Lecture 6: Neural Networks for Representing Word Meaning
|
|
|
- Harry Barrett
- 6 years ago
- Views:
Transcription
1 Lecture 6: Neural Networks for Representing Word Meaning Mirella Lapata School of Informatics University of Edinburgh February 7, / 28
2 Logistic Regression Input is a feature vector, output is one (binary classification) or many (multinomial distribution) Weights matrix (or vector) directly connects inputs and output Trained by gradient descent (neural network; no hidden units). x 1 x 2 x 3 x 4 w 1 w 2 w 3 w 4 w 5 y x 5 2 / 28
3 Logistic Functions Logistic Function Sigmoid L f (x) = f (x) = 1 1+e k(x x 0 ) 1+e x Softmax function P(y = j x) = ex w j K k=1 ex w k e natural logarithm base, x 0 the x-value of the sigmoid s midpoint, L the curve s maximum value, k steepness of curve Sigmoid is special case of the logistic function Softmax is a generalization of the logistic function x T w denotes the inner product of x and w 3 / 28
4 Neural Networks x 1 x 2 x 3 y x 4 x 5 W : input weights, matrix I : input signal, feature vector (one per example) Activation function: sigmoid, tanh 4 / 28
5 Training of Neural Networks Forward Pass Input signal is presented first Hidden layer state is computed (vector times matrix operation and non-linear activation) Outputs are computed (vectors times matrix operation and usually non-linear activation) Backpropagation To train the network, we need to compute gradient of the error The gradients are sent back using the same weights that were used in the forward pass Gradient Descent Batch gradient descent: compute gradient from batch of N training examples Stochastic gradient descent: compute the gradient from 1 training example each time Minibatch: compute the gradient from minibatch of M training examples (M > 1, M < N) 5 / 28
6 Training of Neural Networks Learning Rate: Controls how much we change the weights Too little value will result in long training time, too high value will erase previously learned patterns We start with high learning rate and reduce it during training Training Epochs: several passes over the training data are often performed (epoch: number of iterations over the data set in order to train the neural network). Regularization: Network often overfits (it fails to generalize at test time) High weights are used to model only some small subset of data We can try to force the weights to stay small during training to avoid this problem (L1 & L2 regularization) 6 / 28
7 Model Parameters Choice of the hyper-parameters has to be done manually: Type of activation function Choice of architecture (how many hidden layers, their sizes) Learning rate, number of training epochs What features are presented at the input layer How to regularize 7 / 28
8 N-grams N-gram-based language models are often used to compute the probability of a sentence W : P(W ) = i (w i w 1... w i 1 ) Often simplified to trigrams: P(W ) = i (w i w i 2, w i 1 ) P(this is a sentence) = P(this) P(is this) P(a this, is) P(sentence is, a) P(a this, is) = C(this is a) C(this is) 8 / 28
9 One-hot Representations Simple way how to encode discrete concepts, such as words; also known as 1-of-N where N would be the size of the vocabulary. vocabulary = (Monday, Tuesday, is, a, today) Monday = [ ] Tuesday = [ ] is = [ ] a = [ ] today = [ ] 9 / 28
