MIT 9.520/6.860, Fall 2018 Statistical Learning Theory and Applications. Class 04: Features and Kernels. Lorenzo Rosasco
|
|
|
- Gavin Dean
- 5 years ago
- Views:
Transcription
1 MIT 9.520/6.860, Fall 2018 Statistical Learning Theory and Applications Class 04: Features and Kernels Lorenzo Rosasco
2 Linear functions Let H lin be the space of linear functions f(x) = w x. f w is one to one, inner product f, f H := w w, norm/metric f f H := w w.
3 An observation Function norm controls point-wise convergence. Since then f(x) f(x) x w w, x X w j w f j (x) f(x), x X.
4 ERM 1 min w R d n n (y i w x i ) 2 + λ w 2, λ 0 i=1 λ 0 ordinary least squares (bias to minimal norm), λ > 0 ridge regression (stable).
5 Computations Let Xn R nd and Ŷ R n. The ridge regression solution is ŵ λ = (Xn Xn+nλI) 1 Xn Ŷ time O(nd 2 d 3 ) mem. O(nd d 2 ) but also ŵ λ = Xn (XnXn +nλi) 1 Ŷ time O(dn 2 n 3 ) mem. O(nd n 2 )
6 Representer theorem in disguise We noted that n n ŵ λ = Xn c = x i c i ˆf λ (x) = x x i c i, i=1 i=1 c = (XnXn + nλi) 1 Ŷ, (XnXn ) ij = x i x j.
7 Limits of linear functions Regression

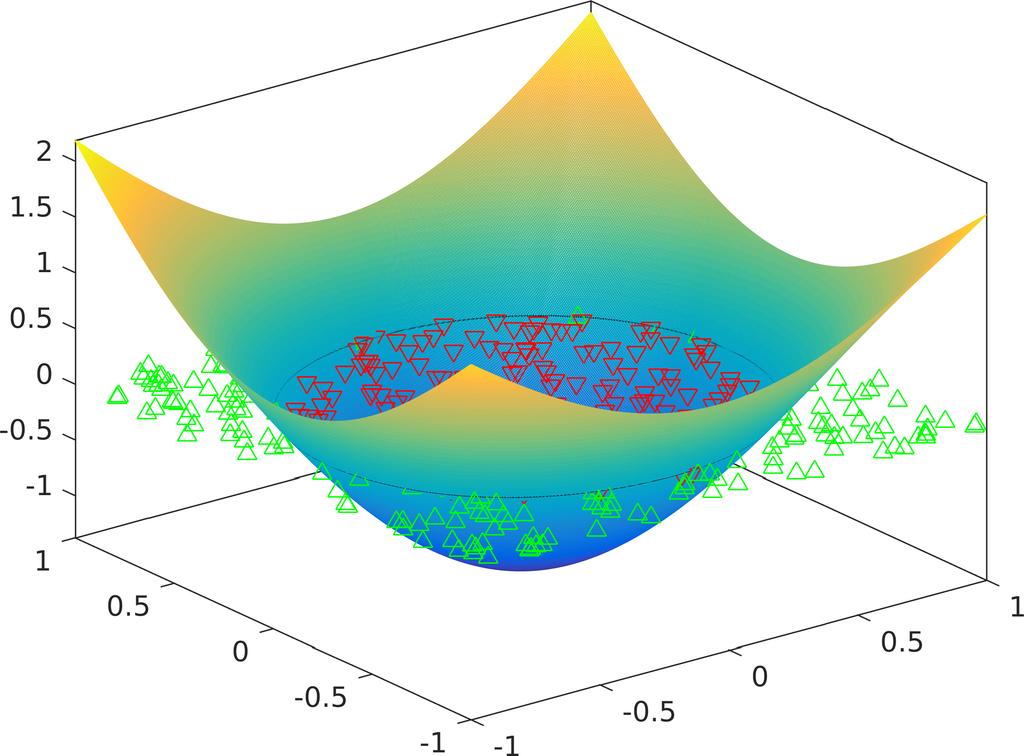
8 Limits of linear functions Classification
9 Nonlinear functions Two main possibilities: f(x) = w Φ(x), f(x) = Φ(w x) where Φ is a non linear map. The former choice leads to linear spaces of functions 1. The latter choice can be iterated f(x) = Φ(w L Φ(w L 1...Φ(w 1 x))). 1 The spaces are linear, NOT the functions!
10 Features and feature maps where Φ : X R p f(x) = w Φ(x), and ϕ j : X R, for j = 1,...,p. Φ(x) = (ϕ 1 (x),...,ϕ p (x)) X need not be R d. We can also write p f(x) = w j ϕ j (x). i=1
11 Geometric view f(x) = w Φ(x)
12 An example
13 More examples The equation p f(x) = w Φ(x) = w j ϕ j (x) i=1 suggests to think of features as some form of basis. Indeed we can consider Fourier basis, wave-lets + their variations,...
14 And even more examples Any set of functions ϕ j : X R, j = 1,...,p can be considered. Feature design/engineering vision: SIFT, HOG audio: MFCC...
15 Nonlinear functions using features Let H Φ be the space of linear functions f(x) = w Φ(x). f w is one to one, if (ϕ j ) j are lin. indip. inner product f, f H Φ := w w, norm/metric f f HΦ := w w. In this case f(x) f(x) Φ(x) w w, x X.
16 Back to ERM 1 min w R p n n (y i w Φ(x i )) 2 + λ w 2, λ 0, i=1 Equivalent to, 1 min f H Φ n n (y i f(x i )) 2 + λ f 2 H Φ, λ 0. i=1
17 Computations using features Let Φ R np with ( Φ) ij = ϕ j (x i ) The ridge regression solution is ŵ λ = ( Φ Φ+nλI) 1 Φ Ŷ time O(np 2 p 3 ) mem. O(np p 2 ), but also ŵ λ = Φ ( Φ Φ +nλi) 1 Ŷ time O(pn 2 n 3 ) mem. O(np n 2 ).
