Optimal Deep Learning and the Information Bottleneck method
|
|
|
- Elvin Lewis
- 6 years ago
- Views:
Transcription


1 1 Optimal Deep Learning and the Information Bottleneck method ICRI-CI retreat, Haifa, May 2015 Naftali Tishby Noga Zaslavsky School of Engineering and Computer Science The Edmond & Lily Safra Center for Brain Sciences Hebrew University, Jerusalem, Israel
 Minimal sufficient statistics DPI & Centroid consistency The IB complexity-accuracy")
2 Outline Deep Neural Networks and Deep Learning What are Deep Neural Networks (DNN)? The incredible success of DNN s Theoretical challenges The Information Bottleneck method Finding (approximate) Minimal sufficient statistics DPI & Centroid consistency The IB complexity-accuracy tradeoff The nature of the optimal solutions IB bifurcations Bifurcation Theory of Deep Neural Networks Statistical characterizations of Neural Nets Learning optimality and sample complexity bound The connection between NN layers and IB phase transitions Design principles for optimal DNN s 3

3 Deep Learning: Neural-Nets strike back 3




4 4

5 We desperately need a Theory Why DNN s work so well? How can they be improved? Optimality bounds What is an optimal DNN? Sample and computational complexity bounds Design principles What determines the number & width of the layers? What determines the connectivity and inter-layer connections? Interpretability What do the layers/neurons capture/represent? Better learning algorithms Is stochastic gradient descent the best we can do? 5

6 Deep Neural Nets and Information Theory?? From causal to predictive systems 6
7 Outline Deep Neural Networks and Deep Learning What are Deep Neural Networks (DNN)? The incredible success of DNN s Theoretical challenges The Information Bottleneck method Finding (approximate) Minimal sufficient statistics DPI & Centroid consistency The IB complexity-accuracy tradeoff The nature of the optimal solutions IB bifurcations Bifurcation Theory of Deep Neural Networks Statistical characterizations of Neural Nets Learning optimality bound The connection between NN layers and IB phase transitions Design principles for optimal DNN s 3
8 The Information Bottleneck Method (Tishby, Pereira, Bialek, 1999) (1) Approximate Minimal Sufficient Statistics: Markov chain: Y X S( X ) Xˆ arg min I( S( X ); X ) S ( X ): I ( S ( X ); Y ) I ( X ; Y ) Relaxation - given p( X, Y ) : p( xˆ x) Xˆ Xˆ arg min I( Xˆ ; X ) I( Xˆ ; Y ), (Shamir, Sabato,T., TCS 2010) 0 (2) A Rate-Distortion problem with KL- divergence distortion: d ( x, x ˆ) [ ( ) ( ˆ IB D p y x p y x )] (Bachrach, Navot,T., COLT 2006) (3) The ONLY distributional qun a tization measure which satisfy both DPI ( Harremoes-T., ISIT 2008) (f-divergences) and Statistical Consistency (Bregman divergences) 8
9 The Information Bottleneck Method (Tishby, Pereira, Bialek, 1999) The IB optimality/stationarity equations: min ( ˆ; ) ( ˆ; ), 0 p( xˆ x):y X Xˆ I X X I X Y px ( ) p( x xˆ) exp( D[ p( y x) p( y xˆ]) Z( x, ) Z( x, ) ˆ ( ˆ)exp( [ ( ) ( ˆ x p x D p y x p y x]) p( xˆ) ( ˆ x p x x) p( x) py ( xˆ ) (y ) ( ˆ x p x p x x) Solved b y Arimoto-Blahut like iterations, but with possibly sub-optimal solutions (!), similar to K-means distributional-clustering with centroids update. 9
10 I T3 F (I T3 P) I T2 F (I T2 P) I( XY ˆ ; ) I T1 F (I T1 P) The limit is always RD like concave envelope with sub-optimal bifurcations I( X; Xˆ ) 10
11 Critical points are 2 nd order phase transitions 11
12 The IB bifurcation (phase-transitions) points The IB bifurcation points can be found as follows: px ( ) ln p( x xˆ) ln D[ p( y x) p( y xˆ)] Z( x, ) then: ln p( x xˆ) ln p(y xˆ) py ( x) y xˆ xˆ ln p(y xˆ ) 1 ln p( x xˆ ) p( y x) p( x xˆ ) x xˆ p( y xˆ) xˆ these equations can be combined into two (non-linear) eigenvalue problems: ln p( x xˆ ) I CX ( xˆ, ) 0 xˆ ln p(y xˆ ) I CY ( xˆ, ) 0 xˆ These eigenvalue problems have non-trivial solutions (eigenvectors) only at the critical bifurcation points (second order phase transitions). 12
13 1 1 ( xˆ ) ( C ( xˆ, ) ( C ( xˆ, ) c 2 X c 2 Y c 13
14 IB bifurcation diagram 1 1 ( xˆ ) ( C ( xˆ, ) ( C ( xˆ, ) c 2 X c 2 Y c 14
15 Outline Deep Neural Networks and Deep Learning What are Deep Neural Networks (DNN)? The incredible success of DNN s Theoretical challenges The Information Bottleneck method Finding (approximate) Minimal sufficient statistics DPI & Centroid consistency The IB complexity-accuracy tradeoff The nature of the optimal solutions IB bifurcations Bifurcation Theory of Deep Neural Networks Statistical characterizations of Neural Nets Learning optimality and sample complexity bound The connection between NN layers and IB phase transitions Design principles for optimal DNN s 3
16 DNN s and the Information Bottleneck Linearly separable units, (pos. stochastic): ln p(h h ) h W h b(h ) T i i i1 i1 i i ln p(h i h i1) h i1 i Wh i Near the optimal IB curve: The inter-layer mapping is of exponential form : ln p(h h ) h W h a(h ) T i i1 i i1 i i1 ln p(h i h i1) ln px ( xˆ ) h xˆ i1 i W - is the i-th layer connection matrix. with h i a x and h i1 a xˆ 16
