ML4NLP Multiclass Classification
|
|
|
- Charleen Beryl Charles
- 5 years ago
- Views:
Transcription

1 ML4NLP Multiclass Classification CS 590NLP Dan Goldwasser Purdue University
2 Social NLP Last week we discussed the speed-dates paper. Interesting perspective on NLP problems- Can we use NLP methods in social science research? Key idea: Find a problem in the real world that you can about. DEFINE THE PROBLEM FORMALLY Identify relevant NLP tools that can measure what you are interested in. Evaluate whether they actually do. Use NLP tools to process large amounts of data and say something meaningful about the world that you couldn't before.
3 Some (free!) pointers for further reading Linguistic Structure Prediction. Noah Smith. 61ED1V01Y201105HLT013 Structured Learning and Prediction in Computer Vision. Nowozin and Lampert 1structured-tutorial.pdf Speech and Language Processing. Jurafsky and Martin
4 Classification A fundamental machine learning tool Widely applicable in NLP Supervised learning: Learner is given a collection of labeled documents s: Spam/not spam; Reviews: Pos/Neg Build a function mapping documents to labels Key property: Generalization function should work well on new data
5 Learning as Optimization Discriminative Linear classifiers So far we looked perceptron Combines model (linear representation) with algorithm (update rule) Let s try to abstract we want to find a linear function performing best on the data What are good properties of this classifier? Want to explicitly control for error + simplicity How can we discuss these terms separately from a specific algorithm? Search space of all possible linear functions Find a specific function that has certain properties..
6 So far: Classification General optimization framework for learning Minimize regularized loss function min w = n loss(y n, w n )+ λ 2 w 2 Gradient descent is an all purpose tool Computed the gradient of the square loss function 6
7 Surrogate Loss functions Surrogate loss function: smooth approximation to the 0-1 loss Upper bound to 0-1 loss 7


8 Convex Error Surfaces Convex functions have a single minimum point Local minimum = global minimum Easier to optimize (Empirical) Error Convex error functions have no local minima Global Minimum Hypothesis space 8
9 Gradient Descent Intuition (3) We also need to determine the step size (aka learning rate). What happens if we overshoot? (1) The derivative of the function at w 1 is the slope of the tangent line à Positive slope (increasing) Which direction should we move to decrease the value of Err(w)? w 3 w 4 w 2 What is the gradient of Error(w) at this point? w 1 (2) The gradient determines the direction of steepest increase of Err(w) (go in the opposite direction) 9
10 Maximal Margin Classification Motivation for the notion of maximal margin Defined w.r.t. a dataset S :
11 Some Definitions Margin: distance of the closest point from a hyperplane This is known as the geometric margin, the numerator is known as the functional margin γ =min x i,y i y i (w T x i + b) w Our new objective function Learning is essentially solving: max w γ

12 Maximal Margin We want to find max w Observation: we don t care about the magnitude of w! Set the functional margin to 1, and minimize W max γ w is equivalent to min w w in this setting To make life easy: let s minimize min w w 2 γ x 1 + x 2 = 0 10x x 2 = 0 100x x 2 =0 12
13 Hard vs. Soft SVM Minimize: ½ w 2 Subject to: (x,y) S: y w T x 1 Minimize: ½ w 2 + c Σ ι ξ i Subject to: (x,y) S: y i w T x i 1-ξ i ; ξ i >0, i=1 m 13
14 Objective Function for Soft SVM The relaxation of the constraint: y i w it x i 1 can be done by introducing a slack variable ξ (per example) and requiring: y i w it x i 1 - ξ i ; (ξ i ) Now, we want to solve: Min ½ w 2 + c Σ ξ i (subject to ξ i 0) Which can be written as: Min ½ w 2 + c Σ max(0, 1 y i w T x i ). What is the interpretation of this? This is the Hinge loss function 14
15 Generalization into Multiclass problems
16 Multiclass classification Tasks So far, our discussion was limited to binary predictions Well, almost (?) What happens if our decision is not over binary labels? Many interesting classification problems are not! POS: Noun,verb, determiner,.. Document classification: sports, finance, politics Sentiment: Positive, negative, objective How can we approach these problems? Can the problem be reduced into a binary classification problem? Hint: What is the computer science solution to: I can solve problem A, but now I have problem B, so 16
