Hidden Markov Models
|
|
|
- Roderick Golden
- 5 years ago
- Views:
Transcription




1 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 19 Nov. 5,
2 Reminders Homework 6: PAC Learning / Generative Models Out: Wed, Oct 31 Due: Wed, Nov 7 at 11:59pm (1 week) Homework 7: HMMs Out: Wed, Nov 7 Due: Mon, Nov 19 at 11:59pm Grades are up on Canvas 2
3 Q&A Q: Why would we use Naïve Bayes? Isn t it too Naïve? A: Naïve Bayes has one key advantage over methods like Perceptron, Logistic Regression, Neural Nets: Training is lightning fast! While other methods require slow iterative training procedures that might require hundreds of epochs, Naïve Bayes computes its parameters in closed form by counting. 3
4 DISCRIMINATIVE AND GENERATIVE CLASSIFIERS 4
5 Generative vs. Discriminative Generative Classifiers: Example: Naïve Bayes Define a joint model of the observations x and the labels y: p(x,y) Learning maximizes (joint) likelihood Use Bayes Rule to classify based on the posterior: p(y x) =p(x y)p(y)/p(x) Discriminative Classifiers: Example: Logistic Regression Directly model the conditional: p(y x) Learning maximizes conditional likelihood 5
6 Generative vs. Discriminative Whiteboard Contrast: To model p(x) or not to model p(x)? 6
7 Generative vs. Discriminative Finite Sample Analysis (Ng & Jordan, 2002) [Assume that we are learning from a finite training dataset] If model assumptions are correct: Naive Bayes is a more efficient learner (requires fewer samples) than Logistic Regression If model assumptions are incorrect: Logistic Regression has lower asymtotic error, and does better than Naïve Bayes 7

8 solid: NB dashed: LR Slide courtesy of William Cohen 8
9 solid: NB dashed: LR Naïve Bayes makes stronger assumptions about the data but needs fewer examples to estimate the parameters On Discriminative vs Generative Classifiers:. Andrew Ng and Michael Jordan, NIPS Slide courtesy of William Cohen 9
10 Generative vs. Discriminative Learning (Parameter Estimation) Naïve Bayes: Parameters are decoupled à Closed form solution for MLE Logistic Regression: Parameters are coupled à No closed form solution must use iterative optimization techniques instead 10
11 Naïve Bayes vs. Logistic Reg. Learning (MAP Estimation of Parameters) Bernoulli Naïve Bayes: Parameters are probabilities à Beta prior (usually) pushes probabilities away from zero / one extremes Logistic Regression: Parameters are not probabilities à Gaussian prior encourages parameters to be close to zero (effectively pushes the probabilities away from zero / one extremes) 11
12 Features Naïve Bayes vs. Logistic Reg. Naïve Bayes: Features x are assumed to be conditionally independent given y. (i.e. Naïve Bayes Assumption) Logistic Regression: No assumptions are made about the form of the features x. They can be dependent and correlated in any fashion. 12
13 MOTIVATION: STRUCTURED PREDICTION 13
14 Structured Prediction Most of the models we ve seen so far were for classification Given observations: x = (x 1, x 2,, x K ) Predict a (binary) label: y Many real-world problems require structured prediction Given observations: x = (x 1, x 2,, x K ) Predict a structure: y = (y 1, y 2,, y J ) Some classification problems benefit from latent structure 14
15 Structured Prediction Examples Examples of structured prediction Part-of-speech (POS) tagging Handwriting recognition Speech recognition Word alignment Congressional voting Examples of latent structure Object recognition 15
16 Dataset for Supervised Part-of-Speech (POS) Tagging Data: D = {x (n), y (n) } N n=1 Sample 1: Sample 2: Sample 3: Sample 4: n v p d n time n n v d n time flies like an arrow flies like an arrow n v p n n flies p n n v v with fly with their wings time you will see y (1) x (1) y (2) x (2) y (3) x (3) y (4) x (4) 16
17 Dataset for Supervised Handwriting Recognition Data: D = {x (n), y (n) } N n=1 Sample 1: u n e x p e c t e d y (1) x (1) Sample 2: v o l c a n i c y (2) x (2) Sample 2: e m b r a c e s y (3) x (3) Figures from (Chatzis & Demiris, 2013) 17
18 Dataset for Supervised Phoneme (Speech) Recognition Data: D = {x (n), y (n) } N n=1 Sample 1: h# dh ih s w uh z iy z iy y (1) x (1) Sample 2: f ao r ah s s h# y (2) x (2) Figures from (Jansen & Niyogi, 2013) 18
 pair, are they linked?")

