Machine Learning. Data visualization and dimensionality reduction. Eric Xing. Lecture 7, August 13, Eric Xing Eric CMU,
|
|
|
- Gervase Gilbert
- 5 years ago
- Views:
Transcription
1 Eric Xing Eric CMU, Machine Learning Data visualization and dimensionality reduction Eric Xing Lecture 7, August 13, 2010
2 Eric Xing Eric CMU, Text document retrieval/labelling Represent each document by a high-dimensional vector in the space of words
3 Eric Xing Eric CMU, Image retrieval/labelling x = x x 1 2 x n
4 Eric Xing Eric CMU, Dimensionality Bottlenecks Data dimension Sensor response variables X: 1,000,000 samples of an EM/Acoustic field on each of N sensors pixels of a projected image on a IR camera sensor N 2 expansion factor to account for all pairwise correlations Information dimension Number of free parameters describing probability densities f(x) or f(s X) For known statistical model: info dim = model dim For unknown model: info dim = dim of density approximation Parametric-model driven dimension reduction DR by sufficiency, DR by maximum likelihood Data-driven dimension reduction Manifold learning, structure discovery

5 Eric Xing Eric CMU, Intuition: how does your brain store these pictures?

6 Brain Representation Eric Xing Eric CMU,

7 Eric Xing Eric CMU, Brain Representation Every pixel? Or perceptually meaningful structure? Up-down pose Left-right pose Lighting direction So, your brain successfully reduced the high-dimensional inputs to an intrinsically 3-dimensional manifold!
 data")

8 Eric Xing Eric CMU, Two Geometries to Consider (Metric) data geometry (Non-metric) information geometry Manifold Embedding Domain are i.i.d. samples from
9 Eric Xing Eric CMU, Data-driven DR Data-driven projection to lower dimensional subsapce Extract low-dim structure from high-dim data Data may lie on curved (but locally linear) subspace [1] Josh.B. Tenenbaum, Vin de Silva, and John C. Langford A Global Geometric Framework for Nonlinear Dimensionality Reduction Science, 22 Dec [2] Jose Costa, Neal Patwari and Alfred O. Hero, Distributed Weighted Multidimensional Scaling for Node Localization in Sensor Networks, IEEE/ACM Trans. Sensor Networks, to appear [3] Misha Belkin and Partha Niyogi, Laplacian eigenmaps for dimensionality reduction and data representation, Neural Computation, 2003.


10 Eric Xing Eric CMU, What is a Manifold? A manifold is a topological space which is locally Euclidean. Represents a very useful and challenging unsupervised learning problem. In general, any object which is nearly "flat" on small scales is a manifold.
11 Eric Xing Eric CMU, Manifold Learning Discover low dimensional structures (smooth manifold) for data in high dimension. Linear Approaches Principal component analysis. Multi dimensional scaling. Non Linear Approaches Local Linear Embedding ISOMAP Laplacian Eigenmap.
12 Eric Xing Eric CMU, Principal component analysis Areas of variance in data are where items can be best discriminated and key underlying phenomena observed If two items or dimensions are highly correlated or dependent They are likely to represent highly related phenomena We want to combine related variables, and focus on uncorrelated or independent ones, especially those along which the observations have high variance We look for the phenomena underlying the observed covariance/codependence in a set of variables These phenomena are called factors or principal components or independent components, depending on the methods used Factor analysis: based on variance/covariance/correlation Independent Component Analysis: based on independence
13 An example: Eric Xing Eric CMU,

14 Eric Xing Eric CMU, Principal Component Analysis The new variables/dimensions Are linear combinations of the original ones Are uncorrelated with one another Orthogonal in original dimension space Capture as much of the original variance in the data as possible Original Variable B PC 2 PC 1 Are called Principal Components Orthogonal directions of greatest variance in data Projections along PC1 discriminate the data most along any one axis First principal component is the direction of greatest variability (covariance) in the data Second is the next orthogonal (uncorrelated) direction of greatest variability So first remove all the variability along the first component, and then find the next direction of greatest variability And so on Original Variable A
15 Computing the Components Projection of vector x onto an axis (dimension) u is u T x Direction of greatest variability is that in which the average square of the projection is greatest: Maximize u T XX T u s.t u T u = 1 Construct Langrangian u T XX T u λu T u Vector of partial derivatives set to zero xx T u λu = (xx T λi) u = 0 As u 0 then u must be an eigenvector of XX T with eigenvalue λ λ is the principal eigenvalue of the correlation matrix C= XX T The eigenvalue denotes the amount of variability captured along that dimension Eric Xing Eric CMU,
16 Computing the Components Similarly for the next axis, etc. So, the new axes are the eigenvectors of the matrix of correlations of the original variables, which captures the similarities of the original variables based on how data samples project to them Geometrically: centering followed by rotation Linear transformation Eric Xing Eric CMU,
17 Eric Xing Eric CMU, Eigenvalues & Eigenvectors For symmetric matrices, eigenvectors for distinct eigenvalues are orthogonal Sv λ }, and λ { 1, 2} = { 1, 2} v{ 1, v1 v2 = λ 0 All eigenvalues of a real symmetric matrix are real. if S λi = 0 and S = T S λ R All eigenvalues of a positive semidefinite matrix are nonnegative w R n T, w Sw 0, then if Sv = λv λ 0
18 Eric Xing Eric CMU, Eigen/diagonal Decomposition Let be a square matrix with m linearly independent eigenvectors (a non-defective matrix) Theorem: Exists an eigen decomposition diagonal Unique for distinct eigenvalues (cf. matrix diagonalization theorem) Columns of U are eigenvectors of S Diagonal elements of are eigenvalues of
19 Eric Xing Eric CMU, PCs, Variance and Least-Squares The first PC retains the greatest amount of variation in the sample The k th PC retains the kth greatest fraction of the variation in the sample The k th largest eigenvalue of the correlation matrix C is the variance in the sample along the k th PC The least-squares view: PCs are a series of linear least squares fits to a sample, each orthogonal to all previous ones
20 How Many PCs? For n original dimensions, sample covariance matrix is nxn, and has up to n eigenvectors. So n PCs. Where does dimensionality reduction come from? Can ignore the components of lesser significance Variance (%) PC1 PC2 PC3 PC4 PC5 PC6 PC7 PC8 PC9 PC10 You do lose some information, but if the eigenvalues are small, you don t lose much n dimensions in original data calculate n eigenvectors and eigenvalues choose only the first p eigenvectors, based on their eigenvalues final data set has only p dimensions Eric Xing Eric CMU,


