Introduction to Machine Learning Eran Halperin, Yishay Mansour, Lior Wolf Lecture 13: Applications
|
|
|
- Amos Lindsey
- 6 years ago
- Views:
Transcription
1 Introduction to Machine Learning Eran Halperin, Yishay Mansour, Lior Wolf Lecture 13: Applications


2 Today Similarity learning ROC curves Probabilistic graphicsl models Neural Networks

3

4
5
6
7

8
9

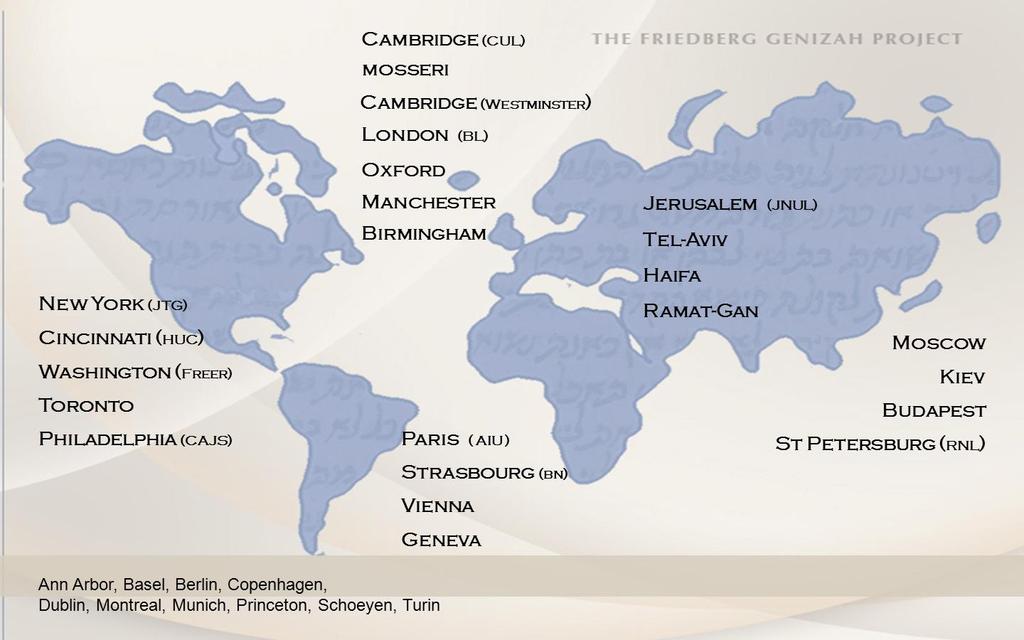
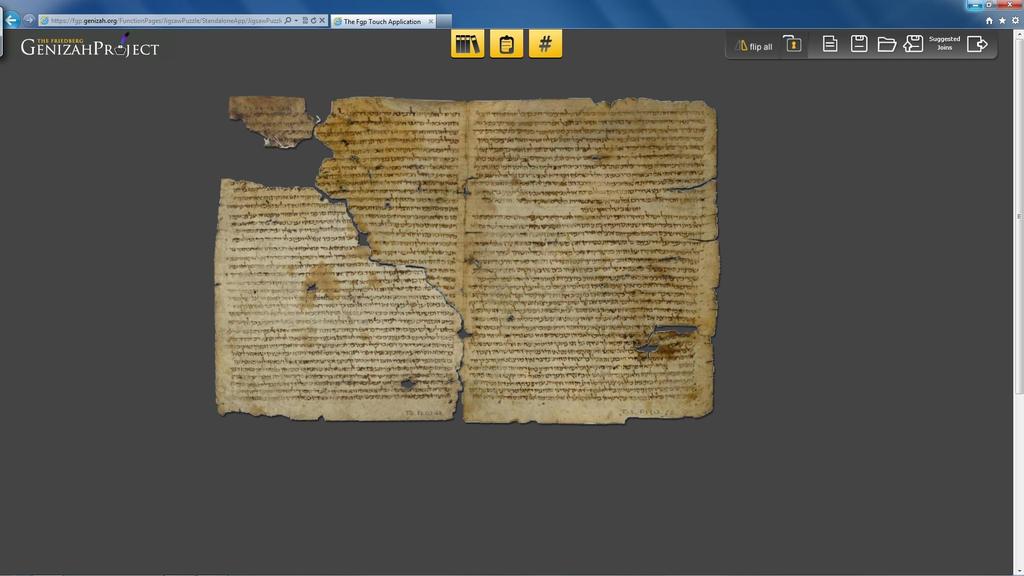
10 Cairo Genizah a collection containing ~250,000 fragments of mainly Jewish texts discovered in the late 19th century discarded codices, scrolls, and documents, written mainly in the 10th to 15th centuries spread out in tens of libraries and private collections worldwide enormous impact on 20th century scholarship in a multitude of fields
 Adler, Elkan Nathan Catalogue of Hebrew Manuscripts")

