Reinforcement Learning as Variational Inference: Two Recent Approaches
|
|
|
- Gary Casey
- 6 years ago
- Views:
Transcription
1 Reinforcement Learning as Variational Inference: Two Recent Approaches Rohith Kuditipudi Duke University 11 August 2017
2 Outline 1 Background 2 Stein Variational Policy Gradient 3 Soft Q-Learning 4 Closing Thoughts/Takeaways
3 Outline 1 Background 2 Stein Variational Policy Gradient 3 Soft Q-Learning 4 Closing Thoughts/Takeaways
4 Background: Reinforcement Learning A Markov Decision Process (MDP) is a tuple (S, A, p, r, γ), where: S is the state space A is the action space p(s t+1 s t, a t ) is the probability of the next state s t+1 S given the current state s t S and action a t A taken by the agent r : S A [r min, r max ] is the reward function γ [0, 1] is the discount factor A policy π( s t ) is a distribution over A conditioned on the current state s t The goal of reinforcement learning is to learn a policy π that maximizes the total expected (discounted) reward J(π), where: [ ] J(π) = E (st,at) π γ t r(s t, a t ) t=0
5 Background: Stein Variational Gradient Descent (SVGD) SVGD 1 is a variational inference algorithm that iteratively transports a set of particles {x i } n i=1 to match a target distribution at each step, particles are updated as follows: x i x i + ɛφ(x i ) where ɛ is the step size and φ is a perturbation direction chosen to greedily minimize KL divergence with target distribution By restricting φ to lie in the unit ball of an RKHS with corresponding kernel k, we can obtain a closed form solution for the optimal perturbation direction... 1 Q. Liu and D. Wang. Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm.
6 Background: Stein Variational Gradient Descent (SVGD) Input : A target distribution with density function p(x) and a set of initial particles {x 0 i }n i=1 Output: A set of particles {x i } n i=1 that approximates the target distribution for iteration l do x l+1 i x l i + ɛ l ˆφ (x l i ) where φ (x l i ) = 1 ] n n j=1 [k(x l j, x) x lj log p(xl j ) + x lj k(xl j, x) and ɛ l is the step size at the l-th iteration end Algorithm 1: Stein Variational Gradient Descent (SVGD)
7 Outline 1 Background 2 Stein Variational Policy Gradient 3 Soft Q-Learning 4 Closing Thoughts/Takeaways
8 Stein Variational Policy Gradient 2 : Preliminaries Policy iteration: parametrize policy as π(a t s t ; θ) and iteratively update θ to maximize J(π(a t s t ; θ)) (a.k.a. J(θ)) MaxEnt Policy Optimization: instead of searching for a single policy θ, optimize a distribution q on θ as follows: max q { Eq(θ) [J(θ)] αd KL (q q 0 ) } where q 0 is a prior on θ. If q 0 = constant, then the objective simplifies to { max Eq(θ) [J(θ)] + αh(q) } q where H(q) is the entropy of q Optimal distribution is ( ) 1 q(θ) exp α J(θ)q 0(θ) 2 Liu et al. Stein Variational Policy Gradient.
9 Stein Variational Policy Gradient: Algorithm Input: Learning rate ɛ, kernel k(x, x ), temperature α, initial particles {θ i } for t = 0, 1,..., T do for i = 0, 1,...n do Compute θi J(θ i ) (using RL method of choice) end for i = 0, 1,...n do θ i = 1 n [ ( 1 n j=1 θj α J(θ j) + log q 0 (θ j ) ) k(θ j, θ i ) + θj k(θ j, θ i ) ] θ i θ i + ɛ θ i end end Algorithm 2: Stein Variational Policy Gradient (SVPG)

10 Stein Variational Policy Gradient: Results

11 Stein Variational Policy Gradient: Results

12 Stein Variational Policy Gradient: Results
13 Stein Variational Policy Gradient: Results

14 Stein Variational Policy Gradient: Results
15 Outline 1 Background 2 Stein Variational Policy Gradient 3 Soft Q-Learning 4 Closing Thoughts/Takeaways
16 Soft Q-Learning 3 : Preliminaries Recall the standard RL objective (assuming γ = 1): π std = arg max π E (st,at) π[r(s t, a t )] t In MaxEnt RL, we augment the reward with an entropy term that encourages exploration: πmaxent = arg max E (st,a π t) π[r(s t, a t ) + αh(π( s t ))] t Note: when γ 1, the MaxEnt RL objective becomes: [ ] arg max E (st,at) π γ l t E (sl,a l )[r(s l, a l ) + αh(π( s l )) s t, a t ] π t l=t 3 Haarnoja et al. Reinforcement Learning with Deep Energy-Based Policies.
17 Soft Q-Learning: Preliminaries Theorem Let the soft Q-function be defined by [ ] Q soft (s t, a t ) = r t + E π MaxEnt γ l (r t+l + αh(πmaxent ( s t+l))) and soft value function by Vsoft (s t) = α log then l=1 A exp ( Q soft (s t, a ) ) da ( ) 1 πmaxent (s t, a t ) = exp α (Q soft (s t, a t ) Vsoft (s t))
18 Soft Q-Learning: Preliminaries Theorem The soft Q-function satisfies the soft Bellman equation Q soft (s t, a t ) = r t + γe st+1 p[v soft (s t+1)] Theorem (Soft Q-iteration) Let Q soft (, ) and V soft ( ) be bounded and assume that A exp( 1 α Q soft(, a ))da < and that Q soft < exists. Then the fixed point iteration Q soft (s t, a t ) r t + γe st+1 p[v soft (s t+1 )], s t, a t V soft (s t ) α log exp( 1 A α Q soft(s t, a ))da, s t converges to Q soft and V soft respectively.