17 DNN s and the Information Bottleneck Near the optimal IB curve: ln p(h i h i1) ln px ( xˆ ) h xˆ i1 with h i a x and h i1 a xˆ But on the optimal IB curve there is a non-trivial derivative only at the IB bifurcation points: ln p(h i h i1) = Wh i i hi (h, ) where v ( x h, ) is the second eigenvector of the bifurcation matrix: i c ( ˆ C ˆ v 2 ln p( x xˆ ) I CX x, ) I c X ( x, c) ( x, c ) 0 xˆ v i c This provides an equation for the optimal weights: i v2( h i, c) W h i h i 0 17

18 Optimal design principles Output layer Hidden layers 18

19 Sample complexity bounds 20
20 Real DNN s on the IB plane 21
21 Summary An Information Theory of Deep Neural Networks Based on the Information Bottleneck (IB) tradeoff Uniquely and consistently quantifies the hidden layers The optimal hidden layers correspond to IB bifurcation points New spectral algorithm for finding the IB bifurcation points Determines number and width of the optimal DNN layers New spectral learning rule: Weights are derived from 2 nd eigenvector New design principles and finite sample complexity bounds Network structure is determined from the bifurcation diagram Finite sample bounds from mutual-information estimation bounds Stochastic networks are proved to be optimal (in terms of complexity) Possible implications on real (biological) layered networks. 21
Deep Learning and Information Theory
 Deep Learning and Information Theory Bhumesh Kumar (13D070060) Alankar Kotwal (12D070010) November 21, 2016 Abstract T he machine learning revolution has recently led to the development of a new flurry
Deep Learning and Information Theory Bhumesh Kumar (13D070060) Alankar Kotwal (12D070010) November 21, 2016 Abstract T he machine learning revolution has recently led to the development of a new flurry
arxiv:physics/ v1 [physics.data-an] 24 Apr 2000 Naftali Tishby, 1,2 Fernando C. Pereira, 3 and William Bialek 1
![arxiv:physics/ v1 [physics.data-an] 24 Apr 2000 Naftali Tishby, 1,2 Fernando C. Pereira, 3 and William Bialek 1](/thumbs/74/70237419.jpg "arxiv:physics/ v1 [physics.data-an] 24 Apr 2000 Naftali Tishby, 1,2 Fernando C. Pereira, 3 and William Bialek 1") The information bottleneck method arxiv:physics/0004057v1 [physics.data-an] 24 Apr 2000 Naftali Tishby, 1,2 Fernando C. Pereira, 3 and William Bialek 1 1 NEC Research Institute, 4 Independence Way Princeton,
The information bottleneck method arxiv:physics/0004057v1 [physics.data-an] 24 Apr 2000 Naftali Tishby, 1,2 Fernando C. Pereira, 3 and William Bialek 1 1 NEC Research Institute, 4 Independence Way Princeton,
the Information Bottleneck
 the Information Bottleneck Daniel Moyer December 10, 2017 Imaging Genetics Center/Information Science Institute University of Southern California Sorry, no Neuroimaging! (at least not presented) 0 Instead,
the Information Bottleneck Daniel Moyer December 10, 2017 Imaging Genetics Center/Information Science Institute University of Southern California Sorry, no Neuroimaging! (at least not presented) 0 Instead,
arxiv: v2 [cs.lg] 9 Mar 2017
![arxiv: v2 [cs.lg] 9 Mar 2017](/thumbs/93/113066568.jpg "arxiv: v2 [cs.lg] 9 Mar 2017") Opening the Black Box of Deep Neural Networks via Information Ravid Shwartz-Ziv 1 Naftali Tishby 1 2 arxiv:1703.00810v2 [cs.lg] 9 Mar 2017 Abstract Despite their great success, there is still no comprehensive
Opening the Black Box of Deep Neural Networks via Information Ravid Shwartz-Ziv 1 Naftali Tishby 1 2 arxiv:1703.00810v2 [cs.lg] 9 Mar 2017 Abstract Despite their great success, there is still no comprehensive
Information Bottleneck for Gaussian Variables
 Information Bottleneck for Gaussian Variables Gal Chechik Amir Globerson Naftali Tishby Yair Weiss {ggal,gamir,tishby,yweiss}@cs.huji.ac.il School of Computer Science and Engineering and The Interdisciplinary
Information Bottleneck for Gaussian Variables Gal Chechik Amir Globerson Naftali Tishby Yair Weiss {ggal,gamir,tishby,yweiss}@cs.huji.ac.il School of Computer Science and Engineering and The Interdisciplinary
The Information Bottleneck Revisited or How to Choose a Good Distortion Measure
 The Information Bottleneck Revisited or How to Choose a Good Distortion Measure Peter Harremoës Centrum voor Wiskunde en Informatica PO 94079, 1090 GB Amsterdam The Nederlands PHarremoes@cwinl Naftali
The Information Bottleneck Revisited or How to Choose a Good Distortion Measure Peter Harremoës Centrum voor Wiskunde en Informatica PO 94079, 1090 GB Amsterdam The Nederlands PHarremoes@cwinl Naftali
Optimal predictive inference
 Optimal predictive inference Susanne Still University of Hawaii at Manoa Information and Computer Sciences S. Still, J. P. Crutchfield. Structure or Noise? http://lanl.arxiv.org/abs/0708.0654 S. Still,
Optimal predictive inference Susanne Still University of Hawaii at Manoa Information and Computer Sciences S. Still, J. P. Crutchfield. Structure or Noise? http://lanl.arxiv.org/abs/0708.0654 S. Still,
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Sequence Modelling with Features: Linear-Chain Conditional Random Fields. COMP-599 Oct 6, 2015
 Sequence Modelling with Features: Linear-Chain Conditional Random Fields COMP-599 Oct 6, 2015 Announcement A2 is out. Due Oct 20 at 1pm. 2 Outline Hidden Markov models: shortcomings Generative vs. discriminative