18 Representer theorem a little less in disguise Analogously to before ŵ λ = Φ n n c = Φ(x i )c i ˆf λ (x) = Φ(x) Φ(x i )c i i=1 i=1 c = ( Φ Φ + λi) 1 Ŷ, ( Φ Φ ) ij = Φ(x i ) Φ(x j ) p Φ(x) Φ( x) = ϕ s (x)ϕ s ( x). s=1
19 Unleash the features Can we consider linearly dependent features? Can we consider p =?
20 An observation For X = R consider with ϕ 1 (x) = 1. Then ϕ j (x)ϕ j ( x) = j=1 ϕ j (x) = x j 1 e x2 γ j=1 (2γ) (j 1) (j 1)!, j = 2,..., x j 1 e x2 γ (2γ) j 1 (j 1)! xj 1 e x2 γ (2γ) j 1 (j 1)! = e x2γ e x2 γ = e x x 2 γ j=1 (2γ) j 1 (j 1)! (x x)j 1 = e x2γ e x2γ e 2x x2 γ
21 From features to kernels Φ(x) Φ( x) = ϕ j (x)ϕ j ( x) = k(x, x) j=1 We might be able to compute the series in closed form. The function k is called kernel. Can we run ridge regression?
22 Kernel ridge regression We have n n ˆf λ (x) = Φ(x) Φ(x i )c i = k(x,x i )c i i=1 i=1 c = ( K + λi) 1 Ŷ, ( K) ij = Φ(x i ) Φ(x j ) = k(x i,x j ) K is the kernel matrix, the Gram (inner products) matrix of the data. The kernel trick
23 Kernels Can we start from kernels instead of features? Which functions k : X X R define kernels we can use?
24 Positive definite kernels A function k : X X R is called positive definite: if the matrix ˆK is positive semidefinite for all choice of points x 1,...,x n, i.e. a Ka 0, a R n. Equivalently n k(x i,x j )a i a j 0, i,j=1 for any a 1,...,a n R, x 1,...,x n X.
25 Inner product kernels are pos. def. Assume Φ : X R p, p and k(x, x) = Φ(x) Φ( x) Note that n n 2 n k(x i,x j )a i a j = Φ(x i ) Φ(x j )a i a j = Φ(x i )a i. i,j=1 i,j=1 i=1 Clearly k is symmetric.
26 But there are many pos. def. kernels Classic examples linear k(x, x) = x x polynomial k(x, x) = (x x + 1) s Gaussian k(x, x) = e x x 2 γ But one can consider kernels on probability distributions kernels on strings kernels on functions kernels on groups kernels graphs... It is natural to think of a kernel as a measure of similarity.
27 From pos. def. kernels to functions Let X be any set/ Given a pos. def. kernel k. consider the space H k of functions f(x) = N k(x,x i )a i i=1 for any a 1,...,a n R, x 1,...,x n X and any N N. Define an inner product on H k N N f, f = k(x Hk i, x j )a i ā j. i=1 j=1 H k can be completed to a Hilbert space.
28 A key result Functions defind by Gaussian kernels with large and small widths.
29 An illustration Theorem Given a pos. def. k there exists Φ s.t. k(x, x) = Φ(x),Φ( x) Hk and H Φ H k Roughly speaking N f(x) = w Φ(x) f(x) = k(x,x i )a i i=1
30 From features and kernels to RKHS and beyond H k and H Φ have many properties, characterizations, connections: reproducing property reproducing kernel Hilbert spaces (RKHS) Mercer theorem (Kar hunen Loéve expansion) Gaussian processes Cameron-Martin spaces
31 Reproducing property Note that by definition of H k k x = k(x, ) is a function in H k For all f H k, x X f(x) = f,k x Hk called the reproducing property Note that f(x) f(x) k x Hk f f Hk, x X. The above observations have a converse.
32 RKHS Definition A RKHS H is a Hilbert with a function k : X X R s.t. k x = k(x, ) H k, and f(x) = f,k x Hk. Theorem If H is a RKHS then k is pos. def.
33 Evaluation functionals in a RKHS If H is a RKHS then the evaluation functionals e x (f) = f(x) are continuous. i.e. e x (f) e x ( f) f f Hk, x X since e x (f) = f,k x Hk. Note that L 2 (R d ) or C(R d ) don t have this property!
34 Alternative RKHS definition Turns out the previous property also characterizes a RKHS. Theorem A Hilbert space with continuous evaluation functionals is a RKHS.
35 Summing up From linear to non linear functions using features using kernels plus pos. def. functions reproducing property RKHS
RegML 2018 Class 2 Tikhonov regularization and kernels
 RegML 2018 Class 2 Tikhonov regularization and kernels Lorenzo Rosasco UNIGE-MIT-IIT June 17, 2018 Learning problem Problem For H {f f : X Y }, solve min E(f), f H dρ(x, y)l(f(x), y) given S n = (x i,
RegML 2018 Class 2 Tikhonov regularization and kernels Lorenzo Rosasco UNIGE-MIT-IIT June 17, 2018 Learning problem Problem For H {f f : X Y }, solve min E(f), f H dρ(x, y)l(f(x), y) given S n = (x i,
Reproducing Kernel Hilbert Spaces
 Reproducing Kernel Hilbert Spaces Lorenzo Rosasco 9.520 Class 03 February 9, 2011 About this class Goal To introduce a particularly useful family of hypothesis spaces called Reproducing Kernel Hilbert
Reproducing Kernel Hilbert Spaces Lorenzo Rosasco 9.520 Class 03 February 9, 2011 About this class Goal To introduce a particularly useful family of hypothesis spaces called Reproducing Kernel Hilbert
CIS 520: Machine Learning Oct 09, Kernel Methods
 CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
Kernel Methods. Outline
 Kernel Methods Quang Nguyen University of Pittsburgh CS 3750, Fall 2011 Outline Motivation Examples Kernels Definitions Kernel trick Basic properties Mercer condition Constructing feature space Hilbert
Kernel Methods Quang Nguyen University of Pittsburgh CS 3750, Fall 2011 Outline Motivation Examples Kernels Definitions Kernel trick Basic properties Mercer condition Constructing feature space Hilbert
Kernel Methods. Foundations of Data Analysis. Torsten Möller. Möller/Mori 1
 Kernel Methods Foundations of Data Analysis Torsten Möller Möller/Mori 1 Reading Chapter 6 of Pattern Recognition and Machine Learning by Bishop Chapter 12 of The Elements of Statistical Learning by Hastie,
Kernel Methods Foundations of Data Analysis Torsten Möller Möller/Mori 1 Reading Chapter 6 of Pattern Recognition and Machine Learning by Bishop Chapter 12 of The Elements of Statistical Learning by Hastie,
Oslo Class 2 Tikhonov regularization and kernels
 RegML2017@SIMULA Oslo Class 2 Tikhonov regularization and kernels Lorenzo Rosasco UNIGE-MIT-IIT May 3, 2017 Learning problem Problem For H {f f : X Y }, solve min E(f), f H dρ(x, y)l(f(x), y) given S n
RegML2017@SIMULA Oslo Class 2 Tikhonov regularization and kernels Lorenzo Rosasco UNIGE-MIT-IIT May 3, 2017 Learning problem Problem For H {f f : X Y }, solve min E(f), f H dρ(x, y)l(f(x), y) given S n
Stat542 (F11) Statistical Learning. First consider the scenario where the two classes of points are separable.
