Modelling Non-homogeneous Markov Processes via Time Transformation
|
|
|
- Peregrine Gibson
- 5 years ago
- Views:
Transcription
1 Modelling Non-homogeneous Markov Processes via Time Transformation Biostat 572 Jon Fintzi
2 Structure of the Talk Recap and motivation Derivation of estimation procedure Simulating data Ongoing/next steps

3 Motivation - Scientic Objectives Scientic Goal: Describe a disease process in terms of its transitions through discrete states. Progressive disease: subjects traverse disease states in one direction. Stages of HIV infection Non-progressive disease: subjects may visit some or all states repeatedly, just once, or not at all. Delirium
4 Motivation - Methodological Objectives Goal:Obtain estimates and covariance matrices for transition intensity parameters in non-homogeneous Markov process models. Problem #1 - Panel Data: Subjects are observed at a sequence of discrete times, observations consist of the states occupied by the subjects at those times. The exact transition times are not observed. The complete sequence of states visited by a subject may not be known.
5 Motivation - Methodological Objectives
6 Motivation - Methodological Objectives
7 Motivation - Methodological Objectives Problem #1 - Panel Data: Solution by Kalbeisch & Lawless Estimation of transition parameters for homogeneous Markov processes via maximum likelihood. A process is Markov if the future state of the process depends only on its current state. i.e. P (X (t + s) = j X (t) = i, X (u) = x(u), 0 u < s) = P (X (t + s) = j X (t) = i) = p ij (t, t+s) A process is homogeneous if the transition probabilities do not depend on the chronological time t. i.e. p ij (t, t + s) = p ij (s) Fisher scoring algorithm based on expectations of rst order derivatives of the log-likelihood provides parameter and variance estimates.
8 Motivation - Methodological Objectives Problem #2 -Non-homogeneity in the Markov Process If the process is non-homogeneous, p ij (t, t + s) p ij (s), so we must estimate a new transition probability matrix for every t. Contribution of this paper: If all of the non-homogeneity in the process is purely due to a time-varying multiplicative change in the transition intensities, we may use the results by Kalbeisch and Lawless with minor adjustments.
9 Key Proposition: Time Transformation Let u denote the original time scale of the observations. If there exists an invertible transformation of the time scale such that the process is homogeneous on t=h(u), with transition intensity matrix Q 0, then P(u 1, u 2 ) = P(h(u 1 ), h(u 2 )) = P(t 2 t 1 ) = exp[q 0 (t 2 t 1 )] = exp[q 0 (h(u 2 ) h(u 1 ))]
10 Key Proposition: Time Transformation Kalbeisch and Lawless suggested that nonhomogeneity arising from a transformation of the time scale could be accounted for using exp(q u2 0 u 1 g(s)ds) An advantage of the method in my paper is that it does not require that the time transformation be integrable. t = h(u) is a time scale, so we require h(u) 0 and h(u) u 0. Examples of time transformations Exponential: t = h(u; θ) = uθ u Nonparameteric: Knots at u k, k = 1,..., d t = h(u) = uθ(u) θ(u) = c(u) = d { ( )} 1 u uk c(u)θ k k=1 γ K γ d ( ) 1 u uk 1 k=1 γ K γ
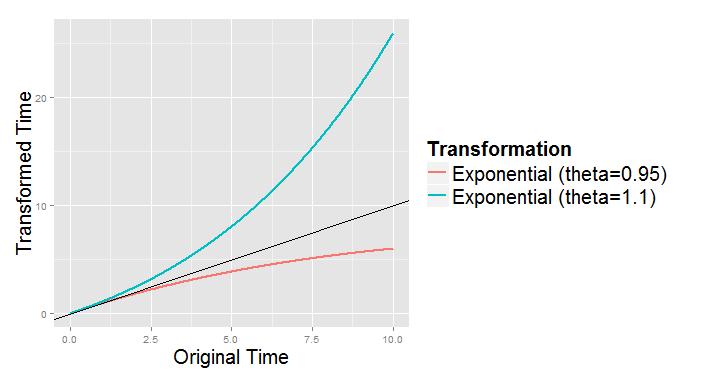
11
12 Maximum Likelihood Estimation Maximum likelihood estimation for a nonhomogeneous Markov process via time transformation proceeds exactly as in Kalbeisch and Lawless. The likelihood for X = (X (u 1 ),..., X (u n )) T is: L(Q 0 ) = P(X (u 1 ) = x 1 ) n p xi 1,x i (u i 1, u i ) i=2 Since the transformed process is homogeneous, we have L(Q 0, θ) = P(X (u 1 ) = x 1 ) = P(X (u 1 ) = x 1 ) n p xi 1,x i (h(u i ; θ) h(u i 1 ; θ)) i=2 n i=2 [ e Q 0(h(u i ;θ) h(u i 1 ;θ)) ] x i 1 x i
13 Seminal Paper: Kalbeish & Lawless (1985) The scoring method proposed in Kalbeisch and Lawless, and implemented in Hubbard et al., uses the expected information matrix. This simplies the algorithm by only requiring use of the rst-order derivatives of the likelihood. Assume independence across subjects. Letting ψ be the vector of functionally independent elements of Q 0 and θ, we have that the MLEs are the solutions to ψ logl m(ψ) = 0 and ˆψ N (0, Im 1 (ψ 0 )), where I m = E [ ( ) ( ) ] T ψ logl m(ψ) ψ logl m(ψ) Given initial estimates ψ ( 0), the (k + 1) st step for the MLEs is ˆψ (k+1) = ˆψ (k) + Î m ( ˆψ (k) ) 1 ψ logl m(ψ)
14 Derivation of rst-order derivatives We require partial derivatives of P(u j 1, u j ) with respect to ψ u when ψ u is a transition intensity parameter in Q 0 and when ψ u is a parameter of the time transformation. Let A( be the matrix of eigenvectors of Q 0, and let D = e λ 1(h(u j ) h(u j 1 )),..., e λ s(h(u j ) h(u j 1 )) ), where λ 1,..., λ s are eigenvalues of Q 0. Let G u = A 1 Q 0 ψ u A, and let g (u) ij be the (i, j) entry of G u. Let h(u) = (h(u j ) h(u j 1 ))
15 Derivation of rst-order derivatives First, when ψ u Q 0, ψ u P(u j 1, u j ) = = = = ψ u e [Q 0 h(u)] Q0 s h(u) s ψ u s=1 s! Q0 s s h(u) s=1 ψ u s! s 1 s=1 l=0 s 1 = s=1 l=0 s 1 = A s=1 l=0 = AV ua 1 Q0 l Q 0 ψ u Q0 s s 1 l h(u) s! AD l A 1 Q 0 ψ u AD s 1 l A D l A 1 Q 0 ψ u AD s 1 h(u) s! s s 1 l h(u) A 1 s!