Sequence Modelling with Features: Linear-Chain Conditional Random Fields COMP-599 Oct 6, 2015 Announcement A2 is out. Due Oct 20 at 1pm. 2 Outline Hidden Markov models: shortcomings Generative vs. discriminative
Complex Systems Methods 3. Statistical complexity of temporal sequences
 Complex Systems Methods 3. Statistical complexity of temporal sequences Eckehard Olbrich MPI MiS Leipzig Potsdam WS 2007/08 Olbrich (Leipzig) 02.11.2007 1 / 24 Overview 1 Summary Kolmogorov sufficient
Complex Systems Methods 3. Statistical complexity of temporal sequences Eckehard Olbrich MPI MiS Leipzig Potsdam WS 2007/08 Olbrich (Leipzig) 02.11.2007 1 / 24 Overview 1 Summary Kolmogorov sufficient
Bioinformatics: Biology X
 Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA Model Building/Checking, Reverse Engineering, Causality Outline 1 Bayesian Interpretation of Probabilities 2 Where (or of what)
Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA Model Building/Checking, Reverse Engineering, Causality Outline 1 Bayesian Interpretation of Probabilities 2 Where (or of what)
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
A minimalist s exposition of EM
 A minimalist s exposition of EM Karl Stratos 1 What EM optimizes Let O, H be a random variables representing the space of samples. Let be the parameter of a generative model with an associated probability
A minimalist s exposition of EM Karl Stratos 1 What EM optimizes Let O, H be a random variables representing the space of samples. Let be the parameter of a generative model with an associated probability
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning
 REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
The connection of dropout and Bayesian statistics
 The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
The connection of dropout and Bayesian statistics Interpretation of dropout as approximate Bayesian modelling of NN http://mlg.eng.cam.ac.uk/yarin/thesis/thesis.pdf Dropout Geoffrey Hinton Google, University
A brief introduction to Conditional Random Fields
 A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
Greedy Layer-Wise Training of Deep Networks
 Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
Greedy Layer-Wise Training of Deep Networks Yoshua Bengio, Pascal Lamblin, Dan Popovici, Hugo Larochelle NIPS 2007 Presented by Ahmed Hefny Story so far Deep neural nets are more expressive: Can learn
U Logo Use Guidelines
 Information Theory Lecture 3: Applications to Machine Learning U Logo Use Guidelines Mark Reid logo is a contemporary n of our heritage. presents our name, d and our motto: arn the nature of things. authenticity
Information Theory Lecture 3: Applications to Machine Learning U Logo Use Guidelines Mark Reid logo is a contemporary n of our heritage. presents our name, d and our motto: arn the nature of things. authenticity
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning
 Neural Networks and Deep Learning") Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Apprentissage, réseaux de neurones et modèles graphiques (RCP209) Neural Networks and Deep Learning Nicolas Thome Prenom.Nom@cnam.fr http://cedric.cnam.fr/vertigo/cours/ml2/ Département Informatique Conservatoire
Quiz 2 Date: Monday, November 21, 2016
 10-704 Information Processing and Learning Fall 2016 Quiz 2 Date: Monday, November 21, 2016 Name: Andrew ID: Department: Guidelines: 1. PLEASE DO NOT TURN THIS PAGE UNTIL INSTRUCTED. 2. Write your name,
10-704 Information Processing and Learning Fall 2016 Quiz 2 Date: Monday, November 21, 2016 Name: Andrew ID: Department: Guidelines: 1. PLEASE DO NOT TURN THIS PAGE UNTIL INSTRUCTED. 2. Write your name,
Reinforcement Learning as Variational Inference: Two Recent Approaches
 Reinforcement Learning as Variational Inference: Two Recent Approaches Rohith Kuditipudi Duke University 11 August 2017 Outline 1 Background 2 Stein Variational Policy Gradient 3 Soft Q-Learning 4 Closing
Reinforcement Learning as Variational Inference: Two Recent Approaches Rohith Kuditipudi Duke University 11 August 2017 Outline 1 Background 2 Stein Variational Policy Gradient 3 Soft Q-Learning 4 Closing
Introduction to Restricted Boltzmann Machines
 Introduction to Restricted Boltzmann Machines Ilija Bogunovic and Edo Collins EPFL {ilija.bogunovic,edo.collins}@epfl.ch October 13, 2014 Introduction Ingredients: 1. Probabilistic graphical models (undirected,
Introduction to Restricted Boltzmann Machines Ilija Bogunovic and Edo Collins EPFL {ilija.bogunovic,edo.collins}@epfl.ch October 13, 2014 Introduction Ingredients: 1. Probabilistic graphical models (undirected,
UNSUPERVISED LEARNING
 UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
UNSUPERVISED LEARNING Topics Layer-wise (unsupervised) pre-training Restricted Boltzmann Machines Auto-encoders LAYER-WISE (UNSUPERVISED) PRE-TRAINING Breakthrough in 2006 Layer-wise (unsupervised) pre-training
Introduction to Machine Learning
 Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Introduction to Machine Learning Neural Networks Varun Chandola x x 5 Input Outline Contents February 2, 207 Extending Perceptrons 2 Multi Layered Perceptrons 2 2. Generalizing to Multiple Labels.................