17 Multiclass classification We will look into two approaches: Combining multiple binary classifiers One-vs-All All-vs-All Training a single classifier Extending SVM to the multiclass case
18 One-Vs-All Assumption: Each class can be separated from the rest using a binary classifier Learning: Decomposed to learning k independent binary classifiers, one corresponding to each class An example (x,y) is considered positive for class y and negative to all others. Assume m examples, k class labels (assume m/k in each) Classifier f i : m/k (positive) and (k-1)m/k (negative) Decision: Winner Takes All: f(x) = argmax i f i (x) = argmax i (v i x) Q: Why do we need the assumption above? 18
19 sd Example: One-vs-All
20 Solving Multi-Class with binary learning Multi-Class classifier Function f : x à {1,2,3,...,k} Decompose into binary problems Not always possible to learn 20
21 Learning via One-Versus-All Find v r,v b,v g,v y R n such that v r x > 0 iff y = red L v b x > 0 iff y = blue J v g x > 0 iff y = green J v y x > 0 iff y = yellow J H = R kn Real Problem Classification: f(x) = argmax i (v i x)
22 All-vs-All Assumption: There is a separation between every pair of classes using a binary classifier in the hypothesis space. Learning: Decomposed to learning [k choose 2] ~ k 2 independent binary classifiers, separating between every two classes Assume m examples, k class labels. For simplicity, say, m/k in each. Classifier f ij : m/k (positive) and m/k (negative) Decision: Winner Decision procedure is more involved since output of binary classifier may not cohere (transitivity no ensured) : Majority: classify example x to label i if i wins on it more often that j (j=1, k) Tournament: start with n/2 pairs; continue with winners
23 s All-vs-All
24 Multiclass by reduction to Binary Decompose the multiclass learning problem into multiple binary learning problems Prediction: combine binary classifiers Learning: optimize local correctness No global view Separation between learning and prediction procedures We can train the classifier to meet the REAL objective Real objective: final performance, not local metric
25 Multiclass SVM Single classifier optimizing a global objective Extend the SVM framework to the multiclass settings Binary SVM: Minimize W such that the closest points to the hyperplane have a score of +/- 1 Multiclass SVM Each label has a different weight vector Maximize multiclass margin


26 Margin in the Multiclass case Revise the definition for the multiclass case: The difference between the score of the correct label and the scores of competing labels margin Colors indicate different labels SVM Objective: Minimize total norm of weights s.t. the 26 true label is scored at least 1 more than the second best.
27 Hard Multiclass SVM Regularization The score of the true label has to be higher than 1, for any label
28 Soft Multiclass SVM asd Regularizer Slack Variables The score of the true label should have a margin of 1-ξ i Relax hard constraints using slack variables Positive slack Introduction to Machine Learning. Fall K. Crammer, Y. Singer: On the Algorithmic Implementation of Multiclass Kernel-based Vector Machines, JMLR, 2001
29 Alternative Notation For examples with label i we want: w it x > w jt x Alternative notation: Stack all weight vectors Define features jointly over the input and output is equivalent to w it x > w jt x
30 Multiclass classification so far Learning: Prediction 30




31 Cost Sensitive Multiclass Classification Sometime we are willing to tolerate some mistakes more than others 31
32 Cost Sensitive Multiclass Classification We can think about it as a hierarchy: Define a distance metric: Δ(y,y ) = tree distance between y and y We would like to incorporate that into our learning model Introduction to Machine Learning. Fall

33 Cost Sensitive Multiclass Classification We can think about it as a hierarchy: Define a distance metric: Δ(y,y ) = tree distance between y and y We would like to incorporate that into our learning model Introduction to Machine Learning. Fall
34 Cost Sensitive Multiclass Classification Instead we can have an unconstrained version - l(w;(x n,y n )) l(w;(x n,y n )) = max y Y (y, y ) w,φ(x n,y n ) + w,φ(x n,y ) Introduction to Machine Learning. Fall