16 Derivation of rst-order derivatives where V u is an s s matrix with (i, j) element g (u) ii g (u) s 1 λ s 1 l ij i λ l h(u) s j s=1 l=0 s! s 1 [ h(uj ) h(u j 1 ) ] s=1 l=0 λ s 1 i s! [ ] [ ] = g (u) e λ i h(u j ) h(u j 1 ) e λ j h(u j ) h(u j 1 ) ij λ i λ j = g (u) [ h(uj ) h(u ii j 1 ) ] [ ] e λ i h(u j ) h(u j 1 ), i j, i = j
17 Derivation of rst-order derivatives When ψ u θ, ψ u P(u j 1, u j ) = = = e [Q 0 h(u)] ψ ( u h(uj ) ψ u ( h(uj ) ψ u h(u j 1) ψ u h(u j 1) ψ u ) Q 0 e [Q 0 h(u)] ) Q 0 P(u j 1, u j )
18 Derivation of the score function The u th element of the score function is given by l (m) u (Q0; θ) = = n m i ψ u i=1 j=2 { [ ]} log p xi,j 1 x ij h(u) m n i 1 p xi,j 1 x i=1 j=2 p xi,j 1 x ij h(u) ψ ij h(u) u
19 Derivation of the expected information matrix The (u, v) th element of the expected information matrix for one subject is given by ( ) 2 I uv (ψ) = E l(ψ) ψ uψ v n i 1 2 = E p xi,j 1 x j=2 p xi,j 1 x ij h(u) ψ ij h(u) uψ v 1 E (p xi,j 1 x ij h(u)) 2 p xi,j 1 x ψ ij h(u) p xi,j 1 x u ψ ij h(u) v
20 Derivation of the expected information matrix If we restrict ourselves to time transformation functions h(h) with second derivatives that are bounded by an integrable function, then we can exchange integration and dierentiation in the rst term in the summand. The (u, v) th element of the expected information matrix reduces to n i 1 I uv (ψ) = E j=2 (p xi,j 1 x ij h(u)) 2 p xi,j 1 x ψ ij h(u) p xi,j 1 x u ψ ij h(u) v We can estimate this by n Î uv ( ˆψ) m i 1 = E i=1 j=2 (p xi,j 1 x ij h(u)) 2 p xi,j 1 x ψ ij h(u) p xi,j 1 x u ψ ij h(u) v
21 We now have derived everything we need in order to do the estimation. Large sample properties of the estimates can be derived using standard asymptotic theory (Billingsley, 1961; Albert, 1962; Bladt and Sorensen, 2005). We can derive many other quantities from what we have shown above Asymptotic distribution of transition probabilities Mean sojourn times in each state and their variances Steady state distribution (for an ergodic process)
22 Data Simulation Procedure The o diagonal elements of Q are like the intensity parameters of independent Poisson processes from state i to state j, while diagonal elements are like the negated intensity of arrival to any non-diagonal state. We can simulate the path for homogeneous process from a given transition intensity matrix by generating transition times, then randomly selecting the new state conditional on a move. Incorporating non-homogeneity and the panel structure of observations is trivial once the path has been simulated.
23 Data Simulation Procedure We simulate data that is homogeneous on a transformed time scale as follows: 1 On the original time scale, simulate i.i.d. Unif (0.2, 1) inter-observation times. Cumulative summation gives the raw observation times. 2 Transform the observation times. This gives observation times in the operational time scale on which the process is homogeneous. 3 Simulate a path from the transition intensity matrix. Record sequence of states and transition times.
24 Data Simulation Procedure
25 Data Simulation Procedure Simulating a path proceeds as follows: 1 Given state i at time t = 0, draw u Unif (0, 1). The sojourn time in state i is given by t = log(u) q ii exp( mean = 1 q i i ) 2 Conditioned on exiting state i, the probability of moving to state j is p ij =. We then partition the interval [0, 1] q ij j i q ij into the lengths p ij for j i, and draw v Unif (0, 1). The interval into which v falls gives it's next state. 3 If the new state is an absorbing state (death), or if the transition data is greater than the termination date of the period of observation, the path is terminated. Otherwise, the state is recorded under the next time in the panel observation, we increment the time, then proceed.
26 In Progress... Currently working on debugging code. Once method is working, select implementation for competing methods. I was hopeful that I would have simulation results for this talk. Suggestions? More theory? Justication for asymptotic results? More comparison vs. other methods?
Recap. Probability, stochastic processes, Markov chains. ELEC-C7210 Modeling and analysis of communication networks
 Recap Probability, stochastic processes, Markov chains ELEC-C7210 Modeling and analysis of communication networks 1 Recap: Probability theory important distributions Discrete distributions Geometric distribution
Recap Probability, stochastic processes, Markov chains ELEC-C7210 Modeling and analysis of communication networks 1 Recap: Probability theory important distributions Discrete distributions Geometric distribution
LTCC. Exercises. (1) Two possible weather conditions on any day: {rainy, sunny} (2) Tomorrow s weather depends only on today s weather
 Two possible weather conditions on any day: {rainy, sunny} (2) Tomorrow s weather depends only on today s weather") 1. Markov chain LTCC. Exercises Let X 0, X 1, X 2,... be a Markov chain with state space {1, 2, 3, 4} and transition matrix 1/2 1/2 0 0 P = 0 1/2 1/3 1/6. 0 0 0 1 (a) What happens if the chain starts in
1. Markov chain LTCC. Exercises Let X 0, X 1, X 2,... be a Markov chain with state space {1, 2, 3, 4} and transition matrix 1/2 1/2 0 0 P = 0 1/2 1/3 1/6. 0 0 0 1 (a) What happens if the chain starts in
Markov processes and queueing networks
 Inria September 22, 2015 Outline Poisson processes Markov jump processes Some queueing networks The Poisson distribution (Siméon-Denis Poisson, 1781-1840) { } e λ λ n n! As prevalent as Gaussian distribution
Inria September 22, 2015 Outline Poisson processes Markov jump processes Some queueing networks The Poisson distribution (Siméon-Denis Poisson, 1781-1840) { } e λ λ n n! As prevalent as Gaussian distribution
Statistics & Data Sciences: First Year Prelim Exam May 2018
 Statistics & Data Sciences: First Year Prelim Exam May 2018 Instructions: 1. Do not turn this page until instructed to do so. 2. Start each new question on a new sheet of paper. 3. This is a closed book
Statistics & Data Sciences: First Year Prelim Exam May 2018 Instructions: 1. Do not turn this page until instructed to do so. 2. Start each new question on a new sheet of paper. 3. This is a closed book
Chapter 3: Markov Processes First hitting times
 Chapter 3: Markov Processes First hitting times L. Breuer University of Kent, UK November 3, 2010 Example: M/M/c/c queue Arrivals: Poisson process with rate λ > 0 Example: M/M/c/c queue Arrivals: Poisson
Chapter 3: Markov Processes First hitting times L. Breuer University of Kent, UK November 3, 2010 Example: M/M/c/c queue Arrivals: Poisson process with rate λ > 0 Example: M/M/c/c queue Arrivals: Poisson
Chapter 1. Vectors, Matrices, and Linear Spaces
 1.7 Applications to Population Distributions 1 Chapter 1. Vectors, Matrices, and Linear Spaces 1.7. Applications to Population Distributions Note. In this section we break a population into states and
1.7 Applications to Population Distributions 1 Chapter 1. Vectors, Matrices, and Linear Spaces 1.7. Applications to Population Distributions Note. In this section we break a population into states and
1. The Polar Decomposition
 A PERSONAL INTERVIEW WITH THE SINGULAR VALUE DECOMPOSITION MATAN GAVISH Part. Theory. The Polar Decomposition In what follows, F denotes either R or C. The vector space F n is an inner product space with
A PERSONAL INTERVIEW WITH THE SINGULAR VALUE DECOMPOSITION MATAN GAVISH Part. Theory. The Polar Decomposition In what follows, F denotes either R or C. The vector space F n is an inner product space with
