Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop
|
|
|
- Morgan Wood
- 5 years ago
- Views:
Transcription
1 Overview Today: From one-layer to multi layer neural networks! Backprop (last bit of heavy math) Different descriptions and viewpoints of backprop Project Tips
2 Announcement: Hint for PSet1: Understand math and dimensionality, then check them with breakpoints or print statements:
3 Why go through all of these derivatives? Actual understanding of math behind deep learning Backprop can be an imperfect abstraction, e.g. During optimization issues (e.g. vanishing gradients) Enables you to debug models, think of and implement completely new models
4 Explanation #1 for backprop


5 Remember: Window-based Neural Net Computing a window s score with a 3-layer neural net: s = score(museums in Paris are amazing ) X window = [ x museums x in x Paris x are x amazing ]
6 Putting all gradients together: Remember: Full objective function for each window was: For example: (sub)gradient for U:
7 Two layer neural nets and full backprop Let s look at a 2 layer neural network Same window definition for x Same scoring function 2 hidden layers (carefully define superscripts now!) U s a (3) W (2) a (2) W (1) x
 W (2) a (2) W (1) Same derivation as before for W (2) (now sitting on a (2)")
8 Two layer neural nets and full backprop Fully written out as one function: a (3) W (2) a (2) W (1) Same derivation as before for W (2) (now sitting on a (2) ) S
9 Two layer neural nets and full backprop Same derivation as before for top W (2) : In matrix notation: where and is the element-wise product also called Hadamard product (, ) Last missing piece for understanding general backprop:
10 Two layer neural nets and full backprop Last missing piece: What s the bottom layer s error message δ (2)? Similar derivation to single layer model Main difference, we already have and need to apply the chain rule again on
11 Two layer neural nets and full backprop Chain rule for: Get intuition by deriving as if it was a scalar Intuitively, we have to sum over all the nodes coming into layer Putting it all together:
12 Two layer neural nets and full backprop Final X A {z In general for any matrix W (l) at internal layer l and any error with regularization E R all backprop in standard multilayer neural networks boils down to 2 equations: (l) = (W (l) ) T (l+1) f 0 (z (l) E R = (l+1) (a (l) ) T + W (l). Top and bottom layers have simpler δ
13 Taking a step back Explanation #2 for backprop: Circuits These examples are from CS231n:
14 Functions as circuits e.g. x = -2, y = 5, z = -4
15 e.g. x = -2, y = 5, z = -4 Want:
16 Recursively walking back through circuit e.g. x = -2, y = 5, z = -4 Want:
17 e.g. x = -2, y = 5, z = -4 Want:
18 e.g. x = -2, y = 5, z = -4 Want:
19 e.g. x = -2, y = 5, z = -4 Want:
20 e.g. x = -2, y = 5, z = -4 Want:
21 e.g. x = -2, y = 5, z = -4 Want:
22 e.g. x = -2, y = 5, z = -4 Want:
23 e.g. x = -2, y = 5, z = -4 Chain rule: Want:
24 e.g. x = -2, y = 5, z = -4 Want:
25 e.g. x = -2, y = 5, z = -4 Chain rule: Want:
26 activations f
27 Recursively apply chain rule through each node activations local gradient f gradients
28 Another example:
29 Another example:
30 Another example:
31 Another example:
32 Another example:
33 Jumping to the end Another example: 0.4 [local gradient] x [its gradient] x0: [2] x [0.2] = 0.4 w0: [-1] x [0.2] = -0.2
34 Combine nodes in the circuit when convenient sigmoid function sigmoid gate (0.73) * (1-0.73) = 0.2 We ll combine a lot in #4 : )
35 Explanation #3 for backprop The high-level flowgraph
36 Backpropagation (Another explanation) Compute gradient of example-wise loss wrt parameters Simply applying the derivative chain rule wisely If computing the loss(example, parameters) is O(n) computation, then so is computing the gradient
37 Simple Chain Rule


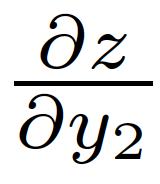
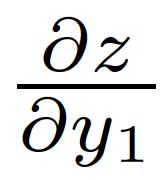
38 Multiple Paths Chain Rule
39 Multiple Paths Chain Rule - General
40 Chain Rule in Flow Graph Flow graph: any directed acyclic graph node = computation result arc = computation dependency = successors of
41 Back-Prop in Multi-Layer Net h = sigmoid(vx)
42 Back-Prop in General Flow Graph Single scalar output 1. Fprop: visit nodes in topo-sort order - Compute value of node given predecessors 2. Bprop: - initialize output gradient = 1 - visit nodes in reverse order: Compute gradient wrt each node using gradient wrt successors = successors of
43 Automatic Differentiation The gradient computation can be automatically inferred from the symbolic expression of the fprop. Each node type needs to know how to compute its output and how to compute the gradient wrt its inputs given the gradient wrt its output. Easy and fast prototyping
44 Explanation #4 for backprop The delta error signals in real neural nets
45 W (2) a (2) Actual error signals for 2 layer neural net a (3) W (1)
46 Visualization of intuition Let s say we want with previous layer and f = σ z (1) a (1) 1 W (1) z (2) a (2) σ W (2) z (3) 1 s δ (3) Gradient w.r.t W (2) = δ (3) a (2)T
47 Visualization of intuition z (1) a (1) 1 W (1) z (2) a (2) σ W (2) z (3) 1 s W (2)T δ (3) δ (3) --Reusing the δ (3) for downstream updates. --Moving error vector across affine transformation simply requires multiplication with the transpose of forward matrix --Notice that the dimensions will line up perfectly too!