, 1954 Halper, Benzion Descriptive")
 Neubauer, Adolf,")

, pp. 107-119, 267-277; LXIII (1911), pp.")
, New York Wickersheimer, Ernest")
11 Basic notion: join A join is a set of manuscriptfragments that are known to originate from the same original work. Known joins are documented in catalogs Catalogs (very partial list) Adler, Elkan Nathan Catalogue of Hebrew Manuscripts in the Collection of Elkan Nathan Adler., Cambridge, 1921 Cowley, Arthur Ernest Photocopy of Unpublished Typescript Catalogue of the Hebrew Manuscripts in the Bodleian Library Gottstein, M.H. "Hebrew Fragments in the Mingana Collection," Journal of Jewish Studies V (1954), 1954 Halper, Benzion Descriptive catalogue of Genizah fragments in Philadelphia, Philadelphia, 1924 Lutzki, Morris Catalogue of Biblical Manuscripts in the Library of the Jewish Theological Seminary, Photocopy of Unpublished Typescript (New York: JTS) Neubauer, Adolf, Cowley, Arthur Ernest Catalogue of the Hebrew Manuscripts in the Bodleian Library, Vol. II, Oxford, Reif, Stefan C. Hebrew manuscripts at Cambridge University Library, Cambridge, 1997 Schwab, Moise "Les Manuscrits du Consistoire Israelite de Paris Provenant de la Gueniza du Caire," REJ LXII (1911), pp , ; LXIII (1911), pp , ; LXIV (1912), pp ,., Schwarz, A.Z., Loewinger D.S. and Roth E. Die hebraieschen handschriften in Oesterreich (ausserhalb der Nationalbibliothek in Wien), New York Wickersheimer, Ernest Catalogue général des manuscrits des bibliothèques publiques de France. Départements, Tome XLVII : Strasbourg, Paris, 1923 Worman, E.J. Hand-list of pieces in Glass of thetayler-schechter Collection. Photocopy of Unpublished Handwriting Worrell, William Hoyt, Gottheill, Richard James Horatio Entries

12 Preprocessing the images Foreground segmentation Ruller removal Line detection Image alignment Character detection Character description Vectorization
13 Similarity computation Take 2 vectors (v 1,v 2 ) return a similarity value 12. Ideally, the is a threshold such that 12 > q join 12 < q not a join Sim (, ) Methods used: L2 distance of vectors L1 distance of vectors Hellinger norm SVM of vector of absolute differences w a b i i i i OneShot Similarity (ECCVLFW 08,ICCV 09)
 Step b: Score1 = classify(q, Model1) Step c: Model2 =")
 /2")
14 Computing the One-Shot Similarity Step a: Model1 = train (p, A) Step b: Score1 = classify(q, Model1) Step c: Model2 = train (q, A) Step d: Score2 = classify(p, Model1) Set A of negative examples One-Shot-Sim = (score1 + score2) /2 Similarity
15 Properties of the 1-shot similarity Using LDA as the underlying classifier: 1. It is a PD kernel (actually Consitionally PD) 2. It can be efficiently computed 3. It has a half-explicit embedding: k(x 1,x 2 ) = ψ(x 1 ) T φ(x 2 )
16 Adding metric learning Using LDA as the underlying classifier: 2 ) ( 2 ) ( ),, OSS( A j i W T A j A i j W T A i j i x x S x x x S x A x x 2 0 not same ML same ML ),,, ( OSS ),,, ( OSS ) ( T T A T x x A T x x T f j i j i Instead of examples x i use Tx i, obtaining T by a gradient decent procedure, optimizing the score:

 Join Sim")
 (b) (c)")



 to")

17 From similarity to decision Sim (, ) Join Sim (, ) = 1 = 2 (a) (b) (c) Compute global descr. for images Measure descr. Similarity Train classifier (e.g., SVM) to threshold join from not-join Not join Sim (, ) Sim (, ) = i = i+1
18 Multi similarities/vectors/descriptors Join Training set Training ( 1,1, 1,2,, 1,n ) ( 2,1, 2,2,, 2,n ) Train with a vector of similarity values Combine with SVM Not join ( i,1, i,2,, i,n ) ( i+1,1, i+1,2,, i+1,n )
19 Combining similarities
20 Original slide credit: Darlene Goldstein True label vs. classifier result classifier Prediction=-1 Real label No disease (D = -1) True negative Disease (D = +1) X Miss Prediction=1 X False positive True positive