9.1 Orthogonal factor model.
 36 Chapter 9 Factor Analysis Factor analysis may be viewed as a refinement of the principal component analysis The objective is, like the PC analysis, to describe the relevant variables in study in terms
36 Chapter 9 Factor Analysis Factor analysis may be viewed as a refinement of the principal component analysis The objective is, like the PC analysis, to describe the relevant variables in study in terms
Master s Written Examination - Solution
 Master s Written Examination - Solution Spring 204 Problem Stat 40 Suppose X and X 2 have the joint pdf f X,X 2 (x, x 2 ) = 2e (x +x 2 ), 0 < x < x 2
Master s Written Examination - Solution Spring 204 Problem Stat 40 Suppose X and X 2 have the joint pdf f X,X 2 (x, x 2 ) = 2e (x +x 2 ), 0 < x < x 2
10708 Graphical Models: Homework 2
 10708 Graphical Models: Homework 2 Due Monday, March 18, beginning of class Feburary 27, 2013 Instructions: There are five questions (one for extra credit) on this assignment. There is a problem involves
10708 Graphical Models: Homework 2 Due Monday, March 18, beginning of class Feburary 27, 2013 Instructions: There are five questions (one for extra credit) on this assignment. There is a problem involves
Master s Written Examination
 Master s Written Examination Option: Statistics and Probability Spring 05 Full points may be obtained for correct answers to eight questions Each numbered question (which may have several parts) is worth
Master s Written Examination Option: Statistics and Probability Spring 05 Full points may be obtained for correct answers to eight questions Each numbered question (which may have several parts) is worth
Introduction to cthmm (Continuous-time hidden Markov models) package
 package") Introduction to cthmm (Continuous-time hidden Markov models) package Abstract A disease process refers to a patient s traversal over time through a disease with multiple discrete states. Multistate models
Introduction to cthmm (Continuous-time hidden Markov models) package Abstract A disease process refers to a patient s traversal over time through a disease with multiple discrete states. Multistate models
Graduate Econometrics I: Maximum Likelihood II
 Graduate Econometrics I: Maximum Likelihood II Yves Dominicy Université libre de Bruxelles Solvay Brussels School of Economics and Management ECARES Yves Dominicy Graduate Econometrics I: Maximum Likelihood
Graduate Econometrics I: Maximum Likelihood II Yves Dominicy Université libre de Bruxelles Solvay Brussels School of Economics and Management ECARES Yves Dominicy Graduate Econometrics I: Maximum Likelihood
Chapter 4: Factor Analysis
 Chapter 4: Factor Analysis In many studies, we may not be able to measure directly the variables of interest. We can merely collect data on other variables which may be related to the variables of interest.
Chapter 4: Factor Analysis In many studies, we may not be able to measure directly the variables of interest. We can merely collect data on other variables which may be related to the variables of interest.
Probability reminders
 CS246 Winter 204 Mining Massive Data Sets Probability reminders Sammy El Ghazzal selghazz@stanfordedu Disclaimer These notes may contain typos, mistakes or confusing points Please contact the author so
CS246 Winter 204 Mining Massive Data Sets Probability reminders Sammy El Ghazzal selghazz@stanfordedu Disclaimer These notes may contain typos, mistakes or confusing points Please contact the author so
Accurate directional inference for vector parameters
 Accurate directional inference for vector parameters Nancy Reid February 26, 2016 with Don Fraser, Nicola Sartori, Anthony Davison Nancy Reid Accurate directional inference for vector parameters York University
Accurate directional inference for vector parameters Nancy Reid February 26, 2016 with Don Fraser, Nicola Sartori, Anthony Davison Nancy Reid Accurate directional inference for vector parameters York University
An Overview of Methods for Applying Semi-Markov Processes in Biostatistics.
 An Overview of Methods for Applying Semi-Markov Processes in Biostatistics. Charles J. Mode Department of Mathematics and Computer Science Drexel University Philadelphia, PA 19104 Overview of Topics. I.
An Overview of Methods for Applying Semi-Markov Processes in Biostatistics. Charles J. Mode Department of Mathematics and Computer Science Drexel University Philadelphia, PA 19104 Overview of Topics. I.
Irreducibility. Irreducible. every state can be reached from every other state For any i,j, exist an m 0, such that. Absorbing state: p jj =1
 Irreducibility Irreducible every state can be reached from every other state For any i,j, exist an m 0, such that i,j are communicate, if the above condition is valid Irreducible: all states are communicate
Irreducibility Irreducible every state can be reached from every other state For any i,j, exist an m 0, such that i,j are communicate, if the above condition is valid Irreducible: all states are communicate
Accurate directional inference for vector parameters
 Accurate directional inference for vector parameters Nancy Reid October 28, 2016 with Don Fraser, Nicola Sartori, Anthony Davison Parametric models and likelihood model f (y; θ), θ R p data y = (y 1,...,
Accurate directional inference for vector parameters Nancy Reid October 28, 2016 with Don Fraser, Nicola Sartori, Anthony Davison Parametric models and likelihood model f (y; θ), θ R p data y = (y 1,...,
Multi-state Models: An Overview
 Multi-state Models: An Overview Andrew Titman Lancaster University 14 April 2016 Overview Introduction to multi-state modelling Examples of applications Continuously observed processes Intermittently observed
Multi-state Models: An Overview Andrew Titman Lancaster University 14 April 2016 Overview Introduction to multi-state modelling Examples of applications Continuously observed processes Intermittently observed
ABC methods for phase-type distributions with applications in insurance risk problems
 ABC methods for phase-type with applications problems Concepcion Ausin, Department of Statistics, Universidad Carlos III de Madrid Joint work with: Pedro Galeano, Universidad Carlos III de Madrid Simon
ABC methods for phase-type with applications problems Concepcion Ausin, Department of Statistics, Universidad Carlos III de Madrid Joint work with: Pedro Galeano, Universidad Carlos III de Madrid Simon
The Transition Probability Function P ij (t)
") The Transition Probability Function P ij (t) Consider a continuous time Markov chain {X(t), t 0}. We are interested in the probability that in t time units the process will be in state j, given that it
The Transition Probability Function P ij (t) Consider a continuous time Markov chain {X(t), t 0}. We are interested in the probability that in t time units the process will be in state j, given that it
simple if it completely specifies the density of x
 3. Hypothesis Testing Pure significance tests Data x = (x 1,..., x n ) from f(x, θ) Hypothesis H 0 : restricts f(x, θ) Are the data consistent with H 0? H 0 is called the null hypothesis simple if it completely
3. Hypothesis Testing Pure significance tests Data x = (x 1,..., x n ) from f(x, θ) Hypothesis H 0 : restricts f(x, θ) Are the data consistent with H 0? H 0 is called the null hypothesis simple if it completely
EIGENVALUES AND EIGENVECTORS 3
 EIGENVALUES AND EIGENVECTORS 3 1. Motivation 1.1. Diagonal matrices. Perhaps the simplest type of linear transformations are those whose matrix is diagonal (in some basis). Consider for example the matrices
EIGENVALUES AND EIGENVECTORS 3 1. Motivation 1.1. Diagonal matrices. Perhaps the simplest type of linear transformations are those whose matrix is diagonal (in some basis). Consider for example the matrices
CS281 Section 4: Factor Analysis and PCA
 CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
CS81 Section 4: Factor Analysis and PCA Scott Linderman At this point we have seen a variety of machine learning models, with a particular emphasis on models for supervised learning. In particular, we
Maximum Likelihood Estimation
 Connexions module: m11446 1 Maximum Likelihood Estimation Clayton Scott Robert Nowak This work is produced by The Connexions Project and licensed under the Creative Commons Attribution License Abstract
Connexions module: m11446 1 Maximum Likelihood Estimation Clayton Scott Robert Nowak This work is produced by The Connexions Project and licensed under the Creative Commons Attribution License Abstract
Math 3191 Applied Linear Algebra
 Math 9 Applied Linear Algebra Lecture 9: Diagonalization Stephen Billups University of Colorado at Denver Math 9Applied Linear Algebra p./9 Section. Diagonalization The goal here is to develop a useful
Math 9 Applied Linear Algebra Lecture 9: Diagonalization Stephen Billups University of Colorado at Denver Math 9Applied Linear Algebra p./9 Section. Diagonalization The goal here is to develop a useful
Homework For each of the following matrices, find the minimal polynomial and determine whether the matrix is diagonalizable.