19 Application: Word Alignment / Phrase Extraction Variables (boolean): For each (Chinese phrase, English phrase) pair, are they linked? Interactions: Word fertilities Few jumps (discontinuities) Syntactic reorderings ITG contraint on alignment Phrases are disjoint (?) (Burkett & Klein, 2012) 19


20 Application: Congressional Voting Variables: Text of all speeches of a representative Local contexts of references between two representatives Interactions: Words used by representative and their vote Pairs of representatives and their local context (Stoyanov & Eisner, 2012) 20
21 Structured Prediction Examples Examples of structured prediction Part-of-speech (POS) tagging Handwriting recognition Speech recognition Word alignment Congressional voting Examples of latent structure Object recognition 21


 rhinoceros y")
 llama")
22 Case Study: Object Recognition Data consists of images x and labels y. x (1) x (2) pigeon y (1) rhinoceros y (2) x (3) x (4) leopard y (3) llama y (4) 22
23 Case Study: Object Recognition Data consists of images x and labels y. Preprocess data into patches Posit a latent labeling z describing the object s parts (e.g. head, leg, tail, torso, grass) Define graphical model with these latent variables in mind z is not observed at train or test time leopard 23
24 Case Study: Object Recognition Data consists of images x and labels y. Preprocess data into patches Posit a latent labeling z describing the object s parts (e.g. head, leg, tail, torso, grass) Define graphical model with these latent variables in mind z is not observed at train or test time Z 7 X 7 Z 2 X 2 leopard Y 24
25 Case Study: Object Recognition Data consists of images x and labels y. Preprocess data into patches Posit a latent labeling z describing the object s parts (e.g. head, leg, tail, torso, grass) Define graphical model with these latent variables in mind z is not observed at train or test time Z 7 ψ 1 X 7 ψ 4 ψ 4 Z 2 ψ 2 ψ 4 ψ 3 X 2 leopard Y 25
 y where y {+1, 1} Structured Prediction ˆ = p( ) where Y and Y is very large")
26 Structured Prediction Preview of challenges to come Consider the task of finding the most probable assignment to the output Classification ŷ = p(y ) y where y {+1, 1} Structured Prediction ˆ = p( ) where Y and Y is very large 26
27 Machine Learning The data inspires the structures we want to predict Inference finds {best structure, marginals, partition function} for a new observation (Inference is usually called as a subroutine in learning) Domain Knowledge Combinatorial Optimization ML Mathematical Modeling Optimization Our model defines a score for each structure It also tells us what to optimize Learning tunes the parameters of the model 27



28 Machine Learning Data Model X 1 time flies like an arrow X2 X 3 X 4 X 5 Objective Inference Learning (Inference is usually called as a subroutine in learning) 28
29 BACKGROUND 29
30 Background: Chain Rule of Probability For random variables A and B: P (A, B) =P (A B)P (B) For random variables X 1,X 2,X 3,X 4 : P (X 1,X 2,X 3,X 4 )=P(X 1 X 2,X 3,X 4 ) P (X 2 X 3,X 4 ) P (X 3 X 4 ) P (X 4 ) 31
31 Background: Conditional Independence Random variables A and B are conditionally independent given C if: P (A, B C) =P (A C)P (B C) (1) or equivalently: P (A B,C) =P (A C) (2) We write this as: A B C (3) Later we will also write: I<A, {C}, B> 32
32 HIDDEN MARKOV MODEL (HMM) 33
33 HMM Outline Motivation Time Series Data Hidden Markov Model (HMM) Example: Squirrel Hill Tunnel Closures [courtesy of Roni Rosenfeld] Background: Markov Models From Mixture Model to HMM History of HMMs Higher-order HMMs Training HMMs (Supervised) Likelihood for HMM Maximum Likelihood Estimation (MLE) for HMM EM for HMM (aka. Baum-Welch algorithm) Forward-Backward Algorithm Three Inference Problems for HMM Great Ideas in ML: Message Passing Example: Forward-Backward on 3-word Sentence Derivation of Forward Algorithm Forward-Backward Algorithm Viterbi algorithm 34
34 Whiteboard Markov Models Example: Squirrel Hill Tunnel Closures [courtesy of Roni Rosenfeld] First-order Markov assumption Conditional independence assumptions 35

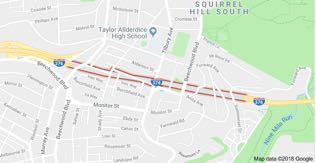
35 36
36 Mixture Model for Time Series Data We could treat each (tunnel state, travel time) pair as independent. This corresponds to a Naïve Bayes model with a single feature (travel time). p(o, S, S, O, C, 2m, 3m, 18m, 9m, 27m) = (.8 *.2 *.1 *.03 * ) O.8 S.1 C.1 O.8 S.1 C.1 O S S O C 1min 2min 3min O S C min 2min 3min 2m 3m 18m O m 27m S C
 = (.8 *.08 *.2 *.7 *.03 * ) O.8 S.1 C.1 O S C O.9.08.02 S.2.7.1 C.9 0.1 O S C O.9.08.02 S.2.7.1 C.9 0.1 O S S O C 1min 2min 3min O.1.2.3 S.01.02.03 C 0 0 0 1min 2min 3min 2m 3m 18m O.")
37 Hidden Markov Model A Hidden Markov Model (HMM) provides a joint distribution over the the tunnel states / travel times with an assumption of dependence between adjacent tunnel states. p(o, S, S, O, C, 2m, 3m, 18m, 9m, 27m) = (.8 *.08 *.2 *.7 *.03 * ) O.8 S.1 C.1 O S C O S C O S C O S C O S S O C 1min 2min 3min O S C min 2min 3min 2m 3m 18m O m 27m S C
38 From Mixture Model to HMM Y 1 Y 2 Y 3 Y 4 Y 5 X 1 X 2 X 3 X 4 X 5 Naïve Bayes : Y 1 Y 2 Y 3 Y 4 Y 5 X 1 X 2 X 3 X 4 X 5 HMM: 40

39 From Mixture Model to HMM Y 1 Y 2 Y 3 Y 4 Y 5 X 1 X 2 X 3 X 4 X 5 Naïve Bayes : Y 0 Y 1 Y 2 Y 3 Y 4 Y 5 X 1 X 2 X 3 X 4 X 5 HMM: 41
40 SUPERVISED LEARNING FOR HMMS 46

41 HMM Parameters: Hidden Markov Model O.8 S.1 C.1 O S C O S C O S C O S C Y 1 Y 2 Y 3 Y 4 Y 5 1min 2min 3min O S C min 2min 3min X 1 X 2 X 3 O X 4 X 5 S C
42 Whiteboard Training HMMs (Supervised) Likelihood for an HMM Maximum Likelihood Estimation (MLE) for HMM 49
43 Learning an HMM decomposes into solving two (independent) Mixture Models Supervised Learning for HMMs Y t Y t+1 Y t X t 50




44 HMM Parameters: Hidden Markov Model Assumption: y 0 = START Generative Story: For notational convenience, we fold the initial probabilities C into the transition matrix B by our assumption. Y 0 Y 1 Y 2 Y 3 Y 4 Y 5 X 1 X 2 X 3 X 4 X 5 51