Trading value and information in MDPs
 Trading value and information in MDPs Jonathan Rubin, Ohad Shamir and Naftali Tishby Abstract Interactions between an organism and its environment are commonly treated in the framework of Markov Decision
Trading value and information in MDPs Jonathan Rubin, Ohad Shamir and Naftali Tishby Abstract Interactions between an organism and its environment are commonly treated in the framework of Markov Decision
The Origin of Deep Learning. Lili Mou Jan, 2015
 The Origin of Deep Learning Lili Mou Jan, 2015 Acknowledgment Most of the materials come from G. E. Hinton s online course. Outline Introduction Preliminary Boltzmann Machines and RBMs Deep Belief Nets
The Origin of Deep Learning Lili Mou Jan, 2015 Acknowledgment Most of the materials come from G. E. Hinton s online course. Outline Introduction Preliminary Boltzmann Machines and RBMs Deep Belief Nets
Graphical models for part of speech tagging
 Indian Institute of Technology, Bombay and Research Division, India Research Lab Graphical models for part of speech tagging Different Models for POS tagging HMM Maximum Entropy Markov Models Conditional
Indian Institute of Technology, Bombay and Research Division, India Research Lab Graphical models for part of speech tagging Different Models for POS tagging HMM Maximum Entropy Markov Models Conditional
Efficiently Training Sum-Product Neural Networks using Forward Greedy Selection
 Efficiently Training Sum-Product Neural Networks using Forward Greedy Selection Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Greedy Algorithms, Frank-Wolfe and Friends
Efficiently Training Sum-Product Neural Networks using Forward Greedy Selection Shai Shalev-Shwartz School of CS and Engineering, The Hebrew University of Jerusalem Greedy Algorithms, Frank-Wolfe and Friends
ECE521 Lectures 9 Fully Connected Neural Networks
 ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
ECE521 Lectures 9 Fully Connected Neural Networks Outline Multi-class classification Learning multi-layer neural networks 2 Measuring distance in probability space We learnt that the squared L2 distance
Lecture 2: Logistic Regression and Neural Networks
 1/23 Lecture 2: and Neural Networks Pedro Savarese TTI 2018 2/23 Table of Contents 1 2 3 4 3/23 Naive Bayes Learn p(x, y) = p(y)p(x y) Training: Maximum Likelihood Estimation Issues? Why learn p(x, y)
1/23 Lecture 2: and Neural Networks Pedro Savarese TTI 2018 2/23 Table of Contents 1 2 3 4 3/23 Naive Bayes Learn p(x, y) = p(y)p(x y) Training: Maximum Likelihood Estimation Issues? Why learn p(x, y)
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Unraveling the mysteries of stochastic gradient descent on deep neural networks
 Unraveling the mysteries of stochastic gradient descent on deep neural networks Pratik Chaudhari UCLA VISION LAB 1 The question measures disagreement of predictions with ground truth Cat Dog... x = argmin
Unraveling the mysteries of stochastic gradient descent on deep neural networks Pratik Chaudhari UCLA VISION LAB 1 The question measures disagreement of predictions with ground truth Cat Dog... x = argmin
Chapter 11. Stochastic Methods Rooted in Statistical Mechanics
 Chapter 11. Stochastic Methods Rooted in Statistical Mechanics Neural Networks and Learning Machines (Haykin) Lecture Notes on Self-learning Neural Algorithms Byoung-Tak Zhang School of Computer Science
Chapter 11. Stochastic Methods Rooted in Statistical Mechanics Neural Networks and Learning Machines (Haykin) Lecture Notes on Self-learning Neural Algorithms Byoung-Tak Zhang School of Computer Science
COMP 551 Applied Machine Learning Lecture 14: Neural Networks
 COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
COMP 551 Applied Machine Learning Lecture 14: Neural Networks Instructor: Ryan Lowe (ryan.lowe@mail.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted,
Machine Learning Basics III
 Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
J. Sadeghi E. Patelli M. de Angelis
 J. Sadeghi E. Patelli Institute for Risk and, Department of Engineering, University of Liverpool, United Kingdom 8th International Workshop on Reliable Computing, Computing with Confidence University of
J. Sadeghi E. Patelli Institute for Risk and, Department of Engineering, University of Liverpool, United Kingdom 8th International Workshop on Reliable Computing, Computing with Confidence University of
Chapter 16. Structured Probabilistic Models for Deep Learning
 Peng et al.: Deep Learning and Practice 1 Chapter 16 Structured Probabilistic Models for Deep Learning Peng et al.: Deep Learning and Practice 2 Structured Probabilistic Models way of using graphs to describe
Peng et al.: Deep Learning and Practice 1 Chapter 16 Structured Probabilistic Models for Deep Learning Peng et al.: Deep Learning and Practice 2 Structured Probabilistic Models way of using graphs to describe
Online solution of the average cost Kullback-Leibler optimization problem
 Online solution of the average cost Kullback-Leibler optimization problem Joris Bierkens Radboud University Nijmegen j.bierkens@science.ru.nl Bert Kappen Radboud University Nijmegen b.kappen@science.ru.nl
Online solution of the average cost Kullback-Leibler optimization problem Joris Bierkens Radboud University Nijmegen j.bierkens@science.ru.nl Bert Kappen Radboud University Nijmegen b.kappen@science.ru.nl