 Statistical Learning. First consider the scenario where the two classes of points are separable.") Linear SVM (separable case) First consider the scenario where the two classes of points are separable. It s desirable to have the width (called margin) between the two dashed lines to be large, i.e., have
Linear SVM (separable case) First consider the scenario where the two classes of points are separable. It s desirable to have the width (called margin) between the two dashed lines to be large, i.e., have
Basis Expansion and Nonlinear SVM. Kai Yu
 Basis Expansion and Nonlinear SVM Kai Yu Linear Classifiers f(x) =w > x + b z(x) = sign(f(x)) Help to learn more general cases, e.g., nonlinear models 8/7/12 2 Nonlinear Classifiers via Basis Expansion
Basis Expansion and Nonlinear SVM Kai Yu Linear Classifiers f(x) =w > x + b z(x) = sign(f(x)) Help to learn more general cases, e.g., nonlinear models 8/7/12 2 Nonlinear Classifiers via Basis Expansion
Deviations from linear separability. Kernel methods. Basis expansion for quadratic boundaries. Adding new features Systematic deviation
 Deviations from linear separability Kernel methods CSE 250B Noise Find a separator that minimizes a convex loss function related to the number of mistakes. e.g. SVM, logistic regression. Systematic deviation
Deviations from linear separability Kernel methods CSE 250B Noise Find a separator that minimizes a convex loss function related to the number of mistakes. e.g. SVM, logistic regression. Systematic deviation
Outline. Motivation. Mapping the input space to the feature space Calculating the dot product in the feature space
 to The The A s s in to Fabio A. González Ph.D. Depto. de Ing. de Sistemas e Industrial Universidad Nacional de Colombia, Bogotá April 2, 2009 to The The A s s in 1 Motivation Outline 2 The Mapping the
to The The A s s in to Fabio A. González Ph.D. Depto. de Ing. de Sistemas e Industrial Universidad Nacional de Colombia, Bogotá April 2, 2009 to The The A s s in 1 Motivation Outline 2 The Mapping the
Kernel methods CSE 250B
 Kernel methods CSE 250B Deviations from linear separability Noise Find a separator that minimizes a convex loss function related to the number of mistakes. e.g. SVM, logistic regression. Deviations from
Kernel methods CSE 250B Deviations from linear separability Noise Find a separator that minimizes a convex loss function related to the number of mistakes. e.g. SVM, logistic regression. Deviations from
Oslo Class 4 Early Stopping and Spectral Regularization
 RegML2017@SIMULA Oslo Class 4 Early Stopping and Spectral Regularization Lorenzo Rosasco UNIGE-MIT-IIT June 28, 2016 Learning problem Solve min w E(w), E(w) = dρ(x, y)l(w x, y) given (x 1, y 1 ),..., (x
RegML2017@SIMULA Oslo Class 4 Early Stopping and Spectral Regularization Lorenzo Rosasco UNIGE-MIT-IIT June 28, 2016 Learning problem Solve min w E(w), E(w) = dρ(x, y)l(w x, y) given (x 1, y 1 ),..., (x
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017
 COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
Support Vector Machines
 Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Perceptron Revisited: Linear Separators. Support Vector Machines
 Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
The Learning Problem and Regularization Class 03, 11 February 2004 Tomaso Poggio and Sayan Mukherjee
 The Learning Problem and Regularization 9.520 Class 03, 11 February 2004 Tomaso Poggio and Sayan Mukherjee About this class Goal To introduce a particularly useful family of hypothesis spaces called Reproducing
The Learning Problem and Regularization 9.520 Class 03, 11 February 2004 Tomaso Poggio and Sayan Mukherjee About this class Goal To introduce a particularly useful family of hypothesis spaces called Reproducing
Kernel Methods. Jean-Philippe Vert Last update: Jan Jean-Philippe Vert (Mines ParisTech) 1 / 444
 1 / 444") Kernel Methods Jean-Philippe Vert Jean-Philippe.Vert@mines.org Last update: Jan 2015 Jean-Philippe Vert (Mines ParisTech) 1 / 444 What we know how to solve Jean-Philippe Vert (Mines ParisTech) 2 / 444
Kernel Methods Jean-Philippe Vert Jean-Philippe.Vert@mines.org Last update: Jan 2015 Jean-Philippe Vert (Mines ParisTech) 1 / 444 What we know how to solve Jean-Philippe Vert (Mines ParisTech) 2 / 444
Reproducing Kernel Hilbert Spaces
 Reproducing Kernel Hilbert Spaces Lorenzo Rosasco 9.520 Class 03 February 11, 2009 About this class Goal To introduce a particularly useful family of hypothesis spaces called Reproducing Kernel Hilbert
Reproducing Kernel Hilbert Spaces Lorenzo Rosasco 9.520 Class 03 February 11, 2009 About this class Goal To introduce a particularly useful family of hypothesis spaces called Reproducing Kernel Hilbert
Reproducing Kernel Hilbert Spaces
 Reproducing Kernel Hilbert Spaces Lorenzo Rosasco 9.520 Class 03 February 9, 2011 About this class Goal In this class we continue our journey in the world of RKHS. We discuss the Mercer theorem which gives
Reproducing Kernel Hilbert Spaces Lorenzo Rosasco 9.520 Class 03 February 9, 2011 About this class Goal In this class we continue our journey in the world of RKHS. We discuss the Mercer theorem which gives
Reproducing Kernel Hilbert Spaces Class 03, 15 February 2006 Andrea Caponnetto
 Reproducing Kernel Hilbert Spaces 9.520 Class 03, 15 February 2006 Andrea Caponnetto About this class Goal To introduce a particularly useful family of hypothesis spaces called Reproducing Kernel Hilbert
Reproducing Kernel Hilbert Spaces 9.520 Class 03, 15 February 2006 Andrea Caponnetto About this class Goal To introduce a particularly useful family of hypothesis spaces called Reproducing Kernel Hilbert
9.2 Support Vector Machines 159
 9.2 Support Vector Machines 159 9.2.3 Kernel Methods We have all the tools together now to make an exciting step. Let us summarize our findings. We are interested in regularized estimation problems of
9.2 Support Vector Machines 159 9.2.3 Kernel Methods We have all the tools together now to make an exciting step. Let us summarize our findings. We are interested in regularized estimation problems of