45 Joint Distribution: y 0 = START Hidden Markov Model Y 0 Y 1 Y 2 Y 3 Y 4 Y 5 X 1 X 2 X 3 X 4 X 5 52
46 Supervised Learning for HMMs Learning an HMM decomposes into solving two (independent) Mixture Models Yt Yt+1 Yt Xt 53


 began to use HMMs for modeling biological")


47 HMMs: History Markov chains: Andrey Markov (1906) Random walks and Brownian motion Used in Shannon s work on information theory (1948) Baum-Welsh learning algorithm: late 60 s, early 70 s. Used mainly for speech in 60s-70s. Late 80 s and 90 s: David Haussler (major player in learning theory in 80 s) began to use HMMs for modeling biological sequences Mid-late 1990 s: Dayne Freitag/Andrew McCallum Freitag thesis with Tom Mitchell on IE from Web using logic programs, grammar induction, etc. McCallum: multinomial Naïve Bayes for text With McCallum, IE using HMMs on CORA Slide from William Cohen 55
48 Higher-order HMMs 1 st -order HMM (i.e. bigram HMM) <START> Y 1 Y 2 Y 3 Y 4 Y 5 X 1 X 2 X 3 X 4 X 5 2 nd -order HMM (i.e. trigram HMM) <START> Y 1 Y 2 Y 3 Y 4 Y 5 3 rd -order HMM X 1 X 2 X 3 X 4 X 5 <START> Y 1 Y 2 Y 3 Y 4 Y 5 X 1 X 2 X 3 X 4 X 5 56
Hidden Markov Models
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Hidden Markov Models Matt Gormley Lecture 22 April 2, 2018 1 Reminders Homework
Bayesian Networks (Part I)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks (Part I) Graphical Model Readings: Murphy 10 10.2.1 Bishop 8.1,
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks (Part I) Graphical Model Readings: Murphy 10 10.2.1 Bishop 8.1,
Directed Graphical Models (aka. Bayesian Networks)
") School of Computer Science 10-601B Introduction to Machine Learning Directed Graphical Models (aka. Bayesian Networks) Readings: Bishop 8.1 and 8.2.2 Mitchell 6.11 Murphy 10 Matt Gormley Lecture 21 November
School of Computer Science 10-601B Introduction to Machine Learning Directed Graphical Models (aka. Bayesian Networks) Readings: Bishop 8.1 and 8.2.2 Mitchell 6.11 Murphy 10 Matt Gormley Lecture 21 November
Naïve Bayes Introduction to Machine Learning. Matt Gormley Lecture 18 Oct. 31, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Naïve Bayes Matt Gormley Lecture 18 Oct. 31, 2018 1 Reminders Homework 6: PAC Learning
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Naïve Bayes Matt Gormley Lecture 18 Oct. 31, 2018 1 Reminders Homework 6: PAC Learning
Bayesian Networks Introduction to Machine Learning. Matt Gormley Lecture 24 April 9, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks Matt Gormley Lecture 24 April 9, 2018 1 Homework 7: HMMs Reminders
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks Matt Gormley Lecture 24 April 9, 2018 1 Homework 7: HMMs Reminders
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes MLE / MAP Readings: Estimating Probabilities (Mitchell, 2016)
Bayesian Networks (Part II)
") 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks (Part II) Graphical Model Readings: Murphy 10 10.2.1 Bishop 8.1,
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Bayesian Networks (Part II) Graphical Model Readings: Murphy 10 10.2.1 Bishop 8.1,
Logistic Regression Introduction to Machine Learning. Matt Gormley Lecture 9 Sep. 26, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 9 Sep. 26, 2018 1 Reminders Homework 3:
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 9 Sep. 26, 2018 1 Reminders Homework 3:
STA 414/2104: Machine Learning
 STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
STA 414/2104: Machine Learning Russ Salakhutdinov Department of Computer Science! Department of Statistics! rsalakhu@cs.toronto.edu! http://www.cs.toronto.edu/~rsalakhu/ Lecture 9 Sequential Data So far
Logistic Regression Introduction to Machine Learning. Matt Gormley Lecture 8 Feb. 12, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Logistic Regression Matt Gormley Lecture 8 Feb. 12, 2018 1 10-601 Introduction
Sequential Supervised Learning
 Sequential Supervised Learning Many Application Problems Require Sequential Learning Part-of of-speech Tagging Information Extraction from the Web Text-to to-speech Mapping Part-of of-speech Tagging Given
Sequential Supervised Learning Many Application Problems Require Sequential Learning Part-of of-speech Tagging Information Extraction from the Web Text-to to-speech Mapping Part-of of-speech Tagging Given
Sequence labeling. Taking collective a set of interrelated instances x 1,, x T and jointly labeling them
 HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
HMM, MEMM and CRF 40-957 Special opics in Artificial Intelligence: Probabilistic Graphical Models Sharif University of echnology Soleymani Spring 2014 Sequence labeling aking collective a set of interrelated
Perceptron & Neural Networks
 School of Computer Science 10-701 Introduction to Machine Learning Perceptron & Neural Networks Readings: Bishop Ch. 4.1.7, Ch. 5 Murphy Ch. 16.5, Ch. 28 Mitchell Ch. 4 Matt Gormley Lecture 12 October
School of Computer Science 10-701 Introduction to Machine Learning Perceptron & Neural Networks Readings: Bishop Ch. 4.1.7, Ch. 5 Murphy Ch. 16.5, Ch. 28 Mitchell Ch. 4 Matt Gormley Lecture 12 October
MLE/MAP + Naïve Bayes
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University MLE/MAP + Naïve Bayes Matt Gormley Lecture 19 March 20, 2018 1 Midterm Exam Reminders
Undirected Graphical Models
 Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
Outline Hong Chang Institute of Computing Technology, Chinese Academy of Sciences Machine Learning Methods (Fall 2012) Outline Outline I 1 Introduction 2 Properties Properties 3 Generative vs. Conditional
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 11 Project
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 23, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 19 Oct, 24, 2016 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models D. Page,
What s an HMM? Extraction with Finite State Machines e.g. Hidden Markov Models (HMMs) Hidden Markov Models (HMMs) for Information Extraction