Lecture 15: MCMC Sanjeev Arora Elad Hazan. COS 402 Machine Learning and Artificial Intelligence Fall 2016
 Lecture 15: MCMC Sanjeev Arora Elad Hazan COS 402 Machine Learning and Artificial Intelligence Fall 2016 Course progress Learning from examples Definition + fundamental theorem of statistical learning,
Lecture 15: MCMC Sanjeev Arora Elad Hazan COS 402 Machine Learning and Artificial Intelligence Fall 2016 Course progress Learning from examples Definition + fundamental theorem of statistical learning,
Sequential Supervised Learning
 Sequential Supervised Learning Many Application Problems Require Sequential Learning Part-of of-speech Tagging Information Extraction from the Web Text-to to-speech Mapping Part-of of-speech Tagging Given
Sequential Supervised Learning Many Application Problems Require Sequential Learning Part-of of-speech Tagging Information Extraction from the Web Text-to to-speech Mapping Part-of of-speech Tagging Given
Basic Principles of Unsupervised and Unsupervised
 Basic Principles of Unsupervised and Unsupervised Learning Toward Deep Learning Shun ichi Amari (RIKEN Brain Science Institute) collaborators: R. Karakida, M. Okada (U. Tokyo) Deep Learning Self Organization
Basic Principles of Unsupervised and Unsupervised Learning Toward Deep Learning Shun ichi Amari (RIKEN Brain Science Institute) collaborators: R. Karakida, M. Okada (U. Tokyo) Deep Learning Self Organization
Computational Systems Biology: Biology X
 Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA L#8:(November-08-2010) Cancer and Signals Outline 1 Bayesian Interpretation of Probabilities Information Theory Outline Bayesian
Bud Mishra Room 1002, 715 Broadway, Courant Institute, NYU, New York, USA L#8:(November-08-2010) Cancer and Signals Outline 1 Bayesian Interpretation of Probabilities Information Theory Outline Bayesian
Learning Tetris. 1 Tetris. February 3, 2009
 Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Distributed Estimation, Information Loss and Exponential Families. Qiang Liu Department of Computer Science Dartmouth College
 Distributed Estimation, Information Loss and Exponential Families Qiang Liu Department of Computer Science Dartmouth College Statistical Learning / Estimation Learning generative models from data Topic
Distributed Estimation, Information Loss and Exponential Families Qiang Liu Department of Computer Science Dartmouth College Statistical Learning / Estimation Learning generative models from data Topic
Gaussian Mixture Models
 Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Gaussian Mixture Models Pradeep Ravikumar Co-instructor: Manuela Veloso Machine Learning 10-701 Some slides courtesy of Eric Xing, Carlos Guestrin (One) bad case for K- means Clusters may overlap Some
Computer Intensive Methods in Mathematical Statistics
 Computer Intensive Methods in Mathematical Statistics Department of mathematics johawes@kth.se Lecture 16 Advanced topics in computational statistics 18 May 2017 Computer Intensive Methods (1) Plan of
Computer Intensive Methods in Mathematical Statistics Department of mathematics johawes@kth.se Lecture 16 Advanced topics in computational statistics 18 May 2017 Computer Intensive Methods (1) Plan of
Artifical Neural Networks
 Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Neural Networks Artifical Neural Networks Neural Networks Biological Neural Networks.................................. Artificial Neural Networks................................... 3 ANN Structure...........................................
Structured Prediction
 Structured Prediction Classification Algorithms Classify objects x X into labels y Y First there was binary: Y = {0, 1} Then multiclass: Y = {1,...,6} The next generation: Structured Labels Structured
Structured Prediction Classification Algorithms Classify objects x X into labels y Y First there was binary: Y = {0, 1} Then multiclass: Y = {1,...,6} The next generation: Structured Labels Structured
A Variance Modeling Framework Based on Variational Autoencoders for Speech Enhancement
 A Variance Modeling Framework Based on Variational Autoencoders for Speech Enhancement Simon Leglaive 1 Laurent Girin 1,2 Radu Horaud 1 1: Inria Grenoble Rhône-Alpes 2: Univ. Grenoble Alpes, Grenoble INP,
A Variance Modeling Framework Based on Variational Autoencoders for Speech Enhancement Simon Leglaive 1 Laurent Girin 1,2 Radu Horaud 1 1: Inria Grenoble Rhône-Alpes 2: Univ. Grenoble Alpes, Grenoble INP,
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Pattern Recognition and Machine Learning. Bishop Chapter 11: Sampling Methods
 Pattern Recognition and Machine Learning Chapter 11: Sampling Methods Elise Arnaud Jakob Verbeek May 22, 2008 Outline of the chapter 11.1 Basic Sampling Algorithms 11.2 Markov Chain Monte Carlo 11.3 Gibbs
Pattern Recognition and Machine Learning Chapter 11: Sampling Methods Elise Arnaud Jakob Verbeek May 22, 2008 Outline of the chapter 11.1 Basic Sampling Algorithms 11.2 Markov Chain Monte Carlo 11.3 Gibbs
Dynamical Systems and Deep Learning: Overview. Abbas Edalat
 Dynamical Systems and Deep Learning: Overview Abbas Edalat Dynamical Systems The notion of a dynamical system includes the following: A phase or state space, which may be continuous, e.g. the real line,
Dynamical Systems and Deep Learning: Overview Abbas Edalat Dynamical Systems The notion of a dynamical system includes the following: A phase or state space, which may be continuous, e.g. the real line,