48 Visualization of intuition z (1) a (1) 1 W (1) z (2) a (2) σ W (2) z (3) 1 s σ (z (2) )!W (2)T δ (3) W (2)T δ (3) = δ (2) --Moving error vector across point-wise non-linearity requires point-wise multiplication with local gradient of the non-linearity
49 Visualization of intuition z (1) a (1) 1 W (1) z (2) a (2) σ W (2) z (3) 1 s W (1)T δ (2) δ (2) Gradient w.r.t W (1) = δ (2) a (1)T
50 You survived Backprop! Congrats! You now understand the inner workings of most deep learning models out there This was the hardest part of the class Everything else from now on is mostly just more matrix multiplications and backprop :)
51 Bag of Tricks for Efficient Text Classification Armand Joulin, Edouard Grave, Piotr Bojanowski, Tomas Mikolov Facebook AI Research
52 Text classification


53 Bag of Words (or n-grams) Natural language processing is fun. fun Natural processing Average is language
54 Simple linear model output Softmax hidden Text vector... x1 x2 xn-1 xn Word vectors
55 Learning label of n- th doc weight matrices normalized bag of features of n-th doc # documents softmax
56 Hierarchical softmax Computer Science k classes AI... Probability of a node is always lower than one of its parent GUI Machine learning NLP Javascript Angular
57 Hierarchical softmax O(hlog(k)) vs O(kh) training time! (Text representation dimension h) Computer Science k classes AI... Probability of a node is always lower than one of its parent GUI Machine learning NLP Javascript Angular

58 Results As good as NN! Fast!
59 Summary fasttext is often on par with deep learning classifiers fasttext takes seconds, instead of days Can learn vector representations of words in different languages (with performance better than word2vec!) Thanks!
60 Class Project Important (30%) and lasting result of the class Final Project Poster Presentation: 2% Choice of doing Assignment 4 or a Final project Mandatory approved mentors à You need to reach out to potential mentors Start early and clearly define your task and dataset See
61 Project types 1. Apply existing neural network model to a new task 2. Implement a complex neural architecture 3. Come up with a new neural network model 4. Theory of deep learning, e.g. optimization
62 Class Project: Apply Existing NNets to Tasks 1. Define Task: Example: Summarization 2. Define Dataset 1. Search for academic datasets They already have baselines E.g.: Document Understanding Conference (DUC) 2. Define your own (harder, need more new baselines) If you re a graduate student: connect to your research Summarization, Wikipedia: Intro paragraph and rest of large article Be creative: Twitter, Blogs, News
63 Class Project: Apply Existing NNets to Tasks 3. Define your metric Search online for well established metrics on this task Summarization: Rouge (Recall-Oriented Understudy for Gisting Evaluation) which defines n-gram overlap to human summaries 4. Split your dataset! Train/Dev/Test Academic dataset often come pre-split Don t look at the test split until ~1 week before deadline! (or at most once a week)
64 Class Project: Apply Existing NNets to Tasks 5. Establish a baseline Implement the simplest model (often logistic regression on unigrams and bigrams) first Compute metrics on train AND dev Analyze errors If metrics are amazing and no errors: done, problem was too easy, restart :) 6. Implement existing neural net model Compute metric on train and dev Analyze output and errors Minimum bar for this class
65 Class Project: Apply Existing NNets to Tasks 7. Always be close to your data! Visualize the dataset Collect summary statistics Look at errors Analyze how different hyperparameters affect performance 8. Try out different model variants Soon you will have more options Word vector averaging model (neural bag of words) Fixed window neural model Recurrent neural network Recursive neural network Convolutional neural network
66 Class Project: A New Model -- Advanced Option Do all other steps first (Start early!) Gain intuition of why existing models are flawed Talk to researcher/mentor, come to project office hours a lot Implement new models and iterate quickly over ideas Set up efficient experimental framework Build simpler new models first Example Summarization: Average word vectors per paragraph, then greedy search Implement language model (introduced later) Stretch goal: Generate summary with seq2seq!
