6 7 8 9 10 11 12 13 14 15 16 17 18 19 age Model 1: A simple broken stick model with knot at 14 fit with
Subject-specific observed profiles of log(fev1) vs age First 50 subjects in Six Cities Study 1.4 0.0-6 7 8 9 10 11 12 13 14 15 16 17 18 19 age Model 1: A simple broken stick model with knot at 14 fit with
Additional Notes: Investigating a Random Slope. When we have fixed level-1 predictors at level 2 we show them like this:
 Ron Heck, Summer 01 Seminars 1 Multilevel Regression Models and Their Applications Seminar Additional Notes: Investigating a Random Slope We can begin with Model 3 and add a Random slope parameter. If
Ron Heck, Summer 01 Seminars 1 Multilevel Regression Models and Their Applications Seminar Additional Notes: Investigating a Random Slope We can begin with Model 3 and add a Random slope parameter. If
Supplemental Materials. In the main text, we recommend graphing physiological values for individual dyad
 1 Supplemental Materials Graphing Values for Individual Dyad Members over Time In the main text, we recommend graphing physiological values for individual dyad members over time to aid in the decision
1 Supplemental Materials Graphing Values for Individual Dyad Members over Time In the main text, we recommend graphing physiological values for individual dyad members over time to aid in the decision
MLMED. User Guide. Nicholas J. Rockwood The Ohio State University Beta Version May, 2017
 MLMED User Guide Nicholas J. Rockwood The Ohio State University rockwood.19@osu.edu Beta Version May, 2017 MLmed is a computational macro for SPSS that simplifies the fitting of multilevel mediation and
MLMED User Guide Nicholas J. Rockwood The Ohio State University rockwood.19@osu.edu Beta Version May, 2017 MLmed is a computational macro for SPSS that simplifies the fitting of multilevel mediation and
36-309/749 Experimental Design for Behavioral and Social Sciences. Dec 1, 2015 Lecture 11: Mixed Models (HLMs)
") 36-309/749 Experimental Design for Behavioral and Social Sciences Dec 1, 2015 Lecture 11: Mixed Models (HLMs) Independent Errors Assumption An error is the deviation of an individual observed outcome (DV)
36-309/749 Experimental Design for Behavioral and Social Sciences Dec 1, 2015 Lecture 11: Mixed Models (HLMs) Independent Errors Assumption An error is the deviation of an individual observed outcome (DV)
Model Estimation Example
 Ronald H. Heck 1 EDEP 606: Multivariate Methods (S2013) April 7, 2013 Model Estimation Example As we have moved through the course this semester, we have encountered the concept of model estimation. Discussions
Ronald H. Heck 1 EDEP 606: Multivariate Methods (S2013) April 7, 2013 Model Estimation Example As we have moved through the course this semester, we have encountered the concept of model estimation. Discussions
Longitudinal Data Analysis of Health Outcomes
 Longitudinal Data Analysis of Health Outcomes Longitudinal Data Analysis Workshop Running Example: Days 2 and 3 University of Georgia: Institute for Interdisciplinary Research in Education and Human Development
Longitudinal Data Analysis of Health Outcomes Longitudinal Data Analysis Workshop Running Example: Days 2 and 3 University of Georgia: Institute for Interdisciplinary Research in Education and Human Development
Analysis of Longitudinal Data: Comparison Between PROC GLM and PROC MIXED. Maribeth Johnson Medical College of Georgia Augusta, GA
 Analysis of Longitudinal Data: Comparison Between PROC GLM and PROC MIXED Maribeth Johnson Medical College of Georgia Augusta, GA Overview Introduction to longitudinal data Describe the data for examples
Analysis of Longitudinal Data: Comparison Between PROC GLM and PROC MIXED Maribeth Johnson Medical College of Georgia Augusta, GA Overview Introduction to longitudinal data Describe the data for examples
Module 8: Linear Regression. The Applied Research Center
 Module 8: Linear Regression The Applied Research Center Module 8 Overview } Purpose of Linear Regression } Scatter Diagrams } Regression Equation } Regression Results } Example Purpose } To predict scores
Module 8: Linear Regression The Applied Research Center Module 8 Overview } Purpose of Linear Regression } Scatter Diagrams } Regression Equation } Regression Results } Example Purpose } To predict scores
MIXED MODELS FOR REPEATED (LONGITUDINAL) DATA PART 2 DAVID C. HOWELL 4/1/2010
 DATA PART 2 DAVID C. HOWELL 4/1/2010") MIXED MODELS FOR REPEATED (LONGITUDINAL) DATA PART 2 DAVID C. HOWELL 4/1/2010 Part 1 of this document can be found at http://www.uvm.edu/~dhowell/methods/supplements/mixed Models for Repeated Measures1.pdf
MIXED MODELS FOR REPEATED (LONGITUDINAL) DATA PART 2 DAVID C. HOWELL 4/1/2010 Part 1 of this document can be found at http://www.uvm.edu/~dhowell/methods/supplements/mixed Models for Repeated Measures1.pdf
Mathematical Notation Math Introduction to Applied Statistics
 Mathematical Notation Math 113 - Introduction to Applied Statistics Name : Use Word or WordPerfect to recreate the following documents. Each article is worth 10 points and should be emailed to the instructor