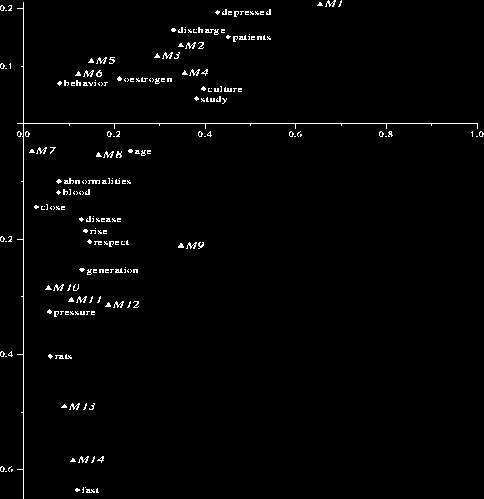
21 Application: querying text doc. Eric Xing Eric CMU,




22 K is the number of singular values used Within.40 threshold Eric Xing Eric CMU,
23 Eric Xing Eric CMU, Summary: Principle Linear projection method to reduce the number of parameters Transfer a set of correlated variables into a new set of uncorrelated variables Map the data into a space of lower dimensionality Form of unsupervised learning Properties It can be viewed as a rotation of the existing axes to new positions in the space defined by original variables New axes are orthogonal and represent the directions with maximum variability Application: In many settings in pattern recognition and retrieval, we have a feature-object matrix. For text, the terms are features and the docs are objects. Could be opinions and users This matrix may be redundant in dimensionality. Can work with low-rank approximation. If entries are missing (e.g., users opinions), can recover if dimensionality is low.
24 Eric Xing Eric CMU, Going beyond What is the essence of the C matrix? The elements in C captures some kind of affinity between a pair of data points in the semantic space We can replace it with any reasonable affinity measure ( ) 2 matrix E.g., D = x i x j : distance MDS ij E.g., the geodistance ISOMAP
![Nonlinear DR Isomap [Josh. Tenenbaum, Vin de Silva, John langford 2000] Constructing neighbourhood graph G For each pair of points in G, Computing shortest path distances ---- geodesic distances.](/docs-images/94/118497262/images/25-0.jpg "Use Dijkstra's or Floyd's algorithm Apply kernel PCA for C given by the centred matrix of squared geodesic distances. Project test points onto principal components as in kernel PCA.")
25 Nonlinear DR Isomap [Josh. Tenenbaum, Vin de Silva, John langford 2000] Constructing neighbourhood graph G For each pair of points in G, Computing shortest path distances ---- geodesic distances. Use Dijkstra's or Floyd's algorithm Apply kernel PCA for C given by the centred matrix of squared geodesic distances. Project test points onto principal components as in kernel PCA. Eric Xing Eric CMU,


26 Swiss Roll dataset 3D data 2D coord chart Error vs. dimensionality of coordinate chart Eric Xing Eric CMU,
, MDS (open circles), and")
27 Eric Xing Eric CMU, PCA, MD vs ISOMAP The residual variance of PCA (open triangles), MDS (open circles), and Isomap
28 Eric Xing Eric CMU, ISOMAP algorithm Pros/Cons Advantages: Nonlinear Globally optimal Guarantee asymptotically to recover the true dimensionality Drawback: May not be stable, dependent on topology of data As N increases, pair wise distances provide better approximations to geodesics, but cost more computation
29 Eric Xing Eric CMU, Local Linear Embedding (a.k.a LLE) LLE is based on simple geometric intuitions. Suppose the data consist of N real-valued vectors X i, each of dimensionality D. Each data point and its neighbors expected to lie on or close to a locally linear patch of the manifold.
30 Eric Xing Eric CMU, Steps in LLE algorithm Assign neighbors to each data point X i Compute the weights W ij that best linearly reconstruct the data point from its neighbors, solving the constrained least-squares problem. Compute the low-dimensional embedding vectors Y i best reconstructed by W ij.
31 Eric Xing Eric CMU, Fit locally, Think Globally From Nonlinear Dimensionality Reduction by Locally Linear Embedding Sam T. Roweis and Lawrence K. Saul Φ Y = Y W ij Y ( ) j 2 i j
32 Super-Resolution Through Neighbor Embedding [Yeung et al CVPR 2004] Training Xs i Training Ys i Testing Xt? Testing Yt Eric Xing Eric CMU,


33 Eric Xing Eric CMU, Intuition Patches of the image lie on a manifold Training Xs i Low dimensional Manifold Training Ys i High dimensional Manifold
34 Eric Xing Eric CMU, Algorithm 1. Get feature vectors for each low resolution training patch. 2. For each test patch feature vector find K nearest neighboring feature vectors of training patches. 3. Find optimum weights to express each test patch vector as a weighted sum of its K nearest neighbor vectors. 4. Use these weights for reconstruction of that test patch in high resolution.

35 Results Training Xs i Training Ys i Testing Xt Testing Yt Eric Xing Eric CMU,
36 Eric Xing Eric CMU, Summary: Principle Linear and nonlinear projection method to reduce the number of parameters Transfer a set of correlated variables into a new set of uncorrelated variables Map the data into a space of lower dimensionality Form of unsupervised learning Applications PCA and Latent semantic indexing for text mining Isomap and Nonparametric Models of Image Deformation LLE and Isomap Analysis of Spectra and Colour Images Image Spaces and Video Trajectories: Using Isomap to Explore Video Sequences Mining the structural knowledge of high-dimensional medical data using isomap Isomap Webpage:
37 Applying PCA and LDA: Eigen-faces and Fisher-faces L. Fei-Fei Computer Science Dept. Stanford University
38 Machine learning in computer vision Aug 13, Lecture 7: Dimensionality reduction, Manifold learning Eigen- and Fisher- faces Applications to object representation 8/8/2010 L. Fei-Fei, Dragon Star 2010, Stanford 38
39 The Space of Faces = + An image is a point in a high dimensional space An N x M image is a point in R NM We can define vectors in this space as we did in the 2D case [Thanks to Chuck Dyer, Steve Seitz, Nishino]
40 Key Idea Images in the possible set χ = xˆ { P RL } are highly correlated. So, compress them to a low-dimensional subspace that captures key appearance characteristics of the visual DOFs. EIGENFACES: [Turk and Pentland] USE PCA!
41 Principal Component Analysis (PCA) PCA is used to determine the most representing features among data points. It computes the p-dimensional subspace such that the projection of the data points onto the subspace has the largest variance among all p-dimensional subspaces.
42 Illustration of PCA x2 4 x X1 x1 x1 One projection PCA projection
43 Illustration of PCA x 2 2rd principal component x 1 1 st principal component
44 Mathematical Formulation Find a transformation, W, m-dimensional Orthonormal n-dimensional Total scatter matrix: W opt corresponds to m eigenvectors of S T

45 Eigenfaces PCA extracts the eigenvectors of A Gives a set of vectors v 1, v 2, v 3,... Each one of these vectors is a direction in face space what do these look like?
46 Projecting onto the Eigenfaces The eigenfaces v 1,..., v K span the space of faces A face is converted to eigenface coordinates by


47 Algorithm Training 1. Align training images x 1, x 2,, x N Note that each image is formulated into a long vector! 2. Compute average face u = 1/N Σ x i 3. Compute the difference image φ i = x i u
48 Algorithm 4. Compute the covariance matrix (total scatter matrix) S T = 1/NΣ φ i φ it = BB T, B=[φ 1, φ 2 φ N ] 5. Compute the eigenvectors of the covariance matrix, W Testing 1. Projection in Eigenface Projection ω i = W (X u), W = {eigenfaces} 2. Compare projections
.")
49 Illustration of Eigenfaces The visualization of eigenvectors: These are the first 4 eigenvectors from a training set of 400 images (ORL Face Database). They look like faces, hence called Eigenface.