67 Project Ideas Summarization NER, like PSet 2 but with larger data Natural Language Processing (almost) from Scratch, Ronan Collobert, Jason Weston, Leon Bottou, Michael Karlen, Koray Kavukcuoglu, Pavel Kuksa, Simple question answering, A Neural Network for Factoid Question Answering over Paragraphs, Mohit Iyyer, Jordan Boyd-Graber, Leonardo Claudino, Richard Socher and Hal Daumé III (EMNLP 2014) Image to text mapping or generation, Grounded Compositional Semantics for Finding and Describing Images with Sentences, Richard Socher, Andrej Karpathy, Quoc V. Le, Christopher D. Manning, Andrew Y. Ng. (TACL 2014) or Deep Visual-Semantic Alignments for Generating Image Descriptions, Andrej Karpathy, Li Fei-Fei Entity level sentiment Use DL to solve an NLP challenge on kaggle, Develop a scoring algorithm for student-written short-answer responses,
68 Another example project: Sentiment Sentiment on movie reviews: Lots of deep learning baselines and methods have been tried
69 Next up Some fun and fundamental linguistics with syntactic parsing TensorFlow lecture (for Ass.2 ) also useful for projects and life : )
Online Videos FERPA. Sign waiver or sit on the sides or in the back. Off camera question time before and after lecture. Questions?
 Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Deep Learning for NLP Part 2
 Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
Deep Learning for NLP Part 2 CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) 2 Part 1.3: The Basics Word Representations The
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Deep Learning for Natural Language Processing. Sidharth Mudgal April 4, 2017
 Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
Deep Learning for Natural Language Processing Sidharth Mudgal April 4, 2017 Table of contents 1. Intro 2. Word Vectors 3. Word2Vec 4. Char Level Word Embeddings 5. Application: Entity Matching 6. Conclusion
text classification 3: neural networks
 text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
text classification 3: neural networks CS 585, Fall 2018 Introduction to Natural Language Processing http://people.cs.umass.edu/~miyyer/cs585/ Mohit Iyyer College of Information and Computer Sciences University
ECE521 Lecture 7/8. Logistic Regression
 ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
ECE521 Lecture 7/8 Logistic Regression Outline Logistic regression (Continue) A single neuron Learning neural networks Multi-class classification 2 Logistic regression The output of a logistic regression
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Christopher Manning Lecture 3: Word Window Classification, Neural Networks, and Matrix Calculus 1. Course plan: coming up Week 2: We learn
Natural Language Processing with Deep Learning CS224N/Ling284 Christopher Manning Lecture 3: Word Window Classification, Neural Networks, and Matrix Calculus 1. Course plan: coming up Week 2: We learn
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
Statistical NLP for the Web
 Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM
![a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM](/thumbs/92/107948882.jpg "a) b) (Natural Language Processing; NLP) (Deep Learning) Bag of words White House RGB [1] IBM") c 1. (Natural Language Processing; NLP) (Deep Learning) RGB IBM 135 8511 5 6 52 yutat@jp.ibm.com a) b) 2. 1 0 2 1 Bag of words White House 2 [1] 2015 4 Copyright c by ORSJ. Unauthorized reproduction of
c 1. (Natural Language Processing; NLP) (Deep Learning) RGB IBM 135 8511 5 6 52 yutat@jp.ibm.com a) b) 2. 1 0 2 1 Bag of words White House 2 [1] 2015 4 Copyright c by ORSJ. Unauthorized reproduction of
Lecture 6: Backpropagation
 Lecture 6: Backpropagation Roger Grosse 1 Introduction So far, we ve seen how to train shallow models, where the predictions are computed as a linear function of the inputs. We ve also observed that deeper
Lecture 6: Backpropagation Roger Grosse 1 Introduction So far, we ve seen how to train shallow models, where the predictions are computed as a linear function of the inputs. We ve also observed that deeper
Lecture 4 Backpropagation
 Lecture 4 Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 5, 2017 Things we will look at today More Backpropagation Still more backpropagation Quiz
Lecture 4 Backpropagation CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 5, 2017 Things we will look at today More Backpropagation Still more backpropagation Quiz
Natural Language Processing
 Natural Language Processing Info 59/259 Lecture 4: Text classification 3 (Sept 5, 207) David Bamman, UC Berkeley . https://www.forbes.com/sites/kevinmurnane/206/04/0/what-is-deep-learning-and-how-is-it-useful
Natural Language Processing Info 59/259 Lecture 4: Text classification 3 (Sept 5, 207) David Bamman, UC Berkeley . https://www.forbes.com/sites/kevinmurnane/206/04/0/what-is-deep-learning-and-how-is-it-useful
Deep Learning for NLP
 Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
Homework 3 COMS 4705 Fall 2017 Prof. Kathleen McKeown
 Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Homework 3 COMS 4705 Fall 017 Prof. Kathleen McKeown The assignment consists of a programming part and a written part. For the programming part, make sure you have set up the development environment as