19 Soft Q-Learning: Soft Q-iteration in Practice In practice, we model the Soft Q function using a function approximator with parameters θ, denoted as Q θ soft To convert Soft Q Iteration into a stochastic optimization problem, we can re-express V soft (s t ) as an expectation via importance sampling (instead of an integral) as follows: [ exp( Vsoft θ 1 (s α t) = α log E Qθ soft (s ] t, a )) q q(a ) where q is the sampling distribution (e.g. current policy) Furthermore, we can update Q soft to minimize [ 1 ( ] 2 J Q (θ) = E ˆQ θsoft (st,at) q (s t, a t ) Q θ soft 2 (s t, a t )) where ˆQ θ soft (s t, a t ) = r t + γe st+1 p[v θ soft (s t+1 )]
20 Soft Q-Learning: Sampling from Soft Q-function Goal: learn a state-conditioned stochastic neural network a t = f φ (ξ; s t ), with parameters φ, that maps Gaussian noise ξ to unbiased action samples from EBM specified by Q θ soft Specifically, we want to minimize the following loss: ( )) 1 J π (φ; s t ) = D KL (π φ ( s t ) exp α (Qθ soft(s t, ) Vsoft(s θ t )) where π φ ( s t ) is the action distribution induced by φ Strategy: Sample actions a (i) t = f φ (ξ (i) ; s t ) and use SVGD to compute optimal greedy perturbations f φ (ξ (i) ; s t ) to minimize J π (φ; s t ), where: f φ (ξ (i) ; s t ) = E at π φ [κ(a t, f φ (ξ (i) ; s t )) a Q θ soft (s t, a ) a =a t + α a κ(a, f φ (ξ (i) ; s t )) a =a t ]
21 Soft Q-Learning: Sampling from Soft Q-function Stein variational gradient can be backpropagated into sampling network using: J π (φ; s t ) φ And so we have: ˆ φ J π (φ; s t ) = 1 KM [ E ξ f φ (ξ; s t ) f φ ] (ξ; s t ) φ K M ( j=1 i=1 κ(a (i) t + α a κ(a, ã (j) t ) a =a (i) t, ã (j) t ) a Q θ soft (s t, a ) a =a (i) t ) φ f φ ( ξ (j) ; s t ) the ultimate update direction ˆ φ J π (φ) is the average of ˆ φ J π (φ; s t ) over a mini-batch sampled from replay memory
22 Soft Q-Learning: Algorithm for each epoch do for each t do Collect Experience a t f φ (ξ, s t) where ξ N (0, I) s t+1 p(s t+1 a t, s t) D D {s t, a t, r(s t, a t), s t+1 } Sample minibatch from replay memory {s (i) t, a (i) t, r (i) t, s (i) t+1 }N i=0 D Update soft Q-function parameters Sample {a (i,j) } M j=0 q for each s(i) t+1 Compute ˆV θ soft (s (i) t+1 ) and ˆ θ J Q, update θ using ADAM Update policy Sample {ξ (i,j) } M j=0 N (0, I) for each s(i) t Compute actions a (i,j) t = f φ (ξ (i,j), s (i) t ) Compute f φ and ˆ φ J π, update φ using ADAM end if epoch mod update interval = 0 then Update target parameters: θ θ, φ φ end end Algorithm 3: Soft Q-Learning
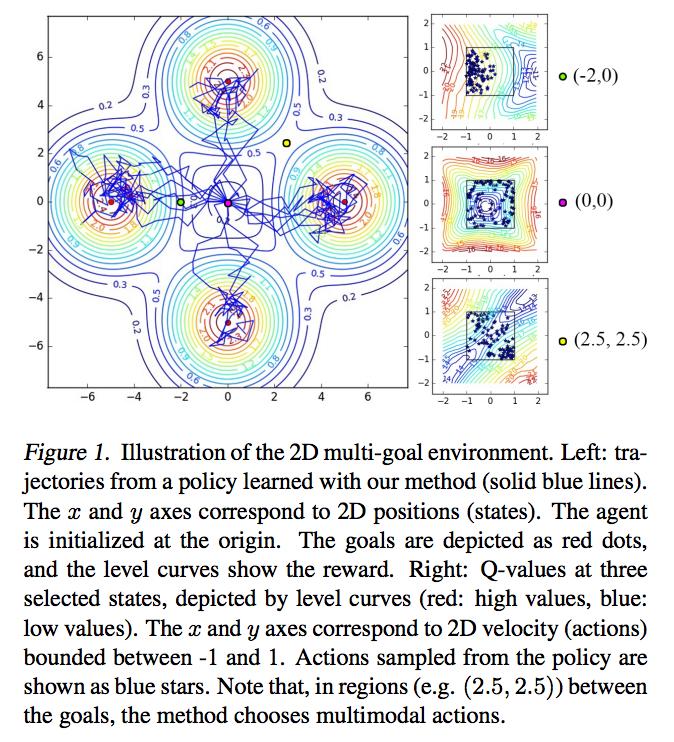
23 Soft Q-Learning: Results

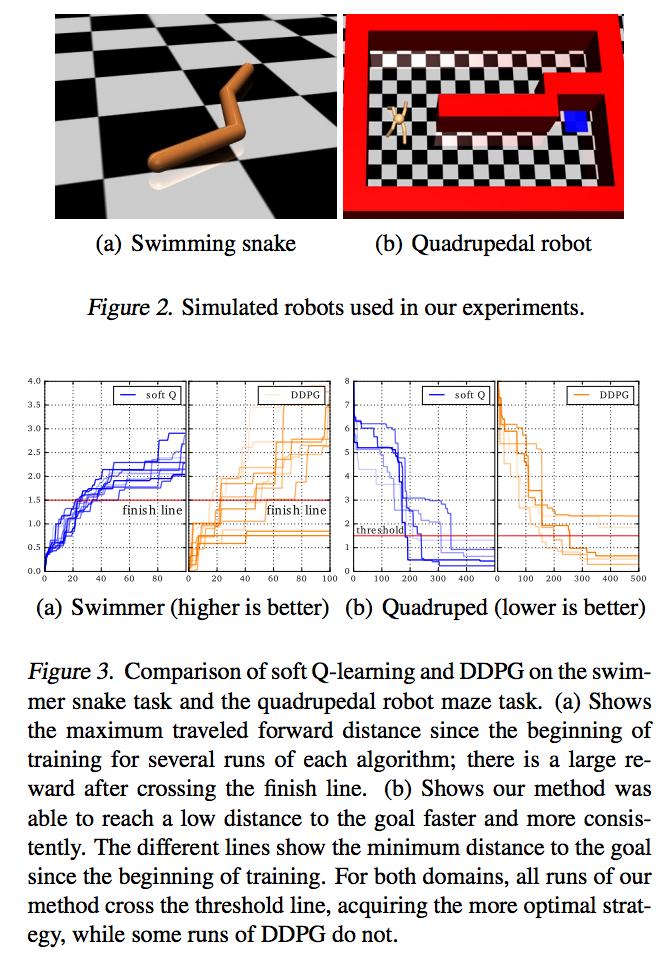
24 Soft Q-Learning: Results
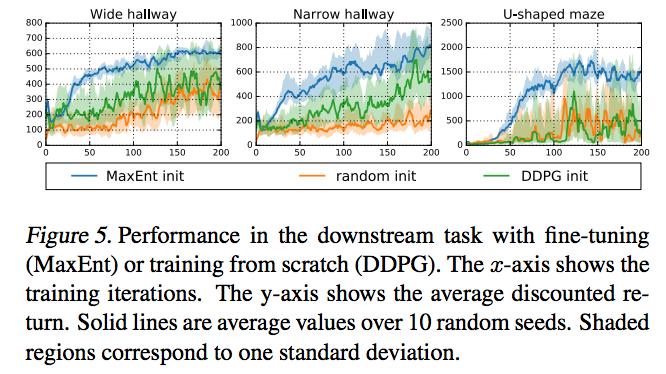
25 Soft Q-Learning: Results
26 Outline 1 Background 2 Stein Variational Policy Gradient 3 Soft Q-Learning 4 Closing Thoughts/Takeaways
Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm
 Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm Qiang Liu and Dilin Wang NIPS 2016 Discussion by Yunchen Pu March 17, 2017 March 17, 2017 1 / 8 Introduction Let x R d
Stein Variational Gradient Descent: A General Purpose Bayesian Inference Algorithm Qiang Liu and Dilin Wang NIPS 2016 Discussion by Yunchen Pu March 17, 2017 March 17, 2017 1 / 8 Introduction Let x R d
Reinforcement Learning. Donglin Zeng, Department of Biostatistics, University of North Carolina
 Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning Introduction Introduction Unsupervised learning has no outcome (no feedback). Supervised learning has outcome so we know what to predict. Reinforcement learning is in between it
Reinforcement Learning and NLP
 1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
1 Reinforcement Learning and NLP Kapil Thadani kapil@cs.columbia.edu RESEARCH Outline 2 Model-free RL Markov decision processes (MDPs) Derivative-free optimization Policy gradients Variance reduction Value
Reinforcement Learning
 Reinforcement Learning Policy gradients Daniel Hennes 26.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Policy based reinforcement learning So far we approximated the action value
Reinforcement Learning Policy gradients Daniel Hennes 26.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Policy based reinforcement learning So far we approximated the action value