10 Bag-of-Words Representations Ignores word order, sum of one-hot vectors. Can be extended to bag-of-n-grams to capture local ordering of words. vocabulary = (Monday, Tuesday, is, a, today) Monday = [ ] Tuesday = [ ] is = [ ] a = [ ] today = [ ] vocabulary = (Monday, Tuesday, is, a, today) Monday Monday = [ ] today is a Monday = [ ] today is a Tuesday = [ ] is a Monday today = [ ] 10 / 28
11 A Basic Neural Language Model PREVIOUS WORD HIDDEN LAYER CURRENT WORD Bigram neural language model Previous word predicts current word via hidden layer As many outputs as there are words in the vocabulary Model learns compressed, continuous representations of words (usually the matrix of weights between input and hidden layer) 11 / 28
12 Another Neural Language Model Bengio et al. (2003, JMLR) Input layer, projection layer, hidden layer and output layer The projection layer is linear The hidden layer is non-linear Softmax at the output computes probability distribution over the whole vocabulary (g(o) = eo i k eo k ) Model is computationally very expensive 12 / 28
13 Continuous bag-of-words model (CBOW) Mikolov et al. (2013, ICLR) CBOW adds inputs from words within short window to predict the current word The weights for different positions are shared Computationally much more efficient than normal NNLM The hidden layer is just linear 13 / 28
14 Skip-gram NNLM We can reformulate the CBOW model by predicting surrounding words using the current word Find word representations useful for predicting surrounding words in a sentence or document. 14 / 28

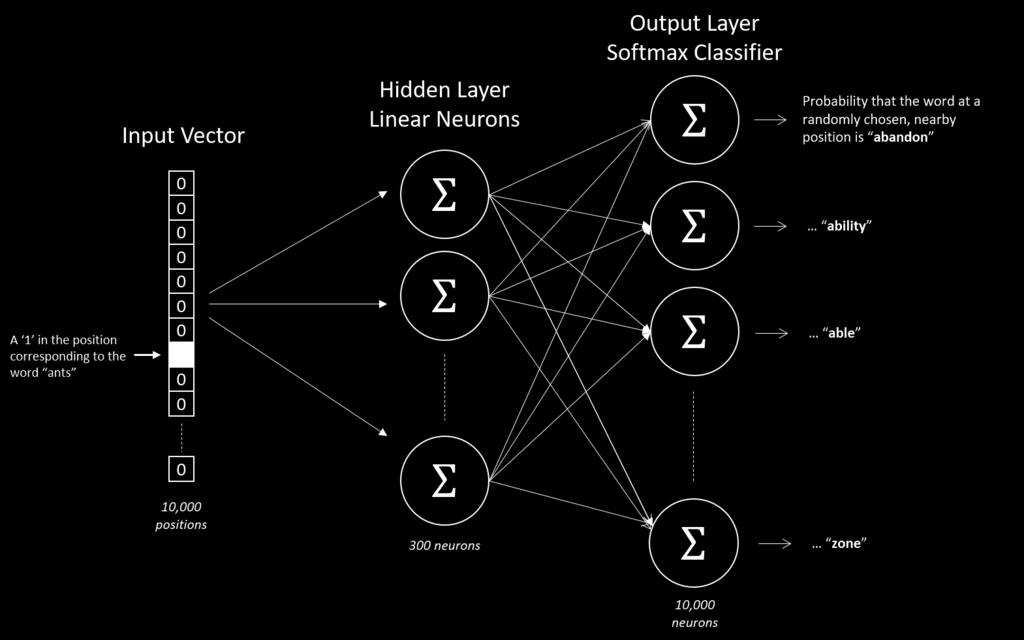
15 Skip-gram NNLM 15 / 28
 and 300 columns")
16 The Hidden Layer We wish to learn word vectors with 300 features. Hidden layer is a weight matrix with 10,000 rows (one for every word in vocabulary) and 300 columns (one for every hidden neuron). 16 / 28

17 Output Weights 17 / 28
18 Skip-gram Details Each word w W is associated with vector v w R d Each context c C is associated with vector v c R d W words vocabulary, C contexts vocabulary d embedding dimensionality Vector components are latent (parameters to be learnt). Objective function maximizes the probability of corpus D (set of all word and context pairs extracted from text): argmax θ (w,c) D p(c w; θ) 18 / 28
19 Skip-gram Details The basic Skip-gram formulation defines p(c w; θ) using the softmax function: p(c w; θ) = evc vw e v c vw c C where v c and v w are vector representations for c and w and C is the set of all available contexts. We seek parameter values (i.e., vector representations for both words and contexts) such that the dot product v w v c associated with good word-context pairs is maximized. The formulation is impractical due to the summation term c C ev c vw over all contexts c. 19 / 28
20 Training Stochastic gradient descent and backpropagation It is useful to sub-sample the frequent words (e.g., the, is, a) Words are thrown out proportional to their frequency (makes things faster, reduces importance of frequent words like IDF) Non-linearity does not seem to improve performance of these models, thus the hidden layer does not use activation function Problem: very large output layer -size equal to vocabulary size, can easily be in order of millions (too many outputs to evaluate) Solution: negative sampling (also Hierarchical softmax) 20 / 28
21 Negative Sampling Instead of propagating signal from the hidden layer to the whole output layer, only the output neuron that represents the positive class + few randomly sampled neurons are evaluated The output neurons are treated as independent logistic regression classifiers This makes the training speed independent of the vocabulary size (can be easily parallelized) 21 / 28