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Introduction to Machine Learning
 Introduction to Machine Learning Kernel Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1 / 21
Introduction to Machine Learning Kernel Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574 1 / 21
Kernel Methods. Barnabás Póczos
 Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
10-701/ Recitation : Kernels
 10-701/15-781 Recitation : Kernels Manojit Nandi February 27, 2014 Outline Mathematical Theory Banach Space and Hilbert Spaces Kernels Commonly Used Kernels Kernel Theory One Weird Kernel Trick Representer
10-701/15-781 Recitation : Kernels Manojit Nandi February 27, 2014 Outline Mathematical Theory Banach Space and Hilbert Spaces Kernels Commonly Used Kernels Kernel Theory One Weird Kernel Trick Representer
Lecture 4 February 2
 4-1 EECS 281B / STAT 241B: Advanced Topics in Statistical Learning Spring 29 Lecture 4 February 2 Lecturer: Martin Wainwright Scribe: Luqman Hodgkinson Note: These lecture notes are still rough, and have
4-1 EECS 281B / STAT 241B: Advanced Topics in Statistical Learning Spring 29 Lecture 4 February 2 Lecturer: Martin Wainwright Scribe: Luqman Hodgkinson Note: These lecture notes are still rough, and have
The Kernel Trick. Carlos C. Rodríguez October 25, Why don t we do it in higher dimensions?
 The Kernel Trick Carlos C. Rodríguez http://omega.albany.edu:8008/ October 25, 2004 Why don t we do it in higher dimensions? If SVMs were able to handle only linearly separable data, their usefulness would
The Kernel Trick Carlos C. Rodríguez http://omega.albany.edu:8008/ October 25, 2004 Why don t we do it in higher dimensions? If SVMs were able to handle only linearly separable data, their usefulness would
Regularization via Spectral Filtering
 Regularization via Spectral Filtering Lorenzo Rosasco MIT, 9.520 Class 7 About this class Goal To discuss how a class of regularization methods originally designed for solving ill-posed inverse problems,
Regularization via Spectral Filtering Lorenzo Rosasco MIT, 9.520 Class 7 About this class Goal To discuss how a class of regularization methods originally designed for solving ill-posed inverse problems,
Kernel Ridge Regression. Mohammad Emtiyaz Khan EPFL Oct 27, 2015
 Kernel Ridge Regression Mohammad Emtiyaz Khan EPFL Oct 27, 2015 Mohammad Emtiyaz Khan 2015 Motivation The ridge solution β R D has a counterpart α R N. Using duality, we will establish a relationship between
Kernel Ridge Regression Mohammad Emtiyaz Khan EPFL Oct 27, 2015 Mohammad Emtiyaz Khan 2015 Motivation The ridge solution β R D has a counterpart α R N. Using duality, we will establish a relationship between
Reproducing Kernel Hilbert Spaces
 Reproducing Kernel Hilbert Spaces Lorenzo Rosasco 9.520 Class 03 February 12, 2007 About this class Goal To introduce a particularly useful family of hypothesis spaces called Reproducing Kernel Hilbert
Reproducing Kernel Hilbert Spaces Lorenzo Rosasco 9.520 Class 03 February 12, 2007 About this class Goal To introduce a particularly useful family of hypothesis spaces called Reproducing Kernel Hilbert
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Regularization in Reproducing Kernel Banach Spaces
 .... Regularization in Reproducing Kernel Banach Spaces Guohui Song School of Mathematical and Statistical Sciences Arizona State University Comp Math Seminar, September 16, 2010 Joint work with Dr. Fred
.... Regularization in Reproducing Kernel Banach Spaces Guohui Song School of Mathematical and Statistical Sciences Arizona State University Comp Math Seminar, September 16, 2010 Joint work with Dr. Fred
Support Vector Machine
 Support Vector Machine Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Linear Support Vector Machine Kernelized SVM Kernels 2 From ERM to RLM Empirical Risk Minimization in the binary
Support Vector Machine Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Linear Support Vector Machine Kernelized SVM Kernels 2 From ERM to RLM Empirical Risk Minimization in the binary
Machine Learning. Kernels. Fall (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang. (Chap. 12 of CIML)
 Professor Liang Huang. (Chap. 12 of CIML)") Machine Learning Fall 2017 Kernels (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang (Chap. 12 of CIML) Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR:
Machine Learning Fall 2017 Kernels (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang (Chap. 12 of CIML) Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR:
Spectral Regularization
 Spectral Regularization Lorenzo Rosasco 9.520 Class 07 February 27, 2008 About this class Goal To discuss how a class of regularization methods originally designed for solving ill-posed inverse problems,
Spectral Regularization Lorenzo Rosasco 9.520 Class 07 February 27, 2008 About this class Goal To discuss how a class of regularization methods originally designed for solving ill-posed inverse problems,
LMS Algorithm Summary
 LMS Algorithm Summary Step size tradeoff Other Iterative Algorithms LMS algorithm with variable step size: w(k+1) = w(k) + µ(k)e(k)x(k) When step size µ(k) = µ/k algorithm converges almost surely to optimal
LMS Algorithm Summary Step size tradeoff Other Iterative Algorithms LMS algorithm with variable step size: w(k+1) = w(k) + µ(k)e(k)x(k) When step size µ(k) = µ/k algorithm converges almost surely to optimal
Direct Learning: Linear Classification. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Direct Learning: Linear Classification Logistic regression models for classification problem We consider two class problem: Y {0, 1}. The Bayes rule for the classification is I(P(Y = 1 X = x) > 1/2) so
Direct Learning: Linear Classification Logistic regression models for classification problem We consider two class problem: Y {0, 1}. The Bayes rule for the classification is I(P(Y = 1 X = x) > 1/2) so