35 Reminder: Subgradient descent asdas Slides by Sebastian Nowozinand Christoph H. Lampert structured models in computer vision tutorial CVPR 2011 Introduction to Machine Learning. Fall
36 Reminder: Subgradient descent Slides by Sebastian Nowozinand Christoph H. Lampert structured models in computer vision tutorial CVPR
37 Reminder: Subgradient descent Slides by Sebastian Nowozinand Christoph H. Lampert structured models in computer vision tutorial CVPR

38 Reminder: Subgradient descent Slides by Sebastian Nowozinand Christoph H. Lampert structured models in computer vision tutorial CVPR
39 Subgradient for the MC case 39
40 Subgradient for the MC case 40
41 Subgradient for the MC case 41
42 Subgradient for the MC case 42
43 Subgradient for the MC case 43

44 Subgradient descent for the MC case Introduction to Machine Learning. Fall

45 Subgradient descent for the MC case asd Question: What is the difference between this algorithm and the perceptron variant for multiclass classification? Introduction to Machine Learning. Fall
46 Can you define NER as a multiclass classification problem? Named entity recognition (NER) Identify mentions of named entity in text People (PER), places (LOC) and organizations (ORG) Begin p Barak Obama visited Mount Sinai hospital in New York PER ORG LOC Conceptually two considerations: Entity boundary (Begin, Inside,Outside) Entity type (PER,ORG,LOC) Given a sentence, are consecutive predictions independent of each other? Our Labels: Begin p,begin L,Begin o Inside p,inside L,Inside o Outside 46
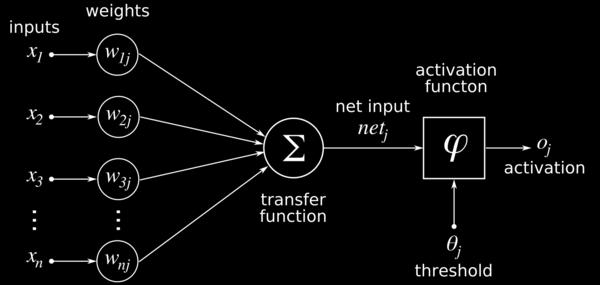
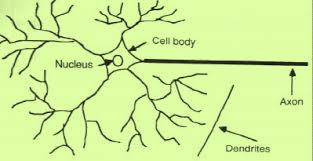
47 Introduction to Deep Learning
48 Deep Learning in NLP So far we used linear models They work fine, but we made some assumptions The problems are linear, or we are willing to work in order to make them linear Feature engineering is a form of expressing domain knowledge We are fine working with very very high dimensional data It s easy to get there. Everything is mostly linear at that point. What could go wrong?
49 Deep Learning Architectures for NLP The key question we follow how can you build complex (compositional?) meaning representation, for larger units than words, to support advanced classification tasks? We will look at several popular architectures. We will build on a recently introduced model from the 70 s Maybe even before that.. NN made a come-back in the last 5 years.
50 Neural Networks Robust approach for approximating functions Functions can be real-valued, discrete or vector valued One of the most effective general purpose learning methods A lot of attention in the 90 s, making a comeback! Especially useful for complex problems, where the input data is hard to interpret Sensory data (speech, vision, etc) Many successful application domains Interesting spin: Learning input representation So far we thought about the feature representation as being fixed 50
51 Neural Network Simply put, NN s are functions f: XàY f is a non-linear function X is a vector of continuous or discrete variables Y is a vector of continuous or discrete variables Very expressive classifier In fact, NN can be used to represent any function The function f is represented using a network of logistic units Introduction to Machine Learning. Fall
52 Multi Layer Neural Networks Multi-layer network were designed to overcome the computational (expressivity) limitation of a single threshold element. The idea is to stack several layers of threshold elements, each layer using the output of the previous layer as input Multi-layer networks can represent arbitrary functions, but building effective learning methods for such network was [thought to be] difficult. activation Output Hidden Input 52
53 Example: NN for speech vowel recognition Introduction to Machine Learning. Fall


54 ALVINN: autonomous land vehicle in a NN Pomerleau 89 Introduction to Machine Learning. Fall
55 ALVINN: autonomous land vehicle in a NN Introduction to Machine Learning. Fall
56 Basic Units in Multi-Layer NN Basic element: linear unit But, we would like to represent nonlinear functions Multiple layers of linear functions are still linear functions Threshold units are not smooth (we would like to use gradient-based algorithms) activation Output Hidden Input Introduction to Machine Learning. Fall