CISC 889 Bioinformatics (Spring 2004) Hidden Markov Models (II)
 Hidden Markov Models (II)") CISC 889 Bioinformatics (Spring 24) Hidden Markov Models (II) a. Likelihood: forward algorithm b. Decoding: Viterbi algorithm c. Model building: Baum-Welch algorithm Viterbi training Hidden Markov models
CISC 889 Bioinformatics (Spring 24) Hidden Markov Models (II) a. Likelihood: forward algorithm b. Decoding: Viterbi algorithm c. Model building: Baum-Welch algorithm Viterbi training Hidden Markov models
Lecture 9: PGM Learning
 13 Oct 2014 Intro. to Stats. Machine Learning COMP SCI 4401/7401 Table of Contents I Learning parameters in MRFs 1 Learning parameters in MRFs Inference and Learning Given parameters (of potentials) and
13 Oct 2014 Intro. to Stats. Machine Learning COMP SCI 4401/7401 Table of Contents I Learning parameters in MRFs 1 Learning parameters in MRFs Inference and Learning Given parameters (of potentials) and
Deep Learning book, by Ian Goodfellow, Yoshua Bengio and Aaron Courville
 Deep Learning book, by Ian Goodfellow, Yoshua Bengio and Aaron Courville Chapter 6 :Deep Feedforward Networks Benoit Massé Dionyssos Kounades-Bastian Benoit Massé, Dionyssos Kounades-Bastian Deep Feedforward
Deep Learning book, by Ian Goodfellow, Yoshua Bengio and Aaron Courville Chapter 6 :Deep Feedforward Networks Benoit Massé Dionyssos Kounades-Bastian Benoit Massé, Dionyssos Kounades-Bastian Deep Feedforward
COMP9444 Neural Networks and Deep Learning 11. Boltzmann Machines. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 11. Boltzmann Machines COMP9444 17s2 Boltzmann Machines 1 Outline Content Addressable Memory Hopfield Network Generative Models Boltzmann Machine Restricted Boltzmann
COMP9444 Neural Networks and Deep Learning 11. Boltzmann Machines COMP9444 17s2 Boltzmann Machines 1 Outline Content Addressable Memory Hopfield Network Generative Models Boltzmann Machine Restricted Boltzmann
Artificial Neural Networks. MGS Lecture 2
 Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Artificial Neural Networks MGS 2018 - Lecture 2 OVERVIEW Biological Neural Networks Cell Topology: Input, Output, and Hidden Layers Functional description Cost functions Training ANNs Back-Propagation
Deep Feedforward Networks. Lecture slides for Chapter 6 of Deep Learning Ian Goodfellow Last updated
 Deep Feedforward Networks Lecture slides for Chapter 6 of Deep Learning www.deeplearningbook.org Ian Goodfellow Last updated 2016-10-04 Roadmap Example: Learning XOR Gradient-Based Learning Hidden Units
Deep Feedforward Networks Lecture slides for Chapter 6 of Deep Learning www.deeplearningbook.org Ian Goodfellow Last updated 2016-10-04 Roadmap Example: Learning XOR Gradient-Based Learning Hidden Units
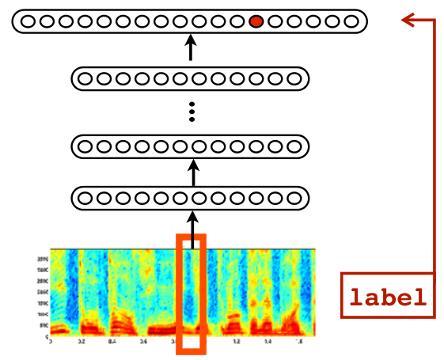
Extracting relevant structures
 Chapter 5 Extracting relevant structures A key problem in understanding auditory coding is to identify the acoustic features that neurons at various levels of the system code. If we can map the relevant
Chapter 5 Extracting relevant structures A key problem in understanding auditory coding is to identify the acoustic features that neurons at various levels of the system code. If we can map the relevant
MGMT 69000: Topics in High-dimensional Data Analysis Falll 2016
 MGMT 69000: Topics in High-dimensional Data Analysis Falll 2016 Lecture 14: Information Theoretic Methods Lecturer: Jiaming Xu Scribe: Hilda Ibriga, Adarsh Barik, December 02, 2016 Outline f-divergence
MGMT 69000: Topics in High-dimensional Data Analysis Falll 2016 Lecture 14: Information Theoretic Methods Lecturer: Jiaming Xu Scribe: Hilda Ibriga, Adarsh Barik, December 02, 2016 Outline f-divergence
Machine Learning Lecture 5
 Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Machine Learning Lecture 5 Linear Discriminant Functions 26.10.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Course Outline Fundamentals Bayes Decision Theory
Clustering. Professor Ameet Talwalkar. Professor Ameet Talwalkar CS260 Machine Learning Algorithms March 8, / 26
 Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Clustering Professor Ameet Talwalkar Professor Ameet Talwalkar CS26 Machine Learning Algorithms March 8, 217 1 / 26 Outline 1 Administration 2 Review of last lecture 3 Clustering Professor Ameet Talwalkar
Probabilistic Graphical Models
 School of Computer Science Probabilistic Graphical Models Variational Inference II: Mean Field Method and Variational Principle Junming Yin Lecture 15, March 7, 2012 X 1 X 1 X 1 X 1 X 2 X 3 X 2 X 2 X 3
School of Computer Science Probabilistic Graphical Models Variational Inference II: Mean Field Method and Variational Principle Junming Yin Lecture 15, March 7, 2012 X 1 X 1 X 1 X 1 X 2 X 3 X 2 X 2 X 3
Probabilistic Reasoning in Deep Learning
 Probabilistic Reasoning in Deep Learning Dr Konstantina Palla, PhD palla@stats.ox.ac.uk September 2017 Deep Learning Indaba, Johannesburgh Konstantina Palla 1 / 39 OVERVIEW OF THE TALK Basics of Bayesian
Probabilistic Reasoning in Deep Learning Dr Konstantina Palla, PhD palla@stats.ox.ac.uk September 2017 Deep Learning Indaba, Johannesburgh Konstantina Palla 1 / 39 OVERVIEW OF THE TALK Basics of Bayesian
3. If a choice is broken down into two successive choices, the original H should be the weighted sum of the individual values of H.