Lecture 17: Neural Networks and Deep Learning
 UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
UVA CS 6316 / CS 4501-004 Machine Learning Fall 2016 Lecture 17: Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287
 Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
Part-of-Speech Tagging + Neural Networks 3: Word Embeddings CS 287 Review: Neural Networks One-layer multi-layer perceptron architecture, NN MLP1 (x) = g(xw 1 + b 1 )W 2 + b 2 xw + b; perceptron x is the
word2vec Parameter Learning Explained
 word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention in recent two years. The vector
Deep Learning Sequence to Sequence models: Attention Models. 17 March 2018
 Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Deep Learning Sequence to Sequence models: Attention Models 17 March 2018 1 Sequence-to-sequence modelling Problem: E.g. A sequence X 1 X N goes in A different sequence Y 1 Y M comes out Speech recognition:
Deep Learning for NLP
 Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
Deep Learning for NLP CS224N Christopher Manning (Many slides borrowed from ACL 2012/NAACL 2013 Tutorials by me, Richard Socher and Yoshua Bengio) Machine Learning and NLP NER WordNet Usually machine learning
11/3/15. Deep Learning for NLP. Deep Learning and its Architectures. What is Deep Learning? Advantages of Deep Learning (Part 1)
") 11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
11/3/15 Machine Learning and NLP Deep Learning for NLP Usually machine learning works well because of human-designed representations and input features CS224N WordNet SRL Parser Machine learning becomes
Sequence Modeling with Neural Networks
 Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Sequence Modeling with Neural Networks Harini Suresh y 0 y 1 y 2 s 0 s 1 s 2... x 0 x 1 x 2 hat is a sequence? This morning I took the dog for a walk. sentence medical signals speech waveform Successes
Natural Language Processing with Deep Learning. CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Christopher Manning and Richard Socher Classifica6on setup and nota6on Generally
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Christopher Manning and Richard Socher Classifica6on setup and nota6on Generally
NEURAL LANGUAGE MODELS
 COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
COMP90042 LECTURE 14 NEURAL LANGUAGE MODELS LANGUAGE MODELS Assign a probability to a sequence of words Framed as sliding a window over the sentence, predicting each word from finite context to left E.g.,
Deep Learning Recurrent Networks 2/28/2018
 Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Deep Learning Recurrent Networks /8/8 Recap: Recurrent networks can be incredibly effective Story so far Y(t+) Stock vector X(t) X(t+) X(t+) X(t+) X(t+) X(t+5) X(t+) X(t+7) Iterated structures are good
Neural Networks for NLP. COMP-599 Nov 30, 2016
 Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
Neural Networks for NLP COMP-599 Nov 30, 2016 Outline Neural networks and deep learning: introduction Feedforward neural networks word2vec Complex neural network architectures Convolutional neural networks
Neural Networks 2. 2 Receptive fields and dealing with image inputs
 CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
CS 446 Machine Learning Fall 2016 Oct 04, 2016 Neural Networks 2 Professor: Dan Roth Scribe: C. Cheng, C. Cervantes Overview Convolutional Neural Networks Recurrent Neural Networks 1 Introduction There
Understanding How ConvNets See
 Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Understanding How ConvNets See Slides from Andrej Karpathy Springerberg et al, Striving for Simplicity: The All Convolutional Net (ICLR 2015 workshops) CSC321: Intro to Machine Learning and Neural Networks,
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 6
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 6 Slides adapted from Jordan Boyd-Graber, Chris Ketelsen Machine Learning: Chenhao Tan Boulder 1 of 39 HW1 turned in HW2 released Office
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 6 Slides adapted from Jordan Boyd-Graber, Chris Ketelsen Machine Learning: Chenhao Tan Boulder 1 of 39 HW1 turned in HW2 released Office
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
CSC321 Lecture 16: ResNets and Attention
 CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
CSC321 Lecture 16: ResNets and Attention Roger Grosse Roger Grosse CSC321 Lecture 16: ResNets and Attention 1 / 24 Overview Two topics for today: Topic 1: Deep Residual Networks (ResNets) This is the state-of-the
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I
 Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
Lecture 11 Recurrent Neural Networks I CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor niversity of Chicago May 01, 2017 Introduction Sequence Learning with Neural Networks Some Sequence Tasks
CSC321 Lecture 6: Backpropagation
 CSC321 Lecture 6: Backpropagation Roger Grosse Roger Grosse CSC321 Lecture 6: Backpropagation 1 / 21 Overview We ve seen that multilayer neural networks are powerful. But how can we actually learn them?