Mathematical Notation Math 113 - Introduction to Applied Statistics Name : Use Word or WordPerfect to recreate the following documents. Each article is worth 10 points and should be emailed to the instructor
EPSY 905: Fundamentals of Multivariate Modeling Online Lecture #7
 Introduction to Generalized Univariate Models: Models for Binary Outcomes EPSY 905: Fundamentals of Multivariate Modeling Online Lecture #7 EPSY 905: Intro to Generalized In This Lecture A short review
Introduction to Generalized Univariate Models: Models for Binary Outcomes EPSY 905: Fundamentals of Multivariate Modeling Online Lecture #7 EPSY 905: Intro to Generalized In This Lecture A short review
Chapter 1 Statistical Inference
 Chapter 1 Statistical Inference causal inference To infer causality, you need a randomized experiment (or a huge observational study and lots of outside information). inference to populations Generalizations
Chapter 1 Statistical Inference causal inference To infer causality, you need a randomized experiment (or a huge observational study and lots of outside information). inference to populations Generalizations
LAB 3 INSTRUCTIONS SIMPLE LINEAR REGRESSION
 LAB 3 INSTRUCTIONS SIMPLE LINEAR REGRESSION In this lab you will first learn how to display the relationship between two quantitative variables with a scatterplot and also how to measure the strength of
LAB 3 INSTRUCTIONS SIMPLE LINEAR REGRESSION In this lab you will first learn how to display the relationship between two quantitative variables with a scatterplot and also how to measure the strength of
SAS Code for Data Manipulation: SPSS Code for Data Manipulation: STATA Code for Data Manipulation: Psyc 945 Example 1 page 1
 Psyc 945 Example page Example : Unconditional Models for Change in Number Match 3 Response Time (complete data, syntax, and output available for SAS, SPSS, and STATA electronically) These data come from
Psyc 945 Example page Example : Unconditional Models for Change in Number Match 3 Response Time (complete data, syntax, and output available for SAS, SPSS, and STATA electronically) These data come from
Longitudinal Invariance CFA (using MLR) Example in Mplus v. 7.4 (N = 151; 6 items over 3 occasions)
 Example in Mplus v. 7.4 (N = 151; 6 items over 3 occasions)") Longitudinal Invariance CFA (using MLR) Example in Mplus v. 7.4 (N = 151; 6 items over 3 occasions) CLP 948 Example 7b page 1 These data measuring a latent trait of social functioning were collected at
Longitudinal Invariance CFA (using MLR) Example in Mplus v. 7.4 (N = 151; 6 items over 3 occasions) CLP 948 Example 7b page 1 These data measuring a latent trait of social functioning were collected at
An Introduction to Multilevel Models. PSYC 943 (930): Fundamentals of Multivariate Modeling Lecture 25: December 7, 2012
: Fundamentals of Multivariate Modeling Lecture 25: December 7, 2012") An Introduction to Multilevel Models PSYC 943 (930): Fundamentals of Multivariate Modeling Lecture 25: December 7, 2012 Today s Class Concepts in Longitudinal Modeling Between-Person vs. +Within-Person
An Introduction to Multilevel Models PSYC 943 (930): Fundamentals of Multivariate Modeling Lecture 25: December 7, 2012 Today s Class Concepts in Longitudinal Modeling Between-Person vs. +Within-Person
Multiple Group CFA Invariance Example (data from Brown Chapter 7) using MLR Mplus 7.4: Major Depression Criteria across Men and Women (n = 345 each)
 using MLR Mplus 7.4: Major Depression Criteria across Men and Women (n = 345 each)") Multiple Group CFA Invariance Example (data from Brown Chapter 7) using MLR Mplus 7.4: Major Depression Criteria across Men and Women (n = 345 each) 9 items rated by clinicians on a scale of 0 to 8 (0
Multiple Group CFA Invariance Example (data from Brown Chapter 7) using MLR Mplus 7.4: Major Depression Criteria across Men and Women (n = 345 each) 9 items rated by clinicians on a scale of 0 to 8 (0
UNIVERSITY OF TORONTO. Faculty of Arts and Science APRIL 2010 EXAMINATIONS STA 303 H1S / STA 1002 HS. Duration - 3 hours. Aids Allowed: Calculator
 UNIVERSITY OF TORONTO Faculty of Arts and Science APRIL 2010 EXAMINATIONS STA 303 H1S / STA 1002 HS Duration - 3 hours Aids Allowed: Calculator LAST NAME: FIRST NAME: STUDENT NUMBER: There are 27 pages
UNIVERSITY OF TORONTO Faculty of Arts and Science APRIL 2010 EXAMINATIONS STA 303 H1S / STA 1002 HS Duration - 3 hours Aids Allowed: Calculator LAST NAME: FIRST NAME: STUDENT NUMBER: There are 27 pages
ANOVA Longitudinal Models for the Practice Effects Data: via GLM
 Psyc 943 Lecture 25 page 1 ANOVA Longitudinal Models for the Practice Effects Data: via GLM Model 1. Saturated Means Model for Session, E-only Variances Model (BP) Variances Model: NO correlation, EQUAL
Psyc 943 Lecture 25 page 1 ANOVA Longitudinal Models for the Practice Effects Data: via GLM Model 1. Saturated Means Model for Session, E-only Variances Model (BP) Variances Model: NO correlation, EQUAL
Designing Multilevel Models Using SPSS 11.5 Mixed Model. John Painter, Ph.D.