 Appendix A Information Theory A.1 Entropy Shannon (Shanon, 1948) developed the concept of entropy to measure the uncertainty of a discrete random variable. Suppose X is a discrete random variable that
Appendix A Information Theory A.1 Entropy Shannon (Shanon, 1948) developed the concept of entropy to measure the uncertainty of a discrete random variable. Suppose X is a discrete random variable that
Bayesian Networks Inference with Probabilistic Graphical Models
 4190.408 2016-Spring Bayesian Networks Inference with Probabilistic Graphical Models Byoung-Tak Zhang intelligence Lab Seoul National University 4190.408 Artificial (2016-Spring) 1 Machine Learning? Learning
4190.408 2016-Spring Bayesian Networks Inference with Probabilistic Graphical Models Byoung-Tak Zhang intelligence Lab Seoul National University 4190.408 Artificial (2016-Spring) 1 Machine Learning? Learning
Unsupervised Neural Nets
 Unsupervised Neural Nets (and ICA) Lyle Ungar (with contributions from Quoc Le, Socher & Manning) Lyle Ungar, University of Pennsylvania Semi-Supervised Learning Hypothesis:%P(c x)%can%be%more%accurately%computed%using%
Unsupervised Neural Nets (and ICA) Lyle Ungar (with contributions from Quoc Le, Socher & Manning) Lyle Ungar, University of Pennsylvania Semi-Supervised Learning Hypothesis:%P(c x)%can%be%more%accurately%computed%using%
Leo Kadanoff and 2d XY Models with Symmetry-Breaking Fields. renormalization group study of higher order gradients, cosines and vortices
 Leo Kadanoff and d XY Models with Symmetry-Breaking Fields renormalization group study of higher order gradients, cosines and vortices Leo Kadanoff and Random Matrix Theory Non-Hermitian Localization in
Leo Kadanoff and d XY Models with Symmetry-Breaking Fields renormalization group study of higher order gradients, cosines and vortices Leo Kadanoff and Random Matrix Theory Non-Hermitian Localization in
Distributed Bayesian Learning with Stochastic Natural-gradient EP and the Posterior Server
 Distributed Bayesian Learning with Stochastic Natural-gradient EP and the Posterior Server in collaboration with: Minjie Xu, Balaji Lakshminarayanan, Leonard Hasenclever, Thibaut Lienart, Stefan Webb,
Distributed Bayesian Learning with Stochastic Natural-gradient EP and the Posterior Server in collaboration with: Minjie Xu, Balaji Lakshminarayanan, Leonard Hasenclever, Thibaut Lienart, Stefan Webb,
CSC2541 Lecture 5 Natural Gradient
 CSC2541 Lecture 5 Natural Gradient Roger Grosse Roger Grosse CSC2541 Lecture 5 Natural Gradient 1 / 12 Motivation Two classes of optimization procedures used throughout ML (stochastic) gradient descent,
CSC2541 Lecture 5 Natural Gradient Roger Grosse Roger Grosse CSC2541 Lecture 5 Natural Gradient 1 / 12 Motivation Two classes of optimization procedures used throughout ML (stochastic) gradient descent,
Neural Networks and Deep Learning
 Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Neural Networks and Deep Learning Professor Ameet Talwalkar November 12, 2015 Professor Ameet Talwalkar Neural Networks and Deep Learning November 12, 2015 1 / 16 Outline 1 Review of last lecture AdaBoost
Machine Learning
 Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Machine Learning 10-315 Maria Florina Balcan Machine Learning Department Carnegie Mellon University 03/29/2019 Today: Artificial neural networks Backpropagation Reading: Mitchell: Chapter 4 Bishop: Chapter
Neural Networks. Intro to AI Bert Huang Virginia Tech
 Neural Networks Intro to AI Bert Huang Virginia Tech Outline Biological inspiration for artificial neural networks Linear vs. nonlinear functions Learning with neural networks: back propagation https://en.wikipedia.org/wiki/neuron#/media/file:chemical_synapse_schema_cropped.jpg
Neural Networks Intro to AI Bert Huang Virginia Tech Outline Biological inspiration for artificial neural networks Linear vs. nonlinear functions Learning with neural networks: back propagation https://en.wikipedia.org/wiki/neuron#/media/file:chemical_synapse_schema_cropped.jpg
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Introduction to Neural Networks
 Introduction to Neural Networks Steve Renals Automatic Speech Recognition ASR Lecture 10 24 February 2014 ASR Lecture 10 Introduction to Neural Networks 1 Neural networks for speech recognition Introduction
Introduction to Neural Networks Steve Renals Automatic Speech Recognition ASR Lecture 10 24 February 2014 ASR Lecture 10 Introduction to Neural Networks 1 Neural networks for speech recognition Introduction
Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm
 Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm Qiang Liu and Dilin Wang NIPS 2016 Discussion by Yunchen Pu March 17, 2017 March 17, 2017 1 / 8 Introduction Let x R d
Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm Qiang Liu and Dilin Wang NIPS 2016 Discussion by Yunchen Pu March 17, 2017 March 17, 2017 1 / 8 Introduction Let x R d
Non-negative Matrix Factorization: Algorithms, Extensions and Applications
 Non-negative Matrix Factorization: Algorithms, Extensions and Applications Emmanouil Benetos www.soi.city.ac.uk/ sbbj660/ March 2013 Emmanouil Benetos Non-negative Matrix Factorization March 2013 1 / 25
Non-negative Matrix Factorization: Algorithms, Extensions and Applications Emmanouil Benetos www.soi.city.ac.uk/ sbbj660/ March 2013 Emmanouil Benetos Non-negative Matrix Factorization March 2013 1 / 25
Chapter 20. Deep Generative Models
 Peng et al.: Deep Learning and Practice 1 Chapter 20 Deep Generative Models Peng et al.: Deep Learning and Practice 2 Generative Models Models that are able to Provide an estimate of the probability distribution
Peng et al.: Deep Learning and Practice 1 Chapter 20 Deep Generative Models Peng et al.: Deep Learning and Practice 2 Generative Models Models that are able to Provide an estimate of the probability distribution
Mixture Models & EM. Nicholas Ruozzi University of Texas at Dallas. based on the slides of Vibhav Gogate
 Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
Mixture Models & EM icholas Ruozzi University of Texas at Dallas based on the slides of Vibhav Gogate Previously We looed at -means and hierarchical clustering as mechanisms for unsupervised learning -means
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014
 UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014 Exam policy: This exam allows two one-page, two-sided cheat sheets (i.e. 4 sides); No other materials. Time: 2 hours. Be sure to write
