Apprentissage non supervisée
|
|
|
- Julia Howard
- 5 years ago
- Views:
Transcription


1 Apprentissage non supervisée Cours 3 Higher dimensions Jairo Cugliari Master ECD
2 From low to high dimension Density estimation Histograms and KDE Calibration can be done automacally But! Let s look at the Mean-Square-Error : E[ˆf h (x) f (x)] 2 Histogramme with p = 1 et h : MISE C/n 2/3 KDE with p = 1 : MISE C/n 4/5 KDE in p : MSE C/n 4/(4+p) So when p grows, the estimator is less attractive. This is a commonc behaviour in data analysis : we just met the curse of dimensionality!
3 Curse of dimensionality (Bellman, 1961) When p increases, the volume of the space increases so fast that the available data become sparse. Data needed to support a reliable result often grows exponentially with p.
4 High-dimensional spaces The curse of dimensionality Empty space phenomenon Norm concentration phenomenon And more funny things A hypercube looks like a sea urchin (many spiky corners!) Hypercube corners collapse towards the center in any projection The volume of a unit hypersphere tends to zero The sphere volume concentrates in a thin shell Tails of a Gaussian get heavier than the central bell Hopefully data convey some information / structure clusters of data manifold data Possible solutions are clustering, dimensionality reduction,...
5 Dimensionality reduction Some notation : Input data : x 1, x 2,..., x n R p Output data : f 1, f 2,..., f n R d, d p We want Observations close on R p should be close on R d Observations distant on R p should be distant on R d We ll try Linear methods (PCA, MDS) Nonlinear methods (IsoMap, LLE, EigenMaps)
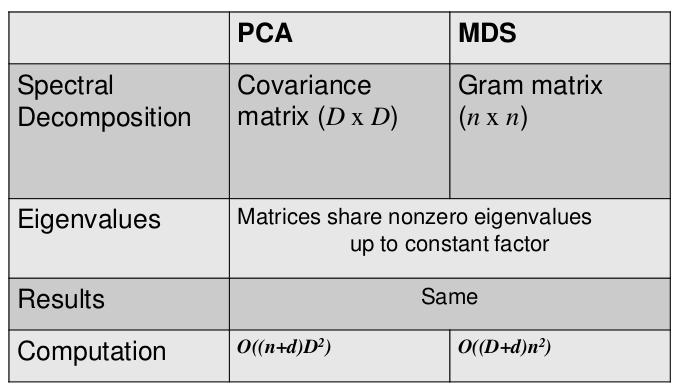
6 PCA Pearson, 1901 ; Hotelling, 1933 ; Karhunen, 1946 ; Loève, Idea Decorrelate zero-mean data Keep large variance axes Fit a plane though the data cloud and project Representation quality
7 Assume inputs are centered (i.e. i x i = 0) Given a unit vector u and a point x, the length of the projection of x onto u is given by x T u Maximize projected variance The inner matrix is called Gramm matrix G = 1 n i x ixi T. Maximizing u T Gu s.t. u = 1 gives the principal eigenvector of G.
8 To project the data into a p dimensional subspace (d p) we take u 1,..., u d the top d eigenvectors of G (which forms a orthogonal basis) The low dimensional outputs are y i = (u T 1 x i, u T 2 x i,..., u T d x i) T How to interpret the PCA : Eigenvectors : principal axes of maximum variance subspace. Eigenvalues : variance of projected inputs along principle axes. Estimated dimensionality : number of significant (nonnegative) eigenvalues.

9
10
11 Multidimensional Scaling (MDS) Preserve pairwise distances Projet n points in an Euclidean space (e.g. R 2 ) using only information about the pairwise distances. Source :
12 MDS Input : a distance matrix Recall : A square matrix D of order n is a distance matrix if it is symmetric, d ii = 0 and d ij >= 0, i j. Aim : find the n data points y 1,..., y n in d dimensions such that y i y j 2 is similar to d ij. Let d (X ) ij be the original distances and d (Y ) ij the new ones, then one wants to min y 1,...,y n n n i=1 j=1 (d (X ) ij d (Y ) ij ) 2
13 Metric MDS Let 1 be a vector of ones Centering matrix H = I 1 n 11T Let A be a square matrix of order n with a ij = d2 ij 2 Then, we define the double certered matrix B B = HAH T B is a Gram matrix (SPD) iff D is an Euclidean distance matrix
14 Metric MDS If B is a Gram matrix we have B = (HX )(HX ) T Using SVD on B we have B = U U T The columns of Y = U 1/2 give the coordinates of the euclidean representation. Algorithm Construct A Compute B = HAH T SVD of B to get B = U U T Obtain Y = U 1/2
15 Metric MDS Interpreting MDS Eigenvectors : Ordered, scaled, and truncated to yield low dimensional embedding. Eigenvalues : Measure how each dimension contributes to dot products. Estimated dimensionality : Number of significant (nonnegative) eigenvalues.
16

17 Non linear structure
18 Graph-Based Methods Tenenbaum et. al s Isomap Algorithm Global approach Preserves global pairwise distances. Roweis and Saul s Locally Linear Embedding Algorithm Local approach Nearby points should map nearby Belkin and Niyogi Laplacian Eigenmaps Algorithm Local approach minimizes approximately the same value as LLE
19 ISOMAP Algorithm Compute the k-nearest neighbours Obtain the shortest paths through graph MDS on geodesic distances

20 Non linear structure
Non-linear Dimensionality Reduction
 Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
Non-linear Dimensionality Reduction CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Introduction Laplacian Eigenmaps Locally Linear Embedding (LLE)
Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations.
 Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Previously Focus was on solving matrix inversion problems Now we look at other properties of matrices Useful when A represents a transformations y = Ax Or A simply represents data Notion of eigenvectors,
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA
 Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
Learning Eigenfunctions: Links with Spectral Clustering and Kernel PCA Yoshua Bengio Pascal Vincent Jean-François Paiement University of Montreal April 2, Snowbird Learning 2003 Learning Modal Structures
Unsupervised dimensionality reduction
 Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
Unsupervised dimensionality reduction Guillaume Obozinski Ecole des Ponts - ParisTech SOCN course 2014 Guillaume Obozinski Unsupervised dimensionality reduction 1/30 Outline 1 PCA 2 Kernel PCA 3 Multidimensional
Lecture 10: Dimension Reduction Techniques
 Lecture 10: Dimension Reduction Techniques Radu Balan Department of Mathematics, AMSC, CSCAMM and NWC University of Maryland, College Park, MD April 17, 2018 Input Data It is assumed that there is a set
Lecture 10: Dimension Reduction Techniques Radu Balan Department of Mathematics, AMSC, CSCAMM and NWC University of Maryland, College Park, MD April 17, 2018 Input Data It is assumed that there is a set
LECTURE NOTE #11 PROF. ALAN YUILLE
 LECTURE NOTE #11 PROF. ALAN YUILLE 1. NonLinear Dimension Reduction Spectral Methods. The basic idea is to assume that the data lies on a manifold/surface in D-dimensional space, see figure (1) Perform
LECTURE NOTE #11 PROF. ALAN YUILLE 1. NonLinear Dimension Reduction Spectral Methods. The basic idea is to assume that the data lies on a manifold/surface in D-dimensional space, see figure (1) Perform
Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis
 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis Alvina Goh Vision Reading Group 13 October 2005 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal
Connection of Local Linear Embedding, ISOMAP, and Kernel Principal Component Analysis Alvina Goh Vision Reading Group 13 October 2005 Connection of Local Linear Embedding, ISOMAP, and Kernel Principal
Dimensionality Reduction AShortTutorial
 Dimensionality Reduction AShortTutorial Ali Ghodsi Department of Statistics and Actuarial Science University of Waterloo Waterloo, Ontario, Canada, 2006 c Ali Ghodsi, 2006 Contents 1 An Introduction to
Dimensionality Reduction AShortTutorial Ali Ghodsi Department of Statistics and Actuarial Science University of Waterloo Waterloo, Ontario, Canada, 2006 c Ali Ghodsi, 2006 Contents 1 An Introduction to
L26: Advanced dimensionality reduction
 L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
L26: Advanced dimensionality reduction The snapshot CA approach Oriented rincipal Components Analysis Non-linear dimensionality reduction (manifold learning) ISOMA Locally Linear Embedding CSCE 666 attern
Nonlinear Methods. Data often lies on or near a nonlinear low-dimensional curve aka manifold.
 Nonlinear Methods Data often lies on or near a nonlinear low-dimensional curve aka manifold. 27 Laplacian Eigenmaps Linear methods Lower-dimensional linear projection that preserves distances between all
Nonlinear Methods Data often lies on or near a nonlinear low-dimensional curve aka manifold. 27 Laplacian Eigenmaps Linear methods Lower-dimensional linear projection that preserves distances between all
CSE 291. Assignment Spectral clustering versus k-means. Out: Wed May 23 Due: Wed Jun 13
 CSE 291. Assignment 3 Out: Wed May 23 Due: Wed Jun 13 3.1 Spectral clustering versus k-means Download the rings data set for this problem from the course web site. The data is stored in MATLAB format as
CSE 291. Assignment 3 Out: Wed May 23 Due: Wed Jun 13 3.1 Spectral clustering versus k-means Download the rings data set for this problem from the course web site. The data is stored in MATLAB format as
Manifold Learning and it s application
 Manifold Learning and it s application Nandan Dubey SE367 Outline 1 Introduction Manifold Examples image as vector Importance Dimension Reduction Techniques 2 Linear Methods PCA Example MDS Perception
Manifold Learning and it s application Nandan Dubey SE367 Outline 1 Introduction Manifold Examples image as vector Importance Dimension Reduction Techniques 2 Linear Methods PCA Example MDS Perception
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi
 presented by Hassan A. Kingravi") Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Face Recognition Using Laplacianfaces He et al. (IEEE Trans PAMI, 2005) presented by Hassan A. Kingravi Overview Introduction Linear Methods for Dimensionality Reduction Nonlinear Methods and Manifold
Manifold Learning: Theory and Applications to HRI
 Manifold Learning: Theory and Applications to HRI Seungjin Choi Department of Computer Science Pohang University of Science and Technology, Korea seungjin@postech.ac.kr August 19, 2008 1 / 46 Greek Philosopher
Manifold Learning: Theory and Applications to HRI Seungjin Choi Department of Computer Science Pohang University of Science and Technology, Korea seungjin@postech.ac.kr August 19, 2008 1 / 46 Greek Philosopher
Nonlinear Dimensionality Reduction. Jose A. Costa
 Nonlinear Dimensionality Reduction Jose A. Costa Mathematics of Information Seminar, Dec. Motivation Many useful of signals such as: Image databases; Gene expression microarrays; Internet traffic time
Nonlinear Dimensionality Reduction Jose A. Costa Mathematics of Information Seminar, Dec. Motivation Many useful of signals such as: Image databases; Gene expression microarrays; Internet traffic time
Unsupervised Learning Techniques Class 07, 1 March 2006 Andrea Caponnetto
 Unsupervised Learning Techniques 9.520 Class 07, 1 March 2006 Andrea Caponnetto About this class Goal To introduce some methods for unsupervised learning: Gaussian Mixtures, K-Means, ISOMAP, HLLE, Laplacian
Unsupervised Learning Techniques 9.520 Class 07, 1 March 2006 Andrea Caponnetto About this class Goal To introduce some methods for unsupervised learning: Gaussian Mixtures, K-Means, ISOMAP, HLLE, Laplacian
Nonlinear Dimensionality Reduction
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Kernel PCA 2 Isomap 3 Locally Linear Embedding 4 Laplacian Eigenmap
Nonlinear Dimensionality Reduction
 Nonlinear Dimensionality Reduction Piyush Rai CS5350/6350: Machine Learning October 25, 2011 Recap: Linear Dimensionality Reduction Linear Dimensionality Reduction: Based on a linear projection of the
Nonlinear Dimensionality Reduction Piyush Rai CS5350/6350: Machine Learning October 25, 2011 Recap: Linear Dimensionality Reduction Linear Dimensionality Reduction: Based on a linear projection of the
Dimension Reduction and Low-dimensional Embedding
 Dimension Reduction and Low-dimensional Embedding Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/26 Dimension
Dimension Reduction and Low-dimensional Embedding Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/26 Dimension
ISSN: (Online) Volume 3, Issue 5, May 2015 International Journal of Advance Research in Computer Science and Management Studies
 Volume 3, Issue 5, May 2015 International Journal of Advance Research in Computer Science and Management Studies") ISSN: 2321-7782 (Online) Volume 3, Issue 5, May 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online at:
ISSN: 2321-7782 (Online) Volume 3, Issue 5, May 2015 International Journal of Advance Research in Computer Science and Management Studies Research Article / Survey Paper / Case Study Available online at:
Dimension Reduction Techniques. Presented by Jie (Jerry) Yu
 Yu") Dimension Reduction Techniques Presented by Jie (Jerry) Yu Outline Problem Modeling Review of PCA and MDS Isomap Local Linear Embedding (LLE) Charting Background Advances in data collection and storage
Dimension Reduction Techniques Presented by Jie (Jerry) Yu Outline Problem Modeling Review of PCA and MDS Isomap Local Linear Embedding (LLE) Charting Background Advances in data collection and storage
Dimensionality Reduc1on
 Dimensionality Reduc1on contd Aarti Singh Machine Learning 10-601 Nov 10, 2011 Slides Courtesy: Tom Mitchell, Eric Xing, Lawrence Saul 1 Principal Component Analysis (PCA) Principal Components are the
Dimensionality Reduc1on contd Aarti Singh Machine Learning 10-601 Nov 10, 2011 Slides Courtesy: Tom Mitchell, Eric Xing, Lawrence Saul 1 Principal Component Analysis (PCA) Principal Components are the
Intrinsic Structure Study on Whale Vocalizations
 1 2015 DCLDE Conference Intrinsic Structure Study on Whale Vocalizations Yin Xian 1, Xiaobai Sun 2, Yuan Zhang 3, Wenjing Liao 3 Doug Nowacek 1,4, Loren Nolte 1, Robert Calderbank 1,2,3 1 Department of
1 2015 DCLDE Conference Intrinsic Structure Study on Whale Vocalizations Yin Xian 1, Xiaobai Sun 2, Yuan Zhang 3, Wenjing Liao 3 Doug Nowacek 1,4, Loren Nolte 1, Robert Calderbank 1,2,3 1 Department of
Laplacian Eigenmaps for Dimensionality Reduction and Data Representation
 Introduction and Data Representation Mikhail Belkin & Partha Niyogi Department of Electrical Engieering University of Minnesota Mar 21, 2017 1/22 Outline Introduction 1 Introduction 2 3 4 Connections to
Introduction and Data Representation Mikhail Belkin & Partha Niyogi Department of Electrical Engieering University of Minnesota Mar 21, 2017 1/22 Outline Introduction 1 Introduction 2 3 4 Connections to
Statistical Pattern Recognition
 Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Statistical Pattern Recognition Feature Extraction Hamid R. Rabiee Jafar Muhammadi, Alireza Ghasemi, Payam Siyari Spring 2014 http://ce.sharif.edu/courses/92-93/2/ce725-2/ Agenda Dimensionality Reduction
Data-dependent representations: Laplacian Eigenmaps
 Data-dependent representations: Laplacian Eigenmaps November 4, 2015 Data Organization and Manifold Learning There are many techniques for Data Organization and Manifold Learning, e.g., Principal Component
Data-dependent representations: Laplacian Eigenmaps November 4, 2015 Data Organization and Manifold Learning There are many techniques for Data Organization and Manifold Learning, e.g., Principal Component
Manifold Learning: From Linear to nonlinear. Presenter: Wei-Lun (Harry) Chao Date: April 26 and May 3, 2012 At: AMMAI 2012
 Chao Date: April 26 and May 3, 2012 At: AMMAI 2012") Manifold Learning: From Linear to nonlinear Presenter: Wei-Lun (Harry) Chao Date: April 26 and May 3, 2012 At: AMMAI 2012 1 Preview Goal: Dimensionality Classification reduction and clustering Main idea:
Manifold Learning: From Linear to nonlinear Presenter: Wei-Lun (Harry) Chao Date: April 26 and May 3, 2012 At: AMMAI 2012 1 Preview Goal: Dimensionality Classification reduction and clustering Main idea:
Machine Learning. Data visualization and dimensionality reduction. Eric Xing. Lecture 7, August 13, Eric Xing Eric CMU,
 Eric Xing Eric Xing @ CMU, 2006-2010 1 Machine Learning Data visualization and dimensionality reduction Eric Xing Lecture 7, August 13, 2010 Eric Xing Eric Xing @ CMU, 2006-2010 2 Text document retrieval/labelling
Eric Xing Eric Xing @ CMU, 2006-2010 1 Machine Learning Data visualization and dimensionality reduction Eric Xing Lecture 7, August 13, 2010 Eric Xing Eric Xing @ CMU, 2006-2010 2 Text document retrieval/labelling
Nonlinear Manifold Learning Summary
 Nonlinear Manifold Learning 6.454 Summary Alexander Ihler ihler@mit.edu October 6, 2003 Abstract Manifold learning is the process of estimating a low-dimensional structure which underlies a collection
Nonlinear Manifold Learning 6.454 Summary Alexander Ihler ihler@mit.edu October 6, 2003 Abstract Manifold learning is the process of estimating a low-dimensional structure which underlies a collection
EECS 275 Matrix Computation
 EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 23 1 / 27 Overview
EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 23 1 / 27 Overview
Lecture: Some Practical Considerations (3 of 4)
") Stat260/CS294: Spectral Graph Methods Lecture 14-03/10/2015 Lecture: Some Practical Considerations (3 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough.
Stat260/CS294: Spectral Graph Methods Lecture 14-03/10/2015 Lecture: Some Practical Considerations (3 of 4) Lecturer: Michael Mahoney Scribe: Michael Mahoney Warning: these notes are still very rough.
Maximum variance formulation
 12.1. Principal Component Analysis 561 Figure 12.2 Principal component analysis seeks a space of lower dimensionality, known as the principal subspace and denoted by the magenta line, such that the orthogonal
12.1. Principal Component Analysis 561 Figure 12.2 Principal component analysis seeks a space of lower dimensionality, known as the principal subspace and denoted by the magenta line, such that the orthogonal
Locality Preserving Projections
 Locality Preserving Projections Xiaofei He Department of Computer Science The University of Chicago Chicago, IL 60637 xiaofei@cs.uchicago.edu Partha Niyogi Department of Computer Science The University
Locality Preserving Projections Xiaofei He Department of Computer Science The University of Chicago Chicago, IL 60637 xiaofei@cs.uchicago.edu Partha Niyogi Department of Computer Science The University
Graph Metrics and Dimension Reduction
 Graph Metrics and Dimension Reduction Minh Tang 1 Michael Trosset 2 1 Applied Mathematics and Statistics The Johns Hopkins University 2 Department of Statistics Indiana University, Bloomington November
Graph Metrics and Dimension Reduction Minh Tang 1 Michael Trosset 2 1 Applied Mathematics and Statistics The Johns Hopkins University 2 Department of Statistics Indiana University, Bloomington November
Laplacian Eigenmaps for Dimensionality Reduction and Data Representation
 Laplacian Eigenmaps for Dimensionality Reduction and Data Representation Neural Computation, June 2003; 15 (6):1373-1396 Presentation for CSE291 sp07 M. Belkin 1 P. Niyogi 2 1 University of Chicago, Department
Laplacian Eigenmaps for Dimensionality Reduction and Data Representation Neural Computation, June 2003; 15 (6):1373-1396 Presentation for CSE291 sp07 M. Belkin 1 P. Niyogi 2 1 University of Chicago, Department
15 Singular Value Decomposition
 15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
15 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center
 Fei Wang and Jimeng Sun IBM TJ Watson Research Center") Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
Distance Metric Learning in Data Mining (Part II) Fei Wang and Jimeng Sun IBM TJ Watson Research Center 1 Outline Part I - Applications Motivation and Introduction Patient similarity application Part II
A Duality View of Spectral Methods for Dimensionality Reduction
 A Duality View of Spectral Methods for Dimensionality Reduction Lin Xiao 1 Jun Sun 2 Stephen Boyd 3 May 3, 2006 1 Center for the Mathematics of Information, California Institute of Technology, Pasadena,
A Duality View of Spectral Methods for Dimensionality Reduction Lin Xiao 1 Jun Sun 2 Stephen Boyd 3 May 3, 2006 1 Center for the Mathematics of Information, California Institute of Technology, Pasadena,
Learning a Kernel Matrix for Nonlinear Dimensionality Reduction
 Learning a Kernel Matrix for Nonlinear Dimensionality Reduction Kilian Q. Weinberger kilianw@cis.upenn.edu Fei Sha feisha@cis.upenn.edu Lawrence K. Saul lsaul@cis.upenn.edu Department of Computer and Information
Learning a Kernel Matrix for Nonlinear Dimensionality Reduction Kilian Q. Weinberger kilianw@cis.upenn.edu Fei Sha feisha@cis.upenn.edu Lawrence K. Saul lsaul@cis.upenn.edu Department of Computer and Information
MACHINE LEARNING. Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA
 1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
1 MACHINE LEARNING Methods for feature extraction and reduction of dimensionality: Probabilistic PCA and kernel PCA 2 Practicals Next Week Next Week, Practical Session on Computer Takes Place in Room GR
A Duality View of Spectral Methods for Dimensionality Reduction
 Lin Xiao lxiao@caltech.edu Center for the Mathematics of Information, California Institute of Technology, Pasadena, CA 91125, USA Jun Sun sunjun@stanford.edu Stephen Boyd boyd@stanford.edu Department of
Lin Xiao lxiao@caltech.edu Center for the Mathematics of Information, California Institute of Technology, Pasadena, CA 91125, USA Jun Sun sunjun@stanford.edu Stephen Boyd boyd@stanford.edu Department of
Robust Laplacian Eigenmaps Using Global Information
 Manifold Learning and its Applications: Papers from the AAAI Fall Symposium (FS-9-) Robust Laplacian Eigenmaps Using Global Information Shounak Roychowdhury ECE University of Texas at Austin, Austin, TX
Manifold Learning and its Applications: Papers from the AAAI Fall Symposium (FS-9-) Robust Laplacian Eigenmaps Using Global Information Shounak Roychowdhury ECE University of Texas at Austin, Austin, TX
Global (ISOMAP) versus Local (LLE) Methods in Nonlinear Dimensionality Reduction
 versus Local (LLE) Methods in Nonlinear Dimensionality Reduction") Global (ISOMAP) versus Local (LLE) Methods in Nonlinear Dimensionality Reduction A presentation by Evan Ettinger on a Paper by Vin de Silva and Joshua B. Tenenbaum May 12, 2005 Outline Introduction The
Global (ISOMAP) versus Local (LLE) Methods in Nonlinear Dimensionality Reduction A presentation by Evan Ettinger on a Paper by Vin de Silva and Joshua B. Tenenbaum May 12, 2005 Outline Introduction The
(Non-linear) dimensionality reduction. Department of Computer Science, Czech Technical University in Prague
 dimensionality reduction. Department of Computer Science, Czech Technical University in Prague") (Non-linear) dimensionality reduction Jiří Kléma Department of Computer Science, Czech Technical University in Prague http://cw.felk.cvut.cz/wiki/courses/a4m33sad/start poutline motivation, task definition,
(Non-linear) dimensionality reduction Jiří Kléma Department of Computer Science, Czech Technical University in Prague http://cw.felk.cvut.cz/wiki/courses/a4m33sad/start poutline motivation, task definition,
Learning a kernel matrix for nonlinear dimensionality reduction
 University of Pennsylvania ScholarlyCommons Departmental Papers (CIS) Department of Computer & Information Science 7-4-2004 Learning a kernel matrix for nonlinear dimensionality reduction Kilian Q. Weinberger
University of Pennsylvania ScholarlyCommons Departmental Papers (CIS) Department of Computer & Information Science 7-4-2004 Learning a kernel matrix for nonlinear dimensionality reduction Kilian Q. Weinberger
Statistical and Computational Analysis of Locality Preserving Projection
 Statistical and Computational Analysis of Locality Preserving Projection Xiaofei He xiaofei@cs.uchicago.edu Department of Computer Science, University of Chicago, 00 East 58th Street, Chicago, IL 60637
Statistical and Computational Analysis of Locality Preserving Projection Xiaofei He xiaofei@cs.uchicago.edu Department of Computer Science, University of Chicago, 00 East 58th Street, Chicago, IL 60637
DIMENSION REDUCTION. min. j=1
 DIMENSION REDUCTION 1 Principal Component Analysis (PCA) Principal components analysis (PCA) finds low dimensional approximations to the data by projecting the data onto linear subspaces. Let X R d and
DIMENSION REDUCTION 1 Principal Component Analysis (PCA) Principal components analysis (PCA) finds low dimensional approximations to the data by projecting the data onto linear subspaces. Let X R d and
Fisher s Linear Discriminant Analysis
 Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Fisher s Linear Discriminant Analysis Seungjin Choi Department of Computer Science and Engineering Pohang University of Science and Technology 77 Cheongam-ro, Nam-gu, Pohang 37673, Korea seungjin@postech.ac.kr
Data dependent operators for the spatial-spectral fusion problem
 Data dependent operators for the spatial-spectral fusion problem Wien, December 3, 2012 Joint work with: University of Maryland: J. J. Benedetto, J. A. Dobrosotskaya, T. Doster, K. W. Duke, M. Ehler, A.
Data dependent operators for the spatial-spectral fusion problem Wien, December 3, 2012 Joint work with: University of Maryland: J. J. Benedetto, J. A. Dobrosotskaya, T. Doster, K. W. Duke, M. Ehler, A.
There are two things that are particularly nice about the first basis
 Orthogonality and the Gram-Schmidt Process In Chapter 4, we spent a great deal of time studying the problem of finding a basis for a vector space We know that a basis for a vector space can potentially
Orthogonality and the Gram-Schmidt Process In Chapter 4, we spent a great deal of time studying the problem of finding a basis for a vector space We know that a basis for a vector space can potentially
Data Mining II. Prof. Dr. Karsten Borgwardt, Department Biosystems, ETH Zürich. Basel, Spring Semester 2016 D-BSSE
 D-BSSE Data Mining II Prof. Dr. Karsten Borgwardt, Department Biosystems, ETH Zürich Basel, Spring Semester 2016 D-BSSE Karsten Borgwardt Data Mining II Course, Basel Spring Semester 2016 2 / 117 Our course
D-BSSE Data Mining II Prof. Dr. Karsten Borgwardt, Department Biosystems, ETH Zürich Basel, Spring Semester 2016 D-BSSE Karsten Borgwardt Data Mining II Course, Basel Spring Semester 2016 2 / 117 Our course
Statistical Machine Learning
 Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Statistical Machine Learning Christoph Lampert Spring Semester 2015/2016 // Lecture 12 1 / 36 Unsupervised Learning Dimensionality Reduction 2 / 36 Dimensionality Reduction Given: data X = {x 1,..., x
Multivariate Statistics Random Projections and Johnson-Lindenstrauss Lemma
 Multivariate Statistics Random Projections and Johnson-Lindenstrauss Lemma Suppose again we have n sample points x,..., x n R p. The data-point x i R p can be thought of as the i-th row X i of an n p-dimensional
Multivariate Statistics Random Projections and Johnson-Lindenstrauss Lemma Suppose again we have n sample points x,..., x n R p. The data-point x i R p can be thought of as the i-th row X i of an n p-dimensional
Advances in Manifold Learning Presented by: Naku Nak l Verm r a June 10, 2008
 Advances in Manifold Learning Presented by: Nakul Verma June 10, 008 Outline Motivation Manifolds Manifold Learning Random projection of manifolds for dimension reduction Introduction to random projections
Advances in Manifold Learning Presented by: Nakul Verma June 10, 008 Outline Motivation Manifolds Manifold Learning Random projection of manifolds for dimension reduction Introduction to random projections
Advanced Machine Learning & Perception
 Advanced Machine Learning & Perception Instructor: Tony Jebara Topic 2 Nonlinear Manifold Learning Multidimensional Scaling (MDS) Locally Linear Embedding (LLE) Beyond Principal Components Analysis (PCA)
Advanced Machine Learning & Perception Instructor: Tony Jebara Topic 2 Nonlinear Manifold Learning Multidimensional Scaling (MDS) Locally Linear Embedding (LLE) Beyond Principal Components Analysis (PCA)
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach
 A First Dimensionality Reduction Approach") LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
LEC 2: Principal Component Analysis (PCA) A First Dimensionality Reduction Approach Dr. Guangliang Chen February 9, 2016 Outline Introduction Review of linear algebra Matrix SVD PCA Motivation The digits
Preprocessing & dimensionality reduction
 Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
Introduction to Data Mining Preprocessing & dimensionality reduction CPSC/AMTH 445a/545a Guy Wolf guy.wolf@yale.edu Yale University Fall 2016 CPSC 445 (Guy Wolf) Dimensionality reduction Yale - Fall 2016
Structure in Data. A major objective in data analysis is to identify interesting features or structure in the data.
 Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
Structure in Data A major objective in data analysis is to identify interesting features or structure in the data. The graphical methods are very useful in discovering structure. There are basically two
ISOMAP TRACKING WITH PARTICLE FILTER
 Clemson University TigerPrints All Theses Theses 5-2007 ISOMAP TRACKING WITH PARTICLE FILTER Nikhil Rane Clemson University, nrane@clemson.edu Follow this and additional works at: https://tigerprints.clemson.edu/all_theses
Clemson University TigerPrints All Theses Theses 5-2007 ISOMAP TRACKING WITH PARTICLE FILTER Nikhil Rane Clemson University, nrane@clemson.edu Follow this and additional works at: https://tigerprints.clemson.edu/all_theses
Robustness of Principal Components
 PCA for Clustering An objective of principal components analysis is to identify linear combinations of the original variables that are useful in accounting for the variation in those original variables.
PCA for Clustering An objective of principal components analysis is to identify linear combinations of the original variables that are useful in accounting for the variation in those original variables.
Dimensionality Reduction
 Dimensionality Reduction Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, UCL Apr/May 2016 High dimensional data Example data: Gene Expression Example data: Web Pages Google
Dimensionality Reduction Maneesh Sahani maneesh@gatsby.ucl.ac.uk Gatsby Computational Neuroscience Unit, UCL Apr/May 2016 High dimensional data Example data: Gene Expression Example data: Web Pages Google
Dimensionality Reduction and Principle Components
 Dimensionality Reduction and Principle Components Ken Kreutz-Delgado (Nuno Vasconcelos) UCSD ECE Department Winter 2012 Motivation Recall, in Bayesian decision theory we have: World: States Y in {1,...,
Dimensionality Reduction and Principle Components Ken Kreutz-Delgado (Nuno Vasconcelos) UCSD ECE Department Winter 2012 Motivation Recall, in Bayesian decision theory we have: World: States Y in {1,...,
Beyond Scalar Affinities for Network Analysis or Vector Diffusion Maps and the Connection Laplacian
 Beyond Scalar Affinities for Network Analysis or Vector Diffusion Maps and the Connection Laplacian Amit Singer Princeton University Department of Mathematics and Program in Applied and Computational Mathematics
Beyond Scalar Affinities for Network Analysis or Vector Diffusion Maps and the Connection Laplacian Amit Singer Princeton University Department of Mathematics and Program in Applied and Computational Mathematics
Graph-Laplacian PCA: Closed-form Solution and Robustness
 2013 IEEE Conference on Computer Vision and Pattern Recognition Graph-Laplacian PCA: Closed-form Solution and Robustness Bo Jiang a, Chris Ding b,a, Bin Luo a, Jin Tang a a School of Computer Science and
2013 IEEE Conference on Computer Vision and Pattern Recognition Graph-Laplacian PCA: Closed-form Solution and Robustness Bo Jiang a, Chris Ding b,a, Bin Luo a, Jin Tang a a School of Computer Science and
Part I Generalized Principal Component Analysis
 Part I Generalized Principal Component Analysis René Vidal Center for Imaging Science Institute for Computational Medicine Johns Hopkins University Principal Component Analysis (PCA) Given a set of points
Part I Generalized Principal Component Analysis René Vidal Center for Imaging Science Institute for Computational Medicine Johns Hopkins University Principal Component Analysis (PCA) Given a set of points
1 Singular Value Decomposition and Principal Component
 Singular Value Decomposition and Principal Component Analysis In these lectures we discuss the SVD and the PCA, two of the most widely used tools in machine learning. Principal Component Analysis (PCA)
Singular Value Decomposition and Principal Component Analysis In these lectures we discuss the SVD and the PCA, two of the most widely used tools in machine learning. Principal Component Analysis (PCA)
Machine Learning. Dimensionality reduction. Hamid Beigy. Sharif University of Technology. Fall 1395
 Machine Learning Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1395 1 / 47 Table of contents 1 Introduction
Machine Learning Dimensionality reduction Hamid Beigy Sharif University of Technology Fall 1395 Hamid Beigy (Sharif University of Technology) Machine Learning Fall 1395 1 / 47 Table of contents 1 Introduction
14 Singular Value Decomposition
 14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
14 Singular Value Decomposition For any high-dimensional data analysis, one s first thought should often be: can I use an SVD? The singular value decomposition is an invaluable analysis tool for dealing
Image Analysis & Retrieval Lec 13 - Feature Dimension Reduction
 CS/EE 5590 / ENG 401 Special Topics, Spring 2018 Image Analysis & Retrieval Lec 13 - Feature Dimension Reduction Zhu Li Dept of CSEE, UMKC http://l.web.umkc.edu/lizhu Office Hour: Tue/Thr 2:30-4pm@FH560E,
CS/EE 5590 / ENG 401 Special Topics, Spring 2018 Image Analysis & Retrieval Lec 13 - Feature Dimension Reduction Zhu Li Dept of CSEE, UMKC http://l.web.umkc.edu/lizhu Office Hour: Tue/Thr 2:30-4pm@FH560E,
Lecture 3: Review of Linear Algebra
 ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters, transforms,
ECE 83 Fall 2 Statistical Signal Processing instructor: R Nowak Lecture 3: Review of Linear Algebra Very often in this course we will represent signals as vectors and operators (eg, filters, transforms,
Methods for sparse analysis of high-dimensional data, II
 Methods for sparse analysis of high-dimensional data, II Rachel Ward May 23, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 47 High dimensional
Methods for sparse analysis of high-dimensional data, II Rachel Ward May 23, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 47 High dimensional
CS168: The Modern Algorithmic Toolbox Lecture #8: How PCA Works
 CS68: The Modern Algorithmic Toolbox Lecture #8: How PCA Works Tim Roughgarden & Gregory Valiant April 20, 206 Introduction Last lecture introduced the idea of principal components analysis (PCA). The
CS68: The Modern Algorithmic Toolbox Lecture #8: How PCA Works Tim Roughgarden & Gregory Valiant April 20, 206 Introduction Last lecture introduced the idea of principal components analysis (PCA). The
Dimensionality Reduction:
 Dimensionality Reduction: From Data Representation to General Framework Dong XU School of Computer Engineering Nanyang Technological University, Singapore What is Dimensionality Reduction? PCA LDA Examples:
Dimensionality Reduction: From Data Representation to General Framework Dong XU School of Computer Engineering Nanyang Technological University, Singapore What is Dimensionality Reduction? PCA LDA Examples:
Principal Component Analysis!! Lecture 11!
 Principal Component Analysis Lecture 11 1 Eigenvectors and Eigenvalues g Consider this problem of spreading butter on a bread slice 2 Eigenvectors and Eigenvalues g Consider this problem of stretching
Principal Component Analysis Lecture 11 1 Eigenvectors and Eigenvalues g Consider this problem of spreading butter on a bread slice 2 Eigenvectors and Eigenvalues g Consider this problem of stretching
Dimensionality Reduction. CS57300 Data Mining Fall Instructor: Bruno Ribeiro
 Dimensionality Reduction CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Visualize high dimensional data (and understand its Geometry) } Project the data into lower dimensional spaces }
Dimensionality Reduction CS57300 Data Mining Fall 2016 Instructor: Bruno Ribeiro Goal } Visualize high dimensional data (and understand its Geometry) } Project the data into lower dimensional spaces }
Chapter XII: Data Pre and Post Processing
 Chapter XII: Data Pre and Post Processing Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 XII.1 4-1 Chapter XII: Data Pre and Post Processing 1. Data
Chapter XII: Data Pre and Post Processing Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 XII.1 4-1 Chapter XII: Data Pre and Post Processing 1. Data
Statistical Learning. Dong Liu. Dept. EEIS, USTC
 Statistical Learning Dong Liu Dept. EEIS, USTC Chapter 6. Unsupervised and Semi-Supervised Learning 1. Unsupervised learning 2. k-means 3. Gaussian mixture model 4. Other approaches to clustering 5. Principle
Statistical Learning Dong Liu Dept. EEIS, USTC Chapter 6. Unsupervised and Semi-Supervised Learning 1. Unsupervised learning 2. k-means 3. Gaussian mixture model 4. Other approaches to clustering 5. Principle
DATA MINING LECTURE 8. Dimensionality Reduction PCA -- SVD
 DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
DATA MINING LECTURE 8 Dimensionality Reduction PCA -- SVD The curse of dimensionality Real data usually have thousands, or millions of dimensions E.g., web documents, where the dimensionality is the vocabulary
EECS 275 Matrix Computation
 EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 6 1 / 22 Overview
EECS 275 Matrix Computation Ming-Hsuan Yang Electrical Engineering and Computer Science University of California at Merced Merced, CA 95344 http://faculty.ucmerced.edu/mhyang Lecture 6 1 / 22 Overview
1 Principal Components Analysis
 Lecture 3 and 4 Sept. 18 and Sept.20-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Principal Components Analysis Principal components analysis (PCA) is a very popular technique for
Lecture 3 and 4 Sept. 18 and Sept.20-2006 Data Visualization STAT 442 / 890, CM 462 Lecture: Ali Ghodsi 1 Principal Components Analysis Principal components analysis (PCA) is a very popular technique for
Dimensionality Reduction: A Comparative Review
 Tilburg centre for Creative Computing P.O. Box 90153 Tilburg University 5000 LE Tilburg, The Netherlands http://www.uvt.nl/ticc Email: ticc@uvt.nl Copyright c Laurens van der Maaten, Eric Postma, and Jaap
Tilburg centre for Creative Computing P.O. Box 90153 Tilburg University 5000 LE Tilburg, The Netherlands http://www.uvt.nl/ticc Email: ticc@uvt.nl Copyright c Laurens van der Maaten, Eric Postma, and Jaap
Large-Scale Manifold Learning
 Large-Scale Manifold Learning Ameet Talwalkar Courant Institute New York, NY ameet@cs.nyu.edu Sanjiv Kumar Google Research New York, NY sanjivk@google.com Henry Rowley Google Research Mountain View, CA
Large-Scale Manifold Learning Ameet Talwalkar Courant Institute New York, NY ameet@cs.nyu.edu Sanjiv Kumar Google Research New York, NY sanjivk@google.com Henry Rowley Google Research Mountain View, CA
Spectral Dimensionality Reduction
 Spectral Dimensionality Reduction Yoshua Bengio, Olivier Delalleau, Nicolas Le Roux Jean-François Paiement, Pascal Vincent, and Marie Ouimet Département d Informatique et Recherche Opérationnelle Centre
Spectral Dimensionality Reduction Yoshua Bengio, Olivier Delalleau, Nicolas Le Roux Jean-François Paiement, Pascal Vincent, and Marie Ouimet Département d Informatique et Recherche Opérationnelle Centre
Dimensionality Reduction and Principal Components
 Dimensionality Reduction and Principal Components Nuno Vasconcelos (Ken Kreutz-Delgado) UCSD Motivation Recall, in Bayesian decision theory we have: World: States Y in {1,..., M} and observations of X
Dimensionality Reduction and Principal Components Nuno Vasconcelos (Ken Kreutz-Delgado) UCSD Motivation Recall, in Bayesian decision theory we have: World: States Y in {1,..., M} and observations of X
Discriminative K-means for Clustering
 Discriminative K-means for Clustering Jieping Ye Arizona State University Tempe, AZ 85287 jieping.ye@asu.edu Zheng Zhao Arizona State University Tempe, AZ 85287 zhaozheng@asu.edu Mingrui Wu MPI for Biological
Discriminative K-means for Clustering Jieping Ye Arizona State University Tempe, AZ 85287 jieping.ye@asu.edu Zheng Zhao Arizona State University Tempe, AZ 85287 zhaozheng@asu.edu Mingrui Wu MPI for Biological
CS168: The Modern Algorithmic Toolbox Lecture #7: Understanding Principal Component Analysis (PCA)
") CS68: The Modern Algorithmic Toolbox Lecture #7: Understanding Principal Component Analysis (PCA) Tim Roughgarden & Gregory Valiant April 0, 05 Introduction. Lecture Goal Principal components analysis
CS68: The Modern Algorithmic Toolbox Lecture #7: Understanding Principal Component Analysis (PCA) Tim Roughgarden & Gregory Valiant April 0, 05 Introduction. Lecture Goal Principal components analysis
Metric Learning on Manifolds
 Journal of Machine Learning Research 0 (2011) 0-00 Submitted 0/00; Published 00/00 Metric Learning on Manifolds Dominique Perrault-Joncas Department of Statistics University of Washington Seattle, WA 98195-4322,
Journal of Machine Learning Research 0 (2011) 0-00 Submitted 0/00; Published 00/00 Metric Learning on Manifolds Dominique Perrault-Joncas Department of Statistics University of Washington Seattle, WA 98195-4322,
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015
 ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
ROBERTO BATTITI, MAURO BRUNATO. The LION Way: Machine Learning plus Intelligent Optimization. LIONlab, University of Trento, Italy, Apr 2015 http://intelligentoptimization.org/lionbook Roberto Battiti
Dimension reduction methods: Algorithms and Applications Yousef Saad Department of Computer Science and Engineering University of Minnesota
 Dimension reduction methods: Algorithms and Applications Yousef Saad Department of Computer Science and Engineering University of Minnesota Université du Littoral- Calais July 11, 16 First..... to the
Dimension reduction methods: Algorithms and Applications Yousef Saad Department of Computer Science and Engineering University of Minnesota Université du Littoral- Calais July 11, 16 First..... to the
Bi-stochastic kernels via asymmetric affinity functions
 Bi-stochastic kernels via asymmetric affinity functions Ronald R. Coifman, Matthew J. Hirn Yale University Department of Mathematics P.O. Box 208283 New Haven, Connecticut 06520-8283 USA ariv:1209.0237v4
Bi-stochastic kernels via asymmetric affinity functions Ronald R. Coifman, Matthew J. Hirn Yale University Department of Mathematics P.O. Box 208283 New Haven, Connecticut 06520-8283 USA ariv:1209.0237v4
Methods for sparse analysis of high-dimensional data, II
 Methods for sparse analysis of high-dimensional data, II Rachel Ward May 26, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 55 High dimensional
Methods for sparse analysis of high-dimensional data, II Rachel Ward May 26, 2011 High dimensional data with low-dimensional structure 300 by 300 pixel images = 90, 000 dimensions 2 / 55 High dimensional
Machine Learning. CUNY Graduate Center, Spring Lectures 11-12: Unsupervised Learning 1. Professor Liang Huang.
 Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Machine Learning CUNY Graduate Center, Spring 2013 Lectures 11-12: Unsupervised Learning 1 (Clustering: k-means, EM, mixture models) Professor Liang Huang huang@cs.qc.cuny.edu http://acl.cs.qc.edu/~lhuang/teaching/machine-learning
Is Manifold Learning for Toy Data only?
 s Manifold Learning for Toy Data only? Marina Meilă University of Washington mmp@stat.washington.edu MMDS Workshop 2016 Outline What is non-linear dimension reduction? Metric Manifold Learning Estimating
s Manifold Learning for Toy Data only? Marina Meilă University of Washington mmp@stat.washington.edu MMDS Workshop 2016 Outline What is non-linear dimension reduction? Metric Manifold Learning Estimating
Chap.11 Nonlinear principal component analysis [Book, Chap. 10]
![Chap.11 Nonlinear principal component analysis [Book, Chap. 10]](/thumbs/84/91178120.jpg "Chap.11 Nonlinear principal component analysis [Book, Chap. 10]") Chap.11 Nonlinear principal component analysis [Book, Chap. 1] We have seen machine learning methods nonlinearly generalizing the linear regression method. Now we will examine ways to nonlinearly generalize
Chap.11 Nonlinear principal component analysis [Book, Chap. 1] We have seen machine learning methods nonlinearly generalizing the linear regression method. Now we will examine ways to nonlinearly generalize
Diffusion Wavelets and Applications
 Diffusion Wavelets and Applications J.C. Bremer, R.R. Coifman, P.W. Jones, S. Lafon, M. Mohlenkamp, MM, R. Schul, A.D. Szlam Demos, web pages and preprints available at: S.Lafon: www.math.yale.edu/~sl349
Diffusion Wavelets and Applications J.C. Bremer, R.R. Coifman, P.W. Jones, S. Lafon, M. Mohlenkamp, MM, R. Schul, A.D. Szlam Demos, web pages and preprints available at: S.Lafon: www.math.yale.edu/~sl349
EM Algorithm & High Dimensional Data
 EM Algorithm & High Dimensional Data Nuno Vasconcelos (Ken Kreutz-Delgado) UCSD Gaussian EM Algorithm For the Gaussian mixture model, we have Expectation Step (E-Step): Maximization Step (M-Step): 2 EM
EM Algorithm & High Dimensional Data Nuno Vasconcelos (Ken Kreutz-Delgado) UCSD Gaussian EM Algorithm For the Gaussian mixture model, we have Expectation Step (E-Step): Maximization Step (M-Step): 2 EM
Dimensionality Reduction: A Comparative Review
 Dimensionality Reduction: A Comparative Review L.J.P. van der Maaten, E.O. Postma, H.J. van den Herik MICC, Maastricht University, P.O. Box 616, 6200 MD Maastricht, The Netherlands. Abstract In recent
Dimensionality Reduction: A Comparative Review L.J.P. van der Maaten, E.O. Postma, H.J. van den Herik MICC, Maastricht University, P.O. Box 616, 6200 MD Maastricht, The Netherlands. Abstract In recent
PCA, Kernel PCA, ICA
 PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
PCA, Kernel PCA, ICA Learning Representations. Dimensionality Reduction. Maria-Florina Balcan 04/08/2015 Big & High-Dimensional Data High-Dimensions = Lot of Features Document classification Features per
A SEMI-SUPERVISED METRIC LEARNING FOR CONTENT-BASED IMAGE RETRIEVAL. {dimane,
 A SEMI-SUPERVISED METRIC LEARNING FOR CONTENT-BASED IMAGE RETRIEVAL I. Daoudi,, K. Idrissi, S. Ouatik 3 Université de Lyon, CNRS, INSA-Lyon, LIRIS, UMR505, F-696, France Faculté Des Sciences, UFR IT, Université
A SEMI-SUPERVISED METRIC LEARNING FOR CONTENT-BASED IMAGE RETRIEVAL I. Daoudi,, K. Idrissi, S. Ouatik 3 Université de Lyon, CNRS, INSA-Lyon, LIRIS, UMR505, F-696, France Faculté Des Sciences, UFR IT, Université
Principal Component Analysis
 Principal Component Analysis November 24, 2015 From data to operators Given is data set X consisting of N vectors x n R D. Without loss of generality, assume x n = 0 (subtract mean). Let P be D N matrix
Principal Component Analysis November 24, 2015 From data to operators Given is data set X consisting of N vectors x n R D. Without loss of generality, assume x n = 0 (subtract mean). Let P be D N matrix