 Math 5327 Fall 2018 Homework 7 1. For each of the following matrices, find the minimal polynomial and determine whether the matrix is diagonalizable. 3 1 0 (a) A = 1 2 0 1 1 0 x 3 1 0 Solution: 1 x 2 0
Math 5327 Fall 2018 Homework 7 1. For each of the following matrices, find the minimal polynomial and determine whether the matrix is diagonalizable. 3 1 0 (a) A = 1 2 0 1 1 0 x 3 1 0 Solution: 1 x 2 0
Previously Monte Carlo Integration
 Previously Simulation, sampling Monte Carlo Simulations Inverse cdf method Rejection sampling Today: sampling cont., Bayesian inference via sampling Eigenvalues and Eigenvectors Markov processes, PageRank
Previously Simulation, sampling Monte Carlo Simulations Inverse cdf method Rejection sampling Today: sampling cont., Bayesian inference via sampling Eigenvalues and Eigenvectors Markov processes, PageRank
Computational statistics
 Computational statistics Markov Chain Monte Carlo methods Thierry Denœux March 2017 Thierry Denœux Computational statistics March 2017 1 / 71 Contents of this chapter When a target density f can be evaluated
Computational statistics Markov Chain Monte Carlo methods Thierry Denœux March 2017 Thierry Denœux Computational statistics March 2017 1 / 71 Contents of this chapter When a target density f can be evaluated
Markov Reliability and Availability Analysis. Markov Processes
 Markov Reliability and Availability Analysis Firma convenzione Politecnico Part II: Continuous di Milano e Time Veneranda Discrete Fabbrica State del Duomo di Milano Markov Processes Aula Magna Rettorato
Markov Reliability and Availability Analysis Firma convenzione Politecnico Part II: Continuous di Milano e Time Veneranda Discrete Fabbrica State del Duomo di Milano Markov Processes Aula Magna Rettorato
TAMS39 Lecture 10 Principal Component Analysis Factor Analysis
 TAMS39 Lecture 10 Principal Component Analysis Factor Analysis Martin Singull Department of Mathematics Mathematical Statistics Linköping University, Sweden Content - Lecture Principal component analysis
TAMS39 Lecture 10 Principal Component Analysis Factor Analysis Martin Singull Department of Mathematics Mathematical Statistics Linköping University, Sweden Content - Lecture Principal component analysis
Modelling of Dependent Credit Rating Transitions
 ling of (Joint work with Uwe Schmock) Financial and Actuarial Mathematics Vienna University of Technology Wien, 15.07.2010 Introduction Motivation: Volcano on Iceland erupted and caused that most of the
ling of (Joint work with Uwe Schmock) Financial and Actuarial Mathematics Vienna University of Technology Wien, 15.07.2010 Introduction Motivation: Volcano on Iceland erupted and caused that most of the
Stochastic Modelling Unit 1: Markov chain models
 Stochastic Modelling Unit 1: Markov chain models Russell Gerrard and Douglas Wright Cass Business School, City University, London June 2004 Contents of Unit 1 1 Stochastic Processes 2 Markov Chains 3 Poisson
Stochastic Modelling Unit 1: Markov chain models Russell Gerrard and Douglas Wright Cass Business School, City University, London June 2004 Contents of Unit 1 1 Stochastic Processes 2 Markov Chains 3 Poisson
Master s Written Examination
 Master s Written Examination Option: Statistics and Probability Spring 016 Full points may be obtained for correct answers to eight questions. Each numbered question which may have several parts is worth
Master s Written Examination Option: Statistics and Probability Spring 016 Full points may be obtained for correct answers to eight questions. Each numbered question which may have several parts is worth
Review. DS GA 1002 Statistical and Mathematical Models. Carlos Fernandez-Granda
 Review DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall16 Carlos Fernandez-Granda Probability and statistics Probability: Framework for dealing with
Review DS GA 1002 Statistical and Mathematical Models http://www.cims.nyu.edu/~cfgranda/pages/dsga1002_fall16 Carlos Fernandez-Granda Probability and statistics Probability: Framework for dealing with
Estimation of arrival and service rates for M/M/c queue system
 Estimation of arrival and service rates for M/M/c queue system Katarína Starinská starinskak@gmail.com Charles University Faculty of Mathematics and Physics Department of Probability and Mathematical Statistics
Estimation of arrival and service rates for M/M/c queue system Katarína Starinská starinskak@gmail.com Charles University Faculty of Mathematics and Physics Department of Probability and Mathematical Statistics
Chapter 4: Asymptotic Properties of the MLE (Part 2)
") Chapter 4: Asymptotic Properties of the MLE (Part 2) Daniel O. Scharfstein 09/24/13 1 / 1 Example Let {(R i, X i ) : i = 1,..., n} be an i.i.d. sample of n random vectors (R, X ). Here R is a response
Chapter 4: Asymptotic Properties of the MLE (Part 2) Daniel O. Scharfstein 09/24/13 1 / 1 Example Let {(R i, X i ) : i = 1,..., n} be an i.i.d. sample of n random vectors (R, X ). Here R is a response
Statistics 150: Spring 2007
 Statistics 150: Spring 2007 April 23, 2008 0-1 1 Limiting Probabilities If the discrete-time Markov chain with transition probabilities p ij is irreducible and positive recurrent; then the limiting probabilities
Statistics 150: Spring 2007 April 23, 2008 0-1 1 Limiting Probabilities If the discrete-time Markov chain with transition probabilities p ij is irreducible and positive recurrent; then the limiting probabilities
f(x θ)dx with respect to θ. Assuming certain smoothness conditions concern differentiating under the integral the integral sign, we first obtain
dx with respect to θ. Assuming certain smoothness conditions concern differentiating under the integral the integral sign, we first obtain") 0.1. INTRODUCTION 1 0.1 Introduction R. A. Fisher, a pioneer in the development of mathematical statistics, introduced a measure of the amount of information contained in an observaton from f(x θ). Fisher
0.1. INTRODUCTION 1 0.1 Introduction R. A. Fisher, a pioneer in the development of mathematical statistics, introduced a measure of the amount of information contained in an observaton from f(x θ). Fisher
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov
Introduction to Machine Learning CMU-10701 Markov Chain Monte Carlo Methods Barnabás Póczos & Aarti Singh Contents Markov Chain Monte Carlo Methods Goal & Motivation Sampling Rejection Importance Markov
Parametric and Non Homogeneous semi-markov Process for HIV Control