CSC321 Lecture 6: Backpropagation Roger Grosse Roger Grosse CSC321 Lecture 6: Backpropagation 1 / 21 Overview We ve seen that multilayer neural networks are powerful. But how can we actually learn them?
Deep Learning Lab Course 2017 (Deep Learning Practical)
") Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
Deep Learning Lab Course 207 (Deep Learning Practical) Labs: (Computer Vision) Thomas Brox, (Robotics) Wolfram Burgard, (Machine Learning) Frank Hutter, (Neurorobotics) Joschka Boedecker University of
CS224n: Natural Language Processing with Deep Learning 1
 CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part I 2 Winter 27 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume Genthial,
CS224n: Natural Language Processing with Deep Learning Lecture Notes: Part I 2 Winter 27 Course Instructors: Christopher Manning, Richard Socher 2 Authors: Francois Chaubard, Michael Fang, Guillaume Genthial,
CSC 411 Lecture 10: Neural Networks
 CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC 411 Lecture 10: Neural Networks Roger Grosse, Amir-massoud Farahmand, and Juan Carrasquilla University of Toronto UofT CSC 411: 10-Neural Networks 1 / 35 Inspiration: The Brain Our brain has 10 11
CSC321 Lecture 5: Multilayer Perceptrons
 CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
CSC321 Lecture 5: Multilayer Perceptrons Roger Grosse Roger Grosse CSC321 Lecture 5: Multilayer Perceptrons 1 / 21 Overview Recall the simple neuron-like unit: y output output bias i'th weight w 1 w2 w3
Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT. Slides credit: Graham Neubig
 Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Slides credit: Graham Neubig Outline Perceptron: recap and limitations Neural networks Multi-layer perceptron Forward propagation
Neural networks CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Slides credit: Graham Neubig Outline Perceptron: recap and limitations Neural networks Multi-layer perceptron Forward propagation
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY
 DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
DEEP LEARNING AND NEURAL NETWORKS: BACKGROUND AND HISTORY 1 On-line Resources http://neuralnetworksanddeeplearning.com/index.html Online book by Michael Nielsen http://matlabtricks.com/post-5/3x3-convolution-kernelswith-online-demo
Sparse vectors recap. ANLP Lecture 22 Lexical Semantics with Dense Vectors. Before density, another approach to normalisation.
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Previous lectures: Sparse vectors recap How to represent
ANLP Lecture 22 Lexical Semantics with Dense Vectors
 ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
ANLP Lecture 22 Lexical Semantics with Dense Vectors Henry S. Thompson Based on slides by Jurafsky & Martin, some via Dorota Glowacka 5 November 2018 Henry S. Thompson ANLP Lecture 22 5 November 2018 Previous
Recurrent Neural Networks. Jian Tang
 Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
Recurrent Neural Networks Jian Tang tangjianpku@gmail.com 1 RNN: Recurrent neural networks Neural networks for sequence modeling Summarize a sequence with fix-sized vector through recursively updating
CSC321 Lecture 15: Recurrent Neural Networks
 CSC321 Lecture 15: Recurrent Neural Networks Roger Grosse Roger Grosse CSC321 Lecture 15: Recurrent Neural Networks 1 / 26 Overview Sometimes we re interested in predicting sequences Speech-to-text and
CSC321 Lecture 15: Recurrent Neural Networks Roger Grosse Roger Grosse CSC321 Lecture 15: Recurrent Neural Networks 1 / 26 Overview Sometimes we re interested in predicting sequences Speech-to-text and
Lecture 15: Recurrent Neural Nets
 Lecture 15: Recurrent Neural Nets Roger Grosse 1 Introduction Most of the prediction tasks we ve looked at have involved pretty simple kinds of outputs, such as real values or discrete categories. But
Lecture 15: Recurrent Neural Nets Roger Grosse 1 Introduction Most of the prediction tasks we ve looked at have involved pretty simple kinds of outputs, such as real values or discrete categories. But
Neural Network Language Modeling
 Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
Neural Network Language Modeling Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Marek Rei, Philipp Koehn and Noah Smith Course Project Sign up your course project In-class presentation
Introduction to Deep Learning
 Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2015 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2015 1 / 39 Outline 1 Universality of Neural Networks
Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2015 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2015 1 / 39 Outline 1 Universality of Neural Networks
Natural Language Processing with Deep Learning CS224N/Ling284. Richard Socher Lecture 2: Word Vectors
 Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
Natural Language Processing with Deep Learning CS224N/Ling284 Richard Socher Lecture 2: Word Vectors Organization PSet 1 is released. Coding Session 1/22: (Monday, PA1 due Thursday) Some of the questions