50 Eigenfaces look somewhat like generic faces.
51 Eigenvalues

52 Reconstruction and Errors P = 4 P = 200 P = 400 Only selecting the top P eigenfaces reduces the dimensionality. Fewer eigenfaces result in more information loss, and hence less discrimination between faces.

53 Summary for PCA and Eigenface Non-iterative, globally optimal solution PCA projection is optimal for reconstruction from a low dimensional basis, but may NOT be optimal for discrimination




54 Linear Discriminant Analysis (LDA) Using Linear Discriminant Analysis (LDA) or Fisher s Linear Discriminant (FLD) Eigenfaces attempt to maximise the scatter of the training images in face space, while Fisherfaces attempt to maximise the between class scatter, while minimising the within class scatter.
55 Illustration of the Projection Using two classes as example: x2 x2 x1 x1 Poor Projection Good Projection
56 Comparing with PCA
57 Variables N Sample images: c classes: Average of each class: Total average: { x,, } µ 1 x N { χ,, } i = µ = 1 1 N 1 i χ c x k x k χ i N x k N k= 1
58 Scatters Scatter of class i: ( )( ) T i k x i k i x x S i k µ µ χ = = = c i S W S i 1 ( )( ) = = c i T i i i S B 1 µ µ µ µ χ B W T S S S + = Within class scatter: Between class scatter: Total scatter:
59 Illustration x2 S W = S 1 + S 2 S 1 S B S 2 x1
60 Mathematical Formulation (1) After projection: y = W k T x k Between class scatter (of y s): Within class scatter (of y s): ~ S ~ S B = W = W W T T S S B W W W
61 Mathematical Formulation (2) The desired projection: W opt ~ SB = arg max ~ = W S W arg max W W W T T S S B W W W How is it found? Generalized Eigenvectors SB wi = λi SW wi i = 1,, m Data dimension is much larger than the number of samples n >> N The matrix is singular: Rank( SW ) N c S W
62 Fisherface (PCA+FLD) Project with PCA to N c space z = W k T pca x k W pca = arg maxw W T S T W Project with FLD to c 1 space y = W k T fld z k W fld = arg max W W W T T W W T pca T pca S S B W W W pca pca W W

63 Illustration of FisherFace Fisherface
64 Results: Eigenface vs. Fisherface (1) Input: Train: Test: 160 images of 16 people 159 images 1 image Variation in Facial Expression, Eyewear, and Lighting With glasses Without glasses 3 Lighting conditions 5 expressions
65 Eigenface vs. Fisherface (2)
66 discussion Removing the first three principal components results in better performance under variable lighting conditions The Firsherface methods had error rates lower than the Eigenface method for the small datasets tested.


67 Manifold Learning for Object Representation L. Fei-Fei Computer Science Dept. Stanford University
 8/8/2010 L.")
68 Machine learning in computer vision Aug 13, Lecture 7: Dimensionality reduction, Manifold learning Eigen- and Fisher- faces Applications to object representation (slides courtesy to David Thompson) 8/8/2010 L. Fei-Fei, Dragon Star 2010, Stanford 68

69 manifolds in vision plenoptic function

70 manifolds in vision appearance variation images from hormel corp.

71 manifolds in vision deformation images from
72 manifold learning Find a low-d basis for describing high-d data. X ~= X' S.T. dim(x') << dim(x) uncovers the intrinsic dimensionality
73 If we knew all pairwise distances Chicago Raleigh Boston Seattle S.F. Austin Orlando Chicago 0 Raleigh Boston Seattle S.F Austin Orlando Distances calculated with geobytes.com/citydistancetool
74 Multidimensional Scaling (MDS) For n data points, and a distance matrix D, i D ij =...we can construct a m-dimensional space to preserve inter-point distances by using the top eigenvectors of D scaled by their eigenvalues j


75 MDS result in 2D

76 Actual plot of cities
77 Don t know distances
78 Don t know distnaces
79 why do manifold learning? 1. data compression 2. curse of dimensionality 3. de-noising 4. visualization 5. reasonable distance metrics
80 reasonable distance metrics?
81 reasonable distance metrics? linear interpolation

82 reasonable distance metrics? manifold interpolation
83 Build a data graph G. Vertices: images Isomap for images (u,v) is an edge iff SSD(u,v) is small For any two images, we approximate the distance between them with the shortest path on G

84 Isomap 1. Build a sparse graph with K-nearest neighbors D g = (distance matrix is sparse)

85 Isomap 2. Infer other interpoint distances by finding shortest paths on the graph (Dijkstra's algorithm). D g =
86 Isomap shortest-distance on a graph is easy to compute

87 Isomap results: hands
88 Isomap: pro and con - preserves global structure - few free parameters - sensitive to noise, noise edges - computationally expensive (dense matrix eigen-reduction)
89 Leakage problem

90 Locally Linear Embedding Find a mapping to preserve local linear relationships between neighbors
91 Locally Linear Embedding
92 LLE: Two key steps 1. Find weight matrix W of linear coefficients: Enforce sum-to-one constraint.
93 LLE: Two key steps 2. Find projected vectors Y to minimize reconstruction error must solve for whole dataset simultaneously

