Kaggle.
|
|
|
- Preston Lloyd
- 5 years ago
- Views:
Transcription
 project presentations: April 23 and 27 final report:")
1 Administrivia Mini-project 2 due April 7, in class implement multi-class reductions, naive bayes, kernel perceptron, multi-class logistic regression and two layer neural networks training set: Project proposals due April 2, in class one page describing the project topic, goals, etc list your team members (2+) project presentations: April 23 and 27 final report: May 3 1/27

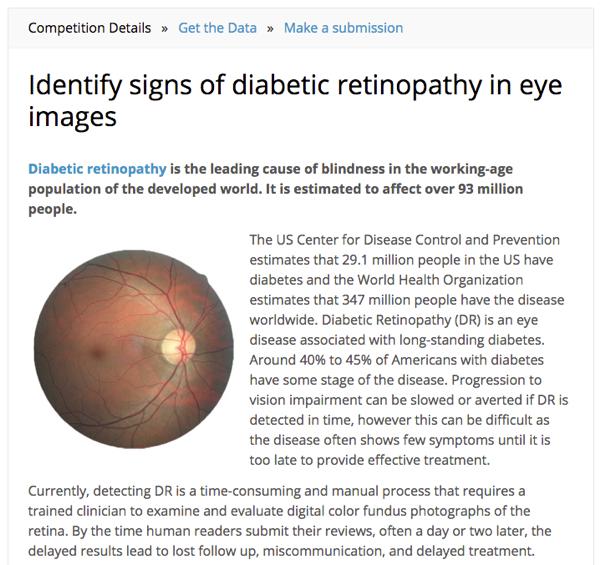
2 Kaggle 2/27
3 Kernel Methods Subhransu Maji CMPSCI 689: Machine Learning 24 March March 2015
4 Feature mapping Learn non-linear classifiers by mapping features Can we learn the XOR function with this mapping? 4/27
5 Quadratic feature map Let, x =[x 1,x 2,...,x D ] Then the quadratic feature map is defined as: p p p (x) =[1, 2x 1, 2x 2,..., 2x D, x 2 1,x 1 x 2,x 1 x 3...,x 1 x D, x 2 x 1,x 2 2,x 2 x 3...,x 2 x D,..., x D x 1,x D x 2,x D x 3...,x 2 D] Contains all single and pairwise terms There are repetitions, e.g., x1x2 and x2x1, but hopefully the learning algorithm can handle redundant features 5/27
6 Drawbacks of feature mapping Computational Suppose training time is linear in feature dimension, quadratic feature map squares the training time Memory Quadratic feature map squares the memory required to store the training data Statistical Quadratic feature mapping squares the number of parameters For now lets assume that regularization will deal with overfitting 6/27
7 Quadratic kernel The dot product between feature maps of x and z is: (x) T (z) =1+2x 1 z 1 +2x 2 z 2,...,2x D z D + x 2 1z1 2 + x 1 x 2 z 1 z x 1 x D z 1 z D x D x 1 z D z 1 + x D x 2 z D z x 2 DzD 2 =1+2 X x i z i + X x i x j z i z j i i,j =1+2 x T z +(x T z) 2 = 1+x T z 2 = K(x, z) quadratic kernel Thus, we can compute φ(x)ᵀφ(z) in almost the same time as needed to compute xᵀz (one extra addition and multiplication) We will rewrite various algorithms using only dot products (or kernel evaluations), and not explicit features 7/27

8 Perceptron revisited Input: training data feature map (x 1,y 1 ), (x 2,y 2 ),...,(x n,y n ) Initialize for iter = 1,,T for i = 1,..,n predict according to the current model ŷ i = Perceptron training algorithm if else, w [0,...,0] +1 if w T (x i ) > 0 y i =ŷ i 1 otherwise, no change w w + y i (x i ) dependence on φ Obtained by replacing x by φ(x) 8/19
 Perceptron representer theorem: During the run of the perceptron training algorithm, the weight vector w is always in the span of φ(x1), φ(x1),, φ(xd) w = P i i (x i ) updates i i +")
9 Properties of the weight vector Linear algebra recap: Let U be set of vectors in Rᴰ, i.e., U = {u1,u2,, ud} and ui Rᴰ Span(U) is the set of all vectors that can be represented as ᵢaᵢuᵢ, such that aᵢ R Null(U) is everything that is left i.e., Rᴰ \ Span(U) Perceptron representer theorem: During the run of the perceptron training algorithm, the weight vector w is always in the span of φ(x1), φ(x1),, φ(xd) w = P i i (x i ) updates i i + y i w T (z) =( P i i (x i )) T (z) = P i i (x i ) T (z) 9/27
10 Kernelized perceptron Input: training data feature map (x 1,y 1 ), (x 2,y 2 ),...,(x n,y n ) Kernelized perceptron training algorithm Initialize for iter = 1,,T for i = 1,..,n predict according to the current model ŷ i = if else, [0, 0,...,0] +1 y i =ŷ i P if n n (x n ) T (x i ) > 0 1 otherwise, no change i = i + y i (x) T (z) =(1+x T z) p polynomial kernel of degree p 10/19
11 Support vector machines Kernels existed long before SVMs, but were popularized by them Does the representer theorem hold for SVMs? Recall that the objective function of an SVM is: Let, min w 1 w = w k + w? 2 w 2 + C X n max(0, 1 y n w T x n ) only w affects classification w T x i =(w k + w? ) T x i = wk T x i + w?x T i = wk T x i norm decomposes w T w =(w k + w? ) T (w k + w? ) = wk T w k + w?w T? wk T w k Hence, w 2 Span({x 1, x 2,...,x n }) 11/27
12 Kernel k-means Initialize k centers by picking k points randomly Repeat till convergence (or max iterations) Assign each point to the nearest center (assignment step) Estimate the mean of each group (update step) Representer theorem is easy here arg min S arg min S kx kx X Exercise: show how to compute x2s i (x) µ i 2 X x2s i (x) µ i 2 using dot products 12/37 µ i 1 S i (x) µ i 2 X x2s i (x)