 Parametric and Non Homogeneous semi-markov Process for HIV Control Eve Mathieu 1, Yohann Foucher 1, Pierre Dellamonica 2, and Jean-Pierre Daures 1 1 Clinical Research University Institute. Biostatistics
Parametric and Non Homogeneous semi-markov Process for HIV Control Eve Mathieu 1, Yohann Foucher 1, Pierre Dellamonica 2, and Jean-Pierre Daures 1 1 Clinical Research University Institute. Biostatistics
Frailty Modeling for clustered survival data: a simulation study
 Frailty Modeling for clustered survival data: a simulation study IAA Oslo 2015 Souad ROMDHANE LaREMFiQ - IHEC University of Sousse (Tunisia) souad_romdhane@yahoo.fr Lotfi BELKACEM LaREMFiQ - IHEC University
Frailty Modeling for clustered survival data: a simulation study IAA Oslo 2015 Souad ROMDHANE LaREMFiQ - IHEC University of Sousse (Tunisia) souad_romdhane@yahoo.fr Lotfi BELKACEM LaREMFiQ - IHEC University
STOCHASTIC PROCESSES Basic notions
 J. Virtamo 38.3143 Queueing Theory / Stochastic processes 1 STOCHASTIC PROCESSES Basic notions Often the systems we consider evolve in time and we are interested in their dynamic behaviour, usually involving
J. Virtamo 38.3143 Queueing Theory / Stochastic processes 1 STOCHASTIC PROCESSES Basic notions Often the systems we consider evolve in time and we are interested in their dynamic behaviour, usually involving
LTCC. Exercises solutions
 1. Markov chain LTCC. Exercises solutions (a) Draw a state space diagram with the loops for the possible steps. If the chain starts in state 4, it must stay there. If the chain starts in state 1, it will
1. Markov chain LTCC. Exercises solutions (a) Draw a state space diagram with the loops for the possible steps. If the chain starts in state 4, it must stay there. If the chain starts in state 1, it will
EXAMINATIONS OF THE HONG KONG STATISTICAL SOCIETY
 EXAMINATIONS OF THE HONG KONG STATISTICAL SOCIETY HIGHER CERTIFICATE IN STATISTICS, 2013 MODULE 5 : Further probability and inference Time allowed: One and a half hours Candidates should answer THREE questions.
EXAMINATIONS OF THE HONG KONG STATISTICAL SOCIETY HIGHER CERTIFICATE IN STATISTICS, 2013 MODULE 5 : Further probability and inference Time allowed: One and a half hours Candidates should answer THREE questions.
QUEUING MODELS AND MARKOV PROCESSES
 QUEUING MODELS AND MARKOV ROCESSES Queues form when customer demand for a service cannot be met immediately. They occur because of fluctuations in demand levels so that models of queuing are intrinsically
QUEUING MODELS AND MARKOV ROCESSES Queues form when customer demand for a service cannot be met immediately. They occur because of fluctuations in demand levels so that models of queuing are intrinsically
Dr. Maddah ENMG 617 EM Statistics 10/15/12. Nonparametric Statistics (2) (Goodness of fit tests)
 (Goodness of fit tests)") Dr. Maddah ENMG 617 EM Statistics 10/15/12 Nonparametric Statistics (2) (Goodness of fit tests) Introduction Probability models used in decision making (Operations Research) and other fields require fitting
Dr. Maddah ENMG 617 EM Statistics 10/15/12 Nonparametric Statistics (2) (Goodness of fit tests) Introduction Probability models used in decision making (Operations Research) and other fields require fitting
7 Likelihood and Maximum Likelihood Estimation
 7 Likelihood and Maximum Likelihood Estimation Exercice 7.1. Let X be a random variable admitting the following probability density : x +1 I x 1 where > 0. It is in fact a particular Pareto law. Consider
7 Likelihood and Maximum Likelihood Estimation Exercice 7.1. Let X be a random variable admitting the following probability density : x +1 I x 1 where > 0. It is in fact a particular Pareto law. Consider
Cover Page. The handle holds various files of this Leiden University dissertation
 Cover Page The handle http://hdlhandlenet/1887/39637 holds various files of this Leiden University dissertation Author: Smit, Laurens Title: Steady-state analysis of large scale systems : the successive
Cover Page The handle http://hdlhandlenet/1887/39637 holds various files of this Leiden University dissertation Author: Smit, Laurens Title: Steady-state analysis of large scale systems : the successive
The SIS and SIR stochastic epidemic models revisited
 The SIS and SIR stochastic epidemic models revisited Jesús Artalejo Faculty of Mathematics, University Complutense of Madrid Madrid, Spain jesus_artalejomat.ucm.es BCAM Talk, June 16, 2011 Talk Schedule
The SIS and SIR stochastic epidemic models revisited Jesús Artalejo Faculty of Mathematics, University Complutense of Madrid Madrid, Spain jesus_artalejomat.ucm.es BCAM Talk, June 16, 2011 Talk Schedule
Lecture 7: Simulation of Markov Processes. Pasi Lassila Department of Communications and Networking
 Lecture 7: Simulation of Markov Processes Pasi Lassila Department of Communications and Networking Contents Markov processes theory recap Elementary queuing models for data networks Simulation of Markov
Lecture 7: Simulation of Markov Processes Pasi Lassila Department of Communications and Networking Contents Markov processes theory recap Elementary queuing models for data networks Simulation of Markov
Flat and multimodal likelihoods and model lack of fit in curved exponential families
 Mathematical Statistics Stockholm University Flat and multimodal likelihoods and model lack of fit in curved exponential families Rolf Sundberg Research Report 2009:1 ISSN 1650-0377 Postal address: Mathematical
Mathematical Statistics Stockholm University Flat and multimodal likelihoods and model lack of fit in curved exponential families Rolf Sundberg Research Report 2009:1 ISSN 1650-0377 Postal address: Mathematical
Stochastic process. X, a series of random variables indexed by t
 Stochastic process X, a series of random variables indexed by t X={X(t), t 0} is a continuous time stochastic process X={X(t), t=0,1, } is a discrete time stochastic process X(t) is the state at time t,
Stochastic process X, a series of random variables indexed by t X={X(t), t 0} is a continuous time stochastic process X={X(t), t=0,1, } is a discrete time stochastic process X(t) is the state at time t,
,..., θ(2),..., θ(n)
,..., θ(n)") Likelihoods for Multivariate Binary Data Log-Linear Model We have 2 n 1 distinct probabilities, but we wish to consider formulations that allow more parsimonious descriptions as a function of covariates.
Likelihoods for Multivariate Binary Data Log-Linear Model We have 2 n 1 distinct probabilities, but we wish to consider formulations that allow more parsimonious descriptions as a function of covariates.