21 Original slide credit: Darlene Goldstein Specific Example Pts without the disease Pts with disease Test Result
22 Original slide credit: Darlene Goldstein Threshold Call these patients negative Call these patients positive Test Result
23 Some definitions... Call these patients negative Call these patients positive True Positives Test Result without the disease with the disease Original slide credit: Darlene Goldstein
24 Call these patients negative Call these patients positive without the disease with the disease Test Result False Positives Original slide credit: Darlene Goldstein
25 Call these patients negative Call these patients positive True negatives Test Result without the disease with the disease Original slide credit: Darlene Goldstein
26 Call these patients negative Call these patients positive False negatives Test Result without the disease with the disease Original slide credit: Darlene Goldstein
27 Moving the Threshold: right - + Test Result without the disease with the disease Original slide credit: Darlene Goldstein
28 Moving the Threshold: left - + Test Result without the disease with the disease Original slide credit: Darlene Goldstein
29 True Positive Rate Original slide credit: Darlene Goldstein ROC curve 100% 0% 0% 100% False Positive Rate
30 True Positive Rate True Positive Rate ROC curve comparison A good classifier: A poor classifier: 100% 100% 0 % 0 % False Positive Rate 100% 0 % 0 % False Positive Rate 100%
31 True Positive Rate True Positive Rate ROC curve extremes Best Classifier: Worst Classifier: 100% 100% 0 % 0 % False Positive Rate 100 % 0 % 0 % False Positive Rate 100 % The distributions don t overlap at all The distributions overlap completely

32 Combining similarities

 in judeo-arabic Geneva New")
33 Example of our discoveries: Lost halakhic monograph of Rav Saadya Gaon (10 cent.) in judeo-arabic Geneva New York
34

35 Sorting face albums a collection containing ~250,000 fragments of mainly Jewish texts discovered in the late 19th century discarded codices, scrolls, and documents, written mainly in the 10th to 15th centuries. by now mostly fragmented pages, spread out in tens of libraries and private collections worldwide

36 Sorting face albums Large scale Unknown number of clusters Some clusters are huge Many small clusters and singletons Pairwise similarities are noisy and misleading Conventional algorithms would fail Commercial solutions?




 hi lij")
37 Clustering via Graphical Models The variables to be inferred are: hi face attributes lij grouping variables (0/1) hi lij lik hk ljk hj
38 Clustering via Probabilistic Graphical Models The variables to be inferred are: hi face attributes χijk lij grouping variables (0/1) The factors: ξi(hi) attribute distributions ψij(hi,hj,lij) pairwise compatibility in attr. γij,φij lij lik γik,φik ljk γjk,φjk γij(lij) visual similarity φij(lij) non visual similarity χijk(lij,lik,ljk) transitivity constraints ξi hi ψij ψik hj ψjk hk ξk ξj
39
40 word2vec Natural Language Processing (NLP) Learned from a large corpus Employs a Neural Network for learning vector representations of words



41 +1 Andrew Ng Logistic regression Logistic regression learns a parameter vector q. On input x, it outputs: x 1 x 2 x 3
42 Neural Network Example 4 layer network with 2 output units: x 1 x 2 x Layer 1 Layer 2 +1 Layer 3 Trained via gradient descent. Backpropagation algorithm. (Susceptible to local optima) Layer 4 Andrew Ng



43 CBOW Architecture In the beginning God created the heaven and the earth. And the earth was without form, and void; and darkness was upon the face of the deep. And the Spirit of God moved upon the face of the waters. And God said, Let there be light: and there was light. And God saw the light, that it was good: and God divided the light from the darkness. Input Layer Hidden Layer Output Layer Huffman code of Spirit

44 word2vec variants Continuous Bag-of-Words Architecture Skip-gram Architecture Predicts the current word given the context Predicts the surrounding words given the current word
45 word2vec Semantic and additive Surprising regularities emerge King-Man+Woman~Queen France+Capital~Paris

46
47

48 Sentiment Analysis unbelievably disappointing Full of zany characters and richly applied satire, and some great plot twists This is the greatest screwball comedy ever filmed It was pathetic. The worst part about it was the boxing scenes. Original slides by Yackov Lubarsky
49 Why Hard? Subtlety: Perfume review in Perfumes: the Guide: If you are reading this because it is your darling fragrance, please wear it at home exclusively, and tape the windows shut. Dorothy Parker on Katherine Hepburn She runs the gamut of emotions from A to B
50 Why Hard? Thwarted Expectations and Ordering Effects This film should be brilliant. It sounds like a great plot, the actors are first grade, and the supporting cast is good as well, and Stallone is attempting to deliver a good performance. However, it can t hold up. Well as usual Keanu Reeves is nothing special, but surprisingly, the very talented Laurence Fishbourne is not so good either, I was surprised.
51 Standard Approaches Bag of Words features Semantic Vector Spaces While enjoyable in spots, 'The Dark World' is haphazard and ultimately unsatisfying. He feels for his subject matter, no doubt, but every once in a while it feels like he falls short on imagination and takes a short cut to move his story forward. Standard approaches ignore phrase compositions
52 Compositionality Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher Manning, Andrew Ng and Christopher Potts. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. Conference on Empirical Methods in Natural Language Processing (EMNLP 2013)
53 Stanford Sentiment Treebank 10,662 sentences from rottentomatoes.com movie reviews Parsed using Stanford Parser to create parse trees 215,154 unique phrases Sentiment classified using Amazon Mechanical Turk 3 judges per phrase


