MACHINE LEARNING FOR NATURAL LANGUAGE PROCESSING
|
|
|
- Dominic Gilmore
- 5 years ago
- Views:
Transcription
1 MACHINE LEARNING FOR NATURAL LANGUAGE PROCESSING
2 Outline Some Sample NLP Task [Noah Smith] Structured Prediction For NLP Structured Prediction Methods Conditional Random Fields Structured Perceptron Discussion
3 MOTIVATING STRUCTURED- OUTPUT PREDICTION FOR NLP
4 Types of machine learning Input Attributes Input Attributes Classifier Density Estimator Prediction of categorical output or class One of a few discrete values Probability Input Attributes Regressor Prediction of real-valued output Copyright Andrew W. Moore
5

6
7
8
9
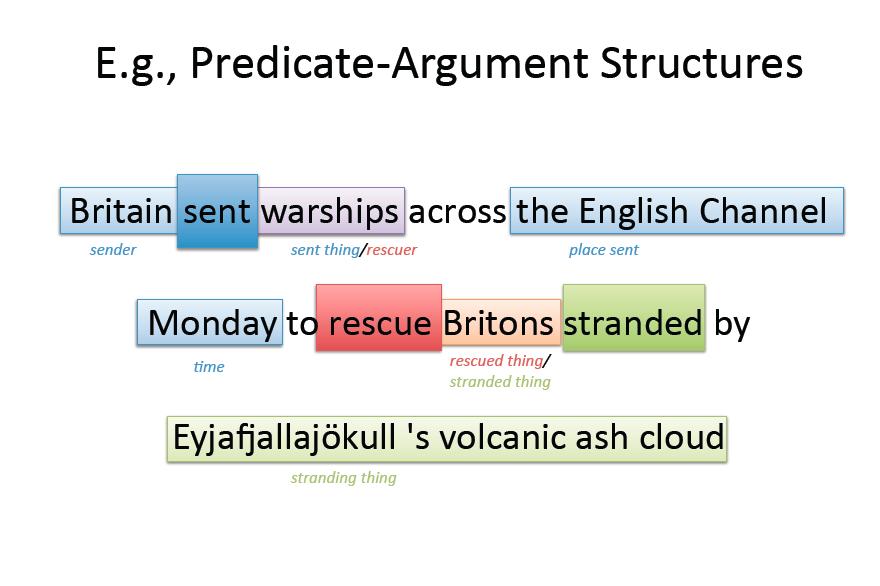
10
11
12 Outline Some Sample NLP Task [Noah Smith] What do these have in common? We re making many related predictions... Structured Prediction For NLP Structured Prediction Methods Structured Perceptron Conditional Random Fields Deep learning and NLP
13
14 via begin-inside-outside token tagging beginx inx* delimits entity X begingpe out out out out begingf ingf
15 via begin-inside-outside token tagging beginx inx* delimits entity X thistoken = english thistokenshape = X+ prevtoken = the prevprevtoken = across nettoken = channel netnettoken = Monday nettokenshape = X+ prevtokenshape = +. thistoken_english = 1 thistokenshape_x+ = 1 prevtoken_the = 1 prevprevtoken_across = 1 begingf begingf ingf a classification task!



16 via begin-inside-outside token tagging A problem: the instances are not i.i.d, nor are the classes. inx usually happens after beginx or inx beginx usually happens after out thistoken_the = 1 thistokenshape_+ = 1 prevtoken_across = 1 thistoken_english = 1 thistokenshape_x+ = 1 prevtoken_the = 1 prevprevtoken_across = 1 thistoken_channel = 1 thistokenshape_x+ = 1 prevtoken_english = 1 prevprevtoken_the = 1 out begingf ingf
17 Structured Output Prediction Structured Output Prediction: deqinition classiqier where output is structured, and input might be structured eample: predict a sequence of begin- in- out tags from a sequence of tokens (represented by a sequence of feature vectors)


18 NER via begin-inside-outside token tagging A problem: with K begin-inside-outside tags and N words, we have N K possible structured labels. = How can we learn to chose among so many possible outputs? y = begingpe out out out out begingf ingf
19 HMMS AND NER



")



20 out begingpe ingpe e.g., HMMs map a sequence of tokens to a sequence of outputs (the hidden states) begingf beginper ingf inper = y = begingpe out out out out begingf ingf
21 Borkar et al s: HMMs for segmentation n n n Eample: Addresses, bib records Problem: some DBs may split records up differently (eg no mail stop field, combine address and apt #, ) or not at all Solution: Learn to segment tetual form of records Author Year Title Journal Volume Page P.P.Wangikar, T.P. Graycar, D.A. Estell, D.S. Clark, J.S. Dordick (1993) Protein and Solvent Engineering of Subtilising BPN' in Nearly Anhydrous Organic Media J.Amer. Chem. Soc. 115,
22 IE with Hidden Markov Models Must learn transition, emission probabilities Smith Cohen Jordan Transition probabilities dddd dd 0.5 Author 0.9 Year Journal 0.2 Title 0.5 Learning Conve Comm. Trans. Chemical Emission probabilities


23 HMMS limitation: not well-suited to modeling a set of features for each token. thistoken = english thistokenshape = X+ prevtoken = the prevprevtoken = across nettoken = channel netnettoken = Monday nettokenshape = X+ prevtokenshape = +. thistoken_english = 1 thistokenshape_x+ = 1 prevtoken_the = 1 prevprevtoken_across = 1 begingf begingf ingf a classification task!