13 What makes a kernel? A kernel is a mapping K: X xx R Functions that can be written as dot products are valid kernels Examples: polynomial kernel K(x, z) = (x) T (z) K d (poly) (x, z) =(1+xT z) d Alternate characterization of a kernel A function K: X xx R is a kernel if K is positive semi-definite (psd) This property is also called as Mercer s condition This means that for all functions f that are squared integrable except the zero function, the following property holds: Z Z f(x)k(x, z)f(z)dzdx > 0 f(x) 2 dx < 1 Z 13/27
14 Why is this characterization useful? We can prove some properties about kernels that are otherwise hard to prove Theorem: If K1 and K2 are kernels, then K1 + K2 is also a kernel Proof: Z Z f(x)k(x, z)f(z)dzdx = = Z Z Z Z 0+0 f(x)(k 1 (x, z)+k 2 (x, z)) f(z)dzdx Z Z f(x)k 1 (x, z)f(z)dzdx + f(x)k 2 (x, z)f(z)dzdx More generally if K1, K2,, Kn are kernels then ᵢαi Ki with αi 0, is a also a kernel Can build new kernels by linearly combining existing kernels 14/27
15 Why is this characterization useful? We can show that the Gaussian function is a kernel Also called as radial basis function (RBF) kernel Lets look at the classification function using a SVM with RBF kernel: f(z) = X i = X i K (rbf) (x, z) =exp x z 2 i K (rbf) (x i, z) i exp x i z 2 This is similar to a two layer network with the RBF as the link function Gaussian kernels are examples of universal kernels they can approximate any function in the limit as training data goes to infinity 15/27
16 Kernels in practice Feature mapping via kernels often improves performance MNIST digits test error: 8.4% SVM linear 1.4% SVM RBF 1.1% SVM polynomial (d=4) 60,000 training examples 16/27
 number This can be computed efficiently using dynamic programming Can be used with SVMs, perceptrons, k-means,")

17 Kernels over general structures Kernels can be defined over any pair of inputs such as strings, trees and graphs Kernel over trees: K(, ) number This can be computed efficiently using dynamic programming Can be used with SVMs, perceptrons, k-means, etc For strings number of common substrings is a kernel Graph kernels that measure graph similarity (e.g. number of common subgraphs) have been used to predict toxicity of chemical structures = of common subtrees 17/27



18 Kernels for computer vision Histogram intersection kernel between two histograms a and b a b min(a,b) Introduced by Swain and Ballard 1991 to compare color histograms 18/27
 = i K(x i, z) Linear: O (feature dimension) Non Linear: O (N X feature dimension)")
19 Kernel classifiers tradeoffs Evaluation time Linear Kernel h(z) =w T z Accuracy Non- linear Kernel h(z) = i K(x i, z) Linear: O (feature dimension) Non Linear: O (N X feature dimension) 19/27
20 Kernel classification function h(z) = i K(x i, z) = i DX j=1 1 min(x ij,z j ) A 20/27
21 Kernel classification function h(z) = i K(x i, z) = i DX j=1 1 min(x ij,z j ) A h(z) = = DX j=1 Key insight: additive property i DX j=1 1 min(x ij,z j ) A i min(x ij,z j ) = DX j=1 h j (z j ) h j (z j )= i min(x ij,z j ) 21/27
22 Kernel classification function h(z) = i K(x i, z) = i j=1 Algorithm 1 DX 1 min(x ij,z j ) A h j (z j )= i min(x ij,z j ) O(N) 22/27
23 Kernel classification function h(z) = i K(x i, z) = i DX j=1 1 min(x ij,z j ) A h j (z j )= = i min(x ij,z j ) i x ij + i:x ij <z j Algorithm 1 i:x ij z j i z j [Maji et al. PAMI 13] O(N) O(log N) Sort the support vector values in each coordinate, and pre-compute these sums for each rank. To evaluate, find the position of zj the sorted list of support vector xij.this can be done in O(log N) time using binary search. 23/27
24 Kernel classification function h(z) = i K(x i, z) = i DX j=1 1 min(x ij,z j ) A Algorithm 2 [Maji et al. PAMI 13] h j (z j )= = i min(x ij,z j ) O(N) i x ij + i z j O(log N) i:x ij <z j i:x ij z j O(1) For many problems h i is smooth (blue plot). Hence, we can approximate it with fewer uniformly spaced segments (red plot). This saves time and space 24/27
25 Kernel classification function h(z) = i K(x i, z) = i DX j=1 1 min(x ij,z j ) A DX K(x, z) = k i (x i,z i ) additive kernels Algorithm 2 [Maji et al. PAMI 13] O(N) Intersection k(a, b) =min(a, b) Chi- squared k(a, b) = 2ab a + b a + b a + b O(1) Jensen- Shannon k(a, b) =a log a + b log b 25/27
26 Linear and intersection kernel SVM Using histograms of oriented gradients feature: Dataset Measure Linear SVM IK SVM Speedup INRIA pedestrians 2 FPPI X DC pedestrians Accuracy X Caltech101, 15 examples Accuracy X Caltech101, 30 examples Accuracy X MNIST digits Error X UIUC cars (Single Scale) Precision@ EER X On average more accurate than linear and x faster than standard kernel classifier. Similar idea can be applied to training as well. Research question: when can we approximate kernels efficiently? 26/27