 Hidden Markov Models (HMMs) for Information Extraction") Hidden Markov Models (HMMs) for Information Extraction Daniel S. Weld CSE 454 Extraction with Finite State Machines e.g. Hidden Markov Models (HMMs) standard sequence model in genomics, speech, NLP, What
Hidden Markov Models (HMMs) for Information Extraction Daniel S. Weld CSE 454 Extraction with Finite State Machines e.g. Hidden Markov Models (HMMs) standard sequence model in genomics, speech, NLP, What
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields
 Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
Statistical NLP for the Web Log Linear Models, MEMM, Conditional Random Fields Sameer Maskey Week 13, Nov 28, 2012 1 Announcements Next lecture is the last lecture Wrap up of the semester 2 Final Project
Brief Introduction of Machine Learning Techniques for Content Analysis
 1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
1 Brief Introduction of Machine Learning Techniques for Content Analysis Wei-Ta Chu 2008/11/20 Outline 2 Overview Gaussian Mixture Model (GMM) Hidden Markov Model (HMM) Support Vector Machine (SVM) Overview
Cheng Soon Ong & Christian Walder. Canberra February June 2018
 Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
Cheng Soon Ong & Christian Walder Research Group and College of Engineering and Computer Science Canberra February June 2018 Outlines Overview Introduction Linear Algebra Probability Linear Regression
10 : HMM and CRF. 1 Case Study: Supervised Part-of-Speech Tagging
 10-708: Probabilistic Graphical Models 10-708, Spring 2018 10 : HMM and CRF Lecturer: Kayhan Batmanghelich Scribes: Ben Lengerich, Michael Kleyman 1 Case Study: Supervised Part-of-Speech Tagging We will
10-708: Probabilistic Graphical Models 10-708, Spring 2018 10 : HMM and CRF Lecturer: Kayhan Batmanghelich Scribes: Ben Lengerich, Michael Kleyman 1 Case Study: Supervised Part-of-Speech Tagging We will
Sequence Modelling with Features: Linear-Chain Conditional Random Fields. COMP-599 Oct 6, 2015
 Sequence Modelling with Features: Linear-Chain Conditional Random Fields COMP-599 Oct 6, 2015 Announcement A2 is out. Due Oct 20 at 1pm. 2 Outline Hidden Markov models: shortcomings Generative vs. discriminative
Sequence Modelling with Features: Linear-Chain Conditional Random Fields COMP-599 Oct 6, 2015 Announcement A2 is out. Due Oct 20 at 1pm. 2 Outline Hidden Markov models: shortcomings Generative vs. discriminative
Lecture 11: Hidden Markov Models
 Lecture 11: Hidden Markov Models Cognitive Systems - Machine Learning Cognitive Systems, Applied Computer Science, Bamberg University slides by Dr. Philip Jackson Centre for Vision, Speech & Signal Processing
Lecture 11: Hidden Markov Models Cognitive Systems - Machine Learning Cognitive Systems, Applied Computer Science, Bamberg University slides by Dr. Philip Jackson Centre for Vision, Speech & Signal Processing
Logistic Regression Review Fall 2012 Recitation. September 25, 2012 TA: Selen Uguroglu
 Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Logistic Regression Review 10-601 Fall 2012 Recitation September 25, 2012 TA: Selen Uguroglu!1 Outline Decision Theory Logistic regression Goal Loss function Inference Gradient Descent!2 Training Data
Machine Learning for Structured Prediction
 Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Machine Learning for Structured Prediction Grzegorz Chrupa la National Centre for Language Technology School of Computing Dublin City University NCLT Seminar Grzegorz Chrupa la (DCU) Machine Learning for
Perceptron (Theory) + Linear Regression
 + Linear Regression") 10601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron (Theory) Linear Regression Matt Gormley Lecture 6 Feb. 5, 2018 1 Q&A
10601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Perceptron (Theory) Linear Regression Matt Gormley Lecture 6 Feb. 5, 2018 1 Q&A
Hidden Markov Models in Language Processing
 Hidden Markov Models in Language Processing Dustin Hillard Lecture notes courtesy of Prof. Mari Ostendorf Outline Review of Markov models What is an HMM? Examples General idea of hidden variables: implications
Hidden Markov Models in Language Processing Dustin Hillard Lecture notes courtesy of Prof. Mari Ostendorf Outline Review of Markov models What is an HMM? Examples General idea of hidden variables: implications
Hidden Markov Models. Aarti Singh Slides courtesy: Eric Xing. Machine Learning / Nov 8, 2010
 Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Hidden Markov Models Aarti Singh Slides courtesy: Eric Xing Machine Learning 10-701/15-781 Nov 8, 2010 i.i.d to sequential data So far we assumed independent, identically distributed data Sequential data
Last Time. Today. Bayesian Learning. The Distributions We Love. CSE 446 Gaussian Naïve Bayes & Logistic Regression
 CSE 446 Gaussian Naïve Bayes & Logistic Regression Winter 22 Dan Weld Learning Gaussians Naïve Bayes Last Time Gaussians Naïve Bayes Logistic Regression Today Some slides from Carlos Guestrin, Luke Zettlemoyer
CSE 446 Gaussian Naïve Bayes & Logistic Regression Winter 22 Dan Weld Learning Gaussians Naïve Bayes Last Time Gaussians Naïve Bayes Logistic Regression Today Some slides from Carlos Guestrin, Luke Zettlemoyer
Conditional Random Field
 Introduction Linear-Chain General Specific Implementations Conclusions Corso di Elaborazione del Linguaggio Naturale Pisa, May, 2011 Introduction Linear-Chain General Specific Implementations Conclusions
Introduction Linear-Chain General Specific Implementations Conclusions Corso di Elaborazione del Linguaggio Naturale Pisa, May, 2011 Introduction Linear-Chain General Specific Implementations Conclusions
Statistical Methods for NLP
 Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
Statistical Methods for NLP Information Extraction, Hidden Markov Models Sameer Maskey Week 5, Oct 3, 2012 *many slides provided by Bhuvana Ramabhadran, Stanley Chen, Michael Picheny Speech Recognition
COMP90051 Statistical Machine Learning
 COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