UNIVERSITY of PENNSYLVANIA CIS 520: Machine Learning Final, Fall 2014 Exam policy: This exam allows two one-page, two-sided cheat sheets (i.e. 4 sides); No other materials. Time: 2 hours. Be sure to write
Neural Networks (Part 1) Goals for the lecture
 Goals for the lecture") Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Neural Networks (Part ) Mark Craven and David Page Computer Sciences 760 Spring 208 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed
Covariance and Correlation Matrix
 Covariance and Correlation Matrix Given sample {x n } N 1, where x Rd, x n = x 1n x 2n. x dn sample mean x = 1 N N n=1 x n, and entries of sample mean are x i = 1 N N n=1 x in sample covariance matrix
Covariance and Correlation Matrix Given sample {x n } N 1, where x Rd, x n = x 1n x 2n. x dn sample mean x = 1 N N n=1 x n, and entries of sample mean are x i = 1 N N n=1 x in sample covariance matrix
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 5
 Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 5 Slides adapted from Jordan Boyd-Graber, Tom Mitchell, Ziv Bar-Joseph Machine Learning: Chenhao Tan Boulder 1 of 27 Quiz question For
Machine Learning: Chenhao Tan University of Colorado Boulder LECTURE 5 Slides adapted from Jordan Boyd-Graber, Tom Mitchell, Ziv Bar-Joseph Machine Learning: Chenhao Tan Boulder 1 of 27 Quiz question For
Plan. Perceptron Linear discriminant. Associative memories Hopfield networks Chaotic networks. Multilayer perceptron Backpropagation
 Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Neural Networks Plan Perceptron Linear discriminant Associative memories Hopfield networks Chaotic networks Multilayer perceptron Backpropagation Perceptron Historically, the first neural net Inspired
Data Mining and Analysis: Fundamental Concepts and Algorithms
 : Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA 2 Department of Computer
: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki 1 Wagner Meira Jr. 2 1 Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA 2 Department of Computer
Neural Network Training
 Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Neural Network Training Sargur Srihari Topics in Network Training 0. Neural network parameters Probabilistic problem formulation Specifying the activation and error functions for Regression Binary classification
Non-Convex Optimization in Machine Learning. Jan Mrkos AIC
 Non-Convex Optimization in Machine Learning Jan Mrkos AIC The Plan 1. Introduction 2. Non convexity 3. (Some) optimization approaches 4. Speed and stuff? Neural net universal approximation Theorem (1989):
Non-Convex Optimization in Machine Learning Jan Mrkos AIC The Plan 1. Introduction 2. Non convexity 3. (Some) optimization approaches 4. Speed and stuff? Neural net universal approximation Theorem (1989):
Probabilistic Models for Sequence Labeling
 Probabilistic Models for Sequence Labeling Besnik Fetahu June 9, 2011 Besnik Fetahu () Probabilistic Models for Sequence Labeling June 9, 2011 1 / 26 Background & Motivation Problem introduction Generative
Probabilistic Models for Sequence Labeling Besnik Fetahu June 9, 2011 Besnik Fetahu () Probabilistic Models for Sequence Labeling June 9, 2011 1 / 26 Background & Motivation Problem introduction Generative
Case Study 1: Estimating Click Probabilities. Kakade Announcements: Project Proposals: due this Friday!
 Case Study 1: Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 4, 017 1 Announcements:
Case Study 1: Estimating Click Probabilities Intro Logistic Regression Gradient Descent + SGD Machine Learning for Big Data CSE547/STAT548, University of Washington Sham Kakade April 4, 017 1 Announcements:
Deep Learning. What Is Deep Learning? The Rise of Deep Learning. Long History (in Hind Sight)
") CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
CSCE 636 Neural Networks Instructor: Yoonsuck Choe Deep Learning What Is Deep Learning? Learning higher level abstractions/representations from data. Motivation: how the brain represents sensory information
11. Learning graphical models
 Learning graphical models 11-1 11. Learning graphical models Maximum likelihood Parameter learning Structural learning Learning partially observed graphical models Learning graphical models 11-2 statistical
Learning graphical models 11-1 11. Learning graphical models Maximum likelihood Parameter learning Structural learning Learning partially observed graphical models Learning graphical models 11-2 statistical
Undirected Graphical Models
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Multilayer Perceptron
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Single Perceptron 3 Boolean Function Learning 4
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Ch 4. Linear Models for Classification
 Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Ch 4. Linear Models for Classification Pattern Recognition and Machine Learning, C. M. Bishop, 2006. Department of Computer Science and Engineering Pohang University of Science and echnology 77 Cheongam-ro,
Statistical Data Mining and Machine Learning Hilary Term 2016
 Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Statistical Data Mining and Machine Learning Hilary Term 2016 Dino Sejdinovic Department of Statistics Oxford Slides and other materials available at: http://www.stats.ox.ac.uk/~sejdinov/sdmml Naïve Bayes
Stochastic Gradient Descent
 Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
Stochastic Gradient Descent Machine Learning CSE546 Carlos Guestrin University of Washington October 9, 2013 1 Logistic Regression Logistic function (or Sigmoid): Learn P(Y X) directly Assume a particular
CS60010: Deep Learning
 CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
CS60010: Deep Learning Sudeshna Sarkar Spring 2018 16 Jan 2018 FFN Goal: Approximate some unknown ideal function f : X! Y Ideal classifier: y = f*(x) with x and category y Feedforward Network: Define parametric
Learning MN Parameters with Approximation. Sargur Srihari
 Learning MN Parameters with Approximation Sargur srihari@cedar.buffalo.edu 1 Topics Iterative exact learning of MN parameters Difficulty with exact methods Approximate methods Approximate Inference Belief
Learning MN Parameters with Approximation Sargur srihari@cedar.buffalo.edu 1 Topics Iterative exact learning of MN parameters Difficulty with exact methods Approximate methods Approximate Inference Belief