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012") Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Modeling Data with Linear Combinations of Basis Functions. Read Chapter 3 in the text by Bishop
 Modeling Data with Linear Combinations of Basis Functions Read Chapter 3 in the text by Bishop A Type of Supervised Learning Problem We want to model data (x 1, t 1 ),..., (x N, t N ), where x i is a vector
Modeling Data with Linear Combinations of Basis Functions Read Chapter 3 in the text by Bishop A Type of Supervised Learning Problem We want to model data (x 1, t 1 ),..., (x N, t N ), where x i is a vector
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Advanced Introduction to Machine Learning
 10-715 Advanced Introduction to Machine Learning Homework Due Oct 15, 10.30 am Rules Please follow these guidelines. Failure to do so, will result in loss of credit. 1. Homework is due on the due date
10-715 Advanced Introduction to Machine Learning Homework Due Oct 15, 10.30 am Rules Please follow these guidelines. Failure to do so, will result in loss of credit. 1. Homework is due on the due date
Chapter 9. Support Vector Machine. Yongdai Kim Seoul National University
 Chapter 9. Support Vector Machine Yongdai Kim Seoul National University 1. Introduction Support Vector Machine (SVM) is a classification method developed by Vapnik (1996). It is thought that SVM improved
Chapter 9. Support Vector Machine Yongdai Kim Seoul National University 1. Introduction Support Vector Machine (SVM) is a classification method developed by Vapnik (1996). It is thought that SVM improved
Review: Support vector machines. Machine learning techniques and image analysis
 Review: Support vector machines Review: Support vector machines Margin optimization min (w,w 0 ) 1 2 w 2 subject to y i (w 0 + w T x i ) 1 0, i = 1,..., n. Review: Support vector machines Margin optimization
Review: Support vector machines Review: Support vector machines Margin optimization min (w,w 0 ) 1 2 w 2 subject to y i (w 0 + w T x i ) 1 0, i = 1,..., n. Review: Support vector machines Margin optimization
Kernel Method: Data Analysis with Positive Definite Kernels
 Kernel Method: Data Analysis with Positive Definite Kernels 2. Positive Definite Kernel and Reproducing Kernel Hilbert Space Kenji Fukumizu The Institute of Statistical Mathematics. Graduate University
Kernel Method: Data Analysis with Positive Definite Kernels 2. Positive Definite Kernel and Reproducing Kernel Hilbert Space Kenji Fukumizu The Institute of Statistical Mathematics. Graduate University
MLCC 2015 Dimensionality Reduction and PCA
 MLCC 2015 Dimensionality Reduction and PCA Lorenzo Rosasco UNIGE-MIT-IIT June 25, 2015 Outline PCA & Reconstruction PCA and Maximum Variance PCA and Associated Eigenproblem Beyond the First Principal Component
MLCC 2015 Dimensionality Reduction and PCA Lorenzo Rosasco UNIGE-MIT-IIT June 25, 2015 Outline PCA & Reconstruction PCA and Maximum Variance PCA and Associated Eigenproblem Beyond the First Principal Component
About this class. Maximizing the Margin. Maximum margin classifiers. Picture of large and small margin hyperplanes
 About this class Maximum margin classifiers SVMs: geometric derivation of the primal problem Statement of the dual problem The kernel trick SVMs as the solution to a regularization problem Maximizing the
About this class Maximum margin classifiers SVMs: geometric derivation of the primal problem Statement of the dual problem The kernel trick SVMs as the solution to a regularization problem Maximizing the
EE613 Machine Learning for Engineers. Kernel methods Support Vector Machines. jean-marc odobez 2015
 EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
Nearest Neighbor. Machine Learning CSE546 Kevin Jamieson University of Washington. October 26, Kevin Jamieson 2
 Nearest Neighbor Machine Learning CSE546 Kevin Jamieson University of Washington October 26, 2017 2017 Kevin Jamieson 2 Some data, Bayes Classifier Training data: True label: +1 True label: -1 Optimal
Nearest Neighbor Machine Learning CSE546 Kevin Jamieson University of Washington October 26, 2017 2017 Kevin Jamieson 2 Some data, Bayes Classifier Training data: True label: +1 True label: -1 Optimal
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Kernel Methods. Machine Learning A W VO
 Kernel Methods Machine Learning A 708.063 07W VO Outline 1. Dual representation 2. The kernel concept 3. Properties of kernels 4. Examples of kernel machines Kernel PCA Support vector regression (Relevance
Kernel Methods Machine Learning A 708.063 07W VO Outline 1. Dual representation 2. The kernel concept 3. Properties of kernels 4. Examples of kernel machines Kernel PCA Support vector regression (Relevance
Kernels A Machine Learning Overview
 Kernels A Machine Learning Overview S.V.N. Vishy Vishwanathan vishy@axiom.anu.edu.au National ICT of Australia and Australian National University Thanks to Alex Smola, Stéphane Canu, Mike Jordan and Peter
Kernels A Machine Learning Overview S.V.N. Vishy Vishwanathan vishy@axiom.anu.edu.au National ICT of Australia and Australian National University Thanks to Alex Smola, Stéphane Canu, Mike Jordan and Peter
Approximate Kernel Methods
 Lecture 3 Approximate Kernel Methods Bharath K. Sriperumbudur Department of Statistics, Pennsylvania State University Machine Learning Summer School Tübingen, 207 Outline Motivating example Ridge regression
Lecture 3 Approximate Kernel Methods Bharath K. Sriperumbudur Department of Statistics, Pennsylvania State University Machine Learning Summer School Tübingen, 207 Outline Motivating example Ridge regression
Designing Kernel Functions Using the Karhunen-Loève Expansion
 July 7, 2004. Designing Kernel Functions Using the Karhunen-Loève Expansion 2 1 Fraunhofer FIRST, Germany Tokyo Institute of Technology, Japan 1,2 2 Masashi Sugiyama and Hidemitsu Ogawa Learning with Kernels
July 7, 2004. Designing Kernel Functions Using the Karhunen-Loève Expansion 2 1 Fraunhofer FIRST, Germany Tokyo Institute of Technology, Japan 1,2 2 Masashi Sugiyama and Hidemitsu Ogawa Learning with Kernels
Support Vector Machines.
 Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Kernel methods, kernel SVM and ridge regression
 Kernel methods, kernel SVM and ridge regression Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Collaborative Filtering 2 Collaborative Filtering R: rating matrix; U: user factor;
Kernel methods, kernel SVM and ridge regression Le Song Machine Learning II: Advanced Topics CSE 8803ML, Spring 2012 Collaborative Filtering 2 Collaborative Filtering R: rating matrix; U: user factor;
Lasso, Ridge, and Elastic Net
 Lasso, Ridge, and Elastic Net David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 14 A Very Simple Model Suppose we have one feature
Lasso, Ridge, and Elastic Net David Rosenberg New York University October 29, 2016 David Rosenberg (New York University) DS-GA 1003 October 29, 2016 1 / 14 A Very Simple Model Suppose we have one feature
Diffeomorphic Warping. Ben Recht August 17, 2006 Joint work with Ali Rahimi (Intel)
") Diffeomorphic Warping Ben Recht August 17, 2006 Joint work with Ali Rahimi (Intel) What Manifold Learning Isn t Common features of Manifold Learning Algorithms: 1-1 charting Dense sampling Geometric Assumptions
Diffeomorphic Warping Ben Recht August 17, 2006 Joint work with Ali Rahimi (Intel) What Manifold Learning Isn t Common features of Manifold Learning Algorithms: 1-1 charting Dense sampling Geometric Assumptions
Compressive Inference
 Compressive Inference Weihong Guo and Dan Yang Case Western Reserve University and SAMSI SAMSI transition workshop Project of Compressive Inference subgroup of Imaging WG Active members: Garvesh Raskutti,
Compressive Inference Weihong Guo and Dan Yang Case Western Reserve University and SAMSI SAMSI transition workshop Project of Compressive Inference subgroup of Imaging WG Active members: Garvesh Raskutti,
Indirect Rule Learning: Support Vector Machines. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Indirect Rule Learning: Support Vector Machines Indirect learning: loss optimization It doesn t estimate the prediction rule f (x) directly, since most loss functions do not have explicit optimizers. Indirection
Indirect Rule Learning: Support Vector Machines Indirect learning: loss optimization It doesn t estimate the prediction rule f (x) directly, since most loss functions do not have explicit optimizers. Indirection
The Representor Theorem, Kernels, and Hilbert Spaces
 The Representor Theorem, Kernels, and Hilbert Spaces We will now work with infinite dimensional feature vectors and parameter vectors. The space l is defined to be the set of sequences f 1, f, f 3,...
The Representor Theorem, Kernels, and Hilbert Spaces We will now work with infinite dimensional feature vectors and parameter vectors. The space l is defined to be the set of sequences f 1, f, f 3,...
SVMs: nonlinearity through kernels
 Non-separable data e-8. Support Vector Machines 8.. The Optimal Hyperplane Consider the following two datasets: SVMs: nonlinearity through kernels ER Chapter 3.4, e-8 (a) Few noisy data. (b) Nonlinearly
Non-separable data e-8. Support Vector Machines 8.. The Optimal Hyperplane Consider the following two datasets: SVMs: nonlinearity through kernels ER Chapter 3.4, e-8 (a) Few noisy data. (b) Nonlinearly
CS798: Selected topics in Machine Learning
 CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
(Kernels +) Support Vector Machines
 Support Vector Machines") (Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
(Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
Statistical Methods for SVM
 Statistical Methods for SVM Support Vector Machines Here we approach the two-class classification problem in a direct way: We try and find a plane that separates the classes in feature space. If we cannot,
Statistical Methods for SVM Support Vector Machines Here we approach the two-class classification problem in a direct way: We try and find a plane that separates the classes in feature space. If we cannot,
Linear regression COMS 4771
 Linear regression COMS 4771 1. Old Faithful and prediction functions Prediction problem: Old Faithful geyser (Yellowstone) Task: Predict time of next eruption. 1 / 40 Statistical model for time between
Linear regression COMS 4771 1. Old Faithful and prediction functions Prediction problem: Old Faithful geyser (Yellowstone) Task: Predict time of next eruption. 1 / 40 Statistical model for time between
Support Vector Machines for Classification: A Statistical Portrait
 Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Introductory Machine Learning Notes 1. Lorenzo Rosasco
 Introductory Machine Learning Notes 1 Lorenzo Rosasco DIBRIS, Universita degli Studi di Genova LCSL, Massachusetts Institute of Technology and Istituto Italiano di Tecnologia lrosasco@mit.edu October 10,
Introductory Machine Learning Notes 1 Lorenzo Rosasco DIBRIS, Universita degli Studi di Genova LCSL, Massachusetts Institute of Technology and Istituto Italiano di Tecnologia lrosasco@mit.edu October 10,
Linear Regression (continued)
") Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Linear Regression (continued) Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 6, 2017 1 / 39 Outline 1 Administration 2 Review of last lecture 3 Linear regression
Lecture 10: Support Vector Machine and Large Margin Classifier
 Lecture 10: Support Vector Machine and Large Margin Classifier Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu
Lecture 10: Support Vector Machine and Large Margin Classifier Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu
The Kernel Trick, Gram Matrices, and Feature Extraction. CS6787 Lecture 4 Fall 2017
 The Kernel Trick, Gram Matrices, and Feature Extraction CS6787 Lecture 4 Fall 2017 Momentum for Principle Component Analysis CS6787 Lecture 3.1 Fall 2017 Principle Component Analysis Setting: find the
The Kernel Trick, Gram Matrices, and Feature Extraction CS6787 Lecture 4 Fall 2017 Momentum for Principle Component Analysis CS6787 Lecture 3.1 Fall 2017 Principle Component Analysis Setting: find the
Regularized Least Squares