27 Slides credit Some of the slides are based on CIML book by Hal Daume III Experiments on various datasets: Efficient Classification for Additive Kernel SVMs, S. Maji, A. C. Berg and J. Malik, PAMI, Jan 2013 Some resources: LIBSVM: kernel SVM classifier training and testing LIBLINEAR: fast linear classifier training LIBSPLINE: fast additive kernel training and testing 27/27
Perceptron. Subhransu Maji. CMPSCI 689: Machine Learning. 3 February February 2015
 Perceptron Subhransu Maji CMPSCI 689: Machine Learning 3 February 2015 5 February 2015 So far in the class Decision trees Inductive bias: use a combination of small number of features Nearest neighbor
Perceptron Subhransu Maji CMPSCI 689: Machine Learning 3 February 2015 5 February 2015 So far in the class Decision trees Inductive bias: use a combination of small number of features Nearest neighbor
Machine Learning. Kernels. Fall (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang. (Chap. 12 of CIML)
 Professor Liang Huang. (Chap. 12 of CIML)") Machine Learning Fall 2017 Kernels (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang (Chap. 12 of CIML) Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR:
Machine Learning Fall 2017 Kernels (Kernels, Kernelized Perceptron and SVM) Professor Liang Huang (Chap. 12 of CIML) Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR:
The Kernel Trick, Gram Matrices, and Feature Extraction. CS6787 Lecture 4 Fall 2017
 The Kernel Trick, Gram Matrices, and Feature Extraction CS6787 Lecture 4 Fall 2017 Momentum for Principle Component Analysis CS6787 Lecture 3.1 Fall 2017 Principle Component Analysis Setting: find the
The Kernel Trick, Gram Matrices, and Feature Extraction CS6787 Lecture 4 Fall 2017 Momentum for Principle Component Analysis CS6787 Lecture 3.1 Fall 2017 Principle Component Analysis Setting: find the
Support Vector Machines
 Support Vector Machines INFO-4604, Applied Machine Learning University of Colorado Boulder September 28, 2017 Prof. Michael Paul Today Two important concepts: Margins Kernels Large Margin Classification
Support Vector Machines INFO-4604, Applied Machine Learning University of Colorado Boulder September 28, 2017 Prof. Michael Paul Today Two important concepts: Margins Kernels Large Margin Classification
Pattern Recognition and Machine Learning. Perceptrons and Support Vector machines
 Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
Nearest Neighbor. Machine Learning CSE546 Kevin Jamieson University of Washington. October 26, Kevin Jamieson 2
 Nearest Neighbor Machine Learning CSE546 Kevin Jamieson University of Washington October 26, 2017 2017 Kevin Jamieson 2 Some data, Bayes Classifier Training data: True label: +1 True label: -1 Optimal
Nearest Neighbor Machine Learning CSE546 Kevin Jamieson University of Washington October 26, 2017 2017 Kevin Jamieson 2 Some data, Bayes Classifier Training data: True label: +1 True label: -1 Optimal
Review: Support vector machines. Machine learning techniques and image analysis
 Review: Support vector machines Review: Support vector machines Margin optimization min (w,w 0 ) 1 2 w 2 subject to y i (w 0 + w T x i ) 1 0, i = 1,..., n. Review: Support vector machines Margin optimization
Review: Support vector machines Review: Support vector machines Margin optimization min (w,w 0 ) 1 2 w 2 subject to y i (w 0 + w T x i ) 1 0, i = 1,..., n. Review: Support vector machines Margin optimization
Workshop on Web- scale Vision and Social Media ECCV 2012, Firenze, Italy October, 2012 Linearized Smooth Additive Classifiers
 Worshop on Web- scale Vision and Social Media ECCV 2012, Firenze, Italy October, 2012 Linearized Smooth Additive Classifiers Subhransu Maji Research Assistant Professor Toyota Technological Institute at
Worshop on Web- scale Vision and Social Media ECCV 2012, Firenze, Italy October, 2012 Linearized Smooth Additive Classifiers Subhransu Maji Research Assistant Professor Toyota Technological Institute at
Announcements. Proposals graded
 Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Announcements Proposals graded Kevin Jamieson 2018 1 Bayesian Methods Machine Learning CSE546 Kevin Jamieson University of Washington November 1, 2018 2018 Kevin Jamieson 2 MLE Recap - coin flips Data:
Deviations from linear separability. Kernel methods. Basis expansion for quadratic boundaries. Adding new features Systematic deviation
 Deviations from linear separability Kernel methods CSE 250B Noise Find a separator that minimizes a convex loss function related to the number of mistakes. e.g. SVM, logistic regression. Systematic deviation
Deviations from linear separability Kernel methods CSE 250B Noise Find a separator that minimizes a convex loss function related to the number of mistakes. e.g. SVM, logistic regression. Systematic deviation
Midterm: CS 6375 Spring 2015 Solutions
 Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
Midterm: CS 6375 Spring 2015 Solutions The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for an
10/05/2016. Computational Methods for Data Analysis. Massimo Poesio SUPPORT VECTOR MACHINES. Support Vector Machines Linear classifiers
 Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
CS798: Selected topics in Machine Learning
 CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
Kernel methods CSE 250B
 Kernel methods CSE 250B Deviations from linear separability Noise Find a separator that minimizes a convex loss function related to the number of mistakes. e.g. SVM, logistic regression. Deviations from
Kernel methods CSE 250B Deviations from linear separability Noise Find a separator that minimizes a convex loss function related to the number of mistakes. e.g. SVM, logistic regression. Deviations from
CS4495/6495 Introduction to Computer Vision. 8C-L3 Support Vector Machines
 CS4495/6495 Introduction to Computer Vision 8C-L3 Support Vector Machines Discriminative classifiers Discriminative classifiers find a division (surface) in feature space that separates the classes Several
CS4495/6495 Introduction to Computer Vision 8C-L3 Support Vector Machines Discriminative classifiers Discriminative classifiers find a division (surface) in feature space that separates the classes Several
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Kernels and the Kernel Trick. Machine Learning Fall 2017
 Kernels and the Kernel Trick Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem Support vectors, duals and kernels
Kernels and the Kernel Trick Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem Support vectors, duals and kernels
Kernel Methods. Foundations of Data Analysis. Torsten Möller. Möller/Mori 1
 Kernel Methods Foundations of Data Analysis Torsten Möller Möller/Mori 1 Reading Chapter 6 of Pattern Recognition and Machine Learning by Bishop Chapter 12 of The Elements of Statistical Learning by Hastie,
Kernel Methods Foundations of Data Analysis Torsten Möller Möller/Mori 1 Reading Chapter 6 of Pattern Recognition and Machine Learning by Bishop Chapter 12 of The Elements of Statistical Learning by Hastie,
Linear vs Non-linear classifier. CS789: Machine Learning and Neural Network. Introduction
 Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Expectation maximization
 Expectation maximization Subhransu Maji CMSCI 689: Machine Learning 14 April 2015 Motivation Suppose you are building a naive Bayes spam classifier. After your are done your boss tells you that there is
Expectation maximization Subhransu Maji CMSCI 689: Machine Learning 14 April 2015 Motivation Suppose you are building a naive Bayes spam classifier. After your are done your boss tells you that there is
CIS 520: Machine Learning Oct 09, Kernel Methods
 CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
EE613 Machine Learning for Engineers. Kernel methods Support Vector Machines. jean-marc odobez 2015
 EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
Support Vector Machines
 Support Vector Machines Hypothesis Space variable size deterministic continuous parameters Learning Algorithm linear and quadratic programming eager batch SVMs combine three important ideas Apply optimization
Support Vector Machines Hypothesis Space variable size deterministic continuous parameters Learning Algorithm linear and quadratic programming eager batch SVMs combine three important ideas Apply optimization
Support Vector Machines (SVM) in bioinformatics. Day 1: Introduction to SVM
 in bioinformatics. Day 1: Introduction to SVM") 1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Each new feature uses a pair of the original features. Problem: Mapping usually leads to the number of features blow up!
