Indirect Rule Learning: Support Vector Machines. Donglin Zeng, Department of Biostatistics, University of North Carolina
|
|
|
- Cecil Porter
- 5 years ago
- Views:
Transcription
1 Indirect Rule Learning: Support Vector Machines
2 Indirect learning: loss optimization It doesn t estimate the prediction rule f (x) directly, since most loss functions do not have explicit optimizers. Indirection learning aims to directly minimize an empirically approximate expected loss function. Most often, it minimizes (empirical risk minimization) L(Y i, f (X i )). For example, least squares estimation: (Y i f (X i )) 2. classification problem: I(Y i f (X i )).
3 Potential challenges What is a good approximation for expected loss function? Empirical risk is most commonly used but there are other alternatives. What is the choice of candidate f for optimization? How to avoid overfitting? Will computation be feasible? global minimizer computation complexity
4 Least squares estimation The empirical risk is (Y i f (X i )) 2. f (x) can be from a class of linear functions; a sieve space of basis functions (splines, wavelets, radial basis); or fully nonparametric (kernel estimation). Overfitting can be addressed using regularization: variable selection for linear models; penalized splines, shrinkage for sieve approximation cross-validation for tuning parameter selection. Computation convex optimization co-ordinate decent optimization for large p
5 Support Vector Machines Consider binary classification problem and use label { 1, 1} for two classes. We start from a simple classification rule which is a linear function of feature variables X. The idea of SVM is to identify a hyperplace on feature space that separates classes as much as possible.
6 SVM illustration
7 Mathematical formulation of SVM The goal is to find a hyperplane β 0 + X T β such that for all i = 1,..., n. Y i (β 0 + X T i β) > 0 Furthermore, we wish to maximize the margin given as M. That is, we solve max M subject to Y i(β 0 + Xi T β) M. β =1
8 Equivalent optimization It is equivalent to min 1 2 β 2 subject to Y i (β 0 + Xi T β) 1. There are two difficulties in practice classes may not be separable so no solution exists; classes may be separable but separation is nonlinear.
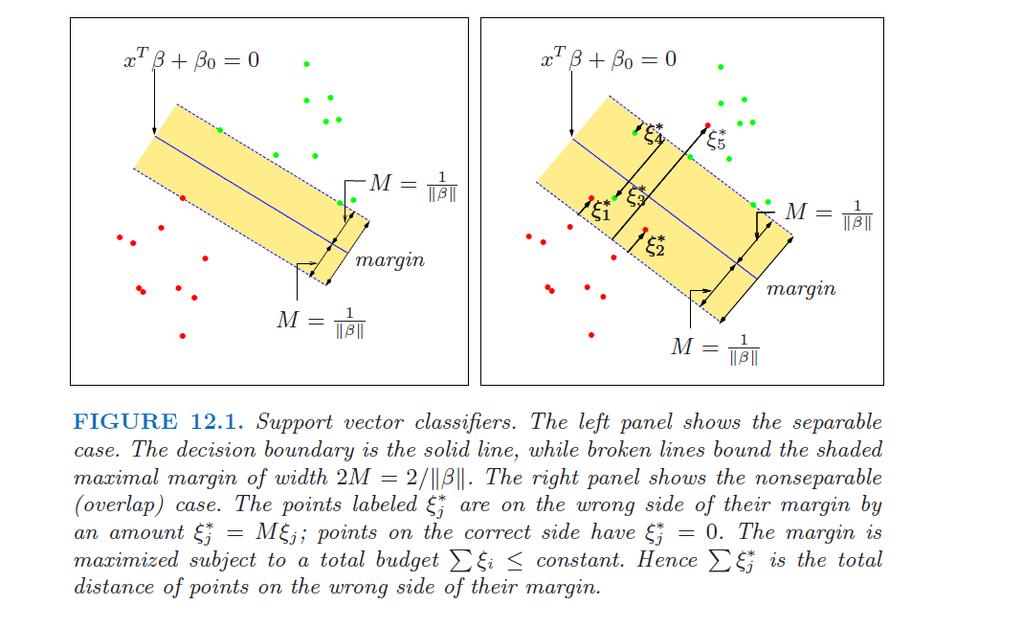
9 Extension to imperfect separation data For imperfect separation, Y i (β 0 + Xi T β) may not be positive, i.e., the prediction is wrong. We should allow this misclassification but impose some penalty for wrong prediction. This can be done by introducing slack variables ξ 1,..., ξ n for each subject. ξ i 0 describes the distance off the correct classification given by margins. However, we should restrict the total penalty to be not too large.