54 Treebank Sentiment Value Short n-grams are mostly neutral Extreme values or mid-tick are rarely used 5-class classification is enough
55 Recursive Neural Models Compositional vector representations for phrases of variable length. Each word/phrase is represented by a vector These vectors are used as features for calculating combined sentiment
56 Recursive Neural Network Word/Phrase vectors a, b, c, p i R d Word embedding matrix L R dx V Classification y a = softmax(w s a) W s R Cxd L, W s are trained parameters What about p i?
57 Recursive Neural Network p 1 = f W b c, p 2 = f W a p 1 W R dx2d is a trained parameter f is usually tanh
58 MV-RNN: Matrix-Vector RNN Composition function depends on words/phrases being combined p 1 = f W Cb Bc B P 1 = f W M C W R dx2d, W M R dx2d W, W M, P i, A, B, C, are trained Number of parameters depends on V
59 Sentiment Prediction Accuracy for fine grained (5-class) and binary predictions at the sentence level (Root) and at all nodes

60 Most Positive/Negative
Adaptive Multi-Compositionality for Recursive Neural Models with Applications to Sentiment Analysis. July 31, 2014
 Adaptive Multi-Compositionality for Recursive Neural Models with Applications to Sentiment Analysis July 31, 2014 Semantic Composition Principle of Compositionality The meaning of a complex expression
Adaptive Multi-Compositionality for Recursive Neural Models with Applications to Sentiment Analysis July 31, 2014 Semantic Composition Principle of Compositionality The meaning of a complex expression
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Deep Learning for Natural Language Processing. Sidharth Mudgal April 4, 2017
 Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Deep Learning For Mathematical Functions
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Online Videos FERPA. Sign waiver or sit on the sides or in the back. Off camera question time before and after lecture. Questions?
 Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Semantics with Dense Vectors. Reference: D. Jurafsky and J. Martin, Speech and Language Processing
 Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
text classification 3: neural networks
 text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
Neural Networks for NLP. COMP-599 Nov 30, 2016
 Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM
![a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM](/thumbs/92/107948882.jpg "a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM") c 1. (Natural Language Processing; NLP) (Deep Learning) RGB IBM 135 8511 5 6 52 yutat@jp.ibm.com a) b) 2. 1 0 2 1 Bag of words White House 2 [1] 2015 4 Copyright c by ORSJ. Unauthorized reproduction of
c 1. (Natural Language Processing; NLP) (Deep Learning) RGB IBM 135 8511 5 6 52 yutat@jp.ibm.com a) b) 2. 1 0 2 1 Bag of words White House 2 [1] 2015 4 Copyright c by ORSJ. Unauthorized reproduction of
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam
 CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
Deep Learning for NLP Part 2
 Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
word2vec Parameter Learning Explained
 word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop
 Different descriptions and viewpoints of backprop") Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop Project Tips Announcement: Hint for PSet1: Understand
Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop Project Tips Announcement: Hint for PSet1: Understand
Regularization Introduction to Machine Learning. Matt Gormley Lecture 10 Feb. 19, 2018
 1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
Probability Review and Naïve Bayes
 Probability Review and Naïve Bayes Instructor: Alan Ritter Some slides adapted from Dan Jurfasky and Brendan O connor What is Probability? The probability the coin will land heads is 0.5 Q: what does this
Probability Review and Naïve Bayes Instructor: Alan Ritter Some slides adapted from Dan Jurfasky and Brendan O connor What is Probability? The probability the coin will land heads is 0.5 Q: what does this
DISTRIBUTIONAL SEMANTICS
 COMP90042 LECTURE 4 DISTRIBUTIONAL SEMANTICS LEXICAL DATABASES - PROBLEMS Manually constructed Expensive Human annotation can be biased and noisy Language is dynamic New words: slangs, terminology, etc.
COMP90042 LECTURE 4 DISTRIBUTIONAL SEMANTICS LEXICAL DATABASES - PROBLEMS Manually constructed Expensive Human annotation can be biased and noisy Language is dynamic New words: slangs, terminology, etc.
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287
 Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
CS230: Lecture 8 Word2Vec applications + Recurrent Neural Networks with Attention
 CS23: Lecture 8 Word2Vec applications + Recurrent Neural Networks with Attention Today s outline We will learn how to: I. Word Vector Representation i. Training - Generalize results with word vectors -