22 Negative Sampling Objective Let D denote dataset of observed (w, c) pairs p(d = 1 w, c) denotes probability that (w, c) came from D p(d = 0 w, c) = 1 p(d = 1 w, c) that it didn t argmax θ argmax θ argmax θ (w,c) D (w,c) D (w,c) D p(d = 1 w, c; θ) p(d = 0 w, c; θ) (w,c) D log p(d = 1 w, c; θ) + log(1 p(d = 1 w, c; θ)) (w,c) D 1 log 1+e vc vw + 1+evc vw (w,c) D log 1 See Goldberg and Levy (2014) for full derivation. 22 / 28
23 Model Evaluation Type of relationship Word Pair 1 Word Pair 2 Common capital city Athens Greece Oslo Norway All capital cities Astana Kazakhstan Harare Zimbabwe Currency Angola kwanza Iran rial City-in-state Chicago Illinois Stockton California Man-Woman brother sister grandson granddaughter Adjective to adverb apparent apparently rapid rapidly Opposite possibly impossibly ethical unethical Comparative great greater tough tougher Superlative easy easiest lucky luckiest Present Participle think thinking read reading Nationality adjective Switzerland Swiss Cambodia Cambodian Past tense walking walked swimming swam Plural nouns mouse mice dollar dollars Plural verbs work works speak speaks 20K questions, 6B words, 1M words vocabulary Find word closest to question word (e.g., Greece), consider it correct if it matches the answer. 23 / 28
24 Model Evaluation Models trained on the same data (640-dimensional word vectors). Model Semantic-Syntactic Word Relationship test set Architecture Semantic Accuracy [%] Syntactic Accuracy [%] RNNLM 9 36 NNLM CBOW Skip-gram Can you think of additional baseline comparisons? 24 / 28
25 Model Evaluation Subtracting two word vectors, and add the result to another word. Check more examples out at: 25 / 28

26 Summary Don t count predict! Baroni et al. (ACL, 2014) 26 / 28
27 Why Does Skip-gram Work? We don t really know! The objective tries to increase the quantity v w v c for good word-context pairs, and decrease it for bad ones. Words that share many contexts will be similar to each other. Lots of parameters here too: contexts, subsampling, rare word pruning, dimension of vectors. 27 / 28
28 Resources Word2vec available at Tool for training the word vectors using CBOW and skip-gram architectures, supports both negative sampling and hierarchical softmax Optimized for very large datasets (>billions of training words) Pre-trained on large datasets (100B words) 28 / 28
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Semantics with Dense Vectors. Reference: D. Jurafsky and J. Martin, Speech and Language Processing
 Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
word2vec Parameter Learning Explained
 word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
Homework 3 COMS 4705 Fall 2017 Prof. Kathleen McKeown
 Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287
 Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
DISTRIBUTIONAL SEMANTICS
 COMP90042 LECTURE 4 DISTRIBUTIONAL SEMANTICS LEXICAL DATABASES - PROBLEMS Manually constructed Expensive Human annotation can be biased and noisy Language is dynamic New words: slangs, terminology, etc.
COMP90042 LECTURE 4 DISTRIBUTIONAL SEMANTICS LEXICAL DATABASES - PROBLEMS Manually constructed Expensive Human annotation can be biased and noisy Language is dynamic New words: slangs, terminology, etc.