Natural Language Processing with Deep Learning. CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Christopher Manning and Richard Socher Overview Today: Classifica(on background Upda(ng
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Christopher Manning and Richard Socher Overview Today: Classifica(on background Upda(ng
Deep Learning (CNNs)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deep Learning (CNNs) Deep Learning Readings: Murphy 28 Bishop - - HTF - - Mitchell
Midterm for CSC321, Intro to Neural Networks Winter 2018, night section Tuesday, March 6, 6:10-7pm
 Midterm for CSC321, Intro to Neural Networks Winter 2018, night section Tuesday, March 6, 6:10-7pm Name: Student number: This is a closed-book test. It is marked out of 15 marks. Please answer ALL of the
Midterm for CSC321, Intro to Neural Networks Winter 2018, night section Tuesday, March 6, 6:10-7pm Name: Student number: This is a closed-book test. It is marked out of 15 marks. Please answer ALL of the
Regularization Introduction to Machine Learning. Matt Gormley Lecture 10 Feb. 19, 2018
 1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
CSC321 Lecture 15: Exploding and Vanishing Gradients
 CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
CSC321 Lecture 15: Exploding and Vanishing Gradients Roger Grosse Roger Grosse CSC321 Lecture 15: Exploding and Vanishing Gradients 1 / 23 Overview Yesterday, we saw how to compute the gradient descent
Artificial Neural Networks 2
 CSC2515 Machine Learning Sam Roweis Artificial Neural s 2 We saw neural nets for classification. Same idea for regression. ANNs are just adaptive basis regression machines of the form: y k = j w kj σ(b
CSC2515 Machine Learning Sam Roweis Artificial Neural s 2 We saw neural nets for classification. Same idea for regression. ANNs are just adaptive basis regression machines of the form: y k = j w kj σ(b
Lecture 6: Neural Networks for Representing Word Meaning
 Lecture 6: Neural Networks for Representing Word Meaning Mirella Lapata School of Informatics University of Edinburgh mlap@inf.ed.ac.uk February 7, 2017 1 / 28 Logistic Regression Input is a feature vector,
Lecture 6: Neural Networks for Representing Word Meaning Mirella Lapata School of Informatics University of Edinburgh mlap@inf.ed.ac.uk February 7, 2017 1 / 28 Logistic Regression Input is a feature vector,
Structured Neural Networks (I)
") Structured Neural Networks (I) CS 690N, Spring 208 Advanced Natural Language Processing http://peoplecsumassedu/~brenocon/anlp208/ Brendan O Connor College of Information and Computer Sciences University
Structured Neural Networks (I) CS 690N, Spring 208 Advanced Natural Language Processing http://peoplecsumassedu/~brenocon/anlp208/ Brendan O Connor College of Information and Computer Sciences University
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
CSC321 Lecture 2: Linear Regression
 CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
CSC32 Lecture 2: Linear Regression Roger Grosse Roger Grosse CSC32 Lecture 2: Linear Regression / 26 Overview First learning algorithm of the course: linear regression Task: predict scalar-valued targets,
CSC321 Lecture 9 Recurrent neural nets
 CSC321 Lecture 9 Recurrent neural nets Roger Grosse and Nitish Srivastava February 3, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 9 Recurrent neural nets February 3, 2015 1 / 20 Overview You
CSC321 Lecture 9 Recurrent neural nets Roger Grosse and Nitish Srivastava February 3, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 9 Recurrent neural nets February 3, 2015 1 / 20 Overview You
Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets)
") COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 8: Introduction to Deep Learning: Part 2 (More on backpropagation, and ConvNets) Sanjeev Arora Elad Hazan Recap: Structure of a deep
CSC321 Lecture 5 Learning in a Single Neuron
 CSC321 Lecture 5 Learning in a Single Neuron Roger Grosse and Nitish Srivastava January 21, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 5 Learning in a Single Neuron January 21, 2015 1 / 14
CSC321 Lecture 5 Learning in a Single Neuron Roger Grosse and Nitish Srivastava January 21, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 5 Learning in a Single Neuron January 21, 2015 1 / 14
Supervised Learning. George Konidaris
 Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Supervised Learning George Konidaris gdk@cs.brown.edu Fall 2017 Machine Learning Subfield of AI concerned with learning from data. Broadly, using: Experience To Improve Performance On Some Task (Tom Mitchell,
Introduction to Deep Learning
 Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2014 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2014 1 / 35 Outline 1 Universality of Neural Networks
Introduction to Deep Learning A. G. Schwing & S. Fidler University of Toronto, 2014 A. G. Schwing & S. Fidler (UofT) CSC420: Intro to Image Understanding 2014 1 / 35 Outline 1 Universality of Neural Networks
Neural Networks. Single-layer neural network. CSE 446: Machine Learning Emily Fox University of Washington March 10, /9/17
 3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
