Stochastic Optimization: First order method
|
|
|
- Chester Richards
- 5 years ago
- Views:
Transcription
1 Stochastic Optimization: First order method Taiji Suzuki Tokyo Institute of Technology Graduate School of Information Science and Engineering Department of Mathematical and Computing Sciences JST, PRESTO Intensive Nagoya University / 6
2 Outline First order method Proximal gradient descent Nesterov s acceleration and optimal convergence 2 / 6
3 Outline First order method Proximal gradient descent Nesterov s acceleration and optimal convergence 3 / 6
4 Regularized learning problem Lasso: min x R p n n i= (y i zi x) 2 + x }{{}. regularization 4 / 6
5 Regularized learning problem Lasso: min x R p n n i= (y i zi x) 2 + x }{{}. regularization General regularized learning problem: min x R p n n l(z i, x) + ψ(x). i= Difficulty: Sparsity inducing regularization is usually non-smooth. 4 / 6
6 First order optimization x t+ x t x t- Optimization methods that use only the function value f (x) and the first order gradient g f (x). Computation per iteration is light, and suited for high dimensional problems. Newton method is a second order method. 5 / 6
7 Outline First order method Proximal gradient descent Nesterov s acceleration and optimal convergence 6 / 6
8 Gradient descent Let f (x) = n i= l(z i, x). min x f (x). Subgradient method Differentiable f (x): x t = x t η t f (x t ). 7 / 6
9 Gradient descent Let f (x) = n i= l(z i, x). Subgradient method Subdifferentiable f (x): min x f (x). g t f (x t ), x t = x t η t g t. 7 / 6
10 Gradient descent Let f (x) = n i= l(z i, x). min x f (x). Subgradient method (equivalent formula) Subdifferentiable f (x): where g t f (x t ). x t = argmin x Proximal point algorithm: x t = argmin x { x, g t + } x x t 2, 2η t { f (x) + } x x t 2. 2η t f (x t ) optimum for any convex f and η t = η > 0 (?). ( ) t If f (x) is strongly convex: f (x t ) f (x ) 2η +ση x0 x 2. 7 / 6
11 Let f (x) = n i= l(z i, x). Proximal gradient descent min x f (x) + ψ(x). Proximal gradient descent { x t = argmin x, g t + ψ(x) + } x x t 2 x 2η t = argmin {η t ψ(x) + 2 } x (x t η t g t ) 2 x where g t f (x t ). The update rule is given by proximal mapping: { prox(q ψ) = argmin ψ(x) + 2 } x q 2 x By using the proximal mapping, we can avoid bad properties (e.g., non-smoothness) of ψ. 8 / 6
 (j-th component) where ST")

12 Example L regularization: ψ(x) = C x. x t,j = ST Cηt (x t,j η t g t,j ) (j-th component) where ST C (q) = sign(q) max{ q C, 0}. Unimportant elements are forced to be 0. For many practically used regularizations, analytic form is obtained. 9 / 6
13 Example of proximal mapping (cont.) Trace norm: ψ(x ) = C X tr = C j σ j(x ) (sum of singular values). Let X t η t G t = U diag(σ,..., σ d )V, then ST Cηt (σ ) X t = U... V. STCη(σd) 0 / 6
14 Convergence of proximal gradient descent Strong convexity and smoothness of f determines the convergence rate. x t = prox(x t η t g t η t ψ(x)). property of f µ-strongly ( convex non-strongly conv γ-smooth exp t µ ) γ γ t Non-smooth µt t The step size η t should be appropriately chosen. Setting of η t Strongly conv non-strongly conv Smooth γ γ 2 Non-smooth µt t To achieve this convergence rate, we need to take an average of {x t } t appropriately; Polyak-Ruppert averaging, polynomially decaying averaging. / 6
15 Convergence of proximal gradient descent Strong convexity and smoothness of f determines the convergence rate. x t = prox(x t η t g t η t ψ(x)). property of f µ-strongly ( convex ) non-strongly conv µ γ γ-smooth exp t γ t 2 Non-smooth µt The step size η t should be appropriately chosen. t Setting of η t Strongly conv non-strongly conv Smooth γ γ 2 Non-smooth µt t To achieve this convergence rate, we need to take an average of {x t } t appropriately; Polyak-Ruppert averaging, polynomially decaying averaging. Convergence for smooth loss can be improved by Nesterov s acceleration. Optimal rate / 6
16 Outline First order method Proximal gradient descent Nesterov s acceleration and optimal convergence 2 / 6
17 Nesterov s acceleration (non-strongly convex) min x {f (x) + ψ(x)} Assumption: f (x) is γ-smooth. Nesterov s acceleration scheme Let s = and η = γ, and iterate the following for t =, 2,... Let g t f (y t ), and update x t = prox(y t ηg t ηψ). 2 Set s t+ = + +4s 2 t 2. 3 Update y t+ = x t + ( st s t+ ) (x t x t ). If f is γ-smooth, then f (x t ) f (x ) 2γ x t x t 2. This is also called Fast Iterative Shrinkage Thresholding Algorithm (FISTA) (?). The step size η = /γ can be adaptively determined: back-tracking. Momentum method is important for deep learning (?). 3 / 6
18 Nesterov s acceleration (strongly convex) min x {f (x) + ψ(x)} Assumption: f (x) is γ-smooth and µ-strongly convex. (it must be γ > µ) Nesterov s acceleration scheme Let A =, α = γ/µ and η = γ, and iterate the following for t =, 2,... Let g t f (y t ), and update x t = prox(y t ηg t ηψ). 2 Set α t+ > so that (γ µ)αt+ 2 (2γ + A t)α t+ + γ = 0, and let A t+ = A t /α t+. ( ) 3 Update y t+ = x t + (x t x t ). µ+a t (γ µ)(α t+ )(α t ) If f is γ-smooth and µ-strongly convex, then ( f (x t ) f (x ) γ ) γ t x 0 x 2. µ 4 / 6
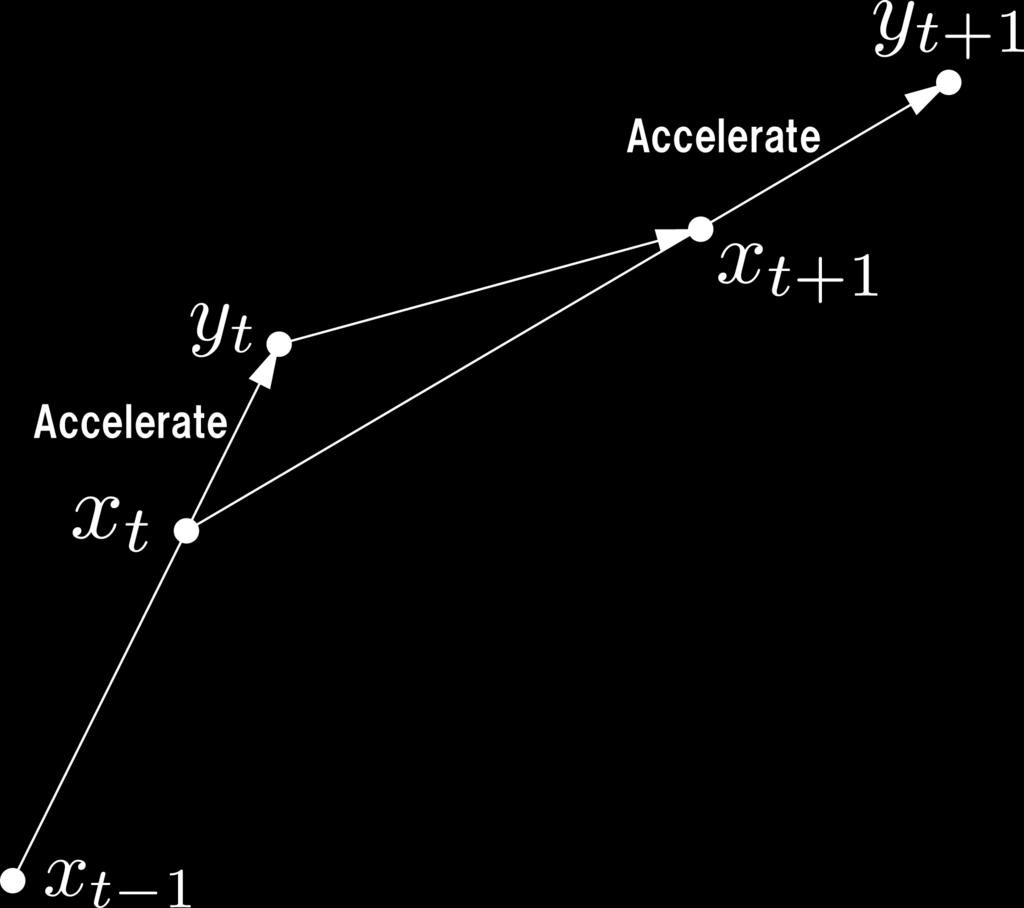
19 5 / 6
20 0 4 Normal Nesterov 0 2 Relative objective (f(x t ) - f * ) Iteration Nesterov s acceleration v.s. normal gradient descent Lasso: n = 8, 000, p = / 6
