Support Vector Machines
|
|
|
- Noah Shepherd
- 5 years ago
- Views:
Transcription
1 Support Vector Machines Reading: Ben-Hur & Weston, A User s Guide to Support Vector Machines (linked from class web page)
2 Notation Assume a binary classification problem. Instances are represented by vector x R n. Training examples: x = (x 1, x 2,, x n ) S = {(x 1, t 1 ), (x 2, t 2 ),..., (x m, t m ) (x k, t k ) R n {+1, 1}} Hypothesis: A function h: R n {+1, 1}. h(x) = h(x 1, x 2,, x n ) {+1, 1}
3 Here, assume positive and negative instances are to be separated by the hyperplane where b is the bias. w x + b = 0 Equation of line: w x + b = w T x + b = w 1 x 1 + w 2 x 2 + b = 0 x 2 x 1
4 w x + b = 0 Intuition: the best hyperplane (for future generalization) will maximally separate the examples
5 Definition of Margin (with respect to a hyperplane): Distance from separating hyperplane to nearest positive (or negative) instance.
6 Definition of Margin (with respect to a hyperplane): Distance from separating hyperplane to nearest positive (or negative) instance. Vapnik (1979) showed that the hyperplane maximizing the margin of S will have minimal VC dimension in the set of all consistent hyperplanes, and will thus be optimal.
7 Definition of Margin (with respect to a hyperplane): Distance from separating hyperplane to nearest positive (or negative) instance. Vapnik (1979) showed that the hyperplane maximizing the margin of S will have minimal VC dimension in the set of all consistent hyperplanes, and will thus be optimal. This is an optimization problem!
8 Support vectors: Training examples that lie on the margin.
9 w x + b = 0 Support vectors: Training examples that lie on the margin.
10 w x + b = 0 w x + b = a Support vectors: Training examples that lie on the margin.
11 w x + b = a w x + b = 0 w x + b = a Support vectors: Training examples that lie on the margin.
12 w x + b = a w x + b = 0 w x + b = a Support vectors: Training examples that lie on the margin. Without changing the problem, we can rescale our data to set a = 1
13 w x + b = 1 w x + b = 0 w x + b =1 Support vectors: Training examples that lie on the margin. Without changing the problem, we can rescale our data to set a = 1
14 w x + b = 0 w x + b =1 Geometry of the margin w x + b = 1 Without changing the problem, we can rescale our data to set a = 1
15 w x + b = 1 w x + b = 0 w x + b =1 Geometry of the margin (w x 1 )+ b = +1 (w x 2 )+ b = 1 w (x 1 x 2 ) = 2 (x 1 x 2 ) = 2 w where w = w w = w w 2 2 Without changing the problem, we can rescale our data to set a = 1
16 The length of the margin is 1 w So to maximize the margin, we need to minimize. w
17 Minimizing w Find w and b by doing the following minimization: min w,b! 1 2 w 2 $ # & " % subject to: t k ( w x k + b) 1, k =1,..., m (t k { 1,+1}) This is a quadratic, constrained optimization problem. Use method of Lagrange multipliers to solve it.
18 Dual Representation It turns out that w can be expressed as a linear combination of the training examples: w = α k x k S x k where α k 0 only if x k is a support vector The results of the SVM training algorithm (involving solving a quadratic programming problem) are the α k and the bias b.
19 SVM Classification Classify new example x as follows: M h(x) = sgn α k x x k k=1 ( ) + b where S = M. (S is the training set)

20 SVM Classification Classify new example x as follows: M h(x) = sgn α k x x k k=1 ( ) + b where S = M. (S is the training set) Note that dot product is a kind of similarity measure
21 Example
22 Example Input to SVM optimzer: x 1 x 2 class Output from SVM optimizer: -2 Support vector α ( 1, 0).208 (1, 1).416 (0, 1).208 b =.376
23 Example Input to SVM optimzer: x 1 x 2 class Output from SVM optimizer: -2 Support vector α ( 1, 0).208 (1, 1).416 (0, 1).208 b =.376
24 Example Input to SVM optimzer: x 1 x 2 class Output from SVM optimizer: Weight vector: w = k {training examples} -2 α k x k =.208 ( 1, 0)+.416 (1,1).208 (0, 1) Support vector α ( 1, 0).208 (1, 1).416 (0, 1).208 b =.376 = (.624,.624)
25 Example Separation line: w 1 x 1 + w 2 x 2 + b = 0 Input to SVM optimzer: x x = 0 x 2 = x x 1 x 2 class Output from SVM optimizer: Weight vector: w = k {training examples} -2 α k x k =.208 ( 1, 0)+.416 (1,1).208 (0, 1) Support vector α ( 1, 0).208 (1, 1).416 (0, 1).208 b =.376 = (.624,.624)
26 Example Separation line: w 1 x 1 + w 2 x 2 + b = 0 Input to SVM optimzer: x x = 0 x 2 = x x 1 x 2 class Output from SVM optimizer: Weight vector: w = k {training examples} -2 α k x k =.208 ( 1, 0)+.416 (1,1).208 (0, 1) Support vector α ( 1, 0).208 (1, 1).416 (0, 1).208 b =.376 = (.624,.624)
27 Example Classifying a new point:
28 Example Classifying a new point: m h((2,2)) = sgn α k x k x k=1 ( ) = sgn.208 ( 1, 0) (2, 2) + b, where sgn(z) = 1 if z > 0 1 if z 0 ( [ ] [(1,1) (2, 2) ].208 [(0, 1) (2, 2) ].376) ( ) = +1 = sgn
29 Example Classifying a new point: m h((2,2)) = sgn α k x k x k=1 ( ) = sgn.208 ( 1, 0) (2, 2) + b, where sgn(z) = 1 if z > 0 1 if z 0 ( [ ] [(1,1) (2, 2) ].208 [(0, 1) (2, 2) ].376) ( ) = +1 = sgn
30 Example Classifying a new point: m h((2,2)) = sgn α k x k x k=1 ( ) = sgn.208 ( 1, 0) (2, 2) + b, where sgn(z) = 1 if z > 0 1 if z 0 ( [ ] [(1,1) (2, 2) ].208 [(0, 1) (2, 2) ].376) ( ) = +1 = sgn
31 In-Class Exercise 1
32 SVM summary Equation of line: w 1 x 1 + w 2 x 2 + b = 0 Define margin using: x k w + b +1 for positive instances (t k = +1) x k w + b 1 for negative instances (t k = 1) Margin distance: 1 w To maximize the margin, we minimize w subject to the constraint that positive examples fall on one side of the margin, and negative examples on the other side: t k ( w x k + b) 1, k =1,..., m where t k { 1,+1} We can relax this constraint using slack variables
33 SVM summary To do the optimization, we use the dual formulation: w = k {training examples} α k x k The results of the optimization black box are and b. {α k }
34 SVM review Once the optimization is done, we can classify a new example x as follows: h(x) = class(x) = sgn( w x + b) ## m & & = sgn% % α k x k ( x + b( $ $ k=1 ' ' ## m = sgn% % α k x k x $ $ k=1 ( ) & & (+ b( ' ' That is, classification is done entirely through a linear combination of dot products with training examples. This is a kernel method.
35 SVM_light demo
36 Non-linearly separable training examples What if the training examples are not linearly separable?
37 Non-linearly separable training examples What if the training examples are not linearly separable? Use old trick: Find a function that maps points to a higher dimensional space ( feature space ) in which they are linearly separable, and do the classification in that higherdimensional space.
38 x 2 x 2 x 1 x 1 x 3 Need to find a function Φ that will perform such a mapping: Φ: R n F Then can find hyperplane in higher dimensional feature space F, and do classification using that hyperplane in higher dimensional space.
39 Challenge Find a 3-dimensional feature space in which XOR is linearly separable. x 2 (0, 1) (1, 1) x 2 (1, 0) x 1 (0, 0) x 1 x 3
40 Problem: Recall that classification of instance x is expressed in terms of dot products of x and support vectors. $ Class(x) = sgn & % k {training examples} ' α k (x x k )+ b ) ( The quadratic programming problem of finding the support vectors and coefficients also depends only on dot products between training examples, rather than on the training examples outside of dot products.
41 So if each x k is replaced by Φ(x k ) in these procedures, we will have to calculate Φ(x k ) for each k as well as calculate a lot of dot products, Φ(x) Φ(x k ) But in general, if the feature space F is high dimensional, Φ(x i ) Φ(x j ) will be expensive to compute.
42 Second trick: Suppose that there were some magic function, K(x i, x j ) = Φ(x i ) Φ(x j ) such that K is cheap to compute even though Φ(x i ) Φ(x j ) is expensive to compute. Then we wouldn t need to compute the dot product directly; we d just need to compute K during both the training and testing phases. The good news is: such K functions exist! They are called kernel functions, and come from the theory of integral operators.
43 Example: Polynomial kernel: Suppose x = (x 1, x 2 ) and z = (z 1, z 2 ). k(x,z) = (x z) 2 Let Φ(x) = ( x 2 2 1, 2 x 1 x 2, x ) 2. Then : 2 x 1 2 z 1 Φ(x) Φ(z) = 2 x 1 x 2 2 x 2 z 1 z z 2 = x 1 x 2 z 1 z 2 2 = (x z) 2 = k(x,z)
44 In-Class Exercise 2
45
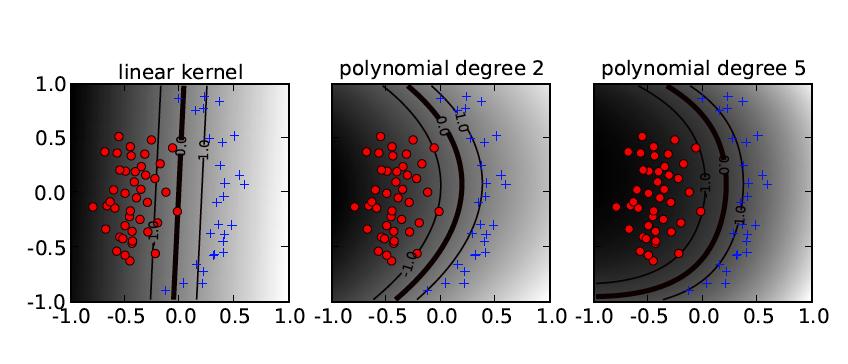
46
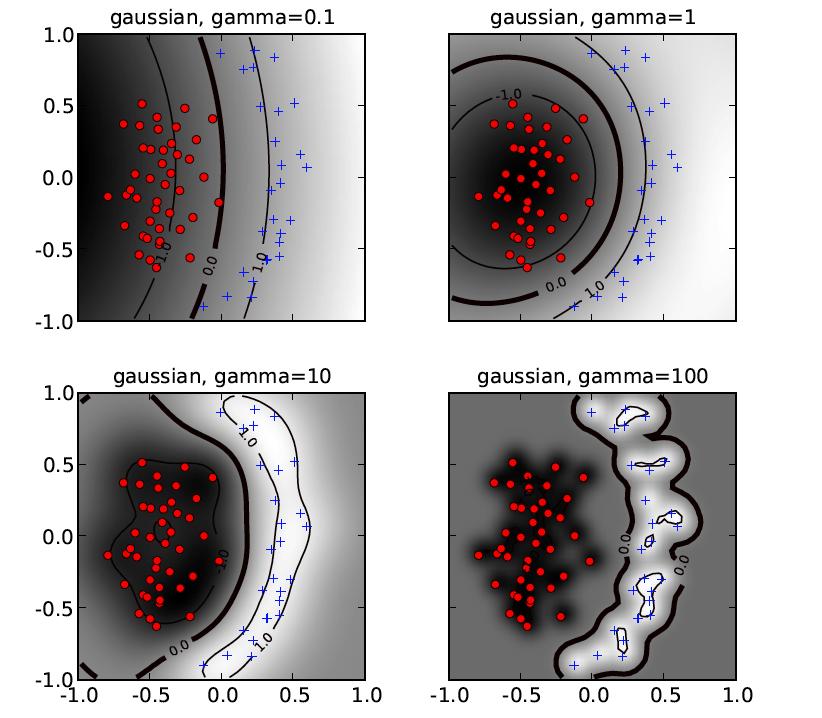
47
48 More on Kernels So far we ve seen kernels that map instances in R n to instances in R z where z > n. One way to create a kernel: Figure out appropriate feature space Φ(x), and find kernel function k which defines inner product on that space. More practically, we usually don t know appropriate feature space Φ(x). What people do in practice is either: 1. Use one of the classic kernels (e.g., polynomial), or 2. Define their own function that is appropriate for their task, and show that it qualifies as a kernel.
49 How to define your own kernel Given training data (x 1, x 2,..., x n ) Algorithm for SVM learning uses kernel matrix (also called Gram matrix): K i, j = K(x i, x j ), for i, j =1,..., n We can choose some function K, and compute the kernel matrix K using the training data. We just have to guarantee that our kernel defines an inner product on some feature space. Not as hard as it sounds.
50 What counts as a kernel? Mercer s Theorem: If the kernel matrix K is positive definite, it defines a kernel, that is, it defines an inner product in some feature space. We don t even have to know what that feature space is! It can have a huge number of dimensions.
51 Structural Kernels In domains such as natural language processing and bioinformatics, the similarities we want to capture are often structural (e.g., parse trees, formal grammars). An important area of kernel methods is defining structural kernels that capture this similarity (e.g., sequence alignment kernels, tree kernels, graph kernels, etc.)
52 From Design criteria - we want kernels to be valid Satisfy Mercer condition of positive semidefiniteness good embody the true similarity between objects appropriate generalize well efficient the computation of K(x, x ) is feasible

53 Example: Watson used tree kernels and SVMs to classify question types for Jeopardy! questions From Moschitti et al., 2011
54 Summary of SVM algorithm Given training set S = {(x 1, t 1 ), (x 2, t 2 ),..., (x m, t m ) (x k, t k ) R n {+1, -1} 1. Choose a kernel function k(x,z). 2. Apply optimization procedure (using the kernel function K) to find support vectors x k, coefficients α k, and bias b. 3. Given a new instance, x, find the classification of x by computing class(x) = sgn α k k(x, x k ) + b k support vectors
55
56 Given training data (x 1, x 2,..., x m ) How to define your own kernel Algorithm for SVM learning uses kernel matrix (also called Gram matrix): K i, j = K(x i, x j ), for i, j =1,..., m
57 How to define your own kernel We can choose some function K, and compute the kernel matrix K using the training data. We just have to guarantee that our kernel defines an inner product on some feature space Mercer s Theorem: : If K is positive semidefinite, it defines a kernel, that is, it defines an inner product in some feature space. We don t even have to know what that feature space is! K is symmetric if K = K T K is positive semidefinite if all the eigenvalues of K are positive.
58 Example of Simple Custom Kernel Similarity between DNA Sequences: E.g., s 1 = GAATGTCCTTTCTCTAAGTCCTAAG s 2 = GGAGACTTACAGGAAAGAGATTCG Define Hamming Distance Kernel : hamming(s 1, s 2 ) = number of sites where strings match
59 Kernel matrix for hamming kernel Suppose training set is s 1 = GAATGTCCTTTCTCTAAGTCCTAAG s 2 = GGAGACTTACAGGAAAGAGATTCG s 3 = GGAAACTTTCGGGAGAGAGTTTCG What is the Kernel matrix K? K s 1 s 2 s 3 s 1 s 2 s 3
60 In-Class Exercise 3
61 Homework 3
62 Data Standardization In general, we need to do data standardization for SVMs to avoid imbalance among feature scales: Let µ i denote the mean value of feature i in the training data, and σ i denote the corresponding standard deviation. For each training example x, replace each x i as follows:!! =!!!!!! Scale the test data in the same way, using the µ i and σ i values computed from the training data, not the test data.
63 Feature Selection Goal: Select a subset of d features (d < n) in order to maximize classification performance with fewer features.
64 Types of Feature Selection Methods Filter Wrapper Embedded
65 Filter Methods Independent of the classification algorithm. Training data Apply a filtering function to the features before applying classifier. Filter Examples of filtering functions: Information gain of individual features Selected features Statistical variance of individual features Statistical correlation among features Classifier
66 Wrapper Methods Training data Choose subset of features Accuracy on validation set Classifier (cross-validation) After cross-validation Classifier (Entire training set with best subset of features) Evaluate classifier on test set
67 Filter Methods Pros: Fast Cons: Chosen filter might not be relevant for a specific kind of classifier. Doesn t take into account interactions among features Often hard to know how many features to select.
68 Filter Methods Wrapper Methods Pros: Fast Cons: Chosen filter might not be relevant for a specific kind of classifier. Doesn t take into account interactions among features Pros: Features are evaluated in context of classification Wrapper method selects number of features to use Cons: Slow Often hard to know how many features to select.
69 Filter Methods Wrapper Methods Pros: Fast Cons: Chosen filter might not be relevant for a specific kind of classifier. Doesn t take into account interactions among features Often hard to know how many features to select. Intermediate method, often used with SVMs: Pros: Features are evaluated in context of classification Wrapper method selects number of features to use Cons: Slow Train SVM using all features Select features f i with highest w i Retrain SVM with selected features Test SVM on test set
70
71 Embedded Methods Feature selection is intrinsic part of learning algorithm One example: L 1 SVM: Instead of minimizing w (the L2 norm ) we minimize the L 1 norm of the weight vector: w 1 = n w i i=1 Result is that most of the weights go to zero, leaving a small subset of the weights. Cf., Field of sparse coding
72
73 Hard- vs. soft- margin SVMs
74 Hard-margin SVMs Find w and b by doing the following minimization: w x + b = 1 w x + b = 0 w x + b =1 min w,b! 1 2 w 2 $ # & " % subject to: t k ( w x k + b) 1, k =1,..., m (t k { 1,+1})
75 Extend to soft-margin SVMs w x + b =1 w x + b = 1 w x + b = 0
76 Extend to soft-margin SVMs Allow some instances to be misclassified, or fall within margins, but penalize them by distance to margin hyperplane. w x + b =1 w x + b = 1 w x + b = 0
77 Extend to soft-margin SVMs Allow some instances to be misclassified, or fall within margins, but penalize them by distance to margin hyperplane. w x + b =1 w x + b = 1 w x + b = 0 ξ 0
78 Extend to soft-margin SVMs Allow some instances to be misclassified, or fall within margins, but penalize them by distance to margin hyperplane. w x + b =1 w x + b = 0 w x + b = 1 ξ 1 ξ 0
79 Extend to soft-margin SVMs Allow some instances to be misclassified, or fall within margins, but penalize them by distance to margin hyperplane. w x + b =1 ξ k are called slack variables. w x + b = 1 w x + b = 0 ξ 1 ξ k > 0 only if x k is misclassified or inside margin ξ 0
80 Extend to soft-margin SVMs Allow some instances to be misclassified, or fall within margins, but penalize them by distance to margin hyperplane. Revised optimization problem: Find w and b by doing the following minimization: w x + b =1 w x + b = 0 w x + b = 1 ξ 1 min w,b 1 2 w 2 + C ξ k subject to: k ξ 0 t k ( w x k + b) 1 ξ k, k =1,..., m (t k { 1,+1})
81 Extend to soft-margin SVMs Allow some instances to be misclassified, or fall within margins, but penalize them by distance to margin hyperplane. Revised optimization problem: Find w and b by doing the following minimization: w x + b =1 w x + b = 0 w x + b = 1 ξ 1 min w,b 1 2 w 2 + C ξ k subject to: k ξ 0 t k ( w x k + b) 1 ξ k, k =1,..., m (t k { 1,+1}) Optimization tries to keep ξ k s to zero while maximizing margin. C is parameter that trades off margin width with misclassifications
82 Why use soft-margin SVMs? Always can be optimized (unlike hard-margin SVMs) More robust to outliers, noise However: Have to set C parameter
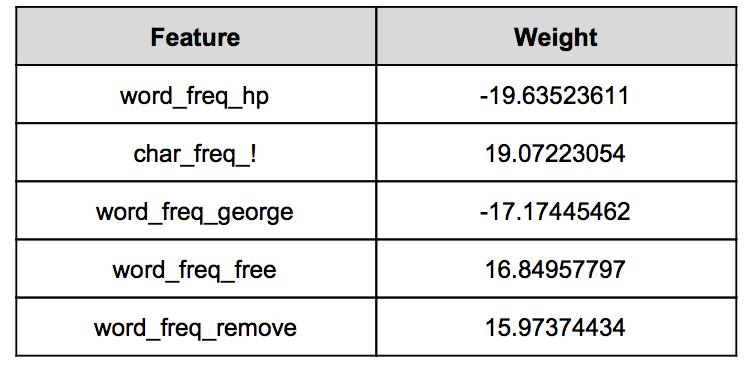
83
SVM merch available in the CS department after lecture
 SVM merch available in the CS department after lecture SVM SVM Introduction Previously we considered Perceptrons based on the McCulloch and Pitts neuron model. We identified a method for updating weights,
SVM merch available in the CS department after lecture SVM SVM Introduction Previously we considered Perceptrons based on the McCulloch and Pitts neuron model. We identified a method for updating weights,
Support Vector Machines.
 Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
CS6375: Machine Learning Gautam Kunapuli. Support Vector Machines
 Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Support Vector Machines. Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar
 Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Perceptron Revisited: Linear Separators. Support Vector Machines
 Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (continued)
") Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Statistical Pattern Recognition
 Statistical Pattern Recognition Support Vector Machine (SVM) Hamid R. Rabiee Hadi Asheri, Jafar Muhammadi, Nima Pourdamghani Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Introduction
Statistical Pattern Recognition Support Vector Machine (SVM) Hamid R. Rabiee Hadi Asheri, Jafar Muhammadi, Nima Pourdamghani Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Introduction
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine
 Support Vector Machine Kernel: Kernel is defined as a function returning the inner product between the images of the two arguments k(x 1, x 2 ) = ϕ(x 1 ), ϕ(x 2 ) k(x 1, x 2 ) = k(x 2, x 1 ) modularity-
Support Vector Machine Kernel: Kernel is defined as a function returning the inner product between the images of the two arguments k(x 1, x 2 ) = ϕ(x 1 ), ϕ(x 2 ) k(x 1, x 2 ) = k(x 2, x 1 ) modularity-
Max Margin-Classifier
 Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Max Margin-Classifier Oliver Schulte - CMPT 726 Bishop PRML Ch. 7 Outline Maximum Margin Criterion Math Maximizing the Margin Non-Separable Data Kernels and Non-linear Mappings Where does the maximization
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
L5 Support Vector Classification
 L5 Support Vector Classification Support Vector Machine Problem definition Geometrical picture Optimization problem Optimization Problem Hard margin Convexity Dual problem Soft margin problem Alexander
L5 Support Vector Classification Support Vector Machine Problem definition Geometrical picture Optimization problem Optimization Problem Hard margin Convexity Dual problem Soft margin problem Alexander
Linear, threshold units. Linear Discriminant Functions and Support Vector Machines. Biometrics CSE 190 Lecture 11. X i : inputs W i : weights
 Linear Discriminant Functions and Support Vector Machines Linear, threshold units CSE19, Winter 11 Biometrics CSE 19 Lecture 11 1 X i : inputs W i : weights θ : threshold 3 4 5 1 6 7 Courtesy of University
Linear Discriminant Functions and Support Vector Machines Linear, threshold units CSE19, Winter 11 Biometrics CSE 19 Lecture 11 1 X i : inputs W i : weights θ : threshold 3 4 5 1 6 7 Courtesy of University
Support Vector Machine & Its Applications
 Support Vector Machine & Its Applications A portion (1/3) of the slides are taken from Prof. Andrew Moore s SVM tutorial at http://www.cs.cmu.edu/~awm/tutorials Mingyue Tan The University of British Columbia
Support Vector Machine & Its Applications A portion (1/3) of the slides are taken from Prof. Andrew Moore s SVM tutorial at http://www.cs.cmu.edu/~awm/tutorials Mingyue Tan The University of British Columbia
Pattern Recognition 2018 Support Vector Machines
 Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
10/05/2016. Computational Methods for Data Analysis. Massimo Poesio SUPPORT VECTOR MACHINES. Support Vector Machines Linear classifiers
 Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Computational Methods for Data Analysis Massimo Poesio SUPPORT VECTOR MACHINES Support Vector Machines Linear classifiers 1 Linear Classifiers denotes +1 denotes -1 w x + b>0 f(x,w,b) = sign(w x + b) How
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie
 A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie Computational Biology Program Memorial Sloan-Kettering Cancer Center http://cbio.mskcc.org/leslielab
A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie Computational Biology Program Memorial Sloan-Kettering Cancer Center http://cbio.mskcc.org/leslielab
SVM optimization and Kernel methods
 Announcements SVM optimization and Kernel methods w 4 is up. Due in a week. Kaggle is up 4/13/17 1 4/13/17 2 Outline Review SVM optimization Non-linear transformations in SVM Soft-margin SVM Goal: Find
Announcements SVM optimization and Kernel methods w 4 is up. Due in a week. Kaggle is up 4/13/17 1 4/13/17 2 Outline Review SVM optimization Non-linear transformations in SVM Soft-margin SVM Goal: Find
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012") Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Linear vs Non-linear classifier. CS789: Machine Learning and Neural Network. Introduction
 Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Support Vector Machines
 Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Introduction to SVM and RVM
 Introduction to SVM and RVM Machine Learning Seminar HUS HVL UIB Yushu Li, UIB Overview Support vector machine SVM First introduced by Vapnik, et al. 1992 Several literature and wide applications Relevance
Introduction to SVM and RVM Machine Learning Seminar HUS HVL UIB Yushu Li, UIB Overview Support vector machine SVM First introduced by Vapnik, et al. 1992 Several literature and wide applications Relevance
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Machine Learning. Support Vector Machines. Manfred Huber
 Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
Support Vector Machines Explained
 December 23, 2008 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
December 23, 2008 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
Linear Classification and SVM. Dr. Xin Zhang
 Linear Classification and SVM Dr. Xin Zhang Email: eexinzhang@scut.edu.cn What is linear classification? Classification is intrinsically non-linear It puts non-identical things in the same class, so a
Linear Classification and SVM Dr. Xin Zhang Email: eexinzhang@scut.edu.cn What is linear classification? Classification is intrinsically non-linear It puts non-identical things in the same class, so a
Applied inductive learning - Lecture 7
 Applied inductive learning - Lecture 7 Louis Wehenkel & Pierre Geurts Department of Electrical Engineering and Computer Science University of Liège Montefiore - Liège - November 5, 2012 Find slides: http://montefiore.ulg.ac.be/
Applied inductive learning - Lecture 7 Louis Wehenkel & Pierre Geurts Department of Electrical Engineering and Computer Science University of Liège Montefiore - Liège - November 5, 2012 Find slides: http://montefiore.ulg.ac.be/
Support Vector Machine. Industrial AI Lab.
 Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Support Vector Machine Industrial AI Lab. Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories / classes Binary: 2 different
Support Vector Machines
 Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classifier Complexity and Support Vector Classifiers
 Classifier Complexity and Support Vector Classifiers Feature 2 6 4 2 0 2 4 6 8 RBF kernel 10 10 8 6 4 2 0 2 4 6 Feature 1 David M.J. Tax Pattern Recognition Laboratory Delft University of Technology D.M.J.Tax@tudelft.nl
Classifier Complexity and Support Vector Classifiers Feature 2 6 4 2 0 2 4 6 8 RBF kernel 10 10 8 6 4 2 0 2 4 6 Feature 1 David M.J. Tax Pattern Recognition Laboratory Delft University of Technology D.M.J.Tax@tudelft.nl
Data Mining. Linear & nonlinear classifiers. Hamid Beigy. Sharif University of Technology. Fall 1396
 Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Support'Vector'Machines. Machine(Learning(Spring(2018 March(5(2018 Kasthuri Kannan
 Support'Vector'Machines Machine(Learning(Spring(2018 March(5(2018 Kasthuri Kannan kasthuri.kannan@nyumc.org Overview Support Vector Machines for Classification Linear Discrimination Nonlinear Discrimination
Support'Vector'Machines Machine(Learning(Spring(2018 March(5(2018 Kasthuri Kannan kasthuri.kannan@nyumc.org Overview Support Vector Machines for Classification Linear Discrimination Nonlinear Discrimination
Support Vector Machines (SVM) in bioinformatics. Day 1: Introduction to SVM
 in bioinformatics. Day 1: Introduction to SVM") 1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
Learning with kernels and SVM
 Learning with kernels and SVM Šámalova chata, 23. května, 2006 Petra Kudová Outline Introduction Binary classification Learning with Kernels Support Vector Machines Demo Conclusion Learning from data find
Learning with kernels and SVM Šámalova chata, 23. května, 2006 Petra Kudová Outline Introduction Binary classification Learning with Kernels Support Vector Machines Demo Conclusion Learning from data find
Support Vector Machines
 EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
Kernel Machines. Pradeep Ravikumar Co-instructor: Manuela Veloso. Machine Learning
 Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
About this class. Maximizing the Margin. Maximum margin classifiers. Picture of large and small margin hyperplanes
 About this class Maximum margin classifiers SVMs: geometric derivation of the primal problem Statement of the dual problem The kernel trick SVMs as the solution to a regularization problem Maximizing the
About this class Maximum margin classifiers SVMs: geometric derivation of the primal problem Statement of the dual problem The kernel trick SVMs as the solution to a regularization problem Maximizing the
Support Vector Machines II. CAP 5610: Machine Learning Instructor: Guo-Jun QI
 Support Vector Machines II CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Outline Linear SVM hard margin Linear SVM soft margin Non-linear SVM Application Linear Support Vector Machine An optimization
Support Vector Machines II CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Outline Linear SVM hard margin Linear SVM soft margin Non-linear SVM Application Linear Support Vector Machine An optimization
Multi-class SVMs. Lecture 17: Aykut Erdem April 2016 Hacettepe University
 Multi-class SVMs Lecture 17: Aykut Erdem April 2016 Hacettepe University Administrative We will have a make-up lecture on Saturday April 23, 2016. Project progress reports are due April 21, 2016 2 days
Multi-class SVMs Lecture 17: Aykut Erdem April 2016 Hacettepe University Administrative We will have a make-up lecture on Saturday April 23, 2016. Project progress reports are due April 21, 2016 2 days
Announcements - Homework
 Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Chapter 9. Support Vector Machine. Yongdai Kim Seoul National University
 Chapter 9. Support Vector Machine Yongdai Kim Seoul National University 1. Introduction Support Vector Machine (SVM) is a classification method developed by Vapnik (1996). It is thought that SVM improved
Chapter 9. Support Vector Machine Yongdai Kim Seoul National University 1. Introduction Support Vector Machine (SVM) is a classification method developed by Vapnik (1996). It is thought that SVM improved
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Lecture Notes on Support Vector Machine
 Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Machine Learning. Lecture 6: Support Vector Machine. Feng Li.
 Machine Learning Lecture 6: Support Vector Machine Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Warm Up 2 / 80 Warm Up (Contd.)
Machine Learning Lecture 6: Support Vector Machine Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Warm Up 2 / 80 Warm Up (Contd.)
Support Vector Machine. Industrial AI Lab. Prof. Seungchul Lee
 Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
Support Vector Machine Industrial AI Lab. Prof. Seungchul Lee Classification (Linear) Autonomously figure out which category (or class) an unknown item should be categorized into Number of categories /
ML (cont.): SUPPORT VECTOR MACHINES
: SUPPORT VECTOR MACHINES") ML (cont.): SUPPORT VECTOR MACHINES CS540 Bryan R Gibson University of Wisconsin-Madison Slides adapted from those used by Prof. Jerry Zhu, CS540-1 1 / 40 Support Vector Machines (SVMs) The No-Math Version
ML (cont.): SUPPORT VECTOR MACHINES CS540 Bryan R Gibson University of Wisconsin-Madison Slides adapted from those used by Prof. Jerry Zhu, CS540-1 1 / 40 Support Vector Machines (SVMs) The No-Math Version
CS798: Selected topics in Machine Learning
 CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
CS798: Selected topics in Machine Learning Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Jakramate Bootkrajang CS798: Selected topics in Machine Learning
(Kernels +) Support Vector Machines
 Support Vector Machines") (Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
(Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
SUPPORT VECTOR MACHINE
 SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
Brief Introduction to Machine Learning