 Designing Multilevel Models Using SPSS 11.5 Mixed Model John Painter, Ph.D. Jordan Institute for Families School of Social Work University of North Carolina at Chapel Hill 1 Creating Multilevel Models
Designing Multilevel Models Using SPSS 11.5 Mixed Model John Painter, Ph.D. Jordan Institute for Families School of Social Work University of North Carolina at Chapel Hill 1 Creating Multilevel Models
Review of Unconditional Multilevel Models for Longitudinal Data
 Review of Unconditional Multilevel Models for Longitudinal Data Topics: Course (and MLM) overview Concepts in longitudinal multilevel modeling Model comparisons and significance testing Describing within-person
Review of Unconditional Multilevel Models for Longitudinal Data Topics: Course (and MLM) overview Concepts in longitudinal multilevel modeling Model comparisons and significance testing Describing within-person
Contingency Tables. Contingency tables are used when we want to looking at two (or more) factors. Each factor might have two more or levels.
 factors. Each factor might have two more or levels.") Contingency Tables Definition & Examples. Contingency tables are used when we want to looking at two (or more) factors. Each factor might have two more or levels. (Using more than two factors gets complicated,
Contingency Tables Definition & Examples. Contingency tables are used when we want to looking at two (or more) factors. Each factor might have two more or levels. (Using more than two factors gets complicated,
Advanced Quantitative Data Analysis
 Chapter 24 Advanced Quantitative Data Analysis Daniel Muijs Doing Regression Analysis in SPSS When we want to do regression analysis in SPSS, we have to go through the following steps: 1 As usual, we choose
Chapter 24 Advanced Quantitative Data Analysis Daniel Muijs Doing Regression Analysis in SPSS When we want to do regression analysis in SPSS, we have to go through the following steps: 1 As usual, we choose
STA 303 H1S / 1002 HS Winter 2011 Test March 7, ab 1cde 2abcde 2fghij 3
 STA 303 H1S / 1002 HS Winter 2011 Test March 7, 2011 LAST NAME: FIRST NAME: STUDENT NUMBER: ENROLLED IN: (circle one) STA 303 STA 1002 INSTRUCTIONS: Time: 90 minutes Aids allowed: calculator. Some formulae
STA 303 H1S / 1002 HS Winter 2011 Test March 7, 2011 LAST NAME: FIRST NAME: STUDENT NUMBER: ENROLLED IN: (circle one) STA 303 STA 1002 INSTRUCTIONS: Time: 90 minutes Aids allowed: calculator. Some formulae
Introduction to Generalized Models
 Introduction to Generalized Models Today s topics: The big picture of generalized models Review of maximum likelihood estimation Models for binary outcomes Models for proportion outcomes Models for categorical
Introduction to Generalized Models Today s topics: The big picture of generalized models Review of maximum likelihood estimation Models for binary outcomes Models for proportion outcomes Models for categorical
Multiple Linear Regression
 Andrew Lonardelli December 20, 2013 Multiple Linear Regression 1 Table Of Contents Introduction: p.3 Multiple Linear Regression Model: p.3 Least Squares Estimation of the Parameters: p.4-5 The matrix approach
Andrew Lonardelli December 20, 2013 Multiple Linear Regression 1 Table Of Contents Introduction: p.3 Multiple Linear Regression Model: p.3 Least Squares Estimation of the Parameters: p.4-5 The matrix approach
Univariate ARIMA Models
 Univariate ARIMA Models ARIMA Model Building Steps: Identification: Using graphs, statistics, ACFs and PACFs, transformations, etc. to achieve stationary and tentatively identify patterns and model components.
Univariate ARIMA Models ARIMA Model Building Steps: Identification: Using graphs, statistics, ACFs and PACFs, transformations, etc. to achieve stationary and tentatively identify patterns and model components.
A Re-Introduction to General Linear Models (GLM)
") A Re-Introduction to General Linear Models (GLM) Today s Class: You do know the GLM Estimation (where the numbers in the output come from): From least squares to restricted maximum likelihood (REML) Reviewing
A Re-Introduction to General Linear Models (GLM) Today s Class: You do know the GLM Estimation (where the numbers in the output come from): From least squares to restricted maximum likelihood (REML) Reviewing
AMS 7 Correlation and Regression Lecture 8
 AMS 7 Correlation and Regression Lecture 8 Department of Applied Mathematics and Statistics, University of California, Santa Cruz Suumer 2014 1 / 18 Correlation pairs of continuous observations. Correlation
AMS 7 Correlation and Regression Lecture 8 Department of Applied Mathematics and Statistics, University of California, Santa Cruz Suumer 2014 1 / 18 Correlation pairs of continuous observations. Correlation
Hierarchical Generalized Linear Models. ERSH 8990 REMS Seminar on HLM Last Lecture!