Introduction to Reinforcement Learning. CMPT 882 Mar. 18
 Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
Introduction to Reinforcement Learning CMPT 882 Mar. 18 Outline for the week Basic ideas in RL Value functions and value iteration Policy evaluation and policy improvement Model-free RL Monte-Carlo and
REINFORCEMENT LEARNING
 REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
REINFORCEMENT LEARNING Larry Page: Where s Google going next? DeepMind's DQN playing Breakout Contents Introduction to Reinforcement Learning Deep Q-Learning INTRODUCTION TO REINFORCEMENT LEARNING Contents
CS Deep Reinforcement Learning HW5: Soft Actor-Critic Due November 14th, 11:59 pm
 CS294-112 Deep Reinforcement Learning HW5: Soft Actor-Critic Due November 14th, 11:59 pm 1 Introduction For this homework, you get to choose among several topics to investigate. Each topic corresponds
CS294-112 Deep Reinforcement Learning HW5: Soft Actor-Critic Due November 14th, 11:59 pm 1 Introduction For this homework, you get to choose among several topics to investigate. Each topic corresponds
Energy-Based Generative Adversarial Network
 Energy-Based Generative Adversarial Network Energy-Based Generative Adversarial Network J. Zhao, M. Mathieu and Y. LeCun Learning to Draw Samples: With Application to Amoritized MLE for Generalized Adversarial
Energy-Based Generative Adversarial Network Energy-Based Generative Adversarial Network J. Zhao, M. Mathieu and Y. LeCun Learning to Draw Samples: With Application to Amoritized MLE for Generalized Adversarial
Christopher Watkins and Peter Dayan. Noga Zaslavsky. The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015
 November 1, 2015") Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
Q-Learning Christopher Watkins and Peter Dayan Noga Zaslavsky The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (67679) November 1, 2015 Noga Zaslavsky Q-Learning (Watkins & Dayan, 1992)
CSC321 Lecture 22: Q-Learning
 CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
CSC321 Lecture 22: Q-Learning Roger Grosse Roger Grosse CSC321 Lecture 22: Q-Learning 1 / 21 Overview Second of 3 lectures on reinforcement learning Last time: policy gradient (e.g. REINFORCE) Optimize
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning
 REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
REINFORCE Framework for Stochastic Policy Optimization and its use in Deep Learning Ronen Tamari The Hebrew University of Jerusalem Advanced Seminar in Deep Learning (#67679) February 28, 2016 Ronen Tamari
Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms *
 Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms
Proceedings of the 8 th International Conference on Applied Informatics Eger, Hungary, January 27 30, 2010. Vol. 1. pp. 87 94. Using Gaussian Processes for Variance Reduction in Policy Gradient Algorithms
arxiv: v2 [cs.lg] 21 Jul 2017
![arxiv: v2 [cs.lg] 21 Jul 2017](/thumbs/75/72685092.jpg "arxiv: v2 [cs.lg] 21 Jul 2017") Tuomas Haarnoja * 1 Haoran Tang * 2 Pieter Abbeel 1 3 4 Sergey Levine 1 arxiv:172.816v2 [cs.lg] 21 Jul 217 Abstract We propose a method for learning expressive energy-based policies for continuous states
Tuomas Haarnoja * 1 Haoran Tang * 2 Pieter Abbeel 1 3 4 Sergey Levine 1 arxiv:172.816v2 [cs.lg] 21 Jul 217 Abstract We propose a method for learning expressive energy-based policies for continuous states
Lecture 10 - Planning under Uncertainty (III)
") Lecture 10 - Planning under Uncertainty (III) Jesse Hoey School of Computer Science University of Waterloo March 27, 2018 Readings: Poole & Mackworth (2nd ed.)chapter 12.1,12.3-12.9 1/ 34 Reinforcement
Lecture 10 - Planning under Uncertainty (III) Jesse Hoey School of Computer Science University of Waterloo March 27, 2018 Readings: Poole & Mackworth (2nd ed.)chapter 12.1,12.3-12.9 1/ 34 Reinforcement
1 Introduction 2. 4 Q-Learning The Q-value The Temporal Difference The whole Q-Learning process... 5
 Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
Table of contents 1 Introduction 2 2 Markov Decision Processes 2 3 Future Cumulative Reward 3 4 Q-Learning 4 4.1 The Q-value.............................................. 4 4.2 The Temporal Difference.......................................