3/9/7 Neural Networks Emily Fox University of Washington March 0, 207 Slides adapted from Ali Farhadi (via Carlos Guestrin and Luke Zettlemoyer) Single-layer neural network 3/9/7 Perceptron as a neural
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
arxiv: v3 [cs.cl] 30 Jan 2016
![arxiv: v3 [cs.cl] 30 Jan 2016](/thumbs/72/66377864.jpg "arxiv: v3 [cs.cl] 30 Jan 2016") word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu arxiv:1411.2738v3 [cs.cl] 30 Jan 2016 Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention
word2vec Parameter Learning Explained Xin Rong ronxin@umich.edu arxiv:1411.2738v3 [cs.cl] 30 Jan 2016 Abstract The word2vec model and application by Mikolov et al. have attracted a great amount of attention
Lecture 15: Exploding and Vanishing Gradients
 Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
Lecture 15: Exploding and Vanishing Gradients Roger Grosse 1 Introduction Last lecture, we introduced RNNs and saw how to derive the gradients using backprop through time. In principle, this lets us train
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Deep Learning Basics Lecture 10: Neural Language Models. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
Deep Learning Basics Lecture 10: Neural Language Models Princeton University COS 495 Instructor: Yingyu Liang Natural language Processing (NLP) The processing of the human languages by computers One of
Instructions for NLP Practical (Units of Assessment) SVM-based Sentiment Detection of Reviews (Part 2)
 SVM-based Sentiment Detection of Reviews (Part 2)") Instructions for NLP Practical (Units of Assessment) SVM-based Sentiment Detection of Reviews (Part 2) Simone Teufel (Lead demonstrator Guy Aglionby) sht25@cl.cam.ac.uk; ga384@cl.cam.ac.uk This is the
Instructions for NLP Practical (Units of Assessment) SVM-based Sentiment Detection of Reviews (Part 2) Simone Teufel (Lead demonstrator Guy Aglionby) sht25@cl.cam.ac.uk; ga384@cl.cam.ac.uk This is the
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSC321 Lecture 10 Training RNNs
 CSC321 Lecture 10 Training RNNs Roger Grosse and Nitish Srivastava February 23, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 10 Training RNNs February 23, 2015 1 / 18 Overview Last time, we saw
CSC321 Lecture 10 Training RNNs Roger Grosse and Nitish Srivastava February 23, 2015 Roger Grosse and Nitish Srivastava CSC321 Lecture 10 Training RNNs February 23, 2015 1 / 18 Overview Last time, we saw
Neural networks COMS 4771
 Neural networks COMS 4771 1. Logistic regression Logistic regression Suppose X = R d and Y = {0, 1}. A logistic regression model is a statistical model where the conditional probability function has a
Neural networks COMS 4771 1. Logistic regression Logistic regression Suppose X = R d and Y = {0, 1}. A logistic regression model is a statistical model where the conditional probability function has a
Bayesian Paragraph Vectors
 Bayesian Paragraph Vectors Geng Ji 1, Robert Bamler 2, Erik B. Sudderth 1, and Stephan Mandt 2 1 Department of Computer Science, UC Irvine, {gji1, sudderth}@uci.edu 2 Disney Research, firstname.lastname@disneyresearch.com
Bayesian Paragraph Vectors Geng Ji 1, Robert Bamler 2, Erik B. Sudderth 1, and Stephan Mandt 2 1 Department of Computer Science, UC Irvine, {gji1, sudderth}@uci.edu 2 Disney Research, firstname.lastname@disneyresearch.com
Neural Networks Learning the network: Backprop , Fall 2018 Lecture 4
 Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Neural Networks Learning the network: Backprop 11-785, Fall 2018 Lecture 4 1 Recap: The MLP can represent any function The MLP can be constructed to represent anything But how do we construct it? 2 Recap:
Deep Learning For Mathematical Functions
 000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
000 001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050
Introduction to Machine Learning Spring 2018 Note Neural Networks
 CS 189 Introduction to Machine Learning Spring 2018 Note 14 1 Neural Networks Neural networks are a class of compositional function approximators. They come in a variety of shapes and sizes. In this class,
CS 189 Introduction to Machine Learning Spring 2018 Note 14 1 Neural Networks Neural networks are a class of compositional function approximators. They come in a variety of shapes and sizes. In this class,
Other Topologies. Y. LeCun: Machine Learning and Pattern Recognition p. 5/3
 Y. LeCun: Machine Learning and Pattern Recognition p. 5/3 Other Topologies The back-propagation procedure is not limited to feed-forward cascades. It can be applied to networks of module with any topology,
Y. LeCun: Machine Learning and Pattern Recognition p. 5/3 Other Topologies The back-propagation procedure is not limited to feed-forward cascades. It can be applied to networks of module with any topology,
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam
 CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
CS224N: Natural Language Processing with Deep Learning Winter 2018 Midterm Exam This examination consists of 17 printed sides, 5 questions, and 100 points. The exam accounts for 20% of your total grade.