57 Basic Units in Multi-Layer NN Basic element: sigmoid unit Input to a unit j is defined as: Σw ij x i Output is defined as : σ (Σw ij x i ) σ is simply the logistic function: Note: similar to previous algorithms, We encode the bias/threshold, as a fake Feature that is always active Introduction to Machine Learning. Fall
58 Basic Units in Multi-Layer NN Basic element: sigmoid unit You can also replace the logistic function with other smooth activation functions Introduction to Machine Learning. Fall
59 Basic Units in Multi-Layer NN Key issue: limited expressivity! Minsky and Papert (1969) published an influential books showing what cannot be learned using perceptron These observation discouraged research on NN for several years But.. we really like linear functions! How did we deal with these issues so far? Introduction to Machine Learning. Fall
60 Basic Units in Multi-Layer NN In fact, Rosenblatt (1959) asked: What pattern recognition problems can be transformed so as to become linearly separable Introduction to Machine Learning. Fall
61 Multi Layer NN Another approach for increasing expressivity: Stacking multiple sigmoid units to form a network Compute the output of the network using a feedforward computation Learn the parameters of the network using the backpropagation algorithm Any Boolean function can be represented using a two layer network Any bounded continuous function can be approximated using a two layer network Introduction to Machine Learning. Fall
Multiclass Classification-1
 CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
Administration. Registration Hw3 is out. Lecture Captioning (Extra-Credit) Scribing lectures. Questions. Due on Thursday 10/6
 Scribing lectures. Questions. Due on Thursday 10/6") Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Administration Registration Hw3 is out Due on Thursday 10/6 Questions Lecture Captioning (Extra-Credit) Look at Piazza for details Scribing lectures With pay; come talk to me/send email. 1 Projects Projects
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
From Binary to Multiclass Classification. CS 6961: Structured Prediction Spring 2018
 From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
Lecture 3: Multiclass Classification
 Lecture 3: Multiclass Classification Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Some slides are adapted from Vivek Skirmar and Dan Roth CS6501 Lecture 3 1 Announcement v Please enroll in
Lecture 3: Multiclass Classification Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Some slides are adapted from Vivek Skirmar and Dan Roth CS6501 Lecture 3 1 Announcement v Please enroll in
Lecture Support Vector Machine (SVM) Classifiers
 Classifiers") Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Natural Language Processing (CSEP 517): Text Classification
: Text Classification") Natural Language Processing (CSEP 517): Text Classification Noah Smith c 2017 University of Washington nasmith@cs.washington.edu April 10, 2017 1 / 71 To-Do List Online quiz: due Sunday Read: Jurafsky
Natural Language Processing (CSEP 517): Text Classification Noah Smith c 2017 University of Washington nasmith@cs.washington.edu April 10, 2017 1 / 71 To-Do List Online quiz: due Sunday Read: Jurafsky
Midterms. PAC Learning SVM Kernels+Boost Decision Trees. MultiClass CS446 Spring 17
 Midterms PAC Learning SVM Kernels+Boost Decision Trees 1 Grades are on a curve Midterms Will be available at the TA sessions this week Projects feedback has been sent. Recall that this is 25% of your grade!
Midterms PAC Learning SVM Kernels+Boost Decision Trees 1 Grades are on a curve Midterms Will be available at the TA sessions this week Projects feedback has been sent. Recall that this is 25% of your grade!
CSC321 Lecture 4: Learning a Classifier
 CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 28 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 28 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CS 446: Machine Learning Lecture 4, Part 2: On-Line Learning
 CS 446: Machine Learning Lecture 4, Part 2: On-Line Learning 0.1 Linear Functions So far, we have been looking at Linear Functions { as a class of functions which can 1 if W1 X separate some data and not
CS 446: Machine Learning Lecture 4, Part 2: On-Line Learning 0.1 Linear Functions So far, we have been looking at Linear Functions { as a class of functions which can 1 if W1 X separate some data and not
Linear models: the perceptron and closest centroid algorithms. D = {(x i,y i )} n i=1. x i 2 R d 9/3/13. Preliminaries. Chapter 1, 7.