Markov Decision Processes and Solving Finite Problems. February 8, 2017
 Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Markov Decision Processes and Solving Finite Problems February 8, 2017 Overview of Upcoming Lectures Feb 8: Markov decision processes, value iteration, policy iteration Feb 13: Policy gradients Feb 15:
Variational Deep Q Network
 Variational Deep Q Network Yunhao Tang Department of IEOR Columbia University yt2541@columbia.edu Alp Kucukelbir Department of Computer Science Columbia University alp@cs.columbia.edu Abstract We propose
Variational Deep Q Network Yunhao Tang Department of IEOR Columbia University yt2541@columbia.edu Alp Kucukelbir Department of Computer Science Columbia University alp@cs.columbia.edu Abstract We propose
Reinforcement Learning. Introduction
 Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Reinforcement Learning Introduction Reinforcement Learning Agent interacts and learns from a stochastic environment Science of sequential decision making Many faces of reinforcement learning Optimal control
Machine Learning I Continuous Reinforcement Learning
 Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Machine Learning I Continuous Reinforcement Learning Thomas Rückstieß Technische Universität München January 7/8, 2010 RL Problem Statement (reminder) state s t+1 ENVIRONMENT reward r t+1 new step r t
Lecture 7: Value Function Approximation
 Lecture 7: Value Function Approximation Joseph Modayil Outline 1 Introduction 2 3 Batch Methods Introduction Large-Scale Reinforcement Learning Reinforcement learning can be used to solve large problems,
Lecture 7: Value Function Approximation Joseph Modayil Outline 1 Introduction 2 3 Batch Methods Introduction Large-Scale Reinforcement Learning Reinforcement learning can be used to solve large problems,
Trust Region Policy Optimization
 Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
Trust Region Policy Optimization Yixin Lin Duke University yixin.lin@duke.edu March 28, 2017 Yixin Lin (Duke) TRPO March 28, 2017 1 / 21 Overview 1 Preliminaries Markov Decision Processes Policy iteration
(Deep) Reinforcement Learning
 Reinforcement Learning") Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Martin Matyášek Artificial Intelligence Center Czech Technical University in Prague October 27, 2016 Martin Matyášek VPD, 2016 1 / 17 Reinforcement Learning in a picture R. S. Sutton and A. G. Barto 2015
Stochastic Primal-Dual Methods for Reinforcement Learning
 Stochastic Primal-Dual Methods for Reinforcement Learning Alireza Askarian 1 Amber Srivastava 1 1 Department of Mechanical Engineering University of Illinois at Urbana Champaign Big Data Optimization,
Stochastic Primal-Dual Methods for Reinforcement Learning Alireza Askarian 1 Amber Srivastava 1 1 Department of Mechanical Engineering University of Illinois at Urbana Champaign Big Data Optimization,
Reinforcement Learning
 Reinforcement Learning RL in continuous MDPs March April, 2015 Large/Continuous MDPs Large/Continuous state space Tabular representation cannot be used Large/Continuous action space Maximization over action
Reinforcement Learning RL in continuous MDPs March April, 2015 Large/Continuous MDPs Large/Continuous state space Tabular representation cannot be used Large/Continuous action space Maximization over action
Introduction to Reinforcement Learning
 CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
CSCI-699: Advanced Topics in Deep Learning 01/16/2019 Nitin Kamra Spring 2019 Introduction to Reinforcement Learning 1 What is Reinforcement Learning? So far we have seen unsupervised and supervised learning.
, and rewards and transition matrices as shown below:
 CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
CSE 50a. Assignment 7 Out: Tue Nov Due: Thu Dec Reading: Sutton & Barto, Chapters -. 7. Policy improvement Consider the Markov decision process (MDP) with two states s {0, }, two actions a {0, }, discount
Q-Learning in Continuous State Action Spaces
 Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Q-Learning in Continuous State Action Spaces Alex Irpan alexirpan@berkeley.edu December 5, 2015 Contents 1 Introduction 1 2 Background 1 3 Q-Learning 2 4 Q-Learning In Continuous Spaces 4 5 Experimental
Decision Theory: Q-Learning
 Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Decision Theory: Q-Learning CPSC 322 Decision Theory 5 Textbook 12.5 Decision Theory: Q-Learning CPSC 322 Decision Theory 5, Slide 1 Lecture Overview 1 Recap 2 Asynchronous Value Iteration 3 Q-Learning
Real Time Value Iteration and the State-Action Value Function
 MS&E338 Reinforcement Learning Lecture 3-4/9/18 Real Time Value Iteration and the State-Action Value Function Lecturer: Ben Van Roy Scribe: Apoorva Sharma and Tong Mu 1 Review Last time we left off discussing
MS&E338 Reinforcement Learning Lecture 3-4/9/18 Real Time Value Iteration and the State-Action Value Function Lecturer: Ben Van Roy Scribe: Apoorva Sharma and Tong Mu 1 Review Last time we left off discussing
Planning in Markov Decision Processes
 Carnegie Mellon School of Computer Science Deep Reinforcement Learning and Control Planning in Markov Decision Processes Lecture 3, CMU 10703 Katerina Fragkiadaki Markov Decision Process (MDP) A Markov
Carnegie Mellon School of Computer Science Deep Reinforcement Learning and Control Planning in Markov Decision Processes Lecture 3, CMU 10703 Katerina Fragkiadaki Markov Decision Process (MDP) A Markov
Lecture 8: Policy Gradient
 Lecture 8: Policy Gradient Hado van Hasselt Outline 1 Introduction 2 Finite Difference Policy Gradient 3 Monte-Carlo Policy Gradient 4 Actor-Critic Policy Gradient Introduction Vapnik s rule Never solve
Lecture 8: Policy Gradient Hado van Hasselt Outline 1 Introduction 2 Finite Difference Policy Gradient 3 Monte-Carlo Policy Gradient 4 Actor-Critic Policy Gradient Introduction Vapnik s rule Never solve
Lecture 8: Policy Gradient I 2
 Lecture 8: Policy Gradient I 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver and John Schulman