Markov Chains. X(t) is a Markov Process if, for arbitrary times t 1 < t 2 <... < t k < t k+1. If X(t) is discrete-valued. If X(t) is continuous-valued
 is a Markov Process if, for arbitrary times t 1 < t 2 <... < t k < t k+1. If X(t) is discrete-valued. If X(t) is continuous-valued") Markov Chains X(t) is a Markov Process if, for arbitrary times t 1 < t 2
Markov Chains X(t) is a Markov Process if, for arbitrary times t 1 < t 2
Submitted to the Brazilian Journal of Probability and Statistics
 Submitted to the Brazilian Journal of Probability and Statistics Multivariate normal approximation of the maximum likelihood estimator via the delta method Andreas Anastasiou a and Robert E. Gaunt b a
Submitted to the Brazilian Journal of Probability and Statistics Multivariate normal approximation of the maximum likelihood estimator via the delta method Andreas Anastasiou a and Robert E. Gaunt b a
Page 0 of 5 Final Examination Name. Closed book. 120 minutes. Cover page plus five pages of exam.
 Final Examination Closed book. 120 minutes. Cover page plus five pages of exam. To receive full credit, show enough work to indicate your logic. Do not spend time calculating. You will receive full credit
Final Examination Closed book. 120 minutes. Cover page plus five pages of exam. To receive full credit, show enough work to indicate your logic. Do not spend time calculating. You will receive full credit
Stochastic Processes
 Stochastic Processes 8.445 MIT, fall 20 Mid Term Exam Solutions October 27, 20 Your Name: Alberto De Sole Exercise Max Grade Grade 5 5 2 5 5 3 5 5 4 5 5 5 5 5 6 5 5 Total 30 30 Problem :. True / False
Stochastic Processes 8.445 MIT, fall 20 Mid Term Exam Solutions October 27, 20 Your Name: Alberto De Sole Exercise Max Grade Grade 5 5 2 5 5 3 5 5 4 5 5 5 5 5 6 5 5 Total 30 30 Problem :. True / False
STA 294: Stochastic Processes & Bayesian Nonparametrics
 MARKOV CHAINS AND CONVERGENCE CONCEPTS Markov chains are among the simplest stochastic processes, just one step beyond iid sequences of random variables. Traditionally they ve been used in modelling a
MARKOV CHAINS AND CONVERGENCE CONCEPTS Markov chains are among the simplest stochastic processes, just one step beyond iid sequences of random variables. Traditionally they ve been used in modelling a
12 Markov chains The Markov property
 12 Markov chains Summary. The chapter begins with an introduction to discrete-time Markov chains, and to the use of matrix products and linear algebra in their study. The concepts of recurrence and transience
12 Markov chains Summary. The chapter begins with an introduction to discrete-time Markov chains, and to the use of matrix products and linear algebra in their study. The concepts of recurrence and transience
Remark By definition, an eigenvector must be a nonzero vector, but eigenvalue could be zero.
 Sec 6 Eigenvalues and Eigenvectors Definition An eigenvector of an n n matrix A is a nonzero vector x such that A x λ x for some scalar λ A scalar λ is called an eigenvalue of A if there is a nontrivial
Sec 6 Eigenvalues and Eigenvectors Definition An eigenvector of an n n matrix A is a nonzero vector x such that A x λ x for some scalar λ A scalar λ is called an eigenvalue of A if there is a nontrivial
Walk-Sum Interpretation and Analysis of Gaussian Belief Propagation
 Walk-Sum Interpretation and Analysis of Gaussian Belief Propagation Jason K. Johnson, Dmitry M. Malioutov and Alan S. Willsky Department of Electrical Engineering and Computer Science Massachusetts Institute
Walk-Sum Interpretation and Analysis of Gaussian Belief Propagation Jason K. Johnson, Dmitry M. Malioutov and Alan S. Willsky Department of Electrical Engineering and Computer Science Massachusetts Institute
Discrete time Markov chains. Discrete Time Markov Chains, Limiting. Limiting Distribution and Classification. Regular Transition Probability Matrices
 Discrete time Markov chains Discrete Time Markov Chains, Limiting Distribution and Classification DTU Informatics 02407 Stochastic Processes 3, September 9 207 Today: Discrete time Markov chains - invariant
Discrete time Markov chains Discrete Time Markov Chains, Limiting Distribution and Classification DTU Informatics 02407 Stochastic Processes 3, September 9 207 Today: Discrete time Markov chains - invariant
Continuous Time Processes
 page 102 Chapter 7 Continuous Time Processes 7.1 Introduction In a continuous time stochastic process (with discrete state space), a change of state can occur at any time instant. The associated point
page 102 Chapter 7 Continuous Time Processes 7.1 Introduction In a continuous time stochastic process (with discrete state space), a change of state can occur at any time instant. The associated point
Contents. 6 Systems of First-Order Linear Dierential Equations. 6.1 General Theory of (First-Order) Linear Systems
 Linear Systems") Dierential Equations (part 3): Systems of First-Order Dierential Equations (by Evan Dummit, 26, v 2) Contents 6 Systems of First-Order Linear Dierential Equations 6 General Theory of (First-Order) Linear
Dierential Equations (part 3): Systems of First-Order Dierential Equations (by Evan Dummit, 26, v 2) Contents 6 Systems of First-Order Linear Dierential Equations 6 General Theory of (First-Order) Linear
Exercises Chapter 4 Statistical Hypothesis Testing
 Exercises Chapter 4 Statistical Hypothesis Testing Advanced Econometrics - HEC Lausanne Christophe Hurlin University of Orléans December 5, 013 Christophe Hurlin (University of Orléans) Advanced Econometrics
Exercises Chapter 4 Statistical Hypothesis Testing Advanced Econometrics - HEC Lausanne Christophe Hurlin University of Orléans December 5, 013 Christophe Hurlin (University of Orléans) Advanced Econometrics
STAT STOCHASTIC PROCESSES. Contents
 STAT 3911 - STOCHASTIC PROCESSES ANDREW TULLOCH Contents 1. Stochastic Processes 2 2. Classification of states 2 3. Limit theorems for Markov chains 4 4. First step analysis 5 5. Branching processes 5
STAT 3911 - STOCHASTIC PROCESSES ANDREW TULLOCH Contents 1. Stochastic Processes 2 2. Classification of states 2 3. Limit theorems for Markov chains 4 4. First step analysis 5 5. Branching processes 5
Gaussian Models (9/9/13)
") STA561: Probabilistic machine learning Gaussian Models (9/9/13) Lecturer: Barbara Engelhardt Scribes: Xi He, Jiangwei Pan, Ali Razeen, Animesh Srivastava 1 Multivariate Normal Distribution The multivariate
STA561: Probabilistic machine learning Gaussian Models (9/9/13) Lecturer: Barbara Engelhardt Scribes: Xi He, Jiangwei Pan, Ali Razeen, Animesh Srivastava 1 Multivariate Normal Distribution The multivariate
Asymptotic Multivariate Kriging Using Estimated Parameters with Bayesian Prediction Methods for Non-linear Predictands
 Asymptotic Multivariate Kriging Using Estimated Parameters with Bayesian Prediction Methods for Non-linear Predictands Elizabeth C. Mannshardt-Shamseldin Advisor: Richard L. Smith Duke University Department
Asymptotic Multivariate Kriging Using Estimated Parameters with Bayesian Prediction Methods for Non-linear Predictands Elizabeth C. Mannshardt-Shamseldin Advisor: Richard L. Smith Duke University Department