} n i=1. x i 2 R d 9/3/13. Preliminaries. Chapter 1, 7.") Preliminaries Linear models: the perceptron and closest centroid algorithms Chapter 1, 7 Definition: The Euclidean dot product beteen to vectors is the expression d T x = i x i The dot product is also
Preliminaries Linear models: the perceptron and closest centroid algorithms Chapter 1, 7 Definition: The Euclidean dot product beteen to vectors is the expression d T x = i x i The dot product is also
Course 395: Machine Learning - Lectures
 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture
AN INTRODUCTION TO NEURAL NETWORKS. Scott Kuindersma November 12, 2009
 AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
AN INTRODUCTION TO NEURAL NETWORKS Scott Kuindersma November 12, 2009 SUPERVISED LEARNING We are given some training data: We must learn a function If y is discrete, we call it classification If it is
CSC 411 Lecture 17: Support Vector Machine
 CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
Machine Learning for NLP
 Machine Learning for NLP Uppsala University Department of Linguistics and Philology Slides borrowed from Ryan McDonald, Google Research Machine Learning for NLP 1(50) Introduction Linear Classifiers Classifiers
Machine Learning for NLP Uppsala University Department of Linguistics and Philology Slides borrowed from Ryan McDonald, Google Research Machine Learning for NLP 1(50) Introduction Linear Classifiers Classifiers
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Warm up: risk prediction with logistic regression
 Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
Warm up: risk prediction with logistic regression Boss gives you a bunch of data on loans defaulting or not: {(x i,y i )} n i= x i 2 R d, y i 2 {, } You model the data as: P (Y = y x, w) = + exp( yw T
CSC321 Lecture 4: Learning a Classifier
 CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 31 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
CSC321 Lecture 4: Learning a Classifier Roger Grosse Roger Grosse CSC321 Lecture 4: Learning a Classifier 1 / 31 Overview Last time: binary classification, perceptron algorithm Limitations of the perceptron
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Introduction to Logistic Regression and Support Vector Machine
 Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Introduction to Logistic Regression and Support Vector Machine guest lecturer: Ming-Wei Chang CS 446 Fall, 2009 () / 25 Fall, 2009 / 25 Before we start () 2 / 25 Fall, 2009 2 / 25 Before we start Feel
Kernelized Perceptron Support Vector Machines
 Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Neural Networks: Introduction
 Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Neural Networks: Introduction Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others 1
Machine Learning for NLP
 Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Machine Learning for NLP Linear Models Joakim Nivre Uppsala University Department of Linguistics and Philology Slides adapted from Ryan McDonald, Google Research Machine Learning for NLP 1(26) Outline
Support Vector Machines: Training with Stochastic Gradient Descent. Machine Learning Fall 2017
 Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w x + w 2 x 2 + w 0 = 0 Feature x 2 = w w 2 x w 0 w 2 Feature 2 A perceptron can separate
Natural Language Processing. Classification. Features. Some Definitions. Classification. Feature Vectors. Classification I. Dan Klein UC Berkeley
 Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Natural Language Processing Classification Classification I Dan Klein UC Berkeley Classification Automatically make a decision about inputs Example: document category Example: image of digit digit Example:
Lecture 12. Neural Networks Bastian Leibe RWTH Aachen
 Advanced Machine Learning Lecture 12 Neural Networks 10.12.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Advanced Machine Learning Lecture 12 Neural Networks 10.12.2015 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de/ leibe@vision.rwth-aachen.de This Lecture: Advanced Machine Learning Regression
Multi-class SVMs. Lecture 17: Aykut Erdem April 2016 Hacettepe University
 Multi-class SVMs Lecture 17: Aykut Erdem April 2016 Hacettepe University Administrative We will have a make-up lecture on Saturday April 23, 2016. Project progress reports are due April 21, 2016 2 days
Multi-class SVMs Lecture 17: Aykut Erdem April 2016 Hacettepe University Administrative We will have a make-up lecture on Saturday April 23, 2016. Project progress reports are due April 21, 2016 2 days
COMP 875 Announcements
 Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
Deep Learning for Computer Vision
 Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Deep Learning for Computer Vision Lecture 4: Curse of Dimensionality, High Dimensional Feature Spaces, Linear Classifiers, Linear Regression, Python, and Jupyter Notebooks Peter Belhumeur Computer Science
Gaussian and Linear Discriminant Analysis; Multiclass Classification
 Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Gaussian and Linear Discriminant Analysis; Multiclass Classification Professor Ameet Talwalkar Slide Credit: Professor Fei Sha Professor Ameet Talwalkar CS260 Machine Learning Algorithms October 13, 2015
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Hsuan-Tien Lin Learning Systems Group, California Institute of Technology Talk in NTU EE/CS Speech Lab, November 16, 2005 H.-T. Lin (Learning Systems Group) Introduction
Introduction to Support Vector Machines Hsuan-Tien Lin Learning Systems Group, California Institute of Technology Talk in NTU EE/CS Speech Lab, November 16, 2005 H.-T. Lin (Learning Systems Group) Introduction
Multilayer Neural Networks. (sometimes called Multilayer Perceptrons or MLPs)
") Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
Multilayer Neural Networks (sometimes called Multilayer Perceptrons or MLPs) Linear separability Hyperplane In 2D: w 1 x 1 + w 2 x 2 + w 0 = 0 Feature 1 x 2 = w 1 w 2 x 1 w 0 w 2 Feature 2 A perceptron
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Online Videos FERPA. Sign waiver or sit on the sides or in the back. Off camera question time before and after lecture. Questions?
 Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Online Videos FERPA Sign waiver or sit on the sides or in the back Off camera question time before and after lecture Questions? Lecture 1, Slide 1 CS224d Deep NLP Lecture 4: Word Window Classification
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Neural networks and support vector machines
 Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Neural netorks and support vector machines Perceptron Input x 1 Weights 1 x 2 x 3... x D 2 3 D Output: sgn( x + b) Can incorporate bias as component of the eight vector by alays including a feature ith
Machine Learning for Structured Prediction
 Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
18.9 SUPPORT VECTOR MACHINES
 744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
SGD and Deep Learning
 SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
SGD and Deep Learning Subgradients Lets make the gradient cheating more formal. Recall that the gradient is the slope of the tangent. f(w 1 )+rf(w 1 ) (w w 1 ) Non differentiable case? w 1 Subgradients
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Machine Learning Neural Networks (slides from Domingos, Pardo, others) Human Brain Neurons Input-Output Transformation Input Spikes Output Spike Spike (= a brief pulse) (Excitatory Post-Synaptic Potential)
Neural Networks: Backpropagation
 Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Neural Networks: Backpropagation Machine Learning Fall 2017 Based on slides and material from Geoffrey Hinton, Richard Socher, Dan Roth, Yoav Goldberg, Shai Shalev-Shwartz and Shai Ben-David, and others
Lecture 4: Training a Classifier
 Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Lecture 4: Training a Classifier Roger Grosse 1 Introduction Now that we ve defined what binary classification is, let s actually train a classifier. We ll approach this problem in much the same way as
Neural Networks biological neuron artificial neuron 1
 Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Neural Networks biological neuron artificial neuron 1 A two-layer neural network Output layer (activation represents classification) Weighted connections Hidden layer ( internal representation ) Input
Machine Learning and Data Mining. Linear classification. Kalev Kask
 Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Machine Learning and Data Mining Linear classification Kalev Kask Supervised learning Notation Features x Targets y Predictions ŷ = f(x ; q) Parameters q Program ( Learner ) Learning algorithm Change q
Day 4: Classification, support vector machines
 Day 4: Classification, support vector machines Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 21 June 2018 Topics so far
Day 4: Classification, support vector machines Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 21 June 2018 Topics so far
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Statistical NLP Spring A Discriminative Approach
 Statistical NLP Spring 2008 Lecture 6: Classification Dan Klein UC Berkeley A Discriminative Approach View WSD as a discrimination task (regression, really) P(sense context:jail, context:county, context:feeding,
Statistical NLP Spring 2008 Lecture 6: Classification Dan Klein UC Berkeley A Discriminative Approach View WSD as a discrimination task (regression, really) P(sense context:jail, context:county, context:feeding,
Support Vector and Kernel Methods
 SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
Machine Learning Lecture 7
 Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
Course Outline Machine Learning Lecture 7 Fundamentals (2 weeks) Bayes Decision Theory Probability Density Estimation Statistical Learning Theory 23.05.2016 Discriminative Approaches (5 weeks) Linear Discriminant
CSCI567 Machine Learning (Fall 2018)
") CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
CSCI567 Machine Learning (Fall 2018) Prof. Haipeng Luo U of Southern California Sep 12, 2018 September 12, 2018 1 / 49 Administration GitHub repos are setup (ask TA Chi Zhang for any issues) HW 1 is due
Support Vector Machine. Industrial AI Lab.
 Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Machine Learning. Support Vector Machines. Fabio Vandin November 20, 2017
 Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
Machine Learning Support Vector Machines Fabio Vandin November 20, 2017 1 Classification and Margin Consider a classification problem with two classes: instance set X = R d label set Y = { 1, 1}. Training
10-701/ Machine Learning - Midterm Exam, Fall 2010
 10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
10-701/15-781 Machine Learning - Midterm Exam, Fall 2010 Aarti Singh Carnegie Mellon University 1. Personal info: Name: Andrew account: E-mail address: 2. There should be 15 numbered pages in this exam
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore
 Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Pattern Recognition Prof. P. S. Sastry Department of Electronics and Communication Engineering Indian Institute of Science, Bangalore Lecture - 27 Multilayer Feedforward Neural networks with Sigmoidal
Logistic Regression. Machine Learning Fall 2018
 Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Logistic Regression Machine Learning Fall 2018 1 Where are e? We have seen the folloing ideas Linear models Learning as loss minimization Bayesian learning criteria (MAP and MLE estimation) The Naïve Bayes
Foundation of Intelligent Systems, Part I. SVM s & Kernel Methods
 Foundation of Intelligent Systems, Part I SVM s & Kernel Methods mcuturi@i.kyoto-u.ac.jp FIS - 2013 1 Support Vector Machines The linearly-separable case FIS - 2013 2 A criterion to select a linear classifier:
Foundation of Intelligent Systems, Part I SVM s & Kernel Methods mcuturi@i.kyoto-u.ac.jp FIS - 2013 1 Support Vector Machines The linearly-separable case FIS - 2013 2 A criterion to select a linear classifier:
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Name (NetID): (1 Point)
: (1 Point)") CS446: Machine Learning Fall 2016 October 25 th, 2016 This is a closed book exam. Everything you need in order to solve the problems is supplied in the body of this exam. This exam booklet contains four
CS446: Machine Learning Fall 2016 October 25 th, 2016 This is a closed book exam. Everything you need in order to solve the problems is supplied in the body of this exam. This exam booklet contains four
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
MIRA, SVM, k-nn. Lirong Xia
 MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
MIRA, SVM, k-nn Lirong Xia Linear Classifiers (perceptrons) Inputs are feature values Each feature has a weight Sum is the activation activation w If the activation is: Positive: output +1 Negative, output
Algorithms for NLP. Classification II. Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley
 Algorithms for NLP Classification II Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Minimize Training Error? A loss function declares how costly each mistake is E.g. 0 loss for correct label,
Algorithms for NLP Classification II Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Minimize Training Error? A loss function declares how costly each mistake is E.g. 0 loss for correct label,
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels
 SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux INRIA 8 Nov 2011 Nicolas Le Roux (INRIA) Neural networks and optimization 8 Nov 2011 1 / 80 1 Introduction 2 Linear classifier 3 Convolutional neural networks
Neural networks and optimization Nicolas Le Roux INRIA 8 Nov 2011 Nicolas Le Roux (INRIA) Neural networks and optimization 8 Nov 2011 1 / 80 1 Introduction 2 Linear classifier 3 Convolutional neural networks
Linear classifiers Lecture 3
 Linear classifiers Lecture 3 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin ML Methodology Data: labeled instances, e.g. emails marked spam/ham
Linear classifiers Lecture 3 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin ML Methodology Data: labeled instances, e.g. emails marked spam/ham
Vote. Vote on timing for night section: Option 1 (what we have now) Option 2. Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9
 Option 2. Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9") Vote Vote on timing for night section: Option 1 (what we have now) Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9 Option 2 Lecture, 6:10-7 10 minute break Lecture, 7:10-8 10 minute break Tutorial,
Vote Vote on timing for night section: Option 1 (what we have now) Lecture, 6:10-7:50 25 minute dinner break Tutorial, 8:15-9 Option 2 Lecture, 6:10-7 10 minute break Lecture, 7:10-8 10 minute break Tutorial,
Day 3: Classification, logistic regression
 Day 3: Classification, logistic regression Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 20 June 2018 Topics so far Supervised
Day 3: Classification, logistic regression Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 20 June 2018 Topics so far Supervised
CPSC 340: Machine Learning and Data Mining. MLE and MAP Fall 2017
 CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
CPSC 340: Machine Learning and Data Mining MLE and MAP Fall 2017 Assignment 3: Admin 1 late day to hand in tonight, 2 late days for Wednesday. Assignment 4: Due Friday of next week. Last Time: Multi-Class
Structured Prediction
 Structured Prediction Classification Algorithms Classify objects x X into labels y Y First there was binary: Y = {0, 1} Then multiclass: Y = {1,...,6} The next generation: Structured Labels Structured
Structured Prediction Classification Algorithms Classify objects x X into labels y Y First there was binary: Y = {0, 1} Then multiclass: Y = {1,...,6} The next generation: Structured Labels Structured
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Machine Learning for Large-Scale Data Analysis and Decision Making A. Neural Networks Week #6
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Neural Networks Week #6 Today Neural Networks A. Modeling B. Fitting C. Deep neural networks Today s material is (adapted)
Support Vector Machines for Classification: A Statistical Portrait
 Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2010 Lecture 22: Nearest Neighbors, Kernels 4/18/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!)