CS23: Lecture 8 Word2Vec applications + Recurrent Neural Networks with Attention Today s outline We will learn how to: I. Word Vector Representation i. Training - Generalize results with word vectors -
Probabilistic Graphical Models: MRFs and CRFs. CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov
 Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Lecture 6: Neural Networks for Representing Word Meaning
 Lecture 6: Neural Networks for Representing Word Meaning Mirella Lapata School of Informatics University of Edinburgh mlap@inf.ed.ac.uk February 7, 2017 1 / 28 Logistic Regression Input is a feature vector,
Lecture 6: Neural Networks for Representing Word Meaning Mirella Lapata School of Informatics University of Edinburgh mlap@inf.ed.ac.uk February 7, 2017 1 / 28 Logistic Regression Input is a feature vector,
Natural Language Processing
 Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
Introduction to Machine Learning. Introduction to ML - TAU 2016/7 1
 Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Introduction to Machine Learning Introduction to ML - TAU 2016/7 1 Course Administration Lecturers: Amir Globerson (gamir@post.tau.ac.il) Yishay Mansour (Mansour@tau.ac.il) Teaching Assistance: Regev Schweiger
Uncertainty in prediction. Can we usually expect to get a perfect classifier, if we have enough training data?
 Logistic regression Uncertainty in prediction Can we usually expect to get a perfect classifier, if we have enough training data? Uncertainty in prediction Can we usually expect to get a perfect classifier,
Logistic regression Uncertainty in prediction Can we usually expect to get a perfect classifier, if we have enough training data? Uncertainty in prediction Can we usually expect to get a perfect classifier,
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Deep Learning for NLP
 Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
11/3/15. Deep Learning for NLP. Deep Learning and its Architectures. What is Deep Learning? Advantages of Deep Learning (Part 1)
") 11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
Statistical NLP for the Web
 Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
9/12/17. Types of learning. Modeling data. Supervised learning: Classification. Supervised learning: Regression. Unsupervised learning: Clustering
 Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Types of learning Modeling data Supervised: we know input and targets Goal is to learn a model that, given input data, accurately predicts target data Unsupervised: we know the input only and want to make
Introduction to Machine Learning Midterm Exam
 10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels
 SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
Logistic regression for conditional probability estimation
 Logistic regression for conditional probability estimation Instructor: Taylor Berg-Kirkpatrick Slides: Sanjoy Dasgupta Course website: http://cseweb.ucsd.edu/classes/wi19/cse151-b/ Uncertainty in prediction
Logistic regression for conditional probability estimation Instructor: Taylor Berg-Kirkpatrick Slides: Sanjoy Dasgupta Course website: http://cseweb.ucsd.edu/classes/wi19/cse151-b/ Uncertainty in prediction
hsnim: Hyper Scalable Network Inference Machine for Scale-Free Protein-Protein Interaction Networks Inference
 CS 229 Project Report (TR# MSB2010) Submitted 12/10/2010 hsnim: Hyper Scalable Network Inference Machine for Scale-Free Protein-Protein Interaction Networks Inference Muhammad Shoaib Sehgal Computer Science
CS 229 Project Report (TR# MSB2010) Submitted 12/10/2010 hsnim: Hyper Scalable Network Inference Machine for Scale-Free Protein-Protein Interaction Networks Inference Muhammad Shoaib Sehgal Computer Science
Homework 3 COMS 4705 Fall 2017 Prof. Kathleen McKeown
 Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Spatial Transformer. Ref: Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu, Spatial Transformer Networks, NIPS, 2015
 Spatial Transormer Re: Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu, Spatial Transormer Networks, NIPS, 2015 Spatial Transormer Layer CNN is not invariant to scaling and rotation
Spatial Transormer Re: Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu, Spatial Transormer Networks, NIPS, 2015 Spatial Transormer Layer CNN is not invariant to scaling and rotation
An overview of word2vec
 An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
Natural Language Processing and Recurrent Neural Networks
 Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Supervised Learning. George Konidaris
 Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Instructions for NLP Practical (Units of Assessment) SVM-based Sentiment Detection of Reviews (Part 2)
 SVM-based Sentiment Detection of Reviews (Part 2)") Instructions for NLP Practical (Units of Assessment) SVM-based Sentiment Detection of Reviews (Part 2) Simone Teufel (Lead demonstrator Guy Aglionby) sht25@cl.cam.ac.uk; ga384@cl.cam.ac.uk This is the