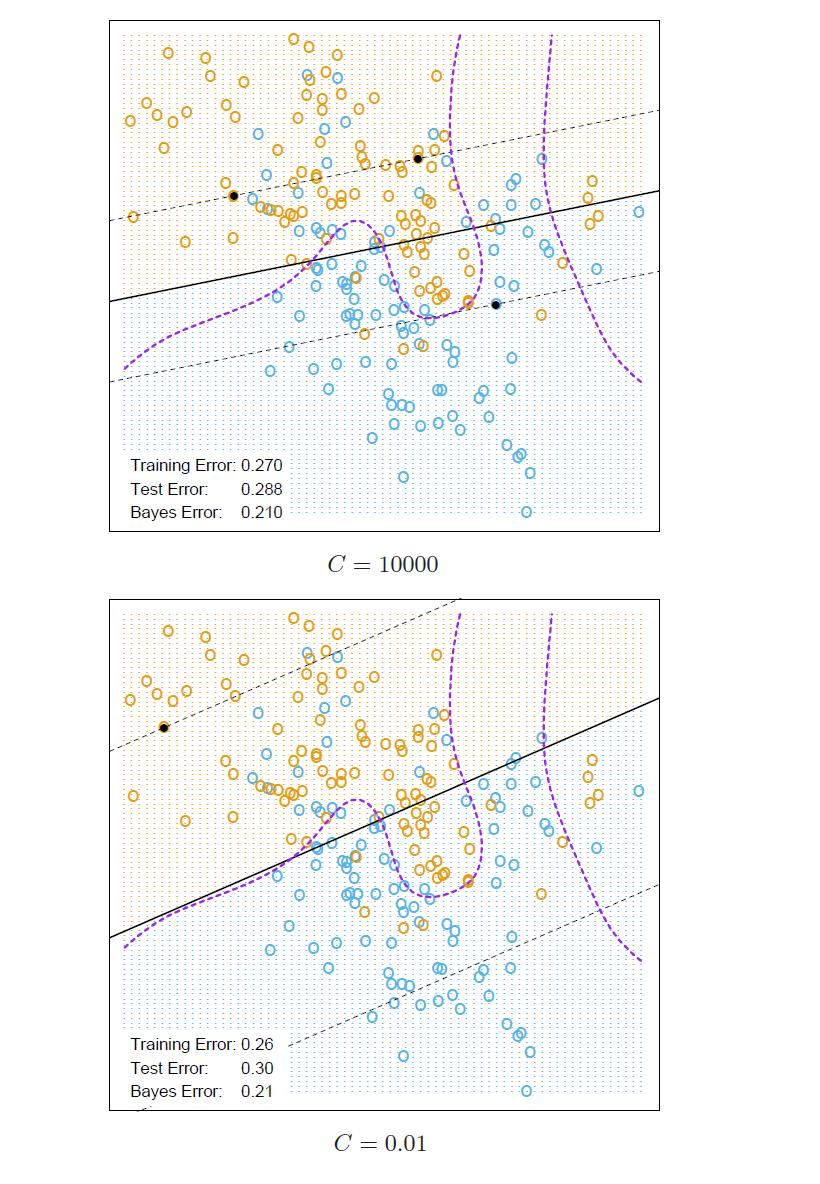
10 SVM optimization The optimization is max β =1 M, subject to Y i(β 0 + X T i β) M(1 ξ i), i = 1,..., n. where ξ i 0 and ξ i a pre-specified constant. Equivalently, min 1 2 β 2 + C ξ i subject to Y i (β 0 + Xi T β) (1 ξ i), ξ i 0, i = 1,..., n, where C is a given constant (called cost parameter). This is a convex minimization problem with linear constraints.
11 Solve SVM problem using duality The Lagrange (primal) function is 1 2 β 2 +C ξ i ] α i [Y i (β 0 + Xi T β) (1 ξ i) where α i 0, µ i 0 are the Lagrange multipliers. Differentiate with respect to β 0, β and ξ i to obtain µ i ξ i, β = α i Y i X i, 0 = α i Y i, α i = C µ i, i = 1,..., n.
12 Dual problem After plugging β into the primal function and using the equations, the dual objective function is L D = α i 1 2 α i α j Y i Y j Xi T X j. j=1 The dual problem becomes max L D subject to 0 α i C, i = 1,..., n, α i Y i = 0. Furthermore, KKT conditions give ] α i [Y i (Xi T β + β 0) (1 ξ i ) = 0, µ i ξ i = 0, Y i (X T i β + β 0) (1 ξ i ) 0.
13 KKT conditions
14 On SVM optimization Solving the dual problem is a simple convex quadratic programming problems (there are many solvers in all packages). Since β = n α iy i X i, the hyperplane is determined by those observations with α i 0, called support vectors. Among support vectors, some are on the margin edges (ξ i = 0) and the remainders have α i = C. Any support vectors with ξ i = 0 can be used to solve for β 0 (often taken to be the average if there are multiple). Sometimes β 0 can be solved by directly minimize the primal function.
15 Illustrative example
16 Go beyond linear SVM The most commonly used nonlinear prediction rule is to restrict f in a RKHS, H K (called kernel trick). Recall that RKHS is given by a kernel function K(x, y) where K(x, y) has an eigen-expansion K(x, y) = γ k φ k (x)φ k (y), k=1 where φ k / γ k is the normalized basis function for {H K, <, > HK }. We can represent f (x) using these basis functions f (x) = β 0 + β k φ k (x)/ γ k. k=1
17 Dual problem with kernel trick Follow the same derivation as linear SVM (replace X i by the vector (φ 1 (X i )/ γ 1, φ 2 (X i ) γ 2,...) T then the dual objective function becomes α i 1 2 α i α j Y i Y j ( φ k (X i )φ k (X j )/γ k ) j=1 k=1 = α i 1 2 α i α j Y i Y j K(X i, X j ). j=1 The prediction function becomes f (x) = β 0 + α i Y i φ k (X i )φ k (x)/γ k = k=1 α i Y i K(X i, x).
18 Advantage of kernel trick Our conclusions are (a) restricting f to H K leads to a nonlinear prediction function depending on the kernel function; (b) solving the dual problem for the prediction function only need to know the kernel function K(x, y) (not necessarily the basis functions); (c) the optimization in the dual problem depends on the number of observations (n) but not the dimensionality of X i s.
19 Choice of the kernel functions polynomial kernel: K(x, x ) = (1 + x T x ) d Radial basis or Gaussian kernel: K(x, x ) = exp{ γ x x 2 } Neural network: K(x, x ) = tanh(k 1 x T x + k 2 ).

20 Revisit SVM example
21 Loss formulation for SVM Revisit linear SVM formulation: we minimize β subject to separation constraints Y i (β 0 + X T i β) 1 ξ i, ξ i 0, i = 1,.., n and that n ξ i is controlled by a constant. We need to understand what exact empirical loss this optimization tries to minimize because by achieving this, we can characterize how SVM will possibly minimize classification loss (Fisher consistency); we can study the stochastic variability of the SVM classification (convergence rate and risk bound).