 Regularized Least Squares Ryan M. Rifkin Google, Inc. 2008 Basics: Data Data points S = {(X 1, Y 1 ),...,(X n, Y n )}. We let X simultaneously refer to the set {X 1,...,X n } and to the n by d matrix whose
Regularized Least Squares Ryan M. Rifkin Google, Inc. 2008 Basics: Data Data points S = {(X 1, Y 1 ),...,(X n, Y n )}. We let X simultaneously refer to the set {X 1,...,X n } and to the n by d matrix whose
MATH 590: Meshfree Methods
 MATH 590: Meshfree Methods Chapter 2 Part 3: Native Space for Positive Definite Kernels Greg Fasshauer Department of Applied Mathematics Illinois Institute of Technology Fall 2014 fasshauer@iit.edu MATH
MATH 590: Meshfree Methods Chapter 2 Part 3: Native Space for Positive Definite Kernels Greg Fasshauer Department of Applied Mathematics Illinois Institute of Technology Fall 2014 fasshauer@iit.edu MATH
Reproducing Kernel Hilbert Spaces
 9.520: Statistical Learning Theory and Applications February 10th, 2010 Reproducing Kernel Hilbert Spaces Lecturer: Lorenzo Rosasco Scribe: Greg Durrett 1 Introduction In the previous two lectures, we
9.520: Statistical Learning Theory and Applications February 10th, 2010 Reproducing Kernel Hilbert Spaces Lecturer: Lorenzo Rosasco Scribe: Greg Durrett 1 Introduction In the previous two lectures, we
10/05/2016. Computational Methods for Data Analysis. Massimo Poesio SUPPORT VECTOR MACHINES. Support Vector Machines Linear classifiers
 Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Foundation of Intelligent Systems, Part I. SVM s & Kernel Methods
 Foundation of Intelligent Systems, Part I SVM s & Kernel Methods mcuturi@i.kyoto-u.ac.jp FIS - 2013 1 Support Vector Machines The linearly-separable case FIS - 2013 2 A criterion to select a linear classifier:
Foundation of Intelligent Systems, Part I SVM s & Kernel Methods mcuturi@i.kyoto-u.ac.jp FIS - 2013 1 Support Vector Machines The linearly-separable case FIS - 2013 2 A criterion to select a linear classifier:
Function Spaces. 1 Hilbert Spaces
 Function Spaces A function space is a set of functions F that has some structure. Often a nonparametric regression function or classifier is chosen to lie in some function space, where the assume structure
Function Spaces A function space is a set of functions F that has some structure. Often a nonparametric regression function or classifier is chosen to lie in some function space, where the assume structure
Each new feature uses a pair of the original features. Problem: Mapping usually leads to the number of features blow up!
 Feature Mapping Consider the following mapping φ for an example x = {x 1,...,x D } φ : x {x1,x 2 2,...,x 2 D,,x 2 1 x 2,x 1 x 2,...,x 1 x D,...,x D 1 x D } It s an example of a quadratic mapping Each new
Feature Mapping Consider the following mapping φ for an example x = {x 1,...,x D } φ : x {x1,x 2 2,...,x 2 D,,x 2 1 x 2,x 1 x 2,...,x 1 x D,...,x D 1 x D } It s an example of a quadratic mapping Each new
Linear vs Non-linear classifier. CS789: Machine Learning and Neural Network. Introduction
 Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Causal Inference by Minimizing the Dual Norm of Bias. Nathan Kallus. Cornell University and Cornell Tech
 Causal Inference by Minimizing the Dual Norm of Bias Nathan Kallus Cornell University and Cornell Tech www.nathankallus.com Matching Zoo It s a zoo of matching estimators for causal effects: PSM, NN, CM,
Causal Inference by Minimizing the Dual Norm of Bias Nathan Kallus Cornell University and Cornell Tech www.nathankallus.com Matching Zoo It s a zoo of matching estimators for causal effects: PSM, NN, CM,
Day 4: Classification, support vector machines
 Day 4: Classification, support vector machines Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 21 June 2018 Topics so far
Day 4: Classification, support vector machines Introduction to Machine Learning Summer School June 18, 2018 - June 29, 2018, Chicago Instructor: Suriya Gunasekar, TTI Chicago 21 June 2018 Topics so far
Statistical Optimality of Stochastic Gradient Descent through Multiple Passes
 Statistical Optimality of Stochastic Gradient Descent through Multiple Passes Francis Bach INRIA - Ecole Normale Supérieure, Paris, France ÉCOLE NORMALE SUPÉRIEURE Joint work with Loucas Pillaud-Vivien
Statistical Optimality of Stochastic Gradient Descent through Multiple Passes Francis Bach INRIA - Ecole Normale Supérieure, Paris, France ÉCOLE NORMALE SUPÉRIEURE Joint work with Loucas Pillaud-Vivien
Stochastic optimization in Hilbert spaces
 Stochastic optimization in Hilbert spaces Aymeric Dieuleveut Aymeric Dieuleveut Stochastic optimization Hilbert spaces 1 / 48 Outline Learning vs Statistics Aymeric Dieuleveut Stochastic optimization Hilbert
Stochastic optimization in Hilbert spaces Aymeric Dieuleveut Aymeric Dieuleveut Stochastic optimization Hilbert spaces 1 / 48 Outline Learning vs Statistics Aymeric Dieuleveut Stochastic optimization Hilbert
Kernel Learning via Random Fourier Representations
 Kernel Learning via Random Fourier Representations L. Law, M. Mider, X. Miscouridou, S. Ip, A. Wang Module 5: Machine Learning L. Law, M. Mider, X. Miscouridou, S. Ip, A. Wang Kernel Learning via Random
Kernel Learning via Random Fourier Representations L. Law, M. Mider, X. Miscouridou, S. Ip, A. Wang Module 5: Machine Learning L. Law, M. Mider, X. Miscouridou, S. Ip, A. Wang Kernel Learning via Random
Kernel Methods in Machine Learning
 Kernel Methods in Machine Learning Autumn 2015 Lecture 1: Introduction Juho Rousu ICS-E4030 Kernel Methods in Machine Learning 9. September, 2015 uho Rousu (ICS-E4030 Kernel Methods in Machine Learning)
Kernel Methods in Machine Learning Autumn 2015 Lecture 1: Introduction Juho Rousu ICS-E4030 Kernel Methods in Machine Learning 9. September, 2015 uho Rousu (ICS-E4030 Kernel Methods in Machine Learning)
Nonlinearity & Preprocessing
 Nonlinearity & Preprocessing Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR: x = (x 1, x 2, x 1 x 2 ) income: add degree + major Perceptron Map data into feature space