21 A. Beck and M. Teboulle. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM journal on imaging sciences, 2(): , O. Güler. On the convergence of the proximal point algorithm for convex minimization. SIAM Journal on Control and Optimization, 29(2): , 99. I. Sutskever, J. Martens, G. Dahl, and G. Hinton. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th international conference on machine learning (ICML-3), pages 39 47, / 6
Stochastic Optimization Part I: Convex analysis and online stochastic optimization
 Stochastic Optimization Part I: Convex analysis and online stochastic optimization Taiji Suzuki Tokyo Institute of Technology Graduate School of Information Science and Engineering Department of Mathematical
Stochastic Optimization Part I: Convex analysis and online stochastic optimization Taiji Suzuki Tokyo Institute of Technology Graduate School of Information Science and Engineering Department of Mathematical
ECE G: Special Topics in Signal Processing: Sparsity, Structure, and Inference
 ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Sparse Recovery using L1 minimization - algorithms Yuejie Chi Department of Electrical and Computer Engineering Spring
ECE 18-898G: Special Topics in Signal Processing: Sparsity, Structure, and Inference Sparse Recovery using L1 minimization - algorithms Yuejie Chi Department of Electrical and Computer Engineering Spring
Lasso: Algorithms and Extensions
 ELE 538B: Sparsity, Structure and Inference Lasso: Algorithms and Extensions Yuxin Chen Princeton University, Spring 2017 Outline Proximal operators Proximal gradient methods for lasso and its extensions
ELE 538B: Sparsity, Structure and Inference Lasso: Algorithms and Extensions Yuxin Chen Princeton University, Spring 2017 Outline Proximal operators Proximal gradient methods for lasso and its extensions
Optimization methods
 Optimization methods Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda /8/016 Introduction Aim: Overview of optimization methods that Tend to
Optimization methods Optimization-Based Data Analysis http://www.cims.nyu.edu/~cfgranda/pages/obda_spring16 Carlos Fernandez-Granda /8/016 Introduction Aim: Overview of optimization methods that Tend to
6. Proximal gradient method
 L. Vandenberghe EE236C (Spring 2016) 6. Proximal gradient method motivation proximal mapping proximal gradient method with fixed step size proximal gradient method with line search 6-1 Proximal mapping
L. Vandenberghe EE236C (Spring 2016) 6. Proximal gradient method motivation proximal mapping proximal gradient method with fixed step size proximal gradient method with line search 6-1 Proximal mapping
A Conservation Law Method in Optimization
 A Conservation Law Method in Optimization Bin Shi Florida International University Tao Li Florida International University Sundaraja S. Iyengar Florida International University Abstract bshi1@cs.fiu.edu
A Conservation Law Method in Optimization Bin Shi Florida International University Tao Li Florida International University Sundaraja S. Iyengar Florida International University Abstract bshi1@cs.fiu.edu
Agenda. Fast proximal gradient methods. 1 Accelerated first-order methods. 2 Auxiliary sequences. 3 Convergence analysis. 4 Numerical examples
 Agenda Fast proximal gradient methods 1 Accelerated first-order methods 2 Auxiliary sequences 3 Convergence analysis 4 Numerical examples 5 Optimality of Nesterov s scheme Last time Proximal gradient method
Agenda Fast proximal gradient methods 1 Accelerated first-order methods 2 Auxiliary sequences 3 Convergence analysis 4 Numerical examples 5 Optimality of Nesterov s scheme Last time Proximal gradient method
Proximal Gradient Descent and Acceleration. Ryan Tibshirani Convex Optimization /36-725
 Proximal Gradient Descent and Acceleration Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: subgradient method Consider the problem min f(x) with f convex, and dom(f) = R n. Subgradient method:
Proximal Gradient Descent and Acceleration Ryan Tibshirani Convex Optimization 10-725/36-725 Last time: subgradient method Consider the problem min f(x) with f convex, and dom(f) = R n. Subgradient method:
Optimization methods
 Lecture notes 3 February 8, 016 1 Introduction Optimization methods In these notes we provide an overview of a selection of optimization methods. We focus on methods which rely on first-order information,
Lecture notes 3 February 8, 016 1 Introduction Optimization methods In these notes we provide an overview of a selection of optimization methods. We focus on methods which rely on first-order information,
Accelerated Proximal Gradient Methods for Convex Optimization
 Accelerated Proximal Gradient Methods for Convex Optimization Paul Tseng Mathematics, University of Washington Seattle MOPTA, University of Guelph August 18, 2008 ACCELERATED PROXIMAL GRADIENT METHODS
Accelerated Proximal Gradient Methods for Convex Optimization Paul Tseng Mathematics, University of Washington Seattle MOPTA, University of Guelph August 18, 2008 ACCELERATED PROXIMAL GRADIENT METHODS
Master 2 MathBigData. 3 novembre CMAP - Ecole Polytechnique
 Master 2 MathBigData S. Gaïffas 1 3 novembre 2014 1 CMAP - Ecole Polytechnique 1 Supervised learning recap Introduction Loss functions, linearity 2 Penalization Introduction Ridge Sparsity Lasso 3 Some
Master 2 MathBigData S. Gaïffas 1 3 novembre 2014 1 CMAP - Ecole Polytechnique 1 Supervised learning recap Introduction Loss functions, linearity 2 Penalization Introduction Ridge Sparsity Lasso 3 Some
Fast proximal gradient methods
 L. Vandenberghe EE236C (Spring 2013-14) Fast proximal gradient methods fast proximal gradient method (FISTA) FISTA with line search FISTA as descent method Nesterov s second method 1 Fast (proximal) gradient