1 EM algorithm: updating the mixing proportions {π k } ik are the posterior probabilities at the qth iteration of EM.
 Université du Sud Toulon - Var Master Informatique Probabilistic Learning and Data Analysis TD: Model-based clustering by Faicel CHAMROUKHI Solution The aim of this practical wor is to show how the Classification
Université du Sud Toulon - Var Master Informatique Probabilistic Learning and Data Analysis TD: Model-based clustering by Faicel CHAMROUKHI Solution The aim of this practical wor is to show how the Classification
Theory of Maximum Likelihood Estimation. Konstantin Kashin
 Gov 2001 Section 5: Theory of Maximum Likelihood Estimation Konstantin Kashin February 28, 2013 Outline Introduction Likelihood Examples of MLE Variance of MLE Asymptotic Properties What is Statistical
Gov 2001 Section 5: Theory of Maximum Likelihood Estimation Konstantin Kashin February 28, 2013 Outline Introduction Likelihood Examples of MLE Variance of MLE Asymptotic Properties What is Statistical
Variations. ECE 6540, Lecture 10 Maximum Likelihood Estimation
 Variations ECE 6540, Lecture 10 Last Time BLUE (Best Linear Unbiased Estimator) Formulation Advantages Disadvantages 2 The BLUE A simplification Assume the estimator is a linear system For a single parameter
Variations ECE 6540, Lecture 10 Last Time BLUE (Best Linear Unbiased Estimator) Formulation Advantages Disadvantages 2 The BLUE A simplification Assume the estimator is a linear system For a single parameter
Stat Lecture 20. Last class we introduced the covariance and correlation between two jointly distributed random variables.
 Stat 260 - Lecture 20 Recap of Last Class Last class we introduced the covariance and correlation between two jointly distributed random variables. Today: We will introduce the idea of a statistic and
Stat 260 - Lecture 20 Recap of Last Class Last class we introduced the covariance and correlation between two jointly distributed random variables. Today: We will introduce the idea of a statistic and
Canonical Correlation Analysis of Longitudinal Data
 Biometrics Section JSM 2008 Canonical Correlation Analysis of Longitudinal Data Jayesh Srivastava Dayanand N Naik Abstract Studying the relationship between two sets of variables is an important multivariate
Biometrics Section JSM 2008 Canonical Correlation Analysis of Longitudinal Data Jayesh Srivastava Dayanand N Naik Abstract Studying the relationship between two sets of variables is an important multivariate
PCA and admixture models
 PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
PCA and admixture models CM226: Machine Learning for Bioinformatics. Fall 2016 Sriram Sankararaman Acknowledgments: Fei Sha, Ameet Talwalkar, Alkes Price PCA and admixture models 1 / 57 Announcements HW1
Math 331 Homework Assignment Chapter 7 Page 1 of 9
 Math Homework Assignment Chapter 7 Page of 9 Instructions: Please make sure to demonstrate every step in your calculations. Return your answers including this homework sheet back to the instructor as a
Math Homework Assignment Chapter 7 Page of 9 Instructions: Please make sure to demonstrate every step in your calculations. Return your answers including this homework sheet back to the instructor as a
MA2501 Numerical Methods Spring 2015
 Norwegian University of Science and Technology Department of Mathematics MA2501 Numerical Methods Spring 2015 Solutions to exercise set 3 1 Attempt to verify experimentally the calculation from class that
Norwegian University of Science and Technology Department of Mathematics MA2501 Numerical Methods Spring 2015 Solutions to exercise set 3 1 Attempt to verify experimentally the calculation from class that
Vertex colorings of graphs without short odd cycles
 Vertex colorings of graphs without short odd cycles Andrzej Dudek and Reshma Ramadurai Department of Mathematical Sciences Carnegie Mellon University Pittsburgh, PA 1513, USA {adudek,rramadur}@andrew.cmu.edu
Vertex colorings of graphs without short odd cycles Andrzej Dudek and Reshma Ramadurai Department of Mathematical Sciences Carnegie Mellon University Pittsburgh, PA 1513, USA {adudek,rramadur}@andrew.cmu.edu
Linear ODEs. Existence of solutions to linear IVPs. Resolvent matrix. Autonomous linear systems
 Linear ODEs p. 1 Linear ODEs Existence of solutions to linear IVPs Resolvent matrix Autonomous linear systems Linear ODEs Definition (Linear ODE) A linear ODE is a differential equation taking the form
Linear ODEs p. 1 Linear ODEs Existence of solutions to linear IVPs Resolvent matrix Autonomous linear systems Linear ODEs Definition (Linear ODE) A linear ODE is a differential equation taking the form
Eigenvalues, Eigenvectors, and Diagonalization
 Math 240 TA: Shuyi Weng Winter 207 February 23, 207 Eigenvalues, Eigenvectors, and Diagonalization The concepts of eigenvalues, eigenvectors, and diagonalization are best studied with examples. We will
Math 240 TA: Shuyi Weng Winter 207 February 23, 207 Eigenvalues, Eigenvectors, and Diagonalization The concepts of eigenvalues, eigenvectors, and diagonalization are best studied with examples. We will
Lecture 3 Eigenvalues and Eigenvectors
 Lecture 3 Eigenvalues and Eigenvectors Eivind Eriksen BI Norwegian School of Management Department of Economics September 10, 2010 Eivind Eriksen (BI Dept of Economics) Lecture 3 Eigenvalues and Eigenvectors
Lecture 3 Eigenvalues and Eigenvectors Eivind Eriksen BI Norwegian School of Management Department of Economics September 10, 2010 Eivind Eriksen (BI Dept of Economics) Lecture 3 Eigenvalues and Eigenvectors
MATH c UNIVERSITY OF LEEDS Examination for the Module MATH2715 (January 2015) STATISTICAL METHODS. Time allowed: 2 hours
 STATISTICAL METHODS. Time allowed: 2 hours") MATH2750 This question paper consists of 8 printed pages, each of which is identified by the reference MATH275. All calculators must carry an approval sticker issued by the School of Mathematics. c UNIVERSITY
MATH2750 This question paper consists of 8 printed pages, each of which is identified by the reference MATH275. All calculators must carry an approval sticker issued by the School of Mathematics. c UNIVERSITY
High dimensional Ising model selection
 High dimensional Ising model selection Pradeep Ravikumar UT Austin (based on work with John Lafferty, Martin Wainwright) Sparse Ising model US Senate 109th Congress Banerjee et al, 2008 Estimate a sparse
High dimensional Ising model selection Pradeep Ravikumar UT Austin (based on work with John Lafferty, Martin Wainwright) Sparse Ising model US Senate 109th Congress Banerjee et al, 2008 Estimate a sparse
On prediction and density estimation Peter McCullagh University of Chicago December 2004
 On prediction and density estimation Peter McCullagh University of Chicago December 2004 Summary Having observed the initial segment of a random sequence, subsequent values may be predicted by calculating