Recurrent Neural Networks Deep Learning Lecture 5. Efstratios Gavves
 Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Recurrent Neural Networks Deep Learning Lecture 5 Efstratios Gavves Sequential Data So far, all tasks assumed stationary data Neither all data, nor all tasks are stationary though Sequential Data: Text
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Convolutional Neural Networks
 Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
Convolutional Neural Networks Books» http://www.deeplearningbook.org/ Books http://neuralnetworksanddeeplearning.com/.org/ reviews» http://www.deeplearningbook.org/contents/linear_algebra.html» http://www.deeplearningbook.org/contents/prob.html»
ML4NLP Multiclass Classification
 ML4NLP Multiclass Classification CS 590NLP Dan Goldwasser Purdue University dgoldwas@purdue.edu Social NLP Last week we discussed the speed-dates paper. Interesting perspective on NLP problems- Can we
ML4NLP Multiclass Classification CS 590NLP Dan Goldwasser Purdue University dgoldwas@purdue.edu Social NLP Last week we discussed the speed-dates paper. Interesting perspective on NLP problems- Can we
Recurrent Neural Networks. COMP-550 Oct 5, 2017
 Recurrent Neural Networks COMP-550 Oct 5, 2017 Outline Introduction to neural networks and deep learning Feedforward neural networks Recurrent neural networks 2 Classification Review y = f( x) output label
Recurrent Neural Networks COMP-550 Oct 5, 2017 Outline Introduction to neural networks and deep learning Feedforward neural networks Recurrent neural networks 2 Classification Review y = f( x) output label
Semantics with Dense Vectors. Reference: D. Jurafsky and J. Martin, Speech and Language Processing
 Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Semantics with Dense Vectors Reference: D. Jurafsky and J. Martin, Speech and Language Processing 1 Semantics with Dense Vectors We saw how to represent a word as a sparse vector with dimensions corresponding
Lecture 35: Optimization and Neural Nets
 Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
Lecture 35: Optimization and Neural Nets CS 4670/5670 Sean Bell DeepDream [Google, Inceptionism: Going Deeper into Neural Networks, blog 2015] Aside: CNN vs ConvNet Note: There are many papers that use
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 3 Linear
Machine Learning (CSE 446): Backpropagation
: Backpropagation") Machine Learning (CSE 446): Backpropagation Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 8, 2017 1 / 32 Neuron-Inspired Classifiers correct output y n L n loss hidden units
Machine Learning (CSE 446): Backpropagation Noah Smith c 2017 University of Washington nasmith@cs.washington.edu November 8, 2017 1 / 32 Neuron-Inspired Classifiers correct output y n L n loss hidden units
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
CSE446: Neural Networks Spring Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer
 CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
CSE446: Neural Networks Spring 2017 Many slides are adapted from Carlos Guestrin and Luke Zettlemoyer Human Neurons Switching time ~ 0.001 second Number of neurons 10 10 Connections per neuron 10 4-5 Scene
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
(Feed-Forward) Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann
 Neural Networks Dr. Hajira Jabeen, Prof. Jens Lehmann") (Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
(Feed-Forward) Neural Networks 2016-12-06 Dr. Hajira Jabeen, Prof. Jens Lehmann Outline In the previous lectures we have learned about tensors and factorization methods. RESCAL is a bilinear model for
An overview of word2vec
 An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
An overview of word2vec Benjamin Wilson Berlin ML Meetup, July 8 2014 Benjamin Wilson word2vec Berlin ML Meetup 1 / 25 Outline 1 Introduction 2 Background & Significance 3 Architecture 4 CBOW word representations
Natural Language Processing and Recurrent Neural Networks
 Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
Natural Language Processing and Recurrent Neural Networks Pranay Tarafdar October 19 th, 2018 Outline Introduction to NLP Word2vec RNN GRU LSTM Demo What is NLP? Natural Language? : Huge amount of information
CSCI 252: Neural Networks and Graphical Models. Fall Term 2016 Prof. Levy. Architecture #7: The Simple Recurrent Network (Elman 1990)
") CSCI 252: Neural Networks and Graphical Models Fall Term 2016 Prof. Levy Architecture #7: The Simple Recurrent Network (Elman 1990) Part I Multi-layer Neural Nets Taking Stock: What can we do with neural
CSCI 252: Neural Networks and Graphical Models Fall Term 2016 Prof. Levy Architecture #7: The Simple Recurrent Network (Elman 1990) Part I Multi-layer Neural Nets Taking Stock: What can we do with neural