L. Vandenberghe EE236C (Spring 2013-14) Fast proximal gradient methods fast proximal gradient method (FISTA) FISTA with line search FISTA as descent method Nesterov s second method 1 Fast (proximal) gradient
Lecture 8: February 9
 0-725/36-725: Convex Optimiation Spring 205 Lecturer: Ryan Tibshirani Lecture 8: February 9 Scribes: Kartikeya Bhardwaj, Sangwon Hyun, Irina Caan 8 Proximal Gradient Descent In the previous lecture, we
0-725/36-725: Convex Optimiation Spring 205 Lecturer: Ryan Tibshirani Lecture 8: February 9 Scribes: Kartikeya Bhardwaj, Sangwon Hyun, Irina Caan 8 Proximal Gradient Descent In the previous lecture, we
SIAM Conference on Imaging Science, Bologna, Italy, Adaptive FISTA. Peter Ochs Saarland University
 SIAM Conference on Imaging Science, Bologna, Italy, 2018 Adaptive FISTA Peter Ochs Saarland University 07.06.2018 joint work with Thomas Pock, TU Graz, Austria c 2018 Peter Ochs Adaptive FISTA 1 / 16 Some
SIAM Conference on Imaging Science, Bologna, Italy, 2018 Adaptive FISTA Peter Ochs Saarland University 07.06.2018 joint work with Thomas Pock, TU Graz, Austria c 2018 Peter Ochs Adaptive FISTA 1 / 16 Some
STA141C: Big Data & High Performance Statistical Computing
 STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
STA141C: Big Data & High Performance Statistical Computing Lecture 8: Optimization Cho-Jui Hsieh UC Davis May 9, 2017 Optimization Numerical Optimization Numerical Optimization: min X f (X ) Can be applied
6. Proximal gradient method
 L. Vandenberghe EE236C (Spring 2013-14) 6. Proximal gradient method motivation proximal mapping proximal gradient method with fixed step size proximal gradient method with line search 6-1 Proximal mapping
L. Vandenberghe EE236C (Spring 2013-14) 6. Proximal gradient method motivation proximal mapping proximal gradient method with fixed step size proximal gradient method with line search 6-1 Proximal mapping
This can be 2 lectures! still need: Examples: non-convex problems applications for matrix factorization
 This can be 2 lectures! still need: Examples: non-convex problems applications for matrix factorization x = prox_f(x)+prox_{f^*}(x) use to get prox of norms! PROXIMAL METHODS WHY PROXIMAL METHODS Smooth
This can be 2 lectures! still need: Examples: non-convex problems applications for matrix factorization x = prox_f(x)+prox_{f^*}(x) use to get prox of norms! PROXIMAL METHODS WHY PROXIMAL METHODS Smooth
Conditional Gradient (Frank-Wolfe) Method
 Method") Conditional Gradient (Frank-Wolfe) Method Lecturer: Aarti Singh Co-instructor: Pradeep Ravikumar Convex Optimization 10-725/36-725 1 Outline Today: Conditional gradient method Convergence analysis Properties
Conditional Gradient (Frank-Wolfe) Method Lecturer: Aarti Singh Co-instructor: Pradeep Ravikumar Convex Optimization 10-725/36-725 1 Outline Today: Conditional gradient method Convergence analysis Properties
Nesterov s Acceleration
 Nesterov s Acceleration Nesterov Accelerated Gradient min X f(x)+ (X) f -smooth. Set s 1 = 1 and = 1. Set y 0. Iterate by increasing t: g t 2 @f(y t ) s t+1 = 1+p 1+4s 2 t 2 y t = x t + s t 1 s t+1 (x
Nesterov s Acceleration Nesterov Accelerated Gradient min X f(x)+ (X) f -smooth. Set s 1 = 1 and = 1. Set y 0. Iterate by increasing t: g t 2 @f(y t ) s t+1 = 1+p 1+4s 2 t 2 y t = x t + s t 1 s t+1 (x
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 29, 2016 Outline Convex vs Nonconvex Functions Coordinate Descent Gradient Descent Newton s method Stochastic Gradient Descent Numerical Optimization
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Sept 29, 2016 Outline Convex vs Nonconvex Functions Coordinate Descent Gradient Descent Newton s method Stochastic Gradient Descent Numerical Optimization
Proximal methods. S. Villa. October 7, 2014
 Proximal methods S. Villa October 7, 2014 1 Review of the basics Often machine learning problems require the solution of minimization problems. For instance, the ERM algorithm requires to solve a problem
Proximal methods S. Villa October 7, 2014 1 Review of the basics Often machine learning problems require the solution of minimization problems. For instance, the ERM algorithm requires to solve a problem
Proximal Newton Method. Ryan Tibshirani Convex Optimization /36-725
 Proximal Newton Method Ryan Tibshirani Convex Optimization 10-725/36-725 1 Last time: primal-dual interior-point method Given the problem min x subject to f(x) h i (x) 0, i = 1,... m Ax = b where f, h
Proximal Newton Method Ryan Tibshirani Convex Optimization 10-725/36-725 1 Last time: primal-dual interior-point method Given the problem min x subject to f(x) h i (x) 0, i = 1,... m Ax = b where f, h
Lecture 9: September 28
 0-725/36-725: Convex Optimization Fall 206 Lecturer: Ryan Tibshirani Lecture 9: September 28 Scribes: Yiming Wu, Ye Yuan, Zhihao Li Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These
0-725/36-725: Convex Optimization Fall 206 Lecturer: Ryan Tibshirani Lecture 9: September 28 Scribes: Yiming Wu, Ye Yuan, Zhihao Li Note: LaTeX template courtesy of UC Berkeley EECS dept. Disclaimer: These
A Multilevel Proximal Algorithm for Large Scale Composite Convex Optimization
 A Multilevel Proximal Algorithm for Large Scale Composite Convex Optimization Panos Parpas Department of Computing Imperial College London www.doc.ic.ac.uk/ pp500 p.parpas@imperial.ac.uk jointly with D.V.
A Multilevel Proximal Algorithm for Large Scale Composite Convex Optimization Panos Parpas Department of Computing Imperial College London www.doc.ic.ac.uk/ pp500 p.parpas@imperial.ac.uk jointly with D.V.