24 What is a symbol? Ideally we would like to use many, arbitrary, overlapping features of words. identity of word ends in -ski is capitalized is part of a noun phrase is in a list of city names is under node X in WordNet is in bold font is indented is in hyperlink anchor is Wisniewski part of noun phrase S t - 1 ends in -ski O t - 1 S t O t S t+1 O t +1 Lots of learning systems are not confounded by multiple, nonindependent features: decision trees, neural nets, SVMs,
25 Outline Some Sample NLP Task [Noah Smith] Structured Prediction For NLP Structured Prediction Methods HMMs Conditional Random Fields Structured Perceptron Discussion
26 CONDITIONAL RANDOM FIELDS
27 What is a symbol? Ideally we would like to use many, arbitrary, overlapping features of words. identity of word ends in -ski is capitalized is part of a noun phrase is in a list of city names is under node X in WordNet is in bold font is indented is in hyperlink anchor is Wisniewski part of noun phrase S t - 1 ends in -ski O t - 1 S t O t S t+1 O t +1 Lots of learning systems are not confounded by multiple, nonindependent features: decision trees, neural nets, SVMs,
28 Inference for linear-chain MRFs When will prof Cohen post the notes Idea 1: features are properties of two adjacent tokens, and the pair of labels assigned to them. (y(i)==b or y(i)==i) and (token(i) is capitalized) (y(i)==i and y(i-1)==b) and (token(i) is hyphenated) (y(i)==b and y(i-1)==b) eg tell Ziv William is on the way Idea 2: construct a graph where each path is a possible sequence labeling.
29 Inference for a linear-chain MRF B I O B I O B I O B I O B I O B I O B I O When will prof Cohen post the notes Inference: find the highest-weight path Learning: optimize the feature weights so that this highest-weight path is correct relative to the data
30 Inference for a linear-chain MRF When will prof Cohen post the notes B B B B B B B I I I I I I I O O O O O O O Feature + weights define edge weights: weight(y i,y i+1 ) = 2*[(y i =B or I) and iscap( i )] + 1*[(y i =B and isfirstname( i )] - 5*[(y i+1 B and islower( i ) and isupper( i+1 )]



31 CRF learning from Sha & Pereira
32 CRF learning from Sha & Pereira
33 CRF learning from Sha & Pereira Something like forward-backward Idea: Define matri of y,y affinities at stage i M i [y,y ] = unnormalized probability of transition from y to y at stage I M i * M i+1 = unnormalized probability of any path through stages i and i+1


34 Sha & Pereira results CRF beats MEMM (McNemar s test); MEMM probably beats voted perceptron

35 Sha & Pereira results in minutes, 375k eamples
36 THE STRUCTURED PERCEPTRON
37 Review: The perceptron A instance i ^ y i B ^ Compute: y i = v k. i If mistake: v k+1 = v k + y i i y i
38 (3a) The guess v 2 after the two positive eamples: v 2 =v (3b) The guess v 2 after the one positive and one negative eample: v 2 =v v 2 u u v 2 >γ v 1 v u -u - 2 2γ 2γ
39 (3a) The guess v 2 after the two positive eamples: v 2 =v (3b) The guess v 2 after the one positive and one negative eample: v 2 =v v 2 u u v 2 v 1 v u -u - 2 2γ 2γ

40 R = γ 2 2

41 The voted perceptron for ranking A instances b* b B ^ Compute: y i = v k. i Return: the inde b* of the best i If mistake: v k+1 = v k + b - b*
42 u Ranking some s with the target vector u γ -u
43 u Ranking some s with some guess vector v part 1 γ v -u
44 u Ranking some s with some guess vector v part 2. -u v The purple-circled is b* - the one the learner has chosen to rank highest. The green circled is b, the right answer.
45 u Correcting v by adding b b* v -u
46 V k+1 Correcting v by adding b b* (part 2) v k
47 (3a) The guess v 2 after the two positive eamples: v 2 =v u + 2 v 2 u >γ v v 1 -u -u 2γ
48 (3a) The guess v 2 after the two positive eamples: v 2 =v u + 2 v 2 u >γ v v 1 -u -u 3 2γ



49 (3a) The guess v 2 after the two positive eamples: v 2 =v u + 2 v 2 u >γ v 1 v -u 2γ -u 3
 The guess v 2 after the two")

50 Notice this doesn t depend at all on the number of s being ranked u (3a) The guess v 2 after the two positive eamples: v 2 =v v 2 u >γ v v 1 -u -u 2γ Neither proof depends on the dimension of the s.
51 The voted perceptron for ranking A instances b* b B ^ Compute: y i = v k. i Return: the inde b* of the best i If mistake: v k+1 = v k + b - b* Change number one is notation: replace with g
52 The voted perceptron for NER A instances g 1 g 2 g 3 g 4 B ^ Compute: y i = v k. g i Return: the inde b* of the best g i b* b If mistake: v k+1 = v k + g b - g b* 1. A sends B the Sha & Pereira paper, some feature functions, and instructions for creating the instances g: A sends a word vector i. Then B could create the instances g 1 =F( i,y 1 ), g 2 = F( i,y 2 ), but instead B just returns the y* that gives the best score for the dot product v k. F( i,y*) by using Viterbi. 2. A sends B the correct label sequence y i. 3. On errors, B sets v k+1 = v k + g b - g b* = v k + F( i,y) - F( i,y*)
53 The voted perceptron for NER A instances z 1 z 2 z 3 z 4 B ^ Compute: y i = v k. z i Return: the inde b* of the best z i b* b If mistake: v k+1 = v k + z b - z b* 1. A sends a word vector i. 2. B just returns the y* that gives the best score for v k. F( i,y*) 3. A sends B the correct label sequence y i. 4. On errors, B sets v k+1 = v k + z b - z b* = v k + F( i,y) - F( i,y*) So, this algorithm can also be viewed as an approimation to the CRF learning algorithm where we re using a Viterbi approimation to the epectations, and stochastic gradient descent to optimize the likelihood.