An overview of word2vec
 An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
text classification 3: neural networks
 text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
arxiv: v3 [cs.cl] 30 Jan 2016
![arxiv: v3 [cs.cl] 30 Jan 2016](/thumbs/72/66377864.jpg "arxiv: v3 [cs.cl] 30 Jan 2016") word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu arxiv:1411.2738v3 [cs.cl] 30 Jan 2016 Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu arxiv:1411.2738v3 [cs.cl] 30 Jan 2016 Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention
Neural Word Embeddings from Scratch
 Neural Word Embeddings from Scratch Xin Li 12 1 NLP Center Tencent AI Lab 2 Dept. of System Engineering & Engineering Management The Chinese University of Hong Kong 2018-04-09 Xin Li Neural Word Embeddings
Neural Word Embeddings from Scratch Xin Li 12 1 NLP Center Tencent AI Lab 2 Dept. of System Engineering & Engineering Management The Chinese University of Hong Kong 2018-04-09 Xin Li Neural Word Embeddings
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
GloVe: Global Vectors for Word Representation 1
 GloVe: Global Vectors for Word Representation 1 J. Pennington, R. Socher, C.D. Manning M. Korniyenko, S. Samson Deep Learning for NLP, 13 Jun 2017 1 https://nlp.stanford.edu/projects/glove/ Outline Background
GloVe: Global Vectors for Word Representation 1 J. Pennington, R. Socher, C.D. Manning M. Korniyenko, S. Samson Deep Learning for NLP, 13 Jun 2017 1 https://nlp.stanford.edu/projects/glove/ Outline Background
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
Natural Language Processing
 Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
Natural Language Processing Word vectors Many slides borrowed from Richard Socher and Chris Manning Lecture plan Word representations Word vectors (embeddings) skip-gram algorithm Relation to matrix factorization
Word Embeddings 2 - Class Discussions
 Word Embeddings 2 - Class Discussions Jalaj February 18, 2016 Opening Remarks - Word embeddings as a concept are intriguing. The approaches are mostly adhoc but show good empirical performance. Paper 1
Word Embeddings 2 - Class Discussions Jalaj February 18, 2016 Opening Remarks - Word embeddings as a concept are intriguing. The approaches are mostly adhoc but show good empirical performance. Paper 1
Natural Language Processing and Recurrent Neural Networks
 Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Natural Language Processing
 Natural Language Processing Info 159/259 Lecture 7: Language models 2 (Sept 14, 2017) David Bamman, UC Berkeley Language Model Vocabulary V is a finite set of discrete symbols (e.g., words, characters);
Natural Language Processing Info 159/259 Lecture 7: Language models 2 (Sept 14, 2017) David Bamman, UC Berkeley Language Model Vocabulary V is a finite set of discrete symbols (e.g., words, characters);
Natural Language Processing
 Natural Language Processing Info 59/259 Lecture 4: Text classification 3 (Sept 5, 207) David Bamman, UC Berkeley . https://www.forbes.com/sites/kevinmurnane/206/04/0/what-is-deep-learning-and-how-is-it-useful
Natural Language Processing Info 59/259 Lecture 4: Text classification 3 (Sept 5, 207) David Bamman, UC Berkeley . https://www.forbes.com/sites/kevinmurnane/206/04/0/what-is-deep-learning-and-how-is-it-useful
Deep Learning for Natural Language Processing. Sidharth Mudgal April 4, 2017
 Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Sequence Modeling with Neural Networks
 Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Neural Networks Language Models
 Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
Neural Networks Language Models Philipp Koehn 10 October 2017 N-Gram Backoff Language Model 1 Previously, we approximated... by applying the chain rule p(w ) = p(w 1, w 2,..., w n ) p(w ) = i p(w i w 1,...,
Neural Networks with Applications to Vision and Language. Feedforward Networks. Marco Kuhlmann
 Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Neural Networks with Applications to Vision and Language Feedforward Networks Marco Kuhlmann Feedforward networks Linear separability x 2 x 2 0 1 0 1 0 0 x 1 1 0 x 1 linearly separable not linearly separable
Deep Learning. Ali Ghodsi. University of Waterloo
 University of Waterloo Language Models A language model computes a probability for a sequence of words: P(w 1,..., w T ) Useful for machine translation Word ordering: p (the cat is small) > p (small the
University of Waterloo Language Models A language model computes a probability for a sequence of words: P(w 1,..., w T ) Useful for machine translation Word ordering: p (the cat is small) > p (small the
Natural Language Processing with Deep Learning CS224N/Ling284. Richard Socher Lecture 2: Word Vectors
 Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
CS224n: Natural Language Processing with Deep Learning 1
 CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part I 2 Winter 27 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume Genthial,
CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part I 2 Winter 27 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume Genthial,
CPSC 340 Assignment 4 (due November 17 ATE)
") CPSC 340 Assignment 4 due November 7 ATE) Multi-Class Logistic The function example multiclass loads a multi-class classification datasetwith y i {,, 3, 4, 5} and fits a one-vs-all classification model
CPSC 340 Assignment 4 due November 7 ATE) Multi-Class Logistic The function example multiclass loads a multi-class classification datasetwith y i {,, 3, 4, 5} and fits a one-vs-all classification model
Midterm sample questions
 Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Algorithms for NLP. Language Modeling III. Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley
 Algorithms for NLP Language Modeling III Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Office hours on website but no OH for Taylor until next week. Efficient Hashing Closed address
Algorithms for NLP Language Modeling III Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Announcements Office hours on website but no OH for Taylor until next week. Efficient Hashing Closed address
Deep Learning for NLP
 Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Neural Network Language Modeling
 Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
11/3/15. Deep Learning for NLP. Deep Learning and its Architectures. What is Deep Learning? Advantages of Deep Learning (Part 1)
") 11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
ATASS: Word Embeddings
 ATASS: Word Embeddings Lee Gao April 22th, 2016 Guideline Bag-of-words (bag-of-n-grams) Today High dimensional, sparse representation dimension reductions LSA, LDA, MNIR Neural networks Backpropagation
ATASS: Word Embeddings Lee Gao April 22th, 2016 Guideline Bag-of-words (bag-of-n-grams) Today High dimensional, sparse representation dimension reductions LSA, LDA, MNIR Neural networks Backpropagation
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Basics Lecture 10: Neural Language Models. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Artificial Neural Networks D B M G. Data Base and Data Mining Group of Politecnico di Torino. Elena Baralis. Politecnico di Torino
 Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Artificial Neural Networks Data Base and Data Mining Group of Politecnico di Torino Elena Baralis Politecnico di Torino Artificial Neural Networks Inspired to the structure of the human brain Neurons as
Assignment 1. Learning distributed word representations. Jimmy Ba
 Assignment 1 Learning distributed word representations Jimmy Ba csc321ta@cstorontoedu Background Text and language play central role in a wide range of computer science and engineering problems Applications
Assignment 1 Learning distributed word representations Jimmy Ba csc321ta@cstorontoedu Background Text and language play central role in a wide range of computer science and engineering problems Applications
Convolutional Neural Networks
 Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Deep Learning. Language Models and Word Embeddings. Christof Monz
 Deep Learning Today s Class N-gram language modeling Feed-forward neural language model Architecture Final layer computations Word embeddings Continuous bag-of-words model Skip-gram Negative sampling 1
Deep Learning Today s Class N-gram language modeling Feed-forward neural language model Architecture Final layer computations Word embeddings Continuous bag-of-words model Skip-gram Negative sampling 1
CSC 411: Lecture 04: Logistic Regression
 CSC 411: Lecture 04: Logistic Regression Raquel Urtasun & Rich Zemel University of Toronto Sep 23, 2015 Urtasun & Zemel (UofT) CSC 411: 04-Prob Classif Sep 23, 2015 1 / 16 Today Key Concepts: Logistic
CSC 411: Lecture 04: Logistic Regression Raquel Urtasun & Rich Zemel University of Toronto Sep 23, 2015 Urtasun & Zemel (UofT) CSC 411: 04-Prob Classif Sep 23, 2015 1 / 16 Today Key Concepts: Logistic
HOMEWORK #4: LOGISTIC REGRESSION
 HOMEWORK #4: LOGISTIC REGRESSION Probabilistic Learning: Theory and Algorithms CS 274A, Winter 2019 Due: 11am Monday, February 25th, 2019 Submit scan of plots/written responses to Gradebook; submit your
HOMEWORK #4: LOGISTIC REGRESSION Probabilistic Learning: Theory and Algorithms CS 274A, Winter 2019 Due: 11am Monday, February 25th, 2019 Submit scan of plots/written responses to Gradebook; submit your
IN FALL NATURAL LANGUAGE PROCESSING. Jan Tore Lønning
 1 IN4080 2018 FALL NATURAL LANGUAGE PROCESSING Jan Tore Lønning 2 Logistic regression Lecture 8, 26 Sept Today 3 Recap: HMM-tagging Generative and discriminative classifiers Linear classifiers Logistic
1 IN4080 2018 FALL NATURAL LANGUAGE PROCESSING Jan Tore Lønning 2 Logistic regression Lecture 8, 26 Sept Today 3 Recap: HMM-tagging Generative and discriminative classifiers Linear classifiers Logistic
Neural Networks for NLP. COMP-599 Nov 30, 2016
 Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression Review Fall 2012 Recitation. September 25, 2012 TA: Selen Uguroglu
 Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
epochs epochs
 Neural Network Experiments To illustrate practical techniques, I chose to use the glass dataset. This dataset has 214 examples and 6 classes. Here are 4 examples from the original dataset. The last values
Neural Network Experiments To illustrate practical techniques, I chose to use the glass dataset. This dataset has 214 examples and 6 classes. Here are 4 examples from the original dataset. The last values
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Reading Group on Deep Learning Session 1
 Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Reading Group on Deep Learning Session 1 Stephane Lathuiliere & Pablo Mesejo 2 June 2016 1/31 Contents Introduction to Artificial Neural Networks to understand, and to be able to efficiently use, the popular
Deep Learning Sequence to Sequence models: Attention Models. 17 March 2018
 Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Deep Learning for NLP Part 2
 Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
Generative Clustering, Topic Modeling, & Bayesian Inference
 Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
Generative Clustering, Topic Modeling, & Bayesian Inference INFO-4604, Applied Machine Learning University of Colorado Boulder December 12-14, 2017 Prof. Michael Paul Unsupervised Naïve Bayes Last week
CSC321 Lecture 7 Neural language models
 CSC321 Lecture 7 Neural language models Roger Grosse and Nitish Srivastava February 1, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 7 Neural language models February 1, 2015 1 / 19 Overview We
CSC321 Lecture 7 Neural language models Roger Grosse and Nitish Srivastava February 1, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 7 Neural language models February 1, 2015 1 / 19 Overview We
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Deep Learning for Natural Language Processing
 Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
Deep Learning for Natural Language Processing Dylan Drover, Borui Ye, Jie Peng University of Waterloo djdrover@uwaterloo.ca borui.ye@uwaterloo.ca July 8, 2015 Dylan Drover, Borui Ye, Jie Peng (University
Artificial Neural Networks
 Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Artificial Neural Networks Oliver Schulte - CMPT 310 Neural Networks Neural networks arise from attempts to model human/animal brains Many models, many claims of biological plausibility We will focus on
Comparison of Modern Stochastic Optimization Algorithms
 Comparison of Modern Stochastic Optimization Algorithms George Papamakarios December 214 Abstract Gradient-based optimization methods are popular in machine learning applications. In large-scale problems,
Comparison of Modern Stochastic Optimization Algorithms George Papamakarios December 214 Abstract Gradient-based optimization methods are popular in machine learning applications. In large-scale problems,
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
Seman&cs with Dense Vectors. Dorota Glowacka
 Semancs with Dense Vectors Dorota Glowacka dorota.glowacka@ed.ac.uk Previous lectures: - how to represent a word as a sparse vector with dimensions corresponding to the words in the vocabulary - the values
Semancs with Dense Vectors Dorota Glowacka dorota.glowacka@ed.ac.uk Previous lectures: - how to represent a word as a sparse vector with dimensions corresponding to the words in the vocabulary - the values
Deep Neural Networks (1) Hidden layers; Back-propagation
 Hidden layers; Back-propagation") Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Deep Neural Networs (1) Hidden layers; Bac-propagation Steve Renals Machine Learning Practical MLP Lecture 3 4 October 2017 / 9 October 2017 MLP Lecture 3 Deep Neural Networs (1) 1 Recap: Softmax single
Lecture 7: Word Embeddings
 Lecture 7: Word Embeddings Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 6501 Natural Language Processing 1 This lecture v Learning word vectors
Lecture 7: Word Embeddings Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 6501 Natural Language Processing 1 This lecture v Learning word vectors
Loss Functions and Optimization. Lecture 3-1
 Lecture 3: Loss Functions and Optimization Lecture 3-1 Administrative: Live Questions We ll use Zoom to take questions from remote students live-streaming the lecture Check Piazza for instructions and
Lecture 3: Loss Functions and Optimization Lecture 3-1 Administrative: Live Questions We ll use Zoom to take questions from remote students live-streaming the lecture Check Piazza for instructions and
Linear classifiers: Overfitting and regularization
 Linear classifiers: Overfitting and regularization Emily Fox University of Washington January 25, 2017 Logistic regression recap 1 . Thus far, we focused on decision boundaries Score(x i ) = w 0 h 0 (x
Linear classifiers: Overfitting and regularization Emily Fox University of Washington January 25, 2017 Logistic regression recap 1 . Thus far, we focused on decision boundaries Score(x i ) = w 0 h 0 (x