Motivation Subgradient Method Stochastic Subgradient Method. Convex Optimization. Lecture 15 - Gradient Descent in Machine Learning
 Convex Optimization Lecture 15 - Gradient Descent in Machine Learning Instructor: Yuanzhang Xiao University of Hawaii at Manoa Fall 2017 1 / 21 Today s Lecture 1 Motivation 2 Subgradient Method 3 Stochastic
Convex Optimization Lecture 15 - Gradient Descent in Machine Learning Instructor: Yuanzhang Xiao University of Hawaii at Manoa Fall 2017 1 / 21 Today s Lecture 1 Motivation 2 Subgradient Method 3 Stochastic
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent
 CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
CSCI 1951-G Optimization Methods in Finance Part 12: Variants of Gradient Descent April 27, 2018 1 / 32 Outline 1) Moment and Nesterov s accelerated gradient descent 2) AdaGrad and RMSProp 4) Adam 5) Stochastic
Adaptive Subgradient Methods for Online Learning and Stochastic Optimization John Duchi, Elad Hanzan, Yoram Singer
 Adaptive Subgradient Methods for Online Learning and Stochastic Optimization John Duchi, Elad Hanzan, Yoram Singer Vicente L. Malave February 23, 2011 Outline Notation minimize a number of functions φ
Adaptive Subgradient Methods for Online Learning and Stochastic Optimization John Duchi, Elad Hanzan, Yoram Singer Vicente L. Malave February 23, 2011 Outline Notation minimize a number of functions φ
Convex Optimization Algorithms for Machine Learning in 10 Slides
 Convex Optimization Algorithms for Machine Learning in 10 Slides Presenter: Jul. 15. 2015 Outline 1 Quadratic Problem Linear System 2 Smooth Problem Newton-CG 3 Composite Problem Proximal-Newton-CD 4 Non-smooth,
Convex Optimization Algorithms for Machine Learning in 10 Slides Presenter: Jul. 15. 2015 Outline 1 Quadratic Problem Linear System 2 Smooth Problem Newton-CG 3 Composite Problem Proximal-Newton-CD 4 Non-smooth,
1 Sparsity and l 1 relaxation
 6.883 Learning with Combinatorial Structure Note for Lecture 2 Author: Chiyuan Zhang Sparsity and l relaxation Last time we talked about sparsity and characterized when an l relaxation could recover the
6.883 Learning with Combinatorial Structure Note for Lecture 2 Author: Chiyuan Zhang Sparsity and l relaxation Last time we talked about sparsity and characterized when an l relaxation could recover the
Composite Objective Mirror Descent
 Composite Objective Mirror Descent John C. Duchi 1,3 Shai Shalev-Shwartz 2 Yoram Singer 3 Ambuj Tewari 4 1 University of California, Berkeley 2 Hebrew University of Jerusalem, Israel 3 Google Research
Composite Objective Mirror Descent John C. Duchi 1,3 Shai Shalev-Shwartz 2 Yoram Singer 3 Ambuj Tewari 4 1 University of California, Berkeley 2 Hebrew University of Jerusalem, Israel 3 Google Research
A Unified Approach to Proximal Algorithms using Bregman Distance
 A Unified Approach to Proximal Algorithms using Bregman Distance Yi Zhou a,, Yingbin Liang a, Lixin Shen b a Department of Electrical Engineering and Computer Science, Syracuse University b Department
A Unified Approach to Proximal Algorithms using Bregman Distance Yi Zhou a,, Yingbin Liang a, Lixin Shen b a Department of Electrical Engineering and Computer Science, Syracuse University b Department
Proximal Minimization by Incremental Surrogate Optimization (MISO)
") Proximal Minimization by Incremental Surrogate Optimization (MISO) (and a few variants) Julien Mairal Inria, Grenoble ICCOPT, Tokyo, 2016 Julien Mairal, Inria MISO 1/26 Motivation: large-scale machine
Proximal Minimization by Incremental Surrogate Optimization (MISO) (and a few variants) Julien Mairal Inria, Grenoble ICCOPT, Tokyo, 2016 Julien Mairal, Inria MISO 1/26 Motivation: large-scale machine
SVRG++ with Non-uniform Sampling
 SVRG++ with Non-uniform Sampling Tamás Kern András György Department of Electrical and Electronic Engineering Imperial College London, London, UK, SW7 2BT {tamas.kern15,a.gyorgy}@imperial.ac.uk Abstract
SVRG++ with Non-uniform Sampling Tamás Kern András György Department of Electrical and Electronic Engineering Imperial College London, London, UK, SW7 2BT {tamas.kern15,a.gyorgy}@imperial.ac.uk Abstract
A Fast Augmented Lagrangian Algorithm for Learning Low-Rank Matrices
 A Fast Augmented Lagrangian Algorithm for Learning Low-Rank Matrices Ryota Tomioka 1, Taiji Suzuki 1, Masashi Sugiyama 2, Hisashi Kashima 1 1 The University of Tokyo 2 Tokyo Institute of Technology 2010-06-22
A Fast Augmented Lagrangian Algorithm for Learning Low-Rank Matrices Ryota Tomioka 1, Taiji Suzuki 1, Masashi Sugiyama 2, Hisashi Kashima 1 1 The University of Tokyo 2 Tokyo Institute of Technology 2010-06-22
Large-scale Stochastic Optimization
 Large-scale Stochastic Optimization 11-741/641/441 (Spring 2016) Hanxiao Liu hanxiaol@cs.cmu.edu March 24, 2016 1 / 22 Outline 1. Gradient Descent (GD) 2. Stochastic Gradient Descent (SGD) Formulation
Large-scale Stochastic Optimization 11-741/641/441 (Spring 2016) Hanxiao Liu hanxiaol@cs.cmu.edu March 24, 2016 1 / 22 Outline 1. Gradient Descent (GD) 2. Stochastic Gradient Descent (SGD) Formulation
Big Data Analytics: Optimization and Randomization
 Big Data Analytics: Optimization and Randomization Tianbao Yang Tutorial@ACML 2015 Hong Kong Department of Computer Science, The University of Iowa, IA, USA Nov. 20, 2015 Yang Tutorial for ACML 15 Nov.
Big Data Analytics: Optimization and Randomization Tianbao Yang Tutorial@ACML 2015 Hong Kong Department of Computer Science, The University of Iowa, IA, USA Nov. 20, 2015 Yang Tutorial for ACML 15 Nov.