 Feature Mapping Consider the following mapping φ for an example x = {x 1,...,x D } φ : x {x1,x 2 2,...,x 2 D,,x 2 1 x 2,x 1 x 2,...,x 1 x D,...,x D 1 x D } It s an example of a quadratic mapping Each new
Feature Mapping Consider the following mapping φ for an example x = {x 1,...,x D } φ : x {x1,x 2 2,...,x 2 D,,x 2 1 x 2,x 1 x 2,...,x 1 x D,...,x D 1 x D } It s an example of a quadratic mapping Each new
Kernel Methods. Barnabás Póczos
 Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
Kernel Methods Barnabás Póczos Outline Quick Introduction Feature space Perceptron in the feature space Kernels Mercer s theorem Finite domain Arbitrary domain Kernel families Constructing new kernels
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
Max-Margin Additive Classifiers for Detection
 Max-Margin Additive Classifiers for Detection Subhransu Maji and Alexander C. Berg Sam Hare VGG Reading Group October 30, 2009 Introduction CVPR08: SVMs with additive kernels can be evaluated efficiently.
Max-Margin Additive Classifiers for Detection Subhransu Maji and Alexander C. Berg Sam Hare VGG Reading Group October 30, 2009 Introduction CVPR08: SVMs with additive kernels can be evaluated efficiently.
Support Vector Machines.
 Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Modelli Lineari (Generalizzati) e SVM
 e SVM") Modelli Lineari (Generalizzati) e SVM Corso di AA, anno 2018/19, Padova Fabio Aiolli 19/26 Novembre 2018 Fabio Aiolli Modelli Lineari (Generalizzati) e SVM 19/26 Novembre 2018 1 / 36 Outline Linear methods
Modelli Lineari (Generalizzati) e SVM Corso di AA, anno 2018/19, Padova Fabio Aiolli 19/26 Novembre 2018 Fabio Aiolli Modelli Lineari (Generalizzati) e SVM 19/26 Novembre 2018 1 / 36 Outline Linear methods
Support Vector Machines
 Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Logistic Regression: Online, Lazy, Kernelized, Sequential, etc.
 Logistic Regression: Online, Lazy, Kernelized, Sequential, etc. Harsha Veeramachaneni Thomson Reuter Research and Development April 1, 2010 Harsha Veeramachaneni (TR R&D) Logistic Regression April 1, 2010
Logistic Regression: Online, Lazy, Kernelized, Sequential, etc. Harsha Veeramachaneni Thomson Reuter Research and Development April 1, 2010 Harsha Veeramachaneni (TR R&D) Logistic Regression April 1, 2010
SVMs: nonlinearity through kernels
 Non-separable data e-8. Support Vector Machines 8.. The Optimal Hyperplane Consider the following two datasets: SVMs: nonlinearity through kernels ER Chapter 3.4, e-8 (a) Few noisy data. (b) Nonlinearly
Non-separable data e-8. Support Vector Machines 8.. The Optimal Hyperplane Consider the following two datasets: SVMs: nonlinearity through kernels ER Chapter 3.4, e-8 (a) Few noisy data. (b) Nonlinearly
Perceptron Revisited: Linear Separators. Support Vector Machines
 Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Support Vector Machine II
 Support Vector Machine II Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 due tonight HW 2 released. Online Scalable Learning Adaptive to Unknown Dynamics and Graphs Yanning
Support Vector Machine II Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 due tonight HW 2 released. Online Scalable Learning Adaptive to Unknown Dynamics and Graphs Yanning
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012") Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Kernel Machines. Pradeep Ravikumar Co-instructor: Manuela Veloso. Machine Learning
 Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Basis Expansion and Nonlinear SVM. Kai Yu
 Basis Expansion and Nonlinear SVM Kai Yu Linear Classifiers f(x) =w > x + b z(x) = sign(f(x)) Help to learn more general cases, e.g., nonlinear models 8/7/12 2 Nonlinear Classifiers via Basis Expansion
Basis Expansion and Nonlinear SVM Kai Yu Linear Classifiers f(x) =w > x + b z(x) = sign(f(x)) Help to learn more general cases, e.g., nonlinear models 8/7/12 2 Nonlinear Classifiers via Basis Expansion
Outline. Motivation. Mapping the input space to the feature space Calculating the dot product in the feature space
 to The The A s s in to Fabio A. González Ph.D. Depto. de Ing. de Sistemas e Industrial Universidad Nacional de Colombia, Bogotá April 2, 2009 to The The A s s in 1 Motivation Outline 2 The Mapping the
to The The A s s in to Fabio A. González Ph.D. Depto. de Ing. de Sistemas e Industrial Universidad Nacional de Colombia, Bogotá April 2, 2009 to The The A s s in 1 Motivation Outline 2 The Mapping the
9.2 Support Vector Machines 159
 9.2 Support Vector Machines 159 9.2.3 Kernel Methods We have all the tools together now to make an exciting step. Let us summarize our findings. We are interested in regularized estimation problems of
9.2 Support Vector Machines 159 9.2.3 Kernel Methods We have all the tools together now to make an exciting step. Let us summarize our findings. We are interested in regularized estimation problems of