22 Loss formulation: continue Equivalently, we minimize (for a given constant C) 1 2 β 2 + C ξ i subject to ξ i [1 Y i (β 0 + X T i β)] +, where (1 z) + = max(1 z, 0). Hence, SVM is equivalent minimizing the following loss [1 Y i (β 0 + Xi T β)] + + λ 2 β 2. For nonlinear SVM, the loss is [1 Y i f (X i )] + + λ 2 f 2 H K. We name L(y, f ) = [1 yf ] + the hinge loss function.
23 Plot of the hinge loss
24 Fisher consistency of SVM Fisher consistency: suppose f minimizes E[(1 Yf (X)) + ]. Then sign(f (x)) is the Bayes rule for the classification problem. Proof: note that E[(1 Yf (X)) + X = x] = (1 f (x))+ P(Y = 1 X = x) +(1 + f (x)) + P(Y = 1 X = x), as a function of f (x), is a 3-piece of linear function, decreasing in (, 1], linear in ( 1, 1] and increasing in [1, ). The minimize is attained at f (x) = 1 if P(Y = 1 X = x) < P(Y = 1 X = 1) and 1 otherwise.. We conclude the Fisher consistency.
25 Extension of the hinge loss The hinge loss is one special case of the so-called large margin loss with form φ(yf ) for some convex function of φ. Additional examples include Binomial deviance: log(1 + e yf ) Squared loss: (1 yf ) 2 square hinge loss: (1 yf ) 2 + AdaBoost: exp{ yf }. A sufficient condition for the Fisher consistency is that φ(x) is differentiable at 0 and φ (0) < 0.
26 SVM for regression Extension of SVM to continuous Y is based on modification of the loss in SVM. Consider prediction f (X) for subject with feature X and Y is his/her true outcome. The inaccuracy of the prediction can be characterized as the so-called ɛ-insensitive loss: L(Y, f (X)) = max( Y f (X) ɛ, 0). The loss is zero if the prediction error is within ɛ.
27 ɛ-insensitive loss
28 Optimization problem in SVM for regression The objective function for linear prediction is min β 2 /2 + C{ξ i + ξ i } subject to ξ i ɛ Y i (β 0 +Xi T β) ɛ+ξ i, ξ i 0, ξ i 0, i = 1,..., n. The dual problem is min ɛ (α i +α i ) Y i (α i α i )+1 2 subject to (α i α i )(α j α j )XT i X j j=1 0 α i, α i C, (α i α i ) = 0, α iα i = 0 The prediction function is β 0 + X T β with β = (α i α i )X i.
Lecture 10: A brief introduction to Support Vector Machine
 Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
Lecture 10: A brief introduction to Support Vector Machine Advanced Applied Multivariate Analysis STAT 2221, Fall 2013 Sungkyu Jung Department of Statistics, University of Pittsburgh Xingye Qiao Department
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2014 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Lecture 10: Support Vector Machine and Large Margin Classifier
 Lecture 10: Support Vector Machine and Large Margin Classifier Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu
Lecture 10: Support Vector Machine and Large Margin Classifier Applied Multivariate Analysis Math 570, Fall 2014 Xingye Qiao Department of Mathematical Sciences Binghamton University E-mail: qiao@math.binghamton.edu
CS6375: Machine Learning Gautam Kunapuli. Support Vector Machines
 Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Gautam Kunapuli Example: Text Categorization Example: Develop a model to classify news stories into various categories based on their content. sports politics Use the bag-of-words representation for this
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2015 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Chapter 9. Support Vector Machine. Yongdai Kim Seoul National University
 Chapter 9. Support Vector Machine Yongdai Kim Seoul National University 1. Introduction Support Vector Machine (SVM) is a classification method developed by Vapnik (1996). It is thought that SVM improved
Chapter 9. Support Vector Machine Yongdai Kim Seoul National University 1. Introduction Support Vector Machine (SVM) is a classification method developed by Vapnik (1996). It is thought that SVM improved
Support Vector Machine (continued)
") Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Support Vector Machine continued) Overlapping class distribution: In practice the class-conditional distributions may overlap, so that the training data points are no longer linearly separable. We need
Support Vector Machine
 Support Vector Machine Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Linear Support Vector Machine Kernelized SVM Kernels 2 From ERM to RLM Empirical Risk Minimization in the binary
Support Vector Machine Fabrice Rossi SAMM Université Paris 1 Panthéon Sorbonne 2018 Outline Linear Support Vector Machine Kernelized SVM Kernels 2 From ERM to RLM Empirical Risk Minimization in the binary
Support Vector Machine (SVM) and Kernel Methods
 and Kernel Methods") Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Support Vector Machine (SVM) and Kernel Methods CE-717: Machine Learning Sharif University of Technology Fall 2016 Soleymani Outline Margin concept Hard-Margin SVM Soft-Margin SVM Dual Problems of Hard-Margin
Pattern Recognition 2018 Support Vector Machines
 Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
Pattern Recognition 2018 Support Vector Machines Ad Feelders Universiteit Utrecht Ad Feelders ( Universiteit Utrecht ) Pattern Recognition 1 / 48 Support Vector Machines Ad Feelders ( Universiteit Utrecht
Support Vector Machines for Classification: A Statistical Portrait
 Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Support Vector Machines for Classification: A Statistical Portrait Yoonkyung Lee Department of Statistics The Ohio State University May 27, 2011 The Spring Conference of Korean Statistical Society KAIST,
Jeff Howbert Introduction to Machine Learning Winter
 Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Classification / Regression Support Vector Machines Jeff Howbert Introduction to Machine Learning Winter 2012 1 Topics SVM classifiers for linearly separable classes SVM classifiers for non-linearly separable
Announcements - Homework
 Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Announcements - Homework Homework 1 is graded, please collect at end of lecture Homework 2 due today Homework 3 out soon (watch email) Ques 1 midterm review HW1 score distribution 40 HW1 total score 35
Support Vector Machines Explained
 December 23, 2008 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