COMP90051 Statistical Machine Learning Semester 2, 2017 Lecturer: Trevor Cohn 24. Hidden Markov Models & message passing Looking back Representation of joint distributions Conditional/marginal independence
Machine Learning Gaussian Naïve Bayes Big Picture
 Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 27, 2011 Today: Naïve Bayes Big Picture Logistic regression Gradient ascent Generative discriminative
Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 27, 2011 Today: Naïve Bayes Big Picture Logistic regression Gradient ascent Generative discriminative
Probabilistic modeling. The slides are closely adapted from Subhransu Maji s slides
 Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Probabilistic modeling The slides are closely adapted from Subhransu Maji s slides Overview So far the models and algorithms you have learned about are relatively disconnected Probabilistic modeling framework
Bias-Variance Tradeoff
 What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
What s learning, revisited Overfitting Generative versus Discriminative Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 19 th, 2007 Bias-Variance Tradeoff
Advanced Data Science
 Advanced Data Science Dr. Kira Radinsky Slides Adapted from Tom M. Mitchell Agenda Topics Covered: Time series data Markov Models Hidden Markov Models Dynamic Bayes Nets Additional Reading: Bishop: Chapter
Advanced Data Science Dr. Kira Radinsky Slides Adapted from Tom M. Mitchell Agenda Topics Covered: Time series data Markov Models Hidden Markov Models Dynamic Bayes Nets Additional Reading: Bishop: Chapter
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs
 Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
Empirical Methods in Natural Language Processing Lecture 11 Part-of-speech tagging and HMMs (based on slides by Sharon Goldwater and Philipp Koehn) 21 February 2018 Nathan Schneider ENLP Lecture 11 21
Generative v. Discriminative classifiers Intuition
 Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 1 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features
Logistic Regression Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 1 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features
Machine Learning, Fall 2012 Homework 2
 0-60 Machine Learning, Fall 202 Homework 2 Instructors: Tom Mitchell, Ziv Bar-Joseph TA in charge: Selen Uguroglu email: sugurogl@cs.cmu.edu SOLUTIONS Naive Bayes, 20 points Problem. Basic concepts, 0
0-60 Machine Learning, Fall 202 Homework 2 Instructors: Tom Mitchell, Ziv Bar-Joseph TA in charge: Selen Uguroglu email: sugurogl@cs.cmu.edu SOLUTIONS Naive Bayes, 20 points Problem. Basic concepts, 0
More on HMMs and other sequence models. Intro to NLP - ETHZ - 18/03/2013
 More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
More on HMMs and other sequence models Intro to NLP - ETHZ - 18/03/2013 Summary Parts of speech tagging HMMs: Unsupervised parameter estimation Forward Backward algorithm Bayesian variants Discriminative
Naïve Bayes Introduction to Machine Learning. Matt Gormley Lecture 3 September 14, Readings: Mitchell Ch Murphy Ch.
 School of Computer Science 10-701 Introduction to Machine Learning aïve Bayes Readings: Mitchell Ch. 6.1 6.10 Murphy Ch. 3 Matt Gormley Lecture 3 September 14, 2016 1 Homewor 1: due 9/26/16 Project Proposal:
School of Computer Science 10-701 Introduction to Machine Learning aïve Bayes Readings: Mitchell Ch. 6.1 6.10 Murphy Ch. 3 Matt Gormley Lecture 3 September 14, 2016 1 Homewor 1: due 9/26/16 Project Proposal:
Machine Learning Tom M. Mitchell Machine Learning Department Carnegie Mellon University. September 20, 2012
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 20, 2012 Today: Logistic regression Generative/Discriminative classifiers Readings: (see class website)
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 20, 2012 Today: Logistic regression Generative/Discriminative classifiers Readings: (see class website)
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 22, 2011 Today: MLE and MAP Bayes Classifiers Naïve Bayes Readings: Mitchell: Naïve Bayes and Logistic
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 22, 2011 Today: MLE and MAP Bayes Classifiers Naïve Bayes Readings: Mitchell: Naïve Bayes and Logistic
Estimating Parameters
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 13, 2012 Today: Bayes Classifiers Naïve Bayes Gaussian Naïve Bayes Readings: Mitchell: Naïve Bayes
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University September 13, 2012 Today: Bayes Classifiers Naïve Bayes Gaussian Naïve Bayes Readings: Mitchell: Naïve Bayes
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 26, 2015 Today: Bayes Classifiers Conditional Independence Naïve Bayes Readings: Mitchell: Naïve Bayes
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University January 26, 2015 Today: Bayes Classifiers Conditional Independence Naïve Bayes Readings: Mitchell: Naïve Bayes
Mini-project 2 (really) due today! Turn in a printout of your work at the end of the class
 due today! Turn in a printout of your work at the end of the class") Administrivia Mini-project 2 (really) due today Turn in a printout of your work at the end of the class Project presentations April 23 (Thursday next week) and 28 (Tuesday the week after) Order will be
Administrivia Mini-project 2 (really) due today Turn in a printout of your work at the end of the class Project presentations April 23 (Thursday next week) and 28 (Tuesday the week after) Order will be
Introduction to Machine Learning
 Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Introduction to Machine Learning Brown University CSCI 1950-F, Spring 2012 Prof. Erik Sudderth Lecture 20: Expectation Maximization Algorithm EM for Mixture Models Many figures courtesy Kevin Murphy s
Conditional Random Fields for Sequential Supervised Learning
 Conditional Random Fields for Sequential Supervised Learning Thomas G. Dietterich Adam Ashenfelter Department of Computer Science Oregon State University Corvallis, Oregon 97331 http://www.eecs.oregonstate.edu/~tgd