94 LLE: Result preserves local topology PCA LLE
95 LLE: Result

96 LLE: Result

97 LLE: Result
98 LLE: pro and con - no local minima, one free parameter - incremental & fast - simple linear algebra operations - can distort global structure
Machine Learning. Principal Components Analysis. Le Song. CSE6740/CS7641/ISYE6740, Fall 2012
 Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Machine Learning CSE6740/CS7641/ISYE6740, Fall 2012 Principal Components Analysis Le Song Lecture 22, Nov 13, 2012 Based on slides from Eric Xing, CMU Reading: Chap 12.1, CB book 1 2 Factor or Component
Lecture: Face Recognition
 Lecture: Face Recognition Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 12-1 What we will learn today Introduction to face recognition The Eigenfaces Algorithm Linear
Lecture: Face Recognition Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 12-1 What we will learn today Introduction to face recognition The Eigenfaces Algorithm Linear
Manifold Learning and it s application
 Manifold Learning and it s application Nandan Dubey SE367 Outline 1 Introduction Manifold Examples image as vector Importance Dimension Reduction Techniques 2 Linear Methods PCA Example MDS Perception
Manifold Learning and it s application Nandan Dubey SE367 Outline 1 Introduction Manifold Examples image as vector Importance Dimension Reduction Techniques 2 Linear Methods PCA Example MDS Perception
Lecture 13 Visual recognition
 Lecture 13 Visual recognition Announcements Silvio Savarese Lecture 13-20-Feb-14 Lecture 13 Visual recognition Object classification bag of words models Discriminative methods Generative methods Object
Lecture 13 Visual recognition Announcements Silvio Savarese Lecture 13-20-Feb-14 Lecture 13 Visual recognition Object classification bag of words models Discriminative methods Generative methods Object
Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations.
 Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Non-linear Dimensionality Reduction
 Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
What is Principal Component Analysis?
 What is Principal Component Analysis? Principal component analysis (PCA) Reduce the dimensionality of a data set by finding a new set of variables, smaller than the original set of variables Retains most
What is Principal Component Analysis? Principal component analysis (PCA) Reduce the dimensionality of a data set by finding a new set of variables, smaller than the original set of variables Retains most
COS 429: COMPUTER VISON Face Recognition
 COS 429: COMPUTER VISON Face Recognition Intro to recognition PCA and Eigenfaces LDA and Fisherfaces Face detection: Viola & Jones (Optional) generic object models for faces: the Constellation Model Reading:
COS 429: COMPUTER VISON Face Recognition Intro to recognition PCA and Eigenfaces LDA and Fisherfaces Face detection: Viola & Jones (Optional) generic object models for faces: the Constellation Model Reading:
Nonlinear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Dimension Reduction Techniques. Presented by Jie (Jerry) Yu
 Yu") Dimension Reduction Techniques Presented by Jie (Jerry) Yu Outline Problem Modeling Review of PCA and MDS Isomap Local Linear Embedding (LLE) Charting Background Advances in data collection and storage
Dimension Reduction Techniques Presented by Jie (Jerry) Yu Outline Problem Modeling Review of PCA and MDS Isomap Local Linear Embedding (LLE) Charting Background Advances in data collection and storage
Face Recognition. Face Recognition. Subspace-Based Face Recognition Algorithms. Application of Face Recognition
 ace Recognition Identify person based on the appearance of face CSED441:Introduction to Computer Vision (2017) Lecture10: Subspace Methods and ace Recognition Bohyung Han CSE, POSTECH bhhan@postech.ac.kr
ace Recognition Identify person based on the appearance of face CSED441:Introduction to Computer Vision (2017) Lecture10: Subspace Methods and ace Recognition Bohyung Han CSE, POSTECH bhhan@postech.ac.kr
Statistical Pattern Recognition
 Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Principal Component Analysis
 Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
Principal Component Analysis Yingyu Liang yliang@cs.wisc.edu Computer Sciences Department University of Wisconsin, Madison [based on slides from Nina Balcan] slide 1 Goals for the lecture you should understand
Deriving Principal Component Analysis (PCA)
") -0 Mathematical Foundations for Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deriving Principal Component Analysis (PCA) Matt Gormley Lecture 11 Oct.
-0 Mathematical Foundations for Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deriving Principal Component Analysis (PCA) Matt Gormley Lecture 11 Oct.
Lecture 17: Face Recogni2on
 Lecture 17: Face Recogni2on Dr. Juan Carlos Niebles Stanford AI Lab Professor Fei-Fei Li Stanford Vision Lab Lecture 17-1! What we will learn today Introduc2on to face recogni2on Principal Component Analysis
Lecture 17: Face Recogni2on Dr. Juan Carlos Niebles Stanford AI Lab Professor Fei-Fei Li Stanford Vision Lab Lecture 17-1! What we will learn today Introduc2on to face recogni2on Principal Component Analysis
Face recognition Computer Vision Spring 2018, Lecture 21
 Face recognition http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 2018, Lecture 21 Course announcements Homework 6 has been posted and is due on April 27 th. - Any questions about the homework?
Face recognition http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 2018, Lecture 21 Course announcements Homework 6 has been posted and is due on April 27 th. - Any questions about the homework?
L26: Advanced dimensionality reduction
 L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation)
") Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
Principal Component Analysis -- PCA (also called Karhunen-Loeve transformation) PCA transforms the original input space into a lower dimensional space, by constructing dimensions that are linear combinations
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi
 presented by Hassan A. Kingravi") Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Lecture 17: Face Recogni2on
 Lecture 17: Face Recogni2on Dr. Juan Carlos Niebles Stanford AI Lab Professor Fei-Fei Li Stanford Vision Lab Lecture 17-1! What we will learn today Introduc2on to face recogni2on Principal Component Analysis
Lecture 17: Face Recogni2on Dr. Juan Carlos Niebles Stanford AI Lab Professor Fei-Fei Li Stanford Vision Lab Lecture 17-1! What we will learn today Introduc2on to face recogni2on Principal Component Analysis
Nonlinear Dimensionality Reduction. Jose A. Costa
 Nonlinear Dimensionality Reduction Jose A. Costa Mathematics of Information Seminar, Dec. Motivation Many useful of signals such as: Image databases; Gene expression microarrays; Internet traffic time
Nonlinear Dimensionality Reduction Jose A. Costa Mathematics of Information Seminar, Dec. Motivation Many useful of signals such as: Image databases; Gene expression microarrays; Internet traffic time
Locality Preserving Projections