Lecture 8: Policy Gradient I 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver and John Schulman
MDP Preliminaries. Nan Jiang. February 10, 2019
 MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
MDP Preliminaries Nan Jiang February 10, 2019 1 Markov Decision Processes In reinforcement learning, the interactions between the agent and the environment are often described by a Markov Decision Process
Reinforcement Learning
 Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
Reinforcement Learning Model-Based Reinforcement Learning Model-based, PAC-MDP, sample complexity, exploration/exploitation, RMAX, E3, Bayes-optimal, Bayesian RL, model learning Vien Ngo MLR, University
Reinforcement Learning
 Reinforcement Learning Policy Search: Actor-Critic and Gradient Policy search Mario Martin CS-UPC May 28, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 28, 2018 / 63 Goal of this lecture So far
Reinforcement Learning Policy Search: Actor-Critic and Gradient Policy search Mario Martin CS-UPC May 28, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 28, 2018 / 63 Goal of this lecture So far
Reinforcement Learning
 Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
Reinforcement Learning Function approximation Mario Martin CS-UPC May 18, 2018 Mario Martin (CS-UPC) Reinforcement Learning May 18, 2018 / 65 Recap Algorithms: MonteCarlo methods for Policy Evaluation
Stein Variational Policy Gradient
 Stein Variational Policy Gradient Yang Liu UIUC liu301@illinois.edu Prajit Ramachandran UIUC prajitram@gmail.com Qiang Liu Dartmouth qiang.liu@dartmouth.edu Jian Peng UIUC jianpeng@illinois.edu Abstract
Stein Variational Policy Gradient Yang Liu UIUC liu301@illinois.edu Prajit Ramachandran UIUC prajitram@gmail.com Qiang Liu Dartmouth qiang.liu@dartmouth.edu Jian Peng UIUC jianpeng@illinois.edu Abstract
State Space Abstractions for Reinforcement Learning
 State Space Abstractions for Reinforcement Learning Rowan McAllister and Thang Bui MLG RCC 6 November 24 / 24 Outline Introduction Markov Decision Process Reinforcement Learning State Abstraction 2 Abstraction
State Space Abstractions for Reinforcement Learning Rowan McAllister and Thang Bui MLG RCC 6 November 24 / 24 Outline Introduction Markov Decision Process Reinforcement Learning State Abstraction 2 Abstraction
Machine Learning and Bayesian Inference. Unsupervised learning. Can we find regularity in data without the aid of labels?
 Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Machine Learning and Bayesian Inference Dr Sean Holden Computer Laboratory, Room FC6 Telephone extension 6372 Email: sbh11@cl.cam.ac.uk www.cl.cam.ac.uk/ sbh11/ Unsupervised learning Can we find regularity
Dueling Network Architectures for Deep Reinforcement Learning (ICML 2016)
") Dueling Network Architectures for Deep Reinforcement Learning (ICML 2016) Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology October 11, 2016 Outline
Dueling Network Architectures for Deep Reinforcement Learning (ICML 2016) Yoonho Lee Department of Computer Science and Engineering Pohang University of Science and Technology October 11, 2016 Outline
Actor-critic methods. Dialogue Systems Group, Cambridge University Engineering Department. February 21, 2017
 Actor-critic methods Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department February 21, 2017 1 / 21 In this lecture... The actor-critic architecture Least-Squares Policy Iteration
Actor-critic methods Milica Gašić Dialogue Systems Group, Cambridge University Engineering Department February 21, 2017 1 / 21 In this lecture... The actor-critic architecture Least-Squares Policy Iteration
Human-level control through deep reinforcement. Liia Butler
 Humanlevel control through deep reinforcement Liia Butler But first... A quote "The question of whether machines can think... is about as relevant as the question of whether submarines can swim" Edsger
Humanlevel control through deep reinforcement Liia Butler But first... A quote "The question of whether machines can think... is about as relevant as the question of whether submarines can swim" Edsger
Reinforcement Learning
 Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Reinforcement Learning Markov decision process & Dynamic programming Evaluative feedback, value function, Bellman equation, optimality, Markov property, Markov decision process, dynamic programming, value
Deep Reinforcement Learning SISL. Jeremy Morton (jmorton2) November 7, Stanford Intelligent Systems Laboratory
 November 7, Stanford Intelligent Systems Laboratory") Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Deep Reinforcement Learning Jeremy Morton (jmorton2) November 7, 2016 SISL Stanford Intelligent Systems Laboratory Overview 2 1 Motivation 2 Neural Networks 3 Deep Reinforcement Learning 4 Deep Learning
Reinforcement Learning Part 2
 Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Reinforcement Learning Part 2 Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ From previous tutorial Reinforcement Learning Exploration No supervision Agent-Reward-Environment
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Grundlagen der Künstlichen Intelligenz Reinforcement learning Daniel Hennes 4.12.2017 (WS 2017/18) University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Reinforcement learning Model based and
Learning Control for Air Hockey Striking using Deep Reinforcement Learning
 Learning Control for Air Hockey Striking using Deep Reinforcement Learning Ayal Taitler, Nahum Shimkin Faculty of Electrical Engineering Technion - Israel Institute of Technology May 8, 2017 A. Taitler,
Learning Control for Air Hockey Striking using Deep Reinforcement Learning Ayal Taitler, Nahum Shimkin Faculty of Electrical Engineering Technion - Israel Institute of Technology May 8, 2017 A. Taitler,
Reinforcement Learning based Multi-Access Control and Battery Prediction with Energy Harvesting in IoT Systems
 1 Reinforcement Learning based Multi-Access Control and Battery Prediction with Energy Harvesting in IoT Systems Man Chu, Hang Li, Member, IEEE, Xuewen Liao, Member, IEEE, and Shuguang Cui, Fellow, IEEE