Conditional Random Fields for Sequential Supervised Learning Thomas G. Dietterich Adam Ashenfelter Department of Computer Science Oregon State University Corvallis, Oregon 97331 http://www.eecs.oregonstate.edu/~tgd
Graphical models for part of speech tagging
 Indian Institute of Technology, Bombay and Research Division, India Research Lab Graphical models for part of speech tagging Different Models for POS tagging HMM Maximum Entropy Markov Models Conditional
Indian Institute of Technology, Bombay and Research Division, India Research Lab Graphical models for part of speech tagging Different Models for POS tagging HMM Maximum Entropy Markov Models Conditional
Introduction to Machine Learning Midterm, Tues April 8
 Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Introduction to Machine Learning 10-701 Midterm, Tues April 8 [1 point] Name: Andrew ID: Instructions: You are allowed a (two-sided) sheet of notes. Exam ends at 2:45pm Take a deep breath and don t spend
Logistic Regression. William Cohen
 Logistic Regression William Cohen 1 Outline Quick review classi5ication, naïve Bayes, perceptrons new result for naïve Bayes Learning as optimization Logistic regression via gradient ascent Over5itting
Logistic Regression William Cohen 1 Outline Quick review classi5ication, naïve Bayes, perceptrons new result for naïve Bayes Learning as optimization Logistic regression via gradient ascent Over5itting
Probabilistic Graphical Models
 Probabilistic Graphical Models David Sontag New York University Lecture 4, February 16, 2012 David Sontag (NYU) Graphical Models Lecture 4, February 16, 2012 1 / 27 Undirected graphical models Reminder
Probabilistic Graphical Models David Sontag New York University Lecture 4, February 16, 2012 David Sontag (NYU) Graphical Models Lecture 4, February 16, 2012 1 / 27 Undirected graphical models Reminder
Machine Learning
 Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 2, 2015 Today: Logistic regression Generative/Discriminative classifiers Readings: (see class website)
Machine Learning 10-601 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 2, 2015 Today: Logistic regression Generative/Discriminative classifiers Readings: (see class website)
Lecture 15. Probabilistic Models on Graph
 Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
Lecture 15. Probabilistic Models on Graph Prof. Alan Yuille Spring 2014 1 Introduction We discuss how to define probabilistic models that use richly structured probability distributions and describe how
ECE521 Tutorial 11. Topic Review. ECE521 Winter Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides. ECE521 Tutorial 11 / 4
 ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
ECE52 Tutorial Topic Review ECE52 Winter 206 Credits to Alireza Makhzani, Alex Schwing, Rich Zemel and TAs for slides ECE52 Tutorial ECE52 Winter 206 Credits to Alireza / 4 Outline K-means, PCA 2 Bayesian
Pattern Recognition and Machine Learning
 Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Christopher M. Bishop Pattern Recognition and Machine Learning ÖSpri inger Contents Preface Mathematical notation Contents vii xi xiii 1 Introduction 1 1.1 Example: Polynomial Curve Fitting 4 1.2 Probability
Generative v. Discriminative classifiers Intuition
 Logistic Regression Machine Learning 070/578 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features Y target
Logistic Regression Machine Learning 070/578 Carlos Guestrin Carnegie Mellon University September 24 th, 2007 Generative v. Discriminative classifiers Intuition Want to Learn: h:x a Y X features Y target
Chapter 4 Dynamic Bayesian Networks Fall Jin Gu, Michael Zhang
 Chapter 4 Dynamic Bayesian Networks 2016 Fall Jin Gu, Michael Zhang Reviews: BN Representation Basic steps for BN representations Define variables Define the preliminary relations between variables Check
Chapter 4 Dynamic Bayesian Networks 2016 Fall Jin Gu, Michael Zhang Reviews: BN Representation Basic steps for BN representations Define variables Define the preliminary relations between variables Check
Probabilistic Time Series Classification
 Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Probabilistic Time Series Classification Y. Cem Sübakan Boğaziçi University 25.06.2013 Y. Cem Sübakan (Boğaziçi University) M.Sc. Thesis Defense 25.06.2013 1 / 54 Problem Statement The goal is to assign
Regularization Introduction to Machine Learning. Matt Gormley Lecture 10 Feb. 19, 2018
 1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
1-61 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Regularization Matt Gormley Lecture 1 Feb. 19, 218 1 Reminders Homework 4: Logistic
CISC 889 Bioinformatics (Spring 2004) Hidden Markov Models (II)
 Hidden Markov Models (II)") CISC 889 Bioinformatics (Spring 24) Hidden Markov Models (II) a. Likelihood: forward algorithm b. Decoding: Viterbi algorithm c. Model building: Baum-Welch algorithm Viterbi training Hidden Markov models
CISC 889 Bioinformatics (Spring 24) Hidden Markov Models (II) a. Likelihood: forward algorithm b. Decoding: Viterbi algorithm c. Model building: Baum-Welch algorithm Viterbi training Hidden Markov models
Logistic Regression & Neural Networks
 Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
Logistic Regression & Neural Networks CMSC 723 / LING 723 / INST 725 Marine Carpuat Slides credit: Graham Neubig, Jacob Eisenstein Logistic Regression Perceptron & Probabilities What if we want a probability
CSCI-567: Machine Learning (Spring 2019)
") CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Mar. 19, 2019 March 19, 2019 1 / 43 Administration March 19, 2019 2 / 43 Administration TA3 is due this week March
Hidden Markov Models
 Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
Hidden Markov Models Slides mostly from Mitch Marcus and Eric Fosler (with lots of modifications). Have you seen HMMs? Have you seen Kalman filters? Have you seen dynamic programming? HMMs are dynamic
From perceptrons to word embeddings. Simon Šuster University of Groningen
 From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