54 And back to the paper.. EMNLP 2002, Best paper
55 Collins Eperiments POS tagging (with MXPOST features) NP Chunking (words and POS tags from Brill s tagger as features) and BIO output tags Compared Maent Tagging/MEMM s (with iterative scaling) and Voted Perceptron trained HMM s With and w/o averaging With and w/o feature selection (count>5)
56 Collins results
57 Outline Some Sample NLP Task [Noah Smith] Structured Prediction For NLP Structured Prediction Methods Conditional Random Fields Structured Perceptron Discussion
58 Discussion Structured prediction is just one part of NLP There is lots of work on learning and NLP It would be much easier to summarize nonlearning related NLP CRFs/HMMs/structured perceptrons are just one part of structured output prediction Chris Dyer course. Hot topic now: representation learning and deep learning for NLP NAACL 2013: Deep learning for NLP, Manning
 http://futurama.wikia.com/wiki/dr._perceptron 1 Where we are Eperiments with a hash-trick implementation of logistic regression Net question: how do you parallelize SGD, or more generally, this kind of
http://futurama.wikia.com/wiki/dr._perceptron 1 Where we are Eperiments with a hash-trick implementation of logistic regression Net question: how do you parallelize SGD, or more generally, this kind of
Announcements. Guest lectures schedule: D. Sculley, Google Pgh, 3/26 Alex Beutel, SGD for tensors, 4/7 Alex Smola, something cool, 4/9
 Announcements Guest lectures schedule: D. Sculley, Google Pgh, 3/26 Ale Beutel, SGD for tensors, 4/7 Ale Smola, something cool, 4/9 Projects Students in 805: First draft of project proposal due 2/17. Some
Announcements Guest lectures schedule: D. Sculley, Google Pgh, 3/26 Ale Beutel, SGD for tensors, 4/7 Ale Smola, something cool, 4/9 Projects Students in 805: First draft of project proposal due 2/17. Some
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields
 Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
Lecture 13: Structured Prediction
 Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
Lecture 13: Structured Prediction Kai-Wei Chang CS @ University of Virginia kw@kwchang.net Couse webpage: http://kwchang.net/teaching/nlp16 CS6501: NLP 1 Quiz 2 v Lectures 9-13 v Lecture 12: before page
What s an HMM? Extraction with Finite State Machines e.g. Hidden Markov Models (HMMs) Hidden Markov Models (HMMs) for Information Extraction
 Hidden Markov Models (HMMs) for Information Extraction") Hidden Markov Models (HMMs) for Information Extraction Daniel S. Weld CSE 454 Extraction with Finite State Machines e.g. Hidden Markov Models (HMMs) standard sequence model in genomics, speech, NLP, What
Hidden Markov Models (HMMs) for Information Extraction Daniel S. Weld CSE 454 Extraction with Finite State Machines e.g. Hidden Markov Models (HMMs) standard sequence model in genomics, speech, NLP, What
Sequential Supervised Learning
 Sequential Supervised Learning Many Application Problems Require Sequential Learning Part-of of-speech Tagging Information Extraction from the Web Text-to to-speech Mapping Part-of of-speech Tagging Given
Sequential Supervised Learning Many Application Problems Require Sequential Learning Part-of of-speech Tagging Information Extraction from the Web Text-to to-speech Mapping Part-of of-speech Tagging Given
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Machine Learning for Structured Prediction
 Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Conditional Random Fields and beyond DANIEL KHASHABI CS 546 UIUC, 2013
 Conditional Random Fields and beyond DANIEL KHASHABI CS 546 UIUC, 2013 Outline Modeling Inference Training Applications Outline Modeling Problem definition Discriminative vs. Generative Chain CRF General
Conditional Random Fields and beyond DANIEL KHASHABI CS 546 UIUC, 2013 Outline Modeling Inference Training Applications Outline Modeling Problem definition Discriminative vs. Generative Chain CRF General
Natural Language Processing
 Natural Language Processing Global linear models Based on slides from Michael Collins Globally-normalized models Why do we decompose to a sequence of decisions? Can we directly estimate the probability
Natural Language Processing Global linear models Based on slides from Michael Collins Globally-normalized models Why do we decompose to a sequence of decisions? Can we directly estimate the probability
Probabilistic Models for Sequence Labeling
 Probabilistic Models for Sequence Labeling Besnik Fetahu June 9, 2011 Besnik Fetahu () Probabilistic Models for Sequence Labeling June 9, 2011 1 / 26 Background & Motivation Problem introduction Generative
Probabilistic Models for Sequence Labeling Besnik Fetahu June 9, 2011 Besnik Fetahu () Probabilistic Models for Sequence Labeling June 9, 2011 1 / 26 Background & Motivation Problem introduction Generative
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Lecture 13: Discriminative Sequence Models (MEMM and Struct. Perceptron)
") Lecture 13: Discriminative Sequence Models (MEMM and Struct. Perceptron) Intro to NLP, CS585, Fall 2014 http://people.cs.umass.edu/~brenocon/inlp2014/ Brendan O Connor (http://brenocon.com) 1 Models for
Lecture 13: Discriminative Sequence Models (MEMM and Struct. Perceptron) Intro to NLP, CS585, Fall 2014 http://people.cs.umass.edu/~brenocon/inlp2014/ Brendan O Connor (http://brenocon.com) 1 Models for
Conditional Random Field
 Introduction Linear-Chain General Specific Implementations Conclusions Corso di Elaborazione del Linguaggio Naturale Pisa, May, 2011 Introduction Linear-Chain General Specific Implementations Conclusions
Introduction Linear-Chain General Specific Implementations Conclusions Corso di Elaborazione del Linguaggio Naturale Pisa, May, 2011 Introduction Linear-Chain General Specific Implementations Conclusions
Predicting Sequences: Structured Perceptron. CS 6355: Structured Prediction
 Predicting Sequences: Structured Perceptron CS 6355: Structured Prediction 1 Conditional Random Fields summary An undirected graphical model Decompose the score over the structure into a collection of