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
Neural Networks: Backpropagation Seung-Hoon Na 1 1 Department of Computer Science Chonbuk National University 2018.10.25 eung-hoon Na (Chonbuk National University) Neural Networks: Backpropagation 2018.10.25
Multilayer Perceptrons and Backpropagation
 Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
Multilayer Perceptrons and Backpropagation Informatics 1 CG: Lecture 7 Chris Lucas School of Informatics University of Edinburgh January 31, 2017 (Slides adapted from Mirella Lapata s.) 1 / 33 Reading:
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam
 CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
Instructions for NLP Practical (Units of Assessment) SVM-based Sentiment Detection of Reviews (Part 2)
 SVM-based Sentiment Detection of Reviews (Part 2)") Instructions for NLP Practical (Units of Assessment) SVM-based Sentiment Detection of Reviews (Part 2) Simone Teufel (Lead demonstrator Guy Aglionby) sht25@cl.cam.ac.uk; ga384@cl.cam.ac.uk This is the
Instructions for NLP Practical (Units of Assessment) SVM-based Sentiment Detection of Reviews (Part 2) Simone Teufel (Lead demonstrator Guy Aglionby) sht25@cl.cam.ac.uk; ga384@cl.cam.ac.uk This is the
Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses about the label (Top-5 error) No Bounding Box
 Make 5 guesses about the label (Top-5 error) No Bounding Box") ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
ImageNet Classification with Deep Convolutional Neural Networks Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton Motivation Classification goals: Make 1 guess about the label (Top-1 error) Make 5 guesses
Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions
 perceptrons: Cannot learn non-linearly separable tasks. Cannot approximate (learn) non-linear functions") BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
BACK-PROPAGATION NETWORKS Serious limitations of (single-layer) perceptrons: Cannot learn non-linearly separable tasks Cannot approximate (learn) non-linear functions Difficult (if not impossible) to design
HOMEWORK #4: LOGISTIC REGRESSION
 HOMEWORK #4: LOGISTIC REGRESSION Probabilistic Learning: Theory and Algorithms CS 274A, Winter 2018 Due: Friday, February 23rd, 2018, 11:55 PM Submit code and report via EEE Dropbox You should submit a
HOMEWORK #4: LOGISTIC REGRESSION Probabilistic Learning: Theory and Algorithms CS 274A, Winter 2018 Due: Friday, February 23rd, 2018, 11:55 PM Submit code and report via EEE Dropbox You should submit a
Statistical Machine Learning from Data
 January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
January 17, 2006 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Multi-Layer Perceptrons Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole
MLPR: Logistic Regression and Neural Networks
 MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition Amos Storkey Amos Storkey MLPR: Logistic Regression and Neural Networks 1/28 Outline 1 Logistic Regression 2 Multi-layer
MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition Amos Storkey Amos Storkey MLPR: Logistic Regression and Neural Networks 1/28 Outline 1 Logistic Regression 2 Multi-layer
Outline. MLPR: Logistic Regression and Neural Networks Machine Learning and Pattern Recognition. Which is the correct model? Recap.
 Outline MLPR: and Neural Networks Machine Learning and Pattern Recognition 2 Amos Storkey Amos Storkey MLPR: and Neural Networks /28 Recap Amos Storkey MLPR: and Neural Networks 2/28 Which is the correct
Outline MLPR: and Neural Networks Machine Learning and Pattern Recognition 2 Amos Storkey Amos Storkey MLPR: and Neural Networks /28 Recap Amos Storkey MLPR: and Neural Networks 2/28 Which is the correct
Learning from Data: Multi-layer Perceptrons
 Learning from Data: Multi-layer Perceptrons Amos Storkey, School of Informatics University of Edinburgh Semester, 24 LfD 24 Layered Neural Networks Background Single Neurons Relationship to logistic regression.
Learning from Data: Multi-layer Perceptrons Amos Storkey, School of Informatics University of Edinburgh Semester, 24 LfD 24 Layered Neural Networks Background Single Neurons Relationship to logistic regression.
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
CS60010: Deep Learning
 CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
Regularization Introduction to Machine Learning. Matt Gormley Lecture 10 Feb. 19, 2018
 1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
CSE 417T: Introduction to Machine Learning. Final Review. Henry Chai 12/4/18
 CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
CSE 417T: Introduction to Machine Learning Final Review Henry Chai 12/4/18 Overfitting Overfitting is fitting the training data more than is warranted Fitting noise rather than signal 2 Estimating! "#$
Online Videos FERPA. Sign waiver or sit on the sides or in the back. Off camera question time before and after lecture. Questions?
 Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
CSC 578 Neural Networks and Deep Learning Fall 2018/19 3. Improving Neural Networks (Some figures adapted from NNDL book) 1 Various Approaches to Improve Neural Networks 1. Cost functions Quadratic Cross
Bayesian Paragraph Vectors
 Bayesian Paragraph Vectors Geng Ji 1, Robert Bamler 2, Erik B. Sudderth 1, and Stephan Mandt 2 1 Department of Computer Science, UC Irvine, {gji1, sudderth}@uci.edu 2 Disney Research, firstname.lastname@disneyresearch.com
Bayesian Paragraph Vectors Geng Ji 1, Robert Bamler 2, Erik B. Sudderth 1, and Stephan Mandt 2 1 Department of Computer Science, UC Irvine, {gji1, sudderth}@uci.edu 2 Disney Research, firstname.lastname@disneyresearch.com
Distributional Semantics and Word Embeddings. Chase Geigle
 Distributional Semantics and Word Embeddings Chase Geigle 2016-10-14 1 What is a word? dog 2 What is a word? dog canine 2 What is a word? dog canine 3 2 What is a word? dog 3 canine 399,999 2 What is a
Distributional Semantics and Word Embeddings Chase Geigle 2016-10-14 1 What is a word? dog 2 What is a word? dog canine 2 What is a word? dog canine 3 2 What is a word? dog 3 canine 399,999 2 What is a
Machine Learning Basics III
 Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
CME323 Distributed Algorithms and Optimization. GloVe on Spark. Alex Adamson SUNet ID: aadamson. June 6, 2016
 GloVe on Spark Alex Adamson SUNet ID: aadamson June 6, 2016 Introduction Pennington et al. proposes a novel word representation algorithm called GloVe (Global Vectors for Word Representation) that synthesizes
GloVe on Spark Alex Adamson SUNet ID: aadamson June 6, 2016 Introduction Pennington et al. proposes a novel word representation algorithm called GloVe (Global Vectors for Word Representation) that synthesizes
Deep Feedforward Networks
 Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
Deep Feedforward Networks Liu Yang March 30, 2017 Liu Yang Short title March 30, 2017 1 / 24 Overview 1 Background A general introduction Example 2 Gradient based learning Cost functions Output Units 3
CS224n: Natural Language Processing with Deep Learning 1
 CS224n: Natural Language Processing with Deep Learning 1 Lecture Notes: Part I 2 Winter 2017 1 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume
CS224n: Natural Language Processing with Deep Learning 1 Lecture Notes: Part I 2 Winter 2017 1 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume
Machine Learning Lecture 12
 Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Machine Learning Lecture 12 Neural Networks 30.11.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory Probability
Gaussian and Linear Discriminant Analysis; Multiclass Classification
 Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Introduction to Convolutional Neural Networks (CNNs)
") Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Introduction to Convolutional Neural Networks (CNNs) nojunk@snu.ac.kr http://mipal.snu.ac.kr Department of Transdisciplinary Studies Seoul National University, Korea Jan. 2016 Many slides are from Fei-Fei
Jakub Hajic Artificial Intelligence Seminar I
 Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Jakub Hajic Artificial Intelligence Seminar I. 11. 11. 2014 Outline Key concepts Deep Belief Networks Convolutional Neural Networks A couple of questions Convolution Perceptron Feedforward Neural Network
Neural Networks. David Rosenberg. July 26, New York University. David Rosenberg (New York University) DS-GA 1003 July 26, / 35
 DS-GA 1003 July 26, / 35") Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Neural Networks David Rosenberg New York University July 26, 2017 David Rosenberg (New York University) DS-GA 1003 July 26, 2017 1 / 35 Neural Networks Overview Objectives What are neural networks? How
Simple Techniques for Improving SGD. CS6787 Lecture 2 Fall 2017
 Simple Techniques for Improving SGD CS6787 Lecture 2 Fall 2017 Step Sizes and Convergence Where we left off Stochastic gradient descent x t+1 = x t rf(x t ; yĩt ) Much faster per iteration than gradient
Simple Techniques for Improving SGD CS6787 Lecture 2 Fall 2017 Step Sizes and Convergence Where we left off Stochastic gradient descent x t+1 = x t rf(x t ; yĩt ) Much faster per iteration than gradient
Linear Models in Machine Learning
 CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
CS540 Intro to AI Linear Models in Machine Learning Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu We briefly go over two linear models frequently used in machine learning: linear regression for, well, regression,
CPSC 340: Machine Learning and Data Mining. Stochastic Gradient Fall 2017
 CPSC 340: Machine Learning and Data Mining Stochastic Gradient Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation code
CPSC 340: Machine Learning and Data Mining Stochastic Gradient Fall 2017 Assignment 3: Admin Check update thread on Piazza for correct definition of trainndx. This could make your cross-validation code
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 17 October 2016 updated 9 September 2017 Recap: tagging POS tagging is a