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/22/2010 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements W7 due tonight [this is your last written for
CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/22/2010 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements W7 due tonight [this is your last written for
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
SVMs, Duality and the Kernel Trick
 SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
NONLINEAR CLASSIFICATION AND REGRESSION. J. Elder CSE 4404/5327 Introduction to Machine Learning and Pattern Recognition
 NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
NONLINEAR CLASSIFICATION AND REGRESSION Nonlinear Classification and Regression: Outline 2 Multi-Layer Perceptrons The Back-Propagation Learning Algorithm Generalized Linear Models Radial Basis Function
Support Vector Machine I
 Support Vector Machine I Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Please use piazza. No emails. HW 0 grades are back. Re-grade request for one week. HW 1 due soon. HW
Support Vector Machine I Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative Please use piazza. No emails. HW 0 grades are back. Re-grade request for one week. HW 1 due soon. HW
Lecture 7: Kernels for Classification and Regression
 Lecture 7: Kernels for Classification and Regression CS 194-10, Fall 2011 Laurent El Ghaoui EECS Department UC Berkeley September 15, 2011 Outline Outline A linear regression problem Linear auto-regressive
Lecture 7: Kernels for Classification and Regression CS 194-10, Fall 2011 Laurent El Ghaoui EECS Department UC Berkeley September 15, 2011 Outline Outline A linear regression problem Linear auto-regressive
Kernel Methods. Charles Elkan October 17, 2007
 Kernel Methods Charles Elkan elkan@cs.ucsd.edu October 17, 2007 Remember the xor example of a classification problem that is not linearly separable. If we map every example into a new representation, then
Kernel Methods Charles Elkan elkan@cs.ucsd.edu October 17, 2007 Remember the xor example of a classification problem that is not linearly separable. If we map every example into a new representation, then
Machine Learning. Classification, Discriminative learning. Marc Toussaint University of Stuttgart Summer 2015
 Machine Learning Classification, Discriminative learning Structured output, structured input, discriminative function, joint input-output features, Likelihood Maximization, Logistic regression, binary
Machine Learning Classification, Discriminative learning Structured output, structured input, discriminative function, joint input-output features, Likelihood Maximization, Logistic regression, binary
Support Vector Machines
 EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
Support Vector Machines. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
From Binary to Multiclass Classification. CS 6961: Structured Prediction Spring 2018
 From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
From Binary to Multiclass Classification CS 6961: Structured Prediction Spring 2018 1 So far: Binary Classification We have seen linear models Learning algorithms Perceptron SVM Logistic Regression Prediction
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017
 COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
COMS 4721: Machine Learning for Data Science Lecture 10, 2/21/2017 Prof. John Paisley Department of Electrical Engineering & Data Science Institute Columbia University FEATURE EXPANSIONS FEATURE EXPANSIONS
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012
 CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the
Lecture 18: Kernels Risk and Loss Support Vector Regression. Aykut Erdem December 2016 Hacettepe University
 Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
Learning with kernels and SVM
 Learning with kernels and SVM Šámalova chata, 23. května, 2006 Petra Kudová Outline Introduction Binary classification Learning with Kernels Support Vector Machines Demo Conclusion Learning from data find
Learning with kernels and SVM Šámalova chata, 23. května, 2006 Petra Kudová Outline Introduction Binary classification Learning with Kernels Support Vector Machines Demo Conclusion Learning from data find
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels
 SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
Kernelized Perceptron Support Vector Machines
 Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Kernelized Perceptron Support Vector Machines Emily Fox University of Washington February 13, 2017 What is the perceptron optimizing? 1 The perceptron algorithm [Rosenblatt 58, 62] Classification setting:
Machine Learning and Data Mining. Support Vector Machines. Kalev Kask