 Locality Preserving Projections Xiaofei He Department of Computer Science The University of Chicago Chicago, IL 60637 xiaofei@cs.uchicago.edu Partha Niyogi Department of Computer Science The University
Locality Preserving Projections Xiaofei He Department of Computer Science The University of Chicago Chicago, IL 60637 xiaofei@cs.uchicago.edu Partha Niyogi Department of Computer Science The University
Unsupervised dimensionality reduction
 Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
Nonlinear Dimensionality Reduction
 Nonlinear Dimensionality Reduction Piyush Rai CS5350/6350: Machine Learning October 25, 2011 Recap: Linear Dimensionality Reduction Linear Dimensionality Reduction: Based on a linear projection of the
Nonlinear Dimensionality Reduction Piyush Rai CS5350/6350: Machine Learning October 25, 2011 Recap: Linear Dimensionality Reduction Linear Dimensionality Reduction: Based on a linear projection of the
PCA FACE RECOGNITION
 PCA FACE RECOGNITION The slides are from several sources through James Hays (Brown); Srinivasa Narasimhan (CMU); Silvio Savarese (U. of Michigan); Shree Nayar (Columbia) including their own slides. Goal
PCA FACE RECOGNITION The slides are from several sources through James Hays (Brown); Srinivasa Narasimhan (CMU); Silvio Savarese (U. of Michigan); Shree Nayar (Columbia) including their own slides. Goal
PCA, Kernel PCA, ICA
 PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
Discriminant Uncorrelated Neighborhood Preserving Projections
 Journal of Information & Computational Science 8: 14 (2011) 3019 3026 Available at http://www.joics.com Discriminant Uncorrelated Neighborhood Preserving Projections Guoqiang WANG a,, Weijuan ZHANG a,
Journal of Information & Computational Science 8: 14 (2011) 3019 3026 Available at http://www.joics.com Discriminant Uncorrelated Neighborhood Preserving Projections Guoqiang WANG a,, Weijuan ZHANG a,
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
CITS 4402 Computer Vision
 CITS 4402 Computer Vision A/Prof Ajmal Mian Adj/A/Prof Mehdi Ravanbakhsh Lecture 06 Object Recognition Objectives To understand the concept of image based object recognition To learn how to match images
CITS 4402 Computer Vision A/Prof Ajmal Mian Adj/A/Prof Mehdi Ravanbakhsh Lecture 06 Object Recognition Objectives To understand the concept of image based object recognition To learn how to match images
Example: Face Detection
 Announcements HW1 returned New attendance policy Face Recognition: Dimensionality Reduction On time: 1 point Five minutes or more late: 0.5 points Absent: 0 points Biometrics CSE 190 Lecture 14 CSE190,
Announcements HW1 returned New attendance policy Face Recognition: Dimensionality Reduction On time: 1 point Five minutes or more late: 0.5 points Absent: 0 points Biometrics CSE 190 Lecture 14 CSE190,
Dimensionality Reduction AShortTutorial
 Dimensionality Reduction AShortTutorial Ali Ghodsi Department of Statistics and Actuarial Science University of Waterloo Waterloo, Ontario, Canada, 2006 c Ali Ghodsi, 2006 Contents 1 An Introduction to
Dimensionality Reduction AShortTutorial Ali Ghodsi Department of Statistics and Actuarial Science University of Waterloo Waterloo, Ontario, Canada, 2006 c Ali Ghodsi, 2006 Contents 1 An Introduction to
Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center
 Fei Wang and Jimeng Sun IBM TJ Watson Research Center") Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
Dimension Reduction and Low-dimensional Embedding
 Dimension Reduction and Low-dimensional Embedding Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/26 Dimension
Dimension Reduction and Low-dimensional Embedding Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/26 Dimension
LECTURE NOTE #11 PROF. ALAN YUILLE
 LECTURE NOTE #11 PROF. ALAN YUILLE 1. NonLinear Dimension Reduction Spectral Methods. The basic idea is to assume that the data lies on a manifold/surface in D-dimensional space, see figure (1) Perform
LECTURE NOTE #11 PROF. ALAN YUILLE 1. NonLinear Dimension Reduction Spectral Methods. The basic idea is to assume that the data lies on a manifold/surface in D-dimensional space, see figure (1) Perform
Course 495: Advanced Statistical Machine Learning/Pattern Recognition
 Course 495: Advanced Statistical Machine Learning/Pattern Recognition Deterministic Component Analysis Goal (Lecture): To present standard and modern Component Analysis (CA) techniques such as Principal
Course 495: Advanced Statistical Machine Learning/Pattern Recognition Deterministic Component Analysis Goal (Lecture): To present standard and modern Component Analysis (CA) techniques such as Principal
Global (ISOMAP) versus Local (LLE) Methods in Nonlinear Dimensionality Reduction
 versus Local (LLE) Methods in Nonlinear Dimensionality Reduction") Global (ISOMAP) versus Local (LLE) Methods in Nonlinear Dimensionality Reduction A presentation by Evan Ettinger on a Paper by Vin de Silva and Joshua B. Tenenbaum May 12, 2005 Outline Introduction The
Global (ISOMAP) versus Local (LLE) Methods in Nonlinear Dimensionality Reduction A presentation by Evan Ettinger on a Paper by Vin de Silva and Joshua B. Tenenbaum May 12, 2005 Outline Introduction The
Lecture 10: Dimension Reduction Techniques
 Lecture 10: Dimension Reduction Techniques Radu Balan Department of Mathematics, AMSC, CSCAMM and NWC University of Maryland, College Park, MD April 17, 2018 Input Data It is assumed that there is a set
Lecture 10: Dimension Reduction Techniques Radu Balan Department of Mathematics, AMSC, CSCAMM and NWC University of Maryland, College Park, MD April 17, 2018 Input Data It is assumed that there is a set
Introduction to Machine Learning
 10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
10-701 Introduction to Machine Learning PCA Slides based on 18-661 Fall 2018 PCA Raw data can be Complex, High-dimensional To understand a phenomenon we measure various related quantities If we knew what
PCA & ICA. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
PCA & ICA CE-717: Machine Learning Sharif University of Technology Spring 2015 Soleymani Dimensionality Reduction: Feature Selection vs. Feature Extraction Feature selection Select a subset of a given
Introduction to Machine Learning. PCA and Spectral Clustering. Introduction to Machine Learning, Slides: Eran Halperin
 1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
1 Introduction to Machine Learning PCA and Spectral Clustering Introduction to Machine Learning, 2013-14 Slides: Eran Halperin Singular Value Decomposition (SVD) The singular value decomposition (SVD)
ECE 521. Lecture 11 (not on midterm material) 13 February K-means clustering, Dimensionality reduction
 13 February K-means clustering, Dimensionality reduction") ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
ECE 521 Lecture 11 (not on midterm material) 13 February 2017 K-means clustering, Dimensionality reduction With thanks to Ruslan Salakhutdinov for an earlier version of the slides Overview K-means clustering
Dimension reduction methods: Algorithms and Applications Yousef Saad Department of Computer Science and Engineering University of Minnesota
 Dimension reduction methods: Algorithms and Applications Yousef Saad Department of Computer Science and Engineering University of Minnesota Université du Littoral- Calais July 11, 16 First..... to the