 Hierarchical Generalized Linear Models ERSH 8990 REMS Seminar on HLM Last Lecture! Hierarchical Generalized Linear Models Introduction to generalized models Models for binary outcomes Interpreting parameter
Hierarchical Generalized Linear Models ERSH 8990 REMS Seminar on HLM Last Lecture! Hierarchical Generalized Linear Models Introduction to generalized models Models for binary outcomes Interpreting parameter
Dynamic Determination of Mixed Model Covariance Structures. in Double-blind Clinical Trials. Matthew Davis - Omnicare Clinical Research
 PharmaSUG2010 - Paper SP12 Dynamic Determination of Mixed Model Covariance Structures in Double-blind Clinical Trials Matthew Davis - Omnicare Clinical Research Abstract With the computing power of SAS
PharmaSUG2010 - Paper SP12 Dynamic Determination of Mixed Model Covariance Structures in Double-blind Clinical Trials Matthew Davis - Omnicare Clinical Research Abstract With the computing power of SAS
Review of Multiple Regression
 Ronald H. Heck 1 Let s begin with a little review of multiple regression this week. Linear models [e.g., correlation, t-tests, analysis of variance (ANOVA), multiple regression, path analysis, multivariate
Ronald H. Heck 1 Let s begin with a little review of multiple regression this week. Linear models [e.g., correlation, t-tests, analysis of variance (ANOVA), multiple regression, path analysis, multivariate
Biostatistics and Design of Experiments Prof. Mukesh Doble Department of Biotechnology Indian Institute of Technology, Madras
 Biostatistics and Design of Experiments Prof. Mukesh Doble Department of Biotechnology Indian Institute of Technology, Madras Lecture - 39 Regression Analysis Hello and welcome to the course on Biostatistics
Biostatistics and Design of Experiments Prof. Mukesh Doble Department of Biotechnology Indian Institute of Technology, Madras Lecture - 39 Regression Analysis Hello and welcome to the course on Biostatistics
Time-Invariant Predictors in Longitudinal Models
 Time-Invariant Predictors in Longitudinal Models Today s Class (or 3): Summary of steps in building unconditional models for time What happens to missing predictors Effects of time-invariant predictors
Time-Invariant Predictors in Longitudinal Models Today s Class (or 3): Summary of steps in building unconditional models for time What happens to missing predictors Effects of time-invariant predictors
Mathematical Notation Math Introduction to Applied Statistics
 Mathematical Notation Math 113 - Introduction to Applied Statistics Name : Use Word or WordPerfect to recreate the following documents. Each article is worth 10 points and can be printed and given to the
Mathematical Notation Math 113 - Introduction to Applied Statistics Name : Use Word or WordPerfect to recreate the following documents. Each article is worth 10 points and can be printed and given to the
Introduction to Random Effects of Time and Model Estimation
 Introduction to Random Effects of Time and Model Estimation Today s Class: The Big Picture Multilevel model notation Fixed vs. random effects of time Random intercept vs. random slope models How MLM =
Introduction to Random Effects of Time and Model Estimation Today s Class: The Big Picture Multilevel model notation Fixed vs. random effects of time Random intercept vs. random slope models How MLM =
Generalized Models: Part 1
 Generalized Models: Part 1 Topics: Introduction to generalized models Introduction to maximum likelihood estimation Models for binary outcomes Models for proportion outcomes Models for categorical outcomes
Generalized Models: Part 1 Topics: Introduction to generalized models Introduction to maximum likelihood estimation Models for binary outcomes Models for proportion outcomes Models for categorical outcomes
Repeated Measures ANOVA Multivariate ANOVA and Their Relationship to Linear Mixed Models
 Repeated Measures ANOVA Multivariate ANOVA and Their Relationship to Linear Mixed Models EPSY 905: Multivariate Analysis Spring 2016 Lecture #12 April 20, 2016 EPSY 905: RM ANOVA, MANOVA, and Mixed Models
Repeated Measures ANOVA Multivariate ANOVA and Their Relationship to Linear Mixed Models EPSY 905: Multivariate Analysis Spring 2016 Lecture #12 April 20, 2016 EPSY 905: RM ANOVA, MANOVA, and Mixed Models
One-Way Repeated Measures Contrasts
 Chapter 44 One-Way Repeated easures Contrasts Introduction This module calculates the power of a test of a contrast among the means in a one-way repeated measures design using either the multivariate test
Chapter 44 One-Way Repeated easures Contrasts Introduction This module calculates the power of a test of a contrast among the means in a one-way repeated measures design using either the multivariate test
Using SPSS for One Way Analysis of Variance
 Using SPSS for One Way Analysis of Variance This tutorial will show you how to use SPSS version 12 to perform a one-way, between- subjects analysis of variance and related post-hoc tests. This tutorial
Using SPSS for One Way Analysis of Variance This tutorial will show you how to use SPSS version 12 to perform a one-way, between- subjects analysis of variance and related post-hoc tests. This tutorial
Chapter 19: Logistic regression
 Chapter 19: Logistic regression Self-test answers SELF-TEST Rerun this analysis using a stepwise method (Forward: LR) entry method of analysis. The main analysis To open the main Logistic Regression dialog
Chapter 19: Logistic regression Self-test answers SELF-TEST Rerun this analysis using a stepwise method (Forward: LR) entry method of analysis. The main analysis To open the main Logistic Regression dialog
Basic IRT Concepts, Models, and Assumptions
 Basic IRT Concepts, Models, and Assumptions Lecture #2 ICPSR Item Response Theory Workshop Lecture #2: 1of 64 Lecture #2 Overview Background of IRT and how it differs from CFA Creating a scale An introduction
Basic IRT Concepts, Models, and Assumptions Lecture #2 ICPSR Item Response Theory Workshop Lecture #2: 1of 64 Lecture #2 Overview Background of IRT and how it differs from CFA Creating a scale An introduction