Predicting Sequences: Structured Perceptron CS 6355: Structured Prediction 1 Conditional Random Fields summary An undirected graphical model Decompose the score over the structure into a collection of
More on HMMs and other sequence models. Intro to NLP - ETHZ - 18/03/2013
 More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
NLP Programming Tutorial 11 - The Structured Perceptron
 NLP Programming Tutorial 11 - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, A book review Oh, man I love this book! This book is
NLP Programming Tutorial 11 - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, A book review Oh, man I love this book! This book is
Statistical Methods for NLP
 Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Probabilistic Graphical Models: MRFs and CRFs. CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov
 Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Conditional Random Fields for Sequential Supervised Learning
 Conditional Random Fields for Sequential Supervised Learning Thomas G. Dietterich Adam Ashenfelter Department of Computer Science Oregon State University Corvallis, Oregon 97331 http://www.eecs.oregonstate.edu/~tgd
Conditional Random Fields for Sequential Supervised Learning Thomas G. Dietterich Adam Ashenfelter Department of Computer Science Oregon State University Corvallis, Oregon 97331 http://www.eecs.oregonstate.edu/~tgd
10 : HMM and CRF. 1 Case Study: Supervised Part-of-Speech Tagging
 10-708: Probabilistic Graphical Models 10-708, Spring 2018 10 : HMM and CRF Lecturer: Kayhan Batmanghelich Scribes: Ben Lengerich, Michael Kleyman 1 Case Study: Supervised Part-of-Speech Tagging We will
10-708: Probabilistic Graphical Models 10-708, Spring 2018 10 : HMM and CRF Lecturer: Kayhan Batmanghelich Scribes: Ben Lengerich, Michael Kleyman 1 Case Study: Supervised Part-of-Speech Tagging We will
Undirected Graphical Models for Sequence Analysis
 Undirected Graphical Models for Sequence Analysis Fernando Pereira University of Pennsylvania Joint work with John Lafferty, Andrew McCallum, and Fei Sha Motivation: Information Extraction Co-reference
Undirected Graphical Models for Sequence Analysis Fernando Pereira University of Pennsylvania Joint work with John Lafferty, Andrew McCallum, and Fei Sha Motivation: Information Extraction Co-reference
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/jv7vj9 Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
Graphical models for part of speech tagging
 Indian Institute of Technology, Bombay and Research Division, India Research Lab Graphical models for part of speech tagging Different Models for POS tagging HMM Maximum Entropy Markov Models Conditional
Indian Institute of Technology, Bombay and Research Division, India Research Lab Graphical models for part of speech tagging Different Models for POS tagging HMM Maximum Entropy Markov Models Conditional
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging
 Tagging") ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
ACS Introduction to NLP Lecture 2: Part of Speech (POS) Tagging Stephen Clark Natural Language and Information Processing (NLIP) Group sc609@cam.ac.uk The POS Tagging Problem 2 England NNP s POS fencers
Hidden Markov Models
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
Sequence Modelling with Features: Linear-Chain Conditional Random Fields. COMP-599 Oct 6, 2015
 Sequence Modelling with Features: Linear-Chain Conditional Random Fields COMP-599 Oct 6, 2015 Announcement A2 is out. Due Oct 20 at 1pm. 2 Outline Hidden Markov models: shortcomings Generative vs. discriminative
Sequence Modelling with Features: Linear-Chain Conditional Random Fields COMP-599 Oct 6, 2015 Announcement A2 is out. Due Oct 20 at 1pm. 2 Outline Hidden Markov models: shortcomings Generative vs. discriminative
Statistical Machine Learning Theory. From Multi-class Classification to Structured Output Prediction. Hisashi Kashima.
 http://goo.gl/xilnmn Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
http://goo.gl/xilnmn Course website KYOTO UNIVERSITY Statistical Machine Learning Theory From Multi-class Classification to Structured Output Prediction Hisashi Kashima kashima@i.kyoto-u.ac.jp DEPARTMENT
Language and Statistics II
 Language and Statistics II Lecture 19: EM for Models of Structure Noah Smith Epectation-Maimization E step: i,, q i # p r $ t = p r i % ' $ t i, p r $ t i,' soft assignment or voting M step: r t +1 # argma
Language and Statistics II Lecture 19: EM for Models of Structure Noah Smith Epectation-Maimization E step: i,, q i # p r $ t = p r i % ' $ t i, p r $ t i,' soft assignment or voting M step: r t +1 # argma
Conditional Random Fields
 Conditional Random Fields Micha Elsner February 14, 2013 2 Sums of logs Issue: computing α forward probabilities can undeflow Normally we d fix this using logs But α requires a sum of probabilities Not
Conditional Random Fields Micha Elsner February 14, 2013 2 Sums of logs Issue: computing α forward probabilities can undeflow Normally we d fix this using logs But α requires a sum of probabilities Not
Chunking with Support Vector Machines
 NAACL2001 Chunking with Support Vector Machines Graduate School of Information Science, Nara Institute of Science and Technology, JAPAN Taku Kudo, Yuji Matsumoto {taku-ku,matsu}@is.aist-nara.ac.jp Chunking
NAACL2001 Chunking with Support Vector Machines Graduate School of Information Science, Nara Institute of Science and Technology, JAPAN Taku Kudo, Yuji Matsumoto {taku-ku,matsu}@is.aist-nara.ac.jp Chunking
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
Brief Introduction of Machine Learning Techniques for Content Analysis
 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
6.047 / Computational Biology: Genomes, Networks, Evolution Fall 2008
 MIT OpenCourseWare http://ocw.mit.edu 6.047 / 6.878 Computational Biology: Genomes, etworks, Evolution Fall 2008 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
MIT OpenCourseWare http://ocw.mit.edu 6.047 / 6.878 Computational Biology: Genomes, etworks, Evolution Fall 2008 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms.