Accelerate Subgradient Methods
 Accelerate Subgradient Methods Tianbao Yang Department of Computer Science The University of Iowa Contributors: students Yi Xu, Yan Yan and colleague Qihang Lin Yang (CS@Uiowa) Accelerate Subgradient Methods
Accelerate Subgradient Methods Tianbao Yang Department of Computer Science The University of Iowa Contributors: students Yi Xu, Yan Yan and colleague Qihang Lin Yang (CS@Uiowa) Accelerate Subgradient Methods
Machine Learning CS 4900/5900. Lecture 03. Razvan C. Bunescu School of Electrical Engineering and Computer Science
 Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Machine Learning CS 4900/5900 Razvan C. Bunescu School of Electrical Engineering and Computer Science bunescu@ohio.edu Machine Learning is Optimization Parametric ML involves minimizing an objective function
Convex Optimization. (EE227A: UC Berkeley) Lecture 15. Suvrit Sra. (Gradient methods III) 12 March, 2013
 Lecture 15. Suvrit Sra. (Gradient methods III) 12 March, 2013") Convex Optimization (EE227A: UC Berkeley) Lecture 15 (Gradient methods III) 12 March, 2013 Suvrit Sra Optimal gradient methods 2 / 27 Optimal gradient methods We saw following efficiency estimates for
Convex Optimization (EE227A: UC Berkeley) Lecture 15 (Gradient methods III) 12 March, 2013 Suvrit Sra Optimal gradient methods 2 / 27 Optimal gradient methods We saw following efficiency estimates for
Optimization for Training I. First-Order Methods Training algorithm
 Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
Optimization for Training I First-Order Methods Training algorithm 2 OPTIMIZATION METHODS Topics: Types of optimization methods. Practical optimization methods breakdown into two categories: 1. First-order
A Brief Overview of Practical Optimization Algorithms in the Context of Relaxation
 A Brief Overview of Practical Optimization Algorithms in the Context of Relaxation Zhouchen Lin Peking University April 22, 2018 Too Many Opt. Problems! Too Many Opt. Algorithms! Zero-th order algorithms:
A Brief Overview of Practical Optimization Algorithms in the Context of Relaxation Zhouchen Lin Peking University April 22, 2018 Too Many Opt. Problems! Too Many Opt. Algorithms! Zero-th order algorithms:
Sparsity Regularization
 Sparsity Regularization Bangti Jin Course Inverse Problems & Imaging 1 / 41 Outline 1 Motivation: sparsity? 2 Mathematical preliminaries 3 l 1 solvers 2 / 41 problem setup finite-dimensional formulation
Sparsity Regularization Bangti Jin Course Inverse Problems & Imaging 1 / 41 Outline 1 Motivation: sparsity? 2 Mathematical preliminaries 3 l 1 solvers 2 / 41 problem setup finite-dimensional formulation
Journal Club. A Universal Catalyst for First-Order Optimization (H. Lin, J. Mairal and Z. Harchaoui) March 8th, CMAP, Ecole Polytechnique 1/19
 March 8th, CMAP, Ecole Polytechnique 1/19") Journal Club A Universal Catalyst for First-Order Optimization (H. Lin, J. Mairal and Z. Harchaoui) CMAP, Ecole Polytechnique March 8th, 2018 1/19 Plan 1 Motivations 2 Existing Acceleration Methods 3 Universal
Journal Club A Universal Catalyst for First-Order Optimization (H. Lin, J. Mairal and Z. Harchaoui) CMAP, Ecole Polytechnique March 8th, 2018 1/19 Plan 1 Motivations 2 Existing Acceleration Methods 3 Universal
Subgradient Method. Guest Lecturer: Fatma Kilinc-Karzan. Instructors: Pradeep Ravikumar, Aarti Singh Convex Optimization /36-725
 Subgradient Method Guest Lecturer: Fatma Kilinc-Karzan Instructors: Pradeep Ravikumar, Aarti Singh Convex Optimization 10-725/36-725 Adapted from slides from Ryan Tibshirani Consider the problem Recall:
Subgradient Method Guest Lecturer: Fatma Kilinc-Karzan Instructors: Pradeep Ravikumar, Aarti Singh Convex Optimization 10-725/36-725 Adapted from slides from Ryan Tibshirani Consider the problem Recall:
Subgradient Method. Ryan Tibshirani Convex Optimization
 Subgradient Method Ryan Tibshirani Convex Optimization 10-725 Consider the problem Last last time: gradient descent min x f(x) for f convex and differentiable, dom(f) = R n. Gradient descent: choose initial
Subgradient Method Ryan Tibshirani Convex Optimization 10-725 Consider the problem Last last time: gradient descent min x f(x) for f convex and differentiable, dom(f) = R n. Gradient descent: choose initial
Tutorial on: Optimization I. (from a deep learning perspective) Jimmy Ba
 Jimmy Ba") Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
Tutorial on: Optimization I (from a deep learning perspective) Jimmy Ba Outline Random search v.s. gradient descent Finding better search directions Design white-box optimization methods to improve computation
1. Gradient method. gradient method, first-order methods. quadratic bounds on convex functions. analysis of gradient method
 L. Vandenberghe EE236C (Spring 2016) 1. Gradient method gradient method, first-order methods quadratic bounds on convex functions analysis of gradient method 1-1 Approximate course outline First-order
L. Vandenberghe EE236C (Spring 2016) 1. Gradient method gradient method, first-order methods quadratic bounds on convex functions analysis of gradient method 1-1 Approximate course outline First-order
Oslo Class 6 Sparsity based regularization
 RegML2017@SIMULA Oslo Class 6 Sparsity based regularization Lorenzo Rosasco UNIGE-MIT-IIT May 4, 2017 Learning from data Possible only under assumptions regularization min Ê(w) + λr(w) w Smoothness Sparsity
RegML2017@SIMULA Oslo Class 6 Sparsity based regularization Lorenzo Rosasco UNIGE-MIT-IIT May 4, 2017 Learning from data Possible only under assumptions regularization min Ê(w) + λr(w) w Smoothness Sparsity
ORIE 4741: Learning with Big Messy Data. Proximal Gradient Method
 ORIE 4741: Learning with Big Messy Data Proximal Gradient Method Professor Udell Operations Research and Information Engineering Cornell November 13, 2017 1 / 31 Announcements Be a TA for CS/ORIE 1380:
ORIE 4741: Learning with Big Messy Data Proximal Gradient Method Professor Udell Operations Research and Information Engineering Cornell November 13, 2017 1 / 31 Announcements Be a TA for CS/ORIE 1380:
Linear Convergence under the Polyak-Łojasiewicz Inequality
 Linear Convergence under the Polyak-Łojasiewicz Inequality Hamed Karimi, Julie Nutini and Mark Schmidt The University of British Columbia LCI Forum February 28 th, 2017 1 / 17 Linear Convergence of Gradient-Based
Linear Convergence under the Polyak-Łojasiewicz Inequality Hamed Karimi, Julie Nutini and Mark Schmidt The University of British Columbia LCI Forum February 28 th, 2017 1 / 17 Linear Convergence of Gradient-Based
Proximal Newton Method. Zico Kolter (notes by Ryan Tibshirani) Convex Optimization
 Convex Optimization") Proximal Newton Method Zico Kolter (notes by Ryan Tibshirani) Convex Optimization 10-725 Consider the problem Last time: quasi-newton methods min x f(x) with f convex, twice differentiable, dom(f) = R
Proximal Newton Method Zico Kolter (notes by Ryan Tibshirani) Convex Optimization 10-725 Consider the problem Last time: quasi-newton methods min x f(x) with f convex, twice differentiable, dom(f) = R
Optimization for Learning and Big Data
 Optimization for Learning and Big Data Donald Goldfarb Department of IEOR Columbia University Department of Mathematics Distinguished Lecture Series May 17-19, 2016. Lecture 1. First-Order Methods for