Answer to exercise: Blood pressure lowering drugs
 Answer to exercise: Blood pressure lowering drugs The data set bloodpressure.txt contains data from a cross-over trial, involving three different formulations of a drug for lowering of blood pressure:
Answer to exercise: Blood pressure lowering drugs The data set bloodpressure.txt contains data from a cross-over trial, involving three different formulations of a drug for lowering of blood pressure:
Confidence Intervals for One-Way Repeated Measures Contrasts
 Chapter 44 Confidence Intervals for One-Way Repeated easures Contrasts Introduction This module calculates the expected width of a confidence interval for a contrast (linear combination) of the means in
Chapter 44 Confidence Intervals for One-Way Repeated easures Contrasts Introduction This module calculates the expected width of a confidence interval for a contrast (linear combination) of the means in
UNIVERSITY OF TORONTO Faculty of Arts and Science
 UNIVERSITY OF TORONTO Faculty of Arts and Science December 2013 Final Examination STA442H1F/2101HF Methods of Applied Statistics Jerry Brunner Duration - 3 hours Aids: Calculator Model(s): Any calculator
UNIVERSITY OF TORONTO Faculty of Arts and Science December 2013 Final Examination STA442H1F/2101HF Methods of Applied Statistics Jerry Brunner Duration - 3 hours Aids: Calculator Model(s): Any calculator
Logistic Regression. Continued Psy 524 Ainsworth
 Logistic Regression Continued Psy 524 Ainsworth Equations Regression Equation Y e = 1 + A+ B X + B X + B X 1 1 2 2 3 3 i A+ B X + B X + B X e 1 1 2 2 3 3 Equations The linear part of the logistic regression
Logistic Regression Continued Psy 524 Ainsworth Equations Regression Equation Y e = 1 + A+ B X + B X + B X 1 1 2 2 3 3 i A+ B X + B X + B X e 1 1 2 2 3 3 Equations The linear part of the logistic regression
Regression, Part I. - In correlation, it would be irrelevant if we changed the axes on our graph.
 Regression, Part I I. Difference from correlation. II. Basic idea: A) Correlation describes the relationship between two variables, where neither is independent or a predictor. - In correlation, it would
Regression, Part I I. Difference from correlation. II. Basic idea: A) Correlation describes the relationship between two variables, where neither is independent or a predictor. - In correlation, it would
Describing Change over Time: Adding Linear Trends
 Describing Change over Time: Adding Linear Trends Longitudinal Data Analysis Workshop Section 7 University of Georgia: Institute for Interdisciplinary Research in Education and Human Development Section
Describing Change over Time: Adding Linear Trends Longitudinal Data Analysis Workshop Section 7 University of Georgia: Institute for Interdisciplinary Research in Education and Human Development Section
Analysing categorical data using logit models
 Analysing categorical data using logit models Graeme Hutcheson, University of Manchester The lecture notes, exercises and data sets associated with this course are available for download from: www.research-training.net/manchester
Analysing categorical data using logit models Graeme Hutcheson, University of Manchester The lecture notes, exercises and data sets associated with this course are available for download from: www.research-training.net/manchester
Chapter 6. Logistic Regression. 6.1 A linear model for the log odds
 Chapter 6 Logistic Regression In logistic regression, there is a categorical response variables, often coded 1=Yes and 0=No. Many important phenomena fit this framework. The patient survives the operation,
Chapter 6 Logistic Regression In logistic regression, there is a categorical response variables, often coded 1=Yes and 0=No. Many important phenomena fit this framework. The patient survives the operation,
MITOCW ocw f99-lec17_300k
 MITOCW ocw-18.06-f99-lec17_300k OK, here's the last lecture in the chapter on orthogonality. So we met orthogonal vectors, two vectors, we met orthogonal subspaces, like the row space and null space. Now
MITOCW ocw-18.06-f99-lec17_300k OK, here's the last lecture in the chapter on orthogonality. So we met orthogonal vectors, two vectors, we met orthogonal subspaces, like the row space and null space. Now
Three Factor Completely Randomized Design with One Continuous Factor: Using SPSS GLM UNIVARIATE R. C. Gardner Department of Psychology
 Data_Analysis.calm Three Factor Completely Randomized Design with One Continuous Factor: Using SPSS GLM UNIVARIATE R. C. Gardner Department of Psychology This article considers a three factor completely
Data_Analysis.calm Three Factor Completely Randomized Design with One Continuous Factor: Using SPSS GLM UNIVARIATE R. C. Gardner Department of Psychology This article considers a three factor completely
A (Brief) Introduction to Crossed Random Effects Models for Repeated Measures Data
 Introduction to Crossed Random Effects Models for Repeated Measures Data") A (Brief) Introduction to Crossed Random Effects Models for Repeated Measures Data Today s Class: Review of concepts in multivariate data Introduction to random intercepts Crossed random effects models
A (Brief) Introduction to Crossed Random Effects Models for Repeated Measures Data Today s Class: Review of concepts in multivariate data Introduction to random intercepts Crossed random effects models
Ron Heck, Fall Week 3: Notes Building a Two-Level Model
 Ron Heck, Fall 2011 1 EDEP 768E: Seminar on Multilevel Modeling rev. 9/6/2011@11:27pm Week 3: Notes Building a Two-Level Model We will build a model to explain student math achievement using student-level
Ron Heck, Fall 2011 1 EDEP 768E: Seminar on Multilevel Modeling rev. 9/6/2011@11:27pm Week 3: Notes Building a Two-Level Model We will build a model to explain student math achievement using student-level
Analysis of Longitudinal Data: Comparison between PROC GLM and PROC MIXED.