Sequence labeling. Taking collective a set of interrelated instances x 1,, x T and jointly labeling them
 HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
Text Mining. March 3, March 3, / 49
 Text Mining March 3, 2017 March 3, 2017 1 / 49 Outline Language Identification Tokenisation Part-Of-Speech (POS) tagging Hidden Markov Models - Sequential Taggers Viterbi Algorithm March 3, 2017 2 / 49
Text Mining March 3, 2017 March 3, 2017 1 / 49 Outline Language Identification Tokenisation Part-Of-Speech (POS) tagging Hidden Markov Models - Sequential Taggers Viterbi Algorithm March 3, 2017 2 / 49
Administrivia. What is Information Extraction. Finite State Models. Graphical Models. Hidden Markov Models (HMMs) for Information Extraction
 for Information Extraction") Administrivia Hidden Markov Models (HMMs) for Information Extraction Group meetings next week Feel free to rev proposals thru weekend Daniel S. Weld CSE 454 What is Information Extraction Landscape of
Administrivia Hidden Markov Models (HMMs) for Information Extraction Group meetings next week Feel free to rev proposals thru weekend Daniel S. Weld CSE 454 What is Information Extraction Landscape of
lecture 6: modeling sequences (final part)
") Natural Language Processing 1 lecture 6: modeling sequences (final part) Ivan Titov Institute for Logic, Language and Computation Outline After a recap: } Few more words about unsupervised estimation of
Natural Language Processing 1 lecture 6: modeling sequences (final part) Ivan Titov Institute for Logic, Language and Computation Outline After a recap: } Few more words about unsupervised estimation of
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch. COMP-599 Oct 1, 2015
 Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
Part of Speech Tagging: Viterbi, Forward, Backward, Forward- Backward, Baum-Welch COMP-599 Oct 1, 2015 Announcements Research skills workshop today 3pm-4:30pm Schulich Library room 313 Start thinking about
A brief introduction to Conditional Random Fields
 A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
A brief introduction to Conditional Random Fields Mark Johnson Macquarie University April, 2005, updated October 2010 1 Talk outline Graphical models Maximum likelihood and maximum conditional likelihood
with Local Dependencies
 CS11-747 Neural Networks for NLP Structured Prediction with Local Dependencies Xuezhe Ma (Max) Site https://phontron.com/class/nn4nlp2017/ An Example Structured Prediction Problem: Sequence Labeling Sequence
CS11-747 Neural Networks for NLP Structured Prediction with Local Dependencies Xuezhe Ma (Max) Site https://phontron.com/class/nn4nlp2017/ An Example Structured Prediction Problem: Sequence Labeling Sequence
Log-Linear Models, MEMMs, and CRFs
 Log-Linear Models, MEMMs, and CRFs Michael Collins 1 Notation Throughout this note I ll use underline to denote vectors. For example, w R d will be a vector with components w 1, w 2,... w d. We use expx
Log-Linear Models, MEMMs, and CRFs Michael Collins 1 Notation Throughout this note I ll use underline to denote vectors. For example, w R d will be a vector with components w 1, w 2,... w d. We use expx
Sequence Labeling: HMMs & Structured Perceptron
 Sequence Labeling: HMMs & Structured Perceptron CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu HMM: Formal Specification Q: a finite set of N states Q = {q 0, q 1, q 2, q 3, } N N Transition
Sequence Labeling: HMMs & Structured Perceptron CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu HMM: Formal Specification Q: a finite set of N states Q = {q 0, q 1, q 2, q 3, } N N Transition
Expectation Maximization (EM)
") Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
Undirected Graphical Models
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Logistic Regression: Online, Lazy, Kernelized, Sequential, etc.
 Logistic Regression: Online, Lazy, Kernelized, Sequential, etc. Harsha Veeramachaneni Thomson Reuter Research and Development April 1, 2010 Harsha Veeramachaneni (TR R&D) Logistic Regression April 1, 2010
Logistic Regression: Online, Lazy, Kernelized, Sequential, etc. Harsha Veeramachaneni Thomson Reuter Research and Development April 1, 2010 Harsha Veeramachaneni (TR R&D) Logistic Regression April 1, 2010
Structured Prediction
 Structured Prediction Classification Algorithms Classify objects x X into labels y Y First there was binary: Y = {0, 1} Then multiclass: Y = {1,...,6} The next generation: Structured Labels Structured
Structured Prediction Classification Algorithms Classify objects x X into labels y Y First there was binary: Y = {0, 1} Then multiclass: Y = {1,...,6} The next generation: Structured Labels Structured
Regularization Introduction to Machine Learning. Matt Gormley Lecture 10 Feb. 19, 2018
 1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
Multiclass Classification-1
 CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
CS 446 Machine Learning Fall 2016 Oct 27, 2016 Multiclass Classification Professor: Dan Roth Scribe: C. Cheng Overview Binary to multiclass Multiclass SVM Constraint classification 1 Introduction Multiclass
Maximum Entropy Markov Models
 Wi nøt trei a høliday in Sweden this yër? September 19th 26 Background Preliminary CRF work. Published in 2. Authors: McCallum, Freitag and Pereira. Key concepts: Maximum entropy / Overlapping features.
Wi nøt trei a høliday in Sweden this yër? September 19th 26 Background Preliminary CRF work. Published in 2. Authors: McCallum, Freitag and Pereira. Key concepts: Maximum entropy / Overlapping features.