 Machine Learning and Data Mining Support Vector Machines Kalev Kask Linear classifiers Which decision boundary is better? Both have zero training error (perfect training accuracy) But, one of them seems
Machine Learning and Data Mining Support Vector Machines Kalev Kask Linear classifiers Which decision boundary is better? Both have zero training error (perfect training accuracy) But, one of them seems
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES. Supervised Learning
 LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
CS 231A Section 1: Linear Algebra & Probability Review
 CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
CS 231A Section 1: Linear Algebra & Probability Review 1 Topics Support Vector Machines Boosting Viola-Jones face detector Linear Algebra Review Notation Operations & Properties Matrix Calculus Probability
(Kernels +) Support Vector Machines
 Support Vector Machines") (Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
(Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
Support Vector Machines: Kernels
 Support Vector Machines: Kernels CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 14.1, 14.2, 14.4 Schoelkopf/Smola Chapter 7.4, 7.6, 7.8 Non-Linear Problems
Support Vector Machines: Kernels CS6780 Advanced Machine Learning Spring 2015 Thorsten Joachims Cornell University Reading: Murphy 14.1, 14.2, 14.4 Schoelkopf/Smola Chapter 7.4, 7.6, 7.8 Non-Linear Problems
Machine Learning. Support Vector Machines. Manfred Huber
 Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
FINAL: CS 6375 (Machine Learning) Fall 2014
 Fall 2014") FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
FINAL: CS 6375 (Machine Learning) Fall 2014 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run out of room for
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
CS 231A Section 1: Linear Algebra & Probability Review. Kevin Tang
 CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
CS 231A Section 1: Linear Algebra & Probability Review Kevin Tang Kevin Tang Section 1-1 9/30/2011 Topics Support Vector Machines Boosting Viola Jones face detector Linear Algebra Review Notation Operations
Kernel Methods. Konstantin Tretyakov MTAT Machine Learning
 Kernel Methods Konstantin Tretyakov (kt@ut.ee) MTAT.03.227 Machine Learning So far Supervised machine learning Linear models Non-linear models Unsupervised machine learning Generic scaffolding So far Supervised
Kernel Methods Konstantin Tretyakov (kt@ut.ee) MTAT.03.227 Machine Learning So far Supervised machine learning Linear models Non-linear models Unsupervised machine learning Generic scaffolding So far Supervised
Nonlinearity & Preprocessing
 Nonlinearity & Preprocessing Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR: x = (x 1, x 2, x 1 x 2 ) income: add degree + major Perceptron Map data into feature space
Nonlinearity & Preprocessing Nonlinear Features x4: -1 x1: +1 x3: +1 x2: -1 Concatenated (combined) features XOR: x = (x 1, x 2, x 1 x 2 ) income: add degree + major Perceptron Map data into feature space
Kernel Methods. Konstantin Tretyakov MTAT Machine Learning
 Kernel Methods Konstantin Tretyakov (kt@ut.ee) MTAT.03.227 Machine Learning So far Supervised machine learning Linear models Least squares regression, SVR Fisher s discriminant, Perceptron, Logistic model,
Kernel Methods Konstantin Tretyakov (kt@ut.ee) MTAT.03.227 Machine Learning So far Supervised machine learning Linear models Least squares regression, SVR Fisher s discriminant, Perceptron, Logistic model,
18.9 SUPPORT VECTOR MACHINES
 744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
1 Machine Learning Concepts (16 points)
") CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
CSCI 567 Fall 2018 Midterm Exam DO NOT OPEN EXAM UNTIL INSTRUCTED TO DO SO PLEASE TURN OFF ALL CELL PHONES Problem 1 2 3 4 5 6 Total Max 16 10 16 42 24 12 120 Points Please read the following instructions
COMP 875 Announcements
 Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
Announcements Tentative presentation order is out Announcements Tentative presentation order is out Remember: Monday before the week of the presentation you must send me the final paper list (for posting
Online Learning With Kernel
 CS 446 Machine Learning Fall 2016 SEP 27, 2016 Online Learning With Kernel Professor: Dan Roth Scribe: Ben Zhou, C. Cervantes Overview Stochastic Gradient Descent Algorithms Regularization Algorithm Issues
CS 446 Machine Learning Fall 2016 SEP 27, 2016 Online Learning With Kernel Professor: Dan Roth Scribe: Ben Zhou, C. Cervantes Overview Stochastic Gradient Descent Algorithms Regularization Algorithm Issues
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2010 Lecture 22: Nearest Neighbors, Kernels 4/18/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!)