1 Reinforcement Learning based Multi-Access Control and Battery Prediction with Energy Harvesting in IoT Systems Man Chu, Hang Li, Member, IEEE, Xuewen Liao, Member, IEEE, and Shuguang Cui, Fellow, IEEE
J. Sadeghi E. Patelli M. de Angelis
 J. Sadeghi E. Patelli Institute for Risk and, Department of Engineering, University of Liverpool, United Kingdom 8th International Workshop on Reliable Computing, Computing with Confidence University of
J. Sadeghi E. Patelli Institute for Risk and, Department of Engineering, University of Liverpool, United Kingdom 8th International Workshop on Reliable Computing, Computing with Confidence University of
Q-learning. Tambet Matiisen
 Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Q-learning Tambet Matiisen (based on chapter 11.3 of online book Artificial Intelligence, foundations of computational agents by David Poole and Alan Mackworth) Stochastic gradient descent Experience
Introduction to Reinforcement Learning Part 1: Markov Decision Processes
 Introduction to Reinforcement Learning Part 1: Markov Decision Processes Rowan McAllister Reinforcement Learning Reading Group 8 April 2015 Note I ve created these slides whilst following Algorithms for
Introduction to Reinforcement Learning Part 1: Markov Decision Processes Rowan McAllister Reinforcement Learning Reading Group 8 April 2015 Note I ve created these slides whilst following Algorithms for
15-780: ReinforcementLearning
 15-780: ReinforcementLearning J. Zico Kolter March 2, 2016 1 Outline Challenge of RL Model-based methods Model-free methods Exploration and exploitation 2 Outline Challenge of RL Model-based methods Model-free
15-780: ReinforcementLearning J. Zico Kolter March 2, 2016 1 Outline Challenge of RL Model-based methods Model-free methods Exploration and exploitation 2 Outline Challenge of RL Model-based methods Model-free
Reinforcement Learning and Deep Reinforcement Learning
 Reinforcement Learning and Deep Reinforcement Learning Ashis Kumer Biswas, Ph.D. ashis.biswas@ucdenver.edu Deep Learning November 5, 2018 1 / 64 Outlines 1 Principles of Reinforcement Learning 2 The Q
Reinforcement Learning and Deep Reinforcement Learning Ashis Kumer Biswas, Ph.D. ashis.biswas@ucdenver.edu Deep Learning November 5, 2018 1 / 64 Outlines 1 Principles of Reinforcement Learning 2 The Q
Lecture 9: Policy Gradient II 1
 Lecture 9: Policy Gradient II 1 Emma Brunskill CS234 Reinforcement Learning. Winter 2019 Additional reading: Sutton and Barto 2018 Chp. 13 1 With many slides from or derived from David Silver and John
Lecture 9: Policy Gradient II 1 Emma Brunskill CS234 Reinforcement Learning. Winter 2019 Additional reading: Sutton and Barto 2018 Chp. 13 1 With many slides from or derived from David Silver and John
Lecture 9: Policy Gradient II (Post lecture) 2
 2") Lecture 9: Policy Gradient II (Post lecture) 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver
Lecture 9: Policy Gradient II (Post lecture) 2 Emma Brunskill CS234 Reinforcement Learning. Winter 2018 Additional reading: Sutton and Barto 2018 Chp. 13 2 With many slides from or derived from David Silver
Deep Reinforcement Learning: Policy Gradients and Q-Learning
 Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Deep Reinforcement Learning: Policy Gradients and Q-Learning John Schulman Bay Area Deep Learning School September 24, 2016 Introduction and Overview Aim of This Talk What is deep RL, and should I use
Reinforcement Learning as Classification Leveraging Modern Classifiers
 Reinforcement Learning as Classification Leveraging Modern Classifiers Michail G. Lagoudakis and Ronald Parr Department of Computer Science Duke University Durham, NC 27708 Machine Learning Reductions
Reinforcement Learning as Classification Leveraging Modern Classifiers Michail G. Lagoudakis and Ronald Parr Department of Computer Science Duke University Durham, NC 27708 Machine Learning Reductions
Policy Gradient Methods. February 13, 2017
 Policy Gradient Methods February 13, 2017 Policy Optimization Problems maximize E π [expression] π Fixed-horizon episodic: T 1 Average-cost: lim T 1 T r t T 1 r t Infinite-horizon discounted: γt r t Variable-length
Policy Gradient Methods February 13, 2017 Policy Optimization Problems maximize E π [expression] π Fixed-horizon episodic: T 1 Average-cost: lim T 1 T r t T 1 r t Infinite-horizon discounted: γt r t Variable-length
Reinforcement Learning
 1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
1 Reinforcement Learning Chris Watkins Department of Computer Science Royal Holloway, University of London July 27, 2015 2 Plan 1 Why reinforcement learning? Where does this theory come from? Markov decision
Reinforcement Learning. Yishay Mansour Tel-Aviv University
 Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Reinforcement Learning Yishay Mansour Tel-Aviv University 1 Reinforcement Learning: Course Information Classes: Wednesday Lecture 10-13 Yishay Mansour Recitations:14-15/15-16 Eliya Nachmani Adam Polyak
Variational inference
 Simon Leglaive Télécom ParisTech, CNRS LTCI, Université Paris Saclay November 18, 2016, Télécom ParisTech, Paris, France. Outline Introduction Probabilistic model Problem Log-likelihood decomposition EM
Simon Leglaive Télécom ParisTech, CNRS LTCI, Université Paris Saclay November 18, 2016, Télécom ParisTech, Paris, France. Outline Introduction Probabilistic model Problem Log-likelihood decomposition EM
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13. Decision Making. Abdeslam Boularias. Wednesday, December 7, 2016
 Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Course 16:198:520: Introduction To Artificial Intelligence Lecture 13 Decision Making Abdeslam Boularias Wednesday, December 7, 2016 1 / 45 Overview We consider probabilistic temporal models where the
Complexity of stochastic branch and bound methods for belief tree search in Bayesian reinforcement learning
 Complexity of stochastic branch and bound methods for belief tree search in Bayesian reinforcement learning Christos Dimitrakakis Informatics Institute, University of Amsterdam, Amsterdam, The Netherlands