8: Hidden Markov Models
 8: Hidden Markov Models Machine Learning and Real-world Data Helen Yannakoudakis 1 Computer Laboratory University of Cambridge Lent 2018 1 Based on slides created by Simone Teufel So far we ve looked at
8: Hidden Markov Models Machine Learning and Real-world Data Helen Yannakoudakis 1 Computer Laboratory University of Cambridge Lent 2018 1 Based on slides created by Simone Teufel So far we ve looked at
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models. The ischool University of Maryland. Wednesday, September 30, 2009
 CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
CMSC 723: Computational Linguistics I Session #5 Hidden Markov Models Jimmy Lin The ischool University of Maryland Wednesday, September 30, 2009 Today s Agenda The great leap forward in NLP Hidden Markov
Hidden Markov Models
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 19 Nov. 5, 2018 1 Reminders Homework
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 19 Nov. 5, 2018 1 Reminders Homework
Lecture 5 Neural models for NLP
 CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CS546: Machine Learning in NLP (Spring 2018) http://courses.engr.illinois.edu/cs546/ Lecture 5 Neural models for NLP Julia Hockenmaier juliahmr@illinois.edu 3324 Siebel Center Office hours: Tue/Thu 2pm-3pm
CSE 490 U Natural Language Processing Spring 2016
 CSE 490 U Natural Language Processing Spring 2016 Feature Rich Models Yejin Choi - University of Washington [Many slides from Dan Klein, Luke Zettlemoyer] Structure in the output variable(s)? What is the
CSE 490 U Natural Language Processing Spring 2016 Feature Rich Models Yejin Choi - University of Washington [Many slides from Dan Klein, Luke Zettlemoyer] Structure in the output variable(s)? What is the
The Noisy Channel Model and Markov Models
 1/24 The Noisy Channel Model and Markov Models Mark Johnson September 3, 2014 2/24 The big ideas The story so far: machine learning classifiers learn a function that maps a data item X to a label Y handle
1/24 The Noisy Channel Model and Markov Models Mark Johnson September 3, 2014 2/24 The big ideas The story so far: machine learning classifiers learn a function that maps a data item X to a label Y handle
A gentle introduction to Hidden Markov Models
 A gentle introduction to Hidden Markov Models Mark Johnson Brown University November 2009 1 / 27 Outline What is sequence labeling? Markov models Hidden Markov models Finding the most likely state sequence
A gentle introduction to Hidden Markov Models Mark Johnson Brown University November 2009 1 / 27 Outline What is sequence labeling? Markov models Hidden Markov models Finding the most likely state sequence
Simple Neural Nets For Pattern Classification
 CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
CHAPTER 2 Simple Neural Nets For Pattern Classification Neural Networks General Discussion One of the simplest tasks that neural nets can be trained to perform is pattern classification. In pattern classification
Conditional Random Fields: An Introduction
 University of Pennsylvania ScholarlyCommons Technical Reports (CIS) Department of Computer & Information Science 2-24-2004 Conditional Random Fields: An Introduction Hanna M. Wallach University of Pennsylvania
University of Pennsylvania ScholarlyCommons Technical Reports (CIS) Department of Computer & Information Science 2-24-2004 Conditional Random Fields: An Introduction Hanna M. Wallach University of Pennsylvania
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
Hidden Markov Models
 Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Andrew McCallum Department of Computer Science University of Massachusetts Amherst, MA
 University of Massachusetts TR 04-49; July 2004 1 Collective Segmentation and Labeling of Distant Entities in Information Extraction Charles Sutton Department of Computer Science University of Massachusetts
University of Massachusetts TR 04-49; July 2004 1 Collective Segmentation and Labeling of Distant Entities in Information Extraction Charles Sutton Department of Computer Science University of Massachusetts
Midterm sample questions
 Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Midterm sample questions CS 585, Brendan O Connor and David Belanger October 12, 2014 1 Topics on the midterm Language concepts Translation issues: word order, multiword translations Human evaluation Parts
Random Field Models for Applications in Computer Vision
 Random Field Models for Applications in Computer Vision Nazre Batool Post-doctorate Fellow, Team AYIN, INRIA Sophia Antipolis Outline Graphical Models Generative vs. Discriminative Classifiers Markov Random
Random Field Models for Applications in Computer Vision Nazre Batool Post-doctorate Fellow, Team AYIN, INRIA Sophia Antipolis Outline Graphical Models Generative vs. Discriminative Classifiers Markov Random
Statistical Methods for NLP
 Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Applied Natural Language Processing
 Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
Applied Natural Language Processing Info 256 Lecture 20: Sequence labeling (April 9, 2019) David Bamman, UC Berkeley POS tagging NNP Labeling the tag that s correct for the context. IN JJ FW SYM IN JJ
Neural Networks. Nicholas Ruozzi University of Texas at Dallas
 Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
Neural Networks Nicholas Ruozzi University of Texas at Dallas Handwritten Digit Recognition Given a collection of handwritten digits and their corresponding labels, we d like to be able to correctly classify
2.2 Structured Prediction
 The hinge loss (also called the margin loss), which is optimized by the SVM, is a ramp function that has slope 1 when yf(x) < 1 and is zero otherwise. Two other loss functions squared loss and exponential
The hinge loss (also called the margin loss), which is optimized by the SVM, is a ramp function that has slope 1 when yf(x) < 1 and is zero otherwise. Two other loss functions squared loss and exponential
Machine Learning Basics III
 Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Machine Learning Basics III Benjamin Roth CIS LMU München Benjamin Roth (CIS LMU München) Machine Learning Basics III 1 / 62 Outline 1 Classification Logistic Regression 2 Gradient Based Optimization Gradient
Segmental Recurrent Neural Networks for End-to-end Speech Recognition
 Segmental Recurrent Neural Networks for End-to-end Speech Recognition Liang Lu, Lingpeng Kong, Chris Dyer, Noah Smith and Steve Renals TTI-Chicago, UoE, CMU and UW 9 September 2016 Background A new wave