 Analysis of Longitudinal Data: Comparison between PROC GLM and PROC MIXED. Maribeth Johnson, Medical College of Georgia, Augusta, GA ABSTRACT Longitudinal data refers to datasets with multiple measurements
Analysis of Longitudinal Data: Comparison between PROC GLM and PROC MIXED. Maribeth Johnson, Medical College of Georgia, Augusta, GA ABSTRACT Longitudinal data refers to datasets with multiple measurements
Categorical and Zero Inflated Growth Models
 Categorical and Zero Inflated Growth Models Alan C. Acock* Summer, 2009 *Alan C. Acock, Department of Human Development and Family Sciences, Oregon State University, Corvallis OR 97331 (alan.acock@oregonstate.edu).
Categorical and Zero Inflated Growth Models Alan C. Acock* Summer, 2009 *Alan C. Acock, Department of Human Development and Family Sciences, Oregon State University, Corvallis OR 97331 (alan.acock@oregonstate.edu).
Latent Growth Models 1
 1 We will use the dataset bp3, which has diastolic blood pressure measurements at four time points for 256 patients undergoing three types of blood pressure medication. These are our observed variables:
1 We will use the dataset bp3, which has diastolic blood pressure measurements at four time points for 256 patients undergoing three types of blood pressure medication. These are our observed variables:
Covariance Structure Approach to Within-Cases
 Covariance Structure Approach to Within-Cases Remember how the data file grapefruit1.data looks: Store sales1 sales2 sales3 1 62.1 61.3 60.8 2 58.2 57.9 55.1 3 51.6 49.2 46.2 4 53.7 51.5 48.3 5 61.4 58.7
Covariance Structure Approach to Within-Cases Remember how the data file grapefruit1.data looks: Store sales1 sales2 sales3 1 62.1 61.3 60.8 2 58.2 57.9 55.1 3 51.6 49.2 46.2 4 53.7 51.5 48.3 5 61.4 58.7
Review of Multilevel Models for Longitudinal Data
 Review of Multilevel Models for Longitudinal Data Topics: Concepts in longitudinal multilevel modeling Describing within-person fluctuation using ACS models Describing within-person change using random
Review of Multilevel Models for Longitudinal Data Topics: Concepts in longitudinal multilevel modeling Describing within-person fluctuation using ACS models Describing within-person change using random
Regression, part II. I. What does it all mean? A) Notice that so far all we ve done is math.
 Notice that so far all we ve done is math.") Regression, part II I. What does it all mean? A) Notice that so far all we ve done is math. 1) One can calculate the Least Squares Regression Line for anything, regardless of any assumptions. 2) But, if
Regression, part II I. What does it all mean? A) Notice that so far all we ve done is math. 1) One can calculate the Least Squares Regression Line for anything, regardless of any assumptions. 2) But, if
Ordinary Least Squares Regression Explained: Vartanian
 Ordinary Least Squares Regression Eplained: Vartanian When to Use Ordinary Least Squares Regression Analysis A. Variable types. When you have an interval/ratio scale dependent variable.. When your independent
Ordinary Least Squares Regression Eplained: Vartanian When to Use Ordinary Least Squares Regression Analysis A. Variable types. When you have an interval/ratio scale dependent variable.. When your independent
y response variable x 1, x 2,, x k -- a set of explanatory variables
 11. Multiple Regression and Correlation y response variable x 1, x 2,, x k -- a set of explanatory variables In this chapter, all variables are assumed to be quantitative. Chapters 12-14 show how to incorporate
11. Multiple Regression and Correlation y response variable x 1, x 2,, x k -- a set of explanatory variables In this chapter, all variables are assumed to be quantitative. Chapters 12-14 show how to incorporate
1 Quantitative Techniques in Practice
 1 Quantitative Techniques in Practice 1.1 Lecture 2: Stationarity, spurious regression, etc. 1.1.1 Overview In the rst part we shall look at some issues in time series economics. In the second part we
1 Quantitative Techniques in Practice 1.1 Lecture 2: Stationarity, spurious regression, etc. 1.1.1 Overview In the rst part we shall look at some issues in time series economics. In the second part we
This module focuses on the logic of ANOVA with special attention given to variance components and the relationship between ANOVA and regression.