Complexity of stochastic branch and bound methods for belief tree search in Bayesian reinforcement learning Christos Dimitrakakis Informatics Institute, University of Amsterdam, Amsterdam, The Netherlands
Optimal sequential decision making for complex problems agents. Damien Ernst University of Liège
 Optimal sequential decision making for complex problems agents Damien Ernst University of Liège Email: dernst@uliege.be 1 About the class Regular lectures notes about various topics on the subject with
Optimal sequential decision making for complex problems agents Damien Ernst University of Liège Email: dernst@uliege.be 1 About the class Regular lectures notes about various topics on the subject with
CS230: Lecture 9 Deep Reinforcement Learning
 CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
CS230: Lecture 9 Deep Reinforcement Learning Kian Katanforoosh Menti code: 21 90 15 Today s outline I. Motivation II. Recycling is good: an introduction to RL III. Deep Q-Learning IV. Application of Deep
Internet Monetization
 Internet Monetization March May, 2013 Discrete time Finite A decision process (MDP) is reward process with decisions. It models an environment in which all states are and time is divided into stages. Definition
Internet Monetization March May, 2013 Discrete time Finite A decision process (MDP) is reward process with decisions. It models an environment in which all states are and time is divided into stages. Definition
INF 5860 Machine learning for image classification. Lecture 14: Reinforcement learning May 9, 2018
 Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Machine learning for image classification Lecture 14: Reinforcement learning May 9, 2018 Page 3 Outline Motivation Introduction to reinforcement learning (RL) Value function based methods (Q-learning)
Decision Theory: Markov Decision Processes
 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
Decision Theory: Markov Decision Processes CPSC 322 Lecture 33 March 31, 2006 Textbook 12.5 Decision Theory: Markov Decision Processes CPSC 322 Lecture 33, Slide 1 Lecture Overview Recap Rewards and Policies
ECE276B: Planning & Learning in Robotics Lecture 16: Model-free Control
 ECE276B: Planning & Learning in Robotics Lecture 16: Model-free Control Lecturer: Nikolay Atanasov: natanasov@ucsd.edu Teaching Assistants: Tianyu Wang: tiw161@eng.ucsd.edu Yongxi Lu: yol070@eng.ucsd.edu
ECE276B: Planning & Learning in Robotics Lecture 16: Model-free Control Lecturer: Nikolay Atanasov: natanasov@ucsd.edu Teaching Assistants: Tianyu Wang: tiw161@eng.ucsd.edu Yongxi Lu: yol070@eng.ucsd.edu
MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti
 AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti") 1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
1 MARKOV DECISION PROCESSES (MDP) AND REINFORCEMENT LEARNING (RL) Versione originale delle slide fornita dal Prof. Francesco Lo Presti Historical background 2 Original motivation: animal learning Early
Lecture 4: Approximate dynamic programming
 IEOR 800: Reinforcement learning By Shipra Agrawal Lecture 4: Approximate dynamic programming Deep Q Networks discussed in the last lecture are an instance of approximate dynamic programming. These are
IEOR 800: Reinforcement learning By Shipra Agrawal Lecture 4: Approximate dynamic programming Deep Q Networks discussed in the last lecture are an instance of approximate dynamic programming. These are
Reinforcement Learning. Machine Learning, Fall 2010
 Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Reinforcement Learning Machine Learning, Fall 2010 1 Administrativia This week: finish RL, most likely start graphical models LA2: due on Thursday LA3: comes out on Thursday TA Office hours: Today 1:30-2:30
Hidden Markov Models (HMM) and Support Vector Machine (SVM)
 and Support Vector Machine (SVM)") Hidden Markov Models (HMM) and Support Vector Machine (SVM) Professor Joongheon Kim School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea 1 Hidden Markov Models (HMM)
Hidden Markov Models (HMM) and Support Vector Machine (SVM) Professor Joongheon Kim School of Computer Science and Engineering, Chung-Ang University, Seoul, Republic of Korea 1 Hidden Markov Models (HMM)
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation
 Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Lecture 3: Policy Evaluation Without Knowing How the World Works / Model Free Policy Evaluation CS234: RL Emma Brunskill Winter 2018 Material builds on structure from David SIlver s Lecture 4: Model-Free
Lecture 6: CS395T Numerical Optimization for Graphics and AI Line Search Applications
 Lecture 6: CS395T Numerical Optimization for Graphics and AI Line Search Applications Qixing Huang The University of Texas at Austin huangqx@cs.utexas.edu 1 Disclaimer This note is adapted from Section
Lecture 6: CS395T Numerical Optimization for Graphics and AI Line Search Applications Qixing Huang The University of Texas at Austin huangqx@cs.utexas.edu 1 Disclaimer This note is adapted from Section
Deterministic Policy Gradient, Advanced RL Algorithms
 NPFL122, Lecture 9 Deterministic Policy Gradient, Advanced RL Algorithms Milan Straka December 1, 218 Charles University in Prague Faculty of Mathematics and Physics Institute of Formal and Applied Linguistics
NPFL122, Lecture 9 Deterministic Policy Gradient, Advanced RL Algorithms Milan Straka December 1, 218 Charles University in Prague Faculty of Mathematics and Physics Institute of Formal and Applied Linguistics
Reinforcement Learning
 Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Reinforcement Learning Ron Parr CompSci 7 Department of Computer Science Duke University With thanks to Kris Hauser for some content RL Highlights Everybody likes to learn from experience Use ML techniques
Reinforcement Learning
 Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Reinforcement Learning Dipendra Misra Cornell University dkm@cs.cornell.edu https://dipendramisra.wordpress.com/ Task Grasp the green cup. Output: Sequence of controller actions Setup from Lenz et. al.