December 23, 2008 Support Vector Machines Explained Tristan Fletcher www.cs.ucl.ac.uk/staff/t.fletcher/ Introduction This document has been written in an attempt to make the Support Vector Machines (SVM),
Review: Support vector machines. Machine learning techniques and image analysis
 Review: Support vector machines Review: Support vector machines Margin optimization min (w,w 0 ) 1 2 w 2 subject to y i (w 0 + w T x i ) 1 0, i = 1,..., n. Review: Support vector machines Margin optimization
Review: Support vector machines Review: Support vector machines Margin optimization min (w,w 0 ) 1 2 w 2 subject to y i (w 0 + w T x i ) 1 0, i = 1,..., n. Review: Support vector machines Margin optimization
Support Vector Machines. Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar
 Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Data Mining Support Vector Machines Introduction to Data Mining, 2 nd Edition by Tan, Steinbach, Karpatne, Kumar 02/03/2018 Introduction to Data Mining 1 Support Vector Machines Find a linear hyperplane
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012
 & Kernel CE-717: Machine Learning Sharif University of Technology. M. Soleymani Fall 2012") Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
Support Vector Machine (SVM) & Kernel CE-717: Machine Learning Sharif University of Technology M. Soleymani Fall 2012 Linear classifier Which classifier? x 2 x 1 2 Linear classifier Margin concept x 2
L5 Support Vector Classification
 L5 Support Vector Classification Support Vector Machine Problem definition Geometrical picture Optimization problem Optimization Problem Hard margin Convexity Dual problem Soft margin problem Alexander
L5 Support Vector Classification Support Vector Machine Problem definition Geometrical picture Optimization problem Optimization Problem Hard margin Convexity Dual problem Soft margin problem Alexander
Support Vector Machines
 EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
EE 17/7AT: Optimization Models in Engineering Section 11/1 - April 014 Support Vector Machines Lecturer: Arturo Fernandez Scribe: Arturo Fernandez 1 Support Vector Machines Revisited 1.1 Strictly) Separable
Statistical Pattern Recognition
 Statistical Pattern Recognition Support Vector Machine (SVM) Hamid R. Rabiee Hadi Asheri, Jafar Muhammadi, Nima Pourdamghani Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Introduction
Statistical Pattern Recognition Support Vector Machine (SVM) Hamid R. Rabiee Hadi Asheri, Jafar Muhammadi, Nima Pourdamghani Spring 2013 http://ce.sharif.edu/courses/91-92/2/ce725-1/ Agenda Introduction
CSC 411 Lecture 17: Support Vector Machine
 CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
CSC 411 Lecture 17: Support Vector Machine Ethan Fetaya, James Lucas and Emad Andrews University of Toronto CSC411 Lec17 1 / 1 Today Max-margin classification SVM Hard SVM Duality Soft SVM CSC411 Lec17
Stat542 (F11) Statistical Learning. First consider the scenario where the two classes of points are separable.
 Statistical Learning. First consider the scenario where the two classes of points are separable.") Linear SVM (separable case) First consider the scenario where the two classes of points are separable. It s desirable to have the width (called margin) between the two dashed lines to be large, i.e., have
Linear SVM (separable case) First consider the scenario where the two classes of points are separable. It s desirable to have the width (called margin) between the two dashed lines to be large, i.e., have
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1394 1 / 34 Table
Support Vector Machines
 Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Wien, June, 2010 Paul Hofmarcher, Stefan Theussl, WU Wien Hofmarcher/Theussl SVM 1/21 Linear Separable Separating Hyperplanes Non-Linear Separable Soft-Margin Hyperplanes Hofmarcher/Theussl SVM 2/21 (SVM)
Support Vector Machines (SVM) in bioinformatics. Day 1: Introduction to SVM
 in bioinformatics. Day 1: Introduction to SVM") 1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
1 Support Vector Machines (SVM) in bioinformatics Day 1: Introduction to SVM Jean-Philippe Vert Bioinformatics Center, Kyoto University, Japan Jean-Philippe.Vert@mines.org Human Genome Center, University
Support Vector Machines for Classification and Regression. 1 Linearly Separable Data: Hard Margin SVMs
 E0 270 Machine Learning Lecture 5 (Jan 22, 203) Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in
E0 270 Machine Learning Lecture 5 (Jan 22, 203) Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are a brief summary of the topics covered in
Perceptron Revisited: Linear Separators. Support Vector Machines
 Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Support Vector Machines Perceptron Revisited: Linear Separators Binary classification can be viewed as the task of separating classes in feature space: w T x + b > 0 w T x + b = 0 w T x + b < 0 Department
Support Vector Machines: Maximum Margin Classifiers
 Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Support Vector Machines: Maximum Margin Classifiers Machine Learning and Pattern Recognition: September 16, 2008 Piotr Mirowski Based on slides by Sumit Chopra and Fu-Jie Huang 1 Outline What is behind
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines
 Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Lecture 9: Large Margin Classifiers. Linear Support Vector Machines Perceptrons Definition Perceptron learning rule Convergence Margin & max margin classifiers (Linear) support vector machines Formulation
Support Vector Machines for Classification and Regression
 CIS 520: Machine Learning Oct 04, 207 Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may
CIS 520: Machine Learning Oct 04, 207 Support Vector Machines for Classification and Regression Lecturer: Shivani Agarwal Disclaimer: These notes are designed to be a supplement to the lecture. They may
Support Vector Machines
 Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Two SVM tutorials linked in class website (please, read both): High-level presentation with applications (Hearst 1998) Detailed tutorial (Burges 1998) Support Vector Machines Machine Learning 10701/15781
Support Vector Machines.
 Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
Support Vector Machines www.cs.wisc.edu/~dpage 1 Goals for the lecture you should understand the following concepts the margin slack variables the linear support vector machine nonlinear SVMs the kernel
SVMs, Duality and the Kernel Trick
 SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
SVMs, Duality and the Kernel Trick Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 26 th, 2007 2005-2007 Carlos Guestrin 1 SVMs reminder 2005-2007 Carlos Guestrin 2 Today
Direct Learning: Linear Classification. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Direct Learning: Linear Classification Logistic regression models for classification problem We consider two class problem: Y {0, 1}. The Bayes rule for the classification is I(P(Y = 1 X = x) > 1/2) so
Direct Learning: Linear Classification Logistic regression models for classification problem We consider two class problem: Y {0, 1}. The Bayes rule for the classification is I(P(Y = 1 X = x) > 1/2) so
Lecture 18: Kernels Risk and Loss Support Vector Regression. Aykut Erdem December 2016 Hacettepe University
 Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
Lecture 18: Kernels Risk and Loss Support Vector Regression Aykut Erdem December 2016 Hacettepe University Administrative We will have a make-up lecture on next Saturday December 24, 2016 Presentations
Outline. Basic concepts: SVM and kernels SVM primal/dual problems. Chih-Jen Lin (National Taiwan Univ.) 1 / 22
 1 / 22") Outline Basic concepts: SVM and kernels SVM primal/dual problems Chih-Jen Lin (National Taiwan Univ.) 1 / 22 Outline Basic concepts: SVM and kernels Basic concepts: SVM and kernels SVM primal/dual problems
Outline Basic concepts: SVM and kernels SVM primal/dual problems Chih-Jen Lin (National Taiwan Univ.) 1 / 22 Outline Basic concepts: SVM and kernels Basic concepts: SVM and kernels SVM primal/dual problems
ICS-E4030 Kernel Methods in Machine Learning
 ICS-E4030 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 28. September, 2016 Juho Rousu 28. September, 2016 1 / 38 Convex optimization Convex optimisation This
ICS-E4030 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 28. September, 2016 Juho Rousu 28. September, 2016 1 / 38 Convex optimization Convex optimisation This
Linear & nonlinear classifiers
 Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Linear & nonlinear classifiers Machine Learning Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Linear & nonlinear classifiers Fall 1396 1 / 44 Table
Mehryar Mohri Foundations of Machine Learning Courant Institute of Mathematical Sciences Homework assignment 3 April 5, 2013 Due: April 19, 2013
 Mehryar Mohri Foundations of Machine Learning Courant Institute of Mathematical Sciences Homework assignment 3 April 5, 2013 Due: April 19, 2013 A. Kernels 1. Let X be a finite set. Show that the kernel
Mehryar Mohri Foundations of Machine Learning Courant Institute of Mathematical Sciences Homework assignment 3 April 5, 2013 Due: April 19, 2013 A. Kernels 1. Let X be a finite set. Show that the kernel
Support Vector Machines
 Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
Support Vector Machines Support vector machines (SVMs) are one of the central concepts in all of machine learning. They are simply a combination of two ideas: linear classification via maximum (or optimal
Kernel Methods and Support Vector Machines
 Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Kernel Methods and Support Vector Machines Oliver Schulte - CMPT 726 Bishop PRML Ch. 6 Support Vector Machines Defining Characteristics Like logistic regression, good for continuous input features, discrete
Machine Learning And Applications: Supervised Learning-SVM
 Machine Learning And Applications: Supervised Learning-SVM Raphaël Bournhonesque École Normale Supérieure de Lyon, Lyon, France raphael.bournhonesque@ens-lyon.fr 1 Supervised vs unsupervised learning Machine
Machine Learning And Applications: Supervised Learning-SVM Raphaël Bournhonesque École Normale Supérieure de Lyon, Lyon, France raphael.bournhonesque@ens-lyon.fr 1 Supervised vs unsupervised learning Machine
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Kernel Machines. Pradeep Ravikumar Co-instructor: Manuela Veloso. Machine Learning
 Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Kernel Machines Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 SVM linearly separable case n training points (x 1,, x n ) d features x j is a d-dimensional vector Primal problem:
Support Vector Machines and Speaker Verification
 1 Support Vector Machines and Speaker Verification David Cinciruk March 6, 2013 2 Table of Contents Review of Speaker Verification Introduction to Support Vector Machines Derivation of SVM Equations Soft
1 Support Vector Machines and Speaker Verification David Cinciruk March 6, 2013 2 Table of Contents Review of Speaker Verification Introduction to Support Vector Machines Derivation of SVM Equations Soft
Data Mining. Linear & nonlinear classifiers. Hamid Beigy. Sharif University of Technology. Fall 1396
 Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Data Mining Linear & nonlinear classifiers Hamid Beigy Sharif University of Technology Fall 1396 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1396 1 / 31 Table of contents 1 Introduction
Bayes rule and Bayes error. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Bayes rule and Bayes error Definition If f minimizes E[L(Y, f (X))], then f is called a Bayes rule (associated with the loss function L(y, f )) and the resulting prediction error rate, E[L(Y, f (X))],
Bayes rule and Bayes error Definition If f minimizes E[L(Y, f (X))], then f is called a Bayes rule (associated with the loss function L(y, f )) and the resulting prediction error rate, E[L(Y, f (X))],
Machine Learning. Support Vector Machines. Manfred Huber
 Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
Machine Learning Support Vector Machines Manfred Huber 2015 1 Support Vector Machines Both logistic regression and linear discriminant analysis learn a linear discriminant function to separate the data
Support vector machines Lecture 4
 Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
Support vector machines Lecture 4 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, and Carlos Guestrin Q: What does the Perceptron mistake bound tell us? Theorem: The
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels
 SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
SVMs: Non-Separable Data, Convex Surrogate Loss, Multi-Class Classification, Kernels Karl Stratos June 21, 2018 1 / 33 Tangent: Some Loose Ends in Logistic Regression Polynomial feature expansion in logistic
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Hsuan-Tien Lin Learning Systems Group, California Institute of Technology Talk in NTU EE/CS Speech Lab, November 16, 2005 H.-T. Lin (Learning Systems Group) Introduction
Introduction to Support Vector Machines Hsuan-Tien Lin Learning Systems Group, California Institute of Technology Talk in NTU EE/CS Speech Lab, November 16, 2005 H.-T. Lin (Learning Systems Group) Introduction
Support Vector Machines
 Support Vector Machines Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: http://www.cs.cmu.edu/~awm/tutorials/ Where Should We Draw the Line????
Support Vector Machines Some material on these is slides borrowed from Andrew Moore's excellent machine learning tutorials located at: http://www.cs.cmu.edu/~awm/tutorials/ Where Should We Draw the Line????
Convex Optimization and Support Vector Machine
 Convex Optimization and Support Vector Machine Problem 0. Consider a two-class classification problem. The training data is L n = {(x 1, t 1 ),..., (x n, t n )}, where each t i { 1, 1} and x i R p. We
Convex Optimization and Support Vector Machine Problem 0. Consider a two-class classification problem. The training data is L n = {(x 1, t 1 ),..., (x n, t n )}, where each t i { 1, 1} and x i R p. We
Linear vs Non-linear classifier. CS789: Machine Learning and Neural Network. Introduction
 Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Linear vs Non-linear classifier CS789: Machine Learning and Neural Network Support Vector Machine Jakramate Bootkrajang Department of Computer Science Chiang Mai University Linear classifier is in the
Learning From Data Lecture 25 The Kernel Trick
 Learning From Data Lecture 25 The Kernel Trick Learning with only inner products The Kernel M. Magdon-Ismail CSCI 400/600 recap: Large Margin is Better Controling Overfitting Non-Separable Data 0.08 random
Learning From Data Lecture 25 The Kernel Trick Learning with only inner products The Kernel M. Magdon-Ismail CSCI 400/600 recap: Large Margin is Better Controling Overfitting Non-Separable Data 0.08 random
Lecture Notes on Support Vector Machine
 Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Lecture Notes on Support Vector Machine Feng Li fli@sdu.edu.cn Shandong University, China 1 Hyperplane and Margin In a n-dimensional space, a hyper plane is defined by ω T x + b = 0 (1) where ω R n is
Mark your answers ON THE EXAM ITSELF. If you are not sure of your answer you may wish to provide a brief explanation.
 CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
CS 189 Spring 2015 Introduction to Machine Learning Midterm You have 80 minutes for the exam. The exam is closed book, closed notes except your one-page crib sheet. No calculators or electronic items.
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Samy Bengio Statistical Machine Learning from Data 1 Statistical Machine Learning from Data Support Vector Machines Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique
Neural Networks. Prof. Dr. Rudolf Kruse. Computational Intelligence Group Faculty for Computer Science
 Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
Neural Networks Prof. Dr. Rudolf Kruse Computational Intelligence Group Faculty for Computer Science kruse@iws.cs.uni-magdeburg.de Rudolf Kruse Neural Networks 1 Supervised Learning / Support Vector Machines
LMS Algorithm Summary
 LMS Algorithm Summary Step size tradeoff Other Iterative Algorithms LMS algorithm with variable step size: w(k+1) = w(k) + µ(k)e(k)x(k) When step size µ(k) = µ/k algorithm converges almost surely to optimal
LMS Algorithm Summary Step size tradeoff Other Iterative Algorithms LMS algorithm with variable step size: w(k+1) = w(k) + µ(k)e(k)x(k) When step size µ(k) = µ/k algorithm converges almost surely to optimal
Machine Learning. Lecture 6: Support Vector Machine. Feng Li.
 Machine Learning Lecture 6: Support Vector Machine Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Warm Up 2 / 80 Warm Up (Contd.)
Machine Learning Lecture 6: Support Vector Machine Feng Li fli@sdu.edu.cn https://funglee.github.io School of Computer Science and Technology Shandong University Fall 2018 Warm Up 2 / 80 Warm Up (Contd.)
A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie
 A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie Computational Biology Program Memorial Sloan-Kettering Cancer Center http://cbio.mskcc.org/leslielab
A short introduction to supervised learning, with applications to cancer pathway analysis Dr. Christina Leslie Computational Biology Program Memorial Sloan-Kettering Cancer Center http://cbio.mskcc.org/leslielab
Introduction to SVM and RVM
 Introduction to SVM and RVM Machine Learning Seminar HUS HVL UIB Yushu Li, UIB Overview Support vector machine SVM First introduced by Vapnik, et al. 1992 Several literature and wide applications Relevance
Introduction to SVM and RVM Machine Learning Seminar HUS HVL UIB Yushu Li, UIB Overview Support vector machine SVM First introduced by Vapnik, et al. 1992 Several literature and wide applications Relevance
Support Vector Machines and Kernel Methods
 2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
2018 CS420 Machine Learning, Lecture 3 Hangout from Prof. Andrew Ng. http://cs229.stanford.edu/notes/cs229-notes3.pdf Support Vector Machines and Kernel Methods Weinan Zhang Shanghai Jiao Tong University
Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron
 CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
CS446: Machine Learning, Fall 2017 Lecture 14 : Online Learning, Stochastic Gradient Descent, Perceptron Lecturer: Sanmi Koyejo Scribe: Ke Wang, Oct. 24th, 2017 Agenda Recap: SVM and Hinge loss, Representer
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Fall 2018 CS 551, Fall
Kernels and the Kernel Trick. Machine Learning Fall 2017
 Kernels and the Kernel Trick Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem Support vectors, duals and kernels
Kernels and the Kernel Trick Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem Support vectors, duals and kernels
Support Vector Machines
 Support Vector Machines Here we approach the two-class classification problem in a direct way: We try and find a plane that separates the classes in feature space. If we cannot, we get creative in two
Support Vector Machines Here we approach the two-class classification problem in a direct way: We try and find a plane that separates the classes in feature space. If we cannot, we get creative in two
Support Vector Machines II. CAP 5610: Machine Learning Instructor: Guo-Jun QI
 Support Vector Machines II CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Outline Linear SVM hard margin Linear SVM soft margin Non-linear SVM Application Linear Support Vector Machine An optimization
Support Vector Machines II CAP 5610: Machine Learning Instructor: Guo-Jun QI 1 Outline Linear SVM hard margin Linear SVM soft margin Non-linear SVM Application Linear Support Vector Machine An optimization
Recita,on: Loss, Regulariza,on, and Dual*
 10-701 Recita,on: Loss, Regulariza,on, and Dual* Jay- Yoon Lee 02/26/2015 *Adopted figures from 10725 lecture slides and from the book Elements of Sta,s,cal Learning Loss and Regulariza,on Op,miza,on problem
10-701 Recita,on: Loss, Regulariza,on, and Dual* Jay- Yoon Lee 02/26/2015 *Adopted figures from 10725 lecture slides and from the book Elements of Sta,s,cal Learning Loss and Regulariza,on Op,miza,on problem
Support Vector Machines, Kernel SVM
 Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
Support Vector Machines, Kernel SVM Professor Ameet Talwalkar Professor Ameet Talwalkar CS260 Machine Learning Algorithms February 27, 2017 1 / 40 Outline 1 Administration 2 Review of last lecture 3 SVM
Support Vector Machines
 Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machines Le Song Machine Learning I CSE 6740, Fall 2013 Naïve Bayes classifier Still use Bayes decision rule for classification P y x = P x y P y P x But assume p x y = 1 is fully factorized
Support Vector Machine
 Andrea Passerini passerini@disi.unitn.it Machine Learning Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
Andrea Passerini passerini@disi.unitn.it Machine Learning Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
Statistical Data Mining and Machine Learning Hilary Term 2016
 Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Introduction to Support Vector Machines
 Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Introduction to Support Vector Machines Shivani Agarwal Support Vector Machines (SVMs) Algorithm for learning linear classifiers Motivated by idea of maximizing margin Efficient extension to non-linear
Basis Expansion and Nonlinear SVM. Kai Yu
 Basis Expansion and Nonlinear SVM Kai Yu Linear Classifiers f(x) =w > x + b z(x) = sign(f(x)) Help to learn more general cases, e.g., nonlinear models 8/7/12 2 Nonlinear Classifiers via Basis Expansion
Basis Expansion and Nonlinear SVM Kai Yu Linear Classifiers f(x) =w > x + b z(x) = sign(f(x)) Help to learn more general cases, e.g., nonlinear models 8/7/12 2 Nonlinear Classifiers via Basis Expansion
Linear, threshold units. Linear Discriminant Functions and Support Vector Machines. Biometrics CSE 190 Lecture 11. X i : inputs W i : weights
 Linear Discriminant Functions and Support Vector Machines Linear, threshold units CSE19, Winter 11 Biometrics CSE 19 Lecture 11 1 X i : inputs W i : weights θ : threshold 3 4 5 1 6 7 Courtesy of University
Linear Discriminant Functions and Support Vector Machines Linear, threshold units CSE19, Winter 11 Biometrics CSE 19 Lecture 11 1 X i : inputs W i : weights θ : threshold 3 4 5 1 6 7 Courtesy of University
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
CS-E4830 Kernel Methods in Machine Learning
 CS-E4830 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 27. September, 2017 Juho Rousu 27. September, 2017 1 / 45 Convex optimization Convex optimisation This
CS-E4830 Kernel Methods in Machine Learning Lecture 3: Convex optimization and duality Juho Rousu 27. September, 2017 Juho Rousu 27. September, 2017 1 / 45 Convex optimization Convex optimisation This
A Magiv CV Theory for Large-Margin Classifiers
 A Magiv CV Theory for Large-Margin Classifiers Hui Zou School of Statistics, University of Minnesota June 30, 2018 Joint work with Boxiang Wang Outline 1 Background 2 Magic CV formula 3 Magic support vector
A Magiv CV Theory for Large-Margin Classifiers Hui Zou School of Statistics, University of Minnesota June 30, 2018 Joint work with Boxiang Wang Outline 1 Background 2 Magic CV formula 3 Magic support vector
A Bahadur Representation of the Linear Support Vector Machine
 A Bahadur Representation of the Linear Support Vector Machine Yoonkyung Lee Department of Statistics The Ohio State University October 7, 2008 Data Mining and Statistical Learning Study Group Outline Support