CS 188: Artificial Intelligence Spring 2010 Lecture 22: Nearest Neighbors, Kernels 4/18/2011 Pieter Abbeel UC Berkeley Slides adapted from Dan Klein Announcements On-going: contest (optional and FUN!)
Nearest Neighbors Methods for Support Vector Machines
 Nearest Neighbors Methods for Support Vector Machines A. J. Quiroz, Dpto. de Matemáticas. Universidad de Los Andes joint work with María González-Lima, Universidad Simón Boĺıvar and Sergio A. Camelo, Universidad
Nearest Neighbors Methods for Support Vector Machines A. J. Quiroz, Dpto. de Matemáticas. Universidad de Los Andes joint work with María González-Lima, Universidad Simón Boĺıvar and Sergio A. Camelo, Universidad
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Support Vector Machines and Kernel Methods
 Support Vector Machines and Kernel Methods Geoff Gordon ggordon@cs.cmu.edu July 10, 2003 Overview Why do people care about SVMs? Classification problems SVMs often produce good results over a wide range
Support Vector Machines and Kernel Methods Geoff Gordon ggordon@cs.cmu.edu July 10, 2003 Overview Why do people care about SVMs? Classification problems SVMs often produce good results over a wide range
Machine Learning for Structured Prediction
 Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
10-701/ Recitation : Kernels
 10-701/15-781 Recitation : Kernels Manojit Nandi February 27, 2014 Outline Mathematical Theory Banach Space and Hilbert Spaces Kernels Commonly Used Kernels Kernel Theory One Weird Kernel Trick Representer
10-701/15-781 Recitation : Kernels Manojit Nandi February 27, 2014 Outline Mathematical Theory Banach Space and Hilbert Spaces Kernels Commonly Used Kernels Kernel Theory One Weird Kernel Trick Representer
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux INRIA 8 Nov 2011 Nicolas Le Roux (INRIA) Neural networks and optimization 8 Nov 2011 1 / 80 1 Introduction 2 Linear classifier 3 Convolutional neural networks
Neural networks and optimization Nicolas Le Roux INRIA 8 Nov 2011 Nicolas Le Roux (INRIA) Neural networks and optimization 8 Nov 2011 1 / 80 1 Introduction 2 Linear classifier 3 Convolutional neural networks
Nonlinear Classification
 Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Nonlinear Classification INFO-4604, Applied Machine Learning University of Colorado Boulder October 5-10, 2017 Prof. Michael Paul Linear Classification Most classifiers we ve seen use linear functions
Machine Learning Support Vector Machines. Prof. Matteo Matteucci
 Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Advanced Machine Learning & Perception
 Advanced Machine Learning & Perception Instructor: Tony Jebara Topic 6 Standard Kernels Unusual Input Spaces for Kernels String Kernels Probabilistic Kernels Fisher Kernels Probability Product Kernels
Advanced Machine Learning & Perception Instructor: Tony Jebara Topic 6 Standard Kernels Unusual Input Spaces for Kernels String Kernels Probabilistic Kernels Fisher Kernels Probability Product Kernels
Neural networks and optimization
 Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
Neural networks and optimization Nicolas Le Roux Criteo 18/05/15 Nicolas Le Roux (Criteo) Neural networks and optimization 18/05/15 1 / 85 1 Introduction 2 Deep networks 3 Optimization 4 Convolutional
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
Classifier Complexity and Support Vector Classifiers
 Classifier Complexity and Support Vector Classifiers Feature 2 6 4 2 0 2 4 6 8 RBF kernel 10 10 8 6 4 2 0 2 4 6 Feature 1 David M.J. Tax Pattern Recognition Laboratory Delft University of Technology D.M.J.Tax@tudelft.nl
Classifier Complexity and Support Vector Classifiers Feature 2 6 4 2 0 2 4 6 8 RBF kernel 10 10 8 6 4 2 0 2 4 6 Feature 1 David M.J. Tax Pattern Recognition Laboratory Delft University of Technology D.M.J.Tax@tudelft.nl
Support Vector Machines and Kernel Methods
 2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
6.036 midterm review. Wednesday, March 18, 15
 6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that
6.036 midterm review 1 Topics covered supervised learning labels available unsupervised learning no labels available semi-supervised learning some labels available - what algorithms have you learned that