Approximate Q-Learning. Dan Weld / University of Washington
 Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Approximate Q-Learning Dan Weld / University of Washington [Many slides taken from Dan Klein and Pieter Abbeel / CS188 Intro to AI at UC Berkeley materials available at http://ai.berkeley.edu.] Q Learning
Reinforcement Learning via Policy Optimization
 Reinforcement Learning via Policy Optimization Hanxiao Liu November 22, 2017 1 / 27 Reinforcement Learning Policy a π(s) 2 / 27 Example - Mario 3 / 27 Example - ChatBot 4 / 27 Applications - Video Games
Reinforcement Learning via Policy Optimization Hanxiao Liu November 22, 2017 1 / 27 Reinforcement Learning Policy a π(s) 2 / 27 Example - Mario 3 / 27 Example - ChatBot 4 / 27 Applications - Video Games
Policy Gradient Reinforcement Learning for Robotics
 Policy Gradient Reinforcement Learning for Robotics Michael C. Koval mkoval@cs.rutgers.edu Michael L. Littman mlittman@cs.rutgers.edu May 9, 211 1 Introduction Learning in an environment with a continuous
Policy Gradient Reinforcement Learning for Robotics Michael C. Koval mkoval@cs.rutgers.edu Michael L. Littman mlittman@cs.rutgers.edu May 9, 211 1 Introduction Learning in an environment with a continuous
Markov decision processes
 CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
CS 2740 Knowledge representation Lecture 24 Markov decision processes Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square Administrative announcements Final exam: Monday, December 8, 2008 In-class Only
Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan
 COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
COS 402 Machine Learning and Artificial Intelligence Fall 2016 Lecture 18: Reinforcement Learning Sanjeev Arora Elad Hazan Some slides borrowed from Peter Bodik and David Silver Course progress Learning
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
 Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel & Sergey Levine Department of Electrical Engineering and Computer
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel & Sergey Levine Department of Electrical Engineering and Computer
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2017 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
6 Reinforcement Learning
 6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
6 Reinforcement Learning As discussed above, a basic form of supervised learning is function approximation, relating input vectors to output vectors, or, more generally, finding density functions p(y,
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning
 CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
CS 229 Project Final Report: Reinforcement Learning for Neural Network Architecture Category : Theory & Reinforcement Learning Lei Lei Ruoxuan Xiong December 16, 2017 1 Introduction Deep Neural Network
Reinforcement Learning
 Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
Reinforcement Learning Function approximation Daniel Hennes 19.06.2017 University Stuttgart - IPVS - Machine Learning & Robotics 1 Today Eligibility traces n-step TD returns Forward and backward view Function
Learning Tetris. 1 Tetris. February 3, 2009
 Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Learning Tetris Matt Zucker Andrew Maas February 3, 2009 1 Tetris The Tetris game has been used as a benchmark for Machine Learning tasks because its large state space (over 2 200 cell configurations are
Reinforcement Learning II. George Konidaris
 Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Reinforcement Learning II George Konidaris gdk@cs.brown.edu Fall 2018 Reinforcement Learning π : S A max R = t=0 t r t MDPs Agent interacts with an environment At each time t: Receives sensor signal Executes
Notes on Reinforcement Learning
 1 Introduction Notes on Reinforcement Learning Paulo Eduardo Rauber 2014 Reinforcement learning is the study of agents that act in an environment with the goal of maximizing cumulative reward signals.
1 Introduction Notes on Reinforcement Learning Paulo Eduardo Rauber 2014 Reinforcement learning is the study of agents that act in an environment with the goal of maximizing cumulative reward signals.
A Tour of Reinforcement Learning The View from Continuous Control. Benjamin Recht University of California, Berkeley
 A Tour of Reinforcement Learning The View from Continuous Control Benjamin Recht University of California, Berkeley trustable, scalable, predictable Control Theory! Reinforcement Learning is the study
A Tour of Reinforcement Learning The View from Continuous Control Benjamin Recht University of California, Berkeley trustable, scalable, predictable Control Theory! Reinforcement Learning is the study
Today s s Lecture. Applicability of Neural Networks. Back-propagation. Review of Neural Networks. Lecture 20: Learning -4. Markov-Decision Processes
 Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
Today s s Lecture Lecture 20: Learning -4 Review of Neural Networks Markov-Decision Processes Victor Lesser CMPSCI 683 Fall 2004 Reinforcement learning 2 Back-propagation Applicability of Neural Networks
CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes
 CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes Kee-Eung Kim KAIST EECS Department Computer Science Division Markov Decision Processes (MDPs) A popular model for sequential decision
CS788 Dialogue Management Systems Lecture #2: Markov Decision Processes Kee-Eung Kim KAIST EECS Department Computer Science Division Markov Decision Processes (MDPs) A popular model for sequential decision
Tutorial on Policy Gradient Methods. Jan Peters
 Tutorial on Policy Gradient Methods Jan Peters Outline 1. Reinforcement Learning 2. Finite Difference vs Likelihood-Ratio Policy Gradients 3. Likelihood-Ratio Policy Gradients 4. Conclusion General Setup
Tutorial on Policy Gradient Methods Jan Peters Outline 1. Reinforcement Learning 2. Finite Difference vs Likelihood-Ratio Policy Gradients 3. Likelihood-Ratio Policy Gradients 4. Conclusion General Setup
Reinforcement Learning for NLP
 Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
Reinforcement Learning for NLP Advanced Machine Learning for NLP Jordan Boyd-Graber REINFORCEMENT OVERVIEW, POLICY GRADIENT Adapted from slides by David Silver, Pieter Abbeel, and John Schulman Advanced
6 Basic Convergence Results for RL Algorithms
 Learning in Complex Systems Spring 2011 Lecture Notes Nahum Shimkin 6 Basic Convergence Results for RL Algorithms We establish here some asymptotic convergence results for the basic RL algorithms, by showing
Learning in Complex Systems Spring 2011 Lecture Notes Nahum Shimkin 6 Basic Convergence Results for RL Algorithms We establish here some asymptotic convergence results for the basic RL algorithms, by showing
Deep Reinforcement Learning via Policy Optimization
 Deep Reinforcement Learning via Policy Optimization John Schulman July 3, 2017 Introduction Deep Reinforcement Learning: What to Learn? Policies (select next action) Deep Reinforcement Learning: What to
Deep Reinforcement Learning via Policy Optimization John Schulman July 3, 2017 Introduction Deep Reinforcement Learning: What to Learn? Policies (select next action) Deep Reinforcement Learning: What to
A Survey on Methods and Applications of Deep Reinforcement Learning
 A Survey on Methods and Applications of Deep Reinforcement Learning Siyi Li Department of Computer Science and Engineering The Hong Kong University of Science and Technology sliay@cse.ust.hk Supervisor
A Survey on Methods and Applications of Deep Reinforcement Learning Siyi Li Department of Computer Science and Engineering The Hong Kong University of Science and Technology sliay@cse.ust.hk Supervisor
Variational Inference via Stochastic Backpropagation
 Variational Inference via Stochastic Backpropagation Kai Fan February 27, 2016 Preliminaries Stochastic Backpropagation Variational Auto-Encoding Related Work Summary Outline Preliminaries Stochastic Backpropagation
Variational Inference via Stochastic Backpropagation Kai Fan February 27, 2016 Preliminaries Stochastic Backpropagation Variational Auto-Encoding Related Work Summary Outline Preliminaries Stochastic Backpropagation