CS 188: Artificial Intelligence Spring 2010 Lecture 22: Nearest Neighbors, Kernels 4/18/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!)
Machine Learning Basics Lecture 2: Linear Classification. Princeton University COS 495 Instructor: Yingyu Liang
 Machine Learning Basics Lecture 2: Linear Classification Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d.
Machine Learning Basics Lecture 2: Linear Classification Princeton University COS 495 Instructor: Yingyu Liang Review: machine learning basics Math formulation Given training data x i, y i : 1 i n i.i.d.
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Natural Language Processing with Deep Learning CS224N/Ling284
 Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
Natural Language Processing with Deep Learning CS224N/Ling284 Lecture 4: Word Window Classification and Neural Networks Richard Socher Organization Main midterm: Feb 13 Alternative midterm: Friday Feb
SUPPORT VECTOR MACHINE
 SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
Binary Classification / Perceptron
 Binary Classification / Perceptron Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Supervised Learning Input: x 1, y 1,, (x n, y n ) x i is the i th data
Binary Classification / Perceptron Nicholas Ruozzi University of Texas at Dallas Slides adapted from David Sontag and Vibhav Gogate Supervised Learning Input: x 1, y 1,, (x n, y n ) x i is the i th data
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Machine Learning. Neural Networks. (slides from Domingos, Pardo, others)
") Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Machine Learning Neural Networks (slides from Domingos, Pardo, others) For this week, Reading Chapter 4: Neural Networks (Mitchell, 1997) See Canvas For subsequent weeks: Scaling Learning Algorithms toward
Support Vector Machines. Machine Learning Fall 2017
 Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
9 Classification. 9.1 Linear Classifiers
 9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
9 Classification This topic returns to prediction. Unlike linear regression where we were predicting a numeric value, in this case we are predicting a class: winner or loser, yes or no, rich or poor, positive
ARTIFICIAL INTELLIGENCE. Artificial Neural Networks
 INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
INFOB2KI 2017-2018 Utrecht University The Netherlands ARTIFICIAL INTELLIGENCE Artificial Neural Networks Lecturer: Silja Renooij These slides are part of the INFOB2KI Course Notes available from www.cs.uu.nl/docs/vakken/b2ki/schema.html
Support Vector Machines
 Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Comments. Assignment 3 code released. Thought questions 3 due this week. Mini-project: hopefully you have started. implement classification algorithms
 Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural networks Comments Assignment 3 code released implement classification algorithms use kernels for census dataset Thought questions 3 due this week Mini-project: hopefully you have started 2 Example:
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Machine Learning. Neural Networks
 Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
Machine Learning Neural Networks Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 Biological Analogy Bryan Pardo, Northwestern University, Machine Learning EECS 349 Fall 2007 THE
1 Machine Learning Concepts (16 points)
") CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
Optimization and Gradient Descent
 Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers
 Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers Erin Allwein, Robert Schapire and Yoram Singer Journal of Machine Learning Research, 1:113-141, 000 CSE 54: Seminar on Learning
Loss Functions, Decision Theory, and Linear Models
 Loss Functions, Decision Theory, and Linear Models CMSC 678 UMBC January 31 st, 2018 Some slides adapted from Hamed Pirsiavash Logistics Recap Piazza (ask & answer questions): https://piazza.com/umbc/spring2018/cmsc678
Loss Functions, Decision Theory, and Linear Models CMSC 678 UMBC January 31 st, 2018 Some slides adapted from Hamed Pirsiavash Logistics Recap Piazza (ask & answer questions): https://piazza.com/umbc/spring2018/cmsc678