Optimization for Learning and Big Data Donald Goldfarb Department of IEOR Columbia University Department of Mathematics Distinguished Lecture Series May 17-19, 2016. Lecture 1. First-Order Methods for
Frank-Wolfe Method. Ryan Tibshirani Convex Optimization
 Frank-Wolfe Method Ryan Tibshirani Convex Optimization 10-725 Last time: ADMM For the problem min x,z f(x) + g(z) subject to Ax + Bz = c we form augmented Lagrangian (scaled form): L ρ (x, z, w) = f(x)
Frank-Wolfe Method Ryan Tibshirani Convex Optimization 10-725 Last time: ADMM For the problem min x,z f(x) + g(z) subject to Ax + Bz = c we form augmented Lagrangian (scaled form): L ρ (x, z, w) = f(x)
Optimization. Benjamin Recht University of California, Berkeley Stephen Wright University of Wisconsin-Madison
 Optimization Benjamin Recht University of California, Berkeley Stephen Wright University of Wisconsin-Madison optimization () cost constraints might be too much to cover in 3 hours optimization (for big
Optimization Benjamin Recht University of California, Berkeley Stephen Wright University of Wisconsin-Madison optimization () cost constraints might be too much to cover in 3 hours optimization (for big
Day 3 Lecture 3. Optimizing deep networks
 Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
Day 3 Lecture 3 Optimizing deep networks Convex optimization A function is convex if for all α [0,1]: f(x) Tangent line Examples Quadratics 2-norms Properties Local minimum is global minimum x Gradient
IFT Lecture 6 Nesterov s Accelerated Gradient, Stochastic Gradient Descent
 IFT 6085 - Lecture 6 Nesterov s Accelerated Gradient, Stochastic Gradient Descent This version of the notes has not yet been thoroughly checked. Please report any bugs to the scribes or instructor. Scribe(s):
IFT 6085 - Lecture 6 Nesterov s Accelerated Gradient, Stochastic Gradient Descent This version of the notes has not yet been thoroughly checked. Please report any bugs to the scribes or instructor. Scribe(s):
Linear Convergence under the Polyak-Łojasiewicz Inequality
 Linear Convergence under the Polyak-Łojasiewicz Inequality Hamed Karimi, Julie Nutini, Mark Schmidt University of British Columbia Linear of Convergence of Gradient-Based Methods Fitting most machine learning
Linear Convergence under the Polyak-Łojasiewicz Inequality Hamed Karimi, Julie Nutini, Mark Schmidt University of British Columbia Linear of Convergence of Gradient-Based Methods Fitting most machine learning
Accelerated Block-Coordinate Relaxation for Regularized Optimization
 Accelerated Block-Coordinate Relaxation for Regularized Optimization Stephen J. Wright Computer Sciences University of Wisconsin, Madison October 09, 2012 Problem descriptions Consider where f is smooth
Accelerated Block-Coordinate Relaxation for Regularized Optimization Stephen J. Wright Computer Sciences University of Wisconsin, Madison October 09, 2012 Problem descriptions Consider where f is smooth
RegML 2018 Class 2 Tikhonov regularization and kernels
 RegML 2018 Class 2 Tikhonov regularization and kernels Lorenzo Rosasco UNIGE-MIT-IIT June 17, 2018 Learning problem Problem For H {f f : X Y }, solve min E(f), f H dρ(x, y)l(f(x), y) given S n = (x i,
RegML 2018 Class 2 Tikhonov regularization and kernels Lorenzo Rosasco UNIGE-MIT-IIT June 17, 2018 Learning problem Problem For H {f f : X Y }, solve min E(f), f H dρ(x, y)l(f(x), y) given S n = (x i,
Stochastic Subgradient Method
 Stochastic Subgradient Method Lingjie Weng, Yutian Chen Bren School of Information and Computer Science UC Irvine Subgradient Recall basic inequality for convex differentiable f : f y f x + f x T (y x)
Stochastic Subgradient Method Lingjie Weng, Yutian Chen Bren School of Information and Computer Science UC Irvine Subgradient Recall basic inequality for convex differentiable f : f y f x + f x T (y x)
Accelerated Dual Gradient-Based Methods for Total Variation Image Denoising/Deblurring Problems (and other Inverse Problems)
") Accelerated Dual Gradient-Based Methods for Total Variation Image Denoising/Deblurring Problems (and other Inverse Problems) Donghwan Kim and Jeffrey A. Fessler EECS Department, University of Michigan
Accelerated Dual Gradient-Based Methods for Total Variation Image Denoising/Deblurring Problems (and other Inverse Problems) Donghwan Kim and Jeffrey A. Fessler EECS Department, University of Michigan
Least Mean Squares Regression. Machine Learning Fall 2018
 Least Mean Squares Regression Machine Learning Fall 2018 1 Where are we? Least Squares Method for regression Examples The LMS objective Gradient descent Incremental/stochastic gradient descent Exercises
Least Mean Squares Regression Machine Learning Fall 2018 1 Where are we? Least Squares Method for regression Examples The LMS objective Gradient descent Incremental/stochastic gradient descent Exercises
Mirror Descent for Metric Learning. Gautam Kunapuli Jude W. Shavlik
 Mirror Descent for Metric Learning Gautam Kunapuli Jude W. Shavlik And what do we have here? We have a metric learning algorithm that uses composite mirror descent (COMID): Unifying framework for metric
Mirror Descent for Metric Learning Gautam Kunapuli Jude W. Shavlik And what do we have here? We have a metric learning algorithm that uses composite mirror descent (COMID): Unifying framework for metric
Stochastic and online algorithms
 Stochastic and online algorithms stochastic gradient method online optimization and dual averaging method minimizing finite average Stochastic and online optimization 6 1 Stochastic optimization problem
Stochastic and online algorithms stochastic gradient method online optimization and dual averaging method minimizing finite average Stochastic and online optimization 6 1 Stochastic optimization problem
Lecture 2 February 25th
 Statistical machine learning and convex optimization 06 Lecture February 5th Lecturer: Francis Bach Scribe: Guillaume Maillard, Nicolas Brosse This lecture deals with classical methods for convex optimization.
Statistical machine learning and convex optimization 06 Lecture February 5th Lecturer: Francis Bach Scribe: Guillaume Maillard, Nicolas Brosse This lecture deals with classical methods for convex optimization.
Second order machine learning
 Second order machine learning Michael W. Mahoney ICSI and Department of Statistics UC Berkeley Michael W. Mahoney (UC Berkeley) Second order machine learning 1 / 88 Outline Machine Learning s Inverse Problem
Second order machine learning Michael W. Mahoney ICSI and Department of Statistics UC Berkeley Michael W. Mahoney (UC Berkeley) Second order machine learning 1 / 88 Outline Machine Learning s Inverse Problem
Block Coordinate Descent for Regularized Multi-convex Optimization
 Block Coordinate Descent for Regularized Multi-convex Optimization Yangyang Xu and Wotao Yin CAAM Department, Rice University February 15, 2013 Multi-convex optimization Model definition Applications Outline
Block Coordinate Descent for Regularized Multi-convex Optimization Yangyang Xu and Wotao Yin CAAM Department, Rice University February 15, 2013 Multi-convex optimization Model definition Applications Outline
Regression Shrinkage and Selection via the Lasso
 Regression Shrinkage and Selection via the Lasso ROBERT TIBSHIRANI, 1996 Presenter: Guiyun Feng April 27 () 1 / 20 Motivation Estimation in Linear Models: y = β T x + ɛ. data (x i, y i ), i = 1, 2,...,
Regression Shrinkage and Selection via the Lasso ROBERT TIBSHIRANI, 1996 Presenter: Guiyun Feng April 27 () 1 / 20 Motivation Estimation in Linear Models: y = β T x + ɛ. data (x i, y i ), i = 1, 2,...,
Learning with stochastic proximal gradient
 Learning with stochastic proximal gradient Lorenzo Rosasco DIBRIS, Università di Genova Via Dodecaneso, 35 16146 Genova, Italy lrosasco@mit.edu Silvia Villa, Băng Công Vũ Laboratory for Computational and
Learning with stochastic proximal gradient Lorenzo Rosasco DIBRIS, Università di Genova Via Dodecaneso, 35 16146 Genova, Italy lrosasco@mit.edu Silvia Villa, Băng Công Vũ Laboratory for Computational and
ECS289: Scalable Machine Learning
 ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
ECS289: Scalable Machine Learning Cho-Jui Hsieh UC Davis Nov 2, 2016 Outline SGD-typed algorithms for Deep Learning Parallel SGD for deep learning Perceptron Prediction value for a training data: prediction
FAST DISTRIBUTED COORDINATE DESCENT FOR NON-STRONGLY CONVEX LOSSES. Olivier Fercoq Zheng Qu Peter Richtárik Martin Takáč
 FAST DISTRIBUTED COORDINATE DESCENT FOR NON-STRONGLY CONVEX LOSSES Olivier Fercoq Zheng Qu Peter Richtárik Martin Takáč School of Mathematics, University of Edinburgh, Edinburgh, EH9 3JZ, United Kingdom
FAST DISTRIBUTED COORDINATE DESCENT FOR NON-STRONGLY CONVEX LOSSES Olivier Fercoq Zheng Qu Peter Richtárik Martin Takáč School of Mathematics, University of Edinburgh, Edinburgh, EH9 3JZ, United Kingdom
Selected Topics in Optimization. Some slides borrowed from
 Selected Topics in Optimization Some slides borrowed from http://www.stat.cmu.edu/~ryantibs/convexopt/ Overview Optimization problems are almost everywhere in statistics and machine learning. Input Model
Selected Topics in Optimization Some slides borrowed from http://www.stat.cmu.edu/~ryantibs/convexopt/ Overview Optimization problems are almost everywhere in statistics and machine learning. Input Model
Worst-Case Complexity Guarantees and Nonconvex Smooth Optimization
 Worst-Case Complexity Guarantees and Nonconvex Smooth Optimization Frank E. Curtis, Lehigh University Beyond Convexity Workshop, Oaxaca, Mexico 26 October 2017 Worst-Case Complexity Guarantees and Nonconvex
Worst-Case Complexity Guarantees and Nonconvex Smooth Optimization Frank E. Curtis, Lehigh University Beyond Convexity Workshop, Oaxaca, Mexico 26 October 2017 Worst-Case Complexity Guarantees and Nonconvex
Non-convex optimization. Issam Laradji
 Non-convex optimization Issam Laradji Strongly Convex Objective function f(x) x Strongly Convex Objective function Assumptions Gradient Lipschitz continuous f(x) Strongly convex x Strongly Convex Objective
Non-convex optimization Issam Laradji Strongly Convex Objective function f(x) x Strongly Convex Objective function Assumptions Gradient Lipschitz continuous f(x) Strongly convex x Strongly Convex Objective
Lecture 6 : Projected Gradient Descent
 Lecture 6 : Projected Gradient Descent EE227C. Lecturer: Professor Martin Wainwright. Scribe: Alvin Wan Consider the following update. x l+1 = Π C (x l α f(x l )) Theorem Say f : R d R is (m, M)-strongly
Lecture 6 : Projected Gradient Descent EE227C. Lecturer: Professor Martin Wainwright. Scribe: Alvin Wan Consider the following update. x l+1 = Π C (x l α f(x l )) Theorem Say f : R d R is (m, M)-strongly
Sparse One Hidden Layer MLPs
 Sparse One Hidden Layer MLPs Alberto Torres, David Díaz and José R. Dorronsoro Universidad Autónoma de Madrid - Departamento de Ingeniería Informática Tomás y Valiente 11, 8049 Madrid - Spain Abstract.
Sparse One Hidden Layer MLPs Alberto Torres, David Díaz and José R. Dorronsoro Universidad Autónoma de Madrid - Departamento de Ingeniería Informática Tomás y Valiente 11, 8049 Madrid - Spain Abstract.
Optimization and Gradient Descent
 Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Optimization and Gradient Descent INFO-4604, Applied Machine Learning University of Colorado Boulder September 12, 2017 Prof. Michael Paul Prediction Functions Remember: a prediction function is the function
Statistical Machine Learning II Spring 2017, Learning Theory, Lecture 4
 Statistical Machine Learning II Spring 07, Learning Theory, Lecture 4 Jean Honorio jhonorio@purdue.edu Deterministic Optimization For brevity, everywhere differentiable functions will be called smooth.
Statistical Machine Learning II Spring 07, Learning Theory, Lecture 4 Jean Honorio jhonorio@purdue.edu Deterministic Optimization For brevity, everywhere differentiable functions will be called smooth.
Second order machine learning
 Second order machine learning Michael W. Mahoney ICSI and Department of Statistics UC Berkeley Michael W. Mahoney (UC Berkeley) Second order machine learning 1 / 96 Outline Machine Learning s Inverse Problem
Second order machine learning Michael W. Mahoney ICSI and Department of Statistics UC Berkeley Michael W. Mahoney (UC Berkeley) Second order machine learning 1 / 96 Outline Machine Learning s Inverse Problem
Coordinate Descent and Ascent Methods
 Coordinate Descent and Ascent Methods Julie Nutini Machine Learning Reading Group November 3 rd, 2015 1 / 22 Projected-Gradient Methods Motivation Rewrite non-smooth problem as smooth constrained problem:
Coordinate Descent and Ascent Methods Julie Nutini Machine Learning Reading Group November 3 rd, 2015 1 / 22 Projected-Gradient Methods Motivation Rewrite non-smooth problem as smooth constrained problem:
CS260: Machine Learning Algorithms
 CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
CS260: Machine Learning Algorithms Lecture 4: Stochastic Gradient Descent Cho-Jui Hsieh UCLA Jan 16, 2019 Large-scale Problems Machine learning: usually minimizing the training loss min w { 1 N min w {
Hamiltonian Descent Methods
 Hamiltonian Descent Methods Chris J. Maddison 1,2 with Daniel Paulin 1, Yee Whye Teh 1,2, Brendan O Donoghue 2, Arnaud Doucet 1 Department of Statistics University of Oxford 1 DeepMind London, UK 2 The
Hamiltonian Descent Methods Chris J. Maddison 1,2 with Daniel Paulin 1, Yee Whye Teh 1,2, Brendan O Donoghue 2, Arnaud Doucet 1 Department of Statistics University of Oxford 1 DeepMind London, UK 2 The
Dual Augmented Lagrangian, Proximal Minimization, and MKL
 Dual Augmented Lagrangian, Proximal Minimization, and MKL Ryota Tomioka 1, Taiji Suzuki 1, and Masashi Sugiyama 2 1 University of Tokyo 2 Tokyo Institute of Technology 2009-09-15 @ TU Berlin (UT / Tokyo
Dual Augmented Lagrangian, Proximal Minimization, and MKL Ryota Tomioka 1, Taiji Suzuki 1, and Masashi Sugiyama 2 1 University of Tokyo 2 Tokyo Institute of Technology 2009-09-15 @ TU Berlin (UT / Tokyo
Optimized first-order minimization methods
 Optimized first-order minimization methods Donghwan Kim & Jeffrey A. Fessler EECS Dept., BME Dept., Dept. of Radiology University of Michigan web.eecs.umich.edu/~fessler UM AIM Seminar 2014-10-03 1 Disclosure
Optimized first-order minimization methods Donghwan Kim & Jeffrey A. Fessler EECS Dept., BME Dept., Dept. of Radiology University of Michigan web.eecs.umich.edu/~fessler UM AIM Seminar 2014-10-03 1 Disclosure