From perceptrons to word embeddings Simon Šuster University of Groningen Outline A basic computational unit Weighting some input to produce an output: classification Perceptron Classify tweets Written
Statistical Methods for NLP
 Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Statistical Methods for NLP Sequence Models Joakim Nivre Uppsala University Department of Linguistics and Philology joakim.nivre@lingfil.uu.se Statistical Methods for NLP 1(21) Introduction Structured
Probabilistic Graphical Models: MRFs and CRFs. CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov
 Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
Probabilistic Graphical Models: MRFs and CRFs CSE628: Natural Language Processing Guest Lecturer: Veselin Stoyanov Why PGMs? PGMs can model joint probabilities of many events. many techniques commonly
CPSC 540: Machine Learning
 CPSC 540: Machine Learning Undirected Graphical Models Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 3: 2 late days to hand it in today, Thursday is final day. Assignment 4:
CPSC 540: Machine Learning Undirected Graphical Models Mark Schmidt University of British Columbia Winter 2016 Admin Assignment 3: 2 late days to hand it in today, Thursday is final day. Assignment 4:
Hidden Markov Models. By Parisa Abedi. Slides courtesy: Eric Xing
 Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Hidden Markov Models By Parisa Abedi Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed data Sequential (non i.i.d.) data Time-series data E.g. Speech
Machine Learning
 Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 1, 2011 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Machine Learning 10-701 Tom M. Mitchell Machine Learning Department Carnegie Mellon University February 1, 2011 Today: Generative discriminative classifiers Linear regression Decomposition of error into
Midterm Review CS 6375: Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
Midterm Review CS 6375: Machine Learning Vibhav Gogate The University of Texas at Dallas Machine Learning Supervised Learning Unsupervised Learning Reinforcement Learning Parametric Y Continuous Non-parametric
We Live in Exciting Times. CSCI-567: Machine Learning (Spring 2019) Outline. Outline. ACM (an international computing research society) has named
 Outline. Outline. ACM (an international computing research society) has named") We Live in Exciting Times ACM (an international computing research society) has named CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Apr. 2, 2019 Yoshua Bengio,
We Live in Exciting Times ACM (an international computing research society) has named CSCI-567: Machine Learning (Spring 2019) Prof. Victor Adamchik U of Southern California Apr. 2, 2019 Yoshua Bengio,
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
Introduction to Machine Learning CMU-10701 Hidden Markov Models Barnabás Póczos & Aarti Singh Slides courtesy: Eric Xing i.i.d to sequential data So far we assumed independent, identically distributed
Deriving Principal Component Analysis (PCA)
") -0 Mathematical Foundations for Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deriving Principal Component Analysis (PCA) Matt Gormley Lecture 11 Oct.
-0 Mathematical Foundations for Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Deriving Principal Component Analysis (PCA) Matt Gormley Lecture 11 Oct.
Machine Learning, Midterm Exam: Spring 2009 SOLUTION
 10-601 Machine Learning, Midterm Exam: Spring 2009 SOLUTION March 4, 2009 Please put your name at the top of the table below. If you need more room to work out your answer to a question, use the back of
10-601 Machine Learning, Midterm Exam: Spring 2009 SOLUTION March 4, 2009 Please put your name at the top of the table below. If you need more room to work out your answer to a question, use the back of
Bayesian Classifiers, Conditional Independence and Naïve Bayes. Required reading: Naïve Bayes and Logistic Regression (available on class website)
") Bayesian Classifiers, Conditional Independence and Naïve Bayes Required reading: Naïve Bayes and Logistic Regression (available on class website) Machine Learning 10-701 Tom M. Mitchell Machine Learning
Bayesian Classifiers, Conditional Independence and Naïve Bayes Required reading: Naïve Bayes and Logistic Regression (available on class website) Machine Learning 10-701 Tom M. Mitchell Machine Learning
Machine Learning & Data Mining Caltech CS/CNS/EE 155 Hidden Markov Models Last Updated: Feb 7th, 2017
 1 Introduction Let x = (x 1,..., x M ) denote a sequence (e.g. a sequence of words), and let y = (y 1,..., y M ) denote a corresponding hidden sequence that we believe explains or influences x somehow
1 Introduction Let x = (x 1,..., x M ) denote a sequence (e.g. a sequence of words), and let y = (y 1,..., y M ) denote a corresponding hidden sequence that we believe explains or influences x somehow
Intelligent Systems (AI-2)
") Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 18 Oct, 21, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models CPSC
Intelligent Systems (AI-2) Computer Science cpsc422, Lecture 18 Oct, 21, 2015 Slide Sources Raymond J. Mooney University of Texas at Austin D. Koller, Stanford CS - Probabilistic Graphical Models CPSC
Machine Learning (CS 567) Lecture 2
 Lecture 2") Machine Learning (CS 567) Lecture 2 Time: T-Th 5:00pm - 6:20pm Location: GFS118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Machine Learning (CS 567) Lecture 2 Time: T-Th 5:00pm - 6:20pm Location: GFS118 Instructor: Sofus A. Macskassy (macskass@usc.edu) Office: SAL 216 Office hours: by appointment Teaching assistant: Cheol
Expectation Maximization (EM)
") Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
Expectation Maximization (EM) The EM algorithm is used to train models involving latent variables using training data in which the latent variables are not observed (unlabeled data). This is to be contrasted
Machine Learning, Midterm Exam: Spring 2008 SOLUTIONS. Q Topic Max. Score Score. 1 Short answer questions 20.