 WISE ANOVA and Regression Lab Introduction to the WISE Correlation/Regression and ANOVA Applet This module focuses on the logic of ANOVA with special attention given to variance components and the relationship
WISE ANOVA and Regression Lab Introduction to the WISE Correlation/Regression and ANOVA Applet This module focuses on the logic of ANOVA with special attention given to variance components and the relationship
Glossary. The ISI glossary of statistical terms provides definitions in a number of different languages:
 Glossary The ISI glossary of statistical terms provides definitions in a number of different languages: http://isi.cbs.nl/glossary/index.htm Adjusted r 2 Adjusted R squared measures the proportion of the
Glossary The ISI glossary of statistical terms provides definitions in a number of different languages: http://isi.cbs.nl/glossary/index.htm Adjusted r 2 Adjusted R squared measures the proportion of the
Investigating Models with Two or Three Categories
 Ronald H. Heck and Lynn N. Tabata 1 Investigating Models with Two or Three Categories For the past few weeks we have been working with discriminant analysis. Let s now see what the same sort of model might
Ronald H. Heck and Lynn N. Tabata 1 Investigating Models with Two or Three Categories For the past few weeks we have been working with discriminant analysis. Let s now see what the same sort of model might
Time Invariant Predictors in Longitudinal Models
 Time Invariant Predictors in Longitudinal Models Longitudinal Data Analysis Workshop Section 9 University of Georgia: Institute for Interdisciplinary Research in Education and Human Development Section
Time Invariant Predictors in Longitudinal Models Longitudinal Data Analysis Workshop Section 9 University of Georgia: Institute for Interdisciplinary Research in Education and Human Development Section
Ch. 16: Correlation and Regression
 Ch. 1: Correlation and Regression With the shift to correlational analyses, we change the very nature of the question we are asking of our data. Heretofore, we were asking if a difference was likely to
Ch. 1: Correlation and Regression With the shift to correlational analyses, we change the very nature of the question we are asking of our data. Heretofore, we were asking if a difference was likely to
Statistical Practice. Selecting the Best Linear Mixed Model Under REML. Matthew J. GURKA
 Matthew J. GURKA Statistical Practice Selecting the Best Linear Mixed Model Under REML Restricted maximum likelihood (REML) estimation of the parameters of the mixed model has become commonplace, even
Matthew J. GURKA Statistical Practice Selecting the Best Linear Mixed Model Under REML Restricted maximum likelihood (REML) estimation of the parameters of the mixed model has become commonplace, even
Ling 289 Contingency Table Statistics
 Ling 289 Contingency Table Statistics Roger Levy and Christopher Manning This is a summary of the material that we ve covered on contingency tables. Contingency tables: introduction Odds ratios Counting,
Ling 289 Contingency Table Statistics Roger Levy and Christopher Manning This is a summary of the material that we ve covered on contingency tables. Contingency tables: introduction Odds ratios Counting,
2/26/2017. PSY 512: Advanced Statistics for Psychological and Behavioral Research 2
 PSY 512: Advanced Statistics for Psychological and Behavioral Research 2 When and why do we use logistic regression? Binary Multinomial Theory behind logistic regression Assessing the model Assessing predictors
PSY 512: Advanced Statistics for Psychological and Behavioral Research 2 When and why do we use logistic regression? Binary Multinomial Theory behind logistic regression Assessing the model Assessing predictors
Using Microsoft Excel
 Using Microsoft Excel Objective: Students will gain familiarity with using Excel to record data, display data properly, use built-in formulae to do calculations, and plot and fit data with linear functions.
Using Microsoft Excel Objective: Students will gain familiarity with using Excel to record data, display data properly, use built-in formulae to do calculations, and plot and fit data with linear functions.
1 A Review of Correlation and Regression
 1 A Review of Correlation and Regression SW, Chapter 12 Suppose we select n = 10 persons from the population of college seniors who plan to take the MCAT exam. Each takes the test, is coached, and then
1 A Review of Correlation and Regression SW, Chapter 12 Suppose we select n = 10 persons from the population of college seniors who plan to take the MCAT exam. Each takes the test, is coached, and then
Week 2 Video 4. Metrics for Regressors
 Week 2 Video 4 Metrics for Regressors Metrics for Regressors Linear Correlation MAE/RMSE Information Criteria Linear correlation (Pearson s correlation) r(a,b) = When A s value changes, does B change in
Week 2 Video 4 Metrics for Regressors Metrics for Regressors Linear Correlation MAE/RMSE Information Criteria Linear correlation (Pearson s correlation) r(a,b) = When A s value changes, does B change in
Path Analysis. PRE 906: Structural Equation Modeling Lecture #5 February 18, PRE 906, SEM: Lecture 5 - Path Analysis
 Path Analysis PRE 906: Structural Equation Modeling Lecture #5 February 18, 2015 PRE 906, SEM: Lecture 5 - Path Analysis Key Questions for Today s Lecture What distinguishes path models from multivariate
Path Analysis PRE 906: Structural Equation Modeling Lecture #5 February 18, 2015 PRE 906, SEM: Lecture 5 - Path Analysis Key Questions for Today s Lecture What distinguishes path models from multivariate
Fixed effects results...32
 1 MODELS FOR CONTINUOUS OUTCOMES...7 1.1 MODELS BASED ON A SUBSET OF THE NESARC DATA...7 1.1.1 The data...7 1.1.1.1 Importing the data and defining variable types...8 1.1.1.2 Exploring the data...12 Univariate
1 MODELS FOR CONTINUOUS OUTCOMES...7 1.1 MODELS BASED ON A SUBSET OF THE NESARC DATA...7 1.1.1 The data...7 1.1.1.1 Importing the data and defining variable types...8 1.1.1.2 Exploring the data...12 Univariate
Correlation & Simple Regression
 Chapter 11 Correlation & Simple Regression The previous chapter dealt with inference for two categorical variables. In this chapter, we would like to examine the relationship between two quantitative variables.