Dual Proximal Gradient Method
 Dual Proximal Gradient Method http://bicmr.pku.edu.cn/~wenzw/opt-2016-fall.html Acknowledgement: this slides is based on Prof. Lieven Vandenberghes lecture notes Outline 2/19 1 proximal gradient method
Dual Proximal Gradient Method http://bicmr.pku.edu.cn/~wenzw/opt-2016-fall.html Acknowledgement: this slides is based on Prof. Lieven Vandenberghes lecture notes Outline 2/19 1 proximal gradient method
Accelerated gradient methods
 ELE 538B: Large-Scale Optimization for Data Science Accelerated gradient methods Yuxin Chen Princeton University, Spring 018 Outline Heavy-ball methods Nesterov s accelerated gradient methods Accelerated
ELE 538B: Large-Scale Optimization for Data Science Accelerated gradient methods Yuxin Chen Princeton University, Spring 018 Outline Heavy-ball methods Nesterov s accelerated gradient methods Accelerated
10. Unconstrained minimization
 Convex Optimization Boyd & Vandenberghe 10. Unconstrained minimization terminology and assumptions gradient descent method steepest descent method Newton s method self-concordant functions implementation
Convex Optimization Boyd & Vandenberghe 10. Unconstrained minimization terminology and assumptions gradient descent method steepest descent method Newton s method self-concordant functions implementation
MIT 9.520/6.860, Fall 2018 Statistical Learning Theory and Applications. Class 08: Sparsity Based Regularization. Lorenzo Rosasco
 MIT 9.520/6.860, Fall 2018 Statistical Learning Theory and Applications Class 08: Sparsity Based Regularization Lorenzo Rosasco Learning algorithms so far ERM + explicit l 2 penalty 1 min w R d n n l(y
MIT 9.520/6.860, Fall 2018 Statistical Learning Theory and Applications Class 08: Sparsity Based Regularization Lorenzo Rosasco Learning algorithms so far ERM + explicit l 2 penalty 1 min w R d n n l(y
Randomized Smoothing for Stochastic Optimization
 Randomized Smoothing for Stochastic Optimization John Duchi Peter Bartlett Martin Wainwright University of California, Berkeley NIPS Big Learn Workshop, December 2011 Duchi (UC Berkeley) Smoothing and
Randomized Smoothing for Stochastic Optimization John Duchi Peter Bartlett Martin Wainwright University of California, Berkeley NIPS Big Learn Workshop, December 2011 Duchi (UC Berkeley) Smoothing and
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Proximal-Gradient Mark Schmidt University of British Columbia Winter 2018 Admin Auditting/registration forms: Pick up after class today. Assignment 1: 2 late days to hand in
CPSC 540: Machine Learning Proximal-Gradient Mark Schmidt University of British Columbia Winter 2018 Admin Auditting/registration forms: Pick up after class today. Assignment 1: 2 late days to hand in
Generalized Conditional Gradient and Its Applications
 Generalized Conditional Gradient and Its Applications Yaoliang Yu University of Alberta UBC Kelowna, 04/18/13 Y-L. Yu (UofA) GCG and Its Apps. UBC Kelowna, 04/18/13 1 / 25 1 Introduction 2 Generalized
Generalized Conditional Gradient and Its Applications Yaoliang Yu University of Alberta UBC Kelowna, 04/18/13 Y-L. Yu (UofA) GCG and Its Apps. UBC Kelowna, 04/18/13 1 / 25 1 Introduction 2 Generalized
Accelerated Gradient Method for Multi-Task Sparse Learning Problem
 Accelerated Gradient Method for Multi-Task Sparse Learning Problem Xi Chen eike Pan James T. Kwok Jaime G. Carbonell School of Computer Science, Carnegie Mellon University Pittsburgh, U.S.A {xichen, jgc}@cs.cmu.edu
Accelerated Gradient Method for Multi-Task Sparse Learning Problem Xi Chen eike Pan James T. Kwok Jaime G. Carbonell School of Computer Science, Carnegie Mellon University Pittsburgh, U.S.A {xichen, jgc}@cs.cmu.edu
LARGE-SCALE NONCONVEX STOCHASTIC OPTIMIZATION BY DOUBLY STOCHASTIC SUCCESSIVE CONVEX APPROXIMATION
 LARGE-SCALE NONCONVEX STOCHASTIC OPTIMIZATION BY DOUBLY STOCHASTIC SUCCESSIVE CONVEX APPROXIMATION Aryan Mokhtari, Alec Koppel, Gesualdo Scutari, and Alejandro Ribeiro Department of Electrical and Systems
LARGE-SCALE NONCONVEX STOCHASTIC OPTIMIZATION BY DOUBLY STOCHASTIC SUCCESSIVE CONVEX APPROXIMATION Aryan Mokhtari, Alec Koppel, Gesualdo Scutari, and Alejandro Ribeiro Department of Electrical and Systems
Dual and primal-dual methods
 ELE 538B: Large-Scale Optimization for Data Science Dual and primal-dual methods Yuxin Chen Princeton University, Spring 2018 Outline Dual proximal gradient method Primal-dual proximal gradient method
ELE 538B: Large-Scale Optimization for Data Science Dual and primal-dual methods Yuxin Chen Princeton University, Spring 2018 Outline Dual proximal gradient method Primal-dual proximal gradient method
Lecture 6 Optimization for Deep Neural Networks
 Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
Lecture 6 Optimization for Deep Neural Networks CMSC 35246: Deep Learning Shubhendu Trivedi & Risi Kondor University of Chicago April 12, 2017 Things we will look at today Stochastic Gradient Descent Things
Smoothing Proximal Gradient Method. General Structured Sparse Regression
 for General Structured Sparse Regression Xi Chen, Qihang Lin, Seyoung Kim, Jaime G. Carbonell, Eric P. Xing (Annals of Applied Statistics, 2012) Gatsby Unit, Tea Talk October 25, 2013 Outline Motivation:
for General Structured Sparse Regression Xi Chen, Qihang Lin, Seyoung Kim, Jaime G. Carbonell, Eric P. Xing (Annals of Applied Statistics, 2012) Gatsby Unit, Tea Talk October 25, 2013 Outline Motivation:
Stochastic Gradient Descent
 Stochastic Gradient Descent Weihang Chen, Xingchen Chen, Jinxiu Liang, Cheng Xu, Zehao Chen and Donglin He March 26, 2017 Outline What is Stochastic Gradient Descent Comparison between BGD and SGD Analysis
Stochastic Gradient Descent Weihang Chen, Xingchen Chen, Jinxiu Liang, Cheng Xu, Zehao Chen and Donglin He March 26, 2017 Outline What is Stochastic Gradient Descent Comparison between BGD and SGD Analysis
On Acceleration with Noise-Corrupted Gradients. + m k 1 (x). By the definition of Bregman divergence:
. By the definition of Bregman divergence:") A Omitted Proofs from Section 3 Proof of Lemma 3 Let m x) = a i On Acceleration with Noise-Corrupted Gradients fxi ), u x i D ψ u, x 0 ) denote the function under the minimum in the lower bound By Proposition
A Omitted Proofs from Section 3 Proof of Lemma 3 Let m x) = a i On Acceleration with Noise-Corrupted Gradients fxi ), u x i D ψ u, x 0 ) denote the function under the minimum in the lower bound By Proposition
The FTRL Algorithm with Strongly Convex Regularizers
 CSE599s, Spring 202, Online Learning Lecture 8-04/9/202 The FTRL Algorithm with Strongly Convex Regularizers Lecturer: Brandan McMahan Scribe: Tamara Bonaci Introduction In the last lecture, we talked
CSE599s, Spring 202, Online Learning Lecture 8-04/9/202 The FTRL Algorithm with Strongly Convex Regularizers Lecturer: Brandan McMahan Scribe: Tamara Bonaci Introduction In the last lecture, we talked
Support Vector Machines: Training with Stochastic Gradient Descent. Machine Learning Fall 2017
 Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem
Support Vector Machines: Training with Stochastic Gradient Descent Machine Learning Fall 2017 1 Support vector machines Training by maximizing margin The SVM objective Solving the SVM optimization problem