Dimension reduction methods: Algorithms and Applications Yousef Saad Department of Computer Science and Engineering University of Minnesota Université du Littoral- Calais July 11, 16 First..... to the
Lecture 24: Principal Component Analysis. Aykut Erdem May 2016 Hacettepe University
 Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Lecture 4: Principal Component Analysis Aykut Erdem May 016 Hacettepe University This week Motivation PCA algorithms Applications PCA shortcomings Autoencoders Kernel PCA PCA Applications Data Visualization
Advanced Introduction to Machine Learning CMU-10715
 Advanced Introduction to Machine Learning CMU-10715 Principal Component Analysis Barnabás Póczos Contents Motivation PCA algorithms Applications Some of these slides are taken from Karl Booksh Research
Advanced Introduction to Machine Learning CMU-10715 Principal Component Analysis Barnabás Póczos Contents Motivation PCA algorithms Applications Some of these slides are taken from Karl Booksh Research
Nonlinear Methods. Data often lies on or near a nonlinear low-dimensional curve aka manifold.
 Nonlinear Methods Data often lies on or near a nonlinear low-dimensional curve aka manifold. 27 Laplacian Eigenmaps Linear methods Lower-dimensional linear projection that preserves distances between all
Nonlinear Methods Data often lies on or near a nonlinear low-dimensional curve aka manifold. 27 Laplacian Eigenmaps Linear methods Lower-dimensional linear projection that preserves distances between all
Image Analysis & Retrieval. Lec 14. Eigenface and Fisherface
 Image Analysis & Retrieval Lec 14 Eigenface and Fisherface Zhu Li Dept of CSEE, UMKC Office: FH560E, Email: lizhu@umkc.edu, Ph: x 2346. http://l.web.umkc.edu/lizhu Z. Li, Image Analysis & Retrv, Spring
Image Analysis & Retrieval Lec 14 Eigenface and Fisherface Zhu Li Dept of CSEE, UMKC Office: FH560E, Email: lizhu@umkc.edu, Ph: x 2346. http://l.web.umkc.edu/lizhu Z. Li, Image Analysis & Retrv, Spring
CSE 291. Assignment Spectral clustering versus k-means. Out: Wed May 23 Due: Wed Jun 13
 CSE 291. Assignment 3 Out: Wed May 23 Due: Wed Jun 13 3.1 Spectral clustering versus k-means Download the rings data set for this problem from the course web site. The data is stored in MATLAB format as
CSE 291. Assignment 3 Out: Wed May 23 Due: Wed Jun 13 3.1 Spectral clustering versus k-means Download the rings data set for this problem from the course web site. The data is stored in MATLAB format as
Recognition Using Class Specific Linear Projection. Magali Segal Stolrasky Nadav Ben Jakov April, 2015
 Recognition Using Class Specific Linear Projection Magali Segal Stolrasky Nadav Ben Jakov April, 2015 Articles Eigenfaces vs. Fisherfaces Recognition Using Class Specific Linear Projection, Peter N. Belhumeur,
Recognition Using Class Specific Linear Projection Magali Segal Stolrasky Nadav Ben Jakov April, 2015 Articles Eigenfaces vs. Fisherfaces Recognition Using Class Specific Linear Projection, Peter N. Belhumeur,
Unsupervised Machine Learning and Data Mining. DS 5230 / DS Fall Lecture 7. Jan-Willem van de Meent
 Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Unsupervised Machine Learning and Data Mining DS 5230 / DS 4420 - Fall 2018 Lecture 7 Jan-Willem van de Meent DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Dimensionality Reduction Goal:
Robot Image Credit: Viktoriya Sukhanova 123RF.com. Dimensionality Reduction
 Robot Image Credit: Viktoriya Sukhanova 13RF.com Dimensionality Reduction Feature Selection vs. Dimensionality Reduction Feature Selection (last time) Select a subset of features. When classifying novel
Robot Image Credit: Viktoriya Sukhanova 13RF.com Dimensionality Reduction Feature Selection vs. Dimensionality Reduction Feature Selection (last time) Select a subset of features. When classifying novel
Principal Component Analysis
 B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
B: Chapter 1 HTF: Chapter 1.5 Principal Component Analysis Barnabás Póczos University of Alberta Nov, 009 Contents Motivation PCA algorithms Applications Face recognition Facial expression recognition
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA
 Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
Methods for sparse analysis of high-dimensional data, II
 Methods for sparse analysis of high-dimensional data, II Rachel Ward May 23, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 47 High dimensional
Methods for sparse analysis of high-dimensional data, II Rachel Ward May 23, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 47 High dimensional
CS4495/6495 Introduction to Computer Vision. 8B-L2 Principle Component Analysis (and its use in Computer Vision)
") CS4495/6495 Introduction to Computer Vision 8B-L2 Principle Component Analysis (and its use in Computer Vision) Wavelength 2 Wavelength 2 Principal Components Principal components are all about the directions
CS4495/6495 Introduction to Computer Vision 8B-L2 Principle Component Analysis (and its use in Computer Vision) Wavelength 2 Wavelength 2 Principal Components Principal components are all about the directions
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab Lecture 11-1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed
Robust Laplacian Eigenmaps Using Global Information
 Manifold Learning and its Applications: Papers from the AAAI Fall Symposium (FS-9-) Robust Laplacian Eigenmaps Using Global Information Shounak Roychowdhury ECE University of Texas at Austin, Austin, TX
Manifold Learning and its Applications: Papers from the AAAI Fall Symposium (FS-9-) Robust Laplacian Eigenmaps Using Global Information Shounak Roychowdhury ECE University of Texas at Austin, Austin, TX
Manifold Learning: Theory and Applications to HRI
 Manifold Learning: Theory and Applications to HRI Seungjin Choi Department of Computer Science Pohang University of Science and Technology, Korea seungjin@postech.ac.kr August 19, 2008 1 / 46 Greek Philosopher
Manifold Learning: Theory and Applications to HRI Seungjin Choi Department of Computer Science Pohang University of Science and Technology, Korea seungjin@postech.ac.kr August 19, 2008 1 / 46 Greek Philosopher
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable models Background PCA
Statistical and Computational Analysis of Locality Preserving Projection
 Statistical and Computational Analysis of Locality Preserving Projection Xiaofei He xiaofei@cs.uchicago.edu Department of Computer Science, University of Chicago, 00 East 58th Street, Chicago, IL 60637
Statistical and Computational Analysis of Locality Preserving Projection Xiaofei He xiaofei@cs.uchicago.edu Department of Computer Science, University of Chicago, 00 East 58th Street, Chicago, IL 60637
Apprentissage non supervisée
 Apprentissage non supervisée Cours 3 Higher dimensions Jairo Cugliari Master ECD 2015-2016 From low to high dimension Density estimation Histograms and KDE Calibration can be done automacally But! Let
Apprentissage non supervisée Cours 3 Higher dimensions Jairo Cugliari Master ECD 2015-2016 From low to high dimension Density estimation Histograms and KDE Calibration can be done automacally But! Let