On prediction and density estimation Peter McCullagh University of Chicago December 2004 Summary Having observed the initial segment of a random sequence, subsequent values may be predicted by calculating
18.440: Lecture 33 Markov Chains
 18.440: Lecture 33 Markov Chains Scott Sheffield MIT 1 Outline Markov chains Examples Ergodicity and stationarity 2 Outline Markov chains Examples Ergodicity and stationarity 3 Markov chains Consider a
18.440: Lecture 33 Markov Chains Scott Sheffield MIT 1 Outline Markov chains Examples Ergodicity and stationarity 2 Outline Markov chains Examples Ergodicity and stationarity 3 Markov chains Consider a
Lecture 17: Likelihood ratio and asymptotic tests
 Lecture 17: Likelihood ratio and asymptotic tests Likelihood ratio When both H 0 and H 1 are simple (i.e., Θ 0 = {θ 0 } and Θ 1 = {θ 1 }), Theorem 6.1 applies and a UMP test rejects H 0 when f θ1 (X) f
Lecture 17: Likelihood ratio and asymptotic tests Likelihood ratio When both H 0 and H 1 are simple (i.e., Θ 0 = {θ 0 } and Θ 1 = {θ 1 }), Theorem 6.1 applies and a UMP test rejects H 0 when f θ1 (X) f
Markov Chain Monte Carlo Lecture 6
 Sequential parallel tempering With the development of science and technology, we more and more need to deal with high dimensional systems. For example, we need to align a group of protein or DNA sequences
Sequential parallel tempering With the development of science and technology, we more and more need to deal with high dimensional systems. For example, we need to align a group of protein or DNA sequences
N.G.Bean, D.A.Green and P.G.Taylor. University of Adelaide. Adelaide. Abstract. process of an MMPP/M/1 queue is not a MAP unless the queue is a
 WHEN IS A MAP POISSON N.G.Bean, D.A.Green and P.G.Taylor Department of Applied Mathematics University of Adelaide Adelaide 55 Abstract In a recent paper, Olivier and Walrand (994) claimed that the departure
WHEN IS A MAP POISSON N.G.Bean, D.A.Green and P.G.Taylor Department of Applied Mathematics University of Adelaide Adelaide 55 Abstract In a recent paper, Olivier and Walrand (994) claimed that the departure
Lecture 26: Likelihood ratio tests
 Lecture 26: Likelihood ratio tests Likelihood ratio When both H 0 and H 1 are simple (i.e., Θ 0 = {θ 0 } and Θ 1 = {θ 1 }), Theorem 6.1 applies and a UMP test rejects H 0 when f θ1 (X) f θ0 (X) > c 0 for
Lecture 26: Likelihood ratio tests Likelihood ratio When both H 0 and H 1 are simple (i.e., Θ 0 = {θ 0 } and Θ 1 = {θ 1 }), Theorem 6.1 applies and a UMP test rejects H 0 when f θ1 (X) f θ0 (X) > c 0 for
Stat 5101 Lecture Notes
 Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
Stat 5101 Lecture Notes Charles J. Geyer Copyright 1998, 1999, 2000, 2001 by Charles J. Geyer May 7, 2001 ii Stat 5101 (Geyer) Course Notes Contents 1 Random Variables and Change of Variables 1 1.1 Random
Lecture 2: Review of Basic Probability Theory
 ECE 830 Fall 2010 Statistical Signal Processing instructor: R. Nowak, scribe: R. Nowak Lecture 2: Review of Basic Probability Theory Probabilistic models will be used throughout the course to represent
ECE 830 Fall 2010 Statistical Signal Processing instructor: R. Nowak, scribe: R. Nowak Lecture 2: Review of Basic Probability Theory Probabilistic models will be used throughout the course to represent
An Efficient Estimation Method for Longitudinal Surveys with Monotone Missing Data
 An Efficient Estimation Method for Longitudinal Surveys with Monotone Missing Data Jae-Kwang Kim 1 Iowa State University June 28, 2012 1 Joint work with Dr. Ming Zhou (when he was a PhD student at ISU)
An Efficient Estimation Method for Longitudinal Surveys with Monotone Missing Data Jae-Kwang Kim 1 Iowa State University June 28, 2012 1 Joint work with Dr. Ming Zhou (when he was a PhD student at ISU)
Linear Methods for Prediction
 Chapter 5 Linear Methods for Prediction 5.1 Introduction We now revisit the classification problem and focus on linear methods. Since our prediction Ĝ(x) will always take values in the discrete set G we
Chapter 5 Linear Methods for Prediction 5.1 Introduction We now revisit the classification problem and focus on linear methods. Since our prediction Ĝ(x) will always take values in the discrete set G we
Markov Chains Handout for Stat 110
 Markov Chains Handout for Stat 0 Prof. Joe Blitzstein (Harvard Statistics Department) Introduction Markov chains were first introduced in 906 by Andrey Markov, with the goal of showing that the Law of
Markov Chains Handout for Stat 0 Prof. Joe Blitzstein (Harvard Statistics Department) Introduction Markov chains were first introduced in 906 by Andrey Markov, with the goal of showing that the Law of
HIERARCHICAL MODELS IN EXTREME VALUE THEORY
 HIERARCHICAL MODELS IN EXTREME VALUE THEORY Richard L. Smith Department of Statistics and Operations Research, University of North Carolina, Chapel Hill and Statistical and Applied Mathematical Sciences
HIERARCHICAL MODELS IN EXTREME VALUE THEORY Richard L. Smith Department of Statistics and Operations Research, University of North Carolina, Chapel Hill and Statistical and Applied Mathematical Sciences
Haruhiko Ogasawara. This article gives the first half of an expository supplement to Ogasawara (2015).
.") Economic Review (Otaru University of Commerce, Vol.66, No. & 3, 9-58. December, 5. Expository supplement I to the paper Asymptotic expansions for the estimators of Lagrange multipliers and associated parameters
Economic Review (Otaru University of Commerce, Vol.66, No. & 3, 9-58. December, 5. Expository supplement I to the paper Asymptotic expansions for the estimators of Lagrange multipliers and associated parameters
Chapter 3: Maximum Likelihood Theory
 Chapter 3: Maximum Likelihood Theory Florian Pelgrin HEC September-December, 2010 Florian Pelgrin (HEC) Maximum Likelihood Theory September-December, 2010 1 / 40 1 Introduction Example 2 Maximum likelihood
Chapter 3: Maximum Likelihood Theory Florian Pelgrin HEC September-December, 2010 Florian Pelgrin (HEC) Maximum Likelihood Theory September-December, 2010 1 / 40 1 Introduction Example 2 Maximum likelihood
Part I Stochastic variables and Markov chains
 Part I Stochastic variables and Markov chains Random variables describe the behaviour of a phenomenon independent of any specific sample space Distribution function (cdf, cumulative distribution function)
Part I Stochastic variables and Markov chains Random variables describe the behaviour of a phenomenon independent of any specific sample space Distribution function (cdf, cumulative distribution function)
Bayesian Inference for Clustered Extremes
 Newcastle University, Newcastle-upon-Tyne, U.K. lee.fawcett@ncl.ac.uk 20th TIES Conference: Bologna, Italy, July 2009 Structure of this talk 1. Motivation and background 2. Review of existing methods Limitations/difficulties
Newcastle University, Newcastle-upon-Tyne, U.K. lee.fawcett@ncl.ac.uk 20th TIES Conference: Bologna, Italy, July 2009 Structure of this talk 1. Motivation and background 2. Review of existing methods Limitations/difficulties