Instructions for NLP Practical (Units of Assessment) SVM-based Sentiment Detection of Reviews (Part 2) Simone Teufel (Lead demonstrator Guy Aglionby) sht25@cl.cam.ac.uk; ga384@cl.cam.ac.uk This is the
Deep Learning for NLP
 Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Final Overview. Introduction to ML. Marek Petrik 4/25/2017
 Final Overview Introduction to ML Marek Petrik 4/25/2017 This Course: Introduction to Machine Learning Build a foundation for practice and research in ML Basic machine learning concepts: max likelihood,
Final Overview Introduction to ML Marek Petrik 4/25/2017 This Course: Introduction to Machine Learning Build a foundation for practice and research in ML Basic machine learning concepts: max likelihood,
Probabilistic Machine Learning. Industrial AI Lab.
 Probabilistic Machine Learning Industrial AI Lab. Probabilistic Linear Regression Outline Probabilistic Classification Probabilistic Clustering Probabilistic Dimension Reduction 2 Probabilistic Linear
Probabilistic Machine Learning Industrial AI Lab. Probabilistic Linear Regression Outline Probabilistic Classification Probabilistic Clustering Probabilistic Dimension Reduction 2 Probabilistic Linear
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Neural Networks: Introduction
 Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
ATASS: Word Embeddings
 ATASS: Word Embeddings Lee Gao April 22th, 2016 Guideline Bag-of-words (bag-of-n-grams) Today High dimensional, sparse representation dimension reductions LSA, LDA, MNIR Neural networks Backpropagation
ATASS: Word Embeddings Lee Gao April 22th, 2016 Guideline Bag-of-words (bag-of-n-grams) Today High dimensional, sparse representation dimension reductions LSA, LDA, MNIR Neural networks Backpropagation
Multi-theme Sentiment Analysis using Quantified Contextual
 Multi-theme Sentiment Analysis using Quantified Contextual Valence Shifters Hongkun Yu, Jingbo Shang, MeichunHsu, Malú Castellanos, Jiawei Han Presented by Jingbo Shang University of Illinois at Urbana-Champaign
Multi-theme Sentiment Analysis using Quantified Contextual Valence Shifters Hongkun Yu, Jingbo Shang, MeichunHsu, Malú Castellanos, Jiawei Han Presented by Jingbo Shang University of Illinois at Urbana-Champaign
A Survey of Techniques for Sentiment Analysis in Movie Reviews and Deep Stochastic Recurrent Nets
 A Survey of Techniques for Sentiment Analysis in Movie Reviews and Deep Stochastic Recurrent Nets Chase Lochmiller Department of Computer Science Stanford University cjloch11@stanford.edu Abstract In this
A Survey of Techniques for Sentiment Analysis in Movie Reviews and Deep Stochastic Recurrent Nets Chase Lochmiller Department of Computer Science Stanford University cjloch11@stanford.edu Abstract In this
Bayesian Paragraph Vectors
 Bayesian Paragraph Vectors Geng Ji 1, Robert Bamler 2, Erik B. Sudderth 1, and Stephan Mandt 2 1 Department of Computer Science, UC Irvine, {gji1, sudderth}@uci.edu 2 Disney Research, firstname.lastname@disneyresearch.com
Bayesian Paragraph Vectors Geng Ji 1, Robert Bamler 2, Erik B. Sudderth 1, and Stephan Mandt 2 1 Department of Computer Science, UC Irvine, {gji1, sudderth}@uci.edu 2 Disney Research, firstname.lastname@disneyresearch.com
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
CS534 Machine Learning - Spring Final Exam
 CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
CS534 Machine Learning - Spring 2013 Final Exam Name: You have 110 minutes. There are 6 questions (8 pages including cover page). If you get stuck on one question, move on to others and come back to the
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Long-Short Term Memory and Other Gated RNNs
 Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Long-Short Term Memory and Other Gated RNNs Sargur Srihari srihari@buffalo.edu This is part of lecture slides on Deep Learning: http://www.cedar.buffalo.edu/~srihari/cse676 1 Topics in Sequence Modeling
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
(COM4513/6513) Week 1. Nikolaos Aletras ( Department of Computer Science University of Sheffield
 Week 1. Nikolaos Aletras ( Department of Computer Science University of Sheffield") Natural Language Processing (COM4513/6513) Week 1 Part II: Text classification with the perceptron Nikolaos Aletras (http://www.nikosaletras.com) n.aletras@sheffield.ac.uk Department of Computer Science
Natural Language Processing (COM4513/6513) Week 1 Part II: Text classification with the perceptron Nikolaos Aletras (http://www.nikosaletras.com) n.aletras@sheffield.ac.uk Department of Computer Science
Sequence Modeling with Neural Networks
 Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Asaf Bar Zvi Adi Hayat. Semantic Segmentation
 Asaf Bar Zvi Adi Hayat Semantic Segmentation Today s Topics Fully Convolutional Networks (FCN) (CVPR 2015) Conditional Random Fields as Recurrent Neural Networks (ICCV 2015) Gaussian Conditional random