Lecture: Face Recognition and Feature Reduction
 Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab 1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed in the
Lecture: Face Recognition and Feature Reduction Juan Carlos Niebles and Ranjay Krishna Stanford Vision and Learning Lab 1 Recap - Curse of dimensionality Assume 5000 points uniformly distributed in the
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 12 Jan-Willem van de Meent (credit: Yijun Zhao, Percy Liang) DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Linear Dimensionality
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 12 Jan-Willem van de Meent (credit: Yijun Zhao, Percy Liang) DIMENSIONALITY REDUCTION Borrowing from: Percy Liang (Stanford) Linear Dimensionality
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 8 Continuous Latent Variable
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 8 Continuous Latent Variable
DATA MINING LECTURE 8. Dimensionality Reduction PCA -- SVD
 DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
Unsupervised Learning: K- Means & PCA
 Unsupervised Learning: K- Means & PCA Unsupervised Learning Supervised learning used labeled data pairs (x, y) to learn a func>on f : X Y But, what if we don t have labels? No labels = unsupervised learning
Unsupervised Learning: K- Means & PCA Unsupervised Learning Supervised learning used labeled data pairs (x, y) to learn a func>on f : X Y But, what if we don t have labels? No labels = unsupervised learning
MACHINE LEARNING. Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA
 1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
Methods for sparse analysis of high-dimensional data, II
 Methods for sparse analysis of high-dimensional data, II Rachel Ward May 26, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 55 High dimensional
Methods for sparse analysis of high-dimensional data, II Rachel Ward May 26, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 55 High dimensional
Dimensionality Reduction Using PCA/LDA. Hongyu Li School of Software Engineering TongJi University Fall, 2014
 Dimensionality Reduction Using PCA/LDA Hongyu Li School of Software Engineering TongJi University Fall, 2014 Dimensionality Reduction One approach to deal with high dimensional data is by reducing their
Dimensionality Reduction Using PCA/LDA Hongyu Li School of Software Engineering TongJi University Fall, 2014 Dimensionality Reduction One approach to deal with high dimensional data is by reducing their
Nonlinear Manifold Learning Summary
 Nonlinear Manifold Learning 6.454 Summary Alexander Ihler ihler@mit.edu October 6, 2003 Abstract Manifold learning is the process of estimating a low-dimensional structure which underlies a collection
Nonlinear Manifold Learning 6.454 Summary Alexander Ihler ihler@mit.edu October 6, 2003 Abstract Manifold learning is the process of estimating a low-dimensional structure which underlies a collection
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Additional reading can be found from non-assessed exercises (week 8) in this course unit teaching page. Textbooks: Sect. 6.3 in [1] and Ch. 12 in [2] Outline Introduction
Principal Component Analysis (PCA) Additional reading can be found from non-assessed exercises (week 8) in this course unit teaching page. Textbooks: Sect. 6.3 in [1] and Ch. 12 in [2] Outline Introduction
Data Mining. Dimensionality reduction. Hamid Beigy. Sharif University of Technology. Fall 1395
 Data Mining Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 42 Outline 1 Introduction 2 Feature selection
Data Mining Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1395 1 / 42 Outline 1 Introduction 2 Feature selection
Laplacian Eigenmaps for Dimensionality Reduction and Data Representation
 Laplacian Eigenmaps for Dimensionality Reduction and Data Representation Neural Computation, June 2003; 15 (6):1373-1396 Presentation for CSE291 sp07 M. Belkin 1 P. Niyogi 2 1 University of Chicago, Department
Laplacian Eigenmaps for Dimensionality Reduction and Data Representation Neural Computation, June 2003; 15 (6):1373-1396 Presentation for CSE291 sp07 M. Belkin 1 P. Niyogi 2 1 University of Chicago, Department
Image Analysis & Retrieval Lec 14 - Eigenface & Fisherface
 CS/EE 5590 / ENG 401 Special Topics, Spring 2018 Image Analysis & Retrieval Lec 14 - Eigenface & Fisherface Zhu Li Dept of CSEE, UMKC http://l.web.umkc.edu/lizhu Office Hour: Tue/Thr 2:30-4pm@FH560E, Contact:
CS/EE 5590 / ENG 401 Special Topics, Spring 2018 Image Analysis & Retrieval Lec 14 - Eigenface & Fisherface Zhu Li Dept of CSEE, UMKC http://l.web.umkc.edu/lizhu Office Hour: Tue/Thr 2:30-4pm@FH560E, Contact:
Dimensionality Reduc1on
 Dimensionality Reduc1on contd Aarti Singh Machine Learning 10-601 Nov 10, 2011 Slides Courtesy: Tom Mitchell, Eric Xing, Lawrence Saul 1 Principal Component Analysis (PCA) Principal Components are the
Dimensionality Reduc1on contd Aarti Singh Machine Learning 10-601 Nov 10, 2011 Slides Courtesy: Tom Mitchell, Eric Xing, Lawrence Saul 1 Principal Component Analysis (PCA) Principal Components are the
Manifold Learning: From Linear to nonlinear. Presenter: Wei-Lun (Harry) Chao Date: April 26 and May 3, 2012 At: AMMAI 2012
 Chao Date: April 26 and May 3, 2012 At: AMMAI 2012") Manifold Learning: From Linear to nonlinear Presenter: Wei-Lun (Harry) Chao Date: April 26 and May 3, 2012 At: AMMAI 2012 1 Preview Goal: Dimensionality Classification reduction and clustering Main idea:
Manifold Learning: From Linear to nonlinear Presenter: Wei-Lun (Harry) Chao Date: April 26 and May 3, 2012 At: AMMAI 2012 1 Preview Goal: Dimensionality Classification reduction and clustering Main idea:
Eigenfaces. Face Recognition Using Principal Components Analysis
 Eigenfaces Face Recognition Using Principal Components Analysis M. Turk, A. Pentland, "Eigenfaces for Recognition", Journal of Cognitive Neuroscience, 3(1), pp. 71-86, 1991. Slides : George Bebis, UNR
Eigenfaces Face Recognition Using Principal Components Analysis M. Turk, A. Pentland, "Eigenfaces for Recognition", Journal of Cognitive Neuroscience, 3(1), pp. 71-86, 1991. Slides : George Bebis, UNR
Machine Learning - MT & 14. PCA and MDS
 Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)
Machine Learning - MT 2016 13 & 14. PCA and MDS Varun Kanade University of Oxford November 21 & 23, 2016 Announcements Sheet 4 due this Friday by noon Practical 3 this week (continue next week if necessary)
Dimensionality Reduction
 Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Lecture 5 1 Outline 1. Overview a) What is? b) Why? 2. Principal Component Analysis (PCA) a) Objectives b) Explaining variability c) SVD 3. Related approaches a) ICA b) Autoencoders 2 Example 1: Sportsball
Unsupervised Learning Techniques Class 07, 1 March 2006 Andrea Caponnetto
 Unsupervised Learning Techniques 9.520 Class 07, 1 March 2006 Andrea Caponnetto About this class Goal To introduce some methods for unsupervised learning: Gaussian Mixtures, K-Means, ISOMAP, HLLE, Laplacian
Unsupervised Learning Techniques 9.520 Class 07, 1 March 2006 Andrea Caponnetto About this class Goal To introduce some methods for unsupervised learning: Gaussian Mixtures, K-Means, ISOMAP, HLLE, Laplacian