A Bahadur Representation of the Linear Support Vector Machine Yoonkyung Lee Department of Statistics The Ohio State University October 7, 2008 Data Mining and Statistical Learning Study Group Outline Support
MLCC 2017 Regularization Networks I: Linear Models
 MLCC 2017 Regularization Networks I: Linear Models Lorenzo Rosasco UNIGE-MIT-IIT June 27, 2017 About this class We introduce a class of learning algorithms based on Tikhonov regularization We study computational
MLCC 2017 Regularization Networks I: Linear Models Lorenzo Rosasco UNIGE-MIT-IIT June 27, 2017 About this class We introduce a class of learning algorithms based on Tikhonov regularization We study computational
Support Vector Machine for Classification and Regression
 Support Vector Machine for Classification and Regression Ahlame Douzal AMA-LIG, Université Joseph Fourier Master 2R - MOSIG (2013) November 25, 2013 Loss function, Separating Hyperplanes, Canonical Hyperplan
Support Vector Machine for Classification and Regression Ahlame Douzal AMA-LIG, Université Joseph Fourier Master 2R - MOSIG (2013) November 25, 2013 Loss function, Separating Hyperplanes, Canonical Hyperplan
Classifier Complexity and Support Vector Classifiers
 Classifier Complexity and Support Vector Classifiers Feature 2 6 4 2 0 2 4 6 8 RBF kernel 10 10 8 6 4 2 0 2 4 6 Feature 1 David M.J. Tax Pattern Recognition Laboratory Delft University of Technology D.M.J.Tax@tudelft.nl
Classifier Complexity and Support Vector Classifiers Feature 2 6 4 2 0 2 4 6 8 RBF kernel 10 10 8 6 4 2 0 2 4 6 Feature 1 David M.J. Tax Pattern Recognition Laboratory Delft University of Technology D.M.J.Tax@tudelft.nl
Support Vector Machines. CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington
 Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Support Vector Machines CSE 6363 Machine Learning Vassilis Athitsos Computer Science and Engineering Department University of Texas at Arlington 1 A Linearly Separable Problem Consider the binary classification
Modelli Lineari (Generalizzati) e SVM
 e SVM") Modelli Lineari (Generalizzati) e SVM Corso di AA, anno 2018/19, Padova Fabio Aiolli 19/26 Novembre 2018 Fabio Aiolli Modelli Lineari (Generalizzati) e SVM 19/26 Novembre 2018 1 / 36 Outline Linear methods
Modelli Lineari (Generalizzati) e SVM Corso di AA, anno 2018/19, Padova Fabio Aiolli 19/26 Novembre 2018 Fabio Aiolli Modelli Lineari (Generalizzati) e SVM 19/26 Novembre 2018 1 / 36 Outline Linear methods
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
CS145: INTRODUCTION TO DATA MINING 5: Vector Data: Support Vector Machine Instructor: Yizhou Sun yzsun@cs.ucla.edu October 18, 2017 Homework 1 Announcements Due end of the day of this Thursday (11:59pm)
Lecture Support Vector Machine (SVM) Classifiers
 Classifiers") Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Introduction to Machine Learning Lecturer: Amir Globerson Lecture 6 Fall Semester Scribe: Yishay Mansour 6.1 Support Vector Machine (SVM) Classifiers Classification is one of the most important tasks in
Machine Learning Support Vector Machines. Prof. Matteo Matteucci
 Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Machine Learning Support Vector Machines Prof. Matteo Matteucci Discriminative vs. Generative Approaches 2 o Generative approach: we derived the classifier from some generative hypothesis about the way
Support Vector Machines
 Support Vector Machines Sridhar Mahadevan mahadeva@cs.umass.edu University of Massachusetts Sridhar Mahadevan: CMPSCI 689 p. 1/32 Margin Classifiers margin b = 0 Sridhar Mahadevan: CMPSCI 689 p.
Support Vector Machines Sridhar Mahadevan mahadeva@cs.umass.edu University of Massachusetts Sridhar Mahadevan: CMPSCI 689 p. 1/32 Margin Classifiers margin b = 0 Sridhar Mahadevan: CMPSCI 689 p.
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
(Kernels +) Support Vector Machines
 Support Vector Machines") (Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
(Kernels +) Support Vector Machines Machine Learning Torsten Möller Reading Chapter 5 of Machine Learning An Algorithmic Perspective by Marsland Chapter 6+7 of Pattern Recognition and Machine Learning
Support vector machines
 Support vector machines Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 SVM, kernel methods and multiclass 1/23 Outline 1 Constrained optimization, Lagrangian duality and KKT 2 Support
Support vector machines Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 SVM, kernel methods and multiclass 1/23 Outline 1 Constrained optimization, Lagrangian duality and KKT 2 Support
SUPPORT VECTOR MACHINE
 SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
SUPPORT VECTOR MACHINE Mainly based on https://nlp.stanford.edu/ir-book/pdf/15svm.pdf 1 Overview SVM is a huge topic Integration of MMDS, IIR, and Andrew Moore s slides here Our foci: Geometric intuition
About this class. Maximizing the Margin. Maximum margin classifiers. Picture of large and small margin hyperplanes
 About this class Maximum margin classifiers SVMs: geometric derivation of the primal problem Statement of the dual problem The kernel trick SVMs as the solution to a regularization problem Maximizing the
About this class Maximum margin classifiers SVMs: geometric derivation of the primal problem Statement of the dual problem The kernel trick SVMs as the solution to a regularization problem Maximizing the
18.9 SUPPORT VECTOR MACHINES
 744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
744 Chapter 8. Learning from Examples is the fact that each regression problem will be easier to solve, because it involves only the examples with nonzero weight the examples whose kernels overlap the
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES. Supervised Learning
 LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
LINEAR CLASSIFICATION, PERCEPTRON, LOGISTIC REGRESSION, SVC, NAÏVE BAYES Supervised Learning Linear vs non linear classifiers In K-NN we saw an example of a non-linear classifier: the decision boundary
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2013 Exam policy: This exam allows two one-page, two-sided cheat sheets; No other materials. Time: 2 hours. Be sure to write your name and
Discriminative Models
 No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
No.5 Discriminative Models Hui Jiang Department of Electrical Engineering and Computer Science Lassonde School of Engineering York University, Toronto, Canada Outline Generative vs. Discriminative models
Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers)
") Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training
Support vector machines In a nutshell Linear classifiers selecting hyperplane maximizing separation margin between classes (large margin classifiers) Solution only depends on a small subset of training