Segmental Recurrent Neural Networks for End-to-end Speech Recognition Liang Lu, Lingpeng Kong, Chris Dyer, Noah Smith and Steve Renals TTI-Chicago, UoE, CMU and UW 9 September 2016 Background A new wave
Machine Learning, Fall 2009: Midterm
 10-601 Machine Learning, Fall 009: Midterm Monday, November nd hours 1. Personal info: Name: Andrew account: E-mail address:. You are permitted two pages of notes and a calculator. Please turn off all
10-601 Machine Learning, Fall 009: Midterm Monday, November nd hours 1. Personal info: Name: Andrew account: E-mail address:. You are permitted two pages of notes and a calculator. Please turn off all
Deep Learning for NLP
 Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
Deep Learning for NLP Instructor: Wei Xu Ohio State University CSE 5525 Many slides from Greg Durrett Outline Motivation for neural networks Feedforward neural networks Applying feedforward neural networks
Final Examination CS 540-2: Introduction to Artificial Intelligence
 Final Examination CS 540-2: Introduction to Artificial Intelligence May 7, 2017 LAST NAME: SOLUTIONS FIRST NAME: Problem Score Max Score 1 14 2 10 3 6 4 10 5 11 6 9 7 8 9 10 8 12 12 8 Total 100 1 of 11
Final Examination CS 540-2: Introduction to Artificial Intelligence May 7, 2017 LAST NAME: SOLUTIONS FIRST NAME: Problem Score Max Score 1 14 2 10 3 6 4 10 5 11 6 9 7 8 9 10 8 12 12 8 Total 100 1 of 11
Linear Models for Classification: Discriminative Learning (Perceptron, SVMs, MaxEnt)
") Linear Models for Classification: Discriminative Learning (Perceptron, SVMs, MaxEnt) Nathan Schneider (some slides borrowed from Chris Dyer) ENLP 12 February 2018 23 Outline Words, probabilities Features,
Linear Models for Classification: Discriminative Learning (Perceptron, SVMs, MaxEnt) Nathan Schneider (some slides borrowed from Chris Dyer) ENLP 12 February 2018 23 Outline Words, probabilities Features,
Intro to Neural Networks and Deep Learning
 Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
Intro to Neural Networks and Deep Learning Jack Lanchantin Dr. Yanjun Qi UVA CS 6316 1 Neurons 1-Layer Neural Network Multi-layer Neural Network Loss Functions Backpropagation Nonlinearity Functions NNs
ML4NLP Multiclass Classification
 ML4NLP Multiclass Classification CS 590NLP Dan Goldwasser Purdue University dgoldwas@purdue.edu Social NLP Last week we discussed the speed-dates paper. Interesting perspective on NLP problems- Can we
ML4NLP Multiclass Classification CS 590NLP Dan Goldwasser Purdue University dgoldwas@purdue.edu Social NLP Last week we discussed the speed-dates paper. Interesting perspective on NLP problems- Can we
A graph contains a set of nodes (vertices) connected by links (edges or arcs)
 connected by links (edges or arcs)") BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
BOLTZMANN MACHINES Generative Models Graphical Models A graph contains a set of nodes (vertices) connected by links (edges or arcs) In a probabilistic graphical model, each node represents a random variable,
Statistical NLP for the Web
 Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Statistical NLP for the Web Neural Networks, Deep Belief Networks Sameer Maskey Week 8, October 24, 2012 *some slides from Andrew Rosenberg Announcements Please ask HW2 related questions in courseworks
Chapter 4 Dynamic Bayesian Networks Fall Jin Gu, Michael Zhang
 Chapter 4 Dynamic Bayesian Networks 2016 Fall Jin Gu, Michael Zhang Reviews: BN Representation Basic steps for BN representations Define variables Define the preliminary relations between variables Check
Chapter 4 Dynamic Bayesian Networks 2016 Fall Jin Gu, Michael Zhang Reviews: BN Representation Basic steps for BN representations Define variables Define the preliminary relations between variables Check
Hidden Markov Models
 CS 2750: Machine Learning Hidden Markov Models Prof. Adriana Kovashka University of Pittsburgh March 21, 2016 All slides are from Ray Mooney Motivating Example: Part Of Speech Tagging Annotate each word
CS 2750: Machine Learning Hidden Markov Models Prof. Adriana Kovashka University of Pittsburgh March 21, 2016 All slides are from Ray Mooney Motivating Example: Part Of Speech Tagging Annotate each word
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
COMS 4771 Introduction to Machine Learning. Nakul Verma
 COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
COMS 4771 Introduction to Machine Learning Nakul Verma Announcements HW1 due next lecture Project details are available decide on the group and topic by Thursday Last time Generative vs. Discriminative
Jessica Wehner. Summer Fellow Bioengineering and Bioinformatics Summer Institute University of Pittsburgh 29 May 2008
 Journal Club Jessica Wehner Summer Fellow Bioengineering and Bioinformatics Summer Institute University of Pittsburgh 29 May 2008 Comparison of Probabilistic Combination Methods for Protein Secondary Structure
Journal Club Jessica Wehner Summer Fellow Bioengineering and Bioinformatics Summer Institute University of Pittsburgh 29 May 2008 Comparison of Probabilistic Combination Methods for Protein Secondary Structure
Learning to translate with neural networks. Michael Auli
 Learning to translate with neural networks Michael Auli 1 Neural networks for text processing Similar words near each other France Spain dog cat Neural networks for text processing Similar words near each
Learning to translate with neural networks Michael Auli 1 Neural networks for text processing Similar words near each other France Spain dog cat Neural networks for text processing Similar words near each
Hidden Markov Models in Language Processing
 Hidden Markov Models in Language Processing Dustin Hillard Lecture notes courtesy of Prof. Mari Ostendorf Outline Review of Markov models What is an HMM? Examples General idea of hidden variables: implications
Hidden Markov Models in Language Processing Dustin Hillard Lecture notes courtesy of Prof. Mari Ostendorf Outline Review of Markov models What is an HMM? Examples General idea of hidden variables: implications
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Lecture 12: Algorithms for HMMs
 Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Lecture 12: Algorithms for HMMs Nathan Schneider (some slides from Sharon Goldwater; thanks to Jonathan May for bug fixes) ENLP 26 February 2018 Recap: tagging POS tagging is a sequence labelling task.