Chapter 11 Correlation & Simple Regression The previous chapter dealt with inference for two categorical variables. In this chapter, we would like to examine the relationship between two quantitative variables.
Introduction to SAS proc mixed
 Faculty of Health Sciences Introduction to SAS proc mixed Analysis of repeated measurements, 2017 Julie Forman Department of Biostatistics, University of Copenhagen 2 / 28 Preparing data for analysis The
Faculty of Health Sciences Introduction to SAS proc mixed Analysis of repeated measurements, 2017 Julie Forman Department of Biostatistics, University of Copenhagen 2 / 28 Preparing data for analysis The
STAT 3900/4950 MIDTERM TWO Name: Spring, 2015 (print: first last ) Covered topics: Two-way ANOVA, ANCOVA, SLR, MLR and correlation analysis
 Covered topics: Two-way ANOVA, ANCOVA, SLR, MLR and correlation analysis") STAT 3900/4950 MIDTERM TWO Name: Spring, 205 (print: first last ) Covered topics: Two-way ANOVA, ANCOVA, SLR, MLR and correlation analysis Instructions: You may use your books, notes, and SPSS/SAS. NO
STAT 3900/4950 MIDTERM TWO Name: Spring, 205 (print: first last ) Covered topics: Two-way ANOVA, ANCOVA, SLR, MLR and correlation analysis Instructions: You may use your books, notes, and SPSS/SAS. NO
CRP 272 Introduction To Regression Analysis
 CRP 272 Introduction To Regression Analysis 30 Relationships Among Two Variables: Interpretations One variable is used to explain another variable X Variable Independent Variable Explaining Variable Exogenous
CRP 272 Introduction To Regression Analysis 30 Relationships Among Two Variables: Interpretations One variable is used to explain another variable X Variable Independent Variable Explaining Variable Exogenous
Midterm 2 - Solutions
 Ecn 102 - Analysis of Economic Data University of California - Davis February 23, 2010 Instructor: John Parman Midterm 2 - Solutions You have until 10:20am to complete this exam. Please remember to put
Ecn 102 - Analysis of Economic Data University of California - Davis February 23, 2010 Instructor: John Parman Midterm 2 - Solutions You have until 10:20am to complete this exam. Please remember to put
Data Analysis and Statistical Methods Statistics 651
 Data Analysis and Statistical Methods Statistics 651 http://www.stat.tamu.edu/~suhasini/teaching.html Suhasini Subba Rao Motivations for the ANOVA We defined the F-distribution, this is mainly used in
Data Analysis and Statistical Methods Statistics 651 http://www.stat.tamu.edu/~suhasini/teaching.html Suhasini Subba Rao Motivations for the ANOVA We defined the F-distribution, this is mainly used in
Modeling the Covariance
 Modeling the Covariance Jamie Monogan University of Georgia February 3, 2016 Jamie Monogan (UGA) Modeling the Covariance February 3, 2016 1 / 16 Objectives By the end of this meeting, participants should
Modeling the Covariance Jamie Monogan University of Georgia February 3, 2016 Jamie Monogan (UGA) Modeling the Covariance February 3, 2016 1 / 16 Objectives By the end of this meeting, participants should
Discrete Structures Proofwriting Checklist
 CS103 Winter 2019 Discrete Structures Proofwriting Checklist Cynthia Lee Keith Schwarz Now that we re transitioning to writing proofs about discrete structures like binary relations, functions, and graphs,
CS103 Winter 2019 Discrete Structures Proofwriting Checklist Cynthia Lee Keith Schwarz Now that we re transitioning to writing proofs about discrete structures like binary relations, functions, and graphs,
t-test for b Copyright 2000 Tom Malloy. All rights reserved. Regression
 t-test for b Copyright 2000 Tom Malloy. All rights reserved. Regression Recall, back some time ago, we used a descriptive statistic which allowed us to draw the best fit line through a scatter plot. We
t-test for b Copyright 2000 Tom Malloy. All rights reserved. Regression Recall, back some time ago, we used a descriptive statistic which allowed us to draw the best fit line through a scatter plot. We
Black White Total Observed Expected χ 2 = (f observed f expected ) 2 f expected (83 126) 2 ( )2 126
 2 f expected (83 126) 2 ( )2 126") Psychology 60 Fall 2013 Practice Final Actual Exam: This Wednesday. Good luck! Name: To view the solutions, check the link at the end of the document. This practice final should supplement your studying;
Psychology 60 Fall 2013 Practice Final Actual Exam: This Wednesday. Good luck! Name: To view the solutions, check the link at the end of the document. This practice final should supplement your studying;
Basic Statistics Exercises 66
 Basic Statistics Exercises 66 42. Suppose we are interested in predicting a person's height from the person's length of stride (distance between footprints). The following data is recorded for a random
Basic Statistics Exercises 66 42. Suppose we are interested in predicting a person's height from the person's length of stride (distance between footprints). The following data is recorded for a random
Time-Invariant Predictors in Longitudinal Models
 Time-Invariant Predictors in Longitudinal Models Today s Topics: What happens to missing predictors Effects of time-invariant predictors Fixed vs. systematically varying vs. random effects Model building
Time-Invariant Predictors in Longitudinal Models Today s Topics: What happens to missing predictors Effects of time-invariant predictors Fixed vs. systematically varying vs. random effects Model building