Asaf Bar Zvi Adi Hayat Semantic Segmentation Today s Topics Fully Convolutional Networks (FCN) (CVPR 2015) Conditional Random Fields as Recurrent Neural Networks (ICCV 2015) Gaussian Conditional random
Introduction to Machine Learning Midterm Exam Solutions
 10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
10-701 Introduction to Machine Learning Midterm Exam Solutions Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes,
Final Exam, Machine Learning, Spring 2009
 Name: Andrew ID: Final Exam, 10701 Machine Learning, Spring 2009 - The exam is open-book, open-notes, no electronics other than calculators. - The maximum possible score on this exam is 100. You have 3
Name: Andrew ID: Final Exam, 10701 Machine Learning, Spring 2009 - The exam is open-book, open-notes, no electronics other than calculators. - The maximum possible score on this exam is 100. You have 3
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
Behavioral Data Mining. Lecture 2
 Behavioral Data Mining Lecture 2 Autonomy Corp Bayes Theorem Bayes Theorem P(A B) = probability of A given that B is true. P(A B) = P(B A)P(A) P(B) In practice we are most interested in dealing with events
Behavioral Data Mining Lecture 2 Autonomy Corp Bayes Theorem Bayes Theorem P(A B) = probability of A given that B is true. P(A B) = P(B A)P(A) P(B) In practice we are most interested in dealing with events
Bag of Words Meets Bags of Popcorn
 Sentiment Analysis via and Natural Language Processing Tarleton State University July 16, 2015 Data Description Sentiment Score tf-idf NDSI AFINN List word score invincible 2 mirthful 3 flops -2 hypocritical
Sentiment Analysis via and Natural Language Processing Tarleton State University July 16, 2015 Data Description Sentiment Score tf-idf NDSI AFINN List word score invincible 2 mirthful 3 flops -2 hypocritical
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
ML4NLP Multiclass Classification
 ML4NLP Multiclass Classification CS 590NLP Dan Goldwasser Purdue University dgoldwas@purdue.edu Social NLP Last week we discussed the speed-dates paper. Interesting perspective on NLP problems- Can we
ML4NLP Multiclass Classification CS 590NLP Dan Goldwasser Purdue University dgoldwas@purdue.edu Social NLP Last week we discussed the speed-dates paper. Interesting perspective on NLP problems- Can we
CME323 Distributed Algorithms and Optimization. GloVe on Spark. Alex Adamson SUNet ID: aadamson. June 6, 2016
 GloVe on Spark Alex Adamson SUNet ID: aadamson June 6, 2016 Introduction Pennington et al. proposes a novel word representation algorithm called GloVe (Global Vectors for Word Representation) that synthesizes
GloVe on Spark Alex Adamson SUNet ID: aadamson June 6, 2016 Introduction Pennington et al. proposes a novel word representation algorithm called GloVe (Global Vectors for Word Representation) that synthesizes
CSC321 Lecture 16: ResNets and Attention
 CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
Prepositional Phrase Attachment over Word Embedding Products
 Prepositional Phrase Attachment over Word Embedding Products Pranava Madhyastha (1), Xavier Carreras (2), Ariadna Quattoni (2) (1) University of Sheffield (2) Naver Labs Europe Prepositional Phrases I
Prepositional Phrase Attachment over Word Embedding Products Pranava Madhyastha (1), Xavier Carreras (2), Ariadna Quattoni (2) (1) University of Sheffield (2) Naver Labs Europe Prepositional Phrases I
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Natural Language Processing with Deep Learning CS224N/Ling284. Richard Socher Lecture 2: Word Vectors
 Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
Discriminative Direction for Kernel Classifiers
 Discriminative Direction for Kernel Classifiers Polina Golland Artificial Intelligence Lab Massachusetts Institute of Technology Cambridge, MA 02139 polina@ai.mit.edu Abstract In many scientific and engineering
Discriminative Direction for Kernel Classifiers Polina Golland Artificial Intelligence Lab Massachusetts Institute of Technology Cambridge, MA 02139 polina@ai.mit.edu Abstract In many scientific and engineering
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Structured Neural Networks (I)
") Structured Neural Networks (I) CS 690N, Spring 208 Advanced Natural Language Processing http://peoplecsumassedu/~brenocon/anlp208/ Brendan O Connor College of Information and Computer Sciences University
Structured Neural Networks (I) CS 690N, Spring 208 Advanced Natural Language Processing http://peoplecsumassedu/~brenocon/anlp208/ Brendan O Connor College of Information and Computer Sciences University
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning for Structured Prediction
 Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields
 Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
Deep Learning. Ali Ghodsi. University of Waterloo
 University of Waterloo Language Models A language model computes a probability for a sequence of words: P(w 1,..., w T ) Useful for machine translation Word ordering: p (the cat is small) > p (small the