Nonlinearity & Preprocessing Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR: x = (x 1, x 2, x 1 x 2 ) income: add degree + major Perceptron Map data into feature space
Support Vector Machines
 Support Vector Machines Reading: Ben-Hur & Weston, A User s Guide to Support Vector Machines (linked from class web page) Notation Assume a binary classification problem. Instances are represented by vector
Support Vector Machines Reading: Ben-Hur & Weston, A User s Guide to Support Vector Machines (linked from class web page) Notation Assume a binary classification problem. Instances are represented by vector
Kernel Methods. Konstantin Tretyakov MTAT Machine Learning
 Kernel Methods Konstantin Tretyakov (kt@ut.ee) MTAT.03.227 Machine Learning So far Supervised machine learning Linear models Non-linear models Unsupervised machine learning Generic scaffolding So far Supervised
Kernel Methods Konstantin Tretyakov (kt@ut.ee) MTAT.03.227 Machine Learning So far Supervised machine learning Linear models Non-linear models Unsupervised machine learning Generic scaffolding So far Supervised
Generalization theory
 Generalization theory Daniel Hsu Columbia TRIPODS Bootcamp 1 Motivation 2 Support vector machines X = R d, Y = { 1, +1}. Return solution ŵ R d to following optimization problem: λ min w R d 2 w 2 2 + 1
Generalization theory Daniel Hsu Columbia TRIPODS Bootcamp 1 Motivation 2 Support vector machines X = R d, Y = { 1, +1}. Return solution ŵ R d to following optimization problem: λ min w R d 2 w 2 2 + 1
Support Vector Machines. Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar
 Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Support Vector Machines and Speaker Verification
 1 Support Vector Machines and Speaker Verification David Cinciruk March 6, 2013 2 Table of Contents Review of Speaker Verification Introduction to Support Vector Machines Derivation of SVM Equations Soft
1 Support Vector Machines and Speaker Verification David Cinciruk March 6, 2013 2 Table of Contents Review of Speaker Verification Introduction to Support Vector Machines Derivation of SVM Equations Soft
EECS 598: Statistical Learning Theory, Winter 2014 Topic 11. Kernels
 EECS 598: Statistical Learning Theory, Winter 2014 Topic 11 Kernels Lecturer: Clayton Scott Scribe: Jun Guo, Soumik Chatterjee Disclaimer: These notes have not been subjected to the usual scrutiny reserved
EECS 598: Statistical Learning Theory, Winter 2014 Topic 11 Kernels Lecturer: Clayton Scott Scribe: Jun Guo, Soumik Chatterjee Disclaimer: These notes have not been subjected to the usual scrutiny reserved
Max Margin-Classifier
 Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
+E x, y ρ. (fw (x) y) 2] (4)
![+E x, y ρ. (fw (x) y) 2] (4)](/thumbs/82/84754402.jpg "+E x, y ρ. (fw (x) y) 2] (4)") Bias-Variance Analysis Let X be a set (or space) of objects and let ρ be a fixed probabiity distribution (or density) on X R. In other worlds ρ is a probability density on pairs x, y with x X and y R.
Bias-Variance Analysis Let X be a set (or space) of objects and let ρ be a fixed probabiity distribution (or density) on X R. In other worlds ρ is a probability density on pairs x, y with x X and y R.
Kernel Methods. Konstantin Tretyakov MTAT Machine Learning
 Kernel Methods Konstantin Tretyakov (kt@ut.ee) MTAT.03.227 Machine Learning So far Supervised machine learning Linear models Least squares regression, SVR Fisher s discriminant, Perceptron, Logistic model,
Kernel Methods Konstantin Tretyakov (kt@ut.ee) MTAT.03.227 Machine Learning So far Supervised machine learning Linear models Least squares regression, SVR Fisher s discriminant, Perceptron, Logistic model,
Outline. Basic concepts: SVM and kernels SVM primal/dual problems. Chih-Jen Lin (National Taiwan Univ.) 1 / 22
 1 / 22") Outline Basic concepts: SVM and kernels SVM primal/dual problems Chih-Jen Lin (National Taiwan Univ.) 1 / 22 Outline Basic concepts: SVM and kernels Basic concepts: SVM and kernels SVM primal/dual problems
Outline Basic concepts: SVM and kernels SVM primal/dual problems Chih-Jen Lin (National Taiwan Univ.) 1 / 22 Outline Basic concepts: SVM and kernels Basic concepts: SVM and kernels SVM primal/dual problems
Representer theorem and kernel examples
 CS81B/Stat41B Spring 008) Statistical Learning Theory Lecture: 8 Representer theorem and kernel examples Lecturer: Peter Bartlett Scribe: Howard Lei 1 Representer Theorem Recall that the SVM optimization
CS81B/Stat41B Spring 008) Statistical Learning Theory Lecture: 8 Representer theorem and kernel examples Lecturer: Peter Bartlett Scribe: Howard Lei 1 Representer Theorem Recall that the SVM optimization
Lecture 10: A brief introduction to Support Vector Machine
 Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
Kernel Methods for Computational Biology and Chemistry
 Kernel Methods for Computational Biology and Chemistry Jean-Philippe Vert Jean-Philippe.Vert@ensmp.fr Centre for Computational Biology Ecole des Mines de Paris, ParisTech Mathematical Statistics and Applications,
Kernel Methods for Computational Biology and Chemistry Jean-Philippe Vert Jean-Philippe.Vert@ensmp.fr Centre for Computational Biology Ecole des Mines de Paris, ParisTech Mathematical Statistics and Applications,
MLCC 2017 Regularization Networks I: Linear Models
 MLCC 2017 Regularization Networks I: Linear Models Lorenzo Rosasco UNIGE-MIT-IIT June 27, 2017 About this class We introduce a class of learning algorithms based on Tikhonov regularization We study computational
MLCC 2017 Regularization Networks I: Linear Models Lorenzo Rosasco UNIGE-MIT-IIT June 27, 2017 About this class We introduce a class of learning algorithms based on Tikhonov regularization We study computational
Kaggle.
 Administrivia Mini-project 2 due April 7, in class implement multi-class reductions, naive bayes, kernel perceptron, multi-class logistic regression and two layer neural networks training set: Project
Administrivia Mini-project 2 due April 7, in class implement multi-class reductions, naive bayes, kernel perceptron, multi-class logistic regression and two layer neural networks training set: Project