 Brief Introduction to Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU August 29, 2016 1 / 49 1 Introduction 2 Binary Classification 3 Support Vector
Brief Introduction to Machine Learning Yuh-Jye Lee Lab of Data Science and Machine Intelligence Dept. of Applied Math. at NCTU August 29, 2016 1 / 49 1 Introduction 2 Binary Classification 3 Support Vector
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
SVMs, Duality and the Kernel Trick
 SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
CIS 520: Machine Learning Oct 09, Kernel Methods
 CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
CIS 520: Machine Learning Oct 09, 207 Kernel Methods Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture They may or may not cover all the material discussed
Modelli Lineari (Generalizzati) e SVM
 e SVM") Modelli Lineari (Generalizzati) e SVM Corso di AA, anno 2018/19, Padova Fabio Aiolli 19/26 Novembre 2018 Fabio Aiolli Modelli Lineari (Generalizzati) e SVM 19/26 Novembre 2018 1 / 36 Outline Linear methods
Modelli Lineari (Generalizzati) e SVM Corso di AA, anno 2018/19, Padova Fabio Aiolli 19/26 Novembre 2018 Fabio Aiolli Modelli Lineari (Generalizzati) e SVM 19/26 Novembre 2018 1 / 36 Outline Linear methods
CSC 411 Lecture 17: Support Vector Machine
 CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
Neural Networks. Prof. Dr. Rudolf Kruse. Computational Intelligence Group Faculty for Computer Science
 Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Support Vector Machines
 Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
Support Vector and Kernel Methods
 SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
SIGIR 2003 Tutorial Support Vector and Kernel Methods Thorsten Joachims Cornell University Computer Science Department tj@cs.cornell.edu http://www.joachims.org 0 Linear Classifiers Rules of the Form:
Support Vector Machines. Machine Learning Fall 2017
 Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Support Vector Machines Machine Learning Fall 2017 1 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost 2 Where are we? Learning algorithms Decision Trees Perceptron AdaBoost Produce
Machine Learning for Structured Prediction
 Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Pattern Recognition and Machine Learning. Perceptrons and Support Vector machines
 Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
Pattern Recognition and Machine Learning James L. Crowley ENSIMAG 3 - MMIS Fall Semester 2016 Lessons 6 10 Jan 2017 Outline Perceptrons and Support Vector machines Notation... 2 Perceptrons... 3 History...3
Support Vector Machines and Kernel Methods
 Support Vector Machines and Kernel Methods Geoff Gordon ggordon@cs.cmu.edu July 10, 2003 Overview Why do people care about SVMs? Classification problems SVMs often produce good results over a wide range
Support Vector Machines and Kernel Methods Geoff Gordon ggordon@cs.cmu.edu July 10, 2003 Overview Why do people care about SVMs? Classification problems SVMs often produce good results over a wide range
FIND A FUNCTION TO CLASSIFY HIGH VALUE CUSTOMERS
 LINEAR CLASSIFIER 1 FIND A FUNCTION TO CLASSIFY HIGH VALUE CUSTOMERS x f y High Value Customers Salary Task: Find Nb Orders 150 70 300 100 200 80 120 100 Low Value Customers Salary Nb Orders 40 80 220
LINEAR CLASSIFIER 1 FIND A FUNCTION TO CLASSIFY HIGH VALUE CUSTOMERS x f y High Value Customers Salary Task: Find Nb Orders 150 70 300 100 200 80 120 100 Low Value Customers Salary Nb Orders 40 80 220
Lecture Support Vector Machine (SVM) Classifiers
 Classifiers") Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Deviations from linear separability. Kernel methods. Basis expansion for quadratic boundaries. Adding new features Systematic deviation
 Deviations from linear separability Kernel methods CSE 250B Noise Find a separator that minimizes a convex loss function related to the number of mistakes. e.g. SVM, logistic regression. Systematic deviation
Deviations from linear separability Kernel methods CSE 250B Noise Find a separator that minimizes a convex loss function related to the number of mistakes. e.g. SVM, logistic regression. Systematic deviation
Support Vector Machines, Kernel SVM
 Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
PAC-learning, VC Dimension and Margin-based Bounds
 More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
More details: General: http://www.learning-with-kernels.org/ Example of more complex bounds: http://www.research.ibm.com/people/t/tzhang/papers/jmlr02_cover.ps.gz PAC-learning, VC Dimension and Margin-based
Support Vector Machines. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines for Classification: A Statistical Portrait
 Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Support Vector Machines
 Support Vector Machines INFO-4604, Applied Machine Learning University of Colorado Boulder September 28, 2017 Prof. Michael Paul Today Two important concepts: Margins Kernels Large Margin Classification
Support Vector Machines INFO-4604, Applied Machine Learning University of Colorado Boulder September 28, 2017 Prof. Michael Paul Today Two important concepts: Margins Kernels Large Margin Classification
Support Vector Machine. Natural Language Processing Lab lizhonghua
 Support Vector Machine Natural Language Processing Lab lizhonghua Support Vector Machine Introduction Theory SVM primal and dual problem Parameter selection and practical issues Compare to other classifier
Support Vector Machine Natural Language Processing Lab lizhonghua Support Vector Machine Introduction Theory SVM primal and dual problem Parameter selection and practical issues Compare to other classifier
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Kernel methods CSE 250B
 Kernel methods CSE 250B Deviations from linear separability Noise Find a separator that minimizes a convex loss function related to the number of mistakes. e.g. SVM, logistic regression. Deviations from
Kernel methods CSE 250B Deviations from linear separability Noise Find a separator that minimizes a convex loss function related to the number of mistakes. e.g. SVM, logistic regression. Deviations from
18.9 SUPPORT VECTOR MACHINES
 744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
Chapter 6: Classification