University of Waterloo Language Models A language model computes a probability for a sequence of words: P(w 1,..., w T ) Useful for machine translation Word ordering: p (the cat is small) > p (small the
4 Bias-Variance for Ridge Regression (24 points)
") Implement Ridge Regression with λ = 0.00001. Plot the Squared Euclidean test error for the following values of k (the dimensions you reduce to): k = {0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500,
Implement Ridge Regression with λ = 0.00001. Plot the Squared Euclidean test error for the following values of k (the dimensions you reduce to): k = {0, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500,
Deep Learning Sequence to Sequence models: Attention Models. 17 March 2018
 Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Seq2Seq Losses (CTC)
") Seq2Seq Losses (CTC) Jerry Ding & Ryan Brigden 11-785 Recitation 6 February 23, 2018 Outline Tasks suited for recurrent networks Losses when the output is a sequence Kinds of errors Losses to use CTC Loss
Seq2Seq Losses (CTC) Jerry Ding & Ryan Brigden 11-785 Recitation 6 February 23, 2018 Outline Tasks suited for recurrent networks Losses when the output is a sequence Kinds of errors Losses to use CTC Loss
Dreem Challenge report (team Bussanati)
") Wavelet course, MVA 04-05 Simon Bussy, simon.bussy@gmail.com Antoine Recanati, arecanat@ens-cachan.fr Dreem Challenge report (team Bussanati) Description and specifics of the challenge We worked on the
Wavelet course, MVA 04-05 Simon Bussy, simon.bussy@gmail.com Antoine Recanati, arecanat@ens-cachan.fr Dreem Challenge report (team Bussanati) Description and specifics of the challenge We worked on the
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 6
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 6 Slides adapted from Jordan Boyd-Graber, Chris Ketelsen Machine Learning: Chenhao Tan Boulder 1 of 39 HW1 turned in HW2 released Office
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 6 Slides adapted from Jordan Boyd-Graber, Chris Ketelsen Machine Learning: Chenhao Tan Boulder 1 of 39 HW1 turned in HW2 released Office
Task-Oriented Dialogue System (Young, 2000)
") 2 Review Task-Oriented Dialogue System (Young, 2000) 3 http://rsta.royalsocietypublishing.org/content/358/1769/1389.short Speech Signal Speech Recognition Hypothesis are there any action movies to see
2 Review Task-Oriented Dialogue System (Young, 2000) 3 http://rsta.royalsocietypublishing.org/content/358/1769/1389.short Speech Signal Speech Recognition Hypothesis are there any action movies to see
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
arxiv: v2 [cs.cl] 1 Jan 2019
![arxiv: v2 [cs.cl] 1 Jan 2019](/thumbs/93/111679653.jpg "arxiv: v2 [cs.cl] 1 Jan 2019") Variational Self-attention Model for Sentence Representation arxiv:1812.11559v2 [cs.cl] 1 Jan 2019 Qiang Zhang 1, Shangsong Liang 2, Emine Yilmaz 1 1 University College London, London, United Kingdom 2
Variational Self-attention Model for Sentence Representation arxiv:1812.11559v2 [cs.cl] 1 Jan 2019 Qiang Zhang 1, Shangsong Liang 2, Emine Yilmaz 1 1 University College London, London, United Kingdom 2
Applied Natural Language Processing
 Applied Natural Language Processing Info 256 Lecture 5: Text classification (Feb 5, 2019) David Bamman, UC Berkeley Data Classification A mapping h from input data x (drawn from instance space X) to a
Applied Natural Language Processing Info 256 Lecture 5: Text classification (Feb 5, 2019) David Bamman, UC Berkeley Data Classification A mapping h from input data x (drawn from instance space X) to a
Support Vector Machines: Kernels
 Support Vector Machines: Kernels CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 14.1, 14.2, 14.4 Schoelkopf/Smola Chapter 7.4, 7.6, 7.8 Non-Linear Problems
Support Vector Machines: Kernels CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 14.1, 14.2, 14.4 Schoelkopf/Smola Chapter 7.4, 7.6, 7.8 Non-Linear Problems
CS224N: Natural Language Processing with Deep Learning Winter 2017 Midterm Exam
 CS224N: Natural Language Processing with Deep Learning Winter 2017 Midterm Exam This examination consists of 14 printed sides, 5 questions, and 100 points. The exam accounts for 17% of your total grade.
CS224N: Natural Language Processing with Deep Learning Winter 2017 Midterm Exam This examination consists of 14 printed sides, 5 questions, and 100 points. The exam accounts for 17% of your total grade.
Support Vector Machines
 Support Vector Machines Here we approach the two-class classification problem in a direct way: We try and find a plane that separates the classes in feature space. If we cannot, we get creative in two
Support Vector Machines Here we approach the two-class classification problem in a direct way: We try and find a plane that separates the classes in feature space. If we cannot, we get creative in two