Revision: Neural Network
 Revision: Neural Network Exercise 1 Tell whether each of the following statements is true or false by checking the appropriate box. Statement True False a) A perceptron is guaranteed to perfectly learn
Revision: Neural Network Exercise 1 Tell whether each of the following statements is true or false by checking the appropriate box. Statement True False a) A perceptron is guaranteed to perfectly learn
Feedforward Neural Networks
 Chapter 4 Feedforward Neural Networks 4. Motivation Let s start with our logistic regression model from before: P(k d) = softma k =k ( λ(k ) + w d λ(k, w) ). (4.) Recall that this model gives us a lot
Chapter 4 Feedforward Neural Networks 4. Motivation Let s start with our logistic regression model from before: P(k d) = softma k =k ( λ(k ) + w d λ(k, w) ). (4.) Recall that this model gives us a lot
Semi-Markov Conditional Random Fields for Information Extraction
 Semi-Markov Conditional Random Fields for Information Extraction Sunita Sarawagi Indian Institute of Technology Bombay, India sunita@iitb.ac.in William W. Cohen Center for Automated Learning & Discovery
Semi-Markov Conditional Random Fields for Information Extraction Sunita Sarawagi Indian Institute of Technology Bombay, India sunita@iitb.ac.in William W. Cohen Center for Automated Learning & Discovery
Generative and Discriminative Approaches to Graphical Models CMSC Topics in AI
 Generative and Discriminative Approaches to Graphical Models CMSC 35900 Topics in AI Lecture 2 Yasemin Altun January 26, 2007 Review of Inference on Graphical Models Elimination algorithm finds single
Generative and Discriminative Approaches to Graphical Models CMSC 35900 Topics in AI Lecture 2 Yasemin Altun January 26, 2007 Review of Inference on Graphical Models Elimination algorithm finds single
Neural Networks, Computation Graphs. CMSC 470 Marine Carpuat
 Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Neural Networks, Computation Graphs CMSC 470 Marine Carpuat Binary Classification with a Multi-layer Perceptron φ A = 1 φ site = 1 φ located = 1 φ Maizuru = 1 φ, = 2 φ in = 1 φ Kyoto = 1 φ priest = 0 φ
Sequential Data Modeling - The Structured Perceptron
 Sequential Data Modeling - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, predict y 2 Prediction Problems Given x, A book review
Sequential Data Modeling - The Structured Perceptron Graham Neubig Nara Institute of Science and Technology (NAIST) 1 Prediction Problems Given x, predict y 2 Prediction Problems Given x, A book review
Algorithms for NLP. Classification II. Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley
 Algorithms for NLP Classification II Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Minimize Training Error? A loss function declares how costly each mistake is E.g. 0 loss for correct label,
Algorithms for NLP Classification II Taylor Berg-Kirkpatrick CMU Slides: Dan Klein UC Berkeley Minimize Training Error? A loss function declares how costly each mistake is E.g. 0 loss for correct label,
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October,
 MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
MIDTERM: CS 6375 INSTRUCTOR: VIBHAV GOGATE October, 23 2013 The exam is closed book. You are allowed a one-page cheat sheet. Answer the questions in the spaces provided on the question sheets. If you run
Structured Prediction
 Machine Learning Fall 2017 (structured perceptron, HMM, structured SVM) Professor Liang Huang (Chap. 17 of CIML) x x the man bit the dog x the man bit the dog x DT NN VBD DT NN S =+1 =-1 the man bit the
Machine Learning Fall 2017 (structured perceptron, HMM, structured SVM) Professor Liang Huang (Chap. 17 of CIML) x x the man bit the dog x the man bit the dog x DT NN VBD DT NN S =+1 =-1 the man bit the
Structure Learning in Sequential Data
 Structure Learning in Sequential Data Liam Stewart liam@cs.toronto.edu Richard Zemel zemel@cs.toronto.edu 2005.09.19 Motivation. Cau, R. Kuiper, and W.-P. de Roever. Formalising Dijkstra's development
Structure Learning in Sequential Data Liam Stewart liam@cs.toronto.edu Richard Zemel zemel@cs.toronto.edu 2005.09.19 Motivation. Cau, R. Kuiper, and W.-P. de Roever. Formalising Dijkstra's development
CISC 889 Bioinformatics (Spring 2004) Hidden Markov Models (II)
 Hidden Markov Models (II)") CISC 889 Bioinformatics (Spring 24) Hidden Markov Models (II) a. Likelihood: forward algorithm b. Decoding: Viterbi algorithm c. Model building: Baum-Welch algorithm Viterbi training Hidden Markov models
CISC 889 Bioinformatics (Spring 24) Hidden Markov Models (II) a. Likelihood: forward algorithm b. Decoding: Viterbi algorithm c. Model building: Baum-Welch algorithm Viterbi training Hidden Markov models
Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function.
 Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted
Bayesian learning: Machine learning comes from Bayesian decision theory in statistics. There we want to minimize the expected value of the loss function. Let y be the true label and y be the predicted