 10-601 Machine Learning, Midterm Exam: Spring 2008 Please put your name on this cover sheet If you need more room to work out your answer to a question, use the back of the page and clearly mark on the
10-601 Machine Learning, Midterm Exam: Spring 2008 Please put your name on this cover sheet If you need more room to work out your answer to a question, use the back of the page and clearly mark on the
Backpropagation Introduction to Machine Learning. Matt Gormley Lecture 13 Mar 1, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 13 Mar 1, 2018 1 Reminders Homework 5: Neural
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Backpropagation Matt Gormley Lecture 13 Mar 1, 2018 1 Reminders Homework 5: Neural
Midterm Review CS 7301: Advanced Machine Learning. Vibhav Gogate The University of Texas at Dallas
 Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Midterm Review CS 7301: Advanced Machine Learning Vibhav Gogate The University of Texas at Dallas Supervised Learning Issues in supervised learning What makes learning hard Point Estimation: MLE vs Bayesian
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation. Volker Tresp Summer 2016
 Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Bayesian Networks: Construction, Inference, Learning and Causal Interpretation Volker Tresp Summer 2016 1 Introduction So far we were mostly concerned with supervised learning: we predicted one or several
Statistical Machine Learning from Data
 Samy Bengio Statistical Machine Learning from Data Statistical Machine Learning from Data Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique Fédérale de Lausanne (EPFL),
Samy Bengio Statistical Machine Learning from Data Statistical Machine Learning from Data Samy Bengio IDIAP Research Institute, Martigny, Switzerland, and Ecole Polytechnique Fédérale de Lausanne (EPFL),
Naïve Bayes. Jia-Bin Huang. Virginia Tech Spring 2019 ECE-5424G / CS-5824
 Naïve Bayes Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 out today. Please start early! Office hours Chen: Wed 4pm-5pm Shih-Yang: Fri 3pm-4pm Location: Whittemore 266
Naïve Bayes Jia-Bin Huang ECE-5424G / CS-5824 Virginia Tech Spring 2019 Administrative HW 1 out today. Please start early! Office hours Chen: Wed 4pm-5pm Shih-Yang: Fri 3pm-4pm Location: Whittemore 266
Naïve Bayes classification
 Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Naïve Bayes classification 1 Probability theory Random variable: a variable whose possible values are numerical outcomes of a random phenomenon. Examples: A person s height, the outcome of a coin toss
Hidden Markov Models
 Hidden Markov Models CI/CI(CS) UE, SS 2015 Christian Knoll Signal Processing and Speech Communication Laboratory Graz University of Technology June 23, 2015 CI/CI(CS) SS 2015 June 23, 2015 Slide 1/26 Content
Hidden Markov Models CI/CI(CS) UE, SS 2015 Christian Knoll Signal Processing and Speech Communication Laboratory Graz University of Technology June 23, 2015 CI/CI(CS) SS 2015 June 23, 2015 Slide 1/26 Content
Introduction to Machine Learning Midterm Exam
 10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
10-701 Introduction to Machine Learning Midterm Exam Instructors: Eric Xing, Ziv Bar-Joseph 17 November, 2015 There are 11 questions, for a total of 100 points. This exam is open book, open notes, but
Directed Probabilistic Graphical Models CMSC 678 UMBC
 Directed Probabilistic Graphical Models CMSC 678 UMBC Announcement 1: Assignment 3 Due Wednesday April 11 th, 11:59 AM Any questions? Announcement 2: Progress Report on Project Due Monday April 16 th,
Directed Probabilistic Graphical Models CMSC 678 UMBC Announcement 1: Assignment 3 Due Wednesday April 11 th, 11:59 AM Any questions? Announcement 2: Progress Report on Project Due Monday April 16 th,
Machine Learning Overview
 Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Machine Learning Overview Sargur N. Srihari University at Buffalo, State University of New York USA 1 Outline 1. What is Machine Learning (ML)? 2. Types of Information Processing Problems Solved 1. Regression
Hidden Markov Model. Ying Wu. Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208
 Hidden Markov Model Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/19 Outline Example: Hidden Coin Tossing Hidden
Hidden Markov Model Ying Wu Electrical Engineering and Computer Science Northwestern University Evanston, IL 60208 http://www.eecs.northwestern.edu/~yingwu 1/19 Outline Example: Hidden Coin Tossing Hidden
Conditional Random Fields and beyond DANIEL KHASHABI CS 546 UIUC, 2013
 Conditional Random Fields and beyond DANIEL KHASHABI CS 546 UIUC, 2013 Outline Modeling Inference Training Applications Outline Modeling Problem definition Discriminative vs. Generative Chain CRF General
Conditional Random Fields and beyond DANIEL KHASHABI CS 546 UIUC, 2013 Outline Modeling Inference Training Applications Outline Modeling Problem definition Discriminative vs. Generative Chain CRF General
Machine Learning for natural language processing
 Machine Learning for natural language processing Hidden Markov Models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 33 Introduction So far, we have classified texts/observations
Machine Learning for natural language processing Hidden Markov Models Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 33 Introduction So far, we have classified texts/observations
Learning with Noisy Labels. Kate Niehaus Reading group 11-Feb-2014
 Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Learning with Noisy Labels Kate Niehaus Reading group 11-Feb-2014 Outline Motivations Generative model approach: Lawrence, N. & Scho lkopf, B. Estimating a Kernel Fisher Discriminant in the Presence of
Hidden Markov Models
 CS769 Spring 2010 Advanced Natural Language Processing Hidden Markov Models Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Part-of-Speech Tagging The goal of Part-of-Speech (POS) tagging is to label each
CS769 Spring 2010 Advanced Natural Language Processing Hidden Markov Models Lecturer: Xiaojin Zhu jerryzhu@cs.wisc.edu 1 Part-of-Speech Tagging The goal of Part-of-Speech (POS) tagging is to label each
Generative v. Discriminative classifiers Intuition
 Logistic Regression (Continued) Generative v. Discriminative Decision rees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University January 31 st, 2007 2005-2007 Carlos Guestrin 1 Generative
Logistic Regression (Continued) Generative v. Discriminative Decision rees Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University January 31 st, 2007 2005-2007 Carlos Guestrin 1 Generative
The Noisy Channel Model and Markov Models
 1/24 The Noisy Channel Model and Markov Models Mark Johnson September 3, 2014 2/24 The big ideas The story so far: machine learning classifiers learn a function that maps a data item X to a label Y handle
1/24 The Noisy Channel Model and Markov Models Mark Johnson September 3, 2014 2/24 The big ideas The story so far: machine learning classifiers learn a function that maps a data item X to a label Y handle