 Chapter 6: Classification 1) Introduction Classification problem, evaluation of classifiers, prediction 2) Bayesian Classifiers Bayes classifier, naive Bayes classifier, applications 3) Linear discriminant
Chapter 6: Classification 1) Introduction Classification problem, evaluation of classifiers, prediction 2) Bayesian Classifiers Bayes classifier, naive Bayes classifier, applications 3) Linear discriminant
Outline. Basic concepts: SVM and kernels SVM primal/dual problems. Chih-Jen Lin (National Taiwan Univ.) 1 / 22
 1 / 22") Outline Basic concepts: SVM and kernels SVM primal/dual problems Chih-Jen Lin (National Taiwan Univ.) 1 / 22 Outline Basic concepts: SVM and kernels Basic concepts: SVM and kernels SVM primal/dual problems
Outline Basic concepts: SVM and kernels SVM primal/dual problems Chih-Jen Lin (National Taiwan Univ.) 1 / 22 Outline Basic concepts: SVM and kernels Basic concepts: SVM and kernels SVM primal/dual problems
Applied Machine Learning Annalisa Marsico
 Applied Machine Learning Annalisa Marsico OWL RNA Bionformatics group Max Planck Institute for Molecular Genetics Free University of Berlin 29 April, SoSe 2015 Support Vector Machines (SVMs) 1. One of
Applied Machine Learning Annalisa Marsico OWL RNA Bionformatics group Max Planck Institute for Molecular Genetics Free University of Berlin 29 April, SoSe 2015 Support Vector Machines (SVMs) 1. One of
Nearest Neighbors Methods for Support Vector Machines
 Nearest Neighbors Methods for Support Vector Machines A. J. Quiroz, Dpto. de Matemáticas. Universidad de Los Andes joint work with María González-Lima, Universidad Simón Boĺıvar and Sergio A. Camelo, Universidad
Nearest Neighbors Methods for Support Vector Machines A. J. Quiroz, Dpto. de Matemáticas. Universidad de Los Andes joint work with María González-Lima, Universidad Simón Boĺıvar and Sergio A. Camelo, Universidad
Lecture 10: A brief introduction to Support Vector Machine
 Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
CS4495/6495 Introduction to Computer Vision. 8C-L3 Support Vector Machines
 CS4495/6495 Introduction to Computer Vision 8C-L3 Support Vector Machines Discriminative classifiers Discriminative classifiers find a division (surface) in feature space that separates the classes Several
CS4495/6495 Introduction to Computer Vision 8C-L3 Support Vector Machines Discriminative classifiers Discriminative classifiers find a division (surface) in feature space that separates the classes Several
Support Vector Machines and Speaker Verification
 1 Support Vector Machines and Speaker Verification David Cinciruk March 6, 2013 2 Table of Contents Review of Speaker Verification Introduction to Support Vector Machines Derivation of SVM Equations Soft
1 Support Vector Machines and Speaker Verification David Cinciruk March 6, 2013 2 Table of Contents Review of Speaker Verification Introduction to Support Vector Machines Derivation of SVM Equations Soft
Introduction to Support Vector Machine
 Introduction to Support Vector Machine Yuh-Jye Lee National Taiwan University of Science and Technology September 23, 2009 1 / 76 Binary Classification Problem 2 / 76 Binary Classification Problem (A Fundamental
Introduction to Support Vector Machine Yuh-Jye Lee National Taiwan University of Science and Technology September 23, 2009 1 / 76 Binary Classification Problem 2 / 76 Binary Classification Problem (A Fundamental
EE613 Machine Learning for Engineers. Kernel methods Support Vector Machines. jean-marc odobez 2015
 EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
EE613 Machine Learning for Engineers Kernel methods Support Vector Machines jean-marc odobez 2015 overview Kernel methods introductions and main elements defining kernels Kernelization of k-nn, K-Means,
Indirect Rule Learning: Support Vector Machines. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Indirect Rule Learning: Support Vector Machines Indirect learning: loss optimization It doesn t estimate the prediction rule f (x) directly, since most loss functions do not have explicit optimizers. Indirection
Indirect Rule Learning: Support Vector Machines Indirect learning: loss optimization It doesn t estimate the prediction rule f (x) directly, since most loss functions do not have explicit optimizers. Indirection
Support vector machines
 Support vector machines Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 SVM, kernel methods and multiclass 1/23 Outline 1 Constrained optimization, Lagrangian duality and KKT 2 Support
Support vector machines Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 SVM, kernel methods and multiclass 1/23 Outline 1 Constrained optimization, Lagrangian duality and KKT 2 Support
LMS Algorithm Summary
 LMS Algorithm Summary Step size tradeoff Other Iterative Algorithms LMS algorithm with variable step size: w(k+1) = w(k) + µ(k)e(k)x(k) When step size µ(k) = µ/k algorithm converges almost surely to optimal
LMS Algorithm Summary Step size tradeoff Other Iterative Algorithms LMS algorithm with variable step size: w(k+1) = w(k) + µ(k)e(k)x(k) When step size µ(k) = µ/k algorithm converges almost surely to optimal
Non-linear Support Vector Machines
 Non-linear Support Vector Machines Andrea Passerini passerini@disi.unitn.it Machine Learning Non-linear Support Vector Machines Non-linearly separable problems Hard-margin SVM can address linearly separable
Non-linear Support Vector Machines Andrea Passerini passerini@disi.unitn.it Machine Learning Non-linear Support Vector Machines Non-linearly separable problems Hard-margin SVM can address linearly separable
Linear classifiers Lecture 3
 Linear classifiers Lecture 3 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin ML Methodology Data: labeled instances, e.g. emails marked spam/ham
Linear classifiers Lecture 3 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin ML Methodology Data: labeled instances, e.g. emails marked spam/ham
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012
 CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the
CSE546: SVMs, Dual Formula5on, and Kernels Winter 2012 Luke ZeClemoyer Slides adapted from Carlos Guestrin Linear classifiers Which line is becer? w. = j w (j) x (j) Data Example i Pick the one with the