A Duality View of Spectral Methods for Dimensionality Reduction
 A Duality View of Spectral Methods for Dimensionality Reduction Lin Xiao 1 Jun Sun 2 Stephen Boyd 3 May 3, 2006 1 Center for the Mathematics of Information, California Institute of Technology, Pasadena,
A Duality View of Spectral Methods for Dimensionality Reduction Lin Xiao 1 Jun Sun 2 Stephen Boyd 3 May 3, 2006 1 Center for the Mathematics of Information, California Institute of Technology, Pasadena,
Linear Subspace Models
 Linear Subspace Models Goal: Explore linear models of a data set. Motivation: A central question in vision concerns how we represent a collection of data vectors. The data vectors may be rasterized images,
Linear Subspace Models Goal: Explore linear models of a data set. Motivation: A central question in vision concerns how we represent a collection of data vectors. The data vectors may be rasterized images,
PCA and admixture models
 PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
Uncorrelated Multilinear Principal Component Analysis through Successive Variance Maximization
 Uncorrelated Multilinear Principal Component Analysis through Successive Variance Maximization Haiping Lu 1 K. N. Plataniotis 1 A. N. Venetsanopoulos 1,2 1 Department of Electrical & Computer Engineering,
Uncorrelated Multilinear Principal Component Analysis through Successive Variance Maximization Haiping Lu 1 K. N. Plataniotis 1 A. N. Venetsanopoulos 1,2 1 Department of Electrical & Computer Engineering,
Principal Component Analysis
 Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Machine Learning Michaelmas 2017 James Worrell Principal Component Analysis 1 Introduction 1.1 Goals of PCA Principal components analysis (PCA) is a dimensionality reduction technique that can be used
Intrinsic Structure Study on Whale Vocalizations
 1 2015 DCLDE Conference Intrinsic Structure Study on Whale Vocalizations Yin Xian 1, Xiaobai Sun 2, Yuan Zhang 3, Wenjing Liao 3 Doug Nowacek 1,4, Loren Nolte 1, Robert Calderbank 1,2,3 1 Department of
1 2015 DCLDE Conference Intrinsic Structure Study on Whale Vocalizations Yin Xian 1, Xiaobai Sun 2, Yuan Zhang 3, Wenjing Liao 3 Doug Nowacek 1,4, Loren Nolte 1, Robert Calderbank 1,2,3 1 Department of
Fisher s Linear Discriminant Analysis
 Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Data-dependent representations: Laplacian Eigenmaps
 Data-dependent representations: Laplacian Eigenmaps November 4, 2015 Data Organization and Manifold Learning There are many techniques for Data Organization and Manifold Learning, e.g., Principal Component
Data-dependent representations: Laplacian Eigenmaps November 4, 2015 Data Organization and Manifold Learning There are many techniques for Data Organization and Manifold Learning, e.g., Principal Component
Manifold Regularization
 9.520: Statistical Learning Theory and Applications arch 3rd, 200 anifold Regularization Lecturer: Lorenzo Rosasco Scribe: Hooyoung Chung Introduction In this lecture we introduce a class of learning algorithms,
9.520: Statistical Learning Theory and Applications arch 3rd, 200 anifold Regularization Lecturer: Lorenzo Rosasco Scribe: Hooyoung Chung Introduction In this lecture we introduce a class of learning algorithms,
Statistical Machine Learning
 Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis
 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis Alvina Goh Vision Reading Group 13 October 2005 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal
Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis Alvina Goh Vision Reading Group 13 October 2005 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal
Pattern Recognition 2
 Pattern Recognition 2 KNN,, Dr. Terence Sim School of Computing National University of Singapore Outline 1 2 3 4 5 Outline 1 2 3 4 5 The Bayes Classifier is theoretically optimum. That is, prob. of error
Pattern Recognition 2 KNN,, Dr. Terence Sim School of Computing National University of Singapore Outline 1 2 3 4 5 Outline 1 2 3 4 5 The Bayes Classifier is theoretically optimum. That is, prob. of error
Dimensionality Reduction:
 Dimensionality Reduction: From Data Representation to General Framework Dong XU School of Computer Engineering Nanyang Technological University, Singapore What is Dimensionality Reduction? PCA LDA Examples:
Dimensionality Reduction: From Data Representation to General Framework Dong XU School of Computer Engineering Nanyang Technological University, Singapore What is Dimensionality Reduction? PCA LDA Examples:
A Duality View of Spectral Methods for Dimensionality Reduction
 Lin Xiao lxiao@caltech.edu Center for the Mathematics of Information, California Institute of Technology, Pasadena, CA 91125, USA Jun Sun sunjun@stanford.edu Stephen Boyd boyd@stanford.edu Department of
Lin Xiao lxiao@caltech.edu Center for the Mathematics of Information, California Institute of Technology, Pasadena, CA 91125, USA Jun Sun sunjun@stanford.edu Stephen Boyd boyd@stanford.edu Department of
Dimensionality Reduction: A Comparative Review
 Tilburg centre for Creative Computing P.O. Box 90153 Tilburg University 5000 LE Tilburg, The Netherlands http://www.uvt.nl/ticc Email: ticc@uvt.nl Copyright c Laurens van der Maaten, Eric Postma, and Jaap
Tilburg centre for Creative Computing P.O. Box 90153 Tilburg University 5000 LE Tilburg, The Netherlands http://www.uvt.nl/ticc Email: ticc@uvt.nl Copyright c Laurens van der Maaten, Eric Postma, and Jaap
Deep Learning Basics Lecture 7: Factor Analysis. Princeton University COS 495 Instructor: Yingyu Liang
 Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Deep Learning Basics Lecture 7: Factor Analysis Princeton University COS 495 Instructor: Yingyu Liang Supervised v.s. Unsupervised Math formulation for supervised learning Given training data x i, y i
Information Retrieval
 Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Introduction to Information CS276: Information and Web Search Christopher Manning and Pandu Nayak Lecture 13: Latent Semantic Indexing Ch. 18 Today s topic Latent Semantic Indexing Term-document matrices
Learning a Kernel Matrix for Nonlinear Dimensionality Reduction
 Learning a Kernel Matrix for Nonlinear Dimensionality Reduction Kilian Q. Weinberger kilianw@cis.upenn.edu Fei Sha feisha@cis.upenn.edu Lawrence K. Saul lsaul@cis.upenn.edu Department of Computer and Information
Learning a Kernel Matrix for Nonlinear Dimensionality Reduction Kilian Q. Weinberger kilianw@cis.upenn.edu Fei Sha feisha@cis.upenn.edu Lawrence K. Saul lsaul@cis.upenn.edu Department of Computer and Information
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015
 ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
STA 414/2104: Lecture 8
 STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
STA 414/2104: Lecture 8 6-7 March 2017: Continuous Latent Variable Models, Neural networks Delivered by Mark Ebden With thanks to Russ Salakhutdinov, Jimmy Ba and others Outline Continuous latent variable
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach
 A First Dimensionality Reduction Approach") LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits